ソリューションアーキテクチャ
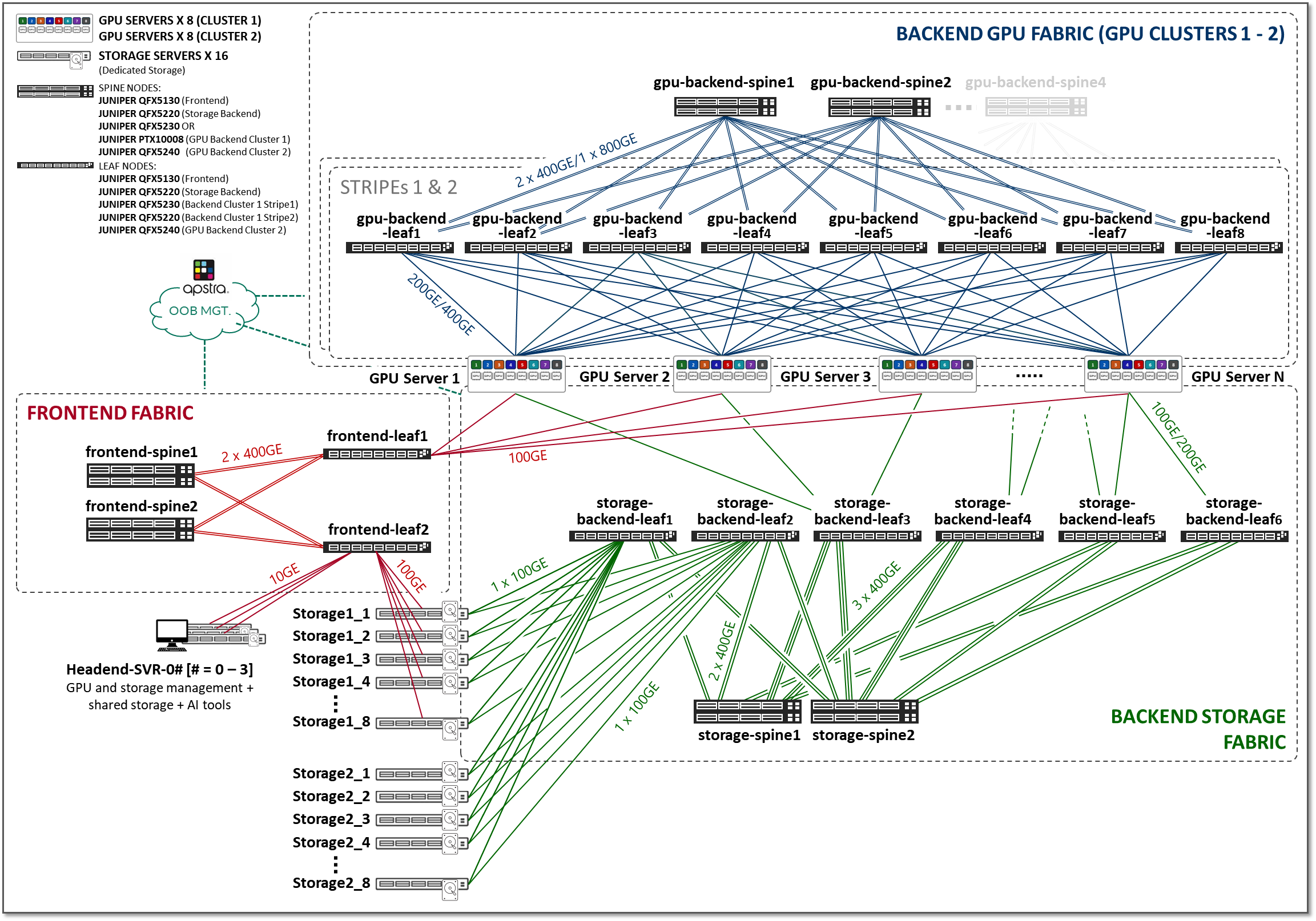
前のセクションで説明した3つのファブリック(フロントエンド、GPUバックエンド、ストレージバックエンド)は、図2に示すAI JVDソリューションアーキテクチャ全体で相互に接続されています。
図2:AI JVDソリューションのアーキテクチャ
フロントエンドファブリック
フロントエンドファブリックは、ユーザーがAIシステムと対話し、ジョブのスケジューリング、リソース割り当て、ライフサイクル管理を処理するSLURM、Kubernetes、その他のAIワークフローマネージャーなどのツールを使用して、トレーニングと推論タスクのワークフローをオーケストレーションするためのインフラストラクチャを提供します。
これらのやり取りは、重いデータフローを生成せず、遅延やパケット損失に厳密な要件を課すことはありません。その結果、コントロールプレーントラフィックはファブリックに厳格なパフォーマンス要求を課すことはありません。
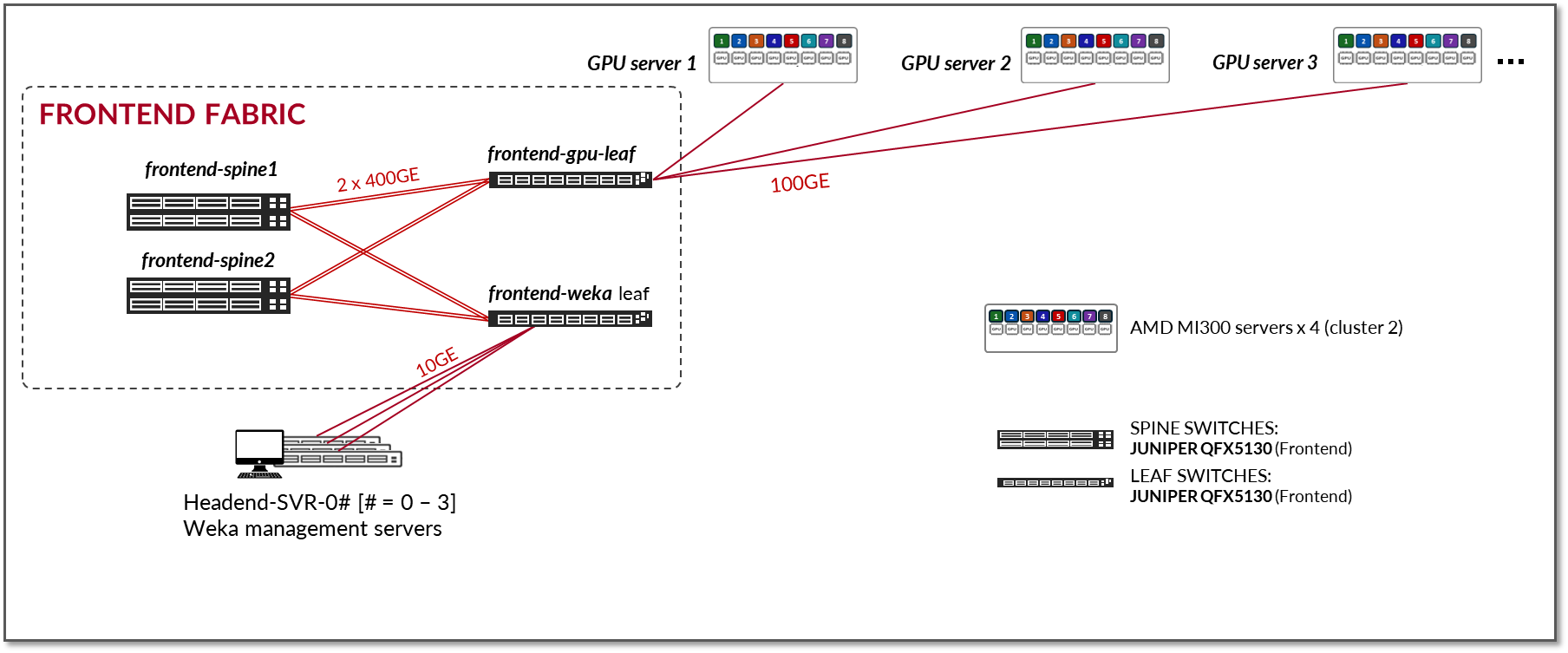
フロントエンドファブリックの設計は、図3に示すように、高可用性(HA)のない3段階のL3 IPファブリックで構成されています。このアーキテクチャは、フロントエンドで必要な接続に対するシンプルで効果的なソリューションを提供します。ただし、EVPN/VXLAN を含むどのファブリック アーキテクチャでも使用できます。HA対応フロントエンドファブリックが必要な場合は、Juniper Apstra JVDを使用した3ステージに従うことをお勧めします。
図3:フロントエンドファブリックアーキテクチャ
リーフ ノードの数は、AI クラスター内のサーバーとストレージ デバイスの数、および AI ジョブのスケジューリング、リソース割り当て、ライフサイクル管理に使用されるその他のデバイスの数によって異なります。
スパインノードの数は、設計に必要なサブスクリプション係数によって異なります。1:1のサブスクリプション係数は必要ありません。設計で耐障害性が維持され、コントロールプレーンの安定性に影響を与える輻輳が回避されることを条件に、コントロールプレーンのトラフィックに関しては中程度のオーバーサブスクリプションが許容されます。
このファブリックは、EBGP をルート アドバタイズメントに使用する L3 IP ファブリックで、このドキュメントの「ネットワーク」セクションで説明されている IP アドレッシングと EBGP 設定の詳細を備えています。特別なロードバランシングメカニズムは必要ありません。通常、冗長L3パスを横断するECMPで十分です。
コントロールプレーンのトラフィックは通常、ストレージやGPUファブリックに比べて帯域幅を大量に消費しないことを考えると、厳密なQoSメカニズムはオプションであり、バースト性のある非制御トラフィックとリンクを共有する場合にのみ推奨されます。
このJVDで検証されたフロントエンドファブリックのデバイスと接続性は、以下の表にまとめられています。
表1:フロントエンドファブリックに接続された検証済みの管理デバイスとGPUサーバー
| AMD GPUサーバー | ヘッドエンドサーバー |
|---|---|
| スーパーマイクロ AS-8125GS-TNMR2 AMD Instinct MI300X 192 GB OAM GPU |
スーパーマイクロ SYS-6019U-TR4 |
表2:検証済みフロントエンドファブリックのリーフおよびスパインノード
| フロントエンドリーフノードスイッチモデル | フロントエンドファブリックスパインノードスイッチモデル |
|---|---|
| QFX5130-32CD | QFX5130-32CD |
| QFX5220-32CD | QFX5220-32CD |
表3:フロントエンドファブリック内のヘッドエンドサーバーとリーフノード間の検証済み接続
| リーフ接続へのGPUサーバーごとのリンク | サーバータイプ |
|---|---|
| 1 x 10GE | スーパーマイクロ SYS-6019U-TR4 |
表4:フロントエンドファブリック内のGPUサーバーとリーフノード間の検証済み接続
| リーフ接続へのGPUサーバーごとのリンク | サーバータイプ |
|---|---|
| 1 x 100GE | AMD Instinct MI300X |
表5:フロントエンドファブリック内のリーフノードとスパインノード間の検証済み接続
| リーフおよびスパイン接続ごとのリンク数 | リーフノードモデル | スパインノードモデル |
|---|---|---|
| 400GE x 2 | QFX5130-32CD | QFX5130-32CD |
このJVDのテストは、図に示すように、4台のAMD Instinct MI300X GPUサーバーを2つのリーフノードに接続し、次に2つのスパインノードに接続して実行しました。
図4:フロントエンドJVDテストトポロジー
- GPUサーバーは、100Gインターフェイス(ConnectX-7 NIC)を使用してリーフノードに接続されます。
- 膨大なデバイスが100Gインターフェイスを使用してリーフノードに接続されています
表6:フロントエンドGPUサーバーの集約<=>フロントエンドリーフノード テスト済みのリンク数と帯域幅
| GPUサーバー<=フロントエンドリーフノード帯域幅> | |
|---|---|
| 100GEリンク数 GPUサーバー ó フロントエンドリーフノード = 4 (サーバーにつき1つ) |
4 x 100GE = 400Gbps |
| ストレージデバイス間の100GEリンク数 ó フロントエンドリーフノード = 8 (ストレージデバイスごとに1つ) |
8 x 100GE = 800Gbps |
| 総帯域幅 = | 1.0Tbps |
表7:フロントエンドリーフノードの集約<=>フロントエンドスパインノード テスト対象のリンク数と帯域幅
| フロントエンドリーフノード<=フロントエンドスパインノード帯域幅> | ||
|---|---|---|
| フロントエンドリーフノードとスパインノード間の400GEリンクの数=8 (リーフノード2個 x スパインノード2個 x リーフからスパインへの接続あたり2個のリンク) |
8 x 400GE = 3.2 Tbps | |
| 総帯域幅 = | 3.2Tbps | |
| オーバーサブスクリプションなし | ||
GPUバックエンドファブリック
GPUバックエンドファブリックは、RDMA over Converged Ethernet(RoCEv2)を使用して、GPUがクラスター内で相互に通信するためのインフラストラクチャを提供します。RoCEv2は、データセンターの効率性を高め、複雑さを軽減し、高速イーサネットネットワーク全体でのデータ配信を最適化します。
フロントエンド ファブリックとは異なり、GPU バックエンド ファブリックは、 帯域幅を大量に消費し、遅延の影響を受けやすいデータ プレーン トラフィックを伝送します。パケットロス、過度の遅延、またはジッターは、ジョブの完了時間に大きな影響を与える可能性があるため、回避する必要があります。
その結果、GPUバックエンドファブリックの主な設計目標の1つは、ほぼ ロスレスのイーサネットファブリックを実現すると同時に、GPU間のトラフィックに対して 最大のススループット、最小限の遅延、最小限のネットワーク干渉 を実現することです。RoCEv2は、パケットロスが最小限に抑えられる環境で最も効率的に動作し、ジョブ完了までの時間を最適化します。
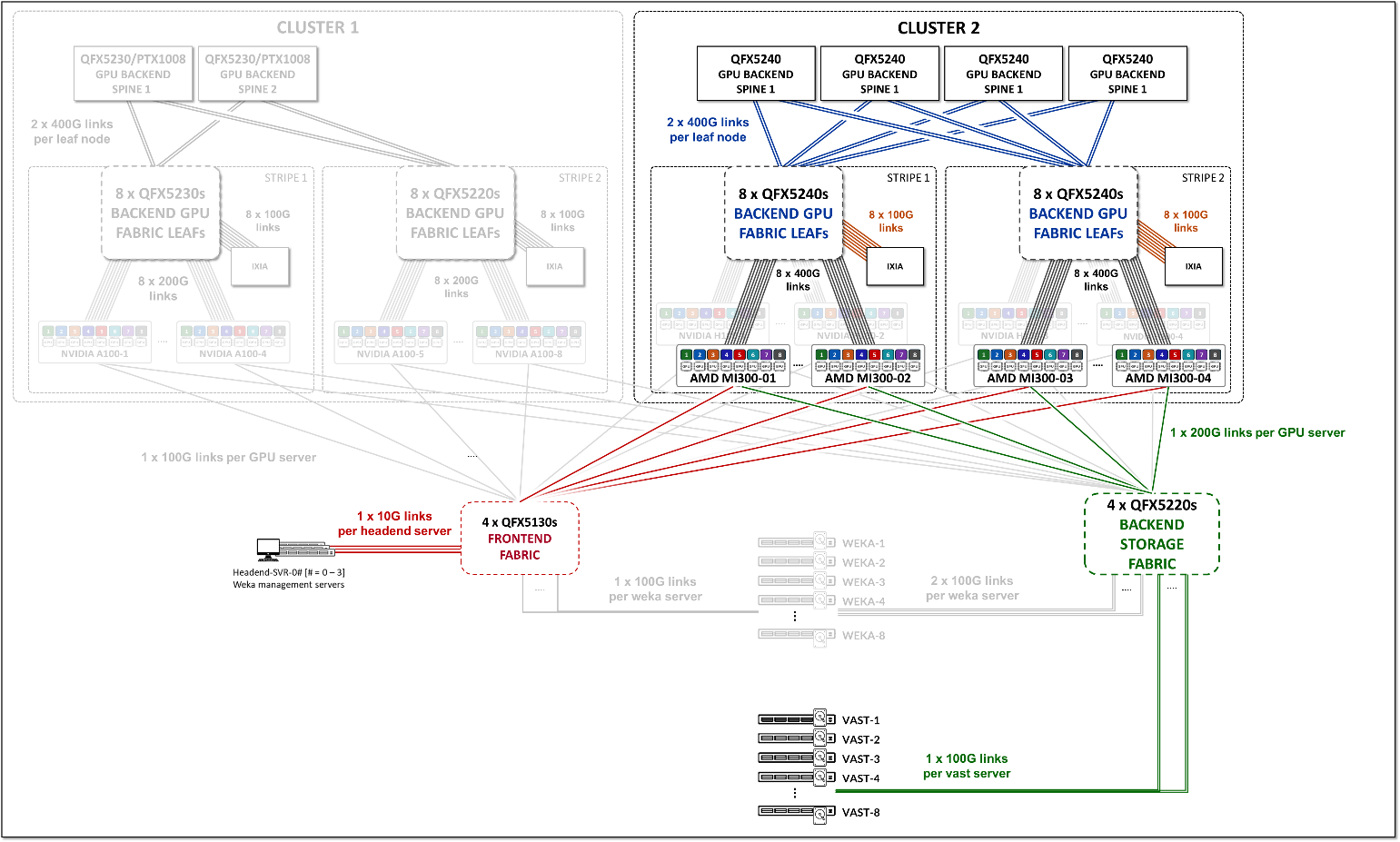
このJVDのGPUバックエンドファブリックは、これらの要件を満たすように設計されています。この設計は、図5に示すように、3ステージのIP Clos、 レール最適化ストライプアーキテクチャに準拠しています。 Rail Optimized Stripe アーキテクチャの詳細については、後のセクションで説明します。
図5:GPUバックエンドファブリックアーキテクチャ
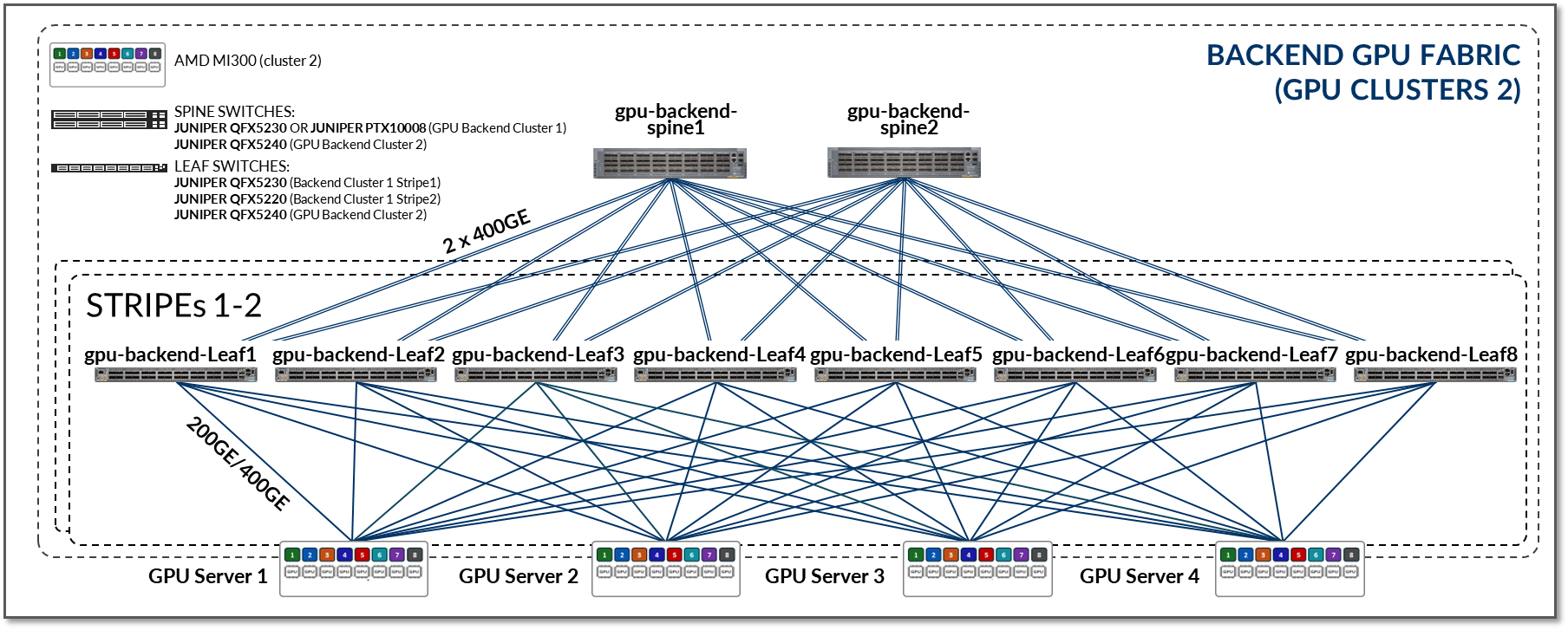
このファブリックは、このドキュメントの「ネットワーキング」セクションで説明されているIPアドレッシングとEBGP設定の詳細を使用して、ルートアドバタイズにEBGPを使用するL3 IPファブリックとして動作します。
レール最適化アーキテクチャでは、 リーフノード の数はサーバーあたりのGPU数によって決まります。このJVDに含まれるAMDサーバーの場合は8です。GPUサーバーとリーフノード間、およびリーフとスパインノード間のリンクの スパインノード 数、速度と数によって、GPUバックエンドファブリックの 有効な帯域幅 と オーバーサブスクリプション特性 が決まります。
フロントエンド ファブリックとは対照的に、GPU バックエンド ファブリックは通常、オーバーサブスクライブされていない (1:1) 設計、または非常に低いオーバーサブスクリプション率をターゲットとしています。これにより、集団操作の同時実行に十分な帯域幅を確保し、パケット損失や遅延変動を引き起こす可能性のある輻輳を防止します。
このファブリックは、EBGP をルート アドバタイズメントに使用する L3 IP ファブリックで、このドキュメントの「ネットワーク」セクションで説明されている IP アドレッシングと EBGP 設定の詳細を備えています。GPUバックエンドファブリック内のトラフィック分散は、動的ロードバランシング(DLB)、グローバルロードバランシング、適応型ロードバランシング(ALB)などの高度なロードバランシング技術と組み合わせた複数の等コストL3パスにわたるECMPに依存しています。これらについては、このドキュメントの「負荷分散」セクションで説明します。
GPUバックエンドファブリックは、損失や遅延の影響を受けやすいRoCEv2トラフィックを伝送するため、設計にはDCQCN(Data Center Quantized Congestion Notification)が組み込まれており、ECN(Explicit Congestion Notification)を活用し、オプションでPFC(優先フロー制御)を使用することで、RDMAトラフィックのロスレスまたはほぼロスレス動作を実現します。これらのメカニズムについては、このドキュメントの「サービスクラス」セクションで詳しく説明しています。
このJVDで検証されたフロントエンドファブリックのデバイスと接続性は、以下の表にまとめられています。
表8:GPUバックエンドファブリックに接続された検証済みの管理デバイスとGPUサーバー
| GPUサーバー、 | ストレージデバイス、 | ヘッドエンドサーバー |
|---|---|---|
| スーパーマイクロ AS-8125GS-TNMR2 AMD Instinct MI300X 192 GB OAM GPU |
|
Supermicro SYS-6019U-TR4 |
表9:検証済みGPUバックエンドファブリックリーフノード
| GPUバックエンドファブリックリーフノードスイッチモデル |
|---|
| QFX5220-32CD |
| QFX5230-64CD |
| QFX5240-64OD |
| QFX5241-64OD |
表10:検証済みGPUバックエンドファブリックスパインノード
| GPUバックエンドスパインファブリックノードスイッチモデル |
|---|
| QFX5230-64CD |
| QFX5240-64OD |
| QFX5241-64OD |
| PTX10008 LC1201 |
| PTX10008 LC1301 |
表11:GPUバックエンドファブリック内のGPUサーバーとリーフノード間の検証済み接続
| リーフ接続へのGPUサーバーごとのリンク | サーバータイプ |
|---|---|
| GPUサーバーあたり1 x 400GEリンクとリーフ接続 | AMD MI300 |
表12:GPUバックエンドファブリック内のリーフノードとスパインノード間の検証済み接続
| リーフおよびスパイン接続ごとのリンク数 | リーフノードモデル | スパインノードモデル |
|---|---|---|
| 1 x 400GE | QFX5220-32CD | QFX5230-32CD |
| 1 x 400GE | QFX5230-32CD | QFX5230-32CD |
| 400GE x 2 | QFX5240-64OD | QFX5240-64OD |
| 1 x 800GE | QFX5240-64OD | QFX5240-64OD |
| 1 x 400GE | QFX5220-32CD | PTX10008 LC1201 |
| 1 x 400GE | QFX5230-32CD | PTX10008 LC1201 |
| 1 x 800GE | QFX5240-64OD | PTX10008 LC1301 |
| 800GE x 2 | QFX5240-64OD | PTX10008 LC1301 |
このJVDのテストは、図に示すように、2つのストライプに接続された4台のMI300 GPUサーバーを使用して実行されました。
図6:GPUバックエンドJVDテストトポロジー
- 各AMD MI300X GPUサーバーは、400Gインターフェイス(Thor2およびPollara NIC)を使用してリーフノードに接続されます。
validated_optics_summary.html#Toc222928841__DAC_5mはBroadcom Thor2カードでテストし、下の図のように接続しました。
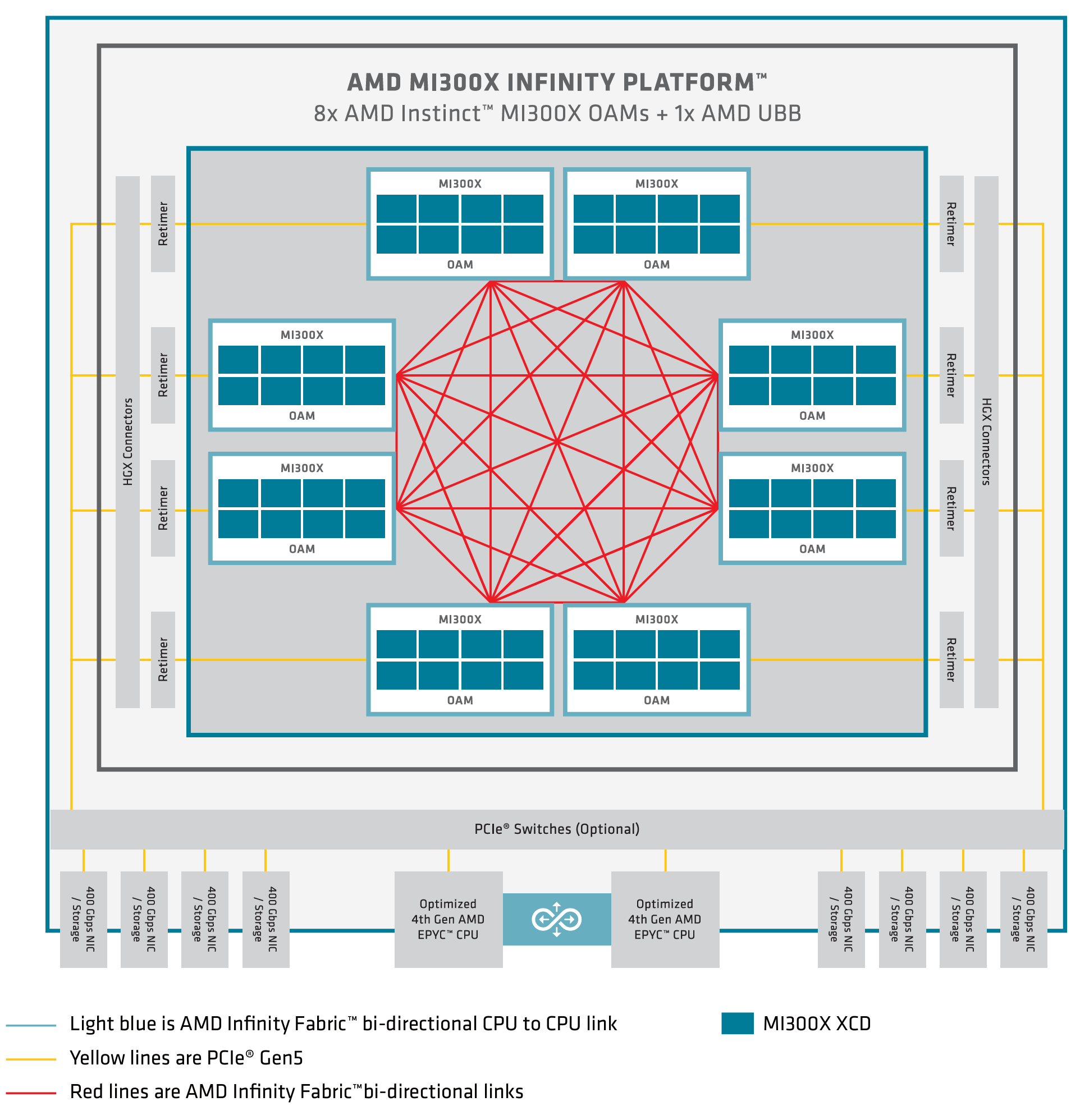
表13:ストライプサーバーからリーフまでの帯域幅
| ストライプ | サーバー数 ストライプごと |
サーバー数<=サーバーあたり>リーフリンク (サーバーごとのリーフノード数とGPU数) |
サーバー<=>リーフリンク帯域幅 [Gbps] |
サーバー合計数<=>リーフリンク ストライプ当たりの帯域幅 [Tbps] |
|---|---|---|---|---|
| 1 | 2 MI300 | 8 | 400Gbps | 2 x 8 x 400Gbps = 6.4Tbps |
| 2 | 2 MI300 | 8 | 400Gbps | 2 x 8 x 400Gbps = 6.4Tbps |
| サーバー合計<=>リーフ帯域幅 | 12.8Tbps | |||
表14:リーフとスパインとしてQFX5240したストライプごとのリーフからスパインへの帯域幅
| ストライプ | 数 リーフノード |
スパインノード数 | 数 400Gbps リーフ<=>スパインリンク リーフノードあたり |
サーバー<=>リーフ リンク帯域幅 [Gbps] |
帯域幅 リーフ<=ストライプあたりのスパイン> [Tbps] |
|---|---|---|---|---|---|
| 1 | 8 | 4 | 2 | 400 | 8 x 2 x 2 x 400Gbps = 12.8Tbps |
| 2 | 8 | 4 | 2 | 400 | 8 x 2 x 2 x 400Gbps = 12.8Tbps |
| サーバー合計<=>リーフ帯域幅 | 25.6Tbps | ||||
GPUバックエンドファブリックサブスクリプションファクター
加入係数は、上記の2つの表の数値を比較して簡単に計算します。
JVDテスト環境では、サーバーとリーフノード間の帯域幅はストライプあたり6.4Tbpsですが、リーフとスパインノード間の利用可能な帯域幅はストライプあたり12.8Tbpsです。つまり、このトラフィックが100%ストライプ間であった場合でも、ファブリックにはGPU間のすべてのトラフィックを処理するのに十分な容量があり、オーバーサブスクライブになることなく追加のサーバーを収容できる容量が備わっているということです。この場合の加入係数は1:2です。
図7:1:2の加入率(オーバープロビジョニング)
オーバーサブスクリプションテストを実行するために、図8の例に示すように、リーフとスパイン間のインターフェイスの一部を無効にし、利用可能な帯域幅を削減しました。
図8:1:1のサブスクリプション係数
さらに、図9の例に示すように、RoCEv2デバイスをエミュレートするIxiaトラフィックジェネレータもファブリックに接続されました。
図9:1:1のサブスクリプション係数
これにより、ストライプ1と2の両方のリーフ2と4に、さらに800Gのトラフィックが追加されます。
GPU間の通信最適化
レール最適化トポロジーにおける最適化とは、スループットを最大化しながら輻輳と遅延を最小限に抑えるためにGPU通信を管理する方法のことです。この最適化戦略の重要な部分は、可能な限りトラフィックをローカルに保つことです。GPU通信が同じレールやストライプ内、あるいはサーバー内でも維持されるため、スパインや外部リンクをトラバースする必要性が減り、遅延が低減し、輻輳が最小限に抑えられ、全体的な効率が向上します。
トラフィックのローカライズが優先される一方で、大規模なGPUクラスターではストライプ間通信が必要になります。ストライプ間通信は、ボトルネックやパケット損失を回避するために、利用可能なリンク上で適切なルーティングとバランシング技術によって最適化されます。
最適化の本質は、トポロジーを活用してトラフィックを最短で輻輳の少ないパスに誘導し、ネットワークを拡張しても一貫したパフォーマンスを確保することにあります。同じサーバー上のGPU間のトラフィックは(ベンダーによって異なります)内部サーバーファブリックを介してローカルに転送できますが、異なるサーバー上のGPU間のトラフィックは外部GPUバックエンドインフラストラクチャ全体で発生します。異なるサーバー上のGPU間の通信は、レール内、レール間/ストライプ間にすることができます。
レール内トラフィックは、ローカルリーフノードでスイッチング(レイヤー2で処理)されます。この設計に従った場合、異なるサーバー上の(ただし同じストライプにある)GPU 間のデータは、常に同じレール上、1台のスイッチ間で移動されます。これにより、GPU間の距離が1ホップになり、独立した高帯域幅チャネルが個別に作成されるため、競合が最小限に抑えられ、パフォーマンスが最大限に向上します。一方、レール間/ストライプ間トラフィックは、リーフノード上のIRBインターフェイスと、リーフノードを接続するスパインノード(レイヤー3で処理)を介してルーティングされます。
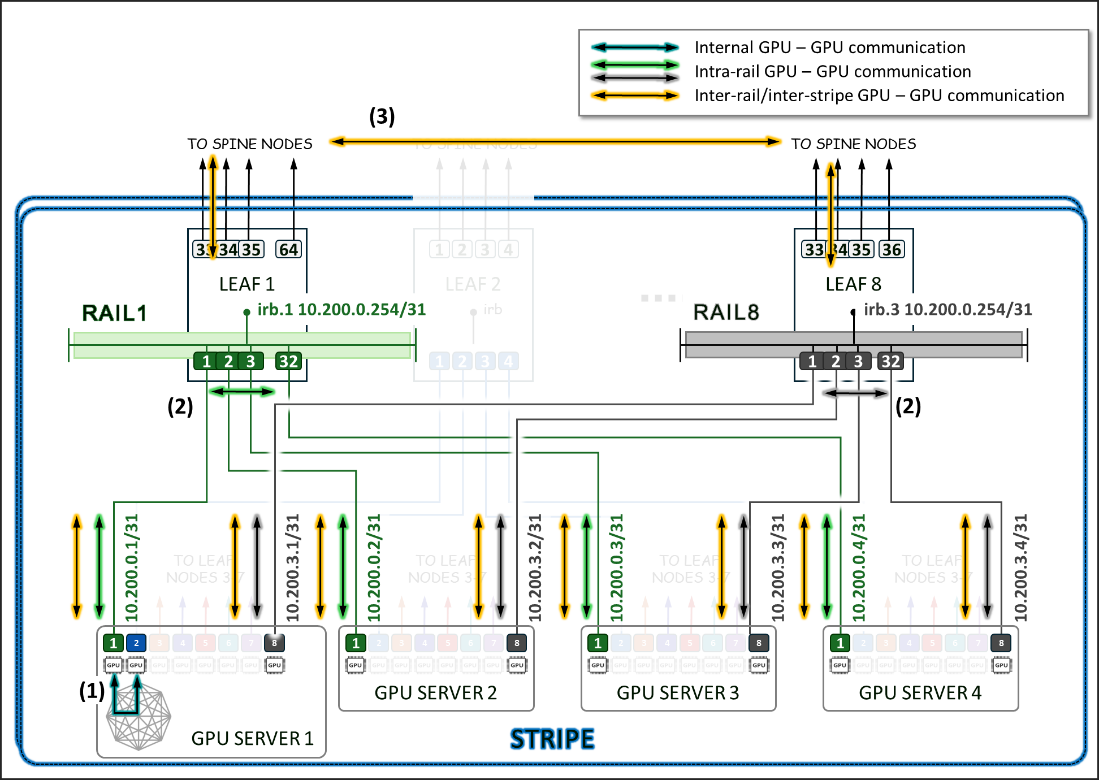
図10に示す例を見てみましょう
- サーバー1のGPU1とGPU 2間の通信は、サーバーの内部ファブリックを介して行われます(1)。
- サーバー1-4のGPU1間とサーバー1-4のGPU8間の通信は、それぞれリーフ1とリーフ8で発生します(2)。
- GPU 1とGPU 8(サーバー1〜4)間の通信は、リーフ1、スパインノード、リーフ8(3)を介して行われます
図10:レール間通信とレール内GPU-GPU通信
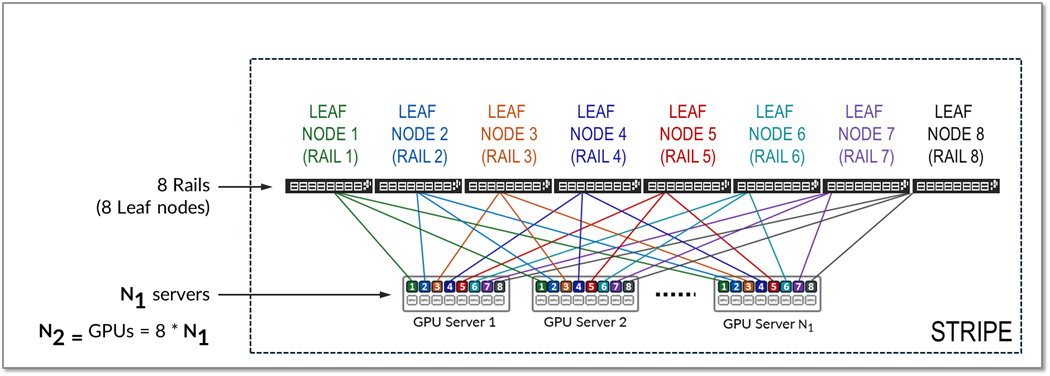
図10は、リーフスイッチ1-8をまたいでGPU1-8をそれぞれ接続する1つの ストライプ と8つの レール を持つトポロジーを示しています。
サーバー1のGPU 7とGPU 8間の通信は内部ファブリックを介して行われ、サーバー1のGPU 1とサーバーN1のGPU 1間の通信は、リーフスイッチ1(同じレール内)を介して行われます。
異なるストライプのGPUと異なるサーバー間の通信が必要な場合(たとえば、サーバー1のGPU 4がサーバーN1のGPU 5と通信する)、データはまず宛先GPUと同じレール内のGPUインターフェイスに移動されるため、レールを越えることなく宛先GPUにデータが送信されます。
この設計では、異なるサーバー上のGPU間(ただし同じストライプにある)データは、常に同じレール上、1台のスイッチ間で移動されます。これにより、GPU同士の距離が1ホップになり、独立した高帯域幅チャネルが別々に作成されるため、競合が最小限に抑えられ、パフォーマンスが最大限に向上します。
AMD GPUサーバーでは、GPUは AMD Infinityファブリックを介して相互接続されており、図11に示すように、1台のサーバー内で7x128GB/sのGPU間高帯域幅、低遅延、GPU間双方向通信を提供します。
図11.AMD MI300Xアーキテクチャ。
詳細については、 AMD Instinct™ MI300 シリーズ マイクロアーキテクチャ — ROCm ドキュメントを参照してください。
AMD MI300X GPU はインフィニティ ファブリックを活用し、GPU、CPU、その他のコンポーネント間の高帯域幅、低遅延通信を提供します。この相互接続は、リンク全体のトラフィックの優先順位付けを動的に管理し、ノード内の通信に最適化されたパスを提供します。
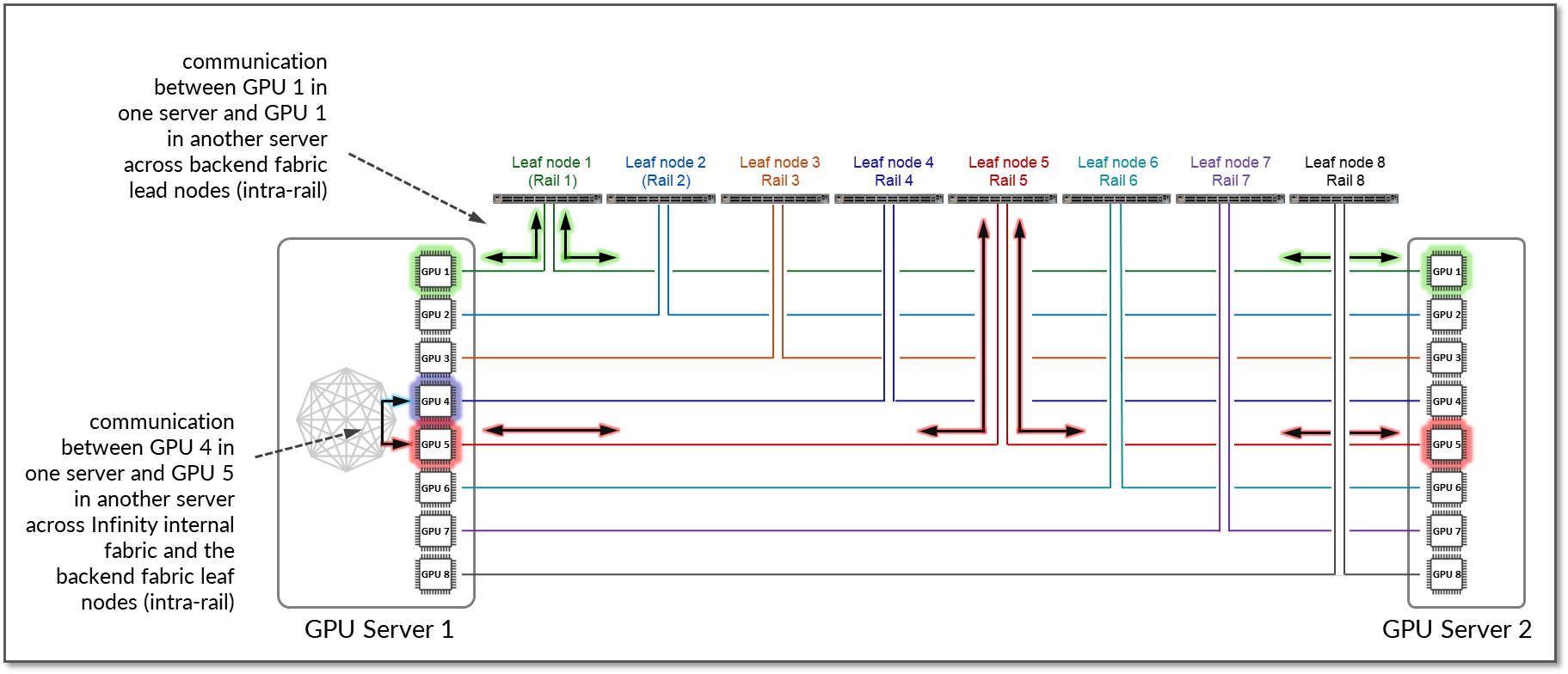
デフォルトでは、AMD MI300X デバイスはローカル最適化を実装して、GPU 間のトラフィックの遅延を最小限に抑えます。同じサーバー上のGPU間の通信は、インフィニティ・ファブリックを介して転送され、 ノード内に とどまり、外部イーサネット・ファブリックを通過しません。複数のサーバー間で同じランクのGPU間のトラフィックは ストライプ内のままです。
図12は、サーバー1のGPU1がサーバー2のGPU1と通信する例を示しています。トラフィックはリーフノード1によって転送され、レール1内にとどまります。
さらに、サーバー1のGPU4がサーバー2のGPU5と通信したいと考えており、サーバー1のGPU5がAMDのインフィニティファブリックのローカルホップとして利用可能な場合、トラフィックは当然このパスを優先してパフォーマンスを最適化し、GPU間の通信をレール内に保つことができます。
図12: ローカル最適化による2台のサーバー間のGPU間のGPU間のレール間通信
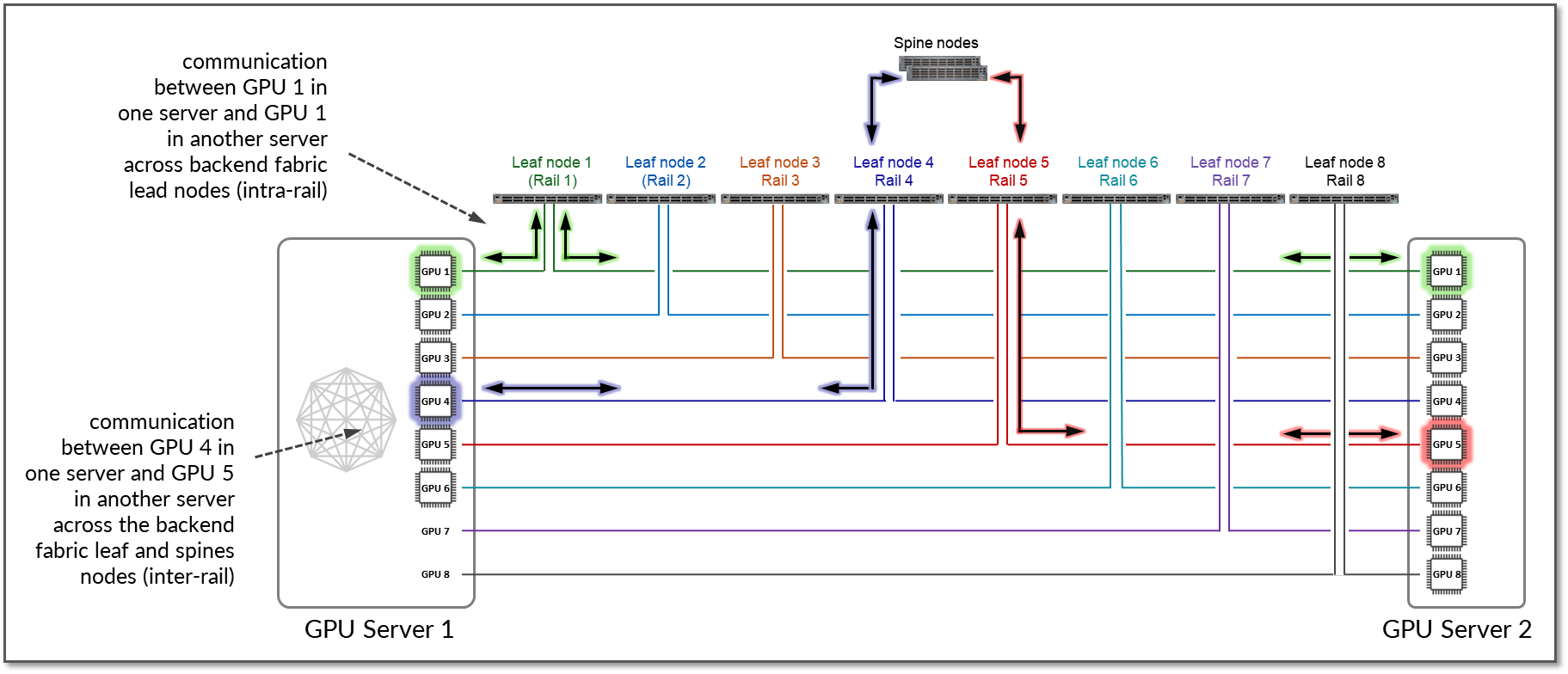
例えば、ワークロードの制約のためにローカル最適化が実現できない場合、トラフィックはローカルホップ(内部ファブリック)をバイパスし、RDMA(オフノードNICベースの通信)を使用する必要があります。この場合、図13に示すように、サーバー1のGPU4は、RDMAを使用してNIC経由で直接データを送信することでサーバー2のGPU5と通信し、そのデータはファブリック上に転送されます。
図13: ローカル最適化なしの2台のサーバー間のGPU間のGPU間のレール間通信
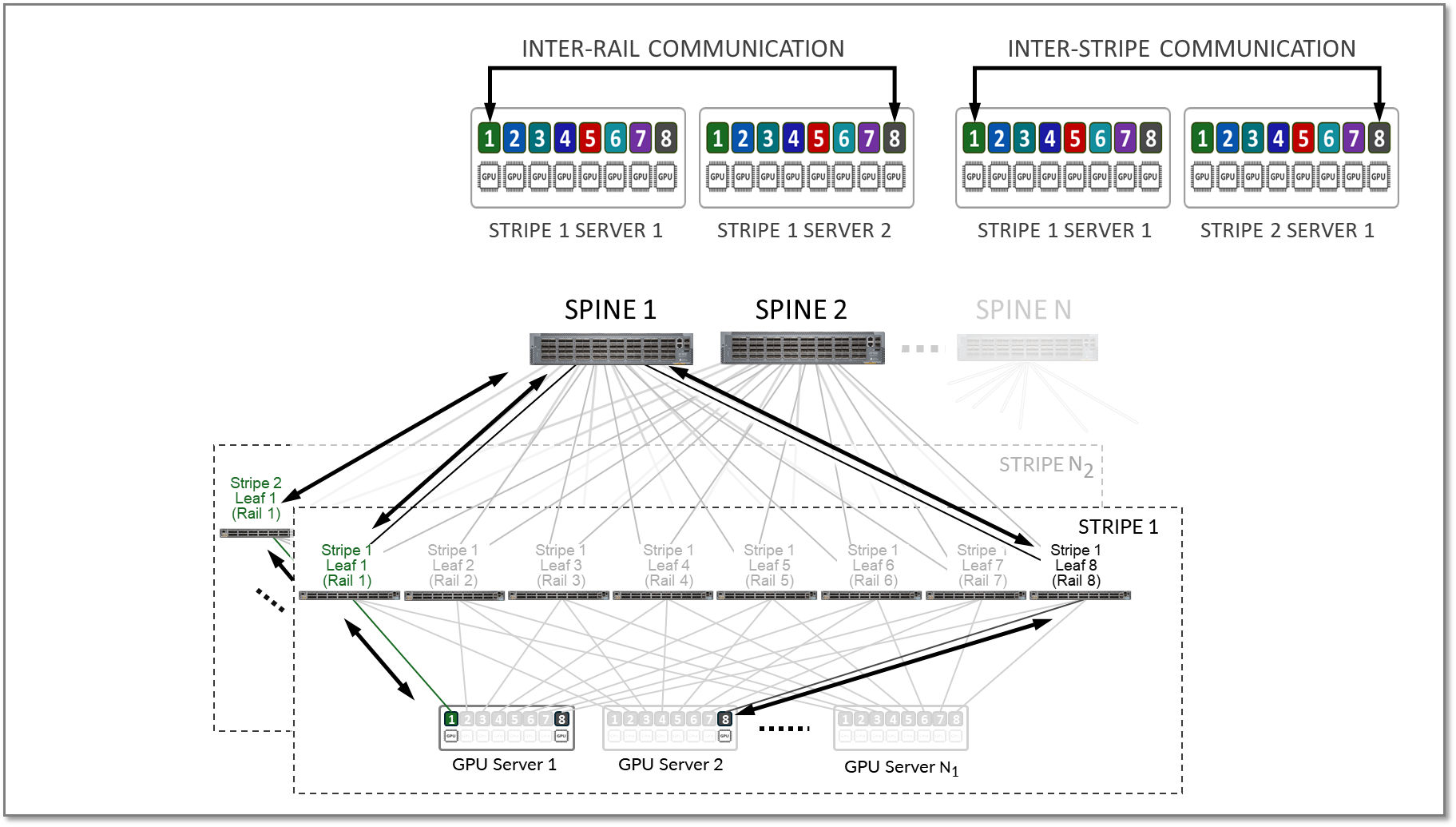
この例では、サーバー1のGPU 4とサーバーN1のGPU 5間の通信が、リーフスイッチ1、スパインノード、およびリーフスイッチ5を経由することを示しています(2つの異なるレール間)。
バックエンドGPUレール最適化アーキテクチャ
前述したように、レール最適化ストライプアーキテクチャは、特にAI大規模言語モデル(LLM)トレーニングワークロードなど、合理的な時間内にタスクを完了するためにシームレスなデータ転送が必要な、計算集約型のタスクにおいて、GPU間の効率的なデータ転送を提供します。レール最適化トポロジーは、帯域幅の競合、最小限の遅延、最小限のネットワーク干渉を提供することでパフォーマンスを最大化し、ネットワーク全体で効率的かつ信頼性の高いデータ送信を可能にすることを目的としています。
レール最適化アーキテクチャには、 レール と ストライプという 2 つの重要な概念があります。
サーバー上のGPUには1から8の番号が付けられており、数字は図14に示すようにサーバー内のGPUの位置を表します。この数値は、GPU が配置されているサーバー内の GPU との関係では ランク、より 具体的には「ローカル ランク」と呼ばれることもあります。1 つのジョブに割り当てられたすべての GPU(複数のサーバー内)との関係では「グローバル ランク」と呼ばれることもあります。
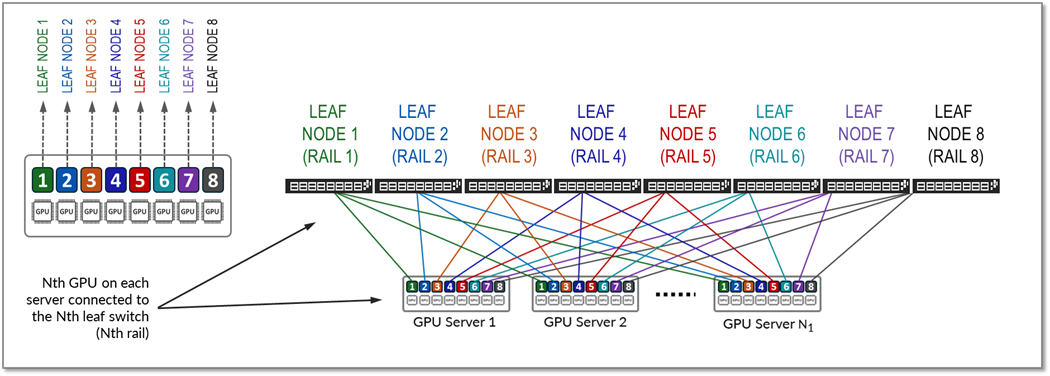
レールは、ファブリック内のリーフノードの1つにまたがって同じ順序のGPUを接続します。つまり、図14に示すように、レールNthは、すべてのサーバー上の位置N番目のすべてのGPUをリーフノードNthに接続します。
図14:レール最適化アーキテクチャのレール
ストライプとは、図15に示すように、複数のレールで構成される設計モジュールまたはビルディングブロックを指し、リーフノードとGPUサーバーが含まれます。この構成要素を複製して、AI クラスターをスケールアップできます。
図15:レール最適化アーキテクチャにおけるストライプ
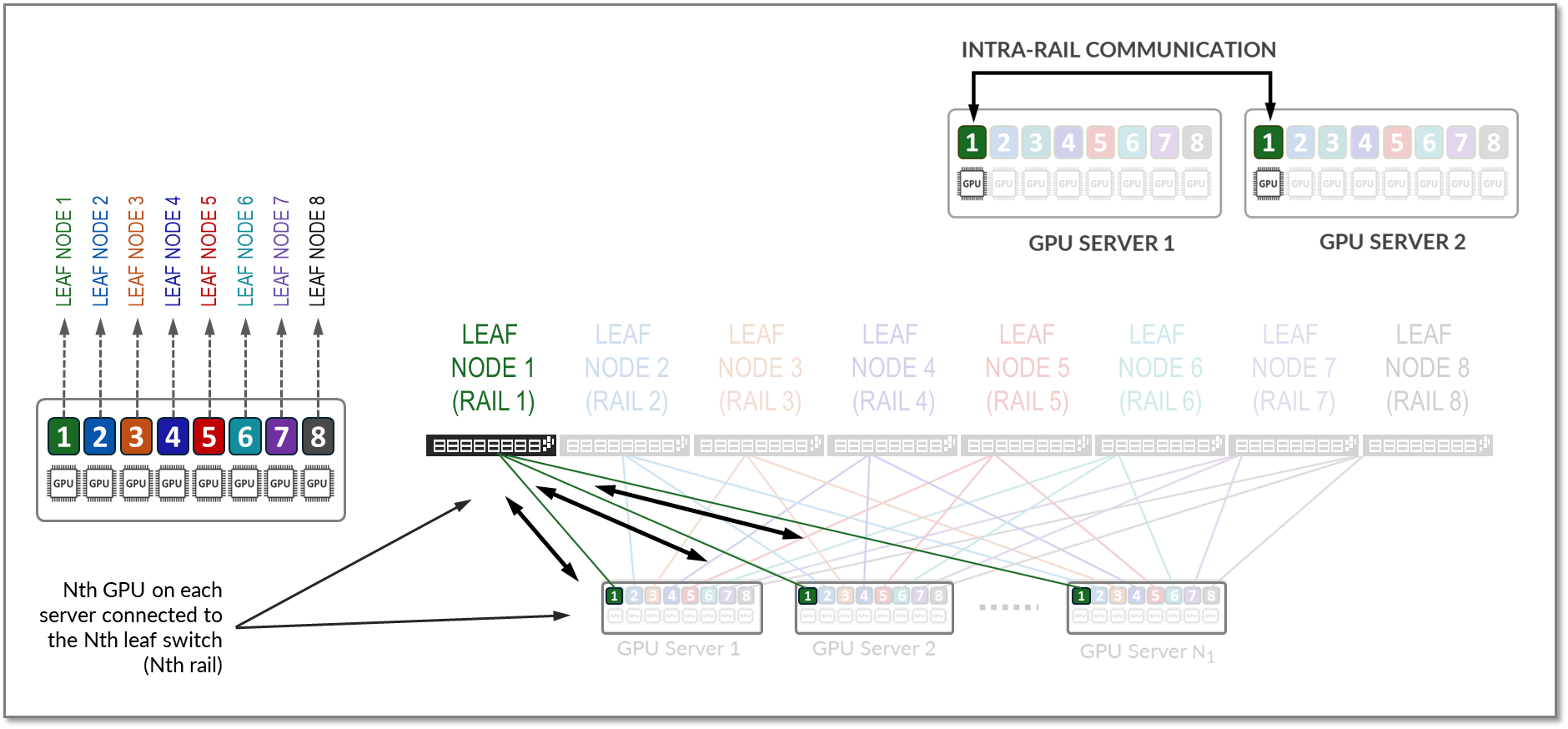
同じランクのGPU間のすべてのトラフィック(レール内トラフィック)は、図16に示すように、リーフノードレベルで転送されます。
図16:鉄道内交通の例。
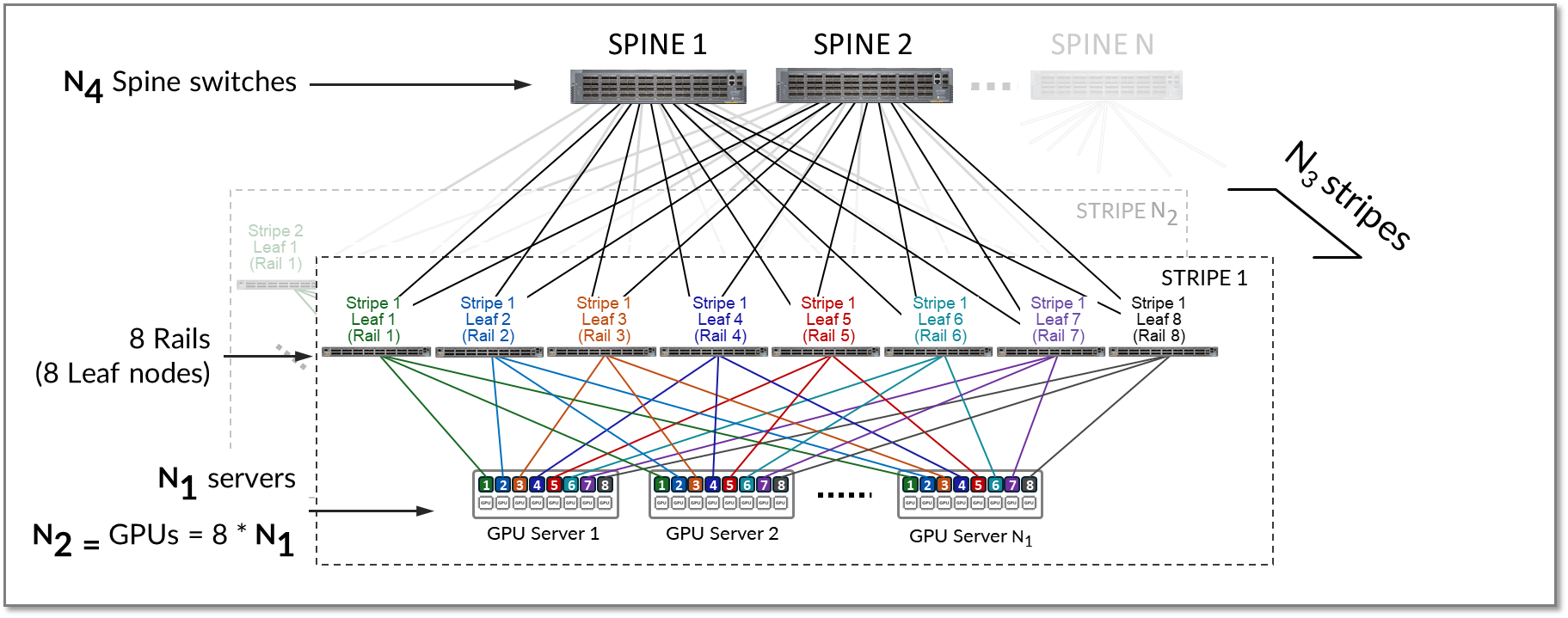
ストライプを複製することで、AIクラスター内のサーバー数(N1)とGPU(N2)の数をスケールアップできます。次に、図17に示すように、複数のストライプ(N3)がスパインスイッチ間で接続されます。
図17:スパインノードを介して接続された複数のストライプ
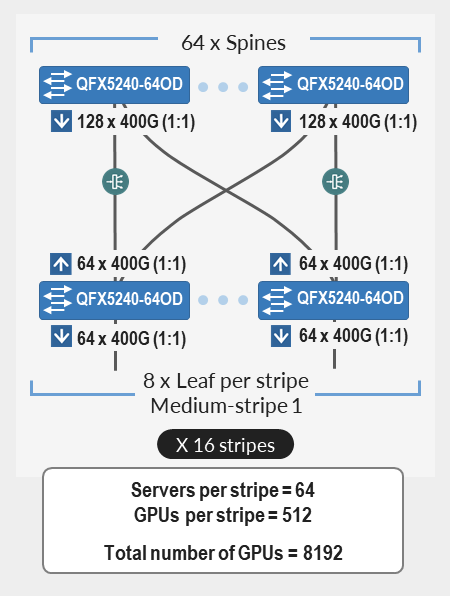
図18に示すように、 レール間 トラフィックと ストライプ間 トラフィックの両方がスパインノード間で転送されます。
図18.レール間、およびストライプ間GPU間のトラフィックの例。
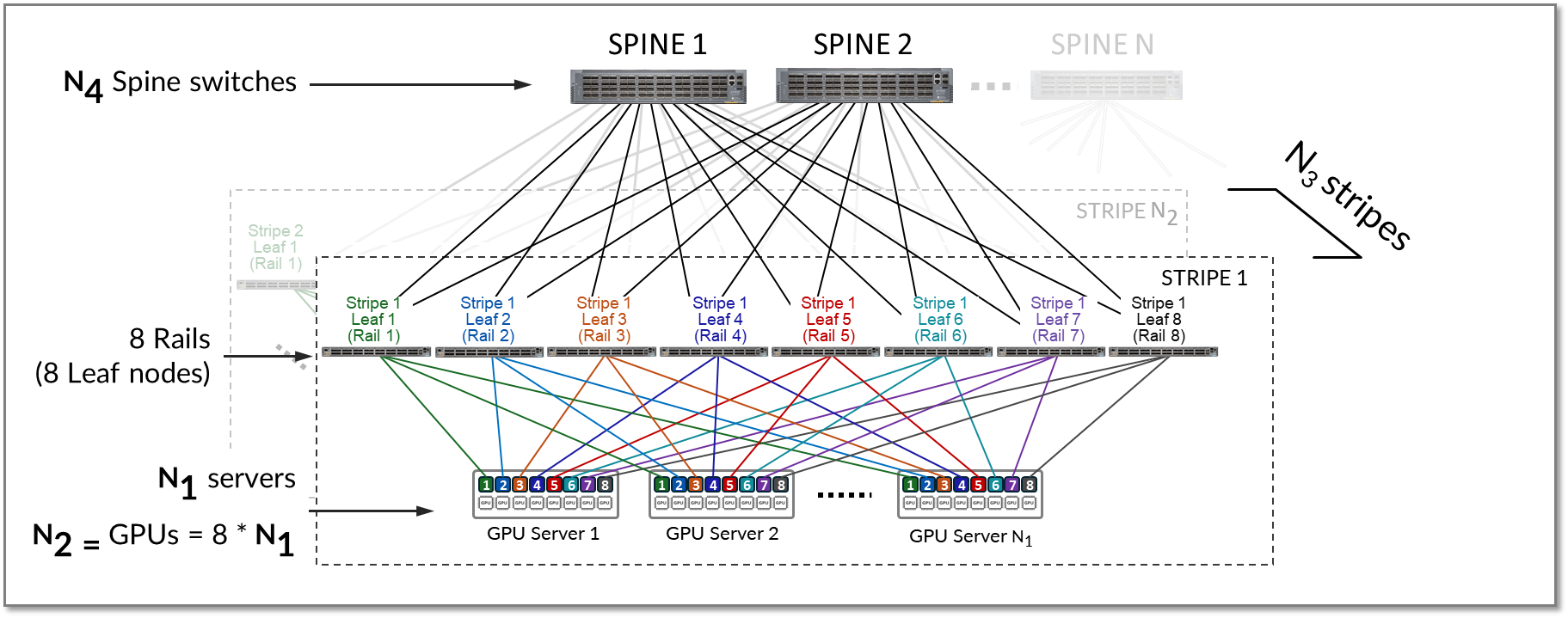
レール最適化アーキテクチャにおけるリーフおよびスパインノード、サーバー、GPUの数の計算
レール最適化アーキテクチャにおける単一ストライプ内の リーフノードの数 は、サーバーごとのGPUの数(レール数)によって定義されます。各 AMD MI300X GPU サーバーには、8 つの AMD Instinct MI300X GPU が含まれています。したがって、1 つのストライプには 8 つのリーフノード(8 つのレール)が含まれます。
リーフノード数 = GPU数 x サーバー = 8
シングルストライプ(N1)でサポートされる サーバーの最大数 は、スイッチモデルに応じてリーフノードで 使用可能なポート数 によって定義されます。
1:1の加入比率を維持するには、GPUサーバーとリーフノード間の総帯域幅がリーフとスパインノード間の総帯域幅と一致する必要があります。
リーフノード上のすべてのインターフェイスが同じ速度で動作すると仮定すると、インターフェイスの半分はGPUサーバーへの接続に使用され、残りの半分はスパインへの接続に使用されます。したがって、ストライプ内の サーバーの最大数 は、各リーフノードで 使用可能なポート数の 半分として計算されます。
図19.1:1のサブスクリプション係数に対するアップリンクとダウンリンクの数
この図では、Xがダウンリンク(リーフノードとGPUサーバー間のリンク)の数を表し、Yがアップリンク(リーフノードとスパインノード間のリンク)の数を表しています。1:1のサブスクリプション係数を許容するには、XがYに等しくなければなりません。
各リーフノードで 使用可能なポートの数 は、X + Yまたは2 * Xに等しくなります。
ストライプ内のすべてのサーバーには、ストライプ内のすべてのリーフに 1 つのポートが接続されているため、ストライプ内のサーバーの最大数 (N1) は X に等しくなります。
N1(ストライプあたりの最大サーバー数)= 使用可能なポート数 ÷ 2
ストライプ内の GPU の最大数 は、サーバーごとの GPU の数を単純に乗算して計算されます。
N2(最大GPU数)=N1(ストライプあたりの最大サーバー数)*8
使用可能なポートの総数は、リーフノードに使用されるスイッチモデルによって異なります。表15に例を示します。
表15:ストライプごとにサポートされるGPUの最大数
| リーフノード QFXスイッチモデル |
スイッチあたり使用可能な400GEポート数 | 1:1サブスクリプションでストライプごとにサポートされるサーバーの最大数 (N1) |
サーバーあたりのGPU | ストライプごとにサポートされるGPUの最大数 (N2) |
|---|---|---|---|---|
| QFX5220-32CD | 32 | 32 ÷ 2 = 16 | 8 | 16台のサーバー x 8 GPU/サーバー = 128 GPU |
| QFX5230-64CD | 64 | 64 ÷ 2 = 32 | 8 | 32台のサーバー x 8 GPU/サーバー = 256 GPU |
| QFX5240-64OD QFX5241-64OD |
128 | 128 ÷ 2 = 64 | 8 | サーバー64台 x 8GPU/サーバー = 512GPU |
- QFX5220-32CDスイッチは、32 x 400GEポートを提供します=>16はサーバーへの接続に使用され、16はスパインノードへの接続に使用されます。
- QFX5230-64CDスイッチは、最大64 x 400GEポートを提供します=>32がサーバーへの接続に使用され、32がスパインノードへの接続に使用されます。
- QFX5240-64ODスイッチは、最大128 x 400GEポートを提供します=>64がサーバーへの接続に使用され、64がスパインノードへの接続に使用されます。
より大きなスケールを実現するには、図20に示すように、一連のスパインノード(N4)を使用して複数のストライプ(N3)を接続できます。
図20.スパインノード間で接続された複数のストライプ

必要なストライプの数(N3 )は、必要なGPUの数と、ストライプあたりのGPUの最大数(N2)に基づいて計算されます。
例えば、 必要なGPU(GPU)の数 が16,000で、ファブリックがリーフノードとしてQFX5240-64ODを使用しているとします。
使用可能な400Gポートの数は128です。これは、次のことを意味します。
- ストライプあたりの最大サーバー数(N1)= 64
- ストライプあたりの最大GPU数(N2)= 512
必要な ストライプの数 (N3)は、必要なGPUの数と、示すようにストライプあたりのGPUの数を割って計算されます。
N 3(必要なストライプ数)= GPU ÷ N 2(ストライプあたりの最大GPU数)= 16000 ÷ 512 = 32ストライプ(切り上げ)
- 32 個のストライプとストライプあたり 64 個のサーバーを備えたこのクラスターは、16,384 個の GPU を提供できます。
必要なストライプの数(N 3)とリーフノードあたりのアップリンクポート数(Y)を知ることで、必要なスパインノードの数を計算できます。
X = Y = N1を覚えておいてください
まず 、リーフノードの総数 は、 必要なストライプの数 に8(ストライプごとのリーフノード数)を掛けて計算できます。
リーフノードの総数 = N3 x 8 = 32 x 8 = 256
次に、アップリンクの総数に、リーフノードあたりのアップリンク数(N1)とリーフノードの総数を掛けた値が得られます。
アップリンクの総数 = N1 x 256 = 64 x 256 = 16384
必要なスパインの数(N4)は、アップリンクの総数を各スパインノードの使用可能なポート数で割ることで決定できます。リーフノードに関しては、スパインロールに使用されるスイッチモデルによって異なります。
必要なスパイン数(N4)= 16384 / 各スパインノードで使用可能なポート数
例えば、スパインノードがQFX5240/41の場合、 各スパインノードで使用可能なポート数 は128です。
表16:2つのストライプのスパインノード数
| スパインノード QFXスイッチモデル |
スイッチあたり最大400GEインターフェイス数 | 必要なスパイン数(N4)、64 ストライプ付き |
|---|---|---|
| QFX5240-64OD | 128 | 16384 ÷ 128 = 128 |
| PTX10008 LC1201 | 288 | 16384 ÷ 288 ~ 57 |
| PTX10008 LC1301 | 576 | 16384 ÷ 576 ~ 29 |
ストレージバックエンドファブリック
ストレージバックエンドファブリックは、GPUサーバーからストレージデバイスにアクセスできるようにするための接続インフラストラクチャを提供します。
ストレージインフラストラクチャのパフォーマンスは、AIワークフローの効率に大きく影響します。データへの迅速なアクセスを提供するストレージシステムにより、AIモデルのトレーニング時間を大幅に短縮できます。同様に、効率的なデータクエリとインデックス作成をサポートするストレージシステムは、AIワークフローにおける前処理と特徴抽出の完了時間を最小限に抑えることができます。
小規模なクラスターでは、各GPUサーバーのローカルストレージを使用するか、オープンソースまたは商用ソフトウェアを使用してこのストレージを集約するだけで十分な場合があります。ワークロードが重い大規模なクラスターでは、取り込み用のデータセット ステージングとトレーニング中のクラスター チェックポイントを提供するために、外部専用ストレージ システムが必要です。
WEKAとVast Storageという2つの主要なプラットフォームは、GPU環境での共有ストレージのための最先端のソリューションを提供します。ラボでは両方のソリューションをテストしてきましたが、 このJVDはVast Storageソリューションに焦点を当てています。したがって、このセクションの残りの部分と、このドキュメントの他のセクションでは、 Vast Storage デバイス とストレージ バックエンド ファブリックへの接続について詳しく説明します。
WEKAストレージの詳細は、Juniper Apstra、NVIDIA GPU、WEKAストレージを備えたAIデータセンターネットワーク—ジュニパー検証済み設計(JVD)に記載されています。
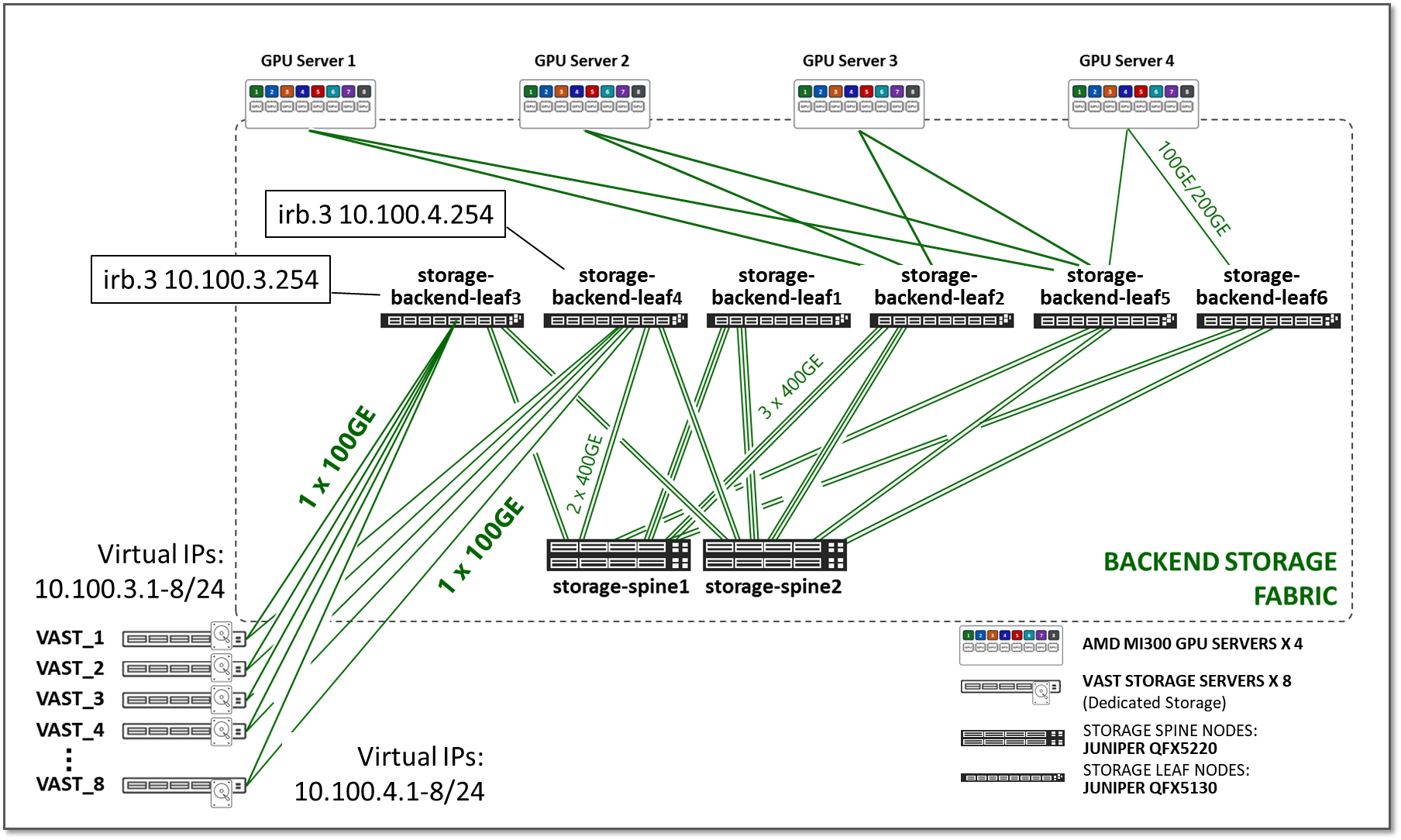
JVDの ストレージバックエンドファブリック 設計も、図21に示すように3ステージIP Closアーキテクチャに準拠しています。ストレージクラスターにはレール最適化の概念はありません。各GPUサーバーは、GPUごとに1つの接続ではなく、リーフノードへの接続が1つあります。
図21:ストレージバックエンドファブリックアーキテクチャ
リーフノードの数は、AIクラスター内のサーバーとストレージデバイスのGPU数によって異なります。
スパインノードの数は、設計に必要なサブスクリプション係数によって異なります。GPUバックエンドファブリックと同様に、ストレージファブリックでは、大量のトラフィックに十分な帯域幅を確保し、輻輳、パケット損失、過度の遅延を防ぐために、オーバーサブスクライブされていない設計(1:1のサブスクリプション係数)が必要です。
ストレージトラフィックは、NFS、POSIX、RoCEv2など、さまざまなトランスポートメカニズムを使用できます。RoCEv2では、GPUバックエンドファブリックで説明されているのと同じロードバランシングとサービスクラスメカニズムを実装する必要があります。これらについては、このドキュメントの「ロードバランシング」セクションと「サービスクラス」セクションで説明します。
このJVDで検証されたストレージファブリックのデバイスと接続は、以下の表にまとめられています。
表17:検証済みストレージファブリックのリーフおよびスパインノード
| ストレージファブリックリーフノードスイッチモデル | ストレージファブリックスパインノードスイッチモデル |
|---|---|
| QFX5130-32CD | QFX5130-32CD |
| QFX5220-32CD | QFX5220-32CD |
| QFX5230-32CD | QFX5230-32CD |
| QFX5240-64OD | QFX5240-64OD |
表18:ストレージファブリック内のGPUサーバー、ストレージデバイス、リーフノード間の検証済み接続
| リーフ接続へのGPUサーバーごとのリンク | サーバータイプ |
|---|---|
| 1 x 100GE | VAST Cノード |
| 1 x 200GE | AMD MI300 GPUサーバー |
表19:ストレージファブリック内のリーフノードとスパインノード間の検証済み接続
| リーフおよびスパイン接続ごとのリンク数 | リーフノードモデル | スパインノードモデル |
|---|---|---|
| 400GE x 2、400GE x 3 | QFX5130-32CD | QFX5130-32CD |
| 400GE x 2、400GE x 3 | QFX5130-32CD | QFX5130-32CD |
| 400GE x 2、400GE x 3 | QFX5240-32CD QFX5241-32CD |
QFX5240-32CD QFX5241-32CD |
このJVDのテストは、図22に示すように、4台のAMD Instinct MI300X GPUサーバーと8台のVASTストレージデバイスを使用して実行され、4つのリーフノードが2つのスパインノードに接続されました。
図22:ストレージ・ファブリックJVDテスト・トポロジー

表20:総ストレージリンク数とテスト対象帯域幅
| GPUサーバー<=>ストレージリーフノード、 | ストレージリーフノード<=>フロントエンドスパインノード |
|---|---|
| 間の200GEリンクの総数 GPUサーバーとストレージリーフノード = 4 (サーバーごとに1つのリンク) + 間の100GEリンクの総数 膨大なストレージデバイスとストレージリーフノード (デバイスあたり 2 つのリンク)= 16 |
間の400GEリンクの総数 フロントエンドリーフノードとスパインノード = 16 (リーフからスパインへの接続あたり 2 つのリンク) |
| 総帯域幅 = 2.4 Tbps | 総帯域幅 = 6.4 Tbps |
| オーバーサブスクリプションなし。 |
GPUバックエンドファブリックのスケーリング
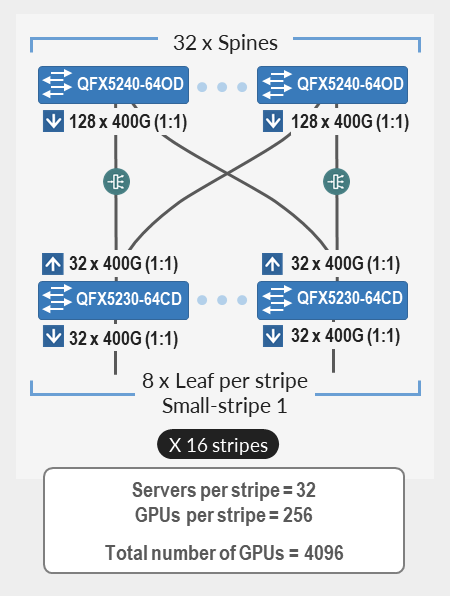
AI クラスターのサイズは、ワークロードの特定の要件によって大きく異なります。AI クラスター内のノードの数は、機械学習モデルの複雑さ、データセットのサイズ、必要なトレーニング速度、利用可能な予算などの要因に影響されます。その数は、ノード数が100未満の小規模なクラスターから、10,000ノードのコンピューティング、ストレージ、ネットワーキングノードで構成されるデータセンター全体のクラスターまでさまざまです。パスの多様性とPFC障害パスの削減のために、常に最低4つのスパインを展開する必要があります。
表21:ファブリックのスケーリング - デバイスと位置決め
| ファブリックのスケーリング | ||
|---|---|---|
| 小 | 中 | 大 |
| 最大4096個のGPU | 最大8192 GPU | 8192および最大73,728 GPU |
| 最大4,096個のGPUをサポートし、ジュニパー台のQFX5240-64CDをスパインノードとして、QFX5230-64CDをリーフノードとして使用(シングルまたはマルチストライプ実装)。 この3ステージのレールベースファブリックは、最大32のスパインと128のリーフノードで構成され、1:1のサブスクリプションを維持します。 このファブリックは、最大16本のストライプに物理的接続を提供し、ストライプごとに32台のサーバー(256 GPU)、合計4,096個のGPUを備えています。 |
4096以上のGPUと最大8192のGPUをサポートし、スパインノードとリーフノードの両方としてジュニパー QFX5240-64CDをサポートします。 この3ステージのレールベースファブリックは、最大64個のスパインと最大128個のリーフノードで構成され、1:1のサブスクリプションを維持します。 このファブリックは、最大16のストライプに物理的な接続を提供し、ストライプごとに64台のサーバー(512 GPU)、合計8192個のGPUを備えています |
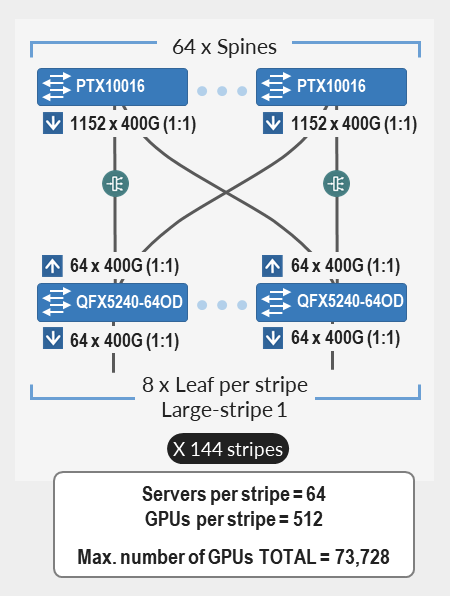
8192以上のGPUをサポート。73,728個のGPU(スパインノードとしてジュニパー PTX10000シャーシ、リーフノードとしてジュニパー QFX5240-64CD)。 この3ステージのレールベースファブリックは、最大64個のスパインと最大1,152個のリーフノードで構成され、1:1のサブスクリプションを維持します。 このファブリックは、最大144のストライプに物理的な接続を提供し、ストライプごとに64台のサーバー(512 GPU)、合計73,728個のGPUを備えています。 |
 |
 |
 |
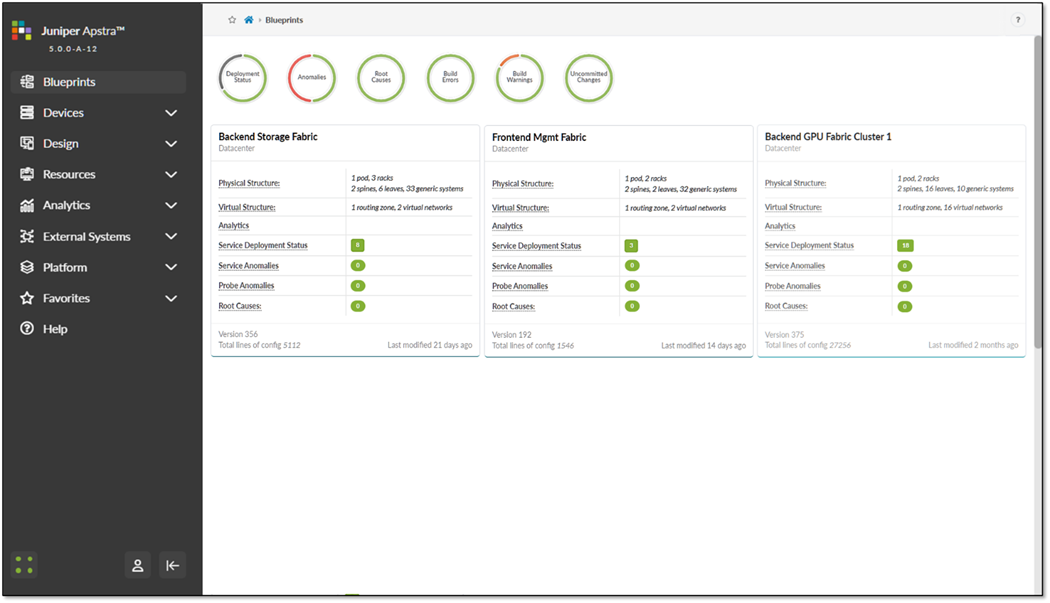
検証済みのジュニパーハードウェアおよびソフトウェアソリューションコンポーネント
以下に示すジュニパー製品とソフトウェアバージョンは、AI DCユースケースで検証済みの最新の構成に対応したものです。継続的な検証プロセスの一環として、さまざまなハードウェアモデルとソフトウェアバージョンを定期的にテストし、それに応じて設計上の推奨事項を更新します。
セットアップのJuniper Apstraのバージョン は6.1です。
次の表は、このJVDで検証済みのジュニパーデバイスをまとめたもので、 Juniper Apstra、NVIDIA GPU、WEKA Storage—ジュニパー検証済み設計(JVD)を使用して、AIデータセンターネットワーク用にテストされたデバイスが含まれています。
表22:検証済みデバイスと位置付け
| デバイス | 、フロントエンドファブリック | 、GPU、バックエンドファブリック | 、ストレージファブリック | |||
|---|---|---|---|---|---|---|
| リーフ | スパイン | リーフ | スパイン | リーフ | スパイン | |
| QFX5130-32CD | X | X | X | X | ||
| QFX5220-32CD | X | X | X | X | X | |
| QFX5230-32CD | X | X | X | |||
| QFX5230-64CD | X | X | X | X | ||
| QFX5240-64OD | X | X | X | X | ||
| QFX5241-64OD | X | X | X | X | ||
| PTX10008 JNP10K-LC1201 | X | |||||
| PTX10008 JNP10K-LC1301 | X | |||||
次の表は、ロール別にテストおよび検証されたソフトウェアバージョンをまとめたものです。
表23:プラットフォーム推奨リリース
| プラットフォーム | の役割 | Junos OSリリース |
|---|---|---|
| QFX5240-64CD | GPUバックエンドリーフ | 23.4X100-D31 |
| QFX5240-64OD/QD | GPUバックエンドスパイン | 23.4X100-D42 |
| QFX5220-32CD | GPUバックエンドリーフ | 23.4X100-D20 |
| QFX5230-64CD | GPUバックエンドリーフ | 23.4X100-D20 |
| QFX5240-64CD | GPUバックエンドスパイン | 23.4X100-D31 |
| QFX5240-64OD/QD | GPUバックエンドスパイン | 23.4X100-D42 |
| QFX5230-64CD | GPUバックエンドスパイン | 23.4X100-D20 |
| LC1201搭載PTX10008 | GPUバックエンドスパイン | 23.4R2-S3 |
| QFX5130-32CD | フロントエンドリーフ | 23.43R2-S3 |
| QFX5130-32CD | フロントエンドスパイン | 23.43R2-S3 |
| QFX5220-32CD | ストレージバックエンドリーフ | 23.4X100-D20 |
| QFX5230-64CD | ストレージバックエンドリーフ | 23.4X100-D20 |
| QFX5240-64CD | ストレージバックエンドリーフ | 23.4X100-D20 |
| QFX5240-64OD/QD | ストレージバックエンドリーフ | 23.4X100-D42 |
| QFX5220-32CD | ストレージバックエンドスパイン | 23.4X100-D20 |
| QFX5230-64CD | ストレージバックエンドスパイン | 23.4X100-D20 |
| QFX5240-64CD | ストレージバックエンドスパイン | 23.4X100-D20 |
| QFX5240-64OD/QD | ストレージバックエンドスパイン | 23.4X100-D42 |