解决方案架构
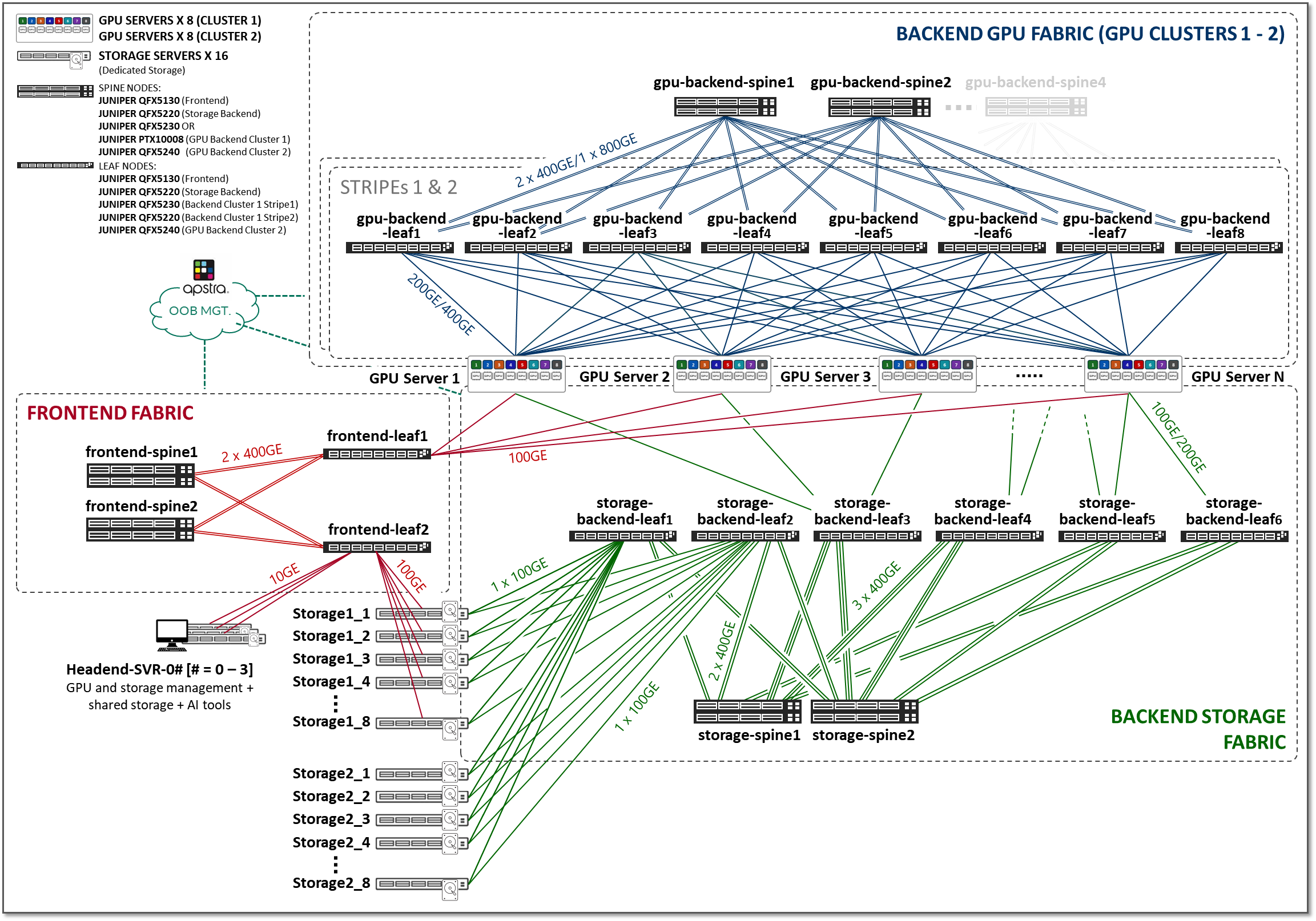
上一节中描述的三个交换矩阵(前端、GPU 后端和存储后端)在图 2 所示的整体 AI JVD 解决方案架构中互连在一起。
图 2:AI JVD 解决方案架构
前端交换矩阵
前端交换矩阵为用户提供了与 AI 系统交互的基础设施,以使用 SLURM、Kubernetes 和其他处理作业调度、资源分配和生命周期管理的 AI 工作流程管理器等工具来编排训练和推理任务工作流程。
这些交互不会产生大量数据流,也不会对延迟或数据包丢失提出严格的要求。因此,控制平面流量不会对交换矩阵提出严格的性能要求。
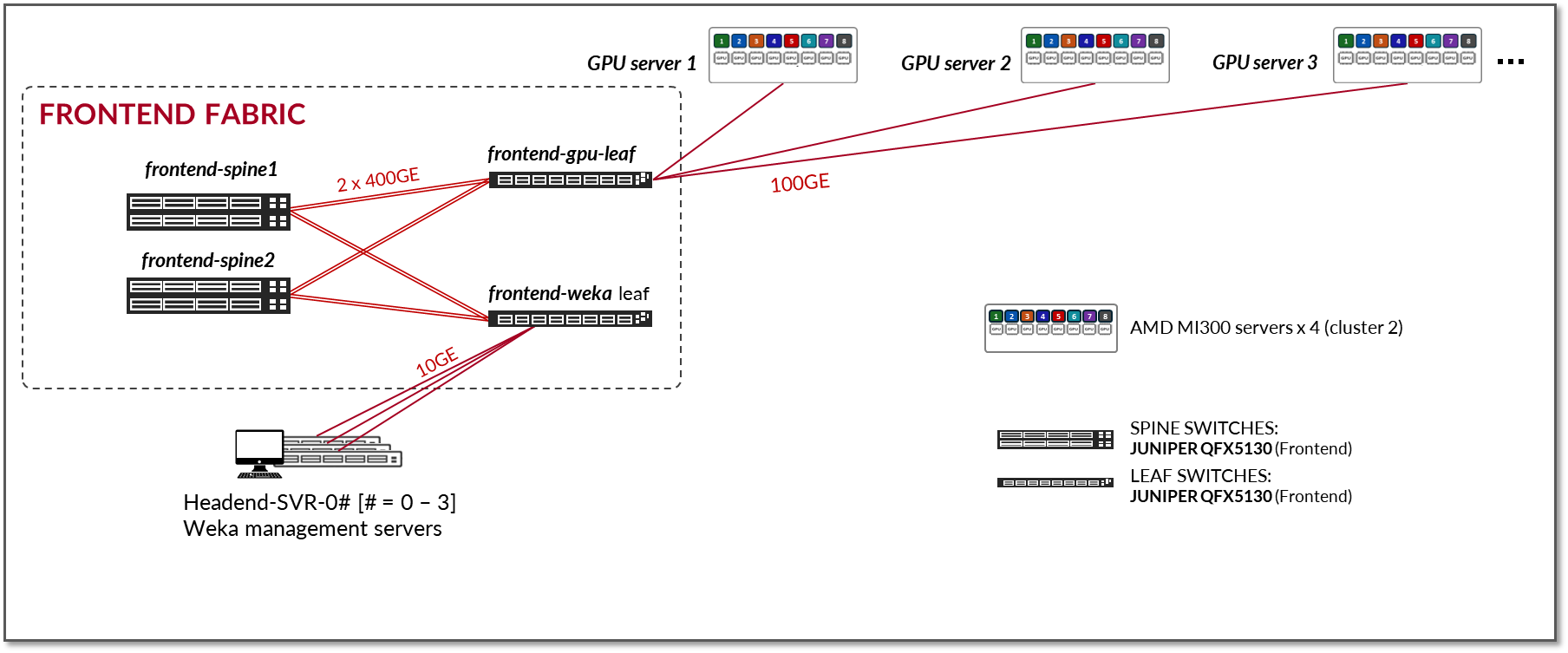
前端交换矩阵设计由一个没有高可用性 (高可用性) 的 3 级 L3 IP 交换矩阵组成,如图 3 所示。该架构为前端所需的连接提供了一个简单有效的解决方案。但是,可以使用包括 EVPN/VXLAN 在内的任何交换矩阵架构。如果需要支持 高可用性的前端交换矩阵,建议您按照 Juniper Apstra JVD 的 3 阶段进行作。
图 3:前端交换矩阵架构
叶节点的数量取决于 AI 群集中的服务器和存储设备的数量,以及用于 AI 作业调度、资源分配和生命周期管理的任何其他设备的数量。
主干节点的数量取决于设计所需的订阅因子。不需要 1:1 订阅系数。对于控制平面流量,适度超额订阅是可以接受的,前提是设计保持弹性并避免影响控制平面稳定性的拥塞。
该交换矩阵是使用 EBGP 进行路由播发的 L3 IP 交换矩阵,具有本文档网络部分中介绍的 IP 寻址和 EBGP 配置详细信息。不需要特殊的负载平衡机制。跨冗余 L3 路径的 ECMP 通常足以满足需求。
鉴于与存储或 GPU 交换矩阵相比,控制平面流量通常不会占用大量带宽,因此严格的 QoS 机制是可选的,仅在与突发非控制流量共享链路时才推荐使用。
下表总结了在此 JVD 中验证的前端交换矩阵中的设备和连接:
表 1:连接到前端交换矩阵的经过验证的管理设备和 GPU 服务器
| AMD GPU 服务器 | 、前端服务器 |
|---|---|
| 美超微 AS-8125GS-TNMR2 AMD Instinct MI300X 192 GB OAM GPU |
Supermicro SYS-6019U-TR4 |
表 2:经过验证的前端交换矩阵叶节点和主干节点
| 前端叶节点 交换机模型 | 前端交换矩阵主干节点 交换机模型 |
|---|---|
| QFX5130-32CD | QFX5130-32CD |
| QFX5220-32CD | QFX5220-32CD |
表 3:前端交换矩阵中前端服务器和叶节点之间经过验证的连接
| 每个 GPU 服务器到叶连接的链接 | 服务器类型 |
|---|---|
| 1 个 10GE | Supermicro SYS-6019U-TR4 |
表 4:前端交换矩阵中 GPU 服务器和叶节点之间的经过验证的连接
| 每个 GPU 服务器到叶连接的链接 | 服务器类型 |
|---|---|
| 1 个 100GE | AMD Instinct MI300X |
表 5:前端交换矩阵中叶节点和主干节点之间的经过验证的连接
| 每个叶和主干连接的链路数 | 叶节点模型 | 主干节点模型 |
|---|---|---|
| 2 个 400GE | QFX5130-32CD | QFX5130-32CD |
该 JVD 的测试是使用 4 台连接到两个叶节点的 AMD Instinct MI300X GPU 服务器执行的,这些服务器又连接到两个主干节点,如图所示:
图 4:前端 JVD 测试拓扑
- GPU 服务器使用 100G 接口(ConnectX-7 NIC)连接到叶节点。
- 大量设备使用 100G 接口连接到叶节点
表 6:聚合前端 GPU 服务器 <=> 前端叶节点链路计数和测试的带宽
| GPU 服务器 <=> 前端叶节点 | 带宽 |
|---|---|
| 100GE 链路数 GPU 服务器 ó 前端叶节点 = 4 (每个服务器 1 个) |
4 个 100GE = 400 Gbps |
| 存储设备 ó 前端叶节点之间的 100GE 链路数 = 8 (每个存储设备 1 个) |
8 个 100GE = 800 Gbps |
| 总带宽 = | 1.0 Tbps |
表 7:聚合前端叶节点 <=> 前端主干节点 链路计数和测试带宽
| 前端叶节点 <=> 前端主干节点带宽 | ||
|---|---|---|
| 前端叶节点和主干节点之间的 400GE 链路数 = 8 (2 个叶节点 x 2 个主干节点 x 每个叶到主干连接 2 个链路) |
8 个 400GE = 3.2 Tbps | |
| 总带宽 = | 3.2 Tbps | |
| 无需逾期订阅 | ||
GPU 后端交换矩阵
GPU 后端交换矩阵使用 RDMA over Converged Ethernet (RoCEv2) 为 GPU 提供基础架构,以便在群集内相互通信。RoCEv2 可提高数据中心效率,降低复杂性,并优化高速以太网网络的数据传输。
与前端交换矩阵不同,GPU 后端交换矩阵传输带宽 密集型和延迟敏感型数据平面流量。数据包丢失、过度延迟或抖动会严重影响工作完成时间,因此必须避免。
因此,GPU 后端交换矩阵的主要设计目标之一是提供 近乎无损的以太网交换矩阵,同时为 GPU 到 GPU 流量提供 最大吞吐量、最小延迟和最小网络干扰 。RoCEv2 在丢包量最小的环境中运行效率最高,直接有助于缩短作业完成时间。
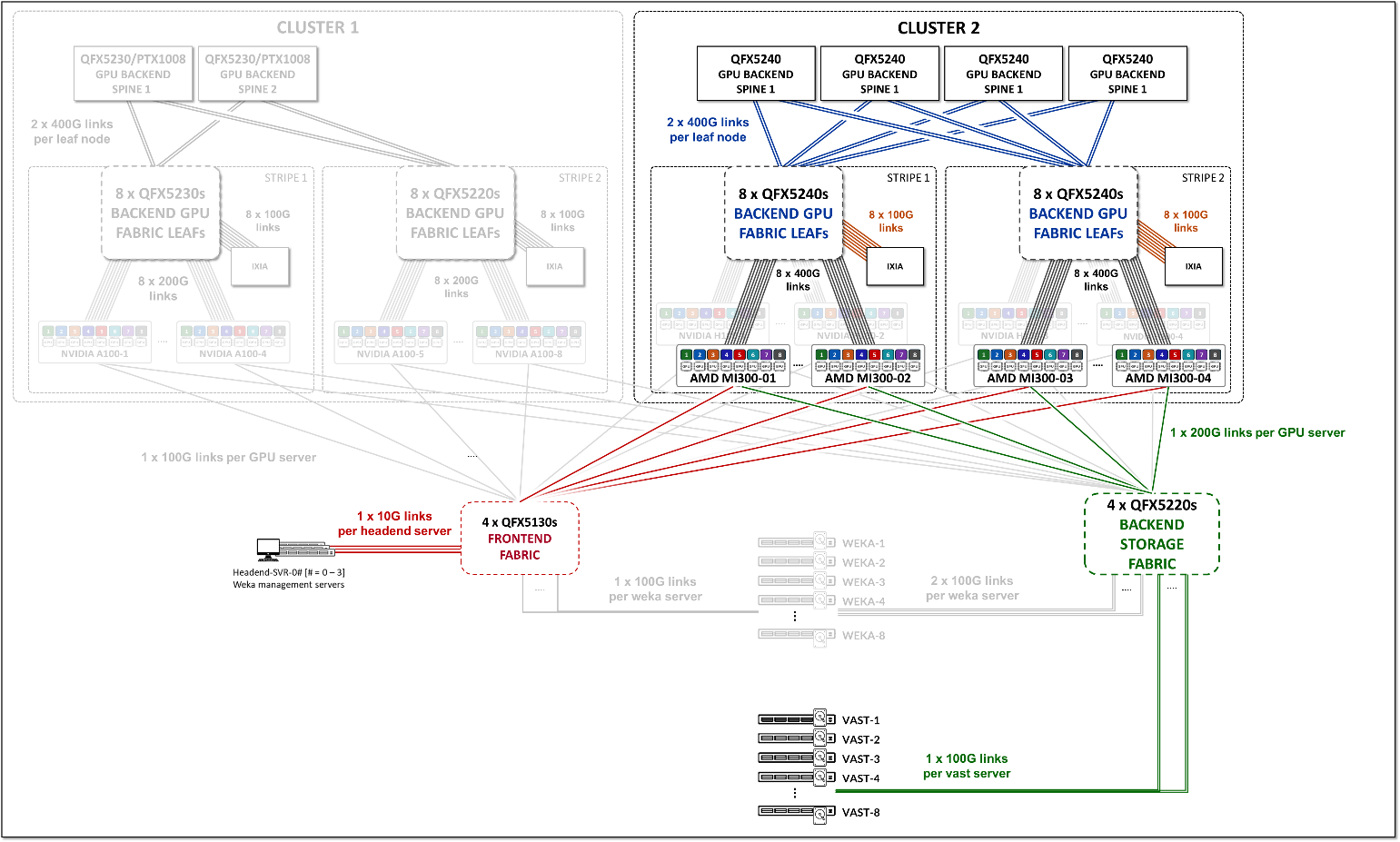
此 JVD 中的 GPU 后端交换矩阵旨在满足这些要求。该设计遵循 3 级 IP Clos、 轨道优化条带架构,如图 5 所示。有关轨道优化条带架构的详细信息将在后面的部分中介绍。
图 5:GPU 后端交换矩阵架构
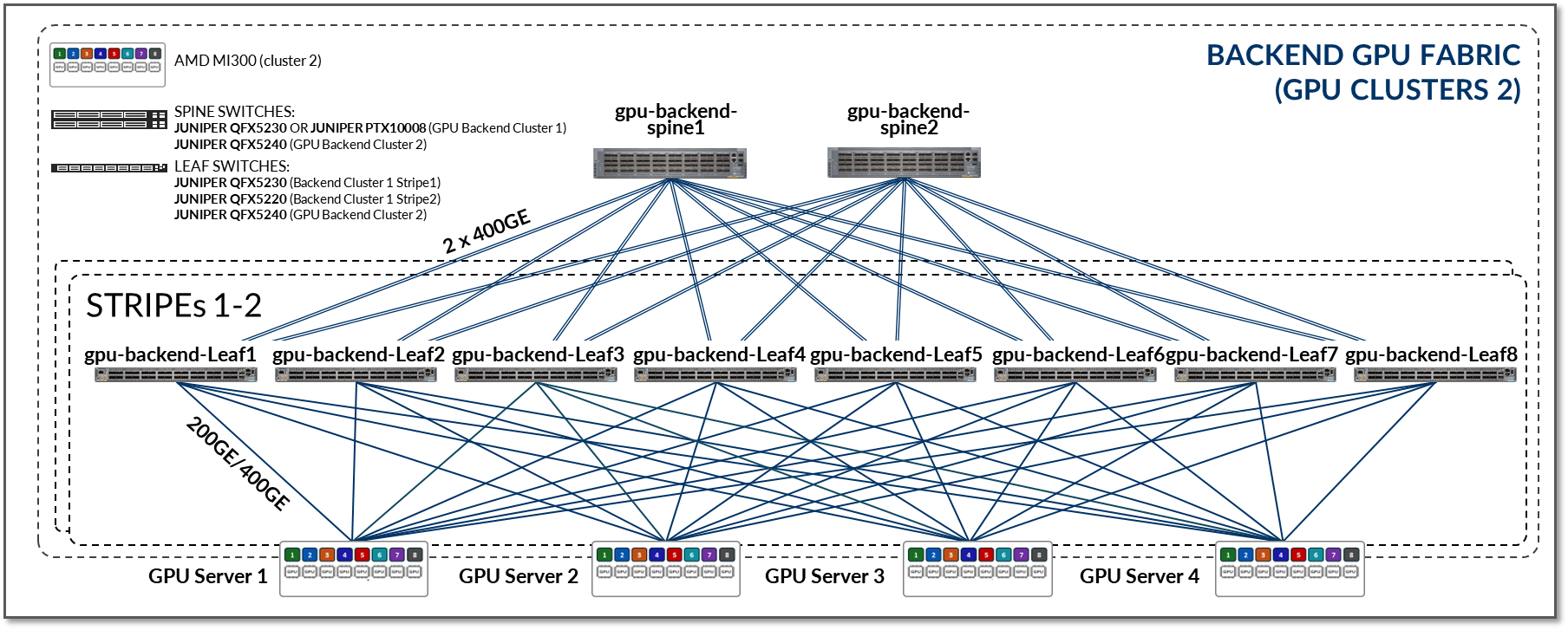
该交换矩阵作为 L3 IP 交换矩阵运行,使用 EBGP 进行路由播发,并具有 IP 寻址和 EBGP 配置详细信息,如本文档的网络部分所述。
在轨道优化架构中, 叶节点 的数量由每台服务器的 GPU 数量决定,对于此 JVD 中包含的 AMD 服务器,叶节点数量为 8 个。 主干节点 的数量以及 GPU 服务器和叶节点之间以及叶节点和主干节点之间的链路速度和数量决定了 GPU 后端交换矩阵的 有效带宽 和 超额订阅特征 。
与 前端交换矩阵相比, GPU 后端交换矩阵 通常以 非超额订阅 (1:1) 设计或非常低的超额订阅率为目标。这样可以确保为同时进行的集体作提供足够的带宽,并防止可能导致数据包丢失或延迟变化的拥塞。
该交换矩阵是使用 EBGP 进行路由播发的 L3 IP 交换矩阵,具有本文档网络部分中介绍的 IP 寻址和 EBGP 配置详细信息。GPU 后端交换矩阵内的流量分配依赖于跨多个等价 L3 路径的 ECMP,并结合使用动态负载平衡 (DLB)、全局负载平衡和自适应负载平衡 (ALB) 等高级负载平衡技术。本文档的负载平衡部分对这些进行了描述。
由于 GPU 后端交换矩阵传输对丢失和延迟敏感的 RoCEv2 流量,因此该设计结合了 DCQCN(数据中心量化拥塞通知),它利用 ECN(显式拥塞通知),并且可以选择使用 PFC(优先流控制),以实现 RDMA 流量的无损或近无损行为。本文档的服务等级部分详细介绍了这些机制。
下表总结了在此 JVD 中验证的前端交换矩阵中的设备和连接:
表 8:连接到 GPU 后端交换矩阵的经过验证的管理设备和 GPU 服务器
| GPU 服务器、 | 存储设备 | 、前端服务器 |
|---|---|---|
| 美超微 AS-8125GS-TNMR2 AMD Instinct MI300X 192 GB OAM GPU |
|
Supermicro 系统-6019U-TR4 |
表 9:经过验证的 GPU 后端交换矩阵叶节点
| GPU 后端交换矩阵叶节点交换机型号 |
|---|
| QFX5220-32CD |
| QFX5230-64CD |
| QFX5240-64OD |
| QFX5241-64OD |
表 10:经过验证的 GPU 后端交换矩阵主干节点
| GPU 后端主干交换矩阵节点交换机型号 |
|---|
| QFX5230-64CD |
| QFX5240-64OD |
| QFX5241-64OD |
| PTX10008 LC1201 |
| PTX10008 LC1301 |
表 11:GPU 服务器与 GPU 后端交换矩阵中叶节点之间的已验证连接
| 每个 GPU 服务器到叶连接的链接 | 服务器类型 |
|---|---|
| 每个 GPU 服务器到叶连接的 1 个 400GE 链路 | AMD MI300 |
表 12:GPU 后端交换矩阵中叶节点和主干节点之间的已验证连接
| 每个叶和主干连接的链路数 | 叶节点模型 | 主干节点模型 |
|---|---|---|
| 1 个 400GE | QFX5220-32CD | QFX5230-32CD |
| 1 个 400GE | QFX5230-32CD | QFX5230-32CD |
| 2 个 400GE | QFX5240-64OD | QFX5240-64OD |
| 1 个 800GE | QFX5240-64OD | QFX5240-64OD |
| 1 个 400GE | QFX5220-32CD | PTX10008 LC1201 |
| 1 个 400GE | QFX5230-32CD | PTX10008 LC1201 |
| 1 个 800GE | QFX5240-64OD | PTX10008 LC1301 |
| 2 个 800GE | QFX5240-64OD | PTX10008 LC1301 |
此 JVD 的测试是使用 4 台连接到两个条带的 MI300 GPU 服务器执行的,如下所示:
图 6:GPU 后端 JVD 测试拓扑结构
- 每个 AMD MI300X GPU 服务器都使用 400G 接口(Thor2 和 Pollara NIC)连接到叶节点。
validated_optics_summary.html#Toc222928841__DAC_5m使用 Broadcom Thor2 卡进行测试并如下图所示进行连接。
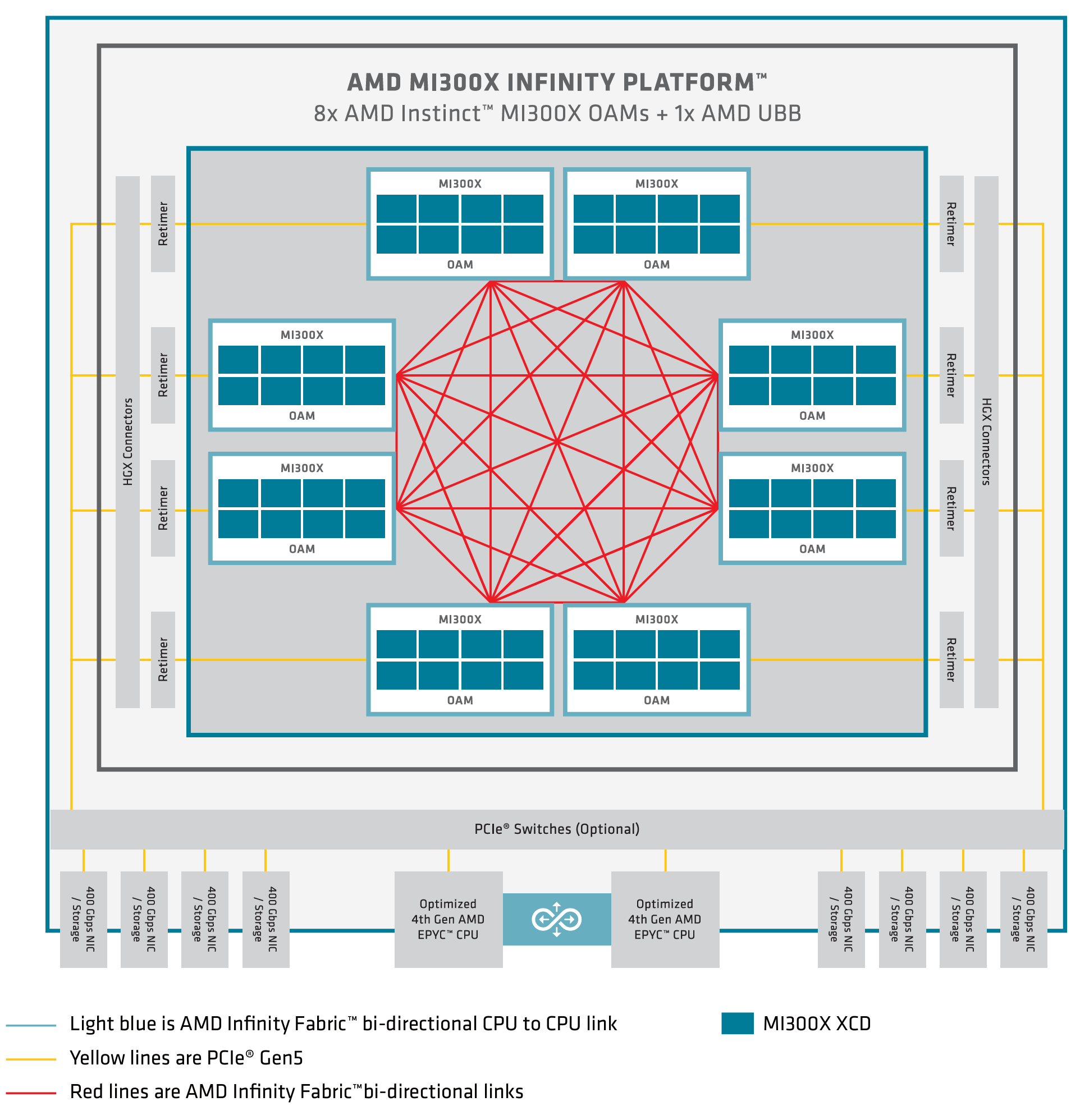
表 13:每条带服务器到叶带宽
| 条纹 | 服务器数量 每条带 |
服务器数量 <=每台服务器 > 个叶链路 (每台服务器的叶节点数和 GPU 数) |
服务器 <=> 叶链路带宽 [Gbps] |
服务器总数 <=> 个叶链路 每条带的带宽 [Tbps] |
|---|---|---|---|---|
| 1 | 2 MI300 | 8 | 400 Gbps | 2 x 8 x 400 Gbps = 6.4 Tbps |
| 2 | 2 MI300 | 8 | 400 Gbps | 2 x 8 x 400 Gbps = 6.4 Tbps |
| 服务器总<=> 分叶带宽 | 12.8 Tbps | |||
表 14:每条带的叶脊到主干带宽(QFX5240为分叶和主干)
| 条纹 | 数量 叶节点 |
主干节点数量 | 数量 400 Gbps 叶 <=> 主干链路 每叶节点 |
服务器 <=> 叶式 链路带宽 [Gbps] |
带宽 分叶 <=每条带 > 主干 [Tbps] |
|---|---|---|---|---|---|
| 1 | 8 | 4 | 2 | 400 | 8 x 2 x 2 x 400 Gbps = 12.8Tbps |
| 2 | 8 | 4 | 2 | 400 | 8 x 2 x 2 x 400 Gbps = 12.8Tbps |
| 服务器总<=> 分叶带宽 | 25.6 Tbps | ||||
GPU 后端交换矩阵订阅系数
订阅系数是通过比较上两个表格中的数字来简单计算的:
在 JVD 测试环境中,服务器和叶节点之间的带宽为每个条带 6.4 Tbps,而叶节点和主干节点之间的可用带宽为每个条带 12.8 Tbps。这意味着即使该流量是 100% 条带间流量,交换矩阵也有足够的容量来处理 GPU 之间的所有流量,同时仍有额外的容量来容纳其他服务器,而不会出现超额订阅。本例中的订阅系数为 1:2。
图 7:1:2 订阅系数(超额配置)
为了运行超额订阅测试,禁用了叶节点和主干之间的某些接口,从而减少了可用带宽,如图 8 中的示例所示:
图 8: 1:1 订阅系数
此外,模拟 RoCEv2 设备的 Ixia 流量生成器也连接到了交换矩阵,如图 9 中的示例所示。
图 9:1:1 订阅系数
这会为条带 1 和 2 上的叶 2 和 4 额外增加 800G 的流量。
GPU 到 GPU 之间的通信优化
轨道优化拓扑中的优化是指如何管理 GPU 通信以最大限度地减少拥塞和延迟,同时最大限度地提高吞吐量。此优化策略的一个关键部分是尽可能保持流量本地。通过确保 GPU 通信保持在同一轨或条带内,甚至在服务器内,可以减少遍历主干或外部链路的需要,从而降低延迟、最大程度地减少拥塞,并提高整体效率。
虽然本地化流量是优先的,但在较大的 GPU 群集中将需要条间通信。通过可用链路上的适当路由和平衡技术来优化条带间通信,以避免瓶颈和数据包丢失。
优化的本质在于利用拓扑结构沿着最短和最不拥塞的路径引导流量,即使在网络扩展时也能确保性能的一致性。相同服务器上的 GPU 之间的流量可以通过内部服务器交换矩阵(取决于供应商)本地转发,而不同服务器上的 GPU 之间的流量则发生在外部 GPU 后端基础架构中。不同服务器上的 GPU 之间的通信可以是轨内通信,也可以是轨间/条间通信。
轨内流量在本地叶节点上进行交换(在第 2 层处理)。按照这种设计,不同服务器上的 GPU 之间(但在同一条带中)的数据始终在同一轨道上跨一台交换机移动。这样可以保证 GPU 之间的 1 跳点间隔,并将创建单独的独立高带宽通道,从而最大限度地减少争用并最大限度地提高性能。另一方面,轨间/条带间流量通过叶节点上的 IRB 接口和连接叶节点的主干节点进行路由(在第 3 层处理)。
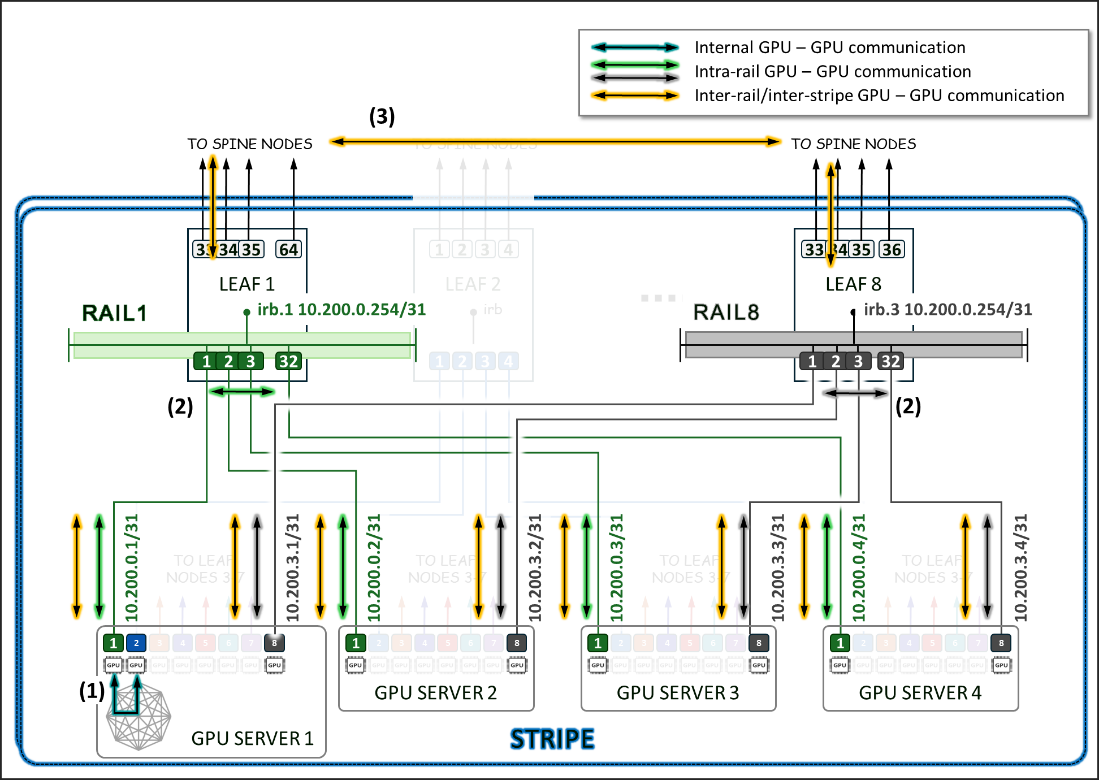
考虑图 10 中描述的示例
- 服务器 1 中的 GPU 1 和 GPU 2 之间的通信通过服务器的内部交换矩阵进行 (1),
- 服务器 1-4 中的 GPU 1 之间和服务器 1-4 中的 GPU 8 之间的通信分别发生在叶 1 和叶 8 上 (2),并且
- GPU 1 和 GPU 8(在服务器 1-4 中)之间的通信发生在 leaf1、主干节点和 leaf8 之间 (3)
图 10:轨间与轨内 GPU-GPU 通信
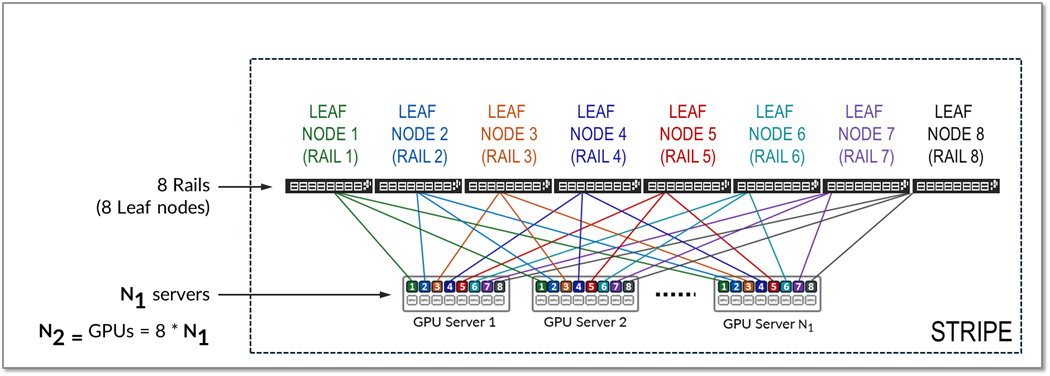
图 10 表示了一个拓扑结构,其中一条 条带 和 8 条 轨道分别跨叶交换机 1-8 连接 GPU 1-8。
服务器 1 中的 GPU 7 和 GPU 8 之间的通信通过内部交换矩阵进行,而服务器 1 中的 GPU 1 与服务器 N1 中的 GPU 1 之间的通信通过叶交换机 1(在同一轨道内)进行。
请注意,如果需要不同条带中的 GPU 和不同服务器之间进行任何通信(例如,服务器 1 中的 GPU 4 与服务器 N1 中的 GPU 5 进行通信),则首先将数据移动到与目标 GPU 位于同一轨道中的 GPU 接口,从而将数据发送到目标 GPU,而无需跨越轨道。
按照这种设计,不同服务器上的 GPU 之间(但采用相同条带)的数据始终在同一轨道上通过单个交换机移动,这可以保证 GPU 彼此之间相距 1 跳,并创建单独的独立高带宽通道,从而最大限度地减少争用并最大限度地提高性能。
在 AMD GPU 服务器上,GPU 通过 AMD Infinity 交换矩阵互连,该交换矩阵在单个服务器内提供 7x128GB/s GPU 到GPU 高带宽、低延迟和双向 GPU 对 GPU 通信,如图 11 所示。
图 11.AMD MI300X 架构。
有关更多详细信息,请参阅 AMD Instinct™ MI300 系列微架构 — ROCm 文档
AMD MI300X GPU 利用无限交换矩阵,在 GPU、CPU 和其他组件之间提供高带宽、低延迟的通信。这种互连可以动态管理跨链路的流量优先级,为节点内的通信提供优化路径。
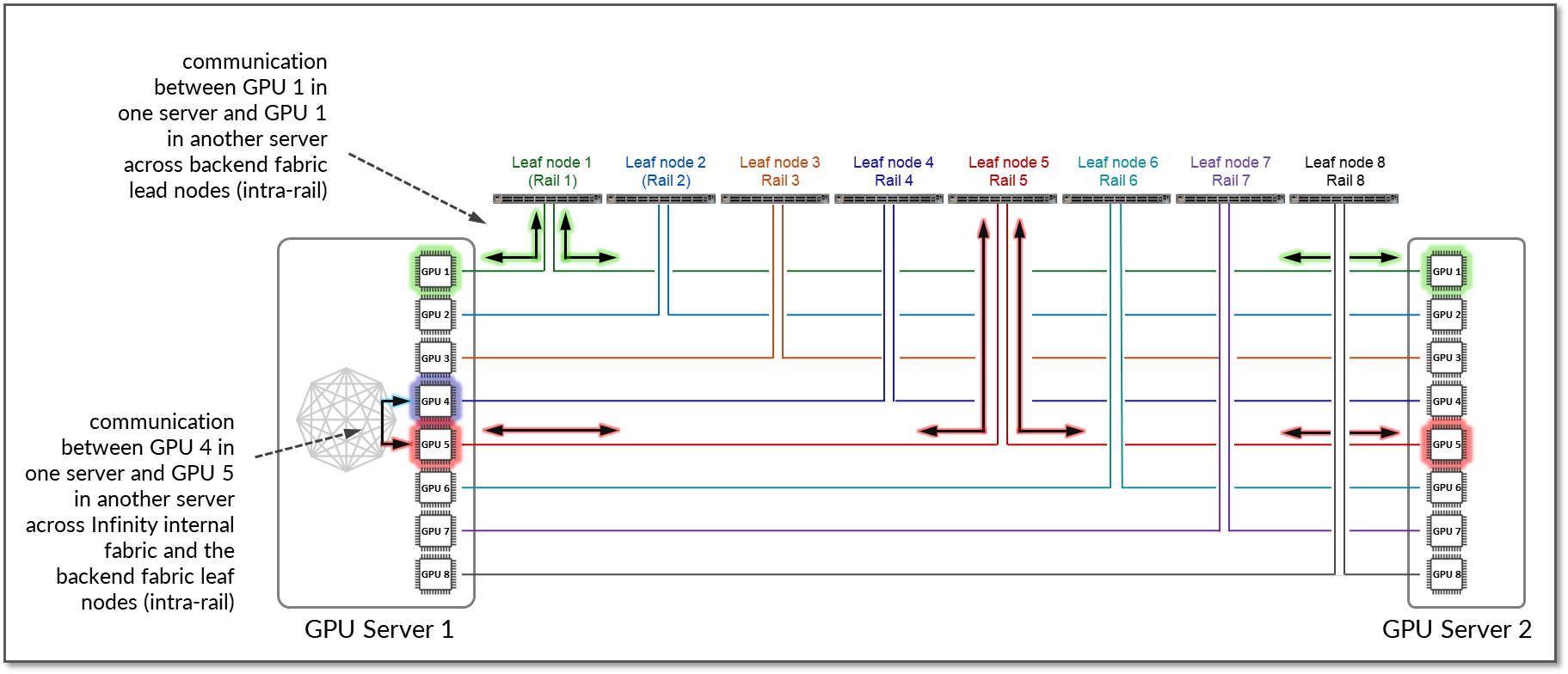
默认情况下,AMD MI300X 设备实现本地优化,以最大限度地减少 GPU 到 GPU 流量的延迟。同一服务器上的 GPU 之间的通信将通过 Infinity 交换矩阵进行转发,并保持在节点内,并且不会遍历外部以太网交换矩阵。跨多个服务器的相同等级的 GPU 之间的流量保持条带内。
图 12 显示了服务器 1 中的 GPU1 与服务器 2 中的 GPU1 通信的示例。流量由叶节点 1 转发,并保留在轨道 1 内。
此外,如果服务器 1 中的 GPU4 想要与服务器 2 中的 GPU5 通信,并且服务器 1 中的 GPU5 可作为 AMD Infinity 交换矩阵中的本地跃点使用,则流量自然更喜欢这条路径来优化性能并将 GPU 到 GPU 之间的通信保持在轨道内。
图 12:具有 局部优化的两台服务器之间的 GPU 到 GPU 轨间通信。
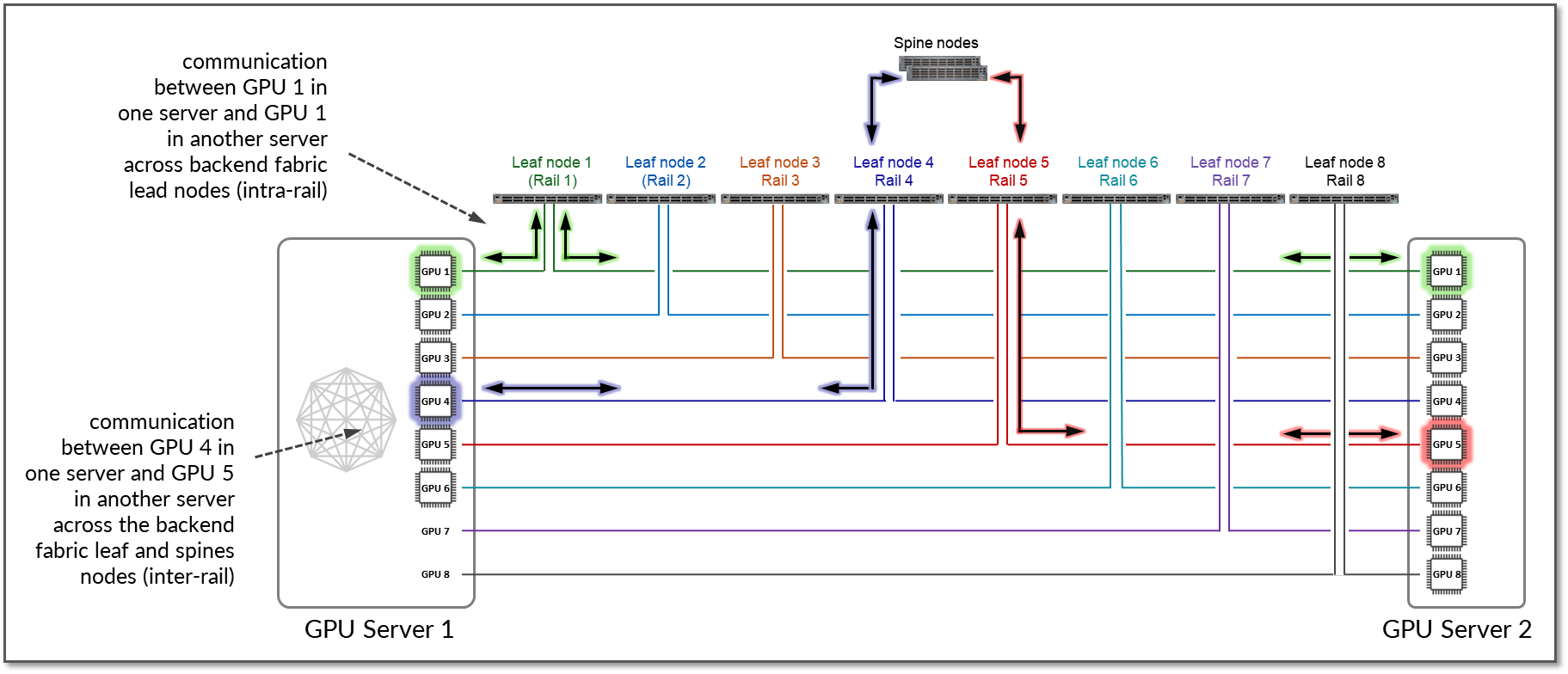
例如,如果由于工作负载限制而无法进行本地优化,则流量必须绕过本地跃点(内部交换矩阵)并使用 RDMA(基于节点外 NIC 的通信)。在这种情况下,服务器 1 中的 GPU4 与服务器 2 中的 GPU5 通信,方法是使用 RDMA 直接通过NIC发送数据,然后通过交换矩阵转发数据,如图 13 所示。
图 13:两台服务器之间 没有局部优化的 GPU 到 GPU 轨间通信。
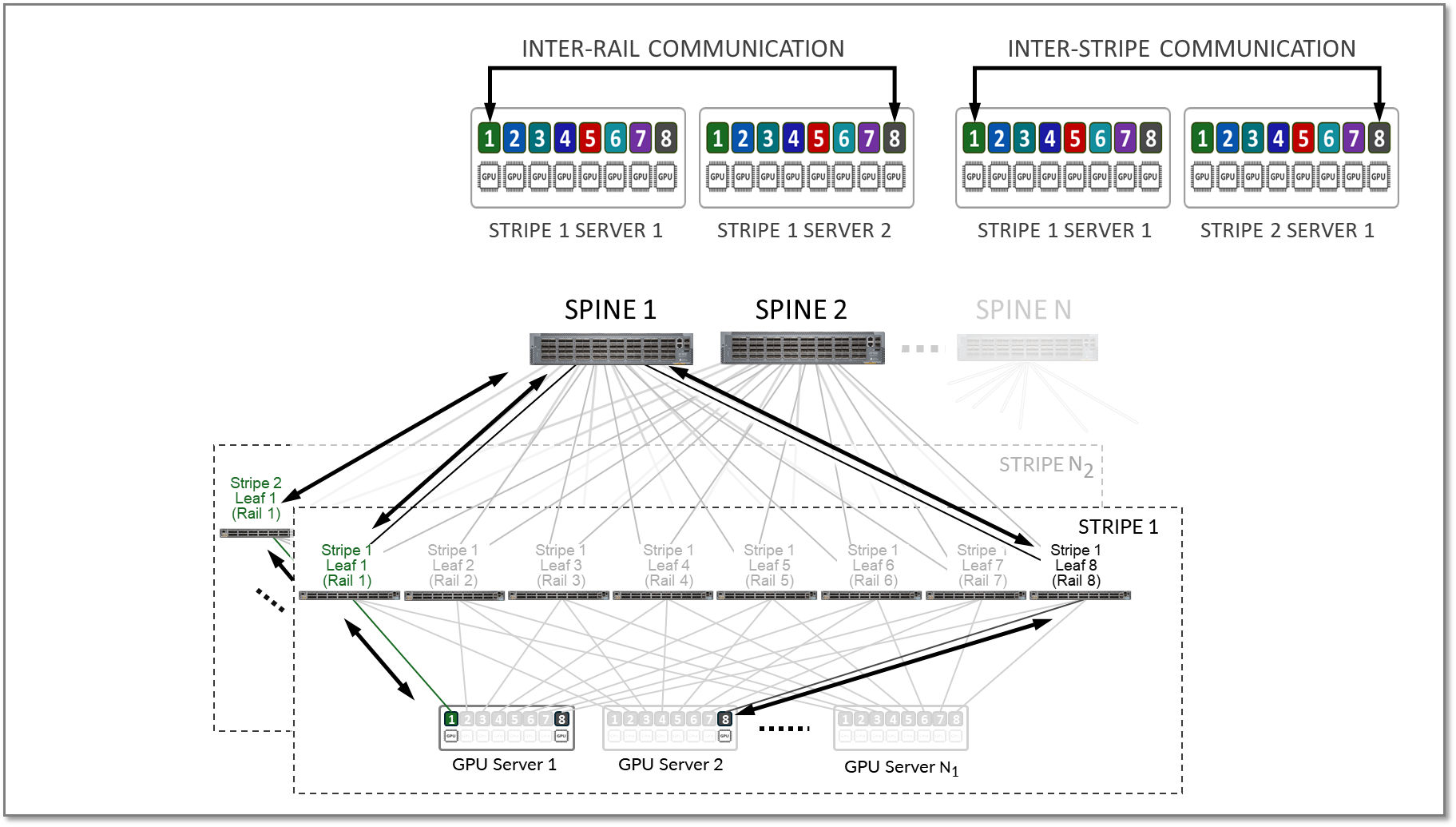
该示例显示,服务器 1 中的 GPU 4 和服务器 N1 中的 GPU 5 之间的通信跨叶交换机 1、主干节点和叶交换机 5(在两个不同的轨道之间)进行。
后端 GPU 轨道优化架构
如前所述,轨道优化条带架构可在 GPU 之间提供高效的数据传输,尤其是在计算密集型任务(例如 AI 大型语言模型 (LLM) 训练工作负载)期间,在这些任务中,需要无缝数据传输才能在合理的时间内完成任务。轨道优化拓扑旨在通过提供最小的带宽争用、最小的延迟和最小的网络干扰来最大限度地提高性能,从而确保数据可以在网络中高效且可靠地传输。
在轨道优化架构中,有两个重要概念: 轨道 和 条带。
服务器上的 GPU 编号为 1-8,其中数字代表 GPU 在服务器中的位置,如图 14 所示。此数字有时称为 “排名 ”,或者更具体地说,与 GPU 所在的服务器中的 GPU 相关的“本地排名”,或者与分配给单个作业的所有 GPU(在多个服务器中)相关的“全局排名”。
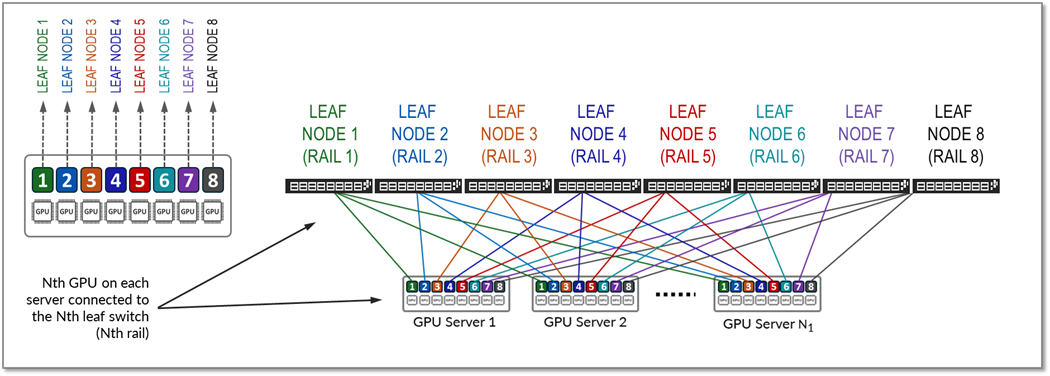
轨道跨交换矩阵中的一个叶节点连接相同顺序的 GPU;也就是说,轨道 Nth 将所有服务器上位置 N 位的所有 GPU 连接到叶节点 Nth,如图 14 所示。
图 14:轨道优化架构中的轨道
条带是指由多个轨道组成的设计模块或构建块,包括叶节点和 GPU 服务器,如图 15 所示。可以复制此构建块以纵向扩展 AI 群集。
图 15:轨道优化架构中的条带
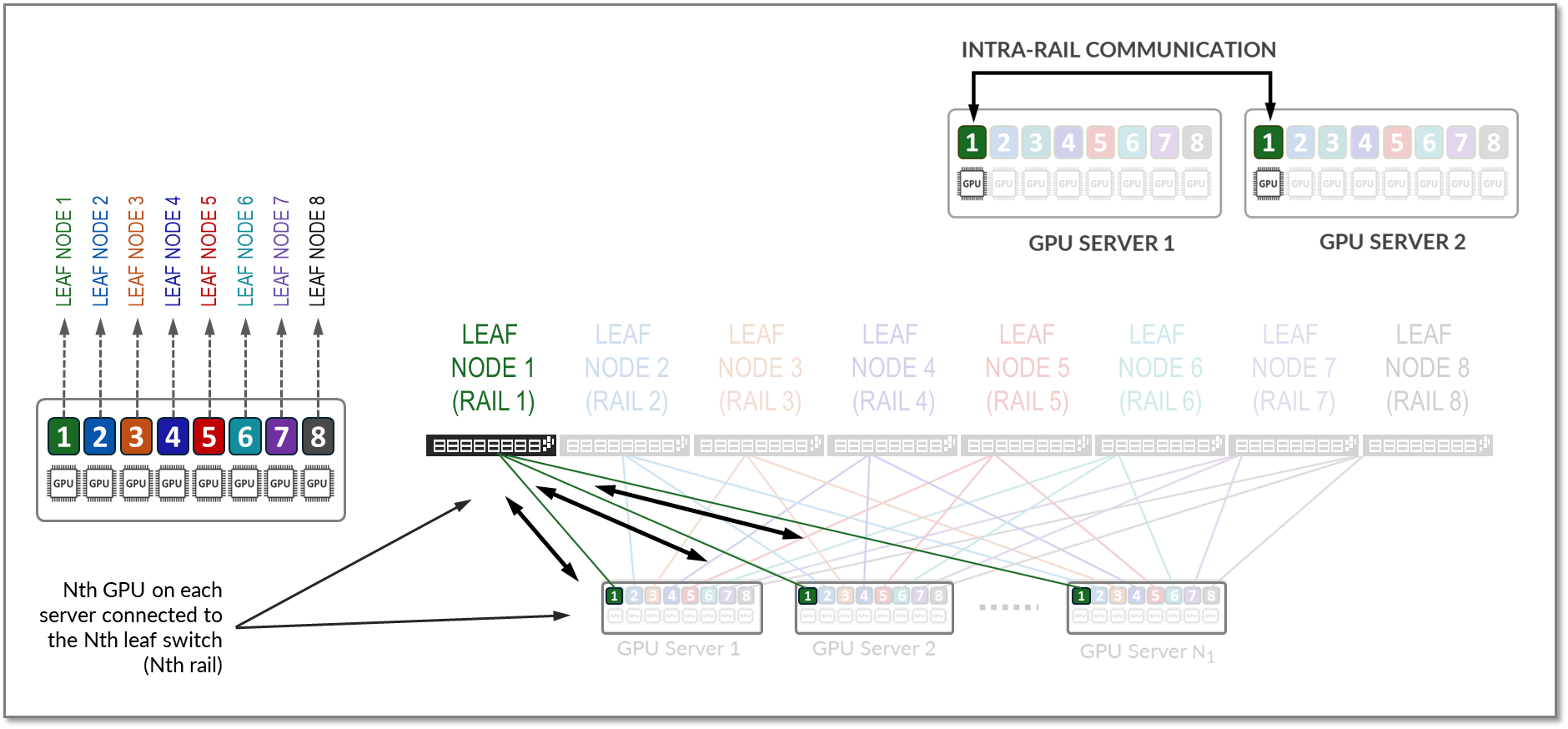
相同等级的 GPU 之间的所有流量(轨内流量)都在叶节点级别转发,如图 16 所示。
图 16:铁路内交通示例。
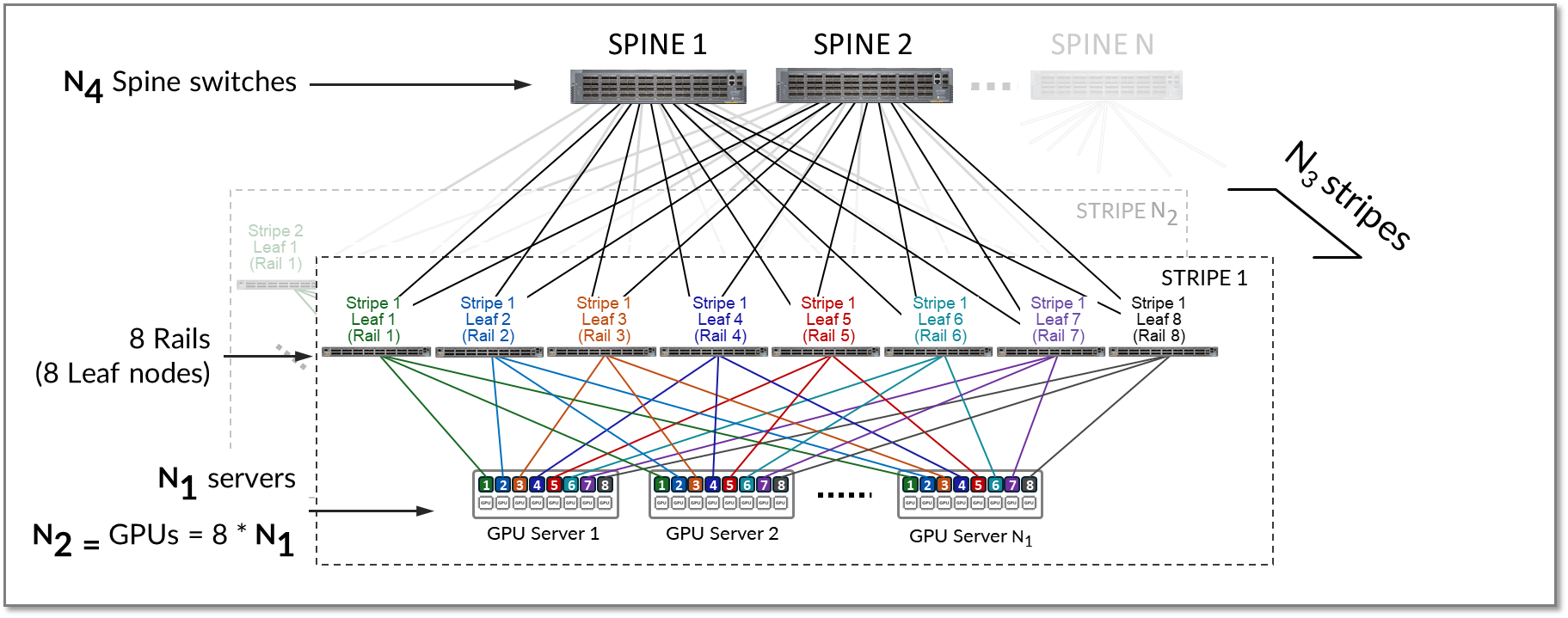
可以复制条带以纵向扩展 AI 群集中的服务器 (N1) 和 GPU (N2) 的数量。然后在主干交换机上连接多个条带(N3),如图17所示。
图 17:通过主干节点连接的多个条带
轨间和条间流量都将跨主干节点转发,如图 18 所示。
图 18.轨道间和条带间 GPU 到 GPU 流量示例。
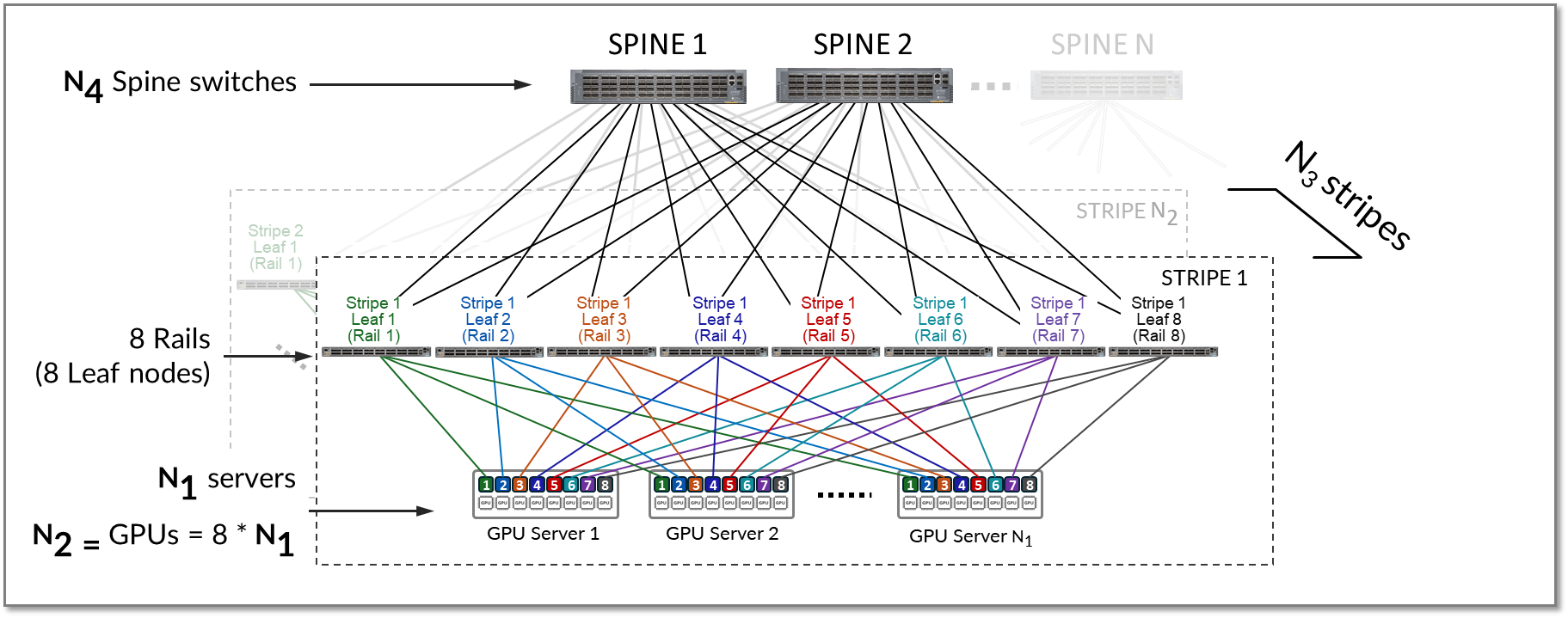
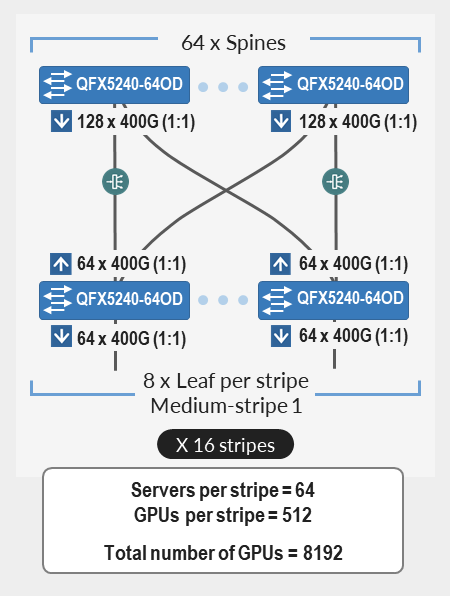
计算轨道优化架构中的叶节点和主干节点、服务器和 GPU 的数量
在轨道优化架构中,单个条带中的 叶节点数 由每台服务器的 GPU 数(轨道数)定义。每台 AMD MI300X GPU 服务器包括 8 个 AMD Instinct MI300X GPU。因此,单个条带包括 8 个叶节点(8 条轨道)。
叶节点数 = GPU 数 x 服务器 = 8
单个条带 (N1) 中支持的最大 服务器数 由叶节点上的 可用端口数 定义,具体取决于交换机型号。
GPU 服务器和叶节点之间的总带宽必须与叶节点和主干节点之间的总带宽相匹配,以保持 1:1 的订阅比。
假设叶节点上的所有接口都以相同的速度运行,则一半接口将用于连接到 GPU 服务器,另一半将用于连接到主干。因此,条带中的 最大服务器数 计算为每个叶节点上 可用端口数的 一半。
图 19.1:1 订阅系数的上行链路和下行链路数量
在图中,X 表示下行链路(叶节点和 GPU 服务器之间的链路)的数量,而 Y 表示上行链路(叶节点和主干节点之间的链路)的数量。要允许 1:1 订阅系数,X 必须等于 Y。
每个叶节点上的 可用端口数 等于 X + Y 或 2 * X。
由于条带中的所有服务器都有一个端口连接到条带中的每个叶,因此条带中的最大服务器数 (N1) 等于 X。
N1(每个条带的最大服务器数)= 可用端口数 ÷ 2
条带中的 最大 GPU 数 是通过简单地将每台服务器的 GPU 数相乘来计算的。
N2(最大 GPU 数)= N1(每个条带的最大服务器数)* 8
可用端口的总数取决于用于叶节点的交换机型号。表 15 显示了一些示例。
表 15:每个条带支持的最大 GPU 数
| 叶节点 QFX 交换机型号 |
每台交换机的可用 400 GE 端口数 | 1:1 订阅中每个条带支持的最大服务器数 (N1) |
每台服务器的 GPU 数 | 每个条带支持的最大 GPU 数 (第2 页) |
|---|---|---|---|---|
| QFX5220-32CD | 32 | 32 ÷ 2 = 16 | 8 | 16 台服务器 x 8 个 GPU/服务器 = 128 个 GPU |
| QFX5230-64CD | 64 | 64 ÷ 2 = 32 | 8 | 32 台服务器 x 8 个 GPU/服务器 = 256 个 GPU |
| QFX5240-64OD QFX5241-64OD |
128 | 128 ÷ 2 = 64 | 8 | 64 台服务器 x 8 个 GPU/服务器 = 512 个 GPU |
- QFX5220-32CD 交换机提供 32 个 400 GE 端口 =>16 个用于连接到服务器,16 个用于连接到主干节点。
- QFX5230-64CD 交换机提供多达 64 个 400 GE 端口 => 32 个用于连接到服务器,32 个用于连接到主干节点。
- QFX5240-64OD 交换机提供多达 128 个 400 GE 端口 => 64 个用于连接到服务器,64 个用于连接到主干节点。
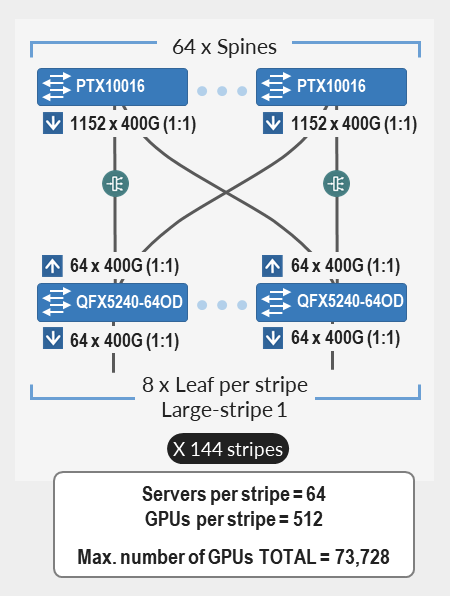
为了实现更大的规模,可以使用一组主干节点 (N4) 连接多个条带 (N3),如图 20 所示。
图 20.跨主干节点连接的多个条带

所需的条带数量 (N3 ) 是根据所需的 GPU 数量和每个条带的最大 GPU 数量 (N2) 计算得出的。
例如,假设 所需的 GPU (GPU) 数量 为 16,000,并且交换矩阵使用 QFX5240-64OD 作为叶节点。
可用 400G 端口 数 为 128,这意味着:
- 每个条带的最大服务器数 (N1) = 64
- 每个条带的最大 GPU 数 (N2) = 512
所需的 条带数 (N3) 通过除以所需的 GPU 数和每个条带的 GPU 数计算得出,如下所示:
N 3(所需的条带数)= GPU ÷ N 2(每个条带的最大 GPU 数)= 16000 ÷ 512 = 32 条带(四舍五入)
- 每个条带有 32 个条带和 64 个服务器,该群集可以提供 16,384 个 GPU。
知道所需的条带数 (N 3) 和每个叶节点的上行链路端口数 (Y),您可以计算出需要多少个主干节点。
记住 X = Y = N1
首先,叶 节点总数 可以通过将 所需的条带数 乘以 8(每个条带的叶节点数)来计算。
叶节点总数 = N3 x 8 = 32 x 8 = 256
然后可以得到上行链路总数乘以每个叶节点的上行链路数(N1)和叶节点总数。
上行链路总数 = N1 x 256 = 64 x 256 = 16384
然后,可以通过将上行链路总数除以每个主干节点上的可用端口数来确定所需的主干数量(N4),就叶节点而言,这取决于用于主干角色的交换机型号。
所需主干数量 (N4 ) = 16384 / 每个主干节点上的可用端口数
例如,如果主干节点为 QFX5240/41,则 每个主干节点上的可用端口数 为 128。
表 16:两个条带的主干节点数。
| 主干节点 QFX 交换机型号 |
每台交换机的最大 400 GE 接口数 | 所需主干数 (N4),带 64 条条带 |
|---|---|---|
| QFX5240-64OD | 128 | 16384 ÷ 128 = 128 |
| PTX10008 LC1201 | 288 | 16384 ÷ 288 ~ 57 |
| PTX10008 LC1301 | 576 | 16384 ÷ 576 ~ 29 |
存储后端交换矩阵
存储后端交换矩阵为可从 GPU 服务器访问的存储设备提供连接基础架构。
存储基础架构的性能显着影响 AI 工作流程的效率。提供快速访问数据的存储系统可以显着减少训练 AI 模型的时间。同样,支持高效数据查询和索引的存储系统可以最大限度地缩短 AI 工作流程中预处理和特征提取的完成时间。
在小型群集中,使用每个 GPU 服务器上的本地存储,或者使用开源或商业软件将此存储聚合在一起可能就足够了。在工作负载较重的大型集群中,需要外部专用存储系统来提供数据集暂存以进行摄取,并在训练期间进行群集检查点。
WEKA 和 Vast Storage 这两个领先的平台为 GPU 环境中的共享存储提供尖端解决方案。虽然我们在实验室中测试了这两种解决方案,但 此 JVD 专注于 Vast Storage 解决方案。因此,本文的其余部分以及本文档中的其他部分将介绍有关 Vast Storage 设备 和与存储后端交换矩阵的连接的详细信息。
有关 WEKA 存储的详细信息包含在配备 Juniper Apstra、NVIDIA GPU 和 WEKA 存储的 AI 数据中心 网络中,瞻博网络验证设计 (JVD)。
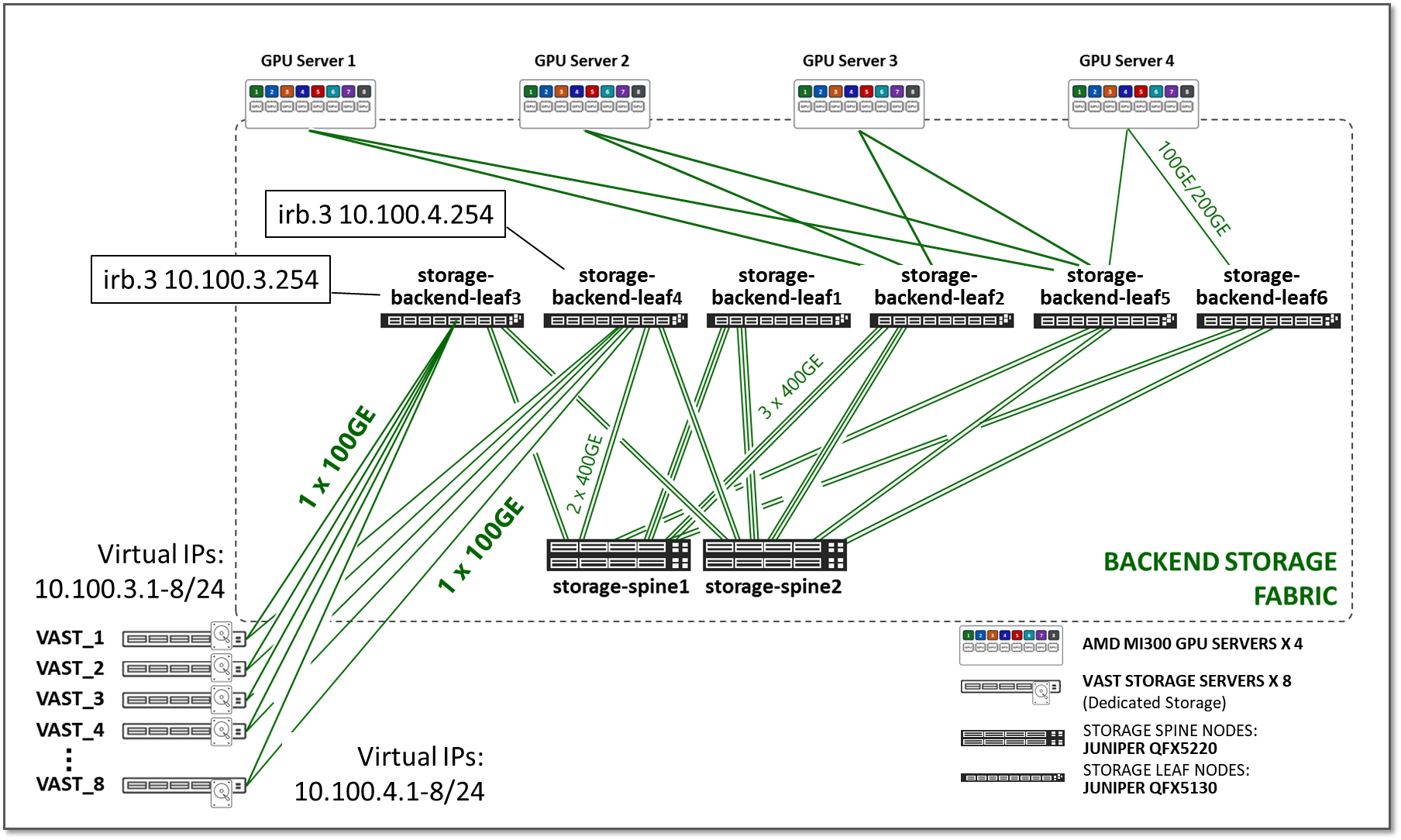
JVD 中的 存储后端交换矩阵 设计也遵循 3 级 IP clos 架构,如图 21 所示。存储群集中没有轨道优化的概念。每个 GPU 服务器都与叶节点只有一个连接,而不是每个 GPU 一个连接。
图 21:存储后端交换矩阵架构
叶节点的数量取决于 GPU 数量、AI 群集中服务器和存储设备。
主干节点的数量取决于设计所需的订阅因子。与 GPU 后端交换矩阵一样,存储交换矩阵需要非超额订阅设计(1:1 订阅系数),以确保为大容量流量提供足够的带宽,并防止拥塞、数据包丢失和过度延迟。
存储流量可以使用不同的传输机制,包括 NFS、POSIX 和 RoCEv2。对于 RoCEv2,必须实现与 GPU 后端交换矩阵相同的负载均衡和服务等级机制。本文档的“负载平衡”和“服务等级”部分对这些内容进行了说明。
下表汇总了在此 JVD 中验证的存储交换矩阵中的设备和连接:
表 17:经过验证的存储交换矩阵叶节点和主干节点
| 存储交换矩阵叶节点交换机型号 | 存储交换矩阵主干节点交换机型号 |
|---|---|
| QFX5130-32CD | QFX5130-32CD |
| QFX5220-32CD | QFX5220-32CD |
| QFX5230-32CD | QFX5230-32CD |
| QFX5240-64OD | QFX5240-64OD |
表 18 :存储交换矩阵中 GPU 服务器、存储设备和叶节点之间的经过验证的连接
| 每个 GPU 服务器到叶连接的链接 | 服务器类型 |
|---|---|
| 1 个 100GE | VAST C 节点 |
| 1 个 200GE | AMD MI300 GPU 服务器 |
表 19 :存储交换矩阵中叶节点和主干节点之间经过验证的连接
| 每个叶和主干连接的链路数 | 叶节点模型 | 主干节点模型 |
|---|---|---|
| 2 个 400GE、3 个 400GE | QFX5130-32CD | QFX5130-32CD |
| 2 个 400GE、3 个 400GE | QFX5130-32CD | QFX5130-32CD |
| 2 个 400GE、3 个 400GE | QFX5240-32CD QFX5241-32CD |
QFX5240-32CD QFX5241-32CD |
该 JVD 的测试是使用 4 台 AMD Instinct MI300X GPU 服务器和 8 个 VAST 存储设备进行的,连接到 4 个叶节点,而叶节点又连接到 2 个主干节点,如图 22 所示:
图 22:存储交换矩阵 JVD 测试拓扑

表 20:聚合存储链路计数和测试带宽
| GPU 服务器 <=> 存储叶节点 | 存储叶节点 <=> 前端主干节点 |
|---|---|
| 两者之间的 200GE 链路总数 GPU 服务器和存储叶节点 = 4 (每台服务器 1 个链路) + 之间的 100GE 链路总数 庞大的存储设备和存储叶节点 (每台设备 2 个链路)= 16 |
之间的 400GE 链路总数 前端叶节点和主干节点 = 16 (每个叶到主干的连接 2 个链路) |
| 总带宽 = 2.4 Tbps | 总带宽 = 6.4 Tbps |
| 不会超额订阅。 |
GPU 后端交换矩阵扩展
AI 群集的大小根据工作负载的具体要求而有很大差异。AI 群集中的节点数量受机器学习模型的复杂性、数据集的大小、所需的训练速度和可用预算等因素的影响。这个数字从少于 100 个节点的小型群集到由 10000 个计算、存储和网络节点组成的数据中心范围群集不等。为了实现路径分集和减少 PFC 故障路径,必须始终部署至少 4 个主干。
表 21:交换矩阵扩展 - 设备和定位
| 交换矩阵扩展 | ||
|---|---|---|
| 小 | 中 | 大 |
| 高达 4096 个 GPU | 高达 8192 个 GPU | 8192 和高达 73728 GPU |
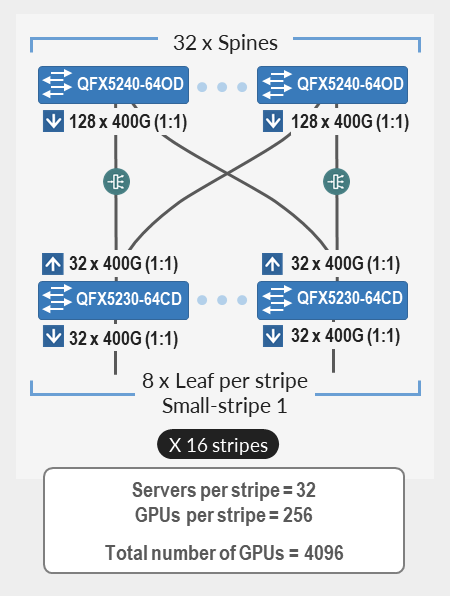
| 支持多达 4096 个 GPU,其中 瞻博网络 个 QFX5240-64CD 作为主干节点,QFX5230-64CD 作为叶节点(单条带或多条带实施)。 这种基于轨道的 3 级交换矩阵由多达 32 个主干和 128 个叶节点组成,保持 1:1 订阅。 该交换矩阵为多达 16 个条带提供物理连接,每个条带有 32 台服务器(256 个 GPU),总共 4096 个 GPU。 |
支持超过 4096 个 GPU 和多达 8192 个 GPU,其中 瞻博网络 个 QFX5240-64CD 可用作主干和叶节点。 这种基于轨道的 3 级交换矩阵由多达 64 个主干和多达 128 个叶节点组成,保持 1:1 订阅。 该交换矩阵为多达 16 个条带提供物理连接,每个条带有 64 台服务器(512 个 GPU),总共 8192 个 GPU |
支持超过 8192 个 GPU 及多达。73,728 个 GPU,其中 瞻博网络 PTX10000机箱作为主干节点,瞻博网络 QFX5240-64CD 作为叶节点。 这种基于轨道的 3 级交换矩阵由多达 64 个主干和多达 1152 个叶节点组成,保持 1:1 订阅。 该交换矩阵为多达 144 个条带提供物理连接,每个条带有 64 台服务器(512 个 GPU),总共 73,728 个 GPU。 |
 |
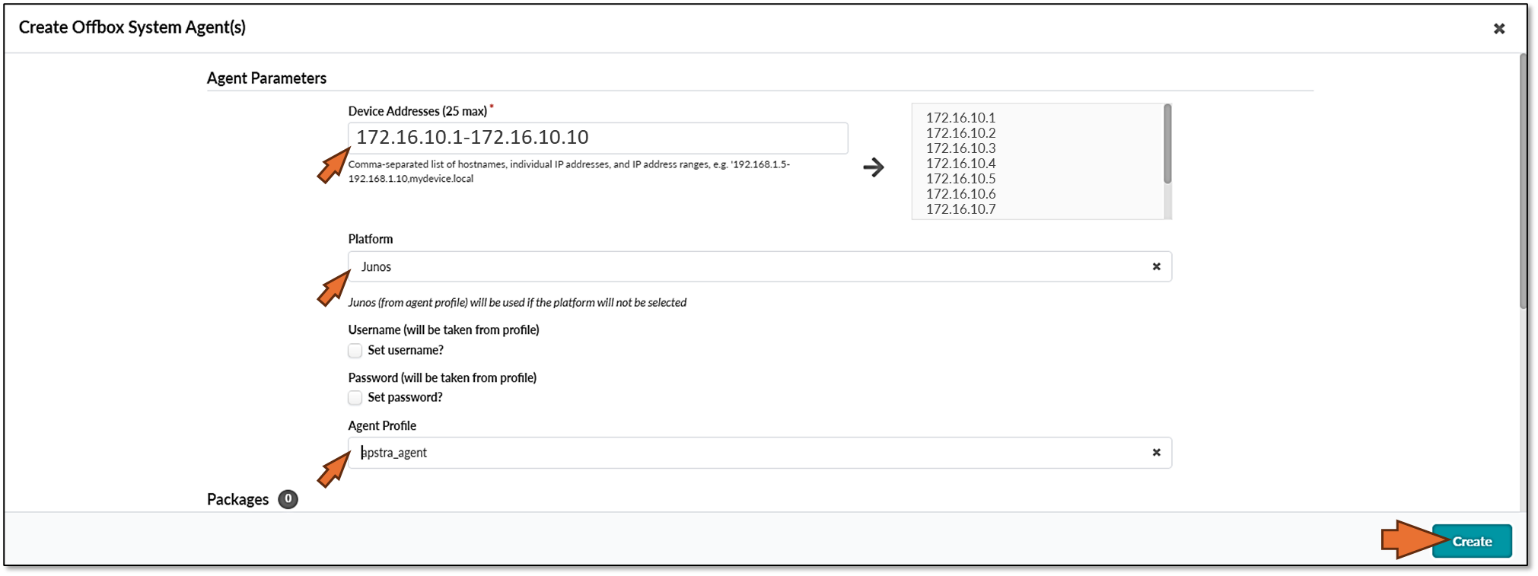 |
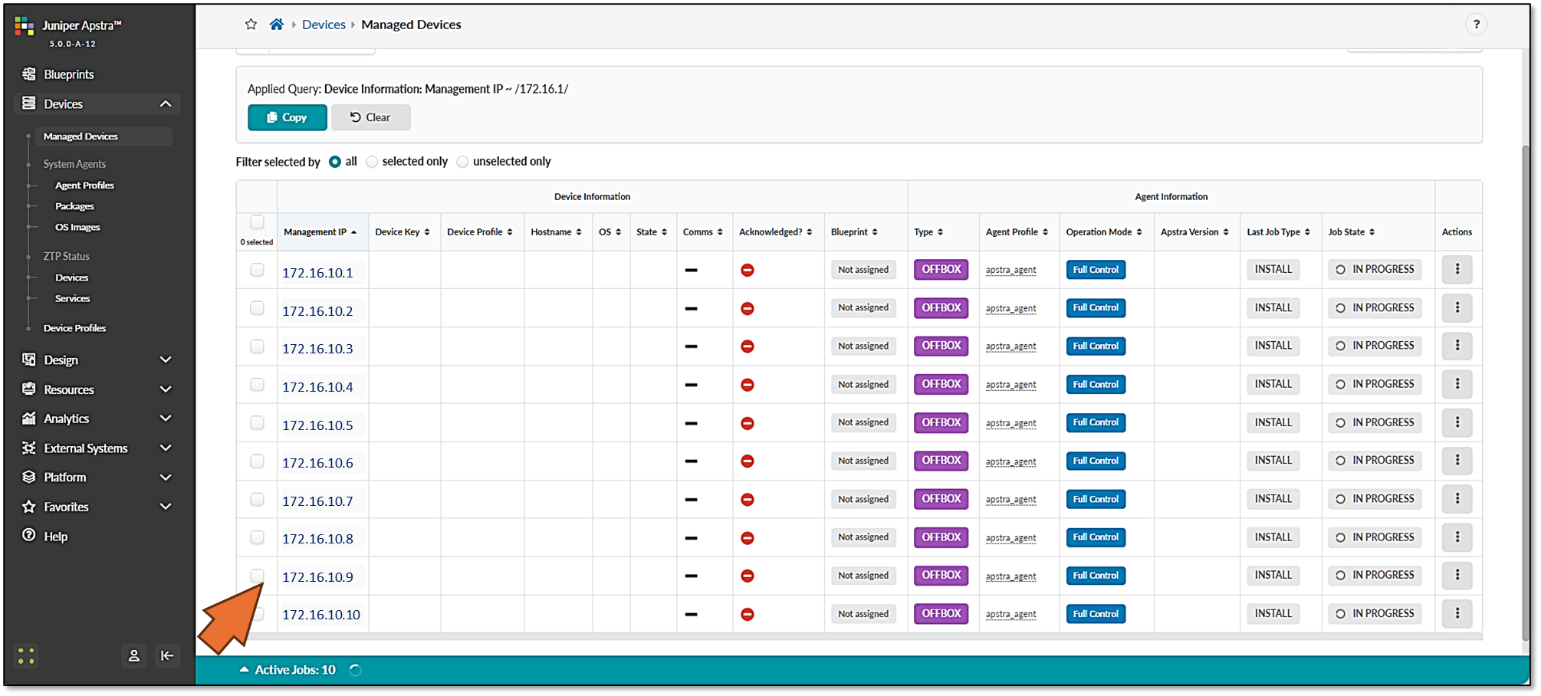 |
经过验证的瞻博网络硬件和软件解决方案组件
下面列出的瞻博网络产品和软件版本与 AI 数据中心用例的最新验证配置有关。作为持续验证过程的一部分,我们会定期测试不同的硬件型号和软件版本,并相应地更新设计建议。
设置中的 Juniper Apstra 版本 为 6.1。
下表总结了为此 JVD 验证的已验证瞻博网络设备,其中包括 采用 Juniper Apstra、NVIDIA GPU 和 WEKA 存储 - 瞻博网络验证设计 (JVD) 进行AI 数据中心网络测试的设备。
表 22:经过验证的设备和定位
| 设备 | ,前端交换矩阵 | ,GPU, 后端交换矩阵 | ,存储交换矩阵 | |||
|---|---|---|---|---|---|---|
| 叶式 | 主干 | 叶式 | 主干 | 叶式 | 主干 | |
| QFX5130-32CD | X | X | X | X | ||
| QFX5220-32CD | X | X | X | X | X | |
| QFX5230-32CD | X | X | X | |||
| QFX5230-64CD | X | X | X | X | ||
| QFX5240-64OD | X | X | X | X | ||
| QFX5241-64OD | X | X | X | X | ||
| PTX10008 JNP10K-LC1201 | X | |||||
| PTX10008 JNP10K-LC1301 | X | |||||
下表汇总了按角色测试和验证的软件版本。
表 23:平台推荐版本
| 平台 | 角色 | Junos OS 版本 |
|---|---|---|
| QFX5240-64CD | GPU 后端叶设备 | 23.4X100-D31 |
| QFX5240-64OD/QD | GPU 后端主干 | 23.4X100-D42 |
| QFX5220-32CD | GPU 后端叶设备 | 23.4X100-D20 |
| QFX5230-64CD | GPU 后端叶设备 | 23.4X100-D20 |
| QFX5240-64CD | GPU 后端主干 | 23.4X100-D31 |
| QFX5240-64OD/QD | GPU 后端主干 | 23.4X100-D42 |
| QFX5230-64CD | GPU 后端主干 | 23.4X100-D20 |
| PTX10008 与 LC1201 | GPU 后端主干 | 23.4R2-S3 |
| QFX5130-32CD | 前端叶设备 | 23.43R2-S3 |
| QFX5130-32CD | 前端主干 | 23.43R2-S3 |
| QFX5220-32CD | 存储后端叶设备 | 23.4X100-D20 |
| QFX5230-64CD | 存储后端叶设备 | 23.4X100-D20 |
| QFX5240-64CD | 存储后端叶设备 | 23.4X100-D20 |
| QFX5240-64OD/QD | 存储后端叶设备 | 23.4X100-D42 |
| QFX5220-32CD | 存储后端主干 | 23.4X100-D20 |
| QFX5230-64CD | 存储后端主干 | 23.4X100-D20 |
| QFX5240-64CD | 存储后端主干 | 23.4X100-D20 |
| QFX5240-64OD/QD | 存储后端主干 | 23.4X100-D42 |