Ejemplo: configuración de la supervisión de multidifusión
Descripción de la supervisión de multidifusión
Los dispositivos de red, como los enrutadores, operan principalmente a nivel de paquete o capa 3. Otros dispositivos de red, como puentes o conmutadores LAN, operan principalmente a nivel de trama o capa 2. La multidifusión funciona principalmente en el nivel de paquete, capa 3, pero hay una manera de asignar direcciones de grupo de multidifusión IP de capa 3 a direcciones de grupo de multidifusión MAC de capa 2 en el nivel de trama.
Los enrutadores pueden manejar información de direccionamiento de capa 2 y capa 3, ya que la trama y sus direcciones deben procesarse para acceder al paquete encapsulado que contiene. Los enrutadores pueden ejecutar protocolos de multidifusión de capa 3, como PIM o IGMP, y determinar dónde reenviar el contenido de multidifusión o cuándo un host de una interfaz se une o abandona un grupo. Sin embargo, se supone que los puentes y los conmutadores LAN, como dispositivos de capa 2, no tienen acceso a la información de multidifusión dentro de los paquetes que transportan sus tramas.
Entonces, ¿cómo pueden los puentes y otros dispositivos de capa 2 determinar cuándo un dispositivo en una interfaz se une o sale de un árbol de multidifusión, o si un host en una LAN conectada desea recibir el contenido de un grupo de multidifusión en particular?
La respuesta es que el dispositivo de capa 2 implemente la supervisión de multidifusión. La supervisión de multidifusión es un término general y se aplica al proceso de "espionaje" de un dispositivo de capa 2 en el contenido del paquete de capa 3 para determinar qué acciones se toman para procesar o reenviar una trama. Existen formas más específicas de espionaje, como el espionaje IGMP o el espionaje PIM. En todos los casos, el espionaje implica un dispositivo configurado para funcionar en la Capa 2 que tiene acceso a información de Capa 3 (paquete) normalmente "prohibida". El espionaje hace que la multidifusión sea más eficiente en estos dispositivos.
Ver también
Descripción de la supervisión de multidifusión y la protección raíz de VPLS
La supervisión se produce cuando un protocolo de capa 2, como un protocolo de árbol de expansión, conoce los detalles operativos de un protocolo de capa 3, como el Protocolo de administración de grupos de Internet (IGMP) u otro protocolo de multidifusión. La supervisión es necesaria cuando los dispositivos de capa 2, como los conmutadores VLAN, deben conocer la información de capa 3, como las direcciones MAC (control de acceso a medios) de los miembros de un grupo de multidifusión.
La protección raíz VPLS es un proceso de protocolo de árbol de expansión en el que solo una interfaz en un entorno de multihost reenvía activamente tramas de protocolo de árbol de expansión. Esto protege la raíz del árbol de expansión contra bucles de puente, pero también evita que ambos dispositivos de la topología multihost reciban información espiada, como los informes de membresía de IGMP.
Por ejemplo, considere una colección de hosts con capacidad de multidifusión conectados a dos enrutadores perimetrales del cliente (CE) (CE1 y CE2) que están conectados entre sí (se configura un vínculo CE1–CE2) y multihost a dos enrutadores perimetrales de proveedor (PE) (PE1 y PE2, respectivamente). El PE activo solo recibe información de protocolo de árbol de expansión reenviada en el vínculo PE-CE activo, debido a la operación de protección de raíz. Mientras el vínculo CE1–CE2 esté operativo, esto no es un problema. Sin embargo, si se produce un error en el vínculo entre CE1 y CE2, y el otro PE se convierte en el vínculo de protocolo de árbol de expansión activo, no hay información de espionaje de multidifusión disponible en el nuevo PE activo. El nuevo PE activo no reenviará tráfico de multidifusión al CE ni a los hosts atendidos por este enrutador CE.
La interrupción del servicio se corrige una vez que los hosts envían nuevos informes IGMP de pertenencia a grupos a los enrutadores CE. Sin embargo, la interrupción del servicio se puede evitar si la información de espionaje de multidifusión está disponible para ambos PE a pesar de la operación normal de protección raíz del protocolo de árbol de expansión.
Puede configurar la supervisión de multidifusión para ignorar los mensajes sobre cambios en la topología del árbol de expansión en dominios de puente en conmutadores virtuales y conmutadores de enrutamiento predeterminados de dominios de puente. Puede usar el comando para omitir los mensajes sobre cambios en la ignore-stp-topology-change topología del árbol de expansión
Ver también
Configuración de la supervisión de multidifusión
Para configurar los parámetros generales de espionaje de multidifusión para los enrutadores de la serie MX, incluya la multicast-snooping-options instrucción:
multicast-snooping-options { flood-groups [ ip-addresses ]; forwarding-cache { threshold suppress value <reuse value>; } graceful-restart <restart-duration seconds>; ignore-stp-topology-change; multichassis-lag-replicate-state; nexthop-hold-time milliseconds; traceoptions { file filename <files number> <size size> <world-readable | no-world-readable>; flag flag <flag-modifier> <disable>; } }
Puede incluir esta instrucción en los siguientes niveles jerárquicos:
[edit routing-instances routing-instance-name][edit logical-systems logical-system-name routing-instances routing-instance-name]
De forma predeterminada, la supervisión de multidifusión está deshabilitada. Puede habilitar la supervisión de multidifusión en VPLS o en tipos de instancia de conmutador virtual en la jerarquía de instancias.
Si hay varios dominios de puente configurados en una instancia de VPLS o de conmutador virtual, las opciones de supervisión de multidifusión configuradas en el nivel de instancia se aplican a todos los dominios de puente.
La ignore-stp-topology-change instrucción se admite únicamente para el tipo de instancia de enrutamiento del conmutador virtual y no se admite en la [edit logical-systems] jerarquía.
La nexthop-hold-time instrucción solo se admite en la [edit routing-instances routing-instance-name] jerarquía y solo para un tipo de instancia de conmutador virtual o vpls.
Ver también
Ejemplo: configuración de la supervisión de multidifusión
En este ejemplo, se muestra cómo configurar la supervisión de multidifusión en un escenario de instancia de enrutamiento de VPLS o puente.
Requisitos
En este ejemplo se utilizan los siguientes componentes de hardware:
Un enrutador serie MX
Un dispositivo de capa 3 que funciona como un enrutador de multidifusión
Antes de empezar:
Configure las interfaces.
Configure un protocolo de puerta de enlace interior. Consulte la biblioteca de protocolos de enrutamiento de Junos OS para dispositivos de enrutamiento.
Configure un protocolo de multidifusión. Esta función funciona con los siguientes protocolos de multidifusión:
DVMRP
PIM-DM
PIM-SM
PIM-SSM
Descripción general y topología
El espionaje IGMP evita que los dispositivos de capa 2 inunden indiscriminadamente el tráfico de multidifusión de todas las interfaces. Los ajustes que configure para la supervisión de multidifusión ayudan a administrar el comportamiento de la supervisión IGMP.
Puede configurar opciones de espionaje de multidifusión en la instancia maestra predeterminada y en instancias individuales de puente o VPLS. La configuración predeterminada de la instancia maestra es global y se aplica a todas las instancias individuales de puente o VPLS del enrutador lógico. La configuración de las instancias individuales anula la configuración global.
En este ejemplo se incluyen las siguientes instrucciones:
flood-groups: permite enumerar las direcciones de grupos de multidifusión para las que se debe inundar el tráfico. Esta configuración es útil para asegurarse de que el espionaje IGMP no evita las inundaciones de multidifusión necesarias. El bloque de direcciones de multidifusión de 224.0.0.1 a 224.0.0.255 está reservado para uso de cable local. Los grupos de este intervalo se asignan para diversos usos, incluidos los protocolos de enrutamiento y los mecanismos de detección local. Por ejemplo, OSPF utiliza 224.0.0.5 para todos los enrutadores OSPF.
forwarding-cache: especifica cómo se antigüan las entradas de reenvío y cómo se controla el número de entradas.
Puede configurar valores de umbral en la caché de reenvío para suprimir (suspender) la intromisión cuando las entradas de caché alcanzan un cierto máximo y reutilizar la memoria caché cuando el número cae a otro valor de umbral. De forma predeterminada, no hay valores de umbral habilitados en el enrutador.
El umbral de supresión suprime las nuevas entradas de caché de reenvío de multidifusión. Un umbral de reutilización opcional especifica el punto en el que el enrutador comienza a crear nuevas entradas de caché de reenvío de multidifusión. El rango para ambos umbrales es de 1 a 200.000. Si está configurado, el valor de reutilización debe ser menor que el valor de supresión. El valor de supresión es obligatorio. Si no especifica el valor de reutilización opcional, el número de entradas de caché de reenvío de multidifusión se limita al valor de supresión. Se crea una nueva entrada tan pronto como el número de entradas de caché de reenvío de multidifusión cae por debajo del valor de supresión.
graceful-restart: configura el tiempo después del cual las rutas aprendidas antes de un reinicio se reemplazan por rutas reaprendidas. Si el reinicio correcto para la supervisión de multidifusión está deshabilitado, la información de espionaje se pierde después de reiniciar el motor de enrutamiento.
De forma predeterminada, la duración del reinicio elegante es de 180 segundos (3 minutos). Puede establecer este valor entre 0 y 300 segundos. Si establece la duración en 0, el reinicio correcto se deshabilita efectivamente. Establezca este valor ligeramente mayor que el intervalo de respuesta de consulta IGMP.
ignore-stp-topology-change: configura el enrutador de la serie MX para que ignore los mensajes sobre el cambio de estado de la topología del árbol de expansión.
De forma predeterminada, el proceso de espionaje IGMP en un enrutador de la serie MX detecta los cambios de estado de interfaz realizados por cualquiera de los protocolos de árbol de expansión (STP).
En un entorno de multiconexión VPLS en el que dos enrutadores PE están conectados a dos enrutadores CE interconectados y la protección raíz STP está habilitada en los enrutadores PE, una de las interfaces del enrutador PE está en estado de reenvío y la otra en estado de bloqueo.
Si se produce un error en el vínculo que interconecta los dos enrutadores CE, la interfaz del enrutador PE en el estado de bloqueo pasa al estado de reenvío.
La interfaz del enrutador PE no espera a recibir informes de membresía en respuesta a la siguiente consulta general o específica del grupo. En su lugar, el proceso de espionaje IGMP envía un mensaje de consulta general al enrutador CE. Los hosts conectados al enrutador CE responden con informes para todos los grupos que les interesan.
Cuando se restaura el vínculo que interconecta los dos enrutadores CE, se restaura el estado original del árbol de expansión en ambos enrutadores PE. El PE de reenvío recibe un mensaje de cambio de topología de árbol de expansión y envía un mensaje de consulta general al enrutador CE para reconstruir inmediatamente el estado de pertenencia al grupo.
Nota:La
ignore-stp-topology-changeinstrucción solo se admite para el tipo de instancia de enrutamiento del conmutador virtual .
Topología
La figura 1 muestra una topología de multiconexión VPLS en la que una red de cliente tiene dos dispositivos CE con un vínculo entre ellos. Cada CE está conectado a un PE.
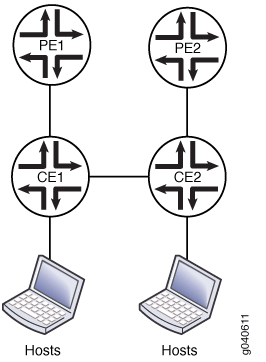 multiconexión de VPLS
multiconexión de VPLS
Configuración
Procedimiento
Configuración rápida de CLI
Para configurar rápidamente este ejemplo, copie los siguientes comandos, péguelos en un archivo de texto, elimine los saltos de línea, cambie los detalles necesarios para que coincidan con su configuración de red, copie y pegue los comandos en la CLI en el nivel de jerarquía y, a continuación, ingrese commit desde el [edit] modo de configuración.
set bridge-domains domain1 multicast-snooping-options forwarding-cache threshold suppress 100 set bridge-domains domain1 multicast-snooping-options forwarding-cache threshold reuse 50 set bridge-domains domain1 multicast-snooping-options graceful-restart restart-duration 120 set routing-instances ce1 instance-type virtual-switch set routing-instances ce1 bridge-domains domain1 domain-type bridge set routing-instances ce1 bridge-domains domain1 vlan-id 100 set routing-instances ce1 bridge-domains domain1 interface ge-0/3/9.0 set routing-instances ce1 bridge-domains domain1 interface ge-0/0/6.0 set routing-instances ce1 bridge-domains domain1 multicast-snooping-options flood-groups 224.0.0.5 set routing-instances ce1 bridge-domains domain1 multicast-snooping-options ignore-stp-topology-change
Procedimiento paso a paso
En el ejemplo siguiente es necesario navegar por varios niveles en la jerarquía de configuración. Para obtener información acerca de cómo navegar por la CLI, consulte el Manual del usuario de la CLI de Junos OS.
Para configurar la supervisión IGMP:
Configure las opciones de espionaje de multidifusión en la instancia de enrutamiento principal.
[edit bridge-domains domain1] user@host# set multicast-snooping-options forwarding-cache threshold suppress 100 reuse 50 user@host# set multicast-snooping-options graceful-restart 120
Configure la instancia de enrutamiento.
[edit routing-instances ce1] user@host# set instance-type virtual-switch
Configure el dominio de puente en la instancia de enrutamiento.
[edit routing-instances ce1 bridge-domains domain1] user@host# set domain-type bridge user@host# set interface ge-0/0/6.0 user@host# set interface ge-0/3/9.0 user@host# set vlan-id 100
Configurar grupos de inundación.
[edit routing-instances ce1 bridge-domains domain1] user@host# set multicast-snooping-options flood-groups 224.0.0.5
Configure el enrutador para que ignore los mensajes sobre cambios de estado de topología de árbol de expansión.
[edit routing-instances ce1 bridge-domains domain1] user@host# set multicast-snooping-options ignore-stp-topology-change
Si ha terminado de configurar el dispositivo, confirme la configuración.
user@host# commit
Resultados
Confirme la configuración introduciendo los show bridge-domains comandos y show routing-instances .
user@host# show bridge-domains
domain1 {
multicast-snooping-options {
forwarding-cache {
threshold {
suppress 100;
reuse 50;
}
}
}
}
user@host# show routing-instances
ce1 {
instance-type virtual-switch;
bridge-domains {
domain1 {
domain-type bridge;
vlan-id 100;
interface ge-0/3/9.0; ## 'ge-0/3/9.0' is not defined
interface ge-0/0/6.0; ## 'ge-0/0/6.0' is not defined
multicast-snooping-options {
flood-groups 224.0.0.5;
ignore-stp-topology-change;
}
}
}
}
Verificación
Para comprobar la configuración, ejecute los siguientes comandos:
Mostrar interfaz de espionaje IGMP
Mostrar membresía de IGMP Snooping
Mostrar estadísticas de espionaje IGMP
Mostrar ruta de espionaje de multidifusión
Mostrar tabla de rutas
Habilitación de actualizaciones masivas para la supervisión de multidifusión
Cada vez que una interfaz individual se une o abandona un grupo de multidifusión, se instala una nueva entrada de salto siguiente en la tabla de enrutamiento y la tabla de reenvío. Puede utilizar la instrucción para especificar un tiempo, de 1 a 1000 milisegundos (ms), durante el nexthop-hold-time cual los cambios salientes de la interfaz se acumulan y, a continuación, se actualizan de forma masiva a la tabla de enrutamiento y a la tabla de reenvío. La actualización masiva reduce el tiempo de procesamiento y la sobrecarga de memoria necesarios para procesar los mensajes de unión y salida. Esto es útil para aplicaciones como Internet Potocol televisión (IPTV), en la que los usuarios que cambian de canal pueden crear miles de interfaces uniéndose o saliendo de un grupo en un corto período de tiempo. En los escenarios de IPTV, normalmente hay un número relativamente pequeño y controlado de flujos y un alto número de interfaces salientes. El uso de actualizaciones masivas puede reducir el retraso de la unión.
En este ejemplo, configure un tiempo de espera de 20 milisegundos para el conmutador virtual de tipo instancia mediante la nexthop-hold-time instrucción:
Puede incluir la nexthop-hold-time instrucción solo para los tipos de instancia de enrutamiento de conmutador virtual o vpls en el siguiente nivel jerárquico.
[edit routing-instances routing-instance-name multicast-snooping-options]
Si la nexthop-hold-time instrucción se elimina de la configuración del enrutador, se deshabilitan las actualizaciones masivas.
Ver también
Habilitación de la supervisión de multidifusión para interfaces de grupo de agregación de vínculos de varios chasis
Incluya la instrucción en el nivel de jerarquía para habilitar la supervisión IGMP y la multichassis-lag-replicate-state [edit multicast-snooping-options] replicación de estado para interfaces de grupo de agregación de vínculos multichasis (MC-LAG).
[edit]
multicast-snooping-options {
multichassis-lag-replicate-state;
}
La replicación de mensajes de unión y salida entre vínculos de una interfaz MC-LAG de doble vínculo permite una recuperación más rápida de la información de membresía para las interfaces MC-LAG que experimentan interrupción del servicio.
Sin replicación de estado, si una interfaz MC-LAG de doble vínculo experimenta una interrupción del servicio (por ejemplo, si un vínculo activo cambia a modo de espera), la información de pertenencia de la interfaz se recupera generando una consulta IGMP a la red. Este método puede tardar de 1 a 10 segundos en completarse, lo que puede ser demasiado largo para algunas aplicaciones.
Cuando se proporciona replicación de estado para interfaces MC-LAG, los mensajes IGMP de unirse o dejar recibidos en un dispositivo MC-LAG se replican desde el vínculo MC-LAG activo al vínculo en espera a través de una conexión de protocolo de comunicación entre chasis (ICCP). El vínculo en espera procesa los mensajes como si se recibieran del vínculo MC-LAG activo correspondiente, excepto que no se agrega a sí mismo como un salto siguiente y no inunda el mensaje a la red. Después de una conmutación por error, el estado de pertenencia a multidifusión del vínculo se puede recuperar en unos segundos o menos recuperando los mensajes replicados.
En este ejemplo se habilita la replicación de estado para interfaces MC-LAG: