Componentes da arquitetura de blueprint de malha de data center
Esta seção fornece uma visão geral dos blocos de construção usados nesta arquitetura de blueprint. A implementação de cada tecnologia de bloco de construção é explorada com mais detalhes nas seções posteriores.
Para obter informações sobre o hardware e o software que servem como base para seus blocos de construção, consulte os Designs de referência de malha EVPN-VXLAN de data center — Resumo do hardware suportado.
Os blocos de construção incluem:
Rede subjacente de malha IP
O bloco de construção da rede subjacente de malha IP moderna oferece conectividade IP em uma topologia baseada em Clos. A Juniper Networks oferece suporte aos seguintes modelos de underlay de malha IP:
-
Uma malha IP de 3 estágios, composta por uma camada de dispositivos spine e uma camada de dispositivos leaf. Veja a Figura 1.
-
Uma malha IP de 5 estágios, que normalmente começa como uma única malha IP de 3 estágios que se transforma em duas malhas IP de 3 estágios. Essas malhas são segmentadas em pontos de entrega (PODs) separados em um data center. Para esse caso de uso, oferecemos suporte à adição de uma camada de dispositivos super spine que permitem a comunicação entre os dispositivos spine e leaf nos dois PODs. Veja a Figura 2.
-
Um modelo de malha IP de spine colapsada, no qual as funções da camada leaf são recolhidas nos dispositivos spine. Esse tipo de malha pode ser configurado e operar de forma semelhante a uma malha IP de 3 ou 5 estágios, exceto sem uma camada separada de dispositivos leaf. Você pode usar uma malha spine colapsada se estiver movendo incrementalmente para um modelo spine-and-leaf da EVPN, ou se tiver dispositivos de acesso ou dispositivos top-of-rack (TOR) que não podem ser usados em uma camada leaf porque não são compatíveis com EVPN-VXLAN.
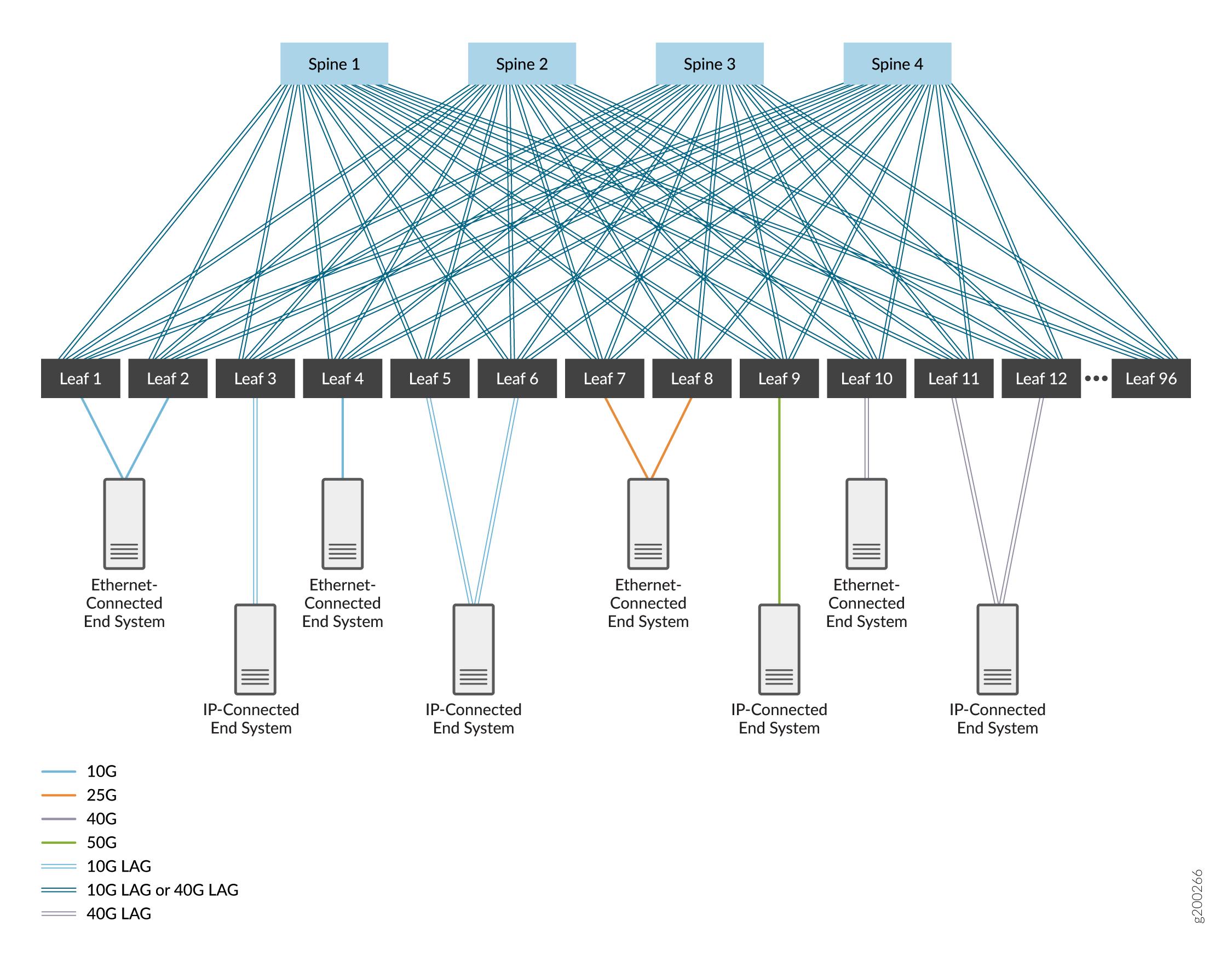 de malha IP de três estágios
de malha IP de três estágios
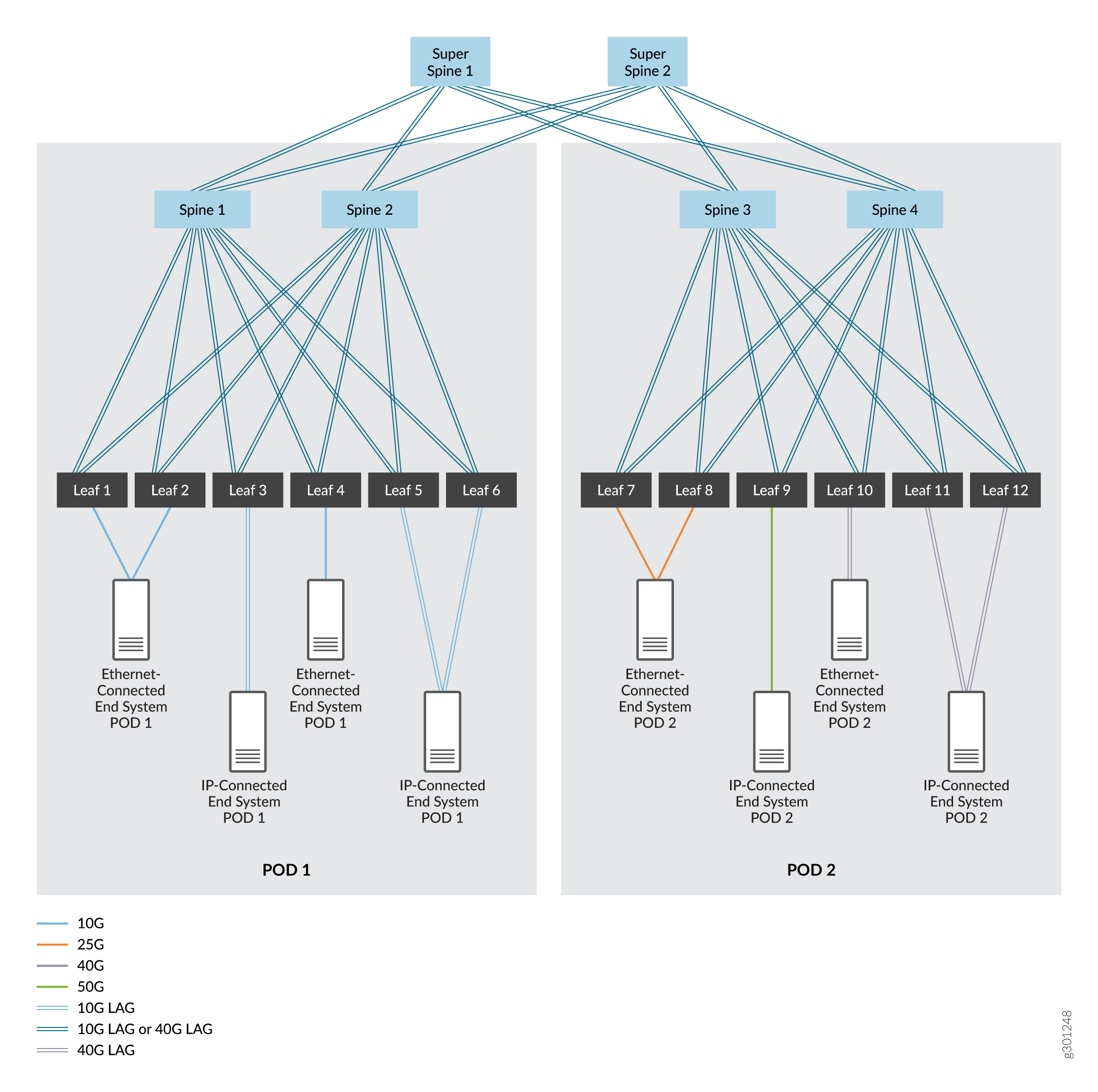 de malha IP de cinco estágios
de malha IP de cinco estágios
Nessas figuras, os dispositivos são interconectados usando interfaces de alta velocidade que são links únicos ou interfaces Ethernet agregadas. As interfaces Ethernet agregadas são opcionais — normalmente é usado um único link entre dispositivos — mas podem ser implantadas para aumentar a largura de banda e fornecer redundância no nível do link. Cobrimos ambas as opções.
Escolhemos o EBGP como protocolo de roteamento na rede subjacente por sua confiabilidade e escalabilidade. Cada dispositivo recebe seu próprio sistema autônomo com um número de sistema autônomo exclusivo para oferecer suporte ao EBGP. Você pode usar outros protocolos de roteamento na rede underlay; O uso desses protocolos está além do escopo deste documento.
Os projetos de arquitetura de referência descritos neste guia são baseados em uma malha de IP que usa EBGP para a conectividade de underlay e IBGP para peering de overlay (consulte IBGP para overlays). Como alternativa, você pode configurar o emparelhamento de sobreposição usando o EBGP.
A partir das versões 21.2R2 e 21.4R1 do Junos OS, também oferecemos suporte à configuração de uma malha IPv6. O design de malha IPv6 neste guia usa EBGP para conectividade underlay e emparelhamento de overlay (consulte EBGP para overlays com underlays IPv6).
A malha de IP pode usar IPv4 ou IPv6 da seguinte maneira:
-
Uma malha IPv4 usa endereçamento de interface IPv4 e sessões BGP de underlay e overlay IPv4 para comunicação de carga de trabalho de ponta a ponta.
-
Uma malha IPv6 usa endereçamento de interface IPv6 e sessões BGP de underlay e overlay IPv6 para comunicação de carga de trabalho de ponta a ponta.
-
Não oferecemos suporte a uma malha de IP que mistura IPv4 e IPv6.
No entanto, tanto as malhas IPv4 quanto as malhas IPv6 oferecem suporte a cargas de trabalho de pilha dupla — as cargas de trabalho podem ser IPv4 ou IPv6, ou IPv4 e IPv6.
A detecção de encaminhamento microbidirecional (BFD) — a capacidade de executar BFD em links individuais em uma interface Ethernet agregada — também pode ser habilitada neste bloco de construção para detectar rapidamente falhas de link em quaisquer links membros em pacotes Ethernet agregados que conectam dispositivos.
Para obter mais informações, consulte estas outras seções deste guia:
-
Configuração de dispositivos spine e leaf em underlays de malha IP de 3 e 5 estágios: Design e implementação de rede de underlay de malha IP.
-
Implementação da camada adicional de dispositivos super spine em uma camada subjacente de malha IP de 5 estágios: projeto e implementação de malha IP de cinco estágios.
-
Configuração de um underlay IPv6 e suporte ao overlay EBGP IPv6: Projeto e implementação de rede overlay e underlay de malha IPv6 com EBGP.
-
Configurando a underlay em um modelo de spine colapsada fabric: Projeto e implementação de malha spine colapsada.
Suporte a cargas de trabalho IPv4 e IPv6
Como muitas redes implementam um ambiente de pilha dupla para cargas de trabalho que inclui protocolos IPv4 e IPv6, este blueprint oferece suporte para ambos os protocolos. As etapas para configurar a malha para oferecer suporte a cargas de trabalho IPv4 e IPv6 estão interligadas ao longo deste guia para permitir que você escolha um ou ambos os protocolos.
O protocolo IP que você usa para o tráfego de carga de trabalho é independente da versão do protocolo IP (IPv4 ou IPv6) que você configura para a subcamada e sobreposição de malha IP. (Veja Rede subjacente de malha IP.) Uma infraestrutura de malha IPv4 ou de malha IPv6 pode oferecer suporte a cargas de trabalho IPv4 e IPv6.
Overlays de virtualização de rede
Uma sobreposição de virtualização de rede é uma rede virtual que é transportada por uma rede IP underlay. Esse bloco de construção permite a multitenancy em uma rede, permitindo que você compartilhe uma única rede física em vários locatários, mantendo o tráfego de rede de cada locatário isolado dos outros locatários.
Um locatário é uma comunidade de usuários (como uma unidade de negócios, departamento, grupo de trabalho ou aplicativo) que contém grupos de pontos de extremidade. Os grupos podem se comunicar com outros grupos na mesma tenancy e os tenants podem se comunicar com outros tenants se permitido pelas políticas de rede. Um grupo é normalmente expresso como uma sub-rede (VLAN) que pode se comunicar com outros dispositivos na mesma sub-rede e alcançar grupos e endpoints externos por meio de uma instância de roteamento e encaminhamento virtual (VRF).
Como visto no exemplo de sobreposição mostrado na Figura 3, as tabelas de ponte Ethernet (representadas por triângulos) lidam com quadros interligados de locatário e as tabelas de roteamento IP (representadas por quadrados) processam pacotes roteados. O roteamento entre VLANs acontece nas interfaces integradas de roteamento e ponte (IRB) (representadas por círculos). As tabelas Ethernet e IP são direcionadas para redes virtuais (representadas por linhas coloridas). Para alcançar sistemas finais conectados a outros dispositivos de endpoint de túnel VXLAN (VTEP), os pacotes de locatário são encapsulados e enviados por um túnel VXLAN sinalizado por EVPN (representado por ícones de túnel verde) para os dispositivos VTEP remotos associados. Os pacotes em túnel são desencapsulados nos dispositivos VTEP remotos e encaminhados aos sistemas finais remotos por meio das respectivas tabelas de ponte ou roteamento do dispositivo VTEP de saída.
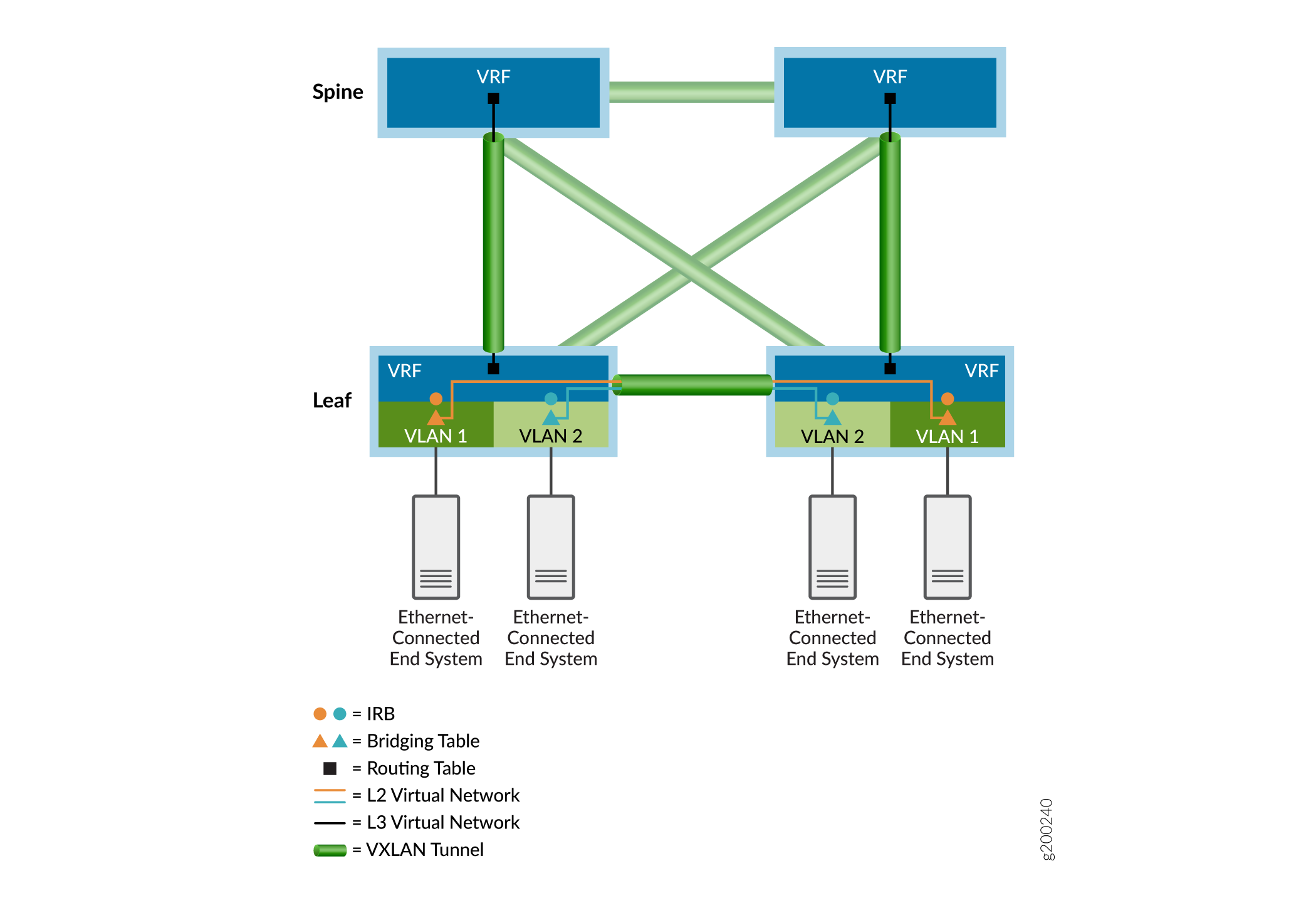
As próximas seções fornecem mais detalhes sobre redes overlay.
- IBGP para overlays
- EBGP para overlays com underlays IPv6
- sobreposição em ponte
- Overlay de ponte com roteamento central
- Overlay de ponte roteada na borda
- Sobreposição spine recolhida
- Comparação de overlays em ponte, CRB e ERB
- Modelos de endereçamento IRB em sobreposições de ponte
- Overlay roteado usando rotas EVPN Tipo 5
- Instâncias MAC-VRF para multitenancy em overlays de virtualização de rede
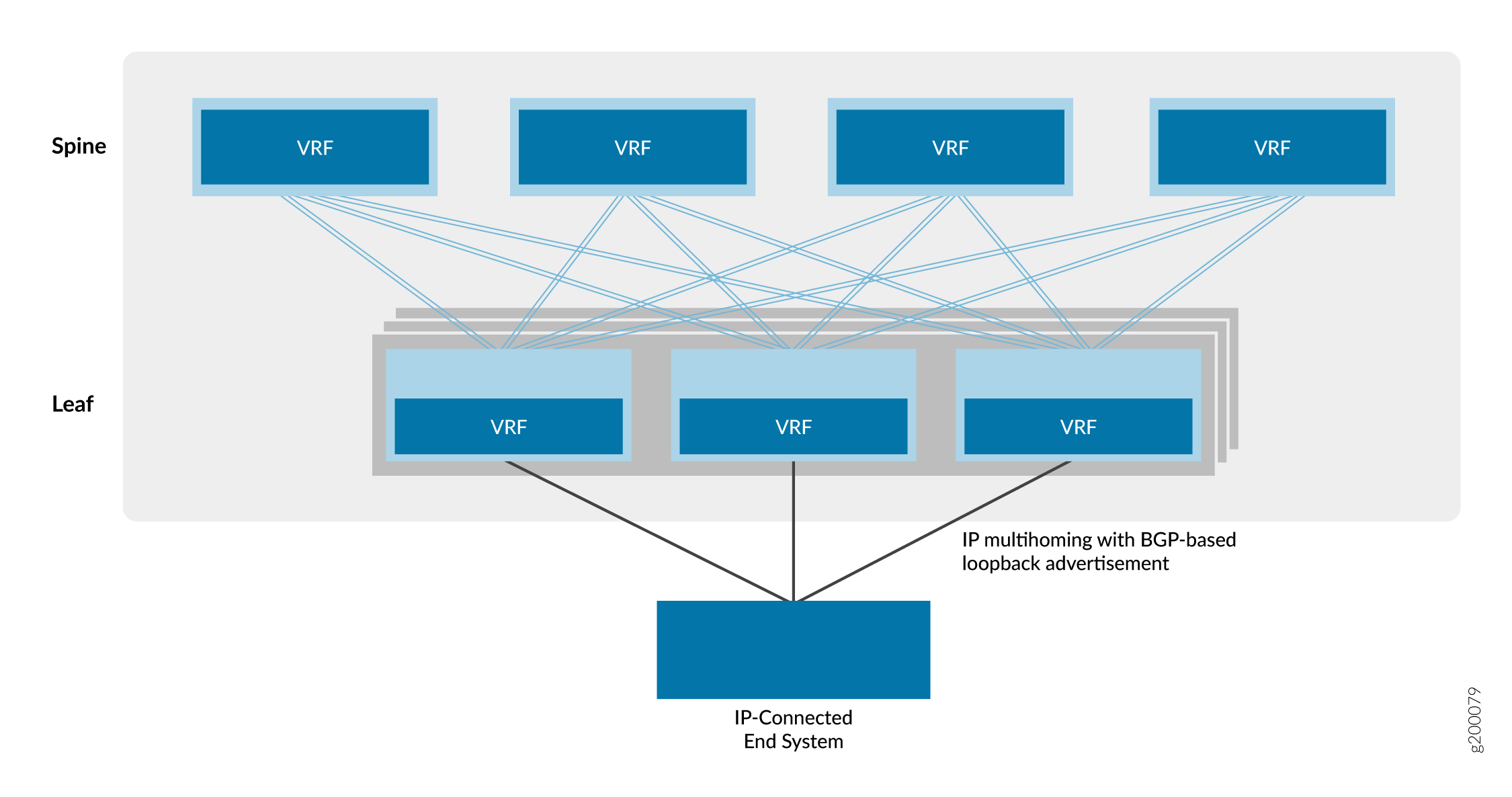
IBGP para overlays
O BGP interno (IBGP) é um protocolo de roteamento que troca informações de alcance em uma rede IP. Quando o IBGP é combinado com o BGP multiprotocolo (MP-IBGP), ele fornece a base para a EVPN trocar informações de alcance entre dispositivos VTEP. Esse recurso é necessário para estabelecer túneis VXLAN inter-VTEP e usá-los para serviços de conectividade de sobreposição.
A Figura 4 mostra que os dispositivos spine e leaf usam seus endereços de loopback para peering em um único sistema autônomo. Nesse design, os dispositivos spine atuam como um cluster de refletores de rota e os dispositivos leaf são clientes refletores de rota. Um refletor de rota atende ao requisito do IBGP para uma malha completa sem a necessidade de emparelhar todos os dispositivos VTEP diretamente uns com os outros. Como resultado, os dispositivos leaf emparelham apenas com os dispositivos spine e os dispositivos spine emparelham com dispositivos spine e dispositivos leaf. Como os dispositivos spine estão conectados a todos os dispositivos leaf, os dispositivos spine podem retransmitir informações do IBGP entre os vizinhos do dispositivo leaf emparelhados indiretamente.
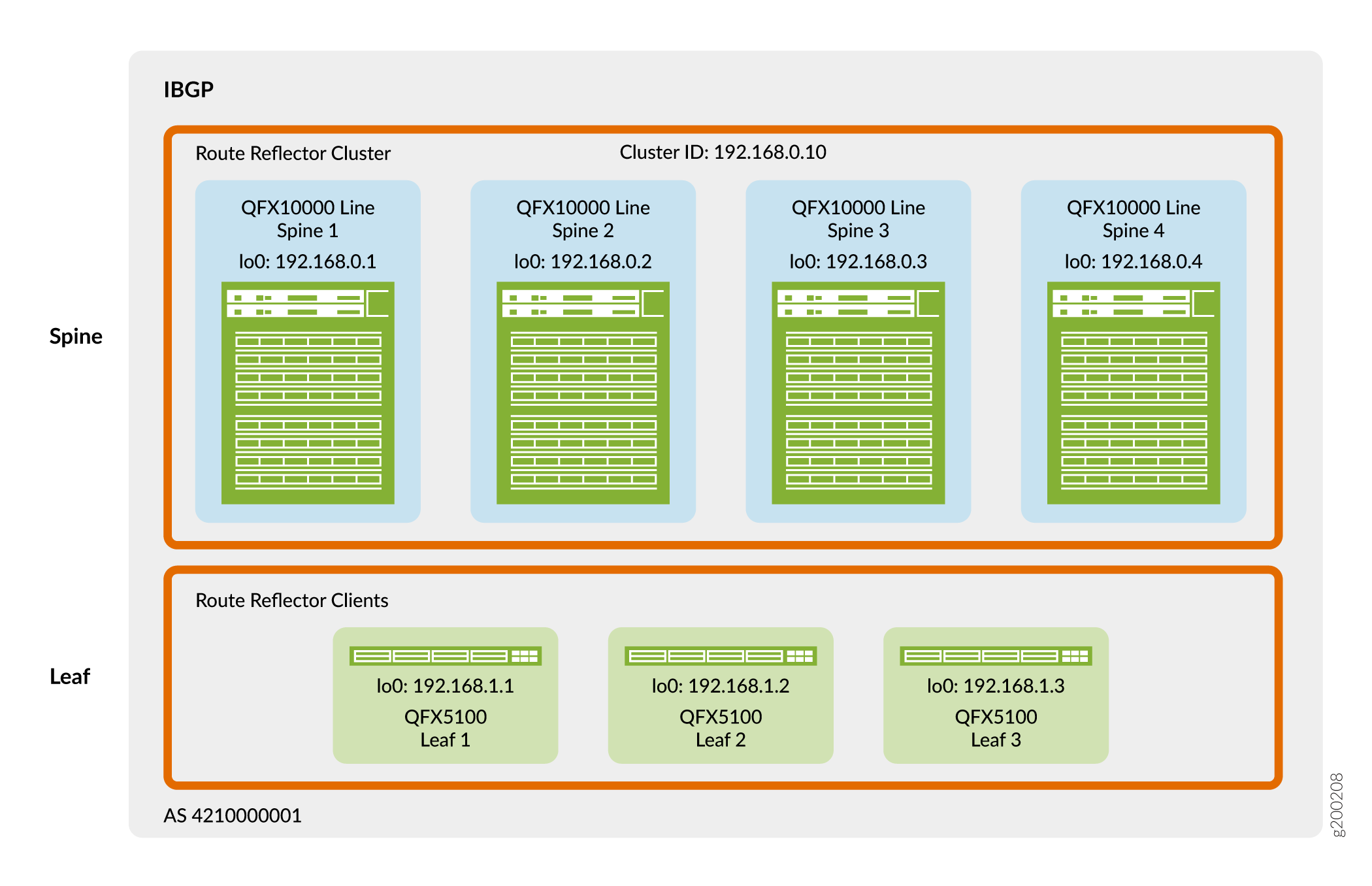
Você pode colocar refletores de rota em praticamente qualquer lugar da rede. No entanto, você deve considerar o seguinte:
-
O dispositivo selecionado tem memória e poder de processamento suficientes para lidar com a carga de trabalho adicional exigida por um refletor de rota?
-
O dispositivo selecionado é equidistante e acessível a partir de todos os alto-falantes EVPN?
-
O dispositivo selecionado tem os recursos de software adequados?
Neste experimento, o cluster de refletores de rota é colocado na camada spine. Os switches QFX que você pode usar como um spine neste design de referência têm ampla velocidade de processamento para lidar com o tráfego do cliente refletor de rota na sobreposição de virtualização de rede.
Para obter detalhes sobre como implementar o IBGP em um overlay, consulte Configurar o IBGP para o overlay.
EBGP para overlays com underlays IPv6
Os casos de uso da arquitetura de referência original neste guia ilustram um projeto de underlay EBGP IPv4 com conectividade de dispositivo overlay IBGP IPv4. Consulte Rede de subcamada de malha IP e IBGP para sobreposições. No entanto, à medida que os dispositivos de borda de virtualização de rede (NVE) começam a adotar VTEPs IPv6 para aproveitar o alcance e os recursos de endereçamento estendidos do IPv6, expandimos o suporte à malha IP para abranger o IPv6.
A partir do Junos OS Release 21.2R2-S1, em plataformas de suporte você pode usar alternativamente uma infraestrutura de malha IPv6 com alguns projetos de sobreposição de arquitetura de referência. O design da malha IPv6 compreende endereçamento de interface IPv6, uma subcamada EBGP IPv6 e uma sobreposição EBGP IPv6 para conectividade de carga de trabalho. Com uma malha IPv6, os dispositivos NVE encapsulam o cabeçalho VXLAN com um cabeçalho externo IPv6 e encapsulam os pacotes em túneis pela malha de ponta a ponta usando o próximo salto IPv6. A carga de trabalho pode ser IPv4 ou IPv6.
A maioria dos elementos configurados nos designs de sobreposição de arquitetura de referência com suporte são independentes de a infraestrutura de underlay e overlay usar IPv4 ou IPv6. Os procedimentos de configuração correspondentes para cada um dos designs de overlay suportados destacam quaisquer diferenças de configuração se a underlay e a overlay usarem o design de malha IPv6.
Para obter mais detalhes, consulte as seguintes referências neste guia e em outros recursos:
Configuração de uma malha IPv6 usando EBGP para conectividade underlay e peering de sobreposição: Projeto e implementação de rede overlay e underlay de malha IPv6 com EBGP.
Iniciando versões nas quais diferentes plataformas suportam um design de malha IPv6 ao desempenhar funções específicas na malha: Designs de referência de malha EVPN-VXLAN de data center — Resumo do hardware suportado.
Visão geral do suporte a peering de sobreposição e underlay IPv6 em malhas EVPN-VXLAN em dispositivos da Juniper Networks: EVPN-VXLAN com um underlay IPv6.
sobreposição em ponte
O primeiro tipo de serviço de overlay descrito neste guia é um overlay em ponte, conforme mostrado na Figura 5.
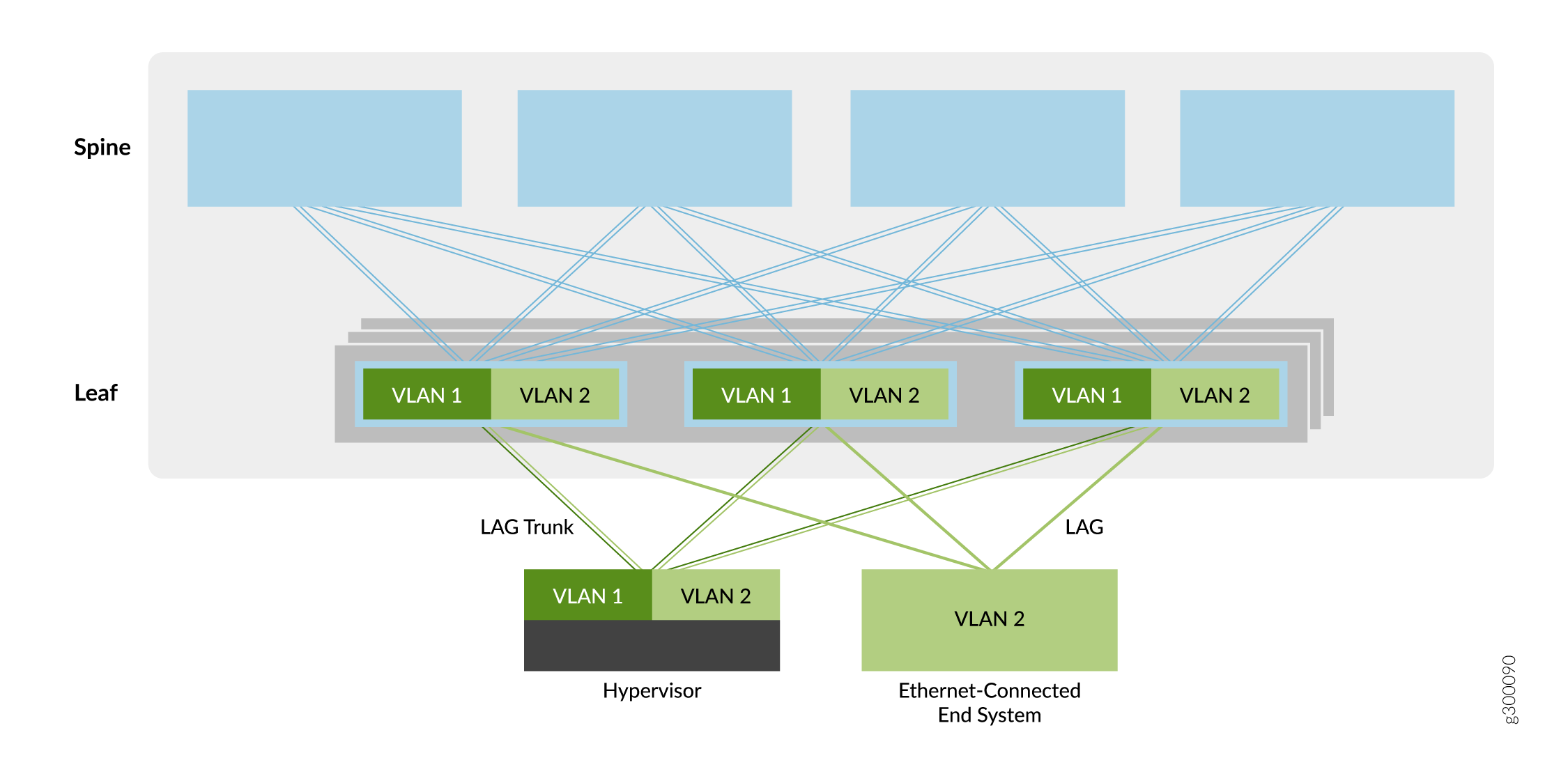 em ponte
em ponte
Neste modelo de overlay, as VLANs Ethernet são estendidas entre dispositivos leaf em túneis VXLAN. Esses túneis VXLAN leaf-to-leaf oferecem suporte a redes de data center que exigem conectividade Ethernet entre dispositivos leaf, mas não precisam de roteamento entre as VLANs. Como resultado, os dispositivos spine fornecem apenas conectividade básica de underlay e overlay para os dispositivos leaf e não executam serviços de roteamento ou gateway vistos com outros métodos de overlay.
Os dispositivos leaf originam VTEPs para se conectar aos outros dispositivos leaf. Os túneis permitem que os dispositivos leaf enviem tráfego VLAN para outros dispositivos leaf e sistemas finais conectados à Ethernet no data center. A simplicidade desse serviço de overlay o torna atraente para operadores que precisam de uma maneira fácil de introduzir o EVPN/VXLAN em seu data center baseado em Ethernet existente.
Você pode adicionar roteamento a uma sobreposição em ponte implementando um roteador da Série MX ou um dispositivo de segurança da Série SRX externo à malha EVPN/VXLAN. Caso contrário, você pode selecionar um dos outros tipos de sobreposição que incorporam o roteamento (como uma sobreposição de ponte com roteamento de borda, uma sobreposição de ponte com roteamento central ou uma sobreposição roteada).
Para obter informações sobre como implementar uma sobreposição em ponte, consulte Design e implementação de sobreposição em ponte.
Overlay de ponte com roteamento central
O segundo tipo de serviço overlay é o centrally rouding bridging (CRB), como mostrado na Figura 6.
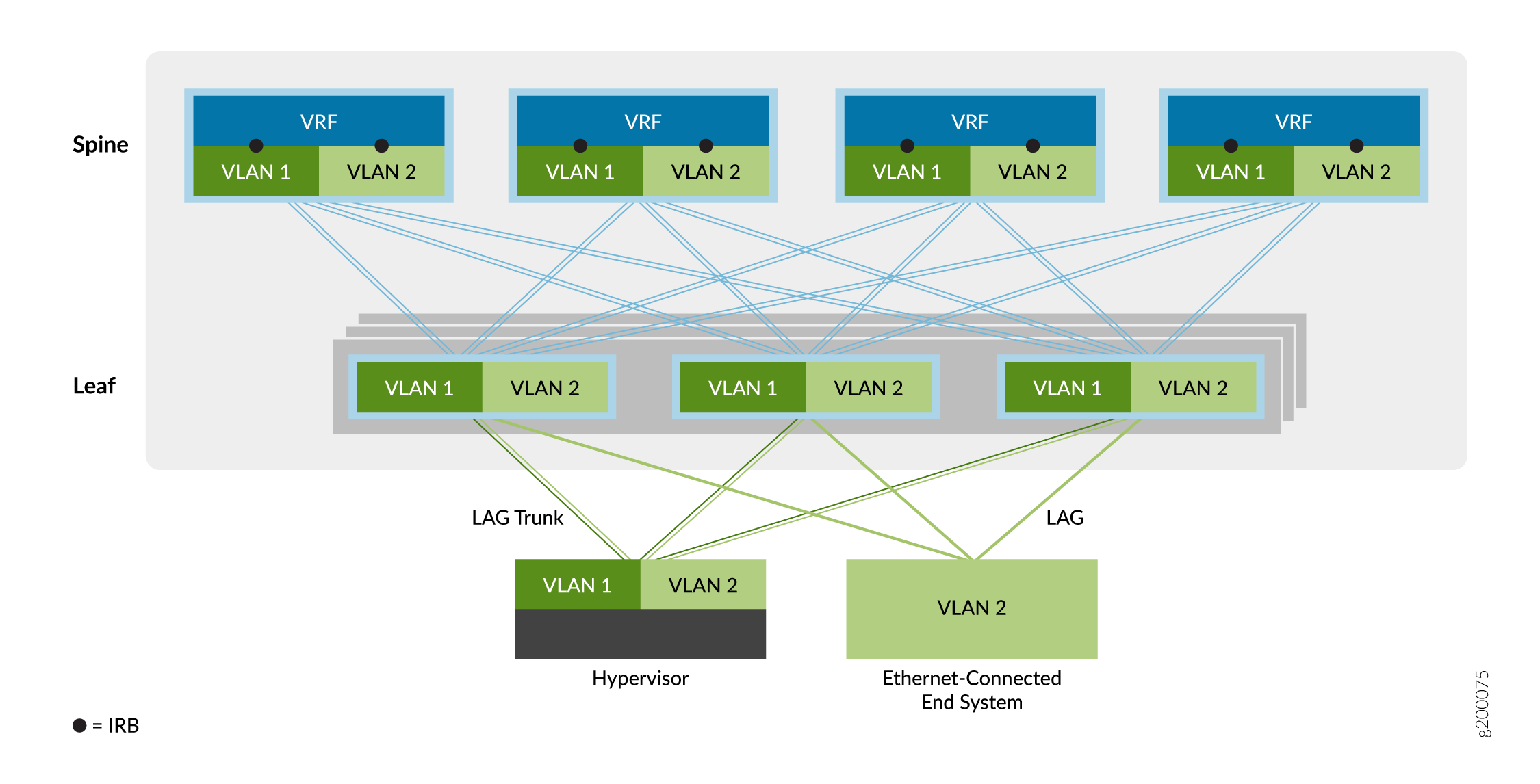 de ponte com roteamento central
de ponte com roteamento central
Em uma overlay CRB, o roteamento ocorre em um gateway central da rede de data center (a camada spine neste exemplo) em vez de no dispositivo VTEP onde os sistemas finais estão conectados (a camada leaf neste exemplo).
Você pode usar esse modelo de sobreposição quando precisar que o tráfego roteado passe por um gateway centralizado ou quando seus dispositivos VTEP de borda não tiverem os recursos de roteamento necessários.
Como mostrado acima, o tráfego que se origina nos sistemas finais conectados à Ethernet é encaminhado para os dispositivos VTEP leaf por meio de um tronco (várias VLANs) ou uma porta de acesso (VLAN única). O dispositivo VTEP encaminha o tráfego para sistemas finais locais ou para um sistema final em um dispositivo VTEP remoto. Uma interface integrada de roteamento e ponte (IRB) em cada dispositivo spine ajuda a rotear o tráfego entre as redes virtuais Ethernet.
O modelo de serviço de sobreposição de ponte com reconhecimento de VLAN permite que você agregue facilmente uma coleção de VLANs na mesma rede virtual de sobreposição. O projeto EVPN da Juniper Networks oferece suporte a três configurações de modelo de serviço Ethernet com reconhecimento de VLAN no data center, como segue:
-
Default instance VLAN-aware— Com essa opção, você implementa uma única instância de comutação padrão que oferece suporte a um total de 4094 VLANs. Todas as plataformas leaf incluídas neste design (Designs de referência de malha EVPN-VXLAN de data center — Resumo do hardware suportado) suportam o estilo de instância padrão de overlay com reconhecimento de VLAN.
Para configurar esse modelo de serviço, consulte Configurando uma sobreposição de ponte roteada centralmente com reconhecimento de VLAN na instância padrão.
-
Virtual switch VLAN-aware— Com essa opção, várias instâncias de switch virtual oferecem suporte a até 4.094 VLANs por instância. Esse modelo de serviço Ethernet é ideal para redes overlay que exigem escalabilidade além de uma única instância padrão. O suporte para esta opção está disponível atualmente na Linha QFX10000 de switches.
Para implementar esse modelo de serviço escalável, consulte a configuração de uma sobreposição de CRB com reconhecimento de VLAN com switches virtuais ou instâncias MAC-VRF.
-
MAC-VRF instance VLAN-aware— Com esta opção, várias instâncias MAC-VRF suportam até 4094 VLANs por instância. Esse modelo de serviço Ethernet é ideal para redes overlay que exigem escalabilidade além de uma única instância padrão e onde você deseja mais opções para garantir o isolamento ou a interconexão de VLAN entre diferentes locatários na mesma malha. O suporte para essa opção está disponível nas plataformas que oferecem suporte a instâncias MAC-VRF (consulte Explorador de recursos: MAC VRF com EVPN-VXLAN).
Para implementar esse modelo de serviço escalável, consulte a configuração de uma sobreposição de CRB com reconhecimento de VLAN com switches virtuais ou instâncias MAC-VRF.
Overlay de ponte roteada na borda
A terceira opção de serviço de overlay é a overlay de ponte roteada de borda (ERB), conforme mostrado na Figura 7.
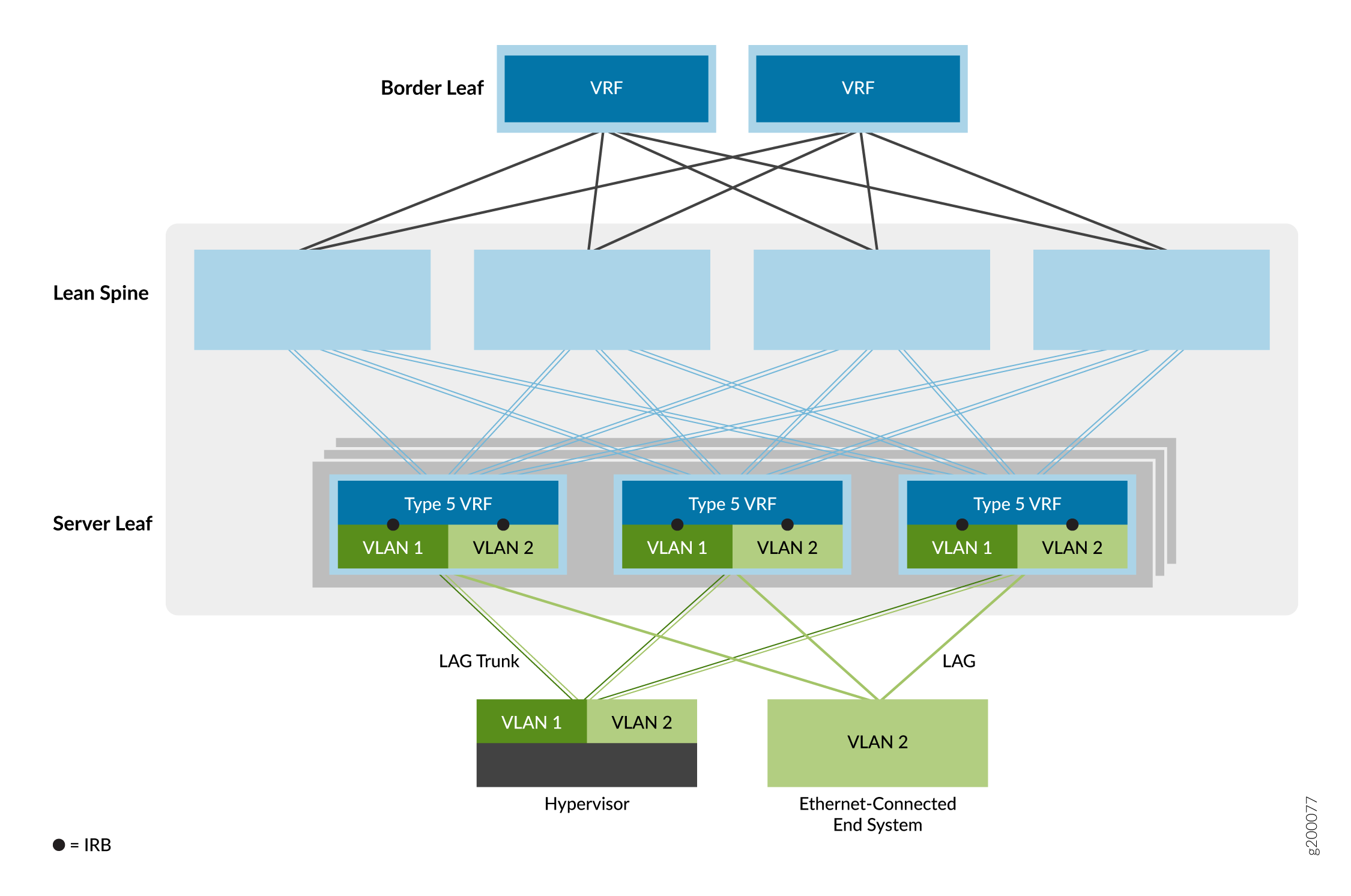 de ponte roteada pela borda
de ponte roteada pela borda
Nesse modelo de serviço Ethernet, as interfaces IRB são movidas para VTEPs de dispositivo leaf na borda da rede overlay para aproximar o roteamento IP dos sistemas finais. Devido aos recursos ASIC especiais necessários para suportar pontes, roteamento e EVPN/VXLAN em um dispositivo, as sobreposições de ERB só são possíveis em determinados switches. Para obter uma lista de switches que oferecemos suporte como dispositivos leaf em um overlay de ERB, consulte Projetos de referência de malha EVPN-VXLAN de data center — Resumo do hardware suportado.
Esse modelo permite uma rede geral mais simples. Os dispositivos spine são configurados para lidar apenas com o tráfego IP, o que elimina a necessidade de estender as sobreposições de ponte para os dispositivos spine.
Essa opção também permite um tráfego intra-data center mais rápido de servidor para servidor (também conhecido como tráfego leste-oeste), onde os sistemas finais são conectados ao mesmo dispositivo leaf VTEP. Como resultado, o roteamento acontece muito mais próximo dos sistemas finais do que com overlays CRB.
Quando você configura interfaces IRB incluídas em instâncias de roteamento EVPN Tipo 5 em switches QFX5110 ou QFX5120 que funcionam como dispositivos leaf, o dispositivo habilita automaticamente o roteamento unicast inter-IRB simétrico para rotas EVPN Tipo 5.
Para obter informações sobre como implementar a sobreposição de ERB, consulte Projeto e implementação de sobreposição de ponte roteada de borda.
Sobreposição spine recolhida
A rede overlay em uma arquitetura de spine colapsada é semelhante a uma overlay ERB. Em uma arquitetura spine colapsada, as funções do dispositivo leaf são recolhidas nos dispositivos spine. Como não há camada leaf, você configura as interfaces VTEPS e IRB nos dispositivos spine, que estão na borda da rede overlay como os dispositivos leaf em um modelo ERB. Os dispositivos spine também podem executar funções de gateway de borda para rotear o tráfego norte-sul ou estender o tráfego de Camada 2 em locais de data center.
Para obter uma lista de switches que suportamos com uma arquitetura spine colapsada, consulte Projetos de referência de malha EVPN-VXLAN de data center — Resumo do hardware suportado.
Comparação de overlays em ponte, CRB e ERB
Para ajudá-lo a decidir qual tipo de overlay é mais adequado para seu ambiente EVPN, consulte a Tabela 1.
Oferecemos suporte à combinação de configurações de sobreposição em ponte, sobreposição de CRB e sobreposição de ERB no mesmo dispositivo ao mesmo tempo em dispositivos que suportam esses tipos de sobreposição. Você não precisa configurar o dispositivo com sistemas lógicos separados para que o dispositivo opere em diferentes tipos de sobreposições em paralelo.
| Pontos de comparação |
Sobreposição de ERB |
Sobreposição de CRB |
sobreposição em ponte |
|---|---|---|---|
| Roteamento entre sub-redes de locatário totalmente distribuído |
✓ |
||
| Impacto mínimo da falha do gateway IP |
✓ |
||
| Roteamento dinâmico para nós de terceiros no nível leaf |
✓ |
||
| Otimizado para alto volume de tráfego leste-oeste |
✓ |
||
| Melhor integração com malhas IP brutas |
✓ |
||
| Virtualização de IP VRF mais próxima do servidor |
✓ |
||
| Multihoming do Contrail vRouter necessário |
✓ |
||
| Interoperabilidade mais fácil da EVPN com diferentes fornecedores |
✓ |
||
| Roteamento simétrico entre sub-redes |
✓ |
✓ |
|
| Sobreposição de ID de VLAN por rack |
✓ |
✓ |
✓ |
| Configuração manual e solução de problemas mais simples |
✓ |
✓ |
|
| Interfaces de estilo corporativo e de provedor de serviços |
✓ |
✓ |
|
| Suporte a switches leaf legados (QFX5100) |
✓ |
✓ |
|
| Controle centralizado de otimização de tráfego de máquina virtual (VMTO) |
✓ |
||
| Gateway de sub-rede de locatário IP no cluster de firewall |
✓ |
Modelos de endereçamento IRB em sobreposições de ponte
A configuração de interfaces IRB em overlays CRB e ERB requer uma compreensão dos modelos para a configuração de IP de gateway padrão e endereço MAC de interfaces IRB da seguinte forma:
Unique IRB IP Address— Neste modelo, um endereço IP exclusivo é configurado em cada interface IRB em uma sub-rede de sobreposição.
O benefício de ter um endereço IP e um endereço MAC exclusivos em cada interface IRB é a capacidade de monitorar e acessar cada uma das interfaces IRB de dentro da sobreposição usando seu endereço IP exclusivo. Este modelo também permite configurar um protocolo de roteamento na interface IRB.
A desvantagem desse modelo é que alocar um endereço IP exclusivo para cada interface IRB pode consumir muitos endereços IP de uma sub-rede.
Unique IRB IP Address with Virtual Gateway IP Address— Esse modelo adiciona um endereço IP de gateway virtual ao modelo anterior e o recomendamos para overlays interligados roteados centralmente. É semelhante ao VRRP, mas sem a sinalização do plano de dados em banda entre as interfaces IRB do gateway. O gateway virtual deve ser o mesmo para todas as interfaces IRB de gateway padrão na sub-rede overlay e está ativo em todas as interfaces IRB de gateway em que está configurado. Você também deve configurar um endereço MAC IPv4 comum para o gateway virtual, que se torna o endereço MAC de origem em pacotes de dados encaminhados pela interface IRB.
Além dos benefícios do modelo anterior, o gateway virtual simplifica a configuração padrão do gateway nos sistemas finais. A desvantagem deste modelo é a mesma do modelo anterior.
IRB with Anycast IP Address and MAC Address— Neste modelo, todas as interfaces IRB de gateway padrão em uma sub-rede overlay são configuradas com o mesmo endereço IP e endereço MAC. Recomendamos este modelo para overlays ERB.
Um benefício desse modelo é que apenas um único endereço IP é necessário por sub-rede para o endereçamento da interface IRB do gateway padrão, o que simplifica a configuração do gateway padrão nos sistemas finais.
Overlay roteado usando rotas EVPN Tipo 5
A opção de sobreposição final é uma sobreposição roteada, conforme mostrado na Figura 8.
 roteada
roteada
Essa opção é um serviço de rede virtual roteado por IP. Ao contrário de uma VPN IP baseada em MPLS, a rede virtual nesse modelo é baseada em EVPN/VXLAN.
Os provedores de nuvem preferem essa opção de rede virtual porque a maioria dos aplicativos modernos são otimizados para IP. Como toda a comunicação entre dispositivos ocorre na camada IP, não há necessidade de usar nenhum componente de ponte Ethernet, como VLANs e ESIs, neste modelo de sobreposição roteada.
Para obter informações sobre como implementar uma sobreposição roteada, consulte Design e implementação de sobreposição roteada.
Instâncias MAC-VRF para multitenancy em overlays de virtualização de rede
As instâncias de roteamento MAC-VRF permitem que você configure várias instâncias de EVPN com diferentes tipos de serviços Ethernet em um dispositivo que atua como um VTEP em uma malha EVPN-VXLAN. Usando instâncias MAC-VRF, você pode gerenciar vários locatários no data center com tabelas VRF específicas do cliente para isolar ou agrupar cargas de trabalho de locatário.
As instâncias MAC-VRF também introduzem suporte para o tipo de serviço baseado em VLAN, além do suporte anterior para o tipo de serviço com reconhecimento de VLAN. Veja a Figura 9.
 de serviço MAC-VRF
de serviço MAC-VRF
-
Serviço baseado em VLAN — você pode configurar uma VLAN e o identificador de rede VXLAN (VNI) correspondente na instância MAC-VRF. Para provisionar uma nova VLAN e VNI, você deve configurar uma nova instância MAC VRF com a nova VLAN e VNI.
-
Serviço com reconhecimento de VLAN — você pode configurar uma ou mais VLANs e os VNIs correspondentes na mesma instância MAC-VRF. Para provisionar uma nova VLAN e VNI, você pode adicionar a nova configuração de VLAN e VNI à instância MAC-VRF existente, o que economiza algumas etapas de configuração em relação ao uso de um serviço baseado em VLAN.
As instâncias MAC-VRF permitem opções de configuração mais flexíveis na Camada 2 e na Camada 3. Por exemplo:
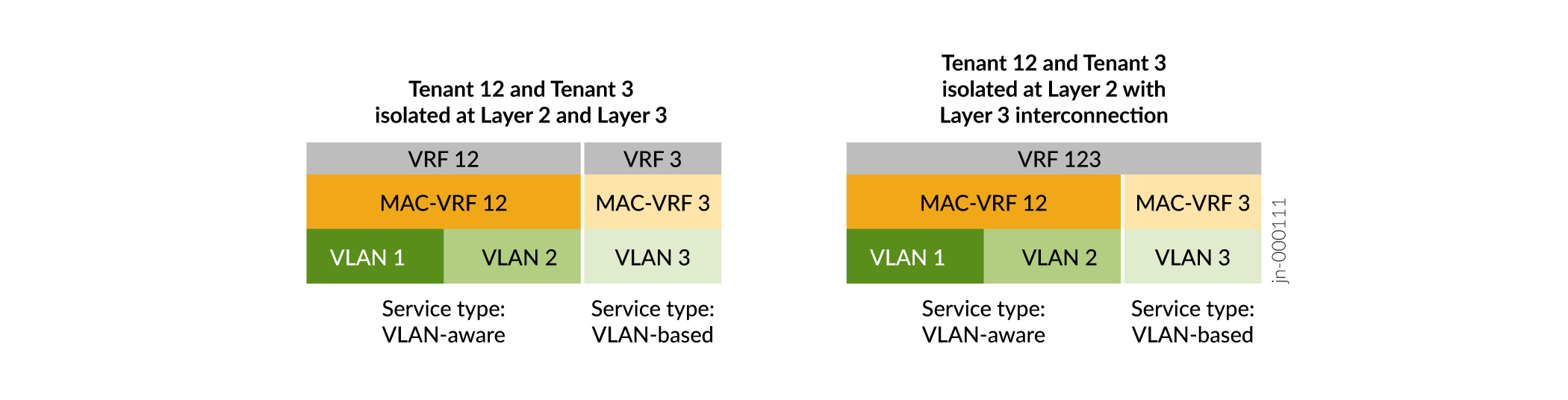
A Figura 10 mostra que, com instâncias MAC-VRF:
-
Você pode configurar diferentes tipos de serviço em diferentes instâncias MAC-VRF no mesmo dispositivo.
-
Você tem opções flexíveis de isolamento de locatários na Camada 2 (instâncias MAC-VRF), bem como na Camada 3 (instâncias VRF). Você pode configurar uma instância VRF que corresponda à VLAN ou VLANs em uma única instância MAC-VRF. Ou você pode configurar uma instância VRF que abrange as VLANs em várias instâncias MAC-VRF.
A Figura 11 mostra uma malha overlay ERB com uma configuração MAC-VRF de amostra para separação de locatários.
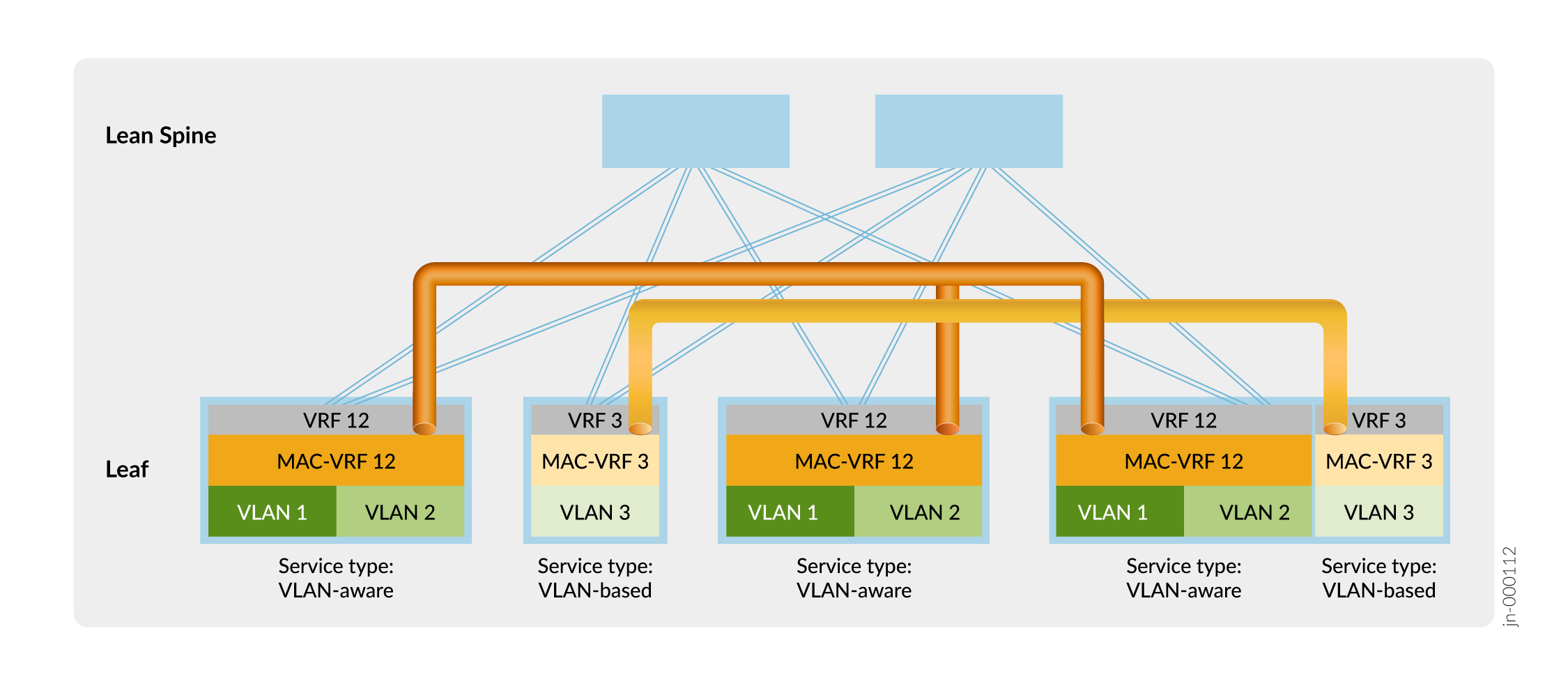 de locatários
de locatários
Na Figura 11, os dispositivos leaf estabelecem túneis VXLAN que mantêm o isolamento na Camada 2 entre o Locatário 12 (VLAN 1 e VLAN 2) e o Locatário 3 (VLAN 3) usando as instâncias MAC-VRF MAC-VRF 12 e MAC-VRF 3. Os dispositivos leaf também isolam os locatários na Camada 3 usando instâncias VRF 12 e VRF 3.
Você pode empregar outras opções para compartilhar o tráfego VLAN entre locatários que são isolados na Camada 2 e na Camada 3 pelas configurações MAC-VRF e VRF, como:
-
Estabeleça uma interconexão externa segura entre VRFs de locatários por meio de um firewall.
-
Configure o vazamento de rota local entre VRFs de Camada 3.
Para obter mais informações sobre instâncias MAC-VRF e usá-las em um exemplo de caso de uso do cliente, consulte Serviços MAC-VRF L2 de malha de IP de DC EVPN-VXLAN.
As instâncias MAC-VRF correspondem às instâncias de encaminhamento da seguinte forma:
-
Instâncias MAC-VRF em switches na linha QFX5000 (incluindo aqueles que executam Junos OS ou Junos OS Evolved) fazem parte da instância de encaminhamento padrão. Nesses dispositivos, você não pode configurar VLANs sobrepostas em uma instância MAC-VRF ou em várias instâncias MAC-VRF.
-
Na Linha QFX10000 de switches, você pode configurar várias instâncias de encaminhamento e mapear uma instância MAC-VRF para uma instância de encaminhamento específica. Você também pode mapear várias instâncias do MAC-VRF para a mesma instância de encaminhamento. Se você configurar cada instância do MAC-VRF para usar uma instância de encaminhamento diferente, poderá configurar VLANs sobrepostas nas várias instâncias do MAC-VRF. Você não pode configurar VLANs sobrepostas em uma única instância MAC-VRF ou em instâncias MAC-VRF mapeadas para a mesma instância de encaminhamento.
-
Na configuração padrão, os switches incluem uma VLAN padrão com VLAN ID=1 associada à instância de encaminhamento padrão. Como os IDs de VLAN devem ser exclusivos em uma instância de encaminhamento, se você quiser configurar um VLAN com VLAN ID=1 em uma instância MAC-VRF que usa a instância de encaminhamento padrão, você deve reatribuir o ID de VLAN do VLAN padrão a um valor diferente de 1. Por exemplo:
set vlans default vlan-id 4094 set routing-instances mac-vrf-instance-name vlans vlan-name vlan-id 1
Os exemplos de configuração de sobreposição de virtualização de rede de referência neste guia incluem etapas para configurar a sobreposição usando instâncias MAC-VRF. Você configura uma instância de roteamento EVPN do tipo mac-vrfe define um diferenciador de rota e um destino de rota na instância. Você também inclui as interfaces desejadas (incluindo uma interface de origem VTEP), VLANs e mapeamentos de VLAN para VNI na instância. Consulte as configurações de referência nos seguintes tópicos:
-
Projeto e implementação de sobreposição em ponte — Você configura instâncias MAC-VRF nos dispositivos leaf.
-
Projeto e implementação de sobreposição de ponte com roteamento central — Você configura instâncias MAC-VRF nos dispositivos spine. Nos dispositivos leaf, a configuração MAC-VRF é semelhante à configuração leaf MAC-VRF em um design de overlay interligado.
-
Projeto e implementação de sobreposição de ponte roteada de borda — Você configura instâncias MAC-VRF nos dispositivos leaf.
Um dispositivo pode ter problemas com a escalabilidade VTEP quando a configuração usa várias instâncias MAC-VRF. Como resultado, para evitar esse problema, exigimos que você habilite o recurso de túneis compartilhados na linha QFX5000 de switches que executam Junos OS com uma configuração de instância MAC-VRF. Quando você configura túneis compartilhados, o dispositivo minimiza o número de entradas de próximo salto para alcançar VTEPs remotos. Você habilita globalmente túneis VXLAN compartilhados no dispositivo usando a shared-tunnels declaração no nível de [edit forwarding-options evpn-vxlan] hierarquia. Essa configuração requer que você reinicie o dispositivo.
Essa declaração é opcional no Linha QFX10000 de switches que executam Junos OS, que podem lidar com uma escalabilidade de VTEP maior do que QFX5000 switches.
Nos dispositivos que executam o Junos OS Evolved em malhas EVPN-VXLAN, os túneis compartilhados são habilitados por padrão. O Junos OS Evolved oferece suporte a EVPN-VXLAN apenas com configurações MAC-VRF.
Suporte multihoming para sistemas finais conectados à ethernet
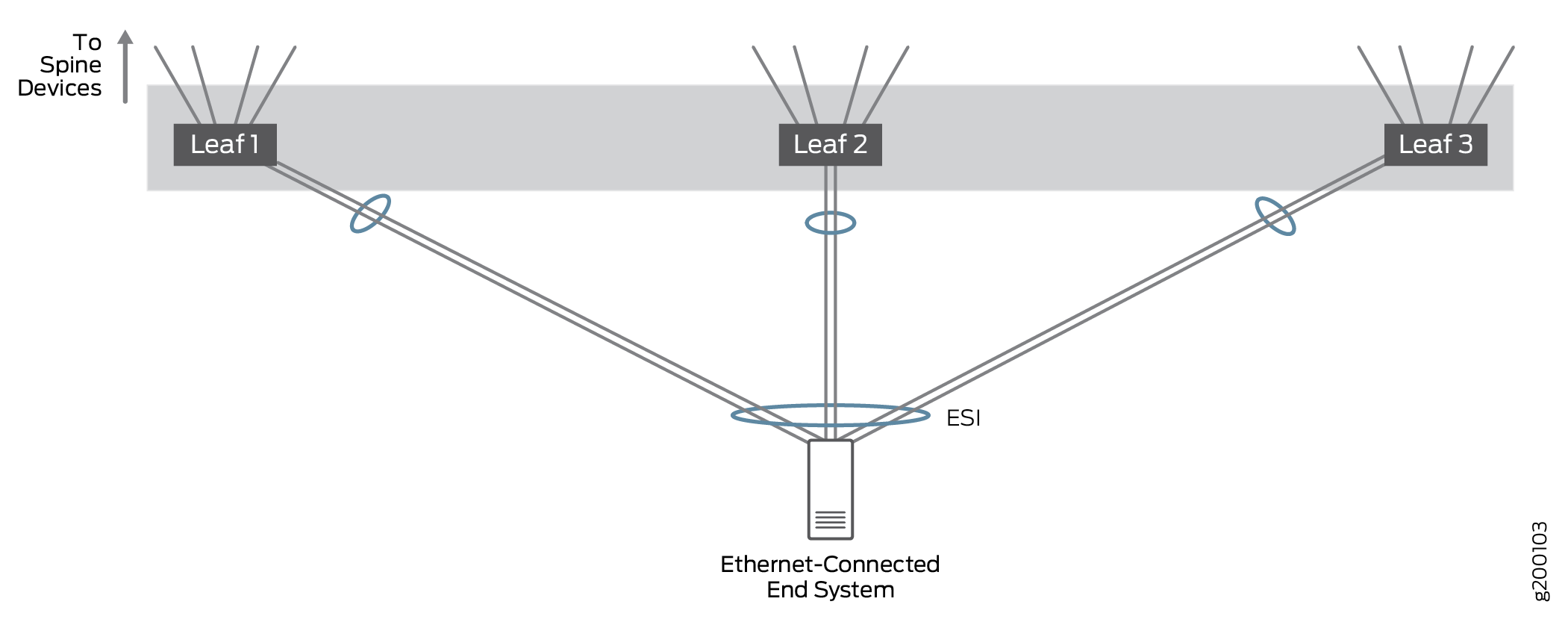 Ethernet
Ethernet
O multihoming conectado à Ethernet permite que os sistemas finais conectados à Ethernet se conectem à rede overlay Ethernet por meio de um link single-homed a um dispositivo VTEP ou em vários links multihomed a diferentes dispositivos VTEP. O tráfego Ethernet tem balanceamento de carga em toda a malha entre VTEPs em dispositivos leaf que se conectam ao mesmo sistema final.
Testamos configurações em que um sistema final conectado por Ethernet foi conectado a um único dispositivo leaf ou multihomed a 2 ou 3 dispositivos leaf para provar que o tráfego é tratado adequadamente em configurações multihomed com mais de dois dispositivos VTEP leaf; na prática, um sistema final conectado à Ethernet pode ser multihomed para um grande número de dispositivos leaf VTEP. Todos os links estão ativos e o tráfego de rede pode ser balanceado em todos os links multihomed.
Nessa arquitetura, a EVPN é usada para multihoming conectado por Ethernet. Os LAGs multihomed EVPN são identificados por um identificador de segmento Ethernet (ESI) na sobreposição de ponte EVPN, enquanto o LACP é usado para melhorar a disponibilidade de LAG.
O entroncamento de VLAN permite que uma interface ofereça suporte a várias VLANs. O entroncamento de VLAN garante que as máquinas virtuais (VMs) em hipervisores não overlay possam operar em qualquer contexto de rede overlay.
Para obter mais informações sobre o suporte a multihoming conectado por Ethernet, consulte Projeto e implementação de multihoming de um sistema final conectado por Ethernet.
Suporte multihoming para sistemas finais conectados por IP
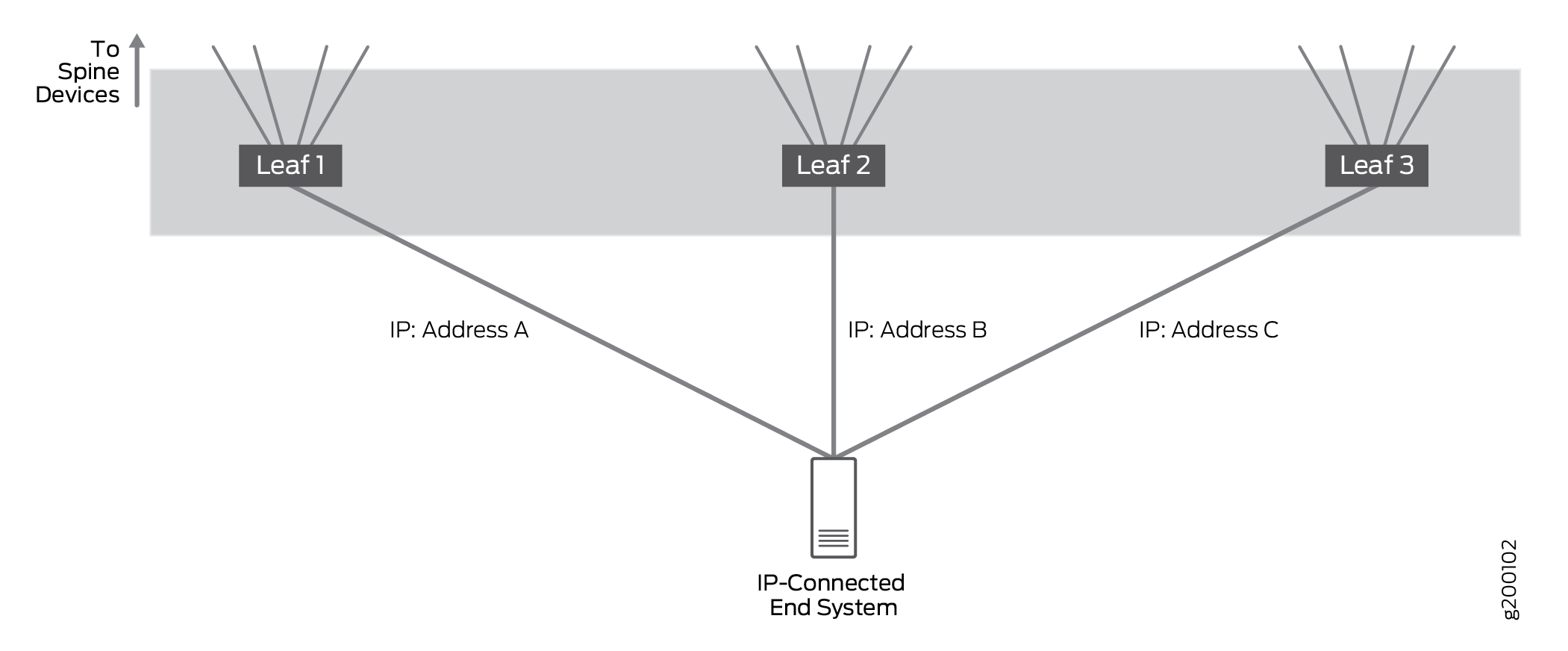 IP
IP
Sistemas de endpoint multihoming conectados por IP para se conectar à rede IP por meio de várias interfaces de acesso baseadas em IP em diferentes dispositivos leaf.
Testamos configurações em que um sistema final conectado por IP foi conectado a uma única folha ou multihomed a dispositivos de 2 ou 3 folhas. A configuração validou que o tráfego é tratado corretamente quando multihomed para vários dispositivos leaf; na prática, um sistema final conectado por IP pode ser multihomed para um grande número de dispositivos leaf.
Em configurações multihomed, todos os links estão ativos e o tráfego de rede é encaminhado e recebido por todos os links multihomed. O tráfego IP é balanceado entre os links multihomed usando um algoritmo de hash simples.
O EBGP é usado para trocar informações de roteamento entre o sistema de endpoint conectado por IP e os dispositivos leaf conectados para garantir que a rota ou rotas para os sistemas de endpoint sejam compartilhadas com todos os dispositivos spine e leaf.
Para obter mais informações sobre o bloco de construção multihoming conectado por IP, consulte Multihoming um design e implementação de sistema final conectado por IP.
Dispositivos de borda
Alguns de nossos designs de referência incluem dispositivos de borda que fornecem conexões com os seguintes dispositivos, que são externos à malha IP local:
Um gateway multicast.
Um gateway de data center para interconexão de data center (DCI).
Um dispositivo como um roteador SRX no qual vários serviços, como firewalls, Network Address Translation (NAT), detecção e prevenção de intrusão (IDP), multicast e assim por diante, são consolidados. A consolidação de vários serviços em um dispositivo físico é conhecida como encadeamento de serviços.
Appliances ou servidores que atuam como firewalls, servidores DHCP, coletores de sFlow e assim por diante.
Observação:Se sua rede incluir dispositivos ou servidores legados que exigem uma conexão Ethernet de 1 Gbps com um dispositivo de borda, recomendamos o uso de um switch QFX10008 ou QFX5120 como dispositivo de borda.
Para fornecer a funcionalidade adicional descrita acima, a Juniper Networks oferece suporte à implantação de um dispositivo de borda das seguintes maneiras:
Como um dispositivo que serve apenas como um dispositivo de borda. Nessa função dedicada, você pode configurar o dispositivo para lidar com uma ou mais das tarefas descritas acima. Para essa situação, o dispositivo normalmente é implantado como uma folha de borda, que é conectada a um dispositivo spine.
Por exemplo, na sobreposição de ERB mostrada na Figura 14, as folhas de borda L5 e L6 fornecem conectividade a gateways de data center para DCI, um coletor de sFlow e um servidor DHCP.
Como um dispositivo que tem duas funções: um dispositivo subjacente de rede e um dispositivo de borda que pode lidar com uma ou mais das tarefas descritas acima. Para essa situação, um dispositivo spine geralmente lida com as duas funções. Portanto, a funcionalidade do dispositivo de borda é chamada de border spine.
Por exemplo, na sobreposição de ERB mostrada na Figura 15, os spines de borda S1 e S2 funcionam como dispositivos lean spine. Eles também fornecem conectividade a gateways de data center para DCI, um coletor de sFlow e um servidor DHCP.
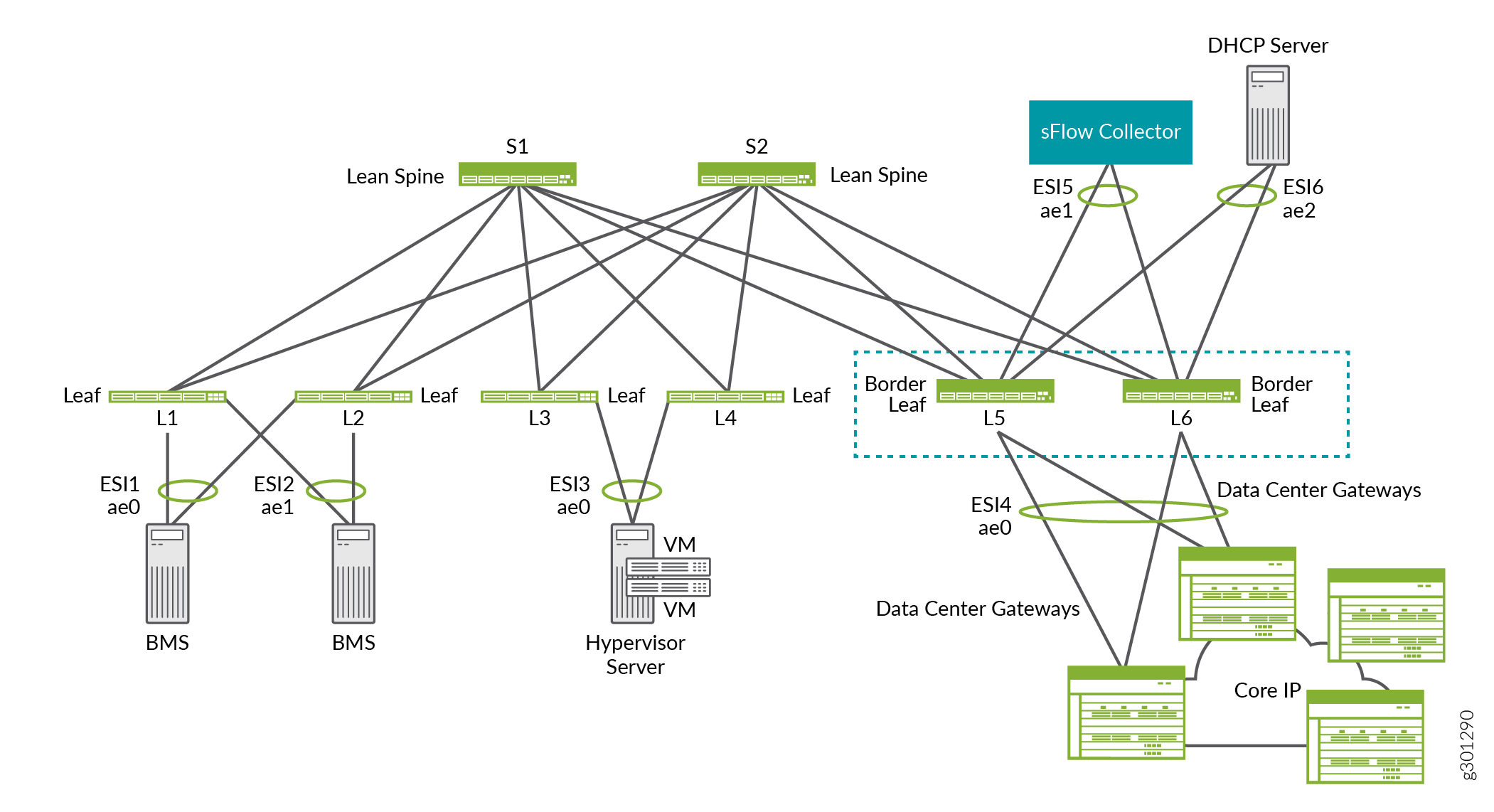 borda
borda
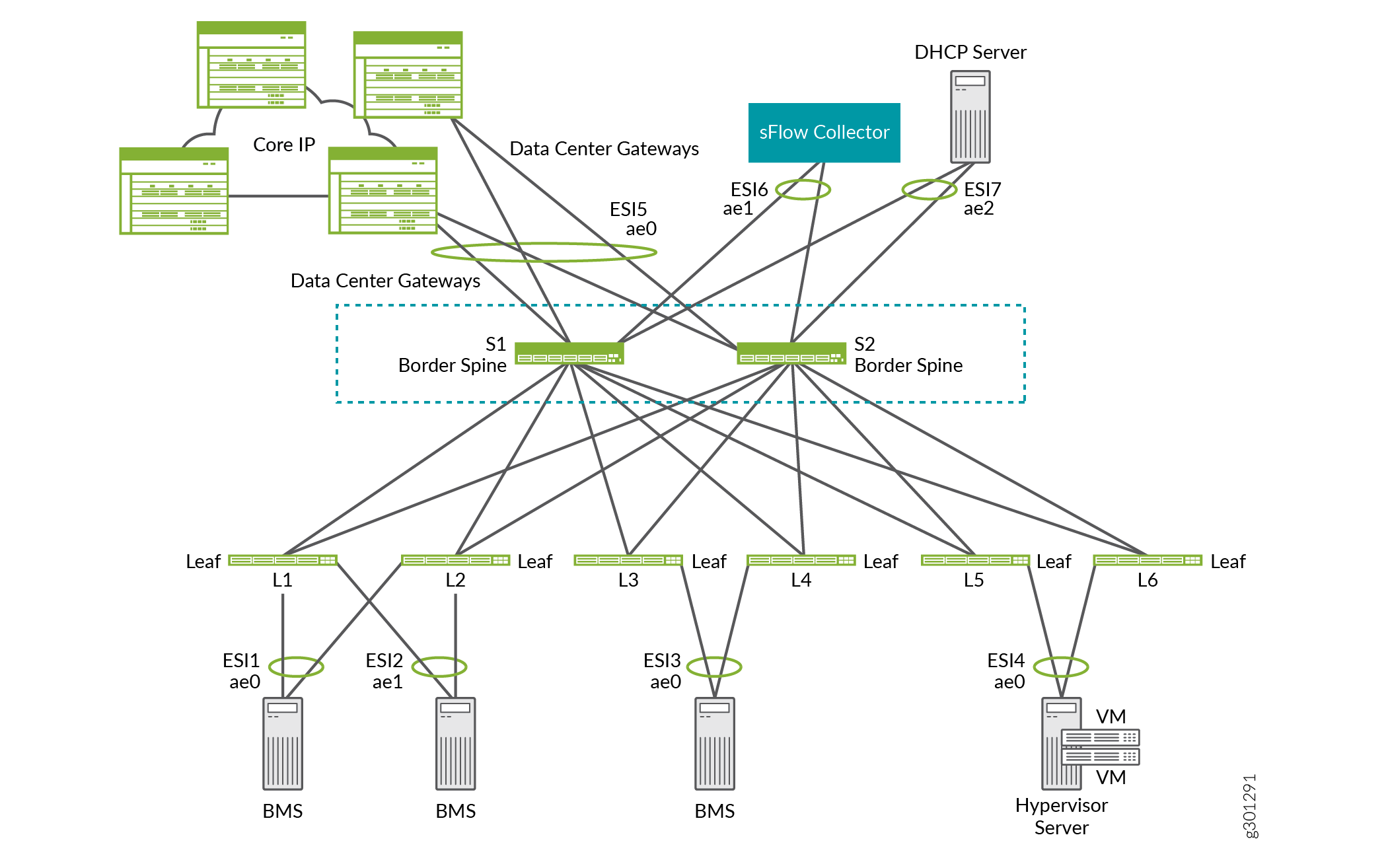 de borda
de borda
Interconexão de data center (DCI)
O bloco de construção de interconexão de data center (DCI) fornece a tecnologia necessária para enviar tráfego entre data centers. O projeto validado oferece suporte à DCI usando rotas EVPN Tipo 5, rotas IPVPN e DCI de Camada 2 com costura VXLAN.
As rotas EVPN Tipo 5 ou IPVPN são usadas em um contexto de DCI para garantir que o tráfego entre data centers entre data centers usando diferentes esquemas de sub-rede de endereço IP possa ser trocado. As rotas são trocadas entre dispositivos spine em diferentes data centers para permitir a passagem de tráfego entre data centers.
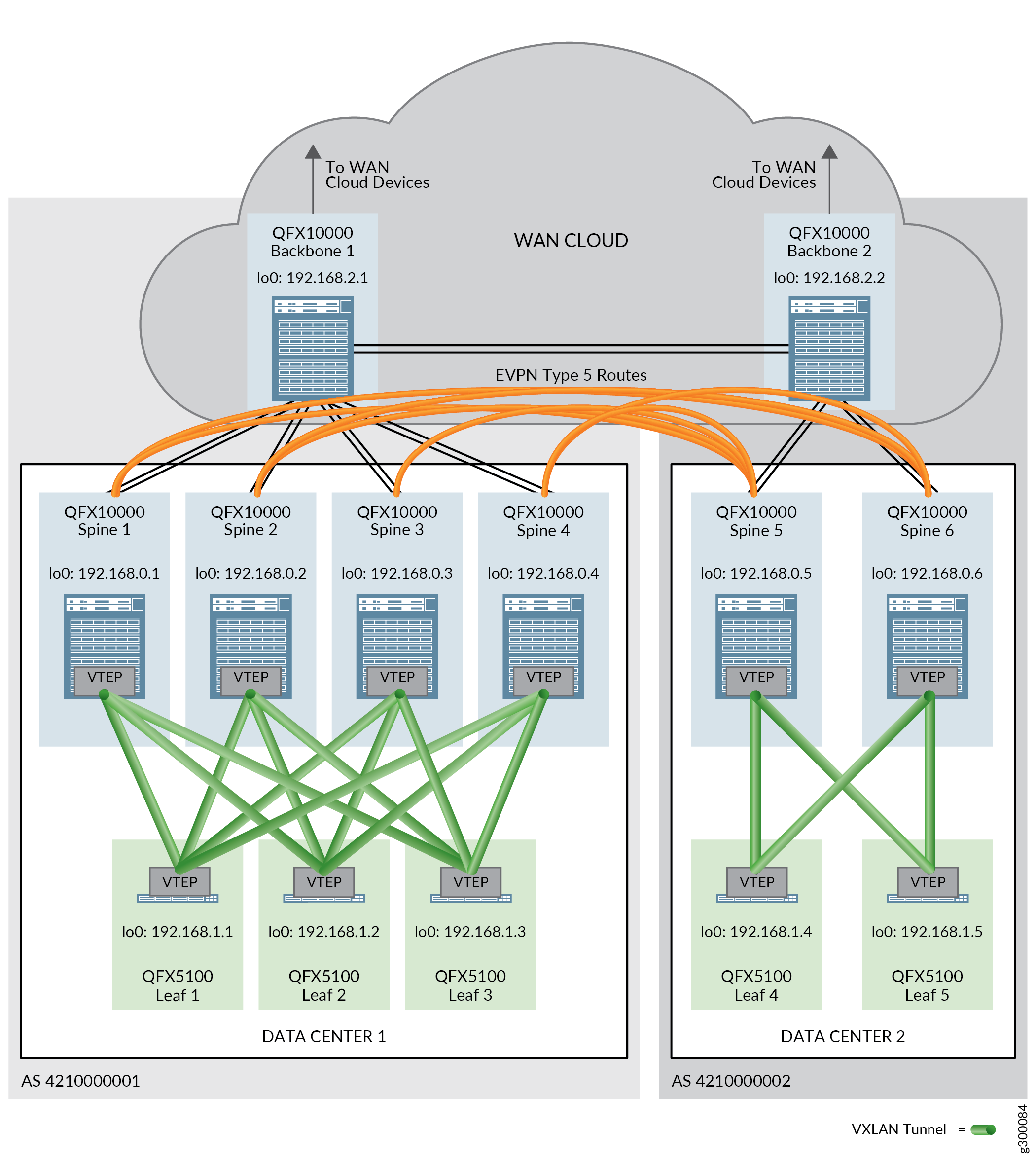
A conectividade física entre os data centers é necessária antes que você possa configurar a DCI. A conectividade física é fornecida por dispositivos de backbone em uma nuvem WAN. Um dispositivo de backbone é conectado a todos os dispositivos spine em um único data center (POD), bem como aos outros dispositivos de backbone conectados aos outros data centers.
Para obter informações sobre como configurar a DCI, consulte:
Encadeamento de serviços
Em muitas redes, é comum que o tráfego flua por dispositivos de hardware separados, cada um fornecendo um serviço, como firewalls, NAT, IDP, multicast e assim por diante. Cada dispositivo requer operação e gerenciamento separados. Esse método de vincular várias funções de rede pode ser considerado como encadeamento de serviços físicos.
Um modelo mais eficiente para o encadeamento de serviços é virtualizar e consolidar funções de rede em um único dispositivo. Em nossa arquitetura de blueprint, estamos usando os roteadores da Série SRX como o dispositivo que consolida funções e processos de rede e aplica serviços. Esse dispositivo é chamado de função de rede física (PNF).
Nessa solução, o encadeamento de serviços é suportado na sobreposição de CRB e na sobreposição de ERB. Ele funciona apenas para tráfego entre locatários.
Visão lógica do encadeamento de serviços
A Figura 17 mostra uma visão lógica do encadeamento de serviços. Ele mostra uma spine com uma configuração do lado direito e uma configuração do lado esquerdo. Em cada lado há uma instância de roteamento VRF e uma interface IRB. O roteador da Série SRX no centro é o PNF e realiza o encadeamento de serviços.
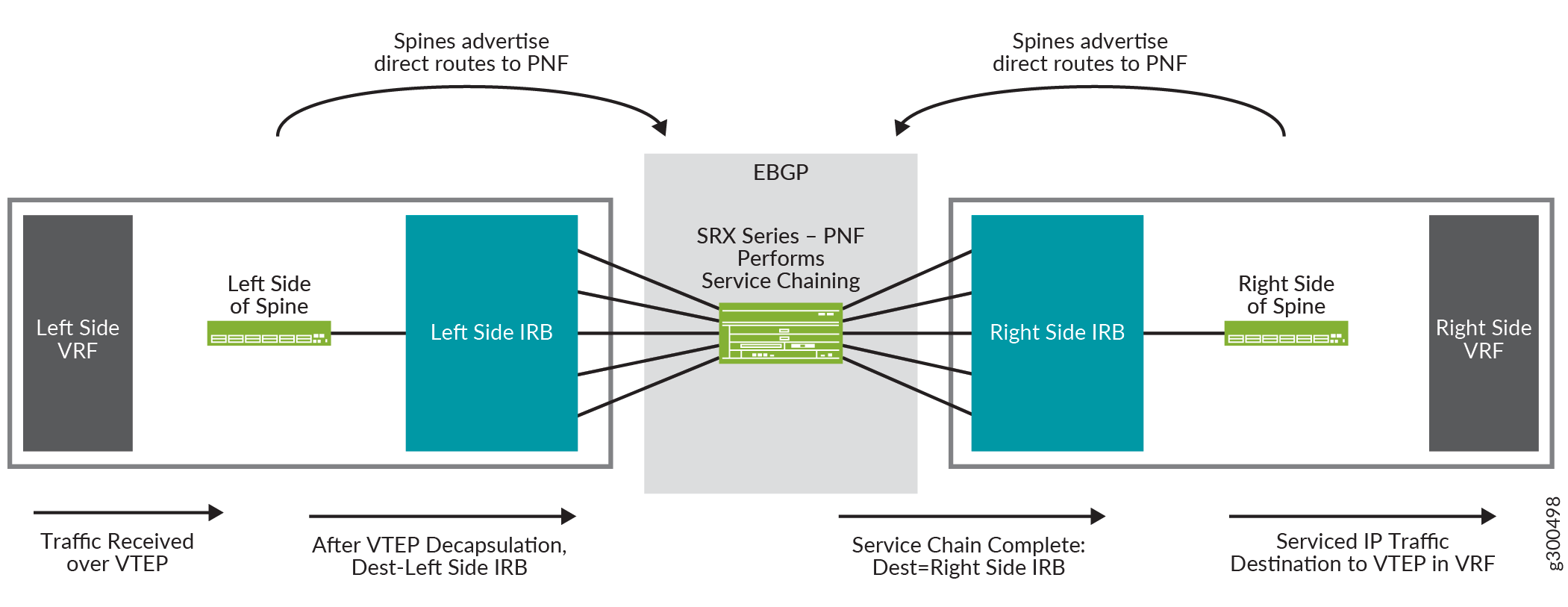 lógica do encadeamento de serviços
lógica do encadeamento de serviços
O fluxo de tráfego nessa visão lógica é:
-
O spine recebe um pacote no VTEP que está no VRF do lado esquerdo.
-
O pacote é desencapsulado e enviado para a interface IRB do lado esquerdo.
-
A interface IRB roteia o pacote para o roteador da Série SRX, que está atuando como PNF.
-
O roteador da Série SRX executa o encadeamento de serviços no pacote e encaminha o pacote de volta para a spine, onde é recebido na interface IRB mostrada no lado direito da spine.
-
A interface IRB roteia o pacote para o VTEP no VRF do lado direito.
Para obter informações sobre como configurar o encadeamento de serviços, consulte Design e implementação do encadeamento de serviços.
Otimizações de multicast
As otimizações multicast ajudam a preservar a largura de banda e rotear o tráfego com mais eficiência em um cenário multicast em ambientes EVPN VXLAN. Sem nenhuma otimização de multicast configurada, toda a replicação de multicast é feita na entrada da folha conectada à fonte de multicast, conforme mostrado na Figura 18. O tráfego multicast é enviado para todos os dispositivos leaf conectados ao spine. Cada dispositivo leaf envia tráfego para hosts conectados.
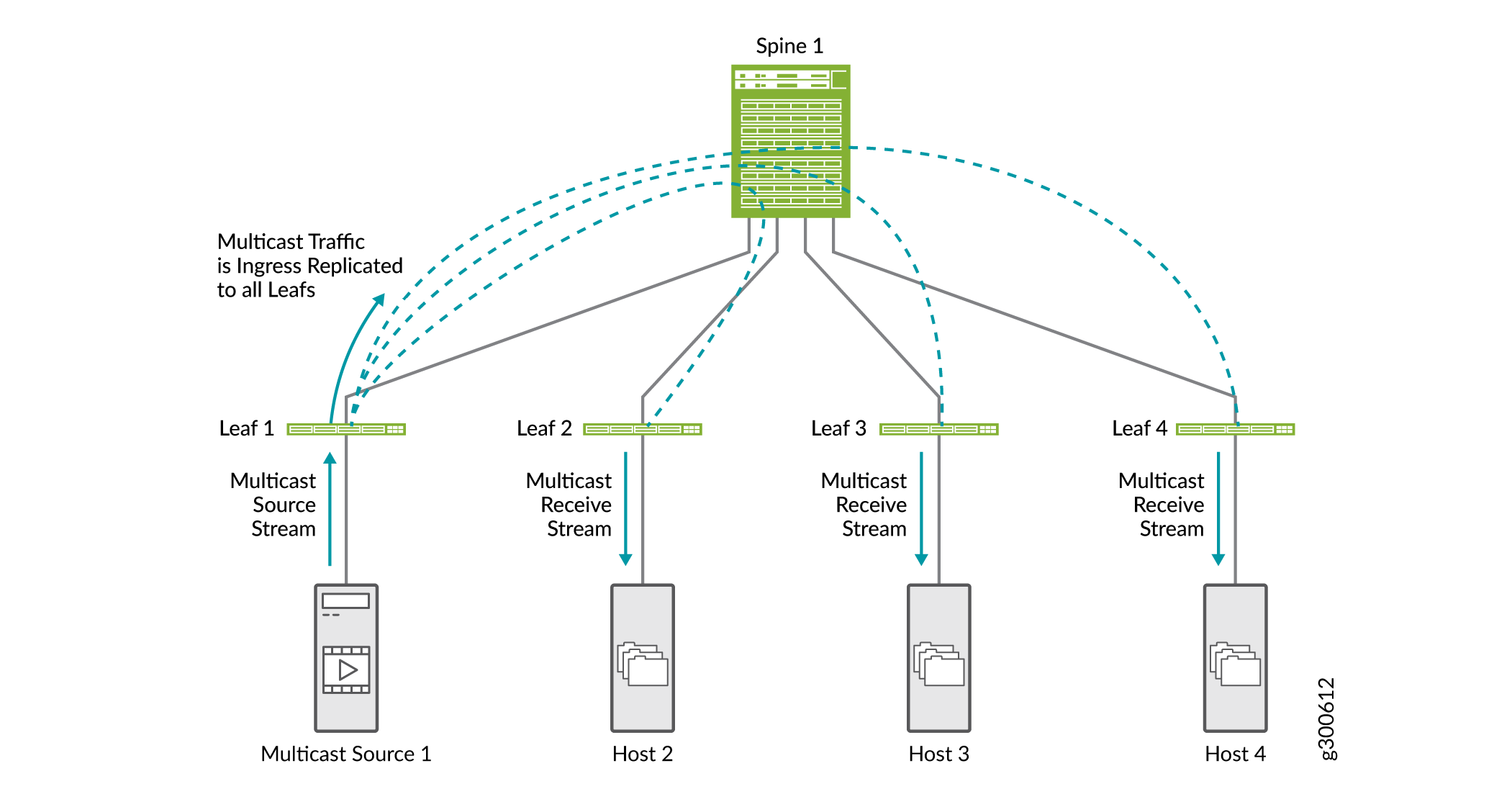
Existem alguns tipos de otimizações multicast suportadas em ambientes EVPN VXLAN que podem funcionar juntas:
Para obter informações sobre como configurar recursos de multicast, consulte:
- Bisbilhotamento IGMP
- Encaminhamento multicast seletivo
- Replicação assistida de tráfego multicast
- Multicast intersubnet otimizado para redes overlay ERB
Bisbilhotamento IGMP
A bisbilhotagem de IGMP em uma malha EVPN-VXLAN é útil para otimizar a distribuição do tráfego multicast. A bisbilhotagem IGMP preserva a largura de banda porque o tráfego multicast é encaminhado apenas em interfaces onde há ouvintes IGMP. Nem todas as interfaces em um dispositivo leaf precisam receber tráfego multicast.
Sem a espionagem do IGMP, os sistemas finais recebem tráfego IP multicast no qual não têm interesse, o que inunda desnecessariamente seus links com tráfego indesejado. Em alguns casos, quando os fluxos de IP multicast são grandes, inundar o tráfego indesejado causa problemas de negação de serviço.
A Figura 19 mostra como o IGMP snooping funciona em uma malha EVPN-VXLAN. Neste exemplo de malha EVPN-VXLAN, o bisbilhotamento IGMP está configurado em todos os dispositivos leaf, e o receptor multicast 2 enviou anteriormente uma solicitação de junção IGMPv2.
-
O receptor multicast 2 envia uma solicitação de licença IGMPv2.
-
Os receptores multicast 3 e 4 enviam uma solicitação de junção IGMPv2.
-
Quando o leaf 1 recebe tráfego multicast de entrada, ele o replica para todos os dispositivos leaf e o encaminha para o spine.
-
O spine encaminha o tráfego para todos os dispositivos leaf.
-
O Leaf 2 recebe o tráfego multicast, mas não o encaminha ao receptor porque o receptor enviou uma mensagem de licença IGMP.
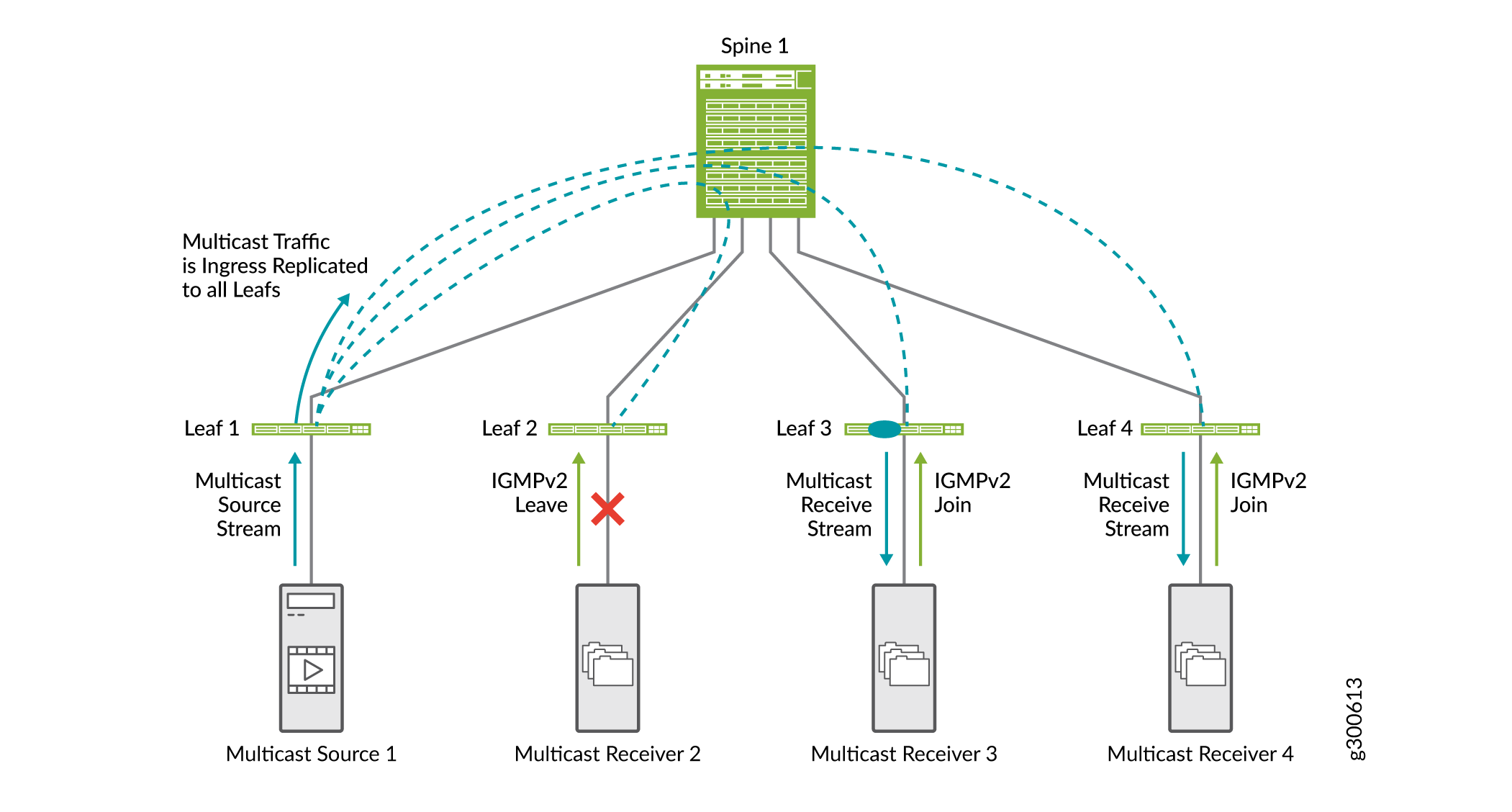
Em redes EVPN-VXLAN, apenas o IGMP versão 2 é suportado.
Para obter mais informações sobre bisbilhotamento IGMP, consulte Visão geral do encaminhamento multicast com bisbilhotamento IGMP ou bisbilhotamento MLD em um ambiente EVPN-VXLAN.
Encaminhamento multicast seletivo
O encaminhamento seletivo de Ethernet multicast (SMET) oferece maior eficiência de rede de ponta a ponta e reduz o tráfego na rede EVPN. Ele conserva o uso de largura de banda no núcleo da malha e reduz a carga em dispositivos de saída que não têm ouvintes.
Dispositivos com IGMP snooping habilitado usam encaminhamento multicast seletivo para encaminhar tráfego multicast de maneira eficiente. Com a bisbilhotagem IGMP habilitada, um dispositivo leaf envia tráfego multicast apenas para a interface de acesso com um receptor interessado. Com o SMET adicionado, o dispositivo leaf envia seletivamente tráfego multicast apenas para os dispositivos leaf no núcleo que manifestaram interesse nesse grupo de multicast.
A Figura 20 mostra o fluxo de tráfego SMET junto com a espionagem IGMP.
-
O receptor multicast 2 envia uma solicitação de licença IGMPv2.
-
Os receptores multicast 3 e 4 enviam uma solicitação de junção IGMPv2.
-
Quando o leaf 1 recebe tráfego multicast de entrada, ele replica o tráfego apenas para dispositivos leaf com receptores interessados (dispositivos leaf 3 e 4) e o encaminha para o spine.
-
O spine encaminha o tráfego para os dispositivos leaf 3 e 4.
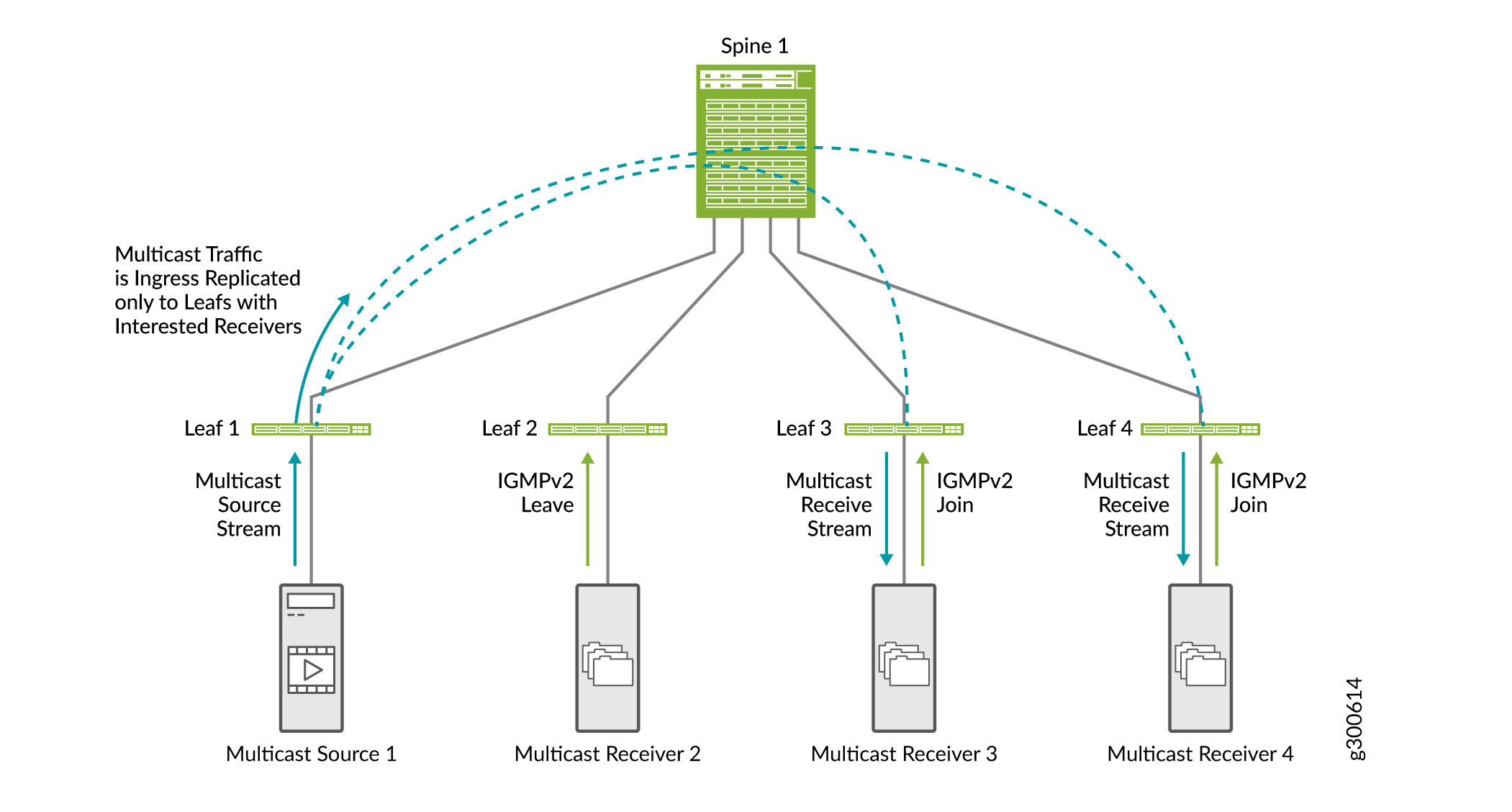
Você não precisa habilitar o SMET; ele é ativado por padrão quando o rastreamento IGMP está configurado no dispositivo.
Para obter mais informações sobre o SMET, consulte Visão geral do encaminhamento multicast seletivo.
Replicação assistida de tráfego multicast
O recurso de replicação assistida (AR) descarrega dispositivos leaf de malha EVPN-VXLAN das tarefas de replicação de entrada. A folha de entrada não replica o tráfego multicast. Ele envia uma cópia do tráfego multicast para um spine configurado como um dispositivo replicador AR. O dispositivo replicador AR distribui e controla o tráfego multicast. Além de reduzir a carga de replicação nos dispositivos leaf de entrada, esse método conserva a largura de banda na malha entre o leaf e o spine.
A Figura 21 mostra como o AR funciona junto com o IGMP snooping e o SMET.
-
O Leaf 1, que é configurado como o dispositivo leaf AR, recebe tráfego multicast e envia uma cópia para o spine que está configurado como o dispositivo replicador AR.
-
O spine replica o tráfego multicast. Ele replica o tráfego para dispositivos leaf que são provisionados com o VLAN VNI no qual o tráfego multicast se originou do Leaf 1.
Como temos bisbilhotamento IGMP e SMET configurados na rede, o spine envia o tráfego multicast apenas para dispositivos leaf com receptores interessados.
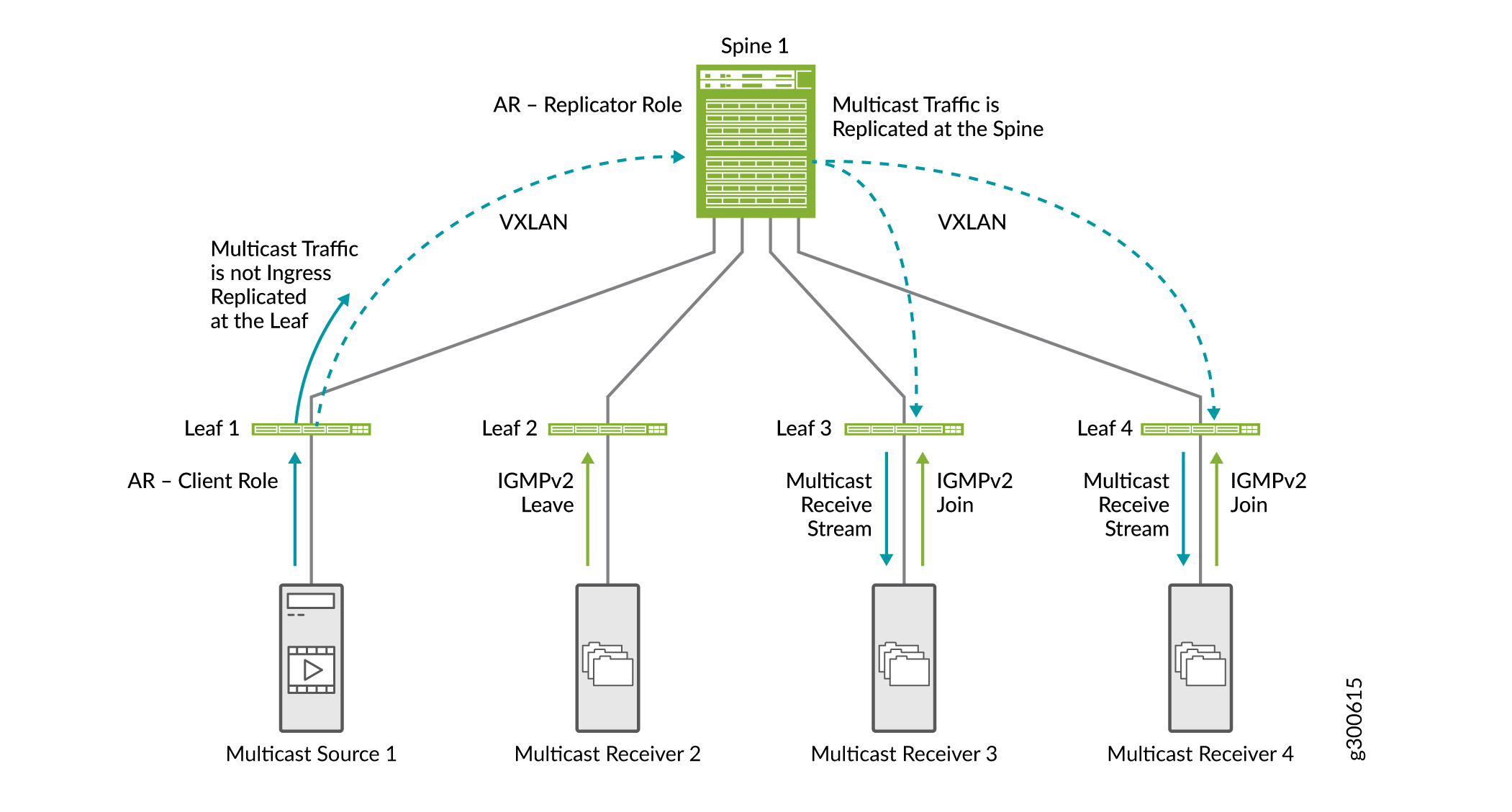
Neste documento, mostramos otimizações de multicast em pequena escala. Em uma rede em grande escala com muitos spines e leafs, os benefícios das otimizações são muito mais aparentes.
Multicast intersubnet otimizado para redes overlay ERB
Quando você tem fontes e receptores de multicast dentro e fora de uma malha de overlay de ERB, pode configurar o multicast intersubnet otimizado (OISM) para permitir um fluxo de tráfego multicast eficiente em escala.
O OISM usa um modelo de roteamento local para tráfego multicast, que evita o hairpinning de tráfego e minimiza a carga de tráfego dentro do núcleo EVPN. O OISM encaminha o tráfego multicast somente na VLAN de origem multicast. Para receptores intersubnet, os dispositivos leaf usam interfaces IRB para rotear localmente o tráfego recebido na VLAN de origem para outras VLANs receptoras no mesmo dispositivo. Para otimizar ainda mais o fluxo de tráfego multicast na malha EVPN-VXLAN, o OISM usa bisbilhotamento IGMP e SMET para encaminhar o tráfego na malha apenas para dispositivos leaf com receptores interessados.
O OISM também permite que a malha encaminhe efetivamente o tráfego de fontes multicast externas para receptores internos e de fontes multicast internas para receptores externos. O OISM usa um domínio de ponte suplementar (SBD) dentro da malha para encaminhar o tráfego multicast recebido nos dispositivos leaf de borda de fontes externas. O design do SBD preserva o modelo de roteamento local para tráfego de origem externa.
Você pode usar o OISM com AR para reduzir a carga de replicação em dispositivos leaf OISM de menor capacidade. (Consulte Replicação assistida de tráfego multicast.)
Veja a Figura 22 para uma malha simples com OISM e AR.
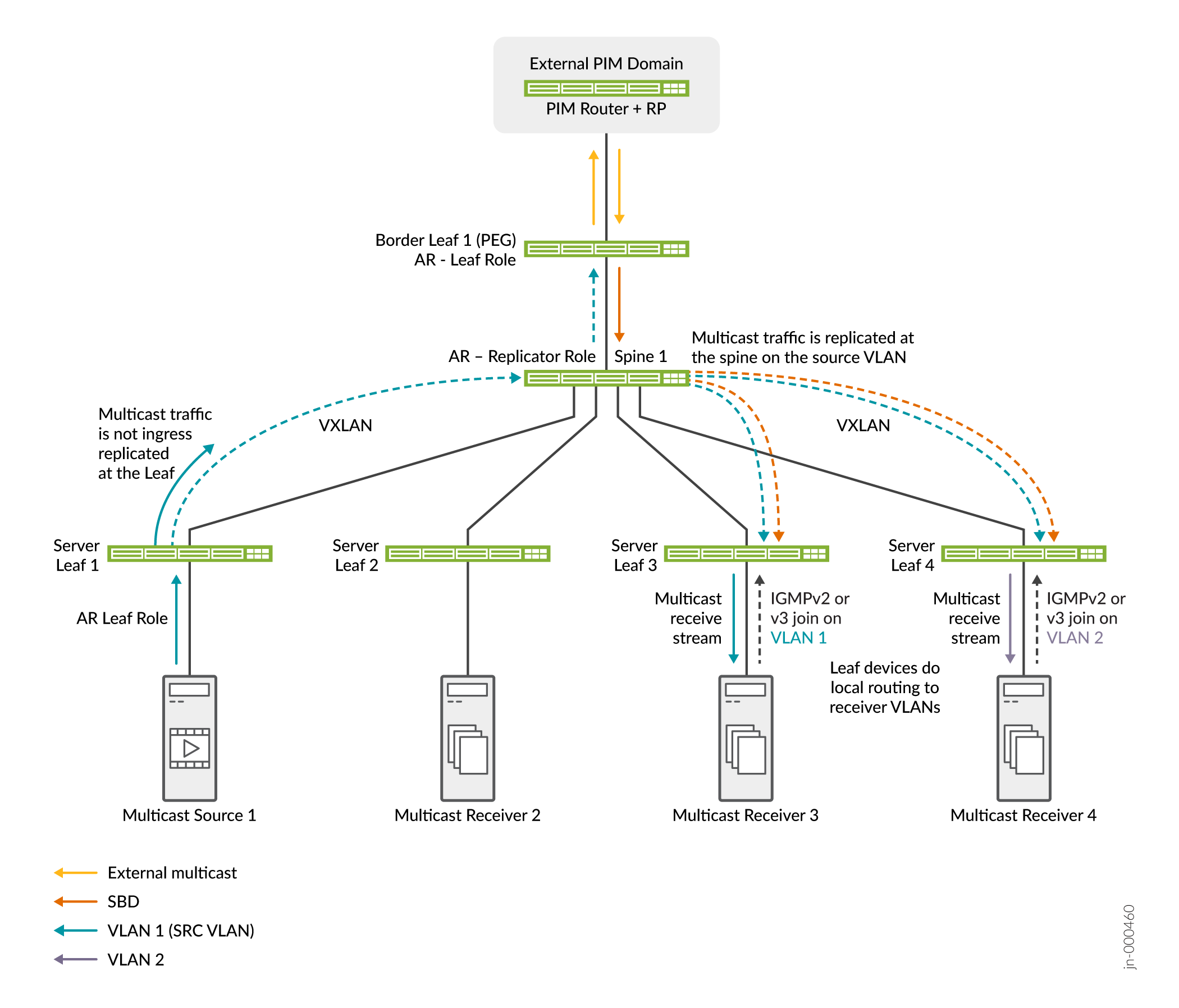
A Figura 22 mostra dispositivos leaf e leaf de servidor OISM, Spine 1 na função de replicador AR e Server Leaf 1 como uma fonte multicast na função leaf AR. Uma fonte externa e receptores também podem existir no domínio PIM externo. OISM e AR trabalham juntos neste cenário da seguinte forma:
-
Os receptores multicast atrás do Server Leaf 3 na VLAN 1 e atrás do Server Leaf 4 na VLAN 2 enviam IGMP Joins mostrando interesse no grupo multicast. Receptores externos também podem ingressar no grupo multicast.
-
A origem multicast por trás do Server Leaf 1 envia tráfego multicast para o grupo na malha na VLAN 1. O Server Leaf 1 envia apenas uma cópia do tráfego para o replicador AR no Spine 1.
-
Além disso, o tráfego de origem externa para o grupo multicast chega ao Border Leaf 1. O Border Leaf 1 encaminha o tráfego no SBD para o Spine 1, o replicador AR.
-
O replicador AR envia cópias da fonte interna na VLAN de origem e da fonte externa no SBD para os dispositivos leaf OISM com receptores interessados.
-
Os dispositivos leaf do servidor encaminham o tráfego para os receptores na VLAN de origem e roteiam localmente o tráfego para os receptores nas outras VLANs.
Otimização de tráfego de máquina virtual de entrada para EVPN
Quando máquinas virtuais e hosts são movidos dentro de um data center ou de um data center para outro, o tráfego de rede pode se tornar ineficiente se não for roteado para o gateway ideal. Isso pode acontecer quando um host é realocado. A tabela ARP nem sempre é liberada e o fluxo de dados para o host é enviado para o gateway configurado, mesmo quando há um gateway mais ideal. O tráfego é "trombonado" e roteado desnecessariamente para o gateway configurado.
A otimização de tráfego de máquina virtual de entrada (VMTO) fornece maior eficiência de rede e otimiza o tráfego de entrada e pode eliminar o efeito trombone entre VLANs. Quando você habilita o VMTO de entrada, as rotas são armazenadas em uma tabela de roteamento e encaminhamento virtual (VRF) de Camada 3 e o dispositivo roteia o tráfego de entrada diretamente de volta ao host que foi realocado.
A Figura 23 mostra o tráfego com trombo sem VMTO de entrada e o tráfego otimizado com o VMTO de entrada habilitado.
Sem o VMTO de entrada, os Spine 1 e 2 de DC1 e DC2 anunciam a rota de host IP remoto 10.0.0.1 quando a rota de origem é de DC2. O tráfego de entrada pode ser direcionado para Spine 1 e 2 no DC1. Em seguida, ele é roteado para Spine 1 e 2 no DC2, onde a rota 10.0.0.1 foi movida. Isso causa o efeito tromboning.
Com o VMTO de entrada, podemos obter o caminho de encaminhamento ideal configurando uma política para a rota do host IP (10.0.01) para ser anunciada apenas pelos Spine 1 e 2 do DC2, e não do DC1 quando o host IP for movido para o DC2.
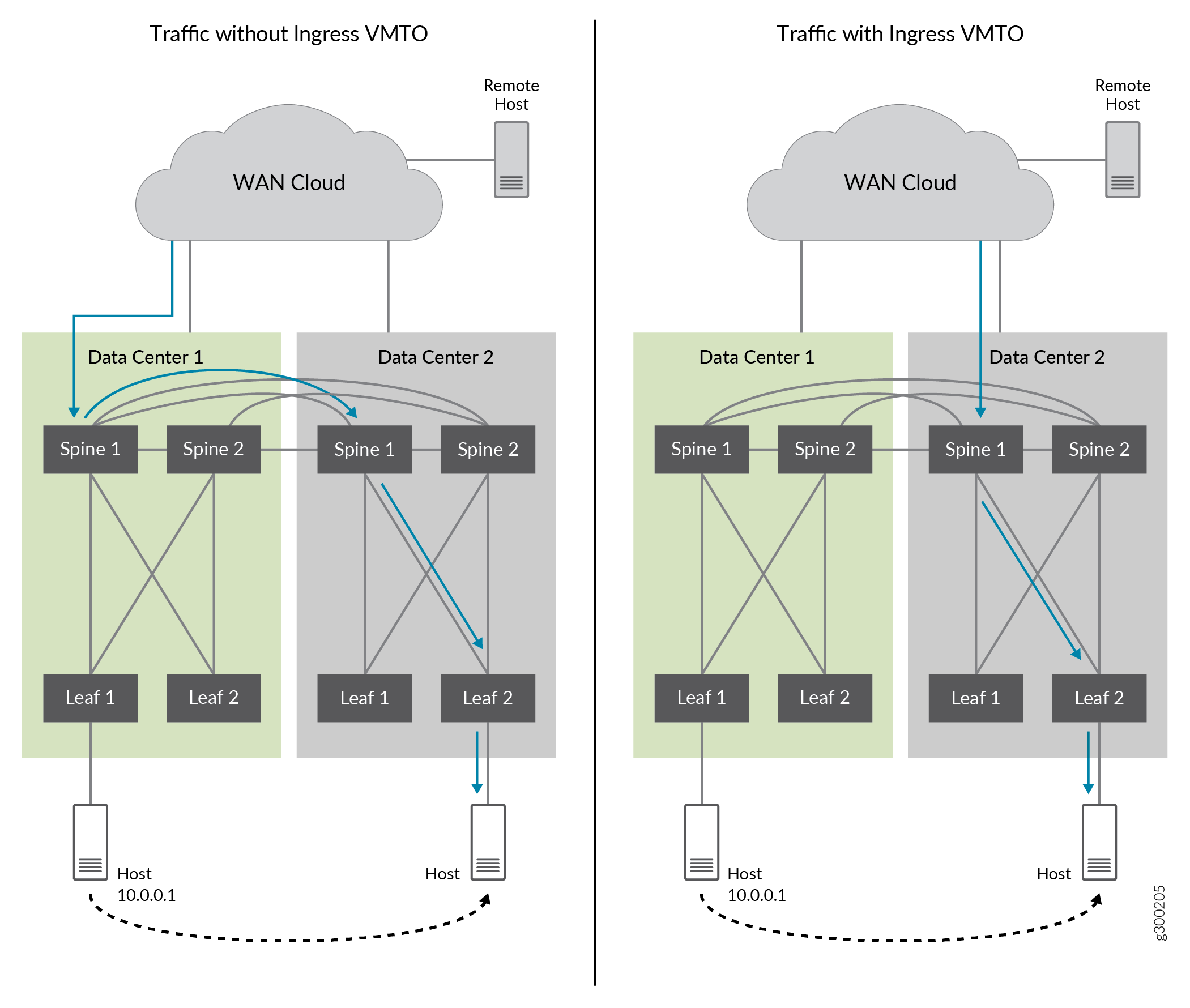 de entrada
de entrada
Para obter informações sobre como configurar o VMTO, consulte Configurando o VMTO.
Transmissão DHCP
 de CRB
de CRB
O bloco de construção de retransmissão do protocolo de configuração dinâmica de host (DHCP) permite que a rede passe mensagens DHCP entre um cliente DHCP e um servidor DHCP. A implementação de retransmissão DHCP neste bloco de construção move pacotes DHCP através de uma sobreposição CRB onde o gateway está localizado na camada spine.
O servidor DHCP e os clientes DHCP se conectam à rede usando interfaces de acesso em dispositivos leaf. O servidor DHCP e os clientes podem se comunicar entre si pela rede existente sem configuração adicional quando o cliente e o servidor DHCP estão na mesma VLAN. Quando um cliente e um servidor DHCP estão em VLANs diferentes, o tráfego DHCP entre o cliente e o servidor é encaminhado entre as VLANs através das interfaces IRB em dispositivos spine. Você deve configurar as interfaces IRB nos dispositivos spine para suportar a retransmissão DHCP entre VLANs.
Para obter informações sobre como implementar a retransmissão DHCP, consulte Design e implementação da retransmissão DHCP.
Reduzindo o tráfego ARP com sincronização e supressão de ARP (Proxy ARP)
O objetivo da sincronização ARP é sincronizar tabelas ARP em todos os VRFs que atendem a uma sub-rede overlay para reduzir a quantidade de tráfego e otimizar o processamento para dispositivos de rede e sistemas finais. Quando um gateway IP de uma sub-rede aprende sobre uma vinculação ARP, ele a compartilha com outros gateways para que eles não precisem descobrir a mesma vinculação ARP de forma independente.
Com a supressão de ARP, quando um dispositivo leaf recebe uma solicitação ARP, ele verifica sua própria tabela ARP que é sincronizada com os outros dispositivos VTEP e responde à solicitação localmente em vez de inundar a solicitação ARP.
O ARP proxy e a supressão de ARP são habilitados por padrão em todos os switches da Série QFX que podem atuar como dispositivos leaf em um overlay de ERB. Para obter uma lista desses switches, consulte Designs de referência de malha EVPN-VXLAN de data center — Resumo do hardware suportado.
As interfaces IRB no dispositivo leaf entregam solicitações ARP e NDP de dispositivos leaf locais e remotos. Quando um dispositivo leaf recebe uma solicitação ARP ou NDP de outro dispositivo leaf, o dispositivo receptor pesquisa seu banco de dados de ligações de endereço MAC+IP para o endereço IP solicitado.
Se o dispositivo encontrar a vinculação de endereço MAC+IP em seu banco de dados, ele responderá à solicitação.
Se o dispositivo não encontrar a vinculação de endereço MAC+IP, ele inundará a solicitação ARP para todos os links Ethernet na VLAN e os VTEPs associados.
Como todos os dispositivos leaf participantes adicionam as entradas ARP e sincronizam suas tabelas de roteamento e ponte, os dispositivos leaf locais respondem diretamente às solicitações de hosts conectados localmente e eliminam a necessidade de dispositivos remotos responderem a essas solicitações ARP.
Para obter informações sobre como implementar a sincronização ARP, o ARP de proxy e a supressão de ARP, consulte Habilitar o ARP de proxy e a supressão de ARP para a sobreposição de ponte roteada de borda.
Recursos de Segurança de Porta de Camada 2 em Sistemas Finais Conectados por Ethernet
As overlays CRB e ERB suportam os recursos de segurança em sistemas finais conectados à Ethernet de Camada 2 que descrevemos nas próximas seções.
Para obter mais informações sobre esses recursos, consulte Filtragem MAC, controle de tempestade e suporte a espelhamento de porta em um ambiente EVPN-VXLAN.
Para obter informações sobre como configurar esses recursos, consulte Configurando Recursos de Segurança de Porta de Camada 2 em Sistemas Finais Conectados à Ethernet.
- Prevenção de tempestades de tráfego BUM com controle de tempestade
- Usando filtragem MAC para aumentar a Segurança da porta
- Analisando o tráfego usando o espelhamento de porta
Prevenção de tempestades de tráfego BUM com controle de tempestade
O controle de tempestade pode impedir que o tráfego excessivo degrade a rede. Ele diminui o impacto das tempestades de tráfego BUM monitorando os níveis de tráfego nas interfaces EVPN-VXLAN e descartando o tráfego BUM quando um nível de tráfego especificado é excedido.
Em um ambiente EVPN-VXLAN, o controle de tempestade monitora:
Tráfego BUM de Camada 2 que se origina em um VXLAN e é encaminhado para interfaces dentro do mesmo VXLAN.
Tráfego multicast de Camada 3 que é recebido por uma interface IRB em um VXLAN e é encaminhado para interfaces em outro VXLAN.
Usando filtragem MAC para aumentar a Segurança da porta
A filtragem MAC aumenta a segurança da porta limitando o número de endereços MAC que podem ser aprendidos dentro de uma VLAN e, portanto, limita o tráfego em uma VXLAN. Limitar o número de endereços MAC protege o switch de inundar a tabela de comutação Ethernet. A inundação da tabela de comutação Ethernet ocorre quando o número de novos endereços MAC aprendidos faz com que a tabela transborde e os endereços MAC aprendidos anteriormente são liberados da tabela. O switch reaprende os endereços MAC, o que pode afetar o desempenho e introduzir vulnerabilidades de segurança.
Neste blueprint, a filtragem MAC limita o número de pacotes aceitos que são enviados para interfaces de acesso voltadas para a entrada com base em endereços MAC. Para obter mais informações sobre como funciona a filtragem de MAC, consulte as informações de limitação de MAC em Entendendo a limitação de MAC e a limitação de movimento de MAC.
Analisando o tráfego usando o espelhamento de porta
Com o espelhamento de porta baseado em analisador, você pode analisar o tráfego até o nível de pacote em um ambiente EVPN-VXLAN. Você pode usar esse recurso para aplicar políticas relacionadas ao uso da rede e ao compartilhamento de arquivos e para identificar fontes de problemas localizando o uso anormal ou intenso da largura de banda por estações ou aplicativos específicos.
O espelhamento de porta copia os pacotes que entram ou saem de uma porta ou entram em uma VLAN e envia as cópias para uma interface local para monitoramento local ou para uma VLAN para monitoramento remoto. Use o espelhamento de porta para enviar tráfego a aplicativos que analisam o tráfego para fins como monitorar a conformidade, aplicar políticas, detectar intrusões, monitorar e prever padrões de tráfego, correlacionar eventos e assim por diante.