了解虚拟输出队列
虚拟输出队列简介
本主题介绍 VOQ 体系结构及其如何与可配置的服务等级 (CoS) 组件配合使用。
在支持的平台上,Junos 硬件 CoS 功能使用入口上的虚拟输出队列来缓冲每个出口输出队列的流量并对其排队。大多数平台支持每个输出端口(物理接口)最多八个出口输出队列。
通过路由器转发流量的传统方法是在入口接口上的输入队列中缓冲入口流量,通过交换矩阵将流量转发到出口接口上的输出队列,然后在输出队列上再次缓冲流量,然后再将流量传输到下一跃点。在入口端口上对数据包进行排队的传统方法是将发往不同出口端口的流量存储在同一输入队列(缓冲区)中。
在拥塞期间,路由器可能会在出口端口丢弃数据包,因此路由器可能会花费资源将流量通过交换机交换矩阵传输到出口端口,但最终只是丢弃该流量,而不是转发该流量。由于输入队列存储发往不同出口端口的流量,一个出口端口上的拥塞可能会影响另一个出口端口上的流量,这种情况称为队头阻塞 (HOLB)。
VOQ架构采用了不同的方法:
-
Junos 设备使用每个数据包转发引擎 (PFE) 入口管道上的物理缓冲区来存储每个出口端口的流量,而不是为输入和输出队列使用单独的物理缓冲区。出口端口上的每个输出队列在路由器上所有 PFE 上的每个入口管道上都有缓冲区存储空间。入口管道存储空间到输出队列的映射是 1 对 1,因此每个输出队列在每个入口管道上接收缓冲区空间。
-
每个输出队列都有一个专用 VOQ,该 VOQ 由每个 PFE 上的专用缓冲区组成,专用于该输出队列(一对多映射),而不是一个包含发往多个不同输出队列的流量的输入队列(一对多映射)。此体系结构可防止任何两个端口之间的通信影响另一个端口。
-
VOQ 不会将流量存储在物理输出队列上,直到可以转发为止,而是在出口端口拥有转发流量的资源之前,不会将流量从入口端口穿过交换矩阵传输到出口端口。VOQ 是输入队列(缓冲区)的集合,用于接收和存储发往一个出口端口上的一个输出队列的流量。每个出口端口上的每个输出队列都有自己的专用 VOQ,其中包含向该输出队列发送流量的所有输入队列。
VOQ 是输入队列(缓冲区)的集合,用于接收和存储发往一个出口端口上的一个输出队列的流量。每个出口端口上的每个输出队列都有自己的专用 VOQ,其中包含向该输出队列发送流量的所有输入队列。
VOQ架构
VOQ 表示特定输出队列的入口缓冲。每个 PFE 都使用特定的输出队列。PFE 上存储的流量包括发往某个端口上某个特定输出队列的流量,该流量是该输出队列的 VOQ。
VOQ 分布在路由器中主动向该输出队列发送流量的所有 PFE 中。每个输出队列是路由器中所有 PFE 分配给该输出队列的总缓冲区总和。因此,尽管输出队列由物理输入队列组成,但输出队列本身是虚拟的,而不是物理的。
往返时间缓冲
虽然在拥塞期间没有输出队列缓冲(没有长期存储),但出口线卡上有一个小型的物理输出队列缓冲区,以适应流量在交换矩阵上从入口到出口的往返时间。往返时间包括入口端口请求出口端口资源、从出口端口接收资源授权以及跨交换矩阵传输数据所花费的时间。
这意味着,如果数据包未丢弃在路由器入口处,并且路由器将数据包通过交换矩阵转发到出口端口,则数据包不会被丢弃,而是会转发到下一跃点。所有数据包丢弃都在入口管道中发生。
VOQ优势
VOQ架构提供两大优势:
消除队头阻塞
VOQ 架构消除了队头阻塞 (HOLB) 问题。在非 VOQ 设备上,当出口端口的拥塞影响到未拥塞的其他出口端口时,就会发生 HOLB。当拥塞端口和非拥塞端口在入口接口上共享同一个输入队列时,就会发生 HOLB。
VOQ 架构通过为每个接口上的每个输出队列创建不同的专用虚拟队列来避免 HOLB。
由于不同的出口队列不会共享同一个输入队列,因此一个端口上的出口队列拥塞不会影响其他端口上的出口队列。出于同样的原因,一个端口上拥塞的出口队列不会影响同一端口上的另一个出口队列 - 每个输出队列都有自己的专用 VOQ,由入口接口输入队列组成。
在入口接口执行队列缓冲可确保路由器仅在出口队列准备好接收流量时,才通过交换矩阵将流量发送到该出口队列。如果出口队列尚未准备好接收流量,则流量仍会缓冲在入口接口上。
提高交换矩阵效率和利用率
传统的输出队列架构存在一些固有的低效率问题,而 VOQ 架构可以解决这些问题。
-
数据包缓冲 — 传统队列架构会在长期 DRAM 存储中对每个数据包进行两次缓冲,一次在入口接口,一次在出口接口。VOQ 架构在长期 DRAM 存储的入口接口上仅对每个数据包进行一次缓冲。交换矩阵的速度足够快,对出口 CoS 策略透明,因此路由器可以以不需要深度出口缓冲区的速率转发流量,而不会影响配置的出口 CoS 策略(调度),而不是在出口接口上第二次缓冲数据包。
-
资源消耗 — 传统队列架构从入口接口输入队列(缓冲区)穿过交换矩阵将数据包发送到出口接口输出队列(缓冲区)。在出口接口上,即使路由器已花费资源跨交换矩阵传输数据包并将其存储在出口队列中,数据包也可能被丢弃。在出口接口准备好传输流量之前,VOQ 架构不会通过交换矩阵将数据包发送到出口接口。这提高了系统利用率,因为不会浪费资源来传输和存储以后丢弃的数据包。
VOQ 是否会改变我配置 CoS 的方式?
CoS 功能的配置方式没有变化。 图 1 显示了 Junoś CoS 组件和 VOQ 选择,说明了它们相互作用的顺序。
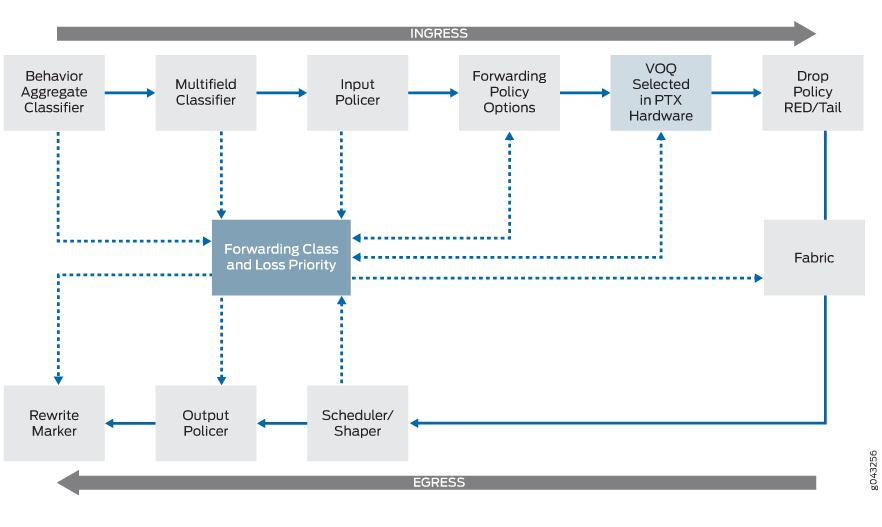
VOQ 选择过程由 ASIC 执行,这些 ASIC 使用行为聚合 (BA) 分类器或多域分类器(具体取决于您的配置)为出口端口选择八个可能的 VOQ 之一。基于您的 CoS 配置的出口端口的入口缓冲区数据上的 VOQ。
虽然 CoS 功能没有改变,但与 VOQ 存在一些作差异:
-
入口 PFE 上发生随机早期检测 (RED)。对于仅支持出口输出排队的设备,出口处会发生 RED 和相关的拥塞下降。在入口上执行 RED 可以节省宝贵的资源并提高路由器性能。
尽管 RED 发生在带有 VOQ 的入口处,但您配置丢弃配置文件的方式没有变化。
-
交换矩阵调度通过请求和授权控制消息进行控制。数据包在入口 VOQ 中缓冲,直到出口 PFE 向入口 PFE 发送授权消息,指示它已准备好接收这些消息。有关交换矩阵调度的详细信息,请参阅 PTX 系列路由器上的交换矩阵调度和虚拟输出队列。
了解 VOQ 的工作原理
本主题介绍 VOQ 进程如何在受支持的 Junos 设备上运行。
了解 VOQ 流程的组成部分
图 2 显示了参与 VOQ 进程的 Junos 设备的硬件组件。
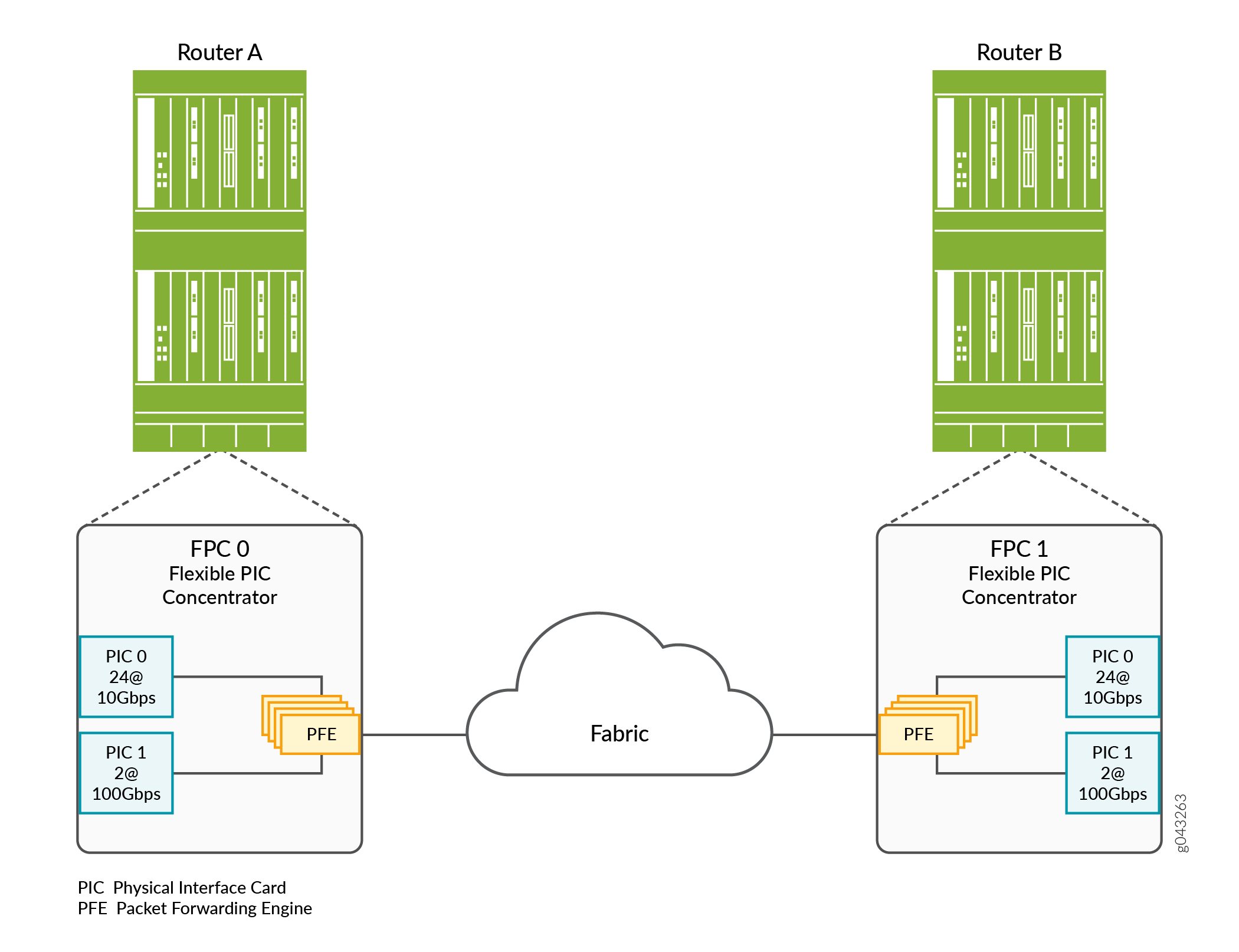 上的 VOQ 组件
上的 VOQ 组件
这些组件执行以下功能:
-
Physical Interface Card (PIC)—提供与各种网络介质类型的物理连接,接收来自网络的传入数据包,并将传出数据包传输到网络。
-
Flexible PIC Concentrator (FPC)- 将安装在其中的 PIC 连接到其他数据包传输路由器组件。
-
Packet Forwarding Engine (PFE)— 提供 L2 和 L3 数据包交换以及封装和解封装。PFE 还提供转发、路由查找功能,并管理数据包缓冲和通知排队。PFE 接收来自安装在 FPC 上的 PIC 的传入数据包,并通过设备平面将数据包转发到相应的目的端口。
-
Output queues—(未显示)这些输出队列由 CoS 调度器配置控制,该配置将确定如何处理输出队列中的流量,以便传输到设备交换矩阵。此外,这些输出队列控制何时将数据包从入口上的 VOQ 发送到出口输出队列。
了解 VOQ 流程
输出队列由 CoS 调度器配置控制,该配置确定如何处理输出队列中的流量,以便传输到交换矩阵。此外,这些输出队列控制何时将数据包从入口上的 VOQ 发送到出口输出队列。
对于每个出口输出队列,VOQ 架构在每个入口 PFE 上提供 虚拟 队列。这些队列称为虚拟队列,因为 仅 当线卡实际有数据包入队时,队列才实际存在于入口 PFE 上。
图 3 显示了三个入口 PFE:PFE0、PFE1 和 PFE2。每个入口 PFE 为单个出口端口 0 提供最多八个 VOQ(PFE.e0.q0n 到 PFE.e0.q7n)。出口 PFE (PFEn) 以轮询方式将带宽分配给每个入口 VOQ。
例如,出口 PFE n 的 VOQ e0.q0 具有 10 Gbps 的可用带宽。PFE 0 对 e0.qo 的提供负载为 10 Gbps,PFE1 和 PFE2 对 e0.q0 的提供负载为 1 Gbps。结果是,PFE1 和 PFE2 将获得 100% 的流量通过,而 PFE0 只能获得 80% 的流量通过。
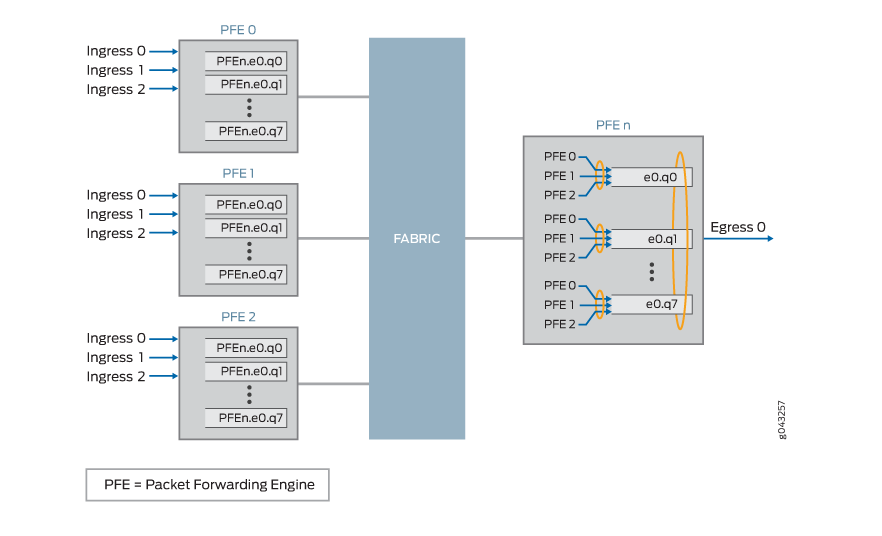
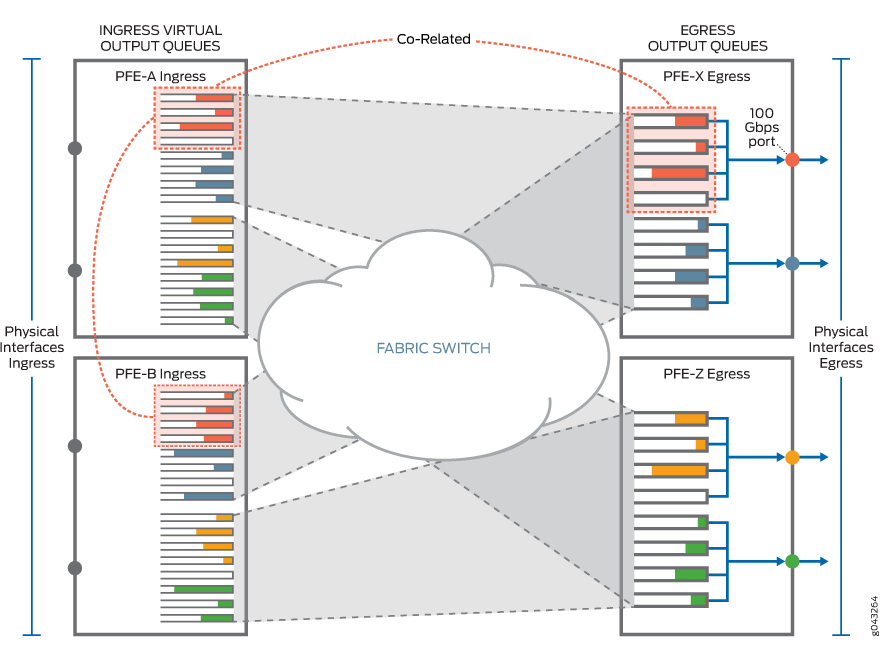
图 4 显示了出口输出队列和入口虚拟输出队列之间关联的示例。在出口端,PFE-X 有一个 100 Gbps 端口,该端口配置了四种不同的转发类。因此,PFE-X 上的 100 Gbps 出口输出端口使用了 8 个可用出口输出队列中的 4 个(由 PFE-X 上用橙色虚线突出显示的 4 个队列表示),而 VOQ 架构在每个入口 PFE 上提供 4 个相应的虚拟输出队列(由 PFE-A 和 PFE-B 上的 4 个虚拟队列用橙色虚线突出显示)。PFE-A 和 PFE-B 上的虚拟队列仅当有要发送的流量时才存在。
 示例
示例
交换矩阵调度和 VOQ
本主题介绍使用 VOQ 的 Junos 设备上的结构调度过程。
VOQ 使用 request 和 grant 消息来控制 Junos 设备上的交换矩阵调度。出口数据包转发引擎通过使用 request 和 grant 消息控制来自入口 VOQ 的数据传输。虚拟队列在入口上缓冲数据包,直到出口数据包转发引擎通过向入口数据包转发引擎发送授权消息来确认它已准备好接收数据包。
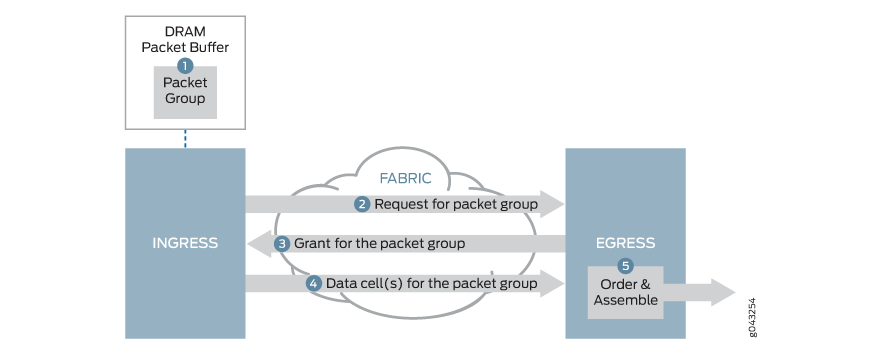
图 5 展示了具有 VOQ 的 Junos 设备使用的交换矩阵调度过程。当数据包到达入口端口时,入口管道会将数据包存储在与目标输出队列关联的入口队列中。路由器在执行数据包查找后做出缓冲决策。如果数据包属于已超过最大流量阈值的转发类,则数据包可能未被缓冲,而可能会被丢弃。计划过程的工作方式如下:
-
入口数据包转发引擎接收数据包并将其缓冲在虚拟队列中,然后将该数据包与发往同一出口接口和数据输出队列的其他数据包分组。
-
入口线卡数据包转发引擎通过交换矩阵向出口数据包转发引擎发送一个请求,其中包含对数据包组的引用。
-
当有可用的出口带宽时,出口线卡授予计划程序通过向入口线卡数据包转发引擎发送带宽授予来做出响应。.
-
当入口线卡数据包转发引擎收到来自出口线卡数据包转发引擎的授权时,入口数据包转发引擎会对数据包组进行分段,并通过交换矩阵将所有片段发送到出口数据包转发引擎。
-
出口数据包转发引擎接收分段,将分段重新组合到数据包组中,并将单个数据包排队到与 VOQ 对应的数据输出队列中。
入口数据包将保留在入口端口输入队列的 VOQ 中,直到输出队列准备好接受和转发更多流量。
在大多数情况下,交换矩阵的速度足够快,可以对出口 CoS 策略保持透明。因此,将流量从入口管道穿过交换矩阵转发到出口端口的过程不会影响为流量配置的 CoS 策略。仅当存在交换矩阵故障或端口公平性问题时,交换矩阵才会影响 CoS 策略。
当数据包进出同一数据包转发引擎(本地交换)时,数据包不会遍历交换矩阵。但是,路由器使用与通过交换矩阵的数据包相同的请求和授权机制来接收出口带宽,因此,当流量争用同一输出队列时,本地路由的数据包和在穿过交换矩阵后到达数据包转发引擎的数据包将得到公平对待。
了解数据包转发引擎公平性和 VOQ 流程
本主题介绍在 Junos 设备上与 VOQ 一起使用的数据包转发引擎公平方案。
数据包转发引擎公平性意味着从出口的角度来看,所有数据包转发引擎都得到平等对待。如果多个出口数据包转发引擎需要从同一个 VOQ 传输数据,则数据包转发引擎将以循环方式提供服务。VOQ 的服务 不 依赖于每个源数据包转发引擎上的负载。
图 6 在一个包含三个数据包转发引擎的简单示例中说明了用于 VOQ 的数据包转发引擎公平方案。入口 PFE-A 有一个发往 PFE-C 上的 VOQx 的 10 Gbps 数据流。PFE-B 有一个 100 Gbps 数据流,也发往 PFE-C 上的 VOQx。在 PFE-C 上,VOQx 由 100 Gbps 接口提供服务,该接口是该接口上唯一的活动 VOQ。
 实现公平性
实现公平性
在 图 6 中,我们总共有 110 Gbps 的源数据,发往 100 Gbps 的输出接口。因此,我们需要丢弃 10 Gbps 的数据。下降发生在哪里?这种下降如何影响来自 PFE-A 与 PFE-B 的流量?
由于 PFE-A 和 PFE-B 由出口 PFE-C 以轮询方式提供服务,因此来自 PFE-A 的所有 10 Gbps 流量都将通过出口输出端口。但是,PFE-B 上会丢弃 10 Gbps 的数据,因此仅允许将 PFE-B 中的 90 Gbps 数据发送到 PFE-C。因此,10 Gbps 流的下降为 0%,而 100 Gbps 流仅下降 10%。
但是,如果 PFE-A 和 PFE-B 各自获取 100 Gbps 的数据,则它们将各自丢弃 50 Gbps 的数据。这是因为出口 PFE-C 实际上使用轮询算法控制入口虚拟队列的服务和清空速率。使用轮询算法时,当存在多个源时,带宽较高的源总是会受到惩罚。该算法试图使两个源的带宽相等;但是,由于它不能提高较慢源的带宽,因此会丢弃较高源的带宽。轮询算法继续此序列,直到源具有相等的出口带宽。
每个入口数据包转发引擎为单个出口端口提供最多八个 VOQ。出口数据包转发引擎将带宽分配给每个入口 VOQ;因此,无论其所呈现的负荷如何,VOQ 都得到平等对待。队列的清空率是队列清空的速率。出口数据包转发引擎在入口数据包转发引擎之间平均分配每个输出队列的带宽。因此,每个入口数据包转发引擎的排空速率=输出队列的排空速率/入口数据包转发引擎的数量。
处理拥塞
可能发生两种主要类型的拥塞:
-
入口拥塞 — 当入口数据包转发引擎提供的负载超过出口可以处理的负载时发生。入口拥塞的情况与传统路由器非常相似,都是队列累积,一旦队列超过配置的阈值,数据包就会被丢弃。
-
出口拥塞 — 当所有入口数据包转发引擎的总和超过出口路由器的能力时发生。所有丢弃均在入口数据包转发引擎上执行。但是,入口队列的大小会因队列的排空速率(出口数据包转发引擎请求数据包的速度)而衰减。此速率实质上取决于出口数据包转发引擎将请求转换为授权的速率。出口数据包转发引擎以轮询方式处理请求到授权的转换;它不依赖于入口数据包转发引擎提供的负载。例如,如果入口数据包转发引擎的清空速率是其预期的一半(如 2 个入口数据包转发引擎为目标输出队列提供超额订阅负载的情况),则入口数据包转发引擎会将此队列的大小减小到其原始大小的一半(当它获得完全清空速率时)。
VOQ队列深度监控
VOQ 队列深度监控或延迟监控可测量 VOQ 的峰值队列占用率。此功能可以为每个单独的数据包转发引擎报告给定物理接口的峰值队列长度。
除了峰值队列长度数据外,每个队列还会在入口数据路径上维护丢弃统计信息和时间平均队列长度。此外,每个队列都会在出口数据路径上维护队列传输统计信息。
在使用严格优先级调度的典型部署方案中, HIGH 优先级队列可能会使 LOW 优先级队列匮乏。因此,此类 LOW 优先级队列中的数据包保留的时间可能比预期的要长。您可以使用此 VOQ 队列深度监控功能以及队列传输统计信息来检测此类停滞情况。
您只能在传输 WAN 接口上启用 VOQ 队列深度监控。
要在接口上启用 VOQ 队列深度监控,请先创建监控配置文件,然后将该配置文件附加到接口。如果将监控配置文件附加到聚合以太网 (ae-) 接口,则每个成员接口都有自己的专用硬件 VOQ 监视器,除非您还将该 shared 选项应用于附加到 ae- 接口的监控配置文件。
监控配置文件会在每个接口上单独报告虚拟输出队列 (VOQ) 深度。但是,如果系统上的硬件监控配置文件 ID 数量有限,则此过程可能会很快消耗大型系统上支持的最大硬件监控配置文件 ID。默认情况下,分配给 ae- 接口的监控配置文件将在 ae- 接口的所有成员之间复制。因此,要保留监控配置文件 ID,请在[set class-of-service interfaces ae-interface monitoring-profile profile-name]层次结构级别包含该shared选项。配置shared的选项仅创建一个监控配置文件 ID,以便在所有成员接口之间共享。该选项还会将成员接口上的最大峰值报告为 ae- 接口的公共峰值。
您无法在混合模式 ae- 接口上启用该 shared 选项。
每个监控配置文件都由一个或多个导出筛选器组成。导出过滤器为物理接口上的一个或多个队列定义峰值队列长度百分比阈值。一旦满足导出过滤器中任何队列定义的峰值队列长度百分比阈值,Junos 就会导出导出过滤器中所有队列的 VOQ 遥测数据。
队列深度监控数据 仅 通过遥测通道发出。除了配置监控配置文件(如下所示)之外, 您还必须 启动定期的传感器订阅才能使数据流出。没有 CLI 显示选项。
配置 VOQ 队列深度监控
配置 VOQ 队列深度监控以导出队列利用率数据。您可以使用此数据来监控微突发,并帮助识别停滞的传输输出队列。要配置 VOQ 队列深度监控,请执行以下作:
- 配置监控配置文件。
- 将监控配置文件附加到接口。
要配置监控配置文件,请执行以下作:
- 命名监控配置文件。例如:
[edit class-of-service] set monitoring-profile mp1
- 为 montoring 配置文件命名导出过滤器。例如:
[edit class-of-service monitoring-profile mp1] set export-filters ef1
- 定义哪些队列(0 到 7)属于导出过滤器。例如:
[edit class-of-service monitoring-profile mp1 export-filters ef1] set queue [0 1]
- (选答)定义阈值峰值队列长度百分比以导出 VOQ 遥测数据。默认百分比为 0。例如:
[edit class-of-service monitoring-profile mp1 export-filters ef1] set peak-queue-length percent 50
- (选答)为监控配置文件定义一个或多个其他导出过滤器。例如:
[edit class-of-service monitoring-profile mp1] set export-filters ef2 queue [2 3]
- 提交更改。
要将监控配置文件附加到接口,请执行以下作:
- 将监控配置文件附加到接口。例如:
[edit class-of-service] set interfaces et-0/0/1 monitoring-profile mp1 set interfaces ae0 monitoring-profile mp1 shared
- 提交更改。
检查您的配置。例如:
[edit class-of-service]
user@host# show
monitoring-profile mp1 {
export-filters ef1 {
peak-queue-length {
percent 50;
}
queue [ 0 1 ];
}
export-filters ef2 {
queue [ 2 3 ];
}
}
interfaces {
ae0 {
monitoring-profile mp1 shared;
}
et-0/0/1 {
monitoring-profile mp1;
}
}
运行以下 show 命令以验证您的配置:
user@host> show class-of-service interface et-0/0/1 Physical interface: et-0/0/1, Index: 1098 Maximum usable queues: 8, Queues in use: 4 Exclude aggregate overhead bytes: disabled Logical interface aggregate statistics: disabled Scheduler map: default, Index: 0 Congestion-notification: Disabled Monitoring Profile Name: mp1 Logical interface: et-0/0/1.16386, Index: 1057 user@host> show class-of-service interface ae0 Physical interface: ae0, Index: 7860 Maximum usable queues: 8, Queues in use: 4 Exclude aggregate overhead bytes: disabled Logical interface aggregate statistics: disabled Scheduler map: default, Index: 0 Congestion-notification: Disabled Monitoring Profile Name: mp1 [shared] user@host> show class-of-service monitoring-profile Monitoring profile: mp1 Export filter Queue Number Peak Queue Length ef1 0 50% ef1 1 50% ef2 2 0% ef2 3 0%
从此示例中可以看出,不为导出筛选器设置 a peak-queue-length percent 会将百分比默认为 0%,如导出筛选器 ef2 所示。此示例显示了物理接口上不同的队列,这些队列在导出 VOQ 遥测数据时具有不同的峰值队列长度阈值。