AUF DIESER SEITE
Grundlegendes zum Failover von Chassis-Cluster-Redundanzgruppen
Grundlegendes zum manuellen Failover von Chassis-Cluster-Redundanzgruppen
Initiieren eines Failovers für eine Chassis-Cluster-Gruppe mit manueller Redundanz
Grundlegendes zu SNMP-Failover-Traps für Chassis-Cluster-Redundanzgruppen-Failover
Chassis-Cluster-Redundanzgruppen-Failover
Eine Redundanzgruppe (RG) umfasst und verwaltet eine Sammlung von Objekten auf beiden Knoten eines Clusters, um Hochverfügbarkeit zu gewährleisten. Jede Redundanzgruppe fungiert als unabhängige Failovereinheit und ist jeweils nur auf einem Knoten primär. Weitere Informationen finden Sie in den folgenden Themen:
Grundlegendes zum Failover von Chassis-Cluster-Redundanzgruppen
Chassis-Cluster verwenden eine Reihe hocheffizienter Failover-Mechanismen , die eine hohe Verfügbarkeit fördern und so die allgemeine Zuverlässigkeit und Produktivität Ihres Systems erhöhen.
Eine Redundanzgruppe ist eine Sammlung von Objekten, für die ein Failover als Gruppe ausgeführt wird. Jede Redundanzgruppe überwacht eine Reihe von Objekten (physische Schnittstellen), und jedem überwachten Objekt wird eine Gewichtung zugewiesen. Jede Redundanzgruppe hat einen anfänglichen Schwellenwert von 255. Wenn ein überwachtes Objekt ausfällt, wird die Gewichtung des Objekts vom Schwellenwert der Redundanzgruppe abgezogen. Wenn der Schwellenwert Null erreicht, führt die Redundanzgruppe ein Failover auf den anderen Knoten durch. Infolgedessen wird auch für alle Objekte, die der Redundanzgruppe zugeordnet sind, ein Failover ausgeführt. Durch den ordnungsgemäßen Neustart der Routing-Protokolle kann die Firewall der SRX-Serie Unterbrechungen des Datenverkehrs während eines Failovers minimieren.
Aufeinanderfolgende Failover einer Redundanzgruppe in einem kurzen Intervall können dazu führen, dass der Cluster ein unvorhersehbares Verhalten aufweist. Um solch unvorhersehbares Verhalten zu verhindern, konfigurieren Sie eine Dämpfungszeit zwischen Failovern. Beim Failover wechselt der vorherige primäre Knoten einer Redundanzgruppe in den Status "Sekundäres Halten" und verbleibt im Zustand des sekundären Anhaltens, bis das Halteintervall abläuft. Nach Ablauf des Halteintervalls wechselt der vorherige primäre Knoten in den sekundären Zustand.
Durch die Konfiguration des Hold-Down-Intervalls wird verhindert, dass innerhalb der Dauer des Hold-Down-Intervalls aufeinanderfolgende Failover auftreten.
Das Halteintervall wirkt sich sowohl auf manuelle Failover als auch auf automatische Failover im Zusammenhang mit Überwachungsfehlern aus.
Die Standard-Dämpfungszeit für eine Redundanzgruppe 0 beträgt 300 Sekunden (5 Minuten) und kann mit der hold-down-interval Anweisung auf bis zu 1800 Sekunden konfiguriert werden. Bei einigen Konfigurationen, z. B. bei einer großen Anzahl von Routen oder logischen Schnittstellen, ist das Standardintervall oder das benutzerdefinierte Intervall möglicherweise nicht ausreichend. In solchen Fällen verlängert das System die Feuchtzeit automatisch in Schritten von 60 Sekunden, bis das System für ein Failover bereit ist.
Redundanzgruppen x (Redundanzgruppen mit den Nummern 1 bis 128) haben eine Standarddämpfungszeit von 1 Sekunde mit einem Bereich von 0 bis 1800 Sekunden.
Bei Firewalls der SRX-Serie ist die Failover-Leistung von Gehäuse-Clustern für die Skalierung mit mehr logischen Schnittstellen optimiert. Bisher wurde während des Redundanzgruppen-Failovers unentgeltliches ARP (GARP) vom Juniper Services Redundancy Protocol (jsrpd)-Prozess gesendet, der in der Routing-Engine auf jeder logischen Schnittstelle ausgeführt wird, um den Datenverkehr zum entsprechenden Knoten zu leiten. Bei der logischen Schnittstellenskalierung wird die Routing-Engine zum Kontrollpunkt, und GARP wird direkt von der Services Processing Unit (SPU) gesendet.
Zeitgeber für präemptive Failover-Verzögerung
Eine Redundanzgruppe befindet sich zu jedem Zeitpunkt im primären Zustand (aktiv) auf einem Knoten und im sekundären Zustand (Backup) auf dem anderen Knoten.
Sie können das präventive Verhalten auf beiden Knoten in einer Redundanzgruppe aktivieren und jedem Knoten in der Redundanzgruppe einen Prioritätswert zuweisen. Der Knoten in der Redundanzgruppe mit der höheren konfigurierten Priorität wird zunächst als primärer Knoten in der Gruppe festgelegt, und der andere Knoten wird zunächst als sekundärer Knoten in der Redundanzgruppe festgelegt.
Wenn eine Redundanzgruppe den Status ihrer Knoten zwischen primär und sekundär austauscht, besteht die Möglichkeit, dass kurz nach dem ersten Zustandstausch ein nachfolgender Zustandstausch ihrer Knoten erneut erfolgen kann. Dieser schnelle Zustandswechsel führt zu einem Flattern des Primär- und Sekundärsystems.
Ab Junos OS Version 17.4R1 wird auf Firewalls der SRX-Serie in einem Chassis-Cluster ein Failover-Verzögerungs-Timer eingeführt, um das Flapping des Redundanzgruppenstatus zwischen dem sekundären und den primären Knoten in einem präemptiven Failover zu begrenzen.
Um das Flapping zu verhindern, können Sie die folgenden Parameter konfigurieren:
-
Präemptive Verzögerung: Die Zeit für die präemptive Verzögerung ist die Zeitspanne, die eine Redundanzgruppe in einem sekundären Zustand wartet, wenn der primäre Zustand in einem präemptiven Failover ausgefallen ist, bevor sie in den primären Zustand wechselt. Dieser Verzögerungstimer verzögert das sofortige Failover für einen konfigurierten Zeitraum zwischen 1 und 21.600 Sekunden.
-
Präemptiver Grenzwert: Der präemptive Grenzwert schränkt die Anzahl der präemptiven Failover (zwischen 1 und 50) während eines konfigurierten Preemptive-Zeitraums ein, wenn
preemptioner für eine Redundanzgruppe aktiviert ist. -
Präemptiver Zeitraum: Zeitspanne (1 bis 1440 Sekunden), in dem der präemptive Grenzwert angewendet wird, d. h. die Anzahl der konfigurierten präemptiven Failovers wird angewendet, wenn die vorzeitige Unterbrechung für eine Redundanzgruppe aktiviert ist.
Stellen Sie sich das folgende Szenario vor, in dem Sie einen vorläufigen Zeitraum von 300 Sekunden und einen vorläufigen Grenzwert von 50 Sekunden konfiguriert haben.
Wenn der präventive Grenzwert als 50 konfiguriert ist, beginnt die Anzahl bei 0 und wird mit einem ersten präventiven Failover inkrementiert. Dieser Vorgang wird fortgesetzt, bis die Zählung den konfigurierten grenzwertigen Grenzwert für vorläufige Zahlungen, d. h. 50, erreicht, bevor der Zeitraum für die vorzeitige Ermittlung abläuft. Wenn der Grenzwert für präventive Entfernungen (50) überschritten wird, müssen Sie die Anzahl der vorzeitigen Unterbrechungen manuell zurücksetzen, damit erneut präventive Failover auftreten können.
Wenn Sie den präventiven Zeitraum auf 300 Sekunden festgelegt haben und der Zeitunterschied zwischen dem ersten präventiven Failover und dem aktuellen Failover bereits 300 Sekunden überschritten hat und der präfertive Grenzwert (50) noch nicht erreicht ist, wird der präfertive Zeitraum zurückgesetzt. Nach dem Zurücksetzen wird das letzte Failover als erstes präemptives Failover des neuen präventiven Zeitraums betrachtet, und der Prozess beginnt von vorne.
Die vorbeugende Verzögerung kann unabhängig vom Failover-Limit konfiguriert werden. Durch die Konfiguration des Zeitgebers für die präemptive Verzögerung wird das vorhandene Verhalten der präemptiven Verzögerung nicht geändert.
Diese Erweiterung ermöglicht es dem Administrator, eine Failoververzögerung einzuführen, die die Anzahl der Failover reduzieren und zu einem stabileren Netzwerkstatus führen kann, da das aktive /Standby-Flapping innerhalb der Redundanzgruppe reduziert wird.
- Verstehen des Übergangs vom primären zum sekundären Zustand mit präemptiver Verzögerung
- Konfigurieren des Zeitgebers für die vorausschauende Verzögerung
Verstehen des Übergangs vom primären zum sekundären Zustand mit präemptiver Verzögerung
Betrachten Sie das folgende Beispiel, in dem eine Redundanzgruppe, die primär auf dem Knoten 0 ist, während eines Failovers für den präemptiven Übergang in den sekundären Zustand bereit ist. Jedem Knoten wird eine Priorität zugewiesen und die preemptive Option ist auch für die Knoten aktiviert.
Abbildung 1 zeigt die Abfolge der Schritte beim Übergang vom primären Zustand zum sekundären Zustand, wenn ein präemptiver Verzögerungs-Timer konfiguriert ist.
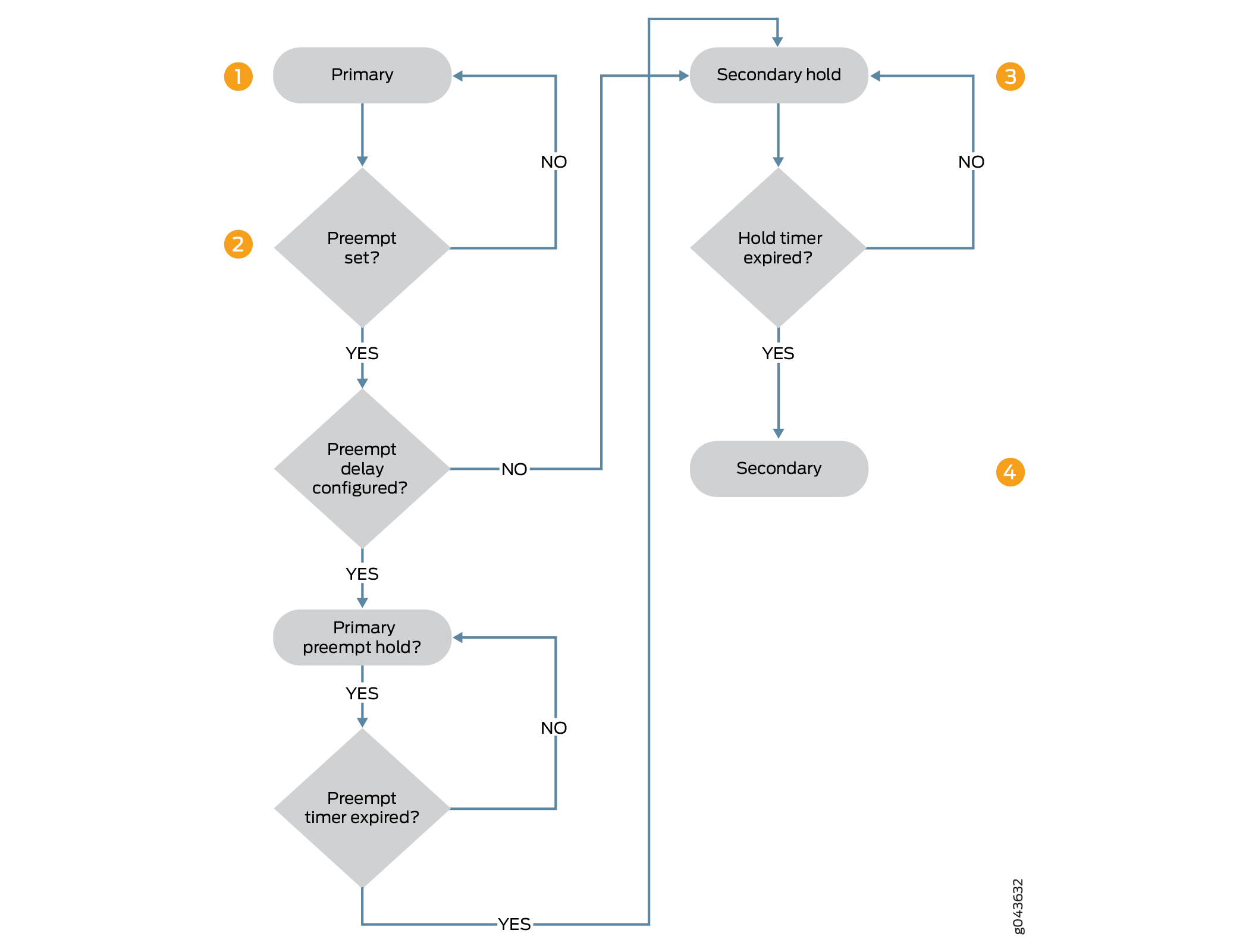
-
Der Knoten im primären Zustand ist bereit für den präemptiven Übergang in den sekundären Zustand, wenn die
preemptiveOption konfiguriert ist, und der Knoten im sekundären Zustand hat Vorrang vor dem Knoten im primären Zustand. Wenn die präemptive Verzögerung konfiguriert ist, wechselt der Knoten im primären Zustand in den primary-preempt-hold-Zustand . Wenn die präemptive Verzögerung nicht konfiguriert ist, erfolgt ein sofortiger Übergang in den sekundären Zustand. -
Der Knoten befindet sich im primären, präemptiven gehaltenen Zustand und wartet darauf, dass der Timer für die präemptive Verzögerung abläuft. Der Timer für die vorbeugende Verzögerung wird überprüft, und der Übergang wird gehalten, bis der Timer abgelaufen ist. Der primäre Knoten verbleibt bis zum Ablauf des Timers im primary-preempt-hold-Zustand, bevor er in den sekundären Zustand übergeht.
-
Der Knoten wechselt vom Primär-Preempt-Hold-Zustand in den Secondary-Hold-Zustand und dann in den sekundären Zustand.
-
Der Knoten verbleibt für die Standardzeit (1 Sekunde) oder die konfigurierte Zeit (mindestens 300 Sekunden) im sekundären Haltezustand, und dann wechselt der Knoten in den sekundären Zustand.
Wenn die Konfiguration Ihres Chassis-Clusters eine ungewöhnliche Anzahl von Störungen aufweist, müssen Sie Ihre Verbindungs- und Überwachungstimer überprüfen, um sicherzustellen, dass sie richtig eingestellt sind. Seien Sie vorsichtig, wenn Sie Timer in Netzwerken mit hoher Latenz einstellen, um Fehlalarme zu vermeiden.
Konfigurieren des Zeitgebers für die vorausschauende Verzögerung
In diesem Thema wird erläutert, wie der Verzögerungs-Timer für Firewalls der SRX-Serie in einem Gehäuse-Cluster konfiguriert wird. Zu schnell ausgeführte aufeinanderfolgende Redundanzgruppen-Failover können dazu führen, dass ein Gehäusecluster ein unvorhersehbares Verhalten aufweist. Durch die Konfiguration des Verzögerungs-Timers und der Failover-Ratenbegrenzung wird das sofortige Failover für einen konfigurierten Zeitraum verzögert.
So konfigurieren Sie den Timer für die präventive Verzögerung und den Grenzwert für die Failoverrate zwischen Redundanzgruppenfailovern:
-
Aktivieren Sie ein präventives Failover für eine Redundanzgruppe.
Sie können den Verzögerungstimer zwischen 1 und 21.600 Sekunden einstellen. Der Standardwert ist 1 Sekunde.
{primary:node1} [edit chassis cluster redundancy-group number preempt] user@host# set delay interval -
Richten Sie einen Grenzwert für ein präventives Failover ein.
Sie können die maximale Anzahl von präemptiven Failovern zwischen 1 und 50 und den Zeitraum, in dem der Grenzwert angewendet wird, zwischen 1 und 1440 Sekunden festlegen.
{primary:node1}[edit chassis cluster redundancy-group number preempt] user@host# set limit limit period period
Im folgenden Beispiel legen Sie den Timer für die präventive Verzögerung auf 300 Sekunden und den präventiven Grenzwert auf 10 für einen Zeitraum von 600 Sekunden fest. Das heißt, diese Konfiguration verzögert das sofortige Failover um 300 Sekunden und begrenzt maximal 10 präventive Failover in einer Dauer von 600 Sekunden.
{primary:node1}[edit chassis cluster redundancy-group 1 preempt]
user@host# set delay 300 limit 10 period 600
Sie können den clear chassis clusters preempt-count Befehl verwenden, um den Schwellenwert für die vorzeitige Unterbrechung für alle Redundanzgruppen zu löschen. Wenn ein Grenzwert für vorzeitige Unterbrechung konfiguriert ist, beginnt der Leistungsindikator mit einem ersten präemptiven Failover, und die Anzahl wird reduziert. Dieser Vorgang wird fortgesetzt, bis die Anzahl Null erreicht, bevor der Timer abläuft. Sie können diesen Befehl verwenden, um den Failover-Zähler zu löschen und zurückzusetzen, um erneut zu starten.
Siehe auch
Grundlegendes zum manuellen Failover von Chassis-Cluster-Redundanzgruppen
Sie können ein Failover der Redundanzgruppe x (Redundanzgruppen mit den Nummern 1 bis 128) manuell initiieren. Ein manuelles Failover gilt so lange, bis ein Failback-Ereignis eintritt.
Angenommen, Sie führen manuell ein Failover der Redundanzgruppe 1 von Knoten 0 auf Knoten 1 durch. Dann schlägt eine Schnittstelle aus, die von Redundanzgruppe 1 überwacht wird, und der Schwellenwert der neuen primären Redundanzgruppe wird auf Null gesenkt. Dieses Ereignis wird als Failbackereignis betrachtet, und das System gibt die Steuerung an die ursprüngliche Redundanzgruppe zurück.
Sie können ein Failover der Redundanzgruppe 0 auch manuell initiieren, wenn Sie den primären Knoten durch Redundanzgruppe 0 ersetzen möchten. Sie können die vorzeitige Trennung für Redundanzgruppe 0 nicht aktivieren.
Wenn Prefert zu einer Redundanzgruppenkonfiguration hinzugefügt wird, kann das Gerät mit der höheren Priorität in der Gruppe ein Failover initiieren, um zum primären Gerät zu werden. Standardmäßig ist die vorzeitige Entfernung deaktiviert. Weitere Informationen zum Preempeption finden Sie unter Preempt (Chassis-Cluster).
Wenn Sie ein manuelles Failover für Redundanzgruppe 0 durchführen, wechselt der Knoten im primären Zustand in den sekundären Haltezustand. Der Knoten verbleibt für die Standard- oder konfigurierte Zeit (mindestens 300 Sekunden) im sekundären Haltezustand und wechselt dann in den sekundären Zustand.
Zustandsübergänge in Fällen, in denen sich ein Knoten im Secondary-Hold-Zustand befindet und der andere Knoten neu gestartet wird oder die Control-Link-Verbindung oder Fabric-Link-Verbindung für diesen Knoten verloren geht, werden wie folgt beschrieben:
Fall für Neustart: Der Knoten im sekundären Haltestatus wechselt in den primären Status. Der andere Knoten wird tot (inaktiv).
Fehlerfall der Steuerverbindung: Der Knoten im sekundären Haltestatus wechselt in den Status "Nicht geeignet" und dann in den Status "Deaktiviert". Der andere Knoten wechselt in den primären Zustand.
Fall eines Fehlers der Fabric-Verbindung: Der Knoten im sekundären Haltestatus wechselt direkt in den Status "Nicht geeignet".
Ab Junos OS Version 12.1X46-D20 und Junos OS Version 17.3R1 ist die Fabric-Überwachung standardmäßig aktiviert. Dadurch wechselt der Knoten bei Ausfällen von Fabric-Verbindungen direkt in den Status "Nicht geeignet".
Ab Junos OS Version 12.1X47-D10 und Junos OS Version 17.3R1 ist die Fabric-Überwachung standardmäßig aktiviert. Dadurch wechselt der Knoten bei Ausfällen von Fabric-Verbindungen direkt in den Status "Nicht geeignet".
Beachten Sie, dass während eines In-Service-Softwareupgrades (ISSU) die hier beschriebenen Übergänge nicht stattfinden können. Stattdessen wechselt der andere (primäre) Knoten direkt in den sekundären Status, da Juniper Networks Versionen vor 10.0 den sekundären Haltestatus nicht interpretieren. Wenn einer der Knoten beim Starten einer ISSU über eine oder mehrere Redundanzgruppen im sekundären Haltestatus verfügt, müssen Sie warten, bis diese in den sekundären Status verschoben wurden, bevor Sie manuelle Failover durchführen können, damit alle Redundanzgruppen auf einem Knoten primär sind.
Seien Sie vorsichtig und umsichtig bei der Verwendung von manuellen Failovern der Redundanzgruppe 0. Ein Failover der Redundanzgruppe 0 impliziert ein Routing-Engine-Failover, bei dem alle Prozesse, die auf dem primären Knoten ausgeführt werden, beendet und dann auf der neuen primären Routing-Engine erzeugt werden. Dieses Failover kann zu Fehlern führen, z. B. des Routing-Status, und die Leistung durch Systemänderung beeinträchtigen.
In einigen Junos OS-Versionen ist es für Redundanzgruppen xmöglich, ein manuelles Failover für einen Knoten mit der Priorität 0 durchzuführen. Es wird empfohlen, den show chassis cluster status Befehl zu verwenden, um die Prioritäten der Redundanzgruppenknoten zu überprüfen, bevor Sie das manuelle Failover ausführen. Ab den Junos OS-Versionen 12.1X44-D25, 12.1X45-D20, 12.1X46-D10 und 12.1X47-D10 und höher wurde der Mechanismus zur Bereitschaftsprüfung für manuelles Failover jedoch restriktiver gestaltet, sodass Sie das manuelle Failover nicht auf einen Knoten in einer Redundanzgruppe mit der Priorität 0 festlegen können. Diese Verbesserung verhindert, dass Datenverkehr aufgrund eines Failover-Versuchs zu einem Knoten mit der Priorität 0, der nicht bereit ist, Datenverkehr anzunehmen, unerwartet unterbrochen wird.
Initiieren eines Failovers für eine Chassis-Cluster-Gruppe mit manueller Redundanz
Bevor Sie beginnen, führen Sie die folgenden Aufgaben aus:
Mit dem request Befehl können Sie ein Failover manuell initiieren. Durch ein manuelles Failover wird die Priorität der Redundanzgruppe für dieses Mitglied auf 255 erhöht.
Seien Sie vorsichtig und umsichtig bei der Verwendung von manuellen Failovern der Redundanzgruppe 0. Ein Failover der Redundanzgruppe 0 impliziert ein Routing-Engine-Failover (RE), bei dem alle Prozesse, die auf dem primären Knoten ausgeführt werden, beendet und dann auf der neuen primären Routing-Engine (RE) erzeugt werden. Dieses Failover kann zu Fehlern führen, z. B. des Routing-Status, und die Leistung durch Systemänderung beeinträchtigen.
Das Ziehen des Netzkabels und das Halten des Netzschalters, um ein Failover einer Gehäuse-Cluster-Redundanzgruppe zu initiieren, kann zu unvorhersehbarem Verhalten führen.
Für Redundanzgruppen x (Redundanzgruppen mit den Nummern 1 bis 128) ist es möglich, ein manuelles Failover auf einem Knoten mit der Priorität 0 durchzuführen. Es wird empfohlen, die Prioritäten der Redundanzgruppenknoten zu überprüfen, bevor Sie das manuelle Failover ausführen.
Verwenden Sie den Befehl show , um den Status der Knoten im Cluster anzuzeigen:
{primary:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 1
node0 254 primary no no
node1 1 secondary no no
Die Ausgabe dieses Befehls gibt an, dass Knoten 0 primär ist.
Verwenden Sie den Befehl request , um ein Failover auszulösen und Knoten 1 zum primären Knoten zu machen:
{primary:node0}
user@host> request chassis cluster failover redundancy-group 0 node 1
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Initiated manual failover for redundancy group 0
Verwenden Sie den Befehl show , um den neuen Status der Knoten im Cluster anzuzeigen:
{secondary-hold:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 2
node0 254 secondary-hold no yes
node1 255 primary no yes
Die Ausgabe dieses Befehls zeigt, dass Knoten 1 jetzt primär und Knoten 0 im sekundären Haltezustand ist. Nach 5 Minuten wechselt Knoten 0 in den sekundären Zustand.
Sie können das Failover für Redundanzgruppen zurücksetzen, indem Sie den request Befehl verwenden. Diese Änderung wird im gesamten Cluster weitergegeben.
{secondary-hold:node0}
user@host> request chassis cluster failover reset redundancy-group 0
node0:
--------------------------------------------------------------------------
No reset required for redundancy group 0.
node1:
--------------------------------------------------------------------------
Successfully reset manual failover for redundancy group 0
Sie können erst nach Ablauf des 5-Minuten-Intervalls ein Back-to-Back-Failover auslösen.
{secondary-hold:node0}
user@host> request chassis cluster failover redundancy-group 0 node 0
node0:
--------------------------------------------------------------------------
Manual failover is not permitted as redundancy-group 0 on node0 is in secondary-hold state.
Verwenden Sie den Befehl show , um den neuen Status der Knoten im Cluster anzuzeigen:
{secondary-hold:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 2
node0 254 secondary-hold no no
node1 1 primary no no
Die Ausgabe dieses Befehls zeigt, dass für keinen der Knoten ein aufeinanderfolgendes Failover stattgefunden hat.
Nachdem Sie ein manuelles Failover durchgeführt haben, müssen Sie den reset failover Befehl ausgeben, bevor Sie ein weiteres Failover anfordern.
Wenn der primäre Knoten ausfällt und wieder hochfährt, erfolgt die Auswahl des primären Knotens auf der Grundlage regulärer Kriterien (Priorität und Unterbrechung).
Beispiel: Konfigurieren eines Chassis-Clusters mit einer Dämpfungszeit zwischen aufeinanderfolgenden Redundanzgruppen-Failovers
In diesem Beispiel wird gezeigt, wie die Dämpfungszeit zwischen aufeinanderfolgenden Redundanzgruppen-Failovers für einen Chassis-Cluster konfiguriert wird. Zu schnell ausgeführte aufeinanderfolgende Redundanzgruppen-Failover können dazu führen, dass ein Gehäusecluster ein unvorhersehbares Verhalten aufweist.
Anforderungen
Bevor Sie beginnen:
Grundlegendes zum Redundanzgruppenfailover. Weitere Informationen finden Sie unter Grundlegendes zum Failover von Chassis-Cluster-Redundanzgruppen .
Grundlegendes zum manuellen Failover von Redundanzgruppen. Weitere Informationen finden Sie unter Grundlegendes zum manuellen Failover von Chassis-Cluster-Redundanzgruppen.
Überblick
Die Dämpfungszeit ist das minimale Intervall, das zwischen aufeinanderfolgenden Failovern für eine Redundanzgruppe zulässig ist. Dieses Intervall wirkt sich auf manuelle Failover und automatische Failover aus, die durch Fehler bei der Schnittstellenüberwachung verursacht werden.
In diesem Beispiel legen Sie das minimal zulässige Intervall zwischen aufeinanderfolgenden Failovern für die Redundanzgruppe 0 auf 420 Sekunden fest.
Konfiguration
Verfahren
Schritt-für-Schritt-Anleitung
So konfigurieren Sie die Dämpfungszeit zwischen aufeinanderfolgenden Redundanzgruppen-Failovers:
Legen Sie die Dämpfungszeit für die Redundanzgruppe fest.
{primary:node0}[edit] user@host# set chassis cluster redundancy-group 0 hold-down-interval 420Wenn Sie mit der Konfiguration des Geräts fertig sind, bestätigen Sie die Konfiguration.
{primary:node0}[edit] user@host# commit
Grundlegendes zu SNMP-Failover-Traps für Chassis-Cluster-Redundanzgruppen-Failover
Chassis-Clustering unterstützt SNMP-Traps, die immer dann ausgelöst werden, wenn ein Redundanzgruppen-Failover vorliegt.
Die Trap-Meldung kann Ihnen bei der Fehlerbehebung bei Failovern helfen. Er enthält die folgenden Informationen:
Die Cluster-ID und die Knoten-ID
Der Grund für das Failover
Die Redundanzgruppe, die am Failover beteiligt ist
Der vorherige und der aktuelle Status der Redundanzgruppe
Dies sind die verschiedenen Zustände, in denen sich ein Cluster zu einem bestimmten Zeitpunkt befinden kann: Halten, Primär, Sekundäres Halten, Sekundär, Nicht geeignet und Deaktiviert. Traps werden für die folgenden Zustandsübergänge generiert (nur ein Übergang aus einem gehaltenen Zustand löst keinen Trap aus):
Primäre <–> Sekundarstufe
primär – > sekundär gespeichert
secondary-hold –> sekundär
Sekundarstufe – > nicht förderfähig
Nicht förderfähig – > deaktiviert
Nicht förderfähig – > primär
sekundär – > deaktiviert
Ein Übergang kann aufgrund jedes Ereignisses ausgelöst werden, z. B. durch Schnittstellenüberwachung, SPU-Überwachung, Fehler und manuelle Failovers.
Der Trap wird über die Steuerverbindung weitergeleitet, wenn sich die ausgehende Schnittstelle auf einem anderen Knoten befindet als der Knoten auf der Routing-Engine, der den Trap generiert.
Sie können angeben, dass ein Ablaufverfolgungsprotokoll generiert wird, indem Sie die traceoptions flag snmp Anweisung festlegen.
Überprüfen des Failover-Status des Gehäuse-Clusters
Zweck
Zeigen Sie den Failover-Status eines Chassis-Clusters an.
Aktion
Geben Sie in der CLI den show chassis cluster status folgenden Befehl ein:
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 3
Node name Priority Status Preempt Manual failover
Redundancy-group: 0, Failover count: 1
node0 254 primary no no
node1 2 secondary no no
Redundancy-group: 1, Failover count: 1
node0 254 primary no no
node1 1 secondary no no
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 15
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 5
node0 200 primary no no
node1 0 lost n/a n/a
Redundancy group: 1 , Failover count: 41
node0 101 primary no no
node1 0 lost n/a n/a
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 15
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 5
node0 200 primary no no
node1 0 unavailable n/a n/a
Redundancy group: 1 , Failover count: 41
node0 101 primary no no
node1 0 unavailable n/a n/a
Löschen des Failover-Status des Chassis-Clusters
Um den Failover-Status eines Chassis-Clusters zu löschen, geben Sie den clear chassis cluster failover-count folgenden Befehl über die CLI ein:
{primary:node1}
user@host> clear chassis cluster failover-count
Cleared failover-count for all redundancy-groups
Tabellarischer Änderungsverlauf
Die Unterstützung der Funktion hängt von der Plattform und der Version ab, die Sie benutzen. Verwenden Sie Funktionen entdecken , um festzustellen, ob eine Funktion auf Ihrer Plattform unterstützt wird.