가상 출력 대기열 이해하기
가상 출력 대기열 소개
이 주제에서는 VOQ 아키텍처와 구성 가능한 CoS(class-of-service) 구성 요소와 함께 작동하는 방식을 소개합니다.
지원되는 플랫폼에서 Junos 하드웨어 CoS 기능은 각 송신 출력 대기열에 대한 트래픽을 버퍼 및 대기열에 넣기 위해 수신 시 가상 출력 대기열을 사용합니다. 대부분의 플랫폼은 출력 포트(물리적 인터페이스)당 최대 8개의 송신 출력 대기열을 지원합니다.
라우터를 통해 트래픽을 전달하는 기존의 방법은 수신 인터페이스의 입력 대기열에서 수신 트래픽을 버퍼링하고, 패브릭 전반에서 송신 인터페이스의 출력 대기열로 트래픽을 전달한 다음, 트래픽을 다음 홉으로 전송하기 전에 출력 대기열에서 트래픽을 다시 버퍼링하는 것을 기반으로 합니다. 수신 포트에서 패킷을 대기열에 넣는 기존의 방법은 서로 다른 송신 포트로 향하는 트래픽을 동일한 입력 대기열(버퍼)에 저장하는 것입니다.
혼잡 기간 동안 라우터는 송신 포트에서 패킷을 드롭할 수 있으므로 라우터는 스위치 패브릭을 통해 송신 포트로 트래픽을 전송하는 데 리소스를 소비할 수 있지만 트래픽을 전달하는 대신 드롭할 수 있습니다. 또한 입력 대기열은 서로 다른 송신 포트로 향하는 트래픽을 저장하기 때문에 한 송신 포트의 혼잡이 다른 송신 포트의 트래픽에 영향을 미칠 수 있으며, 이러한 상태를 HOLB(head-of-line blocking)라고 합니다.
VOQ 아키텍처는 다른 접근 방식을 취합니다.
-
입력 및 출력 큐에 대한 별도의 물리적 버퍼 대신, Junos 디바이스는 각 패킷 포워딩 엔진(PFE)의 수신 파이프라인에 있는 물리적 버퍼를 사용하여 모든 송신 포트에 대한 트래픽을 저장합니다. 송신 포트의 모든 출력 대기열은 라우터의 모든 PFE에 있는 모든 수신 파이프라인에 버퍼 저장 공간을 갖습니다. 출력 큐에 대한 수신 파이프라인 스토리지 공간의 매핑은 1:1이므로 각 출력 큐는 각 수신 파이프라인의 버퍼 공간을 받습니다.
-
여러 개의 서로 다른 출력 대기열(일대다 매핑)로 향하는 트래픽을 포함하는 하나의 입력 대기열 대신, 각 출력 대기열에는 해당 출력 대기열 전용(1:1 매핑)인 각 PFE의 입력 버퍼로 구성된 전용 VOQ가 있습니다. 이 아키텍처는 두 포트 간의 통신이 다른 포트에 영향을 미치지 않도록 합니다.
-
VOQ는 트래픽을 포워딩할 수 있을 때까지 물리적 출력 대기열에 저장하는 대신, 송신 포트에 트래픽을 포워딩할 리소스가 있을 때까지 패브릭을 통해 송신 포트에서 송신 포트로 트래픽을 전송하지 않습니다. VOQ는 하나의 송신 포트에서 하나의 출력 큐로 향하는 트래픽을 수신하고 저장하는 입력 큐(버퍼)의 모음입니다. 각 송신 포트의 각 출력 대기열에는 해당 출력 대기열로 트래픽을 전송하는 모든 입력 대기열로 구성된 고유한 전용 VOQ가 있습니다.
VOQ는 하나의 송신 포트에서 하나의 출력 큐로 향하는 트래픽을 수신하고 저장하는 입력 큐(버퍼)의 모음입니다. 각 송신 포트의 각 출력 대기열에는 해당 출력 대기열로 트래픽을 전송하는 모든 입력 대기열로 구성된 고유한 전용 VOQ가 있습니다.
VOQ 아키텍처
VOQ는 특정 출력 대기열에 대한 수신 버퍼링을 나타냅니다. 각 PFE는 특정 출력 큐를 사용합니다. PFE에 저장된 트래픽은 하나의 포트에서 하나의 특정 출력 대기열로 향하는 트래픽으로 구성되며, 해당 출력 대기열에 대한 VOQ입니다.
VOQ는 해당 출력 대기열로 트래픽을 적극적으로 전송하고 있는 라우터의 모든 PFE에 분산됩니다. 각 출력 대기열은 라우터의 모든 PFE에서 해당 출력 대기열에 할당된 총 버퍼의 합계입니다. 따라서 출력 큐는 물리적 입력 큐로 구성되지만 출력 큐 자체는 물리적인 것이 아니라 가상입니다.
RTT(Round-Trip Time) 버퍼링
혼잡 기간(장기 저장 없음) 동안 출력 대기열 버퍼링이 없더라도, 송신 라인 카드에는 작은 물리적 출력 대기열 버퍼가 있어 트래픽이 수신에서 송신으로 패브릭을 통과하는 왕복 시간을 수용할 수 있습니다. 왕복 시간은 수신 포트가 송신 포트 리소스를 요청하고, 송신 포트로부터 리소스에 대한 보조금을 받고, 패브릭 전반에 데이터를 전송하는 데 걸리는 시간으로 구성됩니다.
즉, 라우터 수신 시 패킷이 드롭되지 않고 라우터가 패브릭을 통해 송신 포트로 패킷을 전달하는 경우, 패킷은 드롭되지 않고 다음 홉으로 포워딩됩니다. 모든 패킷 드롭은 수신 파이프라인에서 발생합니다.
VOQ의 장점
VOQ 아키텍처는 두 가지 주요 이점을 제공합니다.
HOL(head-of-line) 차단 제거
VOQ 아키텍처는 HOLB(head-of-line blocking) 문제를 제거합니다. non-VOQ 디바이스에서 HOLB는 송신 포트의 혼잡이 혼잡하지 않은 다른 송신 포트에 영향을 미칠 때 발생합니다. HOLB는 혼잡한 포트와 혼잡하지 않은 포트가 수신 인터페이스에서 동일한 입력 큐를 공유할 때 발생합니다.
VOQ 아키텍처는 각 인터페이스의 각 출력 대기열에 대해 서로 다른 전용 가상 대기열을 생성하여 HOLB를 방지합니다.
서로 다른 송신 대기열이 동일한 입력 대기열을 공유하지 않기 때문에 한 포트의 혼잡한 송신 대기열은 다른 포트의 송신 대기열에 영향을 미칠 수 없습니다. 같은 이유로, 한 포트의 혼잡한 송신 대기열은 동일한 포트의 다른 송신 대기열에 영향을 미칠 수 없습니다. 각 출력 대기열에는 수신 인터페이스 입력 대기열로 구성된 고유한 전용 VOQ가 있습니다.
수신 인터페이스에서 대기열 버퍼링을 수행하면 송신 대기열이 해당 트래픽을 수신할 준비가 된 경우에만 라우터가 패브릭을 통해 송신 대기열로 트래픽을 전송합니다. 송신 대기열이 트래픽을 수신할 준비가 되지 않은 경우 트래픽은 수신 인터페이스에서 버퍼링된 상태로 유지됩니다.
패브릭 효율성 및 활용도 증대
기존의 출력 대기열 아키텍처에는 VOQ 아키텍처가 해결하는 몇 가지 내재된 비효율성이 있습니다.
-
패킷 버퍼링—기존 큐잉 아키텍처는 각 패킷을 장기 DRAM 스토리지에서 수신 인터페이스와 송신 인터페이스에서 각각 두 번 버퍼링합니다. VOQ 아키텍처는 수신 인터페이스의 장기 DRAM 스토리지에서 각 패킷을 한 번만 버퍼링합니다. 패브릭은 CoS 정책을 송신할 수 있을 만큼 충분히 빠르므로 송신 인터페이스에서 패킷을 두 번째로 버퍼링하는 대신 라우터는 구성된 송신 CoS 정책(스케줄링)에 영향을 주지 않고 깊은 송신 버퍼가 필요하지 않은 속도로 트래픽을 포워딩할 수 있습니다.
-
리소스 소비 - 기존 큐잉 아키텍처는 패브릭 전체에서 수신 인터페이스 입력 큐(버퍼)에서 송신 인터페이스 출력 큐(버퍼)로 패킷을 전송합니다. 송신 인터페이스에서는 라우터가 패브릭 전반에 걸쳐 패킷을 전송하고 송신 대기열에 저장하는 데 리소스를 소비했더라도 패킷이 누락될 수 있습니다. VOQ 아키텍처는 송신 인터페이스가 트래픽을 전송할 준비가 될 때까지 패브릭을 통해 송신 인터페이스로 패킷을 전송하지 않습니다. 이렇게 하면 나중에 삭제되는 패킷을 전송 및 저장하는 데 리소스가 낭비되지 않으므로 시스템 활용도가 높아집니다.
VOQ는 CoS를 구성하는 방법을 변경합니까?
CoS 기능을 구성하는 방법은 변경되지 않습니다. 그림 1 은 Junoś CoS 구성 요소와 VOQ 선택을 보여주며, 상호 작용하는 순서를 보여줍니다.
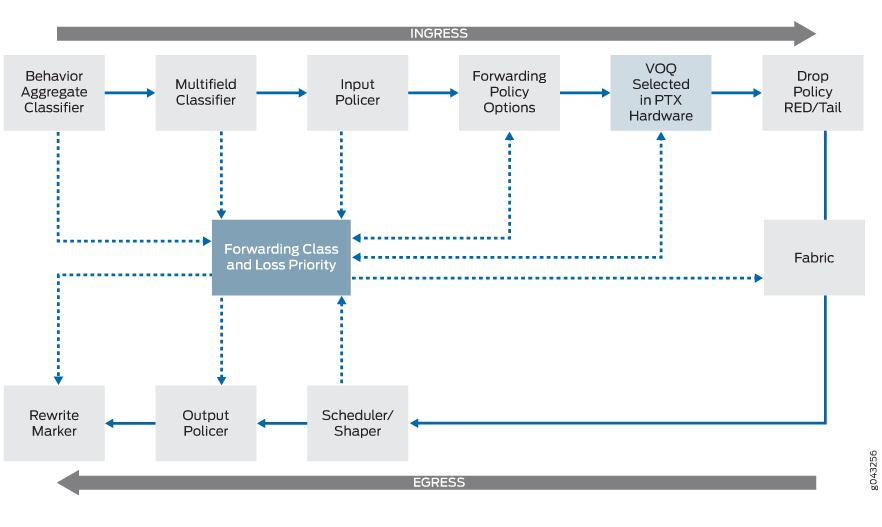
VOQ 선택 프로세스는 구성에 따라 BA(Behavior Aggregate) 분류자 또는 다중 필드 분류기를 사용하여 송신 포트에 가능한 8개의 VOQ 중 하나를 선택하는 ASIC에 의해 수행됩니다. CoS 구성을 기반으로 송신 포트에 대한 수신 버퍼 데이터의 VOQ.
CoS 기능은 변경되지 않지만 VOQ와 몇 가지 운영상의 차이가 있습니다.
-
무작위 조기 탐지(RED)는 수신 PFE에서 발생합니다. 송신 출력 큐잉만 지원하는 디바이스에서는 송신에서 RED 및 관련 혼잡 드롭이 발생합니다. 수신 시 RED를 수행하면 귀중한 리소스를 절약하고 라우터 성능을 높일 수 있습니다.
VOQ와 함께 인그레스(ingress)에서 RED가 발생하더라도 드롭 프로파일 구성 방법에는 변화가 없습니다.
-
패브릭 스케줄링은 요청 및 부여 제어 메시지를 통해 제어됩니다. 패킷은 송신 PFE가 수신 준비가 되었음을 나타내는 부여 메시지를 수신 PFE에 보낼 때까지 수신 VOQ에서 버퍼링됩니다. 패브릭 스케줄링에 대한 자세한 내용은 PTX 시리즈 라우터의 패브릭 스케줄링 및 가상 출력 대기열을 참조하십시오.
VOQ 작동 방식 이해
이 주제는 지원되는 Junos 디바이스에서 VOQ 프로세스가 작동하는 방식을 설명합니다.
VOQ 프로세스의 구성 요소 이해
그림 2 는 VOQ 프로세스와 관련된 Junos 디바이스의 하드웨어 구성 요소를 보여줍니다.
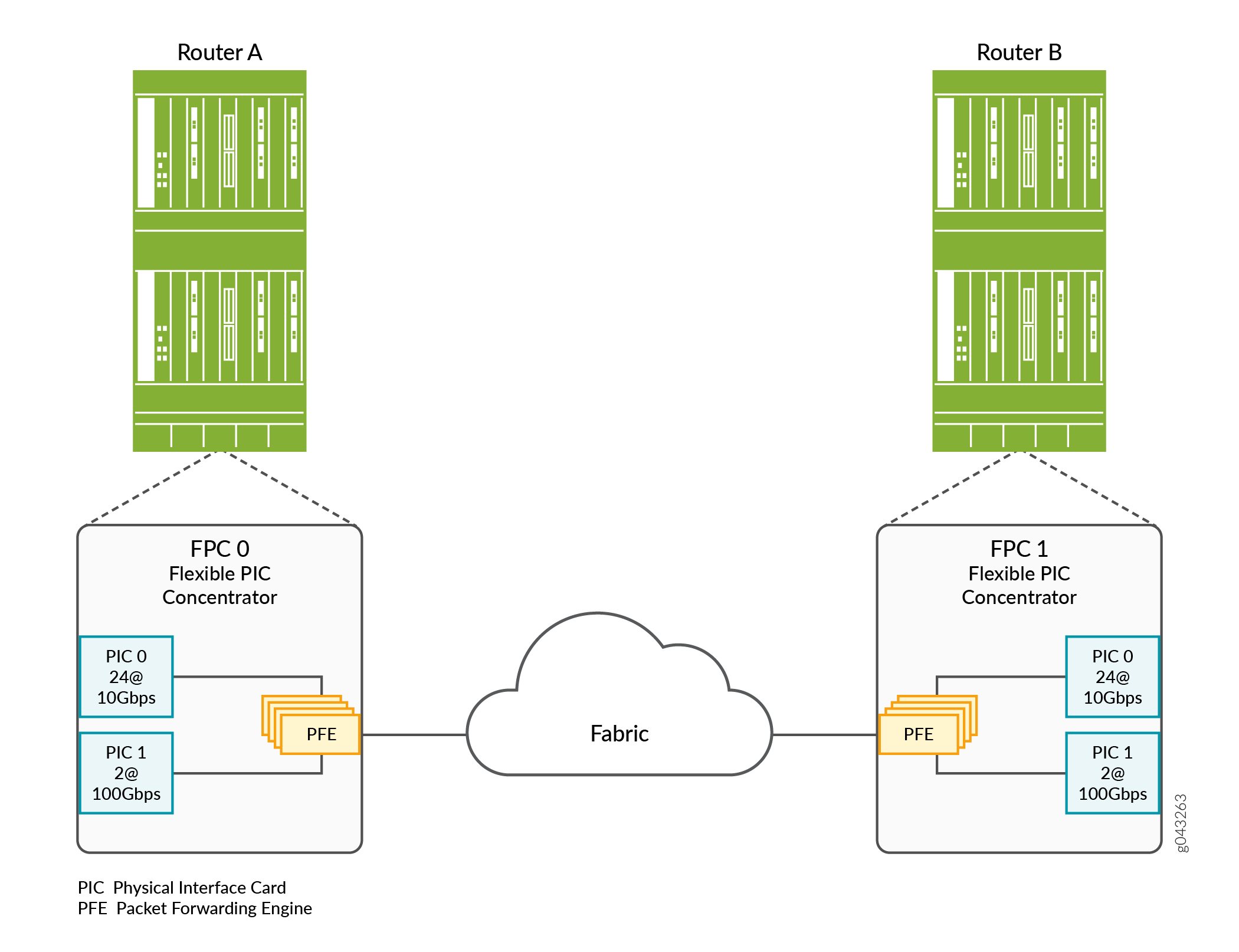 의 VOQ 구성 요소
의 VOQ 구성 요소
이러한 구성 요소는 다음과 같은 기능을 수행합니다.
-
Physical Interface Card (PIC)- 다양한 네트워크 미디어 유형에 물리적 연결을 제공하여 네트워크에서 수신 패킷을 수신하고 발신 패킷을 네트워크로 전송합니다.
-
Flexible PIC Concentrator (FPC)- 설치된 PIC를 다른 패킷 전송 라우터 구성 요소에 연결합니다.
-
Packet Forwarding Engine (PFE)- L2 및 L3 패킷 스위칭 및 캡슐화 및 캡슐화 해제를 제공합니다. PFE는 또한 포워딩, 경로 조회 기능을 제공하고 패킷 버퍼링 및 알림 대기열을 관리합니다. PFE는 FPC에 설치된 PIC로부터 수신 패킷을 수신하고 디바이스 평면을 통해 적절한 대상 포트로 패킷을 전달합니다.
-
Output queues—(표시되지 않음) 이러한 출력 대기열은 CoS 스케줄러 구성에 의해 제어되며, 디바이스 패브릭으로 전송하기 위해 출력 대기열 내의 트래픽을 처리하는 방법을 설정합니다. 또한 이러한 출력 대기열은 패킷이 수신 VOQ에서 송신 출력 대기열로 전송되는 시기를 제어합니다.
VOQ 프로세스 이해하기
출력 대기열은 CoS 스케줄러 구성에 의해 제어되며, 이는 패브릭으로 전송하기 위해 출력 대기열 내의 트래픽을 처리하는 방법을 설정합니다. 또한 이러한 출력 대기열은 패킷이 수신 VOQ에서 송신 출력 대기열로 전송되는 시기를 제어합니다.
모든 송신 출력 대기열에 대해 VOQ 아키텍처는 모든 수신 PFE 각각에 가상 대기열을 제공합니다. 이러한 대기열은 라인 카드에 실제로 패킷이 대기열에 포함된 경우에만 수신 PFE에 물리적으로 존재하기 때문에 가상이라고 합니다.
그림 3 에는 PFE0, PFE1 및 PFE2의 세 가지 입력 PFE가 표시되어 있습니다. 각 수신 PFE는 단일 송신 포트 0에 대해 최대 8개의 VOQ(PFE.e0.q0n에서 PFE.e0.q7n)를 제공합니다. 송신 PFE(PFEn)는 라운드 로빈 방식으로 각 수신 VOQ에 대역폭을 분배합니다.
예를 들어, 송신 PFE n의 VOQ e0.q0에는 10Gbps의 대역폭을 사용할 수 있습니다. PFE 0은 e0.qo에 10Gbps의 부하를 제공하며, PFE1 및 PFE2는 e0.q0에 1Gbps의 부하를 제공합니다. 그 결과 PFE1 및 PFE2는 트래픽의 100%를 통과하는 반면, PFE0은 트래픽의 80%만 통과합니다.
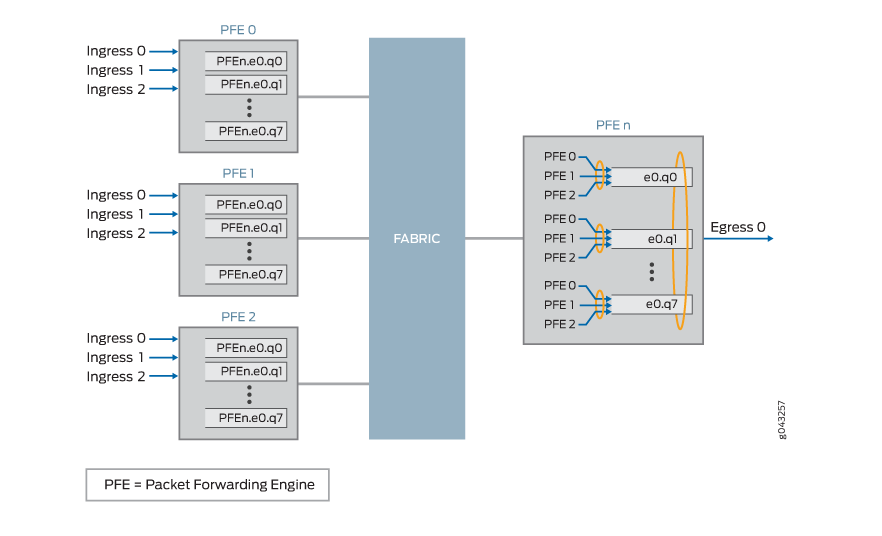
그림 4 는 송신 출력 대기열과 수신 가상 출력 대기열 간의 상관 관계를 보여주는 예입니다. 송신 측에서 PFE-X에는 4개의 다른 포워딩 클래스로 구성된 100Gbps 포트가 있습니다. 그 결과, PFE-X의 100Gbps 송신 출력 포트는 사용 가능한 송신 출력 대기열 8개 중 4개(PFE-X에서 주황색 점선으로 강조 표시된 4개의 대기열로 표시)를 사용하며, VOQ 아키텍처는 각 수신 PFE에 4개의 해당 가상 출력 대기열을 제공합니다(PFE-A 및 PFE-B의 4개의 가상 대기열은 주황색 점선으로 강조 표시). PFE-A 및 PFE-B의 가상 대기열은 전송할 트래픽이 있을 때만 존재합니다.
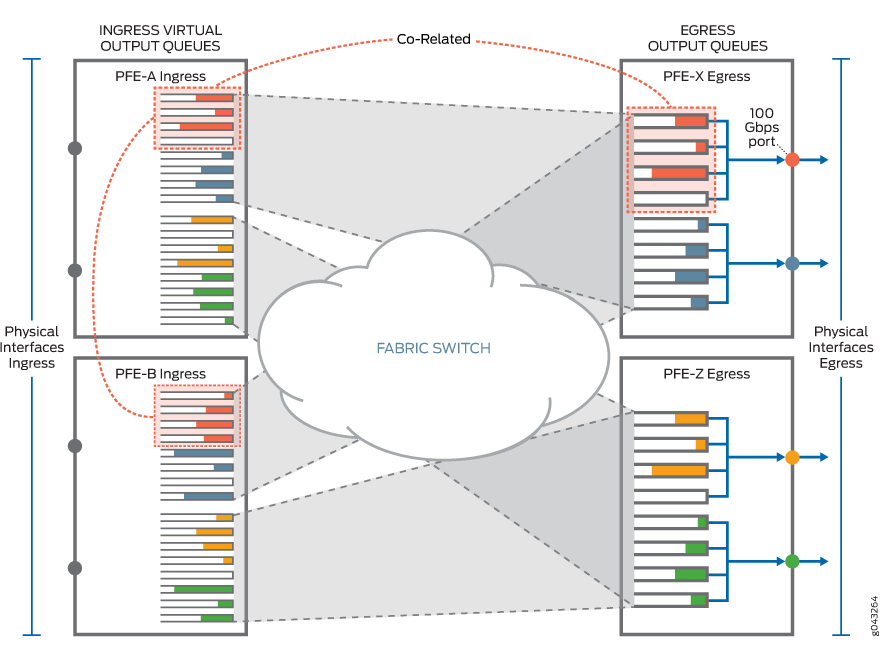 의 예
의 예
패브릭 스케줄링 및 VOQ
이 주제는 VOQ를 사용하는 Junos 디바이스의 패브릭 스케줄링 프로세스에 대해 설명합니다.
VOQ는 요청 및 부여 메시지를 사용하여 Junos 디바이스의 패브릭 스케줄링을 제어합니다. 송신 패킷 전달 엔진은 요청 및 부여 메시지를 사용하여 수신 VOQ로부터의 데이터 전달을 제어합니다. 가상 대기열은 송신 패킷 포워딩 엔진가 수신 패킷 포워딩 엔진에 부여 메시지를 전송하여 패킷을 수신할 준비가 되었음을 확인할 때까지 송신에서 패킷을 버퍼링합니다.
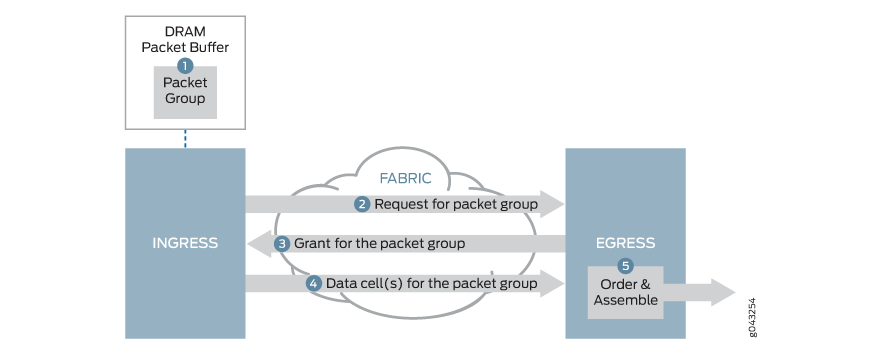
그림 5 는 VOQ가 있는 Junos 디바이스에서 사용하는 패브릭 스케줄링 프로세스를 보여줍니다. 패킷이 수신 포트에 도착하면 수신 파이프라인은 대상 출력 대기열과 연결된 수신 대기열에 패킷을 저장합니다. 라우터는 패킷 검색을 수행한 후 버퍼링 결정을 내립니다. 패킷이 최대 트래픽 임계값을 초과한 포워딩 클래스에 속하는 경우 패킷이 버퍼링되지 않고 삭제될 수 있습니다. 예약 프로세스는 다음과 같이 작동합니다.
-
수신 패킷 포워딩 엔진은 패킷을 수신하여 가상 대기열에 버퍼링한 다음 동일한 송신 인터페이스 및 데이터 출력 대기열로 향하는 다른 패킷과 패킷을 그룹화합니다.
-
수신 라인 카드 패킷 포워딩 엔진은 패브릭을 통해 패킷 그룹에 대한 참조가 포함된 요청을 송신 패킷 포워딩 엔진으로 보냅니다.
-
사용 가능한 송신 대역폭이 있는 경우, 송신 라인 카드 부여 스케줄러는 수신 라인 카드 패킷 포워딩 엔진에 대역폭 부여를 전송하여 응답합니다. .
-
수신 라인 카드 패킷 포워딩 엔진이 송신 라인 카드 패킷 포워딩 엔진으로부터 부여를 받으면 수신 패킷 포워딩 엔진은 패킷 그룹을 세그먼트화하고 패브릭을 통해 송신 패킷 포워딩 엔진으로 모든 조각을 보냅니다.
-
송신 패킷 포워딩 엔진은 조각을 수신하고, 조각을 패킷 그룹으로 리어셈블하고, 개별 패킷을 VOQ에 해당하는 데이터 출력 대기열에 넣습니다.
수신 패킷은 출력 대기열이 더 많은 트래픽을 수락하고 전달할 준비가 될 때까지 수신 포트 입력 대기열의 VOQ에 남아 있습니다.
대부분의 조건에서 패브릭은 CoS 정책을 송신할 수 있을 만큼 충분히 빠릅니다. 따라서 패브릭 전체에서 수신 포트로 트래픽을 수신 파이프라인에서 송신 포트로 전달하는 프로세스는 트래픽에 대해 구성된 CoS 정책에 영향을 미치지 않습니다. 패브릭은 패브릭 장애 또는 포트 공정성 문제가 있는 경우에만 CoS 정책에 영향을 미칩니다.
패킷이 동일한 패킷 포워딩 엔진(로컬 스위칭)을 수신 및 송신할 때, 패킷은 패브릭을 통과하지 않습니다. 그러나 라우터는 동일한 요청 및 권한 부여 메커니즘을 사용하여 패브릭을 교차하는 패킷과 송신 대역폭을 수신하므로 로컬로 라우팅된 패킷과 패브릭을 교차한 후 패킷 포워딩 엔진에 도착하는 패킷은 트래픽이 동일한 출력 대기열을 놓고 경합할 때 공정하게 처리됩니다.
패킷 포워딩 엔진의 이해 공정성 및 VOQ 프로세스
이 주제는 Junos 디바이스에서 VOQ와 함께 사용되는 패킷 포워딩 엔진 공정성 체계에 대해 설명합니다.
패킷 포워딩 엔진의 공정성은 모든 패킷 전달 엔진이 송신 관점에서 동등하게 취급되는 것을 의미합니다. 여러 송신 패킷 전달 엔진이 동일한 VOQ에서 데이터를 전송해야 하는 경우 패킷 전달 엔진은 라운드 로빈 방식으로 서비스됩니다. VOQ 서비스는 각 소스 패킷 전달 엔진에 존재하는 부하에 종속 되지 않습니다 .
그림 6은 3개의 패킷 전달 엔진을 사용하는 간단한 예에서 VOQ와 함께 사용되는 패킷 포워딩 엔진 공정성 체계를 보여줍니다. Ingress PFE-A에는 PFE-C의 VOQx로 향하는 10Gbps 데이터의 단일 스트림이 있습니다. PFE-B는 PFE-C의 VOQx로 향하는 100Gbps 데이터의 단일 스트림을 가지고 있습니다. PFE-C에서 VOQx는 100Gbps 인터페이스에 의해 서비스되며, 이는 해당 인터페이스에서 유일한 활성 VOQ입니다.

그림 6에는 100Gbps 출력 인터페이스로 향하는 총 110Gbps의 소스 데이터가 있습니다. 결과적으로 10Gbps의 데이터를 삭제해야 합니다. 드롭은 어디에서 발생하며, 이 드롭은 PFE-A와 PFE-B의 트래픽에 어떤 영향을 미칩니까?
PFE-A 및 PFE-B는 송신 PFE-C에 의해 라운드 로빈 방식으로 서비스되기 때문에 PFE-A에서 오는 10Gbps의 모든 트래픽은 송신 출력 포트를 통과합니다. 그러나 PFE-B에서 10Gbps의 데이터가 삭제되어 PFE-B에서 90Gbps의 데이터만 PFE-C로 전송할 수 있습니다. 따라서 10Gbps 스트림은 0% 감소하고 100Gbps 스트림은 10%만 감소합니다.
그러나 PFE-A와 PFE-B가 각각 100Gbps의 데이터를 소싱한다면 각각 50Gbps의 데이터를 드롭합니다. 이는 송신 PFE-C가 라운드 로빈 알고리즘을 사용하여 수신 가상 대기열의 서비스 및 드레이닝 속도를 실제로 제어하기 때문입니다. 라운드 로빈 알고리즘을 사용하면 여러 소스가 있을 때 더 높은 대역폭 소스가 항상 불이익을 받습니다. 알고리즘은 두 소스의 대역폭을 동일하게 만들려고 시도합니다. 그러나 느린 소스의 대역폭을 높일 수 없기 때문에 높은 소스의 대역폭을 삭제합니다. 라운드 로빈 알고리즘은 소스의 송신 대역폭이 동일해질 때까지 이 시퀀스를 계속합니다.
각 수신 패킷 포워딩 엔진은 단일 송신 포트에 대해 최대 8개의 VOQ를 제공합니다. 송신 패킷 포워딩 엔진은 각 수신 VOQ에 대역폭을 분배합니다. 따라서 VOQ는 제시된 부하에 관계없이 동등한 대우를 받습니다. 큐의 드레이닝 속도는 큐가 드레이닝되는 속도입니다. 송신 패킷 포워딩 엔진은 각 출력 대기열에 대한 대역폭을 수신 패킷 전달 엔진에 균등하게 나눕니다. 따라서 각 수신 패킷 포워딩 엔진의 드레인 속도=출력 대기열의 드레이닝 속도/수신 패킷 전달 엔진 수.
혼잡 처리
발생할 수 있는 혼잡에는 두 가지 주요 유형이 있습니다.
-
수신 혼잡 — 수신 패킷 포워딩 엔진에 송신이 처리할 수 있는 것보다 더 많은 부하가 제공될 때 발생합니다. 수신 혼잡 사례는 대기열이 쌓이고 대기열이 구성된 임계값을 초과하면 패킷이 손실된다는 점에서 기존 라우터와 매우 유사합니다.
-
송신 혼잡 — 모든 수신 패킷 전달 엔진의 합계가 송신 송신 라우터의 기능을 초과할 때 발생합니다. 모든 삭제는 수신 패킷 전달 엔진에서 수행됩니다. 그러나 수신 대기열의 크기는 대기열의 드레이닝 속도(송신 패킷 포워딩 엔진이 패킷을 요청하는 속도)에 의해 감쇠됩니다. 이 속도는 기본적으로 요청이 송신 패킷 포워딩 엔진에 의해 권한 부여로 전환되는 속도에 따라 결정됩니다. 송신 패킷 포워딩 엔진은 라운드 로빈 방식으로 요청-부여 변환을 서비스합니다. 제공된 로드를 수신 패킷 전달 엔진에 종속하지 않습니다. 예를 들어, 수신 패킷 포워딩 엔진의 드레이닝 속도가 예상치의 절반인 경우(2개의 수신 패킷 전달 엔진이 대상 출력 대기열에 대해 초과 구독 로드를 표시하는 경우), 수신 패킷 포워딩 엔진은 이 대기열의 크기를 원래 크기의 절반으로 줄입니다(전체 드레이닝 속도를 얻을 때).
VOQ 대기열 깊이 모니터링
VOQ 대기열 깊이 모니터링 또는 대기 시간 모니터링은 VOQ의 최대 대기열 점유율을 측정합니다. 이 기능을 사용하면 각 개별 패킷 포워딩 엔진에 대해 주어진 물리적 인터페이스에 대한 최대 대기열 길이를 보고할 수 있습니다.
피크 대기열 길이 데이터 외에도 각 대기열은 수신 데이터 경로에서 삭제 통계 및 시간 평균 대기열 길이를 유지합니다. 또한 각 대기열은 송신 데이터 경로에서 대기열 전송 통계를 유지합니다.
엄격한 우선 순위 예약을 사용하는 일반적인 배포 시나리오에서 우선 순위 큐는 HIGH 우선 순위 큐를 굶주릴 LOW 수 있습니다. 따라서 이러한 LOW 우선순위 대기열의 패킷은 원하는 것보다 더 오래 유지될 수 있습니다. 대기열 전송 통계와 함께 이 VOQ 대기열 깊이 모니터링 기능을 사용하여 이러한 지연된 상태를 감지할 수 있습니다.
전송 WAN 인터페이스에서만 VOQ 대기열 깊이 모니터링을 활성화할 수 있습니다.
인터페이스에서 VOQ 대기열 깊이 모니터링을 활성화하려면 먼저 모니터링 프로필을 생성한 다음 해당 프로필을 인터페이스에 연결합니다. 모니터링 프로필을 어그리게이션 이더넷(ae-) 인터페이스에 연결하면 ae- 인터페이스에 연결된 모니터링 프로필에도 옵션을 적용 shared 하지 않는 한 각 멤버 인터페이스에는 고유한 전용 하드웨어 VOQ 모니터가 있습니다.
모니터링 프로필은 각 인터페이스에서 개별적으로 VOQ(virtual output queue) 깊이를 보고합니다. 그러나 시스템의 하드웨어 모니터링 프로필 ID의 수가 한정되어 있는 경우 이 프로세스는 대형 시스템에서 지원되는 최대 하드웨어 모니터링 프로필 ID를 빠르게 사용할 수 있습니다. 기본적으로 ae- 인터페이스에 할당하는 모니터링 프로필은 ae- 인터페이스의 모든 멤버에 복제됩니다. 따라서 모니터링 프로필 ID를 보존하려면 계층 수준에서 옵션을 포함 shared 하십시오 [set class-of-service interfaces ae-interface monitoring-profile profile-name] . 구성된 shared 옵션은 모든 멤버 인터페이스에서 공유할 하나의 모니터링 프로필 ID만 생성합니다. 또한 옵션은 멤버 인터페이스의 가장 큰 피크를 ae- 인터페이스의 공통 피크로 보고합니다.
혼합 모드 ae- 인터페이스에서는 shared 옵션을 활성화할 수 없습니다.
각 모니터링 프로필은 하나 이상의 내보내기 필터로 구성됩니다. 내보내기 필터는 물리적 인터페이스에 있는 하나 이상의 대기열에 대한 최대 대기열 길이 백분율 임계값을 정의합니다. 내보내기 필터의 모든 대기열에 대해 정의된 피크 대기열 길이 백분율 임계값이 충족되면 Junos는 내보내기 필터의 모든 대기열에 대한 VOQ 텔레메트리 데이터를 내보냅니다.
큐 수준 모니터링 데이터는 텔레메트리 채널을 통해서만 전송됩니다 . 모니터링 프로필을 구성하는 것 외에도(아래 그림 참조) 데이터를 전송하려면 정기적인 센서 구독을 시작해야 합니다 . CLI 표시 옵션은 없습니다.
VOQ 대기열 깊이 모니터링 구성
대기열 활용도 데이터를 내보내도록 VOQ 대기열 깊이 모니터링을 구성합니다. 이 데이터를 사용하여 마이크로 버스트를 모니터링하고 지연된 전송 출력 대기열을 식별하는 데 지원할 수도 있습니다. VOQ 대기열 깊이 모니터링을 구성하려면:
- 모니터링 프로필을 구성합니다.
- 인터페이스에 모니터링 프로필을 연결합니다.
모니터링 프로필을 구성하려면 다음을 수행합니다.
- 모니터링 프로필의 이름을 지정합니다. 예를 들어:
[edit class-of-service] set monitoring-profile mp1
- 모니터링 프로필에 대한 내보내기 필터의 이름을 지정합니다. 예를 들어:
[edit class-of-service monitoring-profile mp1] set export-filters ef1
- 내보내기 필터에 속하는 큐(0 - 7)를 정의합니다. 예를 들어:
[edit class-of-service monitoring-profile mp1 export-filters ef1] set queue [0 1]
- (선택 사항) VOQ 텔레메트리 데이터를 내보내기 위한 임계값 피크 대기열 길이 백분율을 정의합니다. 기본 백분율은 0입니다. 예를 들어:
[edit class-of-service monitoring-profile mp1 export-filters ef1] set peak-queue-length percent 50
- (선택 사항) 모니터링 프로필에 대해 하나 이상의 다른 내보내기 필터를 정의합니다. 예를 들어:
[edit class-of-service monitoring-profile mp1] set export-filters ef2 queue [2 3]
- 변경 내용을 커밋합니다.
인터페이스에 모니터링 프로필을 연결하려면 다음을 수행합니다.
- 인터페이스에 모니터링 프로필을 연결합니다. 예를 들어:
[edit class-of-service] set interfaces et-0/0/1 monitoring-profile mp1 set interfaces ae0 monitoring-profile mp1 shared
- 변경 내용을 커밋합니다.
구성을 확인합니다. 예를 들어:
[edit class-of-service]
user@host# show
monitoring-profile mp1 {
export-filters ef1 {
peak-queue-length {
percent 50;
}
queue [ 0 1 ];
}
export-filters ef2 {
queue [ 2 3 ];
}
}
interfaces {
ae0 {
monitoring-profile mp1 shared;
}
et-0/0/1 {
monitoring-profile mp1;
}
}
다음 표시 명령을 실행하여 구성을 확인합니다:
user@host> show class-of-service interface et-0/0/1 Physical interface: et-0/0/1, Index: 1098 Maximum usable queues: 8, Queues in use: 4 Exclude aggregate overhead bytes: disabled Logical interface aggregate statistics: disabled Scheduler map: default, Index: 0 Congestion-notification: Disabled Monitoring Profile Name: mp1 Logical interface: et-0/0/1.16386, Index: 1057 user@host> show class-of-service interface ae0 Physical interface: ae0, Index: 7860 Maximum usable queues: 8, Queues in use: 4 Exclude aggregate overhead bytes: disabled Logical interface aggregate statistics: disabled Scheduler map: default, Index: 0 Congestion-notification: Disabled Monitoring Profile Name: mp1 [shared] user@host> show class-of-service monitoring-profile Monitoring profile: mp1 Export filter Queue Number Peak Queue Length ef1 0 50% ef1 1 50% ef2 2 0% ef2 3 0%
이 예에서 볼 수 있듯이 내보내기 필터에 대해 을 peak-queue-length percent 설정하지 않으면 내보내기 필터 ef2 가 보여주는 것처럼 백분율이 0%로 기본 설정됩니다. 이 예에서는 VOQ 텔레메트리 데이터를 내보내기 위해 서로 다른 피크 대기열 길이 임계값을 갖는 물리적 인터페이스의 다양한 대기열을 보여 줍니다.