Data Center Fabric Blueprint Architecture Components
This section gives an overview of the building blocks used in this blueprint architecture. The implementation of each building block technology is explored in more detail later sections.
For information about the hardware and software that serve as a foundation to your building blocks, see the Data Center EVPN-VXLAN Fabric Reference Designs—Supported Hardware Summary.
The building blocks include:
IP Fabric Underlay Network
The modern IP fabric underlay network building block provides IP connectivity across a Clos-based topology. Juniper Networks supports the following IP fabric underlay models:
-
A 3-stage IP fabric, which is made up of a tier of spine devices and a tier of leaf devices. See Figure 1.
-
A 5-stage IP fabric, which typically starts as a single 3-stage IP fabric that grows into two 3-stage IP fabrics. These fabrics are segmented into separate points of delivery (PODs) within a data center. For this use case, we support the addition of a tier of super spine devices that enable communication between the spine and leaf devices in the two PODs. See Figure 2.
-
A collapsed spine IP fabric model, in which leaf layer functions are collapsed onto the spine devices. This type of fabric can be set up and operate similarly to either a 3-stage or 5-stage IP fabric except without a separate tier of leaf devices. You might use a collapsed spine fabric if you are moving incrementally to an EVPN spine-and-leaf model, or you have access devices or top-of-rack (TOR) devices that can’t be used in a leaf layer because they don’t support EVPN-VXLAN.
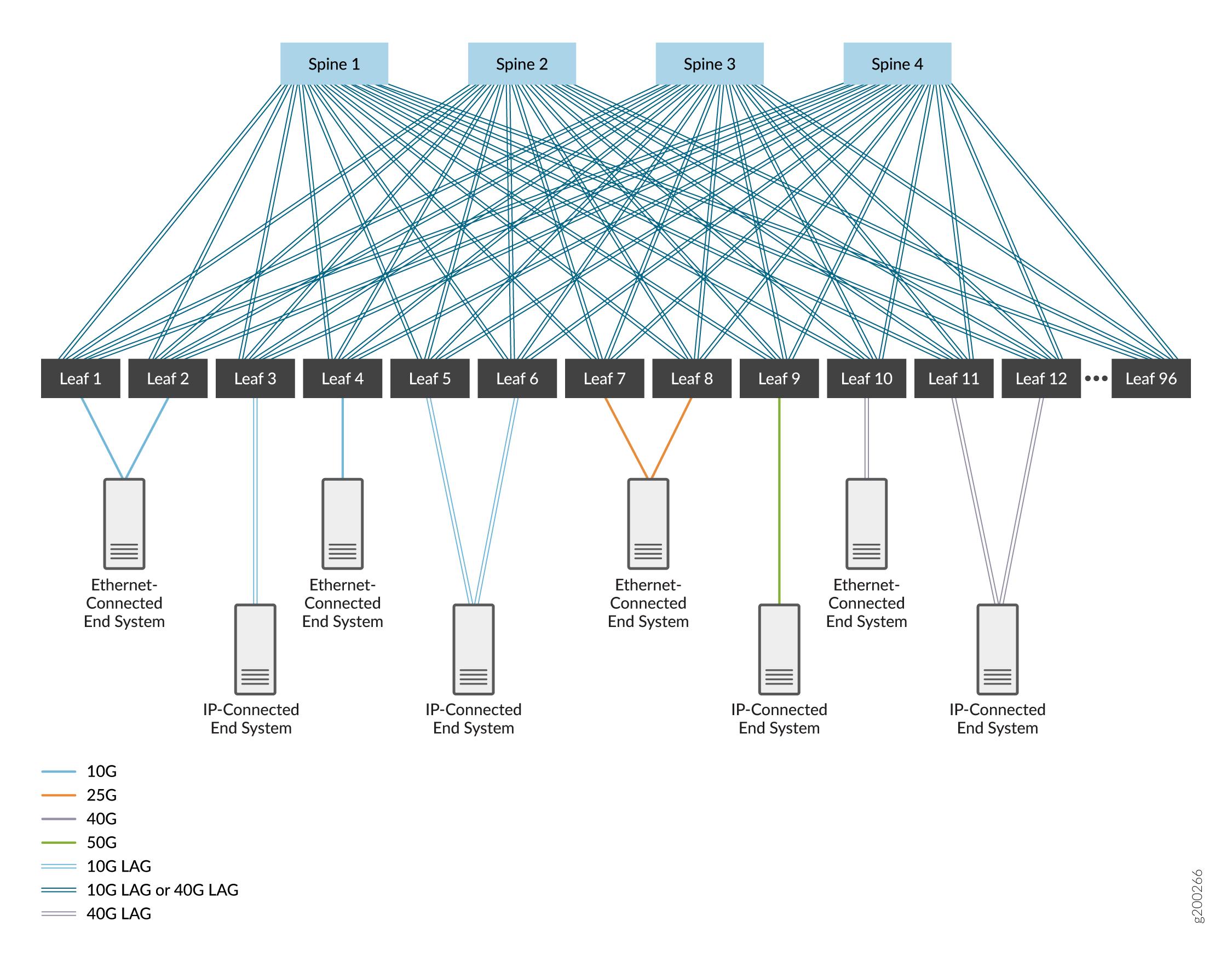
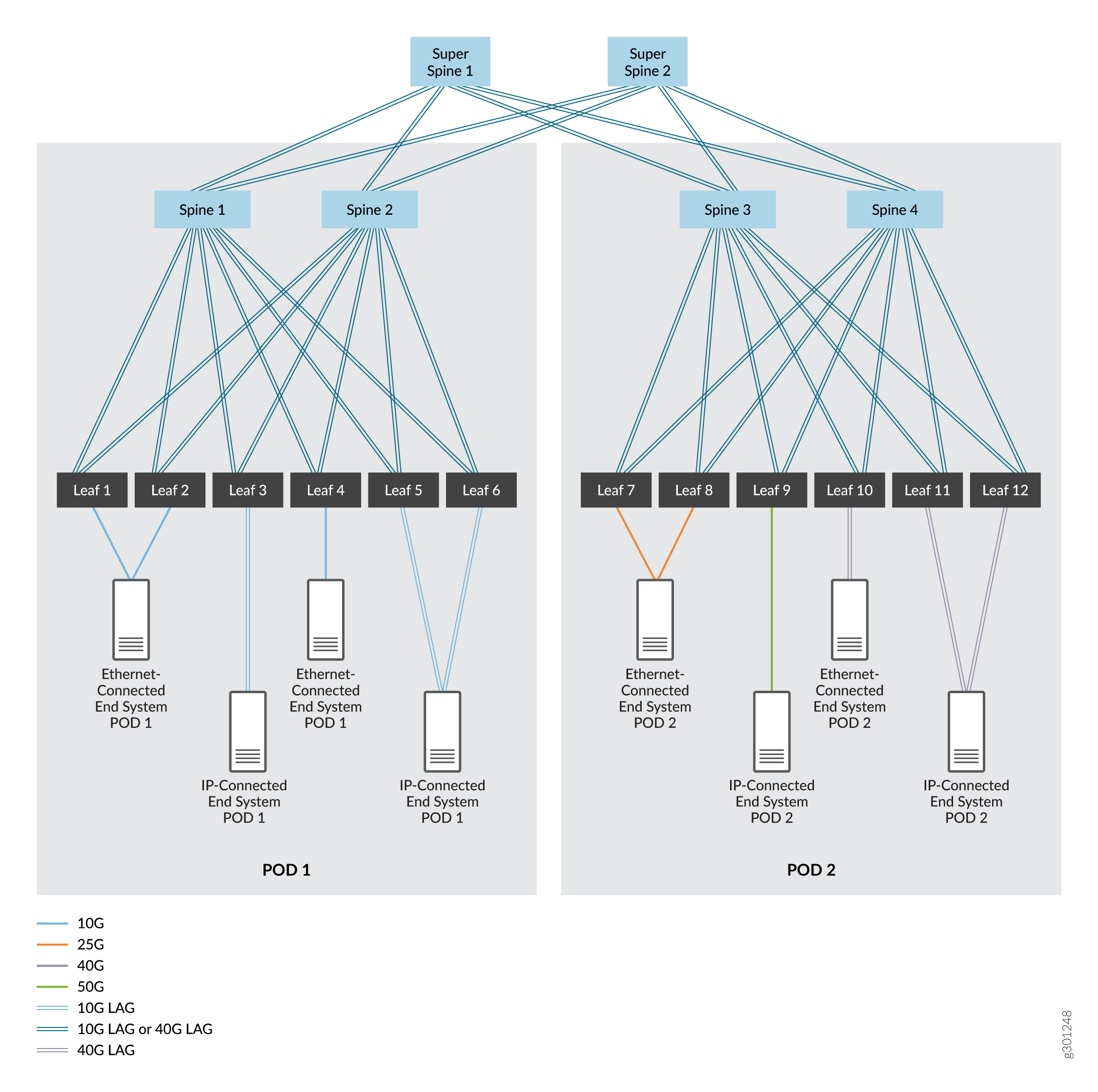
In these figures, the devices are interconnected using high-speed interfaces that are either single links or aggregated Ethernet interfaces. The aggregated Ethernet interfaces are optional—a single link between devices is typically used— but can be deployed to increase bandwidth and provide link level redundancy. We cover both options.
We chose EBGP as the routing protocol in the underlay network for its dependability and scalability. Each device is assigned its own autonomous system with a unique autonomous system number to support EBGP. You can use other routing protocols in the underlay network; the usage of those protocols is beyond the scope of this document.
The reference architecture designs described in this guide are based on an IP Fabric that uses EBGP for the underlay connectivity and IBGP for overlay peering (see IBGP for Overlays). You can alternatively configure the overlay peering using EBGP.
Starting in Junos OS Releases 21.2R2 and 21.4R1, we also support configuring an IPv6 Fabric. The IPv6 Fabric design in this guide uses EBGP for both underlay connectivity and overlay peering (see EBGP for Overlays with IPv6 Underlays).
The IP Fabric can use IPv4 or IPv6 as follows:
-
An IPv4 Fabric uses IPv4 interface addressing, and IPv4 underlay and overlay BGP sessions for end-to-end workload communication.
-
An IPv6 Fabric uses IPv6 interface addressing, and IPv6 underlay and overlay BGP sessions for end-to-end workload communication.
-
We don’t support an IP Fabric that mixes IPv4 and IPv6.
However, both IPv4 Fabrics and IPv6 Fabrics support dual-stack workloads—the workloads can be either IPv4 or IPv6, or both IPv4 and IPv6.
Micro Bidirectional Forwarding Detection (BFD)—the ability to run BFD on individual links in an aggregated Ethernet interface—can also be enabled in this building block to quickly detect link failures on any member links in aggregated Ethernet bundles that connect devices.
For more information, see these other sections in this guide:
-
Configuring spine and leaf devices in 3-stage and 5-stage IP fabric underlays: IP Fabric Underlay Network Design and Implementation.
-
Implementing the additional tier of super spine devices in a 5-stage IP fabric underlay: Five-Stage IP Fabric Design and Implementation.
-
Configuring an IPv6 underlay and supporting EBGP IPv6 overlay: IPv6 Fabric Underlay and Overlay Network Design and Implementation with EBGP.
-
Setting up the underlay in a collapsed spine fabric model: Collapsed Spine Fabric Design and Implementation.
IPv4 and IPv6 Workload Support
Because many networks implement a dual stack environment for workloads that includes IPv4 and IPv6 protocols, this blueprint provides support for both protocols. Steps to configure the fabric to support IPv4 and IPv6 workloads are interwoven throughout this guide to allow you to pick one or both of these protocols.
The IP protocol you use for workload traffic is independent of the IP protocol version (IPv4 or IPv6) that you configure for the IP Fabric underlay and overlay. (See IP Fabric Underlay Network.) An IPv4 Fabric or an IPv6 Fabric infrastructure can support both IPv4 and IPv6 workloads.
Network Virtualization Overlays
A network virtualization overlay is a virtual network that is transported over an IP underlay network. This building block enables multitenancy in a network, allowing you to share a single physical network across multiple tenants, while keeping each tenant’s network traffic isolated from the other tenants.
A tenant is a user community (such as a business unit, department, workgroup, or application) that contains groups of endpoints. Groups may communicate with other groups in the same tenancy, and tenants may communicate with other tenants if permitted by network policies. A group is typically expressed as a subnet (VLAN) that can communicate with other devices in the same subnet, and reach external groups and endpoints by way of a virtual routing and forwarding (VRF) instance.
As seen in the overlay example shown in Figure 3, Ethernet bridging tables (represented by triangles) handle tenant bridged frames and IP routing tables (represented by squares) process routed packets. Inter-VLAN routing happens at the integrated routing and bridging (IRB) interfaces (represented by circles). Ethernet and IP tables are directed into virtual networks (represented by colored lines). To reach end systems attached to other VXLAN Tunnel Endpoint (VTEP) devices, tenant packets are encapsulated and sent over an EVPN-signalled VXLAN tunnel (represented by green tunnel icons) to the associated remote VTEP devices. Tunneled packets are de-encapsulated at the remote VTEP devices and forwarded to the remote end systems by way of the respective bridging or routing tables of the egress VTEP device.
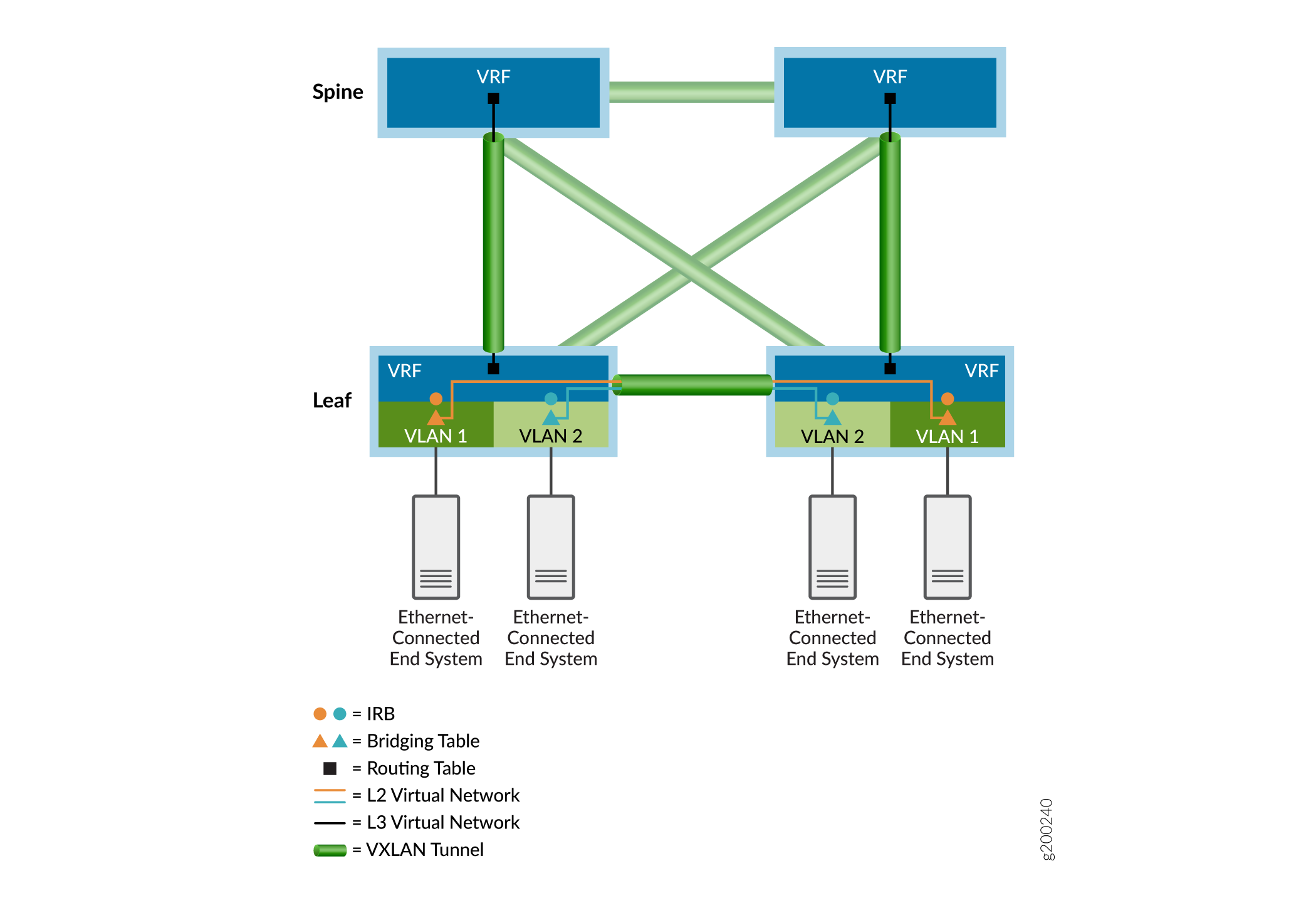
The next sections provide more details about overlay networks.
- IBGP for Overlays
- EBGP for Overlays with IPv6 Underlays
- Bridged Overlay
- Centrally Routed Bridging Overlay
- Edge-Routed Bridging Overlay
- Collapsed Spine Overlay
- Comparison of Bridged, CRB, and ERB Overlays
- IRB Addressing Models in Bridging Overlays
- Routed Overlay using EVPN Type 5 Routes
- MAC-VRF Instances for Multitenancy in Network Virtualization Overlays
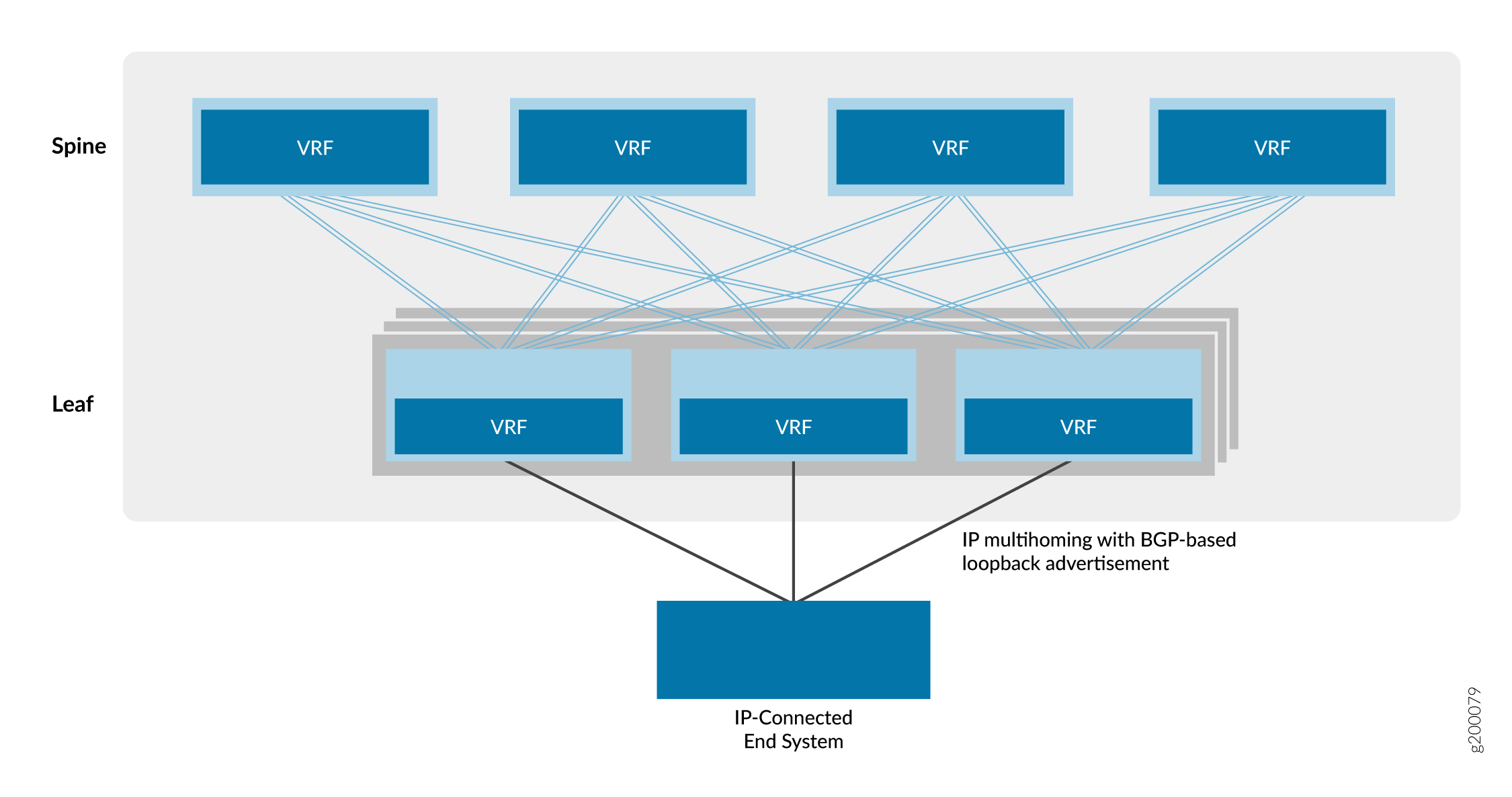
IBGP for Overlays
Internal BGP (IBGP) is a routing protocol that exchanges reachability information across an IP network. When IBGP is combined with Multiprotocol BGP (MP-IBGP), it provides the foundation for EVPN to exchange reachability information between VTEP devices. This capability is required to establish inter-VTEP VXLAN tunnels and use them for overlay connectivity services.
Figure 4 shows that the spine and leaf devices use their loopback addresses for peering in a single autonomous system. In this design, the spine devices act as a route reflector cluster and the leaf devices are route reflector clients. A route reflector satisfies the IBGP requirement for a full mesh without the need to peer all the VTEP devices directly with one another. As a result, the leaf devices peer only with the spine devices and the spine devices peer with both spine devices and leaf devices. Because the spine devices are connected to all the leaf devices, the spine devices can relay IBGP information between the indirectly peered leaf device neighbors.
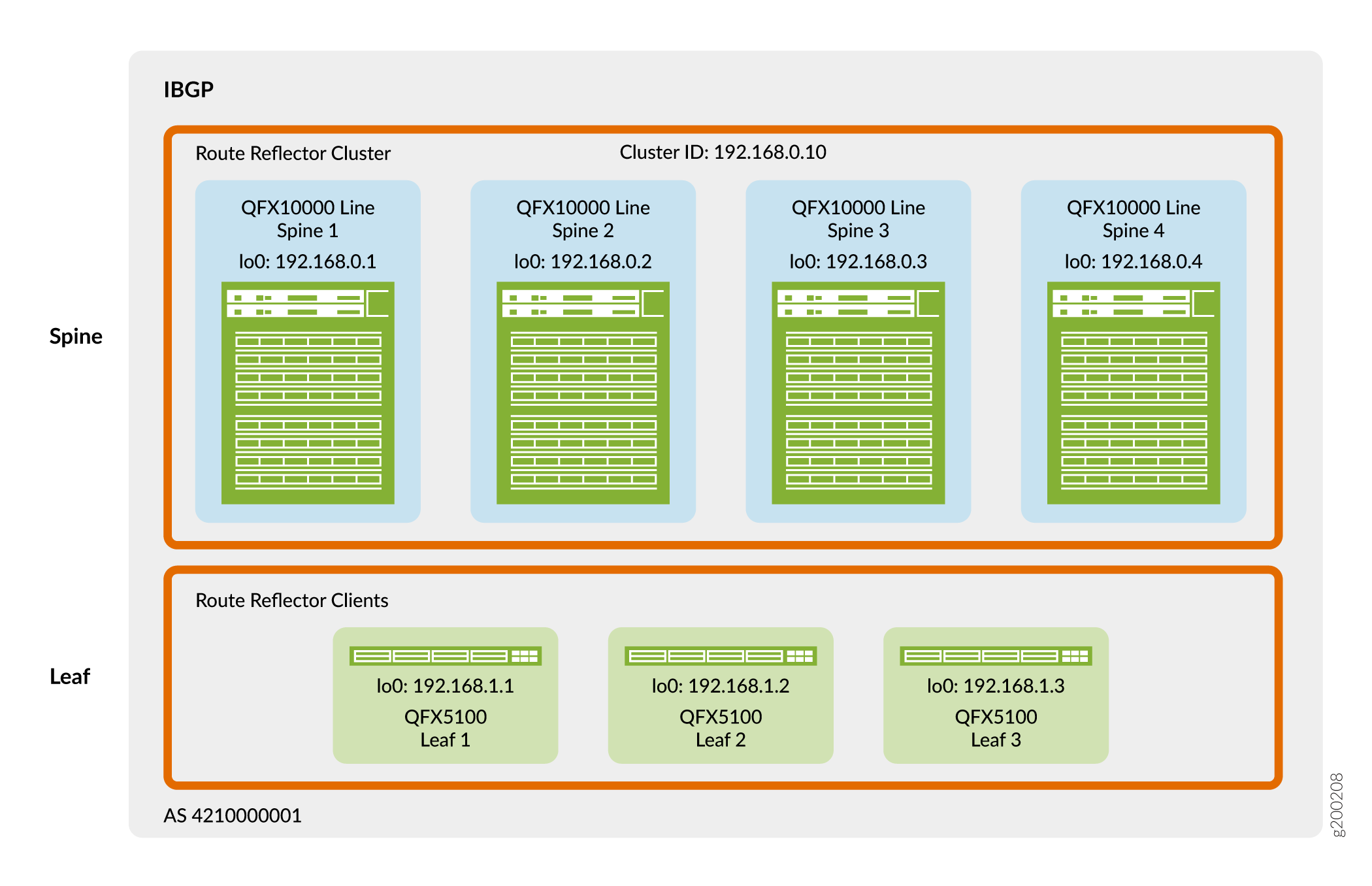
You can place route reflectors almost anywhere in the network. However, you must consider the following:
-
Does the selected device have enough memory and processing power to handle the additional workload required by a route reflector?
-
Is the selected device equidistant and reachable from all EVPN speakers?
-
Does the selected device have the proper software capabilities?
In this design, the route reflector cluster is placed at the spine layer. The QFX switches that you can use as a spine in this reference design have ample processing speed to handle route reflector client traffic in the network virtualization overlay.
For details about implementing IBGP in an overlay, see Configure IBGP for the Overlay.
EBGP for Overlays with IPv6 Underlays
The original reference architecture use cases in this guide illustrate an IPv4 EBGP underlay design with IPv4 IBGP overlay device connectivity. See IP Fabric Underlay Network and IBGP for Overlays. However, as network virtualization edge (NVE) devices start adopting IPv6 VTEPs to take advantage of the extended addressing range and capabilities of IPv6, we have expanded IP Fabric support to encompass IPv6.
Starting in Junos OS Release 21.2R2-S1, on supporting platforms you can alternatively use an IPv6 Fabric infrastructure with some reference architecture overlay designs. The IPv6 Fabric design comprises IPv6 interface addressing, an IPv6 EBGP underlay and an IPv6 EBGP overlay for workload connectivity. With an IPv6 Fabric, the NVE devices encapsulate the VXLAN header with an IPv6 outer header and tunnel the packets across the fabric end to end using IPv6 next hops. The workload can be IPv4 or IPv6.
Most of the elements you configure in the supported reference architecture overlay designs are independent of whether the underlay and overlay infrastructure uses IPv4 or IPv6. The corresponding configuration procedures for each of the supported overlay designs call out any configuration differences if the underlay and overlay uses the IPv6 Fabric design.
For more details, see the following references in this guide and other resources:
Configuring an IPv6 Fabric using EBGP for underlay connectivity and overlay peering: IPv6 Fabric Underlay and Overlay Network Design and Implementation with EBGP.
Starting releases in which different platforms support an IPv6 Fabric design when serving in particular roles in the fabric: Data Center EVPN-VXLAN Fabric Reference Designs—Supported Hardware Summary.
Overview of IPv6 underlay and overlay peering support in EVPN-VXLAN fabrics on Juniper Networks devices: EVPN-VXLAN with an IPv6 Underlay.
Bridged Overlay
The first overlay service type described in this guide is a bridged overlay, as shown in Figure 5.
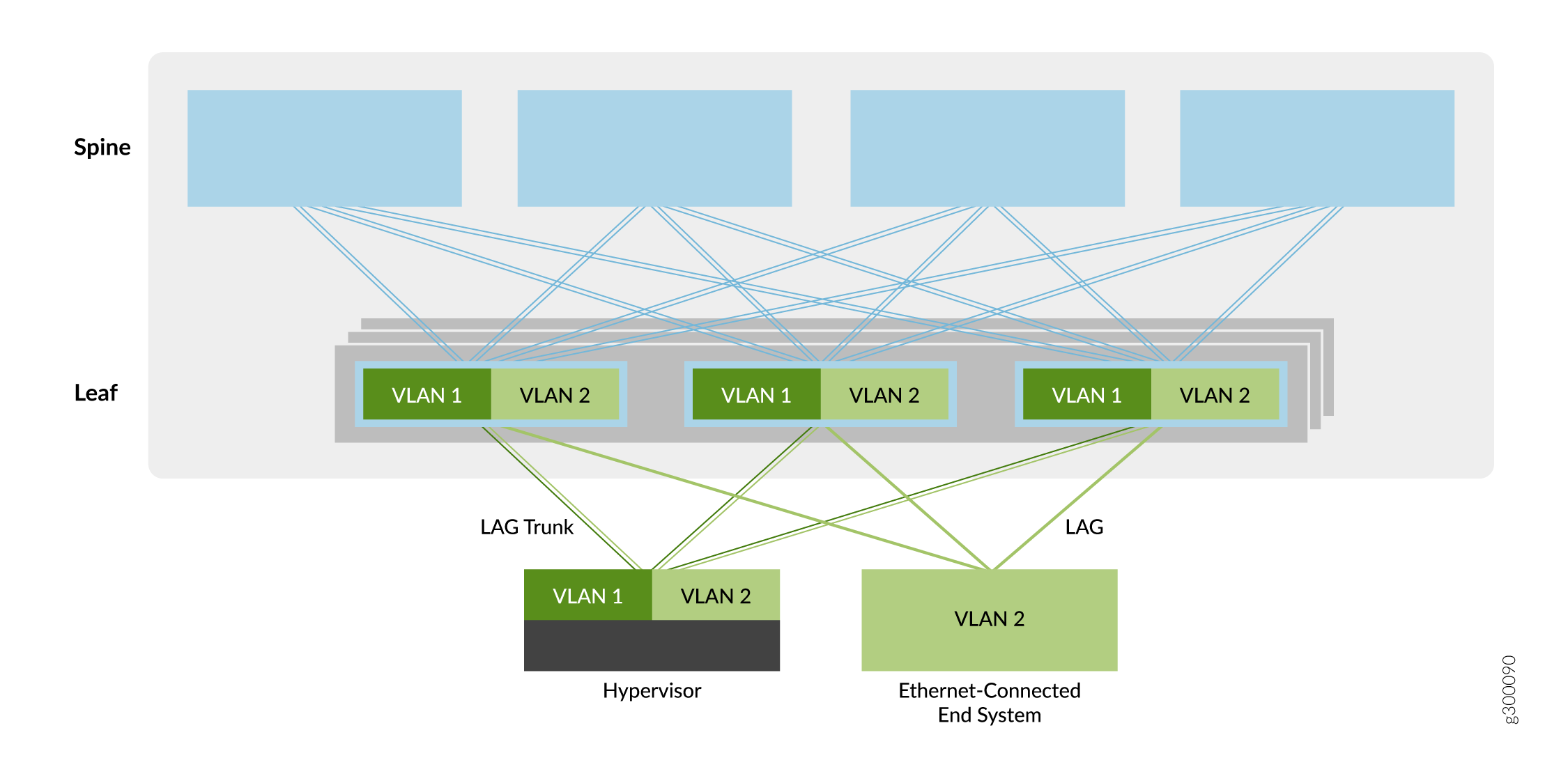
In this overlay model, Ethernet VLANs are extended between leaf devices across VXLAN tunnels. These leaf-to-leaf VXLAN tunnels support data center networks that require Ethernet connectivity between leaf devices but do not need routing between the VLANs. As a result, the spine devices provide only basic underlay and overlay connectivity for the leaf devices, and do not perform routing or gateway services seen with other overlay methods.
Leaf devices originate VTEPs to connect to the other leaf devices. The tunnels enable the leaf devices to send VLAN traffic to other leaf devices and Ethernet-connected end systems in the data center. The simplicity of this overlay service makes it attractive for operators who need an easy way to introduce EVPN/VXLAN into their existing Ethernet-based data center.
You can add routing to a bridged overlay by implementing an MX Series router or SRX Series security device external to the EVPN/VXLAN fabric. Otherwise, you can select one of the other overlay types that incorporate routing (such as an edge-routed bridging overlay, a centrally-routed bridging overlay, or a routed overlay).
For information on implementing a bridged overlay, see Bridged Overlay Design and Implementation.
Centrally Routed Bridging Overlay
The second overlay service type is the centrally routed bridging (CRB) overlay, as shown in Figure 6.
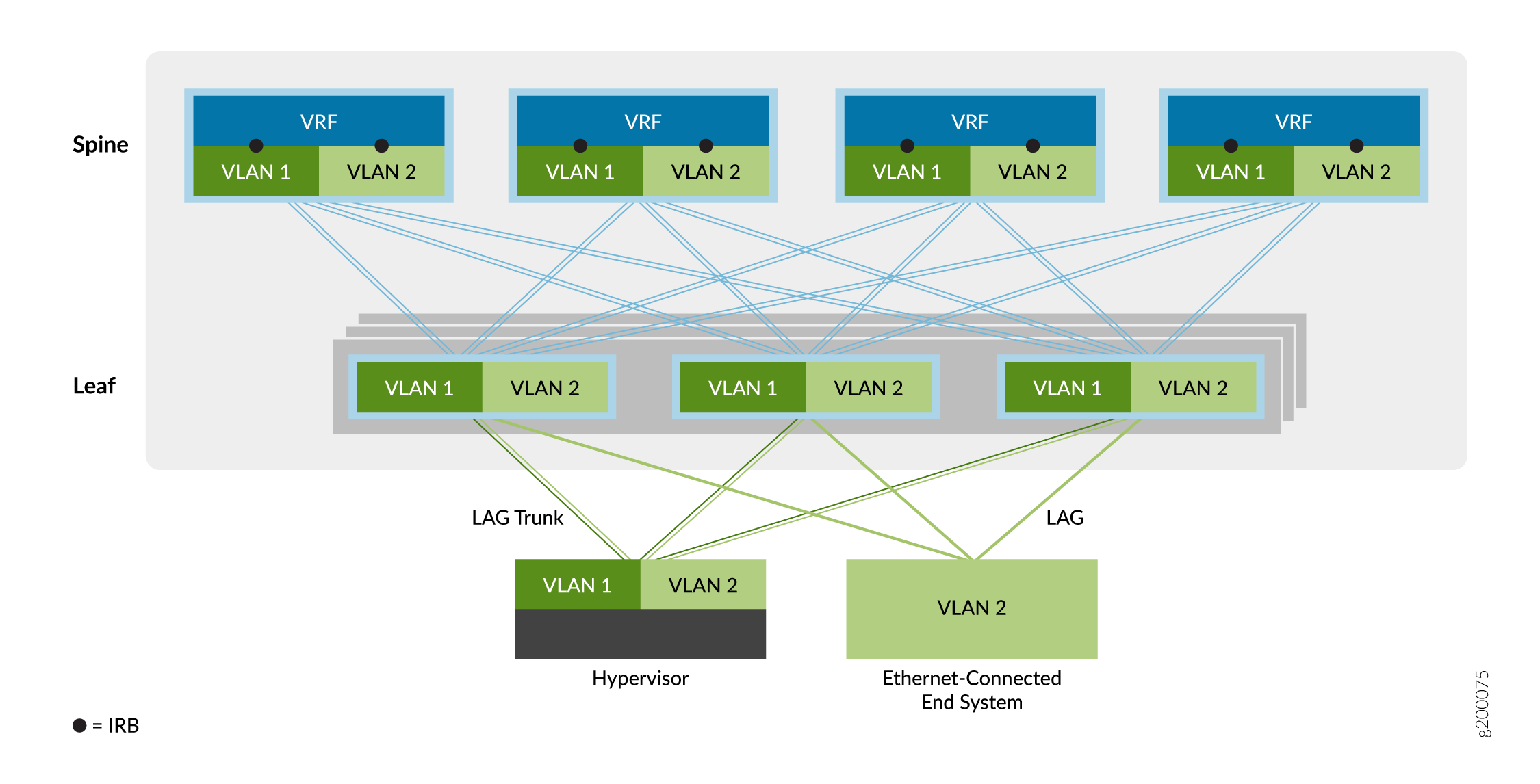
In a CRB overlay, routing occurs at a central gateway of the data center network (the spine layer in this example) rather than at the VTEP device where the end systems are connected (the leaf layer in this example).
You can use this overlay model when you need routed traffic to go through a centralized gateway or when your edge VTEP devices lack the required routing capabilities.
As shown above, traffic that originates at the Ethernet-connected end systems is forwarded to the leaf VTEP devices over a trunk (multiple VLANs) or an access port (single VLAN). The VTEP device forwards the traffic to local end systems or to an end system at a remote VTEP device. An integrated routing and bridging (IRB) interface at each spine device helps route traffic between the Ethernet virtual networks.
The VLAN-aware bridging overlay service model enables you to easily aggregate a collection of VLANs into the same overlay virtual network. The Juniper Networks EVPN design supports three VLAN-aware Ethernet service model configurations in the data center, as follows:
-
Default instance VLAN-aware—With this option, you implement a single, default switching instance that supports a total of 4094 VLANs. All leaf platforms included in this design (Data Center EVPN-VXLAN Fabric Reference Designs—Supported Hardware Summary) support the default instance style of VLAN-aware overlay.
To configure this service model, see Configuring a VLAN-Aware Centrally-Routed Bridging Overlay in the Default Instance.
-
Virtual switch VLAN-aware—With this option, multiple virtual switch instances support up to 4094 VLANs per instance. This Ethernet service model is ideal for overlay networks that require scalability beyond a single default instance. Support for this option is available currently on the QFX10000 line of switches.
To implement this scalable service model, see Configuring a VLAN-Aware CRB Overlay with Virtual Switches or MAC-VRF Instances.
-
MAC-VRF instance VLAN-aware—With this option, multiple MAC-VRF instances support up to 4094 VLANs per instance. This Ethernet service model is ideal for overlay networks that require scalability beyond a single default instance, and where you want more options to ensure VLAN isolation or interconnection among different tenants in the same fabric. Support for this option is available on the platforms that support MAC-VRF instances (see Feature Explorer: MAC VRF with EVPN-VXLAN).
To implement this scalable service model, see Configuring a VLAN-Aware CRB Overlay with Virtual Switches or MAC-VRF Instances.
Edge-Routed Bridging Overlay
The third overlay service option is the edge-routed bridging (ERB) overlay, as shown in Figure 7.
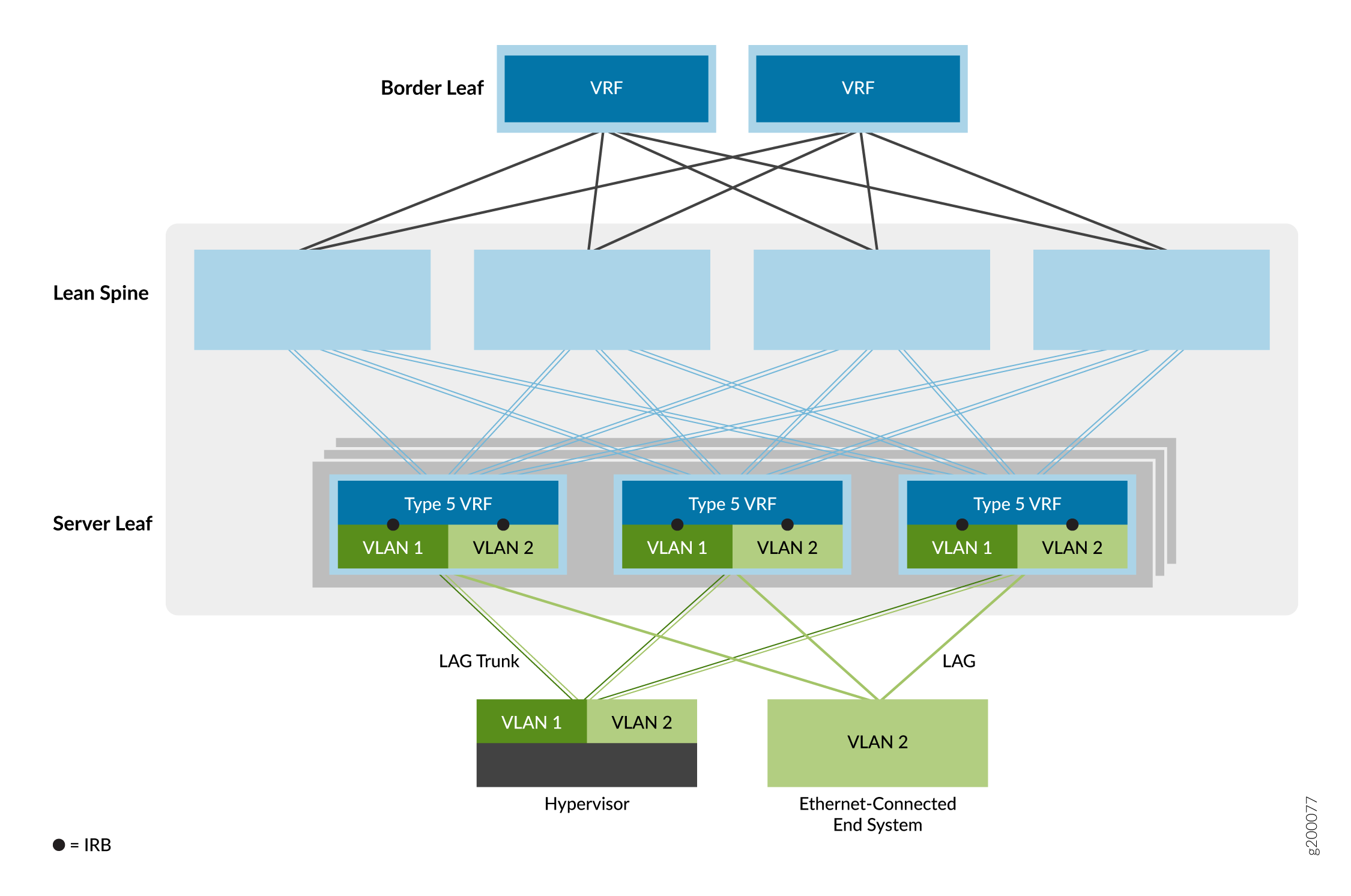
In this Ethernet service model, the IRB interfaces are moved to leaf device VTEPs at the edge of the overlay network to bring IP routing closer to the end systems. Because of the special ASIC capabilities required to support bridging, routing, and EVPN/VXLAN in one device, ERB overlays are only possible on certain switches. For a list of switches that we support as leaf devices in an ERB overlay, see Data Center EVPN-VXLAN Fabric Reference Designs—Supported Hardware Summary.
This model allows for a simpler overall network. The spine devices are configured to handle only IP traffic, which removes the need to extend the bridging overlays to the spine devices.
This option also enables faster server-to-server, intra-data center traffic (also known as east-west traffic) where the end systems are connected to the same leaf device VTEP. As a result, routing happens much closer to the end systems than with CRB overlays.
When you configure IRB interfaces that are included in EVPN Type-5 routing instances on QFX5110 or QFX5120 switches that function as leaf devices, the device automatically enables symmetric inter-IRB unicast routing for EVPN Type 5 routes.
For information on implementing the ERB overlay, see Edge-Routed Bridging Overlay Design and Implementation.
Collapsed Spine Overlay
The overlay network in a collapsed spine architecture is similar to an ERB overlay. In a collapsed spine architecture, the leaf device functions are collapsed onto the spine devices. Because there is no leaf layer, you configure the VTEPS and IRB interfaces on the spine devices, which are at the edge of the overlay network like the leaf devices in an ERB model. The spine devices can also perform border gateway functions to route north-south traffic, or extend Layer 2 traffic across data center locations.
For a list of switches that we support with a collapsed spine architecture, see Data Center EVPN-VXLAN Fabric Reference Designs—Supported Hardware Summary.
Comparison of Bridged, CRB, and ERB Overlays
To help you decide which overlay type is best suited for your EVPN environment, see Table 1.
We support mixing bridged overlay, CRB overlay, and ERB overlay configurations on the same device at the same time on devices that support these overlay types. You don't need to configure the device with separate logical systems for the device to operate in different types of overlays in parallel.
|
Comparison Points |
ERB Overlay |
CRB Overlay |
Bridged Overlay |
|---|---|---|---|
|
Fully distributed tenant inter-subnet routing |
✓ |
||
|
Minimal impact of IP gateway failure |
✓ |
||
|
Dynamic routing to third-party nodes at leaf level |
✓ |
||
|
Optimized for high volume of east-west traffic |
✓ |
||
|
Better integration with raw IP fabrics |
✓ |
||
|
IP VRF virtualization closer to the server |
✓ |
||
|
Contrail vRouter multihoming required |
✓ |
||
|
Easier EVPN interoperability with different vendors |
✓ |
||
|
Symmetric inter-subnet routing |
✓ |
✓ |
|
|
VLAN ID overlapping per rack |
✓ |
✓ |
✓ |
|
Simpler manual configuration and troubleshooting |
✓ |
✓ |
|
|
Service provider- and Enterprise-style interfaces |
✓ |
✓ |
|
|
Legacy leaf switch support (QFX5100) |
✓ |
✓ |
|
|
Centralized virtual machine traffic optimization (VMTO) control |
✓ |
||
|
IP tenant subnet gateway on the firewall cluster |
✓ |
IRB Addressing Models in Bridging Overlays
The configuration of IRB interfaces in CRB and ERB overlays requires an understanding of the models for the default gateway IP and MAC address configuration of IRB interfaces as follows:
Unique IRB IP Address—In this model, a unique IP address is configured on each IRB interface in an overlay subnet.
The benefit of having a unique IP address and MAC address on each IRB interface is the ability to monitor and reach each of the IRB interfaces from within the overlay using its unique IP address. This model also allows you to configure a routing protocol on the IRB interface.
The downside of this model is that allocating a unique IP address to each IRB interface may consume many IP addresses of a subnet.
Unique IRB IP Address with Virtual Gateway IP Address—This model adds a virtual gateway IP address to the previous model, and we recommend it for centrally routed bridged overlays. It is similar to VRRP, but without the in-band data plane signaling between the gateway IRB interfaces. The virtual gateway should be the same for all default gateway IRB interfaces in the overlay subnet and is active on all gateway IRB interfaces where it is configured. You should also configure a common IPv4 MAC address for the virtual gateway, which becomes the source MAC address on data packets forwarded over the IRB interface.
In addition to the benefits of the previous model, the virtual gateway simplifies default gateway configuration on end systems. The downside of this model is the same as the previous model.
IRB with Anycast IP Address and MAC Address—In this model, all default gateway IRB interfaces in an overlay subnet are configured with the same IP and MAC address. We recommend this model for ERB overlays.
A benefit of this model is that only a single IP address is required per subnet for default gateway IRB interface addressing, which simplifies default gateway configuration on end systems.
Routed Overlay using EVPN Type 5 Routes
The final overlay option is a routed overlay, as shown in Figure 8.
This option is an IP-routed virtual network service. Unlike an MPLS-based IP VPN, the virtual network in this model is based on EVPN/VXLAN.
Cloud providers prefer this virtual network option because most modern applications are optimized for IP. Because all communication between devices happens at the IP layer, there is no need to use any Ethernet bridging components, such as VLANs and ESIs, in this routed overlay model.
For information on implementing a routed overlay, see Routed Overlay Design and Implementation.
MAC-VRF Instances for Multitenancy in Network Virtualization Overlays
MAC-VRF routing instances enable you to configure multiple EVPN instances with different Ethernet service types on a device acting as a VTEP in an EVPN-VXLAN fabric. Using MAC-VRF instances, you can manage multiple tenants in the data center with customer-specific VRF tables to isolate or group tenant workloads.
MAC-VRF instances also introduce support for the VLAN-based service type in addition to the prior support for the VLAN-aware service type. See Figure 9.

-
VLAN-based service—You can configure one VLAN and the corresponding VXLAN network identifier (VNI) in the MAC-VRF instance. To provision a new VLAN and VNI, you must configure a new MAC VRF instance with the new VLAN and VNI.
-
VLAN-aware service—You can configure one or more VLANs and the corresponding VNIs in the same MAC-VRF instance. To provision a new VLAN and VNI, you can add the new VLAN and VNI configuration to the existing MAC-VRF instance, which saves some configuration steps over using a VLAN-based service.
MAC-VRF instances enable more flexible configuration options at both Layer 2 and Layer 3. For example:
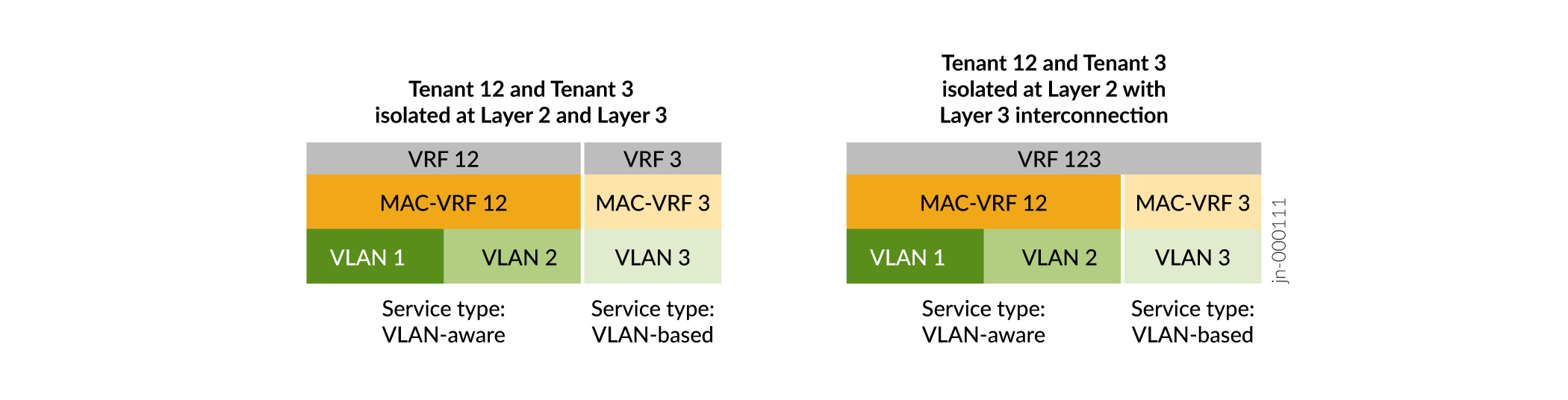
Figure 10 shows that with MAC-VRF instances:
-
You can configure different service types in different MAC-VRF instances on the same device.
-
You have flexible tenant isolation options at Layer 2 (MAC-VRF instances) as well as at Layer 3 (VRF instances). You can configure a VRF instance that corresponds to the VLAN or VLANs in a single MAC-VRF instance. Or you can configure a VRF instance that spans the VLANs in multiple MAC-VRF instances.
Figure 11 shows an ERB overlay fabric with a sample MAC-VRF configuration for tenant separation.
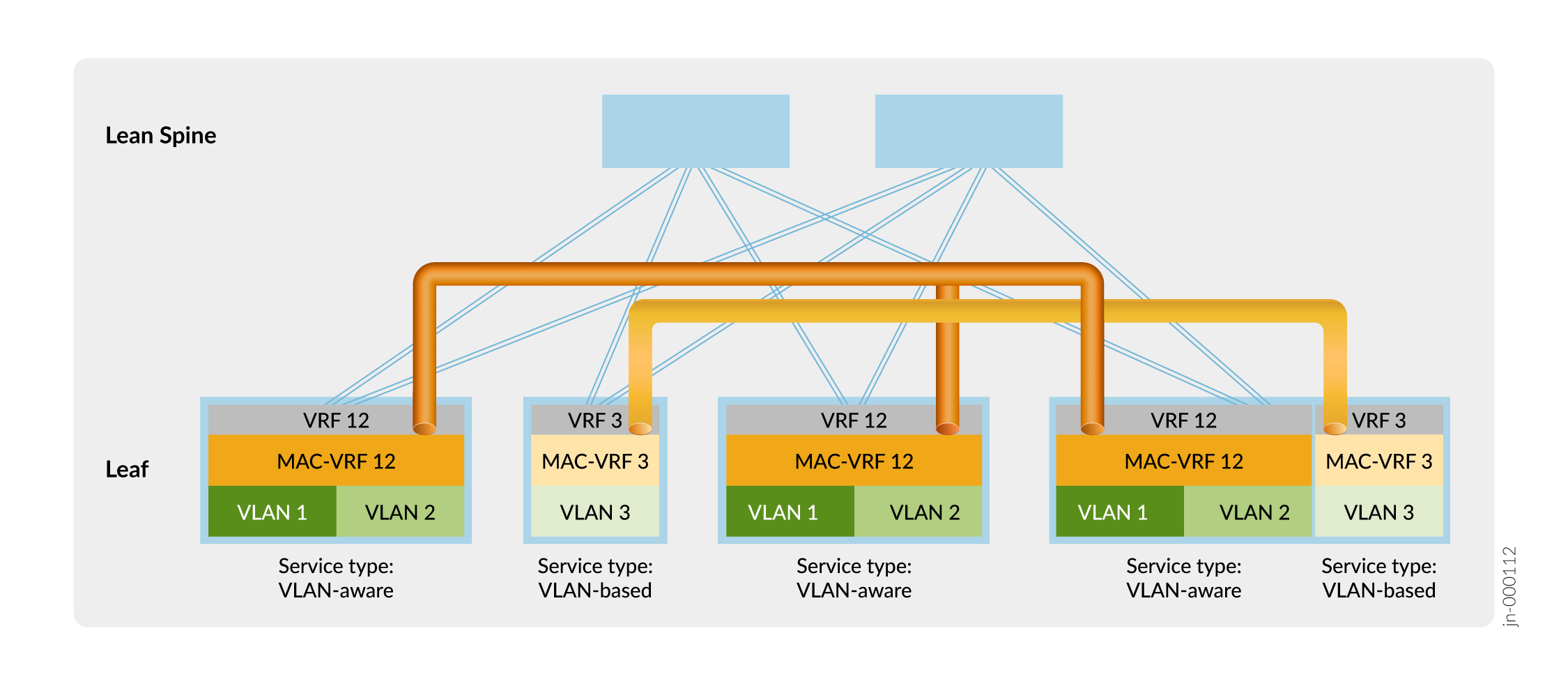
In Figure 11, the leaf devices establish VXLAN tunnels that maintain isolation at Layer 2 between Tenant 12 (VLAN 1 and VLAN 2) and Tenant 3 (VLAN 3) using MAC-VRF instances MAC-VRF 12 and MAC-VRF 3. The leaf devices also isolate the tenants at Layer 3 using VRF instances VRF 12 and VRF 3.
You can employ other options for sharing VLAN traffic between tenants that are isolated at Layer 2 and Layer 3 by the MAC-VRF and VRF configurations, such as:
-
Establish a secure external interconnection between tenant VRFs through a firewall.
-
Configure local route leaking between Layer 3 VRFs.
For more information about MAC-VRF instances and using them in an example customer use case, see EVPN-VXLAN DC IP Fabric MAC-VRF L2 Services.
MAC-VRF instances correspond to forwarding instances as follows:
-
MAC-VRF instances on switches in the QFX5000 line (including those that run Junos OS or Junos OS Evolved) are all part of the default forwarding instance. On these devices, you can’t configure overlapping VLANs in a MAC-VRF instance or across multiple MAC-VRF instances.
-
On the QFX10000 line of switches, you can configure multiple forwarding instances, and map a MAC-VRF instance to a particular forwarding instance. You can also map multiple MAC-VRF instances to the same forwarding instance. If you configure each MAC-VRF instance to use a different forwarding instance, you can configure overlapping VLANs across the multiple MAC-VRF instances. You can’t configure overlapping VLANs in a single MAC-VRF instance or across MAC-VRF instances that map to the same forwarding instance.
-
In the default configuration, switches include a default VLAN with VLAN ID=1 associated with the default forwarding instance. Because VLAN IDs must be unique in a forwarding instance, if you want to configure a VLAN with VLAN ID=1 in a MAC-VRF instance that uses the default forwarding instance, you must reassign the VLAN ID of the default VLAN to a value other than 1. For example:
set vlans default vlan-id 4094 set routing-instances mac-vrf-instance-name vlans vlan-name vlan-id 1
The reference network virtualization overlay configuration examples in this guide include
steps to configure the overlay using MAC-VRF instances. You configure an EVPN routing instance
of type mac-vrf, and set a route distinguisher and a route target in the
instance. You also include the desired interfaces (including a VTEP source interface), VLANs,
and VLAN-to-VNI mappings in the instance. See the reference configurations in the following
topics:
-
Bridged Overlay Design and Implementation—You configure MAC-VRF instances on the leaf devices.
-
Centrally-Routed Bridging Overlay Design and Implementation—You configure MAC-VRF instances on the spine devices. On the leaf devices, the MAC-VRF configuration is similar to the MAC-VRF leaf configuration in a bridged overlay design.
-
Edge-Routed Bridging Overlay Design and Implementation—You configure MAC-VRF instances on the leaf devices.
A device can have problems with VTEP scaling when the configuration uses multiple MAC-VRF
instances. As a result, to avoid this problem, we require that you enable the shared tunnels
feature on the QFX5000 line of switches running Junos OS with a MAC-VRF instance
configuration. When you configure shared tunnels, the device minimizes the number of next-hop
entries to reach remote VTEPs. You globally enable shared VXLAN tunnels on the device using
the shared-tunnels statement at the [edit forwarding-options
evpn-vxlan] hierarchy level. This setting requires you to reboot the device.
This statement is optional on the QFX10000 line of switches running Junos OS, which can handle higher VTEP scaling than QFX5000 switches.
On devices running Junos OS Evolved in EVPN-VXLAN fabrics, shared tunnels are enabled by default. Junos OS Evolved supports EVPN-VXLAN only with MAC-VRF configurations.
Multihoming Support for Ethernet-Connected End Systems
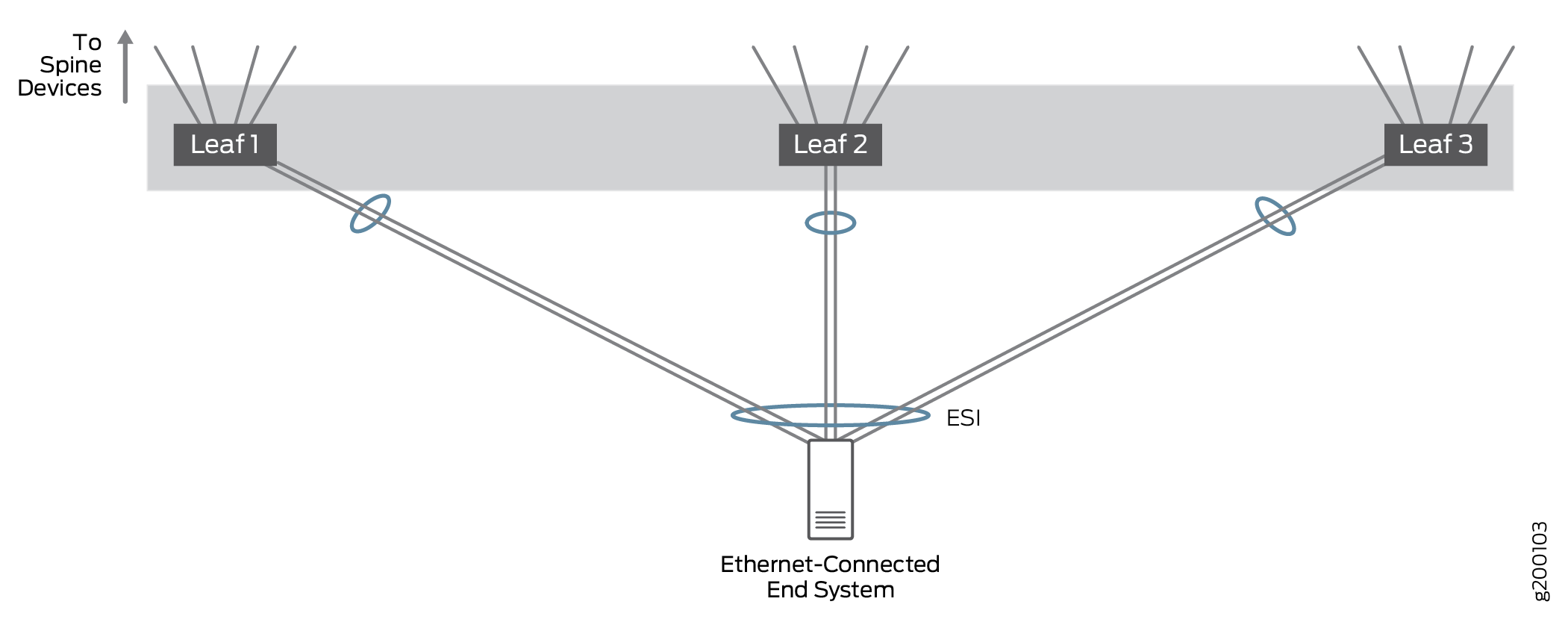
Ethernet-connected multihoming allows Ethernet-connected end systems to connect into the Ethernet overlay network over a single-homed link to one VTEP device or over multiple links multihomed to different VTEP devices. Ethernet traffic is load-balanced across the fabric between VTEPs on leaf devices that connect to the same end system.
We tested setups where an Ethernet-connected end system was connected to a single leaf device or multihomed to 2 or 3 leaf devices to prove traffic is properly handled in multihomed setups with more than two leaf VTEP devices; in practice, an Ethernet-connected end system can be multihomed to a large number of leaf VTEP devices. All links are active and network traffic can be load balanced over all of the multihomed links.
In this architecture, EVPN is used for Ethernet-connected multihoming. EVPN multihomed LAGs are identified by an Ethernet segment identifier (ESI) in the EVPN bridging overlay while LACP is used to improve LAG availability.
VLAN trunking allows one interface to support multiple VLANs. VLAN trunking ensures that virtual machines (VMs) on non-overlay hypervisors can operate in any overlay networking context.
For more information about Ethernet-connected multihoming support, see Multihoming an Ethernet-Connected End System Design and Implementation.
Multihoming Support for IP-Connected End Systems
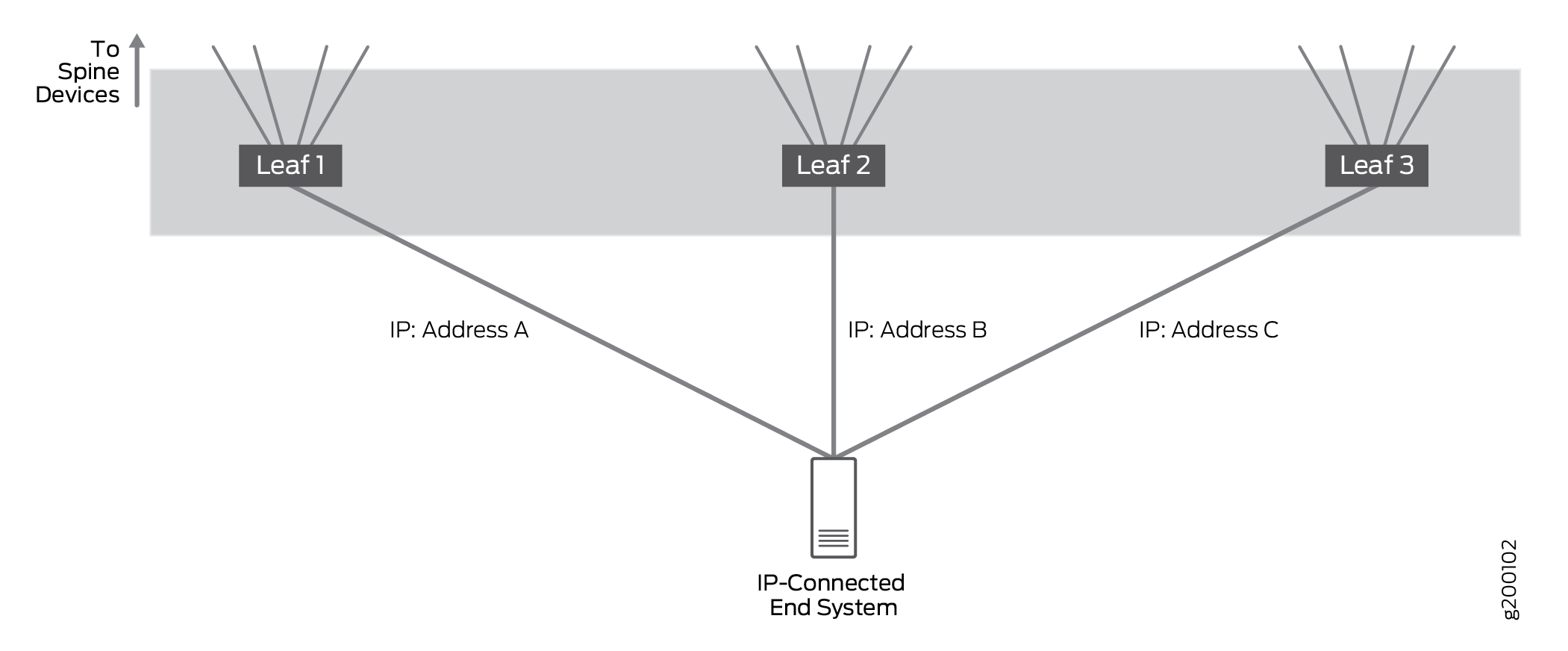
IP-connected multihoming endpoint systems to connect to the IP network over multiple IP-based access interfaces on different leaf devices.
We tested setups where an IP–connected end system was connected to a single leaf or multihomed to 2 or 3 leaf devices. The setup validated that traffic is properly handled when multihomed to multiple leaf devices; in practice, an IP-connected end system can be multihomed to a large number of leaf devices.
In multihomed setups, all links are active and network traffic is forwarded and received over all multihomed links. IP traffic is load balanced across the multihomed links using a simple hashing algorithm.
EBGP is used to exchange routing information between the IP-connected endpoint system and the connected leaf devices to ensure the route or routes to the endpoint systems are shared with all spine and leaf devices.
For more information about the IP-connected multihoming building block, see Multihoming an IP-Connected End System Design and Implementation.
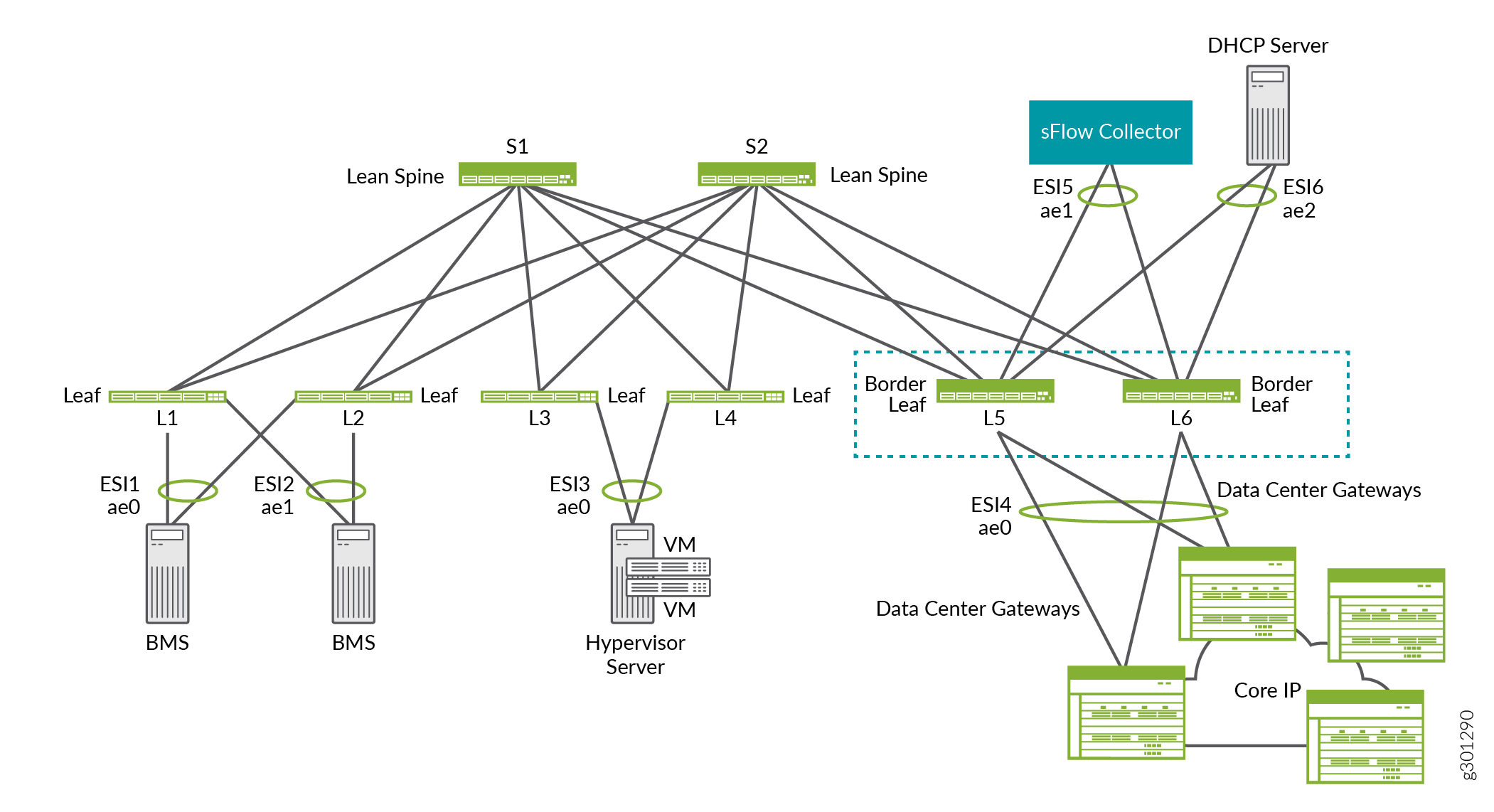
Border Devices
Some of our reference designs include border devices that provide connections to the following devices, which are external to the local IP fabric:
A multicast gateway.
A data center gateway for data center interconnect (DCI).
A device such as an SRX router on which multiple services such as firewalls, Network Address Translation (NAT), intrusion detection and prevention (IDP), multicast, and so on are consolidated. The consolidation of multiple services onto one physical device is known as service chaining.
Appliances or servers that act as firewalls, DHCP servers, sFlow collectors, and so on.
Note:If your network includes legacy appliances or servers that require a 1-Gbps Ethernet connection to a border device, we recommend using a QFX10008 or a QFX5120 switch as the border device.
To provide the additional functionality described above, Juniper Networks supports deploying a border device in the following ways:
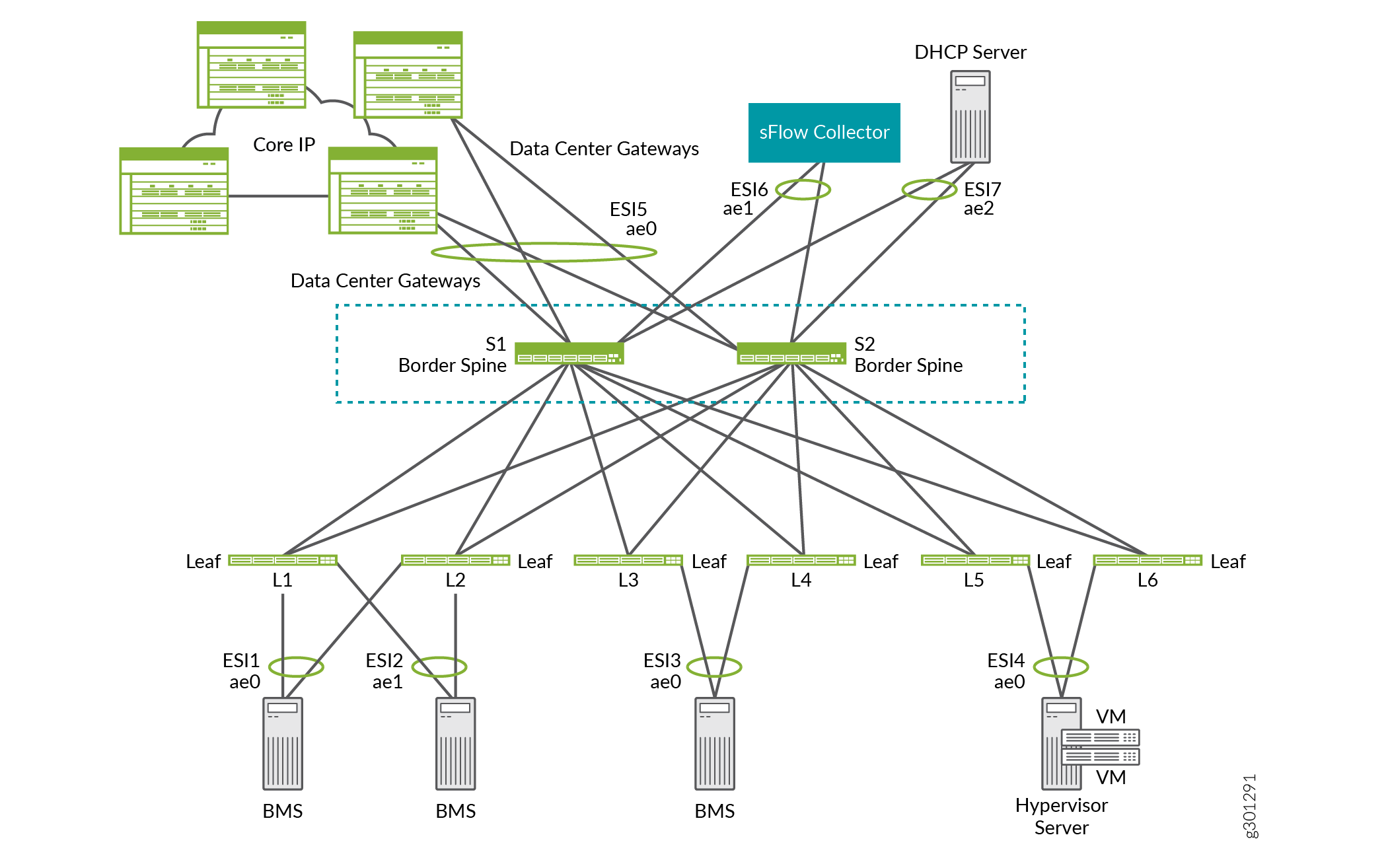
As a device that serves as a border device only. In this dedicated role, you can configure the device to handle one or more of the tasks described above. For this situation, the device is typically deployed as a border leaf, which is connected to a spine device.
For example, in the ERB overlay shown in Figure 14, border leafs L5 and L6 provide connectivity to data center gateways for DCI, an sFlow collector, and a DHCP server.
As a device that has two roles—a network underlay device and a border device that can handle one or more of the tasks described above. For this situation, a spine device usually handles the two roles. Therefore, the border device functionality is referred to as a border spine.
For example, in the ERB overlay shown in Figure 15, border spines S1 and S2 function as lean spine devices. They also provide connectivity to data center gateways for DCI, an sFlow collector, and a DHCP server.
Data Center Interconnect (DCI)
The data center interconnect (DCI) building block provides the technology needed to send traffic between data centers. The validated design supports DCI using EVPN Type 5 routes, IPVPN routes, and Layer 2 DCI with VXLAN stitching.
EVPN Type 5 or IPVPN routes are used in a DCI context to ensure inter-data center traffic between data centers using different IP address subnetting schemes can be exchanged. Routes are exchanged between spine devices in different data centers to allow for the passing of traffic between data centers.
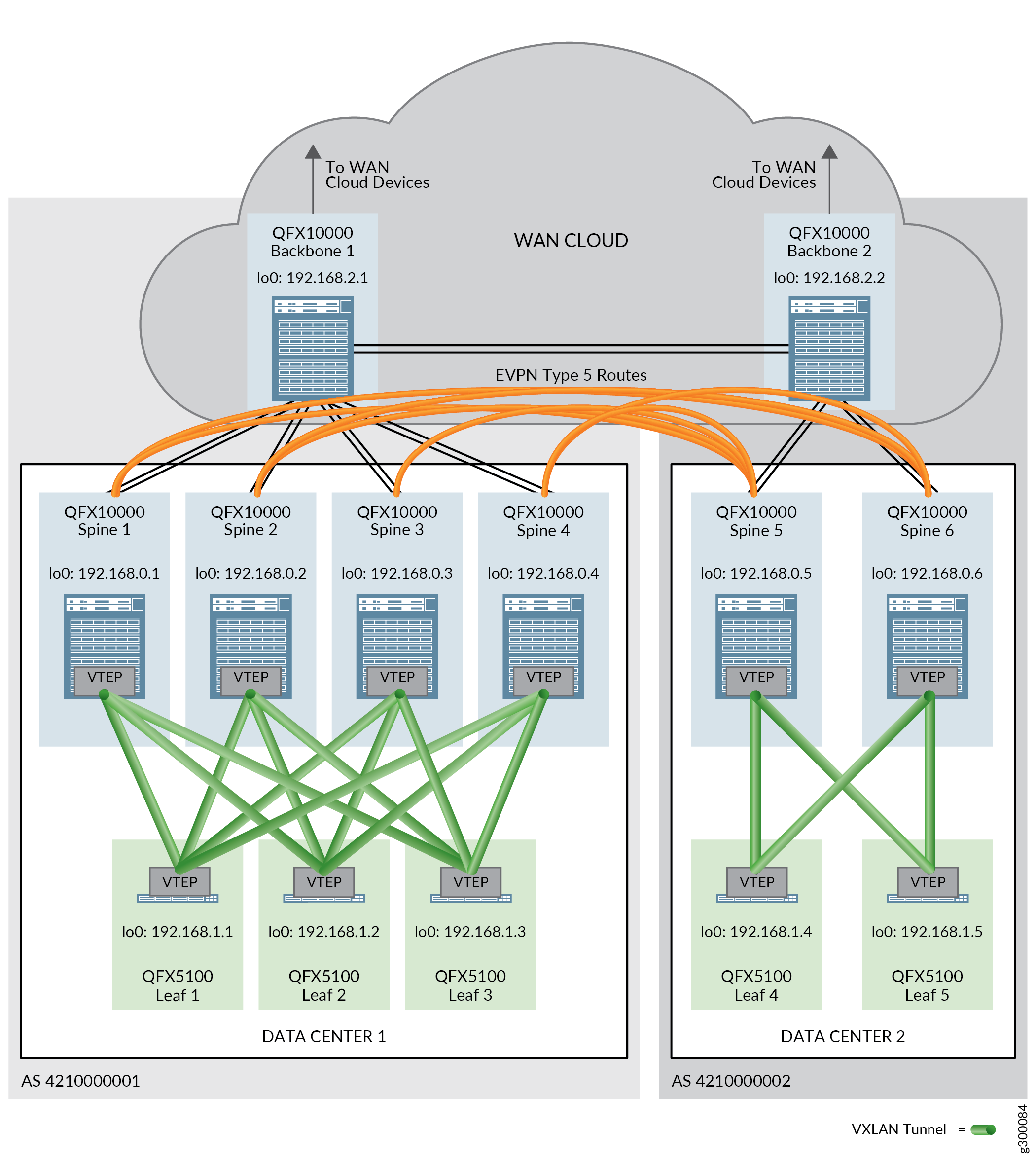
Physical connectivity between the data centers is required before you can configure DCI. The physical connectivity is provided by backbone devices in a WAN cloud. A backbone device is connected to all spine devices in a single data center (POD), as well as to the other backbone devices that are connected to the other data centers.
For information about configuring DCI, see:
Service Chaining
In many networks, it is common for traffic to flow through separate hardware devices that each provide a service, such as firewalls, NAT, IDP, multicast, and so on. Each device requires separate operation and management. This method of linking multiple network functions can be thought of as physical service chaining.
A more efficient model for service chaining is to virtualize and consolidate network functions onto a single device. In our blueprint architecture, we are using the SRX Series routers as the device that consolidates network functions and processes and applies services. That device is called a physical network function (PNF).
In this solution, service chaining is supported on both CRB overlay and ERB overlay. It works only for inter-tenant traffic.
Logical View of Service Chaining
Figure 17 shows a logical view of service chaining. It shows one spine with a right side configuration and a left side configuration. On each side is a VRF routing instance and an IRB interface. The SRX Series router in the center is the PNF, and it performs the service chaining.
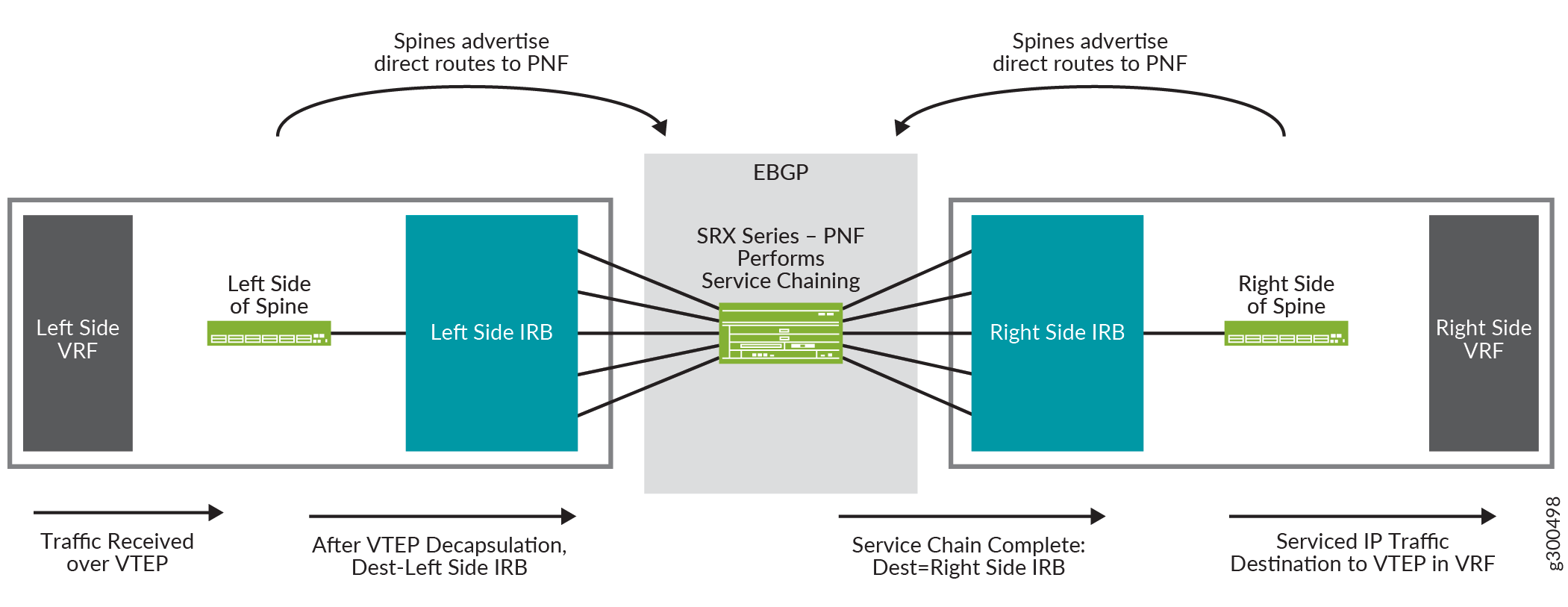
The flow of traffic in this logical view is:
-
The spine receives a packet on the VTEP that is in the left side VRF.
-
The packet is de-encapsulated and sent to the left side IRB interface.
-
The IRB interface routes the packet to the SRX Series router, which is acting as the PNF.
-
The SRX Series router performs service chaining on the packet and forwards the packet back to the spine, where it is received on the IRB interface shown on the right side of the spine.
-
The IRB interface routes the packet to the VTEP in the right side VRF.
For information about configuring service chaining, see Service Chaining Design and Implementation.
Multicast Optimizations
Multicast optimizations help to preserve bandwidth and more efficiently route traffic in a multicast scenario in EVPN VXLAN environments. Without any multicast optimizations configured, all multicast replication is done at the ingress of the leaf connected to the multicast source as shown in Figure 18. Multicast traffic is sent to all leaf devices that are connected to the spine. Each leaf device sends traffic to connected hosts.
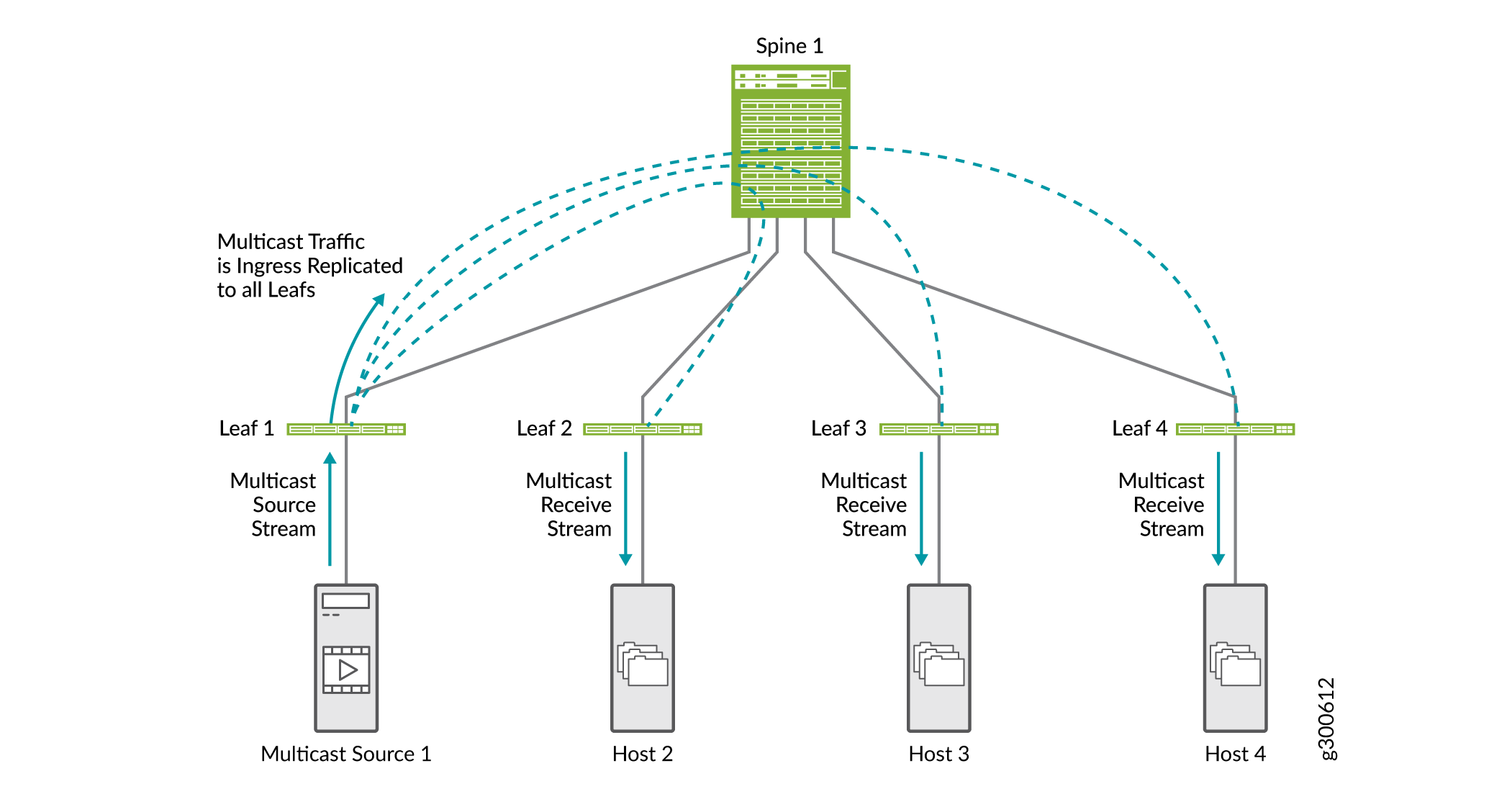
There are a few types of multicast optimizations supported in EVPN VXLAN environments that can work together:
For information about configuring multicast features, see:
- IGMP Snooping
- Selective Multicast Forwarding
- Assisted Replication of Multicast Traffic
- Optimized Intersubnet Multicast for ERB Overlay Networks
IGMP Snooping
IGMP snooping in an EVPN-VXLAN fabric is useful to optimize the distribution of multicast traffic. IGMP snooping preserves bandwidth because multicast traffic is forwarded only on interfaces where there are IGMP listeners. Not all interfaces on a leaf device need to receive multicast traffic.
Without IGMP snooping, end systems receive IP multicast traffic that they have no interest in, which needlessly floods their links with unwanted traffic. In some cases when IP multicast flows are large, flooding unwanted traffic causes denial-of-service issues.
Figure 19 shows how IGMP snooping works in an EVPN-VXLAN fabric. In this sample EVPN-VXLAN fabric, IGMP snooping is configured on all leaf devices, and multicast receiver 2 has previously sent an IGMPv2 join request.
-
Multicast Receiver 2 sends an IGMPv2 leave request.
-
Multicast Receivers 3 and 4 send an IGMPv2 join request.
-
When leaf 1 receives ingress multicast traffic, it replicates it for all leaf devices, and forwards it to the spine.
-
The spine forwards the traffic to all leaf devices.
-
Leaf 2 receives the multicast traffic, but does not forward it to the receiver because the receiver sent an IGMP leave message.
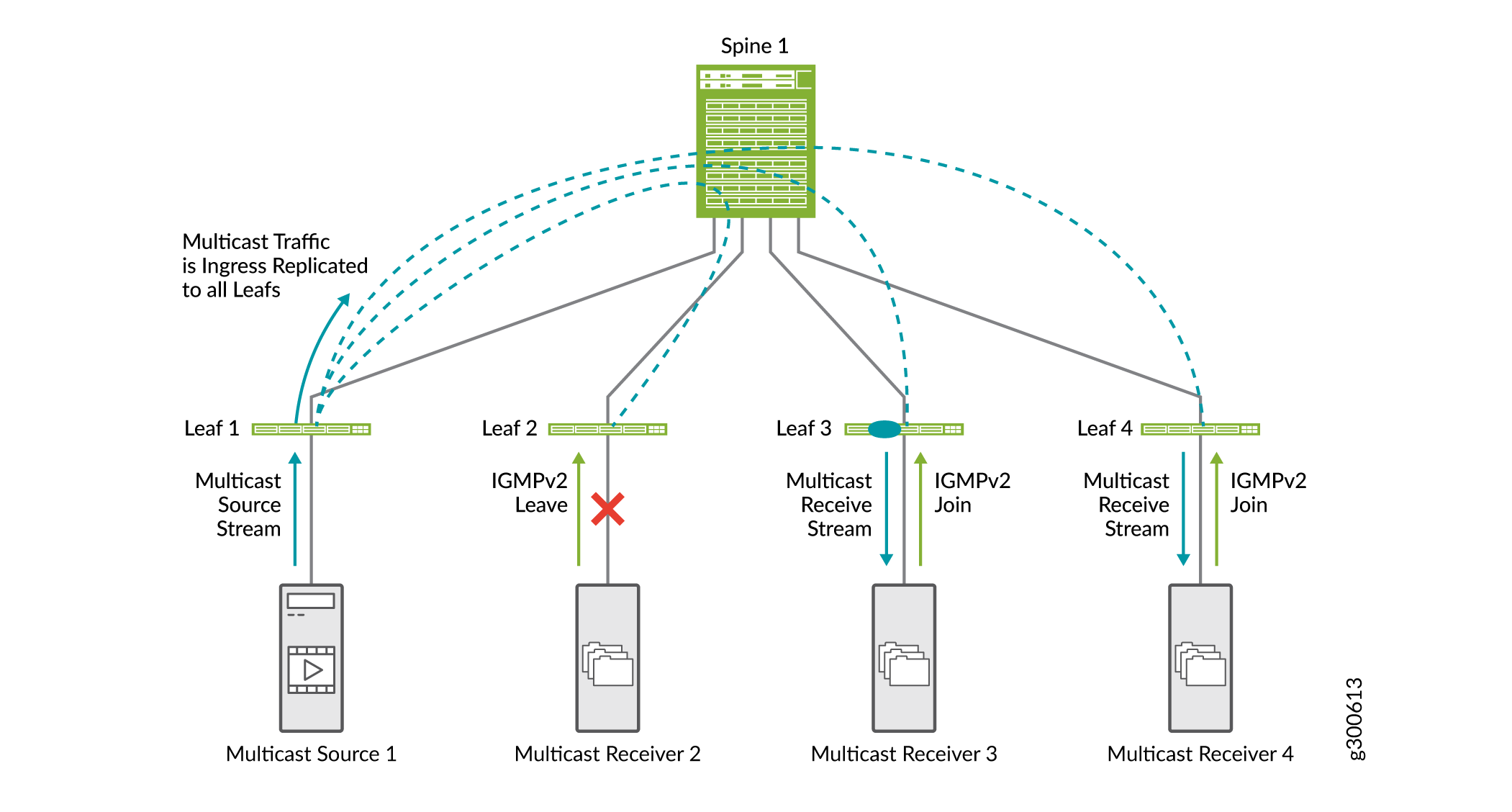
In EVPN-VXLAN networks only IGMP version 2 is supported.
For more information about IGMP snooping, see Overview of Multicast Forwarding with IGMP Snooping or MLD Snooping in an EVPN-VXLAN Environment.
Selective Multicast Forwarding
Selective multicast Ethernet (SMET) forwarding provides greater end-to-end network efficiency and reduces traffic in the EVPN network. It conserves bandwidth usage in the core of the fabric and reduces the load on egress devices that do not have listeners.
Devices with IGMP snooping enabled use selective multicast forwarding to forward multicast traffic in an efficient way. With IGMP snooping enabled a leaf device sends multicast traffic only to the access interface with an interested receiver. With SMET added, the leaf device selectively sends multicast traffic to only the leaf devices in the core that have expressed an interest in that multicast group.
Figure 20 shows the SMET traffic flow along with IGMP snooping.
-
Multicast Receiver 2 sends an IGMPv2 leave request.
-
Multicast Receivers 3 and 4 send an IGMPv2 join request.
-
When leaf 1 receives ingress multicast traffic, it replicates the traffic only to leaf devices with interested receivers (leaf devices 3 and 4), and forwards it to the spine.
-
The spine forwards the traffic to leaf devices 3 and 4.
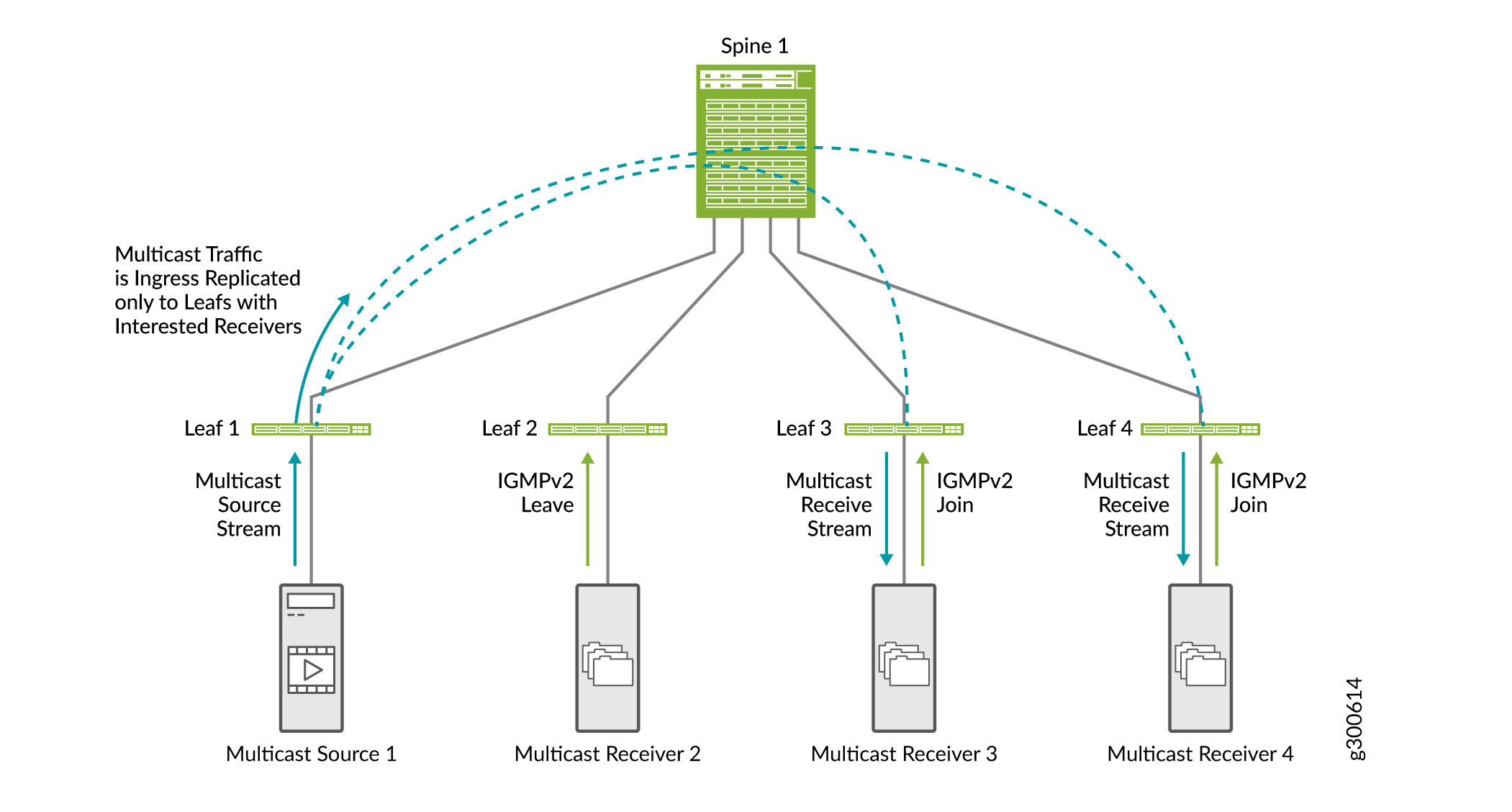
You do not need to enable SMET; it is enabled by default when IGMP snooping is configured on the device.
For more information about SMET, see Overview of Selective Multicast Forwarding.
Assisted Replication of Multicast Traffic
The assisted replication (AR) feature offloads EVPN-VXLAN fabric leaf devices from ingress replication tasks. The ingress leaf does not replicate multicast traffic. It sends one copy of the multicast traffic to a spine that is configured as an AR replicator device. The AR replicator device distributes and controls multicast traffic. In addition to reducing the replication load on the ingress leaf devices, this method conserves bandwidth in the fabric between the leaf and the spine.
Figure 21 shows how AR works along with IGMP snooping and SMET.
-
Leaf 1, which is set up as the AR leaf device, receives multicast traffic and sends one copy to the spine that is set up as the AR replicator device.
-
The spine replicates the multicast traffic. It replicates traffic for leaf devices that are provisioned with the VLAN VNI in which the multicast traffic originated from Leaf 1.
Because we have IGMP snooping and SMET configured in the network, the spine sends the multicast traffic only to leaf devices with interested receivers.
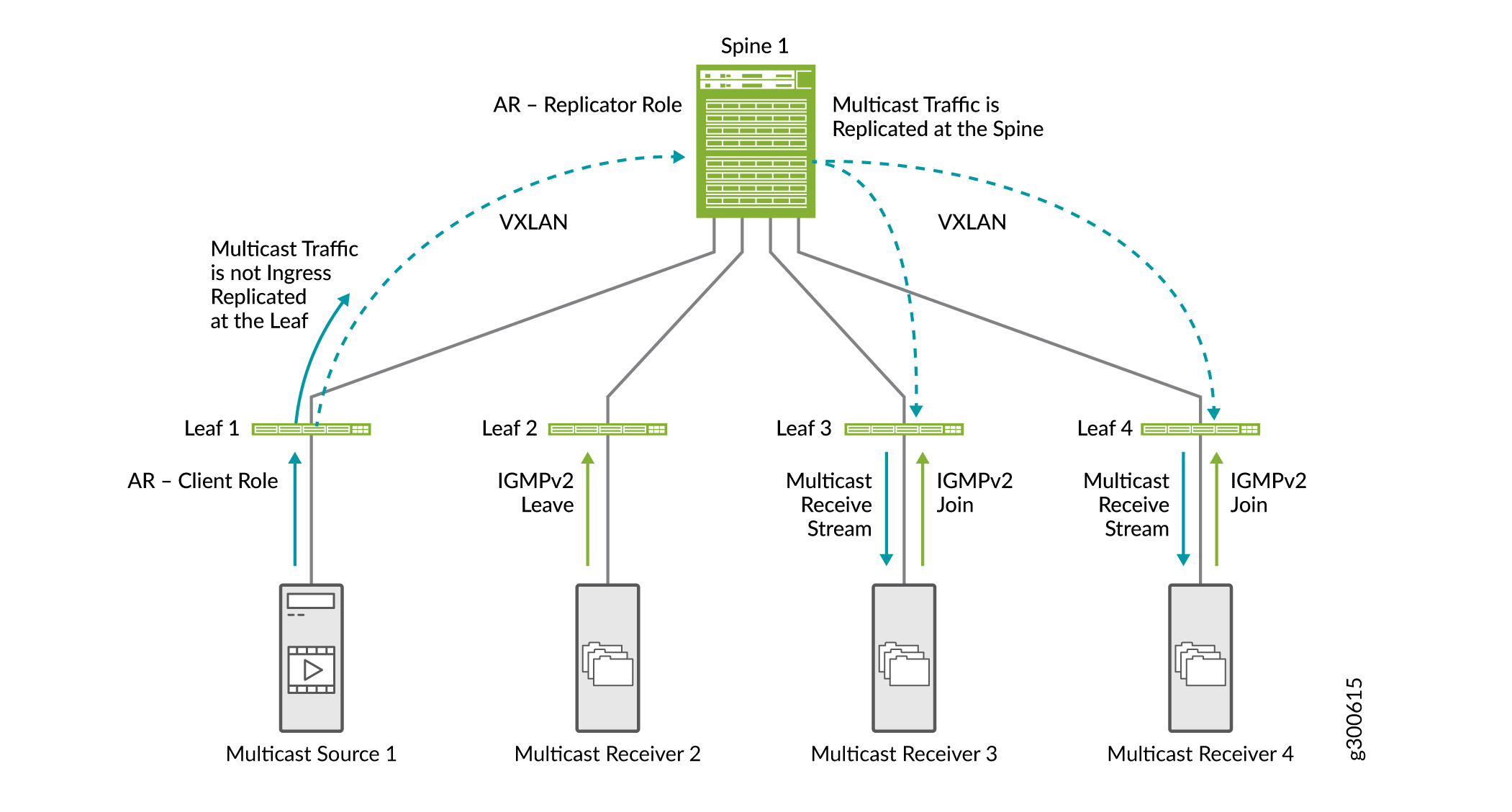
In this document, we show multicast optimizations on a small scale. In a full-scale network with many spines and leafs, the benefits of the optimizations are much more apparent.
Optimized Intersubnet Multicast for ERB Overlay Networks
When you have multicast sources and receivers both inside and outside an ERB overlay fabric, you can configure optimized intersubnet multicast (OISM) to enable efficient multicast traffic flow at scale.
OISM uses a local routing model for multicast traffic, which avoids traffic hairpinning and minimizes the traffic load within the EVPN core. OISM forwards multicast traffic only on the multicast source VLAN. For intersubnet receivers, the leaf devices use IRB interfaces to locally route the traffic received on the source VLAN to other receiver VLANs on the same device. To further optimize multicast traffic flow in the EVPN-VXLAN fabric, OISM uses IGMP snooping and SMET to forward traffic in the fabric only to leaf devices with interested receivers.
OISM also enables the fabric to effectively route traffic from external multicast sources to internal receivers, and from internal multicast sources to external receivers. OISM uses a supplemental bridge domain (SBD) within the fabric to forward multicast traffic received on the border leaf devices from outside sources. The SBD design preserves the local routing model for externally-sourced traffic.
You can use OISM with AR to reduce the replication load on lower-capacity OISM leaf devices. (See Assisted Replication of Multicast Traffic.)
See Figure 22 for a simple fabric with OISM and AR.
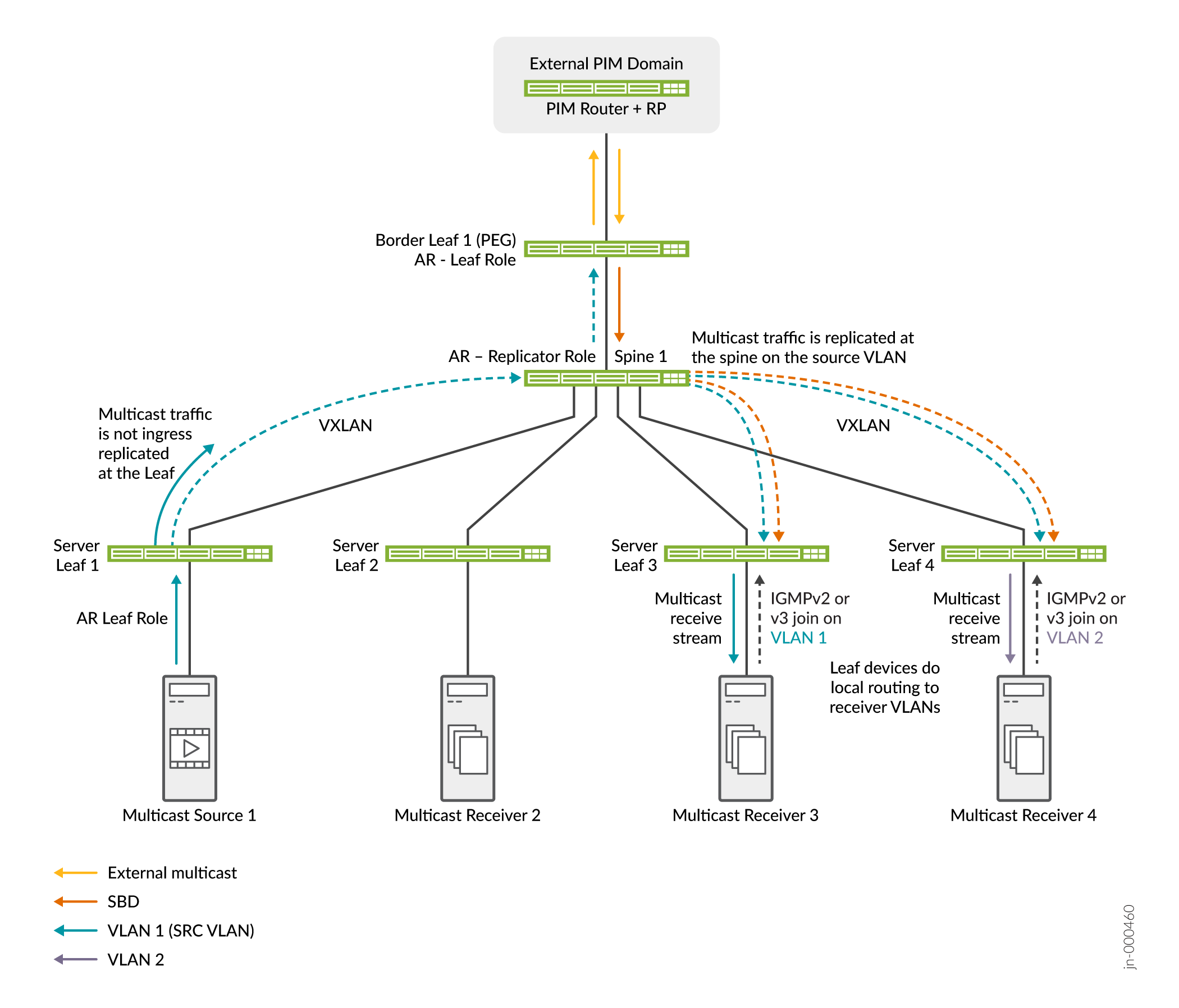
Figure 22 shows OISM server leaf and border leaf devices, Spine 1 in the AR replicator role, and Server Leaf 1 as a multicast source in the AR leaf role. An external source and receivers might also exist in the external PIM domain. OISM and AR work together in this scenario as follows:
-
Multicast receivers behind Server Leaf 3 on VLAN 1 and behind Server Leaf 4 on VLAN 2 send IGMP Joins showing interested in the multicast group. External receivers might also join the multicast group.
-
The multicast source behind Server Leaf 1 sends multicast traffic for the group into the fabric on VLAN 1. Server Leaf 1 sends only one copy of the traffic to the AR replicator on Spine 1.
-
Also, external source traffic for the multicast group arrives at Border Leaf 1. Border Leaf 1 forwards the traffic on the SBD to Spine 1, the AR replicator.
-
The AR replicator sends copies from the internal source on the source VLAN and from the external source on the SBD to the OISM leaf devices with interested receivers.
-
The server leaf devices forward the traffic to the receivers on the source VLAN, and locally route the traffic to the receivers on the other VLANs.
Ingress Virtual Machine Traffic Optimization for EVPN
When virtual machines and hosts are moved within a data center or from one data center to another, network traffic can become inefficient if the traffic is not routed to the optimal gateway. This can happen when a host is relocated. The ARP table does not always get flushed and data flow to the host is sent to the configured gateway even when there is a more optimal gateway. The traffic is “tromboned” and routed unnecessarily to the configured gateway.
Ingress Virtual Machine Traffic Optimization (VMTO) provides greater network efficiency and optimizes ingress traffic and can eliminate the trombone effect between VLANs. When you enable ingress VMTO, routes are stored in a Layer 3 virtual routing and forwarding (VRF) table and the device routes inbound traffic directly back to host that was relocated.
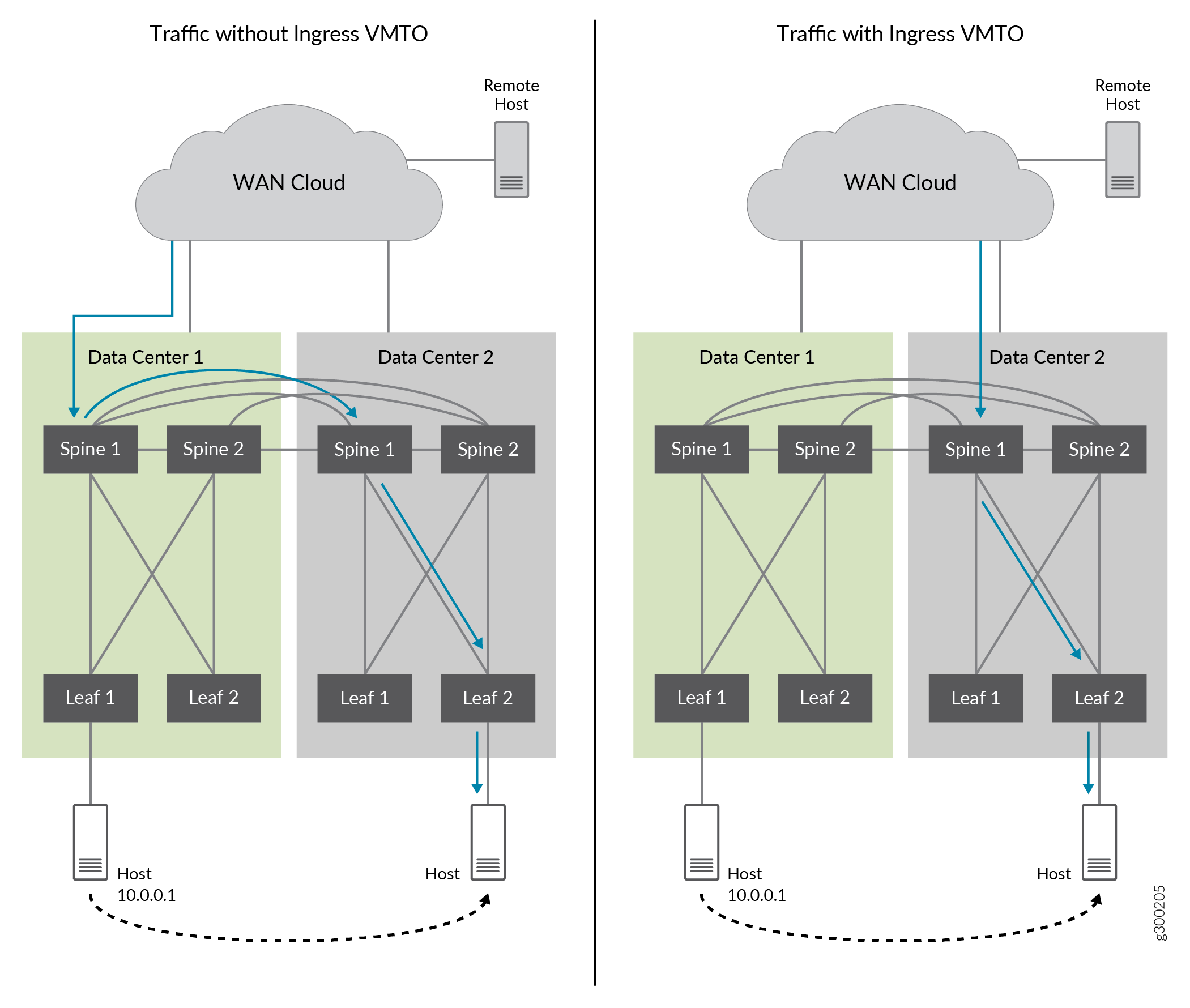
Figure 23 shows tromboned traffic without ingress VMTO and optimized traffic with ingress VMTO enabled.
Without ingress VMTO, Spine 1 and 2 from DC1 and DC2 all advertise the remote IP host route 10.0.0.1 when the origin route is from DC2. The ingress traffic can be directed to either Spine 1 and 2 in DC1. It is then routed to Spine 1 and 2 in DC2 where route 10.0.0.1 was moved. This causes the tromboning effect.
With ingress VMTO, we can achieve optimal forwarding path by configuring a policy for IP host route (10.0.01) to only be advertised by Spine 1 and 2 from DC2, and not from DC1 when the IP host is moved to DC2.
For information about configuring VMTO, see Configuring VMTO.
DHCP Relay

The Dynamic Host Configuration Protocol (DHCP) relay building block allows the network to pass DHCP messages between a DHCP client and a DHCP server. The DHCP relay implementation in this building block moves DHCP packets through a CRB overlay where the gateway is located at the spine layer.
The DHCP server and the DHCP clients connect into the network using access interfaces on leaf devices. The DHCP server and clients can communicate with each other over the existing network without further configuration when the DHCP client and server are in the same VLAN. When a DHCP client and server are in different VLANs, DHCP traffic between the client and server is forwarded between the VLANs via the IRB interfaces on spine devices. You must configure the IRB interfaces on the spine devices to support DHCP relay between VLANs.
For information about implementing the DHCP relay, see DHCP Relay Design and Implementation.
Reducing ARP Traffic with ARP Synchronization and Suppression (Proxy ARP)
The goal of ARP synchronization is to synchronize ARP tables across all the VRFs that serve an overlay subnet to reduce the amount of traffic and optimize processing for both network devices and end systems. When an IP gateway for a subnet learns about an ARP binding, it shares it with other gateways so they do not need to discover the same ARP binding independently.
With ARP suppression, when a leaf device receives an ARP request, it checks its own ARP table that is synchronized with the other VTEP devices and responds to the request locally rather than flooding the ARP request.
Proxy ARP and ARP suppression are enabled by default on all QFX Series switches that can act as leaf devices in an ERB overlay. For a list of these switches, see Data Center EVPN-VXLAN Fabric Reference Designs—Supported Hardware Summary.
IRB interfaces on the leaf device deliver ARP requests and NDP requests from both local and remote leaf devices. When a leaf device receives an ARP request or NDP request from another leaf device, the receiving device searches its MAC+IP address bindings database for the requested IP address.
If the device finds the MAC+IP address binding in its database, it responds to the request.
If the device does not find the MAC+IP address binding, it floods the ARP request to all Ethernet links in the VLAN and the associated VTEPs.
Because all participating leaf devices add the ARP entries and synchronize their routing and bridging tables, local leaf devices respond directly to requests from locally connected hosts and remove the need for remote devices to respond to these ARP requests.
For information about implementing the ARP synchronization, Proxy ARP, and ARP suppression, see Enabling Proxy ARP and ARP Suppression for the Edge-Routed Bridging Overlay.
Layer 2 Port Security Features on Ethernet-Connected End Systems
CRB and ERB overlays support the security features on Layer 2 Ethernet-connected end systems that we describe in the next sections.
For more information about these features, see MAC Filtering, Storm Control, and Port Mirroring Support in an EVPN-VXLAN Environment.
For information about configuring these features, see Configuring Layer 2 Port Security Features on Ethernet-Connected End Systems.
- Preventing BUM Traffic Storms With Storm Control
- Using MAC Filtering to Enhance Port Security
- Analyzing Traffic Using Port Mirroring
Preventing BUM Traffic Storms With Storm Control
Storm control can prevent excessive traffic from degrading the network. It lessens the impact of BUM traffic storms by monitoring traffic levels on EVPN-VXLAN interfaces, and dropping BUM traffic when a specified traffic level is exceeded.
In an EVPN-VXLAN environment, storm control monitors:
Layer 2 BUM traffic that originates in a VXLAN and is forwarded to interfaces within the same VXLAN.
Layer 3 multicast traffic that is received by an IRB interface in a VXLAN and is forwarded to interfaces in another VXLAN.
Using MAC Filtering to Enhance Port Security
MAC filtering enhances port security by limiting the number of MAC addresses that can be learned within a VLAN and therefore limit the traffic in a VXLAN. Limiting the number of MAC addresses protects the switch from flooding the Ethernet switching table. Flooding of the Ethernet switching table occurs when the number of new MAC addresses that are learned causes the table to overflow, and previously learned MAC addresses are flushed from the table. The switch relearns the MAC addresses, which can impact performance and introduce security vulnerabilities.
In this blueprint, MAC filtering limits the number of accepted packets that are sent to ingress-facing access interfaces based on MAC addresses. For more information about how MAC filtering works, see the MAC limiting information in Understanding MAC Limiting and MAC Move Limiting.
Analyzing Traffic Using Port Mirroring
With analyzer-based port mirroring, you can analyze traffic down to the packet level in an EVPN-VXLAN environment. You can use this feature to enforce policies related to network usage and file sharing and to identify problem sources by locating abnormal or heavy bandwidth usage by particular stations or applications.
Port mirroring copies packets entering or exiting a port or entering a VLAN and sends the copies to a local interface for local monitoring or to a VLAN for remote monitoring. Use port mirroring to send traffic to applications that analyze traffic for purposes such as monitoring compliance, enforcing policies, detecting intrusions, monitoring and predicting traffic patterns, correlating events, and so on.