NESTA PÁGINA
Quais recursos e designs o Roteamento por segmentos permite?
O roteamento por segmentos permite muitos recursos úteis, incluindo um núcleo sem BGP, engenharia de tráfego (TE), caminhos de backup de reparo local, roteamento anycast e redes multitopologia. Todos esses recursos não exigem sinalização adicional e são alimentados por protocolos de roteamento existentes. Além disso, controladores centralizados podem criar reservas de largura de banda e caminhos de engenharia de tráfego em áreas e níveis de IGP e sistemas autônomos BGP.
Conhecimento de pré-requisito
Supomos que você tenha lido O que é Roteamento por segmentos e roteamento de pacotes de origem em redes?, juntamente com os tópicos de pré-requisito.
O roteamento por segmentos (SR) oferece muitos recursos poderosos que agregam um valor tremendo a uma variedade de redes, incluindo redes de provedores de serviços, redes de data center, redes móveis e redes empresariais de grande porte.
Alguns desses recursos são exclusivos do roteamento por segmentos. Os protocolos de caminho e os protocolos de tunelamento existentes, como RSVP e LDP, também oferecem alguns outros recursos. Mesmo nesse caso, o roteamento por segmentos oferece novas vantagens e aprimoramentos quando comparado às opções existentes.
Este documento fornece uma visão geral de alto nível desses recursos e uma ampla compreensão dos benefícios da implantação do roteamento por segmentos. Também oferecemos vários documentos que explicam cada um desses recursos com mais detalhes técnicos, incluindo sua configuração e verificação.
Todos os recursos descritos neste guia estão disponíveis para SR-MPLS. A maioria dos recursos também está disponível para SRv6.
Malha completa automática de túneis de caminho mais curto para outros dispositivos habilitados para SR
Quando um operador executa MPLS e LDP em roteadores Junos OS, o resultado é que cada dispositivo cria automaticamente uma malha completa de caminhos comutados por rótulos (LSPs) para todos os outros dispositivos LDP na rede. Esses LSPs simplesmente seguem o caminho mais curto do IGP até o destino. Isso é suficiente para alimentar um núcleo sem BGP ou serviços VPN, como Ethernet VPN (EVPN) e VPNs de camada 3 (L3VPN).
O roteamento por segmentos cria automaticamente túneis de caminho mais curto para todos os outros dispositivos habilitados para SR, tanto para SR-MPLS quanto para SRv6.
Em uma rede SR-MPLS, as tabelas de roteamento inet.3 podem ser preenchidas automaticamente com LSPs IPv4 para todos os outros dispositivos habilitados para SR-MPLS. Isso é verdade mesmo nas implantações SR-MPLS mais básicas. Se você também executa IPv6 em sua rede, também é fácil preencher a tabela inet6.3 com LSPs IPv6.
A Figura 1 demonstra esse conceito. Ele mostra uma rede de dez roteadores, numerados de R1 a R10.
Depois de habilitar SR-MPLS com IS-IS, a saída abaixo mostra que a tabela inet.3 do roteador R1 contém uma malha completa de LSPs para os outros nove roteadores. O SR-MPLS cria automaticamente essa malha completa, sem exigir sinalização adicional.
user@R1> show route table inet.3
inet.3: 9 destinations, 9 routes (9 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
192.168.1.2/32 *[L-ISIS/14] 00:06:45, metric 100
> to 10.1.2.2 via ge-0/0/0.0
192.168.1.3/32 *[L-ISIS/14] 00:02:18, metric 200
> to 10.1.2.2 via ge-0/0/0.0, Push 300403
192.168.1.4/32 *[L-ISIS/14] 00:02:18, metric 300
> to 10.1.2.2 via ge-0/0/0.0, Push 300404
192.168.1.5/32 *[L-ISIS/14] 00:02:18, metric 400
> to 10.1.2.2 via ge-0/0/0.0, Push 300405
192.168.1.6/32 *[L-ISIS/14] 00:06:45, metric 100
> to 10.1.6.6 via ge-0/0/2.0
192.168.1.7/32 *[L-ISIS/14] 00:02:18, metric 200
to 10.1.2.2 via ge-0/0/0.0, Push 300407
> to 10.1.6.6 via ge-0/0/2.0, Push 300407
192.168.1.8/32 *[L-ISIS/14] 00:02:18, metric 300
> to 10.1.2.2 via ge-0/0/0.0, Push 300408
to 10.1.6.6 via ge-0/0/2.0, Push 300408
192.168.1.9/32 *[L-ISIS/14] 00:02:18, metric 400
> to 10.1.2.2 via ge-0/0/0.0, Push 300409
to 10.1.6.6 via ge-0/0/2.0, Push 300409
192.168.1.10/32 *[L-ISIS/14] 00:02:18, metric 500
> to 10.1.2.2 via ge-0/0/0.0, Push 300410
to 10.1.6.6 via ge-0/0/2.0, Push 300410
Observe que o rótulo MPLS de saída parece ser previsível para cada nó remoto. Esse não é o comportamento padrão do SR-MPLS, mas é muito fácil de habilitar com apenas algumas linhas de configuração. Observe que os LSPs para R7, R8, R9 e R10 aproveitam automaticamente as opções de multipath de custo igual (ECMP).
Em uma rede SRv6, se todos os dispositivos executarem SRv6, você poderá criar uma malha completa automática de túneis para todos os outros dispositivos habilitados para SRv6. No entanto, não há nenhum requisito estrito para executar o SRv6 em todos os seus dispositivos de trânsito. Por exemplo, se um dispositivo de trânsito mais antigo não puder executar SRv6, esses dispositivos ainda poderão ser habilitados para IPv6 regular. Isso será suficiente para que esses roteadores ofereçam funcionalidade de trânsito para os túneis SRv6 em sua rede. Nesse caso, você terá pelo menos uma malha parcial de túneis para todos os outros dispositivos habilitados para SRv6.
Algoritmo flexível
Algoritmo Flexível ou Flex Algo é um método escalável de criação de redes multitopologia. Usando grupos de administradores, você pode marcar determinados links como pertencentes a uma topologia específica do Flex Algo. Em seguida, são criadas novas instruções de segmento exclusivas para essa topologia. Isso garante que o tráfego só estará contido em sua topologia. O tráfego nunca vazará para roteadores que não fazem parte da topologia porque os dispositivos dentro da topologia roteiam o tráfego dentro da topologia.
A Figura 2 demonstra esse conceito. Cada roteador participa da topologia principal. Então, certos links também podem participar de uma ou mais topologias menores.
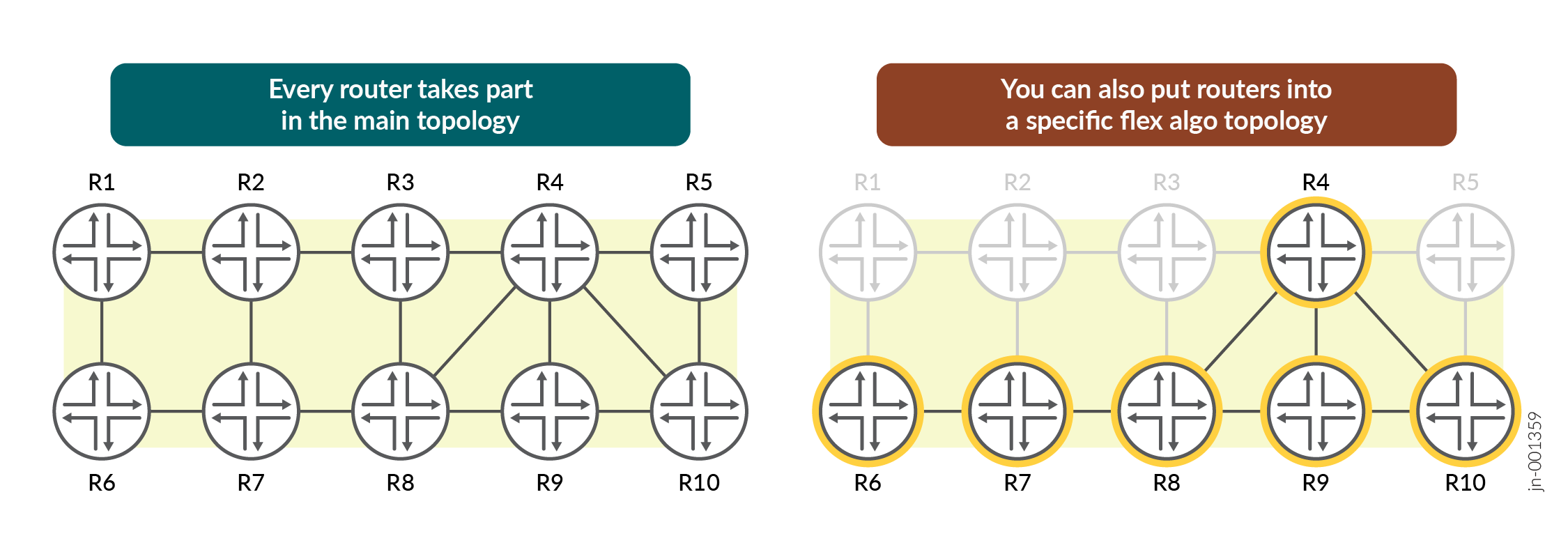
Os métodos tradicionais de multitopologia exigiam um grande esforço para configurar e manter. Por outro lado, o uso de grupos de administradores oferece a opção de reutilizar grupos de administradores entre topologias ou escolher se deseja excluir ou incluir um ou mais grupos de administradores.
Cada topologia está associada a uma cor numérica. Isso permite que o Flex Algo aproveite a comunidade de cores do BGP para vincular automaticamente um prefixo a uma topologia específica. Isso oferece uma solução muito mais escalável do que os métodos históricos de ligação de um prefixo a uma rede multitopologia específica.
Alternativa sem loop independente de topologia (TI-LFA)
O TI-LFA cria caminhos de backup de reparo locais que podem ser usados imediatamente em momentos de falha de link ou nó. Existem outros protocolos que também oferecem caminhos de reparo locais. No entanto, alguns desses protocolos só podem oferecer cobertura de topologia limitada devido à necessidade de evitar caminhos de backup que possam criar um loop. Outros protocolos podem cobrir toda a rede, mas cada caminho de backup precisa ser configurado e mantido separadamente.
Por outro lado, o TI-LFA oferece 100% de cobertura de topologia sem sinalização adicional. Ao empurrar uma série de segmentos para um pacote, os loops topológicos são completamente evitados. Além disso, os caminhos de backup TI-LFA são idênticos ao caminho que será usado quando a rede terminar de convergir a partir da falha do link ou do nó. Isso é chamado de caminho pós-convergência. Isso significa que o tráfego não precisa mudar uma segunda vez para um novo caminho pós-convergência depois de ser movido para um caminho de backup. Isso reduz o jitter da rede.
Quando pré-instalamos esses caminhos de backup no plano de encaminhamento, geralmente observamos que podemos reduzir o tempo de inatividade para apenas 50 ms durante a transição.
Você também pode usar os caminhos de backup TI-LFA para proteger o tráfego de IP simples. Além disso, as topologias do Flex Algo garantem automaticamente que os caminhos de backup TI-LFA estejam contidos apenas na topologia que você projetou. A TI-LFA é um recurso poderoso e é um dos principais motivadores que as operadoras de rede consideram ao escolher se devem implantar o roteamento por segmentos.
Prevenção de microloops
Em redes de estado de enlace, diferentes roteadores aprendem e processam atualizações de alterações de topologia em momentos diferentes. Isso pode criar loops temporários durante eventos de convergência de rede. Por exemplo, se um roteador converge antes de um roteador vizinho e decide que seu vizinho é o próximo melhor salto, o roteador vizinho pode enviar o pacote de volta novamente se o vizinho ainda não tiver terminado a convergência. Esses loops são conhecidos como microloops.
Microloops são eventos breves de milissegundos. No entanto, na era moderna, uma quantidade substancial de tráfego pode transitar por um link nesse período. Os microloops têm o poder de inundar temporariamente um link com tráfego, o que pode causar uma interrupção completa nesse link durante esse período.
A prevenção de microloops (MLA) é um recurso no roteamento por segmentos que identifica áreas em sua topologia onde microloops podem ocorrer. Então, quando um link ou nó falha, o Junos OS pode enviar temporariamente instruções de segmento para garantir que os roteadores remotos encaminhem o tráfego corretamente, mesmo que ainda não tenham terminado de convergir para a nova topologia. Esses segmentos geralmente são usados por não mais do que alguns segundos, mas isso pode ser suficiente para evitar uma interrupção catastrófica durante o processo de convergência.
Anycast
Se você configurar um prefixo em dois ou mais roteadores, ambos os dispositivos poderão anunciar um segmento que representa a instrução para enviar o tráfego pelo caminho mais curto em direção a esse prefixo. Pode ser um prefixo em um link compartilhado ponto a ponto ou de broadcast, ou pode ser um endereço IPv4 /32 ou IPv6 /128 configurado em dois ou mais dispositivos.
Como resultado, você pode enviar tráfego pelo caminho mais curto em direção ao roteador metricamente mais próximo. Ou, se todos os dispositivos tiverem o mesmo custo, você pode balancear a carga do tráfego entre eles.
Esse recurso é conhecido como roteamento anycast. É comum no núcleo de uma rede. Ao configurar dois ou mais roteadores de núcleo para anunciar o mesmo segmento, você pode criar um caminho TE que também tem a capacidade de aproveitar caminhos de custo igual quando eles estiverem disponíveis. Isso não é possível em protocolos como o RSVP, em que você precisa criar dois ou mais caminhos explícitos separados se quiser balancear a carga entre esses caminhos.
Um exemplo menos comum, mas poderoso, é configurar duas ou mais bordas de roteador para anunciar o mesmo prefixo e segmento. Se você usar esse segmento compartilhado como um protocolo BGP next-hop, poderá criar um design em que o tráfego é simplesmente transportado para o ponto de saída mais próximo.
Próximo salto sob demanda
Historicamente, a engenharia de tráfego exigia que os operadores de rede configurassem caminhos TE individuais em cada roteador PE de entrada em direção a cada roteador de saída. Muitos desses caminhos de TE compartilhavam características de TE semelhantes. Por exemplo, cada caminho de TE pode ser configurado para usar métricas de TE em vez de métricas de IGP ou para evitar um grupo de administradores que indique se um link passará por manutenção em breve.
Como alternativa à definição individual de todos os endpoints para seus caminhos em cada roteador PE, o roteamento por segmentos oferece a capacidade de detectar automaticamente quando um caminho TE deve ser criado. Esse recurso é chamado de ODN (Next-Hops sob demanda).
Quando você executa o ODN em uma rede SR, os caminhos são calculados e criados automaticamente para qualquer próximo salto de protocolo BGP válido em qualquer prefixo BGP válido. O caminho para o PE remoto é então calculado usando D-CSPF, com base nas restrições de sua escolha. Isso oferece uma solução muito mais escalável do que definir manualmente todos os seus endpoints individualmente.
Esse recurso também está disponível no RSVP. Mais uma vez, porém, em uma rede roteada por segmentos, você não precisa sinalizar ou manter esses caminhos.
Engenharia de tráfego baseada em controlador
Usando um controlador externo (como o Juniper Paragon Pathfinder), você pode executar um protocolo chamado Path Computation Element Protocol (PCEP) que pode se comunicar diretamente com todos os dispositivos habilitados para SR em sua rede. O controlador pode calcular caminhos TE em nome de todos os dispositivos na rede e, em seguida, usar o PCEP para gravar esses caminhos diretamente no roteador de entrada desse caminho.
Um ou mais roteadores habilitados para SR podem anunciar informações de topologia ao controlador usando o BGP Link-State (BGP-LS). Isso permite que o controlador aprenda sua topologia sem também se tornar parte da mesma topologia de estado de link. O controlador pode então gerar automaticamente uma visão gráfica de sua topologia e dos túneis que viajam por essa topologia.
Se você tiver vários domínios de roteamento (como diferentes áreas de OSPF, níveis de IS-IS ou sistemas autônomos), poderá configurar dispositivos em cada um desses domínios para anunciar a topologia ao seu controlador. Como resultado, o controlador pode calcular caminhos através dos limites de domínio e, em seguida, informar a um roteador de entrada os segmentos exatos que devem ser gravados no pacote, independentemente de quantos domínios de roteamento o túnel atravessa.
O controlador também pode oferecer serviços adicionais que não são oferecidos pelo próprio roteamento por segmentos, como reservas de largura de banda por caminho. O controlador também pode otimizar totalmente os caminhos em resposta a eventos de rede, como mover um túnel menos importante em um dispositivo para outro caminho para liberar espaço para um túnel de prioridade mais alta em outro dispositivo.
Engenharia de tráfego sensível a cores
Os operadores de rede geralmente criam vários túneis entre dois endpoints para que cada túnel possa seguir um caminho diferente com base na importância do tráfego. Por exemplo, o tráfego sensível a atrasos pode seguir um caminho mais curto do que o tráfego de melhor esforço. Da mesma forma, o tráfego de melhor esforço pode ser deliberadamente roteado para longe dos links fisicamente mais curtos em sua rede, de modo que o tráfego sensível a atrasos possa seguir o caminho mais rápido sem competir com o tráfego de melhor esforço.
Historicamente, esse recurso requer o uso de políticas de roteamento complexas para mapear prefixos BGP individuais para caminhos específicos. Essas políticas de roteamento geralmente precisam ser mantidas manualmente e podem ser facilmente configuradas incorretamente.
Por outro lado, o roteamento por segmentos oferece a capacidade de marcar seus túneis com uma cor, que é simplesmente um identificador numérico que representa a intenção do túnel. Por exemplo, você pode optar por atribuir o valor de cor 10 a qualquer túnel em qualquer roteador que transporte tráfego de melhor esforço. Como outro exemplo, você pode usar o valor de cor 20 para representar túneis que transportam tráfego sensível a atrasos.
Em seguida, você pode aproveitar a comunidade de cores do BGP para vincular automaticamente um prefixo aprendido a um túnel TE com uma cor correspondente. Isso elimina a complexidade tradicional de criar manualmente políticas de roteamento para atingir o mesmo objetivo. Ele também oferece um método muito mais escalável de implantar vários caminhos para um destino.
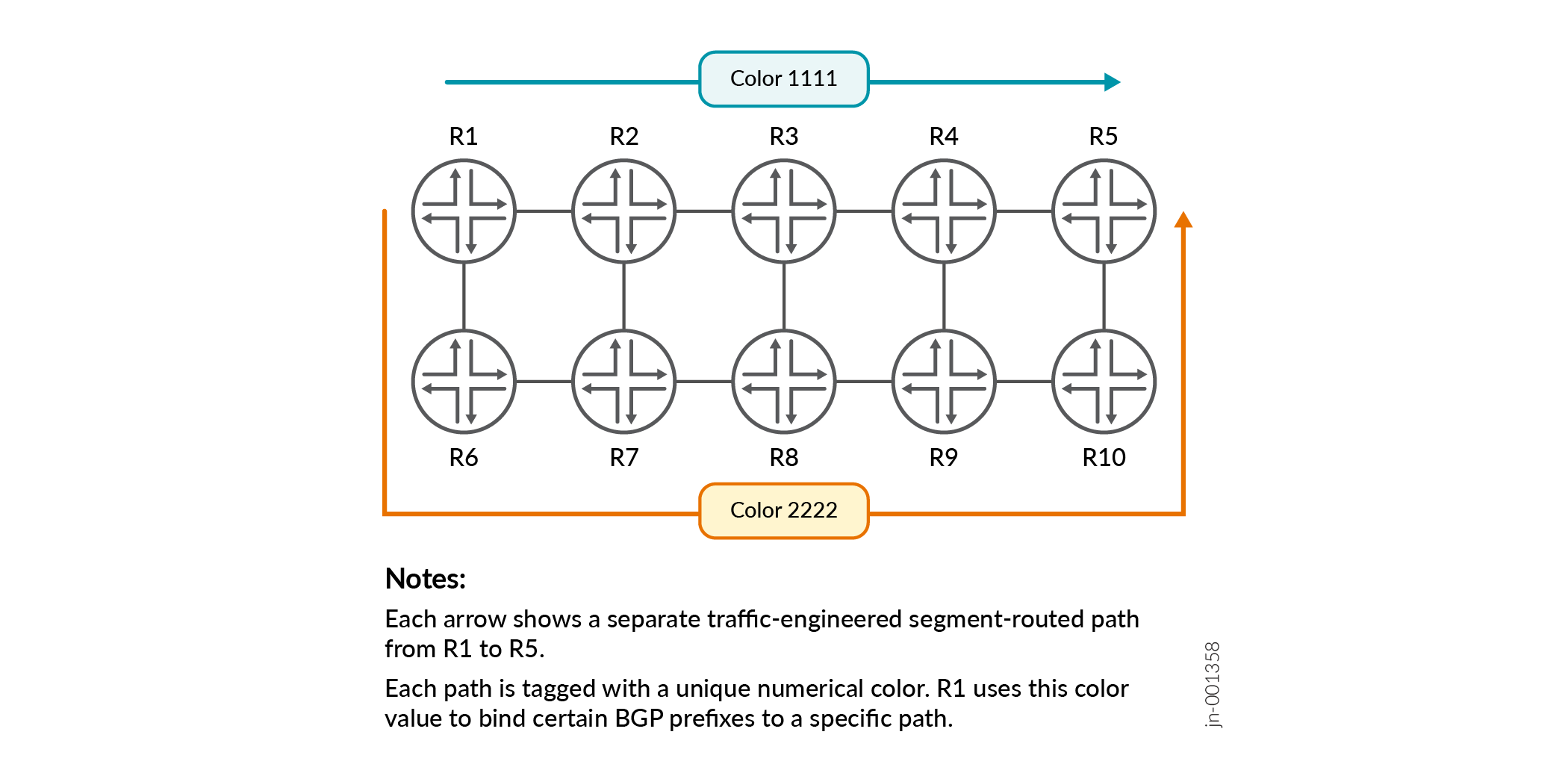
A Figura 3 demonstra esse conceito.
 numérica diferente
numérica diferente
R1 tem dois caminhos para o roteador remoto R5. Um caminho é usado por tráfego sensível a atrasos e o outro é usado para tráfego destinado à Internet pública. Quando R5 anuncia prefixos BGP que são sensíveis a atrasos, R5 pode anexar o valor da comunidade de cores BGP 1111 a esses prefixos. R1 associará automaticamente esses prefixos ao caminho que tem um valor de cor correspondente.