Datencenter-Fabric-Blueprint-Architekturkomponenten
Dieser Abschnitt gibt einen Überblick über die Bausteine, die in dieser Blueprint-Architektur verwendet werden. Die Implementierung der einzelnen Bausteintechnologien wird in späteren Abschnitten ausführlicher erläutert.
Informationen zu der Hardware und Software, die als Grundlage für Ihre Bausteine dienen, finden Sie in der Zusammenfassung der Referenzdesigns für Data Center EVPN-VXLAN Fabric – Unterstützte Hardware.
Zu den Bausteinen gehören:
IP Fabric Underlay-Netzwerk
Der moderne IP-Fabric-Underlay-Netzwerkbaustein bietet IP-Konnektivität über eine Clos-basierte Topologie. Juniper Networks unterstützt die folgenden IP-Fabric-Underlay-Modelle:
-
Eine 3-stufige IP-Fabric, die aus einer Ebene von Spine-Geräten und einer Ebene von Leaf-Geräten besteht. Siehe Abbildung 1.
-
Eine 5-stufige IP-Fabric, die in der Regel als eine einzige 3-stufige IP-Fabric beginnt, die sich zu zwei 3-stufigen IP-Fabrics entwickelt. Diese Fabrics sind in separate Points of Delivery (PODs) innerhalb eines Datencenters segmentiert. Für diesen Anwendungsfall unterstützen wir das Hinzufügen einer Reihe von Super-Spine-Geräten, die die Kommunikation zwischen den Spine- und Leaf-Geräten in den beiden PODs ermöglichen. Siehe Abbildung 2.
-
Ein Collapsed Spine IP-Fabric-Modell, bei dem Leaf-Layer-Funktionen auf den Spine-Geräten zusammengeklappt werden. Diese Art von Fabric kann ähnlich wie eine 3-stufige oder 5-stufige IP-Fabric eingerichtet werden und funktionieren, jedoch ohne separate Ebene von Leaf-Geräten. Sie können eine Collapsed Spine Fabric verwenden, wenn Sie inkrementell zu einem EVPN-Spine-and-Leaf-Modell wechseln oder über Zugriffsgeräte oder Top-of-Rack-Geräte (TOR) verfügen, die nicht in einer Leaf-Schicht verwendet werden können, weil sie EVPN-VXLAN nicht unterstützen.
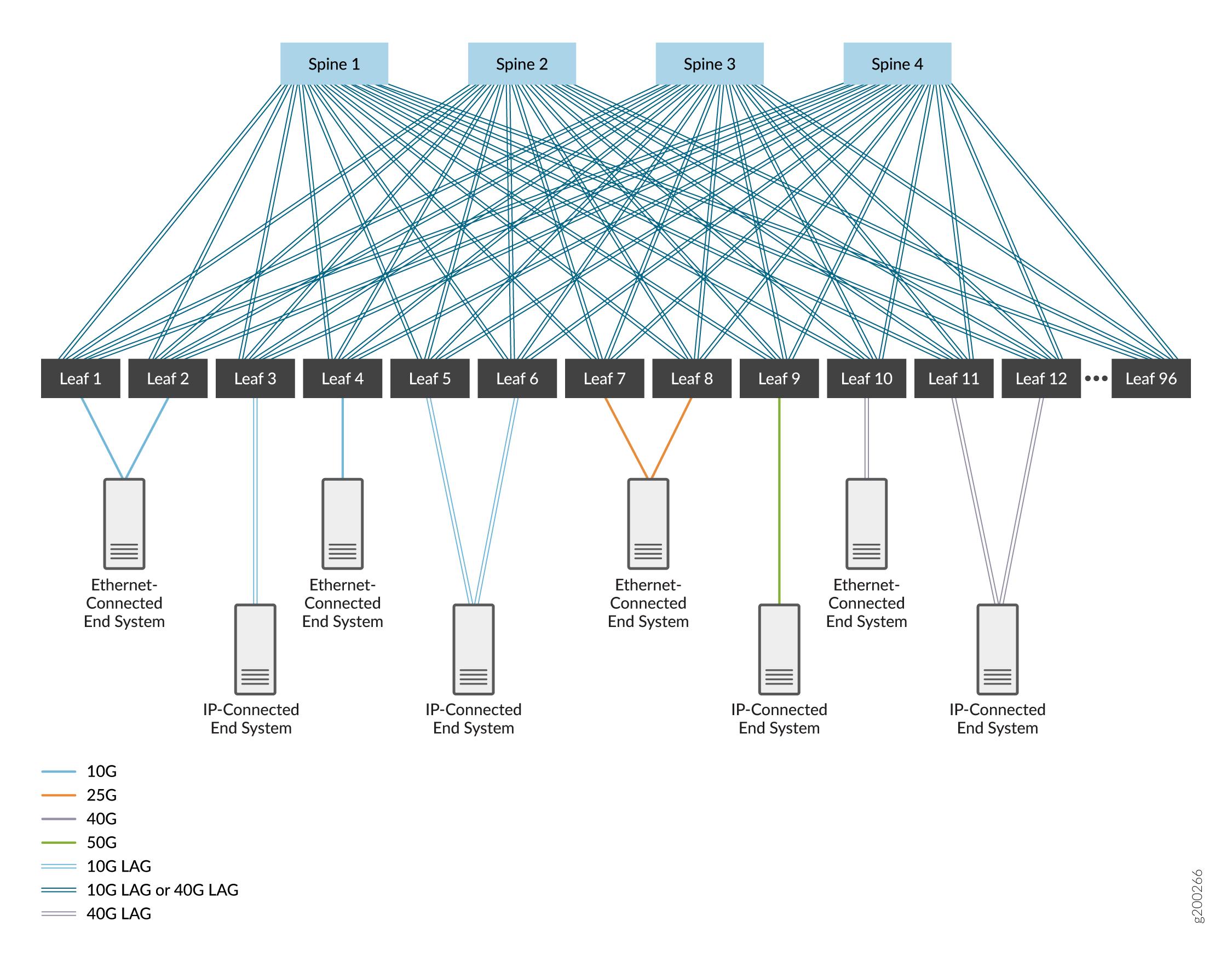
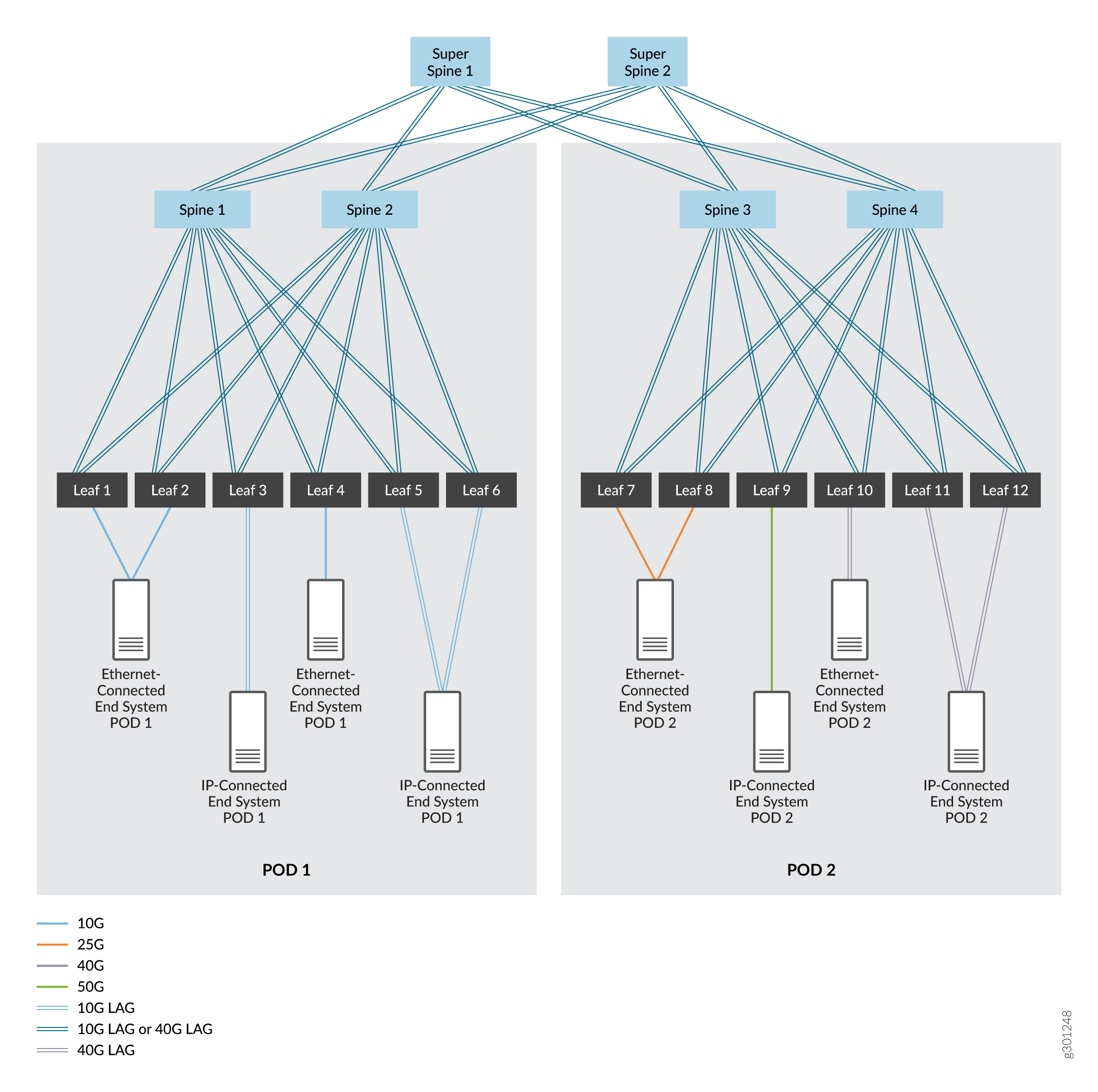
In diesen Abbildungen sind die Geräte über Hochgeschwindigkeitsschnittstellen miteinander verbunden, die entweder Einzelverbindungen oder aggregierte Ethernet-Schnittstellen sind. Die aggregierten Ethernet-Schnittstellen sind optional, d. h. in der Regel wird eine einzelne Verbindung zwischen Geräten verwendet, können aber zur Erhöhung der Bandbreite und zur Bereitstellung von Redundanz auf Verbindungsebene eingesetzt werden. Wir decken beide Optionen ab.
Wir haben EBGP als Routing-Protokoll im Underlay-Netzwerk gewählt, weil es zuverlässig und skalierbar ist. Jedem Gerät wird ein eigenes autonomes System mit einer eindeutigen autonomen Systemnummer zugewiesen, um EBGP zu unterstützen. Sie können andere Routing-Protokolle im Underlay-Netzwerk verwenden. Die Verwendung dieser Protokolle würde den Rahmen dieses Dokuments sprengen.
Die in diesem Handbuch beschriebenen Referenzarchitekturdesigns basieren auf einer IP-Fabric, die EBGP für die Underlay-Konnektivität und IBGP für Overlay-Peering verwendet (siehe IBGP für Overlays). Alternativ können Sie das Overlay-Peering mit EBGP konfigurieren.
Ab den Junos OS-Versionen 21.2R2 und 21.4R1 unterstützen wir auch die Konfiguration einer IPv6-Fabric. Das IPv6-Fabric-Design in diesem Handbuch verwendet EBGP sowohl für Underlay-Konnektivität als auch für Overlay-Peering (siehe EBGP für Overlays mit IPv6-Underlays).
Die IP-Fabric kann IPv4 oder IPv6 wie folgt verwenden:
-
Ein IPv4-Fabric verwendet IPv4-Schnittstellenadressierung und IPv4-Underlay- und -Overlay-BGP-Sitzungen für die End-to-End-Kommunikation der Arbeitsauslastung.
-
Eine IPv6-Fabric verwendet IPv6-Schnittstellenadressierung und IPv6-Underlay- und -Overlay-BGP-Sitzungen für die End-to-End-Kommunikation der Arbeitsauslastung.
-
Wir unterstützen keine IP-Fabric, die IPv4 und IPv6 kombiniert.
Allerdings unterstützen sowohl IPv4-Fabrics als auch IPv6-Fabrics Dual-Stack-Workloads – die Workloads können entweder IPv4 oder IPv6 oder sowohl IPv4 als auch IPv6 sein.
Micro Bidirectional Forwarding Detection (BFD) – die Fähigkeit, BFD auf einzelnen Verbindungen in einer aggregierten Ethernet-Schnittstelle auszuführen – kann ebenfalls in diesem Baustein aktiviert werden, um Verbindungsfehler bei allen Mitgliedsverbindungen in aggregierten Ethernet-Paketen, die Geräte verbinden, schnell zu erkennen.
Weitere Informationen finden Sie in den anderen Abschnitten dieses Handbuchs:
-
Konfiguration von Spine- und Leaf-Geräten in 3-stufigen und 5-stufigen IP-Fabric-Underlays: IP Fabric-Underlay-Netzwerkdesign und -Implementierung.
-
Implementierung der zusätzlichen Ebene von Super-Spine-Geräten in einem 5-stufigen IP-Fabric-Underlay: Fünfstufiges IP-Fabric-Design und -Implementierung.
-
Konfiguration eines IPv6-Underlay und Unterstützung von EBGP IPv6-Overlay: IPv6 Fabric Underlay- und Overlay-Netzwerkdesign und Implementierung mit EBGP.
-
Einrichten des Underlay in einem Collapsed Spine Fabric-Modell: Collapsed Spine Fabric Design und Implementierung.
Unterstützung von IPv4- und IPv6-Workloads
Da viele Netzwerke eine Dual-Stack-Umgebung für Workloads implementieren, die IPv4- und IPv6-Protokolle enthält, bietet dieser Entwurf Unterstützung für beide Protokolle. Schritte zum Konfigurieren der Fabric zur Unterstützung von IPv4- und IPv6-Workloads sind in diesem Leitfaden miteinander verwoben, damit Sie eines oder beide dieser Protokolle auswählen können.
Das IP-Protokoll, das Sie für den Datenverkehr der Arbeitsauslastung verwenden, ist unabhängig von der IP-Protokollversion (IPv4 oder IPv6), die Sie für das IP-Fabric-Underlay und -Overlay konfigurieren. (Siehe IP Fabric Underlay-Netzwerk.) Eine IPv4-Fabric- oder eine IPv6-Fabric-Infrastruktur kann sowohl IPv4- als auch IPv6-Workloads unterstützen.
Overlays der Netzwerkvirtualisierung
Ein Netzwerk-Virtualisierung-Overlay ist ein virtuelles Netzwerk, das über ein IP-Underlay-Netzwerk transportiert wird. Dieser Baustein ermöglicht die Mehrfachmandantenfähigkeit in einem Netzwerk, sodass Sie ein einziges physisches Netzwerk für mehrere Mandanten gemeinsam nutzen können, während der Netzwerkdatenverkehr jedes Mandanten von den anderen Mandanten isoliert bleibt.
Ein Mandant ist eine Benutzergemeinschaft (z. B. eine Unternehmenseinheit, Abteilung, Arbeitsgruppe oder Anwendung), die Gruppen von Endpunkten enthält. Gruppen können mit anderen Gruppen im selben Mandanten kommunizieren, und Mandanten können mit anderen Mandanten kommunizieren, wenn dies nach den Netzwerkrichtlinien zulässig ist. Eine Gruppe wird typischerweise als ein Subnetz (VLAN) ausgedrückt, das mit anderen Geräten im selben Subnetz kommunizieren und externe Gruppen und Endgeräte über eine VRF-Instanz (Virtual Routing and Forwarding) erreichen kann.
Wie im Overlay-Beispiel in Abbildung 3 zu sehen ist, verarbeiten Ethernet-Bridging-Tabellen (dargestellt durch Dreiecke) Mandanten-Bridged-Frames und IP-Routing-Tabellen (dargestellt durch Quadrate) geroutete Pakete. Das Routing zwischen VLANs erfolgt an den Integrated Routing and Bridging (IRB)-Schnittstellen (dargestellt durch Kreise). Ethernet- und IP-Tabellen werden in virtuelle Netzwerke geleitet (dargestellt durch farbige Linien). Um Endsysteme zu erreichen, die mit anderen VXLAN Tunnel Endpoint (VTEP)-Geräten verbunden sind, werden Mandantenpakete gekapselt und über einen EVPN-signalisierten VXLAN-Tunnel (dargestellt durch grüne Tunnel-Symbole) an die zugehörigen Remote-VTEP-Geräte gesendet. Getunnelte Pakete werden auf den Remote-VTEP-Geräten entkapselt und über die jeweiligen Bridging- oder Routing-Tabellen des Ausgangs-VTEP-Geräts an die Remote-End-Systeme weitergeleitet.
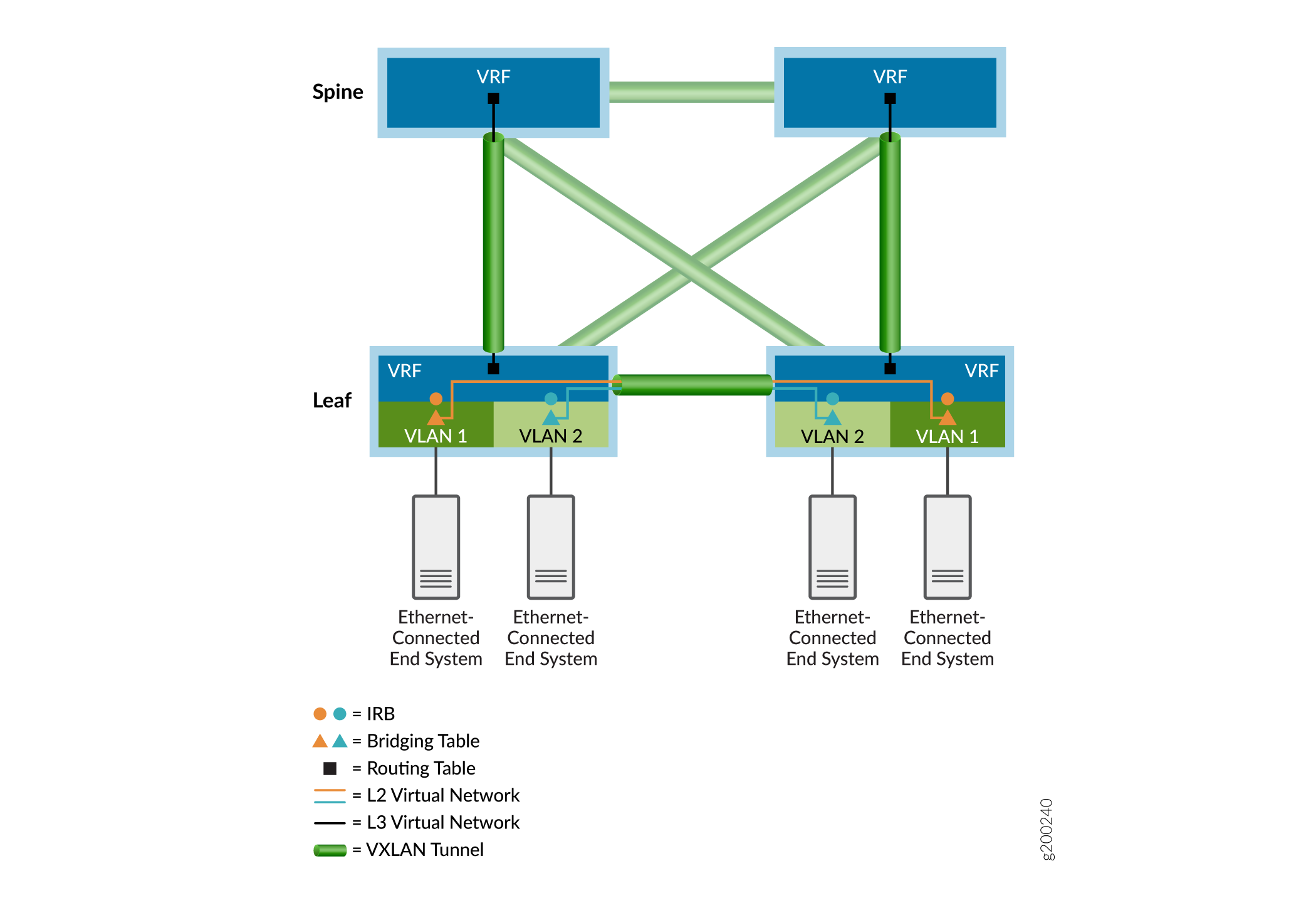
In den nächsten Abschnitten finden Sie weitere Details zu Overlay-Netzwerken.
- IBGP für Overlays
- EBGP für Overlays mit IPv6-Underlays
- Überbrücktes Overlay
- Zentral geroutetes Bridging-Overlay
- Edge-Routing-Bridging-Overlay
- Collapsed Spine-Overlay
- Vergleich von Bridged-, CRB- und ERB-Overlays
- IRB-Adressierungsmodelle in Bridging-Overlays
- Geroutetes Overlay mit EVPN-Routen Typ 5
- MAC-VRF-Instanzen für Mehrfachmandantenfähigkeit in Netzwerkvirtualisierungs-Overlays
IBGP für Overlays
Intern BGP (IBGP) ist ein Routing-Protokoll, das Erreichbarkeitsinformationen über ein IP-Netzwerk austauscht. Wenn IBGP mit Multiprotocol BGP (MP-IBGP) kombiniert wird, bildet es die Grundlage für EVPN zum Austausch von Erreichbarkeitsinformationen zwischen VTEP-Geräten. Diese Fähigkeit ist erforderlich, um Inter-VTEP-VXLAN-Tunnel einzurichten und sie für Overlay-Konnektivitätsservices zu verwenden.
Abbildung 4 zeigt, dass die Spine- und Leaf-Geräte ihre Loopback-Adressen für das Peering in einem einzigen autonomen System verwenden. Bei diesem Design fungieren die Spine-Geräte als Routenreflektor-Cluster, und die Leaf-Geräte sind Routenreflektor-Clients. Ein Routenreflektor erfüllt die IBGP-Anforderung für ein vollständiges Mesh, ohne dass alle VTEP-Geräte direkt miteinander per Peer verbunden werden müssen. Daher führen die Leaf-Geräte nur ein Peer mit den Spine-Geräten und die Spine-Geräte ein Peer mit Spine-Geräten und Leaf-Geräten durch. Da die Spine-Geräte mit allen Leaf-Geräten verbunden sind, können die Spine-Geräte IBGP-Informationen zwischen den indirekt per Peering verknüpften Leaf-Gerätenachbarn weiterleiten.
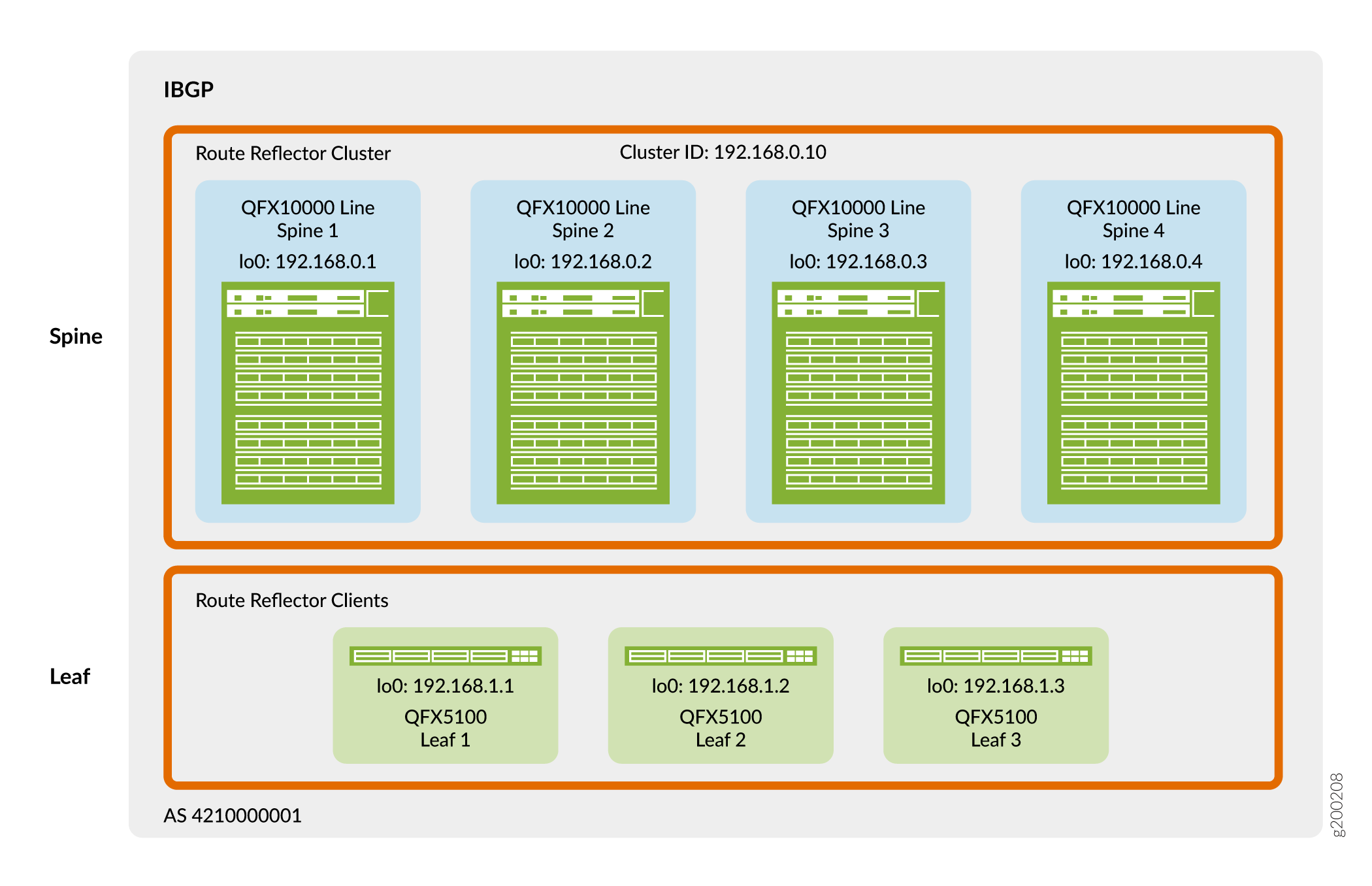
Sie können Routenreflektoren fast überall im Netzwerk platzieren. Sie müssen jedoch Folgendes beachten:
-
Verfügt das ausgewählte Gerät über genügend Arbeitsspeicher und Rechenleistung, um die zusätzliche Arbeitsauslastung zu bewältigen, die von einem Routenreflektor benötigt wird?
-
Ist das ausgewählte Gerät gleich weit entfernt und von allen EVPN-Lautsprechern aus erreichbar?
-
Verfügt das ausgewählte Gerät über die richtigen Softwarefunktionen?
In diesem Design wird der Routenreflektor-Cluster auf dem Spine-Layer platziert. Die QFX-Switches, die Sie in diesem Referenzdesign als Spine verwenden können, verfügen über eine ausreichende Verarbeitungsgeschwindigkeit, um Route Reflector-Client-Datenverkehr im Netzwerk-Virtualisierung-Overlay zu verarbeiten.
Weitere Informationen zum Implementieren von IBGP in einem Overlay finden Sie unter Konfigurieren von IBGP für das Overlay.
EBGP für Overlays mit IPv6-Underlays
Die ursprünglichen Anwendungsszenarien für die Referenzarchitektur in diesem Handbuch veranschaulichen ein IPv4-EBGP-Underlay-Design mit IPv4-IBGP-Overlay-Gerätekonnektivität. Weitere Informationen finden Sie unter IP Fabric Underlay-Netzwerk und IBGP für Overlays. Da NVE-Geräte (Network Virtualisierung Edge) jedoch beginnen, IPv6-VTEPs zu nutzen, um den erweiterten Adressbereich und die erweiterten Fähigkeiten von IPv6 zu nutzen, haben wir die IP-Fabric-Unterstützung auf IPv6 ausgeweitet.
Ab Junos OS Version 21.2R2-S1 können Sie auf unterstützenden Plattformen alternativ eine IPv6-Fabric-Infrastruktur mit einigen Referenzarchitektur-Overlay-Designs verwenden. Das IPv6-Fabric-Design umfasst IPv6-Schnittstellenadressierung, ein IPv6-EBGP-Underlay und ein IPv6-EBGP-Overlay für die Konnektivität der Arbeitsauslastung. Bei einer IPv6-Fabric kapseln die NVE-Geräte den VXLAN-Header mit einem äußeren IPv6-Header ein und tunneln die Pakete mithilfe von IPv6-Next-Hops durchgängig über die Fabric. Die Arbeitsauslastung kann IPv4 oder IPv6 sein.
Die meisten Elemente, die Sie in den unterstützten Overlay-Designs der Referenzarchitektur konfigurieren, sind unabhängig davon, ob die Underlay- und Overlay-Infrastruktur IPv4 oder IPv6 verwendet. Die entsprechenden Konfigurationsverfahren für jedes der unterstützten Overlay-Designs weisen auf Konfigurationsunterschiede hin, wenn das Underlay und das Overlay das IPv6-Fabric-Design verwenden.
Weitere Informationen finden Sie in den folgenden Referenzen in diesem Handbuch und in anderen Ressourcen:
Konfiguration einer IPv6-Fabric mit EBGP für Underlay-Konnektivität und Overlay-Peering: IPv6 Fabric Underlay- und Overlay-Netzwerkdesign und Implementierung mit EBGP.
Starten von Versionen, in denen verschiedene Plattformen ein IPv6-Fabric-Design unterstützen, wenn sie bestimmte Rollen in der Fabric übernehmen: Referenzdesigns für EVPN-VXLAN-Fabric-Datencenter – Zusammenfassung der unterstützten Hardware.
Übersicht über die Unterstützung von IPv6-Underlay- und Overlay-Peering-Peering in EVPN-VXLAN-Fabrics auf Geräten von Juniper Networks: EVPN-VXLAN mit einem IPv6-Underlay.
Überbrücktes Overlay
Der erste Overlay-Servicetyp, der in diesem Handbuch beschrieben wird, ist ein Bridged-Overlay, wie in Abbildung 5 dargestellt.
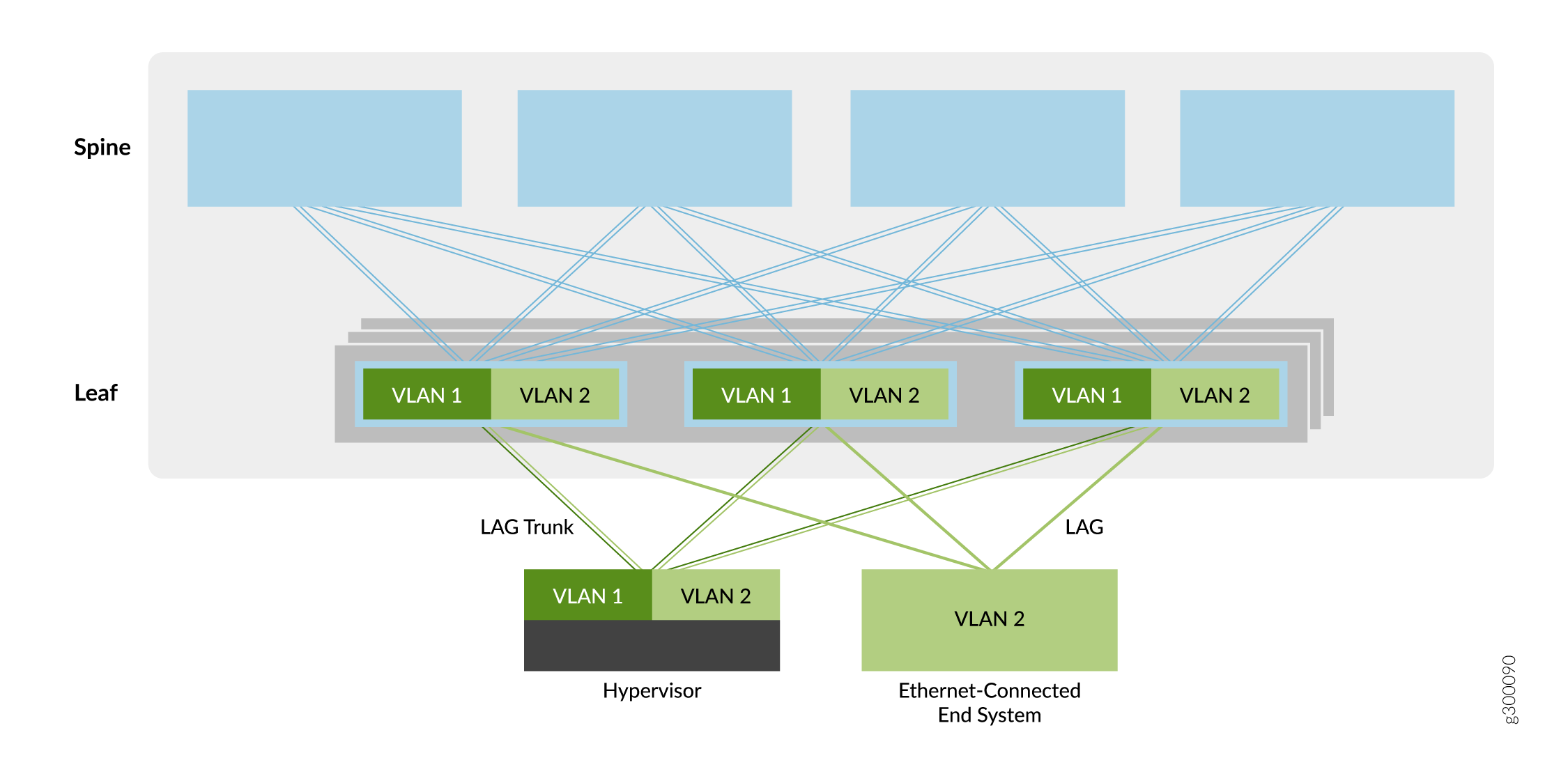
Bei diesem Overlay-Modell werden Ethernet-VLANs zwischen Leaf-Geräten über VXLAN-Tunnel erweitert. Diese Leaf-to-Leaf-VXLAN-Tunnel unterstützen Datencenter-Netzwerke, die Ethernet-Konnektivität zwischen Leaf-Geräten, aber kein Routing zwischen den VLANs erfordern. Infolgedessen stellen die Spine-Geräte nur grundlegende Underlay- und Overlay-Konnektivität für die Leaf-Geräte bereit und führen keine Routing- oder Gateway-Services aus, die bei anderen Overlay-Methoden zu beobachten sind.
Leaf-Geräte erzeugen VTEPs, um eine Verbindung zu den anderen Leaf-Geräten herzustellen. Die Tunnel ermöglichen es den Leaf-Geräten, VLAN-Datenverkehr an andere Leaf-Geräte und Ethernet-verbundene Endsysteme im Datencenter zu senden. Die Einfachheit dieses Overlay-Services macht ihn für Betreiber attraktiv, die eine einfache Möglichkeit benötigen, EVPN/VXLAN in ihr bestehendes Ethernet-basiertes Datencenter einzuführen.
Sie können Routing zu einem Bridged Overlay hinzufügen, indem Sie einen Router der MX-Serie oder ein Sicherheitsgerät der SRX-Serie außerhalb der EVPN/VXLAN-Fabric implementieren. Andernfalls können Sie einen der anderen Overlay-Typen auswählen, die Routing enthalten (z. B. ein Edge-Routing-Bridging-Overlay, ein zentral geroutetes Bridging-Overlay oder ein Routing-Overlay).
Informationen zum Implementieren eines Bridged-Overlays finden Sie unter Bridged-Overlay-Design und -Implementierung.
Zentral geroutetes Bridging-Overlay
Der zweite Overlay-Servicetyp ist das CRB-Overlay (Centrally Routed Bridging), wie in Abbildung 6 dargestellt.
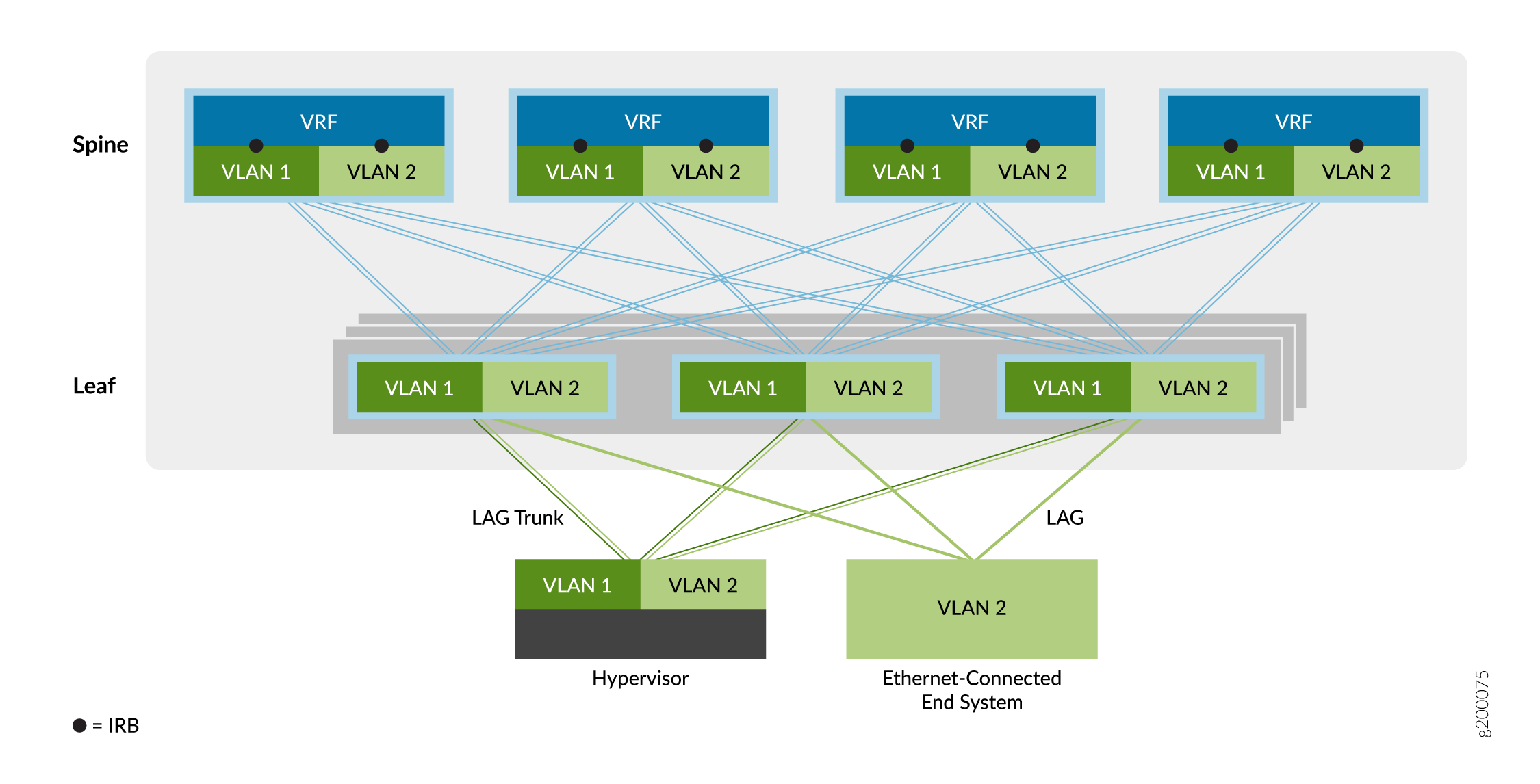
Bei einem CRB-Overlay erfolgt das Routing an einem zentralen Gateway des Datencenter-Netzwerks (in diesem Beispiel die Spine-Schicht) und nicht an dem VTEP-Gerät, mit dem die Endsysteme verbunden sind (in diesem Beispiel die Leaf-Schicht).
Sie können dieses Overlay-Modell verwenden, wenn der Datenverkehr über ein zentrales Gateway geroutet werden muss oder wenn Ihre Edge-VTEP-Geräte nicht über die erforderlichen Routing-Funktionen verfügen.
Wie oben gezeigt, wird der Datenverkehr, der von den Ethernet-verbundenen Endsystemen stammt, über einen Trunk (mehrere VLANs) oder einen Zugriffsport (einzelnes VLAN) an die Leaf-VTEP-Geräte weitergeleitet. Das VTEP-Gerät leitet den Datenverkehr an lokale Endsysteme oder an ein Endsystem auf einem entfernten VTEP-Gerät weiter. Eine integrierte Routing- und Bridging-Schnittstelle (IRB) an jedem Spine-Gerät hilft bei der Weiterleitung des Datenverkehrs zwischen den virtuellen Ethernet-Netzwerken.
Mit dem VLAN-fähigen Bridging-Overlay-Service-Modell können Sie auf einfache Weise eine Sammlung von VLANs in demselben virtuellen Overlay-Netzwerk aggregieren. Das EVPN-Design von Juniper Networks unterstützt drei VLAN-basierte Ethernet-Servicemodellkonfigurationen im Datencenter:
-
Default instance VLAN-aware– Mit dieser Option implementieren Sie eine einzelne Standard-Switching-Instanz, die insgesamt 4094 VLANs unterstützt. Alle in diesem Design enthaltenen Leaf-Plattformen (EVPN-VXLAN Fabric-Referenzdesigns für Datencenter – Zusammenfassung der unterstützten Hardware) unterstützen den standardmäßigen Instanzstil des VLAN-fähigen Overlay.
Informationen zum Konfigurieren dieses Dienstmodells finden Sie unter Konfigurieren eines VLAN-fähigen zentral gerouteten Bridging-Overlays in der Standardinstanz.
-
Virtual switch VLAN-aware– Mit dieser Option unterstützen mehrere virtuelle Switch-Instanzen bis zu 4094 VLANs pro Instanz. Dieses Ethernet-Service-Modell ist ideal für Overlay-Netzwerke, die eine Skalierbarkeit erfordern, die über eine einzige Standardinstanz hinausgeht. Unterstützung für diese Option ist derzeit für die Switches der QFX10000-Reihe verfügbar.
Informationen zur Implementierung dieses skalierbaren Servicemodells finden Sie unter Konfigurieren eines VLAN-fähigen CRB-Overlays mit virtuellen Switches oder MAC-VRF-Instanzen.
-
MAC-VRF instance VLAN-aware– Mit dieser Option unterstützen mehrere MAC-VRF-Instanzen bis zu 4094 VLANs pro Instanz. Dieses Ethernet-Service-Modell ist ideal für Overlay-Netzwerke, die eine Skalierbarkeit erfordern, die über eine einzelne Standardinstanz hinausgeht, und bei denen Sie mehr Optionen benötigen, um die VLAN-Isolierung oder -Verbindung zwischen verschiedenen Mandanten in derselben Fabric sicherzustellen. Unterstützung für diese Option ist auf den Plattformen verfügbar, die MAC-VRF-Instanzen unterstützen (siehe Feature-Explorer: MAC-VRF mit EVPN-VXLAN).
Informationen zur Implementierung dieses skalierbaren Servicemodells finden Sie unter Konfigurieren eines VLAN-fähigen CRB-Overlays mit virtuellen Switches oder MAC-VRF-Instanzen.
Edge-Routing-Bridging-Overlay
Die dritte Overlay-Serviceoption ist das Edge-Routed Bridging (ERB)-Overlay, wie in Abbildung 7 dargestellt.
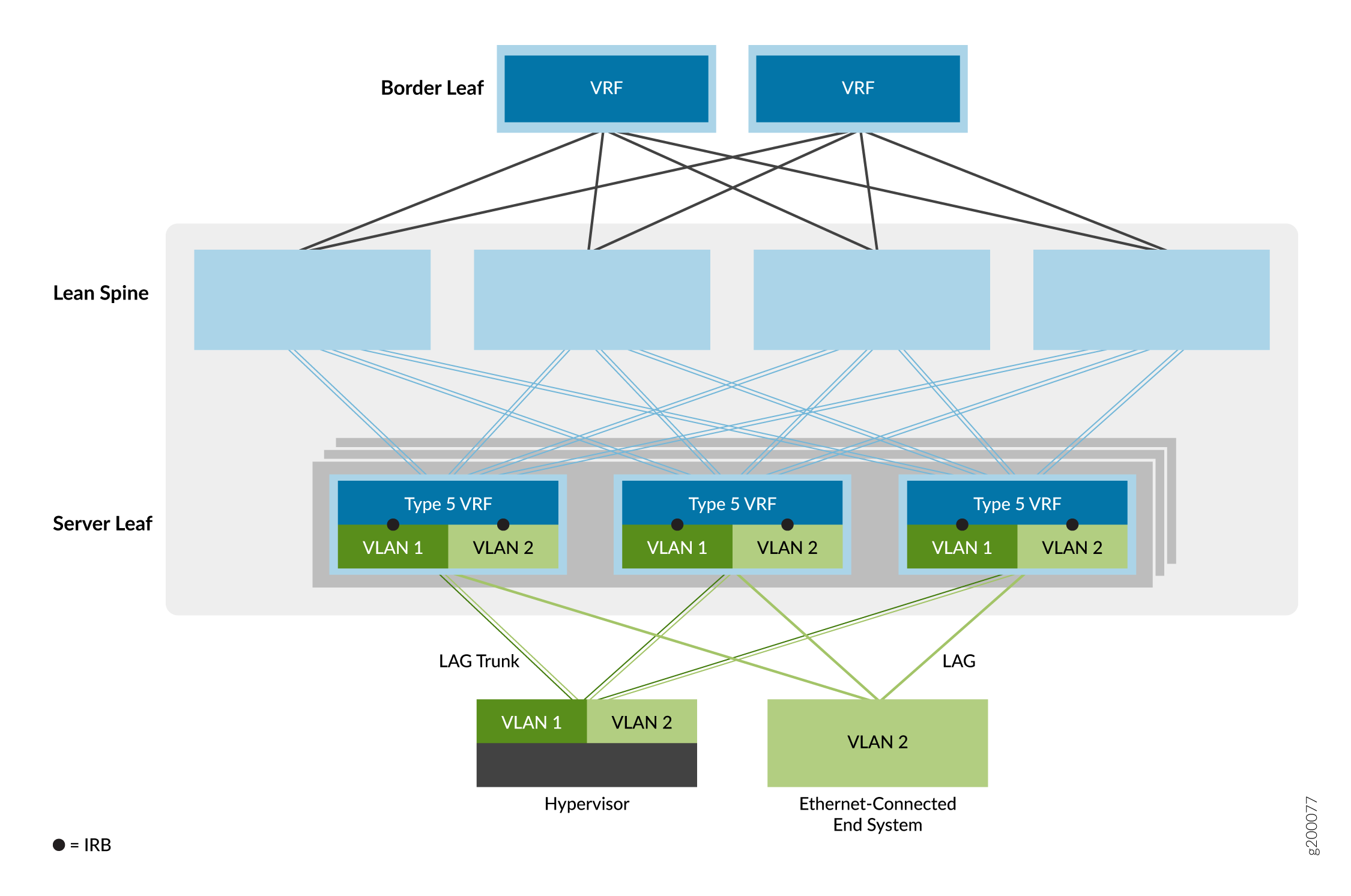
Bei diesem Ethernet-Servicemodell werden die IRB-Schnittstellen zu Leaf-Geräte-VTEPs am Rand des Overlay-Netzwerks verlagert, um das IP-Routing näher an die Endsysteme zu bringen. Aufgrund der speziellen ASIC-Funktionen, die zur Unterstützung von Bridging, Routing und EVPN/VXLAN in einem Gerät erforderlich sind, sind ERB-Overlays nur auf bestimmten Switches möglich. Eine Liste der Switches, die wir als Leaf-Geräte in einem ERB-Overlay unterstützen, finden Sie unter Data Center EVPN-VXLAN Fabric Reference Designs – Supported Hardware Summary.
Dieses Modell ermöglicht ein einfacheres Gesamtnetzwerk. Die Spine-Geräte sind so konfiguriert, dass sie nur IP-Datenverkehr verarbeiten, wodurch die Ausweitung der Bridging-Overlays auf die Spine-Geräte entfällt.
Diese Option ermöglicht auch einen schnelleren Server-zu-Server-Datenverkehr innerhalb des Datencenters (auch bekannt als East-West-Traffic), bei dem die Endsysteme mit demselben Leaf-Geräte-VTEP verbunden sind. Dadurch erfolgt das Routing viel näher an den Endsystemen als bei CRB-Overlays.
Wenn Sie IRB-Schnittstellen konfigurieren, die in EVPN-Typ-5-Routing-Instanzen auf QFX5110- oder QFX5120-Switches enthalten sind, die als Leaf-Geräte fungieren, aktiviert das Gerät automatisch symmetrisches Inter-IRB-Unicast-Routing für EVPN-Typ-5-Routen.
Informationen zum Implementieren des ERB-Overlays finden Sie unter Edge-Routed Bridging Overlay Design and Implementation.
Collapsed Spine-Overlay
Das Overlay-Netzwerk in einer Collapsed Spine-Architektur ähnelt einem ERB-Overlay. In einer Collapsed-Spine-Architektur werden die Leaf-Gerätefunktionen auf den Spine-Geräten zusammengeklappt. Da es keine Leaf-Ebene gibt, konfigurieren Sie die VTEPS- und IRB-Schnittstellen auf den Spine-Geräten, die sich wie die Leaf-Geräte in einem ERB-Modell am Rand des Overlay-Netzwerks befinden. Die Spine-Geräte können auch Border-Gateway-Funktionen ausführen, um den Nord-Süd-Datenverkehr zu routen oder den Layer-2-Datenverkehr über Datencenter-Standorte hinweg auszuweiten.
Eine Liste der Switches, die wir mit einer Collapsed Spine-Architektur unterstützen, finden Sie unter Data Center EVPN-VXLAN Fabric Reference Designs – Supported Hardware Summary.
Vergleich von Bridged-, CRB- und ERB-Overlays
Informationen zur Entscheidung, welcher Overlay-Typ für Ihre EVPN-Umgebung am besten geeignet ist, finden Sie in Tabelle 1.
Wir unterstützen das gleichzeitige Mischen von Bridged-Overlay-, CRB-Overlay- und ERB-Overlay-Konfigurationen auf demselben Gerät auf Geräten, die diese Overlay-Typen unterstützen. Sie müssen das Gerät nicht mit separaten logischen Systemen konfigurieren, damit das Gerät in verschiedenen Arten von Overlays parallel betrieben werden kann.
| Vergleichspunkte |
ERB-Overlay |
CRB-Overlay |
Überbrücktes Overlay |
|---|---|---|---|
| Vollständig verteiltes Mandanten-Routing zwischen Subnetzen |
✓ |
||
| Minimale Auswirkungen eines IP-Gateway-Ausfalls |
✓ |
||
| Dynamisches Routing zu Knoten von Drittanbietern auf Leaf-Ebene |
✓ |
||
| Optimiert für hohes Volumen an Ost-West-Datenverkehr |
✓ |
||
| Bessere Integration mit rohen IP-Fabrics |
✓ |
||
| IP-VRF-Virtualisierung näher am Server |
✓ |
||
| Contrail vRouter Multihoming erforderlich |
✓ |
||
| Einfachere EVPN-Interoperabilität mit verschiedenen Anbietern |
✓ |
||
| Symmetrisches Routing zwischen Subnetzen |
✓ |
✓ |
|
| VLAN-ID überlappt pro Rack |
✓ |
✓ |
✓ |
| Einfachere manuelle Konfiguration und Fehlerbehebung |
✓ |
✓ |
|
| Schnittstellen im Service-Provider- und Enterprise-Stil |
✓ |
✓ |
|
| Unterstützung für Legacy-Leaf-Switches (QFX5100) |
✓ |
✓ |
|
| Zentrale Steuerung für die Optimierung des Datenverkehrs virtueller Maschinen (VMTO) |
✓ |
||
| IP-Mandanten-Subnetz-Gateway im Firewall-Cluster |
✓ |
IRB-Adressierungsmodelle in Bridging-Overlays
Die Konfiguration von IRB-Schnittstellen in CRB- und ERB-Overlays erfordert ein Verständnis der Modelle für die standardmäßige Gateway-IP- und MAC-Adresse-Konfiguration von IRB-Schnittstellen wie folgt:
Unique IRB IP Address– In diesem Modell wird auf jeder IRB-Schnittstelle in einem Overlay-Subnetz eine eindeutige IP-Adresse konfiguriert.
Der Vorteil einer eindeutigen IP- und MAC-Adresse auf jeder IRB-Schnittstelle besteht darin, dass jede der IRB-Schnittstellen innerhalb des Overlays mithilfe ihrer eindeutigen IP-Adresse überwacht und erreicht werden kann. Mit diesem Modell können Sie auch ein Routing-Protokoll auf der IRB-Schnittstelle konfigurieren.
Der Nachteil dieses Modells besteht darin, dass die Zuweisung einer eindeutigen IP-Adresse zu jeder IRB-Schnittstelle viele IP-Adressen eines Subnetzes verbrauchen kann.
Unique IRB IP Address with Virtual Gateway IP Address– Dieses Modell fügt dem vorherigen Modell eine IP-Adresse für ein virtuelles Gateway hinzu, die für zentral geroutete Bridged-Overlays empfohlen wird. Es ähnelt VRRP, jedoch ohne die In-Band-Datenebene-Signalisierung zwischen den Gateway-IRB-Schnittstellen. Das virtuelle Gateway sollte für alle Standard-Gateway-IRB-Schnittstellen im Overlay-Subnetz identisch sein und auf allen Gateway-IRB-Schnittstellen aktiv sein, an denen es konfiguriert ist. Sie sollten auch eine allgemeine IPv4-MAC-Adresse für das virtuelle Gateway konfigurieren, die zur Quell-MAC-Adresse für Datenpakete wird, die über die IRB-Schnittstelle weitergeleitet werden.
Zusätzlich zu den Vorteilen des Vorgängermodells vereinfacht das virtuelle Gateway die Standard-Gateway-Konfiguration auf Endsystemen. Der Nachteil dieses Modells ist der gleiche wie beim Vorgängermodell.
IRB with Anycast IP Address and MAC Address– In diesem Modell sind alle standardmäßigen Gateway-IRB-Schnittstellen in einem Overlay-Subnetz mit derselben IP- und MAC-Adresse konfiguriert. Wir empfehlen dieses Modell für ERB-Overlays.
Ein Vorteil dieses Modells besteht darin, dass nur eine einzige IP-Adresse pro Subnetz für die IRB-Schnittstellenadressierung des Standard-Gateways erforderlich ist, was die Standard-Gateway-Konfiguration auf Endsystemen vereinfacht.
Geroutetes Overlay mit EVPN-Routen Typ 5
Die letzte Overlay-Option ist ein geroutetes Overlay, wie in Abbildung 8 dargestellt.
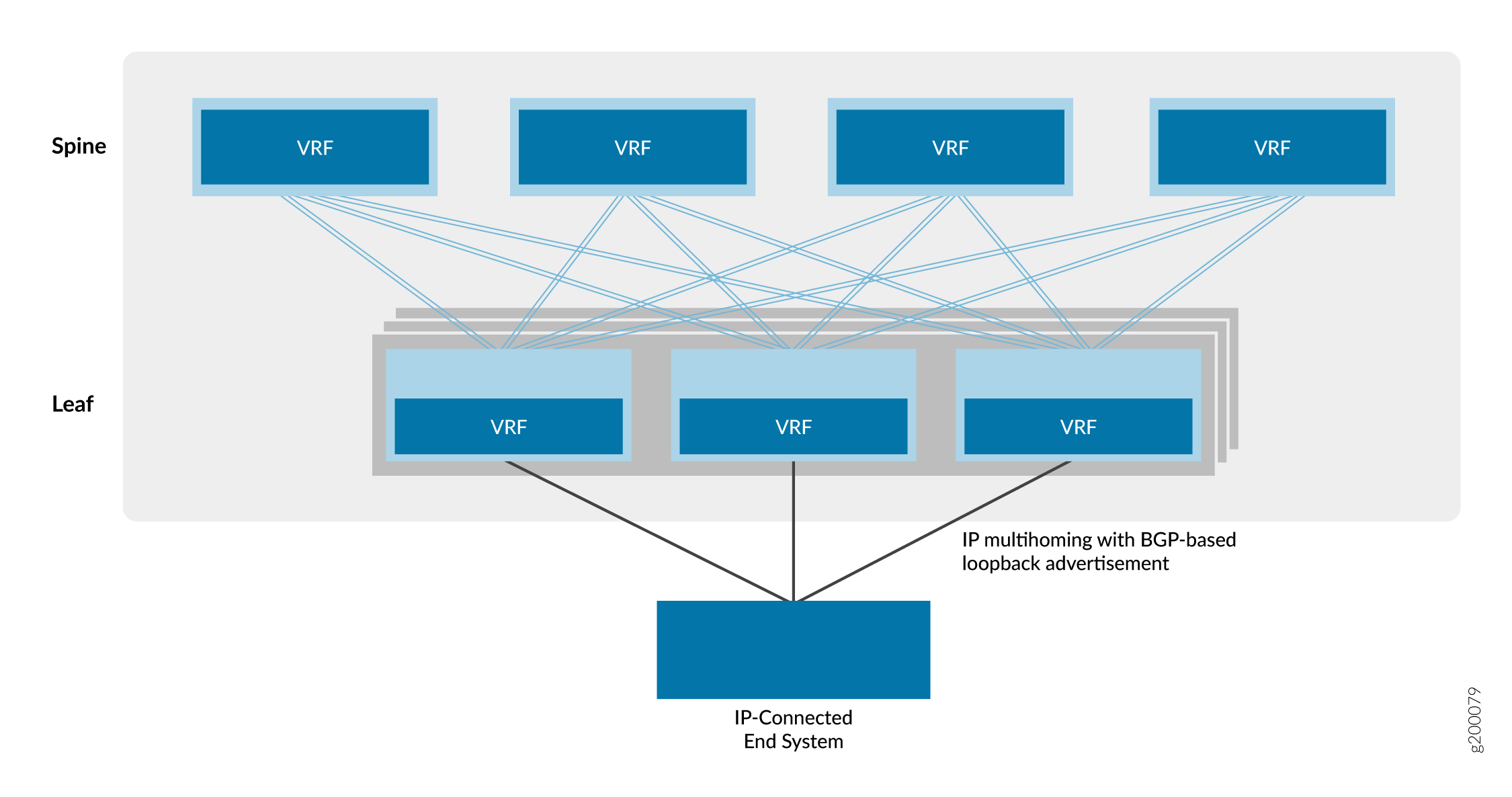
Bei dieser Option handelt es sich um einen IP-gerouteten virtuellen Netzwerkdienst. Im Gegensatz zu einem MPLS-basierten IP-VPN basiert das virtuelle Netzwerk in diesem Modell auf EVPN/VXLAN.
Cloud-Anbieter bevorzugen diese virtuelle Netzwerkoption, da die meisten modernen Anwendungen für IP optimiert sind. Da die gesamte Kommunikation zwischen Geräten auf der IP-Ebene erfolgt, müssen in diesem gerouteten Overlay-Modell keine Ethernet-Bridging-Komponenten wie VLANs und ESIs verwendet werden.
Informationen zum Implementieren eines gerouteten Overlays finden Sie unter Entwurf und Implementierung von geroutetem Overlay.
MAC-VRF-Instanzen für Mehrfachmandantenfähigkeit in Netzwerkvirtualisierungs-Overlays
MAC-VRF-Routing-Instanzen ermöglichen es Ihnen, mehrere EVPN-Instanzen mit unterschiedlichen Ethernet-Service-Typen auf einem Gerät zu konfigurieren, das als VTEP in einer EVPN-VXLAN-Fabric fungiert. Mithilfe von MAC-VRF-Instanzen können Sie mehrere Mandanten im Datencenter mit kundenspezifischen VRF-Tabellen verwalten, um Mandanten-Workloads zu isolieren oder zu gruppieren.
MAC-VRF-Instanzen bieten zusätzlich zur vorherigen Unterstützung für den VLAN-fähigen Diensttyp auch Unterstützung für den VLAN-basierten Servicetyp. Siehe Abbildung 9.

-
VLAN-basierter Dienst: Sie können ein VLAN und den entsprechenden VXLAN Network Identifier (VNI) in der MAC-VRF-Instanz konfigurieren. Für die Bereitstellung eines neuen VLAN und VNI müssen Sie eine neue MAC VRF-Instanz mit dem neuen VLAN und VNI konfigurieren.
-
VLAN-basierter Service: Sie können ein oder mehrere VLANs und die entsprechenden VNIs in derselben MAC-VRF-Instanz konfigurieren. Zur Bereitstellung eines neuen VLAN und VNI können Sie die neue VLAN- und VNI-Konfiguration zur vorhandenen MAC-VRF-Instanz hinzufügen, wodurch einige Konfigurationsschritte gegenüber der Verwendung eines VLAN-basierten Services eingespart werden.
MAC-VRF-Instanzen ermöglichen flexiblere Konfigurationsoptionen sowohl auf Layer 2 als auch auf Layer 3. Zum Beispiel:
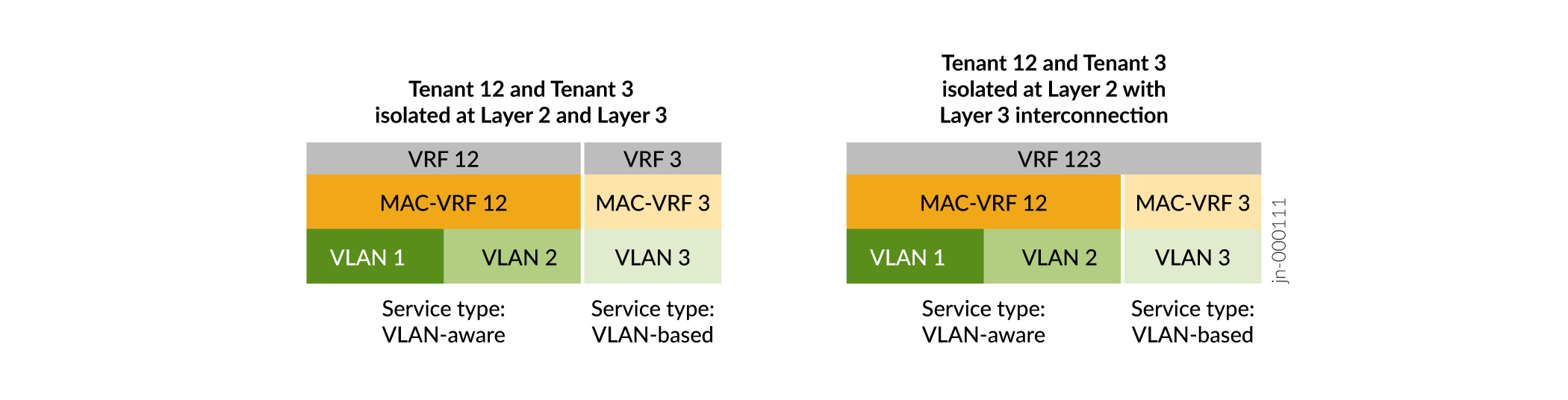
Abbildung 10 zeigt, dass bei MAC-VRF-Instanzen:
-
Sie können verschiedene Servicetypen in verschiedenen MAC-VRF-Instanzen auf demselben Gerät konfigurieren.
-
Sie haben flexible Optionen für die Mandantenisolierung auf Layer 2 (MAC-VRF-Instanzen) und auf Layer 3 (VRF-Instanzen). Sie können eine VRF-Instanz konfigurieren, die dem VLAN oder den VLANs in einer einzelnen MAC-VRF-Instanz entspricht. Oder Sie können eine VRF-Instanz konfigurieren, die die VLANs in mehreren MAC-VRF-Instanzen umfasst.
Abbildung 11 zeigt eine ERB-Overlay-Fabric mit einer Beispiel-MAC-VRF-Konfiguration für die Mandantentrennung.
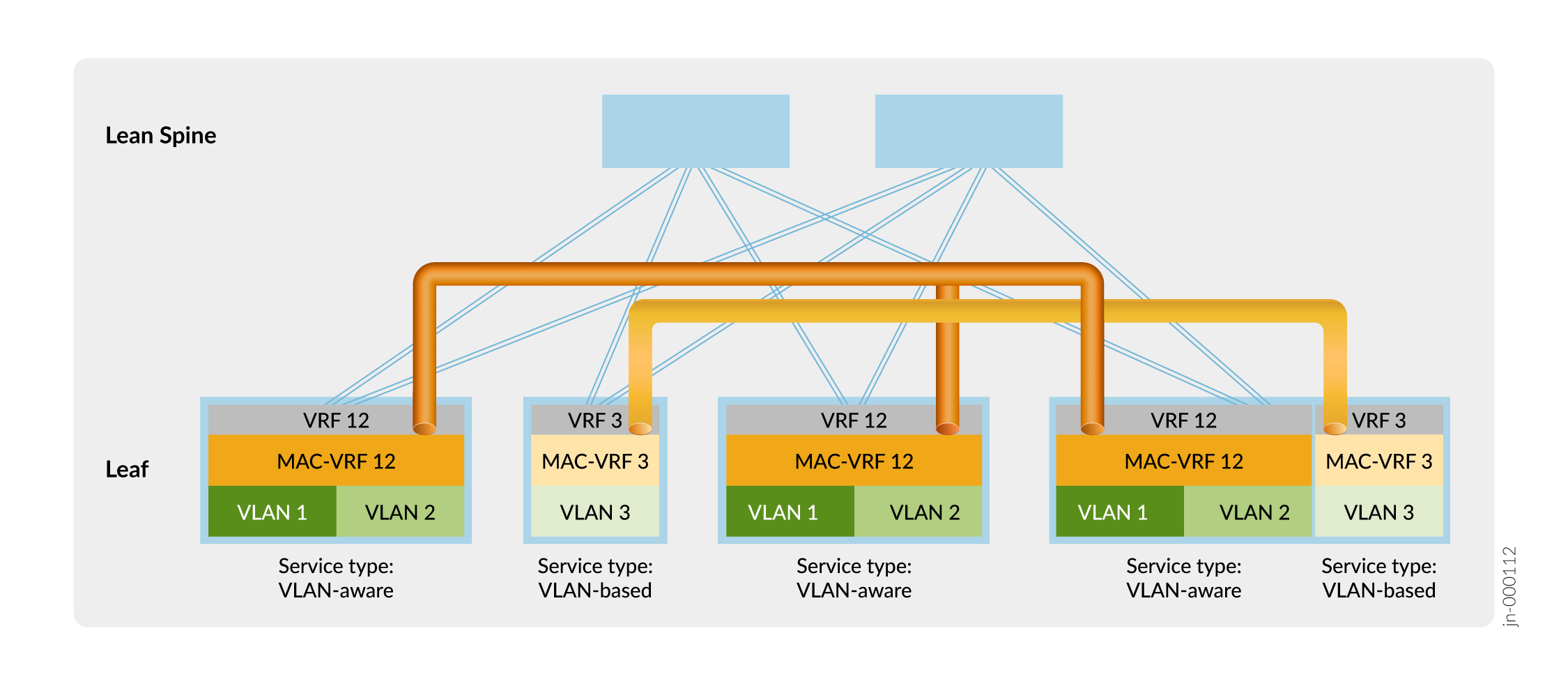
In Abbildung 11 richten die Leaf-Geräte VXLAN-Tunnel ein, die die Isolation auf Layer 2 zwischen Mandant 12 (VLAN 1 und VLAN 2) und Mandant 3 (VLAN 3) mithilfe der MAC-VRF-Instanzen MAC-VRF 12 und MAC-VRF 3 aufrechterhalten. Die Leaf-Geräte isolieren auch die Mandanten auf Layer 3 mithilfe der VRF-Instanzen VRF 12 und VRF 3.
Sie können andere Optionen für die gemeinsame Nutzung des VLAN-Datenverkehrs zwischen Mandanten verwenden, die auf Layer 2 und Layer 3 durch die MAC-VRF- und VRF-Konfigurationen isoliert sind, wie z. B.:
-
Richten Sie eine sichere externe Verbindung zwischen Mandanten-VRFs über eine Firewall ein.
-
Konfigurieren Sie lokale Routenlecks zwischen Layer 3 VRFs.
Weitere Informationen zu MAC-VRF-Instanzen und deren Verwendung in einem Beispielanwendungsszenario für Kunden finden Sie unter EVPN-VXLAN DC IP Fabric MAC-VRF L2 Services.
MAC-VRF-Instanzen entsprechen den Weiterleitungsinstanzen wie folgt:
-
MAC-VRF-Instanzen auf Switches der QFX5000-Reihe (einschließlich solcher, die Junos OS oder Junos OS Evolved ausführen) sind alle Teil der Standard-Weiterleitungsinstanz. Auf diesen Geräten können Sie keine überlappenden VLANs in einer MAC-VRF-Instanz oder über mehrere MAC-VRF-Instanzen hinweg konfigurieren.
-
Auf den Switches der QFX10000-Reihe können Sie mehrere Weiterleitungsinstanzen konfigurieren und eine MAC-VRF-Instanz einer bestimmten Weiterleitungsinstanz zuordnen. Sie können auch mehrere MAC-VRF-Instanzen derselben Weiterleitungsinstanz zuordnen. Wenn Sie jede MAC-VRF-Instanz für die Verwendung einer anderen Weiterleitungsinstanz konfigurieren, können Sie überlappende VLANs über mehrere MAC-VRF-Instanzen hinweg konfigurieren. Sie können keine überlappenden VLANs in einer einzelnen MAC-VRF-Instanz oder über MAC-VRF-Instanzen hinweg konfigurieren, die derselben Weiterleitungsinstanz zugeordnet sind.
-
In der Standardkonfiguration enthalten Switches ein Standard-VLAN mit VLAN-ID=1, das der Standard-Weiterleitungsinstanz zugeordnet ist. Da VLAN-IDs in einer Weiterleitungsinstanz eindeutig sein müssen, müssen Sie die VLAN-ID des Standard-VLANs einem anderen Wert als 1 zuweisen, wenn Sie ein VLAN mit VLAN ID=1 in einer MAC-VRF-Instanz konfigurieren möchten, die die Standard-Weiterleitungsinstanz verwendet. Zum Beispiel:
set vlans default vlan-id 4094 set routing-instances mac-vrf-instance-name vlans vlan-name vlan-id 1
Die Referenzkonfigurationsbeispiele für Overlay-Konfigurationen für die Netzwerk-Virtualisierung in diesem Handbuch enthalten Schritte zum Konfigurieren des Overlays mithilfe von MAC-VRF-Instanzen. Sie konfigurieren eine EVPN-Routing-Instanz vom Typ mac-vrfund legen eine Routenunterscheidung und ein Routenziel in der Instanz fest. Sie schließen auch die gewünschten Schnittstellen (einschließlich einer VTEP-Quellschnittstelle), VLANs und VLAN-zu-VNI-Zuordnungen in die Instanz ein. Weitere Informationen finden Sie in den Referenzkonfigurationen in den folgenden Themen:
-
Bridged-Overlay-Design und -Implementierung – Sie konfigurieren MAC-VRF-Instanzen auf den Leaf-Geräten.
-
Design und Implementierung von Bridging-Overlay mit zentral gerouteten Lösungen: Sie konfigurieren MAC-VRF-Instanzen auf den Spine-Geräten. Auf den Leaf-Geräten ähnelt die MAC-VRF-Konfiguration der MAC-VRF-Leaf-Konfiguration in einem Bridged-Overlay-Design.
-
Edge-Routed Bridging-Overlay-Design und -Implementierung: Sie konfigurieren MAC-VRF-Instanzen auf den Leaf-Geräten.
Ein Gerät kann Probleme mit der VTEP-Skalierung haben, wenn die Konfiguration mehrere MAC-VRF-Instanzen verwendet. Um dieses Problem zu vermeiden, müssen Sie daher die Funktion "Freigegebene Tunnel" auf der QFX5000 Reihe von Switches aktivieren, die Junos OS mit einer MAC-VRF-Instanzkonfiguration ausgeführt werden. Wenn Sie freigegebene Tunnel konfigurieren, minimiert das Gerät die Anzahl der Next-Hop-Einträge, die Remote-VTEPs erreichen. Sie aktivieren freigegebene VXLAN-Tunnel global auf dem Gerät, indem Sie die shared-tunnels Anweisung auf Hierarchieebene [edit forwarding-options evpn-vxlan] verwenden. Diese Einstellung erfordert, dass Sie das Gerät neu starten.
Diese Anweisung ist für die QFX10000-Reihe von Switches mit Junos OS optional, die eine höhere VTEP Skalierung als QFX5000 Switches verarbeiten können.
Auf Geräten, auf denen Junos OS Evolved in EVPN-VXLAN-Fabrics ausgeführt wird, sind freigegebene Tunnel standardmäßig aktiviert. Junos OS Evolved unterstützt EVPN-VXLAN nur mit MAC-VRF-Konfigurationen.
Multihoming-Support für Ethernet-verbundene Endsysteme
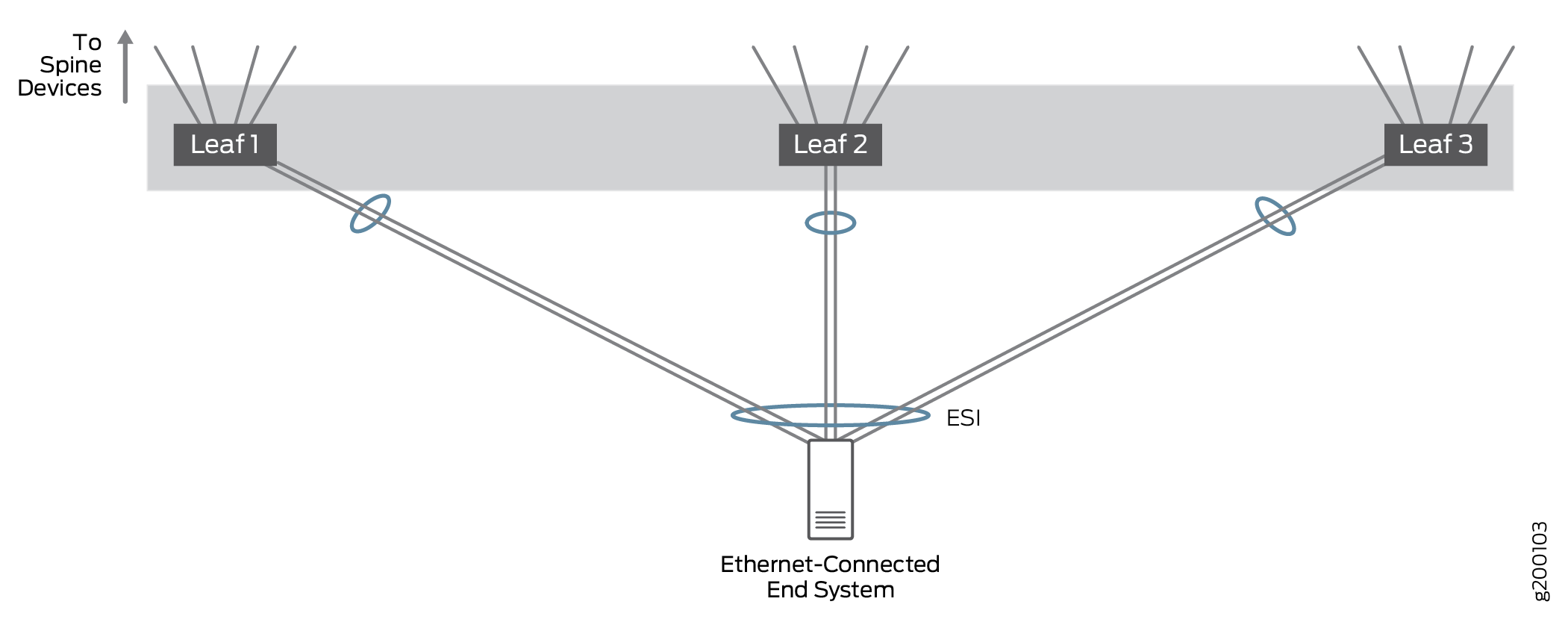
Ethernet-verbundenes Multihoming ermöglicht mit Ethernet verbundenen Endgeräten die Verbindung mit dem Ethernet-Overlay-Netzwerk über eine Single-Homed-Verbindung zu einem VTEP-Gerät oder über mehrere Multihomed-Verbindungen zu verschiedenen VTEP-Geräten. Der Ethernet-Datenverkehr wird über die gesamte Fabric zwischen VTEPs auf Leaf-Geräten, die mit demselben Endsystem verbunden sind, ausgeglichen.
Wir haben Setups getestet, bei denen ein Ethernet-verbundenes Endsystem mit einem Single-Leaf-Gerät oder Multihomed mit 2 oder 3 Leaf-Geräten verbunden war, um nachzuweisen, dass der Datenverkehr in Multihomed-Setups mit mehr als zwei Leaf-VTEP-Geräten ordnungsgemäß verarbeitet wird. In der Praxis kann ein Ethernet-verbundenes Endsystem mit einer großen Anzahl von Leaf-VTEP-Geräten mehrfach vernetzt werden. Alle Verbindungen sind aktiv, und der Netzwerkverkehr kann über alle mehrfach vernetzten Verbindungen ausgeglichen werden.
In dieser Architektur wird EVPN für Ethernet-verbundenes Multihoming verwendet. Multihomed LAGs von EVPN werden durch einen Ethernet Segment Identifier (ESI) im EVPN-Bridging-Overlay identifiziert, während LACP zur Verbesserung der LAG-Verfügbarkeit verwendet wird.
VLAN-Trunking ermöglicht es einer Schnittstelle, mehrere VLANs zu unterstützen. VLAN-Trunking stellt sicher, dass virtuelle Maschinen (VMs) auf Nicht-Overlay-Hypervisoren in jedem Overlay-Netzwerkkontext betrieben werden können.
Weitere Informationen zur Unterstützung von Ethernet-verbundenem Multihoming finden Sie unter Multihoming eines Ethernet-verbundenen Endsystems Design und Implementierung.
Multihoming-Support für IP-verbundene Endsysteme
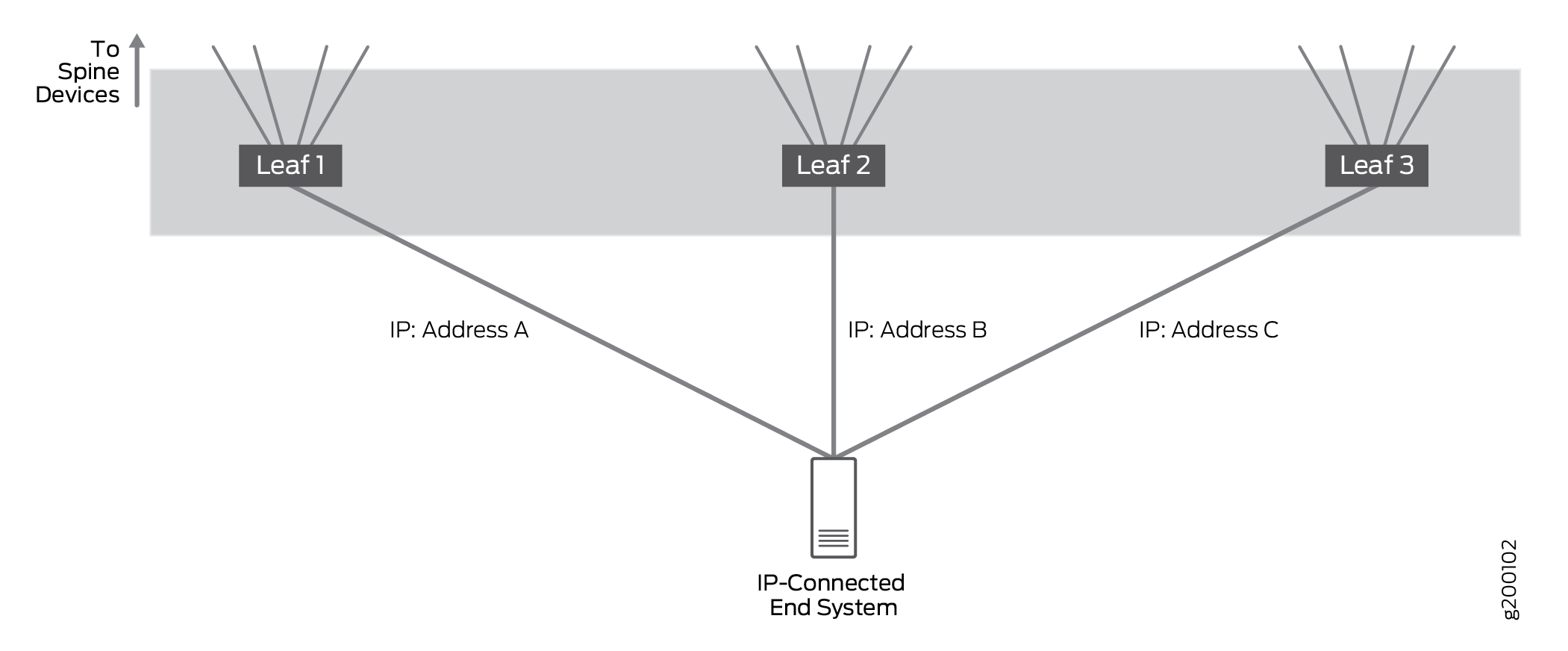 für IP-verbundene Endsysteme
für IP-verbundene Endsysteme
IP-verbundene Multihoming-Endgeräte zur Verbindung mit dem IP-Netzwerk über mehrere IP-basierte Zugriffsschnittstellen auf verschiedenen Leaf-Geräten.
Wir haben Setups getestet, bei denen ein IP-verbundenes Endsystem mit einem Single-Leaf oder Multihomed mit 2 oder 3 Leaf-Geräten verbunden war. Bei der Einrichtung wurde überprüft, ob der Datenverkehr ordnungsgemäß verarbeitet wird, wenn er an mehrere Leaf-Geräte weitergeleitet wird. In der Praxis kann ein IP-verbundenes Endsystem mit einer großen Anzahl von Leaf-Geräten mehrfach vernetzt werden.
In Multihomed-Setups sind alle Links aktiv und der Netzwerkverkehr wird über alle Multihomed-Links weitergeleitet und empfangen. Der IP-Datenverkehr wird mithilfe eines einfachen Hashing-Algorithmus über die mehrfach vernetzten Verbindungen ausgeglichen.
EBGP wird verwendet, um Routing-Informationen zwischen dem IP-verbundenen Endgerät und den angeschlossenen Leaf-Geräten auszutauschen, um sicherzustellen, dass die Route oder die Routen zu den Endgerät-Systemen mit allen Spine- und Leaf-Geräten geteilt werden.
Weitere Informationen zum Baustein für das IP-verbundene Multihoming finden Sie unter Multihoming eines IP-verbundenen Endsystementwurfs und einer Implementierung.
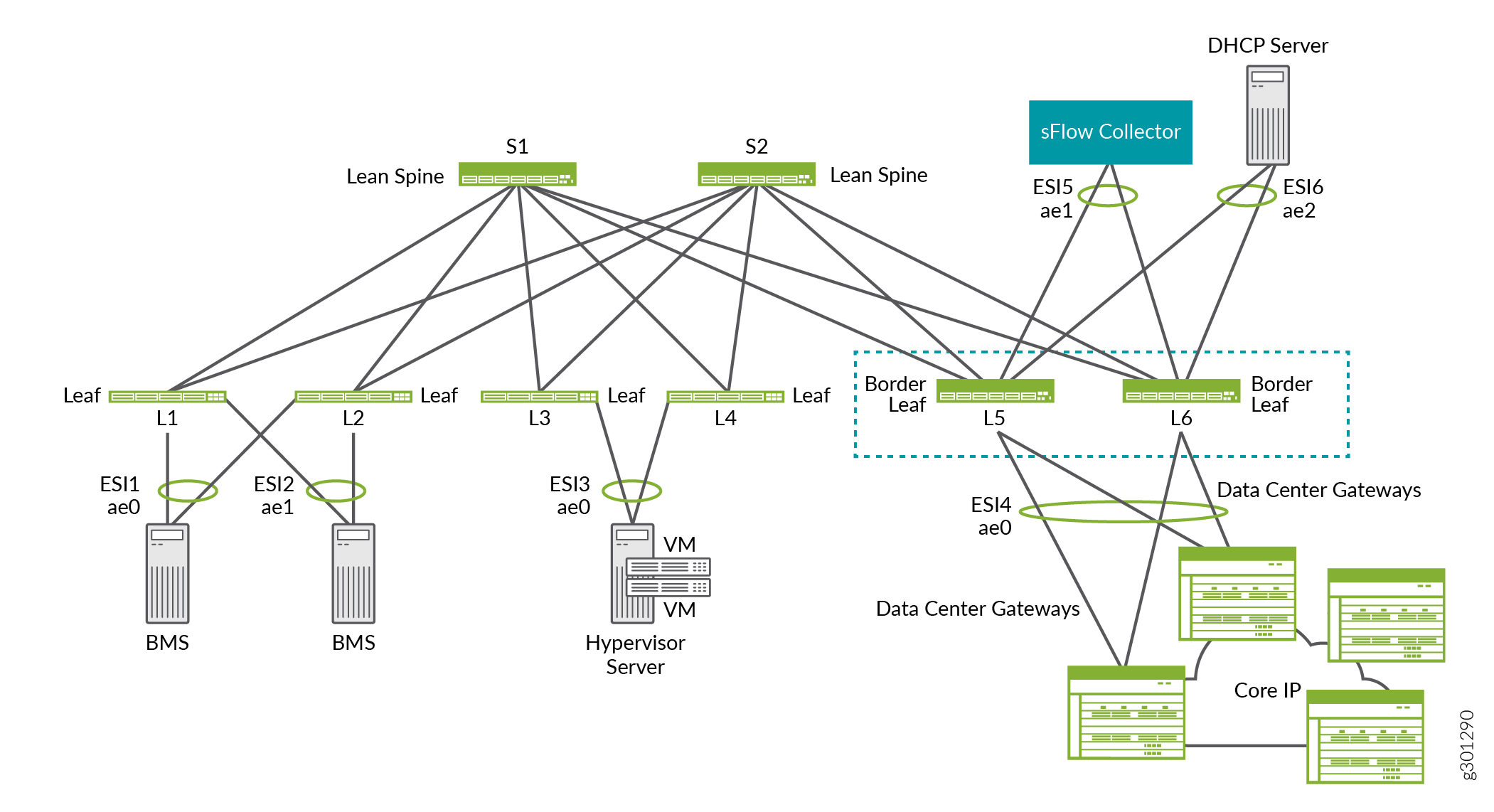
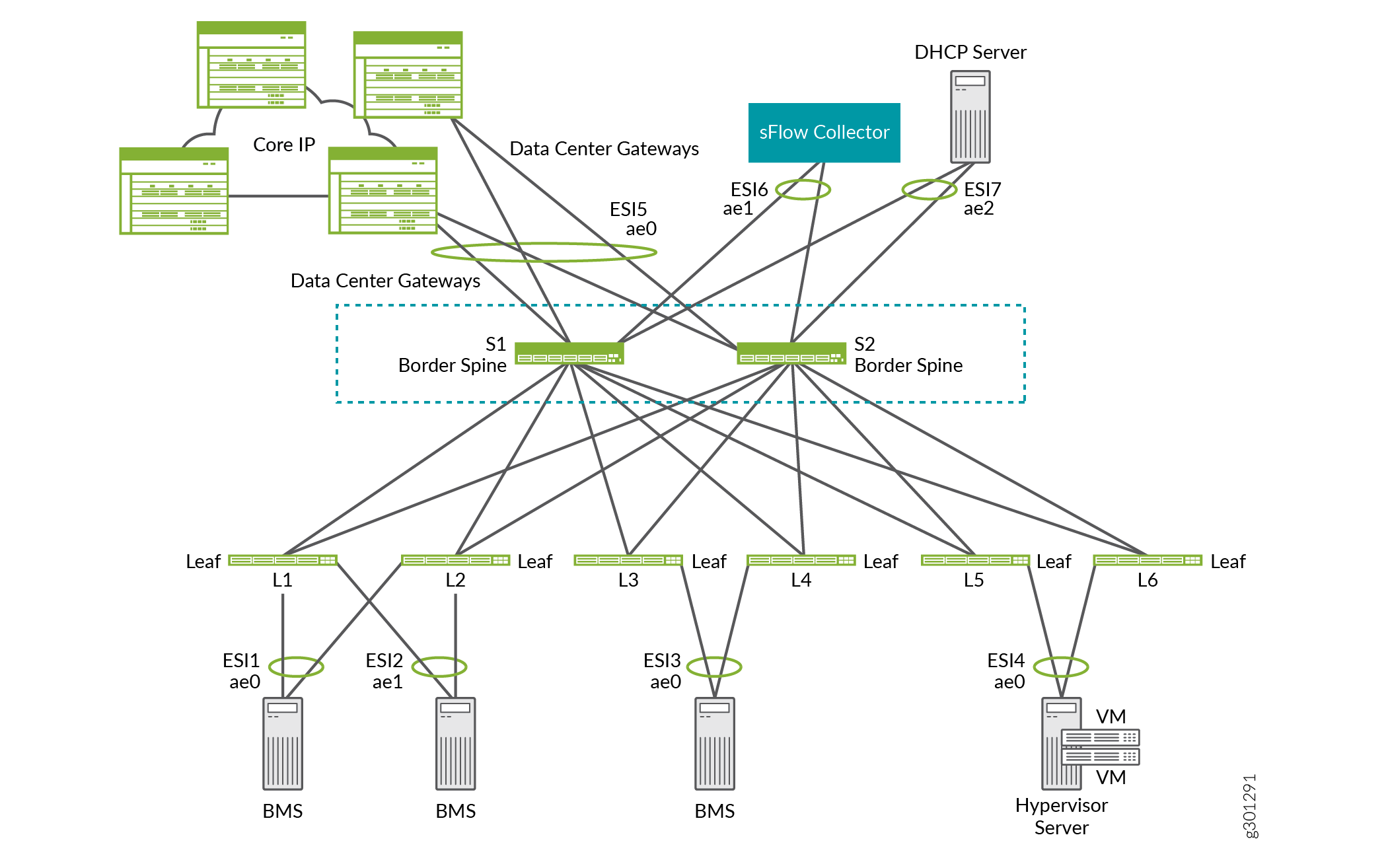
Border-Geräte
Einige unserer Referenzdesigns umfassen Grenzgeräte, die Verbindungen zu den folgenden Geräten bereitstellen, die sich außerhalb der lokalen IP-Fabric befinden:
Ein Multicast-Gateway.
Ein Datencenter-Gateway für Data Center Interconnect (DCI).
Ein Gerät wie ein SRX-Router, auf dem mehrere Services wie Firewalls, Network Address Translation (NAT), Intrusion Detection and Prevention (IDP), Multicast usw. konsolidiert sind. Die Konsolidierung mehrerer Services auf einem physischen Gerät wird als Service Chaining bezeichnet.
Appliances oder Server, die als Firewalls, DHCP-Server, sFlow-Kollektoren usw. fungieren.
Hinweis:Wenn Ihr Netzwerk Legacy-Appliances oder Server umfasst, die eine 1-Gbit/s-Ethernet-Verbindung zu einem Grenzgerät erfordern, empfehlen wir die Verwendung eines QFX10008- oder QFX5120-Switches als Grenzgerät.
Um die oben beschriebenen zusätzlichen Funktionen bereitzustellen, unterstützt Juniper Networks die Bereitstellung eines Grenzgeräts auf folgende Weise:
Als Gerät, das nur als Grenzgerät dient. In dieser dedizierten Rolle können Sie das Gerät so konfigurieren, dass es eine oder mehrere der oben beschriebenen Aufgaben ausführt. In diesem Fall wird das Gerät in der Regel als Border Leaf bereitgestellt, das mit einem Spine-Gerät verbunden ist.
Im ERB-Overlay in Abbildung 14 bieten die Border Leafs L5 und L6 beispielsweise Konnektivität zu Datencenter-Gateways für DCI, einen sFlow-Collector und einen DHCP-Server.
Als Gerät mit zwei Rollen: einem Netzwerk-Underlay-Gerät und einem Grenzgerät, das eine oder mehrere der oben beschriebenen Aufgaben ausführen kann. In diesem Fall übernimmt in der Regel ein Spine-Gerät die beiden Rollen. Daher wird die Border-Gerätefunktionalität als Border-Spine bezeichnet.
In dem in Abbildung 15 gezeigten ERB-Overlay fungieren beispielsweise die Border Spines S1 und S2 als Lean-Spine-Geräte. Sie bieten auch Konnektivität zu Datencenter-Gateways für DCI, einen sFlow-Collector und einen DHCP-Server.
Vernetzung von Datencentern (DCI)
Der Baustein Data Center Interconnect (DCI) stellt die Technologie bereit, die für die Übertragung des Datenverkehrs zwischen Datencentern erforderlich ist. Das validierte Design unterstützt DCI mit EVPN-Typ-5-Routen, IPVPN-Routen und Layer-2-DCI mit VXLAN-Stitching.
EVPN-Typ-5- oder IPVPN-Routen werden in einem DCI-Kontext verwendet, um sicherzustellen, dass Datenverkehr zwischen Datencentern zwischen Datencentern mit unterschiedlichen IP-Adress-Subnetting-Schemata ausgetauscht werden kann. Routen werden zwischen Spine-Geräten in verschiedenen Datencentern ausgetauscht, um den Datenverkehr zwischen den Datencentern weiterleiten zu können.
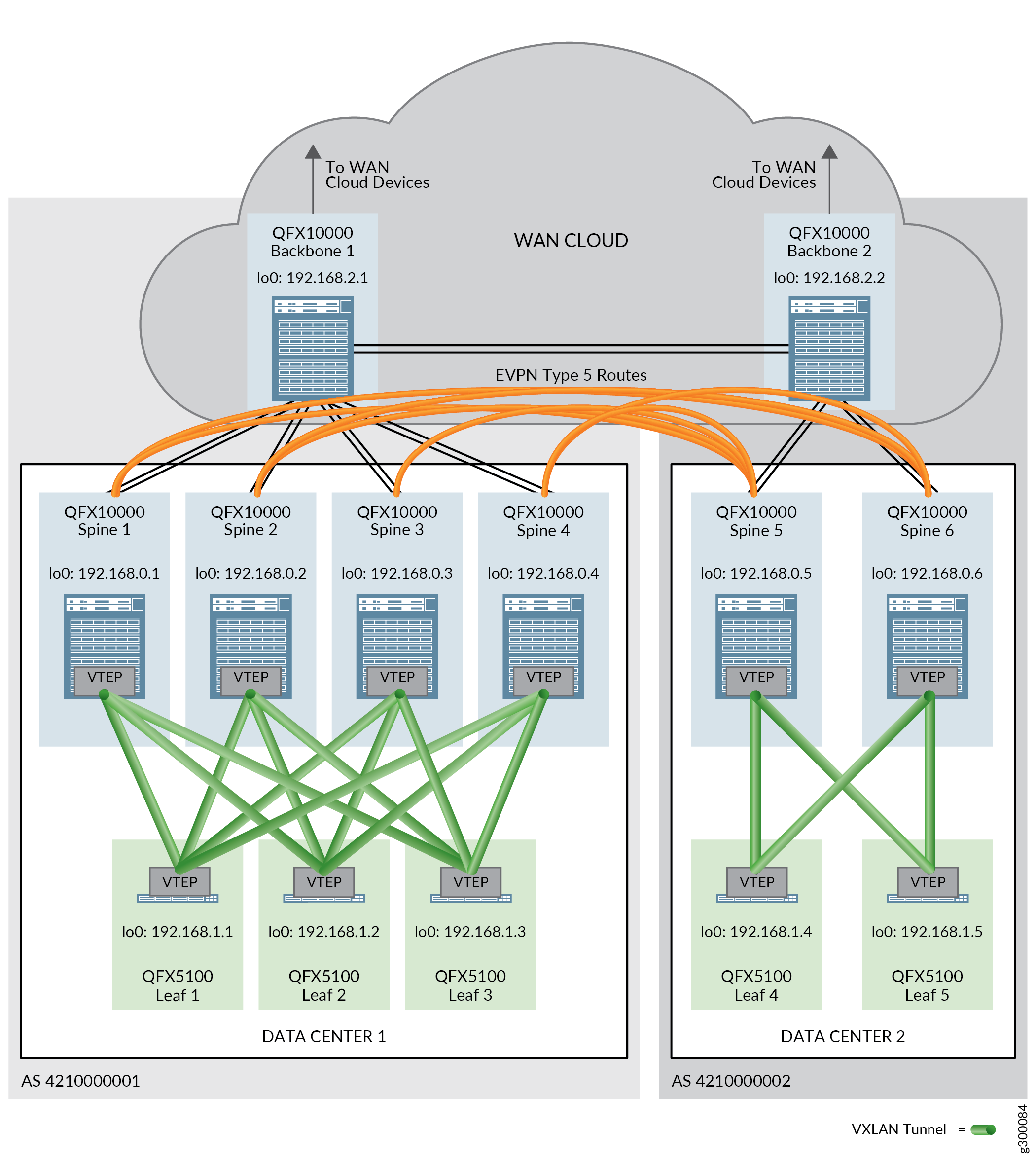
Für die Konfiguration von DCI ist eine physische Verbindung zwischen den Datencentern erforderlich. Die physische Konnektivität wird von Backbone-Geräten in einer WAN-Cloud bereitgestellt. Ein Backbone-Gerät wird mit allen Spine-Geräten in einem einzigen Datencenter (POD) sowie mit den anderen Backbone-Geräten verbunden, die mit den anderen Datencentern verbunden sind.
Informationen zum Konfigurieren von DCI finden Sie unter:
Service-Verkettung
In vielen Netzwerken ist es üblich, dass der Datenverkehr durch separate Hardwaregeräte fließt, die jeweils einen Service bereitstellen, z. B. Firewalls, NAT, IDP, Multicast usw. Jedes Gerät erfordert einen separaten Betrieb und eine separate Verwaltung. Diese Methode der Verknüpfung mehrerer Netzwerkfunktionen kann als physische Serviceverkettung betrachtet werden.
Ein effizienteres Modell für die Serviceverkettung ist die Virtualisierung und Konsolidierung von Netzwerkfunktionen auf einem einzigen Gerät. In unserer Blueprint-Architektur verwenden wir die Router der SRX-Serie als Gerät, das Netzwerkfunktionen, -prozesse konsolidiert und Services anwendet. Dieses Gerät wird als physische Netzwerkfunktion (PNF) bezeichnet.
Bei dieser Lösung wird die Dienstverkettung sowohl auf CRB-Overlay als auch auf ERB-Overlay unterstützt. Er funktioniert nur für Datenverkehr zwischen Mandanten.
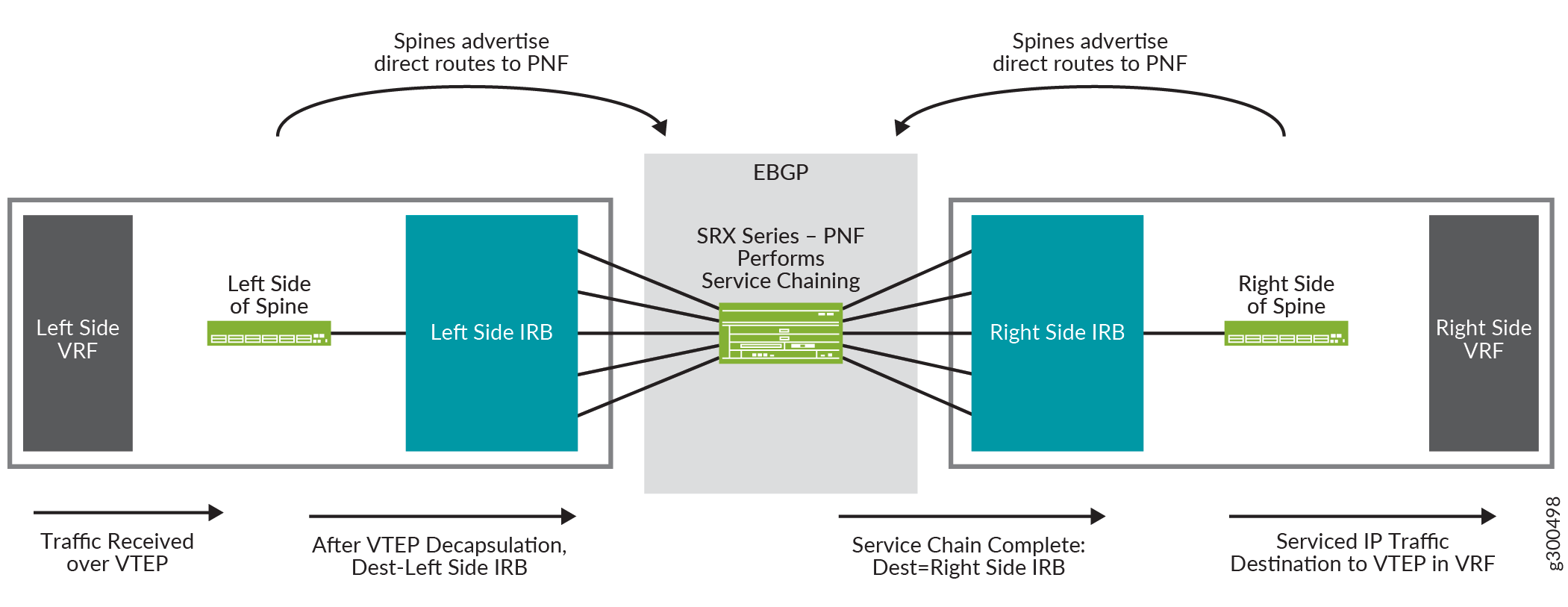
Logische Ansicht der Dienstverkettung
Abbildung 17 zeigt eine logische Ansicht der Dienstverkettung. Es zeigt einen Spine mit einer Konfiguration auf der rechten Seite und einer Konfiguration auf der linken Seite. Auf jeder Seite befinden sich eine VRF-Routing-Instanz und eine IRB-Schnittstelle. Der Router der SRX-Serie in der Mitte ist der PNF, der die Dienstverkettung durchführt.
 der Dienstverkettung
der Dienstverkettung
Der Datenverkehrsfluss in dieser logischen Ansicht ist:
-
Das Spine empfängt ein Paket auf dem VTEP, der sich im linken VRF befindet.
-
Das Paket wird entkapselt und an die linke IRB-Schnittstelle gesendet.
-
Die IRB-Schnittstelle leitet das Paket an den Router der SRX-Serie weiter, der als PNF fungiert.
-
Der Router der SRX-Serie führt eine Serviceverkettung für das Paket durch und leitet das Paket zurück an den Spine, wo es über die IRB-Schnittstelle auf der rechten Seite des Spine empfangen wird.
-
Die IRB-Schnittstelle leitet das Paket an den VTEP im VRF auf der rechten Seite weiter.
Informationen zum Konfigurieren der Dienstverkettung finden Sie unter Design und Implementierung von Dienstverkettungen.
Multicast-Optimierungen
Multicast-Optimierungen helfen dabei, Bandbreite zu sparen und den Datenverkehr in einem Multicast-Szenario in EVPN-VXLAN-Umgebungen effizienter zu routen. Ohne konfigurierte Multicast-Optimierungen erfolgt die gesamte Multicast-Replikation am Eingang des Leafs, das mit der Multicast-Quelle verbunden ist, wie in Abbildung 18 dargestellt. Der Multicast-Datenverkehr wird an alle Leaf-Geräte gesendet, die mit dem Spine verbunden sind. Jedes Leaf-Gerät sendet Datenverkehr an verbundene Hosts.
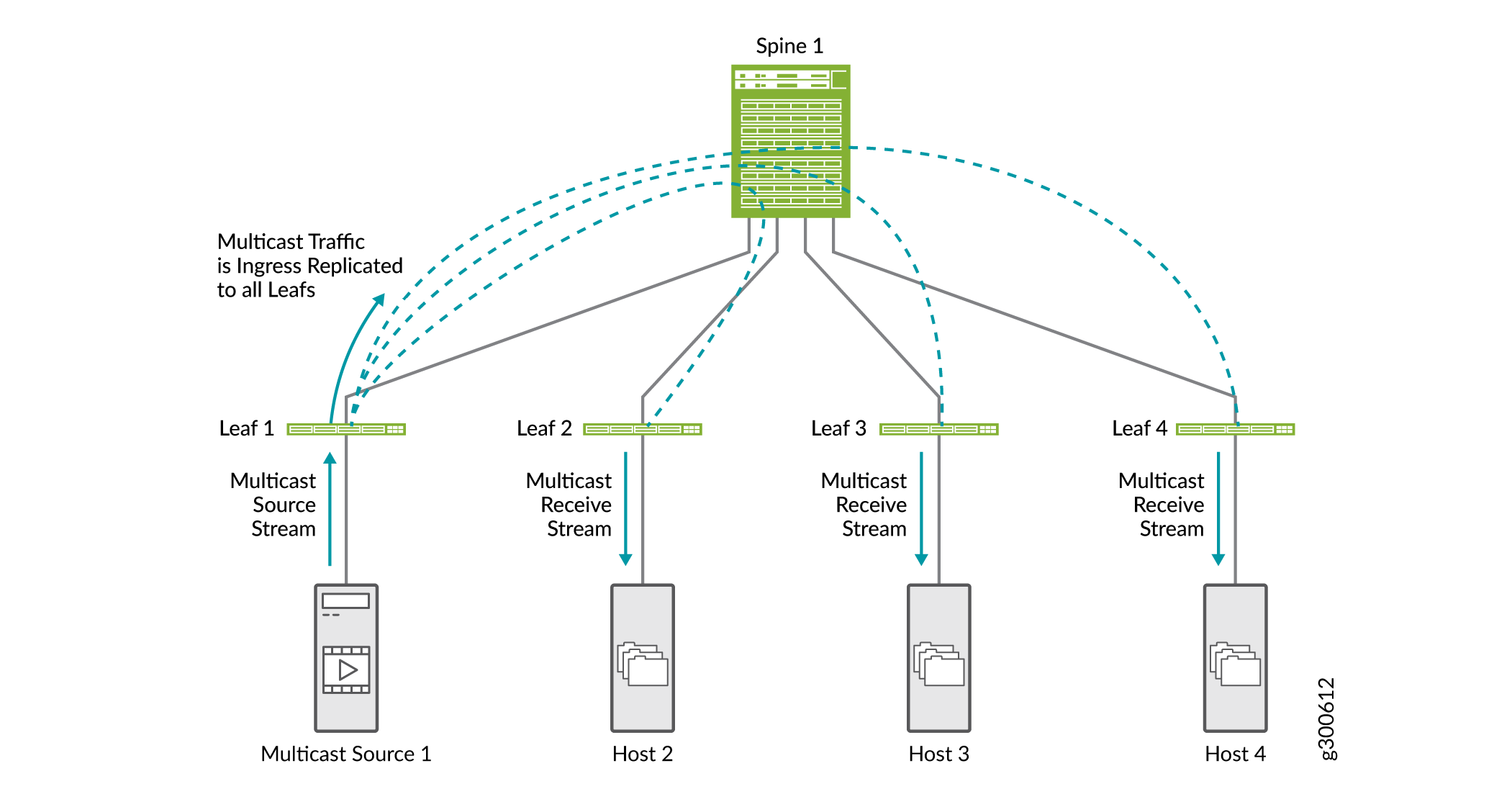
Es gibt einige Arten von Multicast-Optimierungen, die in EVPN VXLAN-Umgebungen unterstützt werden und zusammenarbeiten können:
Informationen zum Konfigurieren von Multicast-Features finden Sie unter:
- IGMP-Snooping
- Selektive Multicast-Weiterleitung
- Unterstützte Replikation von Multicast-Datenverkehr
- Optimiertes Intersubnetz-Multicast für ERB-Overlay-Netzwerke
IGMP-Snooping
IGMP-Snooping in einer EVPN-VXLAN-Fabric ist nützlich, um die Verteilung des Multicast-Datenverkehrs zu optimieren. IGMP-Snooping spart Bandbreite, da Multicast-Datenverkehr nur an Schnittstellen weitergeleitet wird, an denen IGMP-Listener vorhanden sind. Nicht alle Schnittstellen auf einem Leaf-Gerät müssen Multicast-Datenverkehr empfangen.
Ohne IGMP-Snooping empfangen die Endsysteme IP-Multicast-Datenverkehr, an dem sie kein Interesse haben, wodurch ihre Verbindungen unnötigerweise mit unerwünschtem Datenverkehr überflutet werden. In einigen Fällen, wenn die IP-Multicast-Datenströme groß sind, führt die Überflutung von unerwünschtem Datenverkehr zu Denial-of-Service-Problemen.
Abbildung 19 zeigt, wie IGMP-Snooping in einer EVPN-VXLAN-Fabric funktioniert. In diesem EVPN-VXLAN-Beispielfabric ist IGMP-Snooping auf allen Leaf-Geräten konfiguriert, und Multicast-Empfänger 2 hat zuvor eine IGMPv2-Beitrittsanforderung gesendet.
-
Multicast Receiver 2 sendet eine IGMPv2-Abwesenheitsanforderung.
-
Die Multicastempfänger 3 und 4 senden eine IGMPv2-Beitrittsanfrage.
-
Wenn Leaf 1 eingehenden Multicast-Datenverkehr empfängt, repliziert es ihn für alle Leaf-Geräte und leitet ihn an das Spine weiter.
-
Das Spine leitet den Datenverkehr an alle Leaf-Geräte weiter.
-
Leaf 2 empfängt den Multicast-Datenverkehr, leitet ihn aber nicht an den Empfänger weiter, da der Empfänger eine IGMP-Leave-Nachricht gesendet hat.
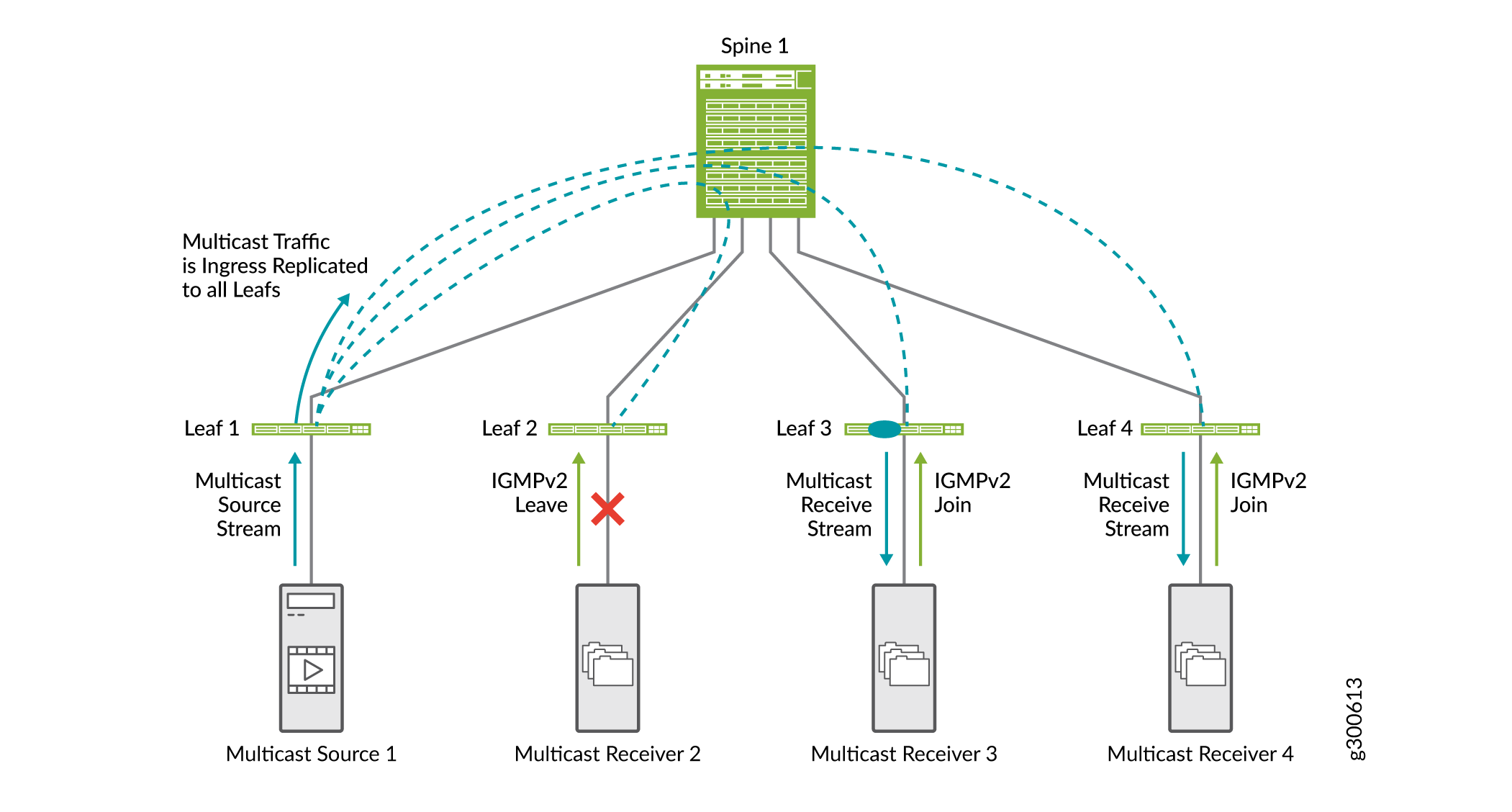
In EVPN-VXLAN-Netzwerken wird nur IGMP Version 2 unterstützt.
Weitere Informationen zu IGMP-Snooping finden Sie unter Übersicht über Multicast-Weiterleitung mit IGMP-Snooping oder MLD-Snooping in einer EVPN-VXLAN-Umgebung.
Selektive Multicast-Weiterleitung
Selektive Multicast-Ethernet-Weiterleitung (SMET) sorgt für eine höhere End-to-End-Netzwerkeffizienz und reduziert den Datenverkehr im EVPN-Netzwerk. Dies spart Bandbreitennutzung im Kern der Fabric und reduziert die Belastung von Ausgangsgeräten ohne Listener.
Geräte mit aktiviertem IGMP-Snooping nutzen selektive Multicast-Weiterleitung, um Multicast-Datenverkehr effizient weiterzuleiten. Wenn IGMP-Snooping aktiviert ist, sendet ein Leaf-Gerät Multicast-Datenverkehr nur an die Zugriffsschnittstelle mit einem interessierten Empfänger. Wenn SMET hinzugefügt wird, sendet das Leaf-Gerät selektiv Multicast-Datenverkehr nur an die Leaf-Geräte im Core, die Interesse an dieser Multicast-Gruppe bekundet haben.
Abbildung 20 zeigt den SMET-Datenverkehrsfluss zusammen mit IGMP-Snooping.
-
Multicast Receiver 2 sendet eine IGMPv2-Abwesenheitsanforderung.
-
Die Multicastempfänger 3 und 4 senden eine IGMPv2-Beitrittsanfrage.
-
Wenn Leaf 1 eingehenden Multicast-Datenverkehr empfängt, repliziert es den Datenverkehr nur an Leaf-Geräte mit interessierten Empfängern (Leaf-Geräte 3 und 4) und leitet ihn an das Spine weiter.
-
Das Spine leitet den Datenverkehr an die Leaf-Geräte 3 und 4 weiter.
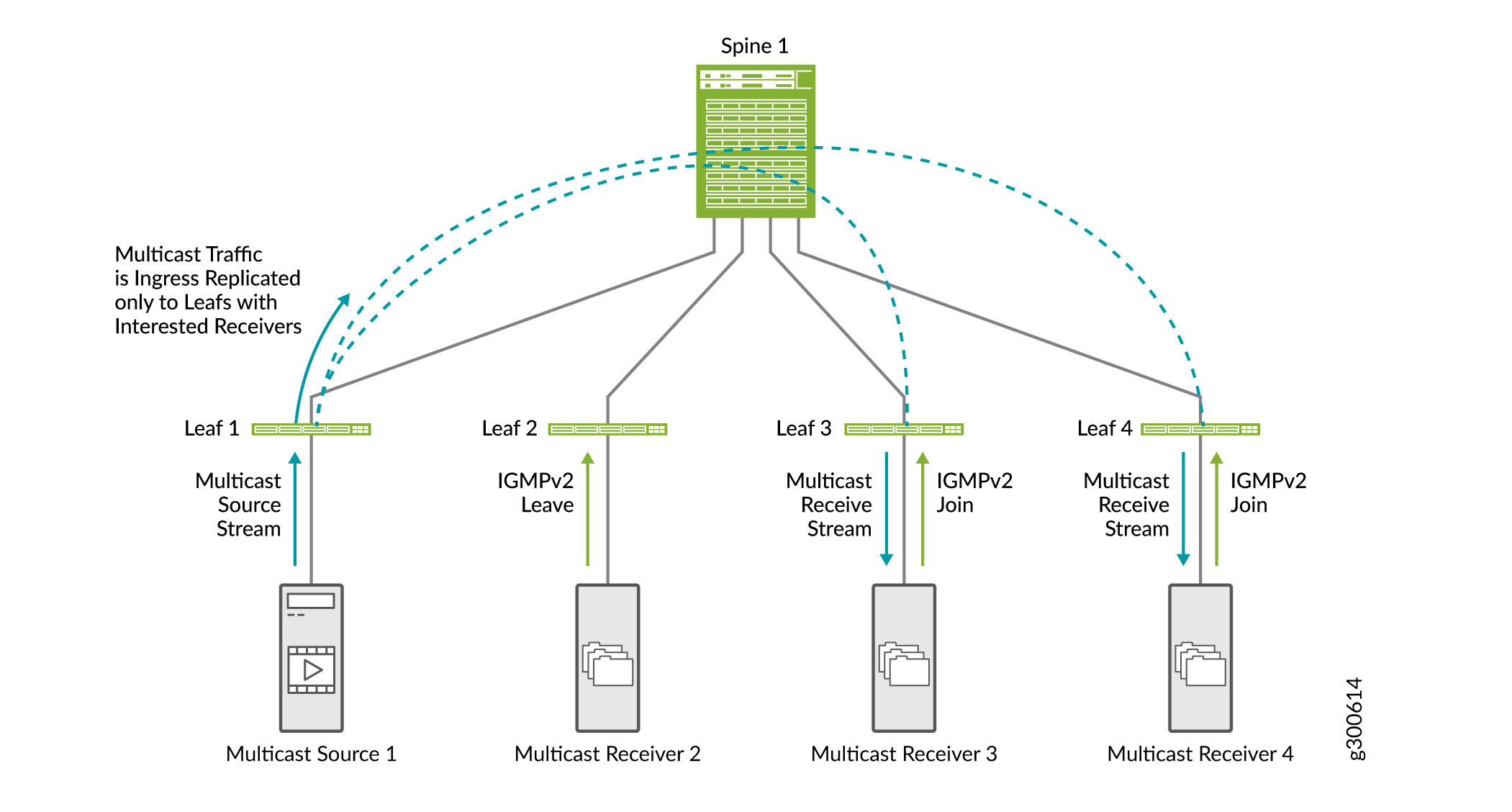
Sie müssen SMET nicht aktivieren. Sie ist standardmäßig aktiviert, wenn IGMP-Snooping auf dem Gerät konfiguriert ist.
Weitere Informationen zu SMET finden Sie unter Übersicht über die selektive Multicastweiterleitung.
Unterstützte Replikation von Multicast-Datenverkehr
Die Funktion für unterstützte Replikation (AR) entlastet EVPN-VXLAN-Fabric-Leaf-Geräte von Eingangsreplikationsaufgaben. Das Eingangsleaf repliziert keinen Multicast-Datenverkehr. Er sendet eine Kopie des Multicast-Datenverkehrs an ein Spine, das als AR-Replikatorgerät konfiguriert ist. Das AR-Replikatorgerät verteilt und steuert den Multicast-Datenverkehr. Diese Methode reduziert nicht nur die Replikationslast auf den Eingangs-Leaf-Geräten, sondern spart auch Bandbreite in der Fabric zwischen dem Leaf und dem Spine.
Abbildung 21 zeigt, wie AR zusammen mit IGMP-Snooping und SMET funktioniert.
-
Leaf 1, das als AR-Leaf-Gerät eingerichtet ist, empfängt Multicast-Datenverkehr und sendet eine Kopie an das Spine, das als AR-Replikatorgerät eingerichtet ist.
-
Die Spine repliziert den Multicast-Datenverkehr. Es repliziert den Datenverkehr für Leaf-Geräte, die mit dem VLAN-VNI bereitgestellt werden, aus dem der Multicast-Datenverkehr von Leaf 1 stammt.
Da wir IGMP-Snooping und SMET im Netzwerk konfiguriert haben, sendet das Spine den Multicast-Datenverkehr nur an Leaf-Geräte mit interessierten Empfängern.
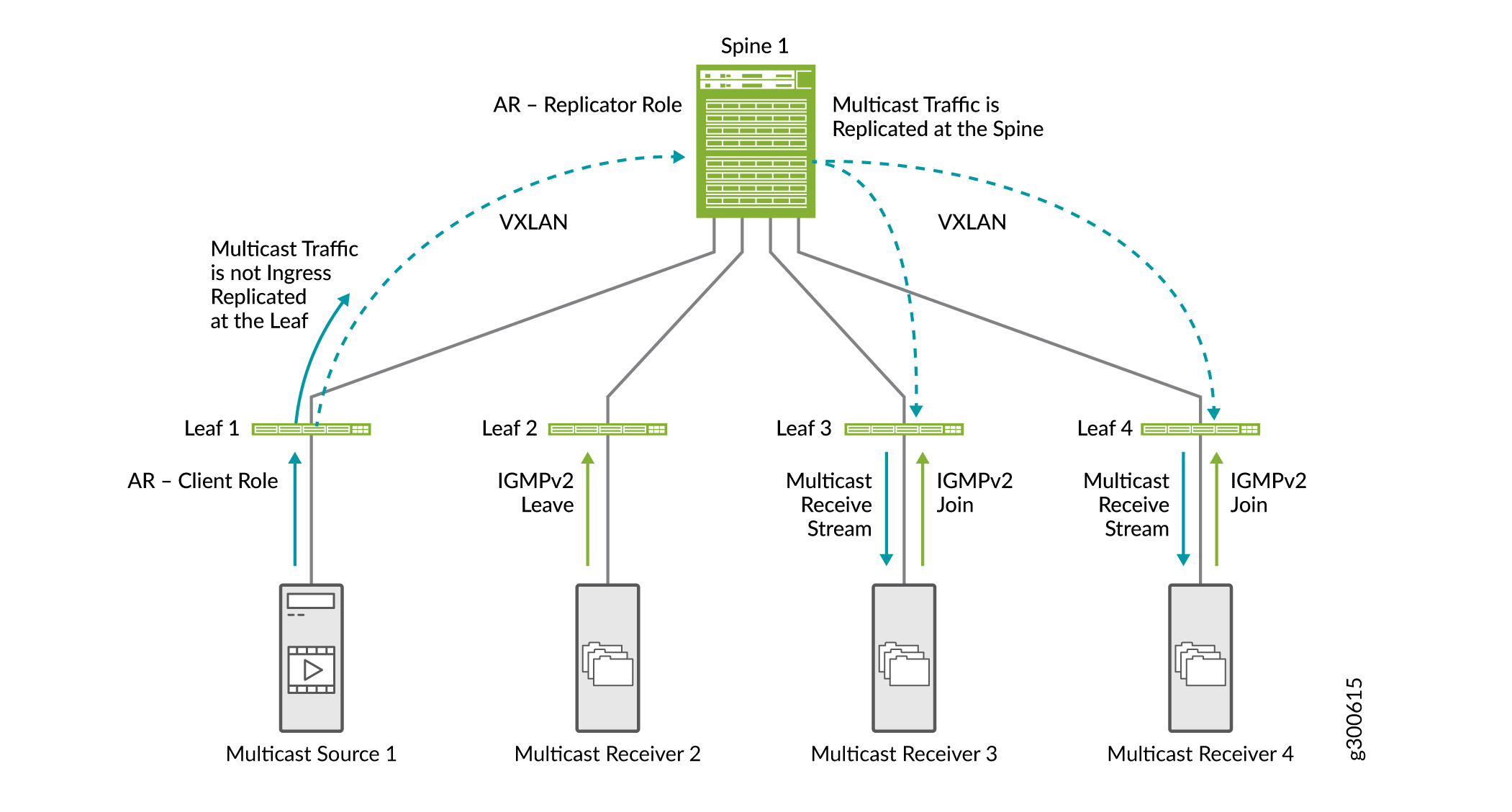
In diesem Dokument zeigen wir Multicast-Optimierungen in kleinem Maßstab. In einem Full-Scale-Netzwerk mit vielen Spines und Leafs sind die Vorteile der Optimierungen viel offensichtlicher.
Optimiertes Intersubnetz-Multicast für ERB-Overlay-Netzwerke
Wenn Sie Multicast-Quellen und -Empfänger sowohl innerhalb als auch außerhalb einer ERB-Overlay-Fabric haben, können Sie optimiertes Intersubnet-Multicast (OISM) konfigurieren, um einen effizienten Multicast-Datenverkehrsfluss in großem Umfang zu ermöglichen.
OISM verwendet ein lokales Routing-Modell für Multicast-Datenverkehr, das Hairpinning des Datenverkehrs vermeidet und die Datenverkehrslast innerhalb des EVPN-Kerns minimiert. OISM leitet Multicast-Datenverkehr nur auf dem Multicast-Quell-VLAN weiter. Bei Intersubnetzempfängern verwenden die Leaf-Geräte IRB-Schnittstellen, um den im Quell-VLAN empfangenen Datenverkehr lokal an andere Empfänger-VLANs auf demselben Gerät weiterzuleiten. Um den Multicast-Datenverkehrsfluss in der EVPN-VXLAN-Fabric weiter zu optimieren, verwendet OISM IGMP-Snooping und SMET, um den Datenverkehr in der Fabric nur an Leaf-Geräte mit interessierten Empfängern weiterzuleiten.
OISM ermöglicht es der Fabric auch, den Datenverkehr von externen Multicast-Quellen zu internen Empfängern und von internen Multicast-Quellen zu externen Empfängern effektiv zu leiten. OISM verwendet eine ergänzende Bridge-Domäne (SBD) innerhalb der Fabric, um den auf den Border-Leaf-Geräten empfangenen Multicast-Datenverkehr von externen Quellen weiterzuleiten. Beim SBD-Design wird das lokale Routing-Modell für Datenverkehr aus externen Quellen beibehalten.
Sie können OISM mit AR verwenden, um die Replikationslast auf OISM-Leaf-Geräten mit geringerer Kapazität zu reduzieren. (Siehe Unterstützte Replikation von Multicast-Datenverkehr.)
In Abbildung 22 sehen Sie eine einfache Fabric mit OISM und AR.
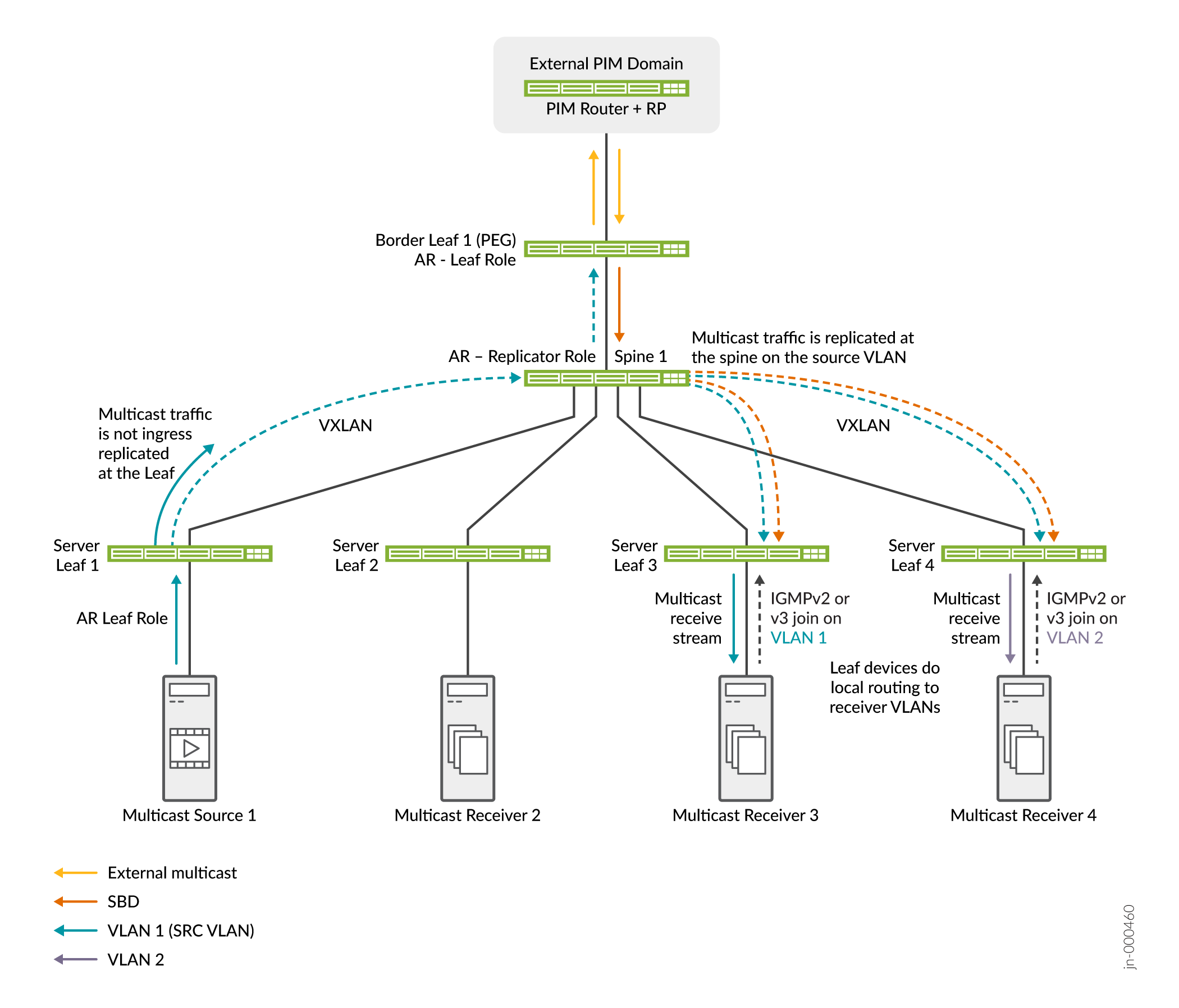
Abbildung 22 zeigt OISM-Server-Leaf- und Border-Leaf-Geräte, Spine 1 in der AR-Replikatorrolle und Server-Leaf 1 als Multicast-Quelle in der AR-Leaf-Rolle. Eine externe Quelle und Empfänger können auch in der externen PIM-Domäne vorhanden sein. OISM und AR arbeiten in diesem Szenario wie folgt zusammen:
-
Multicast-Empfänger hinter Server Leaf 3 auf VLAN 1 und hinter Server Leaf 4 auf VLAN 2 senden IGMP-Joins, die Interesse an der Multicast-Gruppe zeigen. Externe Empfänger können auch der Multicast-Gruppe beitreten.
-
Die Multicast-Quelle hinter Server Leaf 1 sendet Multicast-Datenverkehr für die Gruppe in die Fabric auf VLAN 1. Server Leaf 1 sendet nur eine Kopie des Datenverkehrs an den AR-Replikator auf Spine 1.
-
Außerdem kommt der externe Quelldatenverkehr für die Multicast-Gruppe an Border Leaf 1 an. Border Leaf 1 leitet den Datenverkehr auf dem SBD an Spine 1, den AR-Replikator, weiter.
-
Der AR-Replikator sendet Kopien von der internen Quelle im Quell-VLAN und von der externen Quelle auf dem SBD an die OISM-Leaf-Geräte mit interessierten Empfängern.
-
Die Server-Leaf-Geräte leiten den Datenverkehr an die Empfänger im Quell-VLAN weiter und leiten den Datenverkehr lokal an die Empfänger in den anderen VLANs.
Optimierung des Datenverkehrs eingehender virtueller Maschinen für EVPN
Wenn virtuelle Maschinen und Hosts innerhalb eines Datencenters oder von einem Datencenter in ein anderes verschoben werden, kann der Netzwerkverkehr ineffizient werden, wenn der Datenverkehr nicht zum optimalen Gateway geleitet wird. Dies kann passieren, wenn ein Host verlagert wird. Die ARP-Tabelle wird nicht immer geleert, und der Datenstrom zum Host wird an das konfigurierte Gateway gesendet, selbst wenn ein optimaleres Gateway vorhanden ist. Der Datenverkehr wird "aufgegeben" und unnötigerweise zum konfigurierten Gateway geleitet.
Ingress Virtual Machine Traffic Optimization (VMTO) bietet eine höhere Netzwerkeffizienz, optimiert den eingehenden Datenverkehr und kann den Posauneneffekt zwischen VLANs eliminieren. Wenn Sie Eingangs-VMTO aktivieren, werden Routen in einer virtuellen Layer-3-Routing- und Weiterleitungstabelle (VRF) gespeichert, und das Gerät leitet eingehenden Datenverkehr direkt zurück an den Host, der verlagert wurde.
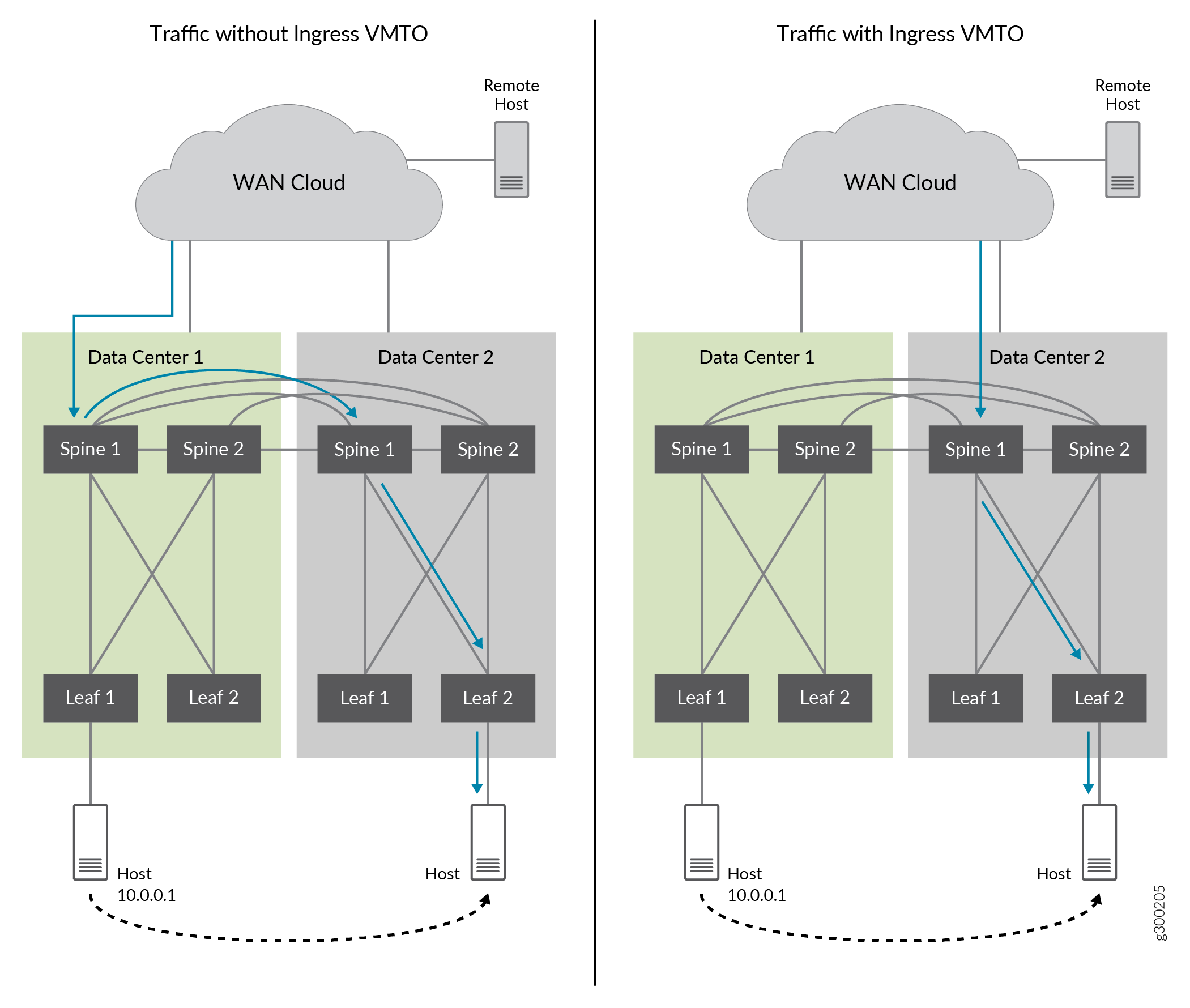
Abbildung 23 zeigt verlorenen Datenverkehr ohne eingehendes VMTO und optimierten Datenverkehr mit aktiviertem eingehendem VMTO.
Ohne eingehendes VMTO kündigen Spine 1 und 2 von DC1 und DC2 alle die Remote-IP-Hostroute 10.0.0.1 an, wenn die Ursprungsroute von DC2 stammt. Der eingehende Datenverkehr kann entweder an Spine 1 und 2 in DC1 weitergeleitet werden. Sie wird dann zu Spine 1 und 2 in DC2 geroutet, wo Route 10.0.0.1 verschoben wurde. Dies verursacht den Tromboning-Effekt.
Mit eingehendem VMTO können wir einen optimalen Weiterleitungspfad erreichen, indem wir eine Richtlinie für die IP-Hostroute (10.0.01) so konfigurieren, dass sie nur von Spine 1 und 2 von DC2 und nicht von DC1 angekündigt wird, wenn der IP-Host nach DC2 verschoben wird.
Informationen zum Konfigurieren von VMTO finden Sie unter Konfigurieren von VMTO.
DHCP-Relais

Der DHCP-Relaybaustein (Dynamic Host Configuration Protocol) ermöglicht es dem Netzwerk, DHCP-Nachrichten zwischen einem DHCP-Client und einem DHCP-Server weiterzuleiten. Die DHCP-Relay-Implementierung in diesem Baustein bewegt DHCP-Pakete durch ein CRB-Overlay, bei dem sich das Gateway auf der Spine-Schicht befindet.
Der DHCP-Server und die DHCP-Clients verbinden sich über Zugriffsschnittstellen auf Leaf-Geräten mit dem Netzwerk. Der DHCP-Server und die DHCP-Clients können ohne weitere Konfiguration über das bestehende Netzwerk miteinander kommunizieren, wenn sich DHCP-Client und -Server im selben VLAN befinden. Wenn sich ein DHCP-Client und ein DHCP-Server in unterschiedlichen VLANs befinden, wird der DHCP-Datenverkehr zwischen dem Client und dem Server zwischen den VLANs über die IRB-Schnittstellen auf Spine-Geräten weitergeleitet. Sie müssen die IRB-Schnittstellen auf den Spine-Geräten so konfigurieren, dass sie DHCP-Relay zwischen VLANs unterstützen.
Informationen zum Implementieren des DHCP-Relays finden Sie unter DHCP-Relayentwurf und -implementierung.
Reduzierung des ARP-Datenverkehrs mit ARP-Synchronisierung und -Unterdrückung (Proxy-ARP)
Das Ziel der ARP-Synchronisierung ist die Synchronisierung von ARP-Tabellen über alle VRFs, die ein Overlay-Subnetz bedienen, um den Datenverkehr zu reduzieren und die Verarbeitung sowohl für Netzwerkgeräte als auch für Endsysteme zu optimieren. Wenn ein IP-Gateway für ein Subnetz von einer ARP-Bindung erfährt, teilt es sie mit anderen Gateways, sodass diese dieselbe ARP-Bindung nicht unabhängig voneinander ermitteln müssen.
Wenn ein Leaf-Gerät mit ARP-Unterdrückung eine ARP-Anforderung empfängt, überprüft es seine eigene ARP-Tabelle, die mit den anderen VTEP-Geräten synchronisiert ist, und antwortet lokal auf die Anfrage, anstatt die ARP-Anforderung zu überfluten.
Proxy-ARP und ARP-Unterdrückung sind standardmäßig auf allen Switches der QFX-Serie aktiviert, die als Leaf-Geräte in einem ERB-Overlay fungieren können. Eine Liste dieser Switches finden Sie unter Data Center EVPN-VXLAN Fabric Reference Designs – Supported Hardware Summary.
IRB-Schnittstellen auf dem Leaf-Gerät liefern ARP-Anfragen und NDP-Anfragen sowohl von lokalen als auch von Remote-Leaf-Geräten. Wenn ein Leaf-Gerät eine ARP-Anforderung oder NDP-Anforderung von einem anderen Leaf-Gerät empfängt, durchsucht das empfangende Gerät seine MAC+IP-Adressbindungsdatenbank nach der angeforderten IP-Adresse.
Wenn das Gerät die MAC+IP-Adressbindung in seiner Datenbank findet, antwortet es auf die Anfrage.
Wenn das Gerät die MAC+IP-Adressbindung nicht findet, überflutet es die ARP-Anfrage an alle Ethernet-Verbindungen im VLAN und die zugehörigen VTEPs.
Da alle teilnehmenden Leaf-Geräte die ARP-Einträge hinzufügen und ihre Routing- und Bridging-Tabellen synchronisieren, antworten lokale Leaf-Geräte direkt auf Anforderungen von lokal verbundenen Hosts und machen Remote-Geräte überflüssig, auf diese ARP-Anforderungen zu antworten.
Informationen zum Implementieren der ARP-Synchronisation, des Proxy-ARP und der ARP-Unterdrückung finden Sie unter Aktivieren von Proxy-ARP und ARP-Unterdrückung für das Edge-Routed Bridging-Overlay.
Layer 2-Port-Sicherheitsfunktionen auf Ethernet-verbundenen Endsystemen
CRB- und ERB-Overlays unterstützen die Sicherheitsfunktionen auf Ethernet-verbundenen Layer-2-Endsystemen, die wir in den nächsten Abschnitten beschreiben.
Weitere Informationen zu diesen Features finden Sie unter Unterstützung für MAC-Filterung, Sturmsteuerung und Portspiegelung in einer EVPN-VXLAN-Umgebung.
Informationen zum Konfigurieren dieser Funktionen finden Sie unter Konfigurieren von Layer 2-Port-Sicherheitsfunktionen auf Ethernet-verbundenen Endsystemen.
- Verhindern von BUM-Datenverkehrsstürmen mit Storm Control
- Verwendung von MAC-Filterung zur Verbesserung der Port-Sicherheit
- Analysieren des Datenverkehrs mithilfe der Portspiegelung
Verhindern von BUM-Datenverkehrsstürmen mit Storm Control
Sturmkontrolle kann verhindern, dass übermäßiger Datenverkehr das Netzwerk beeinträchtigt. Es verringert die Auswirkungen von BUM-Datenverkehrsstürmen, indem es das Datenverkehrsniveau auf EVPN-VXLAN-Schnittstellen überwacht und BUM-Datenverkehr verwirft, wenn ein bestimmtes Datenverkehrsniveau überschritten wird.
In einer EVPN-VXLAN-Umgebung überwacht Storm Control:
Layer 2 BUM-Datenverkehr, der aus einem VXLAN stammt und an Schnittstellen innerhalb desselben VXLAN weitergeleitet wird.
Layer-3-Multicast-Datenverkehr, der von einer IRB-Schnittstelle in einem VXLAN empfangen und an Schnittstellen in einem anderen VXLAN weitergeleitet wird.
Verwendung von MAC-Filterung zur Verbesserung der Port-Sicherheit
Die MAC-Filterung verbessert die Portsicherheit, indem sie die Anzahl der MAC-Adressen begrenzt, die in einem VLAN erlernt werden können, und somit den Datenverkehr in einem VXLAN begrenzt. Die Begrenzung der Anzahl der MAC-Adressen schützt den Switch vor einer Überflutung der Ethernet-Switching-Tabelle. Eine Überflutung der Ethernet-Switching-Tabelle tritt auf, wenn die Anzahl der neuen MAC-Adressen, die gelernt werden, dazu führt, dass die Tabelle überläuft und zuvor gelernte MAC-Adressen aus der Tabelle geleert werden. Der Switch lernt die MAC-Adressen neu, was sich auf die Leistung auswirken und Sicherheitslücken einführen kann.
In diesem Blueprint begrenzt die MAC-Filterung die Anzahl der akzeptierten Pakete, die basierend auf MAC-Adressen an Eingangsschnittstellen gesendet werden. Weitere Informationen zur Funktionsweise der MAC-Filterung finden Sie in den Informationen zur MAC-Begrenzung unter Grundlegendes zur MAC-Begrenzung und zur Begrenzung der MAC-Verschiebung.
Analysieren des Datenverkehrs mithilfe der Portspiegelung
Mit der analysatorbasierten Portspiegelung können Sie den Datenverkehr in einer EVPN-VXLAN-Umgebung bis auf Paketebene analysieren. Sie können diese Funktion verwenden, um Richtlinien in Bezug auf Netzwerknutzung und Dateifreigabe durchzusetzen und Problemquellen zu identifizieren, indem Sie abnormale oder hohe Bandbreitennutzung durch bestimmte Stationen oder Anwendungen lokalisieren.
Die Portspiegelung kopiert Pakete, die in einen Port eintreten oder einen Port verlassen oder in ein VLAN gelangen, und sendet die Kopien zur lokalen Überwachung an eine lokale Schnittstelle oder zur Remote-Überwachung an ein VLAN. Verwenden Sie die Portspiegelung, um Datenverkehr an Anwendungen zu senden, die den Datenverkehr für Zwecke wie die Überwachung der Compliance, die Durchsetzung von Richtlinien, die Erkennung von Eindringlingen, die Überwachung und Vorhersage von Datenverkehrsmustern, die Korrelation von Ereignissen usw. analysieren.