Présentation de BGP
Comprendre BGP
BGP est un protocole de passerelle extérieure (EGP) utilisé pour échanger des informations de routage entre les routeurs de différents systèmes autonomes (AS). Les informations de routage BGP incluent l’itinéraire complet vers chaque destination. BGP utilise les informations de routage pour gérer une base de données d’informations d’accessibilité du réseau, qu’il échange avec d’autres systèmes BGP. BGP utilise les informations d’accessibilité du réseau pour construire un graphique de la connectivité AS, ce qui permet à BGP de supprimer les boucles de routage et d’appliquer les décisions de stratégie au niveau AS.
Les extensions BGP multiprotocoles (MBGP) permettent à BGP de prendre en charge la version IP 6 (IPv6).MBGP définit les attributs MP_REACH_NLRI et MP_UNREACH_NLRI, qui sont utilisés pour transporter les informations d’accessibilité IPv6. Les messages de mise à jour des informations d’accessibilité de la couche réseau (NLRI) portent des préfixes d’adresse IPv6 correspondant aux itinéraires possibles.
BGP permet un routage basé sur des stratégies. Vous pouvez utiliser des stratégies de routage pour choisir parmi plusieurs chemins d’accès à une destination et pour contrôler la redistribution des informations de routage.
BGP utilise TCP comme protocole de transport, avec le port 179 pour établir les connexions. BGP n’a plus besoin de mettre en uvre la fragmentation, la retransmission, l’acquittement et le séquençage des mises à jour pour s’exécuter sur un protocole de transport fiable.
Le logiciel de protocole de routage Junos OS prend en charge BGP version 4. Cette version de BGP ajoute la prise en charge du Classless Interdomain Routing (CIDR), ce qui élimine le concept de classes de réseau. Au lieu de supposer quels bits d’une adresse représentent le réseau en examinant le premier octet, CIDR vous permet de spécifier explicitement le nombre de bits dans l’adresse réseau, fournissant ainsi un moyen de réduire la taille des tables de routage. BGP version 4 prend également en charge l’agrégation de routes, y compris l’agrégation de chemins AS.
Cette section aborde les sujets suivants :
- Systèmes autonomes
- Chemins et attributs AS
- BGP externe et interne
- Instances multiples de BGP
- Autoriser le trafic de protocole pour les interfaces d’une zone de sécurité
Systèmes autonomes
Un système autonome (AS) est un ensemble de routeurs qui sont sous une administration technique unique et utilisent normalement un protocole de passerelle intérieure unique et un ensemble commun de mesures pour propager les informations de routage au sein de l’ensemble de routeurs. Pour d’autres AS, un AS semble avoir un plan d’itinéraire intérieur unique et cohérent et présente une image cohérente des destinations qu’il est possible d’atteindre.
Chemins et attributs AS
Les informations de routage échangées par les systèmes BGP comprennent l’itinéraire complet vers chaque destination, ainsi que des informations supplémentaires sur le routage. Le chemin AS est la séquence de systèmes autonomes traversés par l’itinéraire, et des informations supplémentaires sur l’itinéraire sont incluses dans les attributs de chemin. BGP utilise le chemin AS et les attributs de chemin pour déterminer complètement la topologie du réseau. Une fois que BGP a compris la topologie, il peut détecter et éliminer les boucles de routage et choisir parmi des groupes de routes pour appliquer les préférences administratives et les décisions relatives aux stratégies de routage.
BGP externe et interne
BGP prend en charge deux types d’échanges d’informations de routage : les échanges entre différents AS et les échanges au sein d’un même AS. Lorsqu’il est utilisé entre AS, BGP est appelé BGP externe (EBGP) et les sessions BGP effectuent un routage inter-AS. Lorsqu’il est utilisé au sein d’un AS, BGP est appelé BGP interne (IBGP) et les sessions BGP effectuent un routage intra-AS. Figure 1 illustre les AS, IBGP et EBGP.
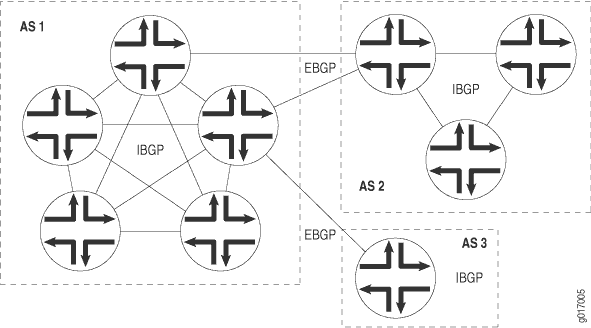
Un système BGP partage des informations d’accessibilité réseau avec des systèmes BGP adjacents, appelés « voisins » ou « pairs ».
Les systèmes BGP sont disposés en groupes. Dans un groupe IBGP, tous les homologues du groupe, appelés homologues internes, se trouvent dans le même AS. Les homologues internes peuvent se trouver n’importe où dans l’AS local et n’ont pas besoin d’être directement connectés les uns aux autres. Les groupes internes utilisent les routes d’un IGP pour résoudre les adresses de transfert. Ils propagent également les routes externes parmi tous les autres routeurs internes exécutant IBGP, en calculant le prochain saut en prenant le prochain saut BGP reçu avec la route et en le résolvant à l’aide des informations de l’un des protocoles de passerelle intérieure.
Dans un groupe EBGP, les homologues du groupe, appelés homologues externes, se trouvent dans des AS différents et partagent normalement un sous-réseau. Dans un groupe externe, le saut suivant est calculé par rapport à l’interface partagée entre l’homologue externe et le routeur local.
Instances multiples de BGP
Vous pouvez configurer plusieurs instances de BGP aux niveaux hiérarchiques suivants :
-
[edit routing-instances routing-instance-name protocols] -
[edit logical-systems logical-system-name routing-instances routing-instance-name protocols]
Plusieurs instances de BGP sont principalement utilisées pour la prise en charge des VPN de couche 3.
Les homologues IGP et les homologues BGP externes (EBGP) (à la fois non multi-sauts et multi-sauts) sont tous pris en charge pour les instances de routage. L’appairage BGP est établi sur l’une des interfaces configurées sous la routing-instances hiérarchie.
Lorsqu’un voisin BGP envoie des messages BGP à l’unité de routage locale, l’interface entrante sur laquelle ces messages sont reçus doit être configurée dans la même instance de routage que celle dans laquelle la configuration du voisin BGP existe. Cela est vrai pour les voisins qui sont à un ou plusieurs sauts.
Les routes apprises à partir du pair BGP sont ajoutées à la instance-name.inet.0 table par défaut. Vous pouvez configurer des stratégies d’importation et d’exportation pour contrôler le flux d’informations entrant et sortant de la table de routage d’instance.
Pour la prise en charge du VPN de couche 3, configurez BGP sur le routeur Provider Edge (PE) afin qu’il reçoive les routes du routeur CE (Customer Edge) et envoie les routes des instances au routeur CE si nécessaire. Vous pouvez utiliser plusieurs instances de BGP pour gérer des tables de transfert distinctes par site afin de séparer le trafic VPN sur le routeur PE.
Vous pouvez configurer des stratégies d’importation et d’exportation qui permettent au fournisseur de services de contrôler et de limiter le débit du trafic à destination et en provenance du client.
Vous pouvez configurer une session EBGP multi-sauts pour une instance de routage VRF. En outre, vous pouvez configurer l’homologue EBGP entre les routeurs PE et CE en utilisant l’adresse de bouclage du routeur CE au lieu des adresses d’interface.
Autoriser le trafic de protocole pour les interfaces d’une zone de sécurité
Sur les pare-feu SRX Series, vous devez activer le trafic entrant attendu sur l’hôte sur les interfaces spécifiées ou sur toutes les interfaces de la zone. Dans le cas contraire, le trafic entrant destiné à cet équipement est abandonné par défaut.
Par exemple, pour autoriser le trafic BGP sur une zone spécifique de votre pare-feu SRX Series, procédez comme suit :
[edit] user@host# set security zones security-zone trust host-inbound-traffic protocols bgp
[edit] user@host# set security zones security-zone trust interfaces ge-0/0/1.0 host-inbound-traffic protocols bgp
Voir également
Présentation des routes BGP
Une route BGP est une destination, décrite comme un préfixe d’adresse IP, et des informations décrivant le chemin d’accès à la destination.
Les informations suivantes décrivent le chemin d’accès :
AS path, qui est une liste de numéros des AS qu’une route traverse pour atteindre le routeur local. Le premier numéro du chemin est celui du dernier AS du chemin, c’est-à-dire l’AS le plus proche du routeur local. Le dernier numéro du chemin est l’AS le plus éloigné du routeur local, qui est généralement l’origine du chemin.
Attributs de chemin, qui contiennent des informations supplémentaires sur le chemin AS utilisé dans la stratégie de routage.
Les homologues BGP s’annoncent mutuellement des chemins dans les messages de mise à jour.
BGP stocke ses routes dans le Junos OS table de routage (inet.0). La table de routage stocke les informations suivantes sur les routes BGP :
Informations de routage apprises à partir des messages de mise à jour reçus des pairs
Informations de routage local que BGP applique aux routes en raison des stratégies locales
Informations que BGP annonce aux homologues BGP dans les messages de mise à jour
Pour chaque préfixe de la table de routage, le processus du protocole de routage sélectionne un seul meilleur chemin, appelé chemin actif. À moins que vous ne configuriez BGP pour annoncer plusieurs chemins d’accès vers la même destination, BGP annonce uniquement le chemin actif.
Le routeur BGP qui annonce d’abord une route lui attribue l’une des valeurs suivantes pour identifier son origine. Lors de la sélection de l’itinéraire, la valeur d’origine la plus basse est préférée.
0: le routeur a initialement appris la route via un IGP (OSPF, IS-IS ou une route statique).
1: le routeur a initialement appris le routage par le biais d’un EGP (très probablement BGP).
2—L’origine de l’itinéraire est inconnue.
Voir également
Présentation de la résolution de route BGP
Le prochain saut d’une route BGP interne (IBGP) avec une adresse next-hop vers un voisin BGP distant (protocole next hop) doit être résolu à l’aide d’une autre route. BGP ajoute cette route au module de résolution rpd pour la résolution du saut suivant. Si RSVP est utilisé dans le réseau, le tronçon suivant BGP est résolu à l’aide de la route d’entrée RSVP. Il en résulte que la route BGP pointe vers un prochain saut indirect et que le prochain saut indirect pointe vers un prochain saut de transfert. Le tronçon suivant de transfert est dérivé du tronçon suivant de la route RSVP. Il existe souvent un grand nombre de routes BGP internes qui ont le même prochain saut de protocole, et dans ce cas, l’ensemble de routes BGP fera référence au même prochain saut indirect.
Avant Junos OS version 17.2R1, le module de résolution du processus de protocole de routage (rpd) résolvait les routes au sein de l’IBGP des manières suivantes :
Résolution de route partielle : le tronçon suivant du protocole est résolu en fonction des routes d’assistance, telles que les routes RSVP ou IGP. Les valeurs de métrique sont dérivées des routes d’assistance, et le saut suivant est appelé le résolveur transférant le tronçon suivant hérité des routes d’assistance. Ces valeurs de métrique sont utilisées pour sélectionner des itinéraires dans la base d’informations de routage (RIB), également appelée table de routage.
Résolution complète du routage : le tronçon suivant final est dérivé et est appelé tronçon suivant de transfert de la table de routage du noyau (KRT) en fonction de la stratégie d’exportation du transfert.
À partir de Junos OS version 17.2R1, le module de résolution de rpd est optimisé pour augmenter le débit du flux de traitement entrant, accélérant ainsi le taux d’apprentissage des protocoles RIB et FIB. Avec cette amélioration, la résolution de l’itinéraire est affectée comme suit :
Les méthodes de résolution de route partielle et complète sont déclenchées pour chaque route IBGP, bien que chaque route puisse hériter du même prochain saut de transfert résolu ou du même prochain saut de transfert KRT.
La sélection du chemin BGP est différée jusqu’à ce qu’une résolution complète du chemin de routage soit effectuée pour les informations d’accessibilité de la couche réseau (NLRI) reçues d’un voisin BGP, qui peut ne pas être le meilleur chemin dans le RIB après la sélection du chemin.
Les avantages de l’optimisation du résolveur rpd sont les suivants :
Coût de recherche de la résolution RIB inférieure : la sortie du chemin résolu est enregistrée dans un cache du résolveur, de sorte que les mêmes valeurs de tronçon suivant et de métrique dérivées peuvent être héritées dans un autre ensemble de routes partageant le même comportement de chemin au lieu d’effectuer un flux de résolution de route partiel et complet. Cela réduit le coût de recherche de la résolution de route en ne conservant que l’état du résolveur le plus fréquent dans un cache avec une profondeur limitée.
Optimisation de la sélection de route BGP : l’algorithme de sélection de route BGP est déclenché deux fois pour chaque route IBGP reçue : d’abord, lors de l’ajout de la route dans le RIB avec le saut suivant comme inutilisable, et ensuite, lors de l’ajout de la route avec un prochain saut résolu dans le RIB (après résolution de route). Cela permet de sélectionner deux fois le meilleur itinéraire. Avec l’optimisation du résolveur, le processus de sélection de route est déclenché dans le flux de réception uniquement après avoir obtenu les informations du prochain saut à partir du module du résolveur.
Mise en cache interne pour éviter les recherches fréquentes : le cache du résolveur conserve l’état du résolveur le plus fréquent et, par conséquent, la fonctionnalité de recherche, telle que la recherche de saut suivant et la recherche d’itinéraire, est effectuée à partir du cache local.
Groupe d’équivalence de chemin : lorsque différents chemins partagent le même état de transfert ou sont reçus du même tronçon suivant de protocole, les chemins peuvent appartenir à un groupe d’équivalence de chemin. Cette approche évite d’avoir à effectuer une résolution de route complète pour de tels chemins. Lorsqu’un nouveau chemin nécessite une résolution de route complète, il est d’abord recherché dans la base de données du groupe d’équivalence de chemin, qui contient la sortie du chemin résolu, telle que le prochain saut indirect et le transfert du prochain saut.
Voir également
Présentation des messages BGP
Tous les messages BGP ont le même en-tête de taille fixe, qui contient un champ de marqueur utilisé à la fois pour la synchronisation et l’authentification, un champ de longueur qui indique la longueur du paquet et un champ de type qui indique le type de message (par exemple, ouvrir, mettre à jour, notification, keepalive, etc.).
Cette section aborde les sujets suivants :
- Messages ouverts
- Mettre à jour les messages
- Keepalive Messages
- Notification Messages
- Messages d’actualisation de l’itinéraire
Messages ouverts
Une fois qu’une connexion TCP est établie entre deux systèmes BGP, ils échangent des messages d’ouverture BGP pour créer une connexion BGP entre eux. Une fois la connexion établie, les deux systèmes peuvent échanger des messages BGP et du trafic de données.
Les messages ouverts sont constitués de l’en-tête BGP et des champs suivants :
Version : le numéro de version actuel de BGP est 4.
Numéro d’AS local : vous pouvez le configurer en incluant l’instruction
autonomous-systemau niveau de la[edit routing-options]hiérarchie ou[edit logical-systems logical-system-name routing-options].Hold time (Temps d’attente) : valeur de temps d’attente proposée. Vous configurez le temps d’attente local à l’aide de l’instruction BGP
hold-time.BGP identifier : adresse IP du système BGP. Cette adresse est déterminée au démarrage du système et est la même pour chaque interface locale et chaque pair BGP. Vous pouvez configurer l’identificateur BGP en incluant l’instruction
router-idau niveau de la[edit routing-options]hiérarchie ou[edit logical-systems logical-system-name routing-options]. Par défaut, BGP utilise l’adresse IP de la première interface qu’il trouve dans le routeur.Parameter field length and the parameter itself (Longueur du champ de paramètre) et paramètre lui-même : il s’agit de champs facultatifs.
Mettre à jour les messages
Les systèmes BGP envoient des messages de mise à jour pour échanger des informations sur l’accessibilité du réseau. Les systèmes BGP utilisent ces informations pour construire un graphique décrivant les relations entre tous les AS connus.
Les messages de mise à jour se composent de l’en-tête BGP et des champs facultatifs suivants :
Longueur des itinéraires irréalisables : longueur du champ des itinéraires retirés
Routes retirées : préfixes d’adresse IP pour les routes retirées du service parce qu’elles ne sont plus considérées comme accessibles
Total path attribute length (Longueur totale de l’attribut de chemin) : longueur du champ des attributs de chemin ; Il répertorie les attributs de chemin pour un itinéraire réalisable vers une destination
Path attributes (Attributs de chemin) : propriétés des routes, y compris l’origine du chemin, le discriminateur de sortie multiple (MED), la préférence du système d’origine pour l’itinéraire, ainsi que des informations sur l’agrégation, les communautés, les confédérations et la réflexion de route
Informations sur l’accessibilité de la couche réseau (NLRI) : préfixes d’adresse IP des routes possibles annoncées dans le message de mise à jour
Keepalive Messages
Les systèmes BGP échangent des messages persistants pour déterminer si un lien ou un hôte est défaillant ou n’est plus disponible. Les messages keepalive sont échangés assez souvent pour que le minuteur d’attente n’expire pas. Ces messages sont uniquement constitués de l’en-tête BGP.
Notification Messages
Les systèmes BGP envoient des messages de notification lorsqu’une condition d’erreur est détectée. Une fois le message envoyé, la session BGP et la connexion TCP entre les systèmes BGP sont fermées. Les messages de notification se composent de l’en-tête BGP, du code et du sous-code d’erreur, ainsi que des données décrivant l’erreur.
Messages d’actualisation de l’itinéraire
Les systèmes BGP envoient des messages d’actualisation de route à un homologue uniquement s’ils ont reçu l’annonce de capacité d’actualisation de route de la part de l’homologue. Un système BGP doit annoncer la fonctionnalité d’actualisation de route à ses homologues à l’aide de la publication de fonctionnalités BGP s’il souhaite recevoir des messages d’actualisation de route. Ce message facultatif est envoyé pour demander des mises à jour de route BGP dynamiques et entrantes auprès d’homologues BGP ou pour envoyer des mises à jour de route sortantes à un pair BGP.
Les messages d’actualisation de route sont constitués des champs suivants :
AFI : identificateur de famille d’adresses (16 bits).
Res : champ réservé (8 bits), qui doit être défini sur 0 par l’expéditeur et ignoré par le destinataire.
SAFI : identificateur de famille d’adresses ultérieures (8 bits).
Si un homologue sans la fonctionnalité d’actualisation de route reçoit un message de demande d’actualisation de route d’un homologue distant, le récepteur ignore le message.
Voir également
Comprendre le partitionnement RIB BGP et le thread d’E/S de mise à jour BGP
Le traitement du routage BGP comporte généralement plusieurs étapes de pipeline, telles que la réception de la mise à jour, l’analyse de la mise à jour, la création d’une route, la résolution du tronçon suivant, l’application de la stratégie d’exportation d’un groupe pair BGP, la formation de mises à jour par homologue et l’envoi de mises à jour aux homologues.
Le partitionnement BGP RIB scinde un RIB BGP unifié en plusieurs sous-RIB et chaque sous-RIB gère un sous-ensemble de routes BGP. Un thread RPD distinct, appelé thread de partition BGP, dessert chaque sous-RIB par pour obtenir la concurrence. Les threads de partition BGP sont responsables de toutes les étapes du pipeline de traitement du routage BGP, à l’exception de la formation de mises à jour par pair et de l’envoi de mises à jour aux homologues. Les threads de partition BGP reçoivent les mises à jour envoyées par les homologues à partir des threads d’E/S de mise à jour BGP, les threads d’E/S de mise à jour BGP hachant les préfixes dans les mises à jour et envoient les mises à jour aux threads de partition BGP applicables en fonction du calcul de hachage. Le thread de partition BGP traite la configuration de la même manière que le thread principal RPD, crée des homologues, des groupes, des tables de routage et utilise les informations de configuration pour le traitement du routage BGP.
Les threads d’E/S de mise à jour BGP sont responsables de la fin de ce pipeline BGP, ce qui implique de générer des mises à jour par homologue pour chaque groupe BGP individuel et de les envoyer au(x) pair(s). Un thread de mise à jour peut servir un ou plusieurs groupes BGP. Les threads d’E/S de mise à jour BGP construisent des mises à jour pour les groupes en parallèle et indépendamment des autres groupes qui sont traités par d’autres threads de mise à jour. Cela pourrait offrir une amélioration significative de la convergence dans une charge de travail lourde en écriture, qui implique de faire de la publicité auprès de nombreux pairs répartis dans de nombreux groupes. Les threads d’E/S de mise à jour BGP sont également responsables de l’écriture et de la lecture à partir des sockets TCP des homologues BGP, qui étaient auparavant fournis par les threads BGPIO (d’où le suffixe E/S dans les E/S de mise à jour BGP).
Les threads d’E/S de mise à jour BGP peuvent être configurés indépendamment de la fonctionnalité de partitionnement RIB, mais il est obligatoire de les utiliser avec le partitionnement RIB, afin d’obtenir une meilleure efficacité d’empaquetage de préfixes dans le message de mise à jour BGP sortant. Le partitionnement BGP divise le RIB en plusieurs sous-RIB qui sont desservies par des threads RPD distincts. Par conséquent, les préfixes qui auraient pu être utilisés dans une seule mise à jour sortante se retrouvent dans des partitions différentes. Pour pouvoir construire des mises à jour BGP avec des préfixes avec le même attribut sortant qui peut appartenir à différents threads de partition RPD, tous les threads de partition envoient des informations de publication compactes pour les préfixes à publier dans un thread de mise à jour desservant ce groupe homologue pair BGP. Cela permet au thread de mise à jour, au service de ce groupe homologue pair BGP, d’emballer des préfixes avec les mêmes attributs, appartenant potentiellement à différentes partitions dans le même message de mise à jour sortant. Cela minimise le nombre de mises à jour à annoncer et contribue ainsi à améliorer la convergence. Le thread d’E/S de mise à jour gère les caches locaux des conteneurs d’homologues, de groupes, de préfixes, TSI et RIB.
Le thread de mise à jour BGP et le partitionnement RIB BGP sont désactivés par défaut. Si vous configurez le threading de mise à jour et le partage de nervures sur un moteur de routage, RPD crée des threads de mise à jour. Par défaut, le nombre de threads de mise à jour et de threads de partition créés est identique au nombre de cœurs de processeur sur le moteur de routage. La mise à jour des threads n’est prise en charge que sur un processus de protocole de routage (rpd) 64 bits. Si vous le souhaitez, vous pouvez spécifier le nombre de threads que vous souhaitez créer à l’aide d’instructions set update-threading <number-of-threads> and set rib-sharding <number-of-threads> au niveau de la [edit system processes routing bgp] hiérarchie. Pour le thread de mise à jour BGP, la plage est actuellement comprise entre 1 et 128 et pour le partitionnement RIB BGP, la plage est actuellement comprise entre 1 et 31.
Lorsque vous configurez NSR pour les fonctionnalités de partitionnement RIB BGP et d’E/S de mise à jour BGP, le RPD de sauvegarde crée le même nombre de threads de partition BGP et d’E/S de mise à jour BGP dans le moteur de routage de sauvegarde. Les threads d’E/S de mise à jour BGP RPD de sauvegarde lisent la mise à jour BGP répliquée, d’autres messages reçus des homologues, ainsi que la mise à jour BGP répliquée et d’autres messages envoyés aux homologues. En fonction du hachage des préfixes, les threads d’E/S BGP de mise à jour RPD de sauvegarde envoient ces messages BGP aux threads BGP et aux threads principaux RPD applicables. La partition BGP et les threads RPD principaux dans le RPD de sauvegarde créent l’état de routage reçu et annoncé à l’aide de ces messages BGP répliqués. Lorsque le moteur de routage principal tombe en panne, le moteur de routage de secours devient le moteur de routage principal et le RPD de secours devient le RPD principal de manière transparente sans impact sur les sessions BGP avec les homologues.
Comprendre la sélection d’un chemin BGP
Pour chaque préfixe de la table de routage, le processus du protocole de routage sélectionne un seul meilleur chemin. Une fois le meilleur chemin sélectionné, l’itinéraire est installé dans la table de routage. Le meilleur chemin devient l’itinéraire actif si le même préfixe n’est pas appris par un protocole avec une valeur de préférence globale inférieure (plus préférée), également connue sous le nom de distance administrative. L’algorithme de détermination de l’itinéraire actif est le suivant :
-
Vérifiez que le saut suivant peut être résolu.
-
Choisissez le chemin avec la valeur de préférence la plus faible (préférence de processus de protocole de routage).
Les routes qui ne peuvent pas être utilisées pour le transfert (par exemple, parce qu’elles ont été rejetées par la stratégie de routage ou parce qu’un tronçon suivant est inaccessible) ont une préférence –1 et ne sont jamais choisies.
-
Privilégiez le chemin avec une préférence locale plus élevée.
Pour les chemins non-BGP, choisissez le chemin dont la valeur est la plus faible preference2 .
-
Si l’attribut AIGP (Accumulated Interior Gateway Protocol) est activé, ajoutez la métrique IGP et préférez le chemin d’accès avec l’attribut AIGP inférieur.
-
Préférez le chemin avec la valeur de chemin d’accès au système autonome (AS) la plus courte (ignorée si l’instruction
as-path-ignoreest configurée).La longueur du chemin d’un segment de confédération (séquence ou ensemble) est égale à 0. Un ensemble AS a une longueur de chemin de 1.
-
Privilégiez l’itinéraire avec le code d’origine le plus bas.
Les routes apprises à partir d’un IGP ont un code d’origine inférieur à ceux appris à partir d’un protocole de passerelle extérieure (EGP), et les deux ont des codes d’origine inférieurs à ceux des routes incomplètes (routes dont l’origine est inconnue).
-
Privilégiez le chemin avec la métrique MED (multiple exit discriminateator) la plus basse.
Selon que le comportement de sélection de chemin de la table de routage non déterministe est configuré, il existe deux cas possibles :
-
Si le comportement de sélection de chemin non déterministe de la table de routage n’est pas configuré (c’est-à-dire si l’instruction
path-selection cisco-nondeterministicn’est pas incluse dans la configuration BGP), pour les chemins avec les mêmes numéros AS voisins au début du chemin AS, préférez le chemin avec la métrique MED la plus basse. Pour toujours comparer les MED, que les AS homologues des routes comparées soient identiques ou non, incluez l’instructionpath-selection always-compare-med. -
Si le comportement non déterministe de sélection de chemin de la table de routage est configuré (c’est-à-dire que l’instruction
path-selection cisco-nondeterministicest incluse dans la configuration BGP), préférez le chemin avec la métrique MED la plus basse.
Les confédérations ne sont pas prises en compte lors de la détermination des AS voisines. Une mesure MED manquante est traitée comme si une MED était présente mais nulle.
REMARQUE :La comparaison MED fonctionne pour la sélection d’un seul chemin au sein d’un AS (lorsque l’itinéraire n’inclut pas de chemin AS), bien que cette utilisation soit peu courante.
Par défaut, seuls les MED des routes qui ont les mêmes systèmes autonomes (AS) homologues sont comparés. Vous pouvez configurer les options de sélection de chemin de la table de routage pour obtenir différents comportements.
-
-
Privilégiez les chemins strictement internes, qui incluent les routes IGP et les routes générées localement (statiques, directes, locales, etc.).
-
Préférez les chemins BGP strictement externes (EBGP) aux chemins externes appris par le biais de sessions BGP internes (IBGP).
-
Préférez le chemin dont le prochain saut est résolu par la voie IGP avec la métrique la plus basse. Les routes BGP résolues via IGP sont préférées aux routes inaccessibles ou rejetées.
REMARQUE :Un chemin est considéré comme un chemin à coût égal BGP (et sera utilisé pour le transfert) si un bris d’égalité est effectué après l’étape précédente. Tous les chemins avec le même AS voisin, appris par un voisin BGP à chemins multiples, sont pris en compte.
Le multichemin BGP ne s’applique pas aux chemins qui partagent le même coût MED-plus-IGP, mais dont le coût IGP diffère. La sélection des chemins multiples est basée sur la mesure du coût IGP, même si deux chemins ont le même coût MED plus IGP.
-
Si les deux chemins sont externes, préférez le chemin le plus ancien, c’est-à-dire le chemin qui a été appris en premier. Ceci est fait pour minimiser les battements d’itinéraires. Cette règle n’est pas utilisée si l’une des conditions suivantes est remplie :
-
path-selection external-router-id est configurée.
-
Les deux homologues ont le même ID de routeur.
-
L’un ou l’autre pair est un pair de la confédération.
-
Aucun des chemins n’est le chemin actif actuel.
-
-
Privilégiez un itinéraire principal à un itinéraire secondaire. Une route principale est une route qui appartient à la table de routage. Une route secondaire est une route qui est ajoutée à la table de routage par le biais d’une stratégie d’exportation.
-
Privilégiez le chemin d’accès à partir de l’homologue avec l’ID de routeur le plus bas. Pour tout chemin avec un attribut d’ID d’origine, remplacez l’ID d’origine par l’ID de routeur lors de la comparaison d’ID de routeur.
-
Privilégiez le chemin d’accès dont la longueur de liste de clusters est la plus courte. La longueur est 0 pour aucune liste.
-
Privilégiez le chemin d’accès à partir de l’homologue avec l’adresse IP de l’homologue la plus basse.
- Sélection du chemin d’accès à la table de routage
- Sélection du chemin d’accès à la table BGP
- Effets de la publicité sur des chemins multiples vers une destination
Sélection du chemin d’accès à la table de routage
Par défaut, l’étape de chemin AS la plus courte de l’algorithme évalue la longueur du chemin AS et détermine le chemin actif. Vous pouvez configurer une option qui permet à Junos OS d’ignorer cette étape de l’algorithme en incluant l’option as-path-ignore .
À partir de Junos OS version 14.1R8, 14.2R7, 15.1R4, 15.1F6 et 16.1R1, l’option est prise en charge pour les as-path-ignore instances de routage.
La sélection du chemin du processus de routage a lieu avant que BGP ne transmette le chemin à la table de routage pour qu’elle prenne sa décision. Pour configurer le comportement de sélection du chemin de sélection de la table de routage, incluez l’instruction path-selection suivante :
path-selection { (always-compare-med | cisco-non-deterministic | external-router-id); as-path-ignore; l2vpn-use-bgp-rules; med-plus-igp { igp-multiplier number; med-multiplier number; } }
Pour obtenir la liste des niveaux hiérarchiques auxquels vous pouvez inclure cette instruction, reportez-vous à la section Résumé de cette instruction.
La sélection du chemin d’accès à la table de routage peut être configurée de l’une des manières suivantes :
-
Émuler le comportement par défaut de Cisco IOS (cisco-non-deterministic). Ce mode évalue les routes dans l’ordre dans lequel elles sont reçues et ne les regroupe pas en fonction de leur AS voisin. Avec
cisco-non-deterministicle mode, le chemin actif est toujours le premier. Tous les chemins inactifs, mais éligibles, suivent le chemin actif et sont conservés dans l’ordre dans lequel ils ont été reçus, en commençant par le chemin le plus récent. Les chemins non éligibles restent à la fin de la liste.À titre d’exemple, supposons que vous ayez trois annonces de chemin pour la route 192.168.1.0 /24 :
-
Parcours 1 – appris par l’intermédiaire de l’EBGP ; Chemin AS de 65010 ; MED de 200
-
Parcours 2 – appris par l’intermédiaire de l’IBGP ; Chemin AS de 65020 ; MED de 150 ; Coût IGP de 5
-
Parcours 3 – appris par l’intermédiaire de l’IBGP ; Chemin AS de 65010 ; MED de 100 ; Coût IGP de 10
Ces annonces sont reçues en succession rapide, dans un délai d’une seconde, dans l’ordre indiqué. Le chemin 3 a été reçu le plus récemment, de sorte que le périphérique de routage le compare au chemin 2, l’annonce la plus récente suivante. Le coût pour l’homologue IBGP est plus élevé pour le chemin 2, de sorte que le périphérique de routage élimine le chemin 3 de la contention. Lors de la comparaison des chemins 1 et 2, le périphérique de routage préfère le chemin 1 car il provient d’un homologue EBGP. Cela permet au périphérique de routage d’installer le chemin 1 en tant que chemin actif pour le chemin.
REMARQUE :Nous vous déconseillons d’utiliser cette option de configuration sur votre réseau. Il est fourni uniquement à des fins d’interopérabilité pour permettre à tous les périphériques de routage du réseau d’effectuer des sélections de route cohérentes.
-
Toujours comparer les MED, que les AS homologues des routes comparées soient identiques ou non (always-compare-med).
Remplace la règle selon laquelle, si les deux chemins sont externes, le chemin actuellement actif est préféré (external-router-id). Passez à l’étape suivante (Étape 12) du processus de sélection du chemin.
Ajout du coût IGP à la destination du saut suivant à la valeur MED avant de comparer les valeurs MED pour la sélection du chemin (
med-plus-igp).Le multichemin BGP ne s’applique pas aux chemins qui partagent le même coût MED-plus-IGP, mais qui diffèrent par leur coût IGP. La sélection des chemins multiples est basée sur la mesure du coût IGP, même si deux chemins ont le même coût MED plus IGP.
Sélection du chemin d’accès à la table BGP
Les paramètres suivants sont suivis pour la sélection du chemin BGP :
-
Préférez la valeur de préférence locale la plus élevée.
-
Préférez la longueur de chemin AS la plus courte.
-
Préférez la valeur d’origine la plus basse.
-
Préférez la valeur MED la plus basse.
-
Privilégiez les routes apprises d’un pair EBGP à celles d’un pair IBGP.
-
Préférez la meilleure sortie de l’AS.
-
Pour les routes reçues par EBGP, préférez la route active actuelle.
-
Privilégiez les routes de l’homologue dont l’ID de routeur est le plus bas.
-
Privilégiez les chemins dont la longueur de cluster est la plus courte.
-
Privilégiez les routes à partir de l’homologue dont l’adresse IP de l’homologue est la plus basse. Les étapes 2, 6 et 12 sont les critères de la SPR.
Effets de la publicité sur des chemins multiples vers une destination
BGP annonce uniquement le chemin actif, sauf si vous configurez BGP pour publier plusieurs chemins vers une destination.
Supposons qu’un périphérique de routage ait dans sa table de routage quatre chemins vers une destination et qu’il soit configuré pour annoncer jusqu’à trois chemins (add-path send path-count 3). Les trois chemins sont choisis en fonction de critères de sélection des chemins. C’est-à-dire que les trois meilleurs chemins sont choisis dans l’ordre de sélection des chemins. Le meilleur chemin est le chemin actif. Ce chemin n’est plus pris en compte et un nouveau meilleur chemin est choisi. Ce processus est répété jusqu’à ce que le nombre de chemins spécifié soit atteint.
Voir également
Amélioration de la résolution de route de service pour BGP Multipath avec List Nexthop
Junos OS améliore la résolution des routes de service vers les routes d’assistance multichemin BGP qui utilisent des structures list-nexthop. Le résolveur de route crée et gère désormais des dépendances internes pour tous les chemins contributeurs d’un itinéraire à chemins multiples, ce qui permet une rerésolution précise et dynamique lorsque les prochains sauts indirects changent, que l’itinéraire contributeur soit actif ou inactif.
Cette fonctionnalité améliore la stabilité des routes de service et empêche les chemins de transfert obsolètes dans les réseaux utilisant BGP ECMP avec résolution indirecte de nexthop.
- Avantages
- Avant de commencer
- Fonctionnement de la fonctionnalité
- Exemple opérationnel
- Référence des commandes CLI
- Limitations
Avantages
- Maintient un transfert précis pour les routes de service résolues par trajets multiples BGP.
- Déclenche la re-résolution lorsqu’un chemin de contribution change, et pas seulement le chemin de prospect.
- Prend en charge les topologies hybrides iBGP et eBGP multichemin avec des nexthops indirects.
- Prévient les pertes de trafic causées par des états de résolution obsolètes ou obsolètes.
Avant de commencer
Assurez-vous que l’instruction de commande BGP multipath list-nexthop est activée pour les familles d’adresses concernées. Aucune nouvelle configuration n’est requise pour activer cette fonctionnalité.
Fonctionnement de la fonctionnalité
Lorsqu’une route de service est résolue sur une route multichemin BGP à l’aide d’un saut list-nexthop, RPD effectue les actions suivantes :
Parcourt tous les composants nexthop dans le list-nexthop.
Établit des relations de dépendance entre l’itinéraire d’assistance multichemin et chaque chemin de contribution.
Stocke ces dépendances dans une base de données interne à l’aide d’une arborescence patricia. Crée ces relations à la demande :
Un noeud d’arborescence Patricia est instancié uniquement lorsque le premier itinéraire de service est résolu via l’itinéraire d’assistance multichemin.
Lorsque la dernière route de service dépendante ne se résout plus par cette route à chemins multiples, le nœud correspondant est automatiquement supprimé de l’arborescence.
Surveille les changements indirects de nexthop à l’aide de rappels de hook KRT.
Résout les routes de service dépendantes chaque fois qu’une route contributive (active ou inactive) change.
Ce comportement s’applique indépendamment du fait que la route contributive soit active ou inactive dans le jeu de chemins multiples.
Exemple opérationnel
Scénario:
Une route de service (9.9.9.9/32) se résout sur une route multichemin BGP (1.1.1.9/32) avec les chemins d’accès suivants :
iBGP path-1(Lead/Actif) : via7.7.7.7→1.2.3.4→10.50.10.1iBGP path-2: via8.8.8.8
En cas iBGP path-2 de changement (par exemple, en raison d’une mise à jour de nexthop), Junos OS détectera la modification et résoudra l’itinéraire de service dépendant.
Référence des commandes CLI
Vous pouvez utiliser les commandes suivantes pour afficher les relations list-nexthop resolver et surveiller les dépendances de routage multichemin sur les nexthop indirects.
-
show route resolution list-nhAffiche les descripteurs de next-hop indirects (INH) dans la base de données de dépendances list-nexthop interne, ainsi que les routes BGP multi-chemin qui en dépendent. Cette commande affiche uniquement les routes d’assistance multichemin à l’aide d’un INH spécifique.
Exemple de sortie :
user@router> show route resolution list-nh Indirect next-hop statistics in List-nexthop database: Inh adds: 9, Inh deletes: 4 Inh change callback: registered Indirect next-hop: Inh handle: 0x8969d30; Inh protocol nexthop: 8.8.8.8 Multipath route: 1.1.1.0/24, resolver node: 0xf9e9ed8 Indirect next-hop: Inh handle: 0x8969b98; Inh protocol nexthop: 7.7.7.7 Multipath route: 1.1.1.0/24, resolver node: 0xf9e9ed8 Multipath route: 3.3.3.0/24, resolver node: 0x8d88cb8
-
show route resolution list-nh protocol-next-hop <nexthop>Affiche toutes les routes multipath qui utilisent un nexthop indirect spécifique.
Exemple :
user@router> show route resolution list-nh protocol-next-hop 9.9.9.9 Protocol Nexthop: 9.9.9.9 Used by: - Multipath Route: 1.1.1.0/24 - Multipath Route: 2.2.2.0/24 - Multipath Route: 3.3.3.0/24 -
show krt indirect-next-hopAffiche les informations de la table de routage du noyau pour un index nexthop indirect donné, y compris le nombre de routes multi-chemins dépendant de ce nexthop. Cette commande affiche le nombre de références et les dépendances de transfert associées aux itinéraires à chemins multiples.
Exemple de sortie :
user@router> show krt indirect-next-hop index 1048574 Indirect Nexthop: Index: 1048574 Protocol next-hop address: 7.7.7.7 ... INH list-nh dependent count: 2
Le
dependent count: 2confirme que deux routes multi-chemins utilisent actuellement ce nexthop indirect.
Limitations
- S’applique uniquement aux chemins multiples BGP avec des list-nexthops composés de chemins iBGP ou hybrides iBGP/eBGP.
- Les chemins multiples BGP avec uniquement des contributeurs eBGP ne sont pas affectés.
- Les familles d’adresses mixtes dans une seule liste-nexthop ne sont pas prises en charge.
Voir également
Normes prises en charge pour BGP
Junos OS prend en charge de manière substantielle les RFC et les brouillons Internet suivants, qui définissent les normes pour le BGP IP version 4 (IPv4).
Pour obtenir la liste des normes BGP IP version 6 (IPv6) prises en charge, consultez Normes IPv6 prises en charge.
BGP Junos OS prend en charge l’authentification pour les échanges de protocoles (authentification MD5).
-
RFC 1745, BGP4/IDRP pour l’interaction IP-OSPF
-
RFC 1772, Application du Border Gateway Protocol dans l’Internet
-
RFC 1997, Attribut des communautés BGP
-
RFC 2283, Extensions multiprotocoles pour BGP-4
-
RFC 2385, Protection des sessions BGP via l’option de signature TCP MD5
-
RFC 2439, Amortissement des volets de route BGP
-
RFC 2545, Utilisation d’extensions multiprotocoles BGP-4 pour le routage interdomaine IPv6
-
RFC 2796, BGP Route Reflection – Une alternative à l’IBGP à maillage intégral
-
RFC 2858, Extensions multiprotocoles pour BGP-4
-
RFC 2918, Capacité d’actualisation de route pour BGP-4
-
RFC 3065, Confédérations de systèmes autonomes pour BGP
-
RFC 3107, Porter des informations sur l’étiquette dans BGP-4
-
RFC 3345, Condition d’oscillation de route persistante du Border Gateway Protocol (BGP)
-
RFC 3392, Capabilities Advertisement with BGP-4
-
RFC 4271, A Border Gateway Protocol 4 (BGP-4)
-
RFC 4273, Définitions des objets gérés pour BGP-4
-
RFC 4360, Attribut Communautés étendues BGP
-
RFC 4364, Réseaux privés virtuels (VPN) BGP/MPLS IP
-
RFC 4456, Réflexion de route BGP : Une alternative au BGP interne à maillage intégral (IBGP)
-
RFC 4486, Sous-codes pour le message de notification de cessation BGP
-
RFC 4576, Utilisation d’un bit d’options LSA (Link State Advertisement) pour empêcher le bouclage dans les réseaux privés virtuels (VPN) IP BGP/MPLS
-
RFC 4659, Extension de réseau privé virtuel (VPN) IP BGP-MPLS pour VPN IPv6
-
RFC 4632, Classless Inter-domain Routing (CIDR) : Plan d’attribution et d’agrégation des adresses Internet
-
RFC 4684, Distribution de routes contraintes pour les réseaux privés virtuels (VPN) BGP/MPLS (Border Gateway Protocol/MultiProtocol Label Switching)
-
RFC 4724, Mécanisme de redémarrage progressif pour BGP
-
RFC 4760, Extensions multiprotocoles pour BGP-4
-
RFC 4781, Mécanisme de redémarrage progressif pour BGP avec MPLS
-
RFC 4798, Connexion d’îlots IPv6 sur MPLS IPv4 à l’aide de routeurs IPv6 Provider Edge (6PE)
L’option 4b (redistribution eBGP des routes IPv6 étiquetées de l’AS vers l’AS voisin) n’est pas prise en charge.
-
RFC 4893, prise en charge de BGP pour les espaces numériques AS de quatre octets
-
RFC 5004, Éviter les transitions BGP du meilleur chemin d’un externe à un autre
-
RFC 5065, Confédérations de systèmes autonomes pour BGP
-
RFC 5082, Mécanisme de sécurité TTL généralisé (GTSM)
-
RFC 5291, Outbound Route Filtering Capability for BGP-4 (prise en charge partielle)
-
RFC 5292, Address-Prefix-Based Outbound Route Filter for BGP-4 (prise en charge partielle)
Les périphériques exécutant Junos OS peuvent recevoir des messages ORF basés sur des préfixes.
-
RFC 5396, Représentation textuelle des numéros de systèmes autonomes (AS)
-
RFC 5492, Capabilities Advertisement with BGP-4
-
RFC 5512, Identificateur de famille d’adresses ultérieures d’encapsulation BGP (SAFI) et attribut d’encapsulation de tunnel BGP
-
RFC 5549, Publicité des informations d’accessibilité de la couche réseau IPv4 avec un saut suivant IPv6
-
RFC 8955, Diffusion des règles de spécification de flux
-
RFC 8956, Diffusion des règles de spécification de flux pour IPv6
-
RFC 5668, communauté étendue BGP spécifique à l’AS sur 4 octets
-
RFC 5701, Attribut de communauté étendue BGP spécifique à l’adresse IPv6
-
RFC 5925, L’option d’authentification TCP
-
RFC 6286, Identificateur BGP unique à l’échelle du système autonome pour BGP-4 entièrement conforme
-
RFC 6368, BGP interne en tant que protocole de périphérie fournisseur/client pour les réseaux privés virtuels (VPN) BGP/MPLS IP
-
RFC 6774, Distribution de divers chemins BGP
-
RFC 6793, Prise en charge BGP de l’espace des nombres des systèmes autonomes (AS) de quatre octets
-
RFC 6810, Infrastructure à clé publique de ressources (RPKI) vers protocole de routeur
-
RFC 6811, Validation de l’origine du préfixe BGP
-
RFC 6996, Réservation d’un système autonome (AS) pour un usage privé
-
RFC 7300, Réservation des numéros du dernier système autonome (AS)
-
RFC 7311, Attribut de métrique IGP cumulé pour BGP
-
RFC 7404, Utilisation uniquement de l’adressage lien-local à l’intérieur d’un réseau IPv6
-
RFC 7432, VPN Ethernet basé sur MPLS BGP (eVPN)
-
RFC 7606, Révision de la gestion des erreurs pour les messages BGP UPDATE
-
RFC 7611, Attribut de communauté BGP ACCEPT_OWN
Nous prenons en charge la RFC en permettant aux routeurs Juniper d’accepter les routes reçues d’un réflecteur de route avec la valeur de la
accept-owncommunauté. -
RFC 7752, Distribution vers le nord des informations sur l’état des liens et l'ingénierie de trafic (TE) à l’aide de BGP
-
RFC 7854, Protocole de surveillance BGP (BMP)
-
RFC 7911, Advertisement of Multiple Paths in BGP (Publication de chemins multiples dans BGP )
-
RFC 8097, Communauté étendue de l’état de validation de l’origine du préfixe BGP
-
RFC 8210, Infrastructure à clé publique (RPKI) vers protocole de routeur, version 1
-
RFC 8212, Comportement de propagation de route BGP externe (EBGP) par défaut sans stratégies - entièrement conforme
Exceptions:
Les comportements de la RFC 8212 ne sont pas implémentés par défaut afin d’éviter toute perturbation de la configuration client existante. Le comportement par défaut est toujours conservé pour accepter et annoncer toutes les routes en ce qui concerne les pairs EBGP.
-
RFC 8277, Utilisation de BGP pour lier des étiquettes MPLS à des préfixes d’adresse
-
RFC 8326, Arrêt de session BGP gracieux
-
RFC 8481, Clarifications de la validation de l’origine BGP basée sur l’infrastructure à clé publique de ressources (RPKI)
-
RFC 8538, Prise en charge des messages de notification pour le redémarrage progressif BGP
-
RFC 8571, BGP - Publication de l’état de la liaison (BGP-LS) des extensions de métriques de performance d’ingénierie du trafic IGP
-
RFC 8584, Framework for Ethernet VPN Designated Forwarder Election Extensibility
-
RFC 8642, Comportement des stratégies pour les communautés BGP connues
-
RFC 8669, Extensions d’identificateur de segment de préfixe de segment routing pour BGP
-
RFC 8810, Révision des procédures d’enregistrement des codes de capacité
-
RFC 8814 Profondeur SID maximale de signalisation (MSD) à l’aide du Border Gateway Protocol - État de la liaison (prise en charge partielle)
-
RFC 8950, Publicité des informations d’accessibilité de la couche réseau (NLRI) IPv4 avec un prochain saut IPv6
-
RFC 8955
-
RFC 8956
-
RFC 9003, Communication d’arrêt administratif BGP étendue
-
RFC 9012, Attribut d’encapsulation de tunnel BGP
-
RFC 9029, Mises à jour de la stratégie d’allocation pour les registres de paramètres BGP-LS (Border Gateway Protocol - Link State)
-
RFC 9069, Prise en charge du RIB local dans le protocole de surveillance BGP (BMP)
-
RFC 9085, Border Gateway Protocol - Extensions d’état de liaison (BGP-LS) pour Segment Routing
-
RFC 9117, Procédure de validation révisée pour la diffusion des spécifications de flux BGP. Cela permet aux spécifications de flux d’être générées dans le même système autonome que l’pair BGP effectuant la validation.
-
RFC 9234, Prévention et détection des fuites de routes à l’aide des rôles dans les messages UPDATE et OPEN
-
RFC 9384, Sous-code de notification de cessation BGP pour la détection de transfert bidirectionnel (BFD)
-
Internet draft draft-idr-rfc8203bis-00, BGP Administrative Shutdown Communication (expire en octobre 2018)
-
Brouillon Internet draft-ietf-grow-bmp-adj-rib-out-01, Prise en charge d’Adj-RIB-Out dans BGP Monitoring Protocol (BMP) (expire le 3 septembre 2018)
-
Internet draft draft-ietf-idr-aigp-06, The Cumulative IGP Metric Attribute for BGP (expire en décembre 2011)
-
Internet draft draft-ietf-idr-as0-06, Codification du traitement AS 0 (expire en février 2013)
-
Internet draft draft-ietf-idr-link-bandwidth-06.txt, BGP Link Bandwidth Extended Community (expire en juillet 2013)
-
Internet draft draft-ietf-sidr-origin-validation-signaling-00, BGP Prefix Origin Validation State Extended Community (prise en charge partielle) (expire en mai 2011)
La communauté étendue (état de validation de l’origine) est prise en charge dans Junos OS stratégie de routage. La modification spécifiée dans la procédure de sélection d’itinéraire n’est pas prise en charge.
-
draft-kato-bgp-ipv6-link-local-00.txt de brouillon Internet, appairage BGP4+ à l’aide de l’adresse lien-locale IPv6
Les RFC et le projet Internet suivants ne définissent pas de normes, mais fournissent des informations sur BGP et les technologies associées. L’IETF les classe diversement comme « expérimentales » ou « informationnelles ».
-
RFC 1965, Confédérations de systèmes autonomes pour BGP
-
RFC 1966, BGP Route Reflection : alternative à l’IBGP à maillage intégral
-
RFC 2270, Utilisation d’un AS dédié pour les sites hébergés auprès d’un seul fournisseur
-
RFC 3345, Condition d’oscillation de route persistante du Border Gateway Protocol (BGP)
-
RFC 3562, Considérations relatives à la gestion des clés pour l’option de signature TCP MD5
-
Projet de draft-ietf-ngtrans-bgp-tunnel-04.txt Internet, Connecting IPv6 Islands across IPv4 Clouds with BGP (expire en juillet 2002)
Voir également
Tableau de l'historique des modifications
La prise en charge des fonctionnalités est déterminée par la plateforme et la version que vous utilisez. Utilisez l' Feature Explorer pour déterminer si une fonctionnalité est prise en charge sur votre plateforme.