이 페이지의 내용
멀티노드 고가용성 모니터링 옵션
모니터링 유형
고가용성 장애 감지는 시스템, 소프트웨어 및 하드웨어 모두에서 내부 장애를 모니터링합니다. 이 시스템은 또한 인터페이스 모니터링, BFD 경로 모니터링 및 IP 모니터링을 사용하여 네트워크 연결 문제 또는 링크 연결을 모니터링하여 더 멀리 떨어진 대상의 도달 가능성을 탐지할 수 있습니다.
표 1 은 멀티노드 고가용성에 사용되는 다양한 모니터링 유형에 대한 세부 정보를 제공합니다.
| 탐지 유형 | 범위는무엇입니까? | ||
|---|---|---|---|
| BFD 모니터링 | 실제 링크와 함께 링크 레이어를 검사하여 다음 홉에 대한 도달 가능성을 모니터링합니다. |
|
|
| IP 모니터링 | 직접 연결된 인터페이스 또는 다음 홉 너머에 위치한 호스트 또는 서비스에 대한 연결을 모니터링합니다. |
|
|
| 인터페이스 모니터링 | 링크 레이어의 작동 여부를 검사합니다. |
링크 장애 |
|
멀티노드 고가용성에서는 모니터링이 호스트 또는 서비스에 대한 연결 장애를 감지하면 영향을 받는 경로를 중단/사용 불능으로 표시하고 영향을 받는 노드의 해당 SRG(Service Route Groups)를 부적격으로 표시합니다. 영향을 받는 SRG는 트래픽 중단 없이 상태 저장 방식으로 다른 노드로 전환됩니다.
트래픽 손실을 방지하기 위해 멀티노드 고가용성은 다음과 같은 예방 조치를 취합니다.
- 레이어 3 모드 - 트래픽이 올바르게 리디렉션되도록 경로가 다시 그려집니다
- 기본 게이트웨이 또는 하이브리드 모드 - SRG의 새로운 활성 노드는 연결된 스위치에 GARP(Gratuitous ARP)를 전송하여 트래픽의 재라우팅을 보장합니다
멀티노드 고가용성 실패 시나리오
다음 섹션에서는 장애가 감지되는 방법, 수행할 복구 조치, 해당되는 경우 장애로 인한 시스템의 영향 등 가능한 장애 시나리오에 대해 설명합니다.노드 장애
하드웨어 장애
- 원인—장애가 발생한 하드웨어 구성 요소 또는 정전과 같은 환경 문제.
- 탐지 - 멀티노드 고가용성
- 영향을 받는 디바이스/노드에 액세스할 수 없음
- 하드웨어 장애가 있는 노드에서 SRG1 상태가 로 변경됩니다
INELIGIBLE.
- 영향 —그림 1과 같이 트래픽이 다른 노드(정상인 경우)로 페일오버됩니다. .
그림 1: 멀티노드 고가용성
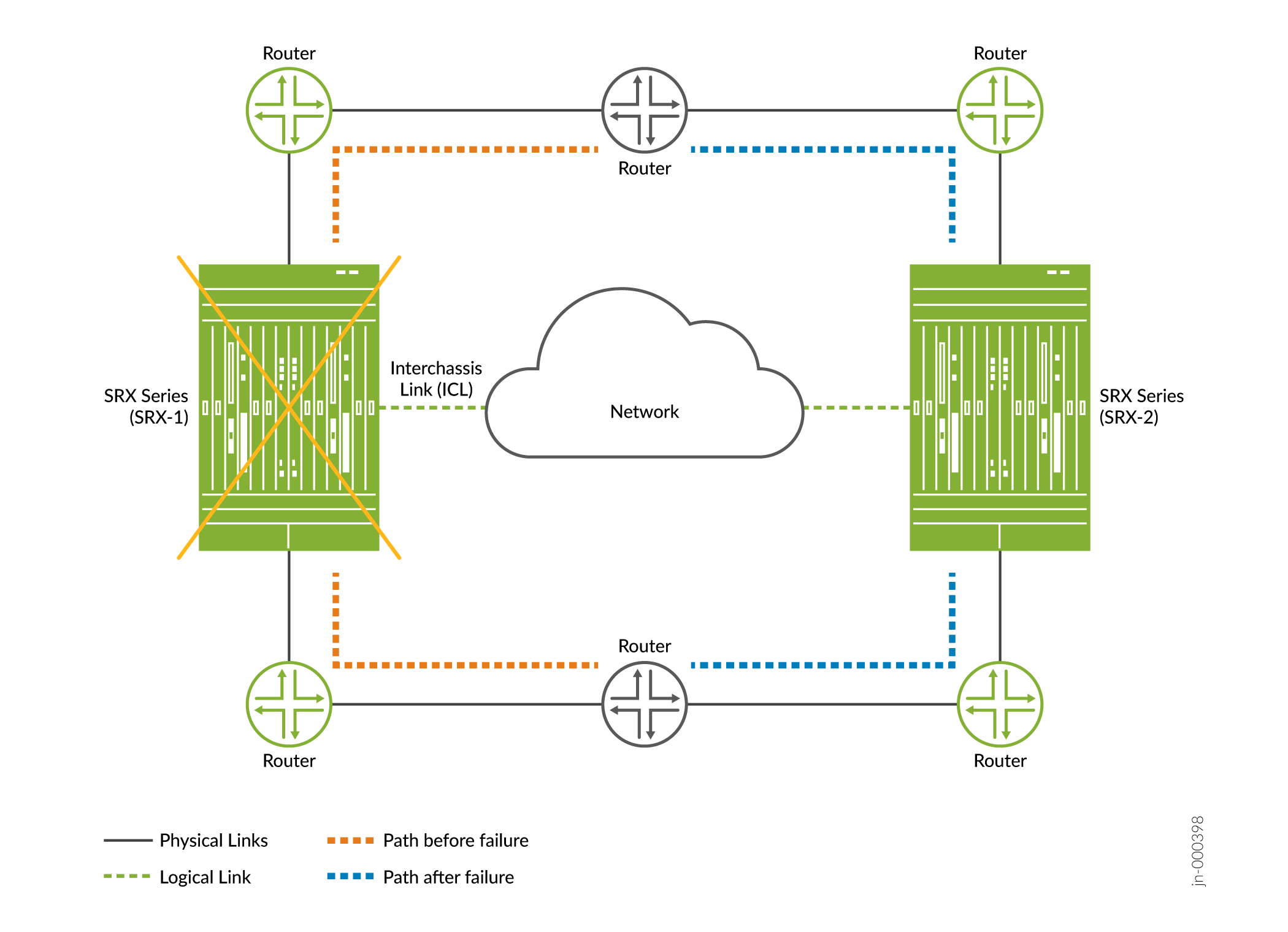 의 하드웨어 장애
의 하드웨어 장애
- 복구—섀시 하드웨어 장애를 제거할 때 장애 복구가 이루어집니다(예: 장애가 발생한 하드웨어 구성 요소 교체 또는 복구.
- 결과 - 다음 명령을 사용하여 상태를 확인합니다.
시스템/소프트웨어 장애
- 원인—소프트웨어 프로세스 또는 서비스의 실패 또는 운영 체제의 문제.
- 탐지 - 멀티노드 고가용성
- 영향을 받는 디바이스/노드에 액세스할 수 없음
- 시스템/소프트웨어 오류가 있는 영향을 받는 노드의 시스템 상태를 으로 변경합니다.
INELIGIBLE
- 영향 —그림 2와 같이 트래픽이 정상일 경우 다른 노드로 페일오버됩니다.
그림 2: 멀티노드 고가용성
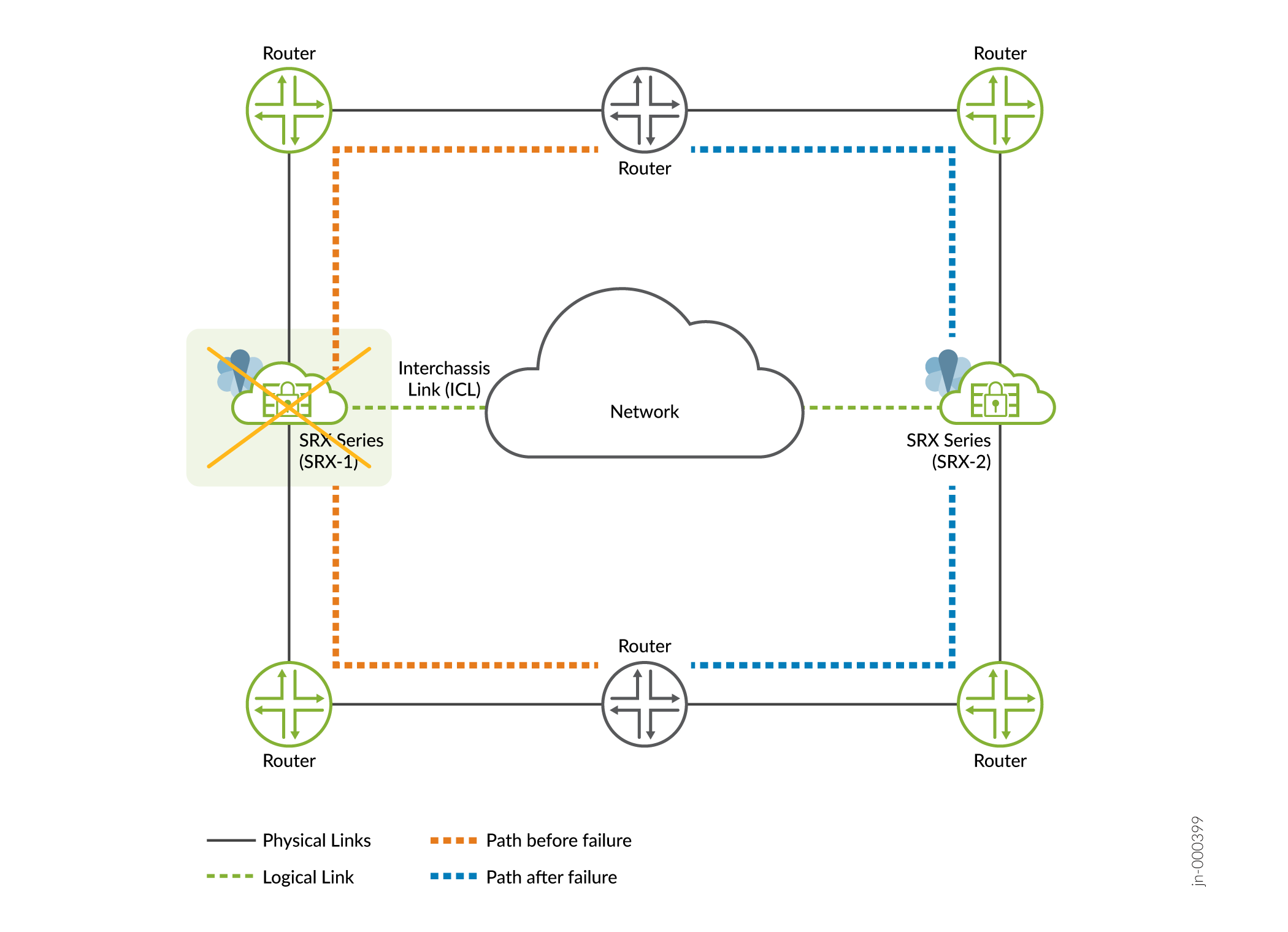 시 발생한 소프트웨어 장애
시 발생한 소프트웨어 장애
- 복구—문제가 해결되면 자동 및 정상적으로 복구합니다. 활성 역할을 맡은 백업 노드는 계속 활성 상태를 유지합니다. 이전 활성 노드는 백업 노드로 유지됩니다.
- 결과 - show chassis high-availability information detail 명령을 사용하여 상태를 확인합니다.
네트워크/연결 장애
물리적 인터페이스(링크) 장애
- 원인—인터페이스 장애는 네트워크 장비 중단, 물리적 케이블 중단 또는 일관되지 않은 구성으로 인해 발생할 수 있습니다.
- 탐지 - 멀티노드 고가용성
- 영향을 받는 디바이스/노드에 액세스할 수 없습니다.
- SRG1 상태는 네트워크 또는 연결 장애가 있는 영향을 받는 노드에서 로 변경됩니다
INELIGIBLE(인터페이스 모니터가 구성된 경우). 또한 경로 연결은 BFD 또는 IP 모니터링으로 감지할 수 있으며 구성된 작업에 따라 이벤트를 트리거할 수 있습니다.
- 영향—인터페이스의 링크 상태 변경이 페일오버를 트리거합니다. 백업 노드가 활성 역할을 맡고 그림 3과 같이 장애가 발생한 노드에서 실행 중이던 서비스가 다른 노드로 마이그레이션됩니다.
그림 3: 인터페이스 장애
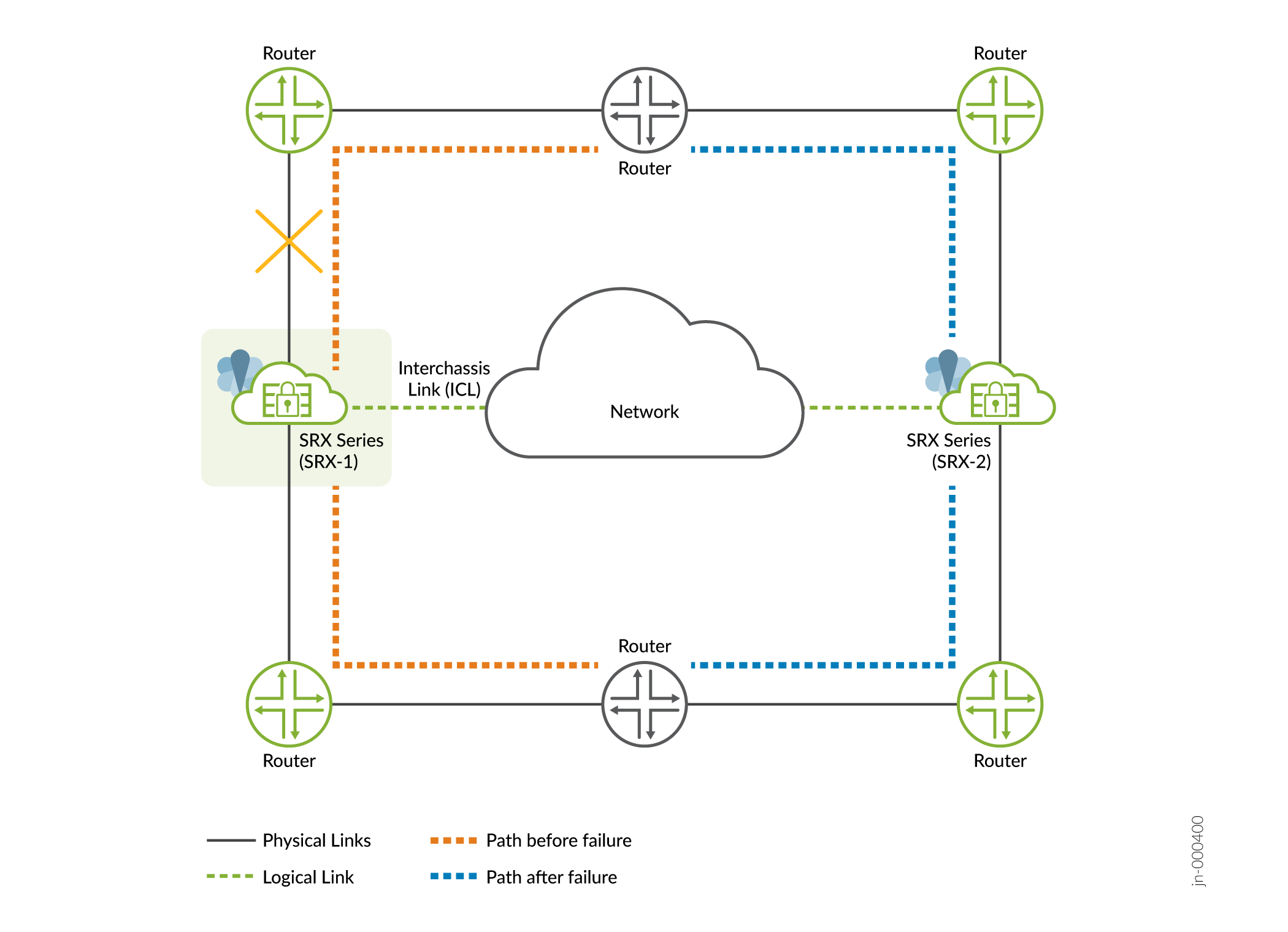
-
구성 - BFD 모니터링 및 인터페이스 모니터링을 구성하려면 다음 구성 문을 사용합니다.
set chassis high-availability services-redundancy-group <1> monitor bfd-liveliness <source-ip-address> <destination-ip-address> routing-instance <routing-instance-name> <single-hop| multihop> <interface-name>
set chassis high-availability services-redundancy-group <1> monitor interface <interface-name>
트래픽 흐름에 중요한 모든 링크를 모니터링해야 합니다.
체크아웃 예: 전체 구성 세부 정보를 위한 레이어 3 네트워크에서 멀티노드 고가용성 구성 .
- 복구—장애가 발생한 인터페이스를 수리/교체할 때 복구됩니다. 네트워크/연결 장애가 복구된 후 SRG1은 INELIGIBLE 상태에서 BACKUP 상태로 이동합니다. 새로운 활성 노드는 업스트림 라우터에 더 나은 메트릭을 계속 보급하고 트래픽을 처리합니다.
- 결과 - 다음 명령을 사용하여 상태를 확인합니다.
-
MMNHA에서 인터페이스를 구성하는 방법에 대한 자세한 내용은 예: 레이어 3 네트워크에서 멀티노드 고가용성 구성을 참조하십시오. 인터페이스 문제 해결은 인터페이스 문제 해결을 참조하십시오.
섀시 간 링크(ICL) 장애
- 원인—ICL의 장애는 네트워크 중단 또는 일관되지 않은 구성으로 인해 발생할 수 있습니다.
- 탐지 - 멀티노드 고가용성에서는 노드가 서로 연결할 수 없으며 활성 상태 결정 프로브(ICMP 프로브)를 시작합니다.
- 영향 - 멀티노드 고가용성 시스템에서 ICL은 활성 노드와 백업 노드를 연결합니다. ICL이 다운되면 두 디바이스 모두 이 변화를 인식하고 활성 프로브(ICMP 프로브)를 시작합니다. 활성 프로브는 각 SRG1+에 대해 활성 역할을 수행할 수 있는 노드를 결정하기 위해 수행됩니다. 프로브 결과에 따라 노드 중 하나가 활성 상태로 전환됩니다.
그림 4에 나온 것처럼 SRX-1과 SRX-2 사이의 ICL이 중단됩니다. 두 디바이스 모두 서로 도달할 수 없으며 업스트림 라우터에 활성 프로브를 보낼 수 없습니다. SRX-1은 라우터 구성에서 더 높은 선호 경로에 있기 때문에 활성 역할을 수행하고 트래픽을 계속 처리하며 더 높은 선호 경로를 보급합니다. 다른 한 명은 백업 역할을 담당합니다.
그림 4: 멀티노드 고가용성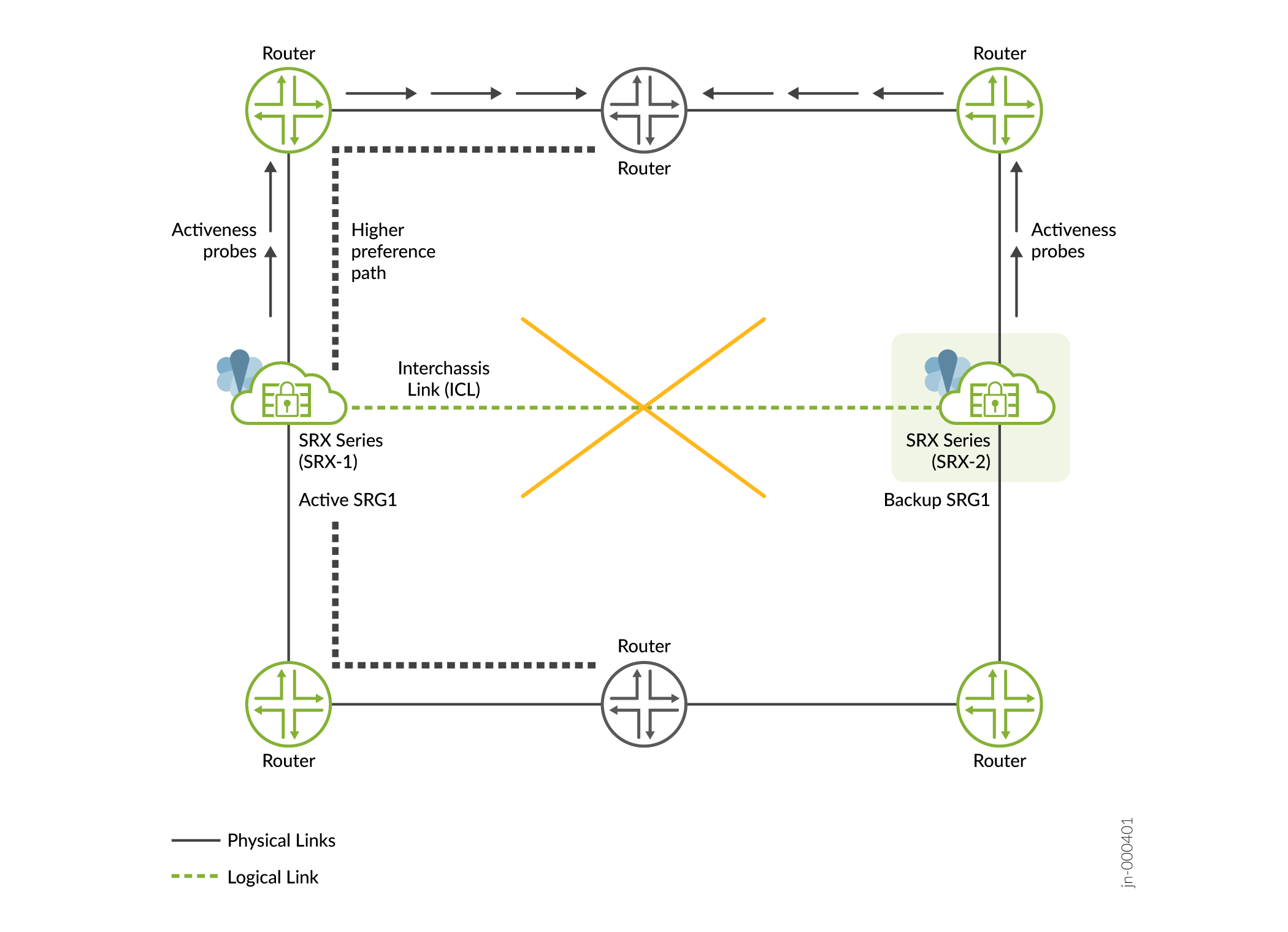 의 ICL 장애
의 ICL 장애
-
구성 - 활성 프로빙을 구성하려면 다음 구성 문을 사용합니다.
set chassis high-availability services-redundancy-group <1> activeness-probe <destination-ip-address> routing-instance <routing-instance-name>
전체 구성 세부 정보는 레이어 3 네트워크에서 멀티노드 고가용성 구성을 확인하십시오.
- 결과 - 다음 명령을 사용하여 상태를 확인합니다.
show chassis high-availability information detailshow chassis high-availability services-redundancy-group 1-
ping 옵션을 사용하여 업스트림 라우터에서 ICMP 패킷 응답을 확인합니다. 예:
ping <activeness-probe-dest-ip> source <activeness-probe-source-ip> routing-instance <routing-instance-name>.
-
복구 - 노드 중 하나가 활성 역할을 맡으면 멀티노드 고가용성은 콜드 동기화 프로세스를 다시 시작하고 컨트롤 플레인 서비스(IPSec VPN)를 재동기화합니다. SRG 상태 정보는 노드 간에 재교환됩니다.
노드가 격리 상태로 유지됨
- 원인—멀티노드 고가용성 설정에서 노드는 재부팅 후에도 격리된 상태로 유지되고 다음과 같은 경우 관련 인터페이스가 계속 다운된 상태로 유지됩니다.
-
ICL(Inter Chassis Link)은 부팅 후 콜드 싱크가 완료될 때까지 다른 노드와 연결되지 않습니다
그리고
-
이
shutdown-on-failure옵션은 SRG0에서 구성됩니다.참고:위의 원인은 다른 디바이스의 서비스가 중단된 경우에도 발생할 수 있습니다.
-
- 감지 - 명령 출력과 같이
ISOLATEDSRG0 상태가 표시됩니다. -
복구 - 노드는 다른 노드가 온라인 상태가 되고 ICL이 시스템 정보를 교환할 수 있거나 문을 제거하고
shutdown-on-failure구성을 커밋할 때 자동으로 복구됩니다.을
delete chassis high-availability services-redundancy-group 0 shutdown-on-failure사용하여 문을 제거합니다.위의 솔루션이 사용자 환경에 적합하지 않은 경우 해당
install-on-failure-route옵션을 사용할 수 있습니다. 이 옵션에서 멀티노드 고가용성 설정은 정의된 신호 경로를 사용하여 SRG1+에서 사용할 수 있는 active-signal-route 및 backup-signal-route 접근 방식과 유사한 라우팅 정책 옵션을 사용하여 위의 상황을 보다 효율적으로 처리합니다.
유연한 경로 모니터링
Junos OS 릴리스 23.4R1부터 다음과 같은 기존 경로 모니터링 기능에 대한 새로운 개선 사항이 추가되었습니다.
- IP 모니터링
- BFD 모니터링
- 인터페이스 모니터링
이러한 개선 사항은 다음을 통해 경로 모니터링 기능에 대한 보다 세분화된 제어를 추가합니다.
- SRG1+ 외에 SRG0에 대한 모니터링 확장
- 모니터링 기능 그룹화
- 서비스 중복 그룹(SRG) 경로와 관련된 방향에 기반한 모니터링 지원
- 각 모니터링 기능과 관련된 가중치 추가
관련 기능을 함께 그룹화함으로써 시스템은 이를 하나의 단위로 처리할 수 있으므로 보다 효율적인 계산과 리소스 활용으로 이어질 수 있습니다.
SRG 모니터링 개체
다음 그림을 통해 개체 모니터링의 개념을 이해하겠습니다.
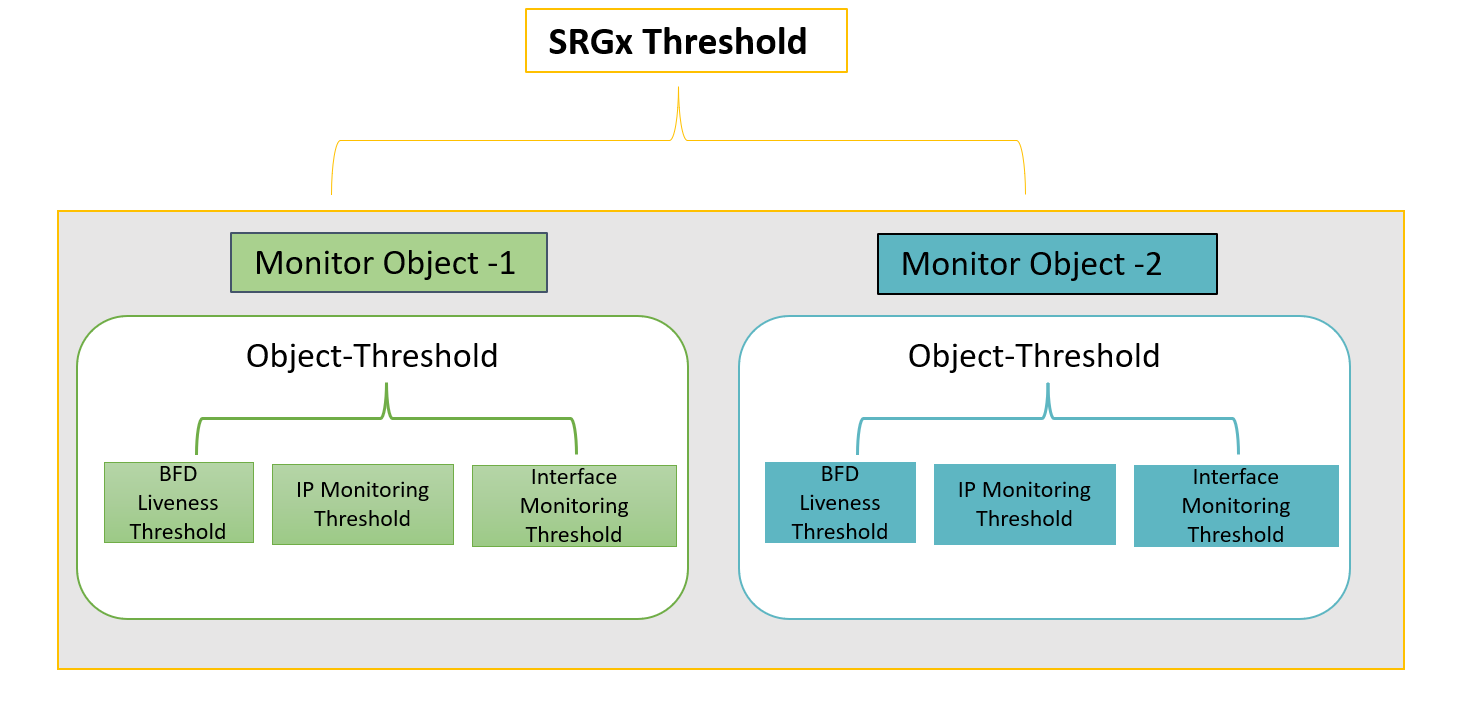
서비스 중복 그룹별로 모니터링 옵션을 구성할 수 있습니다. 즉, SRG의 특정 항목이 실패하면 해당 SRG가 다른 노드로 페일오버될 수 있습니다. 각 SRG에는 하나 이상의 모니터링 개체가 포함됩니다.
모니터링 개체에서 사용할 수 있는 모니터링 기능은 BFD 활성, 인터페이스 모니터링 및 IP 모니터링입니다. 이러한 각 기능은 연관된 임계값과 가중치 속성을 가지고 있습니다.
모니터 객체 내에서 특정 객체가 IP/인터페이스/BFD 모니터링의 결과로 페일오버를 트리거하지 못할 때마다 시스템은 이벤트를 모니터링 실패로 간주합니다. 소프트웨어는 실패한 개체의 가중치를 기반으로 카운트를 추가합니다.
카운트가 IP/인터페이스/BFD의 임계값을 초과하면 시스템은 상위 모니터링 개체의 임계값에 카운트를 추가합니다.
SRG에 바인딩된 모든 모니터링 객체의 임계값 합계가 SRG에 구성된 임계값 이상이면 시스템은 해당 SRG에 대한 모니터 오류를 트리거합니다. SRG가 다른 노드로 페일오버됩니다.
경로 모니터링 구성
그림 6에 표시된 토폴로지에 대한 다음 예를 살펴보겠습니다. 이 설정에서는 노드 2 디바이스의 SRG1에 대한 경로 모니터링 옵션을 구성합니다.
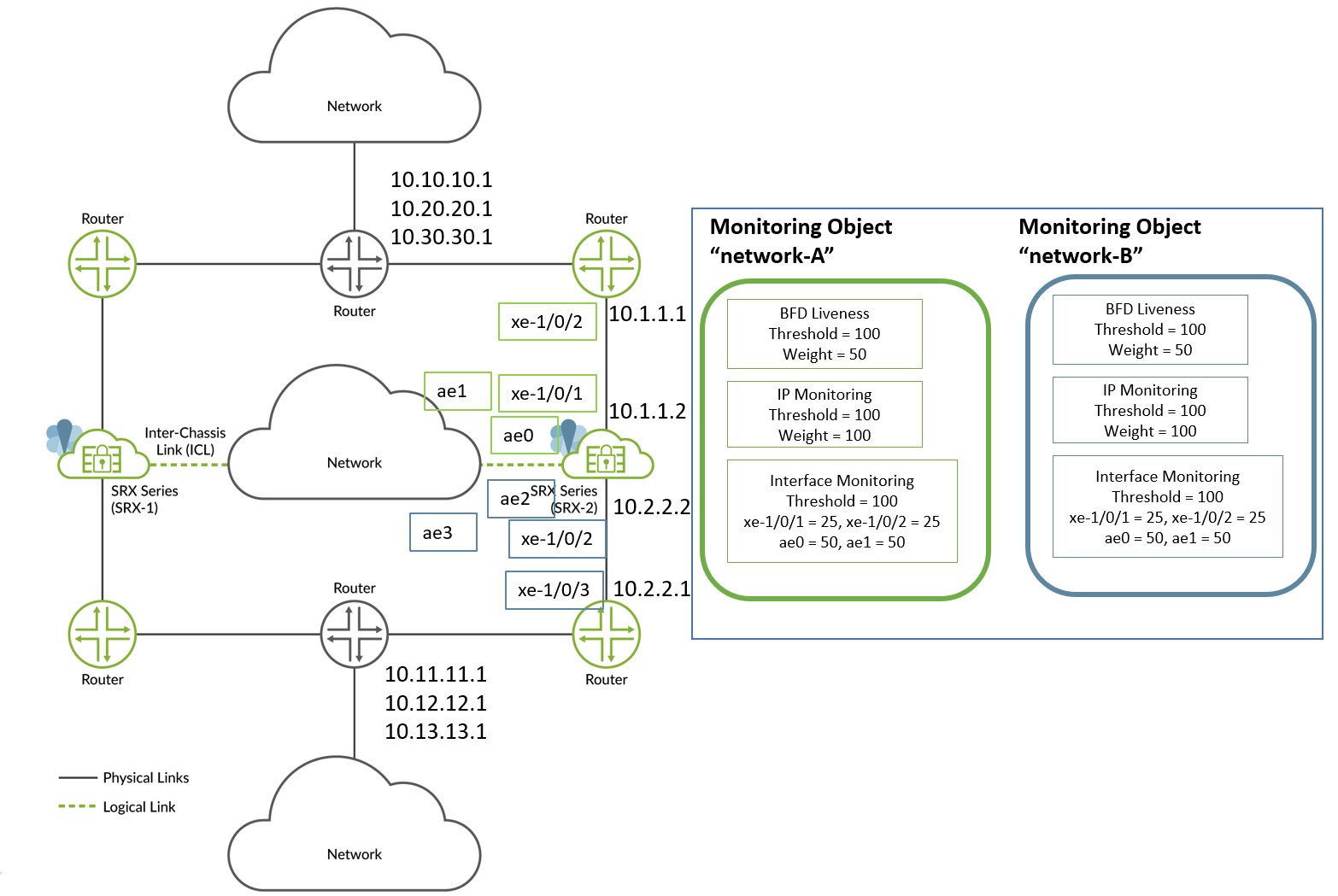
이 예에서 경로 모니터링 옵션을 구성하려면 다음을 수행합니다.
- 섀시 간 링크(ICL)에 어그리게이션 이더넷 인터페이스(ae)를 사용하고 인접 라우터에 연결하기 위해 xe-1/0/x 인터페이스를 사용합니다.
- 두 개의 모니터 개체 "network-A" 및 "network-B"를 생성합니다. network-A 및 network-B 모니터 객체는 모두 SRX 시리즈 디바이스와 이웃 라우터 간에 구성된 모든 IP 주소와 인터페이스를 포함합니다.
- BFD를 구성하여 이웃 경로를 모니터링합니다.
- SRG1에 직접 연결되지 않은 경로를 모니터링하도록 IP 모니터링을 구성합니다.
- 직접 연결된 링크 또는 다음 홉에서 인터페이스 모니터링을 구성합니다.
다음 표는 샘플 가중치 및 임계값 할당을 보여줍니다.
| 모니터 객체 |
BFD |
IP |
인터페이스 |
모니터 객체 임계값 |
SRG 임계값 |
|||
|---|---|---|---|---|---|---|---|---|
| 임계값 |
무게 |
임계값 |
무게 |
임계값 |
무게 |
|||
| 네트워크-A | 100 |
50 |
100 |
50 (10.10.10.1, 10.20.20.1, 10.30.30.1) |
100 |
25(xe-1/0/1 및 xe-1/0/2) 50(ae0 및 ae1) |
100 |
100 |
| 네트워크-B | 100 |
50 |
100 |
50 (10.11.11.1, 10.12.12.1, 10.13.13.1) | 100 |
25(xe-1/0/3 및 xe-1/0/4) 50(ae2 및 ae3) |
200 |
|
- SRG당 최대 10개의 모니터링 개체를 구성할 수 있습니다.
- Junos OS 23.4에서와 같이 SRG 모니터링을 구성하거나(SRG 임계값 및 monitoring-objects 포함) Junos OS 릴리스 23.4R1 이전에 지원되는 모니터링 옵션을 구성할 수 있습니다. 두 구성 스타일의 결합은 지원되지 않습니다.
- 모니터 객체 구성은 SRG 0 및 SRG1+에서와 동일합니다.
구성 샘플:
다음 구성 코드 조각에서 서비스 중복 그룹(SRGx)에는 두 개의 모니터 객체(network-A 와 network-B)가 포함됩니다. 이러한 각 모니터링 개체에는 각각의 가중치와 임계값으로 구성된 IP 모니터링, 인터페이스 모니터링 및 BFD 감지가 있습니다.
- SRG 임계값을 설정합니다.
set chassis high-availability services-redundancy-group x monitor srg-threshold 100
- monitor-object
network-A를 구성합니다.- 모니터 개체 임계값을 설정합니다.
set chassis high-availability services-redundancy-group x monitor monitor-object network-A object-threshold 100
-
BFD 모니터링 옵션을 구성합니다.
set chassis high-availability services-redundancy-group x monitor monitor-object network-A bfd-liveliness threshold 100 set chassis high-availability services-redundancy-group x monitor monitor-object network-A bfd-liveliness dst-ip 10.1.1.1 src-ip 10.1.1.2 session-type multi-hop weight 100
-
IP 모니터링을 위한 가중치 및 임계값을 구성합니다.
set chassis high-availability services-redundancy-group x monitor monitor-object network-A ip threshold 100 set chassis high-availability services-redundancy-group x monitor monitor-object network-A ip destination-ip 10.10.10.1 weight 50 set chassis high-availability services-redundancy-group x monitor monitor-object network-A ip destination-ip 20.20.20.1 weight 50 set chassis high-availability services-redundancy-group x monitor monitor-object network-A ip destination-ip 30.30.30.1 weight 50
- 인터페이스 모니터링을 위한 가중치 및 임계값을 구성합니다.
set chassis high-availability services-redundancy-group x monitor monitor-object network-A interface threshold 100 set chassis high-availability services-redundancy-group x monitor monitor-object network-A interface interface-name xe-1/0/1 weight 25 set chassis high-availability services-redundancy-group x monitor monitor-object network-A interface interface-name xe-1/0/2 weight 25 set chassis high-availability services-redundancy-group x monitor monitor-object network-A interface interface-name ae0 weight 50 set chassis high-availability services-redundancy-group x monitor monitor-object network-A interface interface-name ae1 weight 50
- 모니터 개체 임계값을 설정합니다.
-
monitor-object
network-B를 구성합니다.-
모니터 개체 임계값을 설정합니다.
set chassis high-availability services-redundancy-group x monitor monitor-object network-B object-threshold 200
-
모니터 개체에서 BFD 모니터링을 구성합니다.
set chassis high-availability services-redundancy-group x monitor monitor-object network-B bfd-liveliness threshold 100 set chassis high-availability services-redundancy-group x monitor monitor-object network-B bfd-liveliness dst-ip 10.2.2.1 src-ip 10.2.2.2 session-type multi-hop weight 100
-
IP 모니터링을 위한 가중치 및 임계값을 구성합니다.
set chassis high-availability services-redundancy-group x monitor monitor-object network-B ip threshold 100 set chassis high-availability services-redundancy-group x monitor monitor-object network-B ip destination-ip 10.11.11.1 weight 50 set chassis high-availability services-redundancy-group x monitor monitor-object network-B ip destination-ip 10.21.21.1 weight 50 set chassis high-availability services-redundancy-group x monitor monitor-object network-B ip destination-ip 10.31.31.1 weight 50
-
인터페이스 모니터링을 위한 가중치 및 임계값을 구성합니다.
set chassis high-availability services-redundancy-group x monitor monitor-object network-B interface threshold 100 set chassis high-availability services-redundancy-group x monitor monitor-object network-B interface interface-name xe-1/0/3 weight 25 set chassis high-availability services-redundancy-group x monitor monitor-object network-B interface interface-name xe-1/0/4 weight 25 set chassis high-availability services-redundancy-group x monitor monitor-object network-B interface interface-name ae2 weight 50 set chassis high-availability services-redundancy-group x monitor monitor-object network-B interface interface-name ae3 weight 50
-
샘플에서 network-B monitor-object의 경우를 살펴보겠습니다.
시스템은 인터페이스 모니터링을 위한 임계값이 100이며 멤버 인터페이스(50, 50, 25, 25)에 가중치가 할당되어 있습니다. 가중치 50의 인터페이스가 다운되면 인터페이스의 가중치 값(50)이 카운트에 추가되고 인터페이스 모니터링의 임계값과 비교됩니다. 즉, 개수가 50이고 인터페이스 임계값은 100입니다. 개수는 여전히 인터페이스 임계값보다 작습니다.
가중치 50의 다른 인터페이스가 다운되면 개수가 50씩 증가하고 인터페이스 모니터링의 임계값과 비교됩니다. 이제 개수는 인터페이스 임계값 100과 같습니다. 카운트가 임계값과 같으므로, 시스템은 이 값(100)을 monitor-object(network-B)의 카운트에 추가합니다. monitor-object network-B의 임계값은 200입니다. 개수(100)는 여전히 객체 모니터의 임계값보다 작습니다.
마찬가지로 IP 모니터 또는 BFD 모니터 역시 각각의 임계값에 도달하고 객체 모니터의 카운트에 추가되는 경우, 카운트가 증가하고 객체 모니터의 임계값과 비교됩니다. 카운트가 객체 모니터의 임계값을 억제하면, 시스템은 SRG-1(service-중복 그룹)의 카운트에 카운트를 추가합니다. network-A 및 network-B 객체 모니터 수의 합계가 SRG-1의 임계값을 초과하면 시스템은 다른 노드로의 페일오버를 트리거합니다.
모니터링 개체 구성 확인
또는 show chassis high-availability services-redundancy-group <id> monitor-object <name> 명령을 show chassis high-availability services-redundancy-group 1 사용합니다.
다음 샘플은 명령의 show chassis high-availability services-redundancy-group 1 출력을 보여줍니다.
user@host> show chassis high-availability services-redundancy-group 1
SRG failure event codes:
BF BFD monitoring
IP IP monitoring
IF Interface monitoring
PM Path monitoring
CP Control Plane monitoring
.............................................
SRG Path Monitor Info:
SRG Monitor Status: UP
SRG Monitor Threshold: 100
SRG Monitor Weight: 0
SRG Monitor Failed Objects: [ NONE ]
Object Name: Network-B
Object Status: UP
Object Monitored Entries: [ IP IF BFD ]
Object Failures: [ IP ]
Object Threshold: 200
Object Current Weight: 0
Object Name: Network-A
Object Status: UP
Object Monitored Entries: [ IP IF BFD]
Object Failures: NONE
Object Threshold: 100
Object Current Weight: 0
명령 출력에서 모니터링 개체 Network-B Network-A와 의 상태를 모두 볼 수 있습니다. 또한 임계값 및 가중치와 함께 출력에서 실패 객체의 세부 정보를 확인할 수 있습니다.