EN ESTA PÁGINA
Descripción de la conmutación por error del grupo de redundancia del clúster de chasis
Descripción de la conmutación por error manual del grupo de redundancia del clúster de chasis
Inicio de una conmutación por error de grupo de redundancia manual de clúster de chasis
Comprobación del estado de conmutación por error del clúster de chasis
Borrar el estado de conmutación por error del clúster del chasis
Conmutación por error del grupo de redundancia del clúster de chasis
Un grupo de redundancia (RG) incluye y administra una colección de objetos en ambos nodos de un clúster para proporcionar alta disponibilidad. Cada grupo de redundancia actúa como una unidad independiente de conmutación por error y es principal en un solo nodo a la vez. Para obtener más información, consulte los temas siguientes:
Descripción de la conmutación por error del grupo de redundancia del clúster de chasis
El clúster de chasis emplea una serie de mecanismos de conmutación por error altamente eficientes que promueven la alta disponibilidad para aumentar la confiabilidad y productividad generales del sistema.
Un grupo de redundancia es una colección de objetos que conmutan por error como grupo. Cada grupo de redundancia supervisa un conjunto de objetos (interfaces físicas) y a cada objeto supervisado se le asigna un peso. Cada grupo de redundancia tiene un umbral inicial de 255. Cuando se produce un error en un objeto supervisado, el peso del objeto se resta del valor umbral del grupo de redundancia. Cuando el valor de umbral llega a cero, el grupo de redundancia conmuta por error al otro nodo. Como resultado, todos los objetos asociados con el grupo de redundancia también conmutan por error. El reinicio correcto de los protocolos de enrutamiento permite que el firewall de la serie SRX minimice la interrupción del tráfico durante una conmutación por error.
Las conmutaciones por error consecutivas de un grupo de redundancia en un intervalo corto pueden hacer que el clúster muestre un comportamiento impredecible. Para evitar este comportamiento impredecible, configure un tiempo de amortiguación entre conmutaciones por error. En caso de conmutación por error, el nodo principal anterior de un grupo de redundancia se mueve al estado de retención secundario y permanece en el estado de retención secundario hasta que expira el intervalo de retención. Después de que expire el intervalo de retención, el nodo primario anterior se mueve al estado secundario.
La configuración del intervalo de retención evita que se produzcan conmutaciones por error consecutivas durante el intervalo de retención.
El intervalo de retención afecta a las conmutaciones por error manuales, así como a las conmutaciones por error automáticas asociadas con los errores de supervisión.
El tiempo de amortiguación predeterminado para un grupo de redundancia 0 es de 300 segundos (5 minutos) y se puede configurar hasta 1800 segundos con la hold-down-interval instrucción. Para algunas configuraciones, como aquellas con un gran número de rutas o interfaces lógicas, es posible que el intervalo predeterminado o el intervalo configurado por el usuario no sean suficientes. En tales casos, el sistema extiende automáticamente el tiempo de amortiguación en incrementos de 60 segundos hasta que el sistema esté listo para la conmutación por error.
Los grupos x de redundancia (grupos de redundancia numerados del 1 al 128) tienen un tiempo de amortiguación predeterminado de 1 segundo, con un rango de 0 a 1800 segundos.
En los firewalls de la serie SRX, el rendimiento de la conmutación por error del clúster del chasis se optimiza para escalar con interfaces más lógicas. Anteriormente, durante la conmutación por error del grupo de redundancia, el proceso del Protocolo de redundancia de servicios de Juniper (jsrpd) enviaba arp gratuito (GARP) que se ejecuta en el motor de enrutamiento de cada interfaz lógica para dirigir el tráfico al nodo apropiado. Con el escalado de interfaz lógica, el motor de enrutamiento se convierte en el punto de control y GARP se envía directamente desde la unidad de procesamiento de servicios (SPU).
Temporizador de retardo de conmutación por error preventivo
Un grupo de redundancia está en el estado primario (activo) en un nodo y en el estado secundario (copia de seguridad) en el otro nodo en un momento dado.
Puede habilitar el comportamiento preventivo en ambos nodos de un grupo de redundancia y asignar un valor de prioridad para cada nodo del grupo de redundancia. El nodo del grupo de redundancia con la prioridad configurada más alta se designa inicialmente como el principal del grupo y el otro nodo se designa inicialmente como secundario en el grupo de redundancia.
Cuando un grupo de redundancia intercambia el estado de sus nodos entre primario y secundario, existe la posibilidad de que un intercambio de estado posterior de sus nodos pueda ocurrir de nuevo poco después del primer intercambio de estado. Este rápido cambio en los estados resulta en aleteo de los sistemas primario y secundario.
A partir de Junos OS versión 17.4R1, se introduce un temporizador de retardo de conmutación por error en los firewalls de la serie SRX en un clúster de chasis para limitar la oscilación del estado del grupo de redundancia entre los nodos secundario y primario en una conmutación por error preventiva.
Para evitar el aleteo, puede configurar los siguientes parámetros:
-
Retraso preventivo: el tiempo de retraso preferencial es la cantidad de tiempo que espera un grupo de redundancia en un estado secundario cuando el estado primario está inactivo en una conmutación por error preferencia antes de cambiar al estado primario. Este temporizador de retraso retrasa la conmutación por error inmediata durante un período de tiempo configurado, entre 1 y 21.600 segundos.
-
Límite preferencial: el límite preferencial restringe el número de conmutaciones por error preferenciales (entre 1 y 50) durante un período de preferencia configurado, cuando
preemptionestá habilitado para un grupo de redundancia. -
Período preferencial: período de tiempo (de 1 a 1440 segundos) durante el cual se aplica el límite preferencial, es decir, el número de conmutaciones por error preferenciales configuradas cuando se habilita la preferencia para un grupo de redundancia.
Considere el siguiente escenario en el que ha configurado un período preferencial como 300 segundos y un límite preferencial como 50.
Cuando el límite preferencial se configura como 50, el recuento comienza en 0 y se incrementa con una primera conmutación por error preferencia; Este proceso continúa hasta que el recuento alcanza el límite preferencial configurado, es decir, 50, antes de que expire el período preferencial. Cuando se supera el límite preferencial (50), debe restablecer manualmente el recuento de preferencia para permitir que vuelvan a producirse conmutaciones por error preferentes.
Cuando haya configurado el período de preferencia como 300 segundos, y si la diferencia de tiempo entre la primera conmutación por error preferencial y la conmutación por error actual ya ha superado los 300 segundos, y aún no se ha alcanzado el límite preferencial (50), se restablecerá el período preferencial. Después del restablecimiento, la última conmutación por error se considera la primera conmutación por error preferencia del nuevo período preferencial y el proceso comienza de nuevo.
El retraso preventivo se puede configurar independientemente del límite de conmutación por error. La configuración del temporizador de retardo preventivo no cambia el comportamiento preventivo existente.
Esta mejora permite al administrador introducir un retraso de conmutación por error, que puede reducir el número de conmutaciones por error y dar lugar a un estado de red más estable debido a la reducción de la oscilación activa/en espera dentro del grupo de redundancia.
- Descripción de la transición del estado primario al estado secundario con retraso preventivo
- Configuración del temporizador de retardo preventivo
Descripción de la transición del estado primario al estado secundario con retraso preventivo
Considere el ejemplo siguiente, donde un grupo de redundancia, que es principal en el nodo 0, está listo para la transición preventiva al estado secundario durante una conmutación por error. Se asigna prioridad a cada nodo y la preemptive opción también está habilitada para los nodos.
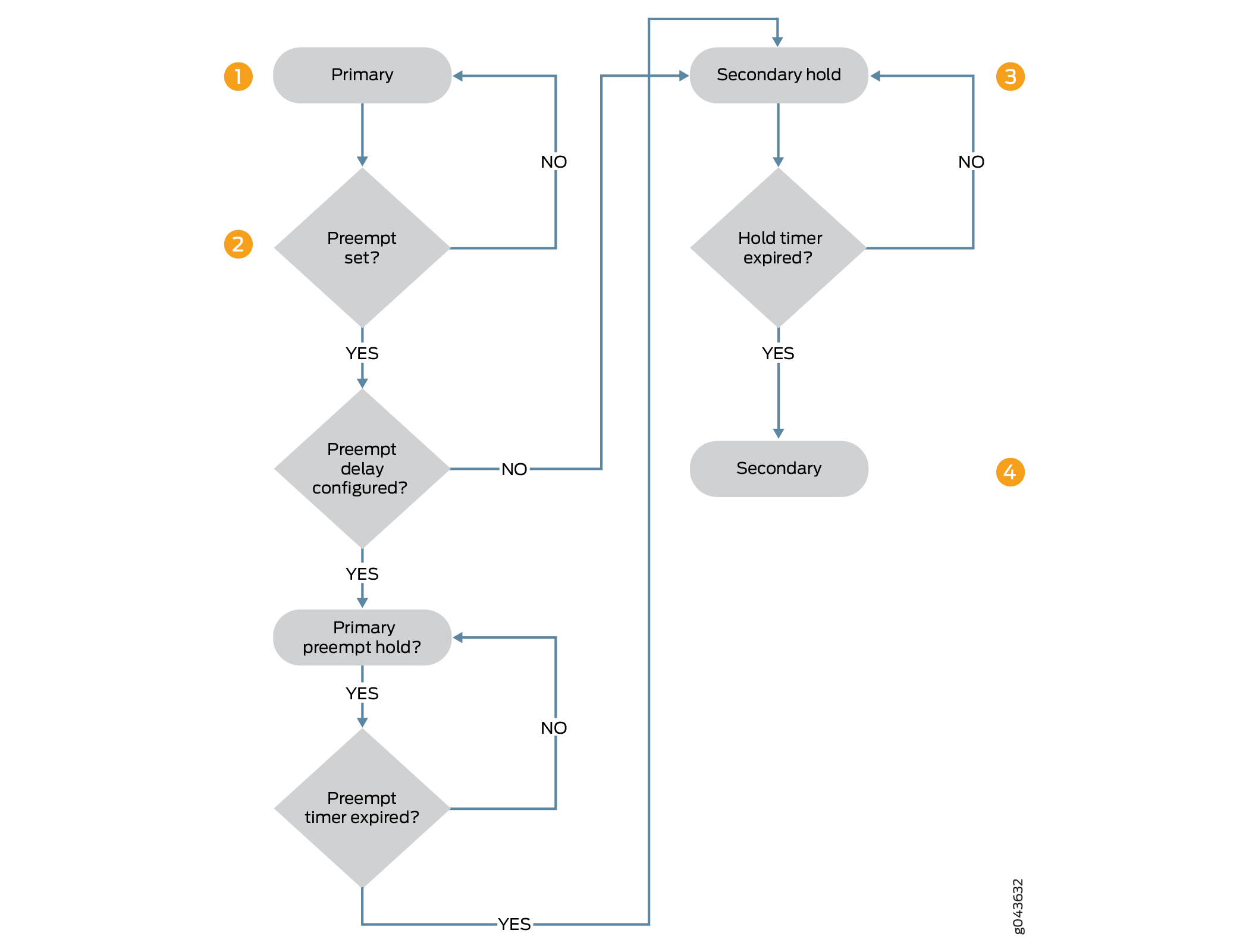
La figura 1 ilustra la secuencia de pasos en la transición del estado primario al estado secundario cuando se configura un temporizador de retardo preventivo.
 preventivo
preventivo
-
El nodo en el estado primario está listo para la transición preventiva al estado secundario si la
preemptiveopción está configurada, y el nodo en estado secundario tiene prioridad sobre el nodo en estado primario. Si se configura el retraso preferencial, el nodo del estado primario pasa al estado primario-preferencia-retención . Si el retraso preventivo no está configurado, se produce una transición instantánea al estado secundario. -
El nodo se encuentra en estado de espera preferencia principal a la espera de que caduque el temporizador de retraso preferencial. Se comprueba el temporizador de retardo preventivo y la transición se mantiene hasta que expire el temporizador. El nodo principal permanece en el estado de espera preferencia primaria hasta que expire el temporizador, antes de pasar al estado secundario.
-
El nodo pasa del estado de retención preferencial primario al estado de retención secundario y, luego, al estado secundario.
-
El nodo permanece en el estado de retención secundaria durante el tiempo predeterminado (1 segundo) o el tiempo configurado (un mínimo de 300 segundos) y, a continuación, el nodo pasa al estado secundario.
Si la configuración del clúster del chasis experimenta un número anormal de flaps, debe comprobar el vínculo y los temporizadores de supervisión para asegurarse de que estén configurados correctamente. Tenga cuidado al configurar temporizadores en redes de alta latencia para evitar falsos positivos.
Configuración del temporizador de retardo preventivo
En este tema se explica cómo configurar el temporizador de retraso en firewalls serie SRX en un clúster de chasis. Las conmutaciones por error consecutivas del grupo de redundancia que se producen demasiado rápido pueden provocar que un clúster de chasis muestre un comportamiento impredecible. La configuración del temporizador de retraso y el límite de velocidad de conmutación por error retrasa la conmutación por error inmediata durante un período de tiempo configurado.
Para configurar el temporizador de retraso preventivo y el límite de velocidad de conmutación por error entre conmutaciones por error del grupo de redundancia:
-
Habilite la conmutación por error preferencia para un grupo de redundancia.
Puede ajustar el temporizador de retardo entre 1 y 21.600 segundos. El valor predeterminado es 1 segundo.
{primary:node1} [edit chassis cluster redundancy-group number preempt] user@host# set delay interval -
Establezca un límite para la conmutación por error preventiva.
Puede establecer el número máximo de conmutaciones por error preventivas entre 1 y 50 y el período de tiempo durante el cual se aplica el límite entre 1 y 1440 segundos.
{primary:node1}[edit chassis cluster redundancy-group number preempt] user@host# set limit limit period period
En el ejemplo siguiente, establece el temporizador de retardo preferencial en 300 segundos y el límite de preferencia en 10 durante un período premptivo de 600 segundos. Es decir, esta configuración retrasa la conmutación por error inmediata durante 300 segundos y limita un máximo de 10 conmutaciones por error preventivas en una duración de 600 segundos.
{primary:node1}[edit chassis cluster redundancy-group 1 preempt]
user@host# set delay 300 limit 10 period 600
Puede usar el clear chassis clusters preempt-count comando para borrar el contador de conmutación por error de preferencia para todos los grupos de redundancia. Cuando se configura un límite de preferencia, el contador comienza con una primera conmutación por error preferencia y el recuento se reduce; Este proceso continúa hasta que el recuento llega a cero antes de que expire el temporizador. Puede usar este comando para borrar el contador de conmutación por error de preferencia y restablecerlo para que se inicie de nuevo.
Ver también
Descripción de la conmutación por error manual del grupo de redundancia del clúster de chasis
Puede iniciar una conmutación por error del grupo de redundancia x (grupos de redundancia numerados del 1 al 128) manualmente. Se aplica una conmutación por error manual hasta que se produce un evento de conmutación por recuperación.
Por ejemplo, supongamos que realiza manualmente una conmutación por error del grupo de redundancia 1 del nodo 0 al nodo 1. A continuación, se produce un error en una interfaz que el grupo de redundancia 1 está supervisando, lo que reduce el valor de umbral del nuevo grupo de redundancia principal a cero. Este evento se considera un evento de conmutación por recuperación y el sistema devuelve el control al grupo de redundancia original.
También puede iniciar manualmente una conmutación por error del grupo de redundancia 0 si desea cambiar el nodo principal por el grupo de redundancia 0. No puede habilitar la preferencia para el grupo de redundancia 0.
Si se agrega preferencia a una configuración de grupo de redundancia, el dispositivo con la prioridad más alta en el grupo puede iniciar una conmutación por error para convertirse en principal. De forma predeterminada, la preferencia está deshabilitada. Para obtener más información acerca de la preferencia, consulte preferencia (clúster de chasis).
Cuando se realiza una conmutación por error manual para el grupo de redundancia 0, el nodo del estado principal pasa al estado de retención secundaria. El nodo permanece en el estado de retención secundaria durante el tiempo predeterminado o configurado (un mínimo de 300 segundos) y, a continuación, pasa al estado secundario.
Las transiciones de estado en los casos en que un nodo está en estado de retención secundaria y el otro nodo se reinicia, o la conexión de vínculo de control o la conexión de vínculo de estructura se pierde en ese nodo, se describen a continuación:
Caso de reinicio: el nodo en el estado de retención secundaria pasa al estado primario; El otro nodo muere (inactivo).
Caso de error de vínculo de control: el nodo del estado de retención secundario pasa al estado no elegible y, a continuación, a un estado deshabilitado; El otro nodo pasa al estado primario.
Caso de error de vínculo de estructura: el nodo en el estado de retención secundaria pasa directamente al estado no elegible.
A partir de Junos OS versión 12.1X46-D20 y Junos OS versión 17.3R1, la supervisión de estructura está habilitada de forma predeterminada. Con esta habilitación, el nodo pasa directamente al estado no elegible en caso de fallas de vínculo de estructura.
A partir de Junos OS versión 12.1X47-D10 y Junos OS versión 17.3R1, la supervisión de estructura está habilitada de forma predeterminada. Con esta habilitación, el nodo pasa directamente al estado no elegible en caso de fallas de vínculo de estructura.
Tenga en cuenta que durante una actualización de software en servicio (ISSU), las transiciones descritas aquí no pueden ocurrir. En su lugar, el otro nodo (primario) pasa directamente al estado secundario porque las versiones de Juniper Networks anteriores a la 10.0 no interpretan el estado de retención secundaria. Mientras inicia una ISSU, si uno de los nodos tiene uno o más grupos de redundancia en el estado de retención secundaria, debe esperar a que se muevan al estado secundario antes de poder realizar conmutaciones por error manuales para que todos los grupos de redundancia sean principales en un nodo.
Sea cauteloso y juicioso en el uso de las conmutaciones por error manuales del grupo de redundancia 0. Una conmutación por error del grupo de redundancia 0 implica una conmutación por error del motor de enrutamiento, en cuyo caso todos los procesos que se ejecutan en el nodo principal se eliminan y luego se generan en el nuevo motor de enrutamiento principal. Esta conmutación por error podría provocar la pérdida de estado, como el estado de enrutamiento, y degradar el rendimiento mediante la introducción de la rotación del sistema.
En algunas versiones de Junos OS, para grupos xde redundancia , es posible realizar una conmutación por error manual en un nodo que tenga prioridad 0. Se recomienda usar el show chassis cluster status comando para comprobar las prioridades del nodo del grupo de redundancia antes de realizar la conmutación por error manual. Sin embargo, a partir de Junos OS versiones 12.1X44-D25, 12.1X45-D20, 12.1X46-D10 y 12.1X47-D10 y posteriores, el mecanismo de comprobación de preparación para la conmutación por error manual se ha mejorado para ser más restrictivo, de modo que no se puede establecer la conmutación por error manual en un nodo de un grupo de redundancia que tenga prioridad 0. Esta mejora evita que el tráfico se pierda inesperadamente debido a un intento de conmutación por error a un nodo de prioridad 0, que no está listo para aceptar tráfico.
Inicio de una conmutación por error de grupo de redundancia manual de clúster de chasis
Antes de comenzar, realice las siguientes tareas:
Puede iniciar una conmutación por error manualmente con el request comando. Una conmutación por error manual aumenta la prioridad del grupo de redundancia para ese miembro a 255.
Sea cauteloso y juicioso en el uso de las conmutaciones por error manuales del grupo de redundancia 0. Una conmutación por error del grupo de redundancia 0 implica una conmutación por error del motor de enrutamiento (RE), en cuyo caso todos los procesos que se ejecutan en el nodo principal se eliminan y luego se generan en el nuevo motor de enrutamiento (RE) principal. Esta conmutación por error podría provocar la pérdida de estado, como el estado de enrutamiento, y degradar el rendimiento mediante la introducción de la rotación del sistema.
Desenchufar el cable de alimentación y mantener presionado el botón de encendido para iniciar una conmutación por error del grupo de redundancia del clúster de chasis puede provocar un comportamiento impredecible.
Para los grupos x de redundancia (grupos de redundancia numerados del 1 al 128), es posible realizar una conmutación por error manual en un nodo que tenga prioridad 0. Se recomienda comprobar las prioridades del nodo del grupo de redundancia antes de realizar la conmutación por error manual.
Utilice el show comando para mostrar el estado de los nodos del clúster:
{primary:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 1
node0 254 primary no no
node1 1 secondary no no
El resultado de este comando indica que el nodo 0 es primario.
Use el comando para desencadenar una conmutación por error y hacer que el request nodo 1 sea principal:
{primary:node0}
user@host> request chassis cluster failover redundancy-group 0 node 1
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Initiated manual failover for redundancy group 0
Utilice el show comando para mostrar el nuevo estado de los nodos del clúster:
{secondary-hold:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 2
node0 254 secondary-hold no yes
node1 255 primary no yes
El resultado de este comando muestra que el nodo 1 es ahora primario y el nodo 0 está en estado de retención secundaria. Después de 5 minutos, el nodo 0 pasará al estado secundario.
Puede restablecer la conmutación por error para los grupos de redundancia mediante el request comando. Este cambio se propaga por todo el clúster.
{secondary-hold:node0}
user@host> request chassis cluster failover reset redundancy-group 0
node0:
--------------------------------------------------------------------------
No reset required for redundancy group 0.
node1:
--------------------------------------------------------------------------
Successfully reset manual failover for redundancy group 0
No puede desencadenar una conmutación por error consecutiva hasta que expire el intervalo de 5 minutos.
{secondary-hold:node0}
user@host> request chassis cluster failover redundancy-group 0 node 0
node0:
--------------------------------------------------------------------------
Manual failover is not permitted as redundancy-group 0 on node0 is in secondary-hold state.
Utilice el show comando para mostrar el nuevo estado de los nodos del clúster:
{secondary-hold:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 2
node0 254 secondary-hold no no
node1 1 primary no no
El resultado de este comando muestra que no se ha producido una conmutación por error consecutiva para ninguno de los nodos.
Después de realizar una conmutación por error manual, debe emitir el comando antes de reset failover solicitar otra conmutación por error.
Cuando el nodo primario falla y vuelve a funcionar, la elección del nodo principal se realiza en función de criterios regulares (prioridad y preferencia).
Ejemplo: configuración de un clúster de chasis con un tiempo de amortiguación entre conmutaciones por error de grupo de redundancia consecutivas
En este ejemplo se muestra cómo configurar el tiempo de amortiguación entre las conmutaciones por error de grupo de redundancia consecutivas para un clúster de chasis. Las conmutaciones por error consecutivas del grupo de redundancia que se producen demasiado rápido pueden provocar que un clúster de chasis muestre un comportamiento impredecible.
Requisitos
Antes de empezar:
Comprender la conmutación por error del grupo de redundancia. Consulte Descripción de la conmutación por error del grupo de redundancia del clúster de chasis .
Comprender la conmutación por error manual del grupo de redundancia. Consulte Descripción de la conmutación por error manual del grupo de redundancia del clúster de chasis.
Visión general
El tiempo de amortiguación es el intervalo mínimo permitido entre las conmutaciones por error consecutivas para un grupo de redundancia. Este intervalo afecta a las conmutaciones por error manuales y automáticas causadas por errores de supervisión de interfaz.
En este ejemplo, el intervalo mínimo permitido entre conmutaciones por error consecutivas se establece en 420 segundos para el grupo de redundancia 0.
Configuración
Procedimiento
Procedimiento paso a paso
Para configurar el tiempo de amortiguación entre conmutaciones por error de grupos de redundancia consecutivas:
Establezca el tiempo de amortiguación para el grupo de redundancia.
{primary:node0}[edit] user@host# set chassis cluster redundancy-group 0 hold-down-interval 420Si ha terminado de configurar el dispositivo, confirme la configuración.
{primary:node0}[edit] user@host# commit
Descripción de las capturas de conmutación por error SNMP para la conmutación por error del grupo de redundancia del clúster de chasis
La agrupación en clústeres de chasis admite capturas SNMP, que se activan siempre que hay una conmutación por error de grupo de redundancia.
El mensaje de interrupción puede ayudarle a solucionar problemas de conmutación por error. Contiene la siguiente información:
El ID de clúster y el ID de nodo
El motivo de la conmutación por error
El grupo de redundancia implicado en la conmutación por error
El estado anterior y el estado actual del grupo de redundancia
Estos son los diferentes estados en los que puede estar un clúster en un momento dado: espera, primario, retención secundario, secundario, no elegible y deshabilitado. Las capturas se generan para las siguientes transiciones de estado (solo una transición desde un estado de espera no activa una interrupción):
primaria <–> secundaria
principal: > retención secundaria
retención secundaria –> secundaria
Secundaria: > no elegible
No elegible –> deshabilitado
No elegible –> primaria
Secundaria –> deshabilitada
Una transición puede desencadenarse debido a cualquier evento, como monitoreo de interfaz, monitoreo de SPU, errores y conmutaciones por error manuales.
La captura se reenvía a través del vínculo de control si la interfaz de salida se encuentra en un nodo diferente del nodo del motor de enrutamiento que genera la captura.
Puede especificar que se genere un registro de seguimiento estableciendo la traceoptions flag snmp instrucción.
Comprobación del estado de conmutación por error del clúster de chasis
Propósito
Muestra el estado de conmutación por error de un clúster de chasis.
Acción
Desde la CLI, escriba el show chassis cluster status comando:
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 3
Node name Priority Status Preempt Manual failover
Redundancy-group: 0, Failover count: 1
node0 254 primary no no
node1 2 secondary no no
Redundancy-group: 1, Failover count: 1
node0 254 primary no no
node1 1 secondary no no
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 15
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 5
node0 200 primary no no
node1 0 lost n/a n/a
Redundancy group: 1 , Failover count: 41
node0 101 primary no no
node1 0 lost n/a n/a
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 15
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 5
node0 200 primary no no
node1 0 unavailable n/a n/a
Redundancy group: 1 , Failover count: 41
node0 101 primary no no
node1 0 unavailable n/a n/a
Borrar el estado de conmutación por error del clúster del chasis
Para borrar el estado de conmutación por error de un clúster de chasis, escriba el clear chassis cluster failover-count comando desde la CLI:
{primary:node1}
user@host> clear chassis cluster failover-count
Cleared failover-count for all redundancy-groups
Tabla de historial de cambios
La compatibilidad con las funciones viene determinada por la plataforma y la versión que esté utilizando. Utilice el Explorador de características para determinar si una característica es compatible con su plataforma.