M:N-Anwenderredundanz auf BNG
M:N-Anwenderredundanz auf BNG – Übersicht
Ab Junos OS Version 19.2R1 können Sie die M:N-Redundanz für Anwender als Mechanismus zur Verbesserung der Ausfallsicherheit des Netzwerks konfigurieren, indem die Teilnehmer vor einer Vielzahl von Software- und Hardwarefehlern geschützt werden. Dieser Schutz ist in einer typischen Netzwerktopologie verfügbar, wie in Abbildung 1 dargestellt.
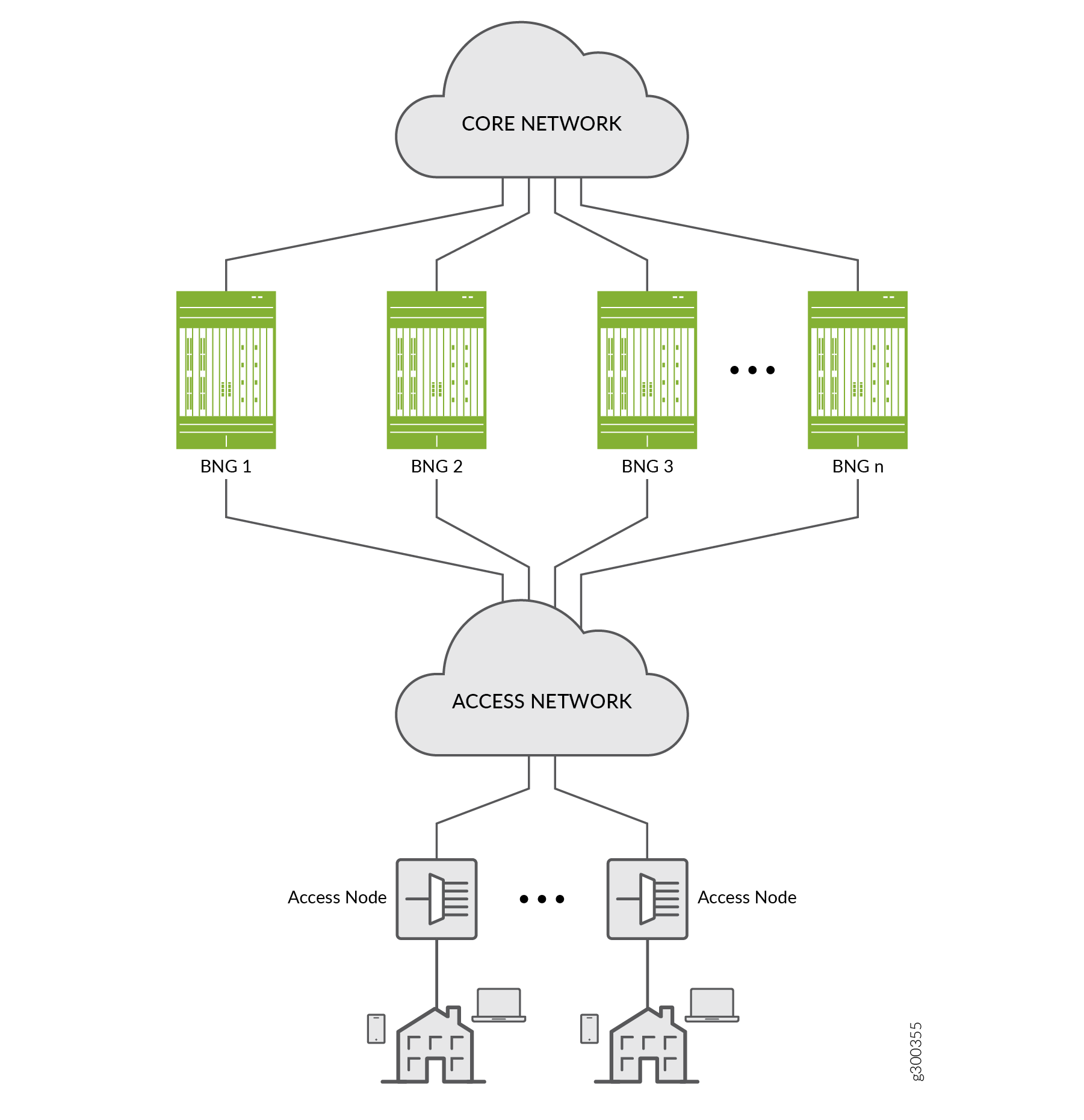
Ein Ausfall an einem der in Tabelle 1 aufgeführten Speicherorte kann dazu führen, dass eine primäre BNG ein Failover auf eine Sicherungs-BNG ausführt.
Access Linecard |
Core-seitige Verbindung |
Link zum Zugriff |
Netzwerk mit teilweisem Zugriff |
Chassis |
Partielles Core-Netzwerk |
Sie können die M:N-Redundanz verwenden, um die folgenden Anwendertypen zu schützen:
Dynamische DHCPv4- und DHCPv6-Abonnenten in statischen 1:1-VLANs über IPoE; VRRP-Redundanz
VLAN-basierte statische Abonnenten; VRRP-Redundanz
IP-Demux-basierte statische Abonnenten; VRRP-Redundanz
DHCPv4- und DHCPv6-Abonnenten auf dynamischen oder statischen VLANs über IP/MPLS; Pseudowire-Redundanz (Diese Unterstützung wurde in Junos OS Version 20.1R1 hinzugefügt.)
- Vorteile der M:N-Anwenderredundanz auf BNG
- Grundlagen der M:N-Redundanz
- Anwendersitzungen und Hot-Standby-Modus
- M:N-Redundanz mit Virtual Router Redundancy Protocol (VRRP)
- VRRP-Failover und Reversion-Timing
- M:N-Redundanz mit Pseudowire-Redundanz
- Statische Abonnenten und M:N-Redundanz
- Konvergenz und M:N-Anwenderredundanz
Vorteile der M:N-Anwenderredundanz auf BNG
Bietet eine leichte, Anwender Redundanz auf Anwendungsebene. Sie können damit mehrere verschiedene Anwendergruppen auf mehreren verschiedenen BNG-Gehäusen sichern. Jede Anwender-Gruppe verfügt über eine Sicherung im Hot-Standby-Modus.
Mehrere BNGs fungieren sowohl als aktives BNG für eine oder mehrere Anwender-Redundanz-Gruppen als auch als Backup-BNG für andere Anwender-Redundanz-Gruppen.
M:N-Redundanz ergänzt die Redundanz des MX-Serie Virtual Chassis. M:N-Redundanz ist für verteilte Umgebungen geeignet. MX-Serie Virtual Chassis erfordert ein dediziertes Gehäuse für Redundanz. Sie bietet 1:1-Redundanz und wird am häufigsten in zentralisierten Bereitstellungen eingesetzt.
Sie können die M:N-Redundanz für aktive Abonnenten aktivieren oder deaktivieren. Wenn Sie die Redundanz-Konfiguration entfernen, bleiben Abonnenten, die über die Konfiguration verfügten, sowohl auf der primären als auch auf der Backup-BNGs intakt.
Sie können M:N-Redundanz mit einer einzigen Core-Schnittstelle bereitstellen. Das bedeutet, dass mehrere Anwender-Redundanz-Gruppen eine gemeinsame Core-Konnektivität nutzen können.
M:N-Redundanz-Abonnenten können mit Nicht-Redundanz-Abonnenten koexistieren. Das bedeutet, dass Sie keine BNGs haben müssen, die für die Redundanz von Anwendern vorgesehen sind.
Sie können M:N-Redundanz-Abonnenten zur Laufzeit konfigurieren, auch nachdem die Abonnenten UP sind. Dies ist nützlich für Software-Upgrades, da Sie Abonnenten zu Backup-BNGs migrieren und dann die Software aktualisieren können.
Grundlagen der M:N-Redundanz
Der Einfachheit halber spiegelt die Erläuterung der M:N-Redundanz in dieser Dokumentation größtenteils die Verwendung von DHCP-Abonnenten in statischen VLANs wider.
Die Grundlage der M:N-Redundanz besteht darin, dass mehrere (M) Anwendergruppen auf einem bestimmten BNG-Chassis auf mehreren (N) verschiedenen Chassis-Zielen gesichert werden können. Wir bezeichnen diese Gruppen als Anwender-Redundanz-Gruppen.
Eine Anwender Gruppe besteht aus allen Abonnenten, die die folgenden Kriterien erfüllen:
(Statische VLANs) Die Teilnehmer gehören zu einem bestimmten statischen VLAN und verwenden dieselbe logische Zugriffsschnittstelle, z. B. ge-1/0/10/1. Ein Zugriffsgerät wie ein Switch, DSLAM oder OLT fasst die Teilnehmer im gemeinsamen VLAN zusammen.
(Dynamische VLANs) Die Teilnehmer gehören demselben dynamischen VLAN an und verwenden dieselbe physische Zugriffsschnittstelle, z. B. ge-1/0/0.
(Statische IP-DemuX) Die Abonnenten haben alle eine Quell-IP-Adresse, die mit dem konfigurierten Subnetz übereinstimmt.
Wenn Sie die Redundanz für eine Anwendergruppe konfigurieren, wird sie zu einer Anwender-Redundanz-Gruppe. Eine bestimmte Anwender-Redundanz-Gruppe verwendet jeweils nur ein BNG. Wir nennen diese BNG die primäre. Für jede Anwender-Redundanz-Gruppe fungiert nur eine der anderen BNGs als Backup im Hot-Standby-Modus. Wenn einer der in Tabelle 1 aufgeführten Fehler für die primäre BNG auftritt, wird ein Failover auf die entsprechende Sicherungs-BNG für die betroffene Redundanz-Gruppe ausgeführt. Diese Backup-BNG ist jetzt die neue primäre BNG für diese Gruppe. Alle aktiven Anwender-Sitzungen für diese Anwender-Redundanz-Gruppe werden über das gesamte Failover zur Backup-BNG beibehalten.
Abbildung 2 ist ein konzeptionelles Diagramm, das die M:N-Primär-/Backup-Beziehungen veranschaulicht. Es zeigt fünf BNGs in einer M:N-Primär-/Backup-Topologie, wobei jedes BNG eine Beziehung zu jedem anderen BNG hat. Wenn BNG 1 der primäre ist, können Sie BNG 2, 3, 4 und 5 als Backup-BNG für verschiedene Anwender-Redundanz-Gruppen konfigurieren. Wenn BNG 2 der primäre ist, können Sie BNG 1, 3, 4 und 5 als Backup-BNG usw. konfigurieren.
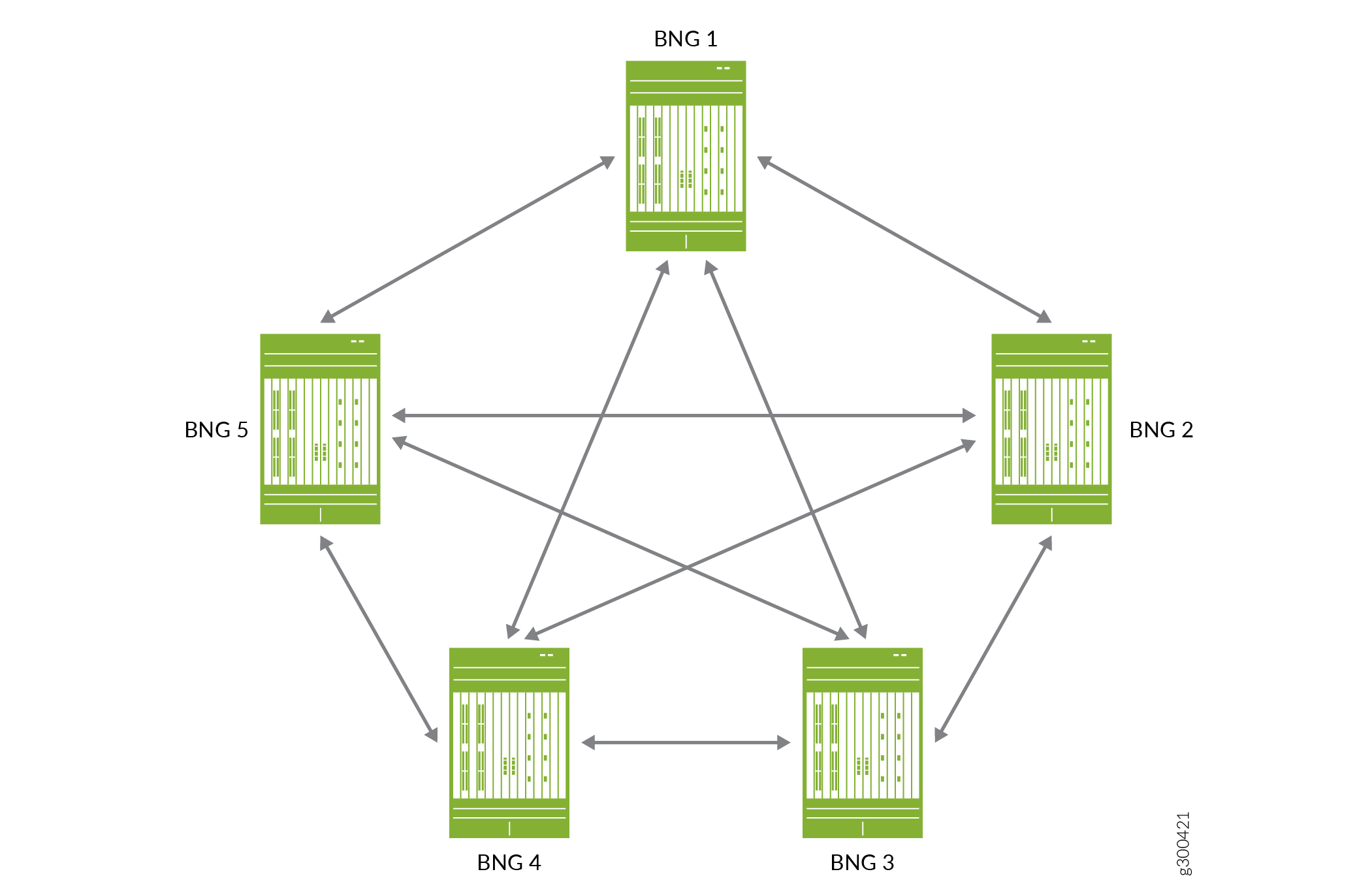
Für die M:N-Redundanz ist es wichtig zu verstehen, dass Sie Folgendes konfigurieren können:
Nur ein Backup-BNG für jede Anwender-Redundanz-Gruppe.
Ein BNG als Backup-Router für mehr als eine Redundanz-Gruppe.
Das bedeutet, dass ein bestimmter BNG gleichzeitig sowohl der primäre Router für viele Redundanz-Gruppen als auch der Backup-Router für viele verschiedene Redundanz-Gruppen sein kann. Wenn ein primärer BNG ausfällt, führt er ein Failover auf den Backup-Router durch, den Sie für jede seiner Redundanzgruppen konfigurieren. Die Anwender-Sitzungen für alle Redundanz-Gruppen auf dem primären BNG werden auf allen Backup-BNGs beibehalten, die zu neuen primären Gruppen werden.
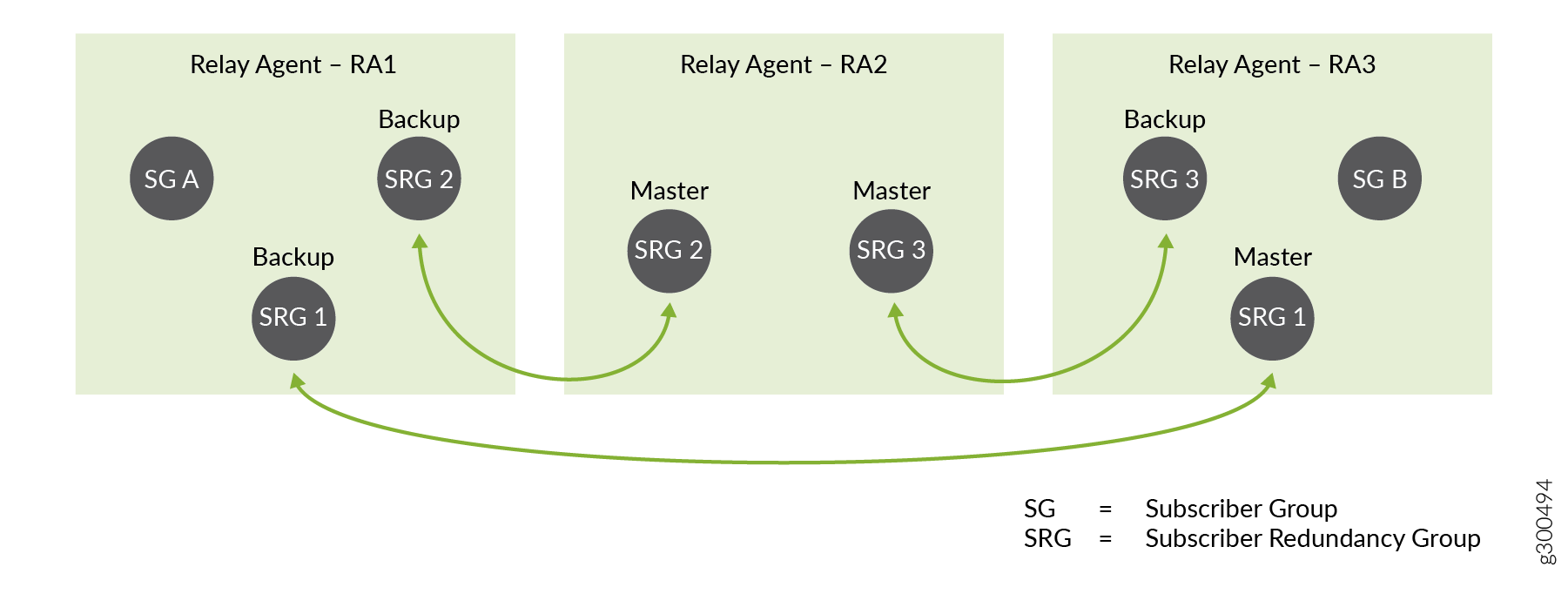
Abbildung 3 zeigt eine einfache Konfiguration von Anwender-Gruppen und Anwender-Redundanz-Gruppen auf drei DHCP-Relay-Agents, die auf drei BNGs gehostet werden. Die BNGs können direkt miteinander verbunden sein oder über die Zugangs- oder Kernnetzwerke verbunden sein.
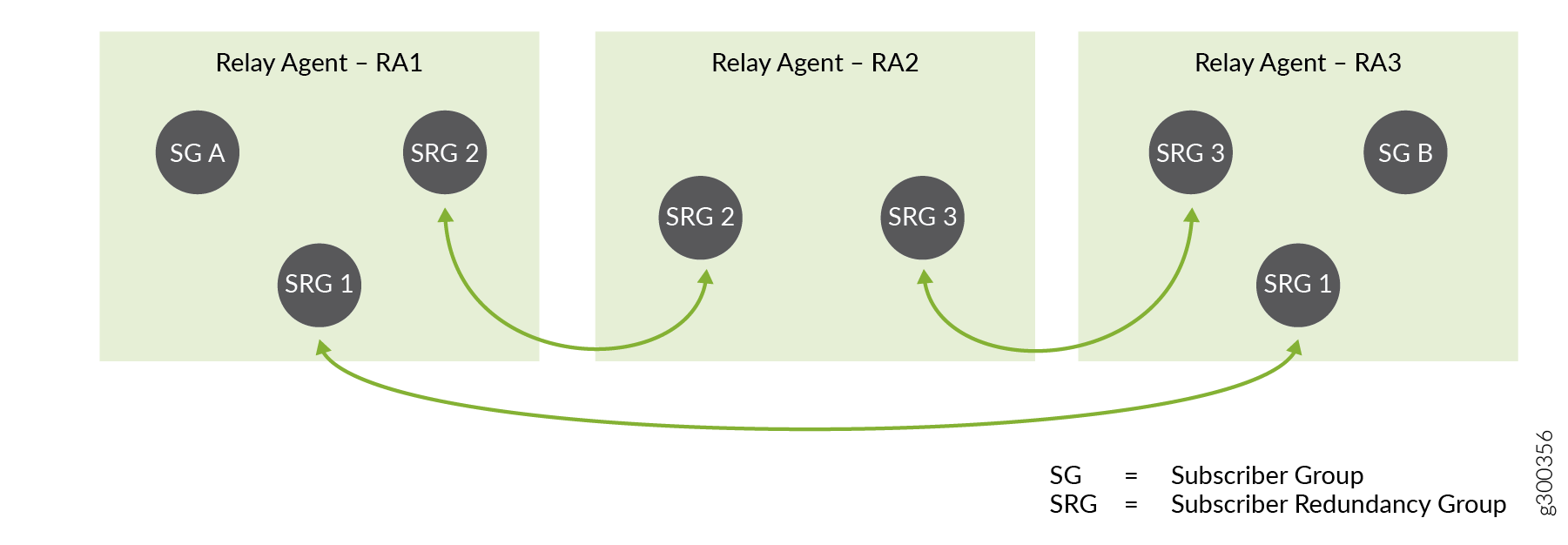
Der Relaisagent RA1 ist für die Anwender-Redundanz-Gruppen, SRG 1 und SRG 2 sowie die Anwender-Gruppe SG A konfiguriert.
Der Relaisagent RA2 ist für SRG 2 und SRG 3 konfiguriert.
Der Relaisagent RA3 ist für SRG 1, SRG 3 und SG B konfiguriert.
Eine andere Sichtweise ist, dass:
SRG 1 kann auf RA1 und RA3 aktiv oder gesichert sein.
SRG 2 kann auf RA1 und RA2 aktiv oder gesichert sein.
SRG 3 kann auf RA2 und RA3 aktiv oder gesichert sein.
SG A und SG B werden nicht gesichert.
Betrachten Sie nun Abbildung 4, die dieselbe Topologie zeigt, aber angibt, welche BNG primär und welche Backup für jede Redundanz-Gruppe ist. Die BNG-Hosting-Registrierungsstelle 1 ist die primäre BNG für SRG 1 und SRG 2.
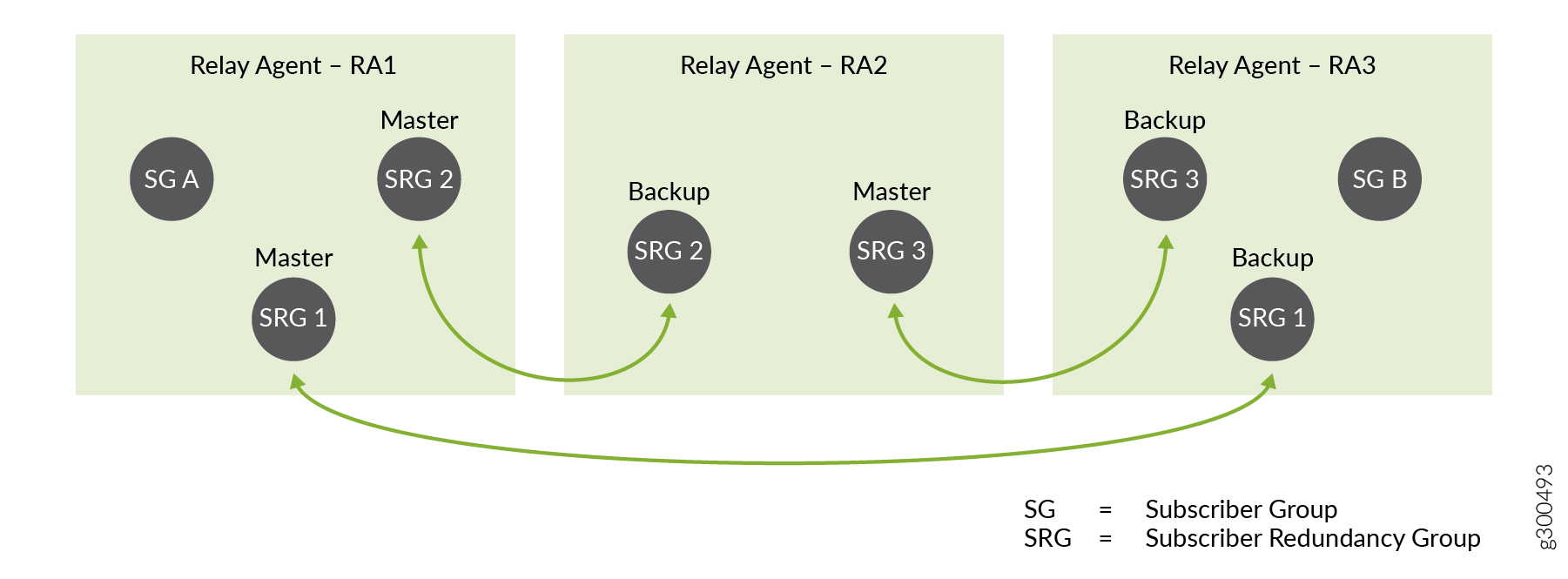
Wenn diese BNG ausfällt, führt sie ein Failover zu einer anderen Backup-BNG für SRG 1 und SRG 2 durch, wie in Abbildung 5 dargestellt.
Für SRG 1 führt ein Failover auf die BNG-Hosting-Registrierungsstelle 3 durch. Die Registrierungsstelle 3 BNG wird die neue primäre für SRG 1.
Für SRG 2 führt ein Failover auf die BNG-Hosting-Registrierungsstelle 2 durch. Die Registrierungsstelle 2 BNG wird die neue primäre für SRG 2.
Der Fehler hat keine Auswirkungen auf SRG 3.
Anwendersitzungen und Hot-Standby-Modus
Jede Backup-BNG befindet sich im Hot-Standby-Modus für die entsprechende primäre BNG für jede Anwender-Redundanz-Gruppe in der Sicherung. Dies bedeutet, dass das Backup-BNG sofort und ohne Unterbrechung bereit ist, das primäre BNG zu ersetzen, wenn ein Failover auftritt. Die folgenden Verhaltensweisen des primären und des Backup-BNGs ermöglichen das Funktionieren des Hot-Standby-Modus.
Abonnentenbindungen und der Status des Anwenders werden synchron zur Sicherungs-BNG gespiegelt, ebenso wie die ARP- und Nachbarerkennungsinformationen der primären BNG. Jeder Anwender wird auf dem Backup-BNG aufgerufen und sein Status ist Aktiv. Da die Abonnenten gleichzeitig auf dem primären und dem Sicherungs-BNG aktiv sind, führt das Sicherungs-BNG während eines Failover-Ereignisses keine Verarbeitung durch den Anwender.
Jede Anwender-Sitzung wird vor, während und nach einem Failover als fortlaufende Sitzung behandelt. Während der ersten Anmeldung des Anwenders senden der primäre und der Backup-BNG jeweils eine RADIUS Accounting-Start-Nachricht oder eine OCS CCR-I-Nachricht für den Anwender.
Während des Failovers sendet der fehlerhafte primäre Anbieter nach bestem Bemühen eine Accounting-Stop- oder CCR-T-Nachricht. Beispielsweise wird die Meldung gesendet, ob die Core-Verbindung noch aktiv ist oder ob das Gehäuse noch läuft. Wenn die Core-Verbindung oder das gesamte Gehäuse ausgefallen ist, kann die fehlerhafte primäre Verbindung keine Accounting-Stop- oder CCR-T-Nachricht senden.
Wenn die Sicherungs-BNG primär wird, sendet sie keine Accounting-Start- oder CCR-I-Nachricht, da die Abonnenten im gesamten Failover aktiv sind. Die Buchhaltungsstatistiken werden ab dem neuen primären System inkrementiert.
Bei der ersten Anmeldung des Anwenders fügt die BNG ihrer Routing-Tabelle Anwender-Routen hinzu und gibt die Routen an das Kernnetzwerk weiter. Wenn das primäre BNG ein Failover durchführt, löscht es keine Anwender-Routen aus seiner eigenen Routing-Tabelle und zieht die Routen nicht aus dem Kernnetzwerk zurück. Nach dem Failover fügt der ausgefallene primäre Routen keine Routen hinzu oder gibt sie weiter. Alternativ können Sie die Anwenderrouten so konfigurieren, dass sie basierend auf der primären BNG-Rolle an den Core angeschrieben oder von ihm zurückgezogen werden, sodass kein Datenverkehrsverlust durch das Failover entsteht.
Die Statussynchronisierung gilt nur für den Status des Anwenders. Der Dienststatus wird nicht synchronisiert. Abhängig von Ihrer Dienstkonfiguration kann die BNG Dienste für die Abonnenten sowohl auf aktiven als auch auf Backup-Abonnenten anfügen. Alternativ können die Services nach dem Failover auf der neuen aktiven BNG wieder angefügt werden.
M:N-Anwender-Redundanz synchronisiert keine Abrechnungsstatistiken vom primären BNG zum Backup-BNG. Es versucht nach besten Kräften, Buchhaltungsinformationen an einen Buchhaltungsserver zu übermitteln. Wenn ein Failover auftritt, werden die Abrechnungsstatistiken vom neuen primären Element inkrementiert und vom ausgefallenen primären Element nicht mehr inkrementiert. Je nach Schwere des Fehlers können Failover zum Verlust von Buchhaltungsinformationen führen.
M:N-Redundanz mit Virtual Router Redundancy Protocol (VRRP)
Sie können VRRP verwenden, um M:N-Redundanz in einem Netzwerk bereitzustellen. M:N-Redundanz verwendet VRRP, um eine virtuelle IP-Adresse und eine MAC-Adresse bereitzustellen, die von zwei BNGs in einer VRRP-Gruppe gemeinsam genutzt werden (manchmal auch als VRRP-Instanz bezeichnet). Die VRRP-Gruppe entspricht einem einzelnen virtuellen Router. Sie konfigurieren die VRRP-Gruppe auf der jeweiligen Zugriffsschnittstelle auf jeder BNG. Die Zugriffsschnittstelle ist die für den Anwender vorgesehene logische Schnittstelle, die mit dem Zugriffsnetzwerk verbunden ist.
Die virtuelle IP-Adresse wird zur Standard-Gateway-Adresse für die BNGs in der Gruppe. Nur die BNG, die als primäre fungiert, sendet VRRP-Ankündigungen oder antwortet auf Datenverkehr, der für die Adresse des virtuellen Routers bestimmt ist. Die BNG gibt nur die virtuelle Gateway-Adresse und die virtuelle MAC-Adresse für Anwender-Hosts bekannt. Da beide Router in der Gruppe dieselbe virtuelle Gateway-Adresse verwenden, ist keine Interaktion mit den Hosts erforderlich, und das Failover vom primären zum Backup-Gateway erfolgt innerhalb weniger Sekunden.
Die VRRP-Lösung für M:N-Redundanz ist auf ein N:1-Anwender-Zugriffsmodell ausgerichtet, das statische zugrunde liegende logische Schnittstellen verwendet.
Ausführliche Informationen zur Funktionsweise von VRRP im Allgemeinen finden Sie unter Grundlegendes zu VRRP und verwandten Themen im Benutzerhandbuch für hohe Verfügbarkeit.
Sie konfigurieren unterschiedliche Prioritäten für die beiden Router in einer VRRP-Gruppe, um zu bestimmen, welchen Router die Gruppe als primären auswählt:
Der Router mit der höheren Priorität für die Gruppe ist der primäre. Je größer die Zahl, desto höher die Priorität. Beispielsweise ist zwischen zwei Gruppenmitgliedern mit den Prioritäten 100 und 50 der Router mit der Priorität 100 der primäre.
Wenn der primäre Router ausfällt, wählt das Protokoll den Backup-Router als neuen primären aus. Die neue primäre IP- und MAC-Adresse übernimmt die Eigentümerschaft der virtuellen IP- und MAC-Adressen. Ein Failover hat keine Auswirkungen auf den Datenverkehr.
-
Wenn die ursprüngliche primäre Datenbank wieder online geht, bestimmt das Protokoll, dass sie eine höhere Priorität hat als die aktuelle primäre (vorherige Sicherung). Der ursprüngliche primäre Benutzer übernimmt dann die primäre Rolle ohne Auswirkungen auf den Datenverkehr.
Hinweis:Bei Verwendung von VRRP für M:N-Anwenderredundanz ist die Anzahl der Anwender-Redundanz-Gruppen auf die Anzahl der unterstützten VRRP-Sitzungen auf dem Gerät beschränkt. Für Dual-Stack erfordert diese Funktion separate VRRP-Sitzungen für IPv4 und IPv6, daher halbiert sich die Anzahl der Redundanz-Gruppen für Anwender.
Abbildung 6 zeigt eine Beispieltopologie mit zwei BNGs und die Konfiguration für die entsprechenden Schnittstellen auf jedem Router:
Die beiden logischen Schnittstellen befinden sich im selben VLAN (1).
Die Schnittstellenadressen befinden sich im selben Subnetz (203.0.113.1/24 und 203.0.113.2/24).
Die Schnittstellenadressen befinden sich in derselben VRRP-Gruppe (27) und teilen sich dieselbe virtuelle IP-Adresse (203.0.113.25).
Der BNG mit der höheren Priorität (254) wird als Vorwahl gewählt; der BNG mit der niedrigeren Priorität (200) ist das Backup.
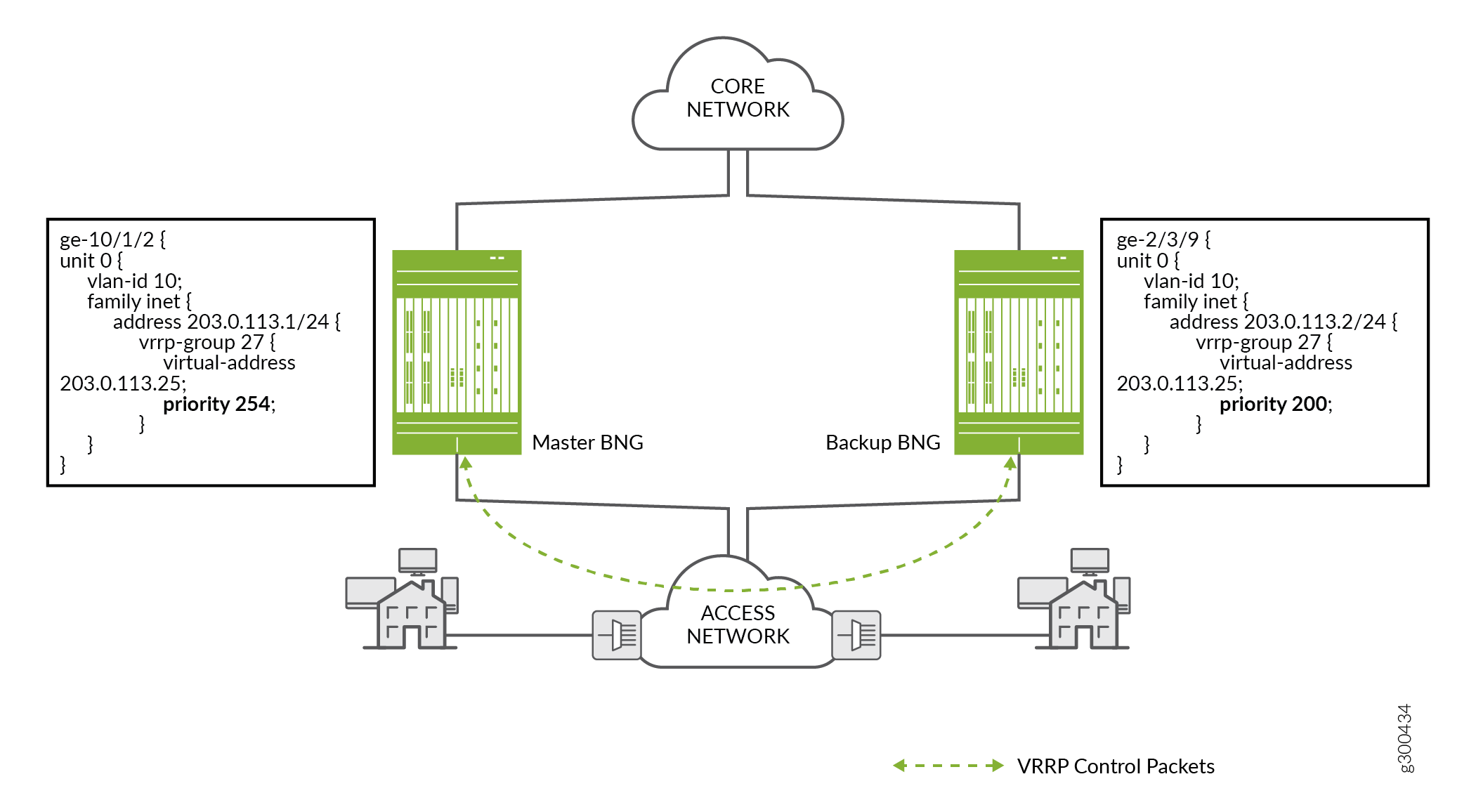
Abbildung 7 zeigt, wie die konfigurierte VRRP-Priorität bestimmt, welches BNG als primäres oder Backup für eine Anwender-Redundanz-Gruppe fungiert.
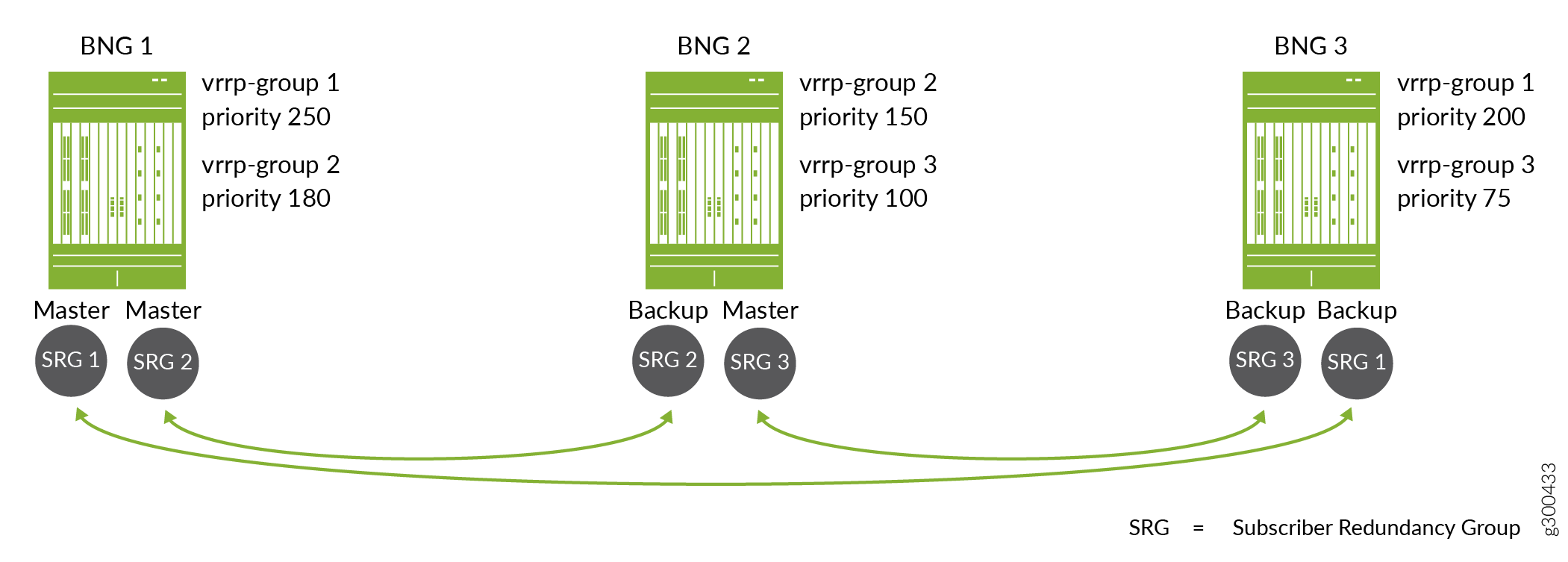
Die Topologie umfasst drei Anwender-Redundanz-Gruppen (M), SRG 1, SRG 2 und SRG 3 auf drei BNGs (N). Jede Anwender-Redundanz-Gruppe entspricht einer anderen VRRP-Gruppe. Die Pfeile zeigen den primären Router und den Backup-Router für jede Gruppe an
Für SRG 1 hat BNG 1 die höhere Priorität, 250. BNG 3 hat eine niedrigere Priorität, 200. Dies bedeutet, dass BNG 1 der primäre für SRG 1 und BNG 3 das Backup ist, sodass BNG 1 ein Failover auf BNG 3 darstellt. Wenn sich BNG 1 erholt, wird es für SRG 1 wiedergewählt, da es eine höhere Priorität als BNG 3 hat.
Für SRG 2 hat BNG 1 auch die höhere Priorität, 180, und ist die primäre. BNG 2 hat eine niedrigere Priorität, 150, und ist das Backup.
Für SRG 3 hat BNG 2 die höhere Priorität, 100, und ist die primäre. BNG 3 hat eine niedrigere Priorität, 75, und ist das Backup.
VRRP-Failover und Reversion-Timing
Angenommen, BNG 1 führt mit der in Abbildung 7 gezeigten Redundanzkonfiguration ein Failover auf BNG 3 für SRG 1 durch, sodass BNG 3 der neue primäre Anbieter für die Gruppe ist. Die primäre Rolle kehrt automatisch zu BNG 1 zurück, wenn sie wieder verfügbar ist. Wenn die Verbindung zwischen den beiden BNGs über das Zugriffsnetzwerk verläuft (im Vergleich zu einer direkten Verbindung zwischen den BNGs), werden die Zustände des Anwenders möglicherweise nicht zwischen den beiden BNGs synchronisiert, wenn die primäre Rolle zurückgesetzt wird. Der VRRP-Status ist unabhängig von der DHCP-aktiven Leasequery-Synchronisation.
Wenn die Zugriffsverbindung auf BNG 1 wiederhergestellt ist, stellt die aktive DHCP-Leasequery die Verbindung für die Anwender-Synchronisation zwischen den BNGs wieder her. DHCP beginnt mit der Neusynchronisierung des Anwenderstatus und der Bindungsinformationen vom aktuellen primären (BNG 3) zum wiederhergestellten primären (BNG 1).
Buchhaltungsstatistiken können beeinträchtigt werden, wenn die primäre Rolle auf BNG 1 zurückgesetzt wird, bevor die Neusynchronisierung abgeschlossen ist. Beispielsweise werden Abrechnungsstatistiken für angemeldete Abonnenten erst nach Abschluss der Neusynchronisierung zur Datenbank hinzugefügt. Abmeldemeldungen für Abonnenten, die sich abmelden, werden erst verarbeitet, wenn die Synchronisierung beendet ist und die Abonnenten auf BNG 1 wiederhergestellt sind.
Sie können diese Auswirkungen abmildern, indem Sie den VRRP-Haltetimer (manchmal auch als Umkehrtimer bezeichnet) so konfigurieren, dass die Neusynchronisierung abgeschlossen wird, bevor der ursprüngliche primäre Timer die primäre Rolle wieder übernimmt. Verwenden Sie die hold-time Anweisung auf Hierarchieebene [edit interfaces] .
Es wird empfohlen, die VRRP-Redundanz im nicht-revertiven Modus zu konfigurieren, wenn Sie mit einer hohen Skalierung arbeiten. Für Systeme, die nicht in großem Umfang betrieben werden, können Sie entweder den nicht revertiven Modus verwenden oder den VRRP-Haltetimer (manchmal auch als revertiven Timer bezeichnet) mit Werten konfigurieren, die hoch genug sind, dass die Neusynchronisierung abgeschlossen ist, bevor der ursprüngliche primäre Timer die primäre Rolle wieder aufnimmt.
M:N-Redundanz mit Pseudowire-Redundanz
Ab Junos OS Version 20.1R1 können Sie Pseudowire-Redundanz verwenden, um M:N-Redundanz bereitzustellen, wenn das Zugriffsnetzwerk aus Layer 2 (L2)-Circuits über IP/MPLS besteht. In dieser Art von Zugangsnetzwerk ist LDP das Signalisierungsprotokoll, das Labels zwischen den Nachbarn der L2-Leitung verteilt. Jeder L2-Circuit ist ein Punkt-zu-Punkt-Pseudowire-Tunnel zwischen dem Zugriffsknoten (oder dem Kunden-Edge-Gerät) und einem BNG. Das Netzwerk kann eine heterogene Mischung von L2- oder L3-Geräten umfassen.
Abbildung 8 zeigt eine einfache Topologie, bei der Access-Knoten den Datenverkehr aggregieren und über das Netzwerk an einen DHCP-Relay-Agent auf dem primären BNG senden. Die Konfiguration der Pseudowire-Redundanz gibt einen aktiven Pseudowire (zum primären BNG) und einen Backup-Pseudowire (zum Backup-BNG) an.
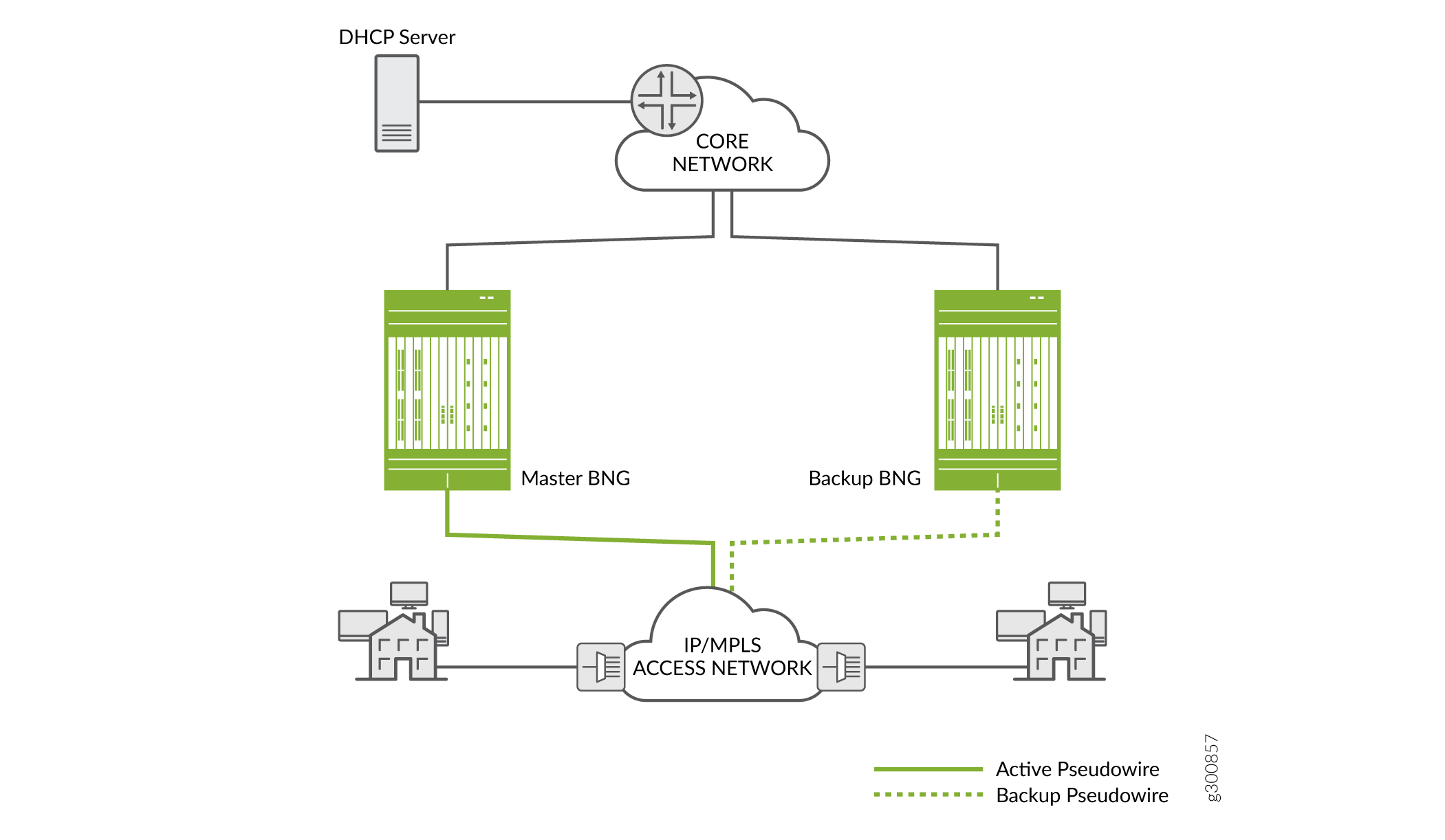
Bei L2-Verbindungen konfigurieren Sie die Pseudowires als zugrunde liegende (zugriffsorientierte) Schnittstellen auf den BNGs. Anschließend konfigurieren Sie die Schnittstellen mit L2-Verbindungen wie Ethernet, dynamischen automatisch erkannten VLANs oder statischen VLANs. Die DHCP-Client-basierten Pseudowire-Schnittstellen werden gebündelt und einer L2-Verbindung (dem Pseudowire-Tunnel) hinzugefügt. In der Regel enthält das Paket eine Reihe dynamischer VLAN-Schnittstellen. Das Paket kann jedoch eine beliebige Kombination aus einzelnen logischen VLAN-Schnittstellen, Listen von VLAN-Schnittstellen und physischen Schnittstellen enthalten.
Eine L2-Verbindung verläuft zwischen zwei L2-Nachbarn. in diesem Fall zwischen einem Zugangsknoten und einem BNG. Jeder Nachbar dient als Endpunktziel für einen MPLS Label-Switched Path (LSP). Sie erstellen den Schaltkreis, indem Sie ihn auf einer Schnittstelle auf jedem Nachbarn konfigurieren:
Auf der BNG geben Sie den Zugriffsknoten als Nachbarn und eine lokale Pseudowire-Schnittstelle auf der BNG an, die die L2-Verbindung beendet.
Auf dem Zugriffsknoten geben Sie den BNG als Nachbarn und eine lokale Schnittstelle an, die den Clients auf dem Knoten am anderen Ende der L2-Verbindung zugewandt ist.
Sowohl auf dem BNG- als auch auf dem Zugriffsknoten konfigurieren Sie einen eindeutigen Virtual Circuit Identifier (VCI), der diesen L2-Circuit von allen anderen L2-Circuits unterscheidet, die auf dem Gerät enden.
Diese L2-Schaltung ist jetzt der primäre Pseudodraht zum BNG. Um Redundanz herzustellen, konfigurieren Sie die Backup-Pseudoleitung auf dem Zugriffsknoten. Auf derselben lokalen Schnittstelle geben Sie einen anderen BNG als Backup-Nachbarn an und geben an, dass sich die Backup-Pseudowire im Hot-Standby-Modus befindet.
Der Hot-Standby-Modus stellt sicher, dass der Backup-Nachbar vollständig bereit ist, die Rolle des primären Stromkreises zu übernehmen, wenn der aktuelle primäre Stromkreis ausfällt. Ein LSP für den Backup-Nachbarn ist bereits durch LDP eingerichtet.
Der Status der Pseudowire-Schnittstelle ist UP auf dem primären BNG. Der Status der Pseudowire-Schnittstelle ist Remote Standby (RS) auf dem Backup-BNG. (Sie können den show l2circuit connections brief Befehl verwenden, um den Verbindungsstatus anzuzeigen.) Sie müssen Ihre Routenrichtlinien so konfigurieren, dass Subnetzrouten für diese Redundanzgruppe nur auf dem primären BNG angekündigt werden. Dadurch wird sichergestellt, dass nur der primäre Datenverkehr Downstream-Datenverkehr empfängt.
LDP verfügt über einen Keepalive-Mechanismus zum Erkennen von Fehlern. Ein Fehler führt dazu, dass die L2-Verbindung vom primären Pseudowire und dem primären BNG zum Backup-Pseudowire und zum Backup-BNG übergeht. Wenn ein Fehler erkannt wird, schaltet LDP die Schaltung vom primären LSP (auf der primären Pseudowire) auf den Backup-LSP (auf der Backup-Pseudowire) um. Der Backup-BNG übernimmt die primäre Rolle und sein Status wechselt zu "Up".
Wenn die alte Primärdatenbank wieder verfügbar ist, gelten für die Pseudowire-Redundanz die gleichen Überlegungen zur Synchronisation wie für VRRP als Redundanzmethode.
Es wird empfohlen, die Pseudowire-Redundanz im nicht-revertiven Modus zu konfigurieren, wenn Sie mit einer hohen Skalierbarkeit arbeiten. Für Systeme, die nicht in großem Umfang betrieben werden, können Sie entweder den nicht-revertiven Modus verwenden oder das revert-time Intervall auf der Zugriffsknotenschnittstelle mit Werten konfigurieren, die hoch genug sind, dass die Neusynchronisierung abgeschlossen ist, bevor der ursprüngliche primäre Benutzer die primäre Rolle wieder aufnimmt.
Statische Abonnenten und M:N-Redundanz
M:N-Anwender-Redundanz unterstützt zwei Kategorien von Abonnenten:
Abonnenten, die das DHCP-Clientprotokoll über ein statisches VLAN verwenden. Dies ist der häufigste Anwendertyp für M:N-Anwender-Redundanz.
Abonnenten auf statischen Schnittstellen, auf denen kein Clientprotokoll ausgeführt wird. Dieser Anwendertyp ist typisch für kleine bis mittlere Unternehmen, die über eine eigene statische IP-Adresse verfügen und so etwas wie DHCP nicht verwenden.
Statische Abonnenten bestehen aus den folgenden Typen:
VLAN-basierte statische Abonnenten: Sie erstellen Abonnenten auf der logischen VLAN-Schnittstelle. Sie konfigurieren die VRRP-Attribute auf der logischen VLAN-Schnittstelle.
IP-Demux-basierte statische Subscribers: Sie erstellen Subscriber auf einer IP-Demux-Schnittstelle über eine zugrunde liegende Schnittstelle. Der Datenverkehr für diese Anwender enthält eine Quell-IP-Adresse, die mit dem konfigurierten Subnetz für die Anwenderschnittstelle übereinstimmt. Sie konfigurieren VRRP-Attribute auf der zugrunde liegenden logischen Schnittstelle.
Diese beiden statischen Anwendertypen werden vom jsscd Daemon verwaltet. Sie werden manchmal als statische JSSCD-Abonnenten bezeichnet.
Die folgenden Beispielkonfigurationsausschnitte zeigen, wie Sie eine statische Anwendergruppe mit zwei Schnittstellen erstellen, die für VRRP auf einem primären BNG und einem Sicherungs-BNG konfiguriert sind. Eine Schnittstelle ist eine IP-Demux-Schnittstelle und die andere ist eine VLAN-Schnittstelle. Die Konfiguration zeigt, wie VRRP auf jeder Schnittstelle konfiguriert ist.
Primäre BNG-Konfiguration:
Der folgende Codeausschnitt konfiguriert die zugrunde liegende Schnittstelle für die logische IP-Demux-Schnittstelle, ge-1/1/9.11. Die VLAN-ID wird als 11 angegeben. Das Subnetz der Zugriffsschnittstelle ist auf 203.0.113.1/24 festgelegt. Die VRRP-Konfiguration in diesem Subnetz legt die Gruppe (die Anwender-Redundanz-Gruppe) auf 11 fest und gibt die Adresse für den virtuellen Router an. Der virtuelle Router besteht aus den primären und Backup-BNGs für diese Anwender-Redundanz-Gruppe. Die VRRP-Priorität ist 230. Wenn das primäre System zum Backup wechselt, verzögert sich die Übernahme der primären Rolle durch das Backup um 30 Sekunden.
[edit] interfaces { ge-1/1/9 { unit 11 { demux-source inet; vlan-id 11; family inet { address 203.0.113.1/24 { vrrp-group 11 { virtual-address 203.0.113.25; priority 230; preempt { hold-time 30; } } } } } } }Der folgende Codeausschnitt konfiguriert die logische VLAN-Schnittstelle ge-1/1/9.20. Die VLAN-ID wird als 20 angegeben. Das Subnetz der Zugriffsschnittstelle ist auf 192.0.2.1/24 festgelegt. Die VRRP-Konfiguration in diesem Subnetz legt die Gruppe (die Anwender-Redundanz-Gruppe) auf 20 fest und gibt die Adresse für den virtuellen Router an. Der virtuelle Router besteht aus den primären und Backup-BNGs für diese Anwender-Redundanz-Gruppe. Die VRRP-Priorität ist 230. Wenn das primäre System zum Backup wechselt, verzögert sich die Übernahme der primären Rolle durch das Backup um 30 Sekunden.
[edit] interfaces { ge-1/1/9 { unit 20 { vlan-id 20 ; family inet { address 192.0.2.1/24 { vrrp-group 20 { virtual-address 192.0.2.25; priority 230; preempt { hold-time 30; } } } } } } }Der folgende Codeausschnitt konfiguriert die logische IP-demux-Schnittstelle demux0.1 über die zugrunde liegende Schnittstelle ge-1/1/9.11. Außerdem konfiguriert es die Loopback-Schnittstelle und ermöglicht die Ableitung der lokalen Adresse für die IP-Demux-Schnittstelle von der Loopback-Schnittstelle.
[edit] interfaces { demux0 { unit 1 { demux-options { underlying-interface ge-1/1/9.11; } family inet { unnumbered-address lo0.0; } } } lo0 { unit 0 { family inet { address 192.168.10.32/32; } } } }Der folgende Codeausschnitt konfiguriert eine statische Anwendergruppe, static-ifl, die sowohl die statische IP-Demux-Anwender-Schnittstelle (demux0.1) als auch die statische VLAN-Anwender-Schnittstelle (ge-1/1/9.20) umfasst. Es ordnet der Gruppe ein Zugriffsprofil zu, legt das Passwort und ein Präfix für den Benutzernamen fest.
[edit system services] static-subscribers { group static-ifl { access-profile { staticauth; } authentication { password "$ABC123$ABC123"; ## SECRET-DATA username-include { user-prefix test-static; } } interface ge-1/1/9.20; interface demux0.1; } }Der folgende Codeausschnitt konfiguriert ein Zugriffsprofil für die Gruppe der statischen Abonnenten.
[edit access] profile staticauth { authentication-order none; }
Backup-BNG-Konfiguration:
In diesem Beispiel sind einige Konfigurationsdetails unterschiedlich, andere müssen identisch sein.
Die Zugriffsschnittstellen sind unterschiedlich. Alternativ können Sie die Zugriffsschnittstellen auf dem primären und dem Backup-Gerät so konfigurieren, dass sie identisch sind.
Die VRRP-Priorität ist für beide Schnittstellen auf 200 festgelegt. Dieser Wert macht dies zum Backup-BNG, weil er niedriger ist als die Priorität des anderen BNG (230).
Die Schnittstellenadressen sind unterschiedlich. Die virtuelle Adresse ist für beide gleich, wie sie sein muss, sodass sich beide BNGs im selben virtuellen Router befinden.
Die Zugriffsschnittstellen befinden sich im selben Subnetz.
Der folgende Codeausschnitt konfiguriert die zugrunde liegende Schnittstelle für die logische IP-Demux-Schnittstelle, ge-3/0/1.11. Die VLAN-ID wird als 11 angegeben. Das Subnetz der Zugriffsschnittstelle ist auf 203.0.113.2/24 festgelegt. Die VRRP-Konfiguration in diesem Subnetz legt die Gruppe (die Anwender-Redundanz-Gruppe) auf 11 fest und gibt die Adresse für den virtuellen Router an. Der virtuelle Router besteht aus den primären und Backup-BNGs für diese Anwender-Redundanz-Gruppe. Die VRRP-Priorität ist 200. Wenn das primäre Failover zur Sicherung erfolgt, wird die Übernahme der primären Rolle durch die Sicherung um 30 Sekunden verzögert.
[edit] interfaces { ge-3/0/1 { unit 11 { demux-source inet; vlan-id 11; family inet { address 203.0.113.2/24 { vrrp-group 11 { virtual-address 203.0.113.25; priority 200; preempt { hold-time 30; } } } } } } }Der folgende Codeausschnitt konfiguriert die logische VLAN-Schnittstelle ge-3/0/1.20. Die VLAN-ID wird als 20 angegeben. Das Subnetz der Zugriffsschnittstelle ist auf 192.0.2.2/24 festgelegt. Die VRRP-Konfiguration in diesem Subnetz legt die Gruppe (die Anwender-Redundanz-Gruppe) auf 20 fest und gibt die Adresse für den virtuellen Router an. Der virtuelle Router besteht aus den primären und Backup-BNGs für diese Anwender-Redundanz-Gruppe. Die VRRP-Priorität ist 200. Wenn das primäre System zum Backup wechselt, verzögert sich die Übernahme der primären Rolle durch das Backup um 30 Sekunden.
[edit] interfaces { ge-3/0/1 { unit 20 { vlan-id 20 ; family inet { address 192.0.2.2/24 { vrrp-group 20 { virtual-address 192.0.2.25; priority 200; preempt { hold-time 30; } } } } } } }Der folgende Codeausschnitt konfiguriert die logische IP-demux-Schnittstelle demux0.1 über die zugrunde liegende Schnittstelle ge-3/0/1.11. Außerdem konfiguriert es die Loopback-Schnittstelle und ermöglicht die Ableitung der lokalen Adresse für die IP-Demux-Schnittstelle von der Loopback-Schnittstelle.
[edit] interfaces { demux0 { unit 1 { demux-options { underlying-interface ge-3/0/1.11; } family inet { unnumbered-address lo0.0; } } } lo0 { unit 0 { family inet { address 192.168.10.32/32; } } } }Der folgende Codeausschnitt konfiguriert eine statische Anwendergruppe, static-ifl, die sowohl die statische IP-Demux-Anwender-Schnittstelle (demux0.1) als auch die statische VLAN-Anwender-Schnittstelle (ge-3/0/1.20) umfasst. Es ordnet der Gruppe ein Zugriffsprofil zu, legt das Passwort und ein Präfix für den Benutzernamen fest.
[edit system services] static-subscribers { group static-ifl { access-profile { staticauth; } authentication { password "$ABC123"; ## SECRET-DATA username-include { user-prefix test-static; } } interface ge-3/0/1.20; interface demux0.1; } }Der folgende Codeausschnitt konfiguriert ein Zugriffsprofil für die Gruppe der statischen Abonnenten.
[edit access] profile staticauth { authentication-order none; }
Konvergenz und M:N-Anwenderredundanz
Konvergenz ist der Prozess, bei dem Router in einem Netzwerk ihre individuellen Routing-Tabellen aktualisieren, wenn Routen auf einem beliebigen Router hinzugefügt, entfernt oder aufgrund eines Verbindungsausfalls nicht mehr erreicht werden. Die Routing-Protokolle auf den Routern kündigen die Routenänderungen im gesamten Netzwerk an. Sobald jeder Router die Aktualisierungen erhält, berechnet er die Routen neu und erstellt dann auf der Grundlage der Ergebnisse neue Routing-Tabellen.
Ein Netzwerk ist konvergiert , wenn alle Routing-Tabellen mit der Gesamtnetzwerktopologie übereinstimmen. Das bedeutet zum Beispiel, dass die Router ein gemeinsames Verständnis darüber haben, welche Verbindungen aktiv oder ausgefallen sind usw. Wie lange die Router brauchen, um einen Zustand der Konvergenz zu erreichen, wird als Konvergenzzeit bezeichnet. Wie lange die Konvergenz dauert, hängt von verschiedenen Faktoren ab, wie z. B. der Größe und Komplexität des Netzwerks und der Leistung der Routing-Protokolle.
M:N Anwender Redundanz unterstützt sowohl zugriffsseitige (Upstream) als auch Core-seitige (Downstream) Routen Konvergenz. Da jeder Anwender gleichzeitig auf der primären und der Backup-BNGs aktiv ist, kann die Konvergenz des Datenverkehrs sehr schnell erfolgen. Die Routen-Konvergenz ist jedoch nach bestem Wissen und Gewissen und hängt vom Grad des Failovers ab. das heißt, ob ein teilweiser oder vollständiger Chassis-Ausfall auftritt.
Es liegt an Ihnen, zu bestimmen, wie Sie den Upstream- und Downstream-Datenverkehr Konvergenz für Ihr Netzwerk nach einem Failover von primärem zu Backup-BNG verwalten.
- Upstream-Datenverkehrskonvergenz (VRRP-Redundanz)
- Upstream-Datenverkehrskonvergenz (Pseudowire-Redundanz)
- Konvergenz des Downstream-Datenverkehrs
Upstream-Datenverkehrskonvergenz (VRRP-Redundanz)
Sie können die Konvergenz des Upstreamdatenverkehrs verbessern, indem Sie kostenloses ARP verwenden, um die Zeit zu verkürzen, die das Zugriffsnetzwerk benötigt, um Datenverkehr an das neue primäre BNG zu senden, nachdem das ursprüngliche primäre BNG ausgefallen ist.
Auf dem primären BNG fällt die Zugriffsschnittstelle oder das Schnittstellen-Modul aus.
VRRP wählt den Backup-BNG als neuen Primärpunkt.
Der neue primäre Sender sendet unentgeltliche ARP-Nachrichten an das Zugangsnetzwerk. Es sendet die Nachrichten von seiner Zugriffsschnittstelle, die der Zugriffsschnittstelle des früheren primären Geräts entspricht. Die ARP-Nachricht enthält die virtuelle VRRP-IP-Adresse und die virtuelle MAC-Adresse, die den virtuellen Router definieren, der die beiden BNGs enthält.
Der Switch oder ein anderes Gerät im Zugriffsnetzwerk lernt die Gateway-IP-Adresse (die virtuelle Adresse) neu. Wenn es Datenverkehr an diese Adresse sendet, empfängt ihn die neue primäre BNG auf der Zugriffsschnittstelle.
Upstream-Datenverkehrskonvergenz (Pseudowire-Redundanz)
Wenn Sie die primären und Backup-Pseudowires im Hot-Standby-Modus auf dem Zugriffsknoten konfigurieren, richtet LDP automatisch LSPs für die primären und Backup-BNGs ein. Das LDP-Signalisierungsprotokoll enthält einen Keepalive-Mechanismus zur Erkennung von Fehlern im Pfad. In diesem Fall wird die Upstream-Konvergenz durch einen pseudowire Layer 2-Tunnel-Switch vom primären BNG zum Backup-BNG erreicht.
Sie können LDP-Keep-Alive-Timer konfigurieren, um Fehler schneller zu erkennen. Alternativ können Sie das BFD-Protokoll für ein schnelleres Failover ausführen. Jede der folgenden Methoden kann einen Wechsel vom primären Pseudowire zum Backup-Pseudowire verursachen:
Verwenden Sie den
request l2circuit-switchoverBefehl, um manuell einen Wechsel vom primären Pseudowire zum Backup-Pseudowire auszulösen.Sie können die bidirektionale Weiterleitungserkennung (Bidirectional Forwarding Detection, BFD) für die LDP-LSPs konfigurieren. Die BFD-Live-Erkennung kann zwei verschiedene Arten von Fehlern erkennen:
Ein Verbindungsfehler im LSP-Pfad zwischen dem Zugriffsknoten und dem primären BNG. In diesem Fall ist die BNG immer noch aktiv.
Ein Neighbor Down Failure, wenn der primäre BNG ausfällt.
Bei beiden Typen steuern Sie die Geschwindigkeit der Erkennung und des Switchovers durch die Konfiguration der
bfd-liveness-detectionAnweisung auf Hierarchieebene[edit protocols ldp oam].
Konvergenz des Downstream-Datenverkehrs
Die für die Konvergenz des Downstreamdatenverkehrs erforderliche Zeit wird von mehreren Faktoren beeinflusst, einschließlich der folgenden:
Die Ankündigung einzelner Anwender-Routen erhöht die Anzahl der Routenneuberechnungen, die die Core-Netzwerkrouter durchführen müssen.
Das Erkennen eines Ausfalls einer Zugriffsschnittstelle und das anschließende Senden der entsprechenden Benachrichtigung über Routenänderungen an den Core kann manchmal schwierig sein oder lange dauern.
Routing-Protokolle im Core lernen möglicherweise nicht sofort, wenn eine Core-Verbindung oder das gesamte Gehäuse ausfällt. Routing-Protokolle sind in der Regel auf eine Art Timeout angewiesen, um den Verlust zu erkennen, sodass immer eine Verzögerung auf den Ablauf des Timeouts wartet.
Wir empfehlen die folgenden Richtlinien:
Stellen Sie sicher, dass die Routen der Anwender nach Möglichkeit für die Werbung zum Core aggregiert werden. Die Aggregation kann durch die Verwendung von Adresspools oder richtlinienbasierter Routenankündigung wie unten beschrieben erreicht werden. Durch die Verringerung der Anzahl der auf den Core-Routern neu zu berechnenden Routen wird die Konvergenzzeit verkürzt, insbesondere mit zunehmender Anzahl der Abonnenten.
Konfigurieren Sie die Routen, die von beiden BNGs mit unterschiedlichen Präferenzen angekündigt werden sollen. Verwenden Sie im Core schnelle Rerouting-Techniken.
Vermeiden Sie das Load Balancing des Downstream-Datenverkehrs zwischen der primären und der Backup-BNGs.
Zwei Methoden, die Sie in Betracht ziehen könnten, sind richtlinienbasierte Routenankündigung und dedizierte BNG-Links.
Richtlinienbasierte Routenankündigung (VRRP und Pseudowire-Redundanz): Diese Technik kann die Zeit für die Konvergenz des nachgelagerten Datenverkehrs reduzieren, da im Kernnetzwerk nur aggregierte Routen aktualisiert werden und nicht zahlreiche einzelne Anwender-Routen. Bei dieser Methode konfigurieren Sie BGP, OSPF oder ein anderes Routingprotokoll so, dass aggregierte Routen zum Core nur dann angekündigt werden, wenn ein BNG zum primären wird.
Für VRRP-Redundanz konfigurieren Sie die BGP-Richtlinien so, dass die virtuelle VRRP-IP-Adresse nachverfolgt wird. BGP aggregiert die Anwender-Routen basierend auf der Anwender-Redundanz-Gruppe, die einer VRRP-Gruppe entspricht. BGP kündigt die aggregierten Routen zum Core an, wenn die primäre VRRP-Rolle von der BNG übernommen wird.
Für Pseudowire-Redundanz konfigurieren Sie die BGP-Richtlinien so, dass der Status der Pseudowire-Schnittstelle (nach oben oder unten) verfolgt wird. BGP aggregiert Routen für die Anwender-Redundanz-Gruppe. BGP kündigt die aggregierten Routen zum Core an, wenn sich der Status in "Up" ändert, was bedeutet, dass das Backup-BNG jetzt das primäre ist.
In beiden Fällen zieht das BGP auf dem ausgefallenen primären die aggregierten Anwenderrouten für den Core zurück, wenn das primäre BNG zum Backup übergeht. Wenn das Backup-BNG zum neuen primären System wird, kündigt es wiederum aggregierte Anwender-Gruppen bis zum Kern an.
Dedizierte BNG-Verbindungen (nur VRRP-Redundanz): Sie können die Zeit zum Erkennen eines Fehlers im primären BNG reduzieren, indem Sie die BNGs mit einer dedizierten Verbindung verbinden. Sie konfigurieren VRRP auf der Zugriffsschnittstelle, um den Status der dedizierten Verbindungsschnittstelle zu verfolgen. Außerdem konfigurieren Sie VRRP auf der dedizierten Verbindungsschnittstelle, um den Status der Zugriffsschnittstelle zu verfolgen.
Ein Ausfall der Zugriffsschnittstelle auf der primären Verbindung führt dazu, dass sich die primäre VRRP-Rolle auf der dedizierten Verbindung ändert. Diese Änderung wiederum führt dazu, dass sich die primäre Rolle sofort auf der Zugriffsschnittstelle des Backup-BNG ändert. Diese Methode ist schneller, als auf den Ablauf des VRRP-Hello-Timers zu warten.
Konfigurieren der M:N-Anwenderredundanz mit VRRP- und DHCP-Bindungssynchronisierung
M:N-Anwender-Redundanz mit VRRP- und DHCP-Bindungssynchronisierung erfordert, dass Sie alle folgenden Einstellungen vornehmen:
Redundante Abonnentengruppen, um die Anwender anzugeben, die Teil des Primär-/Sicherungsvorgangs sind.
VRRP auf allen redundanten Routern in der Topologie. VRRP ist das Protokoll, das die zugrunde liegende Redundanzfunktion für die Anwendergruppen und DHCP-Relay-Agents bereitstellt.
In diesem Thema werden nur die grundlegenden Konfigurationen beschrieben, die für die M:N-Anwender-Redundanz auf den BNGs erforderlich sind, die die Peer-DHCP-Relay-Agents hosten. Es beschreibt nicht jeden Aspekt der folgenden Punkte: globale Anwender-Verwaltung, die VRRP-Konfiguration, die Sie in Ihrem Netzwerk verwenden können, DHCP-Relay-Agents oder DHCP-Leasequery. Weitere Informationen zu diesen Themen finden Sie unter:
M:N-Anwender-Redundanz erfordert, dass die primären und Backup-BNGs dieselben Protokollversionen für DHCP und VRRP unterstützen. Wenn die Protokollunterstützung zwischen den BNGs unterschiedlich ist, können unerwünschte Nebenwirkungen auftreten.
Dual-Stack-Redundanz Abonnenten haben die VRRP-Konfigurationsanforderung. Sie müssen beide Adressfamilien auf der Zugriffsschnittstelle konfigurieren, da Dual-Stack-Abonnenten zwei Sitzungen benötigen, jeweils eine für IPv4 und IPv6. Sie müssen auch dieselbe primäre VRRP-Rollenpriorität für die IPv4- und IPv6-Sitzungen für eine bestimmte Redundanzgruppe konfigurieren, da sie dieselbe logische Schnittstelle verwenden.
- Konfigurieren der Redundanz für Teilnehmergruppen
- Konfigurieren Sie VRRP zur Unterstützung von M:N-Redundanz
Konfigurieren der Redundanz für Teilnehmergruppen
So konfigurieren Sie die Redundanz von Anwendergruppen auf einem BNG:
Konfigurieren Sie VRRP zur Unterstützung von M:N-Redundanz
So konfigurieren Sie VRRP zur Unterstützung von M:N-Redundanz für eine Anwender-Redundanz-Gruppe auf einem BNG:
Konfigurieren der M:N-Anwenderredundanz mit Pseudowires und DHCP-Bindungssynchronisierung
M:N-Anwender-Redundanz mit Pseudowires und DHCP-Bindungssynchronisierung erfordert, dass Sie redundante Anwender-Gruppen konfigurieren, um die Abonnenten anzugeben, die Teil des Primär-/Sicherungsvorgangs sind.
M:N-Anwender-Redundanz mit Pseudowires funktioniert in einem IP/MPLS-Netzwerk, wobei Pseudowire-Tunnel von einem Zugriffsknoten (z. B. einem Switch) die L2-Circuits zu den Primär- und Backup-BNGs bilden, die als DHCP-Relais-Agenten fungieren. Diese Konfigurationen liegen außerhalb des Rahmens dieser Dokumentation.
In diesem Thema werden nur die grundlegenden Konfigurationen beschrieben, die für die M:N-Anwender-Redundanz auf den BNGs erforderlich sind, die die Peer-DHCP-Relay-Agents hosten. Er beschreibt nicht jeden Aspekt der folgenden Punkte: globale Verwaltung von Anwendern, DHCP-Relay-Agents oder DHCP-Leasequery. Er beschreibt nicht, wie Sie Ihr IP/MPLS-Netzwerk, den Zugriffsknoten, der die L2-Circuits zu den DHCP-Relay-Agenten erstellt, oder die Pseudowire-Tunnel konfigurieren. Weitere Informationen zu diesen Themen finden Sie unter:
M:N-Anwender-Redundanz erfordert, dass die primäre und die Backup-BNGs dieselben Protokollversionen für DHCP unterstützen. Wenn die Protokollunterstützung zwischen den BNGs unterschiedlich ist, können unerwünschte Nebenwirkungen auftreten.
Konfigurieren der Redundanz für Teilnehmergruppen
So konfigurieren Sie die Redundanz von Anwendergruppen auf einem BNG:
Sie können z. B. Folgendes auf einem BNG konfigurieren:
[edit system services subscriber-management redundancy] user@host# set protocol pseudo-wire user@host# set interface ps2.0 local-inet-address 10.80.1.2 user@host# set interface ps2.0 local-inet6-address 2001:db8:: user@host# set interface ps2.0 shared-key pskey-2.0-abc-215 user@host# set interface ps3.0 local-inet-address 10.10.0.1 user@host# set interface ps3.0 local-inet6-address 2001:db8:ff:f8:: user@host# set interface ps3.0 shared-key pskey-3.0-def-43 user@host# set no-advertise-routes-on-backup
Konfigurieren Sie dann Folgendes auf einem Peer-BNG. Beachten Sie, dass ps5.0 auf dieser BNG den gleichen Schlüssel hat wie ps2.0 auf der anderen. Das bedeutet, dass ps2.0 und ps5.0 die zugehörigen Zugriffsschnittstellen für Pseudowire-Redundanz sind. Ebenso haben die zugehörigen Schnittstellen ps3.0 und ps4.0 denselben gemeinsamen Schlüssel.
[edit system services subscriber-management redundancy] user@host# set protocol pseudo-wire user@host# set interface ps4.0 local-inet-address 10.55.3.0 user@host# set interface ps4.0 local-inet6-address 2001:db8:1C:44:: user@host# set interface ps4.0 shared-key pskey-3.0-def-43 user@host# set interface ps5.0 local-inet-address 10.60.20.1 user@host# set interface ps5.0 local-inet6-address 2001:db8:01:10:cd:: user@host# set interface ps5.0 shared-key pskey-2.0-abc-215 user@host# set no-advertise-routes-on-backup
Tabellarischer Änderungsverlauf
Die Unterstützung der Funktion hängt von der Plattform und der Version ab, die Sie benutzen. Verwenden Sie den Feature-Explorer , um festzustellen, ob eine Funktion auf Ihrer Plattform unterstützt wird.