Junosノードスライシングについて
Junosノードスライシングの概要
Junos Node Slicingは、サービスプロバイダや大企業が、複数のルーティング機能を1つの物理デバイスに統合したネットワークインフラストラクチャを構築することを可能にします。これは、運用の複雑さを回避しながら、単一の物理インフラストラクチャで複数のサービスをホストするのに役立ちます。また、デバイスでホストされている機能の運用、機能、管理の分離も維持します。
Junos Node Slicingを使用すると、1台の物理MXシリーズルーターに複数のパーティションを作成できます。これらのパーティションは、ゲストネットワーク機能(GNF)と呼ばれます。各GNFは、専用のコントロールプレーン、データプレーン、管理プレーンを備えた独立したルーターとして動作します。これにより、1台の統合型MXシリーズルーター上で複数のサービスを実行し、それらの間の運用上の分離を維持することができます。同じ物理デバイスを利用して、コントロールプレーンや転送プレーンを共有せず、同じシャーシ、スペース、電力のみを共有するパラレルパーティションを作成できます。
また、ファーストクラスのイーサネットインターフェイスとして動作する疑似インターフェイスである抽象化ファブリック(af)インターフェイスを使用することで、スイッチファブリックを介してGNF間のトラフィックを送信することもできます。抽象化されたファブリックインターフェイスにより、GNF間の制御、データ、管理トラフィックのルーティングが容易になります。
Junos Node Slicingには、外部サーバーモデルとシャーシ内モデルの2つのモデルがあります。外部サーバーモデルでは、GNFは業界標準のx86サーバーのペアでホストされます。シャーシ内モデルの場合、GNFはMXシリーズルーター自体のルーティングエンジンでホストされます。
Junos Node Slicingは、マルチバージョンのソフトウェア互換性をサポートしているため、GNFを個別にアップグレードすることができます。
Junos Node Slicingのメリット
Converged network—Junos Node Slicingを使用することで、サービスプロバイダは、映像エッジや音声エッジなど、複数のネットワークサービスを1台の物理ルーターに統合し、それらの運用を分離しておくことができます。水平方向と垂直方向の両方の収束を実現できます。水平収束は、同じ層のルーター機能を1つのルーターに統合し、垂直コンバージェンスは、異なる層のルーター機能を1つのルーターに集約します。
Improved scalability—物理デバイスではなく仮想ルーティングパーティションに重点を置くことで、ネットワークのプログラマビリティと拡張性が向上し、サービスプロバイダや企業はハードウェアを追加購入することなくインフラストラクチャの要件に対応できるようになります。
Easy risk management—複数のネットワーク機能を1つのシャーシに集約しますが、すべての機能が独立して動作し、運用、機能、管理の分離によるメリットを享受できます。ブロードバンドネットワークゲートウェイ(BNG)などの物理システムをパーティション化して複数の独立した論理インスタンスにすることで、障害を確実に分離することができます。パーティションはコントロールプレーンや転送プレーンを共有せず、共有するのはシャーシ、スペース、電力のみです。つまり、1 つのパーティションで障害が発生しても、サービス停止にまでは被害が広がりません。
Reduced network costs—Junos Node Slicingは、内部スイッチングファブリックを介してGNFの相互接続を可能にします。これは、優れたイーサネットインターフェイスの動作を表す疑似インターフェイスである抽象化ファブリック(
af)インターフェイスを活用します。afインターフェイスを導入すると、GNFの接続に物理インターフェイスを使用する必要がなくなり、大幅な削減が実現します。Reduced time-to-market for new services and capabilities—各GNFは、異なるJunosソフトウェアバージョンで動作できます。この利点により、企業は各GNFを独自のペースで進化させることができます。新しいサービスや機能を特定のGNFに展開する必要があり、新しいソフトウェアリリースが必要な場合、更新が必要となるのは関係するGNFのみです。さらに、俊敏性の向上に伴い、Junos Node Slicingサービスプロバイダや企業は柔軟性の高いEverything-as-a-serviceビジネスモデルを導入し、絶えず変化する市場の状況に迅速に対応できます。
Junos Node Slicingのコンポーネント
Junos Node Slicingでは、単一のMXシリーズルーターをパーティション化して、複数の独立したルーターとして表示することができます。各パーティションには、仮想マシン(VM)として実行される独自のJunos OSコントロールプレーンと、専用のラインカードセットがあります。各パーティションは、ゲストネットワーク機能(GNF)と呼ばれます。
MXシリーズルーターは、ベースシステム(BSYS)として機能します。BSYSは、ラインカードやスイッチファブリックなど、ルーターのすべての物理コンポーネントを所有しています。BSYS は、ライン カードを GNF に割り当てます。
ジュニパーデバイスマネージャー(JDM)ソフトウェアがGNF VMをオーケストレーションします。JDMでは、GNF VMは仮想ネットワーク機能(VNF)と呼ばれます。したがって、GNFはVNFと一連のラインカードで構成されます。
BSYSでの設定を通じて、シャーシのラインカードを異なるGNFに割り当てることができます。さらに、ラインカードのタイプによっては、ラインカード内のPFEのセットを異なるGNFに割り当てることもできます。詳細については、 サブラインカードの概要 を参照してください。
Junos Node Slicingは、次の2つのモデルをサポートします。
-
外部サーバーモデル
-
シャーシ内モデル
外部サーバーモデルでは、JDMとVNFは、外部業界標準x86サーバーのペアでホストされます。
図1は、外部サーバー上で実行されている3つのGNFと専用ラインカードを示しています。
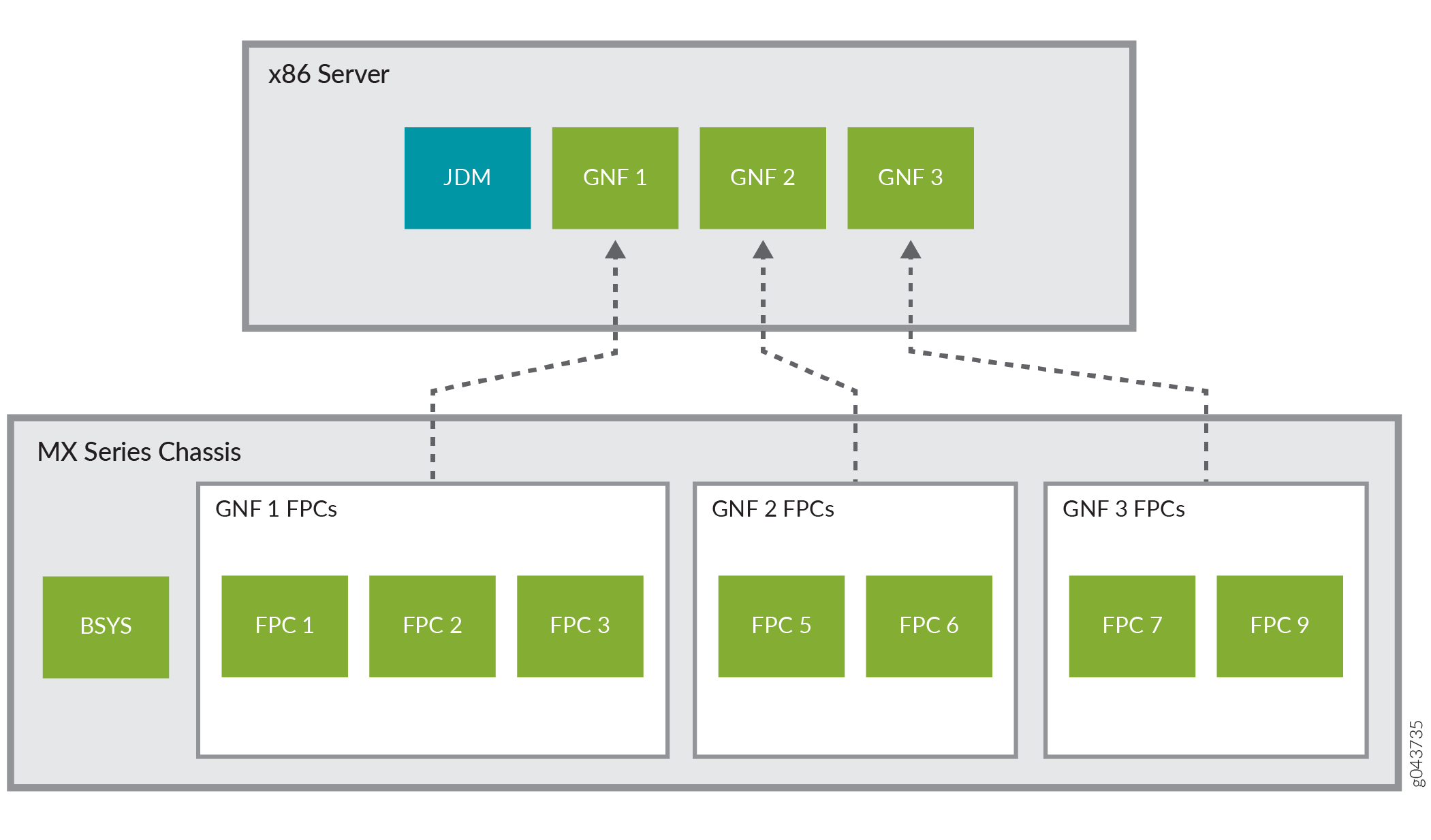
MXシリーズルーターを外部x86サーバーのペアに接続する方法については、 サーバーとルーターの接続 を参照してください。
シャーシ内モデルでは、すべてのコンポーネント(JDM、BSYS、GNF)がMXシリーズルーターのルーティングエンジン内で実行されます。 図2をご覧ください。
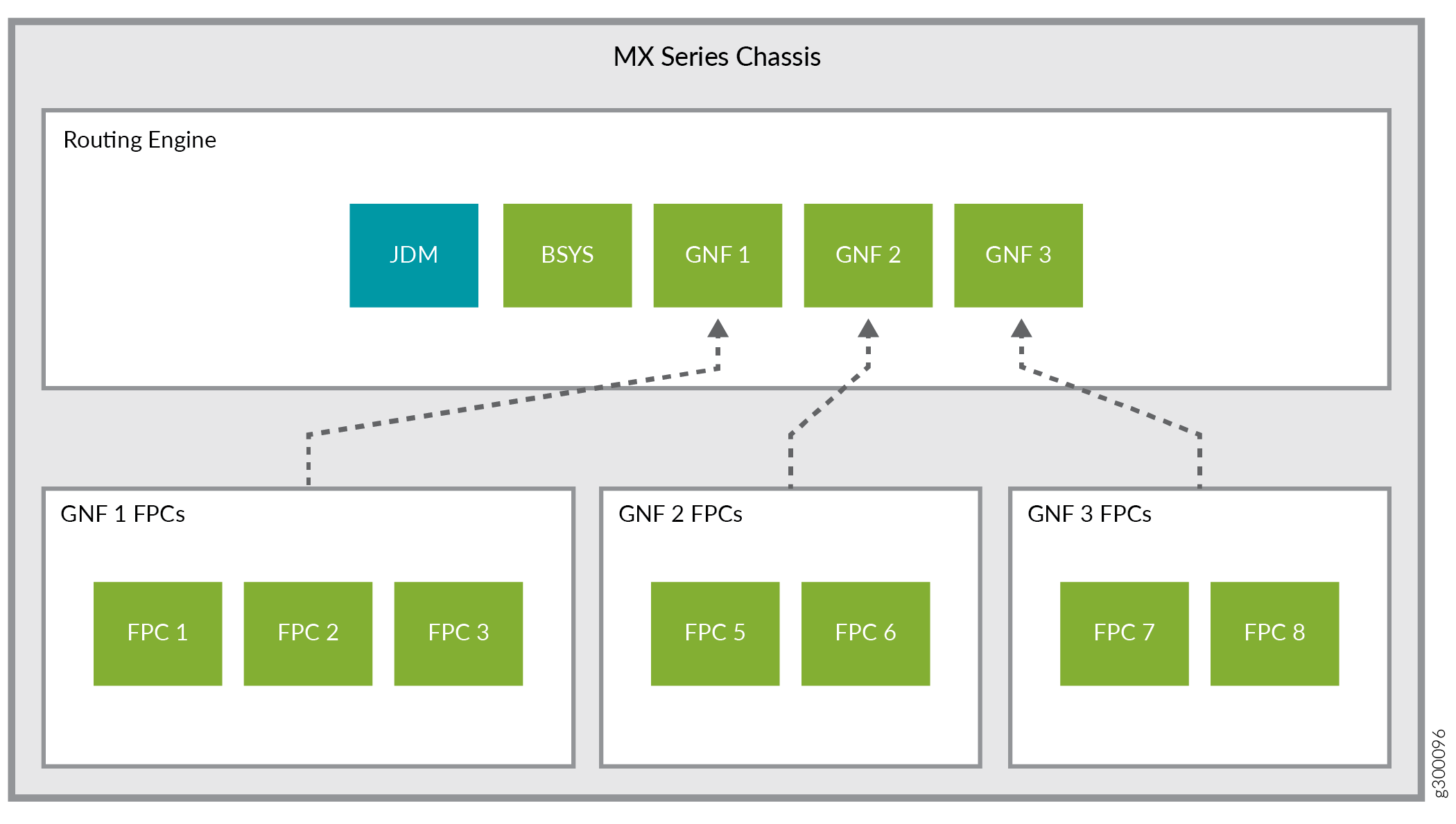
ベースシステム(BSYS)
Junos Node Slicingでは、MXシリーズルーターがベースシステム(BSYS)として機能します。BSYSは、すべてのラインカードとファブリックを含む、ルーターのすべての物理コンポーネントを所有しています。BSYSでのJunos OS設定により、ラインカードをGNFに割り当て、GNF間の抽象化ファブリック(af)インターフェイスを定義できます。BSYSソフトウェアは、MXシリーズルーターの一対の冗長ルーティングエンジンで動作します。
ゲストネットワーク機能(GNF)
ゲストネットワーク機能(GNF)は、ベースシステム(BSYS)によって割り当てられたラインカードを論理的に所有し、ラインカードの転送状態を維持します。MXシリーズルーターには複数のGNFを設定できます( ゲストネットワーク機能の設定を参照してください)。各GNFのJunos OSコントロールプレーンは、仮想マシン(VM)として動作します。ジュニパーデバイスマネージャー(JDM)ソフトウェアがGNF VMをオーケストレーションします。JDMのコンテキストでは、GNFは仮想ネットワーク機能(VNF)と呼ばれます。
GNF はスタンドアロン ルーターに相当します。GNF は独立して設定および管理され、運用上は互いに分離されています。
GNFの作成には2つの設定セットが必要で、1つはBSYSで実行し、もう1つはJDMで実行します。
GNFはIDで定義されます。このIDは、BSYSとJDMで同じである必要があります。
GNF 設定の BSYS 部分は、ID とライン カードのセットの付与で構成されています。
GNF 設定の JDM 部分は、以下の属性を指定することで構成されています。
-
VNF名。
-
GNF ID。この ID は、BSYS で使用される GNF ID と同じである必要があります。
-
MXシリーズプラットフォームタイプ(外部サーバーモデル用)。
-
VNFに使用するJunos OSイメージ
-
VNFサーバーリソーステンプレート。
サーバーリソーステンプレートは、専用(物理)CPUコアの数と、GNFに割り当てるDRAMのサイズを定義します。GNF で使用できる定義済みのサーバーリソーステンプレートのリストについては、Junos Node Slicing のハードウェアおよびソフトウェアの最小要件のサーバーハードウェアリソース要件(GNF ごと)セクションを参照してください。
GNFを設定した後、GNFの仮想コンソールポートに接続してアクセスできます。GNFでJunos OS CLIを使用すると、ホスト名や管理IPアドレスなどのGNFシステムプロパティを設定し、その後、その管理ポートからアクセスできます。
ジュニパーデバイスマネージャー(JDM)
仮想化されたLinuxコンテナであるジュニパーデバイスマネージャー(JDM)を使用することで、GNF VMのプロビジョニングと管理が可能になります。
JDMは、Junos OSのようなCLI、設定と管理用のNETCONF、監視用のSNMPをサポートします。
シャーシ内モデルでは、JDMはSNMPをサポートしていません。
JDMインスタンスは、外部サーバーモデルの各x86サーバーと、シャーシ内モデルの各ルーティングエンジンでホストされます。JDM インスタンスは、通常、GNF 構成を同期するピアとして構成されます。GNF VM が 1 つのサーバーで作成されると、そのバックアップ VM がもう一方のサーバーまたはルーティングエンジンに自動的に作成されます。
IP アドレスと管理者アカウントを JDM で設定する必要があります。これらを設定したら、JDMに直接ログインできます。
関連項目
抽象化されたファブリックインターフェイス
抽象化ファブリック(af)インターフェイスは、ファーストクラスのイーサネットインターフェイスの動作を表す疑似インターフェイスです。 af インターフェイスにより、スイッチファブリックを介してゲストネットワーク機能(GNF)間のトラフィックのルーティング、制御、管理が容易になります。2 つの GNF が相互に接続するように設定されている場合、 af インターフェイスは、そのピア GNF と通信するために GNF 上に作成されます。抽象化されたファブリックインターフェイスは、BSYSで作成する必要があります。 af インターフェイスの帯域幅は、リモート ライン カード/MPC の挿入または到達可能性に基づいて動的に変化します。ファブリックはGNF間の通信媒体であるため、 af インターフェイスはWANインターフェイスと同等と見なされます。 図3をご覧ください。
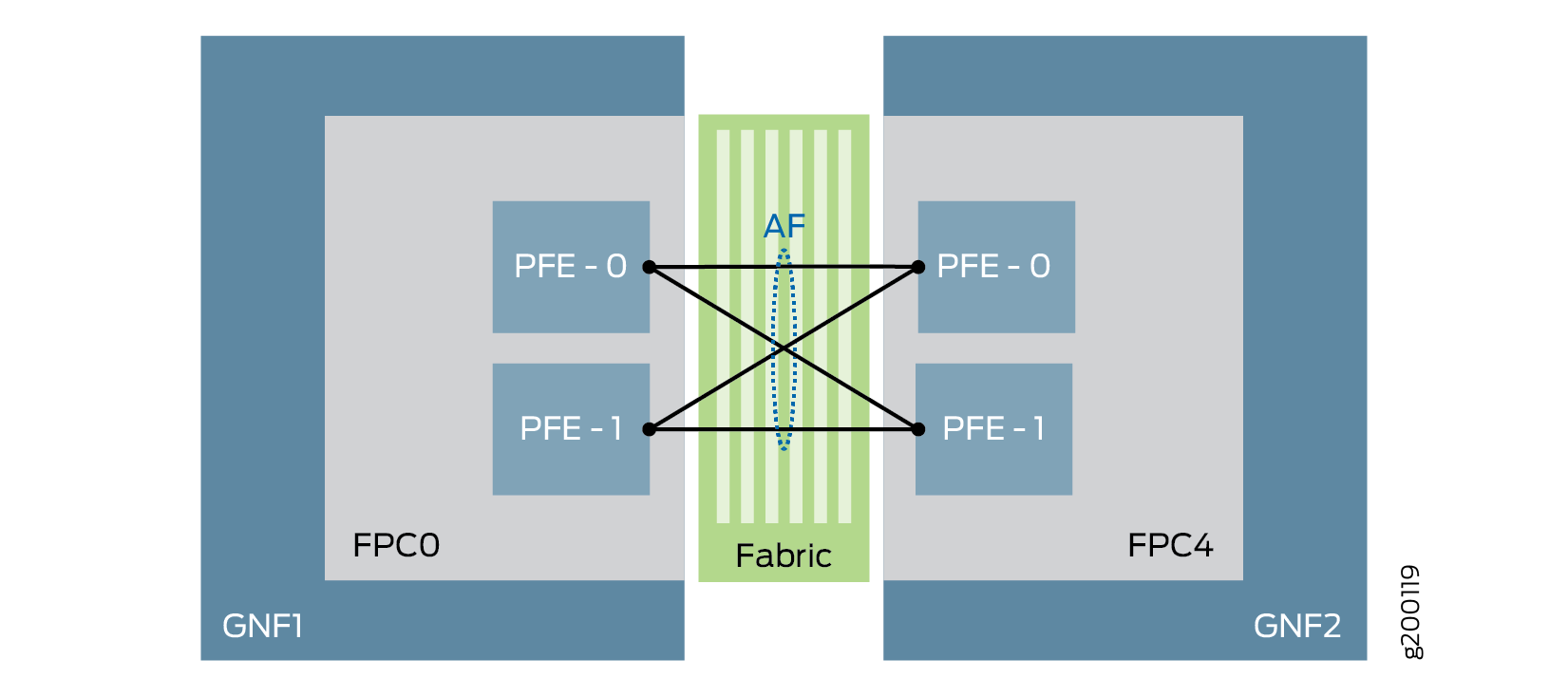
抽象化されたファブリック インターフェイス帯域幅の理解
抽象化ファブリック(af)インターフェイスは、ファブリックを介して2つのGNFを接続し、2つのGNFを接続するすべてのパケット転送エンジン(PFE)を集約します。 af インターフェイスは、 af インターフェイスに属する各パケット転送エンジン帯域幅の合計を活用できます。
例えば、GNF1に1つのMPC8(それぞれ240Gbpsの容量を持つ4つのパケット転送エンジンがあります)があり、GNF1が af インターフェイス(af1およびaf2)を使用してGNF2およびGNF3に接続されている場合、GNF1の最大 af インターフェイス容量は4x240Gbps = 960Gbpsになります。
GNF1—af1——GNF2
GNF1—af2——GNF3
ここでは、af1とaf2は960Gbpsの容量を共有しています。
各 MPC でサポートされている帯域幅の詳細については、 表 1 を参照してください。
抽象化されたファブリックインターフェイスでサポートされている機能
抽象化されたファブリックインターフェイスは、以下の機能をサポートします。
-
統合型稼動中ソフトウェア アップグレード(ISSU)
-
BSYSレベルでのハイパーモード設定(Junos OSリリース19.3R2以降)。この機能は、MPC6E、MPC8E、MPC9E、MPC11Eのラインカードでサポートされています。
注:-
GNF は BSYS から設定を継承するため、個々の GNF に異なるハイパーモード設定を設定することはできません。
-
SFB3を搭載したMX2020およびMX2010ルーターは、デフォルトでハイパーモードで起動します。任意の GNF でハイパー モードを無効にする必要がある場合は、BSYS で設定する必要があり、そのシャーシのすべての GNF に適用されます。
-
-
存在するリモートGNFラインカードに基づくロードバランシング
-
サービスクラス(CoS)のサポート:
-
Inet-precedence classifier and rewrite
-
DSCPの分類子と書き換え
-
MPLS EXPの分類子と書き換え
-
IP v6トラフィック用のDSCP v6分類子と書き換え
-
-
OSPF、IS-IS、BGP、OSPFv3プロトコル、L3VPNのサポート
注:非
afインターフェイスは、Junos OSで動作するすべてのプロトコルをサポートします。 -
Junos OSリリース24.2R1以降のBGP、IS-IS、およびOSPF向けBFD。
-
マルチキャスト転送
-
グレースフルルーティングエンジンスイッチオーバー(GRES)
-
afインターフェイスがコアインターフェイスとして機能するMPLSアプリケーション(L3VPN、VPLS、L2VPN、L2CKT、EVPN、IP over MPLS) -
以下のプロトコルファミリーがサポートされています。
-
IPv4転送
-
IPv6転送
-
MPLS
-
ISO
-
CCC
-
-
Junos Telemetry Interface(JTI)センサーのサポート
-
Junos OSリリース19.1R1以降、ゲストネットワーク機能(GNF)は、仮想拡張LANプロトコル(VXLAN)カプセル化によるイーサネットVPN(EVPN)をサポートします。このサポートは、非
af(つまり物理)インターフェイスとコア向けのインターフェイスとしてのafインターフェイスで利用できます。このサポートは、MPC11Eラインカードでは利用できません。 -
afインターフェイス構成では、GNFはaf対応MPCをサポートします。表1は、af対応MPC、MPCあたりサポートされるPFE数、およびMPCあたりサポートされる帯域幅を示しています。表1:サポートされている抽象化ファブリック対応MPC MPC
初期リリース
PFEの数
総帯域幅
MPC7E-MRATE
17.4R1
2
480G(240*2)
MPC7E-10G
17.4R1
2
480G(240*2)
MX2K-MPC8E
17.4R1
4
960G(240 * 4)
MX2K-MPC9E
17.4R1
4
1.6T(400 * 4)
MPC2E
19.1R1
2
80 (40*2)
MPC2E NG
17.4R1
1
80G
MPC2E NG Q
17.4R1
1
80G
MPC3E
19.1R1
1
130G
MPC3E NG
17.4R1
1
130G
MPC3E NG Q
17.4R1
1
130G
32x10GE MPC4E
19.1R1
2
260G(130*2)
2x100GE + 8x10GE MPC4E
19.1R1
2
260G(130*2)
MPC5E-40G10G
18.3R1
2
240G(120*2)
MPC5EQ-40G10G
18.3R1
2
240G(120*2)
MPC5E-40G100G
18.3R1
2
240G(120*2)
MPC5EQ-40G100G
18.3R1
2
240G(120*2)
MX2K-MPC6E
18.3R1
4
520G(130 * 4)
マルチサービスMPC(MS-MPC)
19.1R1
1
120G
16x10GE MPC
19.1R1
4
160G(40*4)
MX2K-MPC11E
19.3R2
8
4T(500G*8)
afインターフェイスのMTU設定を、XE/GEインターフェイスで許可される最大値に合わせるように設定することをお勧めします。これにより、afインターフェイスを介したパケットのフラグメント化が最小限に抑えられるか、まったく発生しません。
抽象化されたファブリックインターフェイスの制限
抽象化されたファブリックインターフェイスの現在の制限は次のとおりです。
-
単一のエンドポイント
afインターフェイス、afインターフェイスからGNFへのマッピングの不一致、または同じリモートGNFにマッピングされた複数のafインターフェイスなどの設定は、BSYSでのコミット中にチェックされません。設定が正しいことを確認してください。 -
帯域幅の割り当ては、MPC タイプに基づいて静的です。
-
リモートGNFでホストされているMPCのオフライン/再起動中に発生するトラフィックのドロップ(トランジットとホストの両方)は最小限に抑えられます。
-
af対応MPCとaf対応ではないMPC間の相互運用性はサポートされていません。
関連項目
抽象化されたファブリックインターフェイス用のファブリックパスの最適化
ファブリックパス最適化モードを設定することで、2つのゲストネットワーク機能(GNF)間の抽象化ファブリック(af)インターフェイスを介したトラフィックフローを最適化できます。この機能は、パケットが最終的に宛先のパケット転送エンジンに到達する前に、追加のファブリックホップ(あるパケット転送エンジンから別のパケット転送エンジンへのトラフィックフローの切り替え)を防ぐことにより、ファブリック帯域幅の消費を削減します。ファブリックパス最適化は、MPC9EおよびMX2K-MPC11Eを搭載したMX2008、MX2010、MX2020でサポートされており、抽象化されたファブリックインターフェイスのロードバランシングから生じる追加のトラフィックホップを1つだけ防ぐことができます。
以下のファブリックパス最適化モードのいずれかを設定できます。
monitor—このモードを設定すると、ピアGNFはトラフィックフローを監視し、トラフィックが現在転送されているパケット転送エンジンと、最適化されたトラフィックパスを提供できる目的のパケット転送エンジンに関する情報をソースGNFに送信します。このモードでは、送信元 GNF は目的のパケット転送エンジンにトラフィックを転送しません。optimize—このモードを設定すると、ピアGNFはトラフィックフローを監視し、トラフィックが現在転送されているパケット転送エンジンと、最適化されたトラフィックパスを提供できる目的のパケット転送エンジンに関する情報をソースGNFに送信します。次に、送信元 GNF は、目的のパケット転送エンジンに向けてトラフィックを転送します。
ファブリックパス最適化モードを設定するには、BSYSで以下のCLIコマンドを使用します。
user@router#set chassis network-slices guest-network-functions gnf id af-name collapsed-forward (monitor | optimize)user@router#commit
ファブリックパス最適化を設定した後、GNFでコマンド show interfaces af-interface-name を使用して、最適/非最適パスで現在流れているパケット数を表示できます。
関連項目
外部サーバーモデルとシャーシ内モデルの選択
外部サーバーモデルでは、GNFの要件に合わせて十分な容量のサーバーを選択できるため、GNFのインスタンスをより多く設定できます。シャーシ内モデルでは、設定可能なGNFの数は、構成GNFのスケール要件とルーティングエンジンの全体的な容量の関数です。
Junos Node Slicingの外部サーバーモデルとシャーシ内モデルは相互に排他的です。MXシリーズルーターは、これらのモデルのうちの1つだけを一度に動作するように設定できます。
BSYSおよびGNFのプライマリロール動作
以下のセクションでは、ルーティングエンジンの冗長性のコンテキストにおける BSYS と GNF のプライマリロール動作について説明します。
図4は、ルーティングエンジンの冗長性を備えたGNFとBSYSのプライマリロールの動作を示しています。
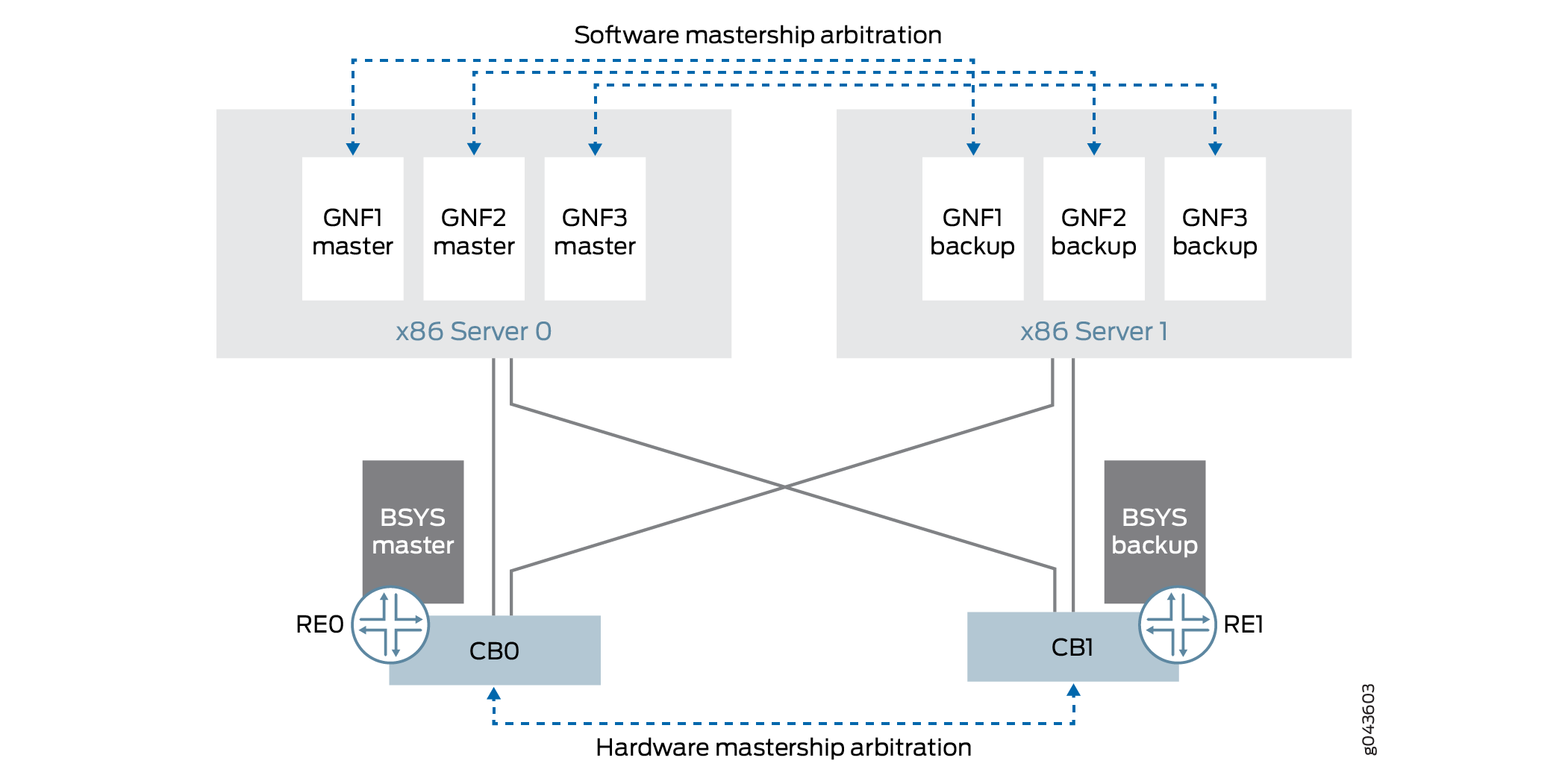 のプライマリロール動作
のプライマリロール動作
BSYSプライマリロール
BSYSルーティングルーティングエンジンのプライマリロールアービトレーションの動作は、MXシリーズルーター上のルーティングエンジンの動作と同じです。
GNFの主な役割
GNF VMのプライマリロールアービトレーションの動作は、MXシリーズルーティングエンジンの動作と似ています。各GNFは、VMのプライマリバックアップペアとして実行されます。 server0 (またはインシャーシの場合は re0 )で実行されるGNF VMは、MXシリーズルーターのスロット0ルーティングエンジン相当であり、 server1 (またはインシャーシの場合は re1 )で実行されるGNF VMは、MXシリーズルーターのスロット1ルーティングエンジン相当です。
GNFプライマリロールは、BSYSプライマリロールや他のGNFのプライマリロールから独立しています。GNFプライマリロールの仲裁は、Junos OSを介して行われます。接続障害条件下では、GNF プライマリ ロールは控えめに処理されます。
GNFプライマリロールモデルは、外部サーバーモデルとシャーシ内モデルの両方で同じです。
MXシリーズルーティングエンジンと同様に、各GNFでグレースフルルーティングエンジンスイッチオーバー(GRES)を設定する必要があります。これは、プライマリGNF VMに障害が発生したり再起動されたりしたときに、バックアップGNF VMが自動的にプライマリロールを引き継ぐための前提条件です。
Junosノードスライシング管理者の役割
以下の管理者ロールを使用して、Node Slicingタスクを実行できます。
BSYS管理者—物理シャーシとGNFプロビジョニング(GNFへのラインカードの割り当て)を担当します。これらのタスクには、Junos OS CLI コマンドを使用できます。
GNF管理者—GNFでのJunos OSの設定、運用、管理を担当します。GNF管理者は、通常のJunos OS CLIコマンドをすべて使用して、これらのタスクに使用できます。
JDM管理者—JDMサーバーポート設定(外部サーバーモデル用)、およびGNF VM(VNF)のプロビジョニングとライフサイクル管理を担当します。JDM CLIコマンドは、これらのタスクに使用できます。
サブラインカードの概要
Junos Node Slicingでは、各GNFはFPC(ラインカード)のセットで構成されています。デフォルトでは、各GNFにラインカード全体(つまり、各ラインカード内のパケット転送エンジンの完全なセット)が割り当てられるため、GNFによって提供される最も細かい粒度はラインカードレベルです。サブラインカード(SLC)機能では、単一のラインカード内のパケット転送エンジンのサブセットを異なるGNFに割り当てることで、パーティショニングの細かい度を定義することができます。
このようなユーザー定義のラインカード内のパケット転送エンジンのサブセットは、サブラインカード(SLC)と呼ばれます。運用面では、SLCは独立したラインカードのように機能します。
ラインカードをスライスする場合、そのラインカードのすべてのSLCを異なるGNFに割り当てる必要があります。
複数のラインカードのSLCを同じGNFに割り当てることができます。
SLC機能を備えたJunos Node Slicingセットアップでは、GNFはラインカード全体のセットとラインカードのSLC(スライスのセット)で構成できるため、より高いレベルの柔軟性が得られます。
ラインカードがスライスされると、そのラインカードで2種類のソフトウェアインスタンスが実行されます。それは、単一のベースラインカード(BLC)インスタンスと複数のSLCインスタンス(そのラインカードのスライス数と同じ数)です。現在、SLC機能は2つのSLCをサポートするMPC11Eでのみ使用できます。BLCインスタンスは、そのラインカードのすべてのSLCに共通するハードウェアの管理を担当し、各SLCインスタンスは、それに排他的に割り当てられたパケット転送エンジンのセットの管理を担当します。BLCインスタンスはBSYSのJunosソフトウェアを実行し、各SLCインスタンスは関連するGNFのJunosソフトウェアを実行します。
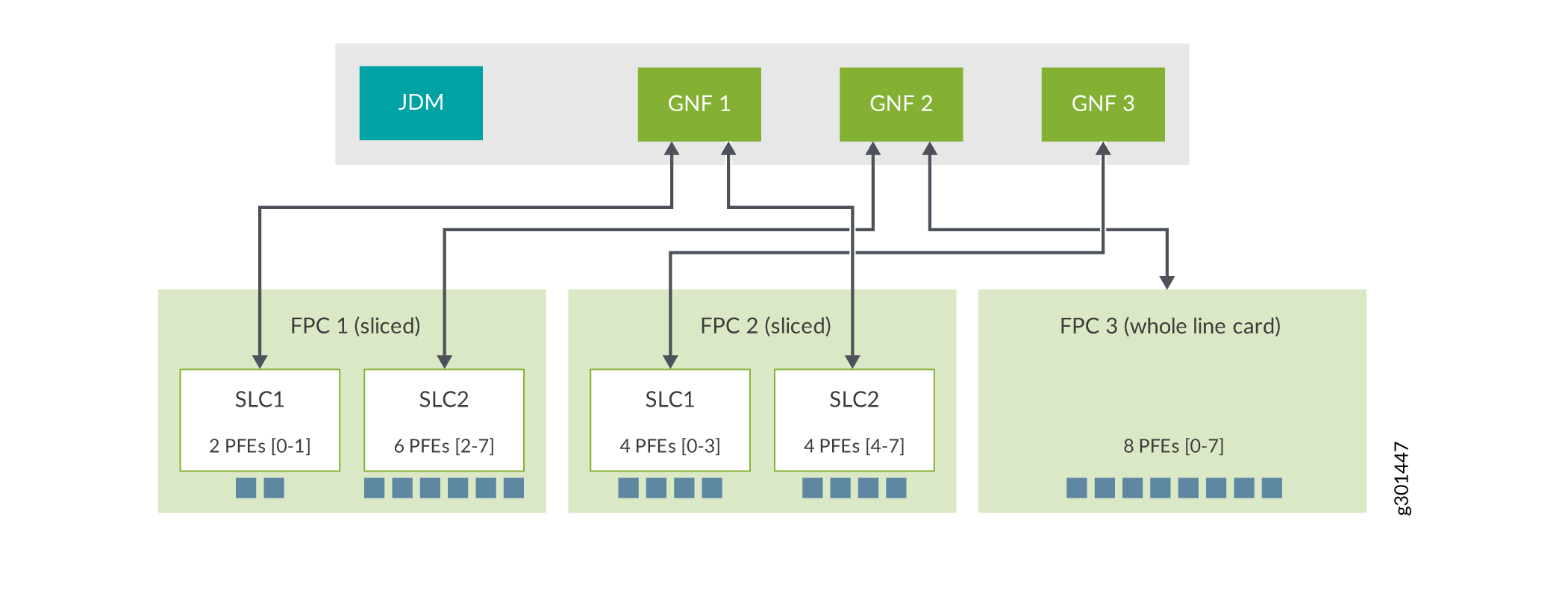 でGNFに割り当てられたSLC
でGNFに割り当てられたSLC
SLCは、 抽象化されたファブリックインターフェイス と折りたたまれたフォワーディングをサポートします(抽象 化されたファブリックインターフェイスのファブリックパスの最適化を参照してください)。 show interface af-interface-name コマンドを使用すると、リモートFPCスライス固有のパケット転送エンジンの負荷分散統計情報を表示できます。詳細については 、show interfaces(抽象化されたファブリック) を参照してください。
SLC機能は、MPC11E(モデル番号:MX2K-MPC11E)でのみ使用できます。
SLCのラインカードリソース
SLCまたはラインカードのスライスは、一緒に動作する必要がある(そのラインカードの)パケット転送エンジンのセットを定義します。ラインカード内のパケット転送エンジンは、数字のIDで識別されます。ラインカードに「n」個のパケット転送エンジンがある場合、個々のパケット転送エンジンには0から(n-1)の番号が付けられます。さらに、ラインカードのコントロールボード上のCPUコアとDRAMも分割して、スライスに割り当てる必要があります。したがって、SLCを定義するには、そのSLC専用となる以下のラインカードリソースを定義する必要があります。
-
パケット転送エンジンの範囲
-
ラインカードのコントロールボード上のCPUコア数
-
ラインカードのコントロールボード上のDRAMのサイズ(GB)
一定量のDRAMは、そのラインカード上のBLCインスタンス用に自動的に予約され、残りはSLCインスタンスで使用できます。
すべてのSLCは、ユーザーが割り当てた数字IDで識別されます。
ラインカードをスライスする場合、そのラインカード上のすべてのスライスのリソースパーティションを完全に定義する必要があります。
SLC用MPC11Eラインカードリソース
MPC11Eラインカードには以下が含まれます。
-
8個のパケット転送エンジン
-
コントロールボード上の8個のCPUコア
-
コントロールボード上に32GBのDRAM
5GBのDRAMが自動的にBLC使用用に予約され、1GBのDRAMがラインカードホストに割り当てられ、残りの26GBがSLCスライスに使用可能です。
MPC11Eは、2つのSLCをサポートできます。
表2は、ここではSLC1とSLC2と呼ぶ2つのSLCに対して、MPC11Eがサポートする2種類のリソース割り当てプロファイルを定義しています。
対称プロファイルでは、パケット転送エンジンとその他のラインカードリソースがスライス間で均等に分散されます。非対称プロファイルでは、 表2 に示す指定されたラインカードリソースの組み合わせのみがサポートされます。
パケット転送エンジン[0-7]が2つのSLC間でどのように分割されているかに基づいて、以下のSLCプロファイルを設定できます。
-
パケット転送エンジン 1 つの SLC で 0-3、もう 1 つの SLC で 4-7(対称プロファイル)
-
パケット転送エンジン 1 つの SLC で 0-1、もう一方の SLC で 2-7(非対称プロファイル)
-
パケット転送エンジン 1 つの SLC は 0-5、もう 1 つの SLC は 6-7(非対称プロファイル)
非対称プロファイルでは、9GBまたは17GBのDRAMをSLCに割り当てることができます。すべてのラインカードリソースを完全に割り当てる必要があり、SLCで使用できるDRAMの合計は26GBであるため、9GBのDRAMをSLCに割り当てるには、残りの17GBを他のSLCに割り当てる必要があります。
| 対称プロファイル |
非対称プロファイル |
|||
|---|---|---|---|---|
| リソースタイプ |
SLC1 |
SLC2 |
SLC1 |
SLC2 |
| パケット転送エンジン |
4 |
4 |
2 |
6 |
| DRAM |
13GB |
13GB |
17GB/9GB |
9GB/17GB |
| CPU |
4 |
4 |
4 |
4 |
マルチバージョンソフトウェアの相互運用性の概要
Junos OSリリース17.4R1以降、Junos Node Slicingはマルチバージョンソフトウェア互換性をサポートしており、BSYSはBSYSのソフトウェアバージョンよりも高いバージョンのJunos OSバージョンを実行するJunos OSバージョンを実行するゲストネットワーク機能(GNF)と相互運用できます。この機能は、GNFとBSYSの間の最大2つのバージョンをサポートします。つまり、GNF ソフトウェアは BSYS ソフトウェアより 2 つのバージョン上位にすることができます。BSYSとGNFの両方が、Junos OSリリース17.4R1の最小バージョン要件を満たす必要があります。
マルチバージョンサポートの制限は、統合型ISSUアップグレードプロセスにも適用されます。
JDMソフトウェアのバージョン管理には、GNFまたはBSYSソフトウェアのバージョンに関して同様の制限はありませんが、JDMソフトウェアを定期的に更新することをお勧めします。JDMアップグレードは、実行中のGNFには影響しません。
Junos Node Slicingの次世代サービス
Junos Node Slicingは、MXプラットフォームで次世代サービスを実行するための追加の処理能力を提供するセキュリティサービスカードである MX-SPC3サービスカードをサポートしています。GNFのCLI request system enable unified-services を使用することで、ゲストネットワーク機能(GNF)で次世代サービスを有効にすることができます。MX-SPC3をサポートするには、GNFにラインカードが関連付けられている必要があります。
Junos Node Slicingのセットアップでは、MX-SPC3とMS-MPCの両方を同じシャーシ上で異なるGNFルーティングエンジンで使用できます。GNFで次世代サービスを有効にしている場合、 request system enable unified-servicesを使用してMX-SPC3をオンラインにします。次世代サービスを有効にしていない場合、MS-MPCはオンラインになります。
MX-SPC3カードのソフトウェアインストールまたはアップグレードは、関連するGNFルーティングエンジンをインストールまたはアップグレードするときに行われます。
MX-SPC3は、抽象化されたファブリックインターフェイスをサポートしていません。そのため、MX-SPC3カードがリンクされているGNFには、ラインカードも関連付けられている必要があります。
Junosノードスライシングと論理システムの比較
Junos Node Slicingは、Junosの論理システムより下位するレイヤーです。どちらのテクノロジーにも重複する機能がいくつかありますが、他の点が異なります。Junos Node Slicingでは、完全なラインカード、ひいては物理インターフェイスがGNFに割り当てられますが、論理システムでは、物理インターフェイス上で定義された複数の論理インターフェイスをすべて別々の論理システムに割り当てることができるため、単一の物理インターフェイス自体を異なる論理システム間で共有できます。つまり、論理システムでは、Junos Node Slicingよりも細かい共有が可能です。しかし、すべての論理システムは単一のJunosカーネルを共有するため、ルーティングエンジンとラインカードのCPU、メモリ、ストレージなどの物理リソースを共有する必要に加えて、同じバージョンのJunosを実行する必要があります。Junos Node Slicing では、各 GNF に相当する独自のルーティング エンジン ペアと、その GNF 専用のライン カードが取得されるため、GNF はほとんどの物理リソースを共有するのではなく、シャーシとスイッチ ファブリックのみを共有します。GNFは、論理システムとは異なり、MXスタンドアロンルーターのように個別にアップグレードおよび管理できます。
Junos Node Slicingは、GNF自体が複数の論理システムを持つことができるため、論理システムを補完し、さらには補強する技術です。物理的な隔離、保証されたリソース、完全な管理上の隔離が最重要事項である場合は、Junos Node Slicingの方が適しています。また、論理インターフェイスレベルに至るまでの細かい共有が最重要である場合は、論理システムの方が適しています。
Junos Node Slicingのライセンスについて
Junos Node Slicingを動作させるには、GNFおよび抽象化されたファブリックインターフェイスのライセンスをBSYSにインストールする必要があります。BSYS にライセンスがインストールされていない状態で GNF を実行すると、以下の syslog メッセージとマイナーなアラームが表示されます。
CHASSISD_LICENSE_EVENT: License Network-Slices: Failed to get valid license('216') 'gnf-creation'
Minor alarm set, 1 Guest network functions creation for JUNOS requires a license.
Junos Node Slicingライセンスに関するご質問は、ジュニパーネットワークスまでお問い合わせください。