섀시 클러스터 이중화 그룹 페일오버
중복 그룹(RG)은 고가용성을 제공하기 위해 클러스터의 두 노드에 있는 개체 모음을 포함하고 관리합니다. 각 중복 그룹은 독립적인 장애 조치 단위로 작동하며 한 번에 하나의 노드에서만 기본입니다. 자세한 내용은 다음 항목을 참조하세요.
섀시 클러스터 이중화 그룹 장애 조치 이해하기
섀시 클러스터는 고가용성을 촉진하는 여러 가지 매우 효율적인 페일오버 메커니즘을 사용하여 시스템의 전반적인 안정성과 생산성을 향상시킵니다.
중복 그룹은 그룹으로 장애 조치되는 객체의 집합입니다. 각 중복 그룹은 일련의 객체(물리적 인터페이스)를 모니터링하며, 모니터링되는 각 객체에는 가중치가 할당됩니다. 각 중복 그룹의 초기 임계값은 입니다 255. 모니터링되는 개체가 실패하면 중복 그룹의 임계값에서 개체의 가중치가 차감됩니다. 임계값이 0에 도달하면, 중복 그룹이 다른 노드로 장애 조치됩니다. 그 결과, 중복 그룹과 연관된 모든 객체도 실패하게 됩니다. 라우팅 프로토콜의 Graceful Restart로 SRX 시리즈 방화벽은 페일오버 중 트래픽 중단을 최소화합니다.
짧은 간격으로 중복 그룹의 연속 페일오버는 클러스터가 예측할 수 없는 동작을 나타내게 할 수 있습니다. 이러한 예측할 수 없는 동작을 방지하려면 장애 조치(failover) 사이에 감쇠 시간을 구성합니다. 페일오버 시, 중복 그룹의 이전 기본 노드는 secondary-hold 상태로 이동하고 hold-down 간격이 만료될 때까지 secondary-hold 상태를 유지합니다. 보류 간격이 만료되면 이전 기본 노드가 보조 상태로 이동합니다.
홀드 다운 간격을 구성하면 홀드 다운 간격 기간 내에 백투백 페일오버가 발생하지 않습니다.
보류 간격은 수동 장애 조치(failover)뿐만 아니라 모니터링 실패와 관련된 자동 장애 조치(failover)에도 영향을 줍니다.
중복 그룹 0의 기본 감쇠 시간은 300초(5분)이며 문을 사용하여 hold-down-interval 최대 1800초까지 구성할 수 있습니다. 많은 수의 경로 또는 논리적 인터페이스가 있는 구성과 같은 일부 구성의 경우 기본 간격 또는 사용자 구성 간격이 충분하지 않을 수 있습니다. 이러한 경우 시스템은 시스템이 페일오버 준비가 될 때까지 60초 단위로 감쇠 시간을 자동으로 연장합니다.
중복 그룹 x (1에서 128까지 번호가 매겨진 중복 그룹)의 기본 감쇠 시간은 1초이며 범위는 0초에서 1800초입니다.
SRX 시리즈 방화벽에서 섀시 클러스터 페일오버 성능은 보다 논리적인 인터페이스를 통해 확장할 수 있도록 최적화됩니다. 이전에는 중복 그룹 페일오버 중에 각 논리 인터페이스 의 라우팅 엔진에서 실행되는 JSRPD(Juniper Services Redundancy Protocol) 프로세스가 GARP(Gratuitous ARP)를 전송하여 트래픽을 적절한 노드로 전달합니다. 논리적 인터페이스 확장을 통해 라우팅 엔진이 체크포인트가 되고 GARP가 SPU(Services Processing Unit)에서 직접 전송됩니다.
선제적 페일오버 지연 타이머
중복 그룹은 주어진 시간에 한 노드에서는 기본 상태(활성)에 있고 다른 노드에서는 보조 상태(백업)에 있습니다.
중복 그룹의 두 노드에서 선점적 동작을 활성화하고 중복 그룹의 각 노드에 우선 순위 값을 할당할 수 있습니다. 더 높은 구성 우선 순위를 가진 중복 그룹의 노드는 처음에 그룹에서 기본으로 지정되고 다른 노드는 처음에 중복 그룹에서 보조로 지정됩니다.
중복 그룹이 기본 노드와 보조 노드 상태를 스왑할 때, 첫 번째 상태 스왑 직후 노드의 후속 상태 스왑이 다시 발생할 가능성이 있습니다. 이러한 급격한 상태 변화는 1차 및 2차 시스템의 플래핑을 초래합니다.
Junos OS 릴리스 17.4R1부터는 섀시 클러스터의 SRX 시리즈 방화벽에 페일오버 지연 타이머가 도입되어 선제적 페일오버에서 보조 노드와 기본 노드 간의 중복 그룹 상태 플래핑을 제한합니다.
플래핑을 방지하기 위해 다음 매개 변수를 구성할 수 있습니다.
-
Preemptive delay(선점형 지연) – preemptive delay time(선점형 지연 시간)은 보조 상태의 중복 그룹이 기본 상태로 전환하기 전에 Preemptive Failover에서 기본 상태가 다운될 때 대기하는 시간입니다. 이 지연 타이머는 구성된 시간(1초에서 21,600초 사이) 동안 즉시 페일오버를 지연합니다.
-
Preemptive limit(선점형 제한) – 선점형 제한은 이(가) 중복 그룹에 대해 활성화된 경우
preemption구성된 preemptive 기간 동안 선점형 장애 조치(failover) 수(1에서 50 사이)를 제한합니다. -
Preemptive period–선점형 제한이 적용되는 기간(1 - 1440초), 즉 중복 그룹에 대해 선점이 활성화되었을 때 구성된 선점형 장애 조치 수입니다.
선점 기간을 300초로 구성하고 선점 제한을 50초로 구성한 다음 시나리오를 고려합니다.
선점형 제한이 50으로 구성된 경우 개수는 0에서 시작하여 첫 번째 선점형 장애 조치(failover)와 함께 증가합니다. 이 프로세스는 카운트가 구성된 선점형 제한인 50에 도달할 때까지 계속된 후 선점형 기간이 만료됩니다. 선점형 제한(50)을 초과하면 선점형 장애 조치(failover)가 다시 발생할 수 있도록 선점형 수를 수동으로 재설정해야 합니다.
선점 기간을 300초로 구성한 경우, 첫 번째 선점형 페일오버와 현재 페일오버의 시간차가 이미 300초를 초과하여 선점형 제한(50)에 도달하지 않은 경우 선점 기간이 재설정됩니다. 재설정 후 마지막 장애 조치(failover)는 새 예비 기간의 첫 번째 예비 장애 조치(failover)로 간주되고 프로세스가 다시 시작됩니다.
선점형 지연은 페일오버 제한과 독립적으로 구성할 수 있습니다. 선점형 지연 타이머를 구성해도 기존 선점형 동작은 변경되지 않습니다.
이 향상된 기능을 통해 관리자는 페일오버 지연을 도입할 수 있으며, 이를 통해 페일오버 수를 줄이고 이중화 그룹 내에서 활성/대기 플래핑의 감소로 인해 보다 안정적인 네트워크 상태를 만들 수 있습니다.
기본 상태에서 보조 상태로의 전환(선제적 지연 포함) 이해
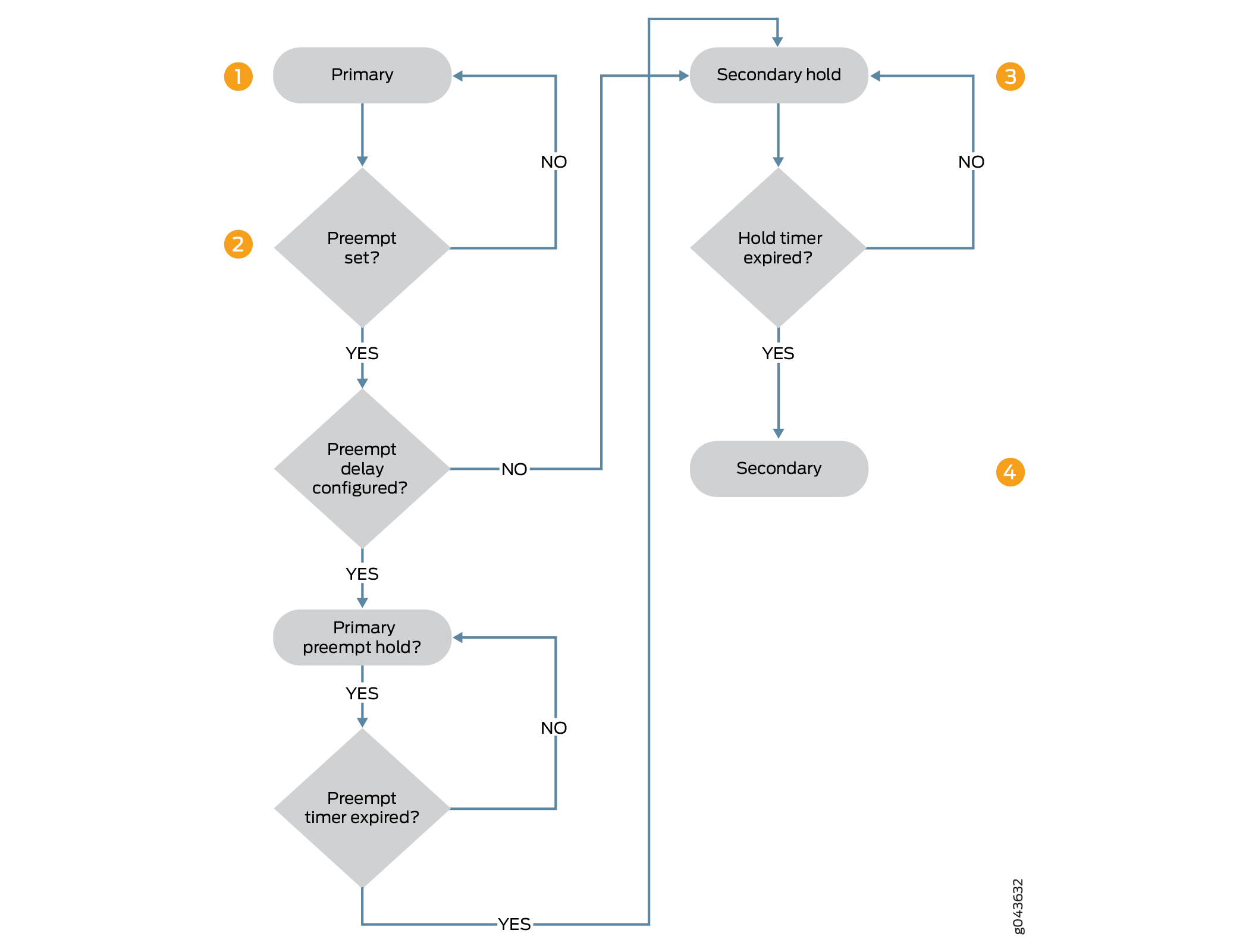
노드 0에서 기본인 중복 그룹이 페일오버 동안 보조 상태로 선제적으로 전환할 준비가 된 다음 예를 고려하십시오. 우선 순위는 각 노드에 할당되며 preemptive 노드에 대해서도 옵션이 활성화됩니다.
그림 1 은 선점형 지연 타이머가 구성될 때 기본 상태에서 보조 상태로 전환되는 일련의 단계를 보여줍니다.
-
옵션이 구성된 경우
preemptive, 기본 상태의 노드는 보조 상태로 선제적으로 전환할 준비가 되며, 보조 상태의 노드는 기본 상태의 노드보다 우선권을 갖습니다. 선점형 지연이 구성된 경우, 기본 상태의 노드는 1차 선점 상태로 전환됩니다. 선점형 지연이 구성되지 않은 경우 보조 상태로의 즉각적인 전환이 발생합니다. -
노드는 1차 선점 지연 타이머가 만료되기를 기다리는 1차 보류 상태입니다. 선점형 지연 타이머가 확인되고 타이머가 만료될 때까지 전환이 유지됩니다. 기본 노드는 타이머가 만료될 때까지 기본 노드가 기본 선점 상태로 유지된 후 보조 상태로 전환됩니다.
-
노드는 1차 선점 보류 상태에서 2차 보류 상태로 전환된 다음 보조 상태로 전환됩니다.
-
노드는 기본 시간(1초) 또는 구성된 시간(최소 300초) 동안 보조 보류 상태로 유지된 다음 보조 상태로 전환됩니다.
섀시 클러스터 설정에 비정상적인 플랩 수가 발생하면 링크 및 모니터링 타이머가 올바르게 설정되었는지 확인해야 합니다. 지연 시간이 긴 네트워크에서 타이머를 설정할 때 오탐을 방지할 수 있도록 주의하십시오.
Preemptive Delay Timer 구성
이 주제는 섀시 클러스터의 SRX 시리즈 방화벽에서 지연 타이머를 구성하는 방법을 설명합니다. 너무 빨리 발생하는 백투백 중복 그룹 장애 조치는 섀시 클러스터가 예측할 수 없는 동작을 나타내게 할 수 있습니다. 지연 타이머와 페일오버 속도 제한을 구성하면 구성된 기간 동안 즉각적인 페일오버가 지연됩니다.
중복 그룹 장애 조치 간의 선점형 지연 타이머 및 장애 조치 속도 제한을 구성하려면,
-
중복 그룹에 대한 선제적 장애 조치를 활성화합니다.
지연 타이머는 1초에서 21,600초 사이로 설정할 수 있습니다. 기본값은 1초입니다.
{primary:node1} [edit chassis cluster redundancy-group number preempt] user@host# set delay interval -
선점형 장애 조치(failover)에 대한 제한을 설정합니다.
최대 선점형 장애 조치(failover) 수는 1초에서 50초 사이이고 제한이 적용되는 기간은 1초에서 1440초 사이로 설정할 수 있습니다.
{primary:node1}[edit chassis cluster redundancy-group number preempt] user@host# set limit limit period period
다음 예에서는 600초의 예상 기간 동안 선점형 지연 타이머를 300초로 설정하고, 선점형 제한을 10으로 설정합니다. 즉, 이 구성은 300초 동안 즉시 장애 조치(failover)를 지연하고 600초 동안 최대 10개의 선점형 장애 조치(failover)를 제한합니다.
{primary:node1}[edit chassis cluster redundancy-group 1 preempt]
user@host# set delay 300 limit 10 period 600
명령을 사용하여 모든 중복 그룹에 대한 선점 페일오버 카운터를 지울 수 있습니다 clear chassis clusters preempt-count . 선점 제한이 구성되면 카운터는 첫 번째 선점형 장애 조치(failover)로 시작되고 개수가 줄어듭니다. 이 프로세스는 타이머가 만료되기 전에 카운트가 0에 도달할 때까지 계속됩니다. 이 명령을 사용하여 선점 장애 조치(failover) 카운터를 지우고 다시 시작하도록 재설정할 수 있습니다.
참조
섀시 클러스터 중복 그룹 수동 장애 조치 이해하기
중복 그룹 x (1에서 128까지 번호가 매겨진 중복 그룹) 장애 조치를 수동으로 시작할 수 있습니다. 수동 장애 조치(failover)는 장애 복구(failback) 이벤트가 발생할 때까지 적용됩니다.
예를 들어, 노드 0에서 노드 1로 중복 그룹 1 페일오버를 수동으로 수행한다고 가정합니다. 그런 다음 중복 그룹 1이 모니터링하는 인터페이스가 실패하여 새로운 기본 중복 그룹의 임계값이 0으로 떨어집니다. 이 이벤트는 장애 복구 이벤트로 간주되며, 시스템은 원래의 중복 그룹에 제어를 반환합니다.
중복 그룹 0의 기본 노드를 변경하려는 경우 중복 그룹 0 페일오버를 수동으로 시작할 수도 있습니다. 중복 그룹 0에 대한 선점을 활성화할 수 없습니다.
중복 그룹 구성에 선점이 추가되면 그룹에서 더 높은 우선 순위를 가진 디바이스가 기본 디바이스가 되기 위해 장애 조치를 시작할 수 있습니다. 기본적으로 선점은 비활성화됩니다. 선점(섀시 클러스터)에 대한 자세한 내용은 선점(섀시 클러스터)을 참조하십시오.
중복 그룹 0에 대한 수동 페일오버를 수행하면 기본 상태의 노드가 보조 보류 상태로 전환됩니다. 노드는 기본 또는 구성된 시간(최소 300초) 동안 보조 보류 상태로 유지된 다음 보조 상태로 전환됩니다.
한 노드가 secondary-hold 상태이고 다른 노드가 재부팅되거나 해당 노드에 대한 제어 링크 연결 또는 패브릭 링크 연결이 손실되는 경우의 상태 전환은 다음과 같이 설명됩니다.
Reboot case(재부팅 케이스) - 보조 보류 상태의 노드가 기본 상태로 전환됩니다. 다른 노드가 중단(비활성)됩니다.
Control link failure case(링크 실패 케이스 제어) - 보조 보류 상태의 노드가 부적합 상태로 전환된 다음 비활성화 상태로 전환됩니다. 다른 노드는 기본 상태로 전환됩니다.
패브릭 링크 실패 사례 - 보조 보류 상태의 노드가 부적격 상태로 직접 전환됩니다.
Junos OS 릴리스 12.1X46-D20 및 Junos OS 릴리스 17.3R1부터는 패브릭 모니터링이 기본적으로 활성화됩니다. 이렇게 활성화하면 패브릭 링크 실패 시 노드가 부적격 상태로 직접 전환됩니다.
Junos OS 릴리스 12.1X47-D10 및 Junos OS 릴리스 17.3R1부터는 패브릭 모니터링이 기본적으로 활성화됩니다. 이렇게 활성화하면 패브릭 링크 실패 시 노드가 부적격 상태로 직접 전환됩니다.
ISSU(in-service software upgrade) 중에는 여기에 설명된 전환이 발생할 수 없습니다. 대신 10.0 이전의 주니퍼 네트웍스 릴리스는 보조 보류 상태를 해석하지 않기 때문에 다른(기본) 노드가 보조 상태로 직접 전환됩니다. ISSU를 시작하는 동안 노드 중 하나에 보조 보류 상태의 하나 이상의 중복 그룹이 있는 경우 수동 장애 조치를 수행하여 모든 중복 그룹을 하나의 노드에서 기본 노드로 만들기 전에 보조 상태로 이동할 때까지 기다려야 합니다.
중복 그룹 0 수동 장애 조치를 사용할 때는 신중하고 신중해야 합니다. 중복 그룹 0 장애 조치는 라우팅 엔진 장애 조치를 의미하며, 이 경우 기본 노드에서 실행 중인 모든 프로세스가 종료된 다음 새 기본 라우팅 엔진에서 생성됩니다. 이 장애 조치(failover)로 인해 라우팅 상태와 같은 상태가 손실되고 시스템 변동이 발생하여 성능이 저하될 수 있습니다.
일부 Junos OS 릴리스에서는 중복 그룹의 x경우 우선 순위가 0인 노드에서 수동 페일오버를 수행할 수 있습니다. 수동 페일오버를 수행하기 전에 명령을 사용하여 show chassis cluster status 중복 그룹 노드 우선 순위를 확인하는 것이 좋습니다. 그러나 Junos OS 릴리스 12.1X44-D25, 12.1X45-D20, 12.1X46-D10 및 12.1X47-D10 이상부터는 수동 페일오버를 위한 준비 검사 메커니즘이 더욱 제한적으로 향상되어 우선 순위가 0인 중복 그룹의 노드에 수동 페일오버를 설정할 수 없습니다. 이 향상된 기능은 트래픽을 수락할 준비가 되지 않은 0 우선 순위 노드로의 페일오버 시도로 인해 트래픽이 예기치 않게 삭제되는 것을 방지합니다.
섀시 클러스터 수동 중복 그룹 장애 조치 시작
시작하기 전에 다음 태스크를 완료하십시오.
명령을 사용하여 request 수동으로 장애 조치를 시작할 수 있습니다. 수동 페일오버는 해당 멤버에 대한 중복 그룹의 우선 순위를 255로 높입니다.
중복 그룹 0 수동 장애 조치를 사용할 때는 신중하고 신중해야 합니다. 중복 그룹 0 장애 조치는 라우팅 엔진(RE) 장애 조치를 의미하며, 이 경우 기본 노드에서 실행 중인 모든 프로세스가 종료된 다음 새로운 기본 라우팅 엔진(RE)에서 생성됩니다. 이 장애 조치(failover)로 인해 라우팅 상태와 같은 상태가 손실되고 시스템 변동이 발생하여 성능이 저하될 수 있습니다.
전원 코드를 뽑고 전원 버튼을 길게 눌러 섀시 클러스터 중복 그룹 장애 조치를 시작하면 예기치 않은 동작이 발생할 수 있습니다.
중복 그룹 x (1에서 128까지 번호가 매겨진 중복 그룹)의 경우 우선 순위가 0인 노드에서 수동 페일오버를 수행할 수 있습니다. 수동 장애 조치를 수행하기 전에 중복 그룹 노드 우선 순위를 확인하는 것이 좋습니다.
show 명령을 사용하여 클러스터의 노드 상태를 표시합니다.
{primary:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 1
node0 254 primary no no
node1 1 secondary no no
이 명령의 출력은 노드 0이 기본임을 나타냅니다.
request 명령을 사용하여 장애 조치를 트리거하고 노드 1을 기본 노드로 만듭니다.
{primary:node0}
user@host> request chassis cluster failover redundancy-group 0 node 1
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Initiated manual failover for redundancy group 0
show 명령을 사용하여 클러스터에 있는 노드의 새 상태를 표시합니다.
{secondary-hold:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 2
node0 254 secondary-hold no yes
node1 255 primary no yes
이 명령의 출력은 노드 1이 현재 기본 상태이고 노드 0이 보조 보류 상태임을 보여줍니다. 5분 후 노드 0은 보조 상태로 전환됩니다.
명령을 사용하여 중복 그룹에 대한 페일오버를 request 재설정할 수 있습니다. 이 변경 내용은 클러스터 전체에 전파됩니다.
{secondary-hold:node0}
user@host> request chassis cluster failover reset redundancy-group 0
node0:
--------------------------------------------------------------------------
No reset required for redundancy group 0.
node1:
--------------------------------------------------------------------------
Successfully reset manual failover for redundancy group 0
5분 간격이 만료될 때까지 연속 장애 조치(failover)를 트리거할 수 없습니다.
{secondary-hold:node0}
user@host> request chassis cluster failover redundancy-group 0 node 0
node0:
--------------------------------------------------------------------------
Manual failover is not permitted as redundancy-group 0 on node0 is in secondary-hold state.
show 명령을 사용하여 클러스터에 있는 노드의 새 상태를 표시합니다.
{secondary-hold:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 2
node0 254 secondary-hold no no
node1 1 primary no no
이 명령의 출력은 두 노드 모두에 대해 백투백 장애 조치가 발생하지 않았음을 보여줍니다.
수동 장애 조치(failover)를 수행한 후 다른 장애 조치(failover)를 요청하기 전에 명령을 실행 reset failover 해야 합니다.
기본 노드에 장애가 발생했다가 다시 켜지면 일반 기준(우선 순위 및 선점)에 따라 기본 노드의 선택이 수행됩니다.
예: 백투백 이중화 그룹 페일오버 간 감쇠 시간으로 섀시 클러스터 구성
이 예는 섀시 클러스터에 대한 백투백 중복 그룹 장애 조치 간의 감쇠 시간을 구성하는 방법을 보여줍니다. 너무 빨리 발생하는 백투백 중복 그룹 장애 조치는 섀시 클러스터가 예측할 수 없는 동작을 나타내게 할 수 있습니다.
요구 사항
시작하기 전에:
중복 그룹 페일오버를 이해합니다. 섀시 클러스터 중복 그룹 장애 극복 을 참조하십시오.
중복 그룹 수동 장애 조치에 대해 이해합니다. 섀시 클러스터 이중화 그룹 수동 장애 조치 이해하기를 참조하십시오.
개요
감쇠 시간은 중복 그룹에 대한 연속 장애 조치 간에 허용되는 최소 간격입니다. 이 간격은 인터페이스 모니터링 실패로 인한 수동 장애 조치 및 자동 장애 조치에 영향을 미칩니다.
이 예에서는 중복 그룹 0에 대해 백투백 장애 조치 사이에 허용되는 최소 간격을 420초로 설정합니다.
구성
절차
단계별 절차
백투백 중복 그룹 장애 조치 간의 감쇠 시간을 구성하려면 다음을 수행합니다.
중복 그룹의 감쇠 시간을 설정합니다.
{primary:node0}[edit] user@host# set chassis cluster redundancy-group 0 hold-down-interval 420디바이스 구성을 완료하면 해당 구성을 커밋합니다.
{primary:node0}[edit] user@host# commit
섀시 클러스터 중복 그룹 장애 조치를 위한 SNMP 장애 조치 트랩 이해
섀시 클러스터링은 중복 그룹 페일오버가 있을 때마다 트리거되는 SNMP 트랩을 지원합니다.
트랩 메시지는 장애 조치(failover) 문제를 해결하는 데 도움이 될 수 있습니다. 여기에는 다음 정보가 포함됩니다.
클러스터 ID 및 노드 ID
장애 조치(failover)의 이유
페일오버에 관여하는 중복 그룹
중복 그룹의 이전 상태 및 현재 상태
클러스터가 지정된 순간에 있을 수 있는 다양한 상태(보류, 기본, 보조-보류, 보조, 부적격 및 사용 안 함)입니다. 트랩은 다음과 같은 상태 전환에 대해 생성됩니다(보류 상태에서 전환만 트랩을 트리거하지 않음).
기본 <–> 보조
primary –> secondary-hold
secondary-hold – > 보조
보조 > 부적격
부적격 - > 비활성화
부적격–> 기본
보조 - > 사용 안 함
전환은 인터페이스 모니터링, SPU 모니터링, 실패 및 수동 페일오버와 같은 모든 이벤트로 인해 트리거될 수 있습니다.
발신 인터페이스가 트랩을 생성하는 라우팅 엔진의 노드와 다른 노드에 있는 경우 트랩은 제어 링크를 통해 전달됩니다.
문을 설정하여 추적 로그가 traceoptions flag snmp 생성되도록 지정할 수 있습니다.
섀시 클러스터 페일오버 상태 확인
목적
섀시 클러스터의 페일오버 상태를 표시합니다.
행동
CLI에서 명령을 입력합니다.show chassis cluster status
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 3
Node name Priority Status Preempt Manual failover
Redundancy-group: 0, Failover count: 1
node0 254 primary no no
node1 2 secondary no no
Redundancy-group: 1, Failover count: 1
node0 254 primary no no
node1 1 secondary no no
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 15
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 5
node0 200 primary no no
node1 0 lost n/a n/a
Redundancy group: 1 , Failover count: 41
node0 101 primary no no
node1 0 lost n/a n/a
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 15
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 5
node0 200 primary no no
node1 0 unavailable n/a n/a
Redundancy group: 1 , Failover count: 41
node0 101 primary no no
node1 0 unavailable n/a n/a
섀시 클러스터 장애 조치 상태 지우기
섀시 클러스터의 페일오버 상태를 지우려면 CLI에서 명령을 입력합니다 clear chassis cluster failover-count .
{primary:node1}
user@host> clear chassis cluster failover-count
Cleared failover-count for all redundancy-groups
변경 내역 표
기능 지원은 사용 중인 플랫폼과 릴리스에 따라 결정됩니다. 기능 탐색기 를 사용하여 플랫폼에서 기능이 지원되는지 확인하세요.