Haute disponibilité multinodale à deux nœuds
Découvrez la solution haute disponibilité multinodale à deux nœuds.
La haute disponibilité multinodale à deux nœuds prend en charge deux pare-feu SRX Series qui se présentent comme des nœuds indépendants du reste du réseau. Les nœuds sont connectés à des infrastructures adjacentes appartenant au même réseau ou à des réseaux différents, en fonction du mode de déploiement. Ces nœuds peuvent être colocalisés ou séparés dans différentes zones géographiques. Les nœuds participants se sauvegardent mutuellement pour assurer un basculement rapide et synchronisé en cas de panne du système ou du matériel.
Nous prenons en charge la haute disponibilité multinodale en mode actif/de secours et en mode actif-actif (avec prise en charge de plusieurs groupes de redondance de services (SRG). Pour obtenir la liste complète des fonctionnalités et plates-formes prises en charge, consultez Haute disponibilité multi nodale dans l’explorateur de fonctionnalités.
Scénarios de déploiement
Nous prenons en charge les types de modèles de déploiement réseau suivants pour la haute disponibilité multi nodale :
- Mode de routage (toutes les interfaces connectées à l’aide d’une topologie de couche 3)
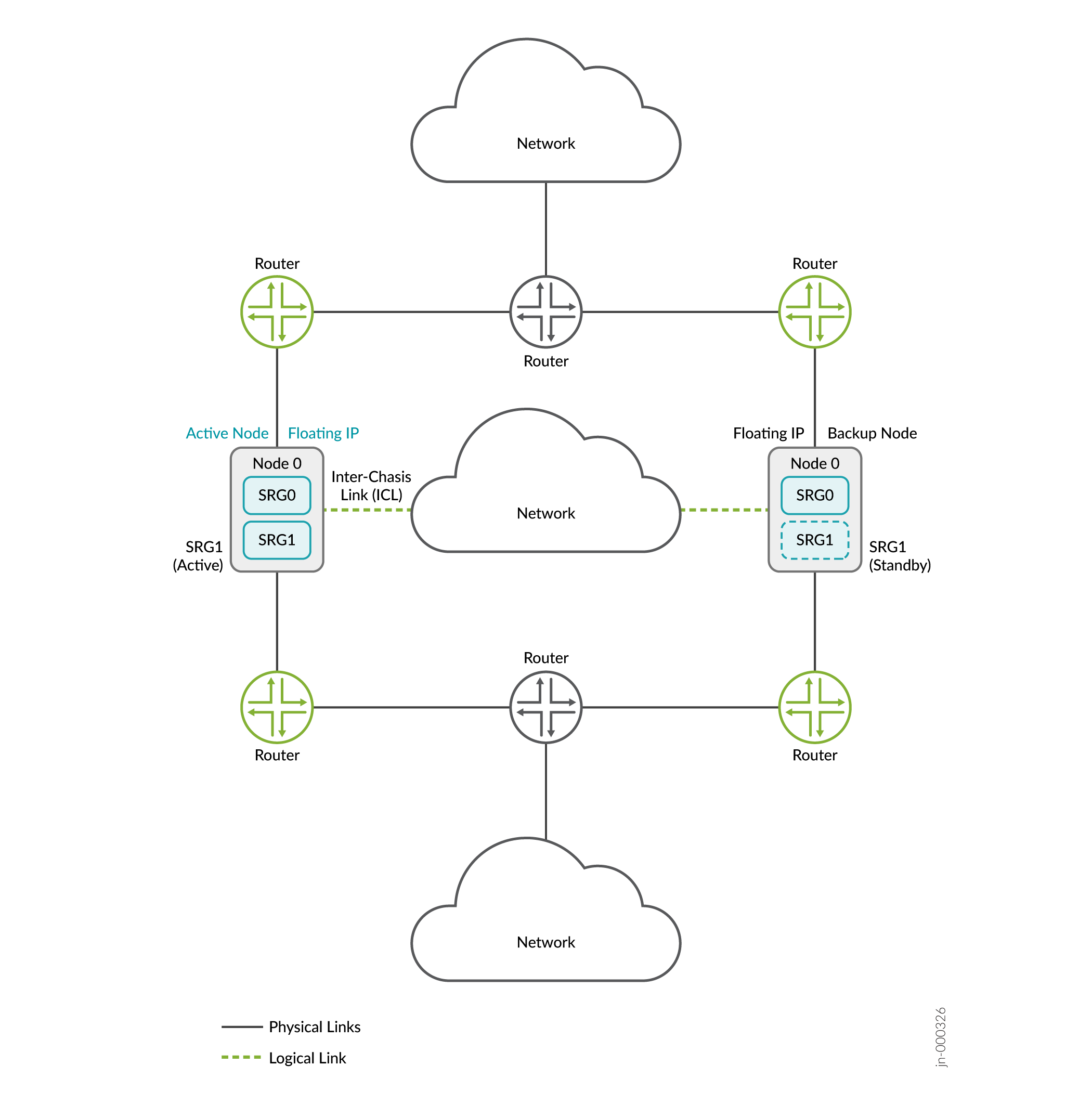
Figure 1 : Mode
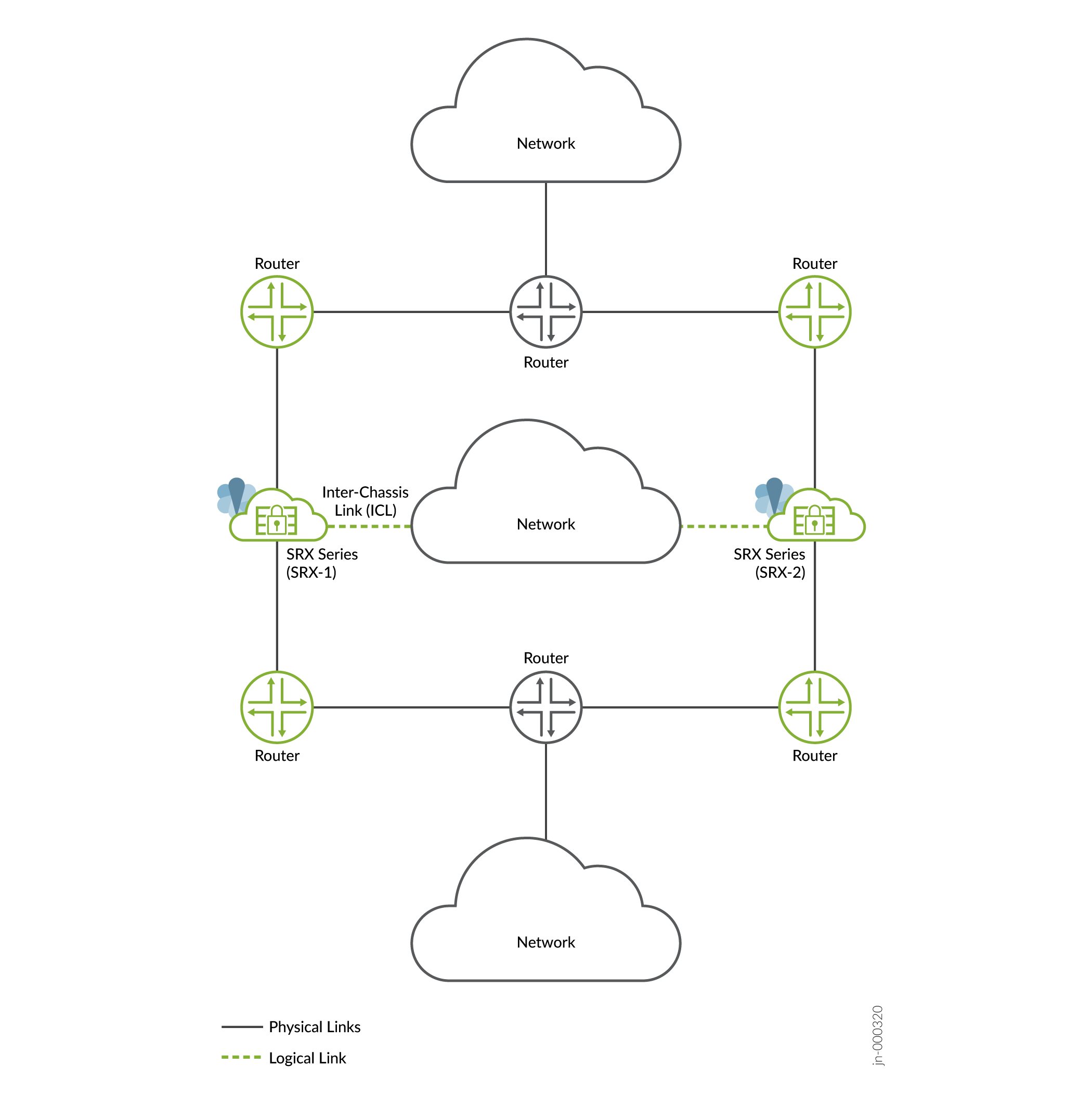 Couche 3
Couche 3
- Mode passerelle par défaut (toutes les interfaces connectées à l’aide d’une topologie de couche 2) utilisé dans les environnements plus traditionnels. Déploiement courant de réseaux DMZ, dans lequel les pare-feu servent de passerelle par défaut pour les hôtes et les applications sur le même segment.
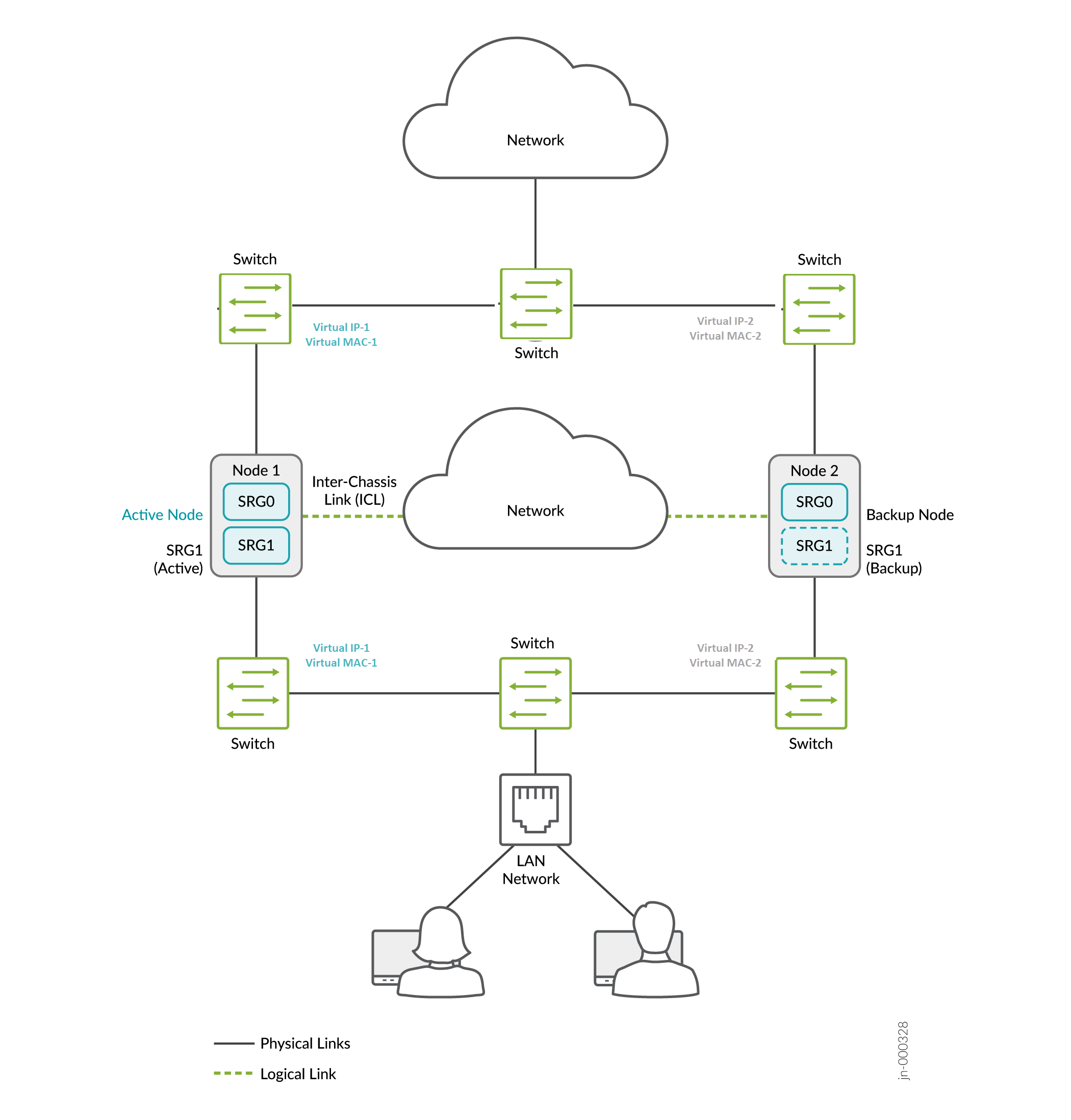
Figure 2 : mode
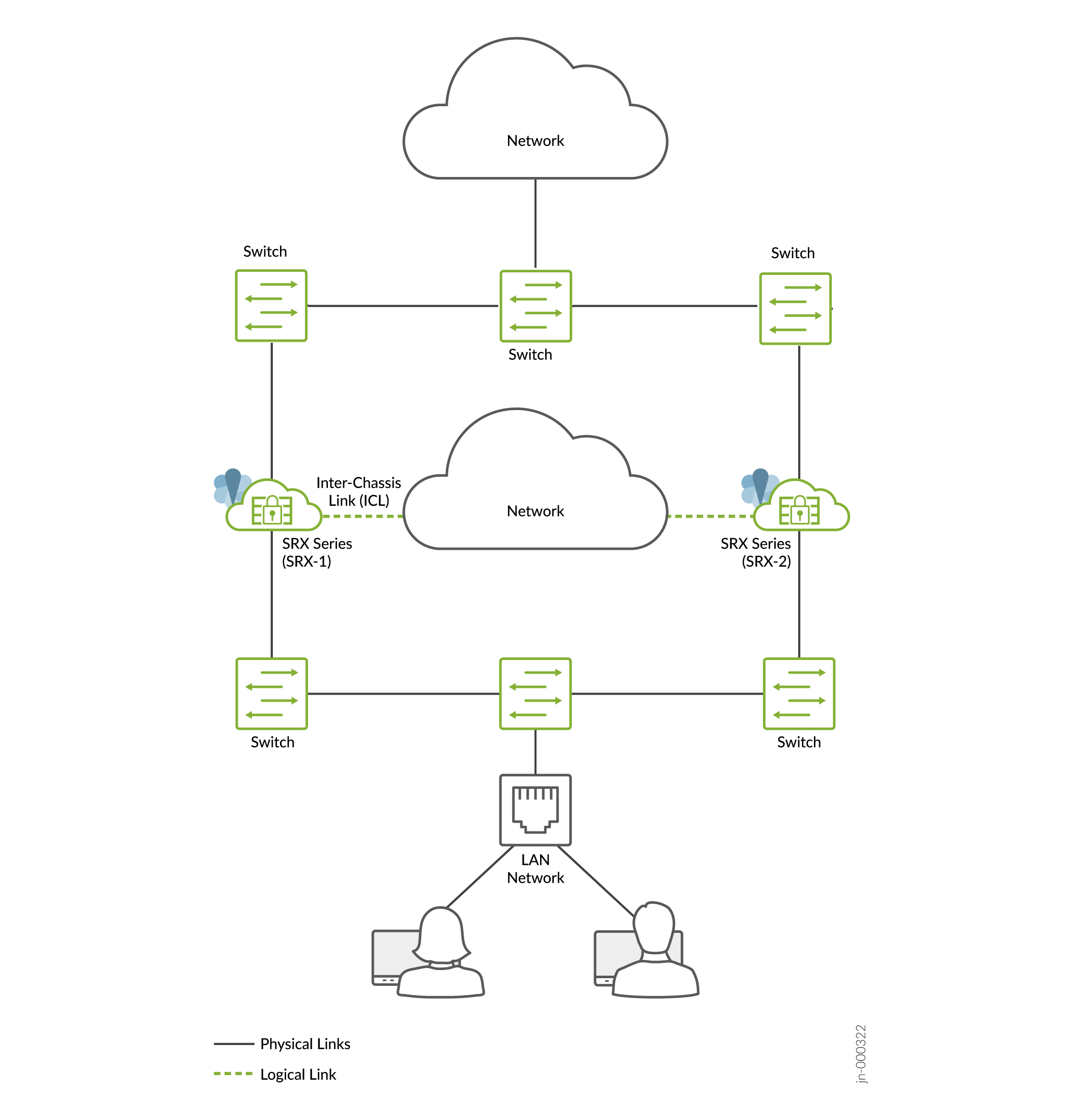 de passerelle par défaut
de passerelle par défaut
- Mode hybride (une ou plusieurs interfaces sont connectées à l’aide d’une topologie de couche 3 et une ou plusieurs interfaces sont connectées à l’aide d’une topologie de couche 2)
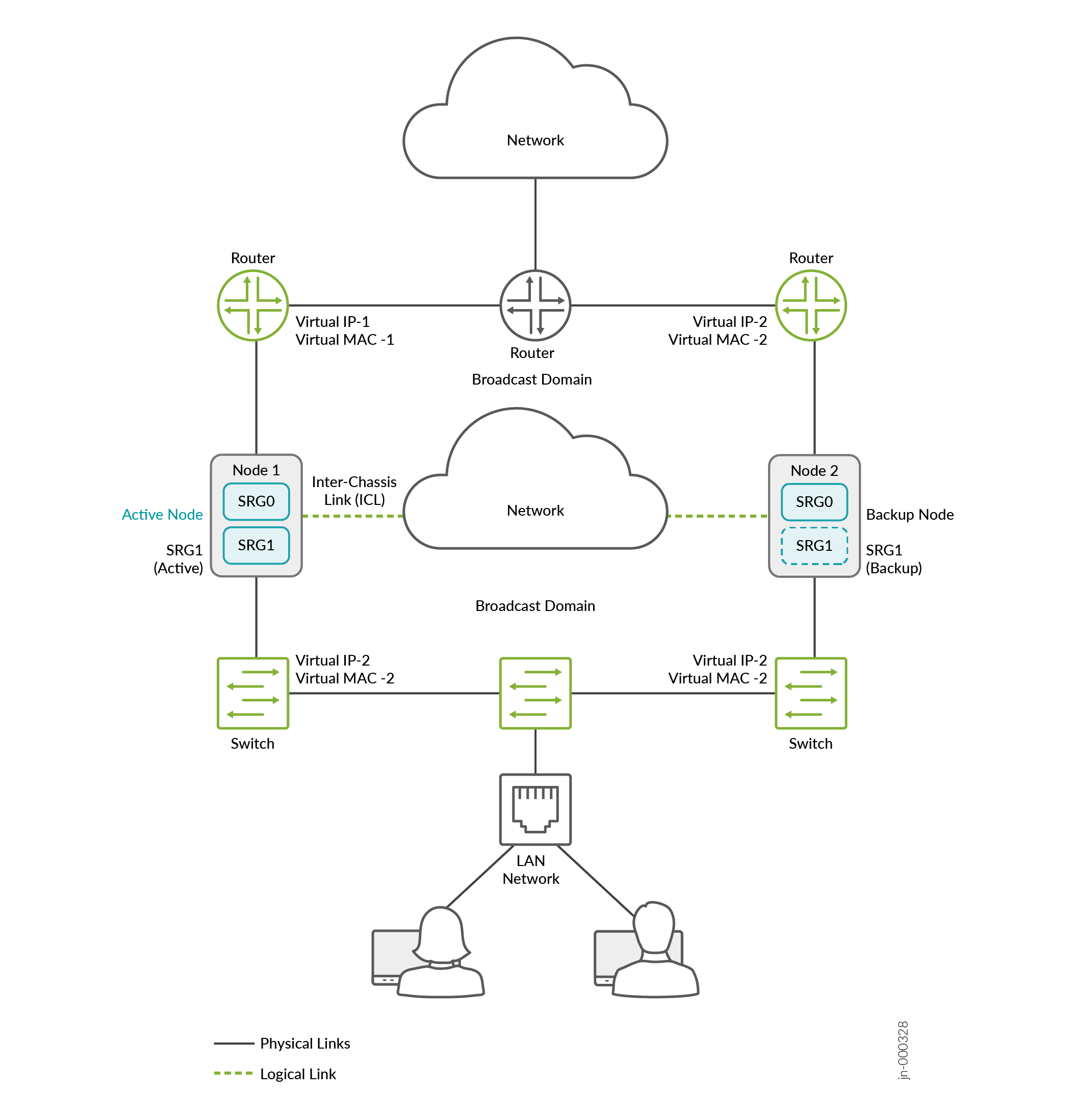
Figure 3 : Mode
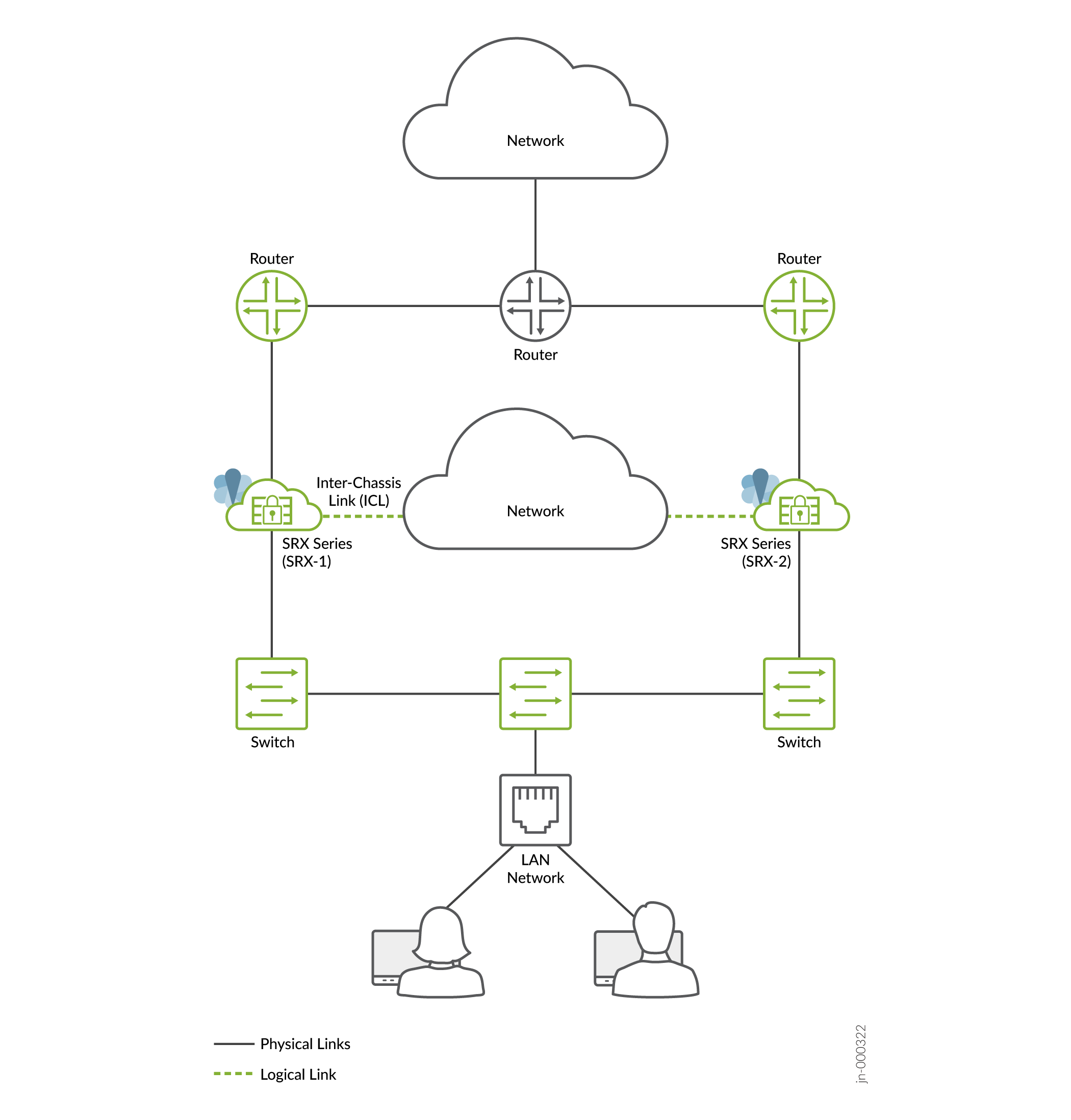 hybride
hybride
- Déploiement sur le cloud public
Figure 4 : Déploiement du cloud public (exemple : AWS)
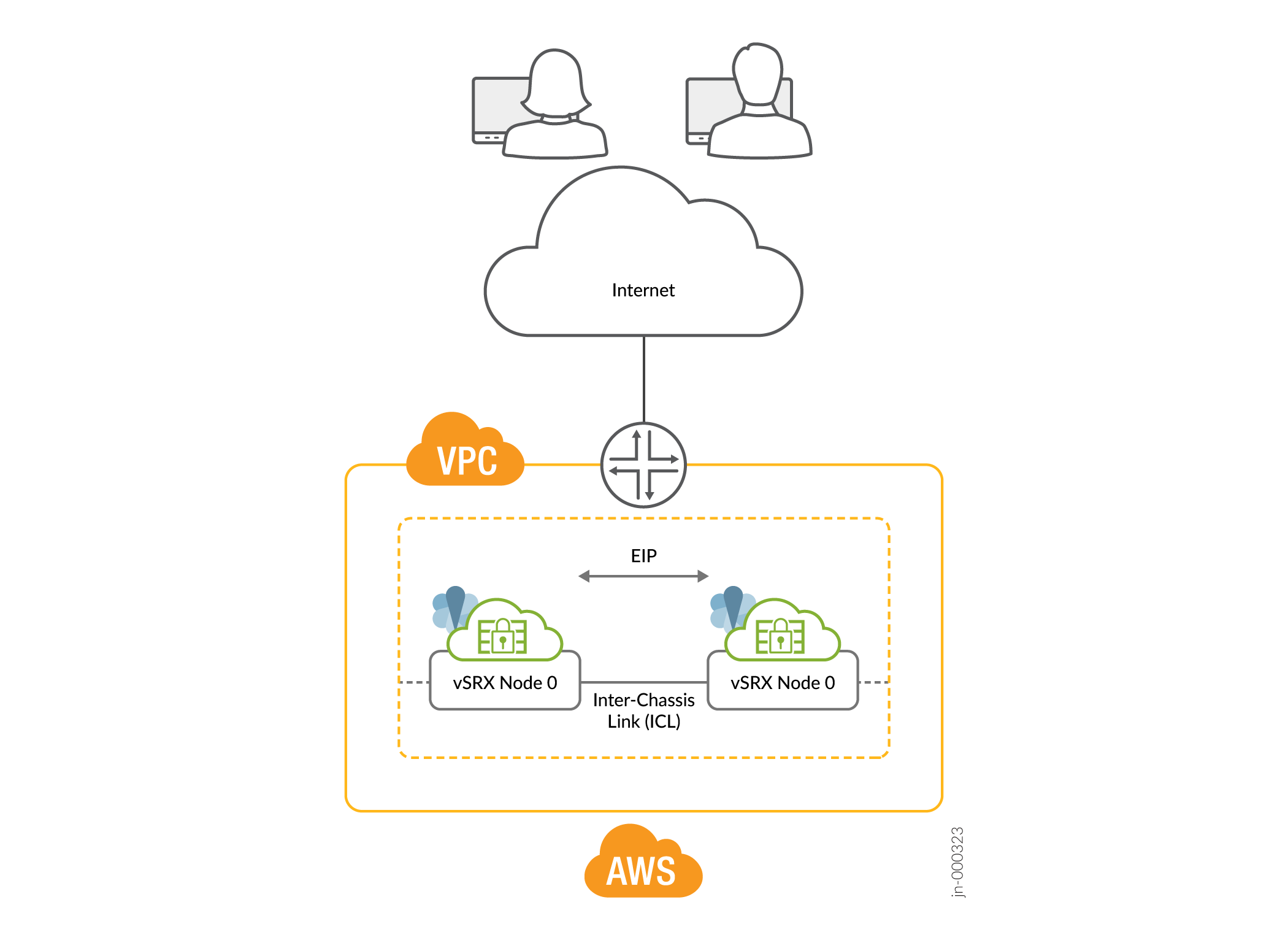
Fonctionnement de la haute disponibilité multi nodale à deux nœuds
Nous prenons en charge une configuration à deux nœuds pour la solution de haute disponibilité multi-nœuds.
Dans une configuration haute disponibilité à plusieurs nœuds, vous connectez deux pare-feu SRX Series à des routeurs adjacents en amont et en aval (pour les déploiements de couche 3), à des routeurs et des commutateurs (déploiement hybride) ou à des commutateurs (déploiement de passerelle par défaut) à l’aide des interfaces de revenus.
Les nœuds communiquent entre eux via une liaison interchâssis (ICL). La liaison ICL utilise la connectivité de couche 3 pour communiquer entre elles. Cette communication peut avoir lieu sur un réseau routé (couche 3) ou un chemin de couche 2 directement connecté. Il est recommandé de lier l’ICL à l’interface de bouclage et d’avoir plusieurs liaisons physiques (LAG/LACP) pour garantir la diversité des chemins pour une résilience maximale.
La haute disponibilité multinodale fonctionne en mode actif/actif pour le plan de données et en mode actif/de secours pour les services de plan de contrôle. Le pare-feu SRX Series actif héberge l’adresse IP flottante et dirige le trafic vers celle-ci à l’aide de l’adresse IP flottante
La haute disponibilité multinodale intervient dans les domaines suivants :
- Mode actif/actif (SRG0) pour les services de sécurité
- Mode actif/de secours (SRG1 et supérieur) pour les services de sécurité et système
Les adresses IP flottantes contrôlées par SRG1 ou supérieur se déplacent entre les nœuds. Le SRG1+ actif héberge et contrôle l’adresse IP flottante. Dans les scénarios de basculement, cette adresse IP « flotte » vers un autre SRG1 actif en fonction des décisions de configuration, d'intégrité du système ou de surveillance du chemin. Le SRG1+ nouvellement actif peut assumer la fonction d’un SRG1 désormais en veille et commence à répondre aux requêtes entrantes.
Les figures 5, 6 et 7 montrent les déploiements en mode de passerelle de couche 3, hybride et par défaut.
 de couche 3
de couche 3
Dans cette topologie, deux pare-feu SRX Series font partie d’une configuration haute disponibilité multi nodale. La configuration dispose d’une connectivité de couche 3 entre les pare-feu SRX Series et les routeurs voisins. Les appareils s’exécutent sur des réseaux physiques de couche 3 distincts et fonctionnent comme deux nœuds indépendants. Les nœuds représentés sur l’illustration sont colocalisés dans la topologie. Les nœuds peuvent également être séparés géographiquement.
 de la passerelle par défaut
de la passerelle par défaut
Dans un déploiement de passerelle par défaut classique, les hôtes et les serveurs d’un LAN sont configurés avec une passerelle par défaut du périphérique de sécurité. L’équipement de sécurité doit donc héberger une adresse IP virtuelle (VIP) qui se déplace entre les nœuds en fonction de l’activité. La configuration sur les hôtes reste statique et le basculement des appareils de sécurité est transparent du point de vue des hôtes.
Vous devez créer des routes statiques ou dynamiques sur les pare-feu SRX Series pour atteindre d’autres réseaux qui ne sont pas directement connectés.
 hybride
hybride
En mode hybride, un pare-feu SRX Series utilise une adresse VIP du côté de la couche 2 pour attirer le trafic vers lui. Vous pouvez éventuellement configurer l’ARP statique de l’adresse IP virtuelle à l’aide de l’adresse VMAC pour vous assurer qu’aucune modification de l’adresse IP ne change pendant le basculement
Voyons maintenant en détail les composants et les fonctionnalités de la haute disponibilité multinodale.
- Groupes de redondance de services
- Détermination de l’activité et application
- Résilience et basculement
- Chiffrement des liaisons interchâssis (ICL)
Groupes de redondance de services
Un groupe de redondance de services (SRG) est une unité de basculement dans une configuration haute disponibilité à plusieurs nœuds. Il existe deux types de SSR :
- SRG0 : gère le service de sécurité de la couche 4 à la couche 7, à l’exception des services VPN IPsec. Le SRG0 fonctionne en mode actif sur les deux nœuds à tout moment. Sur SRG0, chaque session de sécurité doit traverser le nœud dans un flux symétrique, La sauvegarde de ces flux est entièrement synchronisée avec l’autre nœud,
- SRG1+ : gère les services IPsec et les adresses IP virtuelles en mode passerelle hybride et par défaut, et les sauvegarde sur l’autre nœud. Le SRG1 fonctionne en mode actif sur un nœud et en nœud de secours sur un autre nœud.
La figure 8 montre SRG0 et SRG1 dans une configuration haute disponibilité à plusieurs nœuds.
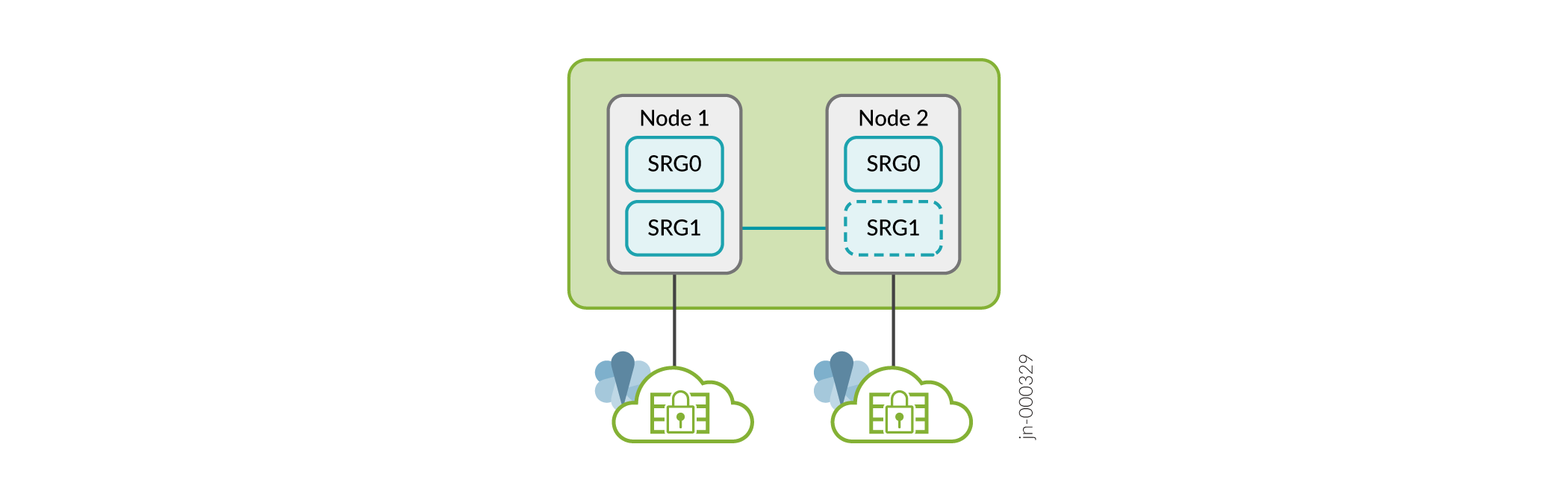
La figure 9 montre SRG0 et SRG1+ dans une configuration haute disponibilité à plusieurs nœuds.
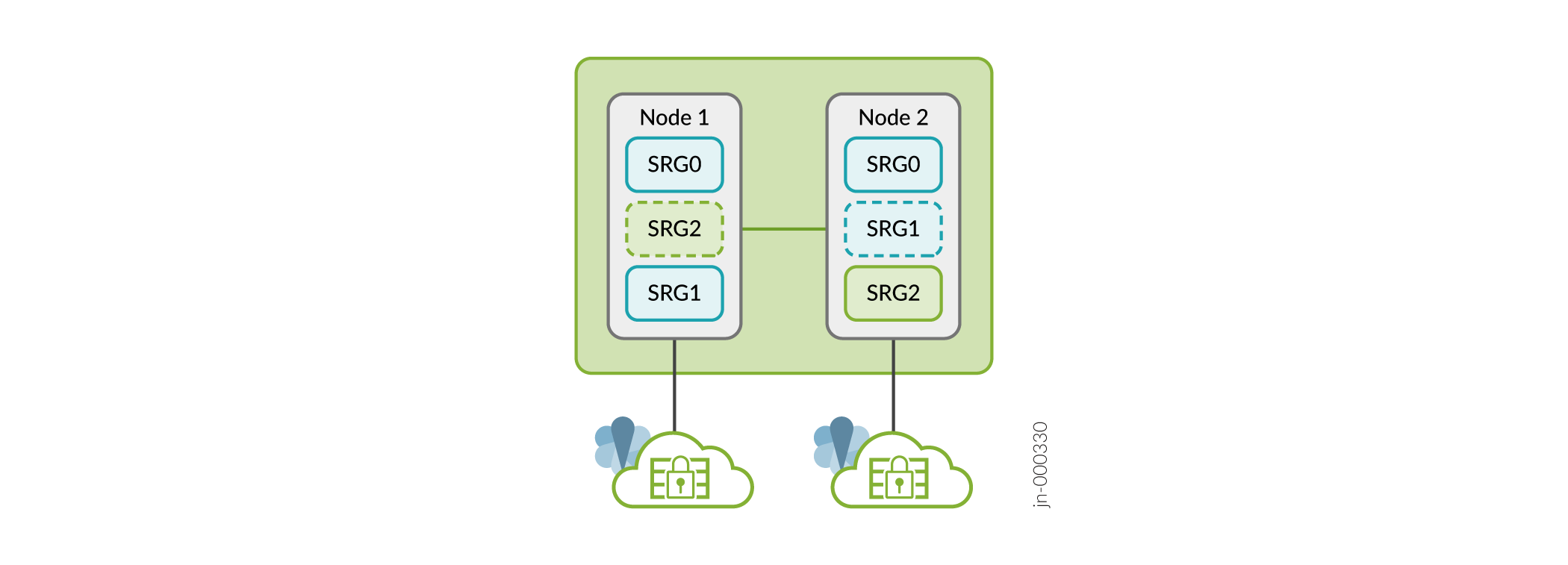
À partir de la version 22.4R1 de Junos OS, vous pouvez configurer la haute disponibilité multinodale pour qu’elle fonctionne en mode actif-actif avec prise en charge de plusieurs SRG1 (SRG1+). Dans ce mode, certains SRG restent actifs sur un nœud et d’autres restent actifs sur un autre nœud. Un SRG particulier fonctionne toujours en mode de sauvegarde active ; Il fonctionne en mode actif sur un nœud et en mode sauvegarde sur un autre nœud. Dans ce cas, les deux nœuds peuvent avoir les services dynamiques de transfert SRG1 actifs. Chaque nœud possède un ensemble différent d’adresses IP flottantes attribuées à SRG1+.
À partir de la version 22.4R1 de Junos OS, vous pouvez configurer jusqu’à 20 SRG dans une configuration haute disponibilité à plusieurs nœuds.
Le Tableau 1 explique le comportement des SRG dans une configuration haute disponibilité à plusieurs nœuds.
| services gérés | dugroupe de redondance (SRG) | fonctionnent de | type synchronisation | en cas d’échec du nœud actif | Options de configuration |
|---|---|---|---|---|---|
| SRG0 | Gère le service de sécurité L4-L7 sauf VPN IPsec. | Mode actif/actif | Synchronisation à états des services de sécurité | Le trafic traité sur le nœud défaillant est transféré vers le nœud sain de manière dynamique. |
|
| SRG1+ | Gère les adresses IPsec et IP virtuelles ainsi que les services de sécurité associés | Mode actif/de secours | Synchronisation à états des services de sécurité | Le trafic traité sur le nœud défaillant est transféré vers le nœud sain de manière dynamique. |
|
Lorsque vous configurez les options de surveillance (BFD ou IP ou Interface) sur SRG1+, nous vous recommandons de ne pas configurer l’option d’arrêt en cas de défaillance sur SRG0.
À partir de la version 23.4R1 de Junos OS, la configuration haute disponibilité multi nœuds fonctionne en mode combiné. Vous n’avez pas besoin de redémarrer le système lorsque vous ajoutez ou supprimez des configurations SRG (SRG0 ou SRG1+).
Détermination de l’activité et application
Dans une configuration haute disponibilité à plusieurs nœuds, l’activité est déterminée au niveau du service et non au niveau du nœud. L’état actif/de secours se situe au niveau du SRG et le trafic est dirigé vers le SRG actif. SRG0 reste actif sur les deux nœuds, tandis que SRG1 peut rester actif ou en état de sauvegarde dans chaque nœud
Si vous préférez qu’un certain nœud prenne le relais en tant que nœud actif au démarrage, vous pouvez effectuer l’une des opérations suivantes :
- Configurez les routeurs en amont pour inclure des préférences pour le chemin où se trouve le nœud.
- Configurez la priorité d’activité.
- Autorisez le nœud avec un ID de nœud plus élevé (dans le cas où les deux options ci-dessus ne sont pas configurées) à prendre le rôle actif.
Dans une configuration haute disponibilité à plusieurs nœuds, les deux pare-feu SRX Series annoncent initialement la route de l’adresse IP flottante vers les routeurs en amont. Il n’y a pas de préférence spécifique entre les deux chemins annoncés par les pare-feu SRX Series. Cependant, le routeur peut avoir ses propres préférences sur l’un des chemins en fonction des mesures configurées.
La figure 10 représente la séquence d’événements pour la détermination de l’activité et l’application de l’activité.
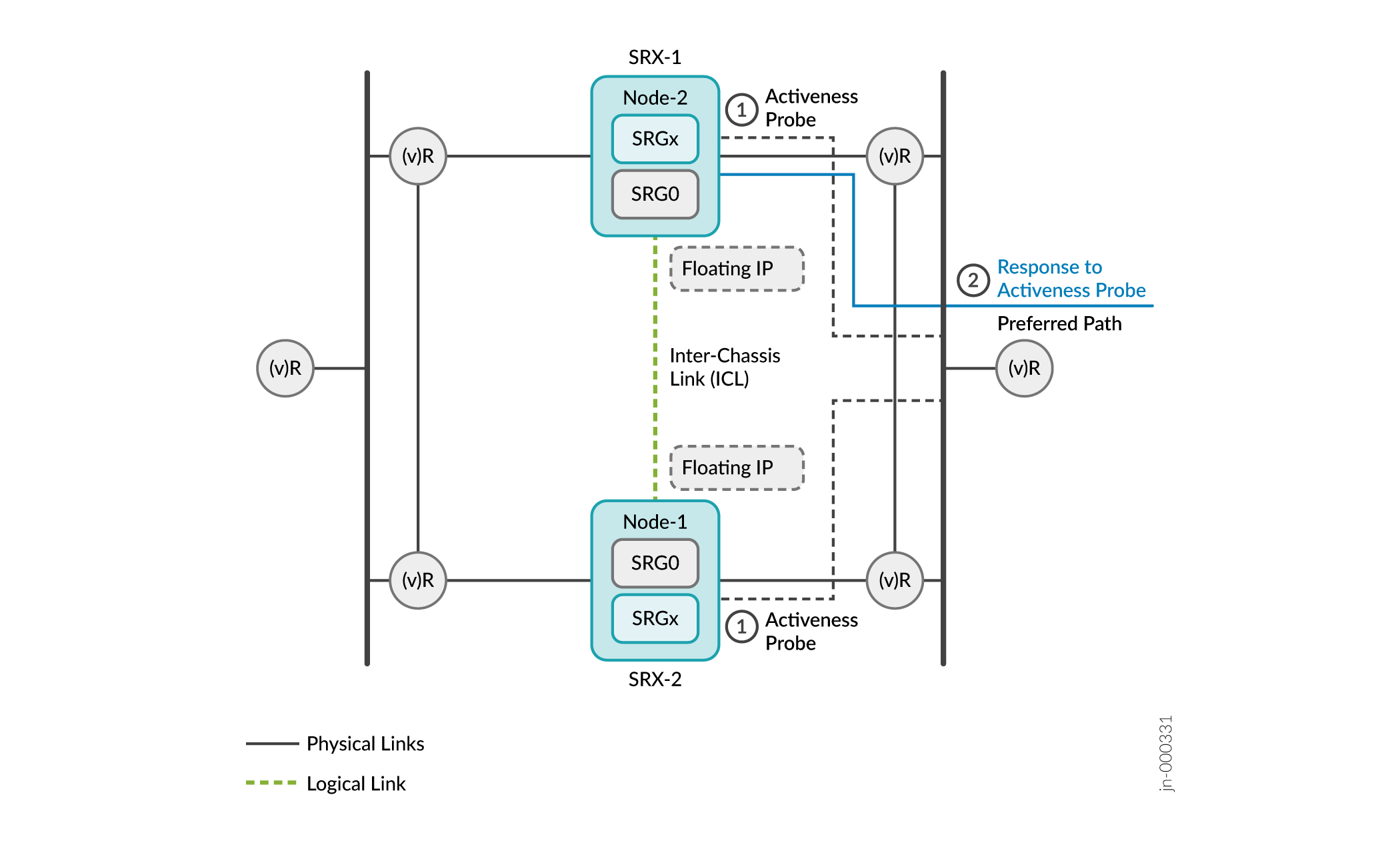
- Au démarrage, les appareils passent en mode attente et commencent à sonder en continu. Les appareils utilisent l’adresse IP flottante (adresse IP source de sonde d’activité) comme adresse IP source et les adresses IP des routeurs en amont comme adresse IP de destination pour la sonde de détermination de l’activité.
-
Le routeur hébergeant l’adresse IP de destination de la sonde répond au pare-feu SRX Series disponible sur son chemin de routage préféré. Dans l’exemple suivant, SRX-1 obtient la réponse du routeur en amont.
Figure 11 : Détermination de l’activité et application de la loi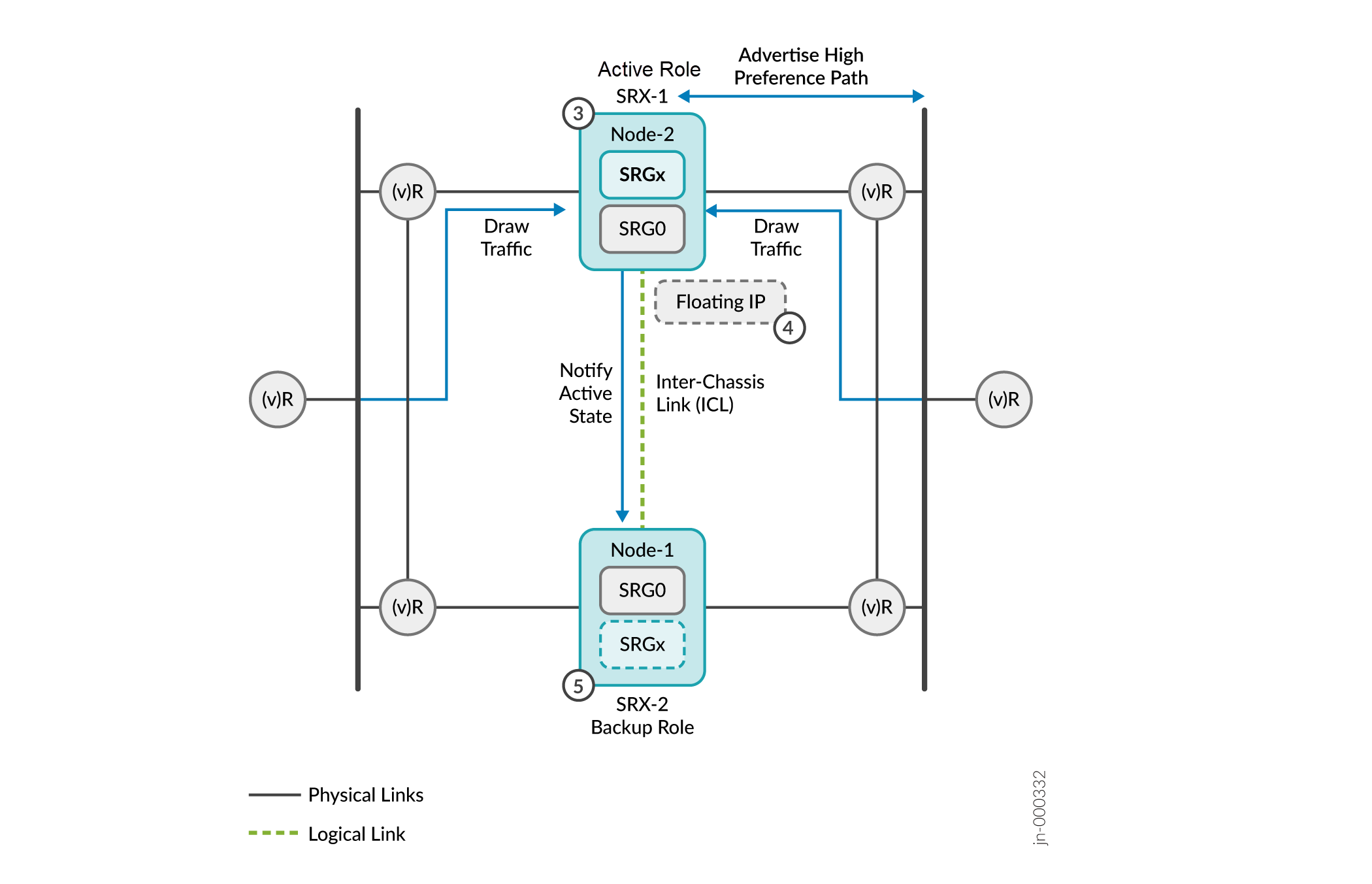
-
SRX-1 se promeut au rôle actif depuis qu’il a reçu la réponse de la sonde. Le SRX-1 communique son changement de rôle à l’autre appareil et assume le rôle actif.
-
Une fois l’activité déterminée, le nœud actif (SRX-1) :
- Héberge l’adresse IP flottante qui lui a été attribuée.
- Annonce le chemin de préférence élevée aux voisins BGP adjacents.
- Continue d’annoncer le chemin de préférence actif (le plus élevé) pour toutes les routes distantes et locales afin d’attirer le trafic.
- Notifie l’état du nœud actif à l’autre nœud via l’ICL.
-
L’autre périphérique (SRX-2) arrête de sonder et prend le rôle de sauvegarde. Le nœud de sauvegarde annonce la priorité par défaut (inférieure), ce qui permet aux routeurs en amont de ne pas transférer de paquets au nœud de secours.
Le module Multinode High Availability ajoute des routes de signal actives et de secours pour le SRG à la table de routage lorsque le nœud passe au rôle actif. En cas de défaillance d’un nœud, l’ICL tombe en panne et le nœud actif actuel libère son rôle actif et supprime la route du signal actif. Le nœud de secours détecte alors la condition via ses sondes et passe au rôle actif. La préférence de route est permutée pour diriger tout le trafic vers le nouveau nœud actif.
Le commutateur dans l’annonce des préférences de routage fait partie des stratégies de routage configurées sur les pare-feu SRX Series. Vous devez configurer la politique de routage pour inclure la route du signal actif avec la if-route-exists condition.
- Pour les déploiements de passerelles par défaut
- Pour les déploiements hybrides
- Priorité active et préemption
- Configuration des paramètres de sonde d’activité
Pour les déploiements de passerelles par défaut
Si les deux nœuds démarrent en même temps, le système de haute disponibilité à plusieurs nœuds utilise la valeur de priorité configurée d’un SRG pour déterminer l’activité. L’application de l’activité a lieu lorsque le nœud avec un SRG1+ actif possède l’adresse IP virtuelle (VIP) et l’adresse MAC virtuelle (VMAC). Cette action déclenche l’ARP gratuit (GARP) vers les commutateurs des deux côtés et entraîne la mise à jour des tables MAC sur les commutateurs.
Pour les déploiements hybrides
L’application de l’activité a lieu du côté de la couche 3, lorsque la route de signal configurée applique l’activité avec les annonces de route correspondantes. Du côté de la couche 2, le pare-feu SRX Series déclenche un ARP gratuit (GARP) sur la couche de commutation et est propriétaire des adresses VIP et VMAC
Lorsque le basculement se produit et que l’ancien nœud de secours passe au rôle actif, la préférence de route est permutée pour diriger tout le trafic vers le nouveau nœud actif.
Priorité active et préemption
Configurez la priorité de préemption (1-254) pour SRG1+. Vous devez configurer la valeur de préemption sur les deux nœuds. L’option preempt garantit que le trafic revient toujours au nœud spécifié lorsque celui-ci se remet d’un basculement.
Vous pouvez configurer l’activité, la priorité et la préemption pour un SRG1+ comme dans l’exemple suivant :
[edit]
user@host# show chassis high-availability
services-redundancy-group 1 {
preemption;
activeness-priority 200;
}
Voir Configuration de la haute disponibilité multinodale dans un réseau de couche 3 pour obtenir un exemple de configuration complet.
Tant que les nœuds peuvent communiquer entre eux via l’ICL, la priorité d’activité est honorée.
Configuration des paramètres de sonde d’activité
À partir de Junos OS 22.4R1, passerelle par défaut (commutation) et dans les déploiements hybrides de haute disponibilité multinodale, vous pouvez éventuellement configurer les paramètres de la sonde d’activité à l’aide des instructions suivantes :
[edit] user@host# set chassis high-availability services-redundancy-group 1 activeness-probe multiplier <> user@host# set chassis high-availability services-redundancy-group 1 activeness-probe minimal-interval <>
L’intervalle de sonde définit le délai entre les sondes envoyées aux adresses IP de destination. Vous pouvez définir l’intervalle de sonde sur 1000 millisecondes.
La valeur multiplicateur détermine la période après laquelle le nœud de sauvegarde passe à l’état actif si le nœud de sauvegarde ne reçoit pas de réponse aux sondes d’activité du nœud pair.
La valeur par défaut est 2, la valeur minimale est 2 et la valeur maximale est 15.
Exemple : Si vous configurez la valeur multiplicateur sur deux, le nœud de sauvegarde passera à l’état actif s’il ne reçoit pas de réponse à la demande d’analyse d’activité du nœud pair après deux secondes.
Vous pouvez configurer multiplier et minimal-interval dans les déploiements de commutation et hybrides.
Dans les déploiements en mode hybride, si vous avez configuré les détails de l'adresse IP de destination de la sonde pour déterminer l'activité (à l'aide de l activeness-probe dest-ip 'instruction), ne configurez pas les multiplier valeurs and minimal-interval . Configurez ces paramètres lorsque vous utilisez un sondage d’activité basé sur des VIP.
Résilience et basculement
La solution haute disponibilité multinodale prend en charge la redondance au niveau du service. La redondance au niveau du service minimise l’effort nécessaire pour synchroniser le plan de contrôle sur les nœuds.
Une fois que le programme d’installation de haute disponibilité multinodale a déterminé l’activité, il négocie l’état de haute disponibilité (HA) suivant via l’ICL. Le nœud de secours envoie des sondes ICMP à l’aide de l’adresse IP flottante. Si l’ICL est actif, le nœud reçoit la réponse à sa sonde et reste le nœud de secours. Si l’ICL est en panne et qu’il n’y a pas de réponse de la sonde, le nœud de secours passe au nœud actif.
Le SRG1 du nœud de sauvegarde précédent passe maintenant à l’état actif et continue de fonctionner de manière transparente. Lorsque la transition se produit, l’adresse IP flottante est attribuée au SRG1 actif. De cette façon, l’adresse IP flotte entre les nœuds actifs et de secours et reste accessible à tous les hôtes connectés. Ainsi, le trafic continue à circuler sans aucune perturbation.
Les services, tels que le VPN IPsec, qui nécessitent à la fois des états de plan de contrôle et de plan de données sont synchronisés sur les nœuds. Chaque fois qu’un nœud actif échoue pour cette fonction de service, le plan de contrôle et le plan de données basculent simultanément vers le nœud de secours.
Les nœuds utilisent les messages suivants pour synchroniser les données :
- Messages de l’application de contrôle du moteur de routage vers le moteur de routage
- Messages liés à la configuration du moteur de routage
- Messages RTO du plan de données
Chiffrement des liaisons interchâssis (ICL)
Dans la haute disponibilité multinodale, les nœuds actif et de secours communiquent entre eux à l’aide d’une liaison interchâssis (ICL) connectée sur un réseau routé ou connectée directement. L’ICL est une liaison IP logique établie à l’aide d’adresses IP routables dans le réseau.
Les nœuds utilisent l’ICL pour synchroniser les états du plan de contrôle et du plan de données entre eux. La communication ICL peut passer par un réseau partagé ou non fiable, et les paquets envoyés sur l’ICL peuvent emprunter un chemin qui n’est pas toujours fiable. Par conséquent, vous devez sécuriser les paquets traversant l’ICL en chiffrant le trafic à l’aide des normes IPsec.
IPsec protège le trafic en établissant un tunnel de chiffrement pour l’ICL. Lorsque vous appliquez le chiffrement de liaison HA, le trafic HA circule entre les nœuds uniquement via le tunnel sécurisé et chiffré. Sans chiffrement des liaisons HA, la communication entre les nœuds peut ne pas être sécurisée.
Pour chiffrer le lien HA pour l’ICL :
- Installez le package Junos IKE sur votre pare-feu SRX Series à l’aide de la commande suivante :
request system software add optional://junos-ike.tgz. - Configurez un profil VPN pour le trafic HA et appliquez le profil aux deux nœuds. Le tunnel IPsec négocié entre les pare-feu SRX Series utilise le protocole IKEv2.
-
Assurez-vous d’avoir inclus la déclaration ha-link-encryption dans votre configuration VPN IPsec. Exemple : user@host# set security ipsec vpn vpn-name ha-link-encryption.
Nous vous recommandons ce qui suit pour configurer une ICL :
-
Utilisez des ports et un réseau moins saturés.
-
Ne pas utiliser les ports HA dédiés (ports de contrôle et de fabric, si disponibles sur votre pare-feu SRX Series)
-
Liez l’ICL à l’interface de bouclage (lo0) ou à une interface Ethernet agrégée (ae0) et disposez de plusieurs liaisons physiques (LAG/LACP) qui garantissent une diversité de chemins pour une résilience maximale.
-
Vous pouvez utiliser un port Ethernet payant sur les pare-feu SRX Series pour configurer une connexion ICL. Assurez-vous de séparer le trafic de transit dans les interfaces payantes du trafic haute disponibilité (HA).
-
Des contrôles de validation ont été introduits pour restreindre la configuration de tunnel MTU pour les tunnels de chiffrement de liens HA dans une configuration à haute disponibilité multi-nœuds. Le contrôle de validation garantit que la MTU de bout en bout pour les liaisons HA utilisant le chiffrement IPv6 répond à l’exigence minimale de 2000 octets, ce qui permet de maintenir des performances et une fiabilité optimales pendant les opérations de haute disponibilité.
Par exemple, si votre configuration inclut la strophe suivante où tunnel-mtu est inférieur à 2000, vous recevrez une erreur de vérification de validation : user@host# set security ipsec vpn L3HA_IPSEC_VPN tunnel-mtu <octets>
Voir Configuration de la haute disponibilité multi nodale pour plus de détails.
Chiffrement des liens PKI pour ICL
À partir de la version 22.3R1 de Junos OS, nous prenons en charge le chiffrement des liens PKI pour les liaisons interchâssis (ICL) en haute disponibilité multinodale. Dans le cadre de cette prise en charge, vous pouvez désormais générer et stocker des objets PKI spécifiques à un nœud, tels que des paires de clés locales, des certificats locaux et des demandes de signature de certificat sur les deux nœuds. Les objets sont spécifiques aux nœuds locaux et sont stockés à des emplacements spécifiques sur les deux nœuds.
Les objets locaux du nœud vous permettent de distinguer les objets PKI utilisés pour le chiffrement ICL des objets PKI utilisés pour le tunnel VPN IPsec créé entre deux points de terminaison.
Vous pouvez utiliser les commandes suivantes exécutées sur le nœud local pour utiliser des objets PKI spécifiques au nœud.
| Génération d’une paire de clés privée/publique pour un nœud local | |
| Génération et inscription d’un certificat numérique local dans un nœud local |
|
| Effacer les certificats spécifiques aux nœuds | |
| Affichez les certificats locaux et les demandes de certificats spécifiques aux nœuds. |
Sur votre équipement de sécurité en haute disponibilité multinodale, si vous avez configuré l'option de réinscription automatique et si l'ICL tombe en panne au moment du déclenchement de la réinscription, les deux appareils commencent à enrôler le même certificat séparément auprès du serveur d'AC et téléchargent le même fichier CRL. Une fois que la haute disponibilité multinodale rétablit l’ICL, la configuration n’utilise qu’un seul certificat local. Vous devez synchroniser les certificats du nœud actif vers le nœud de sauvegarde à l’aide de la user@host> request security pki sync-from-peer commande sur le nœud de sauvegarde.
Si vous ne synchronisez pas les certificats, le problème d'incompatibilité de certificat entre les nœuds pairs persiste jusqu'à la prochaine réinscription.
En option, vous pouvez activer le TPM (module Trusted Platform) sur les deux nœuds avant de générer des paires de clés sur les nœuds. Voir Utilisation du Trusted Platform Module pour lier des secrets sur les périphériques SRX Series.
Détection et prévention Split-Brain
La détection split-brain ou le conflit d’activité se produit lorsque l’ICL entre deux nœuds de haute disponibilité multinodale est en panne et que les deux nœuds ne peuvent plus se joindre pour collecter le statut de nœud pair.
- Split-Brain Sablage basé sur l’ICMP
- Split-Brain Sobing basé sur BFD
- Configurer le Split-Brain Probing
- Prise en charge des systèmes logiques et des systèmes de location
Split-Brain Sablage basé sur l’ICMP
Imaginez un scénario dans lequel deux équipements SRX Series font partie d’une configuration haute disponibilité multi nodale. Considérons SRX-1 comme nœud local et SRX-2 comme nœud distant. Le nœud local joue actuellement un rôle actif et héberge une adresse IP flottante pour diriger le trafic vers lui. Le routeur en amont a un chemin de priorité plus élevé pour le nœud local.
Lorsque l’ICL entre les nœuds tombe en panne, les deux nœuds lancent une sonde de détermination de l’activité (sonde ICMP). Les nœuds utilisent l’adresse IP flottante (détermination de l’activité, adresse IP) comme adresse IP source, et les adresses IP des routeurs en amont comme adresse IP de destination pour les sondes.
Cas 1 : Si le nœud actif est actif
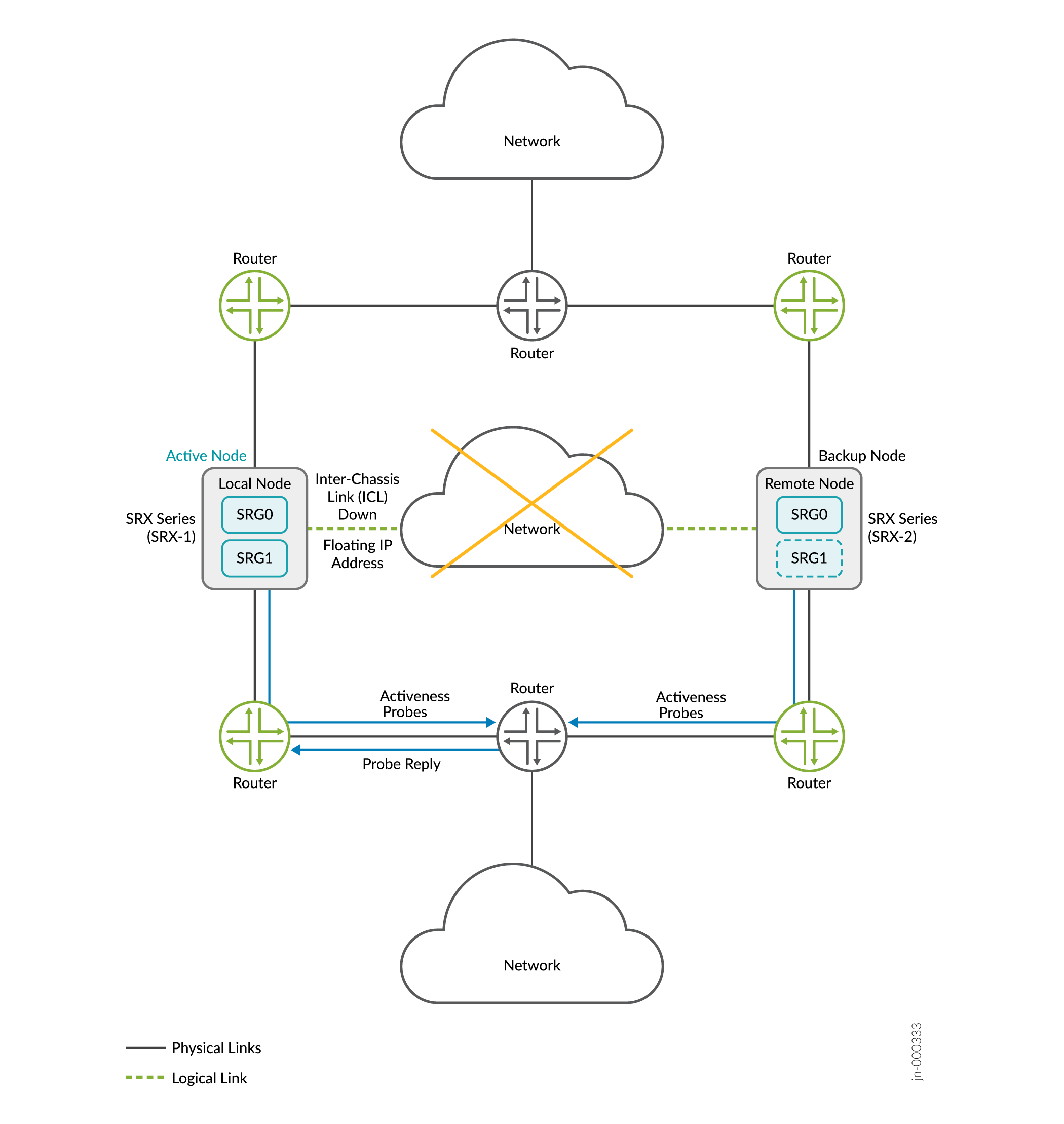
- Le routeur en amont, qui héberge l’adresse IP de destination de la sonde, reçoit les sondes ICMP des deux nœuds.
- Le routeur en amont ne répond qu’au nœud actif ; car sa configuration a un chemin de préférence plus élevé pour le nœud actif
- Le nœud actif conserve le rôle actif.
Si le nœud actif est en panne :
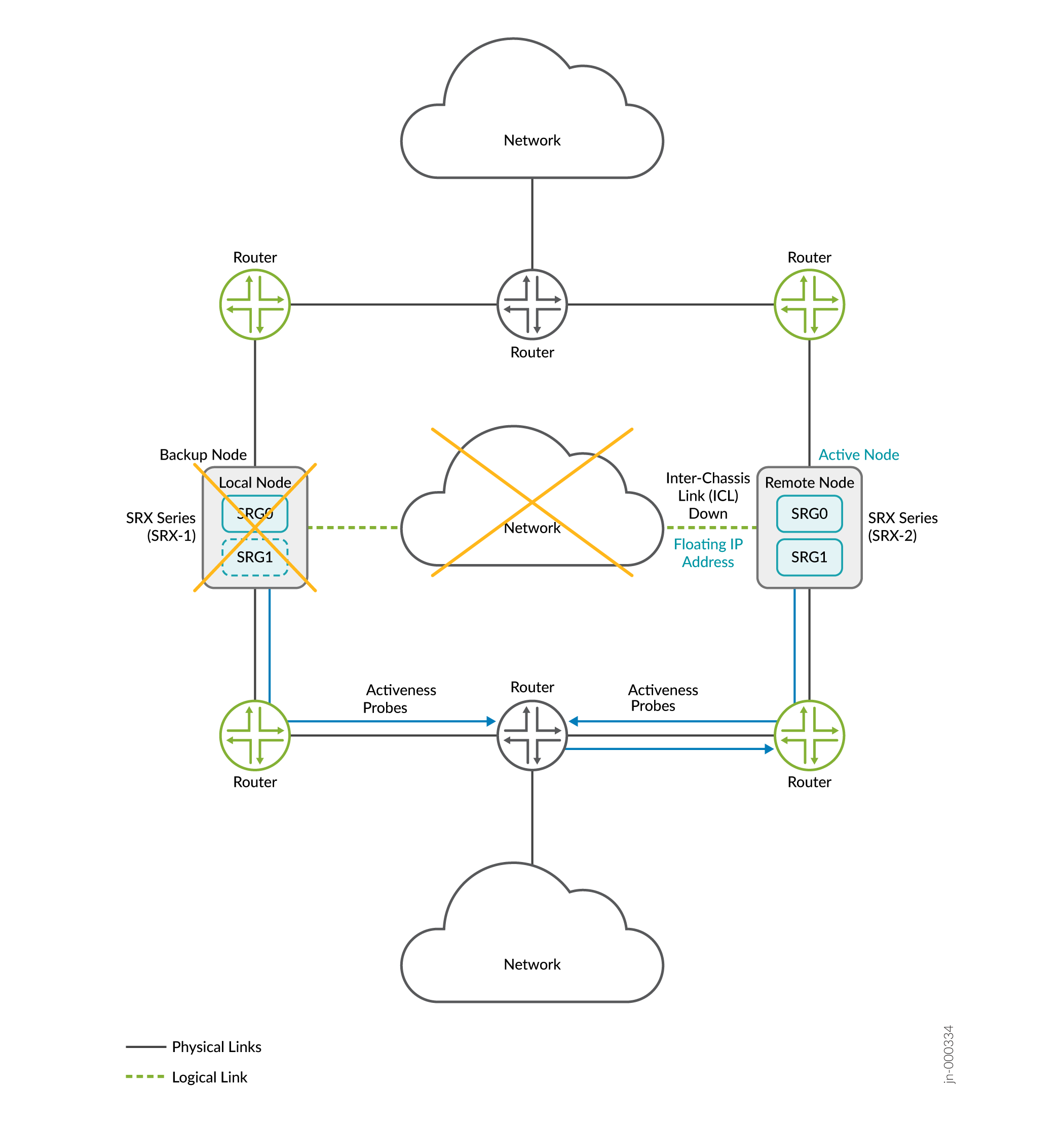
- Le nœud distant redémarre les sondes de détermination de l’activité.
- Le routeur hébergeant l’adresse IP de destination de la sonde a perdu son chemin de préférence le plus élevé (de l’ancien nœud actif) et répond au nœud distant.
- Le résultat de la sonde est un succès pour le nœud distant et le nœud distant passe à l’état actif.
- Comme démontré dans les cas ci-dessus, les sondes de détermination de l’activité et la configuration d’une préférence de chemin plus élevée dans le routeur en amont garantissent qu’un nœud reste toujours dans le rôle actif et empêchent le fractionnement du cerveau.
Split-Brain Sobing basé sur BFD
Dans Junos OS version 23.4R1, nous prenons en charge le sondage Split-Brain basé sur BFD pour la passerelle par défaut et le mode hybride des déploiements pour la haute disponibilité multi nodale.
La défaillance de la liaison interchâssis (ICL) peut souvent être attribuée à deux facteurs clés : des perturbations du réseau ou des configurations incohérentes. Vous pouvez utiliser une sonde d’activité pour déterminer le nœud qui peut jouer un rôle actif pour chaque SRG1+. En fonction du résultat de la sonde, l’un des nœuds passe à l’état actif et cette action empêche le scénario de déversement de cerveau.
Grâce au sondage Split-Brain basé sur BFD, vous pouvez désormais avoir un contrôle plus précis sur les sondes car vous pouvez définir l’interface, l’intervalle minimal et les multiplicateurs. Dans le sondage Split-Brain basé sur BFD, le sondage commence immédiatement après la configuration d’un SRG et commence à fonctionner. Dans le sondage Split-Brain basé sur ICMP par défaut, le sondage ne démarre qu’après l’interruption de la liaison ICL.
En comparaison, le sondage basé sur le BFD est beaucoup plus proactif de la manière suivante pour assurer une réponse plus rapide afin d’éviter les scénarios de cerveau divisé :
-
Le sondage démarre directement après une configuration SRG.
-
Si ICL BFD et la sonde Split-Brain se cassent en même temps, le nœud de secours assume immédiatement le rôle actif et prend en charge le VIP.
Cela garantit une réponse plus rapide pour éviter les scénarios de split-brain.
Comment ça marche ?
Lorsque l’ICL est en panne et que les deux équipements démarrent, les nœuds passent initialement en état HOLD et attendent que le nœud homologue s’affiche et se connecte. Pour une raison quelconque, si l’autre nœud n’apparaît pas, le système lance des sondes Split Brain vers les adresses IP hébergées sur différents appareils du réseau. Si le processus se termine correctement, un nœud passe en mode actif et l’autre en nœud de sauvegarde. Avant que la sonde ne réussisse, si une défaillance de surveillance du chemin ou d’un moniteur matériel interne se produit, les deux nœuds deviennent inéligibles afin d’éviter un scénario Split-Brain.
Si la sonde Split-Brain échoue pour une raison quelconque, les nœuds resteront à l’état HOLD et continueront à sonder. L’IP de la sonde split-brain doit toujours être disponible sur le réseau. À l’exception d’IPsec, tout autre trafic applicatif ne subira aucune perte sur SRX tant que le routage est disponible, même à l’état HOLD.
Lorsque les deux nœuds sont à l’état En attente ou Inéligible, aucun trafic n’est transféré tant que le nœud ne redevient pas actif/sauvegardé.
Remarque :
- Le cerveau fractionné est basé sur des sondes d’activité différentes des sondes de surveillance de chemin. Il ne se déclenche que lorsque la communication/ICL est interrompue par les nœuds MNHA
- Lorsque la liaison interchâssis (ICL) entre les nœuds est rompue, les deux nœuds initient des sondes à cerveau divisé. Le nœud actif conserve la maîtrise tant que sa sonde ne tombe pas en panne. Il est recommandé d’héberger l’adresse IP de sondage sur un chemin qui assure une accessibilité continue, à condition que le nœud SRX Series soit sain. Un changement d’état n’est déclenché que si la sonde du nœud actif actuel échoue et que la sonde du nœud de secours actuel réussit.
- En mode commutation et hybride, l’orientation du trafic utilise l’IP virtuelle (VIP), qui ne fonctionne qu’à l’état ACTIF. Le système ne doit pas rester à l’état HOLD après l’expiration du minuteur de mise en attente, car il sondera l’homologue du MNHA pour résoudre la situation de cerveau divisé.
Différence entre les sondages ICMP et BFD
Le tableau suivant montre les différences entre le sondage basé sur ICMP et le sondage basé sur BFD pour la détection de cerveau divisé.
| Paramètres |
Sondage basé sur ICMP |
Sondage basé sur BFD |
|---|---|---|
| Type de sonde | Paquet ICMP | Paquet BFD, BFD à saut unique |
| Intervalle minimal | 1000 ms | L'intervalle BFD minimal du pare-feu SRX Series dépend de la plate-forme. Par exemple : Pare-feu SRX5000 ligne avec SPC3, l’intervalle est de 100 ms. SRX4200, l’intervalle est de 300 ms. |
| Sondes de nœud de secours SRG | Oui | Oui |
| Sondes de nœud actif SRG | Non | Oui |
| Résolution du cerveau divisé SRG lorsque l’ICL est en panne | Seulement quand ICL tombe en panne. | Après la configuration de SRG. |
| Impossible | Possible | |
| Options de configuration |
show chassis
high-availability services-redundancy-group 1
activeness-probe
dest-ip {
192.168.21.1;
src-ip 192.168.21.2;
} |
show chassis
high-availability services-redundancy-group 1
activeness-probe
bfd-liveliness {
source-ip 192.168.21.1; (inet address of the local SRX sub interface)
destination-ip 192.168.21.2; (inet address of the peers SRX sub interface)
interface xe-0/0/1.0;
} |
La figure suivante illustre les options de configuration pour le sondage basé sur ICMP et le sondage BFD pour la détection Split-Brain.
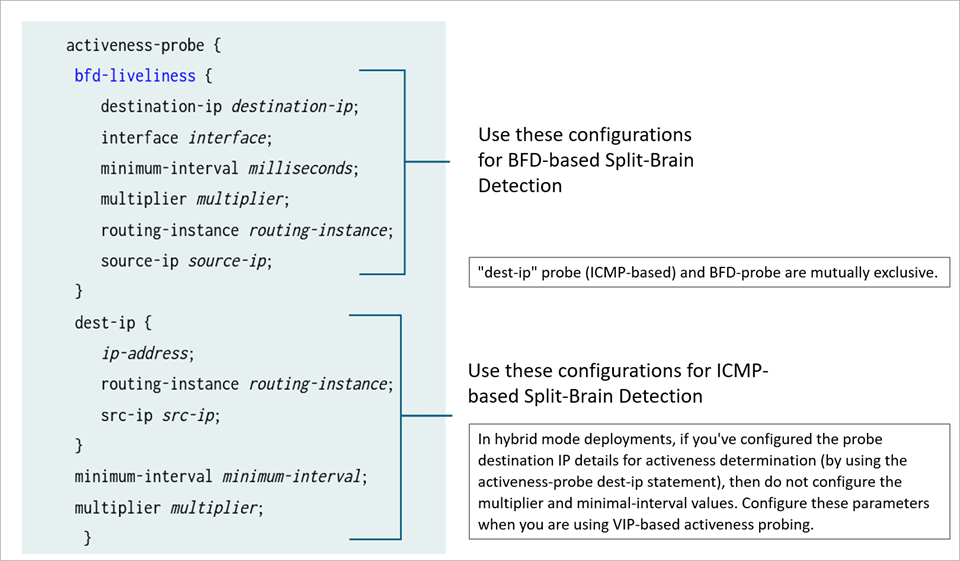
Les sondes ICMP et BFD s’excluent mutuellement.
En mode hybride et dans les déploiements de passerelle par défaut, vous pouvez configurer l’intervalle et le seuil d’activité-sonde aux deux niveaux suivants :
-
Niveau global, applicable aux sondages Split-Brain basés sur l’ICMP
-
Niveau de vivacité BFD spécifique à la sonde BFD à cerveau divisé. Lorsque vous configurez le sondage basé sur BFD, ne configurez pas les options globales
minimum-intervaletmultipliersous l’instructionactiveness-probe.
Pour configurer la sonde d’activité pour les déploiements de passerelle par défaut, utilisez l’interface d’adresse IP virtuelle principale (VIP1) sur les deux nœuds (local et pair) pour configurer votre sonde d’activité. L’adresse IP de destination provient du nœud homologue et l’adresse IP source provient de votre nœud local. Les deux VIP doivent avoir la même valeur d’index. Les adresses IP doivent être les adresses inet attribuées à l’interface LAN du pare-feu SRX Series.
Configurer le Split-Brain Probing
Vous pouvez configurer le sondage Split-Brain sur une configuration haute disponibilité à nœud multinodal des manières suivantes :-
Mode Routage et hybride : si vous avez configuré les détails de l'adresse IP de destination de la sonde pour la détermination de l'activité (à l'aide de l
activeness-probe dest-ip'instruction), ne configurez pas les valeurs multiplicateur et d'intervalle minimal. Configurez ces paramètres lorsque vous utilisez un sondage d’activité basé sur des VIP.[edit] [set chassis high-availability services-redundancy-group 1 activeness-probe dest-ip <neighbor_ip_address> src-ip <srx_anycast_IP>]
-
Mode hybride et de commutation : sondage Split-Brain de couche 2 à l’aide d’ICMP. Utilisez le type de sonde ICMP et définissez l’intervalle et le seuil de délai d’attente à l’aide de l’instruction suivante :
[edit] [set chassis high-availability services-redundancy-group 1 activeness-probe minimum-interval <interval> multiplier <integer>
-
Mode hybride et de commutation : sondage Split-Brain de couche 2 à l’aide de BFD. Utilisez le type de sonde BFD et définissez le seuil de temporisation qui peut être inférieur à la seconde en fonction de l’intervalle minimum BFD configuré.
[edit] [set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness source-ip <ip-address> destination-ip <ip-address> interface <vip1_ifl_interface> minimum-interval <interval> multiplier <integer>
La figure 15 montre un exemple de topologie. Deux pare-feu SRX Series sont connectés à des routeurs adjacents (trust et non trust), formant ainsi un voisinage BGP. Une liaison logique interchâssis (ICL) chiffrée relie les nœuds sur un réseau routé. Les nœuds communiquent entre eux à l’aide d’une adresse IP routable (adresse IP flottante) sur le réseau.
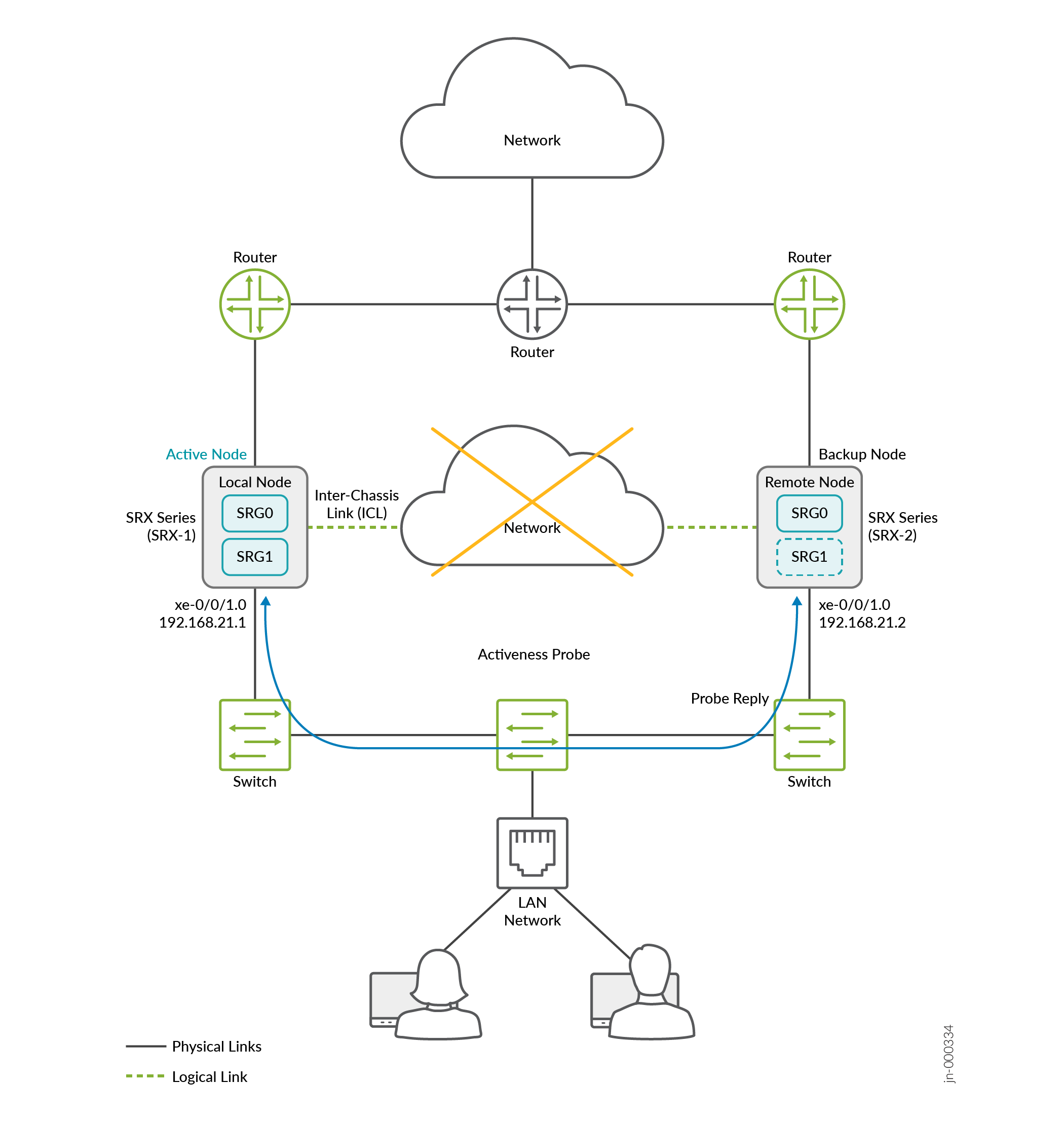 sondage Split-Brain
sondage Split-Brain
Considérons SRX-1 comme un nœud local et SRX-2 comme un nœud distant. Le nœud local joue actuellement un rôle actif et le routeur en amont dispose d’un chemin de priorité plus élevé pour le nœud local.
Pour activeness-probe, vous devez configurer les options suivantes :
-
Adresse IP source : utilisez l’adresse IP virtuelle 1 (VIP1) de SRG1 du nœud local.
-
Adresse IP de destination : Utilisez l’adresse VIP1 de SRG1 du nœud homologue.
-
Interface : Interface associée à VIP1
Dans cet exemple, attribuez une adresse IP virtuelle (VIP) (192.168.21.1) et une interface xe-0/0/1.0 pour la vivacité du BFD. Ici, vous configurez le sondage Split-Brain basé sur BFD en spécifiant les adresses IP source et de destination ainsi que l’interface.
Les nœuds utilisent l’adresse inet de famille de l’interface associée à l’adresse IP virtuelle (VIP1) de SRG1.
Les deux nœuds lancent une sonde de détermination de l’activité (sonde basée sur BFD) dès que les SRG commencent à fonctionner.
Pour le sondage Split-Brain basé sur BFD, vous devez :
- Configurez la correspondance des adresses IP source et de destination pour le même SRG sur les deux nœuds.
- Configurez l’option permettant de déterminer le
activeness-prioritynœud actif à la suite d’un sondage Split-Brain.
Le tableau suivant montre comment la configuration haute disponibilité multinodale résout une situation de cerveau divisé avec un sondage basé sur BFD lorsque l’ICL est en panne. En fonction de l’état des nœuds et des résultats des sondes, le système de haute disponibilité multinœud sélectionne le nœud qui jouera le rôle actif.
Le Tableau 4 montre comment la configuration haute disponibilité multinodale résout les problèmes de cerveau partagé avec l’exploration basée sur BFD lorsque l’ICL est en panne. En fonction de l’état des nœuds et des résultats des sondes, le système de haute disponibilité multinœud sélectionne le nœud qui jouera le rôle actif.
Dans cet exemple, nous supposons que SRG1 du nœud 1 a la priorité d’activité la plus élevée.
| État du nœud 1 | Sonder l’état du nœud 1 | État du nœud 2 | Sonder l’état du nœud 2 | Nœud en transition vers l’état actif SRG1 |
| Actif | Vers le bas | Non éligible | Pas de sondage | Nœud 1 |
| Actif | Haut | Sauvegarde | Haut | Nœud 1 |
| Actif | Haut | Actif | Haut | Nœud 1 (bris d’égalité) |
| Sauvegarde | Vers le bas | Non éligible | Pas de sondage | Nœud 1 |
| Sauvegarde | Haut | Sauvegarde | Haut | Nœud 1 (bris d’égalité) |
| Sauvegarde | Haut | Actif | Haut | Nœud 2 |
| Non éligible | Pas de sondage | Non éligible | Pas de sondage | Aucun des deux nœuds |
| Non éligible | Pas de sondage | Sauvegarde | Vers le bas | Nœud 2 |
| Non éligible | Pas de sondage | Actif | Vers le bas | Nœud 2 |
Exemple de configuration
Nœud 1 :
set chassis high-availability services-redundancy-group 1 activeness-priority 1 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness destination-ip 192.168.21.2 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness source-ip 192.168.21.1 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness interface xe-0/0/1.0 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness minimum-interval 300 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness multiplier 3
Nœud 2 :
set chassis high-availability services-redundancy-group 1 activeness-priority 200 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness destination-ip 192.168.21.1 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness source-ip 192.168.21.2 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness interface xe-0/0/1.0 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness minimum-interval 300 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness multiplier 3
Vérification
-
Utilisez la
(Sondage basé sur BFD)show chassis high-availability services-redundancy-group 1commande pour voir le type de sonde split-brain configuré sur l’appareil.user@host> show chassis high-availability services-redundancy-group 1 .. Split-brain Prevention Probe Info: DST-IP: 192.168.21.2 SRC-IP: N/A Routing Instance: default Type: BFD Probe Interval: 300ms Multiplier: 3 Status: RUNNING Result: REACHABLE Reason: N/A ..user@host> show chassis high-availability services-redundancy-group 1 .. Split-brain Prevention Probe Info: DST-IP: 192.168.21.2 SRC-IP: 192.168.21.1 Routing Instance: default Type: ICMP Probe Status: NOT RUNNING Result: N/A Reason: N/A .. -
Utilisez la commande pour voir si l’état de la sonde basée sur BFD
show bfd session.user@host> show bfd session Detect Transmit Address State Interface Time Interval Multiplier 192.168.0.2 Up 0.300 0.100 3 192.168.21.2 Up xe-0/0/1.0 0.300 0.100 3 1 sessions, 1 clients Cumulative transmit rate 0.5 pps, cumulative receive rate 0.0 ppsDans l’exemple, vous pouvez remarquer que le sondage Split-Brain basé sur BFD est en cours d’exécution pour l’interface xe-0/0/1.0.
-
Utilisez la
show chassis high-availability services-redundancy-group 1commande pour obtenir les détails des sondes basées sur BFD.user@host> show chassis high-availability services-redundancy-group 1 SRG failure event codes: BF BFD monitoring IP IP monitoring IF Interface monitoring CP Control Plane monitoring Services Redundancy Group: 1 Deployment Type: ROUTING Status: ACTIVE Activeness Priority: 200 Preemption: ENABLED Process Packet In Backup State: NO Control Plane State: READY System Integrity Check: N/A Failure Events: NONE Peer Information: Peer Id: 1 Status : N/A Health Status: SRG NOT CONFIGURED Failover Readiness: UNKNOWN Activeness Remote Priority: 100
Prise en charge des systèmes logiques et des systèmes de location
Les systèmes logiques des pare-feu SRX Series vous permettent de partitionner un seul périphérique en contextes sécurisés et Un système de locataire partitionne logiquement le pare-feu physique en pare-feu logique séparés et isolés.
Un système de locataire partitionne logiquement le pare-feu physique en pare-feu logiques distincts et isolés. Bien que similaires aux systèmes logiques, les systèmes de location présentent une évolutivité beaucoup plus élevée et moins de fonctionnalités de routage.
Pare-feu SRX Series en haute disponibilité multi nœuds Configurer les systèmes logiques et les systèmes de location sur les services Groupe de redondance 0 (SRG0).
Le comportement d’une configuration haute disponibilité multinodale avec des pare-feu SRX Series exécutant des systèmes logiques est le même que celui d’une configuration où les nœuds SRX Series n’exécutent pas de systèmes logiques. Il n’y a aucune différence dans les événements qui déclenchent un basculement de nœud. Plus précisément, si la surveillance de l’interface est activée sous SRG0 et qu’une liaison associée à un seul système logique tombe en panne (ce qui est en cours de surveillance), l’équipement bascule vers un autre nœud. Ce basculement s’effectue par le biais d’annonces de préférences de routage dans la configuration de haute disponibilité multi nodale.
Avant de configurer les systèmes logiques ou locataires, vous devez configurer la haute disponibilité multi nodale. Chaque nœud de la configuration haute disponibilité doit avoir une configuration identique. Assurez-vous que le nom, le profil et les fonctionnalités de sécurité correspondantes des systèmes logiques ou des systèmes locataires sont identiques. Toutes les configurations du système logique ou du système de location sont synchronisées et répliquées entre les deux nœuds.
Utilisez les groupes de configuration Junos pour configurer les caractéristiques et les fonctions, puis synchronisez la configuration à l’aide de l’option [edit system commit peers-synchronize] de votre configuration haute disponibilité multi-nœuds. Voir Synchronisation de la configuration entre des nœuds à haute disponibilité multinodale.
Lorsque vous utilisez des pare-feu SRX Series avec des systèmes logiques dans une haute disponibilité multi nodale, vous devez acheter et installer le même nombre de licences pour chaque nœud de la configuration.
Pour plus d’informations, consultez Guide de l’utilisateur des systèmes logiques et des systèmes de location pour les appareils de sécurité.
Tableau de l’historique des modifications
La prise en charge des fonctionnalités est déterminée par la plateforme et la version que vous utilisez. Utilisez l’explorateur de fonctionnalités pour déterminer si une fonctionnalité est prise en charge sur votre plateforme.