机箱群集冗余组故障切换
冗余组 (RG) 在群集的两个节点上包含并管理对象集合,以提供高可用性。每个冗余组充当独立的故障切换单元,一次仅是一个节点上的主节点。有关更多信息,请参阅以下主题:
了解机箱群集冗余组故障切换
机箱群集采用多种高效的故障切换机制来促进高可用性,从而提高系统的整体可靠性和生产力。
冗余组是作为一个组进行故障转移的对象的集合。每个冗余组监控一组对象(物理接口),并为每个受监控对象分配一个权重。每个冗余组的初始阈值为 255。当受监控对象发生故障时,将从冗余组的阈值中减去该对象的权重。当阈值达到零时,冗余组将故障转移到另一个节点。因此,与冗余组关联的所有对象也会进行故障转移。路由协议的平稳重新启动使 SRX 系列防火墙能够在故障切换期间将流量中断降至最低。
冗余组在短时间间隔内的背靠背故障转移可能会导致群集表现出不可预测的行为。为防止此类不可预测的行为,请在故障转移之间配置抑制时间。故障转移时,冗余组的前一个主节点将移动到辅助保持状态,并保持辅助保留状态,直到抑制间隔到期。抑制间隔到期后,前一个主节点将移动到辅助状态。
配置抑制间隔可防止在抑制间隔持续时间内发生背靠背故障转移。
抑制间隔会影响手动故障转移以及与监视故障关联的自动故障转移。
冗余组 0 的默认衰减时间为 300 秒(5 分钟),可通过 hold-down-interval 语句配置为最长 1800 秒。对于某些配置(如具有大量路由或逻辑接口的配置),默认间隔或用户配置的时间间隔可能不够。在这种情况下,系统会自动以 60 秒的增量延长阻尼时间,直到系统准备好进行故障切换。
冗余组 x (编号为 1 到 128 的冗余组)的默认衰减时间为 1 秒,范围为 0 到 1800 秒。
在 SRX 系列防火墙上,机箱群集故障切换性能已经过优化,可通过更多逻辑接口进行扩展。以前,在冗余组故障切换期间,在每个 逻辑接口 上的路由引擎中运行的瞻博网络服务冗余协议 (jsrpd) 进程会发送免费 ARP (GARP),以便将流量引导到适当的节点。借助逻辑接口扩展,路由引擎成为检查点,GARP 直接从服务处理单元 (SPU) 发送。
抢占式故障切换延迟计时器
在任何给定时间,冗余组在一个节点上处于主要状态(活动),在另一个节点上处于辅助状态(备份)。
您可以在冗余组中的两个节点上启用抢占行为,并为冗余组中的每个节点分配优先级值。冗余组中配置优先级较高的节点最初被指定为组中的主节点,而另一个节点最初被指定为冗余组中的辅助节点。
当冗余组在主节点和辅助节点之间交换其节点的状态时,其节点的后续状态交换可能会在第一次状态交换后不久再次发生。这种状态的快速变化导致一级和二级系统的抖动。
从 Junos OS 17.4R1 版开始,会在机箱群集中的 SRX 系列防火墙上引入故障切换延迟计时器,以限制抢占式故障切换中辅助节点和主节点之间冗余组状态的摆动。
为了防止翻动,您可以配置以下参数:
-
抢占式延迟 – 抢占式延迟时间是指在抢占式故障切换中处于辅助状态的冗余组在切换到主要状态之前等待的时间量。此延迟计时器将立即故障切换延迟配置的时间段(1 到 21,600 秒之间)。
-
抢占式限制 – 抢占式限制限制在配置的抢占式期间(当为冗余组启用时
preemption)的抢占式故障转移次数(介于 1 到 50 之间)。 -
抢占期 – 应用抢占式限制的时间段(1 到 1440 秒),即,当为冗余组启用抢占式故障转移时,将应用已配置的抢占式故障切换数。
请考虑以下方案,其中已将抢占时间段配置为 300 秒,将抢占式限制配置为 50。
当抢占式限制配置为 50 时,计数从 0 开始,并随着第一次抢占式故障切换而递增;此过程一直持续到计数达到配置的抢占式限制(即 50)为止,抢占式期限到期。当超过抢占式限制 (50) 时,必须手动重置抢占式计数,以允许再次发生抢占式故障转移。
如果已将抢占时间段配置为 300 秒,并且第一次抢占式故障切换与当前故障转移之间的时间差已超过 300 秒,且尚未达到抢占式限制 (50),则将重置抢占时间。重置后,最后一次故障切换被视为新抢占式期间的第一次抢占式故障切换,并且该过程将重新开始。
可以独立于故障切换限制来配置抢占式延迟。配置抢占式延迟计时器不会更改现有的抢占式行为。
此增强功能使管理员能够引入故障切换延迟,从而减少故障切换次数,并且由于冗余组内活动/备用翻动的减少,从而产生更稳定的网络状态。
了解具有抢占式延迟时从主要状态到辅助状态的转换
请考虑以下示例,其中位于节点 0 上的主冗余组已准备好在故障转移期间抢先转换为辅助状态。系统会为每个节点分配优先级,并且还会为节点启用该 preemptive 选项。
图 1 显示了配置抢占式延迟计时器时从主要状态过渡到辅助状态的步骤顺序。
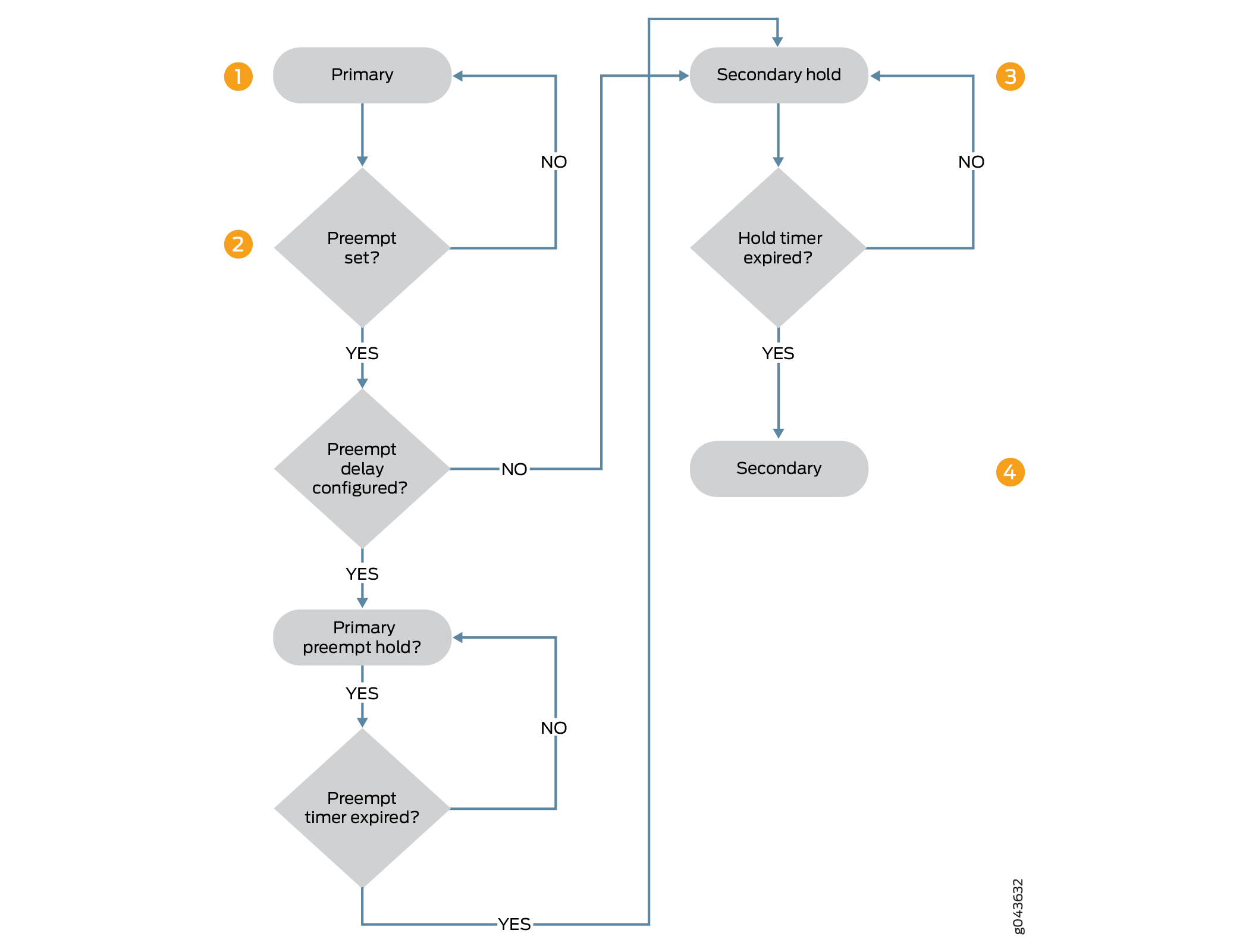 转换
转换
-
如果
preemptive配置了选项,则处于主要状态的节点已准备好抢先转换为辅助状态,并且处于辅助状态的节点优先于处于主要状态的节点。如果配置了抢占式延迟,则处于主状态的节点将转换为主抢占式保持状态。如果未配置抢占式延迟,则会立即转换为辅助状态。 -
节点处于主抢占保持状态,等待抢占式延迟计时器过期。检查抢占式延迟计时器并保持过渡,直到计时器过期。在转换为辅助状态之前,主节点将保持主抢占保持状态,直到计时器过期。
-
节点从主抢占保持状态转换为辅助保持状态,然后转换为辅助状态。
-
节点在默认时间(1 秒)或配置时间(至少 300 秒)内保持辅助保持状态,然后节点转换为辅助状态。
如果机箱群集设置遇到异常数量的抖动,您必须检查链路和监控计时器,确保设置正确。在高延迟网络中设置计时器时要小心,以免误报。
配置抢占式延迟计时器
本主题介绍如何在机箱群集中的 SRX 系列防火墙上配置延迟计时器。发生得太快的背对背冗余组故障切换可能会导致机箱群集出现不可预测的行为。配置延迟计时器和故障切换速率限制会在配置的时间段内延迟即时故障切换。
要在冗余组故障转移之间配置抢占式延迟计时器和故障切换速率限制,请执行以下作:
-
为冗余组启用抢占式故障切换。
您可以将延迟计时器设置为 1 到 21,600 秒之间。默认值为 1 秒。
{primary:node1} [edit chassis cluster redundancy-group number preempt] user@host# set delay interval -
设置抢占式故障转移限制。
可以将抢占式故障转移的最大次数设置在 1 到 50 秒之间,将应用限制的时间段设置为 1 到 1440 秒。
{primary:node1}[edit chassis cluster redundancy-group number preempt] user@host# set limit limit period period
在下面的示例中,您要将抢占式延迟计时器设置为 300 秒,并将抢占式限制设置为 10,抢占式周期为 600 秒。也就是说,此配置会将立即故障切换延迟 300 秒,并在 600 秒的持续时间内限制最多 10 次抢占式故障切换。
{primary:node1}[edit chassis cluster redundancy-group 1 preempt]
user@host# set delay 300 limit 10 period 600
您可以使用 clear chassis clusters preempt-count 命令清除所有冗余组的抢占故障切换计数器。配置抢占限制时,计数器从第一次抢占式故障切换开始,计数将减少;此过程一直持续到计数在计时器过期之前达到零为止。可以使用此命令清除抢占式故障切换计数器,并重置它以重新启动。
另见
了解机箱群集冗余组 手动故障切换
您可以手动启动冗余组 x (编号为 1 到 128 的冗余组)故障切换。在发生故障恢复事件之前,将采用手动故障切换。
例如,假设您手动执行从节点 0 到节点 1 的冗余组 1 故障切换。然后,冗余组 1 正在监控的接口发生故障,新的主冗余组的阈值降至零。此事件被视为故障回复事件,并且系统会将控制权返回给原始冗余组。
如果要更改冗余组 0 的主节点,也可以手动启动冗余组 0 故障切换。无法为冗余组 0 启用抢占。
如果将抢占选项添加到冗余组配置中,则组中优先级较高的设备可以发起故障切换,成为主设备。默认情况下,抢占处于禁用状态。有关 preemeption 的更多信息,请参阅 preempt (Chassis Cluster)。
对冗余组 0 执行手动故障转移时,处于主状态的节点将转换为辅助保持状态。节点在默认或配置的时间(至少 300 秒)内保持辅助保持状态,然后转换为辅助状态。
当一个节点处于辅助保持状态而另一个节点重新启动,或者该节点的控制链路连接或结构链路连接丢失时,状态转换说明如下:
重新启动情况 — 处于辅助保持状态的节点转换为主要状态;另一个节点失效(非活动)。
控制链路故障情况 — 处于辅助保持状态的节点将转换为不合格状态,然后转换为禁用状态;另一个节点转换为主要状态。
结构链路故障情况 — 处于辅助保持状态的节点将直接转换为不合格状态。
从 Junos OS 12.1X46-D20 版和 Junos OS 17.3R1 版开始,交换矩阵监控默认处于启用状态。启用此功能后,在发生结构链路故障时,节点会直接转换为不合格状态。
从 Junos OS 12.1X47-D10 版和 Junos OS 17.3R1 版开始,交换矩阵监控默认处于启用状态。启用此功能后,在发生结构链路故障时,节点会直接转换为不合格状态。
请记住,在不中断服务的软件升级 (ISSU) 期间,不会发生此处描述的转换。相反,另一个(主)节点会直接转换为辅助状态,因为早于 10.0 的瞻博网络版本不会解释辅助保持状态。启动 ISSU 时,如果其中一个节点有一个或多个冗余组处于辅助保留状态,则必须等待它们移动到辅助状态,然后才能进行手动故障转移,以使所有冗余组在一个节点上成为主冗余组。
在使用冗余组 0 手动故障转移时要谨慎和明智。冗余组 0 故障切换意味着路由引擎故障切换,在这种情况下,主节点上运行的所有进程都将被终止,然后在新的主路由引擎上生成。此故障切换可能导致状态丢失(如路由状态),并通过引入系统改动而降低性能。
在某些 Junos OS 版本中,对于冗余组 x,可以在优先级为 0 的节点上执行手动故障转移。建议在执行手动故障转移之前,先使用 show chassis cluster status 命令检查冗余组节点优先级。但是,从 Junos OS 12.1X44-D25、12.1X45-D20、12.1X46-D10 和 12.1X47-D10 及更高版本开始,手动故障转移的就绪情况检查机制已得到增强,使其更具限制性,因此无法将手动故障转移设置为冗余组中优先级为 0 的节点。此增强功能可防止流量因故障转移到尚未准备好接受流量的 0 优先级节点而意外丢弃流量。
启动机箱群集 手动冗余组故障切换
开始之前,请完成以下任务:
您可以使用 request 命令手动启动故障转移。手动故障转移会将该成员的冗余组优先级提高到 255。
在使用冗余组 0 手动故障转移时要谨慎和明智。冗余组 0 故障切换意味着路由引擎 (RE) 故障切换,在这种情况下,主节点上运行的所有进程都将被终止,然后在新的主路由引擎 (RE) 上生成。此故障切换可能导致状态丢失(如路由状态),并通过引入系统改动而降低性能。
拔下电源线并按住电源按钮启动机箱群集冗余组故障切换可能会导致不可预测的行为。
对于冗余组 x (编号为 1 到 128 的冗余组),可以在优先级为 0 的节点上执行手动故障转移。建议在执行手动故障转移之前检查冗余组节点优先级。
show使用命令显示群集中节点的状态:
{primary:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 1
node0 254 primary no no
node1 1 secondary no no
此命令的输出指示节点 0 为主节点。
request使用命令触发故障转移并使节点 1 成为主节点:
{primary:node0}
user@host> request chassis cluster failover redundancy-group 0 node 1
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Initiated manual failover for redundancy group 0
show使用命令显示群集中节点的新状态:
{secondary-hold:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 2
node0 254 secondary-hold no yes
node1 255 primary no yes
此命令的输出显示节点 1 现在是主节点,节点 0 处于辅助保持状态。5 分钟后,节点 0 将转换为辅助状态。
您可以使用 request 命令重置冗余组的故障转移。此更改将在整个群集中传播。
{secondary-hold:node0}
user@host> request chassis cluster failover reset redundancy-group 0
node0:
--------------------------------------------------------------------------
No reset required for redundancy group 0.
node1:
--------------------------------------------------------------------------
Successfully reset manual failover for redundancy group 0
在 5 分钟的间隔到期之前,无法触发背靠背故障切换。
{secondary-hold:node0}
user@host> request chassis cluster failover redundancy-group 0 node 0
node0:
--------------------------------------------------------------------------
Manual failover is not permitted as redundancy-group 0 on node0 is in secondary-hold state.
show使用命令显示群集中节点的新状态:
{secondary-hold:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 2
node0 254 secondary-hold no no
node1 1 primary no no
此命令的输出显示,任一节点均未发生背靠背故障切换。
执行手动故障转移后,必须发出 reset failover 命令,然后才能请求另一个故障转移。
当主节点发生故障并重新启动时,将根据常规标准(优先级和抢占)选择主节点。
示例:在配置机箱群集时,在背靠背冗余组故障切换之间留出抑制时间
此示例说明如何为机箱群集配置连续冗余组故障切换之间的衰减时间。发生得太快的背对背冗余组故障切换可能会导致机箱群集出现不可预测的行为。
要求
开始之前:
了解冗余组故障转移。请参 阅了解机箱群集冗余组故障转移 。
了解冗余组手动故障切换。请参阅 了解机箱群集冗余组手动故障切换。
概述
抑制时间是冗余组在背靠背故障转移之间允许的最小间隔。此时间间隔会影响由接口监控故障引起的手动故障转移和自动故障转移。
在此示例中,您将冗余组 0 的背靠背故障转移之间允许的最小间隔设置为 420 秒。
配置
程序
分步过程
要配置连续冗余组故障切换之间的衰减时间:
设置冗余组的衰减时间。
{primary:node0}[edit] user@host# set chassis cluster redundancy-group 0 hold-down-interval 420如果完成设备配置,请提交配置。
{primary:node0}[edit] user@host# commit
了解机箱群集冗余组故障切换的 SNMP 故障切换陷阱
机箱群集支持 SNMP 陷阱,只要出现冗余组故障切换,就会触发该陷阱。
陷阱消息可帮助你排除故障转移。它包含以下信息:
群集 ID 和节点 ID
故障切换的原因
故障转移中涉及的冗余组
冗余组的先前状态和当前状态
这些是群集在任何给定时刻可能处于的不同状态:保留、主要、辅助保留、辅助、不合格和禁用。将为以下状态转换生成陷阱(只有从保持状态的转换不会触发陷阱):
小学<->次级
主 –> 辅助保持
辅助保持 –>辅助
中学 – >不符合条件
不符合条件 – >已禁用
不符合条件 – >主要内容
辅助 - >禁用
任何事件(例如接口监控、SPU 监控、故障和手动故障切换)都可能触发转换。
如果传出接口所在的节点与生成陷阱的路由引擎上的节点不同,则通过控制链路转发陷阱。
您可以通过设置 traceoptions flag snmp 语句来指定生成跟踪日志。
验证机箱群集故障切换状态
目的
显示机箱群集的故障切换状态。
行动
从 CLI 中输入 show chassis cluster status 命令:
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 3
Node name Priority Status Preempt Manual failover
Redundancy-group: 0, Failover count: 1
node0 254 primary no no
node1 2 secondary no no
Redundancy-group: 1, Failover count: 1
node0 254 primary no no
node1 1 secondary no no
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 15
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 5
node0 200 primary no no
node1 0 lost n/a n/a
Redundancy group: 1 , Failover count: 41
node0 101 primary no no
node1 0 lost n/a n/a
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 15
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 5
node0 200 primary no no
node1 0 unavailable n/a n/a
Redundancy group: 1 , Failover count: 41
node0 101 primary no no
node1 0 unavailable n/a n/a
清除机箱群集故障切换状态
要清除机箱群集的故障切换状态,请从 CLI 中输入 clear chassis cluster failover-count 命令:
{primary:node1}
user@host> clear chassis cluster failover-count
Cleared failover-count for all redundancy-groups
变更历史表
是否支持某项功能取决于您使用的平台和版本。使用 功能浏览器 查看您使用的平台是否支持某项功能。