EN ESTA PÁGINA
Opciones de monitoreo de alta disponibilidad de múltiples nodos
Tipos de monitoreo
Una detección de fallas de alta disponibilidad monitorea el sistema, el software y el hardware para detectar fallas internas. El sistema también puede monitorear problemas de conectividad de red o conectividad de vínculo mediante monitoreo de interfaz, monitoreo de ruta BFD y monitoreo de IP para detectar la accesibilidad de objetivos más lejanos.
En la tabla 1, se proporcionan detalles sobre los diferentes tipos de supervisión que se utilizan en la alta disponibilidad multinodo.
| Tipo de montaje | Qué es | Tipo de detección | Alcance |
|---|---|---|---|
| Monitoreo de BFD | Supervisa la accesibilidad al siguiente salto examinando la capa del vínculo junto con el vínculo real. |
|
|
| Monitoreo de IP | Monitorea la conectividad a hosts o servicios ubicados más allá de las interfaces conectadas directamente o los próximos saltos. |
|
|
| Monitoreo de interfaz | Examina si la capa de vínculo está operativa o no. |
Fallas de vínculo |
|
En la alta disponibilidad de múltiples nodos, cuando la supervisión detecta un error de conectividad con un host o servicio, marca la ruta afectada como inactiva o no disponible, y marca los grupos de enrutamiento de servicio (SRG) correspondientes en el nodo afectado como no elegibles. Los SRG afectados pasarán de manera estatal al otro nodo sin causar ninguna interrupción al tráfico.
Para evitar que se pierda tráfico, la alta disponibilidad multinodo toma las siguientes precauciones:
- Modo de capa 3: las rutas se volverán a dibujar para que el tráfico se redirija correctamente
- Puerta de enlace predeterminada o modo híbrido: el nuevo nodo activo para el SRG envía un GARP (ARP gratuito) al conmutador conectado para garantizar el reenrutamiento del tráfico
- Escenarios de falla de alta disponibilidad de múltiples nodos
- Falla de nodo
- Fallo de red/conectividad
Escenarios de falla de alta disponibilidad de múltiples nodos
En las secciones siguientes se describen posibles escenarios de error: cómo se detecta un error, qué acción de recuperación se debe realizar y, si corresponde, el impacto en el sistema causado por el error.Falla de nodo
Fallo de hardware
- Causa: un componente de hardware defectuoso o un problema ambiental, como un corte de energía.
- Detección: en alta disponibilidad de múltiples nodos
- No se puede acceder al dispositivo o nodo afectado
- El estado de SRG1 cambia a
INELIGIBLEEn el nodo con error de hardware.
- Impacto: el tráfico conmutará por tolerancia a fallos al otro nodo (si está en buen estado), como se muestra en la Figura 1. .
Figura 1: Fallo de hardware en alta disponibilidad
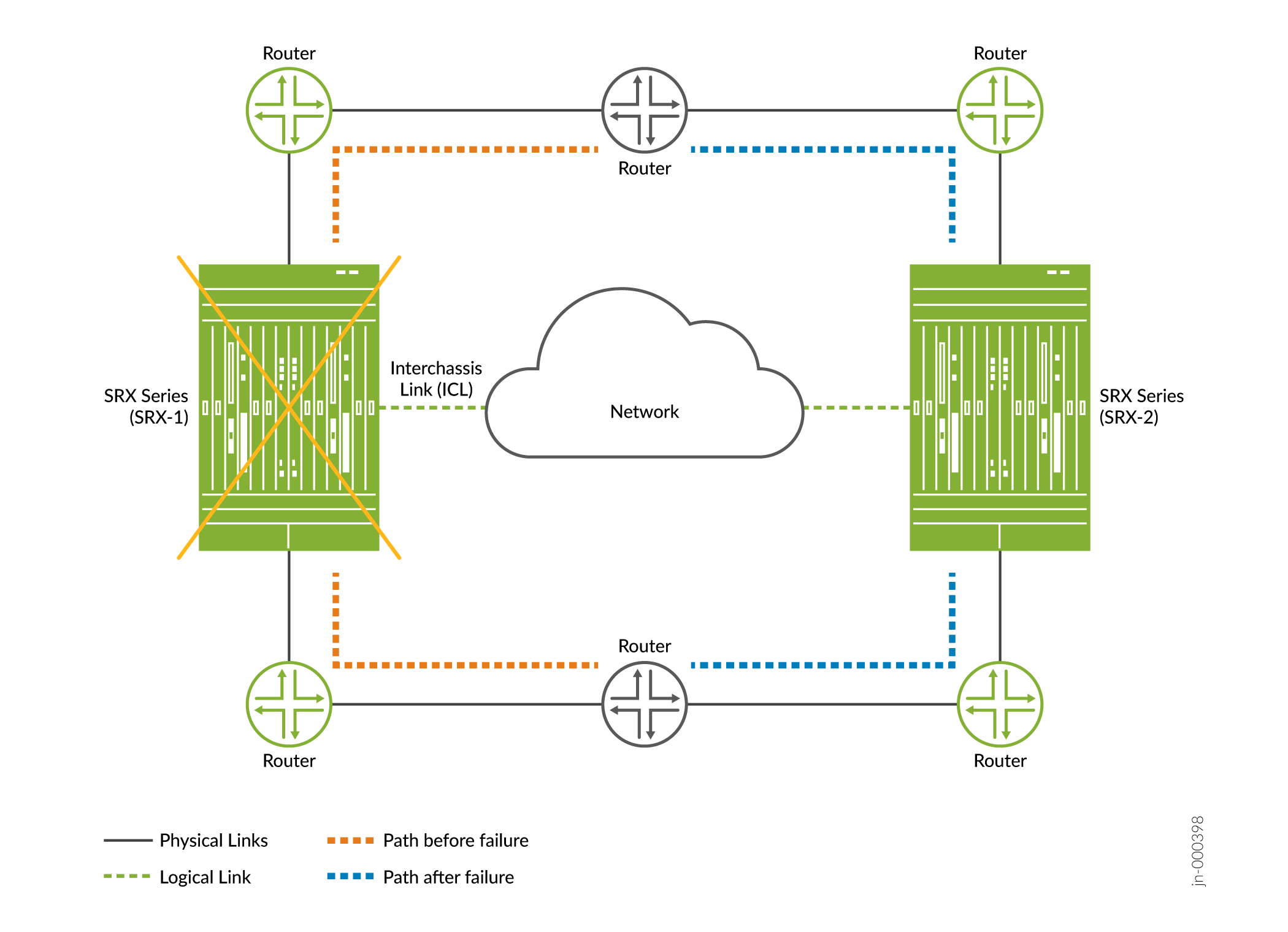 multinodo
multinodo
- Recuperación: la recuperación de la falla se produce cuando se borra la falla de hardware del chasis (por ejemplo, reemplazar o reparar el componente de hardware que falla).
- Resultados: compruebe el estado mediante los siguientes comandos:
Fallo de sistema o software
- Causa: un fallo en un proceso o servicio de software o problemas con el sistema operativo.
- Detección: en alta disponibilidad de múltiples nodos
- No se puede acceder al dispositivo o nodo afectado
- Cambia el estado del sistema a
INELIGIBLEen el nodo afectado con un error del sistema o software.
- Impacto: el tráfico conmutará por tolerancia a fallos al otro nodo si está en buen estado, como se muestra en la Figura 2
Figura 2: Fallo de software en alta disponibilidad
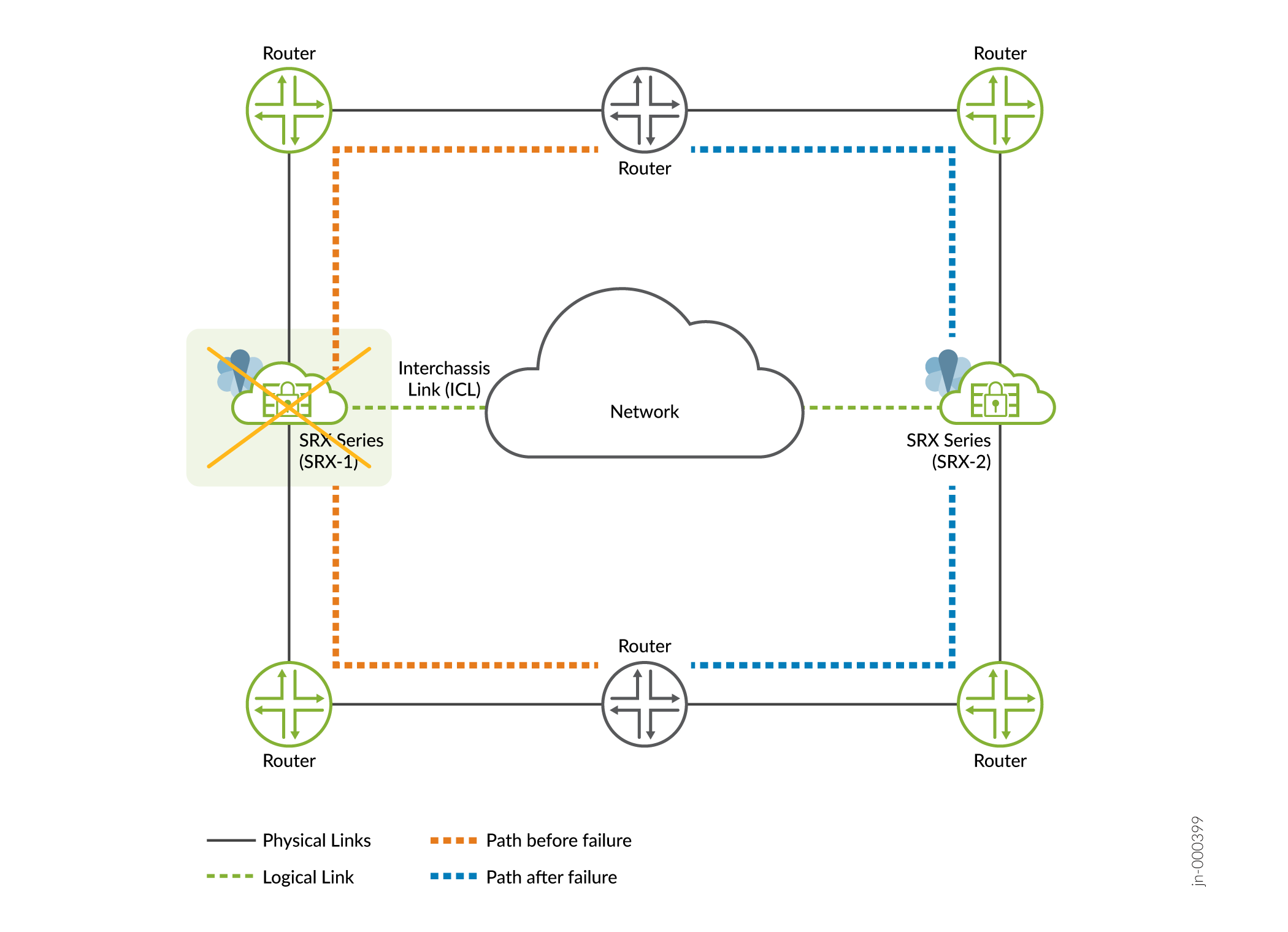 multinodo
multinodo
- Recuperación: se recupera automática y ágilmente de la interrupción una vez que se soluciona el problema. El nodo de copia de seguridad que ha asumido el rol activo sigue permaneciendo activo. El nodo anteriormente activo permanece como nodo de respaldo.
- Resultados: compruebe el estado con el comando mostrar detalle de información de alta disponibilidad del chasis.
Fallo de red/conectividad
- Error en las interfaces físicas (vínculo)
- Fallo de vínculo de interchasis (ICL)
- El nodo permanece en estado aislado
Error en las interfaces físicas (vínculo)
- Causa: un error en las interfaces puede deberse a interrupciones en el equipo de red, a una interrupción en el cable físico o a configuraciones incoherentes.
- Detección: en alta disponibilidad de múltiples nodos
- No se puede acceder al dispositivo o nodo afectado.
- El estado de SRG1 cambia a
INELIGIBLEen el nodo afectado con un error de red o conectividad (si la interfaz está configurada). La conectividad de ruta también podría detectarse con BFD o monitoreo de IP, y desencadenar un evento basado en la acción configurada.
- Impacto: un cambio en el estado del vínculo de las interfaces desencadena una tolerancia a fallos. El nodo de copia de seguridad asume el rol activo y los servicios que se ejecutaban en el nodo con errores se migran a otro nodo, como se muestra en la Figura 3.
Figura 3: Fallo de
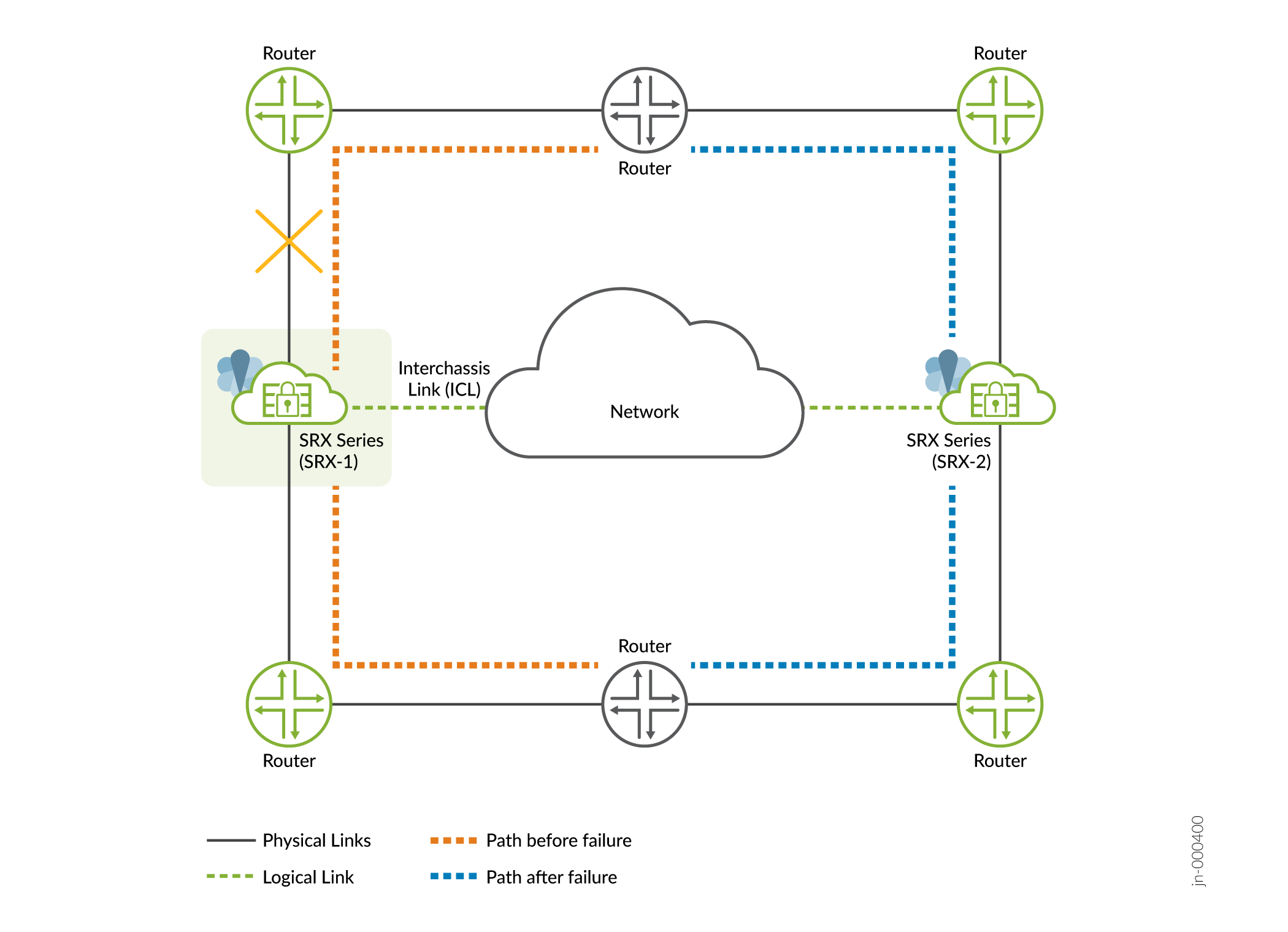 interfaz
interfaz
-
Configuración: para configurar la supervisión de BFD y la supervisión de interfaces, utilice la siguiente instrucción de configuración:
set chassis high-availability services-redundancy-group <1> monitor bfd-liveliness <source-ip-address> <destination-ip-address> routing-instance <routing-instance-name> <single-hop| multihop> <interface-name>
set chassis high-availability services-redundancy-group <1> monitor interface <interface-name>
Se deben monitorear todos los vínculos críticos para el flujo de tráfico.
Ejemplo de pago : Configure la alta disponibilidad de múltiples nodos en una red de capa 3 para obtener detalles completos de configuración.
- Recuperación: se recupera cuando repara o reemplaza la interfaz con errores. Una vez que se recupera el error de red o conectividad, SRG1 pasa del estado INELEGIBLE al estado BACKUP. El nuevo nodo activo continúa anunciando mejores métricas a su enrutador ascendente y procesa el tráfico.
- Resultados: compruebe el estado mediante los siguientes comandos:
-
Para obtener información sobre cómo configurar interfaces en MNHA, consulte Ejemplo: Configurar alta disponibilidad de múltiples nodos en una red de capa 3. Para solucionar problemas de interfaces, consulte Solución de problemas de interfaces.
Fallo de vínculo de interchasis (ICL)
- Causa: un error en la ICL podría deberse a interrupciones de la red o a configuraciones incoherentes.
- Detección: en la alta disponibilidad de múltiples nodos, los nodos no pueden comunicarse entre sí e inician una sonda de determinación de actividad (sonda ICMP).
- Impacto: en un sistema de alta disponibilidad multinodo, ICL conecta los nodos activos y de respaldo; si la ICL deja de funcionar, ambos dispositivos notarán este cambio e iniciarán la sonda de actividad (sonda ICMP). El sondeo de actividad se realiza para determinar el nodo que puede asumir un rol activo para cada SRG1+. Según el resultado del sondeo, uno de los nodos pasa al estado activo.
Como se muestra en la Figura 4, la ICL entre SRX-1 y SRX-2 desciende. Ambos dispositivos no pueden comunicarse entre sí y comienzan a enviar sondeos de actividad al enrutador ascendente. Dado que SRX-1 se encuentra en la ruta preferida más alta en la configuración del enrutador, asume un rol activo y continúa procesando el tráfico y anuncia una ruta de preferencia más alta. El otro asume el papel de respaldo.
Figura 4: Fallo de ICL en alta disponibilidad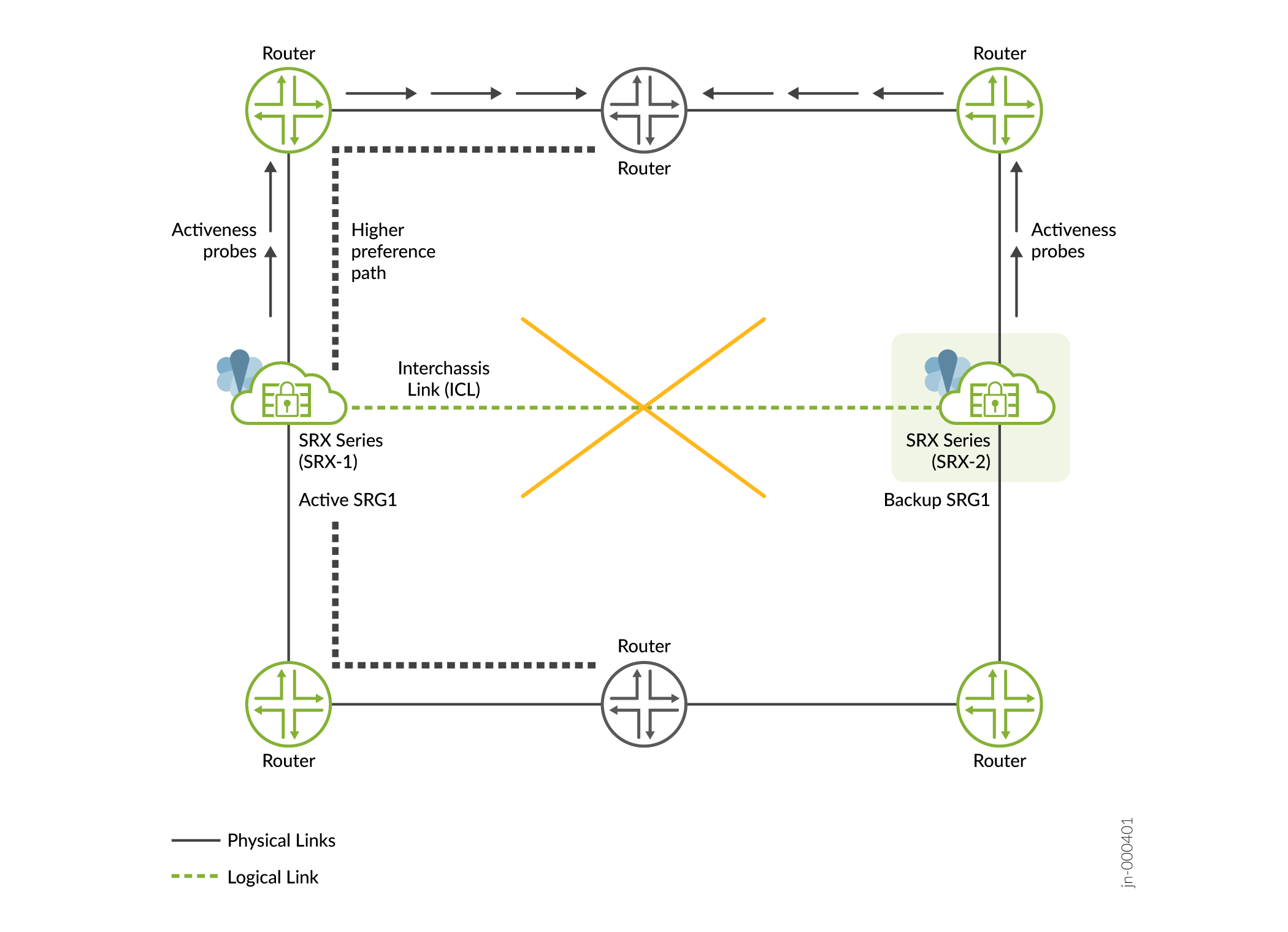 multinodo
multinodo
-
Configuración: para configurar el sondeo de actividad, utilice la siguiente instrucción de configuración:
set chassis high-availability services-redundancy-group <1> activeness-probe <destination-ip-address> routing-instance <routing-instance-name>
Consulte Configuración de la alta disponibilidad de múltiples nodos en una red de capa 3 para obtener detalles completos de configuración.
- Resultados: compruebe el estado mediante los siguientes comandos:
show chassis high-availability information detailshow chassis high-availability services-redundancy-group 1-
Compruebe la respuesta del paquete ICMP desde el enrutador ascendente mediante la opción ping. Ejemplo:
ping <activeness-probe-dest-ip> source <activeness-probe-source-ip> routing-instance <routing-instance-name>.
-
Recuperación: una vez que uno de los nodos asume un rol activo, la alta disponibilidad multinodo reinicia el proceso de sincronización en frío y vuelve a sincronizar los servicios de plano de control (VPN IPSec). La información de estado de SRG se vuelve a intercambiar entre los nodos.
El nodo permanece en estado aislado
- Causa: en una configuración de alta disponibilidad multinodo, el nodo permanece aislado después de un reinicio y las interfaces asociadas siguen inactivas cuando:
-
El vínculo entre chasis (ICL) no tiene conectividad con el otro nodo después del arranque hasta que se complete la sincronización en frío
y
-
La
shutdown-on-failureopción está configurada en SRG0Nota:La causa anterior también podría ocurrir si el otro dispositivo está fuera de servicio.
-
- Detección: el estado de SRG0 se muestra como
ISOLATEDen la salida del comando. -
Recuperación: el nodo se recupera automáticamente cuando el otro nodo se conecta y la ICL puede intercambiar información del sistema o cuando elimina la
shutdown-on-failureinstrucción y confirma la configuración.Utilice el
delete chassis high-availability services-redundancy-group 0 shutdown-on-failurepara eliminar la instrucción.Si la solución anterior no es adecuada para su entorno, puede utilizar la
install-on-failure-routeopción. En esta opción, la configuración de alta disponibilidad multinodo utiliza una ruta de señal definida para un manejo más ágil de la situación anterior mediante las opciones de la política de enrutamiento, que es similar al enfoque de ruta de señal activa y ruta de señal de respaldo disponible en SRG1+.
Monitoreo de ruta flexible
A partir de la versión 23.4R1 de Junos OS, agregamos nuevas mejoras para las siguientes funciones de monitoreo de rutas existentes:
- Monitoreo de IP
- Monitoreo de BFD
- Monitoreo de interfaz
Las mejoras agregan un control más granular para la función de monitoreo de rutas al:
- Extensión de la monitorización para SRG0 además de SRG1+
- Agrupación de funciones de supervisión
- Supervisión de soporte según la dirección asociada con una ruta de grupo de redundancia de servicio (SRG)
- Sumar pesos asociados con cada función de monitoreo
Al agrupar funciones relacionadas, el sistema puede procesarlas como una unidad, lo que puede conducir a una computación y utilización de recursos más eficientes.
- Objetos de supervisión de SRG
- Configuración de monitoreo de ruta
- Comprobar la configuración de los objetos de supervisión
Objetos de supervisión de SRG
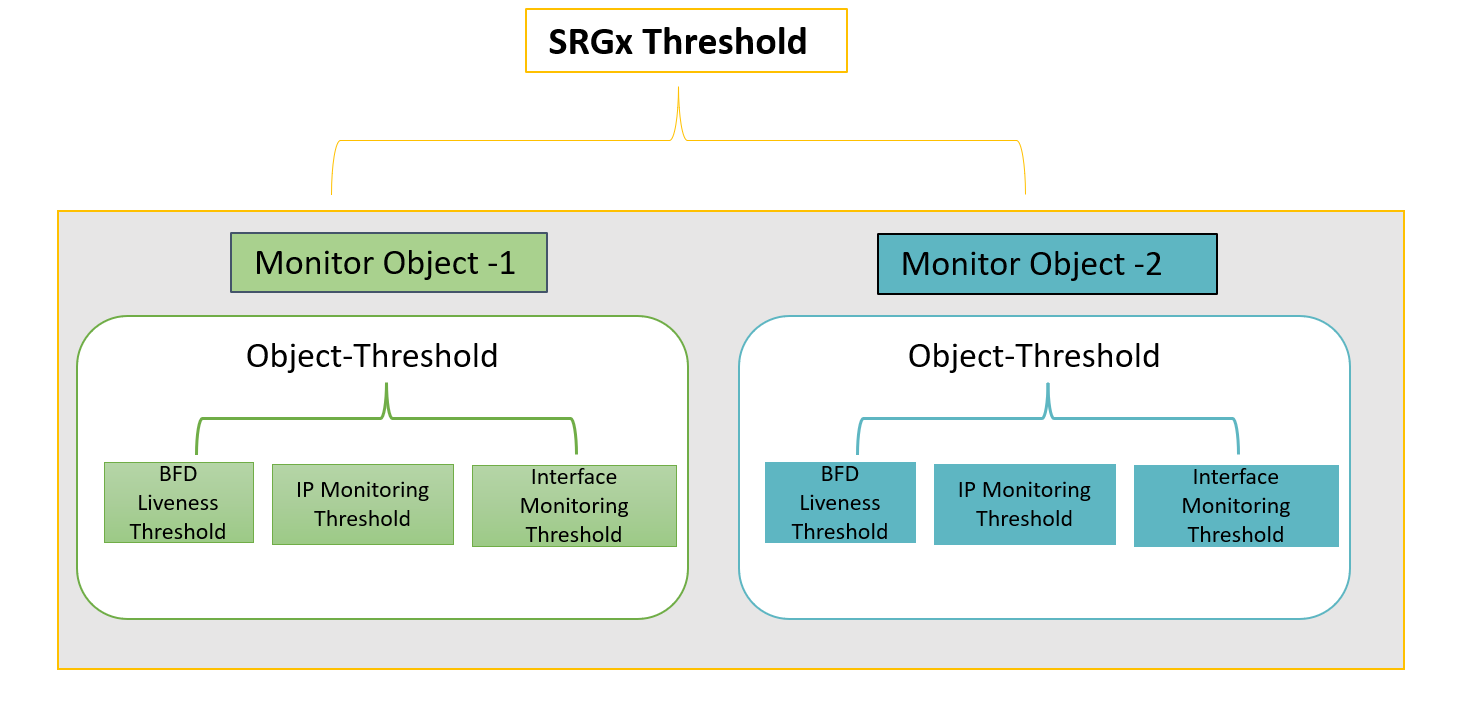
Entendamos el concepto de supervisión de objetos con la siguiente ilustración.
 de monitoreo de SRG
de monitoreo de SRG
Puede configurar las opciones de supervisión por grupo de redundancia de servicio. Es decir, si se produjera un error en elementos específicos del SRG, ese SRG puede dar una tolerancia a fallos al otro nodo. Cada SRG incluye uno o más objetos de supervisión.
Las funciones de supervisión disponibles en la supervisión de objetos son: BFD liveness, supervisión de interfaces y supervisión de IP. Cada una de estas entidades tiene un valor de umbral asociado y atributos de peso.
Dentro de un objeto de monitoreo, cada vez que el objeto determinado no puede desencadenar una conmutación por tolerancia a fallos como resultado de la supervisión de IP/interfaz/BFD, el sistema considera el evento como un error de supervisión. El software agrega el recuento en función del peso del objeto fallido.
Cuando el recuento supera el valor de umbral de IP/interface/BFD, el sistema agrega el recuento al valor de umbral del objeto de supervisión principal.
Cuando la suma de los umbrales de todos los objetos de supervisión enlazados al SRG es igual o mayor que el valor de umbral configurado en el SRG, el sistema desencadena un error de supervisión para ese SRG. SRG conmuta por error al otro nodo.
Configuración de monitoreo de ruta
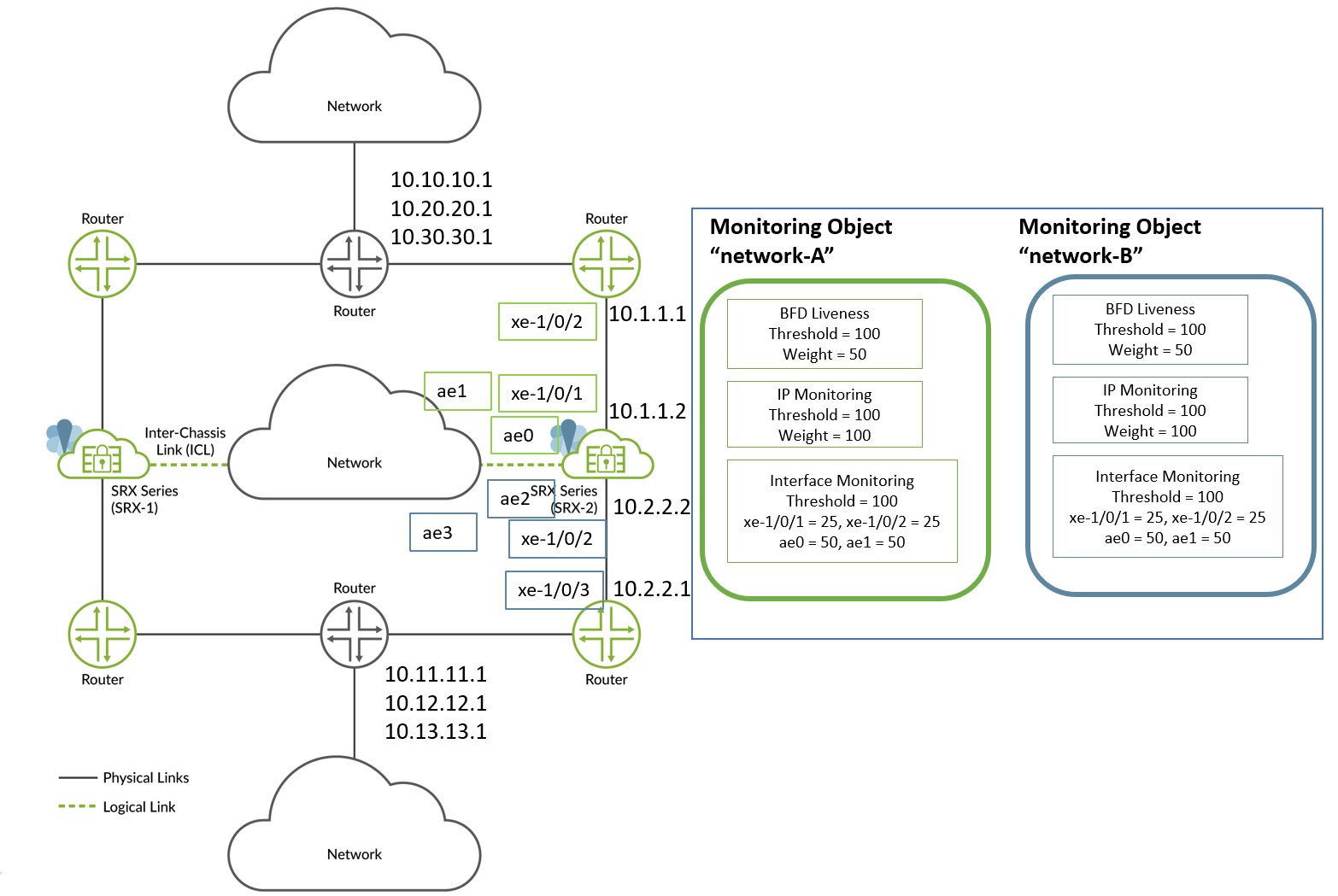
Consideremos el siguiente ejemplo para la topología que se muestra en la Figura 6. En esta configuración, estamos configurando las opciones de monitoreo de ruta para SRG1 en el dispositivo del nodo 2.
 de configuración de monitoreo de ruta
de configuración de monitoreo de ruta
En este ejemplo, para configurar las opciones de supervisión de rutas:
- Utilice una interfaz Ethernet agregada (ae) para el vínculo entre chasis (ICL) y utilice interfaces xe-1/0/x para conectarse a los enrutadores vecinos.
- Cree dos objetos de monitoreo "red-A" y "red-B". Los objetos de monitoreo de red A y red B incluyen todas las direcciones IP e interfaces configuradas entre el dispositivo de la serie SRX y los enrutadores vecinos.
- Configure BFD para supervisar las rutas vecinas.
- Configure la supervisión de IP para supervisar las rutas que no están conectadas directamente con SRG1.
- Configure la supervisión de la interfaz en vínculos conectados directamente o en los próximos saltos.
En la tabla siguiente se muestran las ponderaciones de muestra y las asignaciones de umbrales.
| Monitorear objetos |
BFD |
IP |
Interfaz |
Umbral de objeto de monitoreo |
Umbral de SRG |
|||
|---|---|---|---|---|---|---|---|---|
| Umbral |
Peso |
Umbral |
Peso |
Umbral |
Peso |
|||
| red-A | 100 |
50 |
100 |
50 (10.10.10.1, 10.20.20.1, 10.30.30.1) |
100 |
25 (xe-1/0/1 y xe-1/0/2) 50 (ae0 y ae1) |
100 |
100 |
| red B | 100 |
50 |
100 |
50 (10.11.11.1, 10.12.12.1, 10.13.13.1) | 100 |
25 (xe-1/0/3 y xe-1/0/4) 50 (ae2 y ae3) |
200 |
|
- Puede configurar hasta 10 objetos de supervisión por SRG.
- Puede configurar la supervisión de SRG como en Junos OS 23.4 (con umbral de SRG y objetos de supervisión) o configurar las opciones de supervisión como se admitían antes de la versión 23.4R1 de Junos OS. No se admite la combinación de ambos estilos de configuración.
- La configuración de los objetos de monitoreo es la misma que en SRG 0 y SRG1+.
Ejemplos de configuración:
En el siguiente fragmento de configuración, el grupo de redundancia de servicio (SRGx) incluye dos objetos de monitoreo: red A y red B. Cada uno de estos objetos de supervisión tiene configuradas la supervisión de IP, la supervisión de interfaces y la detección de BFD con sus respectivos pesos y valores de umbral.
- Establezca el valor de umbral de SRG.
set chassis high-availability services-redundancy-group x monitor srg-threshold 100
- Configure monitor-object
network-A.- Establezca el valor de umbral del objeto de monitoreo.
set chassis high-availability services-redundancy-group x monitor monitor-object network-A object-threshold 100
-
Configure las opciones de supervisión de BFD.
set chassis high-availability services-redundancy-group x monitor monitor-object network-A bfd-liveliness threshold 100 set chassis high-availability services-redundancy-group x monitor monitor-object network-A bfd-liveliness dst-ip 10.1.1.1 src-ip 10.1.1.2 session-type multi-hop weight 100
-
Configure los valores de peso y umbral para la supervisión de IP.
set chassis high-availability services-redundancy-group x monitor monitor-object network-A ip threshold 100 set chassis high-availability services-redundancy-group x monitor monitor-object network-A ip destination-ip 10.10.10.1 weight 50 set chassis high-availability services-redundancy-group x monitor monitor-object network-A ip destination-ip 20.20.20.1 weight 50 set chassis high-availability services-redundancy-group x monitor monitor-object network-A ip destination-ip 30.30.30.1 weight 50
- Configure los valores de peso y umbral para la supervisión de interfaces.
set chassis high-availability services-redundancy-group x monitor monitor-object network-A interface threshold 100 set chassis high-availability services-redundancy-group x monitor monitor-object network-A interface interface-name xe-1/0/1 weight 25 set chassis high-availability services-redundancy-group x monitor monitor-object network-A interface interface-name xe-1/0/2 weight 25 set chassis high-availability services-redundancy-group x monitor monitor-object network-A interface interface-name ae0 weight 50 set chassis high-availability services-redundancy-group x monitor monitor-object network-A interface interface-name ae1 weight 50
- Establezca el valor de umbral del objeto de monitoreo.
-
Configure monitor-object
network-B.-
Establezca el valor de umbral del objeto de monitoreo.
set chassis high-availability services-redundancy-group x monitor monitor-object network-B object-threshold 200
-
Configure la supervisión de BFD en el objeto monitor.
set chassis high-availability services-redundancy-group x monitor monitor-object network-B bfd-liveliness threshold 100 set chassis high-availability services-redundancy-group x monitor monitor-object network-B bfd-liveliness dst-ip 10.2.2.1 src-ip 10.2.2.2 session-type multi-hop weight 100
-
Configure los valores de peso y umbral para la supervisión de IP.
set chassis high-availability services-redundancy-group x monitor monitor-object network-B ip threshold 100 set chassis high-availability services-redundancy-group x monitor monitor-object network-B ip destination-ip 10.11.11.1 weight 50 set chassis high-availability services-redundancy-group x monitor monitor-object network-B ip destination-ip 10.21.21.1 weight 50 set chassis high-availability services-redundancy-group x monitor monitor-object network-B ip destination-ip 10.31.31.1 weight 50
-
Configure los valores de peso y umbral para la supervisión de interfaces.
set chassis high-availability services-redundancy-group x monitor monitor-object network-B interface threshold 100 set chassis high-availability services-redundancy-group x monitor monitor-object network-B interface interface-name xe-1/0/3 weight 25 set chassis high-availability services-redundancy-group x monitor monitor-object network-B interface interface-name xe-1/0/4 weight 25 set chassis high-availability services-redundancy-group x monitor monitor-object network-B interface interface-name ae2 weight 50 set chassis high-availability services-redundancy-group x monitor monitor-object network-B interface interface-name ae3 weight 50
-
Tomemos el caso del objeto monitor de red B en el ejemplo.
El sistema tiene un valor de umbral de 100 para la supervisión de interfaces y ponderaciones asignadas para las interfaces miembro (50, 50, 25 y 25). Si una interfaz de peso 50 deja de funcionar, el valor de peso de la interfaz (50) se agrega al recuento y se compara con el valor de umbral de la supervisión de interfaces. Es decir, el recuento es 50 y el umbral de interfaz es 100. El recuento sigue siendo menor que el valor de umbral de la interfaz.
Si otra interfaz de peso 50 deja de funcionar, el recuento se incrementa en 50 y se compara con el valor de umbral de la supervisión de interfaces. El recuento ahora es igual al valor de umbral de interfaz 100. Como el recuento es igual al valor de umbral, el sistema agrega este valor (100) al recuento de objetos de monitoreo (red-B). El valor umbral de la red de objeto de supervisión B es 200. El recuento (100) sigue siendo menor que el valor umbral del monitor de objetos.
Del mismo modo, si el monitor de IP o el monitor BFD también alcanzan sus valores de umbral respectivos y se suman al recuento del monitor de objetos, el recuento se incrementa y se compara con el valor de umbral del monitor de objetos. Una vez que el recuento suprime el valor de umbral del monitor de objetos, el sistema agrega el recuento al recuento del grupo de redundancia de servicio (SRG-1). Si la suma de los recuentos de monitores de objetos de red A y red B supera el umbral de SRG-1, el sistema activa la tolerancia a fallos en otro nodo.
Comprobar la configuración de los objetos de supervisión
Use los comandos o show chassis high-availability services-redundancy-group 1 show chassis high-availability services-redundancy-group <id> monitor-object <name> .
En el ejemplo siguiente se muestra el resultado del show chassis high-availability services-redundancy-group 1 comando.
user@host> show chassis high-availability services-redundancy-group 1
SRG failure event codes:
BF BFD monitoring
IP IP monitoring
IF Interface monitoring
PM Path monitoring
CP Control Plane monitoring
.............................................
SRG Path Monitor Info:
SRG Monitor Status: UP
SRG Monitor Threshold: 100
SRG Monitor Weight: 0
SRG Monitor Failed Objects: [ NONE ]
Object Name: Network-B
Object Status: UP
Object Monitored Entries: [ IP IF BFD ]
Object Failures: [ IP ]
Object Threshold: 200
Object Current Weight: 0
Object Name: Network-A
Object Status: UP
Object Monitored Entries: [ IP IF BFD]
Object Failures: NONE
Object Threshold: 100
Object Current Weight: 0
En la salida del comando, puede ver el estado de los objetos Network-B de supervisión y Network-A. También puede observar que los detalles del objeto de error en la salida junto con sus valores de umbral y peso.