EN ESTA PÁGINA
Soporte de multiconexión para sistemas finales conectados por Ethernet
Soporte de multiconexión para sistemas finales conectados a IP
Optimización del tráfico de la máquina virtual de entrada para EVPN
Reducción del tráfico ARP con sincronización y supresión de ARP (ARP de proxy)
Características de seguridad del puerto de capa 2 en sistemas finales conectados a Ethernet
Componentes de la arquitectura de planos de la estructura del centro de datos
En esta sección, se ofrece una descripción general de los componentes básicos que se utilizan en esta arquitectura de modelo. La implementación de cada tecnología de bloques de construcción se explora con más detalle en secciones posteriores.
Para obtener información sobre el hardware y el software que sirven de base para sus bloques de construcción, consulte el Resumen de diseños de referencia de estructuras EVPN-VXLAN de centros de datos: hardware compatible.
Los componentes básicos incluyen:
Red subyacente de estructura IP
El bloque de construcción de red subyacente de estructura IP moderna proporciona conectividad IP a través de una topología basada en Clos. Juniper Networks admite los siguientes modelos subyacentes de estructura IP:
-
Una estructura IP de 3 etapas, que se compone de un nivel de dispositivos spine y un nivel de dispositivos leaf. Vea la Figura 1.
-
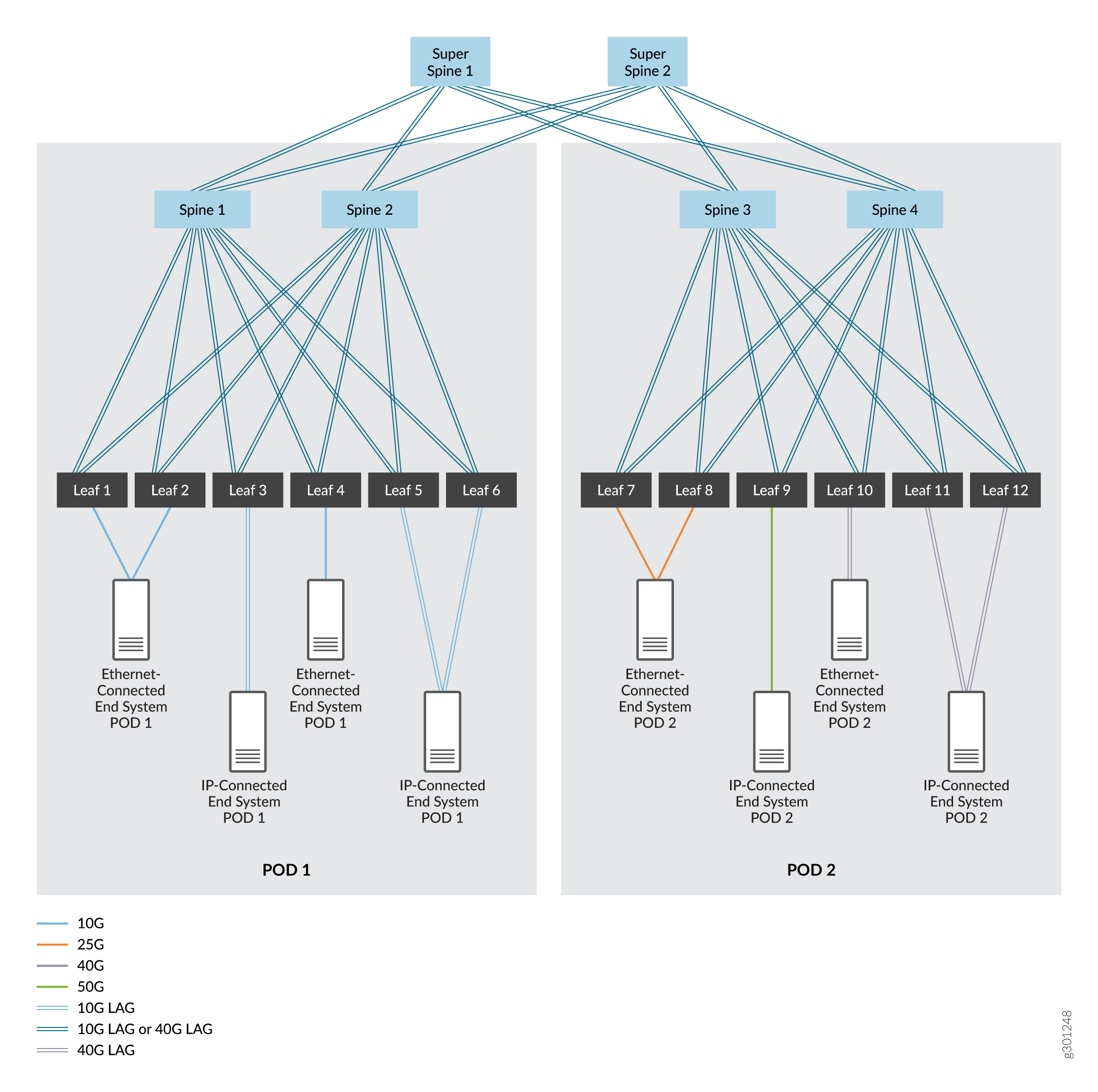
Una estructura IP de 5 etapas, que normalmente comienza como una única estructura IP de 3 etapas que se convierte en dos estructuras IP de 3 etapas. Estas estructuras se segmentan en puntos de entrega (POD) separados dentro de un centro de datos. Para este caso de uso, admitimos la adición de un nivel de dispositivos súper spine que permiten la comunicación entre los dispositivos spine y leaf en los dos POD. Vea la Figura 2.
-
Un modelo de estructura IP de spine colapsada, en el que las funciones de capa de hoja se colapsan en los dispositivos spine. Este tipo de estructura se puede configurar y operar de manera similar a una estructura IP de 3 o 5 etapas, excepto sin un nivel separado de dispositivos leaf. Puede usar una estructura spine colapsada si se está moviendo incrementalmente a un modelo spine-and-leaf de EVPN, o si tiene dispositivos de acceso o dispositivos de la parte superior del rack (TOR) que no se pueden usar en una capa de hoja porque no admiten EVPN-VXLAN.
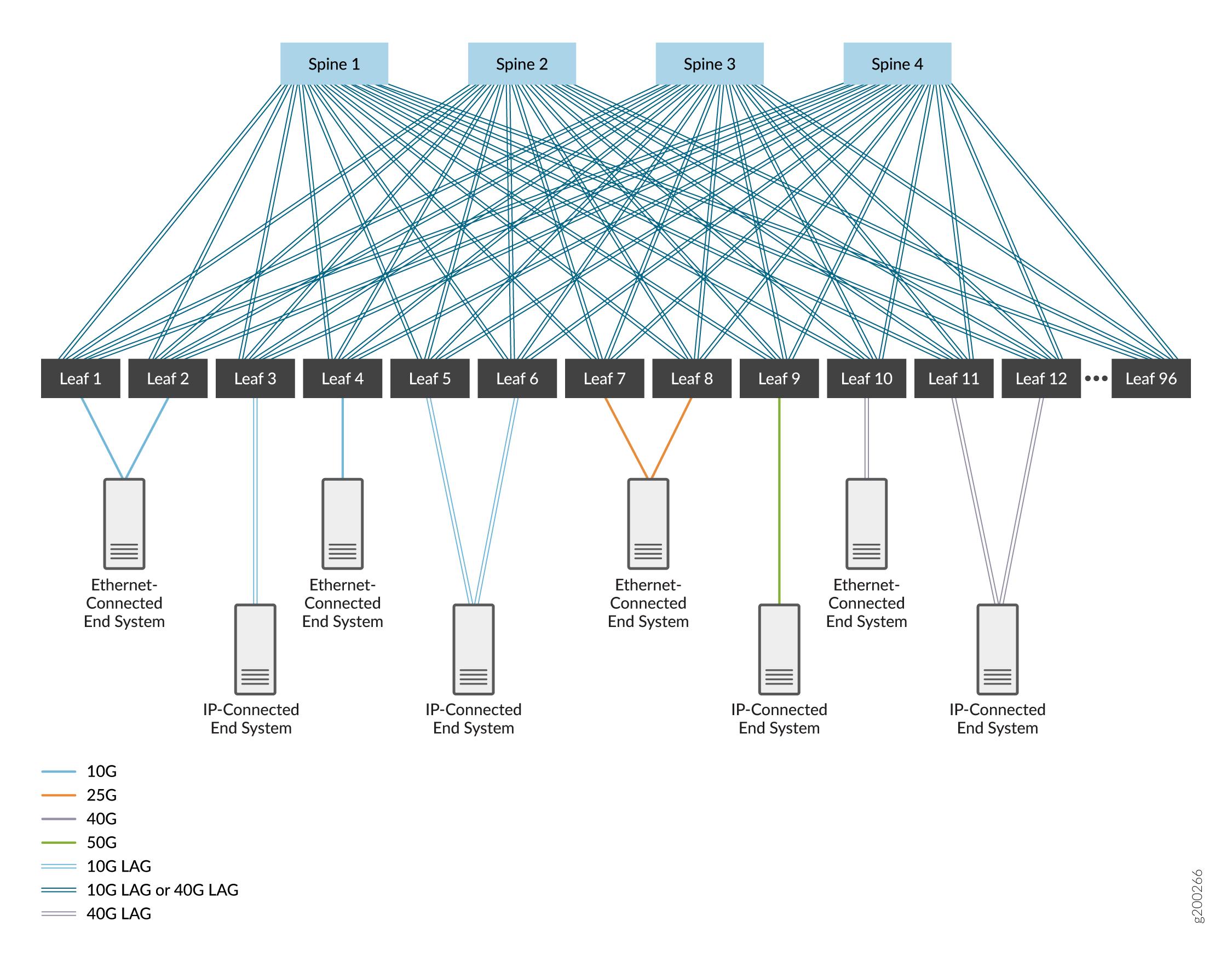 de la estructura IP de tres etapas
de la estructura IP de tres etapas
En estas figuras, los dispositivos están interconectados mediante interfaces de alta velocidad que son vínculos únicos o interfaces Ethernet agregadas. Las interfaces Ethernet agregadas son opcionales (normalmente se usa un único vínculo entre dispositivos), pero se pueden implementar para aumentar el ancho de banda y proporcionar redundancia a nivel de vínculo. Cubrimos ambas opciones.
Elegimos EBGP como protocolo de enrutamiento en la red subyacente por su confiabilidad y escalabilidad. A cada dispositivo se le asigna su propio sistema autónomo con un número de sistema autónomo único para admitir EBGP. Puede utilizar otros protocolos de enrutamiento en la red subyacente; El uso de esos protocolos está fuera del alcance de este documento.
Los diseños de arquitectura de referencia descritos en esta guía se basan en una estructura IP que utiliza EBGP para la conectividad subyacente y IBGP para el emparejamiento de superposiciones (consulte IBGP para superposiciones). También puede configurar el emparejamiento de superposición mediante EBGP.
A partir de las versiones 21.2R2 y 21.4R1 de Junos OS, también admitimos la configuración de una estructura IPv6. El diseño de la estructura IPv6 de esta guía utiliza EBGP tanto para la conectividad subyacente como para el emparejamiento de superposiciones (consulte EBGP para superposiciones con bases IPv6).
La estructura de IP puede usar IPv4 o IPv6 de la siguiente manera:
-
Una estructura IPv4 utiliza direccionamiento de interfaz IPv4 y sesiones de BGP subyacentes y superpuestas IPv4 para la comunicación de carga de trabajo de extremo a extremo.
-
Una estructura IPv6 utiliza direccionamiento de interfaz IPv6 y sesiones de BGP subyacentes y superpuestas IPv6 para la comunicación de carga de trabajo de extremo a extremo.
-
No admitimos una estructura de IP que combine IPv4 e IPv6.
Sin embargo, tanto las estructuras IPv4 como las estructuras IPv6 admiten cargas de trabajo de doble pila: las cargas de trabajo pueden ser IPv4 o IPv6, o IPv4 e IPv6.
La detección de reenvío bidireccional micro (BFD), la capacidad de ejecutar BFD en vínculos individuales en una interfaz de Ethernet agregada, también se puede habilitar en este bloque de construcción para detectar rápidamente fallas de vínculos en cualquier vínculo de miembro en paquetes de Ethernet agregados que conectan dispositivos.
Para obtener más información, consulte estas otras secciones de esta guía:
-
Configuración de dispositivos spine y leaf en bases de estructura IP de 3 y 5 etapas: Diseño e implementación de red subyacente de estructura IP.
-
Implementación del nivel adicional de dispositivos súper spine en una estructura IP subyacente de 5 etapas: Diseño e implementación de estructuras IP de cinco etapas.
-
Configuración de una base IPv6 y soporte de la superposición IPv6 del EBGP: Redes subyacentes y de superposición de la estructura IPv6 Diseño e implementación de red con EBGP.
-
Configuración de la capa subyacente en un modelo de estructura de spine colapsada: Diseño e implementación de estructuras de estructura de spine colapsada.
Soporte de cargas de trabajo IPv4 e IPv6
Dado que muchas redes implementan un entorno de doble pila para cargas de trabajo que incluye protocolos IPv4 e IPv6, este modelo proporciona compatibilidad con ambos protocolos. Los pasos para configurar la estructura para que admita cargas de trabajo IPv4 e IPv6 se entrelazan a lo largo de esta guía para permitirle elegir uno o ambos protocolos.
El protocolo IP que se utiliza para el tráfico de carga de trabajo es independiente de la versión del protocolo IP (IPv4 o IPv6) que configure para la capa subyacente y superpuesta de la estructura IP. ( Consulte Red subyacente de estructura IP.) Una infraestructura de estructura IPv4 o de estructura IPv6 puede admitir cargas de trabajo IPv4 e IPv6.
Superposiciones de virtualización de red
Una superposición de virtualización de red es una red virtual que se transporta a través de una red subyacente IP. Este bloque de construcción permite la multitenencia en una red, lo que le permite compartir una única red física entre varios inquilinos, a la vez que mantiene el tráfico de red de cada inquilino aislado de los demás inquilinos.
Un inquilino es una comunidad de usuarios (como una unidad de negocio, un departamento, un grupo de trabajo o una aplicación) que contiene grupos de puntos de conexión. Los grupos pueden comunicarse con otros grupos en el mismo arrendamiento y los inquilinos pueden comunicarse con otros inquilinos si lo permiten las políticas de red. Un grupo se expresa normalmente como una subred (VLAN) que puede comunicarse con otros dispositivos en la misma subred y llegar a grupos y puntos de conexión externos mediante una instancia de enrutamiento y reenvío virtual (VRF).
Como se ve en el ejemplo de superposición que se muestra en la Figura 3, las tablas de puentes Ethernet (representadas por triángulos) manejan las tramas puente de inquilinos y las tablas de enrutamiento IP (representadas por cuadrados) procesan paquetes enrutados. El enrutamiento entre VLAN se produce en las interfaces de enrutamiento y puente integrados (IRB) (representadas por círculos). Las tablas Ethernet e IP se dirigen a redes virtuales (representadas por líneas de colores). Para llegar a los sistemas finales conectados a otros dispositivos VXLAN Tunnel Endpoint (VTEP), los paquetes de inquilino se encapsulan y se envían a través de un túnel VXLAN señalizado por EVPN (representado por iconos de túnel verdes) a los dispositivos VTEP remotos asociados. Los paquetes en túnel se desencapsulan en los dispositivos VTEP remotos y se reenvían a los sistemas finales remotos a través de las respectivas tablas de enrutamiento o puente del dispositivo VTEP de salida.
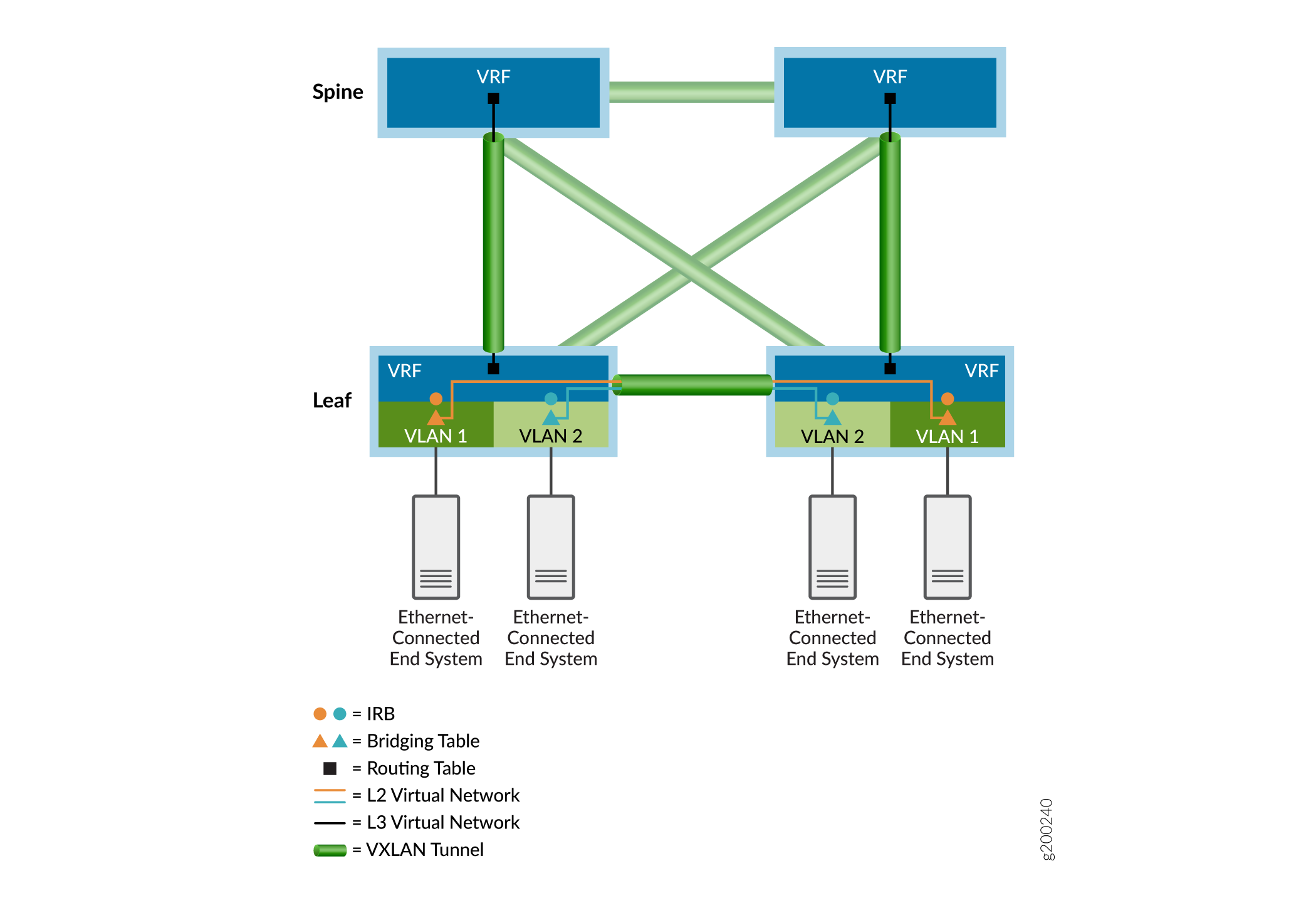
En las siguientes secciones se proporcionan más detalles sobre las redes superpuestas.
- IBGP para superposiciones
- EBGP para superposiciones con bases IPv6
- superposición en puente
- Superposición de puentes con enrutamiento centralizado
- Superposición de puentes enrutados en el borde
- Superposición de spine colapsada
- Comparación de superposiciones en puente, CRB y ERB
- Modelos de direccionamiento IRB en superposiciones de puentes
- Superposición enrutada mediante rutas EVPN tipo 5
- Instancias MAC-VRF para multitenencia en superposiciones de virtualización de red
IBGP para superposiciones
El BGP interno (IBGP) es un protocolo de enrutamiento que intercambia información de accesibilidad a través de una red IP. Cuando el IBGP se combina con el BGP multiprotocolo (MP-IBGP), proporciona la base para que EVPN intercambie información de accesibilidad entre dispositivos VTEP. Esta capacidad es necesaria para establecer túneles VXLAN entre VTEP y usarlos para servicios de conectividad superpuestos.
La figura 4 muestra que los dispositivos spine y leaf utilizan sus direcciones de circuito cerrado para el emparejamiento en un único sistema autónomo. En este diseño, los dispositivos spine actúan como un clúster de reflector de ruta y los dispositivos leaf son clientes de reflector de ruta. Un reflector de ruta satisface el requisito del IBGP para una malla completa sin la necesidad de emparejar todos los dispositivos VTEP directamente entre sí. Como resultado, los dispositivos leaf solo se emparejan con los dispositivos spine y los dispositivos spine se emparejan con dispositivos spine y dispositivos leaf. Dado que los dispositivos spine están conectados a todos los dispositivos leaf, los dispositivos spine pueden retransmitir información de IBGP entre los vecinos del dispositivo leaf emparejados indirectamente.
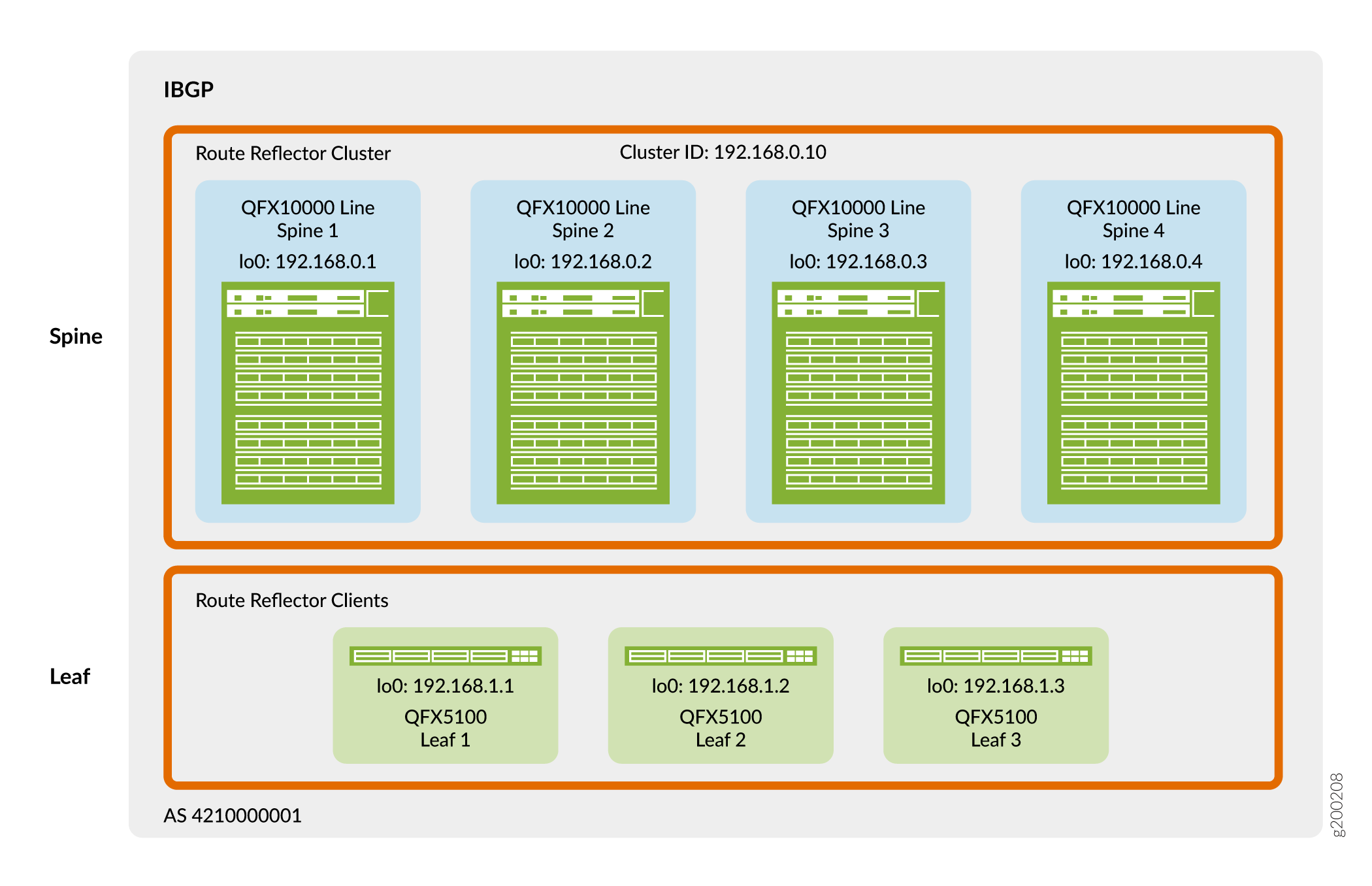
Puede colocar reflectores de ruta en casi cualquier lugar de la red. Sin embargo, debe considerar lo siguiente:
-
¿El dispositivo seleccionado tiene suficiente memoria y potencia de procesamiento para manejar la carga de trabajo adicional que requiere un reflector de ruta?
-
¿El dispositivo seleccionado es equidistante y accesible desde todos los altavoces EVPN?
-
¿El dispositivo seleccionado tiene las capacidades de software adecuadas?
En este diseño, el clúster reflector de ruta se coloca en la capa spine. Los conmutadores QFX que puede utilizar como spine en este diseño de referencia tienen una velocidad de procesamiento suficiente para manejar el tráfico de cliente de reflector de ruta en la superposición de virtualización de red.
Para obtener más información sobre cómo implementar IBGP en una superposición, consulte Configurar IBGP para la superposición.
EBGP para superposiciones con bases IPv6
Los casos de uso de arquitectura de referencia originales en esta guía ilustran un diseño subyacente de EBGP IPv4 con conectividad de dispositivo de superposición de IBGP IPv4. Consulte Red subyacente de estructura IP y IBGP para obtener superposiciones. Sin embargo, a medida que los dispositivos de borde de virtualización de red (NVE) comienzan a adoptar VTEP IPv6 para aprovechar el rango de direccionamiento extendido y las capacidades de IPv6, hemos ampliado el soporte de la estructura IP para abarcar IPv6.
A partir de Junos OS versión 21.2R2-S1, en las plataformas compatibles puede usar alternativamente una infraestructura de estructura IPv6 con algunos diseños de superposición de arquitectura de referencia. El diseño de la estructura IPv6 comprende direccionamiento de interfaz IPv6, una capa subyacente de EBGP IPv6 y una superposición de EBGP IPv6 para la conectividad de la carga de trabajo. Con una estructura IPv6, los dispositivos NVE encapsulan el encabezado VXLAN con un encabezado externo IPv6 y túnel los paquetes a través de la estructura de extremo a extremo mediante los siguientes saltos IPv6. La carga de trabajo puede ser IPv4 o IPv6.
La mayoría de los elementos que configure en los diseños de superposición de arquitectura de referencia compatibles son independientes de si la infraestructura subyacente y de superposición utiliza IPv4 o IPv6. Los procedimientos de configuración correspondientes para cada uno de los diseños de superposición compatibles señalan cualquier diferencia de configuración si la capa subyacente y la superpuesta utilizan el diseño de estructura IPv6.
Para obtener más detalles, consulte las siguientes referencias en esta guía y otros recursos:
Configuración de una estructura IPv6 mediante EBGP para la conectividad subyacente y el emparejamiento de superposición: Diseño e implementación de redes subyacentes y superpuestas de estructura IPv6 con EBGP.
A partir de versiones en las que diferentes plataformas admiten un diseño de estructura IPv6 cuando se prestan funciones específicas en la estructura: Diseños de referencia de estructura EVPN-VXLAN de centro de datos: resumen de hardware compatible.
Descripción general de la compatibilidad de emparejamiento de capas superpuestas y subyacentes IPv6 en estructuras EVPN-VXLAN en dispositivos de Juniper Networks: EVPN-VXLAN con una base IPv6.
superposición en puente
El primer tipo de servicio de superposición descrito en esta guía es una superposición en puente, como se muestra en la Figura 5.
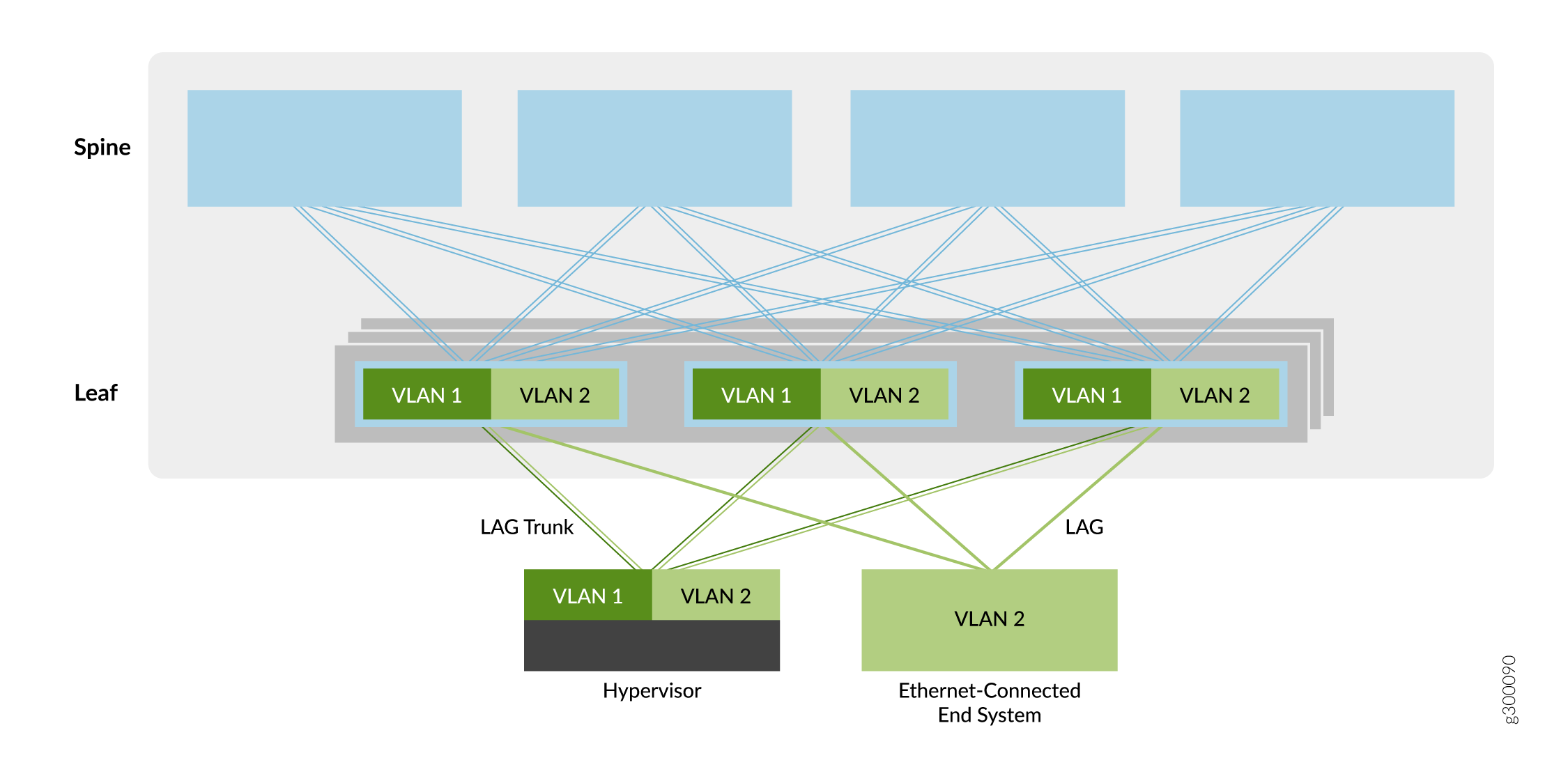 en puente
en puente
En este modelo de superposición, las VLAN Ethernet se extienden entre dispositivos leaf a través de túneles VXLAN. Estos túneles VXLAN de hoja a hoja admiten redes de centros de datos que requieren conectividad Ethernet entre dispositivos leaf, pero no necesitan enrutamiento entre las redes VLAN. Como resultado, los dispositivos spine solo proporcionan conectividad básica subyacente y de superposición para los dispositivos leaf, y no realizan servicios de enrutamiento o puerta de enlace vistos con otros métodos de superposición.
Los dispositivos leaf originan VTEP para conectarse a los otros dispositivos leaf. Los túneles permiten que los dispositivos leaf envíen tráfico de VLAN a otros dispositivos leaf y sistemas finales conectados a Ethernet en el centro de datos. La simplicidad de este servicio de superposición lo hace atractivo para los operadores que necesitan una forma sencilla de introducir EVPN/VXLAN en su centro de datos existente basado en Ethernet.
Puede agregar enrutamiento a una superposición en puente implementando un enrutador de la serie MX o un dispositivo de seguridad de la serie SRX externo a la estructura EVPN/VXLAN. De lo contrario, puede seleccionar uno de los otros tipos de superposición que incorporen enrutamiento (como una superposición de puente enrutado en el eje, una superposición de puente enrutado centralmente o una superposición enrutada).
Para obtener información sobre cómo implementar una superposición en puente, consulte Diseño e implementación de superposición en puente.
Superposición de puentes con enrutamiento centralizado
El segundo tipo de servicio de superposición es la superposición de puente de enrutamiento centralizado (CRB), como se muestra en la Figura 6.
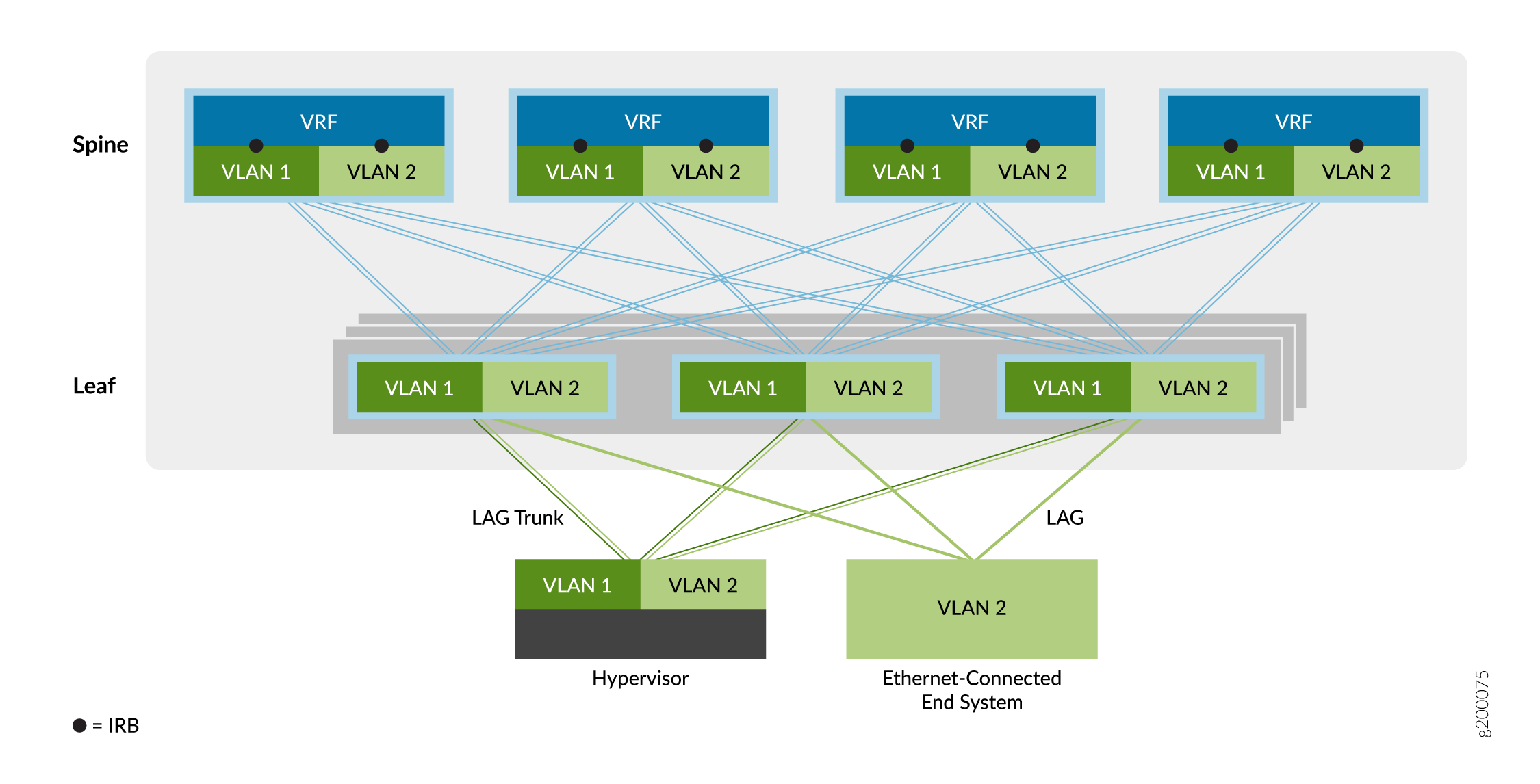 de puentes enrutados centralmente
de puentes enrutados centralmente
En una superposición CRB, el enrutamiento se produce en una puerta de enlace central de la red del centro de datos (la capa spine en este ejemplo) en lugar de en el dispositivo VTEP donde están conectados los sistemas finales (la capa leaf en este ejemplo).
Puede utilizar este modelo de superposición cuando necesite que el tráfico enrutado pase por una puerta de enlace centralizada o cuando sus dispositivos VTEP de borde carezcan de las capacidades de enrutamiento necesarias.
Como se mostró anteriormente, el tráfico que se origina en los sistemas finales conectados a Ethernet se reenvía a los dispositivos leaf VTEP a través de un puerto troncal (varias VLAN) o un puerto de acceso (una sola VLAN). El dispositivo VTEP reenvía el tráfico a sistemas finales locales o a un sistema final en un dispositivo VTEP remoto. Una interfaz de enrutamiento y puente integrados (IRB) en cada dispositivo spine ayuda a enrutar el tráfico entre las redes virtuales de Ethernet.
El modelo de servicio de superposición de puente compatible con VLAN le permite agregar fácilmente una colección de VLAN en la misma red virtual superpuesta. El diseño de EVPN de Juniper Networks admite tres configuraciones de modelo de servicio Ethernet compatibles con VLAN en el centro de datos, como se indica a continuación:
-
Default instance VLAN-aware: con esta opción, implementa una única instancia de conmutación predeterminada que admite un total de 4094 VLAN. Todas las plataformas leaf incluidas en este diseño (diseños de referencia de estructura EVPN-VXLAN de centro de datos: resumen de hardware compatible) admiten el estilo de instancia predeterminado de superposición compatible con VLAN.
Para configurar este modelo de servicio, consulte Configuración de una superposición de puente enrutado centralmente compatible con VLAN en la instancia predeterminada.
-
Virtual switch VLAN-aware: con esta opción, varias instancias de conmutador virtual admiten hasta 4094 VLAN por instancia. Este modelo de servicio Ethernet es ideal para redes superpuestas que requieren escalabilidad más allá de una única instancia predeterminada. La compatibilidad con esta opción está disponible actualmente en la línea QFX10000 de conmutadores.
Para implementar este modelo de servicio escalable, consulte Configurar una superposición CRB compatible con VLAN con conmutadores virtuales o instancias de MAC-VRF.
-
MAC-VRF instance VLAN-aware: con esta opción, varias instancias MAC-VRF admiten hasta 4094 VLAN por instancia. Este modelo de servicio Ethernet es ideal para redes superpuestas que requieren escalabilidad más allá de una única instancia predeterminada y en las que desea tener más opciones para garantizar el aislamiento o la interconexión de VLAN entre diferentes inquilinos de la misma estructura. La compatibilidad con esta opción está disponible en las plataformas que admiten instancias MAC-VRF (consulte Explorador de características: MAC VRF con EVPN-VXLAN).
Para implementar este modelo de servicio escalable, consulte Configurar una superposición CRB compatible con VLAN con conmutadores virtuales o instancias de MAC-VRF.
Superposición de puentes enrutados en el borde
La tercera opción de servicio de superposición es la superposición de puente enrutado en el borde (ERB), como se muestra en la Figura 7.
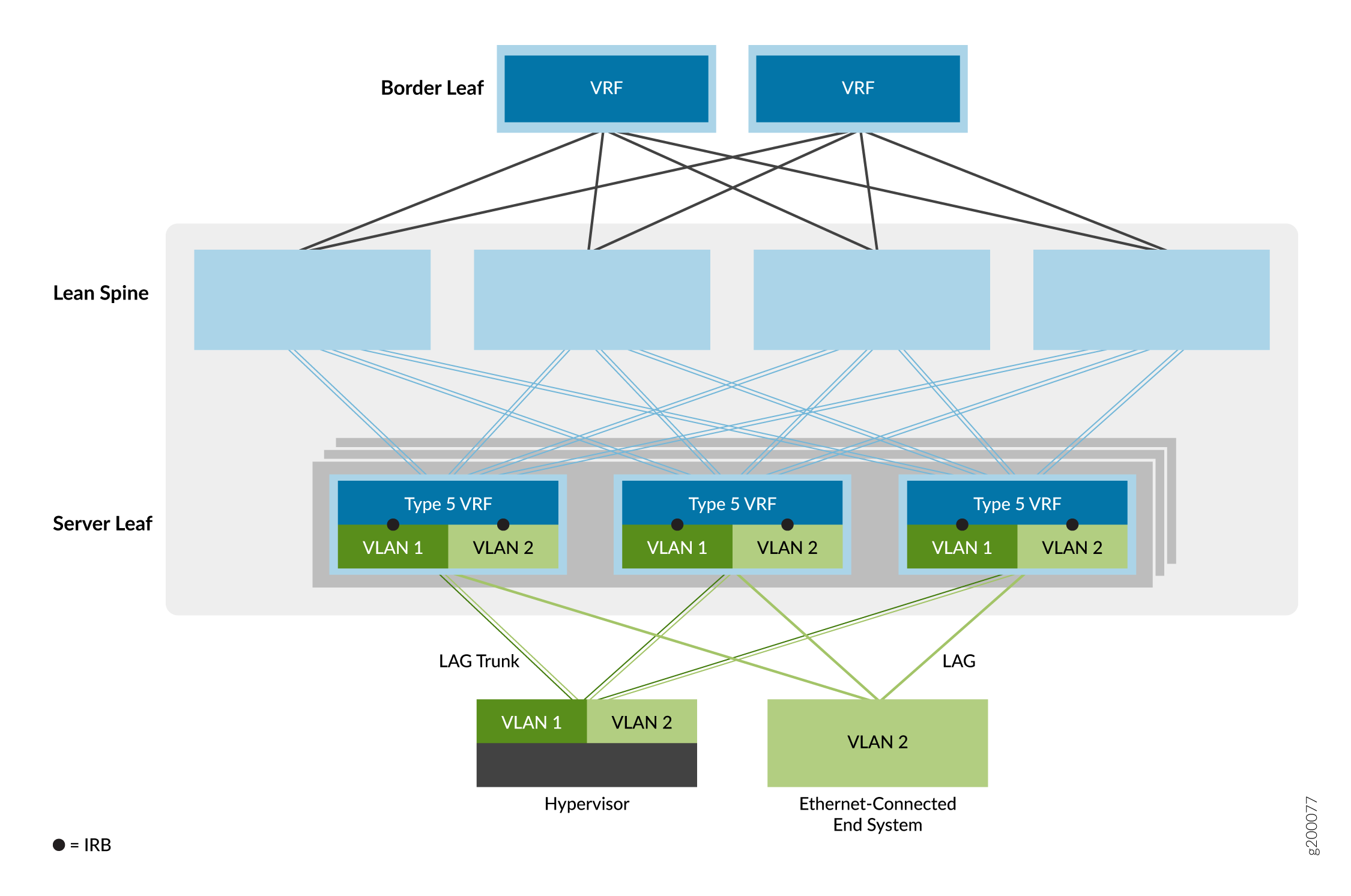 de puentes enrutados en el borde
de puentes enrutados en el borde
En este modelo de servicio Ethernet, las interfaces IRB se mueven a VTEP de dispositivo leaf en el borde de la red superpuesta para acercar el enrutamiento IP a los sistemas finales. Debido a las capacidades especiales de ASIC necesarias para admitir puentes, enrutamiento y EVPN/VXLAN en un dispositivo, las superposiciones de ERB solo son posibles en ciertos conmutadores. Para obtener una lista de los conmutadores que admitimos como dispositivos leaf en una superposición de ERB, consulte Diseños de referencia de estructuras EVPN-VXLAN de centros de datos: resumen de hardware compatible.
Este modelo permite una red general más simple. Los dispositivos spine están configurados para manejar solo tráfico IP, lo que elimina la necesidad de extender las superposiciones de puente a los dispositivos spine.
Esta opción también permite un tráfico más rápido de servidor a servidor dentro del centro de datos (también conocido como tráfico este-oeste) donde los sistemas finales están conectados al mismo dispositivo leaf VTEP. Como resultado, el enrutamiento ocurre mucho más cerca de los sistemas finales que con las superposiciones de CRB.
Cuando configure interfaces IRB incluidas en instancias de enrutamiento EVPN tipo 5 en conmutadores QFX5110 o QFX5120 que funcionan como dispositivos leaf, el dispositivo habilita automáticamente el enrutamiento simétrico de unidifusión entre IRB para rutas EVPN tipo 5.
Para obtener información sobre cómo implementar la superposición ERB, consulte Diseño e implementación de superposición de puentes enrutados en el borde.
Superposición de spine colapsada
La red superpuesta en una arquitectura de spine colapsada es similar a una superposición ERB. En una arquitectura spine colapsada, las funciones del dispositivo leaf se colapsan en los dispositivos spine. Dado que no hay capa leaf, configure las interfaces VTEPS e IRB en los dispositivos spine, los cuales se encuentran en el borde de la red superpuesta como los dispositivos leaf en un modelo ERB. Los dispositivos spine también pueden realizar funciones de puerta de enlace de borde para enrutar el tráfico de norte a sur o extender el tráfico de capa 2 a través de ubicaciones de centros de datos.
Para obtener una lista de los conmutadores que admitimos con una arquitectura de spine colapsada, consulte Diseños de referencia de estructura EVPN-VXLAN de centros de datos: resumen de hardware compatible.
Comparación de superposiciones en puente, CRB y ERB
Para ayudarle a decidir qué tipo de superposición es el más adecuado para su entorno de EVPN, consulte la Tabla 1.
Admitimos la combinación de configuraciones de superposición en puente, superposición CRB y superposición ERB en el mismo dispositivo al mismo tiempo en dispositivos que admiten estos tipos de superposición. No es necesario configurar el dispositivo con sistemas lógicos independientes para que funcione en diferentes tipos de superposiciones en paralelo.
| Puntos de comparación |
Superposición de ERB |
Superposición de CRB |
superposición en puente |
|---|---|---|---|
| Enrutamiento entre subredes de inquilinos totalmente distribuidos |
✓ |
||
| Impacto mínimo de una falla de la puerta de enlace de IP |
✓ |
||
| Enrutamiento dinámico a nodos de terceros a nivel de hoja |
✓ |
||
| Optimizado para alto volumen de tráfico este-oeste |
✓ |
||
| Mejor integración con estructuras IP sin formato |
✓ |
||
| La virtualización de IP VRF más cerca del servidor |
✓ |
||
| Se requiere multiconexión de Contrail vRouter |
✓ |
||
| Interoperabilidad más fácil de EVPN con diferentes proveedores |
✓ |
||
| Enrutamiento simétrico entre subredes |
✓ |
✓ |
|
| Superposición de ID de VLAN por bastidor |
✓ |
✓ |
✓ |
| Configuración manual y resolución de problemas más sencillas |
✓ |
✓ |
|
| Interfaces de estilo empresarial y de proveedor de servicios |
✓ |
✓ |
|
| Soporte de conmutador leaf heredado (QFX5100) |
✓ |
✓ |
|
| Control centralizado de optimización del tráfico de máquinas virtuales (VMTO) |
✓ |
||
| Puerta de enlace de subred de inquilino IP en el clúster de firewall |
✓ |
Modelos de direccionamiento IRB en superposiciones de puentes
La configuración de interfaces IRB en superposiciones CRB y ERB requiere comprender los modelos para la configuración predeterminada de puerta de enlace IP y dirección MAC de las interfaces IRB de la siguiente manera:
Unique IRB IP Address: en este modelo, se configura una dirección IP única en cada interfaz IRB de una subred superpuesta.
La ventaja de tener una dirección IP y una dirección MAC únicas en cada interfaz IRB es la capacidad de supervisar y alcanzar cada una de las interfaces IRB desde la superposición mediante su dirección IP única. Este modelo también le permite configurar un protocolo de enrutamiento en la interfaz IRB.
La desventaja de este modelo es que la asignación de una dirección IP única a cada interfaz IRB puede consumir muchas direcciones IP de una subred.
Unique IRB IP Address with Virtual Gateway IP Address: este modelo agrega una dirección IP de puerta de enlace virtual al modelo anterior y lo recomendamos para superposiciones en puente enrutadas de forma centralizada. Es similar a VRRP, pero sin la señalización del plano de datos en banda entre las interfaces IRB de la puerta de enlace. La puerta de enlace virtual debe ser la misma para todas las interfaces IRB de puerta de enlace predeterminadas de la subred superpuesta y está activa en todas las interfaces IRB de puerta de enlace en las que esté configurada. También debe configurar una dirección MAC IPv4 común para la puerta de enlace virtual, la cual se convierte en la dirección MAC de origen en los paquetes de datos reenviados a través de la interfaz IRB.
Además de las ventajas del modelo anterior, la puerta de enlace virtual simplifica la configuración predeterminada de la puerta de enlace en los sistemas finales. La desventaja de este modelo es la misma que la del modelo anterior.
IRB with Anycast IP Address and MAC Address: en este modelo, todas las interfaces IRB de puerta de enlace predeterminadas de una subred superpuesta se configuran con la misma dirección IP y dirección MAC. Recomendamos este modelo para superposiciones ERB.
Un beneficio de este modelo es que solo se requiere una dirección IP por subred para el direccionamiento de interfaz IRB de puerta de enlace predeterminado, lo que simplifica la configuración de puerta de enlace predeterminada en los sistemas finales.
Superposición enrutada mediante rutas EVPN tipo 5
La última opción de superposición es una superposición enrutada, como se muestra en la Figura 8.
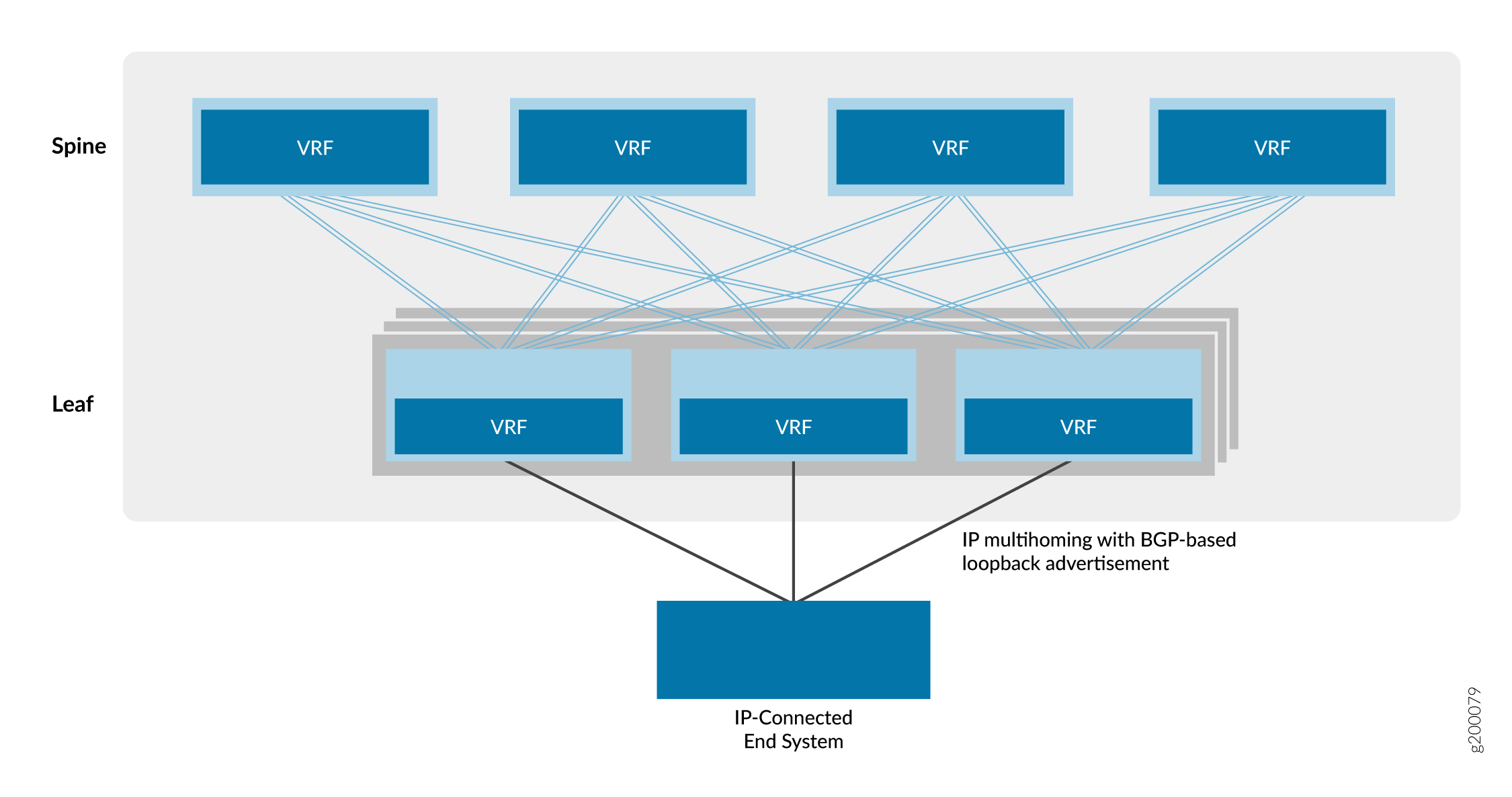 enrutada
enrutada
Esta opción es un servicio de red virtual enrutado por IP. A diferencia de una VPN IP basada en MPLS, la red virtual de este modelo se basa en EVPN/VXLAN.
Los proveedores de nube prefieren esta opción de red virtual porque la mayoría de las aplicaciones modernas están optimizadas para IP. Dado que toda la comunicación entre dispositivos se produce en la capa IP, no es necesario utilizar ningún componente de puente Ethernet, como VLAN y ESI, en este modelo de superposición enrutada.
Para obtener información sobre cómo implementar una superposición enrutada, consulte Diseño e implementación de superposición enrutada.
Instancias MAC-VRF para multitenencia en superposiciones de virtualización de red
Las instancias de enrutamiento MAC-VRF permiten configurar varias instancias de EVPN con distintos tipos de servicio Ethernet en un dispositivo que actúa como VTEP en una estructura EVPN-VXLAN. Con las instancias MAC-VRF, puede administrar varios inquilinos en el centro de datos con tablas VRF específicas del cliente para aislar o agrupar cargas de trabajo de inquilinos.
Las instancias MAC-VRF también introducen compatibilidad con el tipo de servicio basado en VLAN, además de la compatibilidad anterior con el tipo de servicio compatible con VLAN. Vea la Figura 9.
 de servicio MAC-VRF
de servicio MAC-VRF
-
Servicio basado en VLAN: puede configurar una VLAN y el identificador de red VXLAN (VNI) correspondiente en la instancia de MAC-VRF. Para aprovisionar una VLAN y un VNI nuevos, debe configurar una nueva instancia de VRF de MAC con la VLAN y el VNI nuevos.
-
Servicio compatible con VLAN: puede configurar una o varias VLAN y los VNI correspondientes en la misma instancia de MAC-VRF. Para aprovisionar una VLAN y un VNI nuevos, puede agregar la configuración de VLAN y VNI nuevos a la instancia de MAC-VRF existente, lo que ahorra algunos pasos de configuración en comparación con el uso de un servicio basado en VLAN.
Las instancias MAC-VRF permiten opciones de configuración más flexibles tanto en la capa 2 como en la capa 3. Por ejemplo:
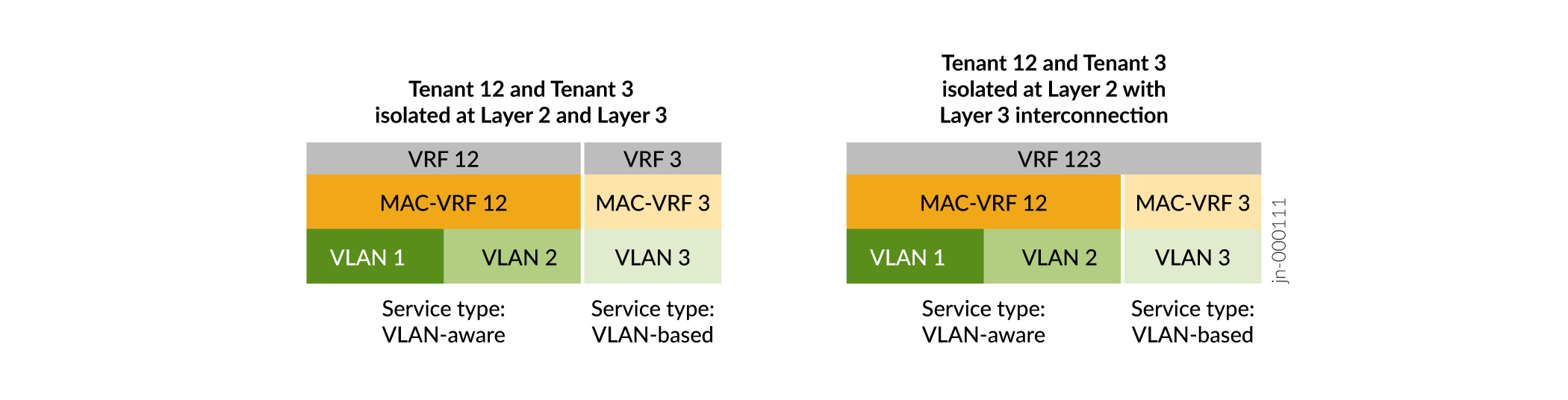 MAC-VRF
MAC-VRF
La Figura 10 muestra que con instancias MAC-VRF:
-
Puede configurar distintos tipos de servicio en distintas instancias de MAC-VRF en el mismo dispositivo.
-
Tiene opciones flexibles de aislamiento de inquilinos en la capa 2 (instancias MAC-VRF), así como en la capa 3 (instancias VRF). Puede configurar una instancia VRF que corresponda a la VLAN o VLAN en una sola instancia de MAC-VRF. O bien, puede configurar una instancia de VRF que abarque las VLAN en varias instancias de MAC-VRF.
La Figura 11 muestra una estructura superpuesta ERB con una configuración MAC-VRF de ejemplo para la separación de inquilinos.
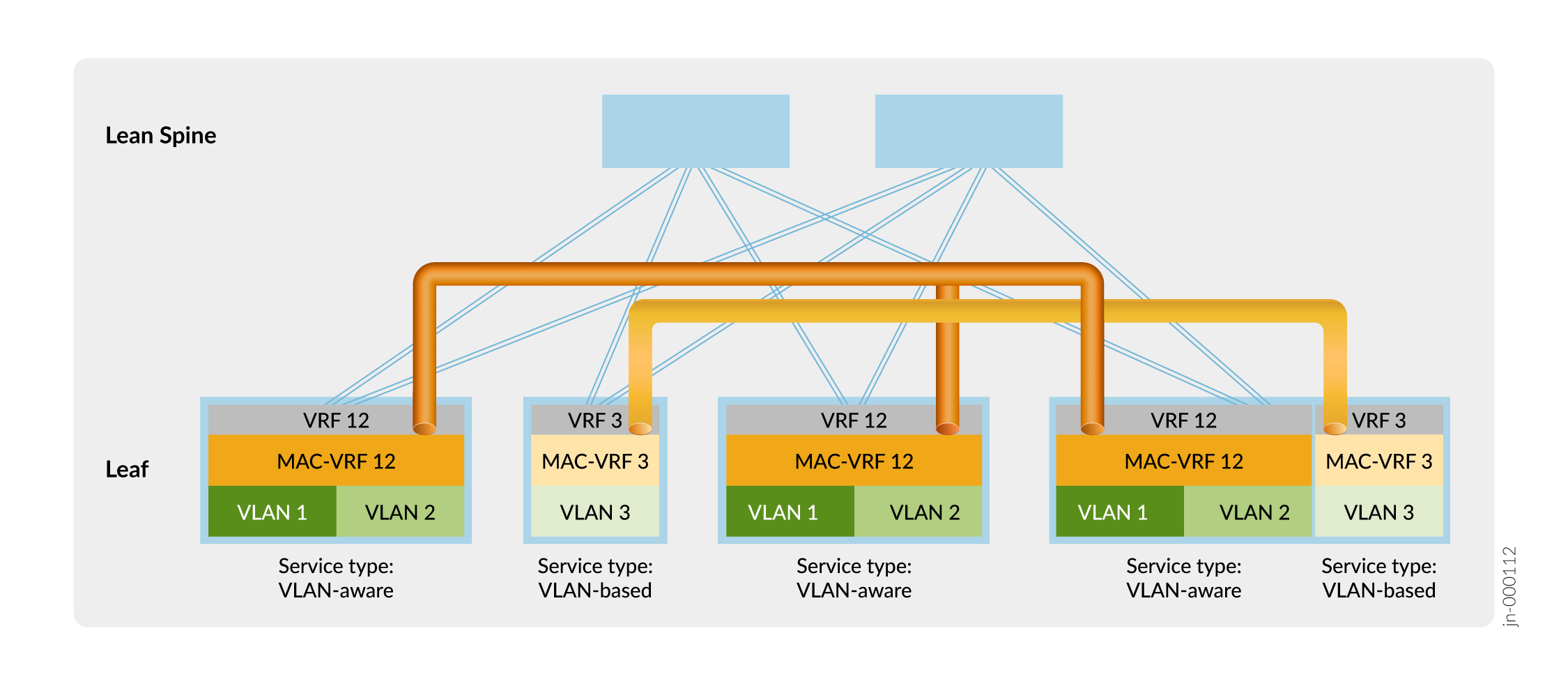
En la Figura 11, los dispositivos leaf establecen túneles VXLAN que mantienen el aislamiento en la capa 2 entre el inquilino 12 (VLAN 1 y VLAN 2) y el inquilino 3 (VLAN 3) mediante las instancias MAC-VRF MAC-VRF 12 y MAC-VRF 3. Los dispositivos leaf también aíslan a los inquilinos en la capa 3 mediante instancias VRF VRF 12 y VRF 3.
Puede emplear otras opciones para compartir el tráfico de VLAN entre inquilinos que están aislados en la capa 2 y la capa 3 por las configuraciones MAC-VRF y VRF, como por ejemplo:
-
Establezca una interconexión externa segura entre los VRF de inquilino a través de un firewall.
-
Configure la fuga de ruta local entre VRF de capa 3.
Para obtener más información sobre las instancias MAC-VRF y usarlas en un caso de uso de cliente de ejemplo, consulte IP de DC EVPN-VXLAN estructura servicios L2 MAC-VRF.
Las instancias MAC-VRF corresponden a las instancias de reenvío de la siguiente manera:
-
Las instancias MAC-VRF en conmutadores de la línea QFX5000 (incluidos los que se ejecutan Junos OS o Junos OS evolucionado) forman parte de la instancia de reenvío predeterminada. En estos dispositivos, no puede configurar VLAN superpuestas en una instancia de MAC-VRF o en varias instancias de MAC-VRF.
-
En la línea QFX10000 de conmutadores, puede configurar varias instancias de reenvío y asignar una instancia de MAC-VRF a una instancia de reenvío determinada. También puede asignar varias instancias de MAC-VRF a la misma instancia de reenvío. Si configura cada instancia de MAC-VRF para que utilice una instancia de reenvío diferente, puede configurar VLAN superpuestas en las distintas instancias de MAC-VRF. No puede configurar VLAN superpuestas en una sola instancia de MAC-VRF o en instancias de MAC-VRF que se asignen a la misma instancia de reenvío.
-
En la configuración predeterminada, los conmutadores incluyen una VLAN predeterminada con un ID de VLAN =1 asociado con la instancia de reenvío predeterminada. Dado que los ID de VLAN deben ser únicos en una instancia de reenvío, si desea configurar una VLAN con VLAN ID=1 en una instancia de MAC-VRF que utilice la instancia de reenvío predeterminada, debe reasignar el ID de VLAN de la VLAN predeterminada a un valor distinto de 1. Por ejemplo:
set vlans default vlan-id 4094 set routing-instances mac-vrf-instance-name vlans vlan-name vlan-id 1
Los ejemplos de configuración de superposición de virtualización de red de referencia de esta guía incluyen pasos para configurar la superposición mediante instancias de MAC-VRF. Configure una instancia de enrutamiento EVPN de tipo mac-vrfy establezca un diferenciador de ruta y un destino de ruta en la instancia. También debe incluir las interfaces deseadas (incluida una interfaz de origen VTEP), las VLAN y las asignaciones de VLAN a VNI en la instancia. Consulte las configuraciones de referencia en los temas siguientes:
-
Diseño e implementación de superposiciones en puente: las instancias de MAC-VRF se configuran en los dispositivos leaf.
-
Diseño e implementación de superposición de puentes enrutados centralmente: las instancias de MAC-VRF se configuran en los dispositivos spine. En los dispositivos leaf, la configuración MAC-VRF es similar a la configuración de leaf MAC-VRF en un diseño de superposición en puente.
-
Diseño e implementación de superposición de puentes enrutados en el borde: las instancias de MAC-VRF se configuran en los dispositivos leaf.
Un dispositivo puede tener problemas con el escalado de VTEP cuando la configuración utiliza varias instancias de MAC-VRF. Como resultado, para evitar este problema, requerimos que habilite la función de túneles compartidos en la línea QFX5000 de conmutadores que ejecutan Junos OS con una configuración de instancia MAC-VRF. Cuando se configuran túneles compartidos, el dispositivo minimiza el número de entradas del próximo salto para llegar a VTEP remotos. Los túneles VXLAN compartidos se habilitan globalmente en el dispositivo mediante la shared-tunnels instrucción en el nivel jerárquico [edit forwarding-options evpn-vxlan] . Esta configuración requiere que reinicie el dispositivo.
Esta instrucción es opcional en el Línea QFX10000 de conmutadores que ejecutan Junos OS, que pueden manejar un escalado de VTEP mayor que QFX5000 conmutadores.
En los dispositivos que ejecutan Junos OS evolucionado en estructuras EVPN-VXLAN, los túneles compartidos están habilitados de forma predeterminada. Junos OS evolucionado solo admite EVPN-VXLAN con configuraciones MAC-VRF.
Soporte de multiconexión para sistemas finales conectados por Ethernet
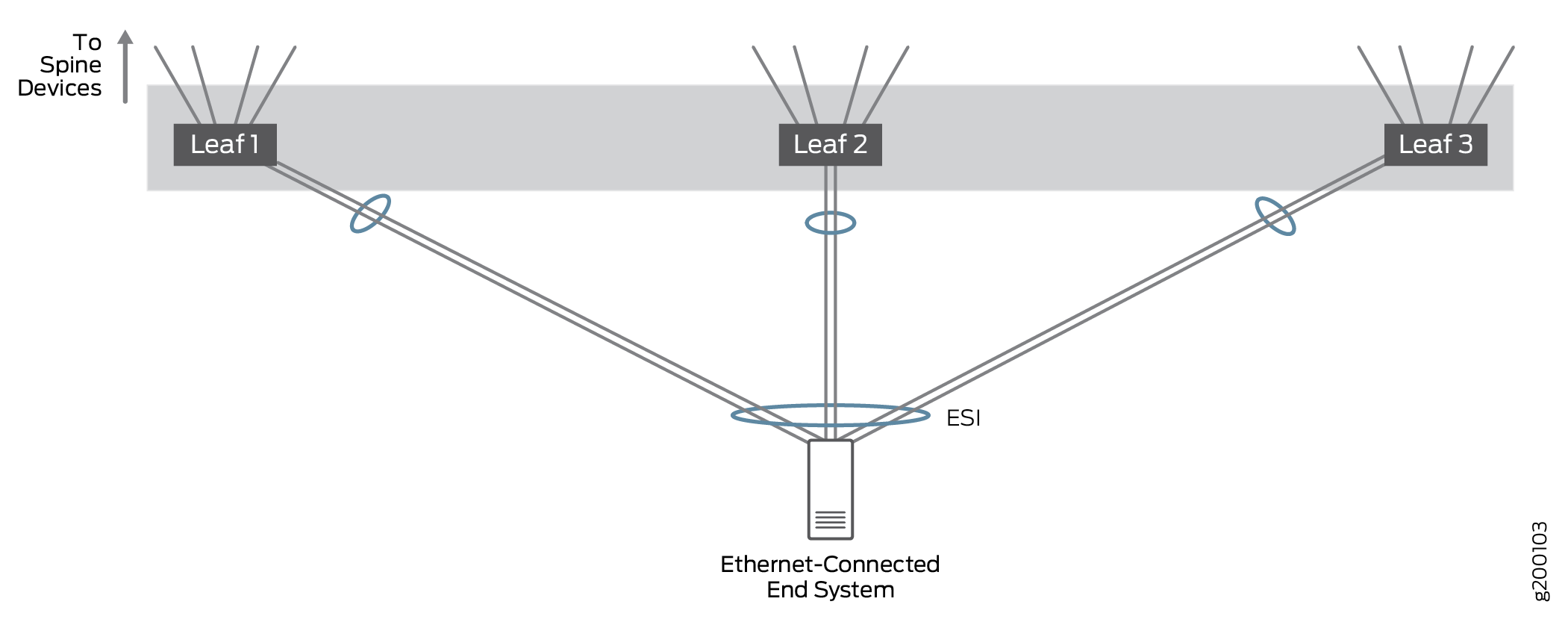 Ethernet
Ethernet
La multiconexión conectada por Ethernet permite que los sistemas finales conectados por Ethernet se conecten a la red superpuesta Ethernet mediante un vínculo de conexión única a un dispositivo VTEP o mediante varios vínculos de multiconexión a diferentes dispositivos VTEP. El tráfico de Ethernet tiene un equilibrio de carga en la estructura entre VTEP en dispositivos leaf que se conectan al mismo sistema final.
Probamos configuraciones en las que un sistema final conectado por Ethernet estaba conectado a un solo dispositivo leaf o multiconexión a 2 o 3 dispositivos leaf para demostrar que el tráfico se maneja correctamente en configuraciones multiconexión con más de dos dispositivos VTEP leaf; en la práctica, un sistema final conectado a Ethernet se puede multiconexión a una gran cantidad de dispositivos leaf VTEP. Todos los vínculos están activos y el tráfico de red se puede equilibrar en todos los vínculos de multiconexión.
En esta arquitectura, EVPN se utiliza para la multiconexión conectada por Ethernet. Los LAG multiconexión de EVPN se identifican mediante un identificador de segmento Ethernet (ESI) en la superposición de puente de EVPN, mientras que LACP se usa para mejorar la disponibilidad del LAG.
El enlace troncal de VLAN permite que una interfaz admita varias VLAN. El enlace troncal de VLAN garantiza que las máquinas virtuales (VM) en hipervisores que no son superpuestos puedan funcionar en cualquier contexto de redes superpuestas.
Para obtener más información sobre la compatibilidad con multiconexión conectada a Ethernet, consulte Diseño e implementación de multiconexión de un sistema final conectado a Ethernet.
Soporte de multiconexión para sistemas finales conectados a IP
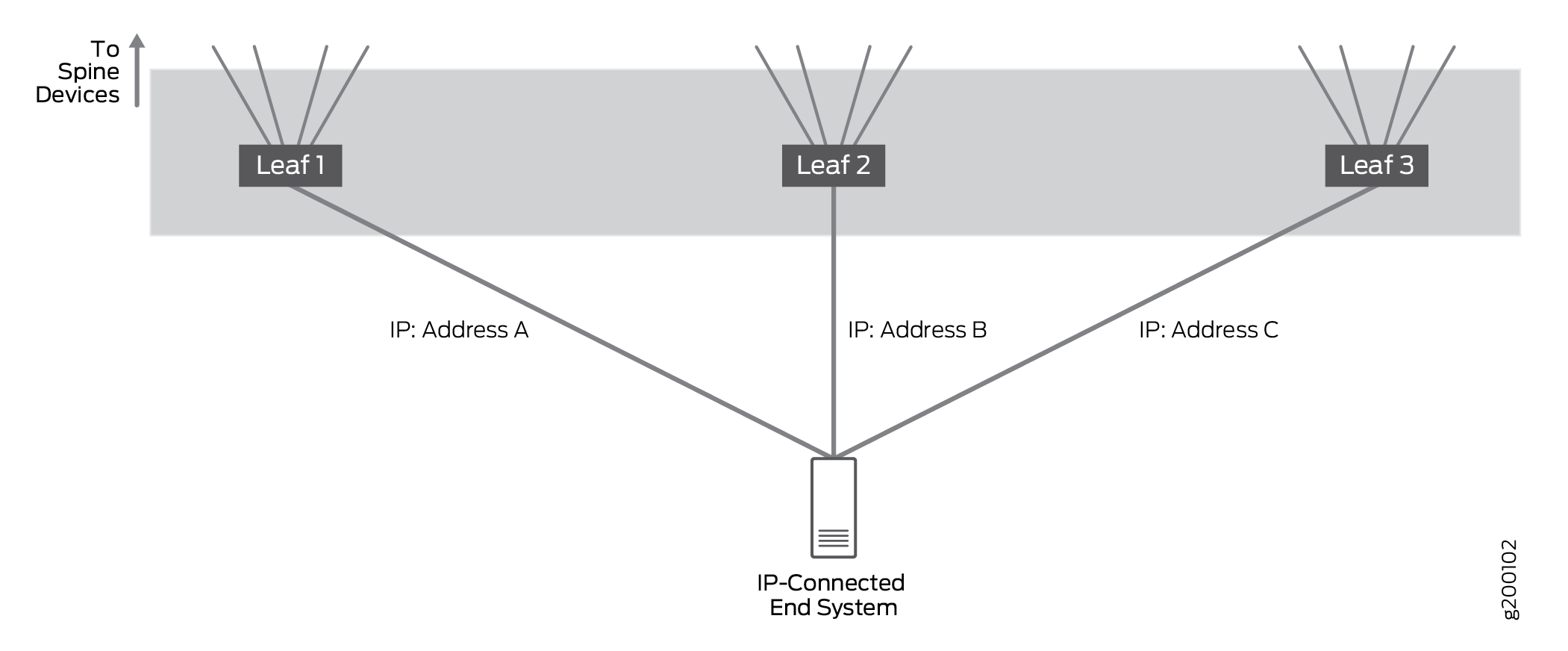
Sistemas de puntos de conexión de multihoming conectados a IP para conectarse a la red IP a través de múltiples interfaces de acceso basadas en IP en diferentes dispositivos leaf.
Probamos configuraciones en las que un sistema final conectado a IP estaba conectado a un solo leaf o multiconexión a dispositivos de 2 o 3 leaf. La configuración validó que el tráfico se maneja correctamente cuando se realiza multiconexión a múltiples dispositivos leaf; en la práctica, un sistema final conectado a IP se puede multiconexión a una gran cantidad de dispositivos leaf.
En las configuraciones de multiconexión, todos los vínculos están activos y el tráfico de red se reenvía y recibe a través de todos los vínculos de multiconexión. La carga del tráfico IP se equilibra en los vínculos multiconexión mediante un algoritmo hash simple.
El EBGP se utiliza para intercambiar información de enrutamiento entre el sistema de punto de conexión conectado a IP y los dispositivos leaf conectados para garantizar que la ruta o rutas a los sistemas de punto de conexión se compartan con todos los dispositivos spine y leaf.
Para obtener más información sobre el bloque de creación de multiconexión conectado a IP, consulte Diseño e implementación de multiconexión de un sistema final conectado a IP.
Dispositivos de borde
Algunos de nuestros diseños de referencia incluyen dispositivos de borde que proporcionan conexiones a los siguientes dispositivos, que son externos a la estructura de IP local:
Una puerta de enlace de multidifusión.
Una puerta de enlace de centro de datos para la interconexión del centro de datos (DCI).
Un dispositivo como un enrutador SRX en el que se consolidan varios servicios, como firewalls, traducción de direcciones de red (TDR), detección y prevención de intrusiones (DPI), multidifusión, etc. La consolidación de varios servicios en un solo dispositivo físico se conoce como encadenamiento de servicios.
Dispositivos o servidores que actúan como firewalls, servidores DHCP, recopiladores de sFlow, etc.
Nota:Si su red incluye dispositivos o servidores heredados que requieren una conexión Ethernet de 1 Gbps a un dispositivo de borde, recomendamos usar un conmutador QFX10008 o QFX5120 como dispositivo de borde.
Para proporcionar la funcionalidad adicional descrita anteriormente, Juniper Networks admite el despliegue de un dispositivo de borde de las siguientes maneras:
Como un dispositivo que sirve solo como dispositivo de borde. En esta función dedicada, puede configurar el dispositivo para que gestione una o varias de las tareas descritas anteriormente. Para esta situación, el dispositivo se despliega normalmente como una leaf de borde, que se conecta a un dispositivo spine.
Por ejemplo, en la superposición de ERB que se muestra en la Figura 14, las hojas de borde L5 y L6 proporcionan conectividad a puertas de enlace de centros de datos para DCI, un recopilador de sFlow y un servidor DHCP.
Como un dispositivo que tiene dos roles: un dispositivo subyacente de red y un dispositivo de borde que puede manejar una o más de las tareas descritas anteriormente. Para esta situación, un dispositivo spine generalmente maneja los dos roles. Por lo tanto, la funcionalidad de dispositivo de borde se conoce como border spine.
Por ejemplo, en la superposición ERB que se muestra en la Figura 15, las espinas de borde S1 y S2 funcionan como dispositivos lean spine. También proporcionan conectividad a puertas de enlace de centros de datos para DCI, un recopilador de sFlow y un servidor DHCP.
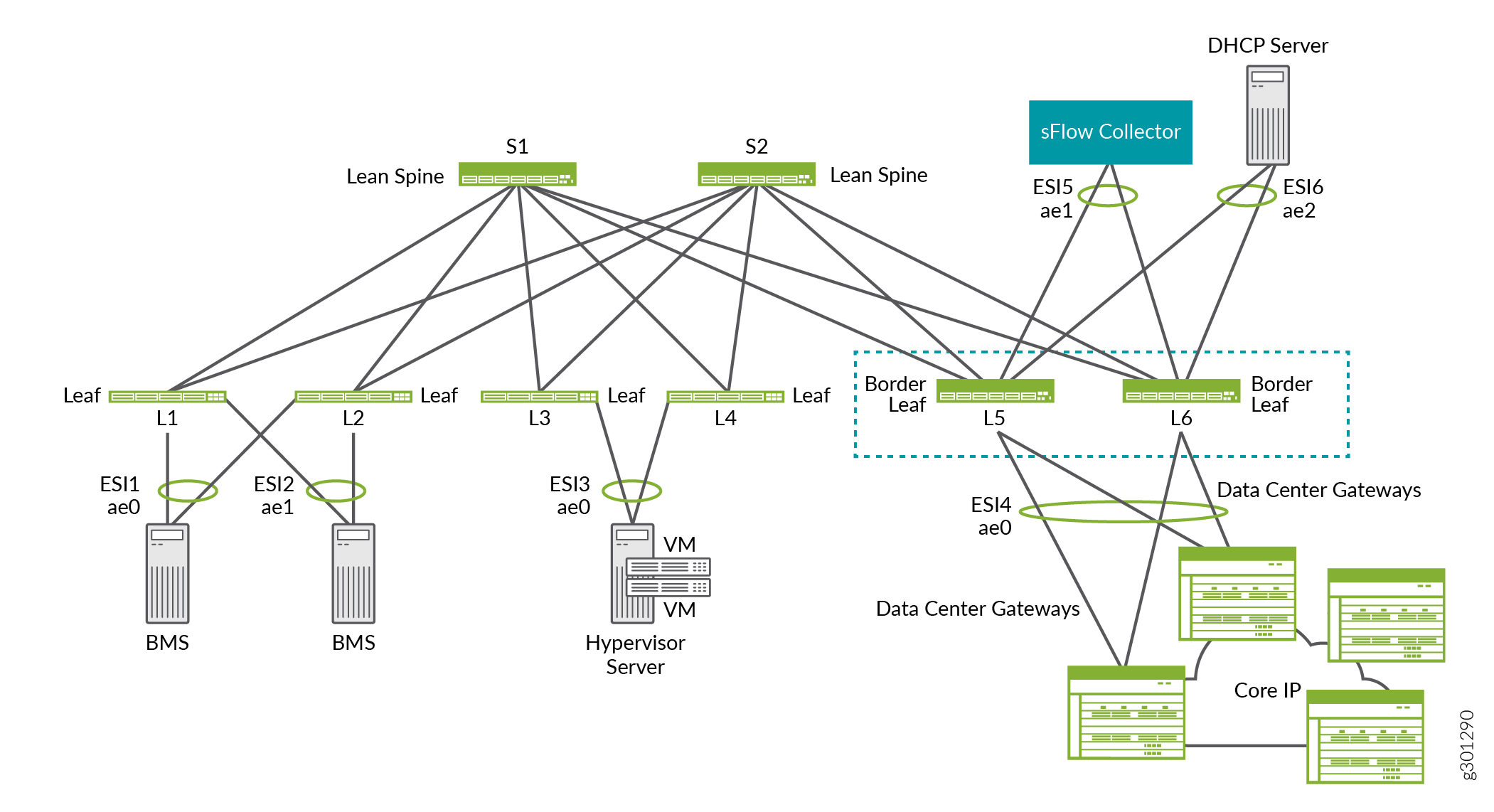 borde
borde
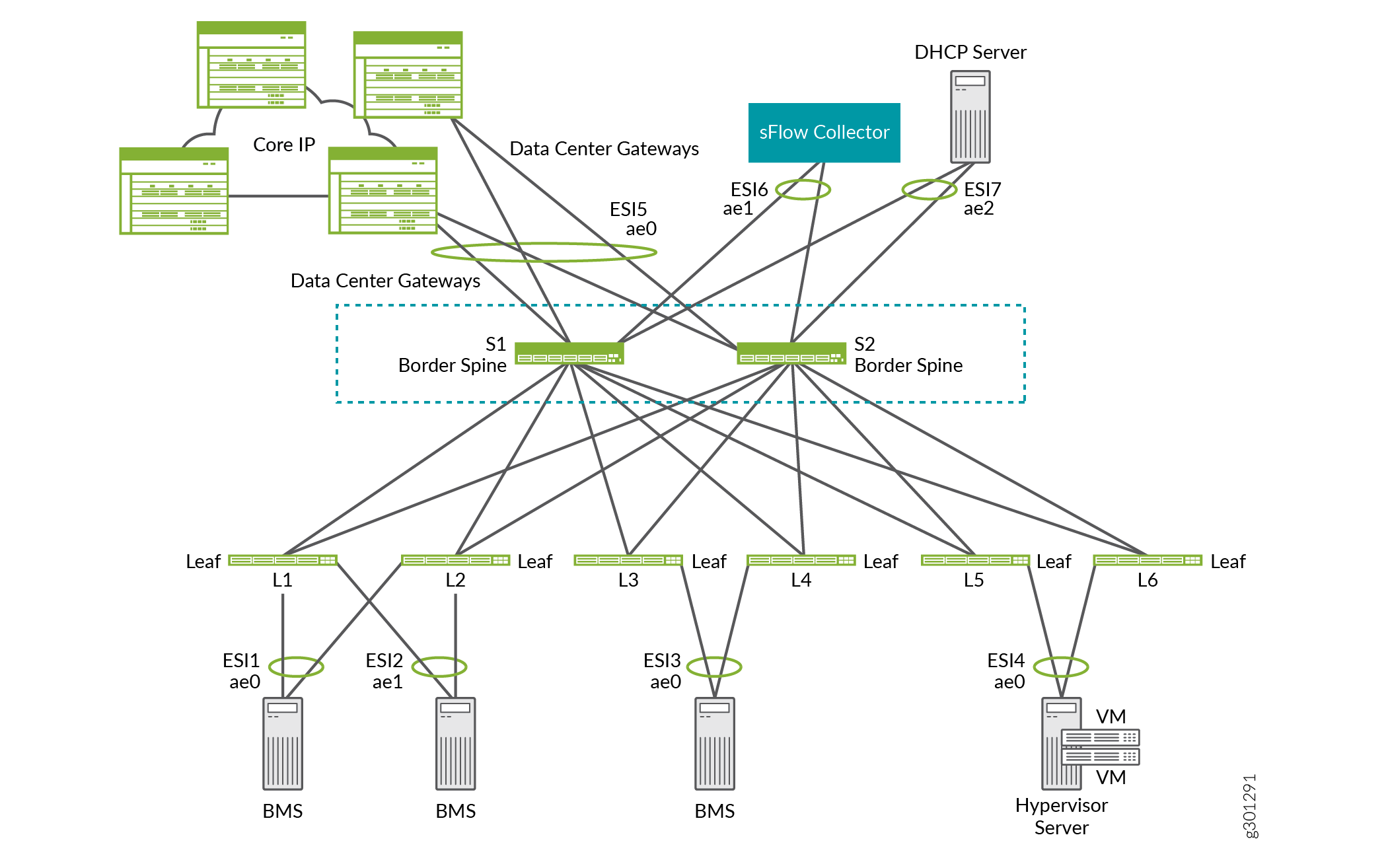 de borde
de borde
Interconector del centro de datos (DCI)
El bloque de construcción de interconexión del centro de datos (DCI) proporciona la tecnología necesaria para enviar tráfico entre centros de datos. El diseño validado admite DCI mediante rutas EVPN tipo 5, rutas IPVPN y DCI de capa 2 con unión VXLAN.
Las rutas EVPN tipo 5 o IPVPN se utilizan en un contexto DCI para garantizar que se pueda intercambiar tráfico entre centros de datos que utilizan diferentes esquemas de subcompensación de direcciones IP. Las rutas se intercambian entre dispositivos spine en diferentes centros de datos para permitir el paso del tráfico entre centros de datos.
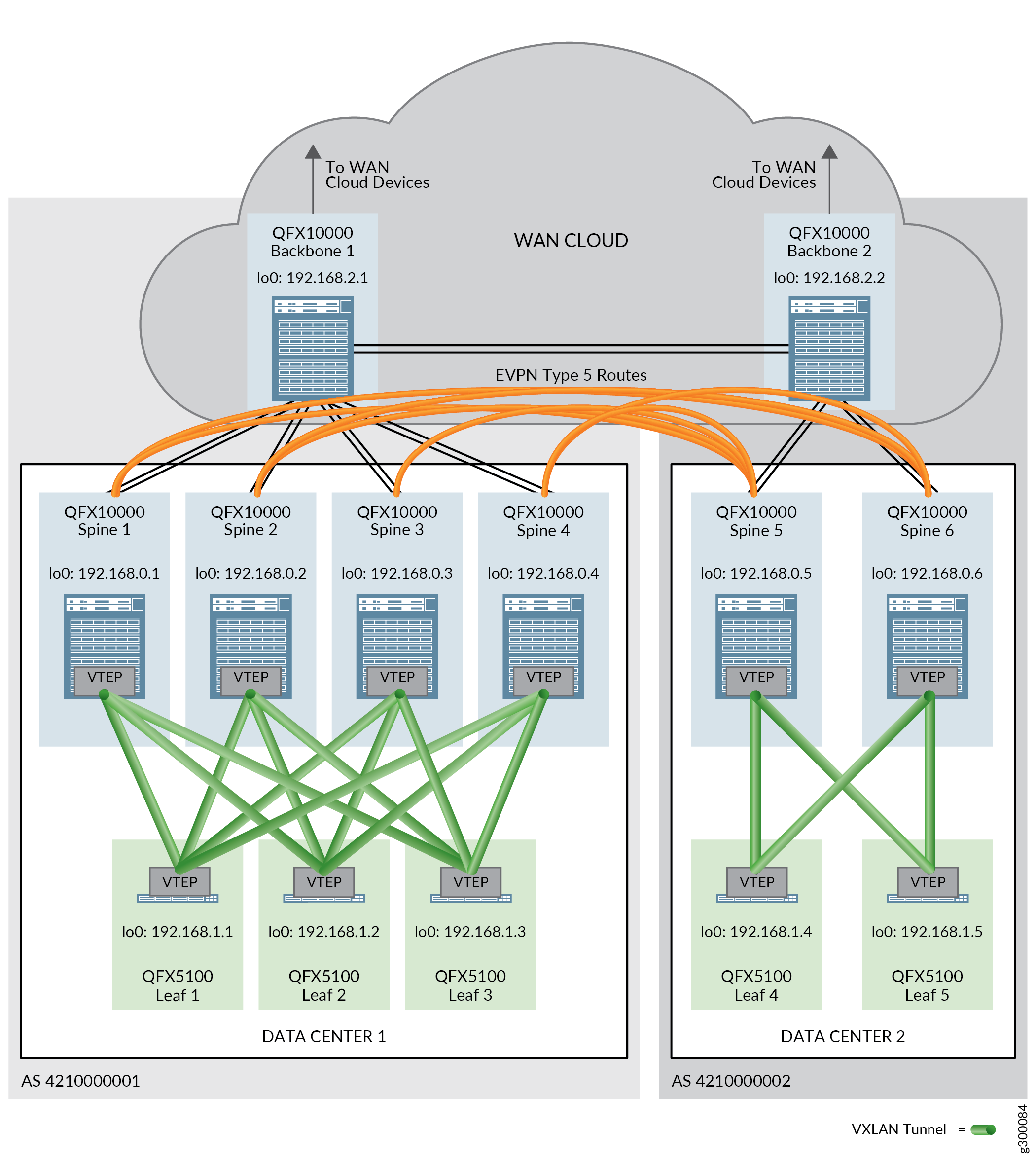
Se requiere conectividad física entre los centros de datos antes de poder configurar DCI. La conectividad física la proporcionan los dispositivos troncales en una nube WAN. Un dispositivo troncal está conectado a todos los dispositivos spine en un único centro de datos (POD), así como a los otros dispositivos troncales que están conectados a los otros centros de datos.
Para obtener más información acerca de cómo configurar DCI, consulte:
Encadenamiento de servicios
En muchas redes, es común que el tráfico fluya a través de dispositivos de hardware independientes que proporcionan un servicio, como firewalls, TDR, DPI, multidifusión, etc. Cada dispositivo requiere una operación y administración separadas. Este método de vinculación de múltiples funciones de red se puede considerar como un encadenamiento de servicios físicos.
Un modelo más eficiente para el encadenamiento de servicios es virtualizar y consolidar las funciones de red en un único dispositivo. En nuestra arquitectura de modelo, estamos utilizando los enrutadores de la serie SRX como el dispositivo que consolida las funciones de la red, procesa y aplica servicios. Ese dispositivo se denomina función de red física (PNF).
En esta solución, el encadenamiento de servicios se admite tanto en la superposición CRB como en la superposición ERB. Solo funciona para el tráfico entre inquilinos.
Vista lógica del encadenamiento de servicios
La Figura 17 muestra una vista lógica del encadenamiento de servicios. Muestra un spine con una configuración del lado derecho y una configuración del lado izquierdo. A cada lado hay una instancia de enrutamiento VRF y una interfaz IRB. El enrutador de la serie SRX en el centro es el PNF y realiza el encadenamiento de servicios.
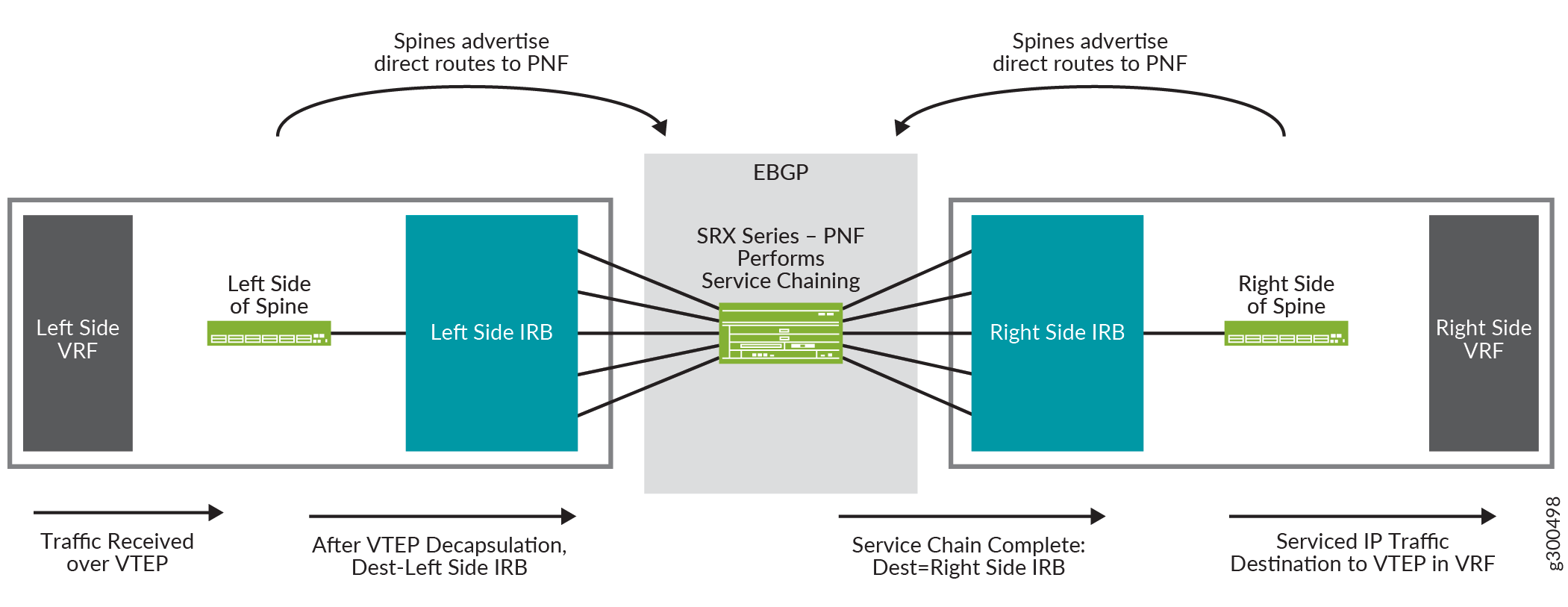 lógica de encadenamiento de servicios
lógica de encadenamiento de servicios
El flujo de tráfico en esta vista lógica es:
-
El spine recibe un paquete en el VTEP que se encuentra en el VRF del lado izquierdo.
-
El paquete se desencapsula y se envía a la interfaz IRB del lado izquierdo.
-
La interfaz IRB enruta el paquete al enrutador de la serie SRX, el cual actúa como PNF.
-
El enrutador de la serie SRX realiza el encadenamiento de servicios en el paquete y lo reenvía de vuelta al spine, donde se recibe en la interfaz IRB que se muestra en el lado derecho del spine.
-
La interfaz IRB enruta el paquete al VTEP en el VRF del lado derecho.
Para obtener información acerca de cómo configurar el encadenamiento de servicios, consulte Diseño e implementación del encadenamiento de servicios.
Optimizaciones de multidifusión
Las optimizaciones de multidifusión ayudan a conservar el ancho de banda y enrutar el tráfico de manera más eficiente en un escenario de multidifusión en entornos EVPN VXLAN. Sin ninguna optimización de multidifusión configurada, toda la replicación de multidifusión se realiza en la entrada del leaf conectado a la fuente de multidifusión, como se muestra en la Figura 18. El tráfico de multidifusión se envía a todos los dispositivos leaf que están conectados al spine. Cada dispositivo leaf envía tráfico a los hosts conectados.
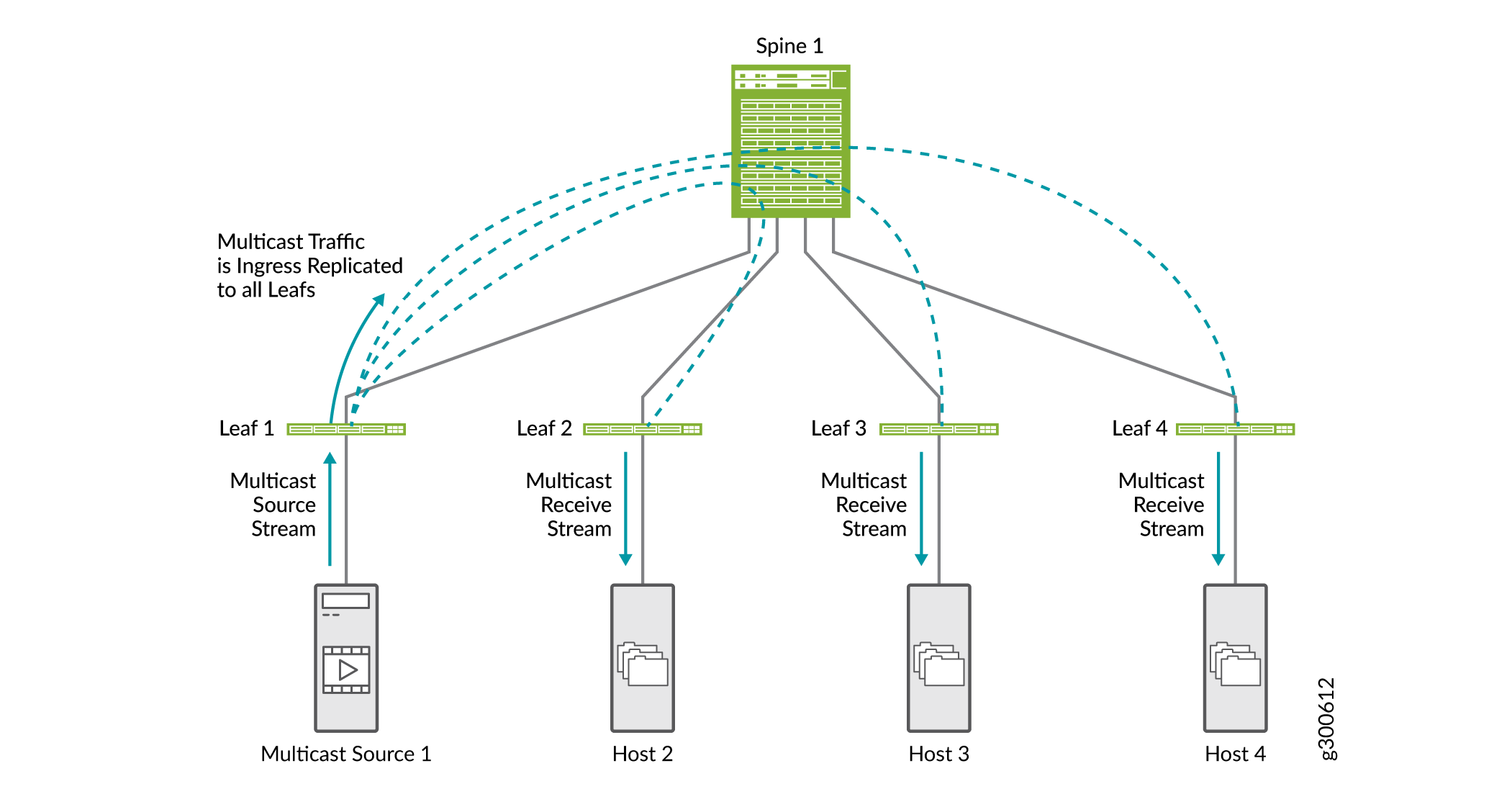
Hay algunos tipos de optimizaciones de multidifusión compatibles con entornos EVPN VXLAN que pueden funcionar juntos:
Para obtener más información acerca de cómo configurar las funciones de multidifusión, consulte:
- Supervisión IGMP
- Reenvío selectivo de multidifusión
- Replicación asistida de tráfico de multidifusión
- Multidifusión entre subredes optimizada para redes superpuestas ERB
Supervisión IGMP
La supervisión IGMP en una estructura EVPN-VXLAN es útil para optimizar la distribución del tráfico de multidifusión. La supervisión IGMP conserva el ancho de banda, ya que el tráfico de multidifusión solo se reenvía en interfaces en las que hay oyentes IGMP. No todas las interfaces de un dispositivo leaf necesitan recibir tráfico de multidifusión.
Sin la supervisión IGMP, los sistemas finales reciben tráfico de multidifusión IP en el que no tienen interés, lo que inunda innecesariamente sus enlaces con tráfico no deseado. En algunos casos, cuando los flujos de multidifusión IP son grandes, inundar el tráfico no deseado causa problemas de denegación de servicio.
La Figura 19 muestra cómo funciona la supervisión IGMP en una estructura EVPN-VXLAN. En esta estructura EVPN-VXLAN de ejemplo, la supervisión IGMP está configurada en todos los dispositivos leaf, y el receptor de multidifusión 2 envió previamente una solicitud de unión IGMPv2.
-
El receptor de multidifusión 2 envía una solicitud de permiso IGMPv2.
-
Los receptores de multidifusión 3 y 4 envían una solicitud de unión IGMPv2.
-
Cuando la hoja 1 recibe tráfico de multidifusión de entrada, lo replica para todos los dispositivos leaf y lo reenvía al spine.
-
El spine reenvía el tráfico a todos los dispositivos leaf.
-
Leaf 2 recibe el tráfico de multidifusión, pero no lo reenvía al receptor porque el receptor envió un mensaje IGMP leave.
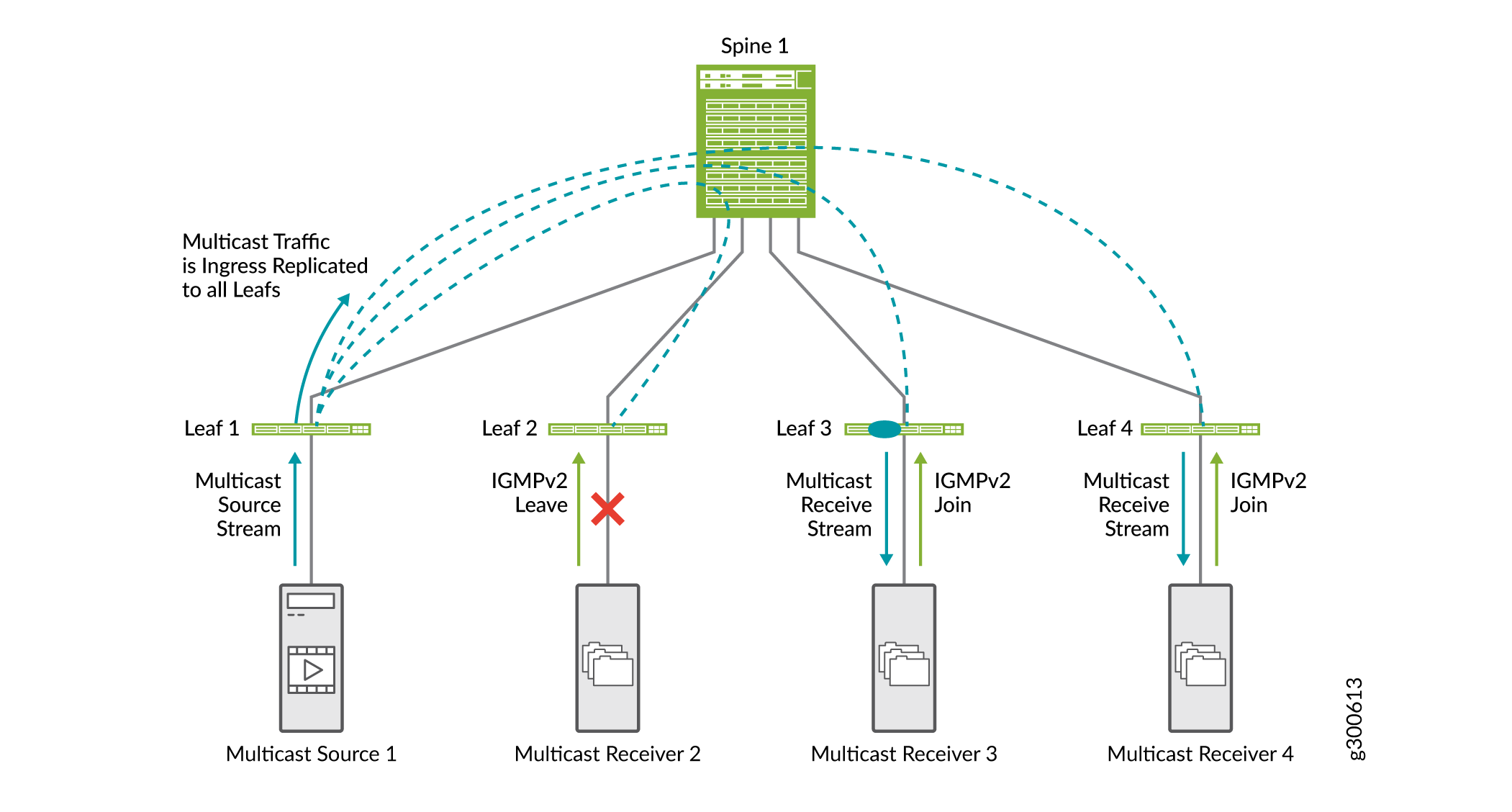
En redes EVPN-VXLAN solo se admite IGMP versión 2.
Para obtener más información acerca de la supervisión IGMP, consulte Descripción general del reenvío de multidifusión con supervisión IGMP o Supervisión MLD en un entorno EVPN-VXLAN.
Reenvío selectivo de multidifusión
El reenvío Ethernet de multidifusión selectiva (SMET) proporciona una mayor eficiencia de red de extremo a extremo y reduce el tráfico en la red EVPN. Conserva el uso del ancho de banda en el núcleo de la estructura y reduce la carga en los dispositivos de salida que no tienen oyentes.
Los dispositivos con IGMP snooping habilitado utilizan el reenvío de multidifusión selectivo para reenviar el tráfico de multidifusión de una manera eficiente. Con la supervisión IGMP habilitada, un dispositivo leaf envía tráfico de multidifusión solo a la interfaz de acceso con un receptor interesado. Con SMET agregado, el dispositivo leaf envía selectivamente tráfico de multidifusión solo a los dispositivos leaf en el núcleo que han expresado interés en ese grupo de multidifusión.
La Figura 20 muestra el flujo de tráfico de SMET junto con la supervisión IGMP.
-
El receptor de multidifusión 2 envía una solicitud de permiso IGMPv2.
-
Los receptores de multidifusión 3 y 4 envían una solicitud de unión IGMPv2.
-
Cuando la hoja 1 recibe tráfico de multidifusión de entrada, replica el tráfico solo a los dispositivos leaf con receptores interesados (dispositivos leaf 3 y 4) y lo reenvía a la red spine.
-
El spine reenvía el tráfico a los dispositivos leaf 3 y 4.
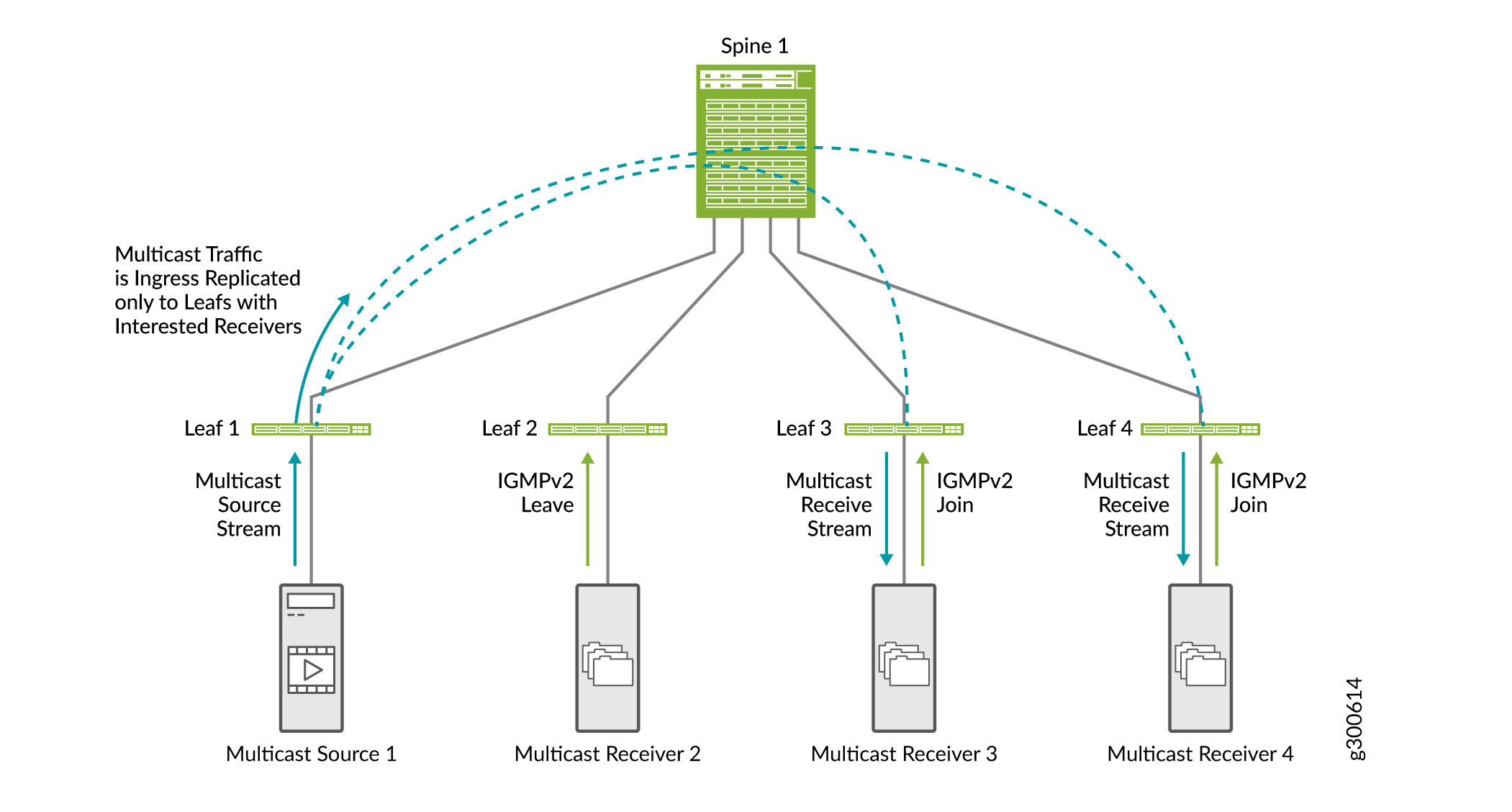 IGMP
IGMP
No es necesario activar SMET; Está habilitado de forma predeterminada cuando se configura la supervisión IGMP en el dispositivo.
Para obtener más información acerca de SMET, consulte Descripción general del reenvío de multidifusión selectiva.
Replicación asistida de tráfico de multidifusión
La función de replicación asistida (AR) descarga los dispositivos leaf de estructura EVPN-VXLAN de las tareas de replicación de entrada. La hoja de entrada no replica el tráfico de multidifusión. Envía una copia del tráfico de multidifusión a un spine configurado como dispositivo replicador de AR. El dispositivo replicador de AR distribuye y controla el tráfico de multidifusión. Además de reducir la carga de replicación en los dispositivos leaf de entrada, este método conserva el ancho de banda en la estructura entre el leaf y el spine.
La Figura 21 muestra cómo funciona la RA junto con la supervisión IGMP y SMET.
-
La hoja 1, que se configura como dispositivo leaf de AR, recibe tráfico de multidifusión y envía una copia al spine que se configura como dispositivo replicador de AR.
-
El spine replica el tráfico de multidifusión. Replica el tráfico para los dispositivos leaf que se aprovisionan con la VLAN VNI en la que el tráfico de multidifusión se originó en la hoja 1.
Dado que tenemos IGMP snooping y SMET configurados en la red, el spine envía el tráfico de multidifusión solo a los dispositivos leaf con receptores interesados.
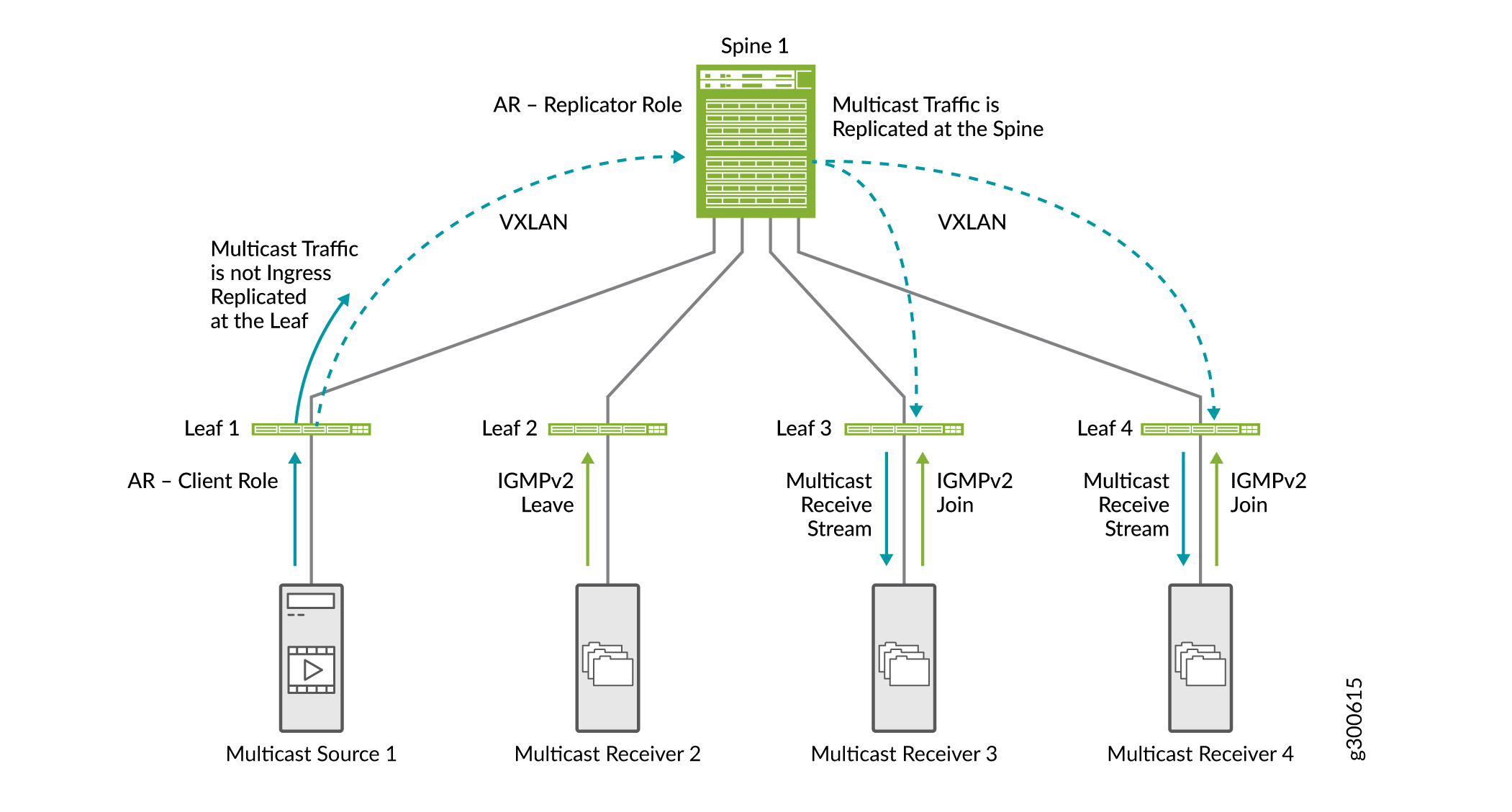
En este documento, mostramos las optimizaciones de multidifusión a pequeña escala. En una red a gran escala con muchos spines y leafs, los beneficios de las optimizaciones son mucho más evidentes.
Multidifusión entre subredes optimizada para redes superpuestas ERB
Cuando dispone de fuentes y receptores de multidifusión tanto dentro como fuera de una estructura superpuesta ERB, puede configurar una multidifusión entre subredes optimizada (OISM) para habilitar un flujo de tráfico de multidifusión eficiente a escala.
OISM utiliza un modelo de enrutamiento local para el tráfico de multidifusión, lo que evita la horquilla del tráfico y minimiza la carga de tráfico dentro del núcleo de EVPN. OISM reenvía el tráfico de multidifusión solo en la VLAN de origen de multidifusión. En el caso de los receptores entre subredes, los dispositivos leaf utilizan interfaces IRB para enrutar localmente el tráfico recibido en la VLAN de origen a otras VLAN receptoras en el mismo dispositivo. Para optimizar aún más el flujo de tráfico de multidifusión en la estructura EVPN-VXLAN, OISM utiliza IGMP snooping y SMET para reenviar el tráfico en la estructura solo a dispositivos leaf con receptores interesados.
OISM también permite que la estructura enrute eficazmente el tráfico desde fuentes externas de multidifusión a receptores internos, y desde fuentes internas de multidifusión a receptores externos. OISM utiliza un dominio de puente suplementario (SBD) dentro de la estructura para reenviar el tráfico de multidifusión recibido en los dispositivos leaf de borde desde fuentes externas. El diseño de SBD conserva el modelo de enrutamiento local para el tráfico de origen externo.
Puede utilizar OISM con AR para reducir la carga de replicación en dispositivos leaf OISM de menor capacidad. ( Consulte Replicación asistida del tráfico de multidifusión.)
Consulte la Figura 22 para ver una estructura simple con OISM y AR.
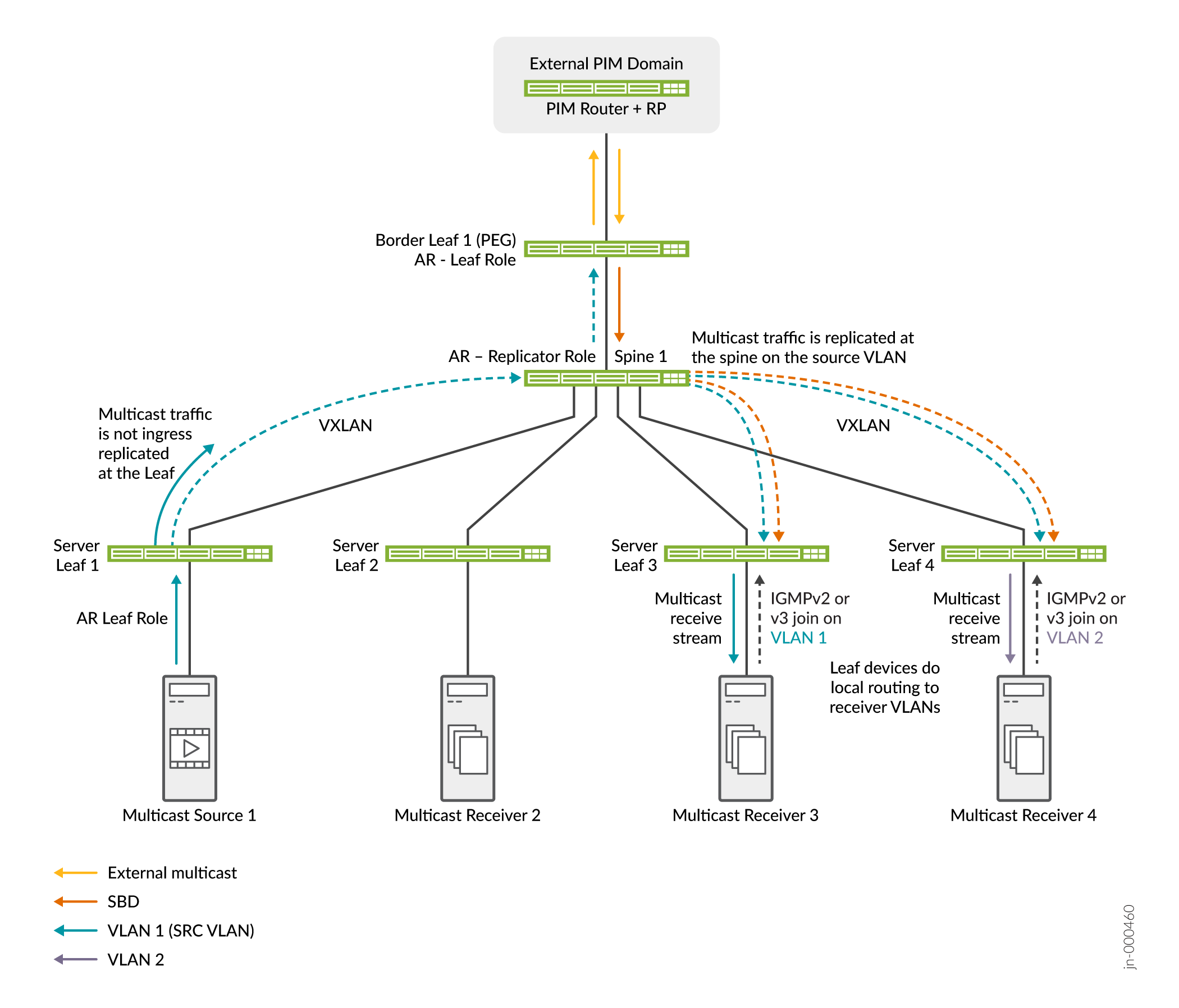
La Figura 22 muestra los dispositivos leaf y leaf de borde del servidor OISM, Spine 1 en el rol de replicador de AR y Server Leaf 1 como fuente de multidifusión en el rol de leaf de AR. También pueden existir una fuente y receptores externos en el dominio PIM externo. OISM y AR trabajan juntos en este escenario de la siguiente manera:
-
Los receptores de multidifusión detrás de la hoja de servidor 3 en VLAN 1 y detrás de la hoja de servidor 4 en VLAN 2 envían uniones IGMP que muestran interés en el grupo de multidifusión. Los receptores externos también pueden unirse al grupo de multidifusión.
-
La fuente de multidifusión detrás de la hoja de servidor 1 envía tráfico de multidifusión para el grupo a la estructura en la VLAN 1. La hoja de servidor 1 envía solo una copia del tráfico al replicador de AR en la columna 1.
-
Además, el tráfico de origen externo para el grupo de multidifusión llega a la hoja de borde 1. La leaf de borde 1 reenvía el tráfico en el SBD a Spine 1, el replicador de AR.
-
El replicador de AR envía copias desde la fuente interna en la VLAN de fuente y desde la fuente externa en el SBD a los dispositivos leaf OISM con receptores interesados.
-
Los dispositivos leaf del servidor reenvían el tráfico a los receptores de la VLAN de origen y enrutan localmente el tráfico a los receptores de las otras VLAN.
Optimización del tráfico de la máquina virtual de entrada para EVPN
Cuando las máquinas virtuales y los hosts se trasladan dentro de un centro de datos o de un centro de datos a otro, el tráfico de red puede volverse ineficiente si el tráfico no se enruta a la puerta de enlace óptima. Esto puede suceder cuando se reubica un host. La tabla ARP no siempre se vacía y el flujo de datos al host se envía a la puerta de enlace configurada, incluso cuando hay una puerta de enlace más óptima. El tráfico está "trombón" y se enruta innecesariamente a la puerta de enlace configurada.
La optimización del tráfico de la máquina virtual de entrada (VMTO) proporciona una mayor eficiencia de red, optimiza el tráfico de entrada y puede eliminar el efecto trombón entre las redes VLAN. Cuando se habilita la VMTO de entrada, las rutas se almacenan en una tabla de enrutamiento y reenvío virtual (VRF) de capa 3 y el dispositivo enruta el tráfico entrante directamente al host que se reubicó.
La Figura 23 muestra el tráfico trombón sin VMTO de entrada y el tráfico optimizado con VMTO de entrada habilitado.
Sin VMTO de entrada, las spine 1 y 2 de DC1 y DC2 anuncian la ruta del host IP remoto 10.0.0.1 cuando la ruta de origen es de DC2. El tráfico de entrada se puede dirigir a las spine 1 y 2 en DC1. Luego se enruta a las spine 1 y 2 en DC2, donde se movió la ruta 10.0.0.1. Esto provoca el efecto trombón.
Con VMTO de entrada, podemos lograr una ruta de reenvío óptima configurando una política para que la ruta del host IP (10.0.01) solo sea anunciada por Spine 1 y 2 desde DC2, y no desde DC1 cuando el host IP se mueve a DC2.
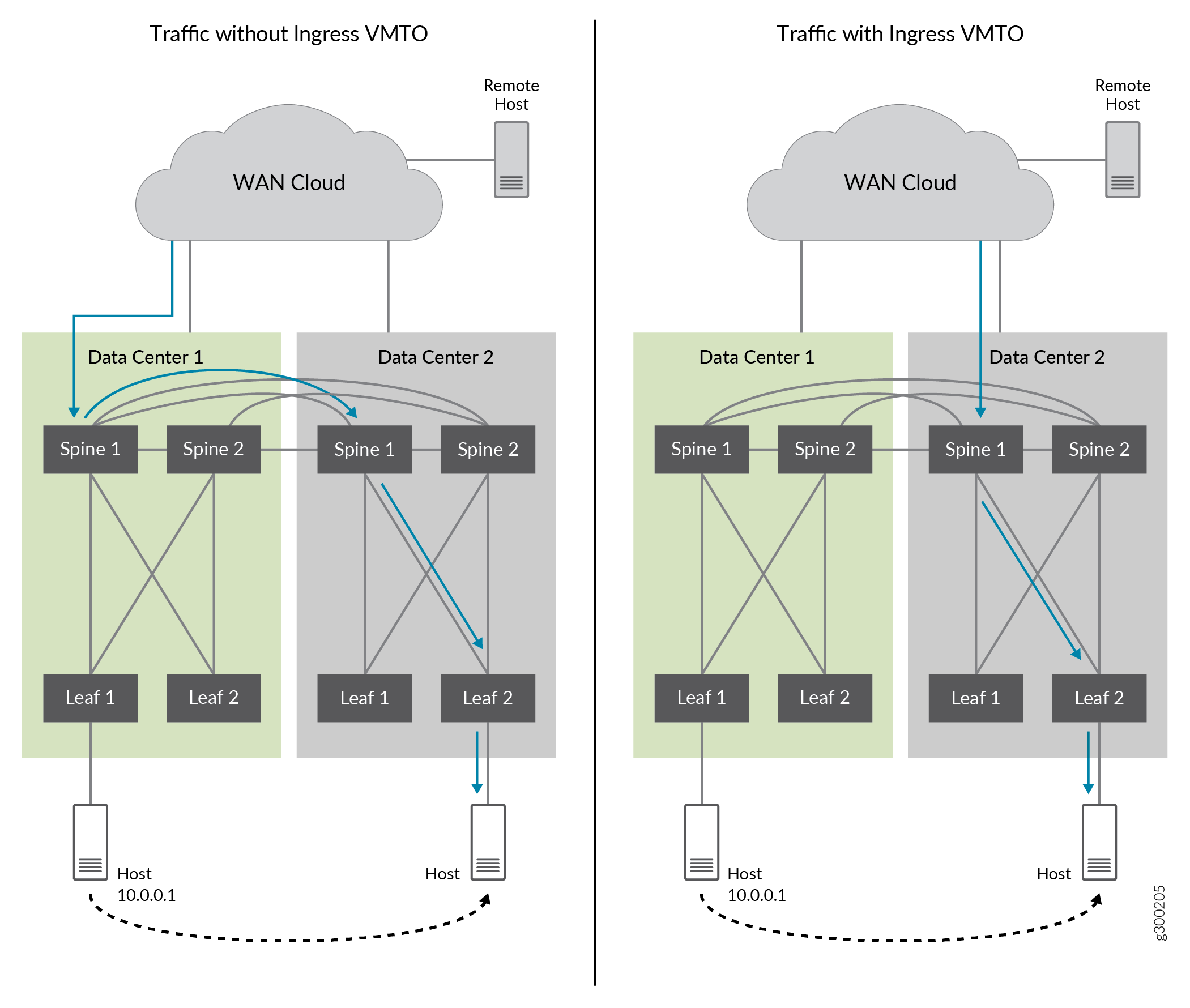 de entrada
de entrada
Para obtener más información acerca de cómo configurar VMTO, consulte Configurar VMTO.
Relé DHCP
 CRB
CRB
El bloque de creación de relé del Protocolo de configuración dinámica de host (DHCP) permite que la red pase mensajes DHCP entre un cliente DHCP y un servidor DHCP. La implementación de relé DHCP en este bloque de construcción mueve los paquetes DHCP a través de una superposición CRB donde la puerta de enlace se encuentra en la capa spine.
El servidor DHCP y los clientes DHCP se conectan a la red mediante interfaces de acceso en dispositivos leaf. El servidor y los clientes DHCP pueden comunicarse entre sí a través de la red existente sin más configuración cuando el cliente y el servidor DHCP están en la misma VLAN. Cuando un cliente y un servidor DHCP se encuentran en redes VLAN diferentes, el tráfico DHCP entre el cliente y el servidor se reenvía entre las VLAN a través de las interfaces IRB en dispositivos spine. Debe configurar las interfaces IRB en los dispositivos spine para que admitan el relé DHCP entre redes VLAN.
Para obtener información acerca de cómo implementar el relé DHCP, consulte Diseño e implementación de relés DHCP.
Reducción del tráfico ARP con sincronización y supresión de ARP (ARP de proxy)
El objetivo de la sincronización ARP es sincronizar las tablas ARP en todos los VRF que sirven a una subred superpuesta para reducir la cantidad de tráfico y optimizar el procesamiento tanto para los dispositivos de red como para los sistemas finales. Cuando un puerta de enlace de IP de una subred aprende acerca de un enlace ARP, lo comparte con otras puertas de enlace, por lo que no necesitan descubrir el mismo enlace ARP de forma independiente.
Con la supresión de ARP, cuando un dispositivo leaf recibe una solicitud ARP, comprueba su propia tabla ARP que está sincronizada con los otros dispositivos VTEP y responde a la solicitud localmente en lugar de inundar la solicitud ARP.
El ARP de proxy y la supresión de ARP están habilitados de forma predeterminada en todos los conmutadores de la serie QFX que pueden actuar como dispositivos leaf en una superposición de ERB. Para obtener una lista de estos conmutadores, consulte Diseños de referencia de estructura EVPN-VXLAN de centros de datos: resumen de hardware compatible.
Las interfaces IRB en el dispositivo leaf entregan solicitudes ARP y NDP desde dispositivos leaf locales y remotos. Cuando un dispositivo leaf recibe una solicitud ARP o NDP de otro dispositivo leaf, el dispositivo receptor busca en su base de datos de enlaces de direcciones MAC+IP la dirección IP solicitada.
Si el dispositivo encuentra el enlace de dirección MAC+IP en su base de datos, responde a la solicitud.
Si el dispositivo no encuentra el enlace de dirección MAC+IP, inunda la solicitud ARP a todos los vínculos Ethernet en la VLAN y los VTEP asociados.
Dado que todos los dispositivos leaf participantes agregan las entradas ARP y sincronizan sus tablas de enrutamiento y puente, los dispositivos leaf locales responden directamente a las solicitudes de los hosts conectados localmente y eliminan la necesidad de que los dispositivos remotos respondan a estas solicitudes ARP.
Para obtener información sobre cómo implementar la sincronización ARP, el ARP de proxy y la supresión de ARP, consulte Habilitar ARP de proxy y supresión de ARP para la superposición de puentes enrutados por borde.
Características de seguridad del puerto de capa 2 en sistemas finales conectados a Ethernet
Las superposiciones CRB y ERB admiten las características de seguridad de los sistemas finales conectados a Ethernet de capa 2 que describimos en las siguientes secciones.
Para obtener más información acerca de estas funciones, consulte Filtrado de MAC, control de tormentas y compatibilidad con la duplicación de puertos en un entorno EVPN-VXLAN.
Para obtener información sobre la configuración de estas funciones, consulte Configuración de funciones de seguridad de puerto de capa 2 en sistemas finales conectados a Ethernet.
- Prevención de tormentas de tráfico BUM con control de tormentas
- Uso del filtrado de MAC para mejorar la seguridad del puerto
- Análisis de tráfico mediante la duplicación de puertos
Prevención de tormentas de tráfico BUM con control de tormentas
El control de tormentas puede evitar que el tráfico excesivo degrade la red. Reduce el impacto de las tormentas de tráfico BUM mediante la supervisión de los niveles de tráfico en interfaces EVPN-VXLAN y la caída del tráfico BUM cuando se supera un nivel de tráfico especificado.
En un entorno de EVPN-VXLAN, el control de tormentas monitorea:
Tráfico BUM de capa 2 que se origina en una VXLAN y se reenvía a interfaces dentro de la misma VXLAN.
Tráfico de multidifusión de capa 3 que recibe una interfaz IRB en una VXLAN y se reenvía a interfaces en otra VXLAN.
Uso del filtrado de MAC para mejorar la seguridad del puerto
El filtrado MAC mejora la seguridad de los puertos al limitar la cantidad de direcciones MAC que se pueden aprender dentro de una VLAN y, por lo tanto, limitar el tráfico en una VXLAN. Limitar el número de direcciones MAC protege el conmutador de inundar la tabla de conmutación Ethernet. La inundación de la tabla de conmutación Ethernet se produce cuando el número de direcciones MAC nuevas que se aprenden hace que la tabla se desborde y las direcciones MAC aprendidas anteriormente se vacían de la tabla. El conmutador vuelve a aprender las direcciones MAC, lo que puede afectar el rendimiento e introducir vulnerabilidades de seguridad.
En este blueprint, el filtrado de MAC limita la cantidad de paquetes aceptados que se envían a las interfaces de acceso de entrada en función de las direcciones MAC. Para obtener más información sobre cómo funciona el filtrado de MAC, consulte la información de limitación de MAC en Descripción de la limitación de MAC y la limitación de movimiento de MAC.
Análisis de tráfico mediante la duplicación de puertos
Con la duplicación de puertos basada en analizadores, puede analizar el tráfico hasta el nivel de paquete en un entorno EVPN-VXLAN. Puede usar esta función para aplicar políticas relacionadas con el uso de la red y el uso compartido de archivos, y para identificar fuentes de problemas mediante la localización de un uso anormal o intenso del ancho de banda por estaciones o aplicaciones particulares.
La duplicación de puertos copia los paquetes que entran o salen de un puerto o que ingresan una VLAN y envía las copias a una interfaz local para monitoreo local o a una VLAN para monitoreo remoto. Utilice la duplicación de puertos para enviar tráfico a aplicaciones que analizan el tráfico con fines como monitorear el cumplimiento, aplicar políticas, detectar intrusiones, monitorear y predecir patrones de tráfico, correlacionar eventos, etc.