Solution Architecture
The three fabrics described in the previous section (Frontend, GPU Backend, and Storage Backend), are interconnected together in the overall AI JVD solution architecture as shown in Figure 2.
Figure 2: AI JVD Solution Architecture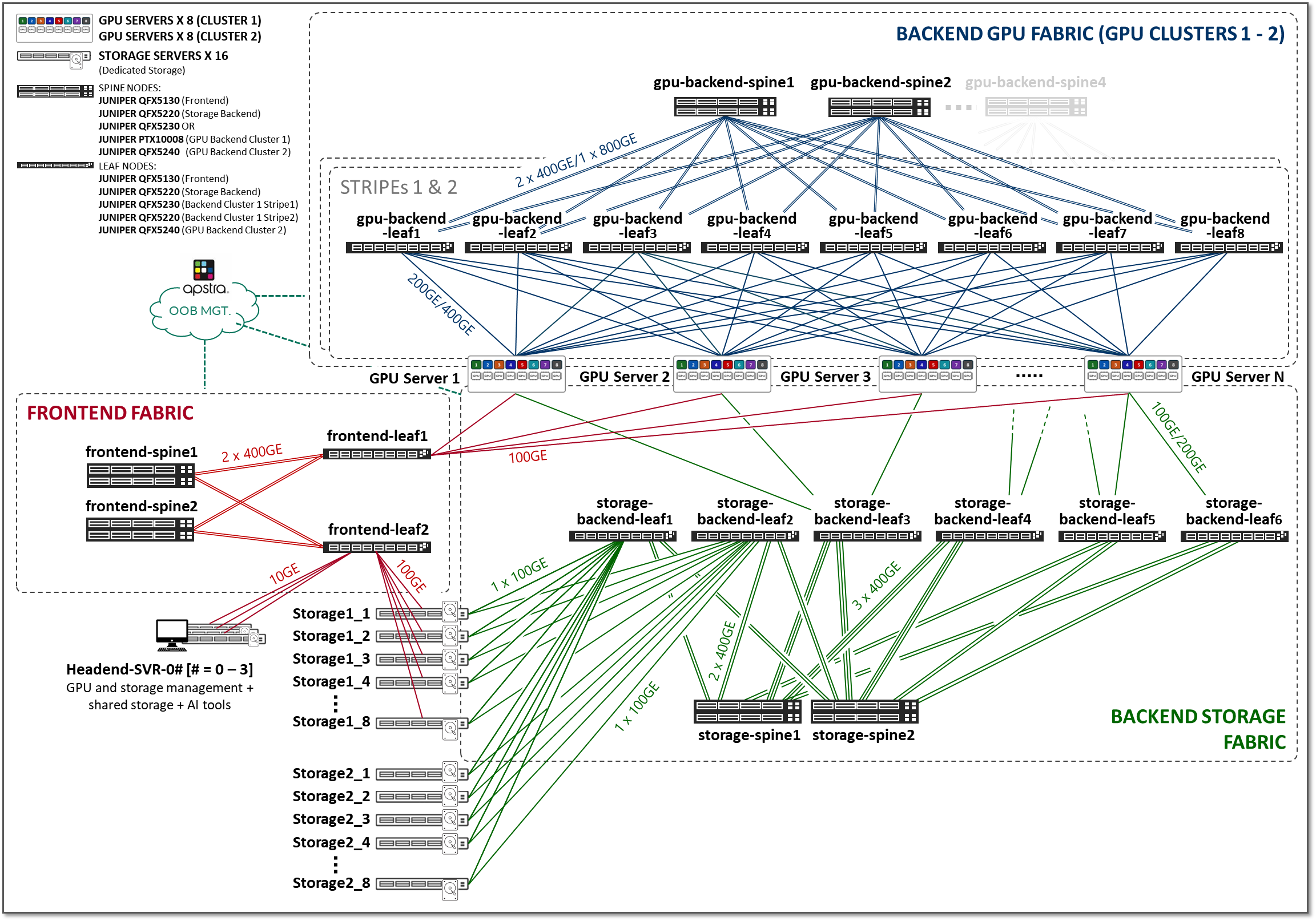
Frontend Fabric
For details about connecting Nvidia A100 and H100 GPU servers, as well as Weka Storage devices, to the Frontend Fabric, see Frontend Fabric section of the AI Data Center Network with Juniper Apstra, NVIDIA GPUs, and Weka Storage—Juniper Validated Design (JVD).
For details about connecting AMD MI300x GPU servers to the Frontend Fabric, see Frontend Fabric section of the AI Data Center Network with Juniper Apstra, AMD GPUs, and Vast Storage—Juniper Validated Design (JVD).
Storage Backend Fabric
In small clusters, it may be sufficient to use the local storage on each GPU server, or to aggregate this storage together using open-source or commercial software. In larger clusters with heavier workloads, an external dedicated storage system is required to provide dataset staging for ingest, and for cluster checkpointing during training.
Two leading platforms, WEKA and Vast Storage, provide cutting-edge solutions for shared storage in GPU environments, and have been tested in AI lab.
For details about connecting Weka storage devices to the Storage Backend Fabric, refer to the Storage fabric section of the AI Data Center Network with Juniper Apstra, NVIDIA GPUs, and WEKA Storage—Juniper Validated Design (JVD) as well as the WEKA Storage Solution section in the same document.
For details about connecting Vast storage devices to the Storage Backend Fabric, refer to the Storage fabric section of the AI Data Center Network with Juniper Apstra, AMD GPUs, and Vast Storage—Juniper Validated Design (JVD) as well as the VAST Storage Configuration section in the same document.
GPU Backend Fabric
The GPU Backend fabric provides the infrastructure for GPUs to communicate with each other within a cluster, using RDMA over Converged Ethernet (RoCEv2). RoCEv2 enhances data center efficiency, reduces complexity, and optimizes data delivery across high-speed Ethernet networks.
Packet loss can significantly impact job completion times and therefore should be avoided. Therefore, when designing the compute network infrastructure to support RoCEv2 for an AI cluster, one of the key objectives is to provide a near lossless fabric, while also achieving maximum throughput, minimal latency, and minimal network interference for the AI traffic flows. ROCEv2 is more efficient over lossless networks, resulting in optimum job completion times.
The GPU Backend fabric in this JVD was designed with these goals in mind.
We have built two different Clusters, as shown in Figure 3, which share the Frontend fabric and Storage Backend fabric but have separate GPU Backend fabrics . Each cluster is made of two stripes following the Rail Optimized Stripe Architecture , but include different switch models as Leaf and Spine nodes, as well as different GPU server models.
Figure 3: AI JVD Lab Clusters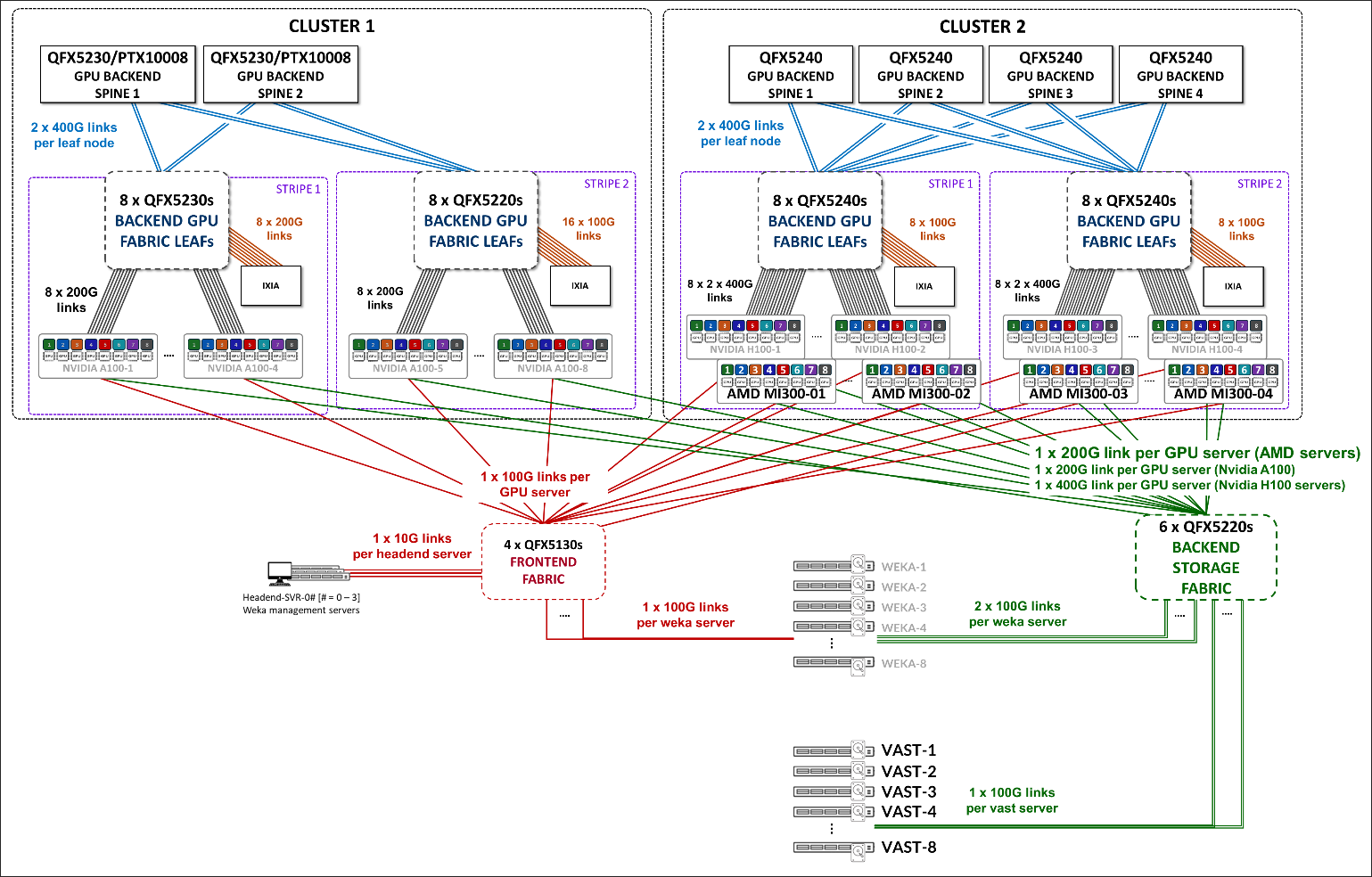
The GPU Backend in Cluster 1 consists of Juniper QFX5220 and QFX5230 switches as leaf nodes, and either QFX5230 switches or PTX10008 routers as spine nodes, along with NVIDIA A100 GPU servers. QFX5230 and PTX10008 devices have been validated independently as spine nodes while maintaining the same leaf configuration. The GPU backend fabric in this cluster follows a 3-stage Clos IP fabric architecture. Further details are available in the AI Data Center Network with Juniper Apstra, NVIDIA GPUs, and WEKA Storage—Juniper Validated Design (JVD).
The GPU Backend in Cluster 2 consists of Juniper QFX5240 switches acting as both leaf and spine nodes, along with AMD MI300X and NVIDIA H100 GPU servers. This cluster supports either a 3-stage IP fabric architecture or a 3-stage EVPN/VXLAN fabric architecture. Further details about the IP Fabric implementation are available in the AI Data Center Network with Juniper Apstra, AMD GPUs, and Vast Storage—Juniper Validated Design (JVD).
The EVPN/VXLAN-based implementation is the focus of this document.