SUR CETTE PAGE
Prise en charge du multihébergement pour les systèmes finaux connectés par Ethernet
Prise en charge du multihébergement pour les systèmes terminaux connectés par IP
Optimisation du trafic des machines virtuelles entrantes pour EVPN
Réduction du trafic ARP avec la synchronisation et la suppression ARP (ARP proxy)
Fonctionnalités de sécurité des ports de couche 2 sur les terminaux connectés par Ethernet
Composants de l’architecture du plan de fabric de datacenter
Cette section donne une vue d’ensemble des blocs de construction utilisés dans cette architecture de blueprint. La mise en œuvre de chaque technologie de blocs modulaires est explorée plus en détail dans les sections suivantes.
Pour plus d’informations sur le matériel et les logiciels qui servent de base à vos blocs modulaires, consultez le résumé Conceptions de référence de la fabric EVPN-VXLAN de datacenter - Matériel pris en charge.
Les éléments de base comprennent :
Réseau underlay de fabric IP
Le bloc modulaire de réseau underlay de fabric IP moderne fournit une connectivité IP sur une topologie Clos. Juniper Networks prend en charge les modèles underlay de fabric IP suivants :
-
Une fabric IP à trois niveaux, composée d’un niveau d’équipements de cœur de réseau et d’un niveau d’équipements de branche. Voir Figure 1.
-
Une fabric IP à 5 niveaux, qui commence généralement par une seule structure IP à 3 niveaux et se développe en deux fabrics IP à 3 niveaux. Ces fabrics sont segmentées en points de livraison (POD) distincts au sein d’un datacenter. Pour ce cas d’usage, nous prenons en charge l’ajout d’un niveau de super équipements spine qui permettent la communication entre les équipements spine et leaf dans les deux POD. Voir Figure 2.
-
Modèle de fabric IP de cœur de réseau réduit, dans lequel les fonctions de la couche leaf sont réduites aux équipements de cœur de réseau. Ce type de structure peut être configuré et fonctionner de la même manière qu’une structure IP à 3 ou 5 niveaux, sauf sans niveau distinct d’équipements de branche. Vous pouvez utiliser une fabric de cœur de réseau réduite si vous passez de manière incrémentielle à un modèle spine-and-leaf EVPN, ou si vous avez des équipements d’accès ou des équipements top-of-rack (TOR) qui ne peuvent pas être utilisés dans une couche leaf car ils ne prennent pas en charge EVPN-VXLAN.
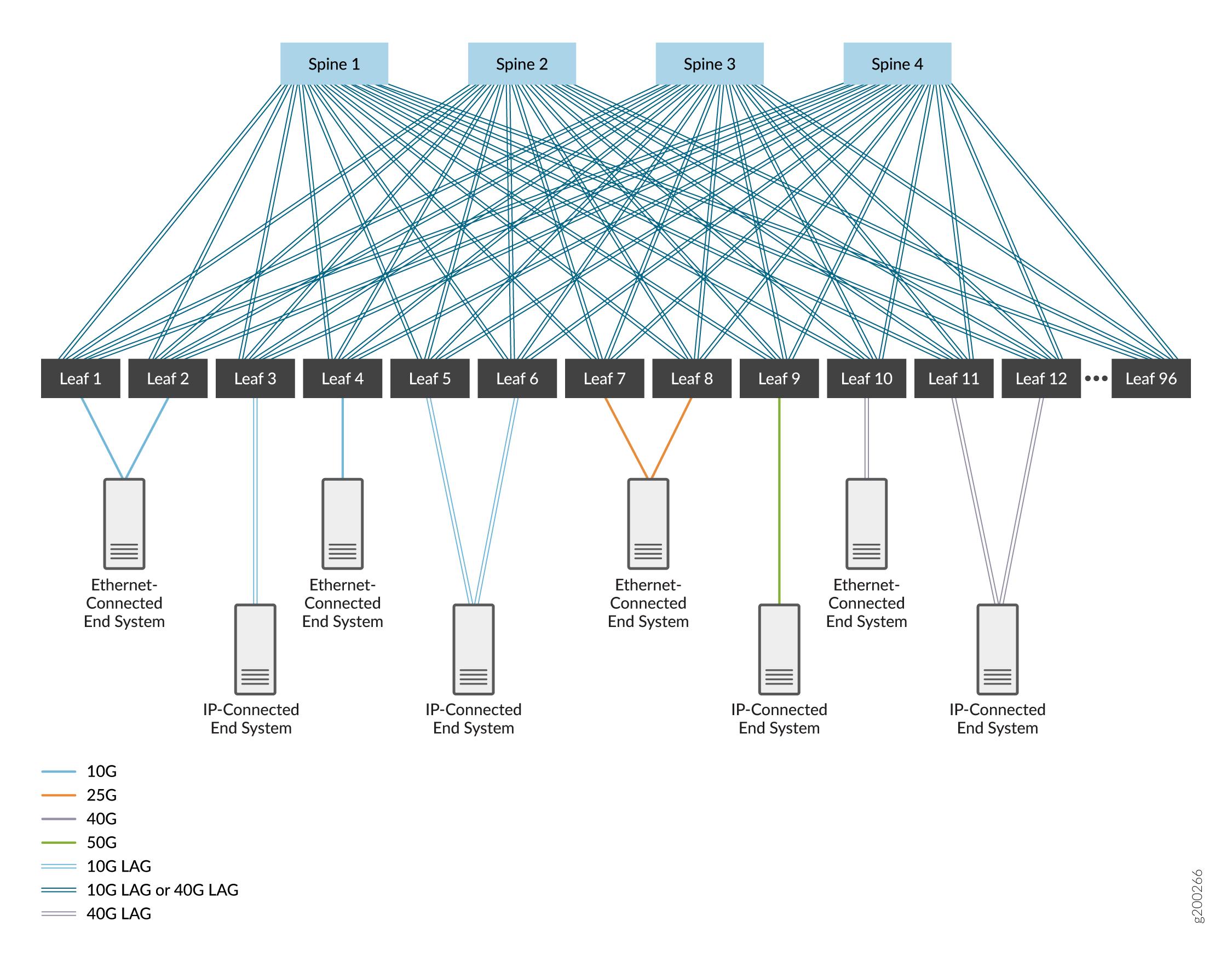 de fabric IP en trois étapes
de fabric IP en trois étapes
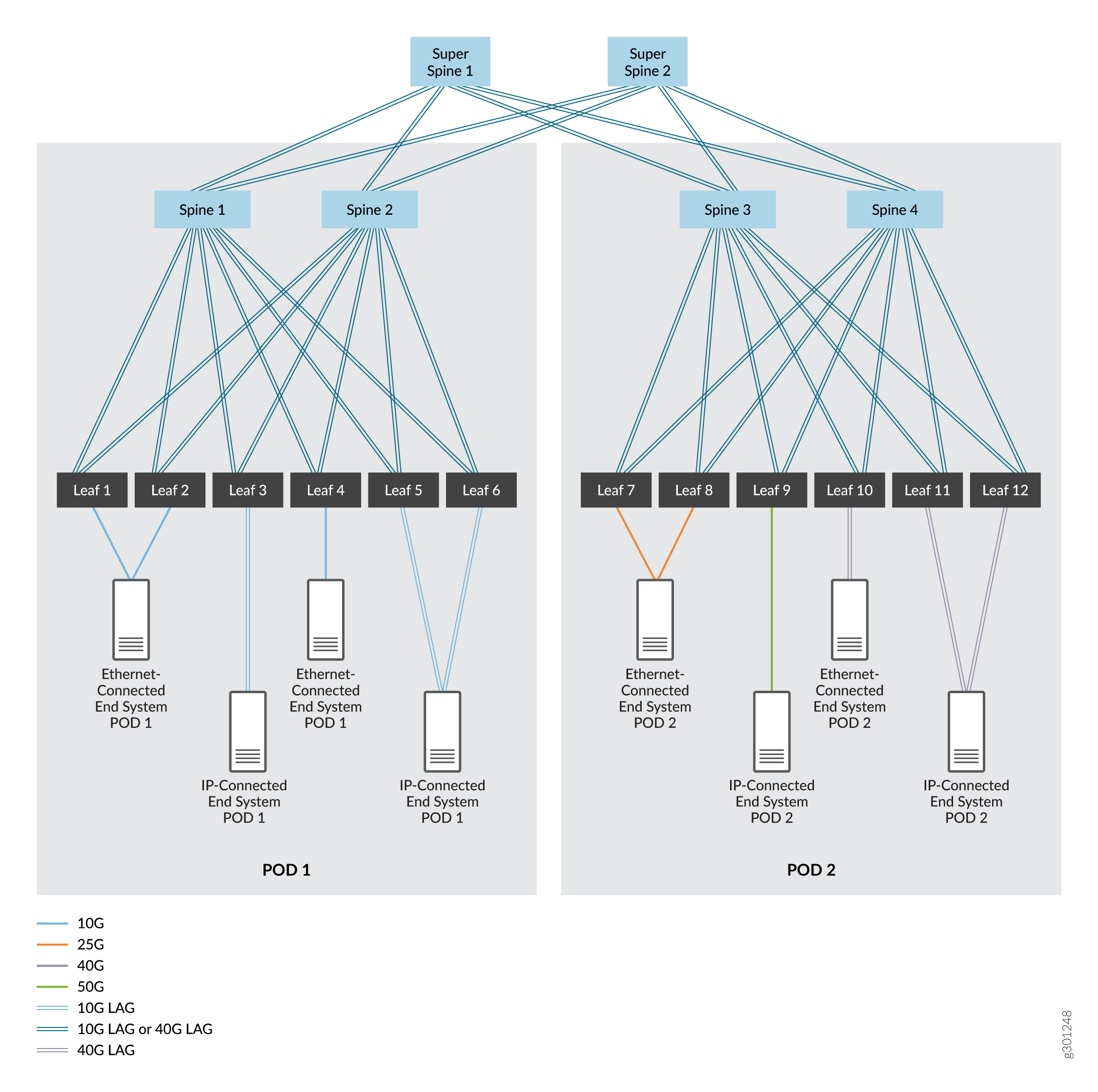 de fabric IP en cinq étapes
de fabric IP en cinq étapes
Dans ces figures, les appareils sont interconnectés à l’aide d’interfaces à haut débit qui sont soit des liaisons simples, soit des interfaces Ethernet agrégées. Les interfaces Ethernet agrégées sont facultatives (une liaison unique entre les appareils est généralement utilisée), mais peuvent être déployées pour augmenter la bande passante et fournir une redondance au niveau de la liaison. Nous couvrons les deux options.
Nous avons choisi EBGP comme protocole de routage dans le réseau sous-jacent pour sa fiabilité et son évolutivité. Chaque appareil se voit attribuer son propre système autonome avec un numéro de système autonome unique pour prendre en charge EBGP. Vous pouvez utiliser d’autres protocoles de routage dans le réseau sous-jacent ; L’utilisation de ces protocoles dépasse le cadre du présent document.
Les architectures de référence décrites dans ce guide reposent sur une fabric IP qui utilise EBGP pour la connectivité sous-jacente et IBGP pour l’appairage overlay (voir IBGP pour les superpositions). Vous pouvez également configurer l’appairage overlay à l’aide d’EBGP.
À partir des versions 21.2R2 et 21.4R1 de Junos OS, nous prenons également en charge la configuration d’une fabric IPv6. La conception de la fabric IPv6 décrite dans ce guide utilise EBGP à la fois pour la connectivité des sous-couches et l’appairage des superpositions (voir EBGP pour les superpositions avec des sous-couches IPv6).
La fabric IP peut utiliser IPv4 ou IPv6 comme suit :
-
Une fabric IPv4 utilise l’adressage d’interface IPv4 et les sessions BGP underlay et overlay IPv4 pour la communication des charges de travail de bout en bout.
-
Une fabric IPv6 utilise l’adressage d’interface IPv6 et les sessions BGP underlay et overlay IPv6 pour la communication des charges de travail de bout en bout.
-
Nous ne prenons pas en charge une fabric IP qui mélange IPv4 et IPv6.
Cependant, les structures IPv4 et IPv6 prennent toutes deux en charge les charges de travail à double pile, qui peuvent être IPv4 ou IPv6, ou IPv4 et IPv6.
La microdétection de transfert bidirectionnel (BFD), qui permet d’exécuter la fonction BFD sur des liaisons individuelles dans une interface Ethernet agrégée, peut également être activée dans ce bloc modulaire pour détecter rapidement les défaillances de liaison sur toutes les liaisons membres des bundles Ethernet agrégés qui connectent des appareils.
Pour plus d’informations, consultez les autres sections suivantes de ce guide :
-
Configuration des équipements Spine et Leaf dans les underlays de fabric IP à 3 et 5 niveaux : Conception et implémentation du réseau underlay de la fabric IP.
-
Implémentation du niveau supplémentaire des équipements super spine dans un underlay de fabric IP à 5 étapes : conception et implémentation d’une fabric IP en cinq étapes.
-
Configuration d’une sous-couche IPv6 et prise en charge de la superposition IPv6 EBGP : Conception et implémentation d’un réseau sous-jacent et superposition de fabric IPv6 avec EBGP.
-
Configuration de l’underlay dans un modèle de fabric Collapsed Spine : Collapsed Spine fabric Design and Implementation.
Prise en charge des charges de travail IPv4 et IPv6
Étant donné que de nombreux réseaux implémentent un environnement à double pile pour les charges de travail qui incluent des protocoles IPv4 et IPv6, ce plan prend en charge les deux protocoles. Les étapes de configuration de la fabric pour prendre en charge les charges de travail IPv4 et IPv6 sont entrelacées tout au long de ce guide pour vous permettre de choisir l’un de ces protocoles ou les deux.
Le protocole IP que vous utilisez pour le trafic des charges de travail est indépendant de la version du protocole IP (IPv4 ou IPv6) que vous configurez pour la sous-couche et l’overlay de la fabric IP. (Voir Réseau underlay de fabric IP.) Une infrastructure de fabric IPv4 ou de fabric IPv6 peut prendre en charge des charges de travail IPv4 et IPv6.
Superpositions de virtualisation réseau
Une superposition de virtualisation de réseau est un réseau virtuel qui est transporté sur un réseau IP sous-jacent. Ce bloc modulaire permet de multilocataire dans un réseau, ce qui vous permet de partager un seul réseau physique entre plusieurs locataires, tout en isolant le trafic réseau de chaque locataire des autres locataires.
Un locataire est une communauté d’utilisateurs (telle qu’une unité commerciale, un service, un groupe de travail ou une application) qui contient des groupes de points de terminaison. Les groupes peuvent communiquer avec d’autres groupes dans le même locataire, et les locataires peuvent communiquer avec d’autres locataires si les stratégies réseau le permettent. Un groupe est généralement exprimé sous la forme d’un sous-réseau (VLAN) qui peut communiquer avec d’autres périphériques du même sous-réseau et atteindre des groupes et des points de terminaison externes par le biais d’une instance VRF (Virtual Routing and Forwarding).
Comme le montre l’exemple de superposition illustré à la Figure 3, les tables de pontage Ethernet (représentées par des triangles) gèrent les trames pontées par des locataires et les tables de routage IP (représentées par des carrés) traitent les paquets routés. Le routage inter-VLAN s’effectue aux interfaces IRB (Integrated Routing and Bridging) (représentées par des cercles). Les tables Ethernet et IP sont dirigées vers des réseaux virtuels (représentés par des lignes colorées). Pour atteindre les systèmes finaux connectés à d’autres appareils VXLAN Tunnel Endpoint (VTEP), les paquets des locataires sont encapsulés et envoyés via un tunnel VXLAN signalé par EVPN (représenté par des icônes tunnel vertes) aux équipements de VTEP distants associés. Les paquets tunnelisés sont désencapsulés au niveau des équipements VTEP distants et transférés vers les systèmes terminaux distants via les tables de pontage ou de routage correspondantes du périphérique VTEP de sortie.
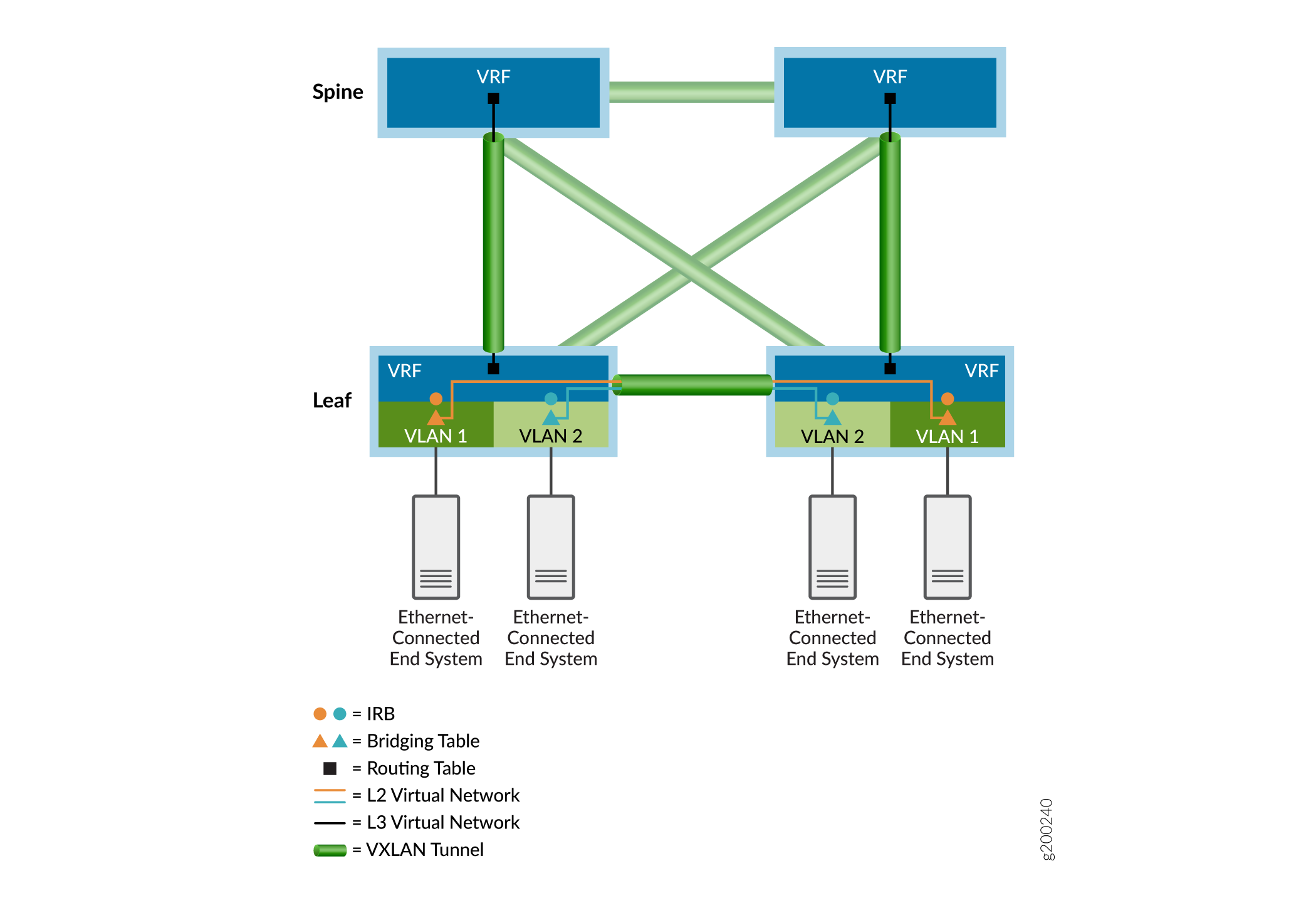
Les sections suivantes fournissent plus de détails sur les réseaux de superposition.
- IBGP pour les superpositions
- EBGP pour les superpositions avec sous-couches IPv6
- Superposition pontée
- Superposition de pontage à routage central
- Superposition de pontage à routage périphérique
- Superposition de dos réduite
- Comparaison des superpositions pontées, CRB et ERB
- Modèles d’adressage IRB dans les superpositions de pontage
- Superposition routée à l’aide de routes EVPN de type 5
- Instances MAC-VRF pour la mutualisation dans les superpositions de virtualisation de réseau
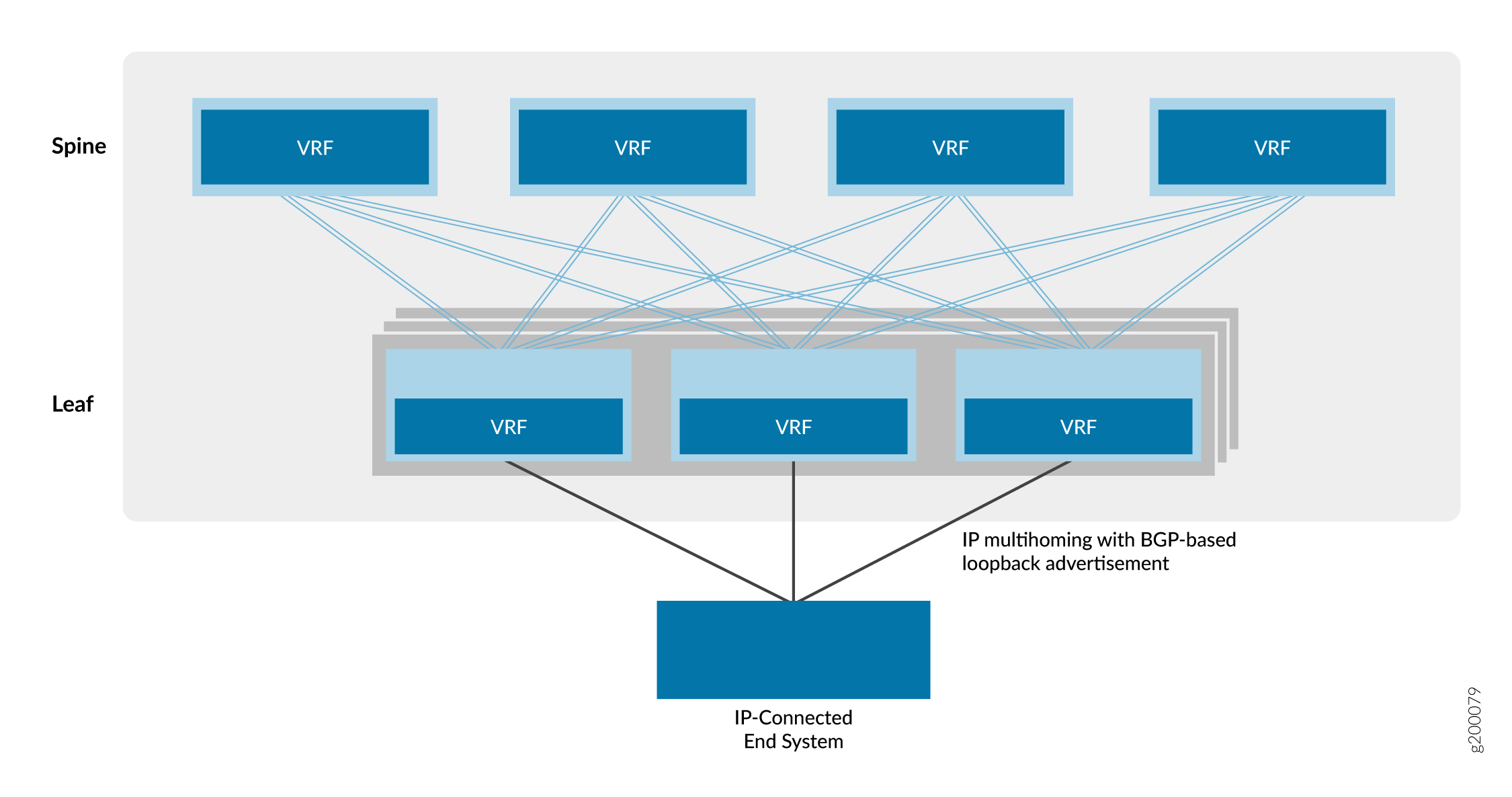
IBGP pour les superpositions
Internal BGP (IBGP) est un protocole de routage qui échange des informations d’accessibilité sur un réseau IP. Lorsque l’IBGP est combiné avec le Multiprotocol BGP (MP-IBGP), il fournit la base permettant à EVPN d’échanger des informations d’accessibilité entre les périphériques VTEP. Cette capacité est nécessaire pour établir des tunnels VXLAN entre VTEP et les utiliser comme services de connectivité overlay.
La figure 4 montre que les équipements Spine et Leaf utilisent leurs adresses de bouclage pour l’appairage dans un seul système autonome. Dans cette conception, les équipements de cœur de réseau agissent comme un cluster de réflecteurs de route et les équipements leaf comme des clients de réflecteur de route. Un réflecteur de route répond aux exigences de l’IBGP pour un maillage complet sans qu’il soit nécessaire d’appairer tous les périphériques VTEP directement les uns avec les autres. Par conséquent, les équipements de branche s’apparient uniquement avec les équipements de cœur de réseau et les équipements de cœur de réseau s’apparient à la fois avec les équipements de cœur de réseau et les équipements de branche. Étant donné que les équipements de cœur de réseau sont connectés à tous les équipements de branche, les équipements de cœur de réseau peuvent relayer des informations IBGP entre les voisins de périphérique de branche appairés indirectement.
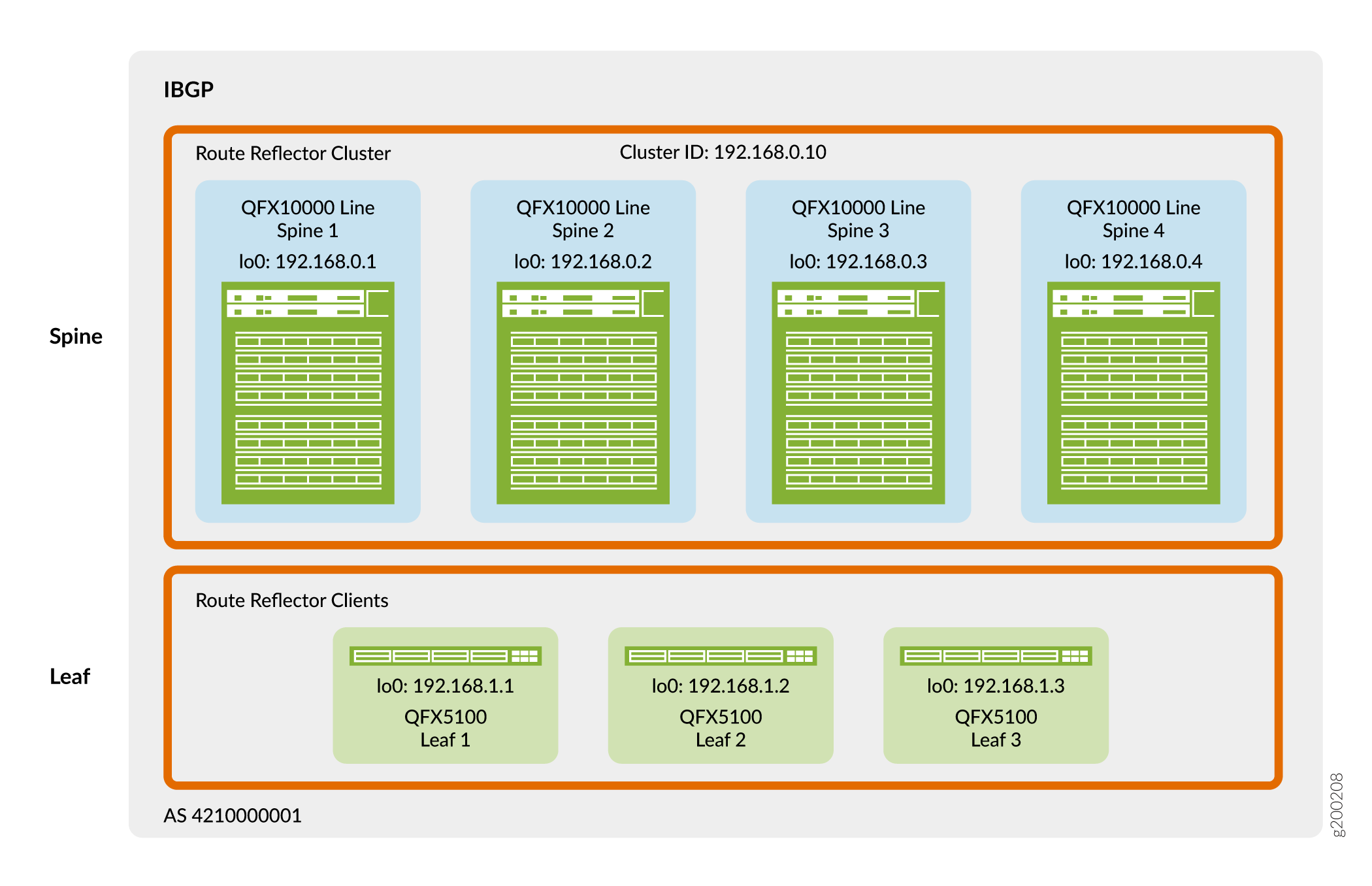 superpositions
superpositions
Vous pouvez placer des réflecteurs de route presque n’importe où sur le réseau. Cependant, vous devez tenir compte des éléments suivants :
-
L’équipement sélectionné dispose-t-il de suffisamment de mémoire et de puissance de traitement pour gérer la charge de travail supplémentaire requise par un réflecteur de route ?
-
L’appareil sélectionné est-il équidistant et accessible depuis tous les haut-parleurs EVPN ?
-
L’équipement sélectionné dispose-t-il des fonctionnalités logicielles appropriées ?
Dans cette conception, le cluster de réflecteurs de route est placé au niveau de la couche spine. Les commutateurs QFX que vous pouvez utiliser comme cœur de réseau dans cette conception de référence ont une vitesse de traitement suffisante pour gérer le trafic client de réflecteur de route dans la superposition de virtualisation du réseau.
Pour plus de détails sur l’implémentation d’IBGP dans une superposition, consultez Configurer IBGP pour la superposition.
EBGP pour les superpositions avec sous-couches IPv6
Les cas d’usage d’architecture de référence d’origine de ce guide illustrent une conception de sous-couche EBGP IPv4 avec une connectivité overlay IBGP IPv4. Voir Réseau underlay de fabric IP et IBGP pour les superpositions. Toutefois, alors que les appareils NVE (Network virtualization Edge) commencent à adopter les VTEP IPv6 pour tirer parti de la plage d’adressage et des capacités étendues d’IPv6, nous avons étendu la prise en charge de la fabric IP à IPv6.
À partir de la version 21.2R2-S1 de Junos OS, vous pouvez également utiliser une infrastructure de fabric IPv6 avec certaines conceptions d’architecture de référence superposées. La conception de la fabric IPv6 comprend un adressage d’interface IPv6, un underlay EBGP IPv6 et un overlay EBGP IPv6 pour la connectivité des charges de travail. Avec un fabric IPv6, les équipements NVE encapsulent l’en-tête VXLAN avec un en-tête externe IPv6 et tunnel les paquets dans la fabric de bout en bout à l’aide des sauts suivants IPv6. La charge de travail peut être IPv4 ou IPv6.
La plupart des éléments que vous configurez dans les conceptions de superposition d’architecture de référence prises en charge sont indépendants de l’utilisation d’IPv4 ou d’IPv6 pour l’infrastructure sous-jacente et superposée. Les procédures de configuration correspondantes pour chacune des conceptions de superposition prises en charge signalent les différences de configuration si la sous-couche et la superposition utilisent la conception de la fabric IPv6.
Pour plus de détails, consultez les références suivantes dans ce guide et d’autres ressources :
Configuration d’une fabric IPv6 à l’aide d’EBGP pour la connectivité underlay et l’appairage overlay : Conception et implémentation du réseau underlay et overlay de fabric IPv6 avec EBGP.
Lancement de versions dans lesquelles différentes plates-formes prennent en charge une conception de fabric IPv6 lorsqu’elles remplissent des rôles particuliers dans la structure : Conceptions de référence fabric EVPN-VXLAN de datacenter - Résumé du matériel pris en charge.
Présentation de la prise en charge de l’appairage IPv6 underlay et overlay dans les fabrics EVPN-VXLAN sur les équipements Juniper Networks : EVPN-VXLAN avec un underlay IPv6.
Superposition pontée
Le premier type de service de superposition décrit dans ce guide est une superposition pontée, comme illustré à la figure 5.
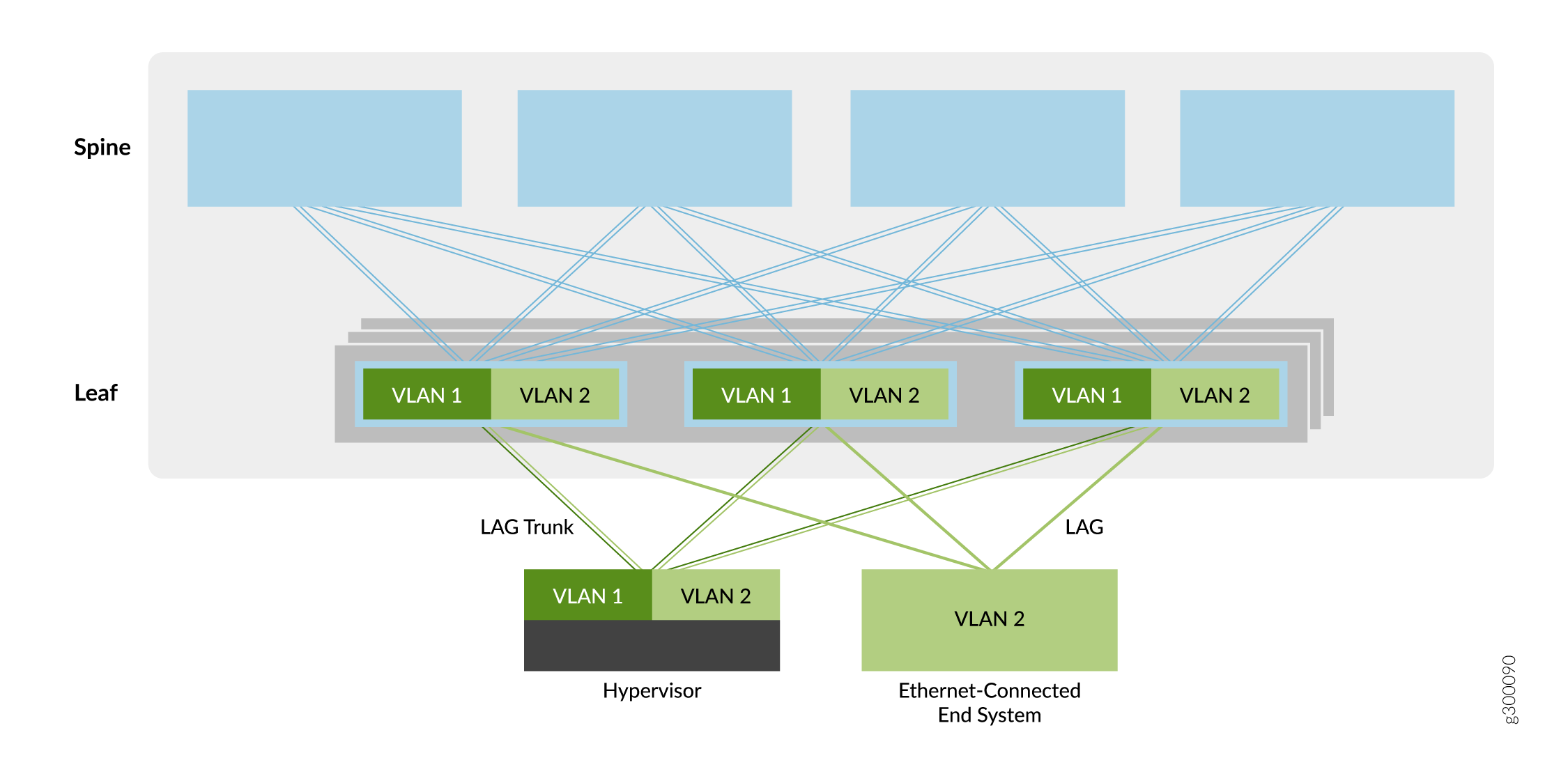 pontée
pontée
Dans ce modèle de superposition, les VLAN Ethernet sont étendus entre les équipements leaf sur les tunnels VXLAN. Ces tunnels VXLAN leaf à leaf prennent en charge les réseaux de datacenter qui nécessitent une connectivité Ethernet entre les équipements leaf, mais qui n’ont pas besoin de routage entre les VLAN. Par conséquent, les équipements de cœur de réseau n’offrent qu’une connectivité de base en sous-couche et en superposition pour les équipements de branche, et n’exécutent pas les services de routage ou de passerelle observés avec d’autres méthodes de superposition.
Les équipements de branche créent des VTEP pour se connecter aux autres équipements de branche. Les tunnels permettent aux équipements leaf d’envoyer du trafic VLAN vers d’autres équipements leaf et des terminaux connectés Ethernet dans le datacenter. La simplicité de ce service de superposition le rend attrayant pour les opérateurs qui ont besoin d’un moyen facile d’introduire EVPN/VXLAN dans leur datacenter Ethernet existant.
Vous pouvez ajouter du routage à une superposition pontée en implémentant un routeur MX Series ou un équipement de sécurité SRX Series externe à la fabric EVPN/VXLAN. Sinon, vous pouvez sélectionner l’un des autres types de superposition qui intègrent le routage (par exemple, une superposition de pontage à routage périphérique, une superposition de pontage à routage central ou une superposition routée).
Pour plus d’informations sur l’implémentation d’une superposition pontée, consultez Conception et implémentation d’une superposition pontée.
Superposition de pontage à routage central
Le deuxième type de service de superposition est le pontage à routage central (CRB), comme illustré à la Figure 6.
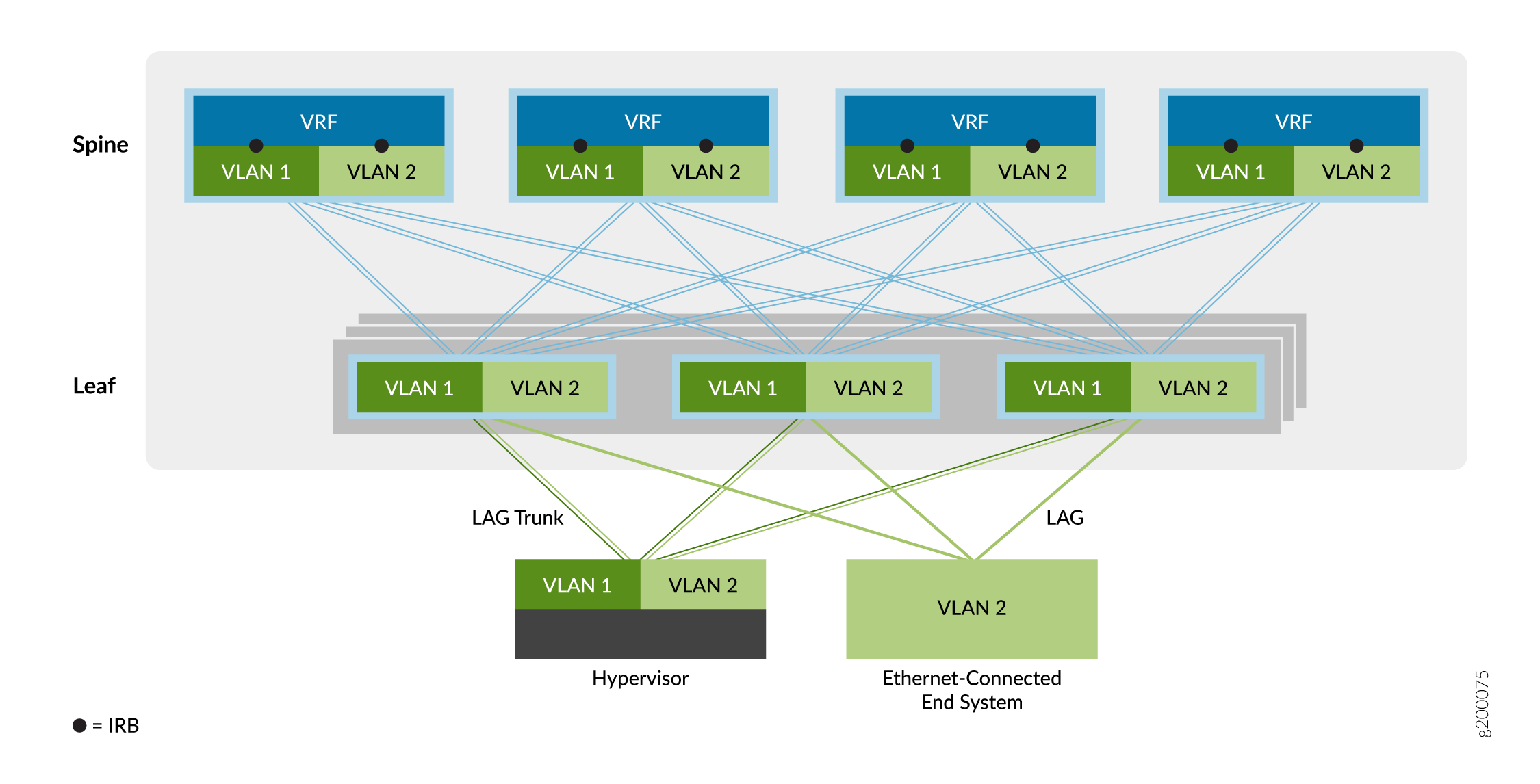 de pontage à routage central
de pontage à routage central
Dans une superposition CRB, le routage a lieu au niveau d’une passerelle centrale du réseau du datacenter (la couche spine dans cet exemple) plutôt qu’au niveau de l’équipement VTEP où les systèmes finaux sont connectés (la couche leaf dans cet exemple).
Vous pouvez utiliser ce modèle de superposition lorsque vous avez besoin que le trafic routé passe par une passerelle centralisée ou lorsque vos équipements VTEP de périphérie ne disposent pas des capacités de routage requises.
Comme indiqué ci-dessus, le trafic provenant des systèmes finaux connectés par Ethernet est transféré vers les équipements VTEP leaf sur une agrégation (plusieurs VLAN) ou un port d’accès (un seul VLAN). Le périphérique VTEP transfère le trafic vers des systèmes terminaux locaux ou vers un système final d’un périphérique VTEP distant. Une interface de routage et de pontage intégrée (IRB) au niveau de chaque équipement Spine permet d’acheminer le trafic entre les réseaux virtuels Ethernet.
Le modèle de service de pontage superposé compatible VLAN vous permet d’agréger facilement un ensemble de VLAN dans le même réseau virtuel superposé. La conception EVPN de Juniper Networks prend en charge trois configurations de modèle de service Ethernet compatible VLAN dans le datacenter, comme suit :
-
Default instance VLAN-aware: avec cette option, vous implémentez une seule instance de commutation par défaut qui prend en charge un total de 4094 VLAN. Toutes les plates-formes leaf incluses dans cette conception (conceptions de référence de la fabric EVPN-VXLAN de datacenter - Résumé du matériel pris en charge) prennent en charge le style d’instance par défaut de superposition sensible aux VLAN.
Pour configurer ce modèle de service, reportez-vous à la section Configuration d’une superposition de pontage à routage central compatible VLAN dans l’instance par défaut.
-
Virtual switch VLAN-aware: avec cette option, plusieurs instances de commutateur virtuel prennent en charge jusqu’à 4 094 VLAN par instance. Ce modèle de service Ethernet est idéal pour les réseaux de superposition qui nécessitent une évolutivité au-delà d’une seule instance par défaut. Cette option est actuellement prise en charge sur la gamme QFX10000 de commutateurs.
Pour implémenter ce modèle de service évolutif, consultez Configuration d’une superposition CRB compatible VLAN avec des commutateurs virtuels ou des instances MAC-VRF.
-
MAC-VRF instance VLAN-aware: avec cette option, plusieurs instances MAC-VRF prennent en charge jusqu’à 4 094 VLAN par instance. Ce modèle de service Ethernet est idéal pour les réseaux de superposition qui nécessitent une évolutivité au-delà d’une instance par défaut unique et pour lesquels vous souhaitez plus d’options pour assurer l’isolation VLAN ou l’interconnexion entre différents locataires dans la même structure. La prise en charge de cette option est disponible sur les plates-formes qui prennent en charge les instances MAC-VRF (voir Explorateur de fonctionnalités : MAC VRF avec EVPN-VXLAN).
Pour implémenter ce modèle de service évolutif, consultez Configuration d’une superposition CRB compatible VLAN avec des commutateurs virtuels ou des instances MAC-VRF.
Superposition de pontage à routage périphérique
La troisième option de service de superposition est la superposition ERB (Edge-Routed Bridging), comme illustré à la Figure 7.
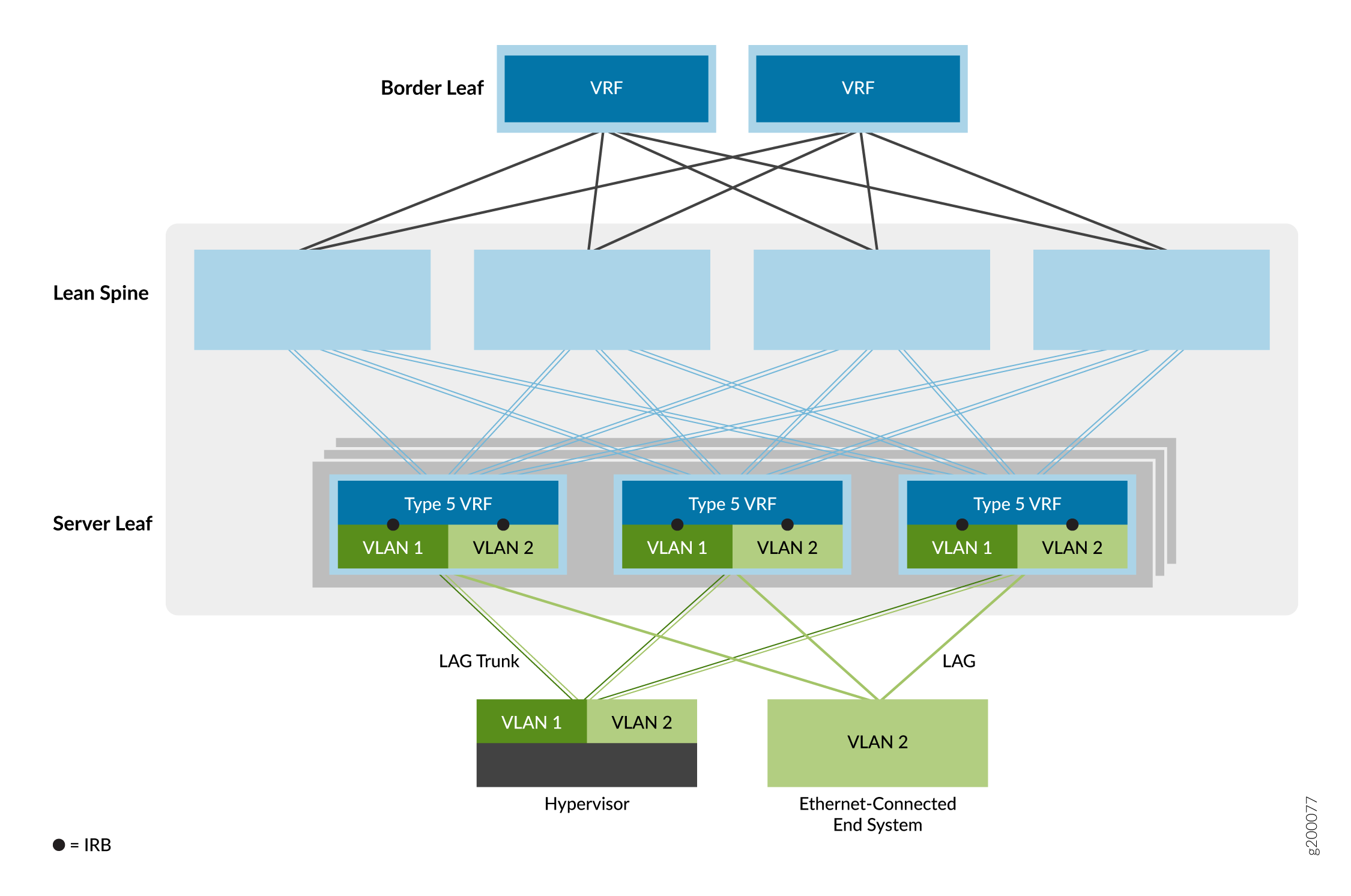 de pontage à routage périphérique
de pontage à routage périphérique
Dans ce modèle de service Ethernet, les interfaces IRB sont déplacées vers des VTEP de branche à la périphérie du réseau de superposition afin de rapprocher le routage IP des systèmes finaux. En raison des capacités ASIC spéciales requises pour prendre en charge le pontage, le routage et EVPN/VXLAN dans un seul équipement, les superpositions ERB ne sont possibles que sur certains commutateurs. Pour obtenir la liste des commutateurs que nous prenons en charge en tant que périphériques de branche dans une superposition ERB, consultez Conceptions de référence de fabric EVPN-VXLAN de datacenter - Résumé du matériel pris en charge.
Ce modèle simplifie l’ensemble du réseau. Les équipements de cœur de réseau sont configurés pour gérer uniquement le trafic IP, ce qui élimine le besoin d’étendre les superpositions de pontage aux équipements de cœur de réseau.
Cette option permet également d’accélérer le trafic de serveur à serveur à l’intérieur du datacenter (également appelé trafic est-ouest) où les systèmes finaux sont connectés au même équipement leaf VTEP. Par conséquent, le routage se fait beaucoup plus près des systèmes finaux qu’avec les superpositions CRB.
Lorsque vous configurez des interfaces IRB incluses dans les instances de routage EVPN de type 5 sur des commutateurs QFX5110 ou QFX5120 qui fonctionnent comme des équipements de branche, l’équipement active automatiquement le routage symétrique inter-IRB unicast pour les routes EVPN de type 5.
Pour plus d’informations sur l’implémentation de la superposition ERB, consultez Conception et implémentation de la superposition de pontage à routage en périphérie.
Superposition de dos réduite
Dans une architecture de cœur de réseau réduit, le réseau overlay est similaire à un réseau overlay ERB. Dans une architecture de cœur de réseau réduite, les fonctions des équipements de branche sont réduites aux équipements de cœur de réseau. Comme il n’y a pas de couche leaf, vous configurez les interfaces VTEPS et IRB sur les équipements de cœur de réseau, qui se trouvent à la périphérie du réseau de superposition comme les équipements de branche d’un modèle ERB. Les équipements de cœur de réseau peuvent également remplir des fonctions de passerelle de bordure pour acheminer le trafic nord-sud ou étendre le trafic de couche 2 à travers les datacenters.
Pour obtenir la liste des commutateurs que nous prenons en charge avec une architecture de cœur de réseau réduite, consultez Conceptions de référence de fabric EVPN-VXLAN de datacenter - Matériel pris en charge.
Comparaison des superpositions pontées, CRB et ERB
Pour vous aider à choisir le type de superposition le mieux adapté à votre environnement EVPN, reportez-vous au Tableau 1.
Nous prenons en charge le mélange de configurations de superposition pontée, de superposition CRB et de superposition ERB sur le même équipement en même temps sur les appareils qui prennent en charge ces types de superposition. Vous n'avez pas besoin de configurer l'appareil avec des systèmes logiques distincts pour qu'il fonctionne dans différents types de superpositions en parallèle.
| Points de comparaison |
Superposition ERB |
Superposition CRB |
Superposition pontée |
|---|---|---|---|
| Routage inter-sous-réseau de locataires entièrement distribué |
✓ |
||
| Impact minimal d’une défaillance de la passerelle IP |
✓ |
||
| Routage dynamique vers des nœuds tiers au niveau leaf |
✓ |
||
| Optimisé pour un volume élevé de trafic est-ouest |
✓ |
||
| Meilleure intégration avec les fabrics IP brutes |
✓ |
||
| Virtualisation IP VRF plus proche du serveur |
✓ |
||
| Multihébergement Contrail vRouter requis |
✓ |
||
| Interopérabilité EVPN facilitée avec différents fournisseurs |
✓ |
||
| Routage symétrique entre sous-réseaux |
✓ |
✓ |
|
| Chevauchement d’ID de VLAN par rack |
✓ |
✓ |
✓ |
| Configuration et dépannage manuels simplifiés |
✓ |
✓ |
|
| Interfaces de type fournisseur de services et d’entreprise |
✓ |
✓ |
|
| Prise en charge des commutateurs leaf hérités (QFX5100) |
✓ |
✓ |
|
| Contrôle centralisé de l’optimisation du trafic des machines virtuelles (VMTO) |
✓ |
||
| Passerelle de sous-réseau de locataire IP sur le cluster de pare-feu |
✓ |
Modèles d’adressage IRB dans les superpositions de pontage
La configuration des interfaces IRB dans les superpositions CRB et ERB nécessite de comprendre les modèles de configuration IP et adresse MAC passerelle par défaut des interfaces IRB comme suit :
Unique IRB IP Address: dans ce modèle, une adresse IP unique est configurée sur chaque interface IRB dans un sous-réseau overlay.
L’avantage d’avoir une adresse IP et une adresse MAC uniques sur chaque interface IRB est la possibilité de surveiller et d’atteindre chacune des interfaces IRB à partir de la superposition à l’aide de son adresse IP unique. Ce modèle vous permet également de configurer un protocole de routage sur l’interface IRB.
L’inconvénient de ce modèle est que l’attribution d’une adresse IP unique à chaque interface IRB peut consommer de nombreuses adresses IP d’un sous-réseau.
Unique IRB IP Address with Virtual Gateway IP Address: ce modèle ajoute une adresse IP de passerelle virtuelle au modèle précédent, ce que nous recommandons pour les superpositions pontées à routage central. Il est similaire au VRRP, mais sans les signaux du plan de données intrabande entre les interfaces IRB de la passerelle. La passerelle virtuelle doit être la même pour toutes les interfaces IRB de passerelle par défaut dans le sous-réseau de superposition et est active sur toutes les interfaces IRB de passerelle où elle est configurée. Vous devez également configurer une adresse MAC IPv4 commune pour la passerelle virtuelle, qui devient l’adresse MAC source sur les paquets de données transférés via l’interface IRB.
Outre les avantages du modèle précédent, la passerelle virtuelle simplifie la configuration de la passerelle par défaut sur les systèmes finaux. L’inconvénient de ce modèle est le même que le modèle précédent.
IRB with Anycast IP Address and MAC Address: dans ce modèle, toutes les interfaces IRB de passerelle par défaut d’un sous-réseau overlay sont configurées avec les mêmes adresses IP et les mêmes adresse MAC. Nous recommandons ce modèle pour les superpositions ERB.
L’un des avantages de ce modèle est qu’une seule adresse IP est requise par sous-réseau pour l’adressage de l’interface IRB de la passerelle par défaut, ce qui simplifie la configuration de la passerelle par défaut sur les systèmes finaux.
Superposition routée à l’aide de routes EVPN de type 5
La dernière option de superposition est une superposition routée, comme illustré sur la Figure 8.
 routée
routée
Cette option est un service de réseau virtuel à routage IP. Contrairement à un VPN IP basé sur le MPLS, le réseau virtuel de ce modèle est basé sur EVPN/VXLAN.
Les fournisseurs de cloud préfèrent cette option de réseau virtuel, car la plupart des applications modernes sont optimisées pour la propriété intellectuelle. Étant donné que toutes les communications entre les appareils ont lieu au niveau de la couche IP, il n’est pas nécessaire d’utiliser des composants de pontage Ethernet, tels que des VLAN et des ESI, dans ce modèle de superposition routée.
Pour plus d’informations sur l’implémentation d’une superposition routée, consultez Conception et implémentation d’une superposition routée.
Instances MAC-VRF pour la mutualisation dans les superpositions de virtualisation de réseau
Les instances de routage MAC-VRF vous permettent de configurer plusieurs instances EVPN avec différents types de services Ethernet sur un équipement agissant comme un VTEP dans une fabric EVPN-VXLAN. À l’aide des instances MAC-VRF, vous pouvez gérer plusieurs locataires dans le datacenter avec des tables VRF spécifiques aux clients pour isoler ou regrouper les charges de travail des locataires.
En plus de la prise en charge antérieure du type de service VLAN, les instances MAC-VRF prennent également en charge le type de service VLAN. Voir Figure 9.
 de services MAC-VRF
de services MAC-VRF
-
Service basé sur VLAN : vous pouvez configurer un VLAN et l’identifiant de réseau VXLAN (VNI) correspondant dans l’instance MAC-VRF. Pour provisionner un nouveau VLAN et un nouveau VNI, vous devez configurer une nouvelle instance MAC VRF avec le nouveau VLAN et le nouveau VNI.
-
Service VLAN : vous pouvez configurer un ou plusieurs VLAN et les VNI correspondants dans la même instance MAC-VRF. Pour provisionner un nouveau VLAN et un nouveau VNI, vous pouvez ajouter la nouvelle configuration de VLAN et de VNI à l’instance MAC-VRF existante, ce qui évite certaines étapes de configuration par rapport à l’utilisation d’un service basé sur VLAN.
Les instances MAC-VRF offrent des options de configuration plus flexibles aux niveaux 2 et 3. Par exemple :
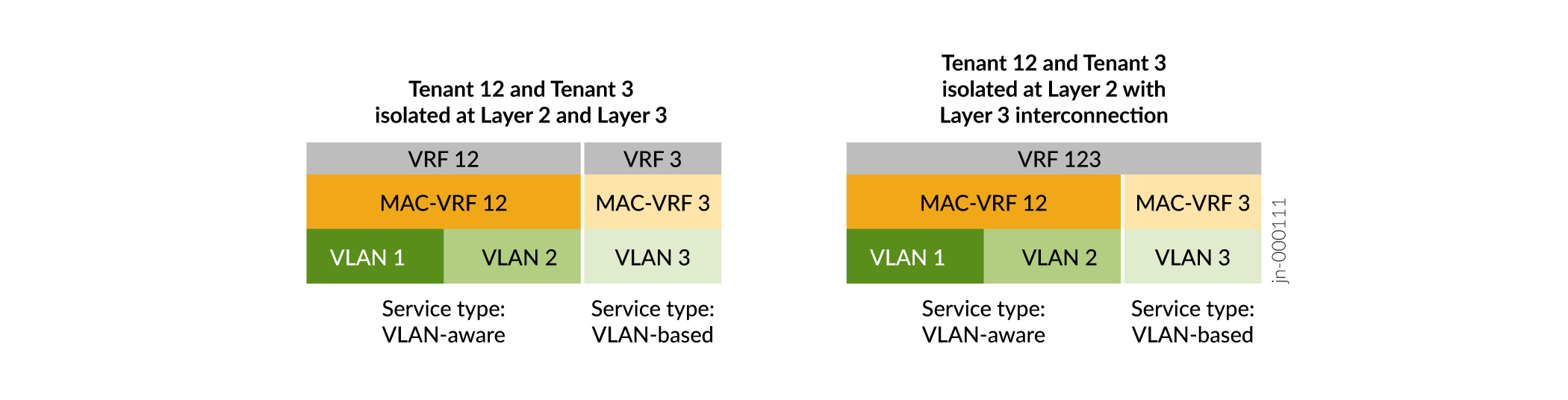 MAC-VRF
MAC-VRF
La figure 10 montre qu’avec les instances MAC-VRF :
-
Vous pouvez configurer différents types de services dans différentes instances MAC-VRF sur le même équipement.
-
Vous disposez d’options flexibles d’isolation des locataires au niveau de la couche 2 (instances MAC-VRF) ainsi qu’au niveau de la couche 3 (instances VRF). Vous pouvez configurer une instance VRF qui correspond au ou aux VLAN d’une seule instance MAC-VRF. Vous pouvez également configurer une instance VRF qui couvre les VLAN de plusieurs instances MAC-VRF.
La figure 11 montre une fabric de superposition ERB avec un exemple de configuration MAC-VRF pour la séparation des locataires.
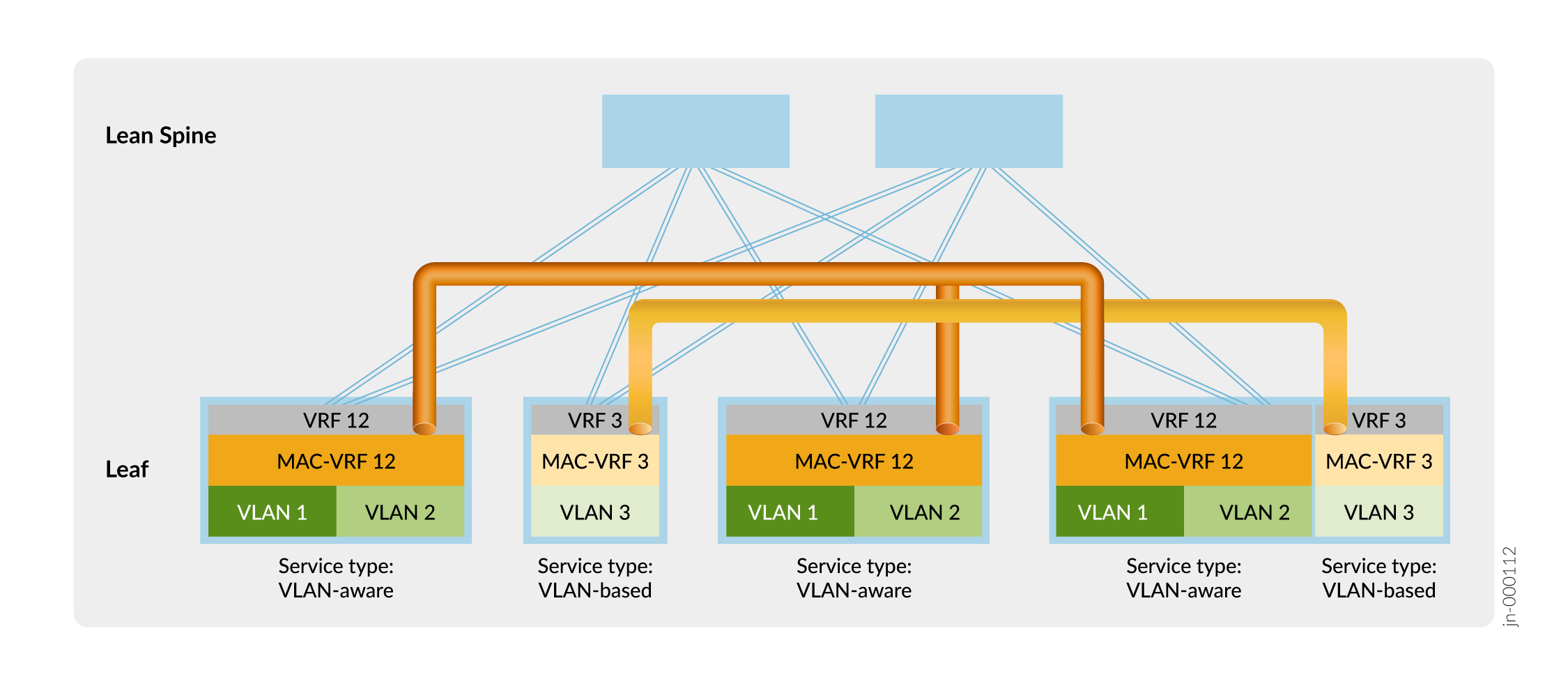 locataires
locataires
Sur la Figure 11, les équipements leaf établissent des tunnels VXLAN qui maintiennent l’isolation au niveau de la couche 2 entre le locataire 12 (VLAN 1 et VLAN 2) et le locataire 3 (VLAN 3) à l’aide des instances MAC-VRF MAC-VRF 12 et MAC-VRF 3. Les équipements leaf isolent également les locataires au niveau de la couche 3 à l’aide des instances VRF VRF 12 et VRF 3.
Vous pouvez utiliser d’autres options pour partager le trafic VLAN entre des locataires isolés au niveau des couches 2 et 3 par les configurations MAC-VRF et VRF, telles que :
-
Établissez une interconnexion externe sécurisée entre les VRF des locataires via un pare-feu.
-
Configurez les fuites de route locale entre les VRF de couche 3.
Pour plus d’informations sur les instances MAC-VRF et leur utilisation dans un exemple de cas d’usage client, consultez Services MAC-VRF L2 de la fabric IP DC EVPN-VXLAN.
Les instances MAC-VRF correspondent aux instances de transfert comme suit :
-
Les instances MAC-VRF des commutateurs de la gamme QFX5000 (y compris ceux qui exécutent Junos OS ou Junos OS Evolved) font toutes partie de l’instance de transfert par défaut. Sur ces appareils, vous ne pouvez pas configurer de VLAN qui se chevauchent dans une instance MAC-VRF ou sur plusieurs instances MAC-VRF.
-
Sur la gamme de commutateurs QFX10000, vous pouvez configurer plusieurs instances de transfert et mapper une instance MAC-VRF à une instance de transfert particulière. Vous pouvez également mapper plusieurs instances MAC-VRF à la même instance de transfert. Si vous configurez chaque instance MAC-VRF pour utiliser une instance de transfert différente, vous pouvez configurer des VLAN qui se chevauchent sur plusieurs instances MAC-VRF. Vous ne pouvez pas configurer des VLAN qui se chevauchent dans une seule instance MAC-VRF ou entre des instances MAC-VRF mappées à la même instance de transfert.
-
Dans la configuration par défaut, les commutateurs incluent un VLAN par défaut avec VLAN ID=1 associé à l’instance de transfert par défaut. Étant donné que les ID de VLAN doivent être uniques dans une instance de transfert, si vous souhaitez configurer un VLAN avec VLAN ID=1 dans une instance MAC-VRF qui utilise l’instance de transfert par défaut, vous devez réaffecter l’ID de VLAN du VLAN par défaut à une valeur autre que 1. Par exemple :
set vlans default vlan-id 4094 set routing-instances mac-vrf-instance-name vlans vlan-name vlan-id 1
Les exemples de configuration de superposition de virtualisation de réseau de référence de ce guide incluent les étapes de configuration de la superposition à l’aide d’instances MAC-VRF. Vous configurez une instance de routage EVPN de type mac-vrf, et définissez un séparateur de route et une cible de route dans l’instance. Vous incluez également les interfaces souhaitées (y compris une interface source VTEP), les VLAN et les mappages VLAN à VNI dans l’instance. Consultez les configurations de référence dans les rubriques suivantes :
-
Conception et implémentation de la superposition pontée : configurez les instances MAC-VRF sur les équipements de branche.
-
Conception et implémentation de la superposition de pontage à routage central : vous configurez les instances MAC-VRF sur les équipements de cœur de réseau. Sur les équipements de branche, la configuration MAC-VRF est similaire à la configuration de branche MAC-VRF dans une conception de superposition pontée.
-
Conception et implémentation de la superposition de pontage à routage périphérique : vous configurez les instances MAC-VRF sur les équipements de branche.
Un équipement peut rencontrer des problèmes de mise à l’échelle des VTEP lorsque la configuration utilise plusieurs instances MAC-VRF. Par conséquent, pour éviter ce problème, nous vous demandons d’activer la fonctionnalité de tunnels partagés sur la QFX5000 gamme de commutateurs qui s’exécutent Junos OS avec une configuration d’instance MAC-VRF. Lorsque vous configurez des tunnels partagés, l’équipement minimise le nombre d’entrées de saut suivant pour atteindre les VTEP distants. Vous activez globalement les tunnels VXLAN partagés sur l’appareil à l’aide de l’instruction shared-tunnels au niveau de la [edit forwarding-options evpn-vxlan] hiérarchie. Ce paramètre nécessite que vous redémarriez l’appareil.
Cette instruction est facultative sur la Gamme QFX10000 des commutateurs exécutant Junos OS, qui peuvent gérer une évolutivité VTEP plus élevée que les commutateurs QFX5000.
Sur les équipements exécutant Junos OS Evolved dans des fabrics EVPN-VXLAN, les tunnels partagés sont activés par défaut. Junos OS Evolved prend en charge EVPN-VXLAN uniquement avec des configurations MAC-VRF.
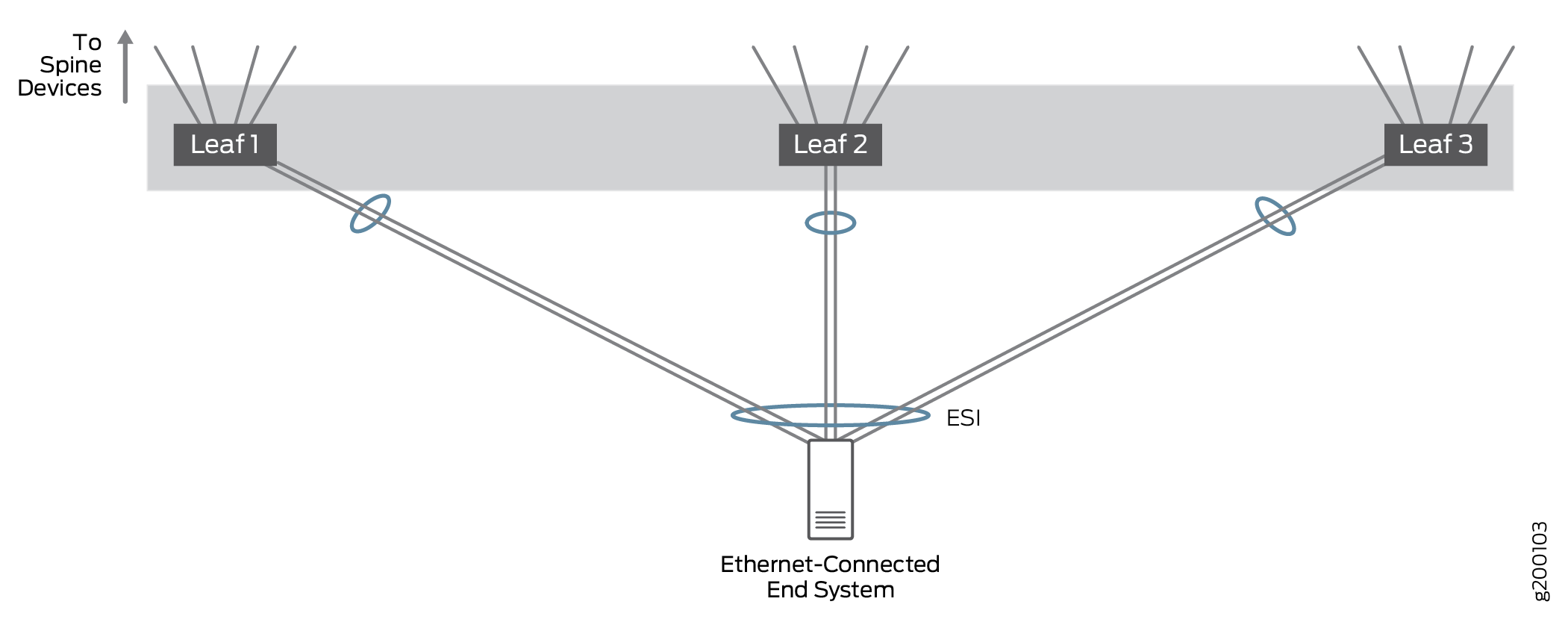
Prise en charge du multihébergement pour les systèmes finaux connectés par Ethernet
 Ethernet
Ethernet
Le multihébergement connecté par Ethernet permet aux terminaux connectés par Ethernet de se connecter au réseau Ethernet superposé via une liaison monohoming vers un périphérique VTEP ou via plusieurs liaisons multihoming vers différents périphériques VTEP. Le trafic Ethernet est réparti en charge sur la fabric entre les VTEP des équipements de branche connectés au même système final.
Nous avons testé des configurations où un système final connecté par Ethernet était connecté à un seul équipement leaf ou multiconnecté à 2 ou 3 périphériques leaf pour prouver que le trafic est correctement géré dans des configurations multirésidents avec plus de deux périphériques VTEP leaf ; en pratique, un système final connecté par Ethernet peut être multihébergé sur un grand nombre de périphériques VTEP Leaf. Toutes les liaisons sont actives et le trafic réseau peut être équilibré sur toutes les liaisons multihomées.
Dans cette architecture, EVPN est utilisé pour le multihébergement connecté Ethernet. Les LAG multirésidents EVPN sont identifiés par un identifiant de segment Ethernet (ESI) dans la superposition de pontage EVPN, tandis que LACP est utilisé pour améliorer la disponibilité des LAG.
L’agrégation de VLAN permet à une interface de prendre en charge plusieurs VLAN. L’agrégation VLAN garantit que les machines virtuelles (VM) sur des hyperviseurs sans overlay peuvent fonctionner dans n’importe quel contexte de réseau overlay.
Pour plus d’informations sur la prise en charge du multihébergement connecté par Ethernet, consultez Conception et implémentation du multihébergement d’un système final connecté par Ethernet.
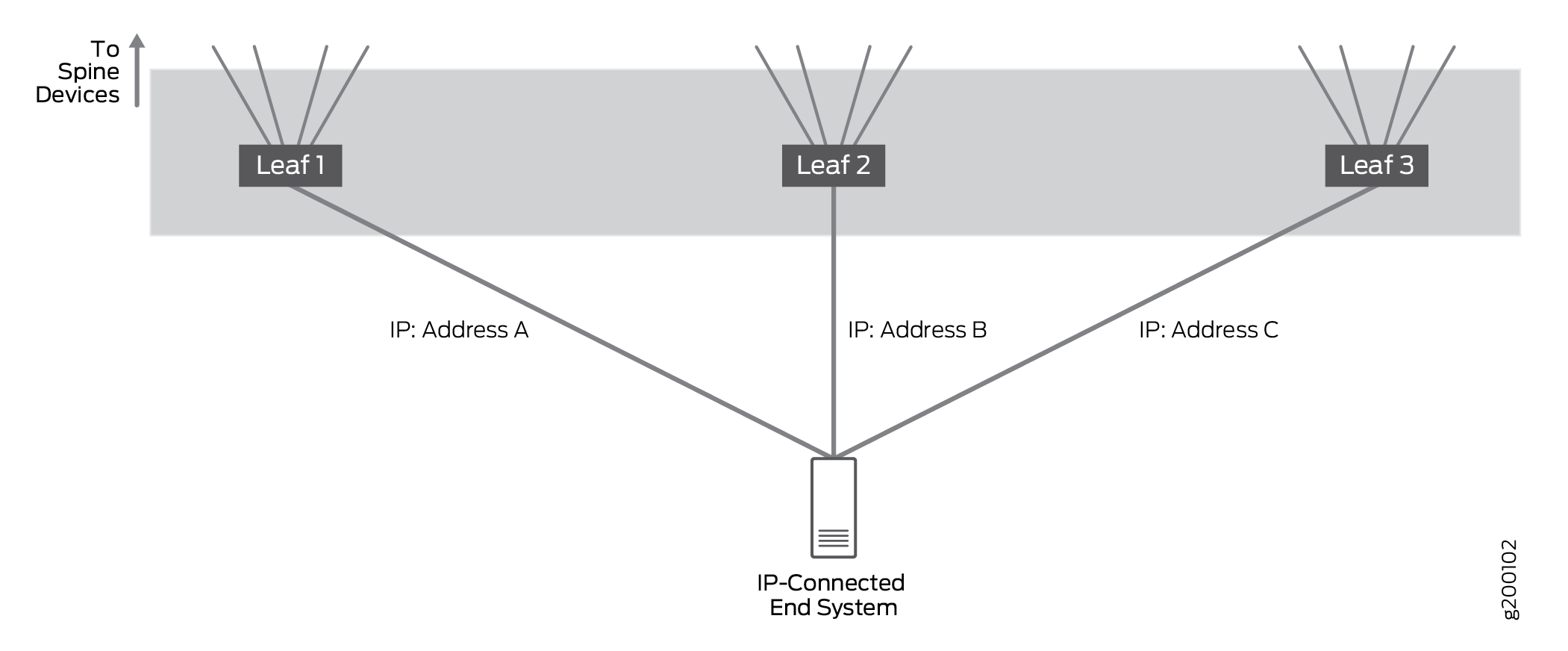
Prise en charge du multihébergement pour les systèmes terminaux connectés par IP
 IP
IP
Systèmes de terminaux multihébergement connectés par IP pour se connecter au réseau IP via plusieurs interfaces d’accès IP sur différents équipements Leaf.
Nous avons testé des configurations dans lesquelles un système terminal connecté par IP était connecté à un seul équipement leaf ou multihébergé à 2 ou 3 appareils leaf. La configuration a confirmé que le trafic est correctement géré lorsqu’il est multihébergé sur plusieurs équipements de branche. dans la pratique, un système final connecté par IP peut être multihébergé vers un grand nombre d’appareils Leaf.
Dans les configurations multihoming, toutes les liaisons sont actives et le trafic réseau est transféré et reçu sur toutes les liaisons multihoming. Le trafic IP est équilibré sur les liaisons multirésidents à l’aide d’un algorithme de hachage simple.
EBGP est utilisé pour échanger des informations de routage entre le système de terminaison connecté par IP et les équipements leaf connectés afin de garantir que la ou les routes vers les systèmes de terminaison sont partagées avec tous les équipements spine et leaf.
Pour plus d’informations sur le bloc modulaire de multihébergement connecté par IP, voir Conception et implémentation du multihébergement d’un système final connecté par IP.
Périphériques de bordure
Certaines de nos conceptions de référence incluent des équipements de bordure qui fournissent des connexions aux équipements suivants, qui sont externes à la fabric IP locale :
Une passerelle multicast.
Une passerelle de datacenter pour l’interconnexion des datacenters (DCI).
Équipement tel qu’un routeur SRX sur lequel sont regroupés plusieurs services tels que les pare-feu, la traduction d’adresses réseau (NAT), la détection et prévention d’intrusion (IDP), le multicast, etc. La consolidation de plusieurs services sur un seul équipement physique est connue sous le nom de chaînage de services.
Appliances ou serveurs faisant office de pare-feu, serveurs DHCP, collecteurs sFlow, etc.
Remarque :Si votre réseau comprend des appliances ou des serveurs hérités qui nécessitent une connexion Ethernet 1 Gbit/s à un équipement de bordure, nous vous recommandons d’utiliser un commutateur QFX10008 ou un commutateur QFX5120 comme équipement de bordure.
Pour fournir les fonctionnalités supplémentaires décrites ci-dessus, Juniper Networks prend en charge le déploiement d’un appareil de bordure des manières suivantes :
En tant qu’appareil qui sert uniquement d’équipement de bordure. Dans ce rôle dédié, vous pouvez configurer l’appareil pour gérer une ou plusieurs des tâches décrites ci-dessus. Dans ce cas, l’équipement est généralement déployé en tant que branche de bordure, qui est connectée à un équipement Spine.
Par exemple, dans la superposition ERB illustrée à la figure 14, les branches de bordure L5 et L6 fournissent une connectivité aux passerelles de centre de données pour DCI, un collecteur sFlow et un serveur DHCP.
Dans le cas d’un équipement ayant deux rôles : un équipement underlay réseau et un équipement de bordure pouvant gérer une ou plusieurs des tâches décrites ci-dessus. Dans ce cas, un équipement Spine gère généralement les deux rôles. Par conséquent, la fonctionnalité d’équipement de bordure est appelée dorsale de bordure.
Par exemple, dans la superposition ERB illustrée à la figure 15, les épines de bordure S1 et S2 fonctionnent comme des équipements de cœur de réseau maigre. Ils fournissent également une connectivité aux passerelles de datacenter pour DCI, un collecteur sFlow et un serveur DHCP.
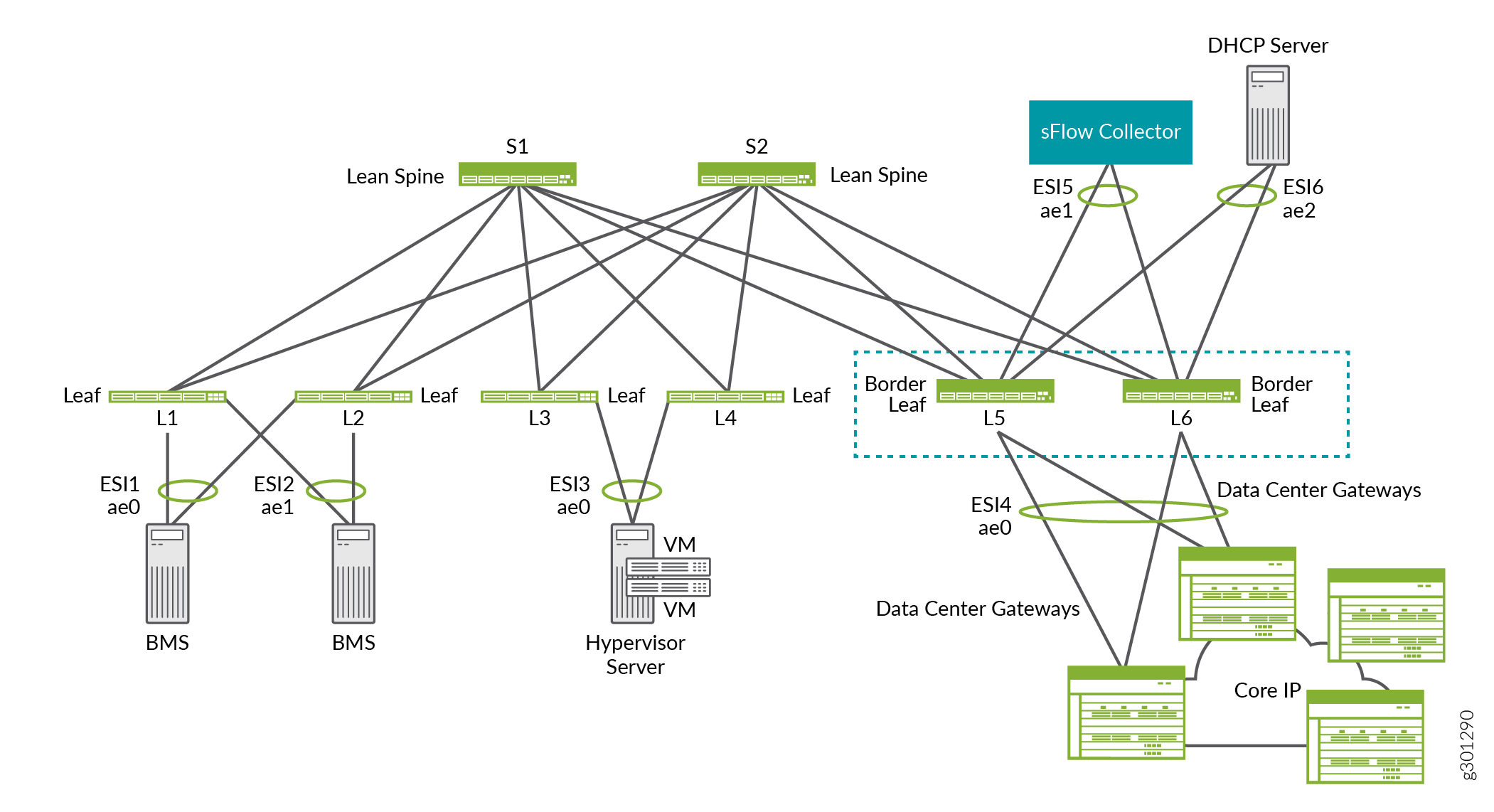 branches de bordure
branches de bordure
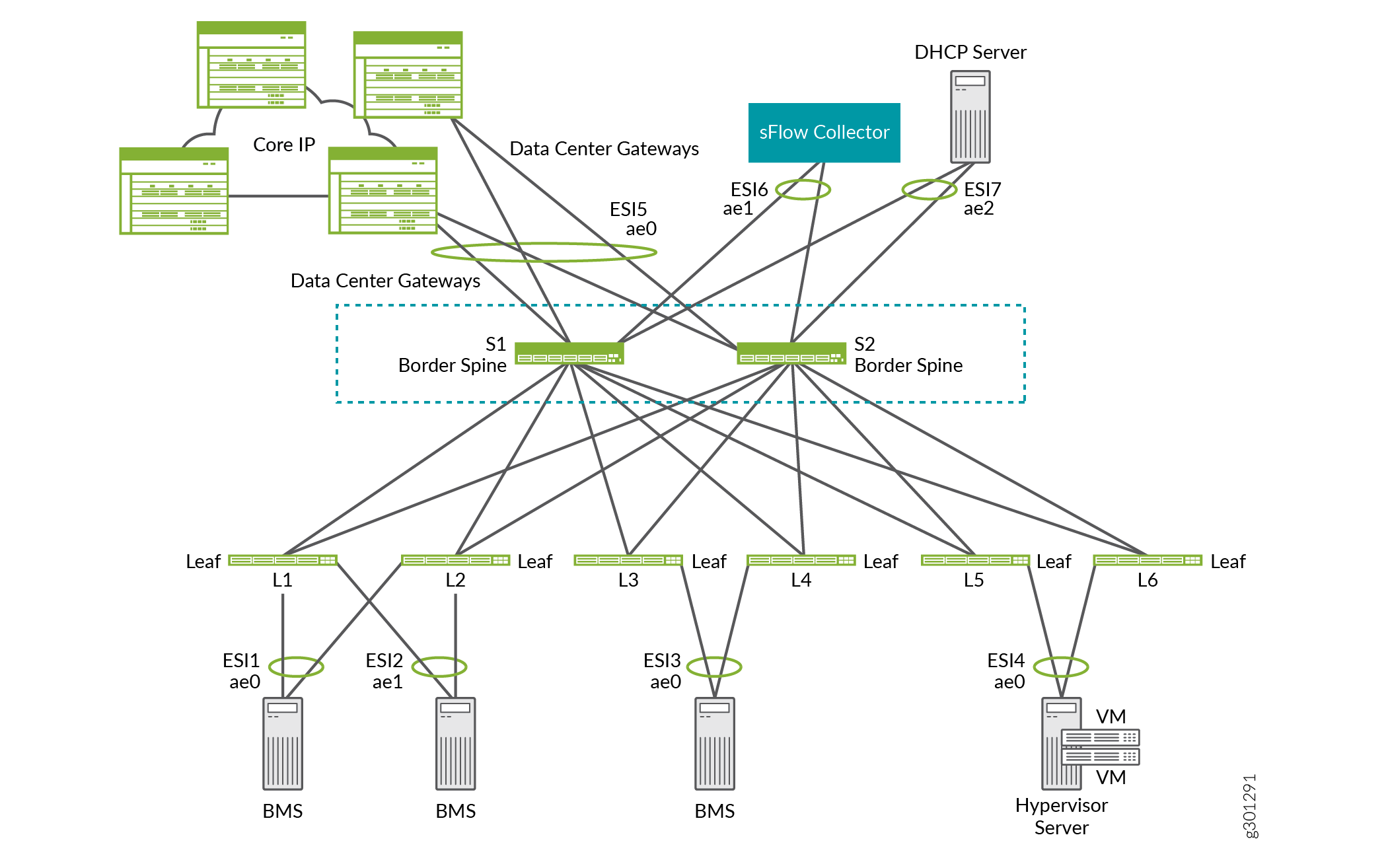 de bordure
de bordure
Interconnexion du datacenter (DCI)
Le module d’interconnexion de datacenters (DCI) fournit la technologie nécessaire pour envoyer le trafic entre les datacenters. La conception validée prend en charge la DCI à l’aide de routes EVPN de type 5, de routes IPVPN et de DCI de couche 2 avec assemblage VXLAN.
Les routes EVPN de type 5 ou IPVPN sont utilisées dans un contexte DCI pour garantir l’échange de trafic entre datacenters utilisant différents schémas de sous-réseau d’adresses IP. Des routes sont échangées entre des équipements de cœur de réseau de différents datacenters pour permettre le transfert du trafic entre les datacenters.
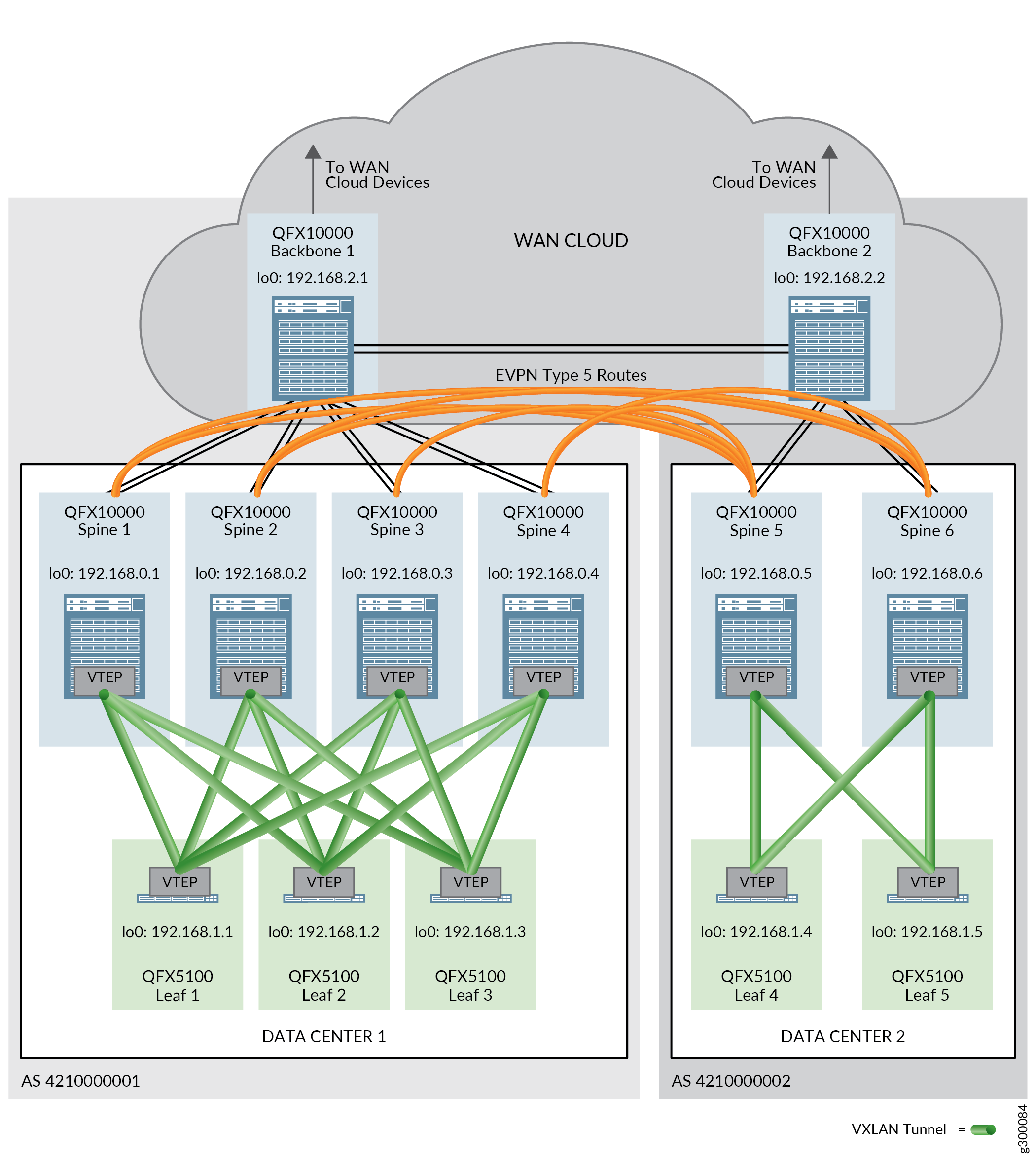
Une connectivité physique entre les datacenters est requise avant de pouvoir configurer DCI. La connectivité physique est assurée par les appareils de backbone dans un cloud WAN. Un équipement dorsal est connecté à tous les équipements de cœur de réseau d’un seul centre de données (POD), ainsi qu’aux autres équipements dorsaux connectés aux autres centres de données.
Pour plus d’informations sur la configuration de DCI, consultez :
Chaînage de services
Dans de nombreux réseaux, il est courant que le trafic passe par des périphériques matériels distincts qui fournissent chacun un service, tels que les pare-feu, le NAT, l’IDP, le multicast, etc. Chaque équipement nécessite une opération et une gestion distinctes. Cette méthode de liaison de plusieurs fonctions réseau peut être considérée comme un chaînage de services physiques.
Un modèle plus efficace pour le chaînage de services consiste à virtualiser et consolider les fonctions réseau sur un seul équipement. Dans notre architecture de blueprint, nous utilisons les routeurs SRX Series comme dispositif qui consolide les fonctions et les processus réseau et applique les services. Cet équipement s’appelle une fonction réseau physique (PNF).
Dans cette solution, le chaînage de services est pris en charge sur les superpositions CRB et ERB. Il fonctionne uniquement pour le trafic interlocataire.
Vue logique du chaînage de services
La figure 17 présente une vue logique du chaînage de services. Il montre un cœur avec une configuration côté droit et une configuration côté gauche. De chaque côté se trouvent une instance de routage VRF et une interface IRB. Le routeur SRX Series au centre est le PNF, qui effectue le chaînage de services.
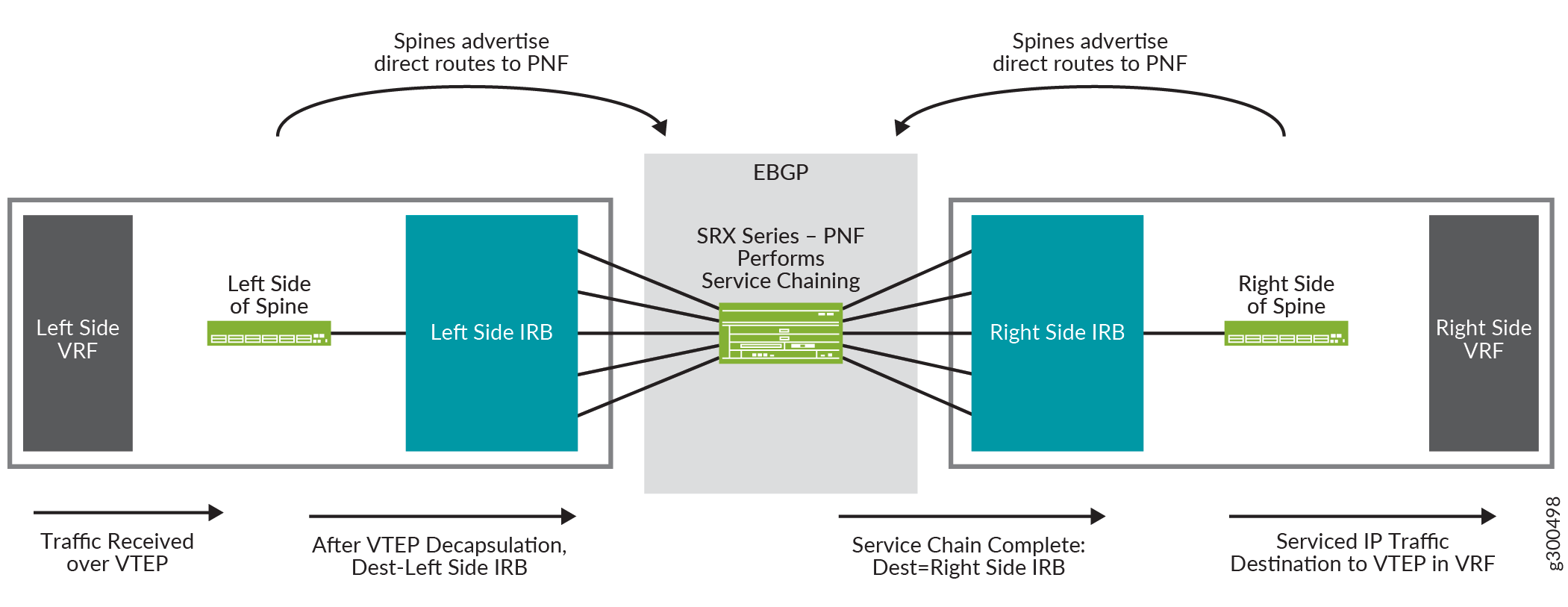 logique du chaînage de services
logique du chaînage de services
Le flux de trafic dans cette vue logique est le suivant :
-
Le spine reçoit un paquet sur le VTEP qui se trouve dans le VRF gauche.
-
Le paquet est désencapsulé et envoyé à l’interface IRB de gauche.
-
L’interface IRB achemine le paquet vers le routeur SRX Series, qui fait office de PNF.
-
Le routeur SRX Series effectue un chaînage de services sur le paquet et le renvoie au cœur de réseau, où il est reçu sur l’interface IRB affichée sur le côté droit du cœur de réseau.
-
L’interface IRB achemine le paquet vers le VTEP dans le VRF latéral droit.
Pour plus d’informations sur la configuration du chaînage de services, consultez Conception et implémentation du chaînage de services.
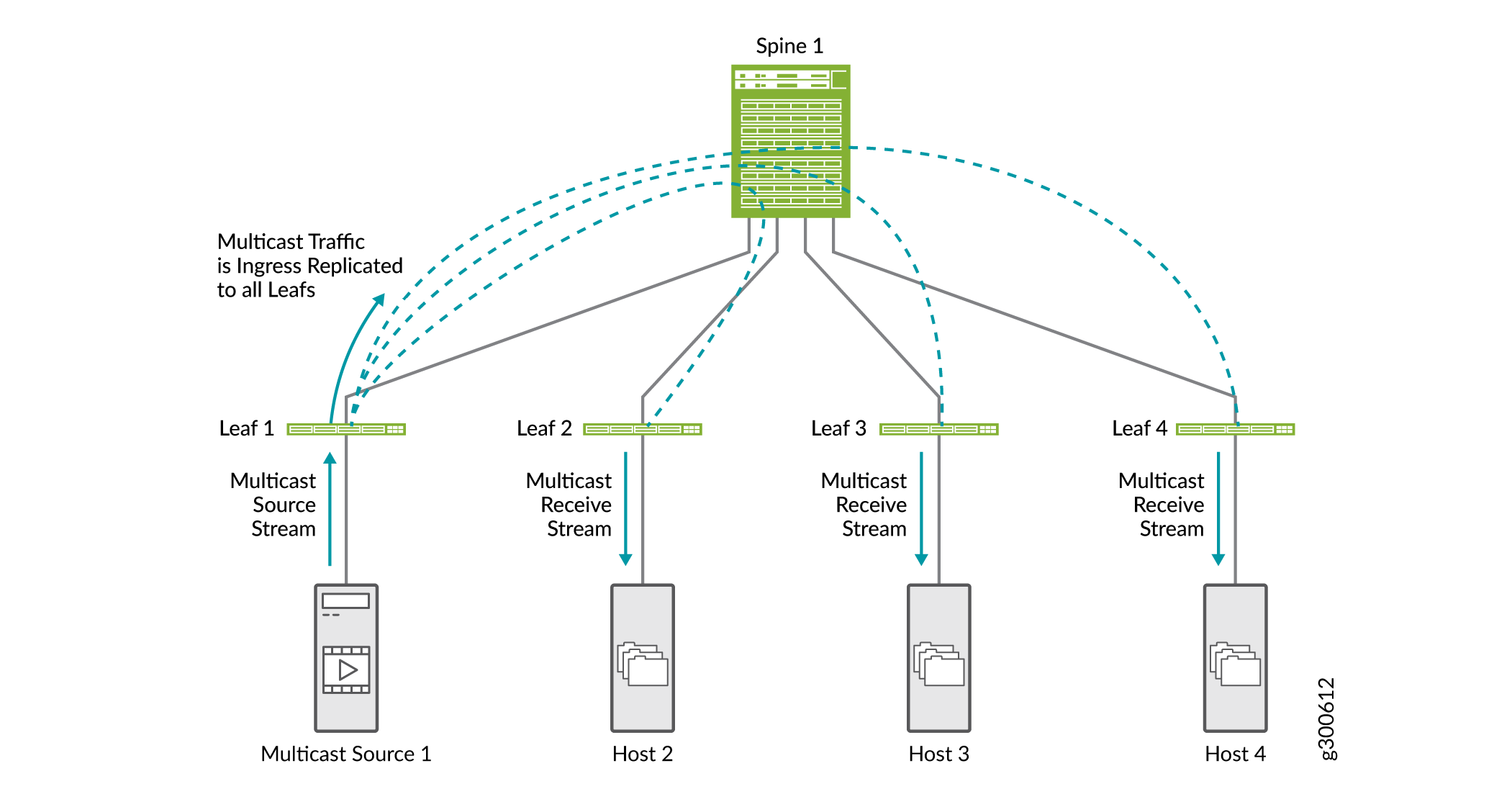
Optimisations multicast
Les optimisations multicast permettent de préserver la bande passante et d’acheminer plus efficacement le trafic dans un scénario de multicast dans les environnements EVPN VXLAN. Sans aucune optimisation de multicast configurée, toute la réplication de multicast est effectuée à l’entrée de la branche connectée à la source de multicast, comme illustré à la Figure 18. Le trafic multicast est envoyé à tous les équipements de branche connectés au cœur de réseau. Chaque équipement leaf envoie du trafic aux hôtes connectés.
Il existe quelques types d’optimisations de multicast prises en charge dans les environnements EVPN VXLAN qui peuvent fonctionner ensemble :
Pour plus d’informations sur la configuration des fonctionnalités de multicast, voir :
- Surveillance IGMP
- Transfert multicast sélectif
- Réplication assistée du trafic multicast
- Multicast intersous-réseau optimisé pour les réseaux overlay ERB
Surveillance IGMP
La surveillance IGMP dans une fabric EVPN-VXLAN est utile pour optimiser la distribution du trafic multicast. La surveillance IGMP préserve la bande passante car le trafic multicast est transféré uniquement sur les interfaces où il y a des écouteurs IGMP. Toutes les interfaces d’un équipement de branche n’ont pas besoin de recevoir du trafic multicast.
Sans surveillance IGMP, les systèmes finaux reçoivent du trafic multicast IP qui ne les intéresse pas, ce qui inonde inutilement leurs liens de trafic indésirable. Dans certains cas, lorsque les flux de multicast IP sont volumineux, l’inondation du trafic indésirable entraîne des problèmes de déni de service.
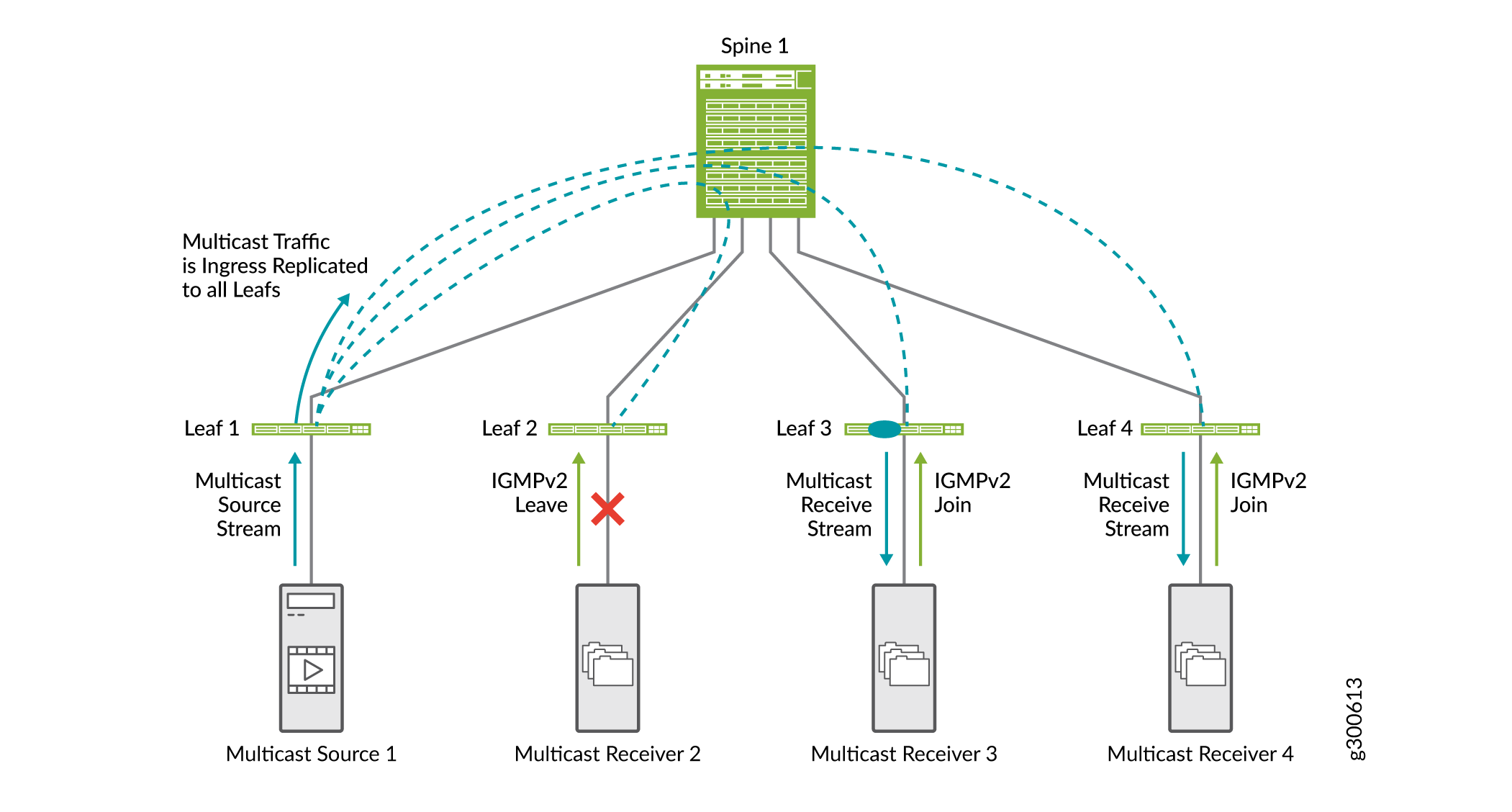
La figure 19 illustre le fonctionnement de la surveillance IGMP dans une fabric EVPN-VXLAN. Dans cet exemple de fabric EVPN-VXLAN, la surveillance IGMP est configurée sur tous les équipements leaf et le récepteur de multicast 2 a déjà envoyé une demande de jonction IGMPv2.
-
Le récepteur multicast 2 envoie une demande de congé IGMPv2.
-
Les récepteurs multicast 3 et 4 envoient une demande de jonction IGMPv2.
-
Lorsque la branche 1 reçoit du trafic multicast entrant, elle le réplique pour tous les équipements de branche et le transmet au cœur de réseau.
-
Le cœur de réseau transfère le trafic à tous les équipements de branche.
-
La branche 2 reçoit le trafic de multicast, mais ne le transfère pas au destinataire car le destinataire a envoyé un message de départ IGMP.
 IGMP
IGMP
Dans les réseaux EVPN-VXLAN, seule la version 2 d’IGMP est prise en charge.
Pour plus d’informations sur la surveillance IGMP, consultez Vue d’ensemble du transfert multicast avec surveillance IGMP ou surveillance MLD dans un environnement EVPN-VXLAN.
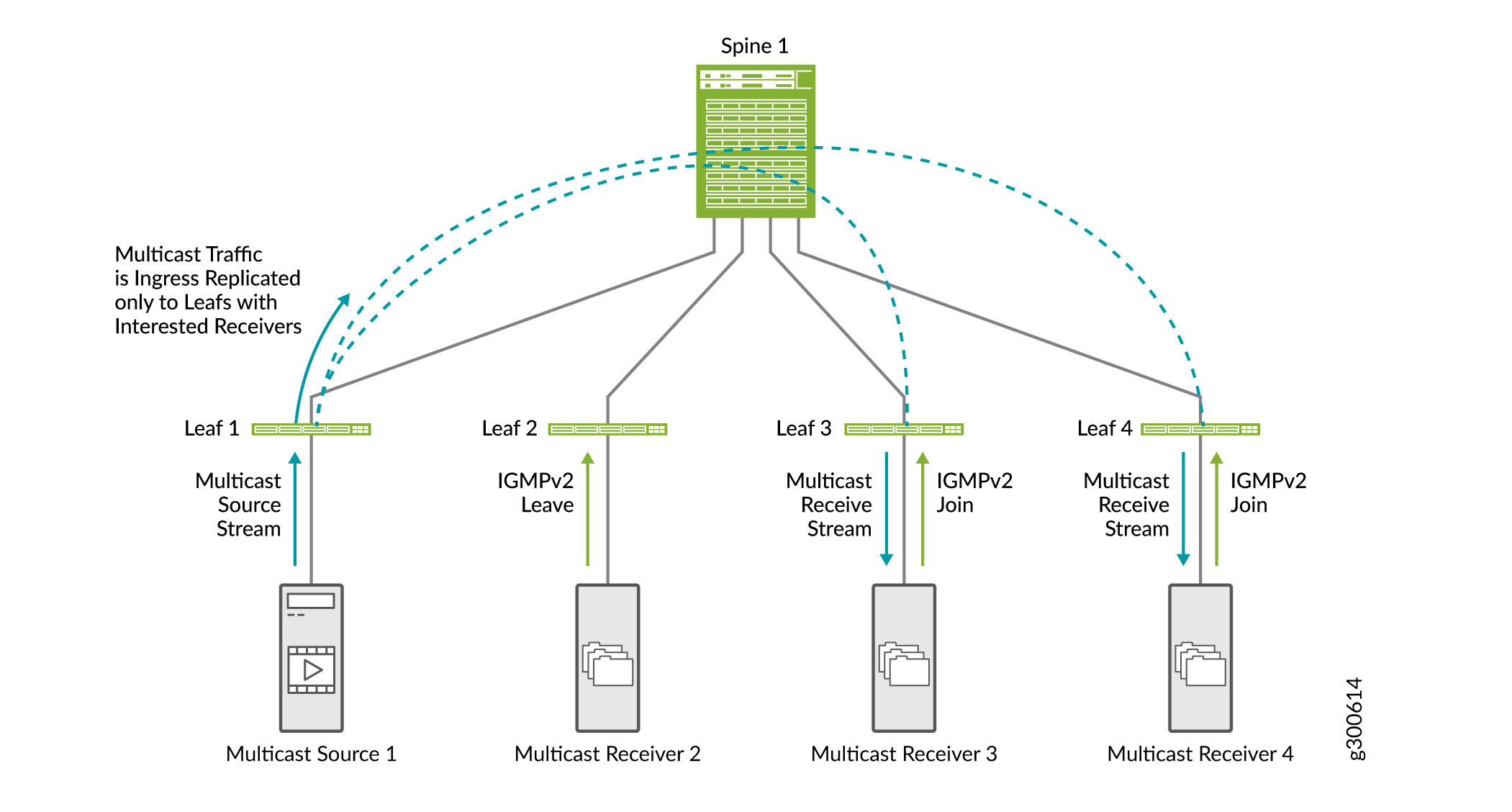
Transfert multicast sélectif
Le transfert SMET (Selective Multicast Ethernet) améliore l’efficacité du réseau de bout en bout et réduit le trafic sur le réseau EVPN. Il permet d’économiser l’utilisation de la bande passante au cœur de la fabric et de réduire la charge sur les équipements sortants qui n’ont pas de récepteur.
Les équipements sur lesquels la surveillance IGMP est activée utilisent le transfert sélectif de multicast pour transférer le trafic multicast de manière efficace. Lorsque la surveillance IGMP est activée, un équipement leaf envoie du trafic multicast uniquement à l’interface d’accès avec un récepteur intéressé. Avec SMET ajouté, le périphérique leaf envoie sélectivement le trafic de multicast uniquement aux équipements leaf du cœur qui ont exprimé un intérêt pour ce groupe de multicast.
La figure 20 montre le flux de trafic SMET ainsi que la surveillance IGMP.
-
Le récepteur multicast 2 envoie une demande de congé IGMPv2.
-
Les récepteurs multicast 3 et 4 envoient une demande de jonction IGMPv2.
-
Lorsque le leaf 1 reçoit du trafic multicast entrant, il le réplique uniquement vers les équipements leaf avec des récepteurs intéressés (équipements leaf 3 et 4) et le transmet au spine.
-
Le cœur de réseau transfère le trafic vers les équipements de branche 3 et 4.
 IGMP
IGMP
Vous n’avez pas besoin d’activer SMET ; elle est activée par défaut lorsque la surveillance IGMP est configurée sur l’appareil.
Pour plus d’informations sur SMET, consultez Vue d’ensemble du transfert multicast sélectif.
Réplication assistée du trafic multicast
La fonctionnalité de réplication assistée (AR) décharge les équipements leaf de fabric EVPN-VXLAN des tâches de réplication entrante. Le leaf entrant ne réplique pas le trafic multicast. Il envoie une copie du trafic de multicast à un cœur de réseau configuré en tant que périphérique de réplication AR. Le réplicateur AR distribue et contrôle le trafic multicast. En plus de réduire la charge de réplication sur les équipements leaf entrants, cette méthode conserve la bande passante dans la fabric entre le leaf et le spine.
La figure 21 montre comment la RA fonctionne avec la surveillance IGMP et SMET.
-
La branche 1, qui est configurée en tant que périphérique de branche AR, reçoit le trafic de multicast et envoie une copie au cœur de réseau configuré en tant que périphérique de réplication AR.
-
Le cœur de réseau reproduit le trafic multicast. Elle réplique le trafic des équipements leaf provisionnés avec le VNI VLAN dans lequel le trafic multicast provient de Leaf 1.
Étant donné que la surveillance IGMP et SMET sont configurés dans le réseau, le cœur de réseau envoie le trafic de multicast uniquement aux équipements de branche dont les récepteurs sont intéressés.
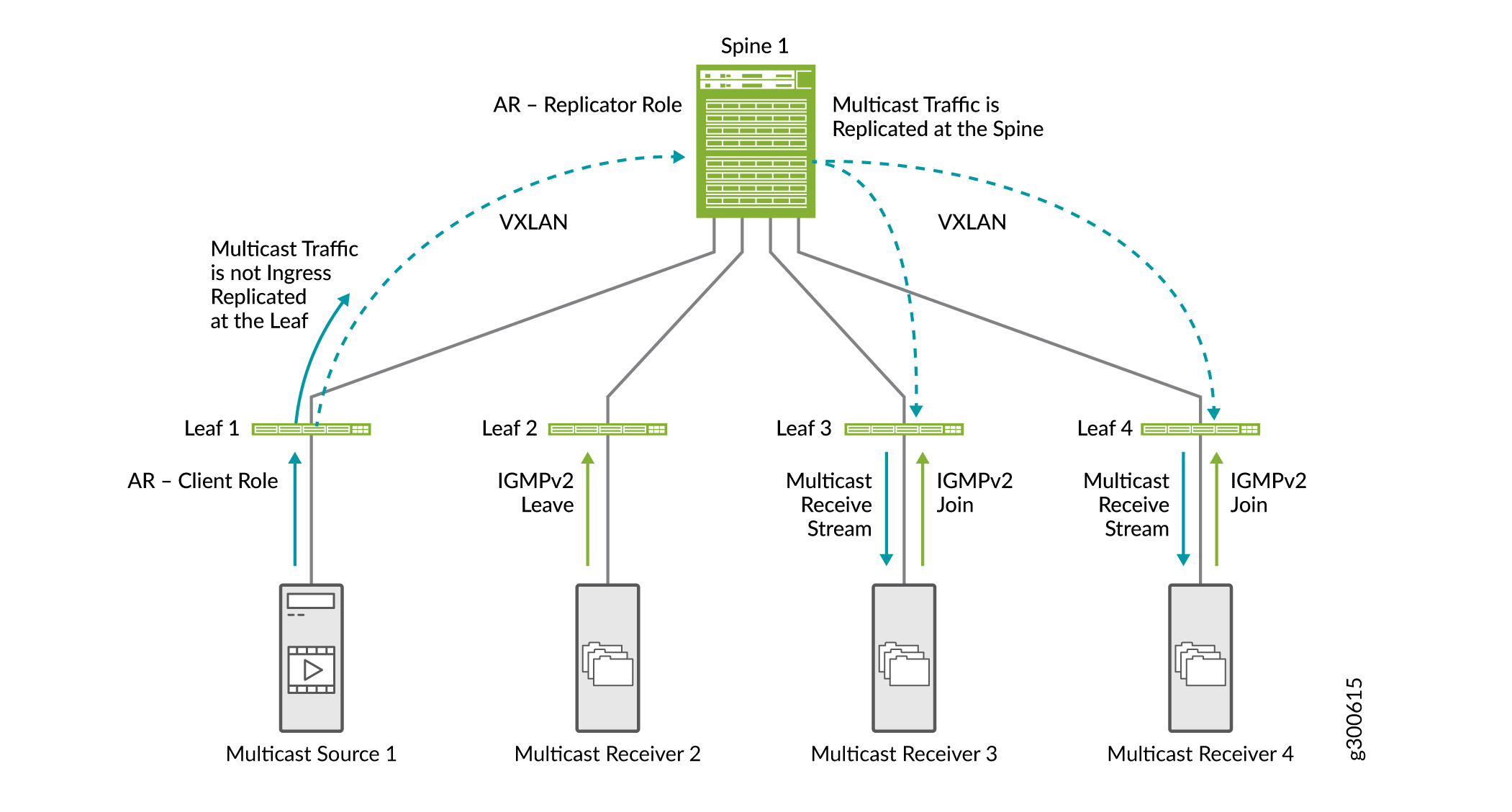
Dans ce document, nous montrons des optimisations de multicast à petite échelle. Dans un réseau complet comportant de nombreux spines et leafs, les avantages des optimisations sont beaucoup plus évidents.
Multicast intersous-réseau optimisé pour les réseaux overlay ERB
Lorsque vous disposez de sources et de récepteurs de multicast à l’intérieur et à l’extérieur d’une fabric de superposition ERB, vous pouvez configurer l’OISM (Optimized Intersubnet Multicast) pour assurer un flux de trafic multicast efficace à grande échelle.
L’OISM utilise un modèle de routage local pour le trafic multicast, ce qui évite l’épinglage du trafic et minimise la charge du trafic dans le cœur EVPN. L’OISM transfère le trafic multicast uniquement sur le VLAN source de multicast. Pour les récepteurs intersous-réseau, les équipements leaf utilisent des interfaces IRB pour acheminer localement le trafic reçu sur le VLAN source vers d’autres VLAN récepteurs sur le même équipement. Pour optimiser davantage le flux de trafic multicast dans la fabric EVPN-VXLAN, l’OISM utilise la surveillance IGMP et SMET pour transférer le trafic dans la fabric uniquement vers les équipements leaf dont les récepteurs sont intéressés.
L’OISM permet également à la fabric d’acheminer efficacement le trafic des sources de multicast externes vers les récepteurs internes, et des sources de multicast internes vers les récepteurs externes. L’OISM utilise un domaine de pont supplémentaire (SBD) au sein de la fabric pour transférer le trafic multicast reçu sur les équipements leaf de bordure à partir de sources extérieures. La conception du SBD préserve le modèle de routage local pour le trafic provenant de sources externes.
Vous pouvez utiliser OISM avec AR pour réduire la charge de réplication sur les équipements leaf OISM de capacité inférieure. (Voir Réplication assistée du trafic multicast.)
Voir la figure 22 pour une fabric simple avec OISM et AR.
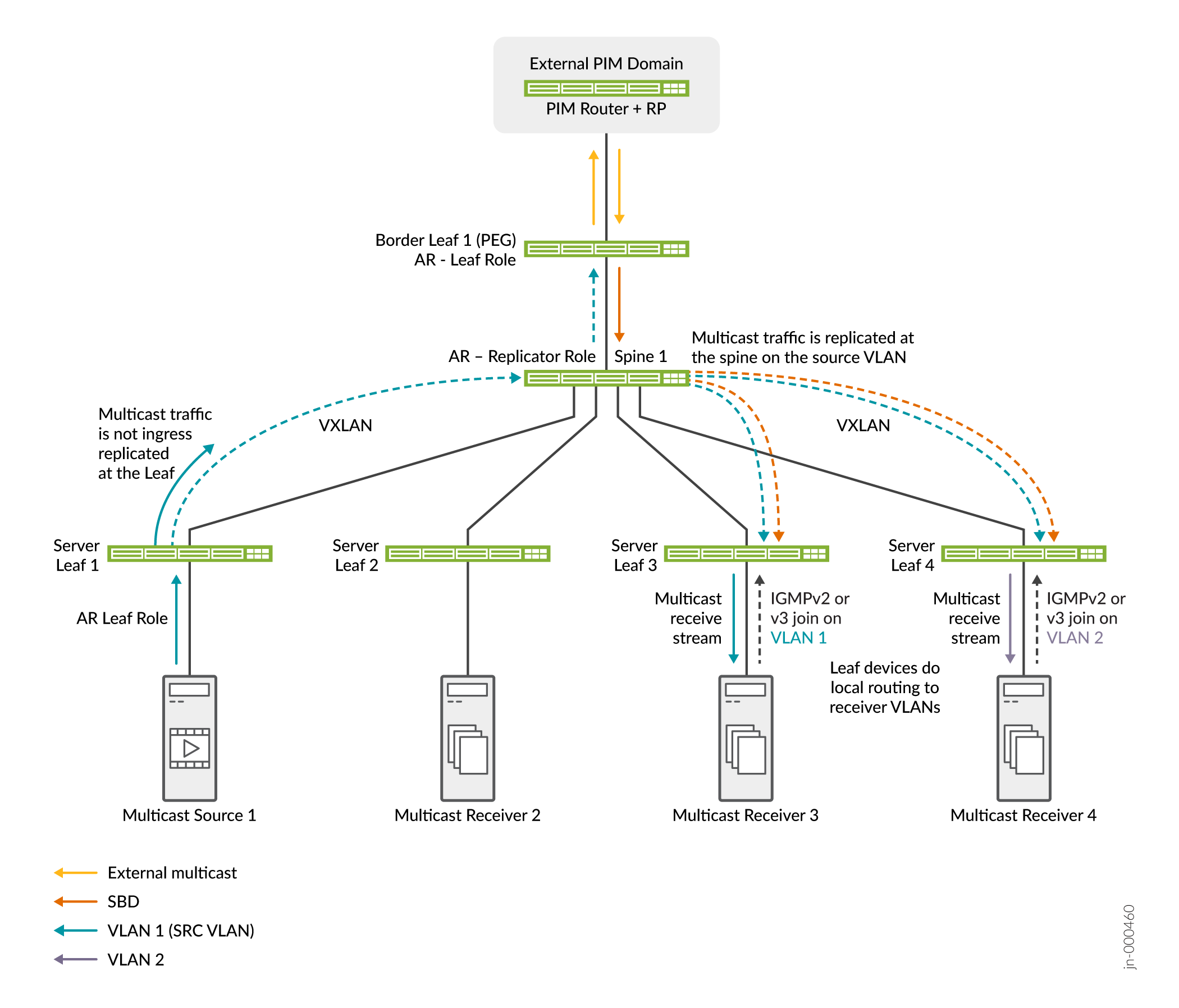
La figure 22 montre les équipements leaf et border leaf de l’OISM, le spine 1 dans le rôle de réplicateur AR et le serveur leaf 1 en tant que source de multicast dans le rôle de leaf AR. Une source et des récepteurs externes peuvent également exister dans le domaine PIM externe. Dans ce scénario, l’OISM et la RA fonctionnent ensemble comme suit :
-
Les récepteurs multicast derrière la branche du serveur 3 sur le VLAN 1 et derrière la branche du serveur 4 sur le VLAN 2 envoient des jointures IGMP indiquant qu’ils sont intéressés par le groupe de multicast. Des récepteurs externes peuvent également rejoindre le groupe de multicast.
-
La source de multicast derrière la branche 1 du serveur envoie le trafic multicast du groupe dans la fabric du VLAN 1. Server Leaf 1 n’envoie qu’une seule copie du trafic au réplicateur AR sur Spine 1.
-
En outre, le trafic source externe pour le groupe de multicast arrive à la branche de bordure 1. La branche de bordure 1 transfère le trafic du SBD vers le spine 1, le réplicateur de réalité augmentée.
-
Le réplicateur AR envoie des copies de la source interne sur le VLAN source et de la source externe sur le SBD aux équipements leaf OISM avec les récepteurs intéressés.
-
Les équipements leaf serveur transfèrent le trafic aux récepteurs du VLAN source et acheminent localement le trafic vers les récepteurs des autres VLAN.
Optimisation du trafic des machines virtuelles entrantes pour EVPN
Lorsque des machines virtuelles et des hôtes sont déplacés au sein d’un datacenter ou d’un datacenter à un autre, le trafic réseau peut devenir inefficace s’il n’est pas acheminé vers la passerelle optimale. Cela peut se produire lorsqu’un hôte est déplacé. La table ARP n’est pas toujours vidée et le flux de données vers l’hôte est envoyé à la passerelle configurée, même lorsqu’il existe une passerelle plus optimale. Le trafic est « trombone » et acheminé inutilement vers la passerelle configurée.
L’optimisation du trafic des machines virtuelles entrantes (VMTO) améliore l’efficacité du réseau, optimise le trafic entrant et peut éliminer l’effet trombone entre les VLAN. Lorsque vous activez le VMTO entrant, les routes sont stockées dans une table VRF (Virtual Routing and Forwarding) de couche 3 et l’équipement achemine le trafic entrant directement vers l’hôte qui a été déplacé.
La figure 23 montre un trafic trombonné sans VMTO entrant et un trafic optimisé lorsque le VMTO entrant est activé.
Sans VMTO entrant, les spines 1 et 2 de DC1 et DC2 annoncent tous la route d’hôte IP distant 10.0.0.1 lorsque la route d’origine provient de DC2. Le trafic entrant peut être dirigé vers les spines 1 et 2 du DC1. Il est ensuite acheminé vers les spines 1 et 2 dans DC2, où la route 10.0.0.1 a été déplacée. Cela provoque l’effet trombone.
Avec le VMTO entrant, nous pouvons obtenir un chemin de transfert optimal en configurant une stratégie pour que la route de l’hôte IP (10.0.01) ne soit annoncée que par les spines 1 et 2 à partir de DC2, et non à partir de DC1 lorsque l’hôte IP est déplacé vers DC2.
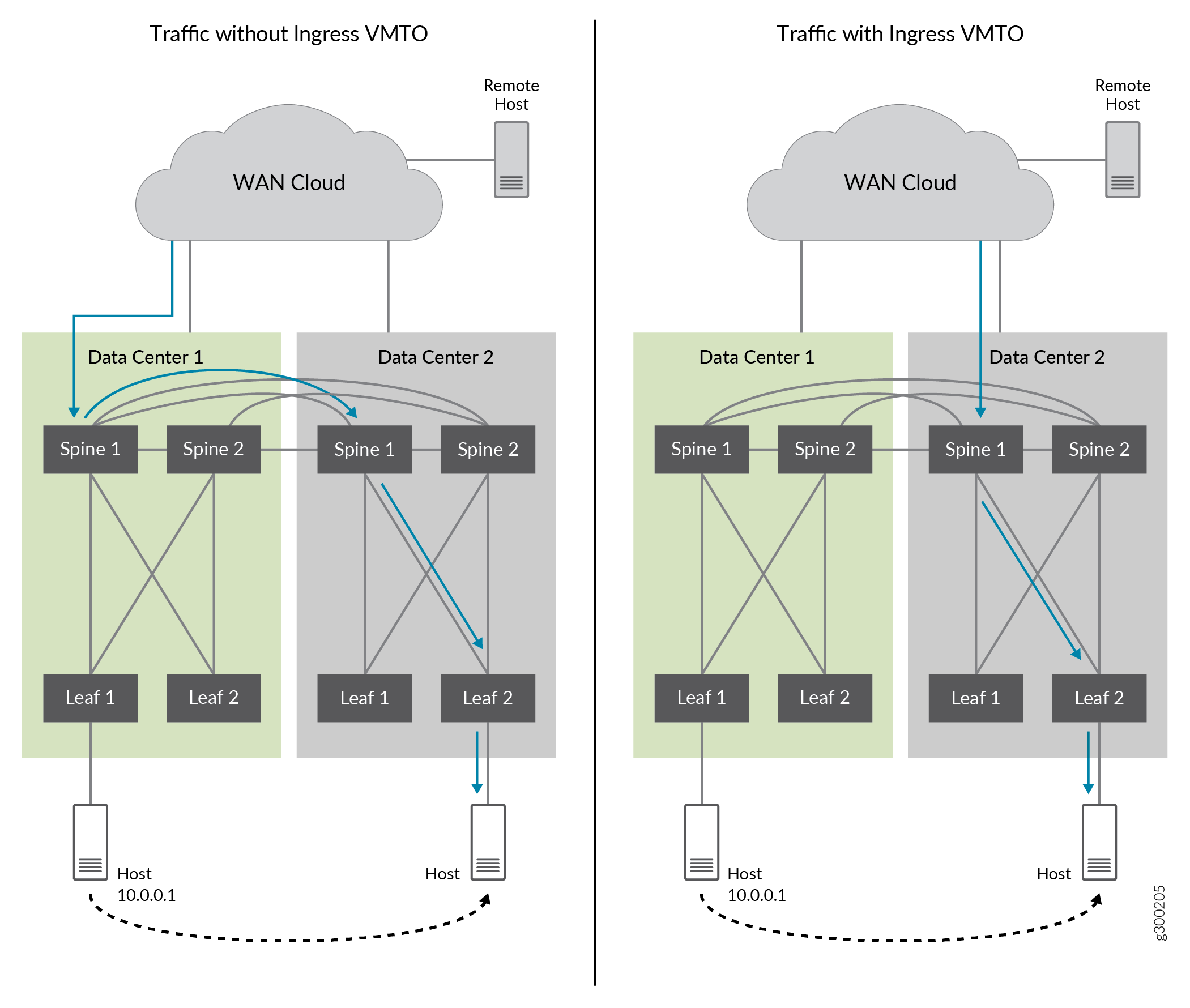 entrant
entrant
Pour plus d’informations sur la configuration de VMTO, reportez-vous à la section Configuration de VMTO.
Relais DHCP
 CRB
CRB
Le bloc de relais DHCP (Dynamic Host Configuration Protocol) permet au réseau de transmettre des messages DHCP entre un client DHCP et un serveur DHCP. L’implémentation du relais DHCP dans ce bloc de construction déplace les paquets DHCP via une superposition CRB où la passerelle est située au niveau de la couche spine.
Le serveur DHCP et les clients DHCP se connectent au réseau via des interfaces d’accès sur les équipements de branche. Le serveur et les clients DHCP peuvent communiquer entre eux sur le réseau existant sans autre configuration lorsque le client et le serveur DHCP se trouvent dans le même VLAN. Lorsqu’un client et un serveur DHCP se trouvent dans des VLAN différents, le trafic DHCP entre le client et le serveur est transféré entre les VLAN via les interfaces IRB sur les équipements de cœur de réseau. Vous devez configurer les interfaces IRB sur les équipements de cœur de réseau pour prendre en charge le relais DHCP entre les VLAN.
Pour plus d’informations sur l’implémentation du relais DHCP, consultez Conception et implémentation du relais DHCP.
Réduction du trafic ARP avec la synchronisation et la suppression ARP (ARP proxy)
L’objectif de la synchronisation ARP est de synchroniser les tables ARP sur tous les VRF qui desservent un sous-réseau overlay afin de réduire la quantité de trafic et d’optimiser le traitement des équipements réseau et des systèmes finaux. Lorsqu’une passerelle IP d’un sous-réseau apprend l’existence d’une liaison ARP, elle la partage avec d’autres passerelles afin qu’elles n’aient pas besoin de découvrir la même liaison ARP indépendamment.
Avec la suppression ARP, lorsqu’un équipement leaf reçoit une demande ARP, il vérifie sa propre table ARP synchronisée avec les autres périphériques VTEP et répond à la demande localement plutôt que de l’inonder.
L’ARP de proxy et la suppression ARP sont activées par défaut sur tous les commutateurs QFX Series qui peuvent agir comme équipements de branche dans une superposition ERB. Pour obtenir la liste de ces commutateurs, consultez Conceptions de référence de fabric EVPN-VXLAN de datacenter - Matériel pris en charge.
Les interfaces IRB de l’équipement leaf transmettent les requêtes ARP et NDP à partir des équipements leaf locaux et distants. Lorsqu’un équipement de branche reçoit une demande ARP ou NDP d’un autre équipement de branche, l’équipement de réception recherche l’adresse IP demandée dans sa base de données de liaisons d’adresses MAC+IP.
Si l’appareil trouve la liaison d’adresse MAC+IP dans sa base de données, il répond à la demande.
Si l’appareil ne trouve pas la liaison d’adresse MAC+IP, il inonde la requête ARP toutes les liaisons Ethernet du VLAN et les VTEP associés.
Étant donné que tous les équipements leaf participants ajoutent les entrées ARP et synchronisent leurs tables de routage et de pontage, les équipements leaf locaux répondent directement aux demandes des hôtes connectés localement, ce qui évite aux équipements distants d’avoir à répondre à ces demandes ARP.
Pour plus d’informations sur l’implémentation de la synchronisation ARP, de l’ARP du proxy et de la suppression ARP, consultez Activation de l’ARP du proxy et de la suppression ARP pour l’overlay de pontage à routage en périphérie.
Fonctionnalités de sécurité des ports de couche 2 sur les terminaux connectés par Ethernet
Les superpositions CRB et ERB prennent en charge les fonctionnalités de sécurité des systèmes d’extrémité connectés Ethernet de couche 2 que nous décrivons dans les sections suivantes.
Pour plus d’informations sur ces fonctionnalités, consultez Filtrage MAC, Storm Control et prise en charge de la mise en miroir des ports dans un environnement EVPN-VXLAN.
Pour plus d’informations sur la configuration de ces fonctionnalités, reportez-vous à la section Configuration des fonctionnalités de sécurité des ports de couche 2 sur les terminaux connectés par Ethernet.
- Prévenir les tempêtes de trafic BUM avec le Storm Control
- Utiliser le filtrage MAC pour améliorer la sécurité des ports
- Analyse du trafic avec la mise en miroir des ports
Prévenir les tempêtes de trafic BUM avec le Storm Control
Le storm control peut empêcher un trafic excessif de dégrader le réseau. Il atténue l’impact des tempêtes de trafic BUM en surveillant les niveaux de trafic sur les interfaces EVPN-VXLAN et en abandonnant le trafic BUM lorsqu’un niveau de trafic spécifié est dépassé.
Dans un environnement EVPN-VXLAN, le storm control surveille :
Trafic BUM de couche 2 provenant d’un VXLAN et transféré aux interfaces du même VXLAN.
Trafic multicast de couche 3 reçu par une interface IRB dans un VXLAN et transféré à des interfaces d’un autre VXLAN.
Utiliser le filtrage MAC pour améliorer la sécurité des ports
Le filtrage MAC renforce la sécurité des ports en limitant le nombre d’adresses MAC pouvant être apprises au sein d’un VLAN, et donc le trafic dans un VXLAN. Limiter le nombre d’adresses MAC protège le commutateur contre l’encombrement de la table de commutation Ethernet. L’inondation de la table de commutation Ethernet se produit lorsque le nombre de nouvelles adresses MAC apprises entraîne un débordement de la table et que les adresses MAC précédemment apprises sont vidées de la table. Le commutateur réapprend les adresses MAC, ce qui peut avoir un impact sur les performances et introduire des failles de sécurité.
Dans ce blueprint, le filtrage MAC limite le nombre de paquets acceptés qui sont envoyés aux interfaces d’accès entrantes en fonction des adresses MAC. Pour plus d’informations sur le fonctionnement du filtrage MAC, consultez les informations sur la limitation MAC dans Présentation de la limitation MAC et de la limitation MAC Move.
Analyse du trafic avec la mise en miroir des ports
La mise en miroir des ports basée sur un analyseur vous permet d’analyser le trafic jusqu’au niveau des paquets dans un environnement EVPN-VXLAN. Vous pouvez utiliser cette fonctionnalité pour appliquer des stratégies relatives à l’utilisation du réseau et au partage de fichiers, et pour identifier les sources de problèmes en localisant l’utilisation anormale ou importante de la bande passante par des stations ou des applications particulières.
La mise en miroir des ports copie les paquets entrant ou sortant d’un port ou entrant dans un VLAN et envoie les copies à une interface locale pour une surveillance locale ou à un VLAN pour une surveillance à distance. Utilisez la mise en miroir des ports pour envoyer du trafic vers des applications qui l’analysent à des fins telles que la surveillance de la conformité, l’application des politiques, la détection des intrusions, la surveillance et la prévision des schémas de trafic, la corrélation d’événements, etc.