マルチノード高可用性監視オプション
監視タイプ
高可用性障害検出は、システム、ソフトウェア、ハードウェアの両方の内部障害を監視します。また、ネットワーク接続の問題を監視したり、インターフェイス監視、BFDパス監視、IP監視を使用してリンク接続を監視し、遠く離れたターゲットの到達可能性を検出することもできます。
表1は、マルチノード高可用性で使用されるさまざまな監視タイプの詳細を示しています。
| 監視タイプ | 検出タイプ | スコープ | とは何ですか |
|---|---|---|---|
| BFD監視 | 実際のリンクとリンク層を調べることで、ネクストホップへの到達可能性を監視します。 |
|
|
| IP監視 | 直接接続されたインターフェイスまたはネクストホップの向こうにあるホストまたはサービスへの接続を監視します。 |
|
|
| インターフェイス監視 | リンク層が動作しているかどうかを調べます。 |
リンク障害 |
|
マルチノード高可用性では、監視がホストまたはサービスへの接続障害を検出すると、影響を受けるパスはダウン/使用不可としてマークされ、影響を受けるノードの対応するサービスルートグループ(SRG)は不適格としてマークされます。影響を受けたSRGは、トラフィックを中断させることなく、ステートフルな方法で別のノードに移行します。
トラフィックの損失を防ぐために、マルチノード高可用性は以下の予防措置を講じています。
- レイヤー3モード—トラフィックが正しくリダイレクトされるようにルートが再描画されます
- デフォルトゲートウェイまたはハイブリッドモード—SRGの新しいアクティブノードは、接続されたスイッチにGARP(Gratuitous ARP)を送信し、トラフィックの再ルーティングを確実にします
マルチノード高可用性障害のシナリオ
次のセクションでは、考えられる障害シナリオについて説明します。障害の検出方法、実行する回復アクション、および該当する場合は、障害によって引き起こされるシステムへの影響。ノード障害
ハードウェアの障害
- 原因—ハードウェアコンポーネントの故障、または電源障害などの環境上の問題。
- 検出—マルチノード高可用性
- 影響を受けるデバイス/ノードにアクセスできません
- ハードウェア障害により、ノードのSRG1ステータスが
INELIGIBLEに変わります。
- 影響—図1に示すように、トラフィックはもう一方のノードにフェイルオーバーします(正常な場合)。.
図1:マルチノード高可用性
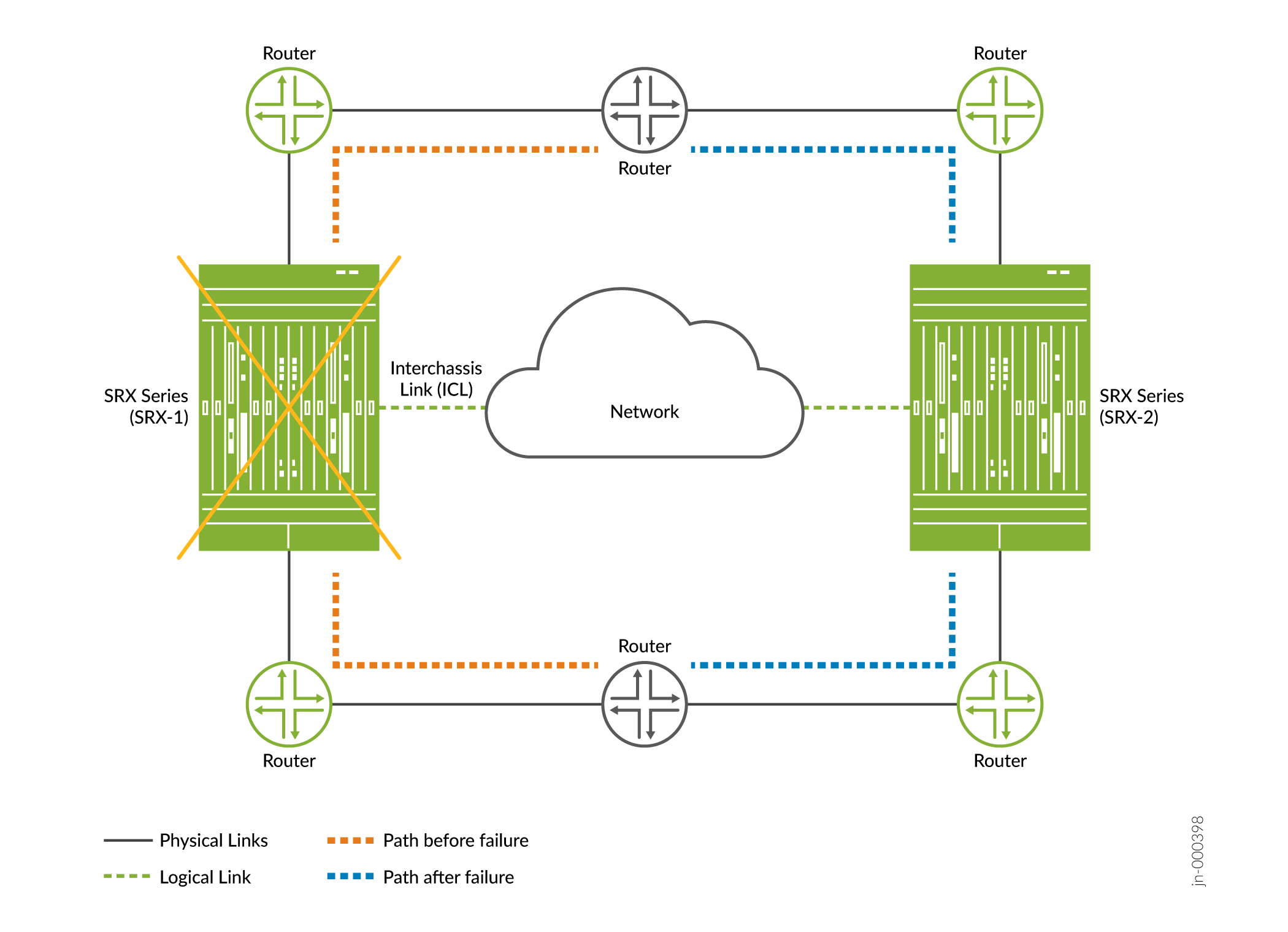 におけるハードウェア障害
におけるハードウェア障害
- 回復—障害の回復は、シャーシのハードウェア障害を解消すると行われます(例:故障したハードウェアコンポーネントの交換または修理。
- 結果—以下のコマンドを使用してステータスを確認します。
システム/ソフトウェアの障害
- 原因—ソフトウェアプロセスまたはサービスの障害、またはオペレーティングシステムの問題。
- 検出—マルチノード高可用性
- 影響を受けるデバイス/ノードにアクセスできません
- システム/ソフトウェアに障害が発生し、影響を受けたノードでシステム状態が
INELIGIBLEに変更されます。
- 影響:図2に示すように、トラフィックが正常であれば他のノードにフェイルオーバーします
図2:マルチノード高可用性
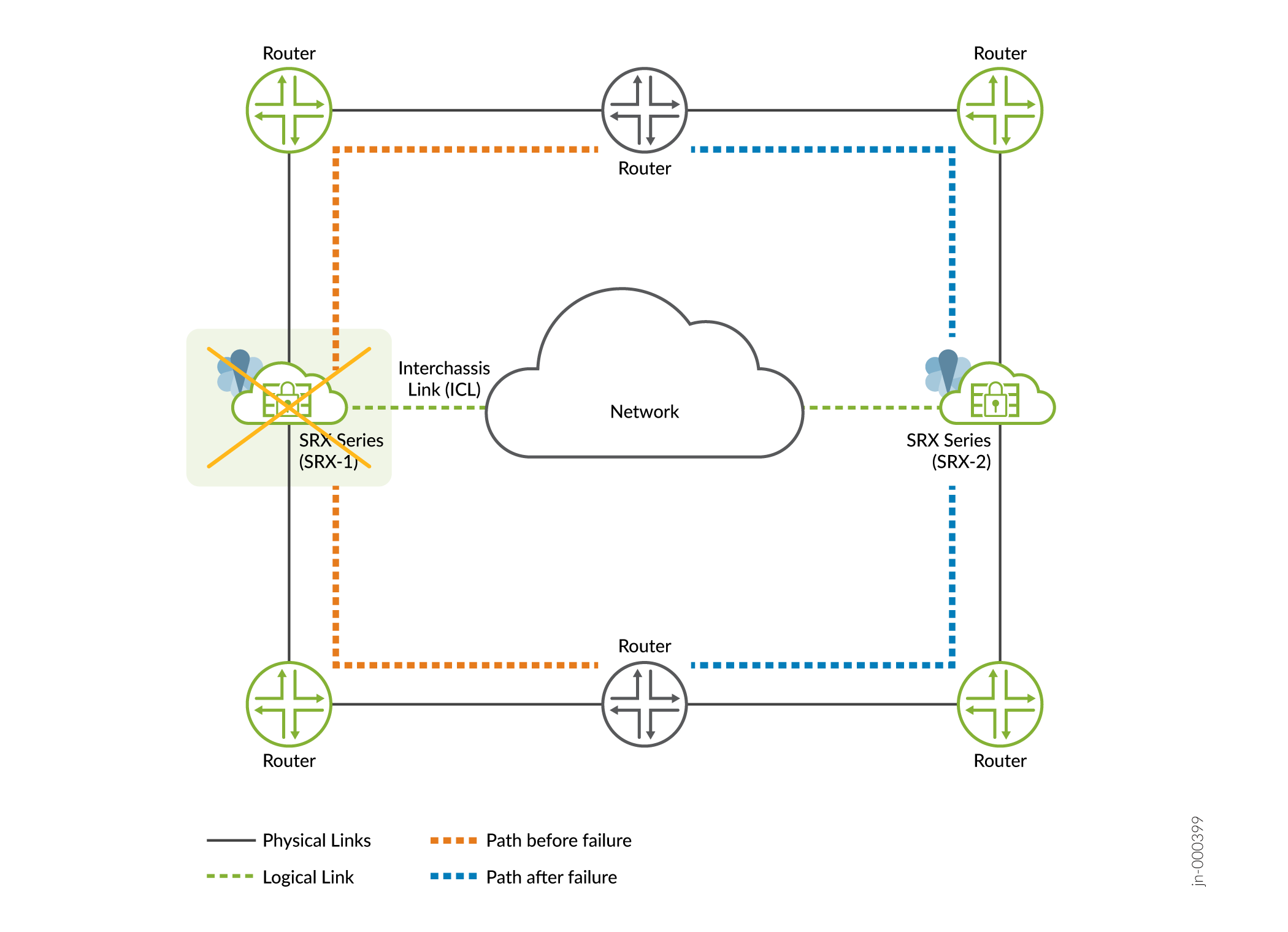 におけるソフトウェアの障害
におけるソフトウェアの障害
- 回復—問題が解決されると、障害から自動的かつ正常に回復します。アクティブなロールを引き受けたバックアップノードは、引き続きアクティブなままです。以前アクティブだったノードは、バックアップノードとして残ります。
- 結果—show chassis high-availability information detailコマンドを使用してステータスを確認します。
ネットワーク/接続障害
物理インターフェイス(リンク)障害
- 原因—インターフェイスの障害は、ネットワーク機器の障害、物理ケーブルの中断、または一貫性のない設定が原因である可能性があります。
- 検出—マルチノード高可用性
- 影響を受けるデバイス/ノードにアクセスできません。
- SRG1のステータスが、ネットワーク障害または接続障害(インターフェイスモニターが設定されている場合)により、影響を受けるノードで
INELIGIBLEに変わります。BFDやIP監視でパス接続を検知し、設定されたアクションに基づいてイベントをトリガーすることもできます。
- 影響—インターフェイスのリンク状態が変化すると、フェイルオーバーがトリガーされます。バックアップノードがアクティブなロールを引き継ぎ、障害が発生したノードで実行されていたサービスは、図3に示すように他のノードに移行されます。
図3:インターフェイス障害
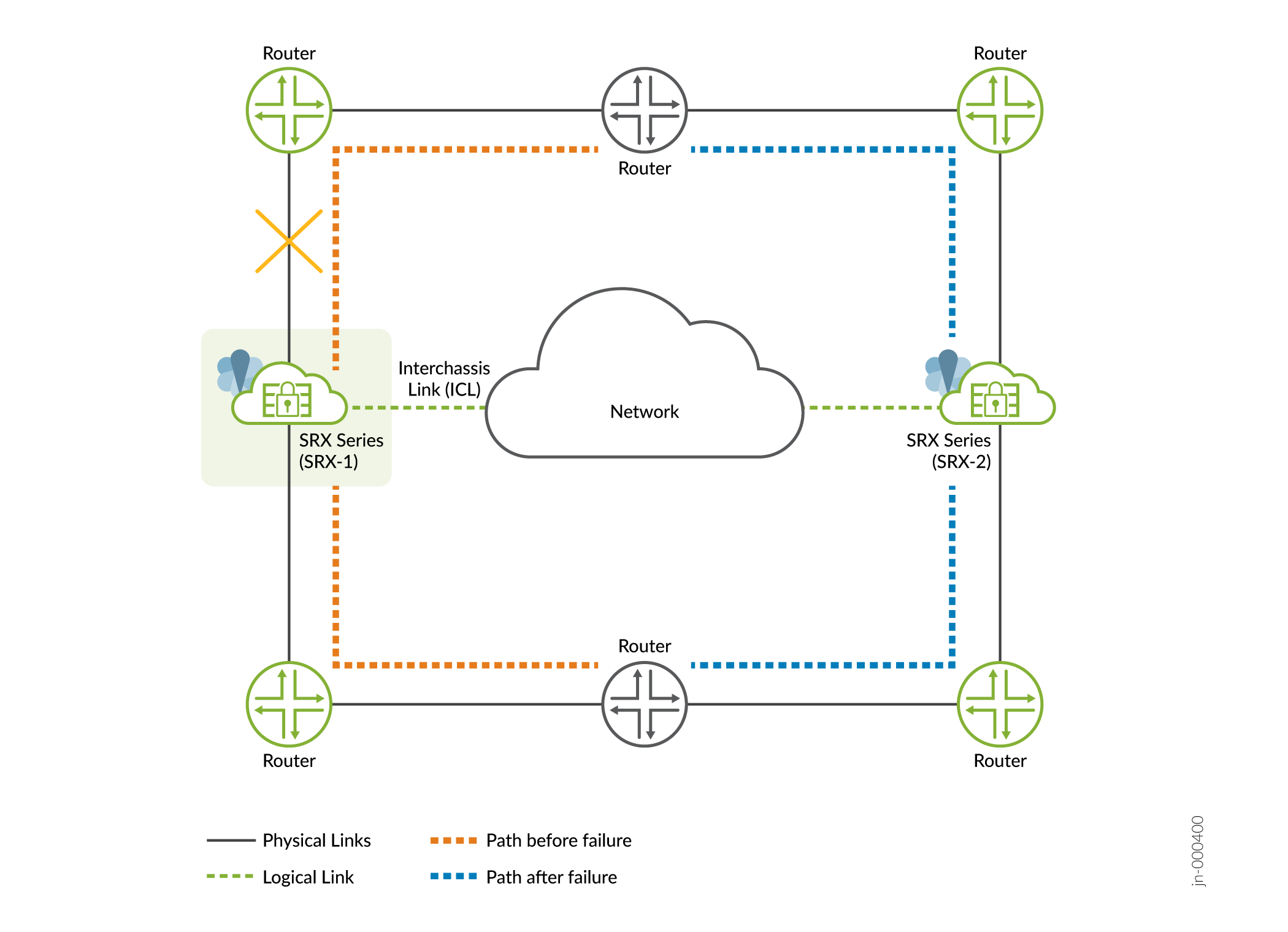
-
設定—BFD監視とインターフェイス監視を設定するには、以下の設定ステートメントを使用します。
set chassis high-availability services-redundancy-group <1> monitor bfd-liveliness <source-ip-address> <destination-ip-address> routing-instance <routing-instance-name> <single-hop| multihop> <interface-name>
set chassis high-availability services-redundancy-group <1> monitor interface <interface-name>
トラフィックフローに重要なすべてのリンクを監視する必要があります。
設定の詳細については、 チェックアウト例:レイヤー3ネットワークでマルチノード高可用性を設定するを参照してください 。
- 回復—障害が発生したインターフェイスを修復/交換すると回復します。ネットワーク障害/接続障害が回復した後、SRG1 は INAPPLICABLE 状態から BACKUP 状態に移行します。新規アクティブノードは、引き続きアップストリームルーターにより良いメトリックをアドバタイズし、トラフィックを処理します。
- 結果—以下のコマンドを使用してステータスを確認します。
-
MNHAでのインターフェイスの設定については、 例:レイヤー3ネットワークでマルチノード高可用性を設定するを参照してください。インターフェイスのトラブルシューティングについては、 インターフェイスのトラブルシューティングを参照してください。
シャーシ間リンク(ICL)障害
- 原因—ICLの障害は、ネットワークの停止、または一貫性のない設定が原因である可能性があります。
- 検出—マルチノード高可用性では、ノードは互いに到達できず、アクティブ性決定プローブ(ICMPプローブ)を開始します。
- 影響—マルチノード高可用性システムでは、ICLがアクティブノードとバックアップノードを接続します。ICLがダウンした場合、両方のデバイスがこの変化に気付き、アクティブ性プローブ(ICMPプローブ)を開始します。アクティビティプローブは、各SRG1+でアクティブなロールを果たすことができるノードを決定するために実行されます。プローブ結果に基づいて、ノードの1つがアクティブな状態に移行します。
図4に示すように、SRX-1とSRX-2の間のICLはダウンしています。両方のデバイスが互いに到達できず、アップストリームルーターにアクティビティプローブの送信を開始することができません。SRX-1は、ルーター設定の上位優先パス上にあるため、アクティブなロールとなり、トラフィックの処理を継続し、より高い優先パスをアドバタイズします。もう一方はバックアップの役割を引き受けます。
図4:マルチノード高可用性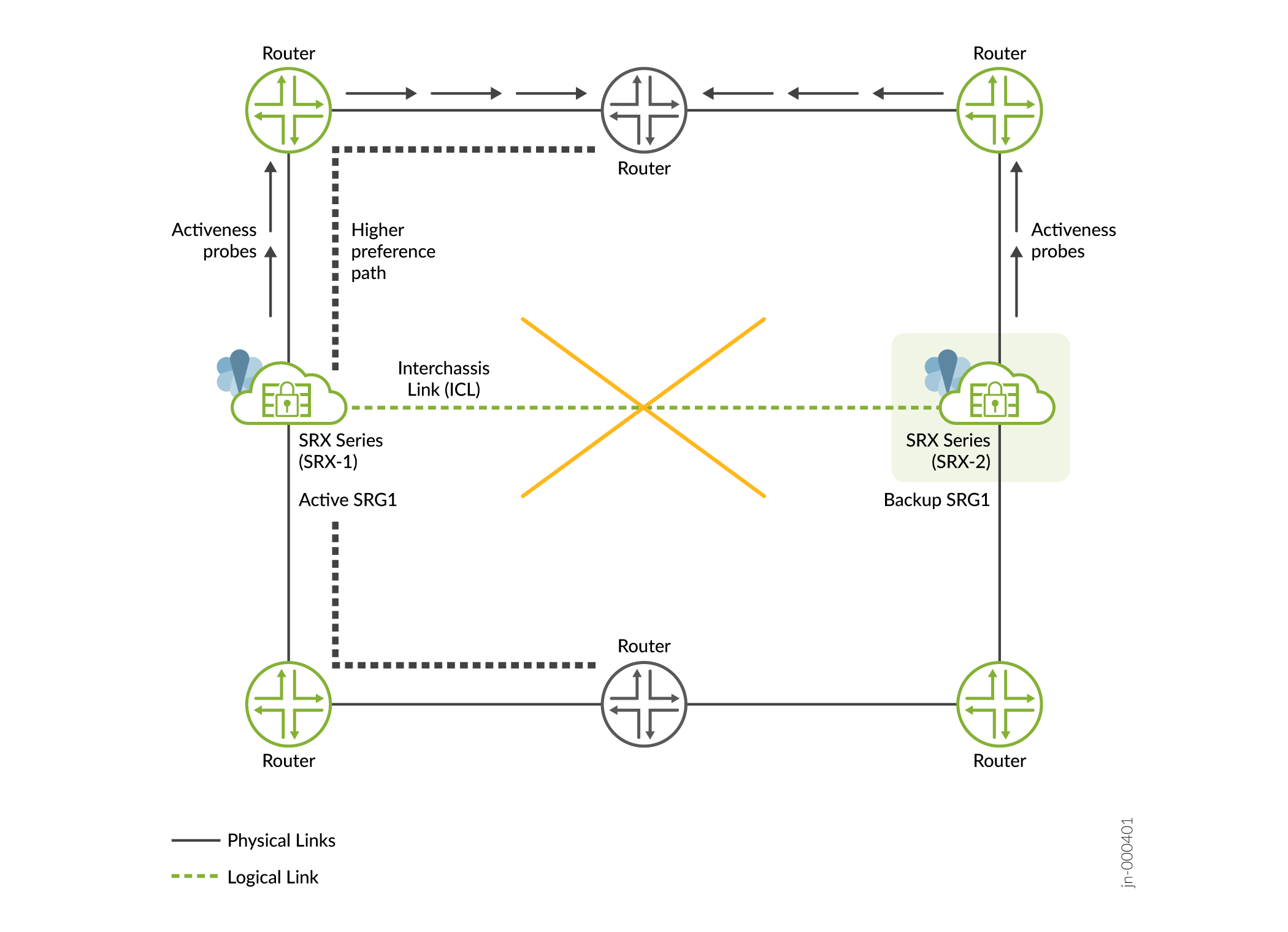 におけるICL障害
におけるICL障害
-
設定—アクティブプローブを設定するには、以下の設定ステートメントを使用します。
set chassis high-availability services-redundancy-group <1> activeness-probe <destination-ip-address> routing-instance <routing-instance-name>
設定の詳細については、 レイヤー3ネットワークにおけるマルチノード高可用性の設定 をご覧ください。
- 結果—以下のコマンドを使用してステータスを確認します。
show chassis high-availability information detailshow chassis high-availability services-redundancy-group 1-
pingオプションを使用して、アップストリームルーターからのICMPパケット応答を確認します。例:
ping <activeness-probe-dest-ip> source <activeness-probe-source-ip> routing-instance <routing-instance-name>。
-
回復—ノードの1つがアクティブなロールを引き継ぐと、マルチノード高可用性はコールド同期プロセスを再起動し、コントロールプレーンサービス(IPSec VPN)を再同期します。SRG状態情報はノード間で再交換されます。
ノードは分離された状態のままです
- 原因—マルチノード高可用性設定では、以下の場合、再起動後もノードは分離された状態のままであり、関連するインターフェイスはダウンしたままです。
-
シャーシ間リンク(ICL)は、起動後、コールド同期が完了するまで他のノードに接続できません
そして
-
shutdown-on-failureオプションはSRG0で設定されています注:上記の原因は、他のデバイスがサービスされていない場合にも発生する可能性があります。
-
- 検出—コマンド出力にSRG0ステータスが
ISOLATEDとして表示されます。 -
回復—もう一方のノードがオンラインになり、ICLがシステム情報を交換できるようになるか、
shutdown-on-failureステートメントを削除して設定をコミットすると、ノードは自動的に回復します。delete chassis high-availability services-redundancy-group 0 shutdown-on-failureを使用してステートメントを削除します。上記のソリューションが環境に適していない場合は、
install-on-failure-routeオプションを使用できます。このオプションでは、マルチノード高可用性設定は、SRG1+ で使用可能なアクティブ信号ルートおよびバックアップ信号ルートアプローチと同様のルーティングポリシーオプションを使用して、上記の状況をより適切に処理するために定義された信号ルートを使用します。
柔軟なパス監視
Junos OSリリース23.4R1より、以下の既存のパス監視機能に新たな機能強化を追加しました。
- IP監視
- BFD監視
- インターフェイス監視
これらの機能強化により、パス監視機能の制御がよりきめ細かくなります。
- SRG1+に加え、SRG0向けの監視を拡張
- 監視機能のグループ化
- サービス冗長性グループ(SRG)パスに関連する方向に基づく監視をサポートします
- 各監視機能に関連付けられた重みの追加
関連する機能をグループ化することで、システムはそれらをユニットとして処理できるため、より効率的な計算とリソースの利用につながる可能性があります。
SRG監視オブジェクト
オブジェクト監視の概念を次の図で理解しましょう。
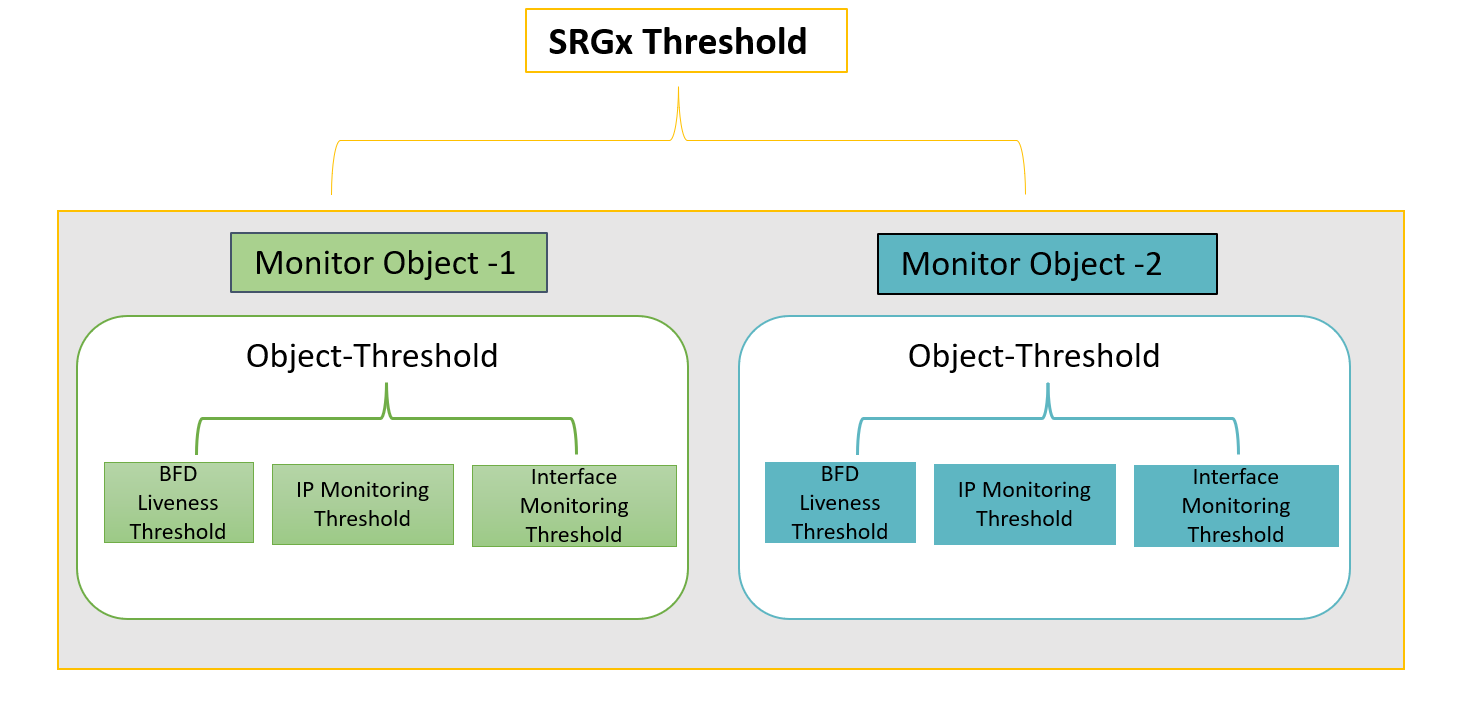
監視オプションは、サービス冗長性グループごとに設定できます。つまり、SRG内の特定の項目に障害が発生した場合、そのSRGは他のノードにフェイルオーバーできます。各SRGには、1つ以上の監視オブジェクトが含まれています。
監視オブジェクトで使用できる監視機能は、BFDライブネス、インターフェイス監視、IP監視です。これらの各機能には、関連するしきい値と重み属性があります。
監視オブジェクト内では、IP/インターフェイス/BFD監視の結果として特定のオブジェクトがフェイルオーバーをトリガーできない場合、システムはそのイベントを監視失敗と見なします。ソフトウェアは、障害が発生したオブジェクトの重量に基づいてカウントを追加します。
カウントがIP/インターフェイス/BFDのしきい値を超えると、システムは親監視オブジェクトのしきい値にカウントを追加します。
SRGにバインドされたすべての監視オブジェクトのしきい値の合計が、SRGに設定されたしきい値と同じかそれ以上になると、システムはそのSRGの監視失敗をトリガーします。SRGは他のノードにフェイルオーバーします。
パス監視の設定
図 6 に示すトポロジーの次の例を考えてみましょう。このセットアップでは、ノード2デバイスでSRG1のパス監視オプションを設定します。
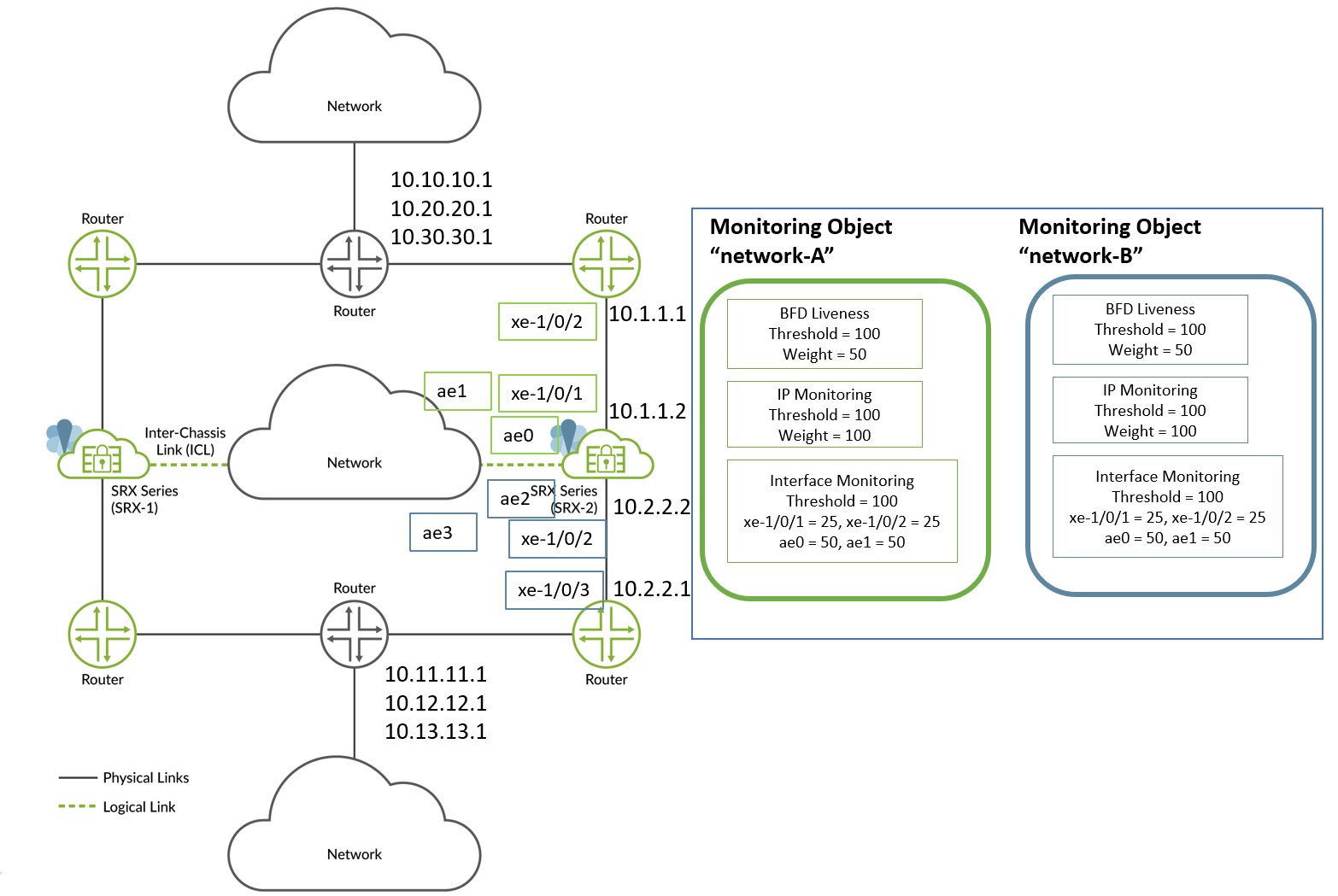
この例では、パス監視オプションを設定します。
- シャーシ間リンク(ICL)には集合型イーサネットインターフェイス(ae)を使用し、隣接ルーターとの接続にはxe-1/0/xインターフェイスを使用します。
- 2つの監視オブジェクト「network-A」と「network-B」を作成します。 ネットワークA と ネットワークB の両方の監視オブジェクトには、SRXシリーズデバイスと隣接するルーターの間で設定されたすべてのIPアドレスとインターフェイスが含まれています。
- BFDを設定して、隣接ルートを監視します。
- IP監視を設定して、SRG1に直接接続されていないルートを監視します。
- 直接接続されたリンクまたはネクストホップのインターフェイス監視を設定します。
以下の表は、重みとしきい値の割り当て例を示しています。
| オブジェクトの監視 |
BFD |
IP |
インターフェース |
監視オブジェクトのしきい値 |
SRGしきい値 |
|||
|---|---|---|---|---|---|---|---|---|
| しきい値 |
重量 |
しきい値 |
重量 |
しきい値 |
重量 |
|||
| ネットワークA | 100 |
50 |
100 |
50 (10.10.10.1, 10.20.20.1, 10.30.30.1) |
100 |
25(xe-1/0/1およびxe-1/0/2) 50(ae0およびae1) |
100 |
100 |
| ネットワーク-B | 100 |
50 |
100 |
50 (10.11.11.1, 10.12.12.1, 10.13.13.1) | 100 |
25(xe-1/0/3およびxe-1/0/4) 50(ae2およびae3) |
200 |
|
- SRGごとに最大10個の監視オブジェクトを設定できます。
- Junos OS 23.4(SRGしきい値と監視オブジェクトを使用)と同じようにSRG監視を設定するか、Junos OSリリース23.4R1以前のサポートと同じように監視オプションを設定することができます。両方の設定スタイルの組み合わせはサポートされていません。
- 監視オブジェクトの設定は、SRG 0およびSRG1+の場合と同じです。
設定サンプル:
次の設定スニペットでは、サービス冗長性グループ(SRGx)には、ネットワークA と ネットワークBの2つの監視オブジェクトが含まれています。これらの監視オブジェクトにはそれぞれ、IP監視、インターフェイス監視、BFD検出があり、それぞれの重みとしきい値が設定されています。
- SRGしきい値を設定します。
set chassis high-availability services-redundancy-group x monitor srg-threshold 100
- 監視オブジェクト
network-Aを設定します。- 監視オブジェクトのしきい値を設定します。
set chassis high-availability services-redundancy-group x monitor monitor-object network-A object-threshold 100
-
BFD監視オプションを設定します。
set chassis high-availability services-redundancy-group x monitor monitor-object network-A bfd-liveliness threshold 100 set chassis high-availability services-redundancy-group x monitor monitor-object network-A bfd-liveliness dst-ip 10.1.1.1 src-ip 10.1.1.2 session-type multi-hop weight 100
-
IP 監視の重みとしきい値を設定します。
set chassis high-availability services-redundancy-group x monitor monitor-object network-A ip threshold 100 set chassis high-availability services-redundancy-group x monitor monitor-object network-A ip destination-ip 10.10.10.1 weight 50 set chassis high-availability services-redundancy-group x monitor monitor-object network-A ip destination-ip 20.20.20.1 weight 50 set chassis high-availability services-redundancy-group x monitor monitor-object network-A ip destination-ip 30.30.30.1 weight 50
- インターフェイス監視用の重みとしきい値を設定します。
set chassis high-availability services-redundancy-group x monitor monitor-object network-A interface threshold 100 set chassis high-availability services-redundancy-group x monitor monitor-object network-A interface interface-name xe-1/0/1 weight 25 set chassis high-availability services-redundancy-group x monitor monitor-object network-A interface interface-name xe-1/0/2 weight 25 set chassis high-availability services-redundancy-group x monitor monitor-object network-A interface interface-name ae0 weight 50 set chassis high-availability services-redundancy-group x monitor monitor-object network-A interface interface-name ae1 weight 50
- 監視オブジェクトのしきい値を設定します。
-
監視オブジェクト
network-Bを設定します。-
監視オブジェクトのしきい値を設定します。
set chassis high-availability services-redundancy-group x monitor monitor-object network-B object-threshold 200
-
モニターオブジェクトでBFD監視を設定します。
set chassis high-availability services-redundancy-group x monitor monitor-object network-B bfd-liveliness threshold 100 set chassis high-availability services-redundancy-group x monitor monitor-object network-B bfd-liveliness dst-ip 10.2.2.1 src-ip 10.2.2.2 session-type multi-hop weight 100
-
IP 監視の重みとしきい値を設定します。
set chassis high-availability services-redundancy-group x monitor monitor-object network-B ip threshold 100 set chassis high-availability services-redundancy-group x monitor monitor-object network-B ip destination-ip 10.11.11.1 weight 50 set chassis high-availability services-redundancy-group x monitor monitor-object network-B ip destination-ip 10.21.21.1 weight 50 set chassis high-availability services-redundancy-group x monitor monitor-object network-B ip destination-ip 10.31.31.1 weight 50
-
インターフェイス監視用の重みとしきい値を設定します。
set chassis high-availability services-redundancy-group x monitor monitor-object network-B interface threshold 100 set chassis high-availability services-redundancy-group x monitor monitor-object network-B interface interface-name xe-1/0/3 weight 25 set chassis high-availability services-redundancy-group x monitor monitor-object network-B interface interface-name xe-1/0/4 weight 25 set chassis high-availability services-redundancy-group x monitor monitor-object network-B interface interface-name ae2 weight 50 set chassis high-availability services-redundancy-group x monitor monitor-object network-B interface interface-name ae3 weight 50
-
サンプルの network-B monitor-objectの場合を見てみましょう。
システムには、インターフェイス監視の閾値100と、メンバーインターフェイス(50、50、25、25)に割り当てられた重みがあります。重み 50 のインターフェイスがダウンした場合、インターフェイスの重み値(50)がカウントに追加され、インターフェイス監視のしきい値と比較されます。つまり、カウントは50で、インターフェイスしきい値は100です。カウントはまだインターフェイスしきい値を下回っています。
ウェイト 50 の別のインターフェイスがダウンした場合、カウントは 50 ずつ増加し、インターフェイス監視のしきい値と比較されます。カウントはインターフェイスのしきい値100と等しくなります。カウントがしきい値と等しくなると、システムはこの値(100)をモニターオブジェクト(network-B)のカウントに追加します。監視オブジェクトネットワーク-Bのしきい値は200です。カウント(100)はまだオブジェクトモニターのしきい値を下回っています。
同様に、IPモニターまたはBFDモニターもそれぞれのしきい値に達し、オブジェクトモニターのカウントに加算された場合、カウントがインクリメントされ、オブジェクトモニターのしきい値と比較されます。カウントがオブジェクトモニターのしきい値を抑制すると、システムはそのカウントをサービス冗長性グループ(SRG-1)のカウントに追加します。ネットワークAとネットワークBの両方のオブジェクトモニターカウントの合計がSRG-1のしきい値を超えると、システムは別のノードへのフェイルオーバーをトリガーします。
監視オブジェクトの設定を確認する
show chassis high-availability services-redundancy-group 1またはshow chassis high-availability services-redundancy-group <id> monitor-object <name> コマンドを使用します。
以下のサンプルは、 show chassis high-availability services-redundancy-group 1 コマンドの出力を示しています。
user@host> show chassis high-availability services-redundancy-group 1
SRG failure event codes:
BF BFD monitoring
IP IP monitoring
IF Interface monitoring
PM Path monitoring
CP Control Plane monitoring
.............................................
SRG Path Monitor Info:
SRG Monitor Status: UP
SRG Monitor Threshold: 100
SRG Monitor Weight: 0
SRG Monitor Failed Objects: [ NONE ]
Object Name: Network-B
Object Status: UP
Object Monitored Entries: [ IP IF BFD ]
Object Failures: [ IP ]
Object Threshold: 200
Object Current Weight: 0
Object Name: Network-A
Object Status: UP
Object Monitored Entries: [ IP IF BFD]
Object Failures: NONE
Object Threshold: 100
Object Current Weight: 0
コマンド出力では、監視オブジェクト Network-B と Network-Aの両方のステータスを確認できます。また、障害オブジェクトの詳細が、そのしきい値と重みとともに出力されていることもわかります。