NESTA PÁGINA
Entendendo grupos de agregação de enlaces em um cluster de chassi
Exemplo: configuração de grupos de agregação de enlaces em um cluster de chassis
Entendendo o failover de grupo de agregação de enlaces em um cluster de chassi
Exemplo: Configuração de VRRP/VRRPv3 em interfaces de ethernet redundantes de cluster de chassi
Comportamento de grupos de agregação de enlaces específicos da plataforma
Interfaces de ethernet agregadas em um cluster de chassi
Use o Feature Explorer para confirmar o suporte de plataforma e versão para recursos específicos.
Analise a seção de comportamento de grupos de agregação de links específicos da plataforma para obter notas relacionadas à sua plataforma.
Consulte a seção informações adicionais da plataforma para obter mais informações.
A agregação de enlaces IEEE 802.3ad permite que você agrupar interfaces Ethernet para formar uma única interface de camada de link, também conhecida como grupo de agregação de links (LAG) ou pacote. Interfaces lag redundantes de ethernet (reth) combinam características de interfaces de reth e interfaces LAG. Para obter mais informações, veja os seguintes tópicos:
Entendendo grupos de agregação de enlaces em um cluster de chassi
O suporte para grupos de agregação de enlaces Ethernet (LAGs) com base no IEEE 802.3ad possibilita agregar interfaces físicas em um dispositivo autônomo. Os LAGs em dispositivos autônomos oferecem maior largura de banda de interface e disponibilidade de enlaces. A agregação de links em um cluster de chassi permite que uma interface de reth adicione mais de duas interfaces físicas para crianças, criando assim um LAG de interface de reth.
Os links agregados em uma interface de reth LAG oferecem os mesmos benefícios de largura de banda e redundância de um LAG em um dispositivo autônomo com a vantagem adicional da redundância de cluster do chassi. Um LAG de interface de reth tem dois tipos de redundância simultânea. Os links agregados dentro da interface de reth em cada nó são redundantes; se um link no agregado primário falhar, sua carga de tráfego é tomada pelos links restantes. Se os links infantis suficientes no nó principal falharem, o LAG da interface de reth pode ser configurado para que todo o tráfego em toda a interface de reth não seja suficiente para o link agregado no outro nó. Você também pode configurar o monitoramento de interface para links infantis de reth child de redundância habilitados para LACP para obter mais proteção.
As interfaces Ethernet agregadas, conhecidas como LAGs locais, também são suportadas em ambos os nós de um cluster de chassi, mas não podem ser adicionadas a interfaces de reth. Os LAGs locais são indicados na lista de interfaces de sistema usando um ae-prefixo. Da mesma forma, qualquer interface infantil de um LAG local existente não pode ser adicionada a uma interface de reth e vice-versa. Observe que é necessário que o switch (ou switches) usado para conectar os nós no cluster tenha um link LAG configurado e 802.3ad habilitado para cada LAG em ambos os nós para que os links agregados sejam reconhecidos como tal e passem o tráfego corretamente. O número máximo total de interfaces de LAG de nós individuais combinadas (ae) e interfaces de reth por cluster é de 128.
Os links infantis LAG de interface de reth de cada nó no cluster do chassi devem ser conectados a um LAG diferente nos dispositivos peer. Se um único switch peer for usado para encerrar o LAG da interface de reth, dois LAGs separados devem ser usados no switch.
Links de diferentes PICs ou IOCs e usando diferentes tipos de cabo (por exemplo, cobre e fibra óptica) podem ser adicionados ao mesmo LAG de interface de reth, mas a velocidade das interfaces deve ser a mesma e todas as interfaces devem estar no modo duplex completo. Recomendamos, no entanto, que, para fins de reduzir a sobrecarga do processamento de tráfego, as interfaces do mesmo PIC ou IOC sejam usadas sempre que viável. Independentemente disso, todas as interfaces configuradas em uma interface de reth LAG compartilham o mesmo endereço MAC virtual.
O recurso de monitoramento de interface de firewalls da Série SRX permite o monitoramento de interfaces Ethernet agregadas e retoques.
A configuração redundante da interface Ethernet também inclui uma configuração de links mínimos que permite definir um número mínimo de links físicos para crianças no nó primário em uma determinada interface de reth que deve estar funcionando para que a interface esteja ativa. O valor padrão de links mínimos é 1. Observe que a configuração de links mínimos só monitora links infantis no nó primário. As interfaces Ethernet redundantes não usam interfaces físicas no nó de backup para tráfego de entrada ou saída.
A seguir, os detalhes do suporte:
-
A qualidade de serviço (QoS) é suportada em um LAG de interface de reth. No entanto, a largura de banda garantida é duplicada em todos os links. Se um link for perdido, há uma perda correspondente de largura de banda garantida.
-
O modo transparente de camada 2 e os recursos de segurança de Camada 2 são suportados em LAGs de interface de reth.
-
O Link Aggregation Control Protocol (LACP) é suportado em implantações de cluster de chassis, onde interfaces Ethernet agregadas e interfaces de reth são suportadas simultaneamente.
-
As interfaces de cluster de chassi, controle e malha não podem ser configuradas como LAGs de interface de reth ou adicionadas a um LAG de interface de reth.
-
O agrupamento de processador de rede (NP) pode coexistir com LAGs de interface de reth no mesmo cluster. No entanto, a atribuição de uma interface simultaneamente a um LAG de interface de reth e um pacote de processador de rede não é suportado.
As placas IOC2 não têm processadores de rede, mas as placas IOC1 as têm.
-
A taxa de transferência de fluxo único é limitada à velocidade de um único link físico, independentemente da velocidade da interface agregada.
Para obter mais informações sobre a agregação de enlaces de interface Ethernet e LACP, veja as informações de "Ethernet agregada" no Guia de usuário de interfaces para dispositivos de segurança.
Consulte a seção de comportamento de grupos de agregação de links específicos da plataforma para obter mais informações.
Veja também
Exemplo: configuração de grupos de agregação de enlaces em um cluster de chassis
Este exemplo mostra como configurar um grupo de agregação de enlaces de interface de reth para um cluster de chassi. A configuração de cluster do chassi oferece suporte a mais de uma interface infantil por nó em uma interface de reth. Quando pelo menos dois links físicos de interface infantil de cada nó são incluídos em uma configuração de interface de reth, as interfaces são combinadas dentro da interface de reth para formar um grupo de agregação de enlaces de interface de reth.
Requisitos
Antes de começar:
Configure interfaces redundantes de cluster de chassi. Veja exemplo: Configuração de interfaces de ethernet redundantes de cluster de chassi.
Entenda os grupos de agregação de enlaces de interface de cluster de chassi. Veja a compreensão de grupos de agregação de enlaces em um cluster de chassi.
Visão geral
Para que a agregação ocorra, o switch usado para conectar os nós no cluster deve habilitar a agregação de enlaces IEEE 802.3ad para a interface de reth interface de links físicos para crianças em cada nó. Como a maioria dos switches oferece suporte ao IEEE 802.3ad e também são capazes de LACP, recomendamos que você habilite o LACP em firewalls da Série SRX. Nos casos em que o LACP não estiver disponível no switch, você não deve habilitar o LACP em firewalls da Série SRX.
Neste exemplo, você atribui seis interfaces Ethernet à reth1 para formar o grupo de agregação de enlaces de interface Ethernet:
ge-1/0/1 — reth1
ge-1/0/2 — reth1
ge-1/0/3 — reth1
ge-12/0/1 — reth1
ge-12/0/2 — reth1
ge-12/0/3 — reth1
No máximo oito interfaces físicas por nó em um cluster, para um total de 16 interfaces infantis, podem ser atribuídas a uma única interface de reth quando um LAG de interface de reth está sendo configurado.
O Junos OS oferece suporte a LACP e LAG em uma interface de reth, que é chamada de RLAG.
Configuração
Procedimento
Configuração rápida da CLI
Para configurar rapidamente este exemplo, copie os seguintes comandos, cole-os em um arquivo de texto, remova quaisquer quebras de linha, altere todos os detalhes necessários para combinar com a configuração da sua rede, copiar e colar os comandos na CLI no nível de [edit] hierarquia e, em seguida, entrar no commit modo de configuração.
{primary:node0}[edit]
set interfaces ge-1/0/1 gigether-options redundant-parent reth1
set interfaces ge-1/0/2 gigether-options redundant-parent reth1
set interfaces ge-1/0/3 gigether-options redundant-parent reth1
set interfaces ge-12/0/1 gigether-options redundant-parent reth1
set interfaces ge-12/0/2 gigether-options redundant-parent reth1
set interfaces ge-12/0/3 gigether-options redundant-parent reth1
Procedimento passo a passo
Para configurar um grupo de agregação de enlaces de interface de reth:
Atribua interfaces Ethernet à reth1.
{primary:node0}[edit] user@host# set interfaces ge-1/0/1 gigether-options redundant-parent reth1 user@host# set interfaces ge-1/0/2 gigether-options redundant-parent reth1 user@host# set interfaces ge-1/0/3 gigether-options redundant-parent reth1 user@host# set interfaces ge-12/0/1 gigether-options redundant-parent reth1 user@host# set interfaces ge-12/0/2 gigether-options redundant-parent reth1 user@host# set interfaces ge-12/0/3 gigether-options redundant-parent reth1
Resultados
A partir do modo de configuração, confirme sua configuração entrando no show interfaces reth1 comando. Se a saída não exibir a configuração pretendida, repita as instruções de configuração neste exemplo para corrigi-la.
Para a brevidade, essa show saída de comando inclui apenas a configuração que é relevante para este exemplo. Qualquer outra configuração no sistema foi substituída por elipses (...).
user@host# show interfaces reth1
...
ge-1/0/1 {
gigether-options {
redundant-parent reth1;
}
}
ge-1/0/2 {
gigether-options {
redundant-parent reth1;
}
}
ge-1/0/3 {
gigether-options {
redundant-parent reth1;
}
}
ge-12/0/1 {
gigether-options {
redundant-parent reth1;
}
}
ge-12/0/2 {
gigether-options {
redundant-parent reth1;
}
}
ge-12/0/3 {
gigether-options {
redundant-parent reth1;
}
}
...
Se você terminar de configurar o dispositivo, entre no commit modo de configuração.
Verificação
Verificando a configuração LAG da interface Ethernet redundante
Propósito
Verifique a configuração LAG da interface de reth.
Ação
A partir do modo operacional, entre no show interfaces terse | match reth comando.
{primary:node0}
user@host> show interfaces terse | match reth
ge-1/0/1.0 up down aenet --> reth1.0
ge-1/0/2.0 up down aenet --> reth1.0
ge-1/0/3.0 up down aenet --> reth1.0
ge-12/0/1.0 up down aenet --> reth1.0
ge-12/0/2.0 up down aenet --> reth1.0
ge-12/0/3.0 up down aenet --> reth1.0
reth0 up down
reth0.0 up down inet 10.10.37.214/24
reth1 up down
reth1.0 up down inet
Entendendo o failover de grupo de agregação de enlaces em um cluster de chassi
Você controla o failover de interfaces de reth de duas maneiras:
- Usando a configuração da
minimum-linksconfiguração. Esses parâmetros determinam quantos membros físicos de um grupo de redundância devem estar em funcionamento antes que o grupo seja declarado desativado. Por padrão, esse parâmetro é definido para um, o que significa que o grupo de redundância permanece ativo se uma única interface física estiver ativa no nó primário.O valor padrão para links mínimos é 1.
- Usando a
interface-monitordeclaração de configuração juntamente com umweightvalor para cada membro no LAG. O mecanismo de ponderação da interface funciona subtraindo o peso configurado de uma interface com falha do grupo de redundância. O grupo começa com um peso de 255, e quando o grupo cai para, ou abaixo de 0, o grupo de redundância é declarado para baixo.Nota:Vale a pena notar que as declarações e
interface-monitorconfiguraçãominimum-linksfuncionam de forma independente. Atravessar o limite de links mínimos (no nó primário) ou o limite de 0 no grupo de redundância desencadeia uma transferência.
Na maioria dos casos, é uma prática recomendada configurar os pesos do monitoramento da interface de acordo com a minimum-links configuração. Essa configuração exige que os pesos sejam igualmente distribuídos entre os links monitorados de modo que, quando o número de links ativos de interface física fica abaixo da minimum-links configuração, o peso computado para esse grupo de redundância também cai para, ou abaixo, zero. Isso desencadeia um failover das interfaces de reth interfaces grupo de agregação de enlaces (LAG) porque tanto o número de links físicos fica abaixo do minimum-links valor e o peso do grupo LAG cai abaixo de 0.
Para demonstrar essa interação, considere um LAG de interface reth0 com quatro links físicos subjacentes:
- O LAG está configurado com uma
minimum-linksconfiguração de 2. Com essa configuração, o failover é desencadeado quando o número de links físicos ativos no nó primário é inferior a 2.Nota:Quando o link físico está ativo e o LACP está desativado, um failover do grupo de agregação de enlaces de interfaces de reth (LAG) é acionado.
-
Os
Interface-monitorvalores de peso são usados para monitorar o status do link LAG e calcular corretamente o peso do failover.
Configure a interface subjacente anexada ao reth LAG.
{primary:node0}[edit]
user@host# set interfaces ge-0/0/4 gigether-options redundant-parent reth0
user@host# set interfaces ge-0/0/5 gigether-options redundant-parent reth0
user@host# set interfaces ge-0/0/6 gigether-options redundant-parent reth0
user@host# set interfaces ge-0/0/7 gigether-options redundant-parent reth0
Especifique o número mínimo de links para a interface de reth como 2.
{primary:node0}[edit]
user@host# set interfaces reth0 redundant-ether-options minimum-links 2
Configure o monitoramento da interface para monitorar a integridade das interfaces e acionar o failover do grupo de redundância.
Esses cenários fornecem exemplos de como o failover de lag de reth opera:
- Cenário 1: O peso da interface monitorada é de 255
- Cenário 2: O peso da interface monitorada é de 75
- Cenário 3: O peso da interface monitorada é de 100
Cenário 1: O peso da interface monitorada é de 255
Especifique o peso da interface monitorada como 255 para cada interface subjacente.
{primary:node0}[edit]
user@host# set chassis cluster redundancy-group 1 interface-monitor ge-0/0/4 weight 255
user@host# set chassis cluster redundancy-group 1 interface-monitor ge-0/0/5 weight 255
user@host# set chassis cluster redundancy-group 1 interface-monitor ge-0/0/6 weight 255
user@host# set chassis cluster redundancy-group 1 interface-monitor ge-0/0/7 weight 255
Quando 1 das 4 interfaces falha, ainda existem 3 links físicos ativos no reth LAG. Embora esse número exceda o parâmetro de links mínimos configurado, a perda de uma interface com um peso de 255 faz com que o peso do grupo caia para 0, desencadeando um failover.
Cenário 2: O peso da interface monitorada é de 75
Especifique o peso da interface monitorada como 75 para cada interface subjacente.
{primary:node0}[edit]
user@host# set chassis cluster redundancy-group 1 interface-monitor ge-0/0/4 weight 75
user@host# set chassis cluster redundancy-group 1 interface-monitor ge-0/0/5 weight 75
user@host# set chassis cluster redundancy-group 1 interface-monitor ge-0/0/6 weight 75
user@host# set chassis cluster redundancy-group 1 interface-monitor ge-0/0/7 weight 75
Neste caso, quando três links físicos estiverem desativados, a interface de reth cairá devido à queda abaixo do minimum-links valor configurado. Observe que, neste cenário, o peso do grupo LAG permanece acima de 0.
Cenário 3: O peso da interface monitorada é de 100
Especifique o peso da interface monitorada como 100 para cada interface subjacente.
{primary:node0}[edit]
user@host# set chassis cluster redundancy-group 1 interface-monitor ge-0/0/4 weight 100
user@host# set chassis cluster redundancy-group 1 interface-monitor ge-0/0/5 weight 100
user@host# set chassis cluster redundancy-group 1 interface-monitor ge-0/0/6 weight 100
user@host# set chassis cluster redundancy-group 1 interface-monitor ge-0/0/7 weight 100
Neste caso, quando 3 dos 4 links físicos estão desativados, a interface de reth é declarada para baixo tanto porque o minimum-links valor não é atendido, quanto devido aos pesos de monitoramento da interface que fazem com que o peso do grupo LAG chegue a 0.
De todos os três cenários, o cenário 3 ilustra a maneira mais ideal de gerenciar o failover de reth LAG e haverá perda de tráfego mínima.
Entender o LACP em clusters de chassi
Você pode combinar várias portas Ethernet físicas para formar um link lógico de ponto a ponto, conhecido como um grupo de agregação de links (LAG) ou pacote, de modo que um cliente de controle de acesso de mídia (MAC) possa tratar o LAG como se fosse um único link.
Os LAGs podem ser estabelecidos em nós em um cluster de chassi para oferecer maior largura de banda de interface e disponibilidade de enlaces.
O Link Aggregation Control Protocol (LACP) oferece funcionalidade adicional para LAGs. O LACP é suportado em implantações independentes, onde interfaces Ethernet agregadas são suportadas e em implantações de cluster de chassi, onde interfaces Ethernet agregadas e interfaces Ethernet redundantes são suportadas simultaneamente.
Você configura o LACP em uma interface Ethernet redundante configurando o modo LACP para o link pai com a lacp declaração. O modo LACP pode estar desativado (o padrão), ativo ou passivo.
Este tópico contém as seguintes seções:
- Grupos de agregação de enlaces de interface ethernet redundantes de clusters
- Sub-LAGs
- Suporte a failover sem sucesso
- Gerenciamento de PDUs de controle de agregação de enlaces
Grupos de agregação de enlaces de interface ethernet redundantes de clusters
Uma interface Ethernet redundante tem links ativos e de espera localizados em dois nós em um cluster de chassi. Todos os links ativos estão localizados em um nó, e todos os links de espera estão localizados no outro nó. Você pode configurar até oito links ativos e oito links de espera por nó.
Quando pelo menos dois links físicos de interface infantil de cada nó são incluídos em uma configuração redundante de interface Ethernet, as interfaces são combinadas dentro da interface Ethernet redundante para formar um LAG de interface Ethernet redundante.
Ter vários links de interface Ethernet redundantes ativos reduz a possibilidade de failover. Por exemplo, quando um link ativo está fora de serviço, todo o tráfego neste link é distribuído para outros links de interface Ethernet redundantes ativos, em vez de acionar um failover ativo/standby Ethernet redundante.
As interfaces Ethernet agregadas, conhecidas como LAGs locais, também são suportadas em ambos os nós de um cluster de chassi, mas não podem ser adicionadas a interfaces Ethernet redundantes. Da mesma forma, qualquer interface infantil de um LAG local existente não pode ser adicionada a uma interface Ethernet redundante, e vice-versa. O número máximo total de interfaces de LAG de nós individuais combinadas (ae) e interfaces redundantes de Ethernet (reth) por cluster é de 128.
No entanto, interfaces Ethernet agregadas e interfaces Ethernet redundantes podem coexistir, porque a funcionalidade de uma interface Ethernet redundante depende da estrutura Ethernet agregada do Junos OS.
Para obter mais informações, consulte Understanding Chassis Cluster RedundantE Interface Link Aggregation Groups.
Links mínimos
A configuração redundante da interface Ethernet inclui uma minimum-links configuração que permite definir um número mínimo de links físicos para crianças em um LAG de interface Ethernet redundante que deve estar funcionando no nó principal para que a interface esteja ativa. O valor padrão minimum-links é 1. Quando o número de links físicos no nó principal em uma interface Ethernet redundante fica abaixo do minimum-links valor, a interface pode estar baixa mesmo que alguns links ainda estejam funcionando. Para obter mais informações, veja Exemplo: configuração de links mínimos de cluster de chassi.
Sub-LAGs
O LACP mantém um LAG ponto a ponto. Qualquer porta conectada ao terceiro ponto é negada. No entanto, uma interface Ethernet redundante se conecta a dois sistemas diferentes ou duas interfaces Ethernet agregadas remotamente por design.
Para oferecer suporte ao LACP em links ativos e de standby da interface Ethernet redundantes, uma interface Ethernet redundante é criada automaticamente para consistir em dois sub-LAGs distintos, onde todos os links ativos formam um sub-LAG ativo e todos os links de espera formam um sub-LAG de espera.
Nesse modelo, a lógica de seleção de LACP é aplicada e limitada a um sub-LAG de cada vez. Dessa forma, dois sub-LAGs redundantes de interface Ethernet são mantidos simultaneamente, enquanto todas as vantagens de LACP são preservadas para cada sub-LAG.
É necessário que os switches usados conectem os nós no cluster tenham um link LAG configurado e 802.3ad habilitado para cada LAG em ambos os nós para que os links agregados sejam reconhecidos como tal e passem o tráfego corretamente.
Os links infantis LAG de interface Ethernet redundantes de cada nó no cluster do chassi devem ser conectados a um LAG diferente nos dispositivos peer. Se um único switch peer for usado para encerrar o LAG redundante da interface Ethernet, dois LAGs separados devem ser usados no switch.
Suporte a failover sem sucesso
Com o LACP, a interface Ethernet redundante oferece suporte a failover sem sucesso entre os links ativos e de espera em operação normal. O termo hitless significa que o estado redundante da interface Ethernet permanece em alta durante um failover.
O processo lacpd gerencia os links ativos e de espera das interfaces Ethernet redundantes. Um estado de interface Ethernet redundante permanece ativo quando o número de links ativos é igual ou superior ao número de links mínimos configurados. Portanto, para oferecer suporte ao failover sem impacto, o estado LACP nos links de espera redundantes da interface Ethernet deve ser coletado e distribuído antes que o failover ocorra.
Gerenciamento de PDUs de controle de agregação de enlaces
As unidades de dados de protocolo (PDUs) contêm informações sobre o estado do link. Por padrão, os links Ethernet agregados e redundantes não trocam PDUs de controle de agregação de enlaces.
Você pode configurar a troca de PDUs das seguintes maneiras:
Configure links Ethernet para transmitir ativamente PDUs de controle de agregação de enlaces
Configure links Ethernet para transmitir passivamente PDUs, enviando PDUs de controle de agregação de links apenas quando eles são recebidos da extremidade remota do mesmo link
O final local de um link infantil é conhecido como o ator e a extremidade remota do link é conhecida como o parceiro. Ou seja, o ator envia PDUs de controle de agregação de enlaces para seu parceiro de protocolo que transmitem o que o ator sabe sobre seu próprio estado e o do estado do parceiro.
Você configura o intervalo em que as interfaces no lado remoto do link transmitem PDUs de controle de agregação de enlaces configurando a periodic declaração nas interfaces do lado local. É a configuração no lado local que especifica o comportamento do lado remoto. Ou seja, o lado remoto transmite PDUs de controle de agregação de enlaces no intervalo especificado. O intervalo pode ser fast (a cada segundo) ou slow (a cada 30 segundos).
Para obter mais informações, veja Exemplo: configuração do LACP em clusters de chassi.
Por padrão, o ator e o parceiro transmitem PDUs de controle de agregação de enlaces a cada segundo. Você pode configurar diferentes taxas periódicas em interfaces ativas e passivas. Quando você configura as interfaces ativas e passivas a taxas diferentes, o transmissor honra a taxa do receptor.
Exemplo: Configuração do LACP em clusters de chassi
Este exemplo mostra como configurar o LACP em clusters de chassi.
Requisitos
Antes de começar:
Preencha as tarefas, como habilitar o cluster do chassi, configurar interfaces e grupos de redundância. Veja a visão geral da configuração de cluster do chassi da Série SRX e exemplo: configuração de interfaces Ethernet redundantes de cluster de chassi para obter mais detalhes.
Visão geral
Você pode combinar várias portas Ethernet físicas para formar um link lógico de ponto a ponto, conhecido como grupo de agregação de links (LAG) ou pacote. Você configura o LACP em uma interface Ethernet redundante do firewall da Série SRX em cluster de chassi.
Neste exemplo, você define o modo LACP para que a interface reth1 acione e defina o intervalo de transmissão de PDU de controle de agregação de enlaces a cada 30 segundos.
Quando você habilita o LACP, os lados local e remoto dos links Ethernet agregados trocam unidades de dados de protocolo (PDUs), que contêm informações sobre o estado do link. Você pode configurar links Ethernet para transmitir Ativamente PDUs, ou pode configurar os links para transmiti-los passivamente (enviando PDUs LACP apenas quando eles os recebem de outro link). Um lado do link deve ser configurado como ativo para que o link esteja ativo.
A Figura 1 mostra a topologia usada neste exemplo.
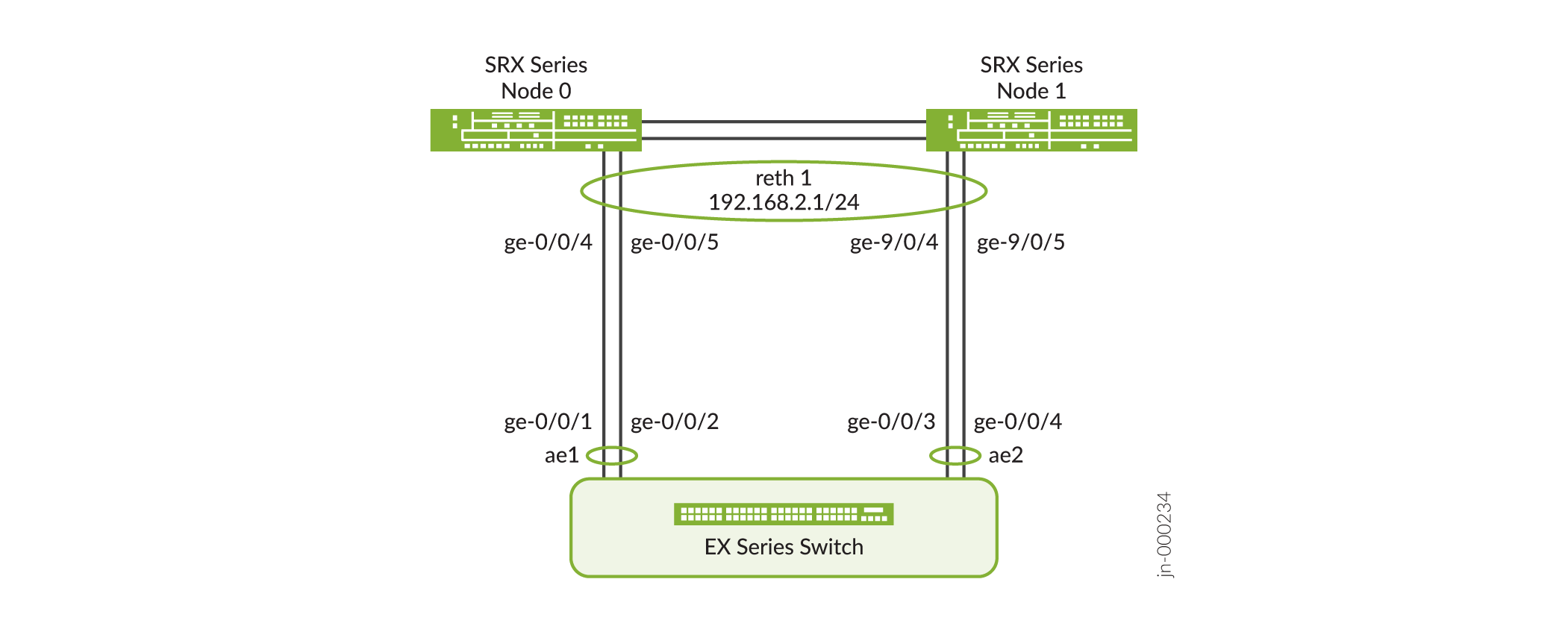 da Série EX
da Série EX
Na Figura 1, SRX1500 dispositivos são usados para configurar as interfaces em nós0 e nó1. Para obter mais informações sobre a configuração do switch da Série EX, consulte Configuração do Ethernet LACP agregado (Procedimento CLI).
Configuração
Configuração do LACP no cluster do chassi
Procedimento passo a passo
Para configurar o LACP em clusters de chassi:
-
Especifique o número de interfaces Ethernet redundantes.
[edit chassis cluster] user@host# set reth-count 2 -
Especifique a prioridade de um grupo de redundância para primazia em cada nó do cluster. O número maior tem precedência.
[edit chassis cluster] user@host# set redundancy-group 1 node 0 priority 200 user@host# set redundancy-group 1 node 1 priority 100 -
Crie uma zona de segurança e atribua interfaces à zona.
[edit security zones] user@host# set security-zone trust host-inbound-traffic system-services all user@host# set security-zone trust interfaces reth1.0 -
Vincule interfaces físicas infantis redundantes à reth1.
[edit interfaces] user@host# set ge-0/0/4 gigether-options redundant-parent reth1 user@host# set ge-0/0/5 gigether-options redundant-parent reth1 user@host# set ge-9/0/4 gigether-options redundant-parent reth1 user@host# set ge-9/0/5 gigether-options redundant-parent reth1 -
Adicione o reth1 ao grupo 1 de redundância.
[edit interfaces] user@host# set reth1 redundant-ether-options redundancy-group 1 -
Configure o LACP em 1º lugar.
[edit interfaces] user@host# set reth1 redundant-ether-options lacp active user@host# set reth1 redundant-ether-options lacp periodic slow -
Atribua um endereço IP para reth1.
[edit interfaces] user@host# set reth1 unit 0 family inet address 192.168.2.1/24 -
Configure o LACP em interfaces Ethernet agregadas (ae1).
-
Configure o LACP em interfaces Ethernet agregadas (ae2).
-
Se você terminar de configurar o dispositivo, confirme a configuração.
[edit interfaces] user@host# commit
Resultados
A partir do modo de configuração, confirme sua configuração entrando no show chassis, show security zonese show interfaces comandos. Se a saída não exibir a configuração pretendida, repita as instruções de configuração neste exemplo para corrigi-la.
[edit]user@host#show chassis cluster { reth-count 2; redundancy-group 1 { node 0 priority 200; node 1 priority 100; } } [edit]user@host#show security zones security-zone trust { host-inbound-traffic { system-services { all; } } interfaces { reth1.0; } } [edit]user@host#show interfaces reth1 { redundant-ether-options { redundancy-group 1; lacp { active; periodic slow; } } unit 0 { family inet { address 192.168.2.1/24; } } }
Configuração do LACP no switch da Série EX
Procedimento passo a passo
Configure o LACP no switch da Série EX.
-
Defina o número de interfaces Ethernet agregadas.
[edit chassis] user@host# set aggregated-devices ethernet device-count 3 -
Associar interfaces físicas com interfaces Ethernet agregadas.
[edit interfaces] user@host# set ge-0/0/1 gigether-options 802.3ad ae1 user@host# set ge-0/0/2 gigether-options 802.3ad ae1 user@host# set ge-0/0/3 gigether-options 802.3ad ae2 user@host# set ge-0/0/4 gigether-options 802.3ad ae2 -
Configure o LACP em interfaces Ethernet agregadas (ae1).
[edit interfaces] user@host# set interfaces ae1 unit 0 family ethernet-switching interface-mode access user@host# set interfaces ae1 unit 0 family ethernet-switching vlan members RETH0_VLAN -
Configure o LACP em interfaces Ethernet agregadas (ae2).
[edit interfaces] user@host# set interfaces ae2 unit 0 family ethernet-switching interface-mode access user@host# set interfaces ae2 unit 0 family ethernet-switching vlan members RETH0_VLAN -
Configure VLAN.
user@host#set vlans RETH0_VLAN vlan-id 10 user@host# set vlans RETH0_VLAN l3-interface vlan.10 user@host# set interfaces vlan unit 10 family inet address 192.168.2.254/24
Resultados
A partir do modo de configuração, confirme sua configuração inserindo os show chassis comandos e show interfaces os comandos. Se a saída não exibir a configuração pretendida, repita as instruções de configuração neste exemplo para corrigi-la.
[edit]user@host#show chassis aggregated-devices { ethernet { device-count 3; } }user@host#show vlans RETH0_VLAN { vlan-id 10; l3-interface vlan.10; }user@host>show vlans RETH0_VLAN Routing instance VLAN name Tag Interfaces default-switch RETH0_VLAN 10 ae1.0* ae2.0*user@host>show ethernet-switching interface ae1 Routing Instance Name : default-switch Logical Interface flags (DL - disable learning, AD - packet action drop, LH - MAC limit hit, DN - interface down, MMAS - Mac-move action shutdown, SCTL - shutdown by Storm-control ) Logical Vlan TAG MAC STP Logical Tagging interface members limit state interface flags ae1.0 131072 untagged RETH0_VLAN 10 131072 Forwarding untaggeduser@host>show ethernet-switching interface ae2 Routing Instance Name : default-switch Logical Interface flags (DL - disable learning, AD - packet action drop, LH - MAC limit hit, DN - interface down, MMAS - Mac-move action shutdown, SCTL - shutdown by Storm-control ) Logical Vlan TAG MAC STP Logical Tagging interface members limit state interface flags ae2.0 131072 untagged RETH0_VLAN 10 131072 Forwarding untaggeduser@host#show interfaces ge-0/0/1 { ether-options { 802.3ad ae1; } } ge-0/0/2 { ether-options { 802.3ad ae1; } } ge-0/0/3 { ether-options { 802.3ad ae2; } } ge-0/0/4 { ether-options { 802.3ad ae2; } } ae1 { aggregated-ether-options { lacp { active; periodic slow; } } unit 0 { family ethernet-switching { interface-mode access; vlan { members RETH0_VLAN; } } } } ae2 { aggregated-ether-options { lacp { active; periodic slow; } } unit 0 { family ethernet-switching { interface-mode access; vlan { members RETH0_VLAN; } } } } vlan { unit 10 { family inet { address 192.168.2.254/24 { } } } }
Verificação
Verificação do LACP em interfaces de ethernet redundantes
Propósito
Exibir informações de status LACP para interfaces Ethernet redundantes.
Ação
A partir do modo operacional, entre no show chassis cluster status comando.
{primary:node0}[edit]
user@host> show chassis cluster status
Monitor Failure codes:
CS Cold Sync monitoring FL Fabric Connection monitoring
GR GRES monitoring HW Hardware monitoring
IF Interface monitoring IP IP monitoring
LB Loopback monitoring MB Mbuf monitoring
NH Nexthop monitoring NP NPC monitoring
SP SPU monitoring SM Schedule monitoring
CF Config Sync monitoring RE Relinquish monitoring
IS IRQ storm
Cluster ID: 1
Node Priority Status Preempt Manual Monitor-failures
Redundancy group: 0 , Failover count: 1
node0 1 primary no no None
node1 1 secondary no no None
Redundancy group: 1 , Failover count: 1
node0 200 primary no no None
node1 100 secondary no no None
{primary:node0}[edit]
user@host> show chassis cluster interfaces
Control link status: Up
Control interfaces:
Index Interface Monitored-Status Internal-SA Security
0 fxp1 Up Disabled Disabled
Fabric link status: Up
Fabric interfaces:
Name Child-interface Status Security
(Physical/Monitored)
fab0 ge-0/0/2 Up / Up Enabled
fab0
fab1 ge-9/0/2 Up / Up Enabled
fab1
Redundant-ethernet Information:
Name Status Redundancy-group
reth0 Down Not configured
reth1 Up 1
Redundant-pseudo-interface Information:
Name Status Redundancy-group
lo0 Up 0
A partir do modo operacional, entre no show lacp interfaces reth1 comando.
{primary:node0}[edit]
user@host> show lacp interfaces reth1
Aggregated interface: reth1
LACP state: Role Exp Def Dist Col Syn Aggr Timeout Activity
ge-0/0/4 Actor No No Yes Yes Yes Yes Slow Active
ge-0/0/4 Partner No No Yes Yes Yes Yes Slow Active
ge-0/0/5 Actor No No Yes Yes Yes Yes Slow Active
ge-0/0/5 Partner No No Yes Yes Yes Yes Slow Active
ge-9/0/4 Actor No No Yes Yes Yes Yes Slow Active
ge-9/0/4 Partner No No Yes Yes Yes Yes Slow Active
ge-9/0/5 Actor No No Yes Yes Yes Yes Slow Active
ge-9/0/5 Partner No No Yes Yes Yes Yes Slow Active
LACP protocol: Receive State Transmit State Mux State
ge-0/0/4 Current Slow periodic Collecting distributing
ge-0/0/5 Current Slow periodic Collecting distributing
ge-9/0/4 Current Slow periodic Collecting distributing
ge-9/0/5 Current Slow periodic Collecting distributing
A saída mostra informações redundantes da interface Ethernet, como:
-
O estado LACP — indica se o link no pacote é um ator (local ou próximo do link) ou um parceiro (remoto ou distante do link).
-
O modo LACP — indica se ambas as extremidades da interface Ethernet agregada estão habilitadas (ativa ou passiva)— pelo menos uma extremidade do pacote deve estar ativa.
-
A taxa de transmissão de PDU de controle de agregação de enlace periódico.
-
O estado de protocolo LACP — indica que o link está funcionando se estiver coletando e distribuindo pacotes.
Exemplo: Configuração de links mínimos de cluster de chassi
Este exemplo mostra como especificar um número mínimo de links físicos atribuídos a uma interface Ethernet redundante no nó primário que deve estar funcionando para que a interface esteja ativa.
Requisitos
Antes de começar:
Configure interfaces Ethernet redundantes. Veja exemplo: Configuração de interfaces de ethernet redundantes de cluster de chassi.
Entenda grupos redundantes de agregação de enlaces de interface Ethernet. Veja exemplo: configuração de grupos de agregação de enlaces em um cluster de chassi.
Visão geral
Quando uma interface Ethernet redundante tem mais de dois links infantis, você pode definir um número mínimo de links físicos atribuídos à interface no nó primário que deve estar funcionando para que a interface esteja ativada. Quando o número de links físicos no nó primário cair abaixo do valor de links mínimos, a interface estará baixa mesmo que alguns links ainda estejam funcionando.
Neste exemplo, você especifica que três links infantis no nó primário e vinculados ao reth1 (valor de links mínimos) estão funcionando para evitar que a interface fique para baixo. Por exemplo, em uma configuração LAG de interface Ethernet redundante na qual seis interfaces são atribuídas à reth1, definir o valor de links mínimos para 3 significa que todos os links infantis reth1 no nó principal devem estar funcionando para evitar que o status da interface mude para baixo.
Embora seja possível definir um valor de links mínimos para uma interface Ethernet redundante com apenas duas interfaces infantis (uma em cada nó), não a recomendamos.
Configuração
Procedimento
Procedimento passo a passo
Para especificar o número mínimo de links:
Especifique o número mínimo de links para a interface Ethernet redundante.
{primary:node0}[edit] user@host# set interfaces reth1 redundant-ether-options minimum-links 3Se você terminar de configurar o dispositivo, confirme a configuração.
{primary:node0}[edit] user@host# commit
Verificação
Verificando a configuração de links mínimos de cluster de chassi
Propósito
Para verificar se a configuração está funcionando corretamente, insira o show interface reth1 comando.
Ação
A partir do modo operacional, entre no comando do show show interfaces reth1 .
{primary:node0}[edit]user@host> show interfaces reth1Physical interface: reth1, Enabled, Physical link is Down Interface index: 129, SNMP ifIndex: 548 Link-level type: Ethernet, MTU: 1514, Speed: Unspecified, BPDU Error: None, MAC-REWRITE Error: None, Loopback: Disabled, Source filtering: Disabled, Flow control: Disabled, Minimum links needed: 3, Minimum bandwidth needed: 0 Device flags : Present Running Interface flags: Hardware-Down SNMP-Traps Internal: 0x0 Current address: 00:10:db:ff:10:01, Hardware address: 00:10:db:ff:10:01 Last flapped : 2010-09-15 15:54:53 UTC (1w0d 22:07 ago) Input rate : 0 bps (0 pps) Output rate : 0 bps (0 pps) Logical interface reth1.0 (Index 68) (SNMP ifIndex 550) Flags: Hardware-Down Device-Down SNMP-Traps 0x0 Encapsulation: ENET2 Statistics Packets pps Bytes bps Bundle: Input : 0 0 0 0 Output: 0 0 0 0 Security: Zone: untrust Allowed host-inbound traffic : bootp bfd bgp dns dvmrp igmp ldp msdp nhrp ospf pgm pim rip router-discovery rsvp sap vrrp dhcp finger ftp tftp ident-reset http https ike netconf ping reverse-telnet reverse-ssh rlogin rpm rsh snmp snmp-trap ssh telnet traceroute xnm-clear-text xnm-ssl lsping ntp sip Protocol inet, MTU: 1500 Flags: Sendbcast-pkt-to-re
Exemplo: Configuração de grupos de agregação de enlaces redundantes de interface de ethernet em um dispositivo de linha de SRX5000 com IOC2 ou IOC3
O suporte para grupos de agregação de enlaces Ethernet (LAGs) com base no IEEE 802.3ad possibilita agregar interfaces físicas em um dispositivo autônomo. Os LAGs em dispositivos autônomos oferecem maior largura de banda de interface e disponibilidade de enlaces. A agregação de links em um cluster de chassi permite que uma interface Ethernet redundante adicione mais de duas interfaces físicas para crianças, criando assim uma interface Ethernet LAG redundante.
Requisitos
Este exemplo usa os seguintes componentes de software e hardware:
Versão Junos OS 15.1X49-D40 ou posterior para firewalls da Série SRX.
SRX5800 com IOC2 ou IOC3 com o Express Path habilitado para IOC2 e IOC3. Para obter mais informações, veja Exemplo: Configuração do SRX5K-MPC3-100G10G (IOC3) e SRX5K-MPC3-40G10G (IOC3) em um dispositivo de linha SRX5000 para oferecer suporte ao Express Path.
Visão geral
Este exemplo mostra como configurar um grupo de agregação de enlaces de interface Ethernet redundante e configurar LACP em clusters de chassi em um firewall da Série SRX usando as portas do IOC2 ou IOC3 no modo Express Path. Observe que a configuração de interfaces infantis ao misturar links do IOC2 e do IOC3 não é suportada.
Uma interface Ethernet redundante ou interface Ethernet agregada (aex) deve conter interfaces infantis do mesmo tipo IOC para IOC2 e IOC3. Por exemplo, se um link infantil é de 10 Gigabit Ethernet no IOC2, o enlace do segundo filho também deve ser do IOC2. Essa limitação não é aplicável para interfaces infantis IOC3 e IOC4 se as interfaces infantis tiverem a mesma velocidade.
A combinação a seguir não é suportada:
- Nó 0-100GbE do IOC2 e 10GbE/40GbE/100GbE do IOC3
- Nó 1-100GbE do IOC2 e 10GbE/40GbE/100GbE do IOC3
A combinação a seguir é suportada (com a mesma velocidade de interface):
- Nó 0-100GbE do IOC3 e 100GbE do IOC4
- Nó 1-100GbE do IOC3 e 100GbE do IOC4
Os links de membros a seguir são usados neste exemplo:
-
xe-1/0/0
-
xe-3/0/0
-
xe-14/0/0
-
xe-16/0/0
Configuração
Configuração rápida da CLI
Para configurar rapidamente este exemplo, copie os seguintes comandos, cole-os em um arquivo de texto, remova quaisquer quebras de linha, altere os detalhes necessários para combinar com a configuração da sua rede, excluir e, em seguida, copiar e colar os comandos no CLI no nível de hierarquia e, em seguida, entrar no [edit] commit modo de configuração.
set chassis cluster reth-count 5 set interfaces reth0 redundant-ether-options redundancy-group 1 set interfaces reth0 redundant-ether-options lacp active set interfaces reth0 redundant-ether-options lacp periodic fast set interfaces reth0 redundant-ether-options minimum-links 1 set interfaces reth0 unit 0 family inet address 192.0.2.1/24 set interfaces xe-1/0/0 gigether-options redundant-parent reth0 set interfaces xe-3/0/0 gigether-options redundant-parent reth0 set interfaces xe-14/0/0 gigether-options redundant-parent reth0 set interfaces xe-16/0/0 gigether-options redundant-parent reth0
Procedimento
Procedimento passo a passo
Para configurar interfaces LAG:
Especifique o número de interfaces Ethernet agregadas a serem criadas.
[edit chassis] user@host# set chassis cluster reth-count 5
Vincule interfaces físicas infantis redundantes à reth0.
[edit interfaces] user@host# set xe-1/0/0 gigether-options redundant-parent reth0 user@host# set xe-3/0/0 gigether-options redundant-parent reth0 user@host# set xe-14/0/0 gigether-options redundant-parent reth0 user@host# set xe-16/0/0 gigether-options redundant-parent reth0
Adicione reth0 ao grupo 1 de redundância.
user@host#set reth0 redundant-ether-options redundancy-group 1
Atribua um endereço IP para reth0.
[edit interfaces] user@host# set reth0 unit 0 family inet address 192.0.2.1/24
Configure o LACP em novo est0.
[edit interfaces] user@host# set reth0 redundant-ether-options lacp active user@host# set reth0 redundant-ether-options lacp periodic fast user@host# set reth0 redundant-ether-options minimum-links 1
Resultados
A partir do modo de configuração, confirme sua configuração entrando no show interfaces comando. Se a saída não exibir a configuração pretendida, repita as instruções de configuração neste exemplo para corrigi-la.
[edit]
user@host# show interfaces
xe-1/0/0 {
gigether-options {
redundant-parent reth0;
}
}
xe-3/0/0 {
gigether-options {
redundant-parent reth0;
}
}
xe-14/0/0 {
gigether-options {
redundant-parent reth0;
}
}
xe-16/0/0 {
gigether-options {
redundant-parent reth0;
}
}
reth0 {
redundant-ether-options {
lacp {
active;
periodic fast;
}
minimum-links 1;
}
unit 0 {
family inet {
address 192.0.2.1/24;
}
}
}
ae1 {
aggregated-ether-options {
lacp {
active;
}
}
unit 0 {
family inet {
address 192.0.2.2/24;
}
}
}
[edit]
user@host# show chassis
chassis cluster {
reth-count 5;
}
Se você terminar de configurar o dispositivo, entre no commit modo de configuração.
Verificação
Verificação do LACP em interfaces de ethernet redundantes
Propósito
Exibir informações de status LACP para interfaces Ethernet redundantes.
Ação
Desde o modo operacional, entre no show lacp interfaces comando para verificar se o LACP foi habilitado como ativo em uma extremidade.
user@host> show lacp interfaces
Aggregated interface: reth0
LACP state: Role Exp Def Dist Col Syn Aggr Timeout Activity
xe-16/0/0 Actor No No Yes Yes Yes Yes Fast Active
xe-16/0/0 Partner No No Yes Yes Yes Yes Fast Active
xe-14/0/0 Actor No No Yes Yes Yes Yes Fast Active
xe-14/0/0 Partner No No Yes Yes Yes Yes Fast Active
xe-1/0/0 Actor No No Yes Yes Yes Yes Fast Active
xe-1/0/0 Partner No No Yes Yes Yes Yes Fast Active
xe-3/0/0 Actor No No Yes Yes Yes Yes Fast Active
xe-3/0/0 Partner No No Yes Yes Yes Yes Fast Active
LACP protocol: Receive State Transmit State Mux State
xe-16/0/0 Current Fast periodic Collecting distributing
xe-14/0/0 Current Fast periodic Collecting distributing
xe-1/0/0 Current Slow periodic Collecting distributing
xe-3/0/0 Current Slow periodic Collecting distributing
A saída indica que o LACP foi configurado corretamente e está ativo em uma extremidade.
Entenda o VRRP em firewalls da Série SRX
Os firewalls da Série SRX oferecem suporte ao Protocolo de redundância de roteador virtual (VRRP) e VRRP para IPv6. Este tópico aborda:
- Visão geral do VRRP em firewalls da Série SRX
- Benefícios do VRRP
- Topologia VRRP de amostra
- Suporte para firewalls da Série SRX para VRRPv3
- Limitações dos recursos VRRPv3
Visão geral do VRRP em firewalls da Série SRX
Configurar hosts finais em sua rede com rotas padrão estáticas minimiza o esforço e a complexidade da configuração e reduz a sobrecarga de processamento nos hosts finais. Quando os hosts são configurados com rotas estáticas, a falha do gateway padrão normalmente resulta em um evento catastrófico, isolando todos os hosts que não conseguem detectar caminhos alternativos disponíveis para o gateway. O uso do Protocolo de redundância de roteador virtual (VRRP) permite que você forneça gateways alternativos dinamicamente para hosts finais se o gateway principal falhar.
Você pode configurar o Protocolo de redundância de roteador virtual (VRRP) ou VRRP para IPv6 em interfaces Gigabit Ethernet, interfaces Ethernet de 10 Gigabit e interfaces lógicas em firewalls da Série SRX. O VRRP permite que hosts em uma LAN façam uso de dispositivos redundantes naquela LAN sem exigir mais do que a configuração estática de uma única rota padrão nos hosts. Dispositivos configurados com VRRP compartilham o endereço IP correspondente à rota padrão configurada nos hosts. A qualquer momento, um dos dispositivos configurados por VRRP é o principal (ativo) e os outros são backups. Se o dispositivo principal falhar, um dos dispositivos de backup se tornará o novo principal, fornecendo um dispositivo padrão virtual e permitindo que o tráfego na LAN seja roteado sem depender de um único dispositivo. Usando VRRP, um firewall backup da Série SRX pode assumir um dispositivo padrão com falha em poucos segundos. Isso é feito com perda mínima de tráfego VRRP e sem qualquer interação com os hosts. O protocolo de redundância de roteador virtual não é suportado em interfaces de gerenciamento.
O VRRP para IPv6 oferece uma transferência muito mais rápida para um dispositivo padrão alternativo do que os procedimentos IPv6 Neighbor Discovery (ND). VRRP para IPv6 não oferece suporte a authentication-type declarações ou authentication-key declarações.
Dispositivos que executam VRRP elegem dinamicamente dispositivos primários e de backup. Você também pode forçar a atribuição de dispositivos primários e de backup usando prioridades de 1 a 255, sendo 255 a maior prioridade. Na operação VRRP, o dispositivo primário padrão envia anúncios para o dispositivo de backup em intervalos regulares. O intervalo padrão é de 1 segundo. Se o dispositivo de backup não receber um anúncio por um período determinado, então o dispositivo de backup com a maior prioridade assume o cargo principal e começa a encaminhar pacotes.
Os dispositivos de backup não tentam antecipar o dispositivo principal a menos que ele tenha maior prioridade. Isso elimina a interrupção do serviço a menos que um caminho mais preferido fique disponível. É possível proibir administrativamente todas as tentativas de preempção, com exceção de um dispositivo VRRP se tornando um dispositivo primário de qualquer dispositivo associado a endereços que possui.
O VRRP não oferece suporte à sincronização de sessão entre os membros. Se o dispositivo principal falhar, o dispositivo de backup com a mais alta prioridade assume o cargo principal e começará a encaminhar pacotes. Quaisquer sessões existentes serão descartadas no dispositivo de backup como fora do estado.
A Prioridade 255 não pode ser definida para interfaces VLAN roteadas (RVIs).
VRRP é definido no RFC 3768, Protocolo de redundância de roteador virtual.
Benefícios do VRRP
-
O VRRP oferece failover dinâmico de endereços IP de um dispositivo para outro em caso de falha.
-
Você pode implementar VRRP para fornecer um caminho padrão altamente disponível para um gateway sem a necessidade de configurar protocolos dinâmicos de roteamento ou descoberta de roteadores em hosts finais.
Topologia VRRP de amostra
A Figura 2 ilustra uma topologia VRRP básica com firewalls da Série SRX. Neste exemplo, os dispositivos A e B estão executando VRRP e compartilham o endereço IP virtual 192.0.2.1. O gateway padrão para cada um dos clientes é 192.0.2.1.
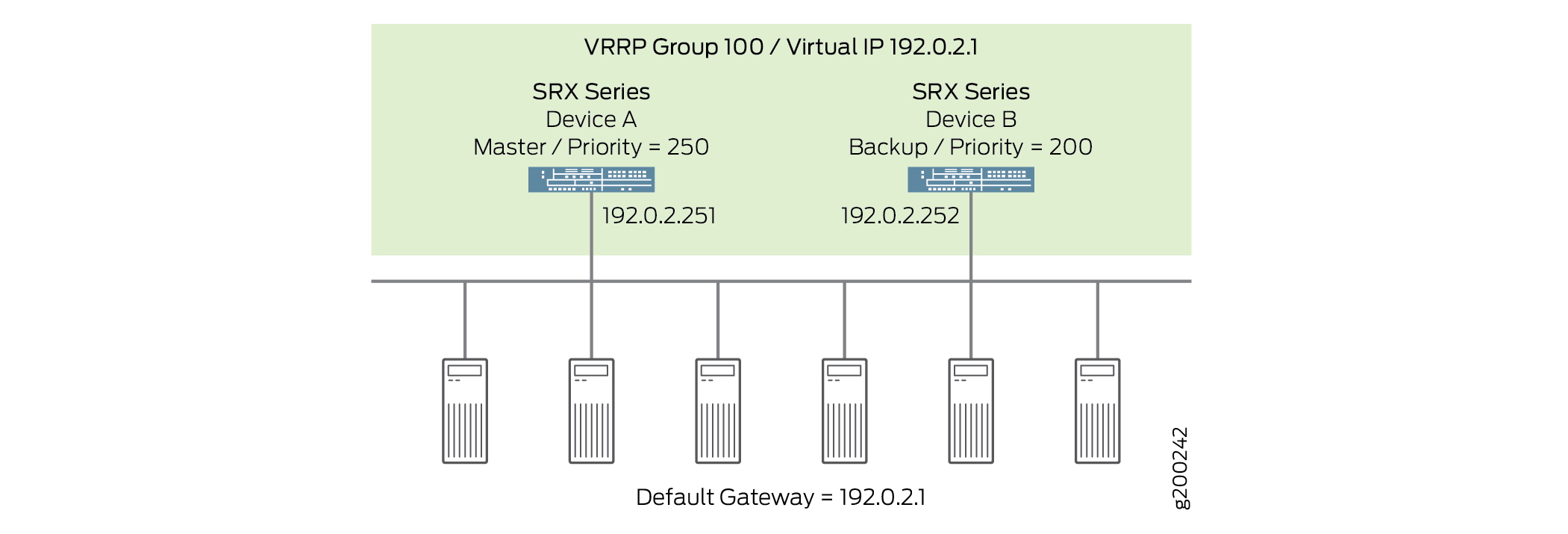 da Série SRX
da Série SRX
O seguinte ilustra o comportamento básico de VRRP usando a Figura 2 para referência:
-
Quando algum dos servidores deseja enviar tráfego para fora da LAN, ele envia o tráfego para o endereço de gateway padrão de 192.0.2.1. Este é um endereço IP virtual (VIP) de propriedade do grupo VRRP 100. Como o Dispositivo A é o principal do grupo, o VIP está associado ao endereço "real" 192.0.2.251 no Dispositivo A, e o tráfego dos servidores é realmente enviado para este endereço. (O dispositivo A é o principal porque foi configurado com um valor de prioridade maior.)
-
Se houver uma falha no Dispositivo A que o impeça de encaminhar o tráfego para ou para os servidores — por exemplo, se a interface conectada à LAN falhar — o dispositivo B se tornará o principal e assumirá a propriedade do VIP. Os servidores continuam a enviar tráfego para o VIP, mas como o VIP agora está associado ao endereço "real" 192.0.2.252 no Dispositivo B (devido à mudança primária), o tráfego é enviado para o Dispositivo B em vez do Dispositivo A.
-
Se o problema que causou a falha no Dispositivo A for corrigido, o Dispositivo A volta a ser o principal e reafirma a propriedade do VIP. Neste caso, os servidores retomam o envio de tráfego ao Dispositivo A.
Observe que não são necessárias alterações de configuração nos servidores para que eles mudem entre o envio de tráfego para o dispositivo A e o dispositivo B. Quando o VIP se move entre 192.0.2.251 e 192.0.2.252, a mudança é detectada pelo comportamento normal de TCP-IP e nenhuma configuração ou intervenção é necessária nos servidores.
Suporte para firewalls da Série SRX para VRRPv3
A vantagem de usar VRRPv3 é que o VRRPv3 oferece suporte às famílias de endereços IPv4 e IPv6, enquanto o VRRP oferece suporte apenas a endereços IPv4.
Habilite o VRRPv3 em sua rede apenas se o VRRPv3 puder ser habilitado em todos os dispositivos configurados com VRRP em sua rede porque o VRRPv3 (IPv4) não interopera com as versões anteriores do VRRP. Por exemplo, se os pacotes de anúncios VRRP IPv4 forem recebidos por um dispositivo no qual o VRRPv3 está habilitado, então o dispositivo faz a transição para o estado de backup para evitar a criação de várias primárias na rede.
Você pode habilitar o VRRPv3 configurando a declaração da versão 3 no nível de [edit protocols vrrp] hierarquia (para redes IPv4 ou IPv6). Configure a mesma versão de protocolo em todos os dispositivos VRRP na LAN.
Limitações dos recursos VRRPv3
Abaixo estão algumas limitações de recursos VRRPv3.
Autenticação VRRPv3
Quando o VRRPv3 (para IPv4) é habilitado, ele não permite a autenticação.
-
As
authentication-typedeclarações eauthentication-keyas declarações não podem ser configuradas para nenhum grupo VRRP. -
Você deve usar a autenticação não VRRP.
Intervalos de anúncio do VRRPv3
Os intervalos de anúncio VRRPv3 (para IPv4 e IPv6) devem ser definidos com a declaração de intervalo rápido no nível de hierarquia de [editar interfaces de nome de interface da unidade 0 da família no endereço ip-endereço vrrp-group nome do grupo] .
-
Não use a
advertise-intervaldeclaração (para IPv4). -
Não use a
inet6-advertise-intervaldeclaração (para IPv6).
Veja também
Visão geral do failover-delay do VRRP
Failover é um modo operacional de backup no qual as funções de um dispositivo de rede são assumidas por um dispositivo secundário quando o dispositivo primário fica indisponível devido a uma falha ou um tempo de inatividade programado. O failover normalmente é parte integral de sistemas de missão crítica que devem estar constantemente disponíveis na rede.
O VRRP não oferece suporte à sincronização de sessão entre os membros. Se o dispositivo principal falhar, o dispositivo de backup com a mais alta prioridade assume o cargo principal e começará a encaminhar pacotes. Quaisquer sessões existentes serão descartadas no dispositivo de backup como fora do estado.
Uma falha rápida requer um pequeno atraso. Assim, o failover-delay configura o tempo de atraso de failover, em milissegundos, para VRRP e VRRP para operações IPv6. O Junos OS oferece suporte a um intervalo de 50 a 10000 milissegundos por atraso no tempo de falha.
O processo VRRP (vrrpd) em execução no Mecanismo de Roteamento comunica uma mudança de função primária vrRP para o Mecanismo de encaminhamento de pacotes para cada sessão VRRP. Cada grupo VRRP pode acionar essa comunicação para atualizar o Packet Forwarding Engine com seu próprio estado ou o estado herdado formam um grupo VRRP ativo. Para evitar sobrecarregar o Mecanismo de encaminhamento de pacotes com essas mensagens, você pode configurar um failover-delay para especificar o atraso entre as comunicações subsequentes do mecanismo de roteamento para o mecanismo de encaminhamento de pacotes.
O Mecanismo de Roteamento comunica uma mudança de função primária de VRRP ao Mecanismo de encaminhamento de pacotes para facilitar a mudança de estado necessária no Mecanismo de encaminhamento de pacotes, como a reprogramação de filtros de hardware do Mecanismo de encaminhamento de pacotes, sessões VRRP e assim por diante. As seções a seguir elaboram o mecanismo de roteamento para a comunicação do mecanismo de encaminhamento de pacotes em dois cenários:
Quando o atraso no failover não estiver configurado
Sem configuração de atraso no failover, a sequência de eventos para sessões VRRP operadas a partir do Mecanismo de Roteamento é a seguinte:
Quando o primeiro grupo VRRP detectado pelo Mecanismo de Roteamento muda de estado, e o novo estado é primário, o Mecanismo de Roteamento gera mensagens de anúncio VRRP apropriadas. O Mecanismo de encaminhamento de pacotes é informado sobre a mudança de estado, de modo que os filtros de hardware para esse grupo sejam reprogramados sem demora. A nova primária então envia uma mensagem ARP gratuita para os grupos VRRP.
O atraso no timer de failover começa. Por padrão, o tempor de atraso de failover é:
500 milisegundos — quando o intervalo de anúncio vrRP configurado é inferior a 1 segundo.
2 segundos — quando o intervalo de anúncio vrRP configurado é de 1 segundo ou mais, e o número total de grupos VRRP no roteador é de 255.
10 segundos — quando o intervalo de anúncio vrRP configurado é de 1 segundo ou mais, e o número de grupos VRRP no roteador é superior a 255.
O Mecanismo de Roteamento realiza mudanças de estado um a um para grupos VRRP subsequentes. Toda vez que há uma mudança de estado, e o novo estado para um determinado grupo VRRP é primário, o Mecanismo de Roteamento gera mensagens de anúncio VRRP apropriadas. No entanto, a comunicação em direção ao Mecanismo de encaminhamento de pacotes é suprimida até que o temporizador de atraso de failover expira.
Após o término do temporização de atraso no failover, o Mecanismo de Roteamento envia uma mensagem ao Mecanismo de encaminhamento de pacotes sobre todos os grupos VRRP que conseguiram mudar o estado. Como conseqüência, os filtros de hardware para esses grupos são reprogramados, e para aqueles grupos cujo novo estado é primário, mensagens ARP gratuitas são enviadas.
Esse processo se repete até que a transição de estado para todos os grupos VRRP esteja concluída.
Assim, sem configurar o failover-delay, a transição completa do estado (incluindo estados no Mecanismo de Roteamento e no Mecanismo de encaminhamento de pacotes) para o primeiro grupo VRRP é realizada imediatamente, enquanto a transição de estado no Mecanismo de encaminhamento de pacotes para grupos VRRP restantes é adiada em pelo menos 0,5-10 segundos, dependendo dos temporizadores de anúncio VRRP configurados e do número de grupos VRRP. Durante este estado intermediário, o tráfego recebido para grupos VRRP para mudanças de estado que ainda não foram concluídas no Mecanismo de encaminhamento de pacotes pode ser descartado no nível do Mecanismo de encaminhamento de pacotes devido à reconfiguração diferida dos filtros de hardware.
Quando o atraso de falha é configurado
Quando o failover-delay é configurado, a sequência de eventos para sessões VRRP operadas a partir do Mecanismo de Roteamento é modificada da seguinte forma:
O Mecanismo de Roteamento detecta que alguns grupos VRRP exigem uma mudança de estado.
O atraso no failover começa para o período configurado. O intervalo de temporizador de atraso de failover permitido é de 50 a 100000 miliseconds.
O Mecanismo de Roteamento realiza mudanças de estado um a um para os grupos VRRP. Toda vez que há uma mudança de estado, e o novo estado para um determinado grupo VRRP é primário, o Mecanismo de Roteamento gera mensagens de anúncio VRRP apropriadas. No entanto, a comunicação em direção ao Mecanismo de encaminhamento de pacotes é suprimida até que o temporizador de atraso de failover expira.
Após o término do temporização de atraso no failover, o Mecanismo de Roteamento envia uma mensagem ao Mecanismo de encaminhamento de pacotes sobre todos os grupos VRRP que conseguiram mudar o estado. Como conseqüência, os filtros de hardware para esses grupos são reprogramados, e para aqueles grupos cujo novo estado é primário, mensagens ARP gratuitas são enviadas.
Esse processo se repete até que a transição de estado para todos os grupos VRRP esteja concluída.
Assim, quando o atraso no failover é configurado, até mesmo o estado do Mecanismo de encaminhamento de pacotes para o primeiro grupo VRRP é adiado. No entanto, a operadora de rede tem a vantagem de configurar um valor de atraso de failover que melhor se adequa à necessidade da implantação da rede para garantir uma interrupção mínima durante a mudança de estado do VRRP.
o failover-delay influencia apenas as sessões VRRP operadas pelo processo VRRP (vrrpd) em execução no Mecanismo de Roteamento. Para sessões de VRRP distribuídas ao Mecanismo de encaminhamento de pacotes, a configuração de atraso no failover não surtiu efeito.
Veja também
Exemplo: Configuração de VRRP/VRRPv3 em interfaces de ethernet redundantes de cluster de chassi
Quando o Protocolo de redundância de roteador virtual (VRRP) é configurado, o VRRP agrupa vários dispositivos em um dispositivo virtual. A qualquer momento, um dos dispositivos configurados com VRRP é o principal (ativo) e os outros dispositivos são backups. Se o principal falhar, um dos dispositivos de backup se tornará o novo dispositivo principal.
Este exemplo descreve como configurar VRRP em interface redundante:
Requisitos
Este exemplo usa os seguintes componentes de hardware e software:
-
Junos OS Versão 18.1 R1 ou posterior para firewalls da Série SRX.
-
Dois firewalls da Série SRX conectados em um cluster de chassi.
-
Um firewall da Série SRX conectado como dispositivo autônomo.
Visão geral
Você configura o VRRP configurando grupos VRRP em interfaces redundantes em dispositivos de cluster de chassi e na interface Gigabit Ethernet em dispositivo autônomo. Uma interface redundante de dispositivos de cluster de chassi e interface Gigabit Ethernet de dispositivo autônomo pode ser um membro de um ou mais grupos VRRP. Dentro de um grupo VRRP, a interface redundante primária de dispositivos de cluster de chassi e a interface Gigabit Ethernet de backup de dispositivo autônomo devem ser configuradas.
Para configurar o grupo VRRP, você deve configurar o identificador de grupo e o endereço IP virtual para as interfaces redundantes e interfaces Gigabit Ethernet que são membros do grupo VRRP. O endereço IP virtual deve ser o mesmo para todas as interfaces do grupo VRRP. Em seguida, você configura a prioridade para as interfaces redundantes e interfaces Gigabit Ethernet para se tornar a interface principal.
Você pode forçar a atribuição de interfaces redundantes primárias e backup e interfaces Gigabit Ethernet usando prioridades de 1 a 255, onde 255 é a maior prioridade.
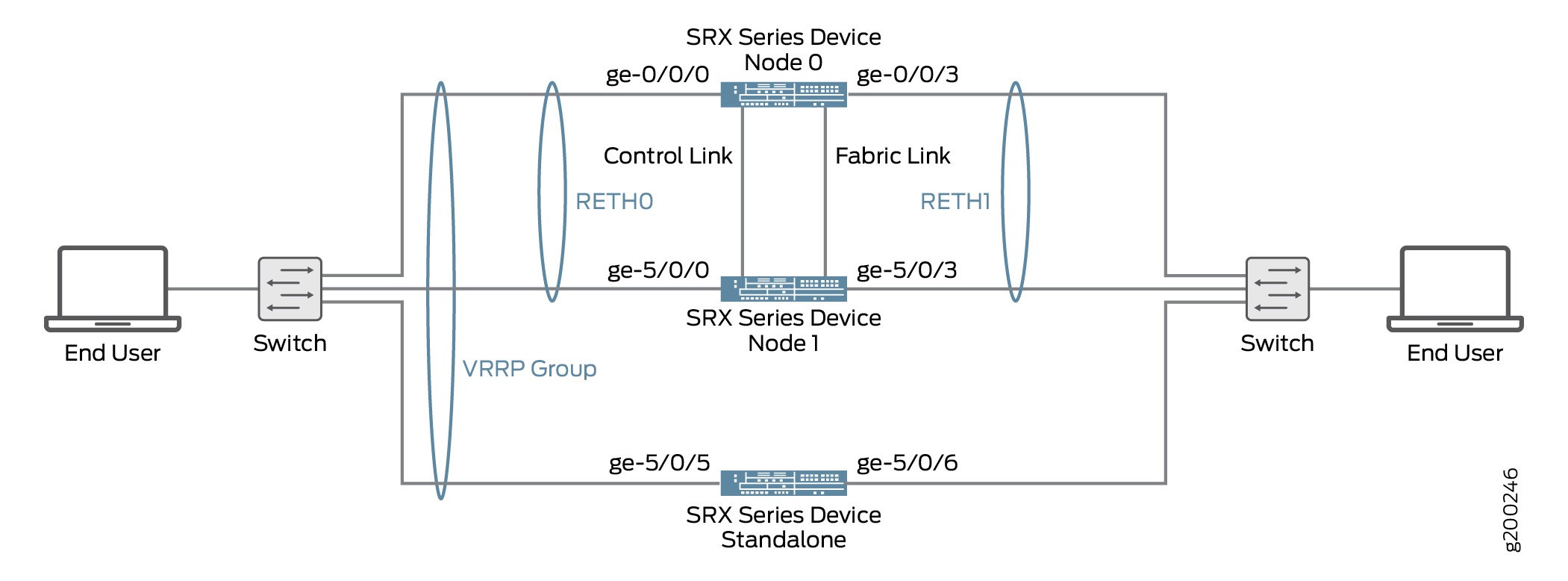
Configuração VRRP
- Configuração do VRRPv3, grupos VRRP e prioridade em interfaces de ethernet redundantes de cluster de chassis
- Configuração de grupos VRRP em dispositivo autônomo
Configuração do VRRPv3, grupos VRRP e prioridade em interfaces de ethernet redundantes de cluster de chassis
Configuração rápida da CLI
Para configurar rapidamente este exemplo, copie os seguintes comandos, cole-os em um arquivo de texto, remova quaisquer quebras de linha, altere todos os detalhes necessários para combinar com a configuração da sua rede, copiar e colar os comandos na CLI no nível de [edit] hierarquia e, em seguida, entrar no commit modo de configuração.
set protocols vrrp traceoptions file vrrp.log
set protocols vrrp traceoptions file size 10000000
set protocols vrrp traceoptions flag all
set protocols vrrp version-3
set protocols vrrp ignore-nonstop-routing
set interfaces ge-0/0/0 gigether-options redundant-parent reth0
set interfaces ge-0/0/3 gigether-options redundant-parent reth1
set interfaces ge-5/0/0 gigether-options redundant-parent reth0
set interfaces ge-5/0/3 gigether-options redundant-parent reth1
set interfaces reth0 redundant-ether-options redundancy-group 1
set interfaces reth0 unit 0 family inet address 192.0.2.2/24 vrrp-group 0 virtual-address 192.0.2.3
set interfaces reth0 unit 0 family inet address 192.0.2.2/24 vrrp-group 0 priority 255
set interfaces reth0 unit 0 family inet address 192.0.2.2/24 vrrp-group 0 accept-data
set interfaces reth0 unit 0 family inet6 address 2001:db8::2/32 vrrp-inet6-group 2 virtual-inet6-address 2001:db8::3
set interfaces reth0 unit 0 family inet6 address 2001:db8::2/32 vrrp-inet6-group 2 priority 255
set interfaces reth0 unit 0 family inet6 address 2001:db8::2/32 vrrp-inet6-group 2 accept-data
set interfaces reth1 redundant-ether-options redundancy-group 2
set interfaces reth1 unit 0 family inet address 192.0.2.4/24 vrrp-group 1 virtual-address 192.168.120.3
set interfaces reth1 unit 0 family inet address 192.0.2.4/24 vrrp-group 1 priority 150
set interfaces reth1 unit 0 family inet address 192.0.2.4/24 vrrp-group 1 accept-data
set interfaces reth1 unit 0 family inet6 address 2001:db8::3/32 vrrp-inet6-group 3 virtual-inet6-address 2001:db8::4
set interfaces reth1 unit 0 family inet6 address 2001:db8::3/32 vrrp-inet6-group 3 priority 150
set interfaces reth1 unit 0 family inet6 address 2001:db8::3/32 vrrp-inet6-group 3 accept-data
Procedimento passo a passo
Para configurar VRRPv3, grupos VRRP e prioridade em dispositivos de cluster de chassi:
-
Configure um nome de arquivo para traceoptions para rastrear o tráfego de protocolo VRRP.
[edit protocols vrrp] user@host#
set traceoptions file vrrp.log -
Especifique o tamanho máximo do arquivo de rastreamento.
[edit protocols vrrp] user@host#
set traceoptions file size 10000000 -
Habilite traceoptions vrrp.
[edit protocols vrrp] user@host#
set traceoptions flag all -
Definir a versão vrrp para 3.
[edit protocols vrrp] user@host#
set version-3 -
Configure este comando para oferecer suporte a switchover gracioso do Mecanismo de Roteamento (GRES) para VRRP e para roteamento ativo ininterrupto quando houver failover de reth VRRP. Usando vrrp, um nó secundário pode assumir um nó primário com falha em poucos segundos e isso é feito com tráfego VRRP mínimo e sem qualquer interação com os hosts
[edit protocols vrrp] user@host#
set ignore-nonstop-routing -
Configure as interfaces redundantes de Ethernet (reth) e atribua a interface redundante a uma zona.
[edit interfaces] user@host#
set ge-0/0/0 gigether-options redundant-parent reth0user@host#set ge-0/0/3 gigether-options redundant-parent reth1user@host#set ge-5/0/0 gigether-options redundant-parent reth0user@host#set ge-5/0/3 gigether-options redundant-parent reth1user@host#set reth0 redundant-ether-options redundancy-group 1user@host#set reth1 redundant-ether-options redundancy-group 2 -
Configure o endereço de inet da família e o endereço virtual para a interface redundante 0 unidade 0.
[edit interfaces] user@host#
set reth0 unit 0 family inet address 192.0.2.2/24 vrrp-group 0 virtual-address 192.168.110.3user@host#set reth0 unit 0 family inet6 address 2001:db8::2/32 vrrp-inet6-group 2 virtual-inet6-address 2001:db8::3 -
Configure o endereço de inet da família e o endereço virtual para a interface redundante 1 unidade 0.
[edit interfaces] user@host#
set reth1 unit 0 family inet address 192.0.2.4/24 vrrp-group 1 virtual-address 192.168.120.3user@host#set reth1 unit 0 family inet6 address 2001:db8::3/32 vrrp-inet6-group 3 virtual-inet6-address 2001:db8::4 -
Definir a prioridade da interface redundante 0 unidade 0 a 255.
[edit interfaces] user@host#
set reth0 unit 0 family inet address 192.0.2.2/24 vrrp-group 0 priority 255user@host#set reth0 unit 0 family inet6 address 2001:db8::2/32 vrrp-inet6-group 2 priority 255 -
Definir a prioridade da interface redundante 1 unidade 0 a 150.
[edit interfaces] user@host#
set reth1 unit 0 family inet address 192.0.2.4/24 vrrp-group 1 priority 150user@host#set reth1 unit 0 family inet6 address 2001:db8::3/32 vrrp-inet6-group 3 priority 150 -
Configure a interface redundante 0 unidade 0 para aceitar todos os pacotes enviados para o endereço IP virtual.
[edit interfaces] user@host#
set reth0 unit 0 family inet address 192.0.2.2/24 vrrp-group 0 accept-datauser@host#set reth0 unit 0 family inet6 address 2001:db8::2/32 vrrp-inet6-group 2 accept-data -
Configure a interface redundante 1 unidade 0 para aceitar todos os pacotes enviados para o endereço IP virtual.
[edit interfaces] user@host#
set reth1 unit 0 family inet address 192.0.2.4/24 vrrp-group 1 accept-datauser@host#set reth1 unit 0 family inet6 address 2001:db8::3/32 vrrp-inet6-group 3 accept-data
Resultados
A partir do modo de configuração, confirme sua configuração inserindo os show interfaces reth0 comandos e show interfaces reth1 os comandos. Se a saída não exibir a configuração pretendida, repita as instruções de configuração neste exemplo para corrigi-la.
[edit]
user@host# show interfaces reth0
redundant-ether-options {
redundancy-group 1;
}
unit 0 {
family inet {
address 192.0.2.2/24 {
vrrp-group 0 {
virtual-address 192.0.2.3;
priority 255;
accept-data;
}
}
}
family inet6 {
address 2001:db8::2/32 {
vrrp-inet6-group 2 {
virtual-inet6-address 2001:db8::3;
priority 255;
accept-data;
}
}
}
}
[edit]
user@host# show interfaces reth1
redundant-ether-options {
redundancy-group 2;
}
unit 0 {
family inet {
address 192.0.2.4/24 {
vrrp-group 1 {
virtual-address 192.0.2.5;
priority 150;
accept-data;
}
}
}
family inet6 {
address 2001:db8::3/32 {
vrrp-inet6-group 3 {
virtual-inet6-address 2001:db8::4;
priority 150;
accept-data;
}
}
}
}
Se você terminar de configurar o dispositivo, entre no commit modo de configuração.
Configuração de grupos VRRP em dispositivo autônomo
Configuração rápida da CLI
Para configurar rapidamente este exemplo, copie os seguintes comandos, cole-os em um arquivo de texto, remova quaisquer quebras de linha, altere todos os detalhes necessários para combinar com a configuração da sua rede, copiar e colar os comandos na CLI no nível de [edit] hierarquia e, em seguida, entrar no commit modo de configuração.
set protocols vrrp version-3
set interfaces xe-5/0/5 unit 0 family inet address 192.0.2.1/24 vrrp-group 0 virtual-address 192.0.2.3
set interfaces xe-5/0/5 unit 0 family inet address 192.0.2.1/24 vrrp-group 0 priority 50
set interfaces xe-5/0/5 unit 0 family inet address 192.0.2.1/24 vrrp-group 0 accept-data
set interfaces xe-5/0/5 unit 0 family inet6 address 2001:db8::1/32 vrrp-inet6-group 2 virtual-inet6-address 2001:db8::3
set interfaces xe-5/0/5 unit 0 family inet6 address 2001:db8::1/32 vrrp-inet6-group 2 priority 50
set interfaces xe-5/0/5 unit 0 family inet6 address 2001:db8::1/32 vrrp-inet6-group 2 accept-data
set interfaces xe-5/0/6 unit 0 family inet address 192.0.2.1/24 vrrp-group 1 virtual-address 192.0.2.5
set interfaces xe-5/0/6 unit 0 family inet address 192.0.2.1/24 vrrp-group 1 priority 50
set interfaces xe-5/0/6 unit 0 family inet address 192.0.2.1/24 vrrp-group 1 accept-data
set interfaces xe-5/0/6 unit 0 family inet6 address 2001:db8::5/32 vrrp-inet6-group 3 virtual-inet6-address 2001:db8::4
set interfaces xe-5/0/6 unit 0 family inet6 address 2001:db8::5/32 vrrp-inet6-group 3 priority 50
set interfaces xe-5/0/6 unit 0 family inet6 address 2001:db8::5/32 vrrp-inet6-group 3 accept-data
Procedimento passo a passo
Para configurar grupos VRRP em dispositivo autônomo:
-
Definir a versão vrrp para 3.
[edit protocols vrrp] user@host#
set version-3 -
Configure o endereço de inet da família e o endereço virtual para a unidade de interface Ethernet Gigabit 0.
[edit interfaces] user@host#
set xe-5/0/5 unit 0 family inet address 192.0.2.1/24 vrrp-group 0 virtual-address 192.0.2.3user@host#set xe-5/0/5 unit 0 family inet6 address 2001:db8::1/32 vrrp-inet6-group 2 virtual-inet6-address 2001:db8::3user@host#set xe-5/0/6 unit 0 family inet address 192.0.2.1/24 vrrp-group 1 virtual-address 192.0.2.5user@host#set xe-5/0/6 unit 0 family inet6 address 2001:db8::5/32 vrrp-inet6-group 3 virtual-inet6-address 2001:db8::4 -
Defina a prioridade da unidade de interface Ethernet Gigabit de 0 a 50.
[edit interfaces] user@host#
set xe-5/0/5 unit 0 family inet address 192.0.2.1/24 vrrp-group 0 priority 50user@host#set xe-5/0/5 unit 0 family inet6 address 2001:db8::1/32 vrrp-inet6-group 2 priority 50user@host#set xe-5/0/6 unit 0 family inet address 192.0.2.1/24 vrrp-group 1 priority 50user@host#set xe-5/0/6 unit 0 family inet6 address 2001:db8::5/32 vrrp-inet6-group 3 priority 50 -
Configure a unidade de interface Ethernet Gigabit 0 para aceitar todos os pacotes enviados para o endereço IP virtual.
[edit interfaces] user@host#
set xe-5/0/5 unit 0 family inet address 192.0.2.1/24 vrrp-group 0 accept-datauser@host#set xe-5/0/5 unit 0 family inet6 address 2001:db8::1/32 vrrp-inet6-group 2 accept-datauser@host#set xe-5/0/6 unit 0 family inet address 192.0.2.1/24 vrrp-group 1 accept-datauser@host#set xe-5/0/6 unit 0 family inet6 address 2001:db8::5/32 vrrp-inet6-group 3 accept-data
Resultados
A partir do modo de configuração, confirme sua configuração inserindo os show interfaces xe-5/0/5 comandos e show interfaces xe-5/0/6 os comandos. Se a saída não exibir a configuração pretendida, repita as instruções de configuração neste exemplo para corrigi-la.
[edit]
user@host# show interfaces xe-5/0/5
unit 0 {
family inet {
address 192.0.2.1/24 {
vrrp-group 0 {
virtual-address 192.0.2.3;
priority 50;
accept-data;
}
}
}
family inet6 {
address 2001:db8::1/32 {
vrrp-inet6-group 2 {
virtual-inet6-address 2001:db8::3;
priority 50;
accept-data;
}
}
}
}
[edit]
user@host# show interfaces xe-5/0/6
unit 0 {
family inet {
address 192.0.2.1/24 {
vrrp-group 1 {
virtual-address 192.0.2.5;
priority 50;
accept-data;
}
}
}
family inet6 {
address 2001:db8::5/32 {
vrrp-inet6-group 3 {
virtual-inet6-address 2001:db8::4;
priority 50;
accept-data;
}
}
}
}
Se você terminar de configurar o dispositivo, entre no commit modo de configuração.
Verificação
Confirme se a configuração está funcionando corretamente.
Verificando o VRRP em dispositivos de cluster de chassi
Propósito
Verifique se o VRRP em dispositivos de cluster de chassi foi configurado corretamente.
Ação
Desde o modo operacional, entre no show vrrp brief comando para exibir o status do VRRP em dispositivos de cluster de chassi.
user@host> show vrrp brief
Interface State Group VR state VR Mode Timer Type Address
reth0.0 up 0 master Active A 0.149 lcl 192.0.2.3
vip 192.0.2.3
reth0.0 up 2 master Active A 0.155 lcl 2001:db8::2
vip 2001:db8:5eff:fe00:202
vip 2001:db8::2
reth1.0 up 1 master Active A 0.445 lcl 192.0.2.4
vip 192.0.2.4
reth1.0 up 3 master Active A 0.414 lcl 2001:db8::4
vip 2001:db8:5eff:fe00:203
vip 2001:db8::4
Significado
A saída de amostra mostra que os quatro grupos VRRP estão ativos e que as interfaces redundantes assumiram as funções primárias corretas. O endereço lcl é o endereço físico da interface e o endereço vip é o endereço virtual compartilhado por interfaces redundantes. O valor do Timer (A 0,149, A 0,155, A 0,445 e A 0,414) indica o tempo restante (em segundos) em que as interfaces redundantes esperam receber um anúncio VRRP das interfaces Gigabit Ethernet. Se um anúncio para o grupo 0, 1, 2 e 3 não chegar antes do temporiza, os dispositivos de cluster chassis se afirmam como o principal.
Verificando o VRRP em dispositivo autônomo
Propósito
Verifique se o VRRP foi configurado corretamente em um dispositivo autônomo.
Ação
Desde o modo operacional, entre no show vrrp brief comando para exibir o status do VRRP em dispositivo autônomo.
user@host> show vrrp brief
Interface State Group VR state VR Mode Timer Type Address
xe-5/0/5.0 up 0 backup Active D 3.093 lcl 192.0.2.2.1
vip 192.0.2.2
mas 192.0.2.2.2
xe-5/0/5.0 up 2 backup Active D 3.502 lcl 2001:db8::2:1
vip 2001:db8:200:5eff:fe00:202
vip 2001:db8::2
mas 2001:db8:210:dbff:feff:1000
xe-5/0/6.0 up 1 backup Active D 3.499 lcl 192.0.2.5.1
vip 192.0.2.5
mas 192.0.2.5.2
xe-5/0/6.0 up 3 backup Active D 3.282 lcl 2001:db8::5
vip 2001:db8:200:5eff:fe00:203
vip 2001:db8::4
mas 2001:db8:210:dbff:feff:1001
Significado
A saída de amostra mostra que os quatro grupos VRRP estão ativos e que as interfaces Gigabit Ethernet assumiram as funções de backup corretas. O endereço lcl é o endereço físico da interface e o endereço vip é o endereço virtual compartilhado pelas interfaces Ethernet Gigabit. O valor do Timer (D 3.093, D 3.502, D 3.499 e D 3.282) indica o tempo restante (em segundos) em que as interfaces Ethernet Gigabit esperam receber um anúncio VRRP das interfaces redundantes. Se um anúncio para o grupo 0, 1, 2 e 3 não chegar antes do temporiza, então o dispositivo autônomo continua a ser um dispositivo de backup.
Exemplo: Configuração de VRRP para IPv6
Este exemplo mostra como configurar propriedades VRRP para IPv6.
Requisitos
Este exemplo usa os seguintes componentes de hardware e software:
-
Três roteadores
-
Versão do Junos OS 11.3 ou posterior
- Este exemplo foi recentemente atualizado e revalidado no Junos OS Release 21.1R1.
- Para obter mais informações sobre o suporte a VRRP para combinações de versão específicas da plataforma e do Junos OS, veja Feature Explorer.
Visão geral
Este exemplo usa um grupo VRRP, que tem um endereço virtual para IPv6. Os dispositivos na LAN usam esse endereço virtual como seu gateway padrão. Se o roteador primário falhar, o roteador de backup assume o controle.
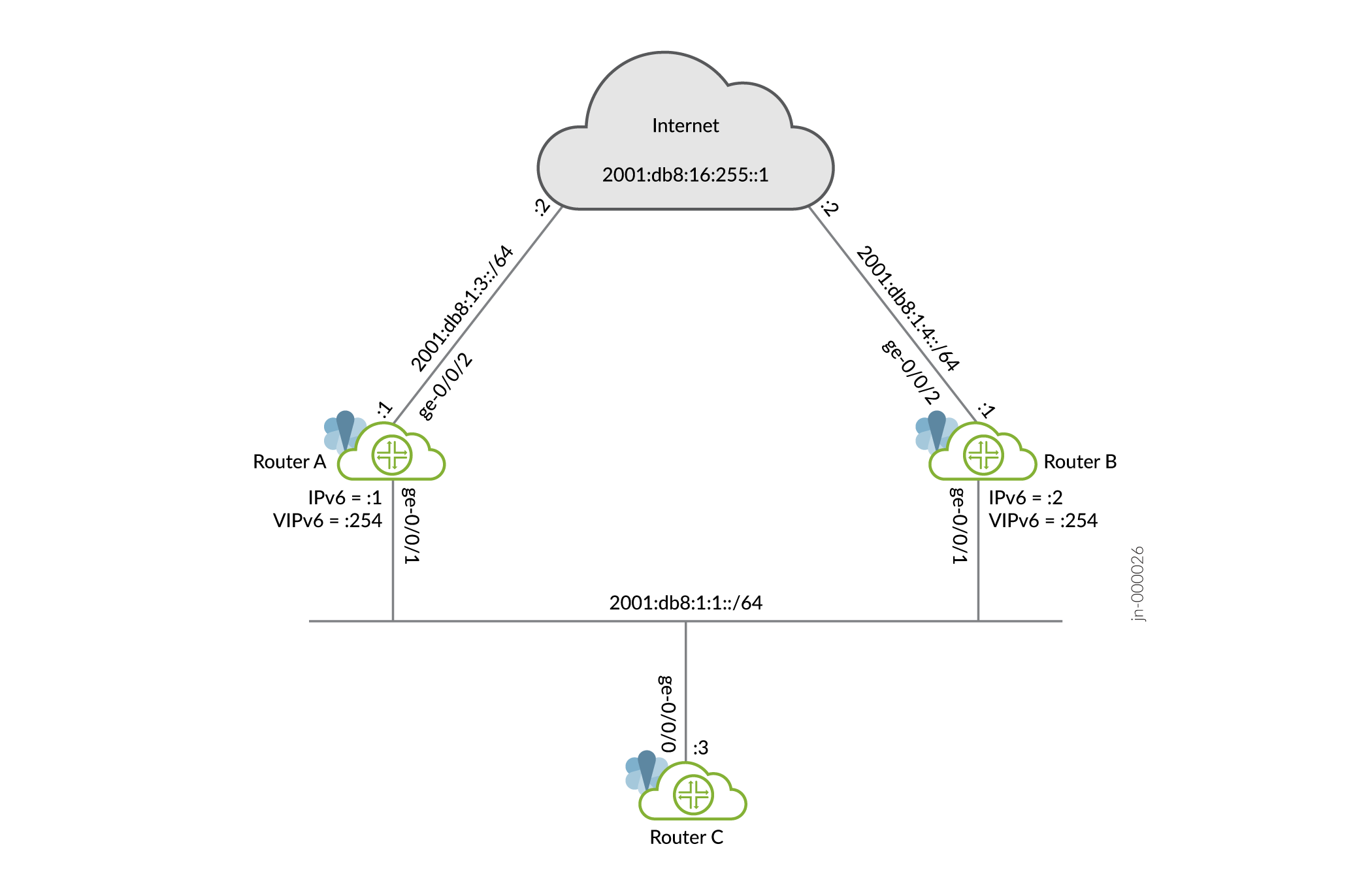
Configuração do VRRP
Configuração do roteador A
Configuração rápida da CLI
Para configurar rapidamente este exemplo, copie os seguintes comandos, cole em um arquivo de texto, remova qualquer quebra de linha, altere os detalhes necessários para combinar com a configuração da sua rede e, em seguida, copie e cole os comandos no CLI no nível de [edit] hierarquia.
set interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8:1:1::1/64 vrrp-inet6-group 1 virtual-inet6-address 2001:db8:1:1::254 set interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8:1:1::1/64 vrrp-inet6-group 1 priority 110 set interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8:1:1::1/64 vrrp-inet6-group 1 accept-data set interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8:1:1::1/64 vrrp-inet6-group 1 track interface ge-0/0/2 priority-cost 20 set interfaces ge-0/0/2 unit 0 family inet6 address 2001:db8:1:3::1/64 set protocols router-advertisement interface ge-0/0/1.0 virtual-router-only set protocols router-advertisement interface ge-0/0/1.0 prefix 2001:db8:1:1::/64 set routing-options rib inet6.0 static route 0::0/0 next-hop 2001:db8:1:3::2
Procedimento passo a passo
Para configurar este exemplo:
-
Configure as interfaces.
[edit] user@routerA# set interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8:1:1::1/64 user@routerA# set interfaces ge-0/0/2 unit 0 family inet6 address 2001:db8:1:3::1/64
-
Configure o identificador de grupo IPv6 VRRP e o endereço IP virtual.
[edit interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8:1:1::1/64] user@routerA# set vrrp-inet6-group 1 virtual-inet6-address 2001:db8:1:1::254
-
Configure a prioridade para o RoteadorA superior ao RoteadorB para se tornar o roteador virtual principal. O RoteadorB está usando a prioridade padrão do 100.
[edit interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8:1:1::1/64] user@routerA# set vrrp-inet6-group 1 priority 110
-
Configure
track interfacepara rastrear se a interface conectada à Internet está para cima, para baixo ou não para mudar a prioridade do grupo VRRP.[edit interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8:1:1::1/64] user@routerA# set vrrp-inet6-group 1 track interface ge-0/0/2 priority-cost 20
-
Configure
accept-datapara permitir que o roteador principal aceite todos os pacotes destinados ao endereço IP virtual.[edit interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8:1:1::1/64] user@routerA# set vrrp-inet6-group 1 accept-data
-
Configure uma rota estática para o tráfego para a Internet.
[edit] user@routerA# set routing-options rib inet6.0 static route 0::0/0 next-hop 2001:db8:1:3::2
-
Para VRRP para iPv6, você deve configurar a interface na qual o VRRP está configurado para enviar anúncios de roteador IPv6 para o grupo VRRP. Quando uma interface recebe uma mensagem de solicitação de roteador IPv6, ela envia um anúncio de roteador IPv6 para todos os grupos VRRP configurados nele.
[edit protocols router-advertisement interface ge-0/0/1.0] user@routerA# set prefix 2001:db8:1:1::/64
-
Configure anúncios de roteador a serem enviados apenas para grupos VRRP IPv6 configurados na interface se os grupos estiverem no estado principal.
[edit protocols router-advertisement interface ge-0/0/1.0] user@routerA# set virtual-router-only
Resultados
A partir do modo de configuração, confirme sua configuração entrando no show interfacese show protocols router-advertisement show routing-options comanda. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
[edit]
user@routerA# show interfaces
ge-0/0/1 {
unit 0 {
family inet6 {
address 2001:db8:1:1::1/64 {
vrrp-inet6-group 1 {
virtual-inet6-address 2001:db8:1:1::254;
priority 110;
accept-data;
track {
interface ge-0/0/2 {
priority-cost 20;
}
}
}
}
}
}
}
ge-0/0/2 {
unit 0 {
family inet6 {
address 2001:db8:1:3::1/64;
}
}
}
[edit]
user@routerA# show protocols router-advertisement
interface ge-0/0/1.0 {
virtual-router-only;
prefix 2001:db8:1:1::/64;
}
[edit]
user@routerA# show routing-options
rib inet6.0 {
static {
route 0::0/0 next-hop 2001:db8:1:3::2;
}
}
Se você terminar de configurar o dispositivo, entre no commit modo de configuração.
Configuração do roteador B
Configuração rápida da CLI
Para configurar este exemplo rapidamente, copie os seguintes comandos, cole-os em um arquivo de texto, remova qualquer quebra de linha, altere os detalhes necessários para combinar com a configuração da sua rede e, em seguida, copie e cole os comandos no CLI no nível de [edit] hierarquia.
set interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8:1:1::2/64 vrrp-inet6-group 1 virtual-inet6-address 2001:db8:1:1::254 set interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8:1:1::2/64 vrrp-inet6-group 1 priority 110 set interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8:1:1::2/64 vrrp-inet6-group 1 accept-data set protocols router-advertisement interface ge-0/0/1.0 virtual-router-only set protocols router-advertisement interface ge-0/0/1.0 prefix 2001:db8:1:1::/64
Procedimento passo a passo
Para configurar este exemplo:
-
Configure as interfaces.
[edit] user@routerB# set interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8:1:1::2/64 user@routerB# set interfaces ge-0/0/2 unit 0 family inet6 address 2001:db8:1:4::1/64
-
Configure o identificador de grupo IPv6 VRRP e o endereço IP virtual.
[edit interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8:1:1::2/64] user@routerB# set vrrp-inet6-group 1 virtual-inet6-address 2001:db8:1:1::254
-
Configure
accept-datapara permitir que o roteador de backup aceite todos os pacotes destinados ao endereço IP virtual caso o roteador de backup se torne primário.[edit interfaces ge-0/0/1 unit 0 family inet6 address 2001:db8:1:1::2/64] user@routerB# set vrrp-inet6-group 1 accept-data
-
Configure uma rota estática para o tráfego para a Internet.
[edit] user@routerB# set routing-options rib inet6.0 static route 0::0/0 next-hop 2001:db8:1:4::2
-
Configure a interface na qual o VRRP está configurado para enviar anúncios de roteador IPv6 para o grupo VRRP. Quando uma interface recebe uma mensagem de solicitação de roteador IPv6, ela envia um anúncio de roteador IPv6 para todos os grupos VRRP configurados nele.
[edit protocols router-advertisement interface ge-0/0/1.0] user@routerB# set prefix 2001:db8:1:1::/64
-
Configure anúncios de roteador a serem enviados apenas para grupos VRRP IPv6 configurados na interface se os grupos estiverem no estado principal.
[edit protocols router-advertisement interface ge-0/0/1.0] user@routerB# set virtual-router-only
Resultados
A partir do modo de configuração, confirme sua configuração entrando no show interfacese show protocols router-advertisement show routing-options comanda. Se a saída não exibir a configuração pretendida, repita as instruções neste exemplo para corrigir a configuração.
[edit]
user@routerB# show interfaces
ge-0/0/1 {
unit 0 {
family inet6 {
address 2001:db8:1:1::2/64 {
vrrp-inet6-group 1 {
virtual-inet6-address 2001:db8:1:1::254;
accept-data;
}
}
}
}
}
ge-0/0/2 {
unit 0 {
family inet6 {
address 2001:db8:1:4::1/64;
}
}
}
[edit]
user@routerB# show protocols router-advertisement
interface ge-0/0/1.0 {
virtual-router-only;
prefix 2001:db8:1:1::/64;
}
[edit]
user@routerB# show routing-options
rib inet6.0 {
static {
route 0::0/0 next-hop 2001:db8:1:4::2;
}
}
Se você terminar de configurar o dispositivo, entre no commit modo de configuração.
Configuração do roteador C
Configuração rápida da CLI
Para configurar este exemplo rapidamente, copie os seguintes comandos, cole-os em um arquivo de texto, remova qualquer quebra de linha, altere os detalhes necessários para combinar com a configuração da sua rede e, em seguida, copie e cole os comandos no CLI no nível de [edit] hierarquia.
set interfaces ge-0/0/0 unit 0 family inet6 address 2001:db8:1:1::3/64 set routing-options rib inet6.0 static route 0::0/0 next-hop 2001:db8:1:1::254
Verificação
- Verificando se o VRRP está trabalhando no roteador A
- Verificando se o VRRP está trabalhando no roteador B
- Verificação do roteador C chega ao roteador de trânsito da Internet A
- Verificar o roteador B torna-se primário para VRRP
Verificando se o VRRP está trabalhando no roteador A
Propósito
Verifique se o VRRP está ativo no Roteador A e se sua função no grupo VRRP está correta.
Ação
Use os seguintes comandos para verificar se o VRRP está ativo no Roteador A, que o roteador é primário para o grupo 1 e a interface conectada à Internet está sendo rastreada.
user@routerA> show vrrp
Interface State Group VR state VR Mode Timer Type Address
ge-0/0/1.0 up 1 master Active A 0.690 lcl 2001:db8:1:1::1
vip fe80::200:5eff:fe00:201
vip 2001:db8:1:1::254
user@routerA> show vrrp track Track Int State Speed VRRP Int Group VR State Current prio ge-0/0/2.0 up 1g ge-0/0/1.0 1 master 110
Significado
O show vrrp comando exibe informações fundamentais sobre a configuração vrRP. Essa saída mostra que o grupo VRRP está ativo e que este roteador assumiu o papel principal. O lcl endereço é o endereço físico da interface e o vip endereço é o endereço virtual compartilhado por ambos os roteadores. O Timer valor (A 0.690) indica o tempo restante (em segundos) em que este roteador espera receber um anúncio VRRP do outro roteador.
Verificando se o VRRP está trabalhando no roteador B
Propósito
Verifique se o VRRP está ativo no Roteador B e se sua função no grupo VRRP está correta.
Ação
Use o comando a seguir para verificar se o VRRP está ativo no Roteador B e que o roteador é backup para o grupo 1.
user@routerB> show vrrp
Interface State Group VR state VR Mode Timer Type Address
ge-0/0/1.0 up 1 backup Active D 2.947 lcl 2001:db8:1:1::2
vip fe80::200:5eff:fe00:201
vip 2001:db8:1:1::254
mas fe80::5668:a0ff:fe99:2d7d
Significado
O show vrrp comando exibe informações fundamentais sobre a configuração vrRP. Essa saída mostra que o grupo VRRP está ativo e que este roteador assumiu a função de backup. O lcl endereço é o endereço físico da interface e o vip endereço é o endereço virtual compartilhado por ambos os roteadores. O Timer valor (D 2.947) indica o tempo restante (em segundos) em que este roteador espera receber um anúncio VRRP do outro roteador.
Verificação do roteador C chega ao roteador de trânsito da Internet A
Propósito
Verifique a conectividade com a Internet a partir do roteador C.
Ação
Use os comandos a seguir para verificar se o roteador C pode chegar à Internet.
user@routerC> ping 2001:db8:16:255::1 count 2 PING6(56=40+8+8 bytes) 2001:db8:1:1::3 --> 2001:db8:16:255::1 16 bytes from 2001:db8:16:255::1, icmp_seq=0 hlim=63 time=12.810 ms 16 bytes from 2001:db8:16:255::1, icmp_seq=1 hlim=63 time=30.139 ms --- 2001:db8:16:255::1 ping6 statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max/std-dev = 12.810/21.474/30.139/8.664 ms
user@routerC> traceroute 2001:db8:16:255::1 traceroute6 to 2001:db8:16:255::1 (2001:db8:16:255::1) from 2001:db8:1:1::3, 64 hops max, 12 byte packets 1 2001:db8:1:1::1 (2001:db8:1:1::1) 9.891 ms 32.353 ms 7.859 ms 2 2001:db8:16:255::1 (2001:db8:16:255::1) 257.483 ms 19.877 ms 7.451 ms
Significado
O ping comando mostra que o alcanceda Internet e o comando mostra que o traceroute Roteador A está sendo transitado.
Verificar o roteador B torna-se primário para VRRP
Propósito
Verifique se o roteador B se torna primário para VRRP quando a interface entre o Roteador A e a Internet cair.
Ação
Use os seguintes comandos para verificar se o roteador B é primário e que o roteador C pode chegar ao roteador B em trânsito da Internet.
user@routerA> show vrrp track detail
Tracked interface: ge-0/0/2.0
State: down, Speed: 1g
Incurred priority cost: 20
Tracking VRRP interface: ge-0/0/1.0, Group: 1
VR State: backup
Current priority: 90, Configured priority: 110
Priority hold-time: disabled
user@routerB> show vrrp
Interface State Group VR state VR Mode Timer Type Address
ge-0/0/1.0 up 1 master Active A 0.119 lcl 2001:db8:1:1::2
vip fe80::200:5eff:fe00:201
vip 2001:db8:1:1::254
user@routerC> traceroute 2001:db8:16:255::1 traceroute6 to 2001:db8:16:255::1 (2001:db8:16:255::1) from 2001:db8:1:1::3, 64 hops max, 12 byte packets 1 2001:db8:1:1::2 (2001:db8:1:1::2) 52.945 ms 344.383 ms 29.540 ms 2 2001:db8:16:255::1 (2001:db8:16:255::1) 46.168 ms 24.744 ms 23.867 ms
Significado
O show vrrp track detail comando mostra que a interface rastreada está no Roteador A, que a prioridade caiu para 90, e que o Roteador A agora é o backup. O show vrrp comando mostra que o roteador B agora é o principal para VRRP e o comando mostra que o traceroute Roteador B está sendo transitado.
Comportamento de grupos de agregação de enlaces específicos da plataforma
Use o Feature Explorer para confirmar o suporte de plataforma e versão para recursos específicos.
Use a tabela a seguir para revisar comportamentos específicos da plataforma para sua plataforma.
| Plataforma |
Diferença |
|---|---|
| Série SRX |
|
Informações adicionais da plataforma
Use o Feature Explorer para confirmar o suporte de plataforma e versão para recursos específicos.
| Plataforma |
Interfaces Ethernet LAG redundantes |
|---|---|
| série SRX4600 e SRX5000 |
Cada interface de reth pode ter até oito links por nó, para um total de 16 links por interface. |
| Série SRX300, SRX1500, SRX1600, SRX2300, SRX4120, SRX4100, SRX4200 e SRX4300 |
Cada interface de reth pode ter até quatro links por nó, para um total de oito links por interface. |