時系列データベース(TSDB)の概要
Paragon Insightsは、さまざまな取り込み方法を通じて、時間的制約のあるデータを大量に収集します。このため、Paragon Insightsは時系列データベース(TSDB)を使用して、さまざまなネットワークデバイスから受信したすべての情報を保存および管理します。このトピックでは、TSDB の概要について説明します。
Paragon Insightsマイクロサービス
Paragon Insightsは、Kubernetesを使用して、複数の物理サーバーまたは仮想サーバー(ノード)間でDockerベースのマイクロサービスをクラスタリングします。Kubernetesクラスタは、1つのプライマリ・ノードと複数のワーカー・ノードで構成されます。Paragon Insightsマルチノードインストールの Healthbot setup 部分で、インストーラーはKubernetesプライマリノードとワーカーノードのIPアドレス(またはホスト名)を要求します。ワーカー・ノードは、必要な数だけセットアップに追加できます。ただし、追加するノードの数は、レプリケーション係数の値より大きくする必要があります。
TSDB の要素
Paragon Insightsは、TSDBの高可用性(HA)を提供するために、以下のTSDB要素をサポートしています。
データベースシャーディング
データベースシャーディングとは、特定のノードにデータを選択的に保存することを指します。この方法では、使用可能なTSDBノード間でデータを分散し、より大きなスケーリングが可能になります。これにより、TSDB インスタンスは、デバイスからの時系列データの一部のみを処理するようになります。
シャーディングを実現するために、Paragon Insightsはデバイスグループ/デバイスペアごとに1つのデータベースを作成し、結果のデータベースを、1つ(または複数)のParagon InsightsノードでホストされているTSDBのシステム決定インスタンスに書き込みます。
たとえば、D1 と D2 の 2 つのデバイスと、G1 と G2 の 2 つのデバイスグループがあるとします。D1 がグループ G1 と G2 に存在し、D2 がグループ G2 にのみ存在する場合、G1:D1、G2:D1、G2:D2 の 3 つのデータベースになります。各データベースは、個別のParagon Insightsノード上の個別のTSDBインスタンスに保存されます( 図1参照)。新しいデバイスがオンボーディングされ、デバイスグループ内に配置されると、Paragon Insightsは、そのデバイスデータを保存するTSDBデータベースインスタンスを選択します。
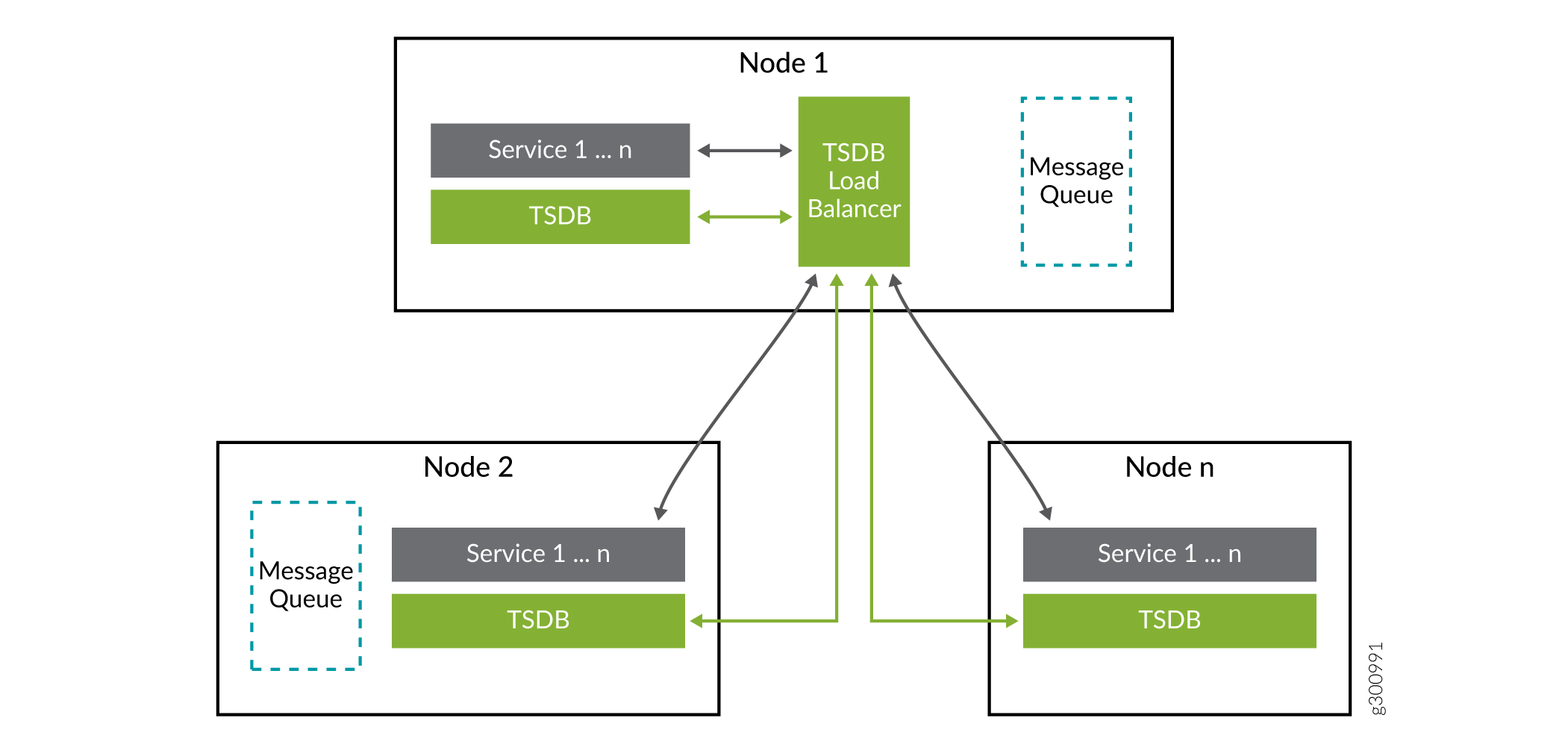
図1は、3つのParagon Insightsノードを示しています。これらの各ノードには、TSDBインスタンスがあり、他のParagon Insightsサービスが実行されています。
-
Paragon Insightsノードには、最大1つのTSDBインスタンスが許可されます。したがって、Paragon Insightsノードは、いつでも0個または1個のTSDBインスタンスを持つことができます。
-
Paragon Insightsノードは、TSDB機能の実行専用にすることができます。他のParagon Insights機能は、TSDB関数の実行専用のノードでは実行できません。これにより、他のParagon Insights機能がTSDBインスタンスのリソースを枯渇させるのを防ぎます。
-
最高のパフォーマンスを提供するために、ノードを TSDB 専用にすることをお勧めします。
-
Paragon InsightsおよびTSDBノードは、Paragon Insights CLIを使用して実行中のシステムに追加できます。
データベース レプリケーション
他のデータベースシステムと同様に、レプリケーションとは、複数のノード上の複数のインスタンスにデータを格納することを指します。Paragon Insightsでは、レプリケーション係数を設定して、必要なデータベースのコピーの数を決定します。
レプリケーション係数が 1 の場合、データのコピーは 1 つしか作成されないため、HA は提供されません。複数のParagon Insightsノードが使用可能で、レプリケーション係数が1に設定されている場合、シャーディングのみが達成されます。レプリケーション係数によって、必要なParagon Insightsノードの最小数が決まります。レプリケーション係数が 3 の場合、データのコピーが 3 つ作成され、少なくとも 3 つの Paragon Insights ノードが必要になり、HA が提供されます。レプリケーション係数が高いほど、HAが強くなり、Paragon Insightsノードに関するリソース要件が高くなります。システムをさらに拡張する場合は、レプリケーション係数の正確な倍数でParagon Insightsノードを追加する必要があります。たとえば、3、6、9 などです。
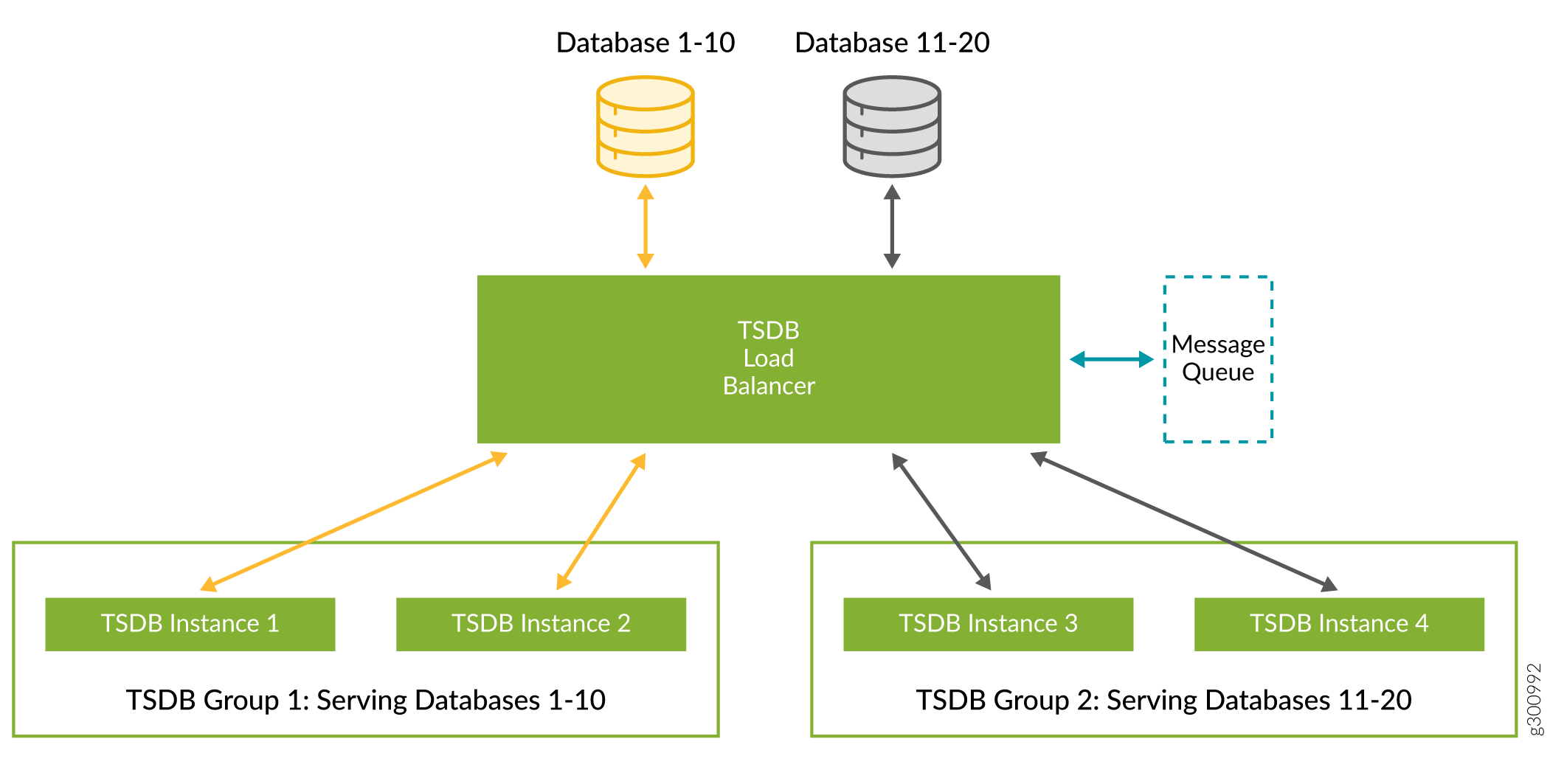
前述のデバイス/デバイスグループのペアリングに基づいて、Paragon Insightsが20個のデータベースを作成した例を考えてみましょう。問題のParagon Insightsシステムのレプリケーション係数は2で、4つのノードでTSDBが実行されています。これに基づいて、2 つの TSDB レプリケーション グループが作成されます。この例では、 TSDB グループ 1 と TSDB グループ 2 です。 図 2 では、データベース 1 から 10 のデータが、TSDB グループ 1 の TSDB インスタンス 1 と 2 に書き込まれています。データベース 11 から 20 のデータは、TSDB グループ 2 の TSDB インスタンス 3 および 4 に書き込まれます。TSDB インスタンスの周りのアウトラインは、TSDB レプリケーション グループを表します。レプリケーション グループのサイズは、レプリケーション係数によって決まります。
データベースの読み取りと書き込み
図1に示すように、Paragon Insightsでは分散メッセージングキューを利用できます。特定のTSDBインスタンス内でパフォーマンスの問題やエラーが発生した場合、これにより、データベースへの書き込みを順次実行できるようになり、すべてのデータが適切な時系列で書き込まれるようになります。
すべてのParagon Insightsマイクロサービスでは、標準化されたデータベースクエリー(読み取り)および書き込み機能を使用します。これは、基盤となるデータベースシステムが将来のある時点で変更された場合でも使用できます。これにより、成長と将来の変更に柔軟に対応できます。データベースシステムのその他の読み取りおよび書き込み機能には、次のものがあります。
-
通常の操作では、データベースの書き込みは TSDB グループ内のすべての TSDB インスタンスに送信されます。
-
データベースの書き込みは、TSDBインスタンスあたり最大1GBまでバッファリングできるため、失敗した書き込みは成功するまで再試行できます。
-
問題が解決せず、バッファーがいっぱいになると、最も古いデータが削除され、新しいデータが優先されます。
-
バッファリングがアクティブな場合、データベースの書き込みは順番に実行されるため、前の書き込みが成功するまで新しいデータを書き込むことはできません。
-
データベース クエリ (読み取り) は、過去 5 分間に報告された書き込みエラーが最も少ない TSDB インスタンスに送信されます。すべてのインスタンスのパフォーマンスが同等である場合、クエリは必要なグループ内のランダムな TSDB インスタンスに送信されます。