Installer un cluster multinodal sur Ubuntu
Lisez les rubriques suivantes pour savoir comment installer Paragon Automation sur un cluster multinodal avec le système d’exploitation hôte Ubuntu. La figure 1 présente un résumé des tâches d’installation à un niveau élevé. Assurez-vous d'avoir effectué les étapes de préconfiguration et de préparation décrites dans Prérequis d'installation sur Ubuntu avant de commencer l'installation.
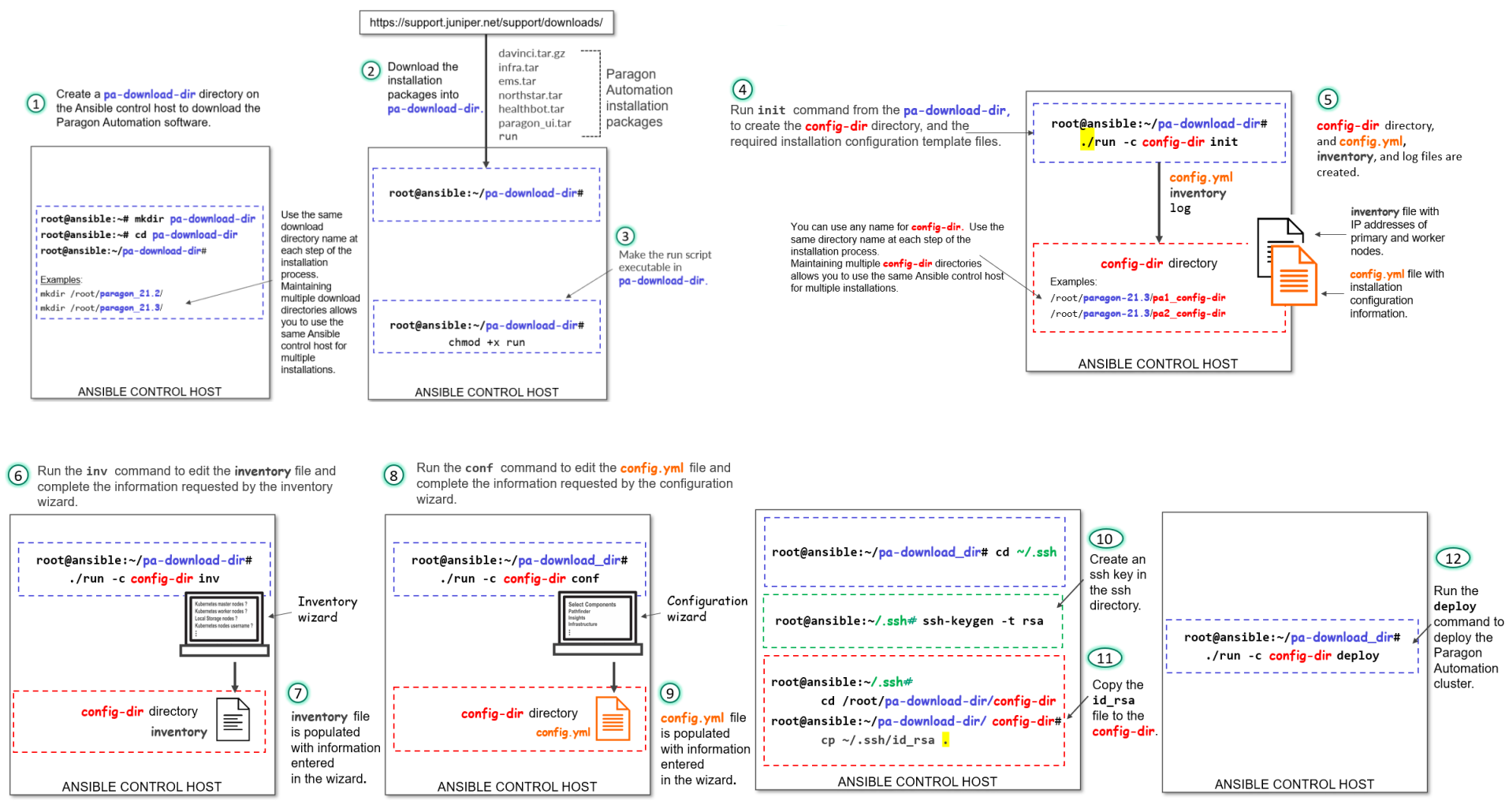
Pour afficher une image de plus haute résolution dans votre navigateur Web, cliquez avec le bouton droit de la souris sur l’image et ouvrez-la dans un nouvel onglet. Pour afficher l’image au format PDF, utilisez l’option de zoom pour effectuer un zoom avant.
Téléchargez le Logiciels Paragon Automation
Prérequis
-
Vous avez besoin d’un compte Juniper pour télécharger le logiciel Paragon Automation.
- Connectez-vous à l’hôte de contrôle.
- Créez un répertoire dans lequel vous téléchargerez le logiciel.
Nous nous référons à ce répertoire comme pa-download-dir dans ce guide.
- Sélectionnez le numéro de version dans la liste Version de la page de téléchargement du logiciel Paragon Automation à https://support.juniper.net/support/downloads/?p=pa.
- Téléchargez les fichiers d’installation de Paragon Automation Setup dans le dossier de téléchargement à l’aide de la
wget "http://cdn.juniper.net/software/file-download-url"commande.Le lot d’installation de Paragon Automation se compose des scripts et fichiers TAR suivants pour installer chacun des modules composants :
-
davinci.tar.gz, qui est le fichier d’installation principal.
-
infra.tar, qui installe les composants de l’infrastructure Kubernetes, notamment Docker et Helm.
-
ems.tar, qui installe le composant de base de la plateforme.
-
northstar.tar, qui installe le Paragon Pathfinder et Paragon Planner composants.
-
healthbot.tar, qui installe le composant Paragon Insights.
-
paragon_ui.tar, qui installe le composant Paragon Automation interface utilisateur.
-
addons.tar, qui installe des composants d’infrastructure qui ne font pas partie de l’installation de base de Kubernetes. Les composants de l’infrastructure comprennent IAM, Kafka, ZooKeeper, cert-manager, Ambassador, Postgres, Metrics, Kubernetes Dashboard, Open Distro for Elasticsearch, Fluentd, Reloader, ArangoDB et Argo.
-
helm-charts.tar, qui contient toutes les cartes de barre nécessaires à l’installation.
- rke2-packages.tgz, qui installe les composants Kubernetes basés sur RKE2.
- 3rdparty.tar.gz, qui installe les utilitaires tiers requis.
-
rhel-84-airgap.tar.gz, qui installe les Paragon Automation à l’aide de la méthode de l’entrefer uniquement sur les nœuds dont le système d’exploitation de base est Red Hat Enterprise Linux (RHEL). Vous pouvez choisir de supprimer ce fichier si vous n’installez pas Paragon Automation à l’aide de la méthode air-gap sur un système d’exploitation de base RHEL.
-
runqui exécute l’image du programme d’installation.
Maintenant que vous avez téléchargé le logiciel, vous êtes prêt à installer Paragon Automation.
-
Installer Paragon Automation sur un cluster à plusieurs nœuds
- Rendez le
runscript exécutable dans le pa-download-dir répertoire.# chmod +x run
- Utilisez le
runscript pour créer et initialiser un répertoire de configuration avec les fichiers de modèle de configuration.# ./run -c config-dir init
config-dir répertoire défini par l’utilisateur sur l’hôte de contrôle qui contient les informations de configuration d’une installation particulière. La
initcommande crée automatiquement le répertoire s’il n’existe pas. Vous pouvez également créer le répertoire avant d’exécuter lainitcommande.Assurez-vous d’inclure le point et la barre oblique (./) avec la
runcommande.Si vous utilisez le même hôte de contrôle pour gérer plusieurs installations de Paragon Automation, vous pouvez différencier les installations en utilisant des répertoires de configuration nommés différemment.
- Assurez-vous que l’hôte de contrôle peut se connecter aux nœuds de cluster via SSH à l’aide du compte install-user.
Copiez la clé privée que vous avez générée dans Configurer l’authentification du client SSH dans le répertoire config-dir défini par l’utilisateur. Le programme d’installation permet au conteneur Docker d’accéder au config-dir répertoire. La clé SSH doit être disponible dans le répertoire pour que l’hôte de contrôle puisse se connecter aux nœuds de cluster.
# cd config-dir # cp ~/.ssh/id_rsa . # cd ..
Assurez-vous d’inclure le point (.) à la fin de la commande de copie (
cp). - Personnalisez le fichier d’inventaire, créé sous le config-dir répertoire, avec les adresses IP ou les noms d’hôte des nœuds de cluster, ainsi que les noms d’utilisateur et les informations d’authentification nécessaires pour se connecter aux nœuds. Le fichier d’inventaire est au format YAML et décrit les nœuds de cluster sur lesquels Paragon Automation sera installé. Vous pouvez modifier le fichier à l’aide de la
invcommande ou d’un éditeur de texte Linux tel que vi.-
Personnalisez le fichier d’inventaire à l’aide de la
invcommande :# ./run -c config-dir inv
Le tableau suivant répertorie les options de configuration que la
invcommande vous invite à saisir.Tableau 1 : inv Options de commande Description des invites de commande inv Nœuds principaux Kubernetes Saisissez les adresses IP des nœuds principaux de Kubernetes. Nœuds de travail Kubernetes Entrez les adresses IP des nœuds de travail Kubernetes. Nœuds de stockage locaux Définissez les nœuds disposant d’espace disque disponible pour les applications. Les nœuds de stockage locaux sont préremplis avec les adresses IP des nœuds principal et de travail. Vous pouvez modifier ces adresses. Entrez les adresses IP des nœuds sur lesquels vous souhaitez exécuter des applications nécessitant un stockage local.
Des services tels que Postgres, ZooKeeper et Kafka utilisent un stockage local ou de l’espace disque partitionné dans des volumes d’exportation/locaux. Par défaut, les nœuds de travail disposent d’un stockage local. Si vous n’ajoutez pas de nœuds principaux ici, vous pouvez exécuter uniquement les applications qui ne nécessitent pas de stockage local sur les nœuds principaux.
Remarque :Le stockage local est différent du stockage Ceph.
Nom d'utilisateur des nœuds Kubernetes (par exemple, root) Configurez le compte d’utilisateur et les méthodes d’authentification pour authentifier le programme d’installation auprès des nœuds de cluster. Le compte d’utilisateur doit être root ou, dans le cas d’utilisateurs non root, le compte doit disposer de privilèges de superutilisateur (sudo). Fichier de clé privée SSH (facultatif) Si vous avez choisi
ssh-keyl’authentification, pour que l’hôte de contrôle s’authentifie auprès des nœuds pendant le processus d’installation, configurez le répertoire ( config-dir ) où se trouve le ansible_ssh_private_key_file et le fichier id_rsa comme «{{ config-dir }}/id_rsa».Mot de passe des nœuds Kubernetes (facultatif) Si vous avez choisi l’authentification par mot de passe pour que l’hôte de contrôle s’authentifie auprès des nœuds pendant le processus d’installation, entrez directement le mot de passe d’authentification. AVERTISSEMENT : le mot de passe est écrit en texte clair.
Nous vous déconseillons d’utiliser cette option pour l’authentification.
Nom du cluster Kubernetes (facultatif) Saisissez un nom pour votre cluster Kubernetes. Écrire un fichier d’inventaire ? Cliquez sur ce bouton
Yespour enregistrer les informations d’inventaire.Par exemple :
$ ./run -c config-dir inv Loaded image: paragonautomation:latest ==================== PO-Runtime installer ==================== Supported command: deploy [-t tags] deploy runtime destroy [-t tags] destroy runtime init init configuration skeleton inv basic inventory editor conf basic configuration editor info [-mc] cluster installation info Starting now: inv INVENTORY This script will prompt for the DNS names or IP addresses of the Kubernetes master and worker nodes. Addresses should be provided as comma-delimited lists. At least three master nodes are recommended. The number of masters should be an odd number. A minimum of four nodes are recommended. Root access to the Kubernetes nodes is required. See https://docs.ansible.com/ansible/2.10/user_guide/intro_inventory.html ? Kubernetes master nodes 10.12.xx.x3,10.12.xx.x4,10.12.xx.x5 ? Kubernetes worker nodes 10.12.xx.x6 ? Local storage nodes 10.12.xx.x3,10.12.xx.x4,10.12.xx.x5,10.12.xx.x6 ? Kubernetes nodes' username (e.g. root) root ? SSH private key file (optional; e.g. "{{ inventory_dir }}/id_rsa") config/id_rsa ? Kubernetes nodes' password (optional; WARNING - written as plain text) ? Kubernetes cluster name (optional) k8scluster ? Write inventory file? Yes -
Vous pouvez également personnaliser le fichier d’inventaire manuellement à l’aide d’un éditeur de texte.
# vi config-dir/inventory
Modifiez les groupes suivants dans le fichier d’inventaire .
-
Ajoutez les adresses IP des nœuds principal et de travail Kubernetes du cluster.
Le
mastergroupe identifie les nœuds principaux et lenodegroupe identifie les nœuds de travail. Vous ne pouvez pas avoir la même adresse IP dans les deuxmastergroupes andnode.Pour créer une configuration de nœud multi-principal, répertoriez les adresses ou les noms d’hôte de tous les nœuds qui agiront en tant que nœuds principaux dans le
mastergroupe. Ajoutez les adresses ou les noms d’hôte des nœuds qui agiront en tant que travailleurs dans lenodegroupe.master: hosts: 10.12.xx.x3: {} 10.12.xx.x4: {} 10.12.xx.x5: {} node: hosts: 10.12.xx.x6: {} -
Définissez les nœuds qui disposent d’espace disque disponible pour les applications du
local_storage_nodes:childrengroupe.local_storage_nodes: children: master: hosts: 10.12.xx.x3: {} 10.12.xx.x4: {} 10.12.xx.x5: {} node: hosts: 10.12.xx.x6: {} -
Configurez le compte d’utilisateur et les méthodes d’authentification pour authentifier le programme d’installation sur l’hôte de contrôle Ansible avec les nœuds de cluster sous le
varsgroupe.vars: ansible_user: root ansible_ssh_private_key_file: config/id_rsa ansible_password: -
(Facultatif) Spécifiez un nom pour votre cluster Kubernetes dans le
kubernetes_cluster_namegroupe.kubernetes_cluster_name: k8scluster
-
-
- Configurez le programme d’installation à l’aide de la
confcommande.# ./run -c config-dir conf
La
confcommande exécute un assistant d’installation interactif qui vous permet de choisir les composants à installer et de configurer une configuration de base de Paragon Automation. La commande remplit le fichier config.yml avec votre configuration d’entrée. Pour une configuration avancée, vous devez modifier le fichier config.yml manuellement.Entrez les informations demandées par l’assistant. Utilisez les touches du curseur pour déplacer le curseur, utilisez la touche espace pour sélectionner une option et utilisez la
atouche ouipour basculer la sélection ou la suppression de toutes les options. Appuyez sur Entrée pour passer à l’option de configuration suivante. Vous pouvez ignorer les options de configuration en saisissant un point (.). Vous pouvez saisir à nouveau tous vos choix en quittant l’assistant et en recommençant depuis le début. Le programme d’installation vous permet de quitter l’assistant après avoir enregistré les choix que vous avez déjà effectués ou de recommencer depuis le début. Vous ne pouvez pas revenir en arrière et rétablir les choix que vous avez déjà effectués dans le workflow actuel sans quitter et redémarrer complètement l’assistant.Le tableau suivant répertorie les options de configuration que la
confcommande vous invite à saisir :Tableau 2 : conf Options de commande confInvites de commandesDescription/Options
Sélectionner les composants
Vous pouvez installer les composants Infrastructure, Pathfinder, Insights et la plate-forme de base. Par défaut, tous les composants sont sélectionnés.
Vous pouvez choisir d’installer Pathfinder en fonction de vos besoins. Cependant, vous devez installer tous les autres composants.
Options d’infrastructure
Ces options apparaissent uniquement si vous avez choisi d’installer le composant Infrastructure à l’invite précédente.
-
Installer le cluster Kubernetes : installez le cluster Kubernetes requis. Si vous installez Paragon Automation sur un cluster existant, vous pouvez effacer cette sélection.
-
Installer MetalLB LoadBalancer : installez un équilibreur de charge interne pour le cluster Kubernetes. Par défaut, cette option est déjà sélectionnée. Si vous installez Paragon Automation sur un cluster existant avec un équilibrage de charge préconfiguré, vous pouvez effacer cette sélection.
-
Installer le contrôleur d’entrée Nginx : l’installation du contrôleur d’entrée Nginx est un proxy d’équilibrage de charge pour les composants Pathfinder.
-
Installer Chrony NTP Client : installez Chrony NTP. Vous avez besoin de NTP pour synchroniser les horloges des nœuds de cluster. Si NTP est déjà installé et configuré, vous n’avez pas besoin d’installer Chrony. Tous les nœuds doivent exécuter NTP ou un autre protocole de synchronisation temporelle à tout moment.
-
Autoriser la planification principale : la planification principale détermine la façon dont les nœuds agissant en tant que nœuds principaux sont utilisés. Master est un autre terme pour désigner un nœud agissant en tant que nœud principal.
Si vous sélectionnez cette option, les nœuds principaux peuvent également agir en tant que nœuds de travail, ce qui signifie qu’ils agissent non seulement comme plan de contrôle, mais peuvent également exécuter des charges de travail d’application. Si vous ne sélectionnez pas la planification principale, les nœuds principaux sont utilisés uniquement comme plan de contrôle.
La planification principale permet aux ressources disponibles des nœuds agissant en tant que principaux d’être disponibles pour les charges de travail. Toutefois, si vous sélectionnez cette option, une charge de travail qui se comporte mal peut épuiser les ressources sur le nœud principal et affecter la stabilité de l’ensemble du cluster. Sans planification générale, si vous avez plusieurs nœuds principaux avec une capacité et un espace disque élevés, vous risquez de gaspiller leurs ressources en ne les utilisant pas complètement.
Remarque :Cette option est requise pour la redondance du stockage Ceph.
Liste des serveurs NTP
Entrez une liste de serveurs NTP séparés par des virgules. Cette option s’affiche uniquement si vous choisissez d’installer Chrony NTP.
Adresse(s) IP virtuelle(s) pour le contrôleur d’entrée
Saisissez une adresse VIP à utiliser pour l’accès Web du cluster Kubernetes ou de l’interface utilisateur de Paragon Automation. Il doit s’agir d’une adresse IP inutilisée gérée par le pool d’équilibrage de charge MetalLB.
Adresse IP virtuelle pour le contrôleur d’entrée Infrastructure Nginx Entrez une adresse VIP pour le contrôleur d’entrée Nginx. Il doit s’agir d’une adresse IP inutilisée gérée par le pool d’équilibrage de charge MetalLB. Cette adresse est utilisée pour le trafic NetFlow.
Adresse IP virtuelle pour les services Insights
Saisissez une adresse VIP pour les services de Paragon Insights. Il doit s’agir d’une adresse IP inutilisée gérée par le pool d’équilibrage de charge MetalLB.
Adresse IP virtuelle du récepteur d’interruption SNMP (facultatif) Entrez une adresse d’adresse IP virtuelle pour le proxy du récepteur d’interruption SNMP uniquement si cette fonctionnalité est requise. Si vous n’avez pas besoin de cette option, saisissez un point (.).
Pathfinder Options Sélectionnez pour installer Netflowd. Vous pouvez configurer une adresse VIP pour netflowd ou utiliser un proxy pour netflowd (identique à l’adresse IP virtuelle du contrôleur d’entrée Infrastructure Nginx). Si vous choisissez de ne pas installer netflowd, vous ne pouvez pas configurer d’adresse IP virtuelle pour netflowd.
Utiliser le proxy netflowd Entrez Ypour utiliser un proxy netflowd. Cette option n’apparaît que si vous avez choisi d’installer netflowd.Si vous avez choisi d'utiliser un proxy netflowd, vous n'avez pas besoin de configurer une adresse VIP pour netflowd. L’adresse VIP du contrôleur d’entrée Infrastructure Nginx est utilisée comme proxy pour netflowd.
Adresse IP virtuelle pour Pathfinder Netflowd Saisissez une adresse VIP à utiliser pour le réseau de Paragon Pathfinder. Cette option n’apparaît que si vous avez choisi de ne pas utiliser le proxy netflowd. Proxy de serveur PCE Sélectionnez le mode proxy pour le serveur PCE. Sélectionnez parmi NoneetNginx-Ingress.Adresse IP virtuelle du serveur PCE Pathfinder Entrez une adresse VIP à utiliser pour l’accès au serveur PCE de Paragon Pathfinder. Cette adresse doit être une adresse IP inutilisée gérée par l’équilibreur de charge.
Si vous avez sélectionné Nginx-Ingress, comme proxy de serveur PCE, cette adresse VIP n’est pas nécessaire. L’assistant ne vous invite pas à saisir cette adresse et PCEP utilisera la même adresse que l’adresse VIP pour le contrôleur d’entrée Infrastructure Nginx.
Remarque :Les adresses du contrôleur d’entrée, du contrôleur d’entrée Nginx d’infrastructure, des services d’analyse et du serveur PCE doivent être uniques. Vous ne pouvez pas utiliser la même adresse pour les quatre adresses VIP.
Toutes ces adresses sont répertoriées automatiquement dans l’option Plages d’adresses IP de LoadBalancer.
Plages d’adresses IP LoadBalancer
Les adresses IP de LoadBalancer sont préremplies à partir de votre plage d’adresses VIP. Vous pouvez modifier ces adresses. Les services accessibles de l’extérieur sont gérés par MetalLB, qui nécessite une ou plusieurs plages d’adresses IP accessibles depuis l’extérieur du cluster. Les adresses VIP des différents serveurs sont sélectionnées parmi ces plages d’adresses.
Les plages d’adresses peuvent (mais pas nécessairement être) dans le même domaine de diffusion que les nœuds de cluster. Pour faciliter la gestion, étant donné que les topologies réseau ont besoin d’accéder aux services Insights et aux clients serveur PCE, nous vous recommandons de sélectionner les adresses VIP dans la même plage.
Pour plus d’informations, consultez Considérations relatives aux adresses IP virtuelles.
Les adresses peuvent être saisies sous forme de valeurs séparées par des virgules (CSV), sous forme de plage ou sous la forme d’une combinaison des deux. Par exemple :
-
10.x.x.1, 10.x.x.2, 10.x.x.3
-
10.x.x.1 à 10.x.x.3
-
10.x.x.1, 10.x.x.3-10.x.x.5
-
10.x.x.1-3 n’est pas un format valide.
Nœud multimaître détecté Voulez-vous configurer plusieurs registres Entrée
Ypour configurer un registre de configuration sur chaque nœud principal.Cette option ne s'affiche que si vous avez configuré plusieurs nœuds principaux dans le fichier d'inventaire (installation principale multiple).
Adresse IP virtuelle pour le registre
Entrez une adresse d’adresse IP virtuelle pour le registre de conteneurs pour un déploiement à plusieurs nœuds principaux uniquement. Assurez-vous que l’adresse VIP se trouve dans le même domaine de couche 2 que les nœuds principaux. Cette adresse VIP ne fait pas partie du pool d’adresses VIP de LoadBalancer.
Cette option ne s’affiche que si vous avez choisi de configurer plusieurs registres de conteneurs.
Activer md5 pour le serveur PCE
Entrez Ypour configurer l’authentification MD5 entre le routeur et Pathfinder.Remarque :Si vous activez MD5 sur les sessions PCEP, vous devez également configurer la clé d’authentification dans l’interface utilisateur de Paragon Automation, ainsi que la même clé d’authentification et l’adresse VIP sur le routeur. Pour plus d’informations sur la configuration de la clé d’authentification et de l’adresse VIP, consultez Adresses IP virtuelles pour l’authentification MD5.
IP pour serveur PCEP (doit être en dehors de la plage metallb et doit être dans le même sous-réseau que l’hôte avec son préfixe de sous-réseau en notation CIDR)
Entrez une adresse VIP pour le serveur PCE. L’adresse IP doit être au format CIDR.
Assurez-vous que l’adresse VIP se trouve dans le même domaine de couche 2 que les nœuds principaux. Cette adresse VIP ne fait pas partie du pool d’adresses VIP de LoadBalancer.
Activer md5 pour BGP
Entrez Ypour configurer l’authentification MD5 entre cRPD et le routeur BGP-LS.IP pour CRPD (doit être en dehors de la plage metallb et doit être dans le même sous-réseau que l’hôte avec son préfixe de sous-réseau en notation CIDR)
Entrez une adresse VIP pour le protocole de surveillance BGP (BMP). L’adresse IP doit être au format CIDR.
Assurez-vous que l’adresse VIP se trouve dans le même domaine de couche 2 que les nœuds principaux. Cette adresse VIP ne fait pas partie du pool d’adresses VIP de LoadBalancer.
Remarque :Si vous activez MD5 sur les sessions cRPD, vous devez également configurer le routeur pour activer MD5 pour cRPD et configurer l’adresse VIP sur le routeur. Pour plus d’informations sur la détermination de la clé d’authentification MD5 et la configuration du routeur, consultez Adresses VIP pour l’authentification MD5.
Interface multifournisseur
Entrez le type d’interface Multus.
Multus Routes de destination ? peut être supérieur à 1 pair avec son préfixe de sous-réseau en notation CIDR
Entrez les routes Multus au format CIDR.
Adresse IP de la passerelle Multus
Entrez l’adresse IP de la passerelle Multus.
Nom d’hôte de l’application Web principale
Entrez un nom d’hôte pour le contrôleur entrant. Vous pouvez configurer cette valeur en tant qu’adresse IP ou en tant que nom de domaine complet (FQDN). Par exemple, vous pouvez entrer 10.12.xx.100 ou www.paragon.juniper.net (nom DNS). N’incluez pas http:// ou https://.
Remarque :Vous utiliserez ce nom d’hôte pour accéder à l’interface utilisateur Web de Paragon Automation à partir de votre navigateur. Par exemple, https://hostname ou https://IP-address.
Numéro de système autonome BGP de l’homologue CRPD
Configurez le démon de protocole de routage conteneurisé (cRPD), les systèmes autonomes et les nœuds avec lesquels cRPD crée ses sessions BGP.
Vous devez configurer le numéro du système autonome (AS) du réseau pour permettre au cRPD de s’appairer avec un ou plusieurs routeurs BGP Link State (BGP-LS) du réseau. Par défaut, le numéro AS est 64500.
Remarque :Bien que vous puissiez configurer le numéro d’AS au moment de l’installation, vous pouvez également modifier la configuration du cRPD ultérieurement. Voir Modifier la configuration de cRPD .
Liste des pairs de la CDPH séparés par des virgules
Configurez cRPD pour qu’il s’appaire avec au moins un routeur BGP-LS dans le réseau afin d’importer la topologie du réseau. Pour un système autonome unique, configurez l’adresse des routeurs BGP-LS qui s’appaireront avec cRPD pour fournir des informations topologiques à Paragon Pathfinder. L’instance cRPD exécutée dans le cadre d’un cluster initie une connexion BGP-LS aux routeurs homologues spécifiés et importe les données de topologie une fois la session établie. Si plusieurs homologues sont nécessaires, vous pouvez ajouter les homologues en tant que CSV, en tant que plage ou en tant que combinaison des deux, de la même manière que vous ajoutez des adresses IP LoadBalancer.
Remarque :Bien que vous puissiez configurer les adresses IP homologues au moment de l’installation, vous pouvez également modifier la configuration de cRPD ultérieurement, comme décrit dans Modifier la configuration de cRPD.
Vous devez configurer les routeurs pair BGP pour accepter les connexions BGP initiées à partir de cRPD. La session BGP sera lancée à partir de cRPD en utilisant l’adresse du worker sur lequel le pod bmp s’exécute comme adresse source.
Étant donné que cRPD peut s’exécuter sur n’importe quel nœud de travail à un moment donné, vous devez autoriser les connexions à partir de l’une de ces adresses. Vous pouvez autoriser la plage d’adresses IP à laquelle appartiennent les adresses du collaborateur (par exemple, 10.xx.43.0/24) ou l’adresse IP spécifique de chaque collaborateur (par exemple, 10.xx.43.1/32, 10.xx.43.2/32 et 10.xx.43.3). Vous pouvez également configurer cela à l’aide de la
neighborcommande avec l’optionpassivepermettant d’empêcher le routeur de tenter d’initier la connexion.Si vous avez choisi d’entrer l’adresse de chaque collaborateur individuel, que ce soit avec la
allowcommande ou laneighborcommande, assurez-vous d’inclure tous les employés, car n’importe quel collaborateur peut exécuter cRPD à un moment donné. Une seule session BGP sera initiée. Si le nœud exécutant cRPD échoue, l’espace bmp qui contient le conteneur cRPD sera créé dans un autre nœud et la session BGP sera redémarrée.La séquence de commandes de l’exemple suivant montre les options permettant de configurer un appareil Juniper pour autoriser les connexions BGP-LS à partir de cRPD.
Les commandes suivantes configurent le routeur pour qu’il accepte les sessions BGP-LS à partir de n’importe quel hôte du réseau 10.xx.43.0/24, où tous les nœuds de travail sont connectés.
[edit groups northstar] root@system# show protocols bgp group northstar type internal; family traffic-engineering { unicast; } export TE; allow 10.xx.43.0/24; [edit groups northstar] root@system# show policy-options policy-statement TE from family traffic-engineering; then accept;Les commandes suivantes configurent le routeur pour qu’il accepte uniquement les sessions BGP-LS de 10.xx.43.1, 10.xx.43.2 et 10.xx.43.3 (les adresses des trois workers du cluster).
[edit protocols bgp group BGP-LS] root@vmx101# show | display set set protocols bgp group BGP-LS family traffic-engineering unicast set protocols bgp group BGP-LS peer-as 11 set protocols bgp group BGP-LS allow 10.x.43.1 set protocols bgp group BGP-LS allow 10.x.43.2 set protocols bgp group BGP-LS allow 10.x.43.3 set protocols bgp group BGP-LS export TE
cRPD initie la session BGP. Une seule session est établie à la fois et est lancée à l’aide de l’adresse du nœud actif en cours d’exécution de cRPD. Si vous choisissez de configurer les adresses IP spécifiques au lieu d’utiliser l’option
allow, configurez les adresses de tous les nœuds de travail pour la redondance.Les commandes suivantes configurent également le routeur pour accepter les sessions BGP-LS de 10.xx.43.1, 10.xx.43.2 et 10.xx.43.3 uniquement (les adresses des trois workers du cluster). Cette
passiveoption empêche le routeur de tenter d’initier une session BGP-LS avec cRPD. Le routeur attendra que la session soit lancée par l’un de ces trois routeurs.[edit protocols bgp group BGP-LS] root@vmx101# show | display set set protocols bgp group BGP-LS family traffic-engineering unicast set protocols bgp group BGP-LS peer-as 11 set protocols bgp group BGP-LS neighbor 10.xx.43.1 set protocols bgp group BGP-LS neighbor 10.xx.43.2 set protocols bgp group BGP-LS neighbor 10.xx.43.3 set protocols bgp group BGP-LS passive set protocols bgp group BGP-LS export TE
Vous devrez également activer OSPF/IS-IS et aspects techniques du trafic MPLS comme indiqué ici :
set protocols rsvp interface interface.unit set protocols isis interface interface.unit set protocols isis traffic-engineering igp-topology Or set protocols ospf area area interface interface.unit set protocols ospf traffic-engineering igp-topology set protocols mpls interface interface.unit set protocols mpls traffic-engineering database import igp-topologyPour plus d’informations, reportez-vous à https://www.juniper.net/documentation/us/en/software/junos/mpls/topics/topic-map/mpls-traffic-engineering-configuration.html.
Terminer et écrire la configuration dans un fichier Cliquez sur ce bouton Yespour enregistrer les informations de configuration.Cette action configure une configuration de base et enregistre les informations du fichier config.yml dans le config-dir répertoire.
Cliquez sur ce bouton
Nopour redémarrer l’assistant sans quitter la session en cours. Les paramètres de configuration et les sélections précédemment saisis apparaissent préconfigurés dans l’assistant. Vous pouvez choisir de les conserver ou de saisir à nouveau de nouvelles valeurs.Cliquez pour
Cancelquitter l’assistant sans enregistrer la configuration.$ ./run -c config conf Loaded image: paragonautomation.latest ==================== PO-Runtime installer ==================== Supported command: deploy [-t tags] deploy runtime destroy [-t tags] destroy runtime init init configuration skeleton inv basic inventory editor conf basic configuration editor info [-mc] cluster installation info Starting now: conf NOTE: depending on options chosen additional IP addresses may be required for: multi-master Kubernetes Master Virtual IP address Infrastructure Virtual IP address(es) for ingress controller Infrastructure Virtual IP address for Infrastructure Nginx Ingress Cont roller Insights Virtual IP address for Insights services Insights Virtual IP address for SNMP Trap receiver (optional) Pathfinder Virtual IP address for Pathfinder Netflowd Pathfinder Virtual IP address for Pathfinder PCE server multi-registry Paragon External Registry Virtual IP address ? Select components done (4 selections) ? Infrastructure Options done (4 selections) ? List of NTP servers 0.pool.ntp.org ? Virtual IP address(es) for ingress controller 10.12.xx.x7 ? Virtual IP address for Insights services 10.12.xx.x8 ? Virtual IP address for SNMP Trap receiver (optional) ? Pathfinder Options [Install Netflowd] ? Use netflowd proxy? Yes ? PCEServer proxy Nginx Ingress ? LoadBalancer IP address ranges 10.12.xx.x7-10.12.xx.x9 ? Multi-master node detected do you want to setup multiple registries Yes ? Virtual IP address for registry 10.12.xx.10 ? Enable md5 for PCE Server ? Yes ? IP for PCEP server (must be outside metallb range and must be in the same subnet as the host with its subnet prefix in CIDR notation) 10.12.xx.219/24 ? Enable md5 for BGP ? Yes ? IP for CRPD (must be outside metallb range and must be in the same subnet as the host with its subnet prefix in CIDR notation) 10.12.xx.220/24 ? Multus Interface ? eth1 ? Multus Destination routes ? can be more than 1 peer with its subnet prefix in CIDR notation 10.12.xx.41/24,10.13.xx.21/24 ? Multus Gateway IP Address ? 10.12.xx.101 ? Hostname of Main web application host.example.net ? BGP autonomous system number of CRPD peer 64500 ? Comma separated list of CRPD peers 10.12.xx.11 ? Finish and write configuration to file Yes -
- (Facultatif) Pour une configuration plus avancée du cluster, utilisez un éditeur de texte pour modifier manuellement le fichier config.yml.
Le fichier config.yml se compose d’une section essentielle au début du fichier qui correspond aux options de configuration que l’assistant d’installation vous invite à saisir. Le fichier contient également une longue liste de sections sous la section essentielle qui vous permet d’entrer des valeurs de configuration complexes directement dans le fichier.
Vous pouvez configurer les options suivantes :
-
(Facultatif) Définissez le
grafana_admin_passwordmot de passe pour vous connecter à l’application Grafana. Grafana est un outil de visualisation couramment utilisé pour visualiser et analyser des données provenant de diverses sources, y compris les journaux.Par défaut, le nom d’utilisateur est préconfiguré en tant qu’administrateur dans
# grafana_admin_user: admin. Utilisez admin comme nom d’utilisateur et le mot de passe que vous configurez pour vous connecter à Grafana.grafana_admin_user: admin grafana_admin_password: grafana_passwordSi vous ne configurez pas le mot de
grafana_admin_passwordpasse, le programme d’installation génère un mot de passe aléatoire. Vous pouvez récupérer le mot de passe à l’aide de la commande :# kubectl get secret -n kube-system grafana -o jsonpath={..grafana-password} | base64 -d -
Définissez l’option de configuration sur true pour la
iam_skip_mail_verificationgestion des utilisateurs sans SMTP par Identity and Access Management (IAM). Par défaut, cette option est définie sur false pour la gestion des utilisateurs avec SMTP. Vous devez configurer SMTP dans Paragon Automation afin de pouvoir avertir les utilisateurs de Paragon Automation lorsque leur compte est créé, activé ou verrouillé, ou lorsque le mot de passe de leur compte est modifié. -
Configurez l’option
callback_vipavec une adresse IP différente de celle de l’adresse IP virtuelle (VIP) du contrôleur entrant. Vous pouvez utiliser une adresse IP du pool d’adresses VIP MetalLB. Vous configurez cette adresse IP pour permettre la séparation du trafic de gestion et de données des interfaces ascendantes et nord. Par défaut,callback_vipest affectée la même adresse ou l’une des adresses du contrôleur entrant.
Enregistrez et quittez le fichier une fois que vous avez terminé de le modifier.
-
- (Facultatif) Si vous souhaitez déployer des certificats SSL personnalisés signés par une autorité de certification (AC) reconnue, stockez la clé privée et le certificat dans le config-dir répertoire. Enregistrez la clé privée sous le nom ambassador.key.pem et le certificat sous le nom ambassador.cert.pem.
Par défaut, Ambassador utilise un certificat généré localement et signé par l’AC interne au cluster Kubernetes.
Remarque :Si le certificat est sur le point d’expirer, enregistrez-le sous le nom ambassador.cert.pem dans le même répertoire et exécutez la
./run -c config-dir deploy -t ambassadorcommande. - Installez le cluster Paragon Automation en fonction des informations que vous avez configurées dans les fichiers de config.yml et d’inventaire.
# ./run -c config-dir deploy
Le temps d’installation pour installer le cluster configuré dépend de la complexité du cluster. Une installation d’installation de base prend au moins 45 minutes.
Le programme d’installation vérifie la synchronisation NTP au début de l’installation. Si les horloges ne sont pas synchronisées, l’installation échoue.
Pour les déploiements à plusieurs nœuds principaux uniquement, le programme d’installation vérifie à la fois le processeur et la mémoire de chaque serveur, ainsi que le nombre total de processeurs et de mémoire disponibles par cluster. Si les conditions suivantes ne sont pas remplies, l’installation échoue.
-
CPU minimum par cluster : 20 CPU
-
Mémoire minimale par cluster : 32 Go
-
CPU minimum par nœud : 4 CPU
-
Mémoire minimale par nœud : 6 Go
Pour désactiver la vérification du processeur et de la mémoire, utilisez la commande suivante et réexécutez le déploiement.
# ./run -c config-dir deploy -e ignore_iops_check=yesSi vous installez Paragon Automation sur un cluster Kubernetes existant, ladeploycommande met à niveau le cluster actuellement déployé vers la dernière version de Kubernetes. La commande met également à niveau la version Docker CE, si nécessaire. Si Docker EE est déjà installé sur les nœuds, ladeploycommande ne l’écrase pas avec Docker CE. Lors de la mise à niveau de la version de Kubernetes ou de Docker, la commande effectue la mise à niveau séquentiellement sur un nœud à la fois. La commande enferme chaque nœud et le retire de la planification. Il effectue des mises à niveau, redémarre Kubernetes sur le nœud, et enfin déconnecte le nœud et le ramène dans la planification. -
- Une fois le déploiement terminé, connectez-vous aux nœuds de travail.
Utilisez un éditeur de texte pour configurer les informations recommandées suivantes pour Paragon Insights dans les fichiers limits.conf et sysctl.conf . Ces valeurs définissent les limites de mémoire souple et dure pour les exigences de mémoire DB entrantes. Si vous ne définissez pas ces limites, vous pouvez voir des erreurs telles que « mémoire insuffisante » ou « trop de fichiers ouverts » en raison des limites système par défaut.
-
# vi /etc/security/limits.conf # End of file * hard nofile 1048576 * soft nofile 1048576 root hard nofile 1048576 root soft nofile 1048576 influxdb hard nofile 1048576 influxdb soft nofile 1048576 -
# vi /etc/sysctl.conf fs.file-max = 2097152 vm.max_map_count=262144 fs.inotify.max_user_watches=524288 fs.inotify.max_user_instances=512
Répétez cette étape pour tous les nœuds de travail.
-
Maintenant que vous avez installé et déployé votre cluster Paragon Automation, vous êtes prêt à vous connecter à l'interface utilisateur de Paragon Automation.
Se connecter à l’interface utilisateur de Paragon Automation
Pour vous connecter à l’interface utilisateur de Paragon Automation :
- Ouvrez un navigateur et entrez le nom d’hôte de l’application Web principale ou l’adresse IP virtuelle du contrôleur entrant que vous avez entré dans le champ URL de l’assistant d’installation.
Par exemple, https:// vip-of-ingress-controller-or-hostname-of-main-web-application . La page de connexion de Paragon Automation s’affiche.
- Pour le premier accès, entrez admin comme nom d’utilisateur et Admin123 ! comme mot de passe pour vous connecter. Vous devez changer le mot de passe immédiatement.
La page Définir le mot de passe s’affiche. Pour accéder à la configuration de Paragon Automation, vous devez définir un nouveau mot de passe.
- Définissez un nouveau mot de passe qui répond aux exigences en matière de mot de passe.
Utilisez entre 6 et 20 caractères et une combinaison de lettres majuscules, de lettres minuscules, de chiffres et de caractères spéciaux. Confirmez le nouveau mot de passe, puis cliquez sur OK.La page Tableau de bord s’affiche. Vous avez installé l’interface utilisateur de Paragon Automation et vous y êtes connecté.
- Mettez à jour l’URL d’accès à l’interface utilisateur Paragon Automation dans les paramètres du portail d’administration > d’authentification > pour vous assurer que l’e-mail d’activation envoyé aux utilisateurs pour l’activation de leur compte contient le lien correct pour accéder à l’interface graphique. Pour plus d’informations, consultez Configurer les paramètres du portail.
Pour connaître les tâches de haut niveau que vous pouvez effectuer après vous être connecté à l’interface utilisateur de Paragon Automation, consultez Démarrage rapide de Paragon Automation - En cours d’exécution.