本页内容
解决方案架构
上一节中描述的三个交换矩阵(前端、GPU 后端和存储后端)在整个 AI JVD 解决方案架构中互连在一起,如图 2 所示。
图 2:AI JVD 解决方案架构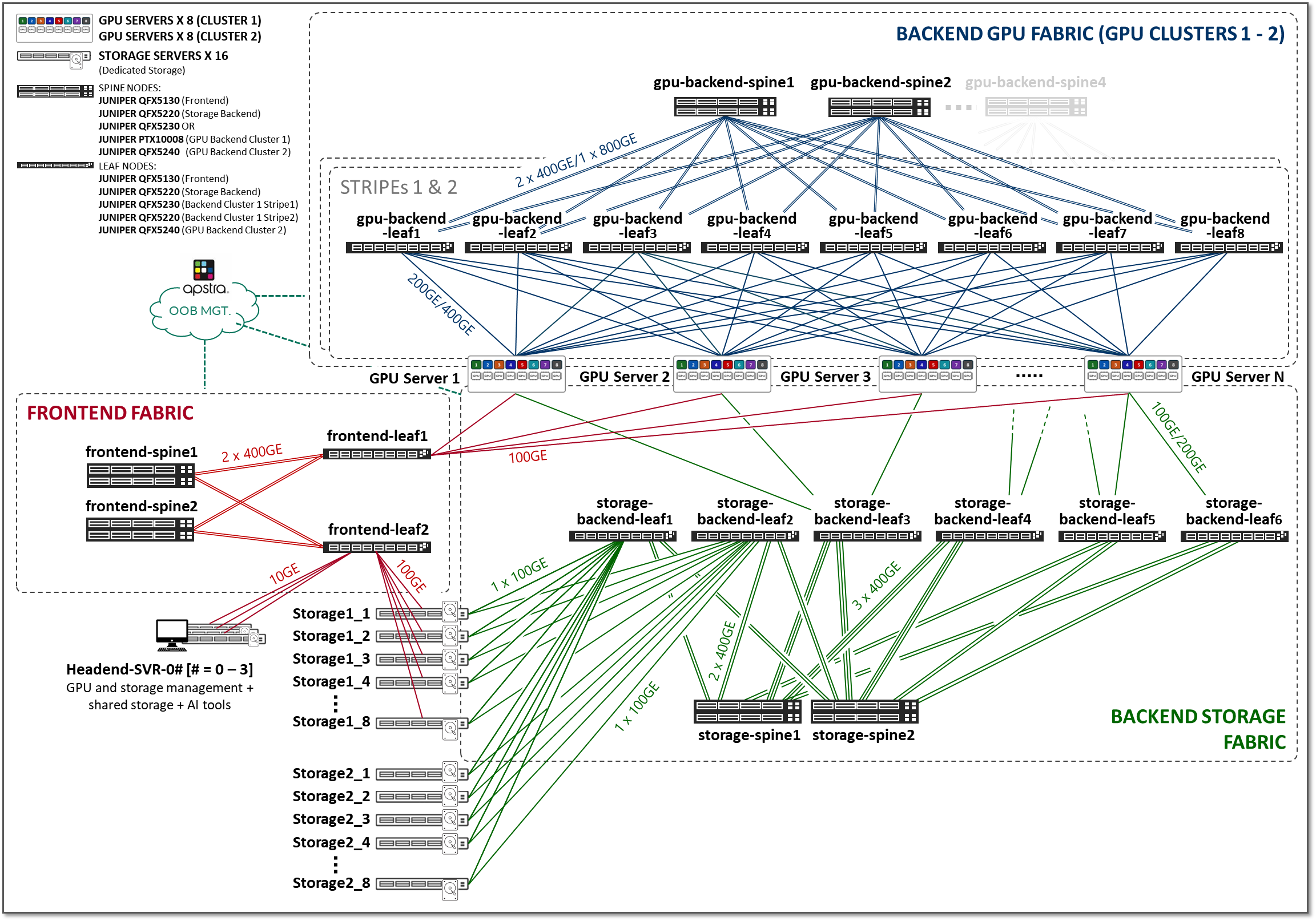
前端交换矩阵
有关将 Nvidia A100 和 H100 GPU 服务器以及 Weka 存储设备连接到 前端交换矩阵的详细信息,请参阅 具有 Juniper Apstra、NVIDIA GPU 和 Weka 存储的 AI 数据中心 网络的前端交换矩阵部分 - 瞻博网络验证设计 (JVD)。
有关将 AMD MI300x GPU 服务器连接到前端交换矩阵的详细信息,请参阅具有 Juniper Apstra、AMD GPU 和 Vast Storage 的 AI 数据中心 Network 的前端交换矩阵部分 - 瞻博网络验证设计 (JVD)。
存储后端交换矩阵
在小型群集中,使用每个 GPU 服务器上的本地存储,或者使用开源或商业软件将此存储聚合在一起可能就足够了。在工作负载较重的大型集群中,需要外部专用存储系统来提供数据集暂存以进行摄取,并在训练期间进行群集检查点。
WEKA 和 Vast Storage 这两个领先的平台为 GPU 环境中的共享存储提供了尖端的解决方案,并已在 AI 实验室中进行了测试。
有关将 Weka 存储设备 连接到 存储后端交换矩阵的详细信息,请参阅具有 Juniper Apstra、NVIDIA GPU 和 WEKA 存储的 AI 数据中心 Network 的存储交换矩阵部分——瞻博网络验证设计 (JVD) 以及同一文档中的 WEKA 存储解决方案 部分。
有关将 VAST 存储设备 连接到 存储后端交换矩阵的详细信息,请参阅具有 Juniper Apstra、AMD GPU 和 VAST 存储的 AI 数据中心 网络的存储交换矩阵部分 - 瞻博网络验证设计 (JVD) 以及同一文档中的 VAST 存储配置 部分。
GPU 后端交换矩阵
GPU 后端交换矩阵使用 RDMA over Converged Ethernet (RoCEv2) 为 GPU 提供基础架构,以便在群集内相互通信。RoCEv2 可提高数据中心效率,降低复杂性,并优化高速以太网网络的数据传输。
丢包会严重影响工作完成时间,因此应避免丢包。因此,在设计计算网络基础架构以支持 AI 群集的 RoCEv2 时,关键目标之一是提供近乎无损的交换矩阵,同时还要实现 AI 流量流的最大吞吐量、最小的延迟和最小的网络干扰。ROCEv2 在无损网络上效率更高,从而尽可能缩短工作完成时间。
此 JVD 中的 GPU 后端交换矩阵在设计时充分考虑到了这些目标。
我们构建了两个不同的集群,如图 3 所示,它们共享前端交换矩阵和存储后端交换矩阵,但具有单独的 GPU 后端交换矩阵。每个群集由遵循轨道优化条带架构的两个条带组成,但包括不同的交换机型号(如叶节点和主干节点)以及不同的 GPU 服务器型号。
图 3:AI JVD 实验室群集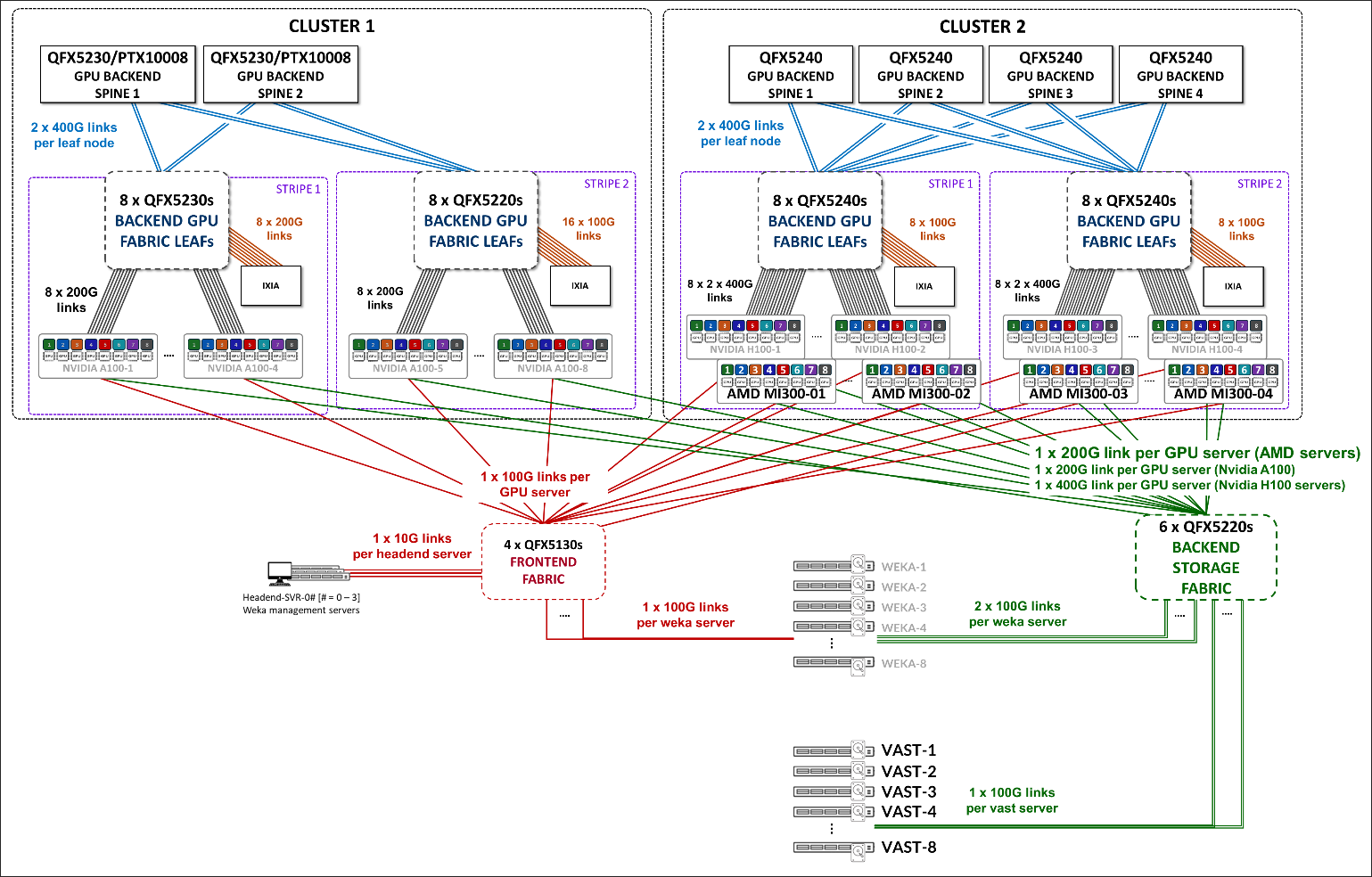
集群 1 中的 GPU 后端包括作为叶节点的 瞻博网络 QFX5220 和 QFX5230 交换机,以及作为主干节点的 QFX5230 交换机或 PTX10008 路由器,以及 NVIDIA A100 GPU 服务器。QFX5230 和 PTX10008 设备已作为主干节点进行独立验证,同时保持相同的叶配置。此群集中的 GPU 后端交换矩阵遵循 3 级 Clos IP 交换矩阵架构。如需了解更多详细信息,请参阅采用 Juniper Apstra、NVIDIA GPU 和 WEKA 存储的 AI 数据中心 网络 — 瞻博网络验证设计 (JVD)。
集群 2 中的 GPU 后端由 瞻博网络 个充当叶交换机和主干节点的 QFX5240 交换机以及 AMD MI300X 和 NVIDIA H100 GPU 服务器组成。此群集支持 3 级 IP 交换矩阵架构或 3 级 EVPN/VXLAN 交换矩阵架构。有关 IP 交换矩阵实施的更多详细信息,请参阅采用 Juniper Apstra、AMD GPU 和 VAST Storage 的 AI 数据中心 网络 — 瞻博网络验证设计 (JVD)。
本文档将重点介绍 基于 EVPN/VXLAN 的 实施。