Failover de grupo de redundância de cluster de chassi
Um grupo de redundância (RG) inclui e gerencia uma coleção de objetos em ambos os nós de um cluster para fornecer alta disponibilidade. Cada grupo de redundância atua como uma unidade independente de failover e é primário em apenas um nó de cada vez. Para obter mais informações, veja os seguintes tópicos:
Entenda o failover do grupo de redundância de clusters de chassi
O cluster de chassis emprega uma série de mecanismos de failover altamente eficientes que promovem alta disponibilidade para aumentar a confiabilidade e a produtividade globais do seu sistema.
Um grupo de redundância é uma coleção de objetos que falham como um grupo. Cada grupo de redundância monitora um conjunto de objetos (interfaces físicas), e cada objeto monitorado recebe um peso. Cada grupo de redundância tem um limite inicial de 255. Quando um objeto monitorado falha, o peso do objeto é subtraído do valor limiar do grupo de redundância. Quando o valor limite chega a zero, o grupo de redundância falha no outro nó. Como resultado, todos os objetos associados ao grupo de redundância também falham. A reinicialização graciosa dos protocolos de roteamento permite que o firewall da Série SRX minimize a interrupção do tráfego durante um failover.
Failovers consecutivos de um grupo de redundância em um curto intervalo podem fazer com que o cluster exponha um comportamento imprevisível. Para evitar tal comportamento imprevisível, configure um tempo de amortecimento entre failovers. No failover, o nó primário anterior de um grupo de redundância se move para o estado de espera secundária e permanece no estado de espera secundária até que o intervalo de espera expira. Após o término do intervalo de espera, o nó primário anterior se move para o estado secundário.
A configuração do intervalo de retenção impede que falhas de costas para trás ocorram dentro da duração do intervalo de retenção.
O intervalo de espera afeta falhas manuais, bem como falhas automáticas associadas a falhas de monitoramento.
O tempo de amortecimento padrão para um grupo de redundância 0 é de 300 segundos (5 minutos) e é configurável para até 1800 segundos com a hold-down-interval declaração. Para algumas configurações, como aquelas com um grande número de rotas ou interfaces lógicas, o intervalo padrão ou o intervalo configurado pelo usuário podem não ser suficientes. Nesses casos, o sistema estende automaticamente o tempo de amortecimento em incrementos de 60 segundos até que o sistema esteja pronto para failover.
Grupos x de redundância (grupos de redundância numerados de 1 a 128) têm um tempo de amortecimento padrão de 1 segundo, com um intervalo de 0 a 1800 segundos.
Nos firewalls da Série SRX, o desempenho de failover de cluster do chassi é otimizado para dimensionar com interfaces mais lógicas. Anteriormente, durante o failover do grupo de redundância, o arp gratuito (GARP) é enviado pelo processo do Protocolo de Redundância de Serviços da Juniper (jsrpd) em execução no Mecanismo de Roteamento em cada interface lógica para direcionar o tráfego para o nó apropriado. Com o dimensionamento lógico da interface, o Mecanismo de Roteamento torna-se o checkpoint e o GARP é enviado diretamente da Unidade de Processamento de Serviços (SPU).
Tempor de atraso de failover preventivo
Um grupo de redundância está no estado primário (ativo) em um nó e no estado secundário (backup) no outro nó a qualquer momento.
Você pode habilitar o comportamento preventivo em ambos os nós em um grupo de redundância e atribuir um valor prioritário para cada nó no grupo de redundância. O nó no grupo de redundância com a maior prioridade configurada é inicialmente designado como o principal do grupo, e o outro nó é inicialmente designado como o secundário no grupo de redundância.
Quando um grupo de redundância troca o estado de seus nós entre primário e secundário, há a possibilidade de que uma troca de estado subsequente de seus nós possa acontecer novamente logo após a primeira troca de estado. Essa rápida mudança nos estados resulta em flapping dos sistemas primários e secundários.
A partir do Junos OS Release 17.4R1, um timer de atraso de failover é introduzido em firewalls da Série SRX em um cluster de chassi para limitar o flapping do estado do grupo de redundância entre os nós secundários e os principais em um failover preventivo.
Para evitar o flapping, você pode configurar os seguintes parâmetros:
-
Atraso preventivo — O tempo de atraso preventivo é a quantidade de tempo que um grupo de redundância em um estado secundário espera quando o estado primário está desativado em um failover preventivo antes de mudar para o estado primário. Esse temporizador de atraso atrasa o failover imediato por um período de tempo configurado — entre 1 e 21.600 segundos.
-
Limite preventivo — O limite preventivo restringe o número de failovers preventivos (entre 1 a 50) durante um período preventivo configurado, quando
preemptioné habilitado para um grupo de redundância. -
Período preventivo — período de tempo (1 a 1440 segundos) durante o qual o limite preventivo é aplicado, ou seja, o número de falhas preventivas configuradas são aplicados quando o preempto é habilitado para um grupo de redundância.
Considere o cenário a seguir em que você configurou um período preventivo como 300 segundos e limite preventivo como 50.
Quando o limite preventivo é configurado como 50, a contagem começa em 0 e aumenta com um primeiro failover preventivo; esse processo continua até que a contagem atinja o limite preventivo configurado, ou seja, 50, antes que o período preventivo expira. Quando o limite preventivo (50) é excedido, você deve redefinir manualmente a contagem de pré-requisitos para permitir que falhas preventivas ocorram novamente.
Quando você tiver configurado o período preventivo como 300 segundos, e se a diferença de tempo entre o primeiro failover preventivo e o failover atual já tiver excedido 300 segundos, e o limite de preventiva (50) ainda não for alcançado, então o período preventivo será reiniciado. Após a redefinição, o último failover é considerado como o primeiro failover preventivo do novo período preventivo e o processo começa tudo de novo.
O atraso preventivo pode ser configurado independentemente do limite de failover. Configurar o timer de atraso preventivo não muda o comportamento preventivo existente.
Esse aprimoramento permite que o administrador introduza um atraso no failover, que pode reduzir o número de failovers e resultar em um estado de rede mais estável devido à redução de flapping ativo/standby dentro do grupo de redundância.
- Entender a transição do estado primário para o estado secundário com atraso preventivo
- Configurando o tempor de atraso preventivo
Entender a transição do estado primário para o estado secundário com atraso preventivo
Considere o exemplo a seguir, quando um grupo de redundância, que é primário no nó 0, estiver pronto para uma transição preventiva para o estado secundário durante um failover. A prioridade é atribuída a cada nó e a opção preemptive também está habilitada para os nós.
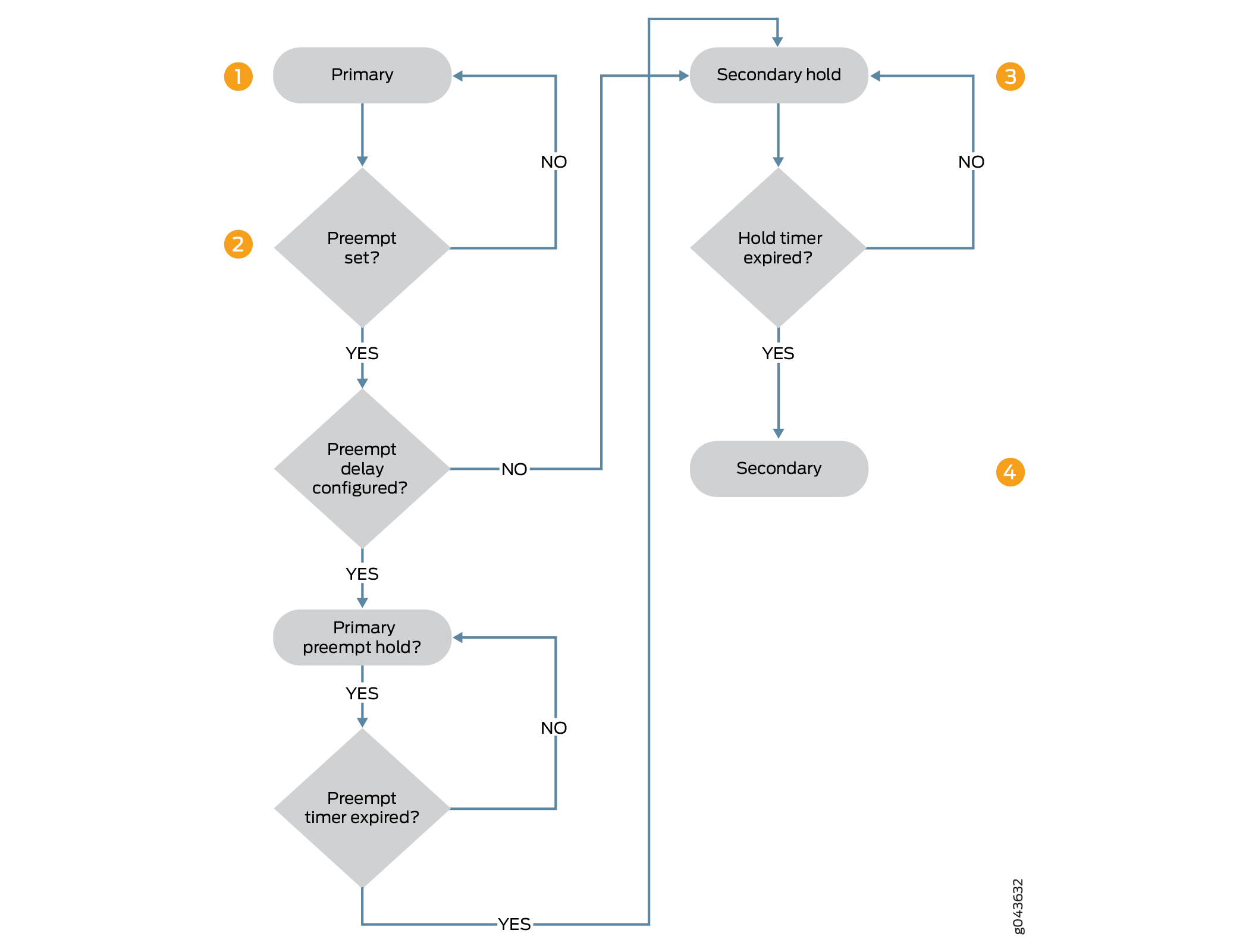
A Figura 1 ilustra a sequência de etapas em transição do estado primário para o estado secundário quando um temporizador de atraso preventivo é configurado.
 preventivo
preventivo
-
O nó no estado primário está pronto para uma transição preventiva para o estado secundário se a opção
preemptiveestiver configurada, e o nó no estado secundário tem a prioridade sobre o nó no estado primário. Se o atraso preventivo estiver configurado, o nó no estado primário faz a transição para o estado de preempência primária. Se o atraso preventivo não estiver configurado, então a transição instantânea para o estado secundário acontece. -
O nó está em estado de espera primária à espera da expiração do temporizante de atraso preventivo. O temporizador de atraso preventivo é verificado e a transição é realizada até que o temporizador expira. O nó primário permanece no estado de preempência primária até que o cronista expire, antes de fazer a transição para o estado secundário.
-
O nó faz a transição do estado de preempições primárias para o estado de espera secundária e, em seguida, para o estado secundário.
-
O nó permanece no estado de espera secundária pelo tempo de padrão (1 segundo) ou pelo tempo configurado (um mínimo de 300 segundos) e, em seguida, o nó faz a transição para o estado secundário.
Se a configuração do cluster do seu chassi experimentar um número anormal de flaps, você deve verificar o seu link e os temporizantes de monitoramento para ter certeza de que eles estão definidos corretamente. Tenha cuidado ao definir os temporizadores em redes de alta latência para evitar obter falsos positivos.
Configurando o tempor de atraso preventivo
Este tópico explica como configurar o timer de atraso em firewalls da Série SRX em um cluster de chassi. Os failovers de grupo de redundância back-to-back que ocorrem muito rapidamente podem fazer com que um cluster de chassi exponha um comportamento imprevisível. Configurar o temporizador de atraso e o limite de taxa de failover atrasa o failover imediato por um período de tempo configurado.
Para configurar o temporizante de atraso preventivo e o limite de taxa de failover entre failovers de grupo de redundância:
-
Habilite o failover preventivo para um grupo de redundância.
Você pode definir o tempor de atraso entre 1 e 21.600 segundos. O valor padrão é de 1 segundo.
{primary:node1} [edit chassis cluster redundancy-group number preempt] user@host# set delay interval -
Configure um limite para failover preventivo.
Você pode definir o número máximo de falhas preventivas entre 1 a 50 e o período durante o qual o limite é aplicado entre 1 a 1440 segundos.
{primary:node1}[edit chassis cluster redundancy-group number preempt] user@host# set limit limit period period
No exemplo a seguir, você está configurando o temporizante de atraso preventivo para 300 segundos, e o limite preventivo para 10 por um período preventivo de 600 segundos. Ou seja, essa configuração atrasa o failover imediato por 300 segundos, e limita um máximo de 10 falhas preventivas em uma duração de 600 segundos.
{primary:node1}[edit chassis cluster redundancy-group 1 preempt]
user@host# set delay 300 limit 10 period 600
Você pode usar o clear chassis clusters preempt-count comando para limpar o balcão de failover preempto para todos os grupos de redundância. Quando um limite antecipado é configurado, o contador começa com um primeiro failover preventivo e a contagem é reduzida; esse processo continua até que a contagem chegue a zero antes que o cronista expire. Você pode usar este comando para limpar o contador de failover preempto e redefini-lo para começar novamente.
Veja também
Entenda o failover manual do grupo de redundância de clusters do chassi
Você pode iniciar manualmente um grupo de redundância x (grupos de redundância numerados de 1 a 128). Um failover manual é aplicado até que ocorra um evento de failback.
Por exemplo, suponha que você faça manualmente um failover do grupo 1 de redundância de nós 0 a nós 1. Em seguida, uma interface que o grupo 1 de redundância está monitorando falha, baixando o valor limite do novo grupo de redundância primária para zero. Este evento é considerado um evento de failback, e o sistema retorna o controle para o grupo de redundância original.
Você também pode iniciar manualmente um failover do grupo 0 de redundância se quiser alterar o nó primário para redundância do grupo 0. Você não pode habilitar a preempção para o grupo 0 de redundância.
Se o preempto for adicionado a uma configuração de grupo de redundância, o dispositivo com maior prioridade no grupo pode iniciar um failover para se tornar primário. Por padrão, a preempção é desativada. Para obter mais informações sobre a preemepção, consulte preempt (Chassis Cluster).
Quando você faz um failover manual para redundância do grupo 0, o nó no estado primário faz a transição para o estado secundário. O nó permanece no estado de espera secundária para o tempo padrão ou configurado (um mínimo de 300 segundos) e depois faz a transição para o estado secundário.
Transições de estado nos casos em que um nó esteja no estado de espera secundária e nas outras reinicializações de nós, ou a conexão de enlace de controle ou conexão de enlace de malha seja perdida para esse nó, são descritas da seguinte forma:
Caso de reinicialização — o nó no estado de espera secundária faz a transição para o estado primário; o outro nó fica inativo.
Caso de falha no enlace de controle — o nó no estado de espera secundária faz a transição para o estado de inelegibilidade e depois para um estado desativado; o outro nó faz a transição para o estado primário.
Caso de falha de enlace de malha — o nó no estado de espera secundária faz a transição diretamente para o estado de inelegibilidade.
Começando pelo Junos OS Release 12.1X46-D20 e Junos OS Release 17.3R1, o monitoramento da malha é habilitado por padrão. Com essa habilitação, o nó faz a transição diretamente para o estado de inelegibilidade em caso de falhas no enlace da malha.
Começando pelo Junos OS Release 12.1X47-D10 e Junos OS Release 17.3R1, o monitoramento da malha é habilitado por padrão. Com essa habilitação, o nó faz a transição diretamente para o estado de inelegibilidade em caso de falhas no enlace da malha.
Tenha em mente que durante uma atualização de software em serviço (ISSU), as transições descritas aqui não podem acontecer. Em vez disso, o outro nó (primário) faz a transição diretamente para o estado secundário porque a Juniper Networks lança mais cedo que 10.0 não interpreta o estado de espera secundária. Embora você inicie um ISSU, se um dos nós tiver um ou mais grupos de redundância no estado de espera secundária, você deve esperar que eles se mudem para o estado secundário antes que você possa fazer failovers manuais para fazer com que todos os grupos de redundância sejam primários em um nó.
Seja cauteloso e justo em seu uso de failovers manuais do grupo 0 de redundância. Um failover do grupo 0 de redundância implica um failover do Mecanismo de Roteamento, nesse caso, todos os processos em execução no nó primário são mortos e, em seguida, gerados no novo mecanismo de roteamento primário. Esse failover pode resultar em perda de estado, como estado de roteamento, e degradar o desempenho introduzindo o churn do sistema.
Em algumas versões do Junos OS, para grupos xde redundância, é possível fazer um failover manual em um nó que tem prioridade 0. Recomendamos que você use o show chassis cluster status comando para verificar as prioridades de nó de grupo de redundância antes de fazer o failover manual. No entanto, das versões Junos OS 12.1X44-D25, 12.1X45-D20, 12.1X46-D10 e 12.1X47-D10 e posteriores, o mecanismo de verificação de prontidão para falha manual é aprimorado para ser mais restritivo, de modo que você não pode definir falha manual em um nó em um grupo de redundância que tem prioridade 0. Essa melhoria impede que o tráfego seja desativado inesperadamente devido a uma tentativa de falha em um nó de prioridade 0, que não está pronto para aceitar o tráfego.
Iniciando um failover de grupo de redundância manual de cluster de chassi
Antes de começar, preencha as seguintes tarefas:
Você pode iniciar um failover manualmente com o request comando. Um failover manual aumenta a prioridade do grupo de redundância para esse membro até 255.
Seja cauteloso e justo em seu uso de failovers manuais do grupo 0 de redundância. Um failover do grupo 0 de redundância implica um failover do Mecanismo de Roteamento (RE), nesse caso todos os processos em execução no nó primário são mortos e depois gerados no novo mecanismo de roteamento primário (RE). Esse failover pode resultar em perda de estado, como estado de roteamento, e degradar o desempenho introduzindo o churn do sistema.
Desligar o cabo de alimentação e segurar o botão de alimentação para iniciar um failover de grupo de redundância de cluster de chassi pode resultar em um comportamento imprevisível.
Para grupos x de redundância (grupos de redundância de 1 a 128), é possível fazer um failover manual em um nó que tem prioridade 0. Recomendamos que você verifique as prioridades de nó de grupo de redundância antes de fazer o failover manual.
Use o show comando para exibir o status dos nós no cluster:
{primary:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 1
node0 254 primary no no
node1 1 secondary no no
A saída para este comando indica que o nó 0 é primário.
Use o request comando para acionar um failover e fazer o nó 1 primário:
{primary:node0}
user@host> request chassis cluster failover redundancy-group 0 node 1
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Initiated manual failover for redundancy group 0
Use o show comando para exibir o novo status de nós no cluster:
{secondary-hold:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 2
node0 254 secondary-hold no yes
node1 255 primary no yes
A saída para este comando mostra que o nó 1 agora é primário e o nó 0 está no estado de espera secundária. Após 5 minutos, o nó 0 fará a transição para o estado secundário.
Você pode redefinir o failover para grupos de redundância usando o request comando. Essa mudança é propagada por todo o cluster.
{secondary-hold:node0}
user@host> request chassis cluster failover reset redundancy-group 0
node0:
--------------------------------------------------------------------------
No reset required for redundancy group 0.
node1:
--------------------------------------------------------------------------
Successfully reset manual failover for redundancy group 0
Você não pode ativar um failover de costas para trás até que o intervalo de 5 minutos expira.
{secondary-hold:node0}
user@host> request chassis cluster failover redundancy-group 0 node 0
node0:
--------------------------------------------------------------------------
Manual failover is not permitted as redundancy-group 0 on node0 is in secondary-hold state.
Use o show comando para exibir o novo status de nós no cluster:
{secondary-hold:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 2
node0 254 secondary-hold no no
node1 1 primary no no
A saída para este comando mostra que um failover de costas para trás não ocorreu para nenhum dos nós.
Depois de fazer um failover manual, você deve emitir o reset failover comando antes de solicitar outro failover.
Quando o nó primário falha e volta, a eleição do nó primário é feita com base em critérios regulares (prioridade e preempto).
Exemplo: configuração de um cluster de chassi com um tempo de amortecimento entre failovers de grupo de redundância back-to-back
Este exemplo mostra como configurar o tempo de amortecimento entre failovers de grupo de redundância de back-to-back para um cluster de chassi. Os failovers de grupo de redundância back-to-back que ocorrem muito rapidamente podem fazer com que um cluster de chassi exponha um comportamento imprevisível.
Requisitos
Antes de começar:
Entenda o failover do grupo de redundância. Veja a compreensão do failover do grupo de redundância de clusters do chassi .
Entenda o failover manual do grupo de redundância. Veja a compreensão do failover manual do grupo de redundância de clusters do chassi.
Visão geral
O tempo de amortecimento é o intervalo mínimo permitido entre failovers back-to-back para um grupo de redundância. Esse intervalo afeta falhas manuais e falhas automáticas causadas por falhas no monitoramento da interface.
Neste exemplo, você define o intervalo mínimo permitido entre failovers back-to-back a 420 segundos para redundância do grupo 0.
Configuração
Procedimento
Procedimento passo a passo
Para configurar o tempo de amortecimento entre failovers de grupo de redundância de back-to-back:
Definir o tempo de amortecimento para o grupo de redundância.
{primary:node0}[edit] user@host# set chassis cluster redundancy-group 0 hold-down-interval 420Se você terminar de configurar o dispositivo, confirme a configuração.
{primary:node0}[edit] user@host# commit
Entenda as armadilhas de failover do SNMP para failover de grupo de redundância de clusters de chassi
O clustering de chassi oferece suporte a armadilhas SNMP, que são acionadas sempre que há um failover de grupo de redundância.
A mensagem de armadilha pode ajudá-lo a solucionar problemas de failovers. Ela contém as seguintes informações:
ID de cluster e ID de nós
O motivo do failover
O grupo de redundância que está envolvido no failover
O estado e o estado atual do grupo de redundância
Estes são os diferentes estados em que um cluster pode estar em qualquer momento: hold, primário, secundário, insignificante e desativado. As armadilhas são geradas para as seguintes transições de estado (apenas uma transição de um estado de espera não desencadeia uma armadilha):
secundários <-> primários
primário — > porão secundário
porão secundário — > secundário
secundário — > iniligível
iniligível — > desativado
iniligível — > primário
secundário — > desativado
Uma transição pode ser desencadeada por qualquer evento, como monitoramento de interfaces, monitoramento de SPU, falhas e falhas manuais.
A armadilha é encaminhada sobre o link de controle se a interface de saída estiver em um nó diferente do nó no mecanismo de roteamento que gera a armadilha.
Você pode especificar se um log de rastreamento será gerado configurando a traceoptions flag snmp declaração.
Verificação do status de failover do cluster do chassi
Propósito
Exibir o status de failover de um cluster de chassi.
Ação
A partir da CLI, entre no show chassis cluster status comando:
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 3
Node name Priority Status Preempt Manual failover
Redundancy-group: 0, Failover count: 1
node0 254 primary no no
node1 2 secondary no no
Redundancy-group: 1, Failover count: 1
node0 254 primary no no
node1 1 secondary no no
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 15
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 5
node0 200 primary no no
node1 0 lost n/a n/a
Redundancy group: 1 , Failover count: 41
node0 101 primary no no
node1 0 lost n/a n/a
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 15
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 5
node0 200 primary no no
node1 0 unavailable n/a n/a
Redundancy group: 1 , Failover count: 41
node0 101 primary no no
node1 0 unavailable n/a n/a
Limpar o status de failover de cluster de chassi
Para limpar o status de failover de um cluster de chassi, insira o clear chassis cluster failover-count comando da CLI:
{primary:node1}
user@host> clear chassis cluster failover-count
Cleared failover-count for all redundancy-groups
Tabela de histórico de mudanças
O suporte de recursos é determinado pela plataforma e versão que você está usando. Use o Feature Explorer para determinar se um recurso é suportado em sua plataforma.