Juniper Networks Contrail Pipelines Demo


Let’s get technical: A Contrail pipelines demo in less than 20 minutes
In this video from Tech Field Day 2021, Juniper’s Shean Legion and Rosh PR provide a step-by-step demo of the GitOps mechanism approach to bringing infrastructure as code to Kibernetes-based network environments.
You’ll learn
How you can use Contrail pipelines to validate the stack
How to automate reliability with CN2 and GitOps based on Argo workflow
How you can leverage Contrail test suites with qualified Argo versions
Who is this for?
Host
Guest speakers
Transcript
0:08 yeah so so contrail pipelines this is
0:10 really our uh our get ops mechanism and
0:12 the get ops approach that we're bringing
0:13 into control for kubernetes environment
0:16 though the whole real idea behind this
0:19 here
0:20 is being able to turn around and take
0:22 automate some of the reliability for
0:24 contrail
0:25 and this is based off an argos 2d you
0:28 know workflow so some of the nice parts
0:30 here for those that are familiar with
0:31 argo it's designed specifically for
0:32 kubernetes
0:34 and it's already included in some other
0:35 uh you know distros such as open shift
0:37 and so forth um you know it's
0:39 facilitating get ops
0:41 method single source of truth
0:43 uh towards that environment so you're
0:45 able to turn around and leverage a bunch
0:47 of different test suites that we're
0:48 going to have uh with this as well and
0:50 then also do uh you know kind of
0:52 handling of
0:53 configuration drift in in some of those
0:55 things and we'll uh we'll kind of jump
0:57 right into it here
1:02 quick overview here just kind of some
1:04 some ideas around validating the stack
1:05 and how you can use control pipelines to
1:07 do that
1:08 um so you know you're you have a cicd
1:11 test repository
1:13 you're able to turn around and bring
1:14 that into the the argo workflow
1:17 and then run some pre-checks if you'd
1:18 like
1:20 and you can do this based upon the
1:22 control networking releases so the idea
1:23 here is to go ahead and be able to do uh
1:26 more
1:27 additional testing and qualification in
1:30 a development environment and then
1:32 being able to handle upgrades and so
1:34 forth in a very holistic manner where
1:37 it's not one component at a time
1:39 but you can integrate multiple
1:40 components together for some of those
1:42 functional tests
1:44 as you go to to upgrade your production
1:46 environment
1:48 so again another component of kind of
1:50 extending a lot of work that's already
1:52 been done within the kubernetes
1:53 ecosystem
1:54 in this case it's it's uh specifically
1:56 with um argo and with that said i think
1:59 rosh is going to go ahead and uh walk us
2:01 through a demo
2:03 i'm rush and i'm a devops engineer at
2:05 juniper
2:06 so as sean uh has mentioned uh um
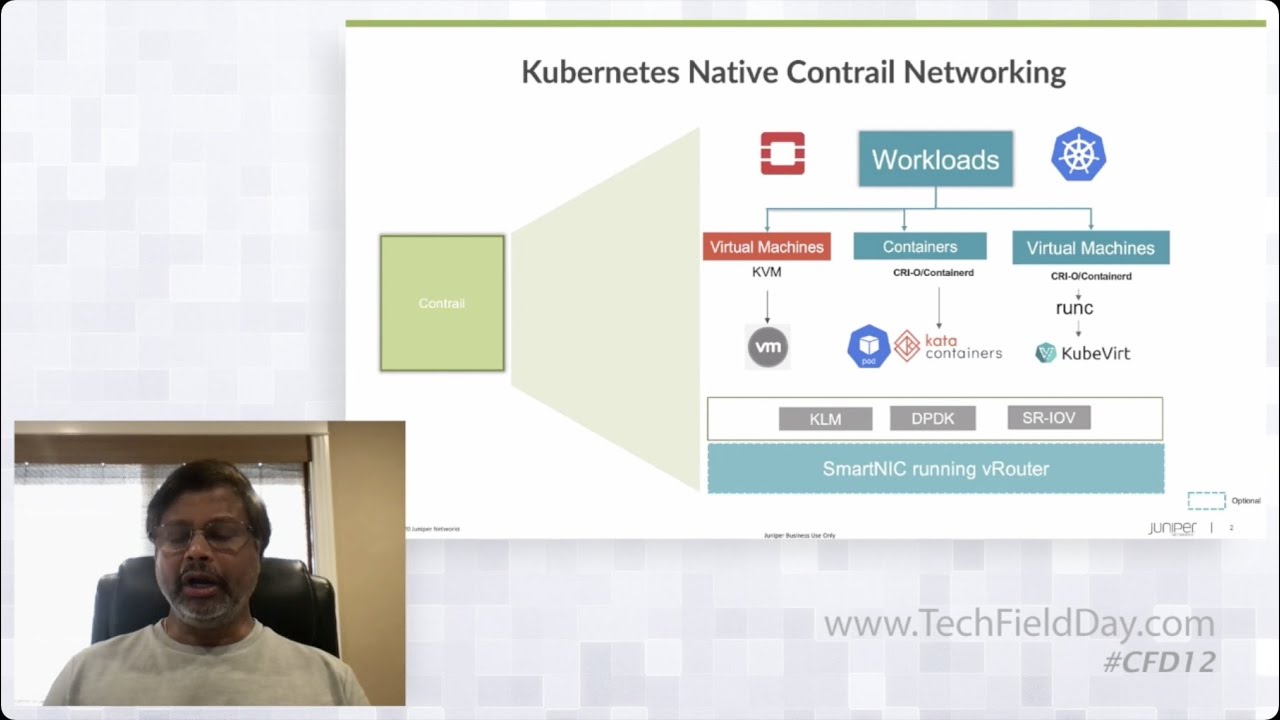
2:10 the control pipeline uh totally
2:13 automates uh um
2:15 most of these configs uh provisioning
2:17 and uh uh updates extra and this uh
2:21 really helps in a larger system
2:23 especially when you have a huge large
2:26 number of clusters and uh the the number
2:28 of conflicts when it goes uh
2:30 more than uh what uh as a user can
2:33 manage or an administrator can manage
2:35 themselves so um so as a part of this
2:38 demo uh i will be uh
2:40 uh sure you know uh creating uh two uh
2:44 namespaces so which is pre-provisioned
2:47 and these are isolated name spaces and i
2:50 will be creating uh
2:51 the virtual network router in each of
2:53 these namespaces plus
2:55 i've provisioned a a
2:58 an app a wordpress app a shop away and i
3:01 also approached and
3:03 in the db tire approach and
3:05 the uh mysql database application so
3:08 there's there's a web tire and there's a
3:09 db tire these are the two name spaces
3:11 so um the virtual network router in the
3:14 db tire i haven't provisioned yet
3:17 because of which
3:18 the uh shop away application is unable
3:21 to access
3:23 the db uh
3:24 at 3306 board so i'll show you
3:28 how i approaching that to the gate and
3:31 that gets
3:32 immediately uh
3:34 applied into the system
3:36 so let's jump into the demo so this is
3:38 the git repo that i'll be using for the
3:40 demo uh here as part of the demo i have
3:43 created a base
3:46 application and network application and
3:48 the applications itself so the uh the
3:51 base folder basically contains all the
3:53 configurations related to the name space
3:55 and the network folder contains all the
3:58 network router configurations and the
4:00 application has the configuration
4:01 related to the database and the shop
4:04 away application
4:05 so just to give an idea what's there in
4:08 these
4:10 so if you could notice this the virtual
4:12 network router configuration that's
4:13 present here
4:15 um
4:16 so these are mapped as
4:18 an application basically that's a
4:21 arguable construct uh so there are three
4:23 uh three different constructs that
4:25 will be created here in argo cd so i
4:27 have created
4:29 the system base which basically is
4:33 configured to use the base directory in
4:35 the uh
4:36 in the git repo similarly i have the
4:39 network
4:41 application which is configured to use
4:42 the network and i have also deployed the
4:46 database and the shopping application so
4:48 as you could see this traffic
4:49 application is currently
4:51 is in progress and it is basically
4:54 not
4:55 able to reach out to the port so it is
4:57 in crash loop back so i i'll show that
4:59 as a part of the uh the cube con
5:02 console
5:05 so
5:06 yeah going back here uh
5:09 to the network configuration
5:11 so as you could see here i have
5:13 these uh
5:15 two configurations pulled up from the
5:17 network
5:19 here so there's a network policy and
5:21 then there's this vnr so this is got
5:24 pulled in and that is what you are
5:26 seeing here and this is another conflict
5:29 that is
5:31 pre-created by the
5:32 network router once it is deployed so
5:36 let me go ahead and create
5:40 and
5:41 i have i have a sample folder here where
5:44 i have placed uh
5:46 some sample configs which is basically
5:48 has the vnr configs what i want so let
5:51 me just show you what's there as a part
5:54 of the vnr config so here if you could
5:56 there's a virtual network router and
5:58 as a web type that is uh being created
6:01 and it's being attached to the uh a db
6:03 tire
6:04 so let me copy it
6:10 into the network folder here
6:26 it's uh
6:27 four to five minutes for the
6:29 ergo to get itself refreshed but on the
6:31 interest of time i will go ahead and
6:33 refresh it manually
6:35 so if you could see the new
6:37 configuration got pulled in
6:40 and i'll go for the sync
6:43 so
6:44 this gets
6:45 synced into the system
6:51 yeah you see all the
6:54 configs in here
6:57 that's got created so
7:00 now
7:01 let's go to the application so i have
7:04 the
7:05 uh shopping application here let's see
7:07 whether the application is reachable now
7:10 so let me
7:12 go and
7:14 check out the logs okay so as you would
7:17 have noticed
7:22 the application initially was unable to
7:26 reach the the database server so
7:29 once we move the we push the config it
7:33 is able to reach out the server now
7:37 and it should come up in a minute
7:40 yes it's come up
7:43 there we go
7:44 uh yeah the application is live
7:46 um so this basically eases the whole uh
7:49 operation so
7:51 um so we we
7:53 we are giving this as a part of uh the
7:56 test suit for
7:57 as a part of the contrail itself so
8:01 now let me showcase you how the drift uh
8:04 happens and uh and i'll go ahead and
8:06 manually change the
8:08 system configuration manually and uh the
8:10 ergo
8:11 identifies this automatically and it is
8:15 able to notify you about the change that
8:17 happened out of bound and once that is
8:21 found
8:22 we can we have a choice to make that uh
8:25 sync manual or uh automated so currently
8:28 i've made that manual because uh it is
8:31 too fast that it just reapplies the
8:32 config so i wanna show you how it uh
8:35 showcase it it shows it makes the diff
8:38 between the old and the new
8:39 configuration that got changed
8:41 so as you could see here uh in the
8:45 config so so this is the configuration
8:48 that we have here now let me go ahead
8:50 and change the network policy which is
8:53 here where we have
8:56 the following network con
8:58 policy here with the 3303 and 80 port so
9:02 this is the live config that you see
9:03 here
9:04 so as a part of this this this is the
9:06 live config in the system
9:08 so let me go ahead and change the config
9:14 so this is the npdb tire config that i'm
9:16 going to change
9:17 uh which is an out of bound change
9:21 so let me try to remove these two ports
9:28 so as you could notice there it is ergo
9:31 is showing that particular policy as out
9:33 of sync so you if you could go in and
9:35 look for the diff you would specifically
9:38 be able to see the difference between
9:39 the uh
9:40 the the one that is present and then one
9:43 one
9:44 was there earlier and so if you
9:47 so if you make this automated sync
9:48 policy has automated which currently
9:50 have disabled here
9:51 so if we make this automated this this
9:53 would have synced by now so let me go
9:55 ahead and try
9:56 to sync it manually
10:00 yep it's got sync and
10:04 so as you could see just got uh so this
10:05 this basically you know identifies the
10:07 configuration tips and it is able to uh
10:09 reprovision it um
10:10 so
10:12 so as a summary uh you know uh it it
10:15 totally avoids the whole git the
10:17 pipeline really avoids the repeatability
10:20 part of it and it helps you in uh idea
10:23 auditing the whole conflicts that is
10:25 being
10:26 managed across all different systems and
10:29 since we are using gate it also helps in
10:32 reviewing the kind of changes that is
10:34 being provisioned into the system uh
10:37 similarly uh git being a single source
10:38 of truth it can be uh
10:42 that's the only place where the user the
10:44 administrators will be provisioning
10:45 their confidence they really don't need
10:47 to go into the different kubernetes
10:50 clusters that they have and manage it
10:52 which becomes more cumbersome with more
10:54 more the number of or the larger the
10:56 system is
10:58 it also helps you in uh you know having
11:00 our back policies uh to manage your
11:03 configuration so that only specific
11:05 users are given specific
11:06 uh uh uh right access to uh some of the
11:09 conflicts so uh overall uh um the the
11:13 git pipeline uses the whole operations
11:15 part of uh
11:17 uh your kubernetes config and cn2 config
11:20 management
11:21 that's really awesome rosh um thank you
11:24 so much for the phenomenal demo um first
11:26 of all i want to thank you all for the
11:27 great questions today we covered a broad
11:30 range of topics hopefully we showed you
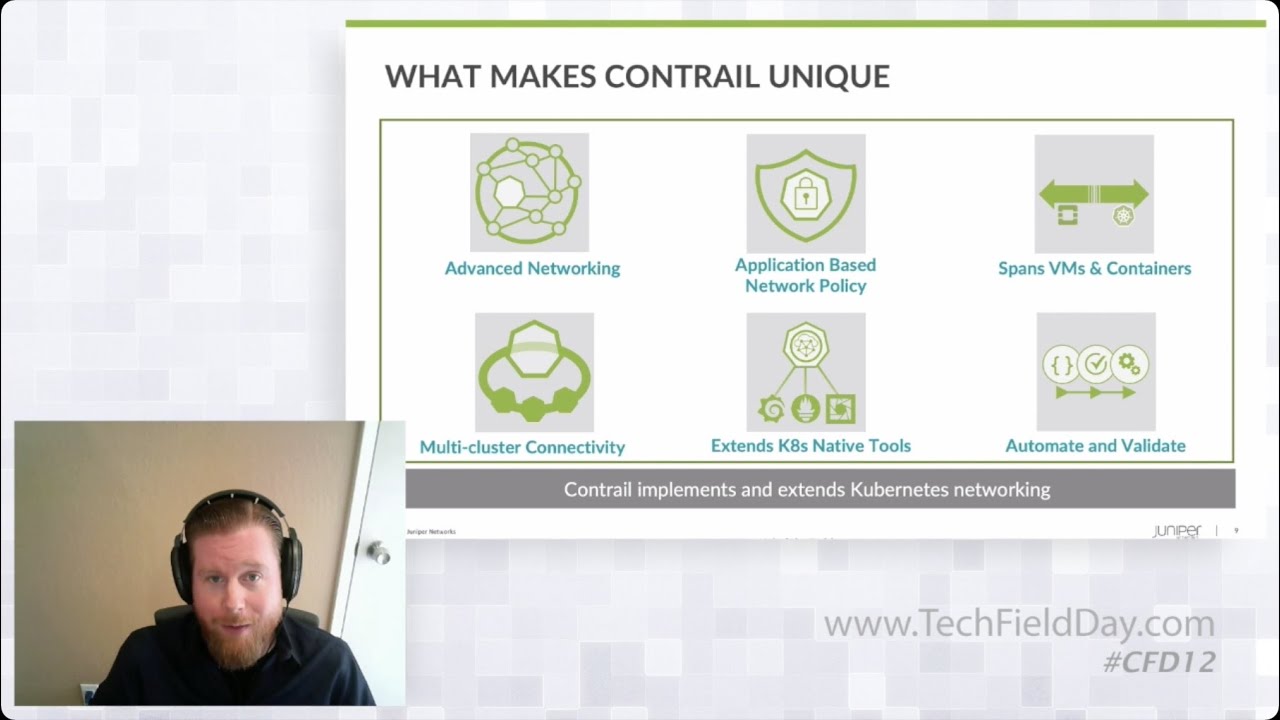
11:32 how contrail extends the default
11:34 networking behavior of kubernetes uh
11:37 offering
11:38 um
11:39 just a very flexible powerful way to
11:42 deliver default pod networking but at
11:44 the same time augmenting the default
11:46 networking behaviors with a really rich
11:49 set of tools that you can use to build
11:50 custom topologies manage security
11:53 and then you can further extend what
11:56 we've created uh using pipelines and get
11:59 ops to add reliability and scale to your
12:01 cluster management
12:03 something sneaky we actually showed you
12:05 i think three or four different
12:06 interfaces today
12:08 and that really goes a long way to show
12:11 the power of our kubernetes api
12:13 integration essentially whether you're
12:14 using kubecuttle canines lens or argo cd
12:18 you can control and configure contrail
12:21 in a kubernetes cluster so you can pick
12:22 the right tool to to do the job
12:25 uh this is frank was i got a quick
12:27 question uh on on your cni in general i
12:31 i assume you guys don't do any like
12:33 network like low-level encryption
12:35 between these networks right like it's
12:36 just a straight old normal ip network
12:38 right like there's no
12:40 you know encryption between
12:43 clusters for example yeah there's
12:45 there's no encryption in the overlay the
12:46 overlay tunnels that we use are um
12:49 either mpls or udp based so just normal
12:52 udp traffic or vxlan base depending on
12:54 what network devices we're trying to
12:56 talk to and then we leverage encryption
12:58 from other layers of the stack
13:00 i i figured um
13:03 one my other question is you have you
13:05 done any performance comparison with
13:07 other cni's i i you guys are doing a lot
13:09 more and i was just curious you know if
13:13 what if any performance hit would you
13:15 see
13:16 switching to contrail
13:18 um so like percent was mentioning we
13:20 have a couple different flavors of the
13:21 data plan and each flavor is really fit
13:24 for a different performance profile so
13:26 the kernel modules are capable of
13:28 multiple tens of gigs of traffic um
13:31 depending on the amount of hardware they
13:32 have like newer cpus will get better
13:34 throughput
13:35 um one once we need to get up above the
13:38 multi-10 gig mark
13:40 closer to 100 gig of throughput we
13:42 leverage dpdk or smartnex
13:44 dpdk carves off cpus from the system
13:47 itself to give you more assured
13:49 forwarding performance and fixed latency
13:51 and
13:54 the
13:55 smartnics move the entire data plane to
13:57 an accelerator on the network interface
14:00 itself a lot of this seemed to be seemed
14:03 to me like it wouldn't be something i'd
14:05 run in my own data center
14:07 do you have people currently using this
14:09 solution in
14:10 aws and azure are they doing it on
14:13 managed services like aks or are they
14:16 doing it on
14:18 their own self-provisioned kubernetes
14:20 clusters
14:21 there's a mix we have customers who are
14:23 using self-provision clusters in the
14:26 cloud we also have a subset of those
14:28 using managed kubernetes instances
14:32 there is
14:33 pretty much
14:35 everything we've shown you today can be
14:37 used
14:39 in public cloud
14:41 but the the interfaces or the way that
14:43 we expose services changes a little so
14:46 for example we'll use a network load
14:47 balancer to front-end um
14:50 services when we're deploying in a
14:51 public cloud versus advertising routes
14:53 out to a gateway
14:55 that'll change like
14:57 the front end service will change from
14:58 say a load balancer to just node port as
15:00 we plug into the the nlbs and the public
15:02 cloud
15:03 um but yeah the the overlay traffic for
15:05 it is uh
15:07 overlay traffic forwarding network
15:08 policy enforcement virtual networks all
15:11 of that is abstracted away from the
15:13 public cloud so regardless of whether
15:14 you're using a managed instance or a
15:16 self-provisioned instance of kubernetes
15:18 you can still consume all of these
15:20 features
15:23 okay i think that that could enable some
15:25 topologies that are not
15:26 normally available um
15:29 on the public clouds just because of the
15:31 limitations of how they present the
15:33 network to you
15:34 um adding your own virtual network on
15:36 top of it gives you some new options
15:38 yeah definitely and that's why we do
15:40 this right it gives you the ability to
15:43 do horrible things like stretch subnets
15:45 and wonderful things like overlap ips
15:48 one more question where do you think
15:49 this is moving like in two three years
15:51 where do you want to have that product
15:53 what is what's the future for it i think
15:56 in um a couple years time we're going to
15:59 see uh more of a shift from openstack
16:03 and some of the classic vm orchestrators
16:05 over to kubernetes so we'll see less
16:06 concern about bridging orchestrators and
16:09 more concern about connecting clouds as
16:12 we have kubernetes clusters scattered
16:14 across public and private clouds
16:16 i think what multi-cluster is going to
16:18 become even more of a focus over the
16:21 next couple years
16:22 multi-clustering kubernetes has just
16:24 really started to be solved as a problem
16:27 so i will see more maturity in that
16:29 space as well
16:31 i'm still holding out i hope that
16:33 smartnics are going to become ubiquitous
16:35 within the next couple years so we'll
16:37 see where we need it just ludicrous data
16:39 plane performance out of the smartnix
16:42 but also i'm i'm really hoping on the
16:44 total opposite side that we gain more
16:46 portability from operating systems and
16:48 infrastructure through enhancements like
16:50 ebpf and the data plane
16:54 and other areas are like between the
16:57 openstack to kubernetes
16:59 we can have the bridge using uh
17:02 current trail networking