シャーシ クラスタ冗長グループのフェイルオーバー
冗長性グループ(RG)は、高可用性を提供するために、クラスターの両方のノード上のオブジェクトのコレクションを含み、管理します。各冗長性グループは、独立したフェイルオーバー ユニットとして機能し、一度に 1 つのノードでのみプライマリになります。詳細については、次のトピックを参照してください。
シャーシ クラスタ冗長グループのフェイルオーバーについて
シャーシ クラスタでは、システムの全体的な信頼性と生産性を向上させるために、高可用性を促進する高効率のフェイルオーバー メカニズムが多数採用されています。
冗長性グループは、グループとしてフェールオーバーするオブジェクトの集まりです。各冗長性グループは一連のオブジェクト(物理インターフェイス)を監視し、各監視対象オブジェクトには重みが割り当てられます。各冗長性グループには、 255の初期しきい値があります。監視対象オブジェクトに障害が発生すると、冗長グループのしきい値からオブジェクトの重みが差し引かれます。しきい値がゼロに達すると、冗長性グループは他のノードにフェイルオーバーします。その結果、冗長性グループに関連付けられているすべてのオブジェクトもフェイルオーバーします。ルーティングプロトコルのグレースフルリスタートにより、SRXシリーズファイアウォールはフェイルオーバー中のトラフィックの中断を最小限に抑えることができます。
冗長性グループが短い間隔で連続してフェイルオーバーすると、クラスターで予期しない動作が発生する可能性があります。このような予期しない動作を防ぐには、フェールオーバー間のダンピング時間を構成します。フェイルオーバー時に、冗長性グループの前のプライマリノードはセカンダリホールド状態に移行し、ホールドダウン間隔が終了するまでセカンダリホールド状態のままになります。ホールドダウン間隔が経過すると、前のプライマリノードはセカンダリ状態に移行します。
ホールドダウン間隔を設定することで、ホールドダウン間隔内に連続してフェイルオーバーが発生するのを防ぎます。
ホールドダウン間隔は、手動フェールオーバーと、監視エラーに関連付けられた自動フェールオーバーに影響します。
冗長グループ0のデフォルトの減衰時間は300秒(5分)で、 hold-down-interval ステートメントで最大1800秒まで設定できます。ルートや論理インターフェイスの数が多い設定など、設定によっては、デフォルトの間隔やユーザーが設定した間隔では不十分な場合があります。このような場合、システムは、システムがフェールオーバーの準備が整うまで、減衰時間を 60 秒単位で自動的に延長します。
冗長グループ x (1〜128の番号が付けられた冗長グループ)のデフォルトの減衰時間は1秒で、0〜1800秒の範囲です。
SRXシリーズファイアウォールでは、シャーシ クラスタのフェイルオーバーのパフォーマンスを最適化して、より多くの論理インターフェイスで拡張できます。これまでは、冗長グループのフェイルオーバー時に、各 論理インターフェイス のルーティングエンジンで実行されているジュニパーサービス冗長プロトコル(jsrpd)プロセスによってGratuitous ARP(GARP)が送信され、トラフィックを適切なノードに誘導していました。論理インターフェイスのスケーリングにより、ルーティングエンジンがチェックポイントとなり、GARPがSPU(サービス処理ユニット)から直接送信されます。
プリエンプティブ フェイルオーバー遅延タイマー
冗長性グループは、常に一方のノードではプライマリ状態(アクティブ)になり、もう一方のノードではセカンダリ状態(バックアップ)になります。
冗長性グループ内の両方のノードで先制動作を有効にし、冗長性グループの各ノードに優先度値を割り当てることができます。冗長性グループ内で優先度を設定したノードは、最初はグループ内のプライマリとして指定され、もう一方のノードは、最初は冗長性グループのセカンダリとして指定されます。
冗長性グループがプライマリとセカンダリの間でノードの状態をスワップすると、最初の状態スワップの直後に、ノードの後続の状態スワップが再び発生する可能性があります。この状態の急激な変化により、プライマリシステムとセカンダリシステムのフラッピングが発生します。
Junos OS リリース 17.4R1 以降、シャーシ クラスタ内の SRXシリーズ ファイアウォールにフェイルオーバー遅延タイマーが導入され、プリエンプティブ フェイルオーバーにおいてセカンダリ ノードとプライマリ ノード間の冗長グループ状態のフラッピングを制限します。
フラッピングを防止するには、以下のパラメータを設定します。
-
プリエンプティブ遅延:プリエンプティブ遅延時間とは、プリエンプティブフェイルオーバーでプライマリステートがダウンした場合に、セカンダリステートの冗長性グループがプライマリステートに切り替えるまで待機する時間です。この遅延タイマーは、1 秒から 21,600 秒の間の設定された期間、即時フェールオーバーを遅らせます。
-
プリエンプティブ制限 - プリエンプティブ制限は、冗長性グループに対して
preemptionが有効になっている場合に、設定されたプリエンプティブ期間中のプリエンプティブフェイルオーバーの数(1〜50)を制限します。 -
プリエンプティブ期間 - プリエンプティブ制限が適用される時間帯(1〜1440秒)、つまり、冗長性グループに対してプリエンプションが有効になっている場合に、設定されたプリエンプティブフェイルオーバーの数。
プリエンプティブ期間を 300 秒、プリエンプティブ制限を 50 秒に設定した以下のシナリオを考えてみましょう。
プリエンプティブ制限が 50 に設定されている場合、カウントは 0 から始まり、最初のプリエンプティブ フェイルオーバーでインクリメントされます。このプロセスは、プリエンプティブ期間が終了する前に、カウントが設定されたプリエンプティブ制限である 50 に達するまで続きます。プリエンプティブ制限(50)を超えた場合、プリエンプティブ フェイルオーバーが再び発生するように、プリエンプティブ数を手動でリセットする必要があります。
プリエンプティブ期間を300秒に設定している場合、最初のプリエンプティブ・フェイルオーバーと現在のフェイルオーバーの時間差がすでに300秒を超えており、プリエンプティブ制限(50)にまだ達していない場合、プリエンプティブ期間はリセットされます。リセット後、最後のフェールオーバーは新しいプリエンプティブ期間の最初のプリエンプティブ フェールオーバーと見なされ、プロセスは最初からやり直されます。
プリエンプティブ遅延は、フェイルオーバー制限とは無関係に構成できます。プリエンプティブ遅延タイマーを設定しても、既存のプリエンプティブ動作は変更されません。
この機能拡張により、管理者はフェイルオーバーの遅延を導入できます。これによりフェイルオーバーの数が減り、冗長グループ内のアクティブ/スタンバイフラッピングが減少するため、ネットワーク状態がより安定します。
プリエンプティブ遅延による一次状態から二次状態への遷移の理解
次の例では、ノード0のプライマリである冗長グループが、フェイルオーバー中にセカンダリ状態にプリエンプティブに移行する準備ができています。各ノードに優先度が割り当てられ、ノードに対して preemptive オプションも有効になります。
図 1 は、プリエンプティブ遅延タイマーが設定されている場合に、プライマリ状態からセカンダリ状態に移行する一連の手順を示しています。
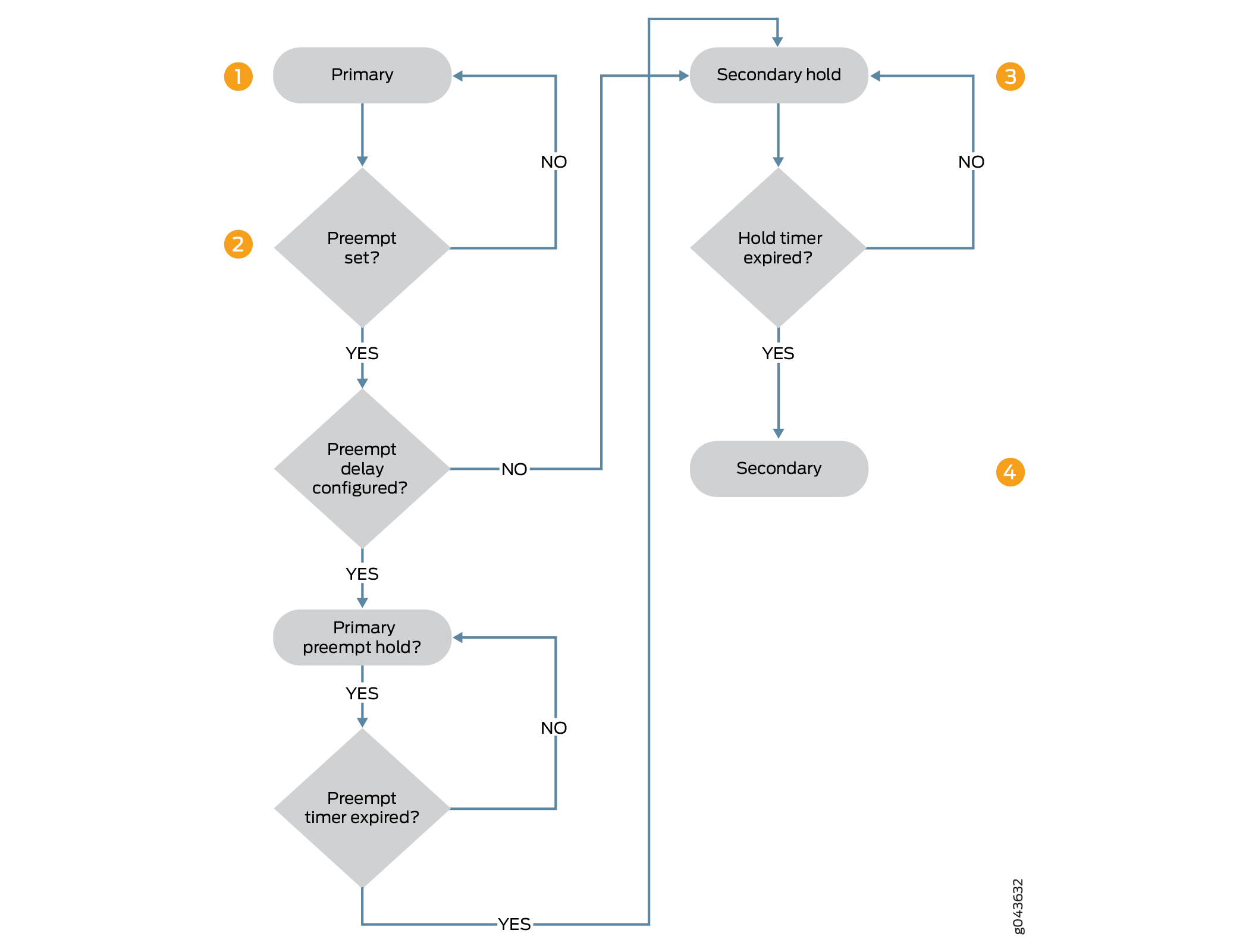 によるプライマリ状態からセカンダリ状態への遷移
によるプライマリ状態からセカンダリ状態への遷移
-
プライマリ状態のノードは、
preemptiveオプションが設定されている場合、セカンダリ状態へのプリエンプティブ移行の準備ができており、セカンダリ状態のノードがプライマリ状態のノードよりも優先されます。プリエンプティブ遅延が設定されている場合、プライマリ状態のノードは primary-preempt-hold ステートに移行します。プリエンプティブ遅延が設定されていない場合、セカンダリ状態への即時遷移が発生します。 -
ノードは primary-preempt-hold 状態であり、プリエンプティブ遅延タイマーが終了するのを待ちます。プリエンプティブ遅延タイマーがチェックされ、タイマーが切れるまで遷移が保持されます。プライマリノードは、セカンダリ状態に移行する前に、タイマーが切れるまで primary-preempt-hold 状態を維持します。
-
ノードは、primary-preempt-hold 状態から secondary-hold 状態に移行し、次にセカンダリ状態に移行します。
-
ノードは、デフォルトの時間(1 秒)または設定された時間(最低 300 秒)の間、セカンダリ保留状態に留まり、その後セカンダリ状態に移行します。
シャーシ クラスタの設定でフラップ回数が異常に発生する場合は、リンクタイマーとモニタリングタイマーが正しく設定されていることを確認する必要があります。遅延の大きいネットワークでタイマーを設定する際は、誤検知が発生しないように注意してください。
プリエンプティブ遅延タイマーの設定
このトピックでは、シャーシクラスター内のSRXシリーズファイアウォールで遅延タイマーを設定する方法について説明します。冗長グループの連続フェイルオーバーの発生が速すぎると、シャーシ クラスタで予測不能な動作が発生する可能性があります。遅延タイマーとフェイルオーバー レート制限を設定すると、設定された期間、即時フェールオーバーが遅延します。
冗長グループのフェイルオーバー間でプリエンプティブ遅延タイマーとフェイルオーバーレート制限を設定するには:
-
冗長性グループのプリエンプティブ フェイルオーバーを有効にします。
遅延タイマーは 1 秒から 21,600 秒の間で設定できます。デフォルト値は 1 秒です。
{primary:node1} [edit chassis cluster redundancy-group number preempt] user@host# set delay interval -
プリエンプティブ フェールオーバーの制限を設定します。
プリエンプティブ フェイルオーバーの最大数は 1 から 50 の間で、制限が適用される時間は 1 秒から 1440 秒の間で設定できます。
{primary:node1}[edit chassis cluster redundancy-group number preempt] user@host# set limit limit period period
次の例では、プリエンプティブ遅延タイマーを 300 秒に設定し、プリエンプティブ制限を 10 に設定して、600 秒のプリエンプティブ期間を設定しています。つまり、この構成では、即時フェールオーバーが 300 秒間遅延し、600 秒の期間に最大 10 個のプリエンプティブ フェイルオーバーが制限されます。
{primary:node1}[edit chassis cluster redundancy-group 1 preempt]
user@host# set delay 300 limit 10 period 600
clear chassis clusters preempt-count コマンドを使用すると、すべての冗長グループのプリエンプト フェイルオーバー カウンターをクリアできます。プリエンプション制限が設定されている場合、カウンターは最初のプリエンプティブ フェイルオーバーで開始され、カウントは減少します。このプロセスは、タイマーが期限切れになる前にカウントが 0 に達するまで続きます。このコマンドを使用して、プリエンプション フェイルオーバー カウンターをクリアし、リセットして再起動できます。
参照
シャーシ クラスタ冗長グループの手動フェイルオーバーについて
冗長グループ x (1〜128の番号が付けられた冗長グループ)フェイルオーバーを手動で開始できます。手動フェールオーバーは、フェールバック イベントが発生するまで適用されます。
たとえば、冗長グループ1でノード0からノード1へのフェイルオーバーを手動で実行するとします。その後、冗長グループ1が監視しているインターフェイスに障害が発生し、新しいプライマリ冗長グループのしきい値がゼロに低下します。このイベントはフェールバック イベントと見なされ、システムは元の冗長グループに制御を戻します。
また、冗長グループ 0 のプライマリ ノードを変更する場合は、冗長グループ 0 のフェイルオーバーを手動で開始することもできます。冗長グループ0のプリエンプションを有効にすることはできません。
冗長グループ設定にプリエンプションを追加すると、グループ内で優先度の高いデバイスがフェイルオーバーを開始してプライマリになることができます。デフォルトでは、プリエンプションは無効になっています。preemeptionの詳細については、「 preempt(シャーシクラスタ)」を参照してください。
冗長グループ 0 に対して手動フェイルオーバーを行うと、プライマリ状態のノードはセカンダリホールド状態に移行します。ノードは、デフォルトまたは設定された時間(最低 300 秒)の間、セカンダリ保留状態を維持し、その後セカンダリ状態に移行します。
1 つのノードが 2 次保留状態にあり、もう 1 つのノードが再起動した場合、またはそのノードに対する制御リンク接続またはファブリック リンク接続が失われた場合の状態遷移は、以下のとおりです。
再起動の場合:セカンダリ保留状態のノードはプライマリ状態に移行します。もう一方のノードは停止します(非アクティブ)。
制御リンク障害の場合:セカンダリ保留状態のノードは、不適格状態に移行し、その後無効状態に移行します。もう一方のノードはプライマリ状態に移行します。
ファブリックリンク障害ケース:セカンダリホールド状態のノードは、不適格な状態に直接遷移します。
Junos OS リリース 12.1X46-D20 および Junos OS リリース 17.3R1 以降、ファブリック監視はデフォルトで有効になっています。これを有効にすると、ファブリックリンクに障害が発生した場合、ノードは直接不適格な状態に移行します。
Junos OS リリース 12.1X47-D10 および Junos OS リリース 17.3R1 以降、ファブリック監視はデフォルトで有効になっています。これを有効にすると、ファブリックリンクに障害が発生した場合、ノードは直接不適格な状態に移行します。
インサービスソフトウェアアップグレード(ISSU)中は、ここで説明する移行は発生しないことに注意してください。代わりに、もう一方(プライマリ)ノードは、10.0より前のジュニパーネットワークスリリースではセカンダリ保留状態を解釈しないため、セカンダリ状態に直接遷移します。ISSU の起動中に、ノードの 1 つにセカンダリ保留状態の冗長グループが 1 つ以上ある場合は、手動フェールオーバーを実行して 1 つのノードですべての冗長性グループをプライマリにする前に、それらがセカンダリ状態に移行するのを待つ必要があります。
冗長グループ 0 の手動フェールオーバーの使用には慎重かつ慎重に行ってください。冗長グループ0のフェイルオーバーは、ルーティングエンジンのフェイルオーバーを意味し、この場合、プライマリノード上で実行されているすべてのプロセスが強制終了され、新しいプライマリルーティングエンジンで生成されます。このフェイルオーバーにより、ルーティング状態などの状態が失われたり、システムチャーンの発生によってパフォーマンスが低下したりする可能性があります。
一部のJunos OSリリースでは、冗長グループ xに対して、優先度が0のノードで手動フェイルオーバーを実行できます。手動フェイルオーバーを行う前に、 show chassis cluster status コマンドを使用して冗長グループノードの優先順位を確認することを推奨します。ただし、Junos OS リリース 12.1X44-D25、12.1X45-D20、12.1X46-D10、12.1X47-D10 以降では、手動フェイルオーバーの準備状況チェック メカニズムが強化され、より制限が厳しくなりました。これにより、優先度が 0 の冗長グループ内のノードに手動フェイルオーバーを設定できなくなります。この機能拡張により、トラフィックを受け入れる準備ができていない優先度 0 のノードへのフェイルオーバーの試行により、トラフィックが予期せずドロップされるのを防ぎます。
シャーシ クラスタの手動冗長グループ フェイルオーバーの開始
開始する前に、以下のタスクを完了してください。
requestコマンドを使用して、フェイルオーバーを手動で開始できます。手動フェイルオーバーにより、そのメンバーの冗長グループの優先度が255に上がります。
冗長グループ 0 の手動フェールオーバーの使用には慎重かつ慎重に行ってください。冗長グループ0のフェイルオーバーは、ルーティングエンジン(RE)のフェイルオーバーを意味します。この場合、プライマリノードで実行されているすべてのプロセスが強制終了され、新しいプライマリルーティングエンジン(RE)で生成されます。このフェイルオーバーにより、ルーティング状態などの状態が失われたり、システムチャーンの発生によってパフォーマンスが低下したりする可能性があります。
電源コードを抜き、電源ボタンを押したままにしてシャーシ クラスタ冗長グループのフェイルオーバーを開始すると、予期しない動作が発生する可能性があります。
冗長グループ x (1 から 128 までの番号が付けられた冗長グループ)の場合、優先度が 0 のノードで手動フェイルオーバーを実行できます。手動フェイルオーバーを行う前に、冗長グループノードの優先順位を確認することをお勧めします。
show コマンドを使用して、クラスタ内のノードのステータスを表示します。
{primary:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 1
node0 254 primary no no
node1 1 secondary no no
このコマンドの出力は、ノード 0 がプライマリであることを示しています。
requestコマンドを使用してフェイルオーバーをトリガーし、ノード1をプライマリにします。
{primary:node0}
user@host> request chassis cluster failover redundancy-group 0 node 1
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Initiated manual failover for redundancy group 0
show コマンドを使用して、クラスタ内のノードの新しいステータスを表示します。
{secondary-hold:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 2
node0 254 secondary-hold no yes
node1 255 primary no yes
このコマンドの出力は、ノード 1 がプライマリになり、ノード 0 がセカンダリ保留状態になっていることを示しています。5 分後、ノード 0 はセカンダリ状態に移行します。
requestコマンドを使用して、冗長グループのフェイルオーバーをリセットできます。この変更は、クラスタ全体に伝播されます。
{secondary-hold:node0}
user@host> request chassis cluster failover reset redundancy-group 0
node0:
--------------------------------------------------------------------------
No reset required for redundancy group 0.
node1:
--------------------------------------------------------------------------
Successfully reset manual failover for redundancy group 0
5 分の間隔が経過するまで、連続したフェールオーバーをトリガーすることはできません。
{secondary-hold:node0}
user@host> request chassis cluster failover redundancy-group 0 node 0
node0:
--------------------------------------------------------------------------
Manual failover is not permitted as redundancy-group 0 on node0 is in secondary-hold state.
show コマンドを使用して、クラスタ内のノードの新しいステータスを表示します。
{secondary-hold:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 2
node0 254 secondary-hold no no
node1 1 primary no no
このコマンドの出力は、どちらのノードでもバックツーバック フェイルオーバーが発生していないことを示しています。
手動フェイルオーバーを実行した後、別のフェイルオーバーを要求する前に reset failover コマンドを発行する必要があります。
プライマリノードに障害が発生して復旧すると、プライマリノードの選択が通常の基準(優先度とプリエンプト)に基づいて行われます。
例:バックツーバック冗長グループフェールオーバー間の減衰時間を設定するシャーシクラスタの設定
この例では、シャーシ クラスタのバックツーバック冗長グループ フェイルオーバー間のダンピング時間を設定する方法を示しています。冗長グループの連続フェイルオーバーの発生が速すぎると、シャーシ クラスタで予測不能な動作が発生する可能性があります。
必要条件
開始する前に、以下を実行します。
冗長グループのフェールオーバーについて理解する。 シャーシ クラスタ冗長グループのフェールオーバーについて を参照してください。
冗長グループの手動フェールオーバーについて理解します。 シャーシ クラスタ冗長グループの手動フェールオーバーについてを参照してください。
概要
ダンピング時間は、冗長性グループのバックツーバックのフェイルオーバーの間に許容される最小間隔です。この間隔は、インターフェイス監視の障害によって発生する手動フェイルオーバーと自動フェイルオーバーに影響します。
この例では、冗長グループ 0 のバックツーバック フェイルオーバーの最小許容間隔を 420 秒に設定します。
構成
プロシージャ
手順
バックツーバックの冗長グループのフェイルオーバー間の減衰時間を設定するには:
冗長グループの減衰時間を設定します。
{primary:node0}[edit] user@host# set chassis cluster redundancy-group 0 hold-down-interval 420デバイスの設定が完了したら、設定をコミットします。
{primary:node0}[edit] user@host# commit
シャーシ クラスタ冗長グループ フェイルオーバーの SNMP フェイルオーバー トラップについて
シャーシクラスタリングは、冗長グループのフェイルオーバーがあるたびにトリガーされるSNMPトラップをサポートしています。
トラップ メッセージは、フェールオーバーのトラブルシューティングに役立ちます。これには、次の情報が含まれています。
クラスタ ID とノード ID
フェールオーバーの理由
フェイルオーバーに関与する冗長性グループ
冗長性グループの以前の状態と現在の状態
これらは、クラスターが任意の時点でなり得るさまざまな状態です: 保留、プライマリ、セカンダリ保留、セカンダリ、不適格、および無効。トラップは、以下の状態遷移に対して生成されます(トラップはトリガーされないのは、保持状態からの遷移のみです)。
プライマリ<>セカンダリ
プライマリ –>セカンダリ保留
セカンダリホールド–>セカンダリ
セカンダリ –> 対象外
不適格 –>無効
不適格 –> プライマリ
セカンダリ–>無効
遷移は、インターフェイス監視、SPU監視、障害、手動フェイルオーバーなど、あらゆるイベントによってトリガーされる可能性があります。
トラップを生成するルーティングエンジン上のノードと異なるノードに発信インターフェイスがある場合、トラップは制御リンクを介して転送されます。
traceoptions flag snmp ステートメントを設定することで、トレース ログが生成されるように指定できます。
シャーシ クラスタ フェイルオーバー ステータスの検証
目的
シャーシ クラスタのフェイルオーバー ステータスを表示します。
アクション
CLIから、 show chassis cluster status コマンドを入力します。
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 3
Node name Priority Status Preempt Manual failover
Redundancy-group: 0, Failover count: 1
node0 254 primary no no
node1 2 secondary no no
Redundancy-group: 1, Failover count: 1
node0 254 primary no no
node1 1 secondary no no
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 15
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 5
node0 200 primary no no
node1 0 lost n/a n/a
Redundancy group: 1 , Failover count: 41
node0 101 primary no no
node1 0 lost n/a n/a
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 15
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 5
node0 200 primary no no
node1 0 unavailable n/a n/a
Redundancy group: 1 , Failover count: 41
node0 101 primary no no
node1 0 unavailable n/a n/a
シャーシ クラスタ フェールオーバー ステータスのクリア
シャーシ クラスタのフェールオーバー ステータスをクリアするには、CLIから clear chassis cluster failover-count コマンドを入力します。
{primary:node1}
user@host> clear chassis cluster failover-count
Cleared failover-count for all redundancy-groups
変更履歴
サポートされる機能は、使用しているプラットフォームとリリースによって決まります。特定の機能がお使いのプラットフォームでサポートされているかどうかを確認するには、 Feature Explorer を使用します。