Alta disponibilidade de múltiplos nós de dois nós
Saiba mais sobre a solução de alta disponibilidade de múltiplos nós para dois nós.
A alta disponibilidade de múltiplos nós oferece suporte a dois firewalls da Série SRX, apresentando-se como nós independentes do restante da rede. Os nós são conectados a infraestruturas adjacentes pertencentes à mesma rede ou a redes diferentes, dependendo do modo de implantação. Esses nós podem ser colocados ou separados entre geografias. Os nós participantes fazem backup uns dos outros para garantir um failover sincronizado rápido em caso de falha do sistema ou do hardware.
Oferecemos suporte à alta disponibilidade de vários nós no modo ativo/backup e no modo ativo-ativo (com suporte a vários grupos de redundância de serviços (SRGs). Para obter a lista completa de recursos e plataformas com suporte, consulte Alta disponibilidade de vários nós no Explorador de Recursos.
Cenários de implantação
Oferecemos suporte aos seguintes tipos de modelos de implantação de rede para alta disponibilidade de vários nós:
- Modo de rota (todas as interfaces conectadas usando uma topologia de Camada 3)
Figura 1: Modo
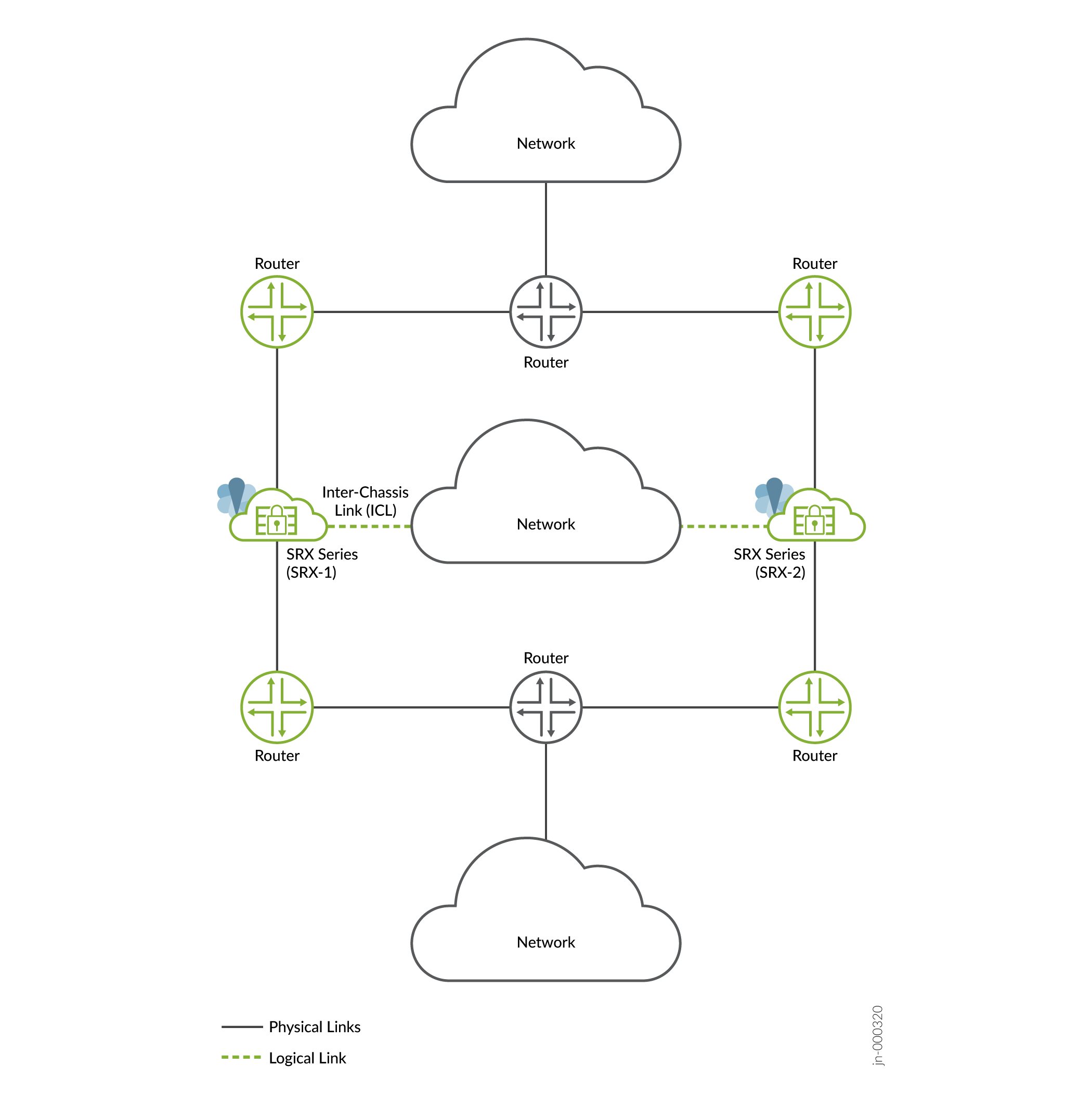 de Camada 3
de Camada 3
- Modo de gateway padrão (todas as interfaces conectadas usando uma topologia de Camada 2) usado em ambientes mais tradicionais. Implantação comum de redes DMZ onde os dispositivos de firewall atuam como o gateway padrão para os hosts e aplicativos no mesmo segmento.
Figura 2: Modo
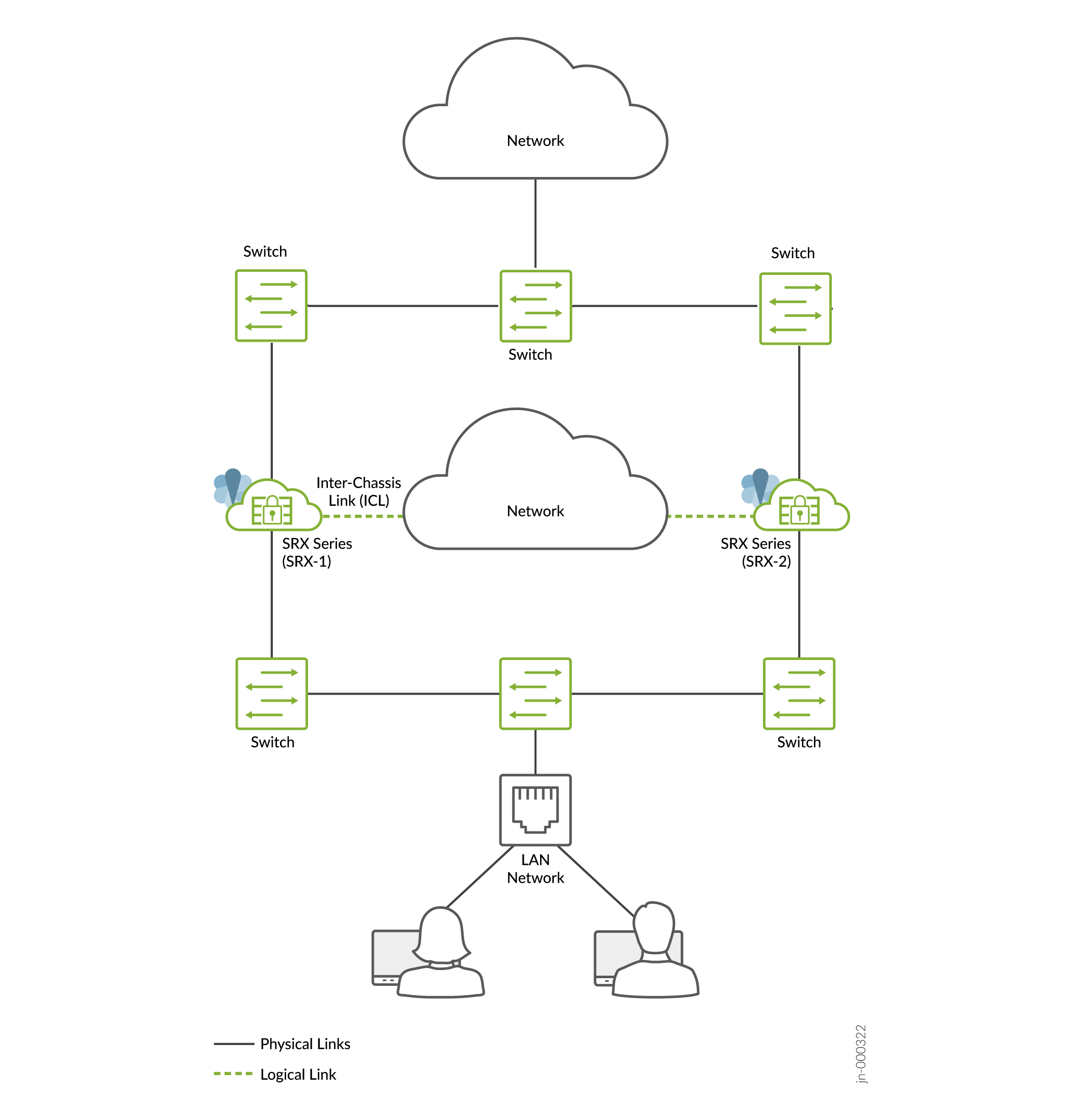 de gateway padrão
de gateway padrão
- Modo híbrido (uma ou mais interfaces são conectadas usando uma topologia de Camada 3 e uma ou mais interfaces são conectadas usando uma topologia de Camada 2)
Figura 3: Modo
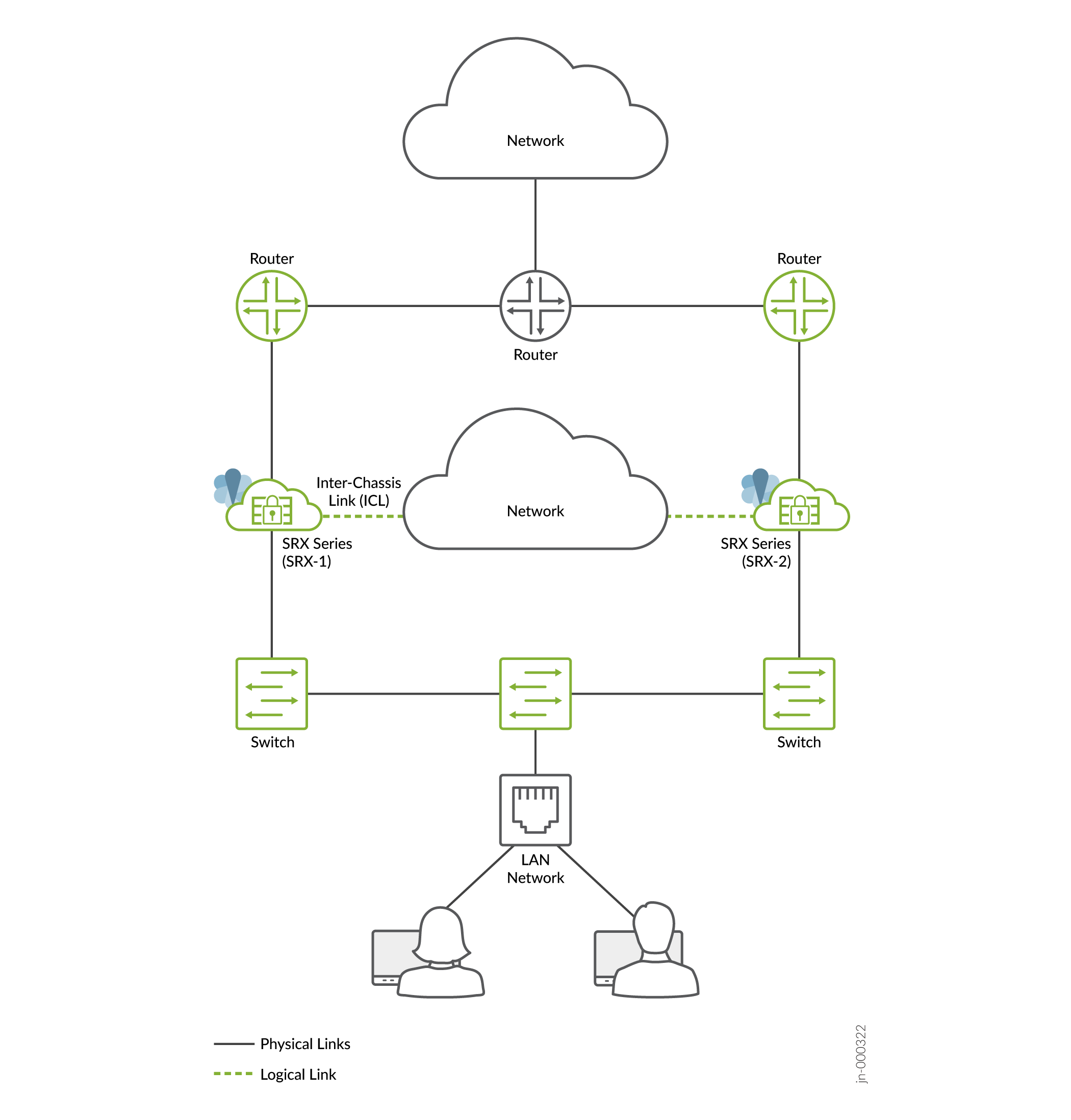 híbrido
híbrido
- Implantação de nuvem pública
Figura 4: Implantação de nuvem pública (exemplo: AWS)
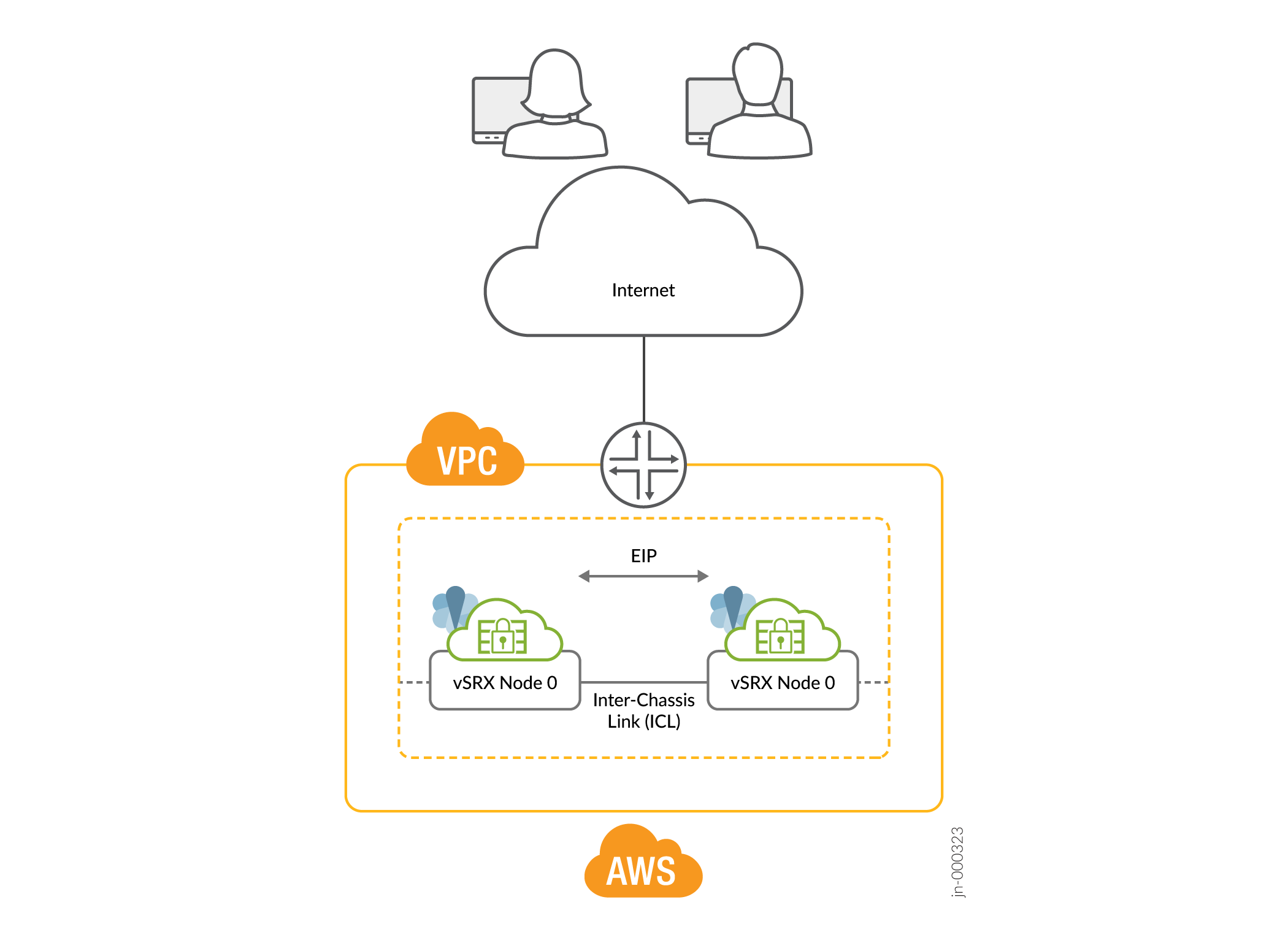
Como funciona a alta disponibilidade de dois nós e múltiplos nós
Oferecemos suporte a uma configuração de dois nós para a solução de alta disponibilidade de múltiplos nós.
Em uma configuração de alta disponibilidade de vários nós, você conecta dois firewalls da Série SRX a roteadores upstream e downstream adjacentes (para implantações de Camada 3), roteadores e switches (implantação híbrida) ou switches (implantação de gateway padrão) usando as interfaces de receita.
Os nós se comunicam entre si usando um enlace de interchassis (ICL). O enlace ICL usa conectividade de Camada 3 para se comunicar entre si, Essa comunicação pode ocorrer por meio de uma rede roteada (Camada 3) ou de um caminho de Camada 2 conectado diretamente. É recomendável vincular a ICL à interface de loopback e ter mais de um link físico (LAG/LACP) para garantir a diversidade de caminhos para a mais alta resiliência.
A alta disponibilidade de múltiplos nós opera no modo ativo/ativo para o plano de dados e no modo ativo/backup para serviços do plano de controle. O firewall da Série SRX ativo hospeda o endereço IP flutuante e direciona o tráfego para ele usando o endereço IP flutuante
A alta disponibilidade multinode opera em:
- Modo ativo/ativo (SRG0) para os serviços de segurança
- Modo ativo/backup (SRG1 e superior) para serviços de segurança e sistema
Os endereços IP flutuantes controlados pelo SRG1 ou superior se movem entre os nós. O SRG1+ ativo hospeda e controla o endereço IP flutuante. Em cenários de failover, esse endereço IP "flutua" para outro SRG1 ativo com base na configuração, integridade do sistema ou decisões de monitoramento de caminho. O SRG1+ recém-ativo pode assumir a função de um SRG1 agora em espera e começar a responder às solicitações recebidas.
A Figura 5, a Figura 6 e a Figura 7 mostram implantações nos modos de gateway de Camada 3, híbrido e padrão.
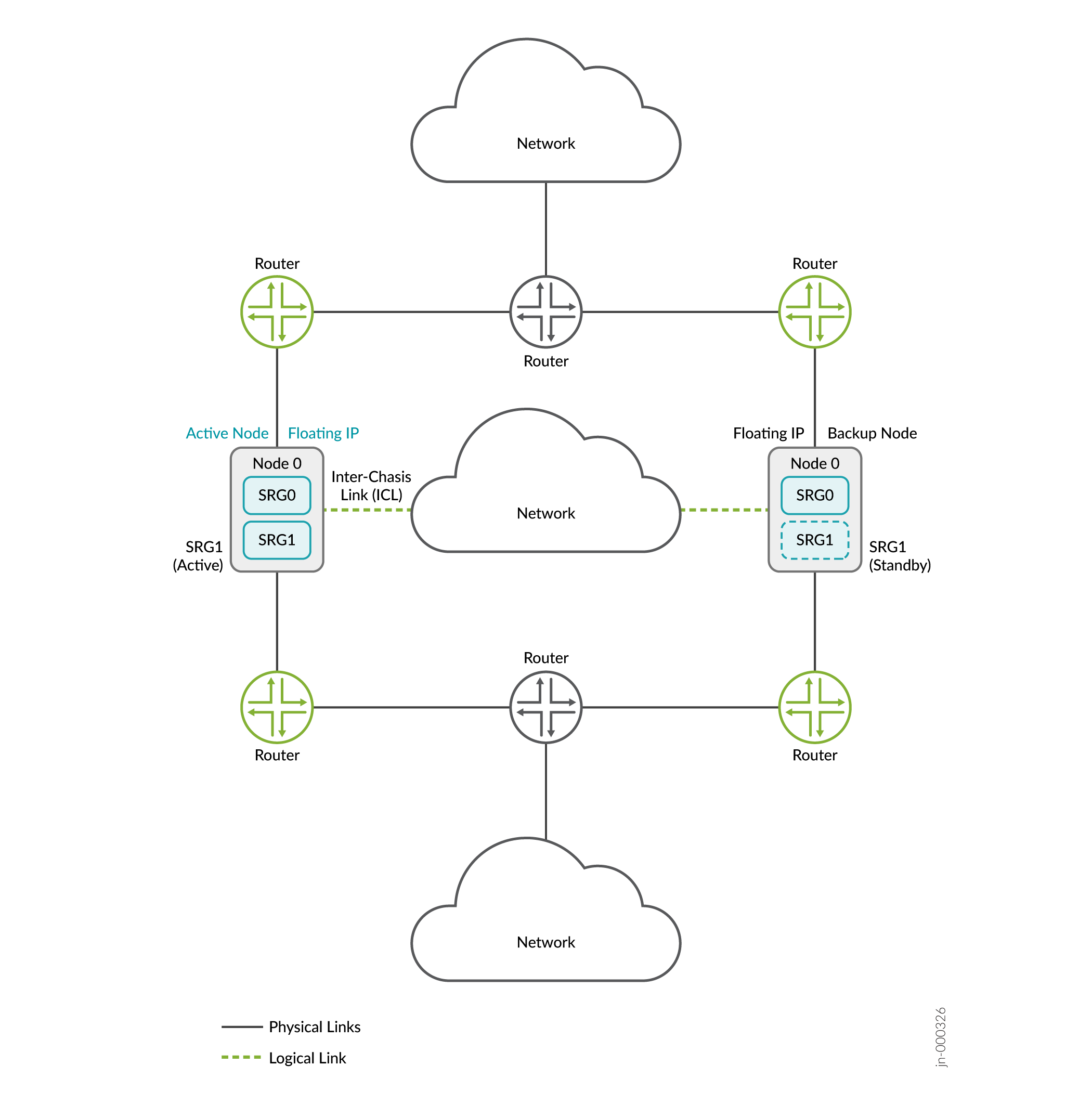 da camada 3
da camada 3
Nessa topologia, dois firewalls da Série SRX fazem parte de uma configuração de alta disponibilidade de múltiplos nós. A configuração tem conectividade de Camada 3 entre os firewalls da Série SRX e os roteadores vizinhos. Os dispositivos estão sendo executados em redes físicas de Camada 3 separadas e estão operando como dois nós independentes. Os nós mostrados na ilustração estão colocalizados na topologia. Os nós também podem ser separados geograficamente.
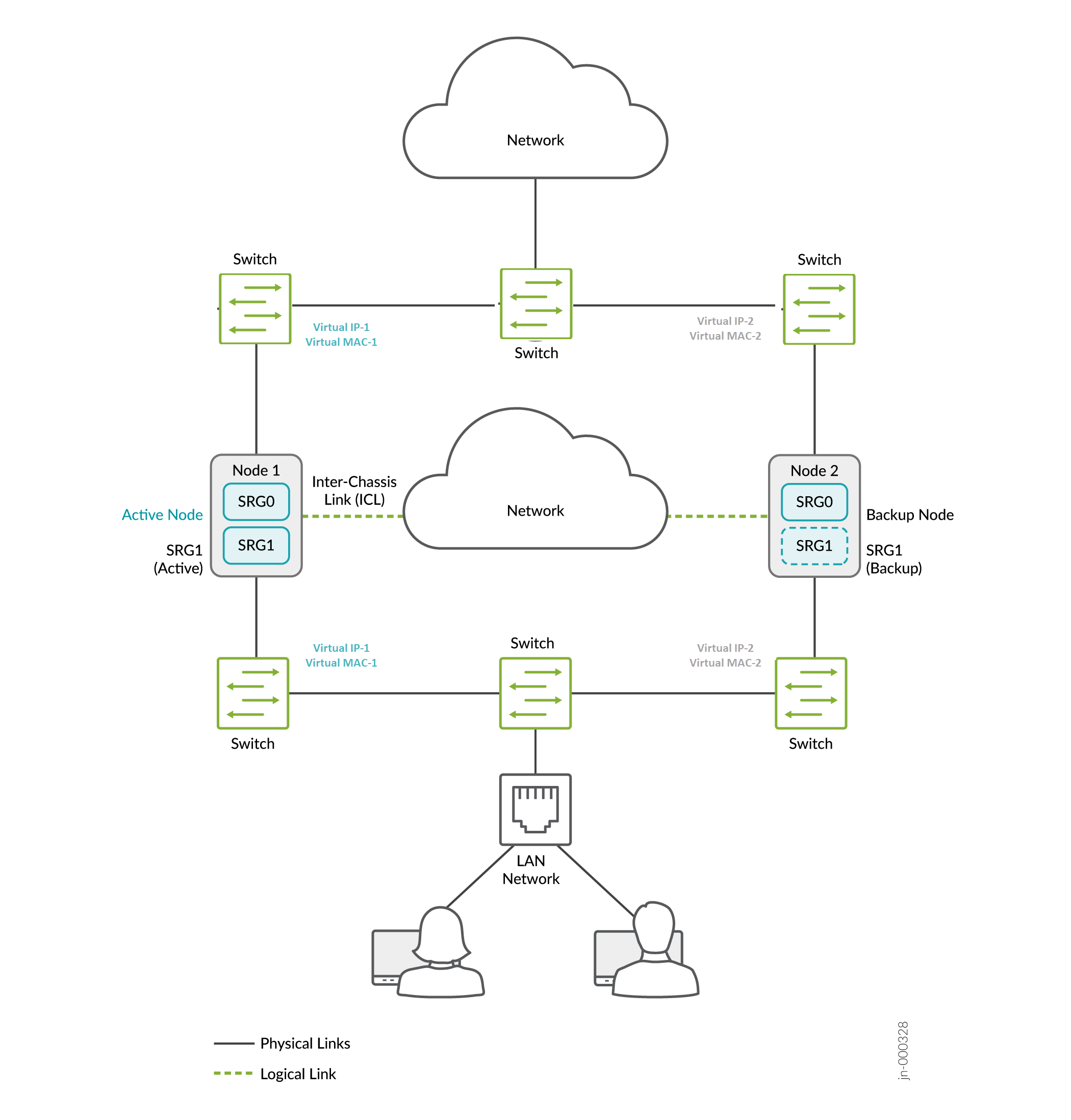 de gateway padrão
de gateway padrão
Em uma implantação típica de gateway padrão, hosts e servidores em uma LAN são configurados com um gateway padrão do dispositivo de segurança. Portanto, o dispositivo de segurança deve hospedar um endereço IP virtual (VIP) que se move entre os nós com base na atividade. A configuração nos hosts permanece estática e o failover do dispositivo de segurança é perfeito do ponto de vista dos hosts.
Você deve criar rotas estáticas ou roteamento dinâmico nos firewalls da Série SRX para alcançar outras redes que não estão conectadas diretamente.
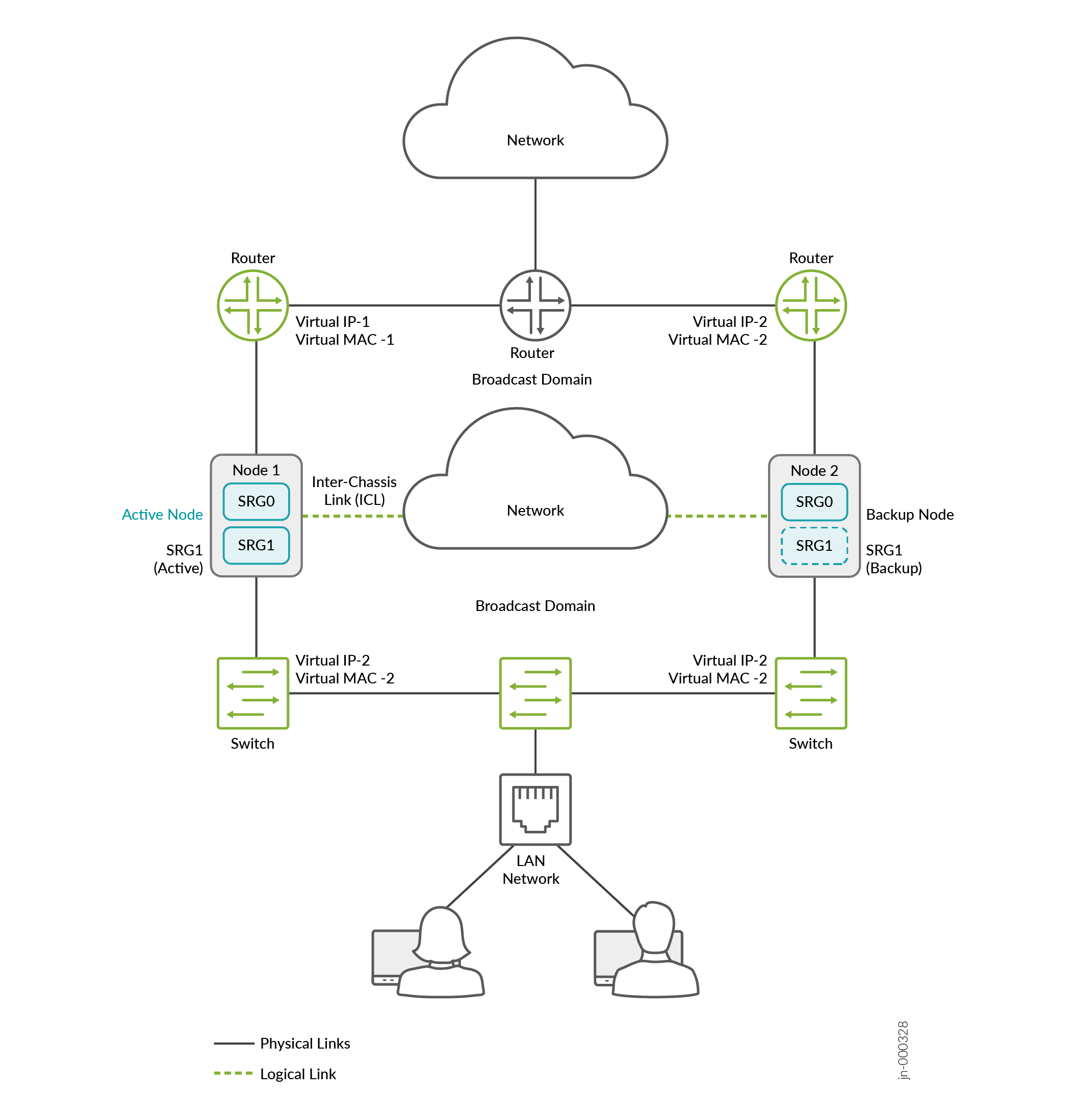 híbrida
híbrida
No modo híbrido, um firewall da Série SRX usa um endereço VIP no lado da Camada 2 para atrair tráfego em sua direção. Opcionalmente, você pode configurar o ARP estático para o VIP usando o endereço VMAC para garantir que não haja alteração no endereço IP durante o failover
Vamos agora entender os componentes e a funcionalidade do Multinode High Availability em detalhes.
- Grupos de redundância de serviços
- Determinação e aplicação de atividade
- Resiliência e failover
- Criptografia de link interchassis (ICL)
Grupos de redundância de serviços
Um grupo de redundância de serviços (SRG) é uma unidade de failover em uma configuração de alta disponibilidade de vários nós. Existem dois tipos de SRGs:
- SRG0 — Gerencia o serviço de segurança da Camada 4 à Camada 7, exceto serviços VPN IPsec. O SRG0 opera no modo ativo em ambos os nós a qualquer momento. No SRG0, cada sessão de segurança deve atravessar o nó em um fluxo simétrico, O backup desses fluxos é totalmente sincronizado com o outro nó,
- SRG1+ — Gerencia serviços IPsec e IPs virtuais para o modo de gateway híbrido e padrão e é feito backup no outro nó. O SRG1 opera no modo ativo em um nó e no nó de backup em outro nó.
A Figura 8 mostra SRG0 e SRG1 em uma configuração de alta disponibilidade de múltiplos nós.
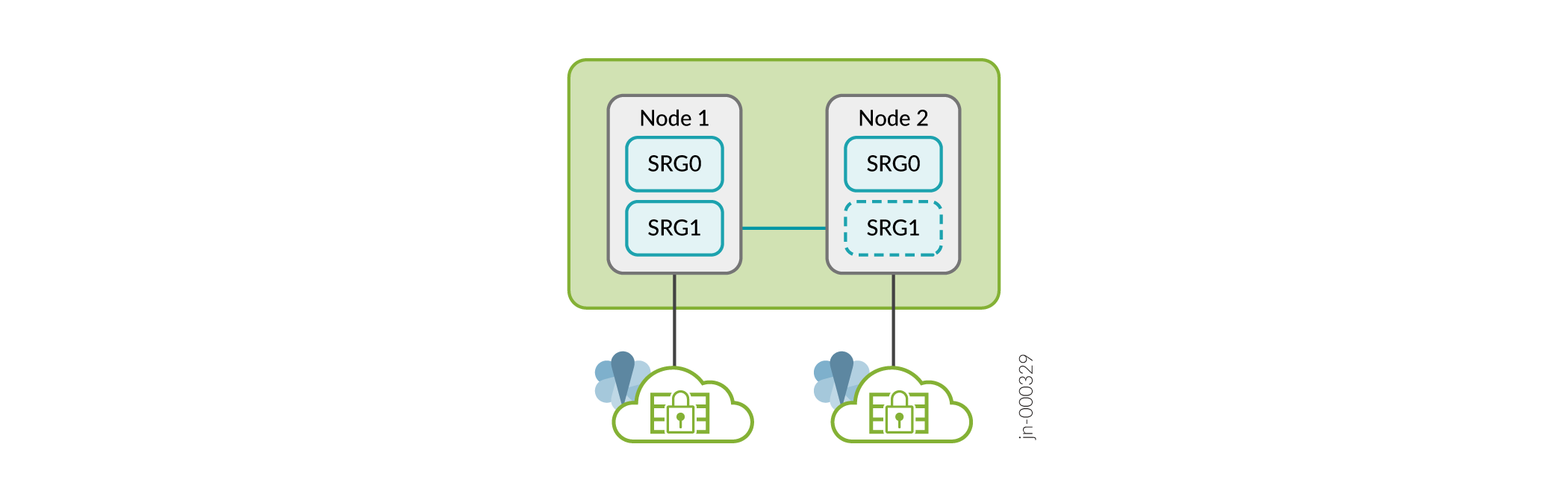
A Figura 9 mostra SRG0 e SRG1+ em uma configuração de alta disponibilidade de múltiplos nós.
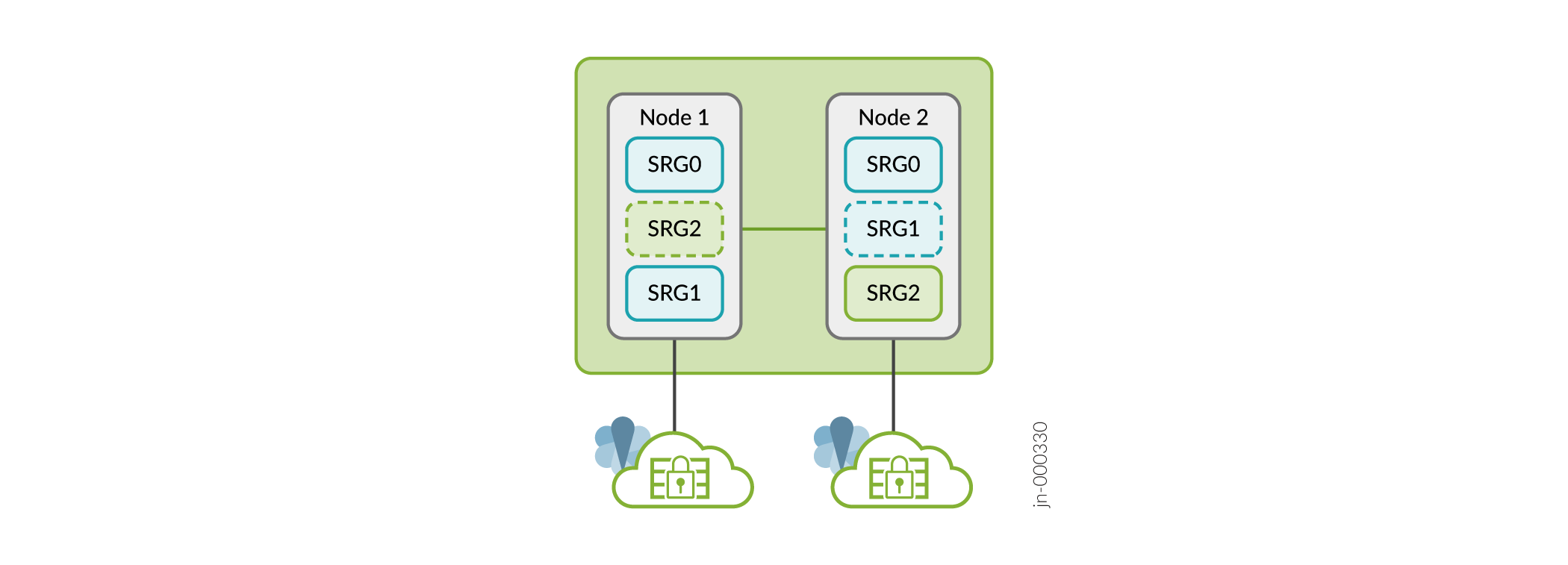
A partir do Junos OS Release 22.4R1, você pode configurar a alta disponibilidade de múltiplos nós para operar em modo ativo-ativo com suporte a multi SRG1s (SRG1+). Nesse modo, alguns SRGs permanecem ativos em um nó e alguns SRGs permanecem ativos em outro nó. Um SRG específico sempre opera no modo de backup ativo; Ele opera no modo ativo em um nó e no modo de backup em outro nó. Nesse caso, ambos os nós podem ter o SRG1 ativo encaminhando serviços stateful. Cada nó tem um conjunto diferente de endereços IP flutuantes atribuídos ao SRG1+.
A partir do Junos OS Release 22.4R1, você pode configurar até 20 SRGs em uma configuração de alta disponibilidade de vários nós.
A Tabela 1 explica o comportamento dos SRGs em uma configuração de alta disponibilidade de vários nós.
| serviços gerenciados | dogrupo de redundância (SRG) | operam no | tipo de sincronização | quando o nó ativo falha Opções de | configuração |
|---|---|---|---|---|---|
| SRG0 | Gerencia o serviço de segurança L4-L7, exceto VPN IPsec. | Modo ativo/ativo | Sincronização dinâmica de serviços de segurança | O tráfego processado no nó com falha fará a transição para o nó íntegro de maneira stateful. |
|
| SRG1+ | Gerencia endereços IPsec e IP virtuais com serviços de segurança associados | Modo ativo/backup | Sincronização dinâmica de serviços de segurança | O tráfego processado no nó com falha fará a transição para o nó íntegro de maneira stateful. |
|
Ao configurar opções de monitoramento (BFD, IP ou Interface) no SRG1+, recomendamos não configurar a opção shutdown-on-failure no SRG0.
A partir do Junos OS Release 23.4R1, a configuração de alta disponibilidade de múltiplos nós opera em modo combinado. Você não precisa reinicializar o sistema ao adicionar ou excluir qualquer configuração SRG (SRG0 ou SRG1+).
Determinação e aplicação de atividade
Em uma configuração de alta disponibilidade de vários nós, a atividade é determinada no nível de serviço, não no nível do nó. O estado ativo/backup está no nível SRG e o tráfego é direcionado para o SRG ativo. O SRG0 permanece ativo em ambos os nós, enquanto o SRG1 pode permanecer ativo ou no estado de backup em cada nó
Se você preferir que um determinado nó assuma o controle como o nó ativo na inicialização, você pode fazer o seguinte:
- Configure os roteadores upstream para incluir preferências para o caminho onde o nó está localizado.
- Configure a prioridade de ativação.
- Permita que o nó com ID de nó mais alto (caso as duas opções acima não estejam configuradas) assuma a função ativa.
Em uma configuração de alta disponibilidade multinode, ambos os firewalls da Série SRX anunciam inicialmente a rota do endereço IP flutuante para os roteadores upstream. Não há uma preferência específica entre os dois caminhos anunciados pelos firewalls da Série SRX. No entanto, o roteador pode ter suas próprias preferências em um dos caminhos, dependendo das métricas configuradas.
A Figura 10 representa a sequência de eventos para determinação e imposição de ativação.
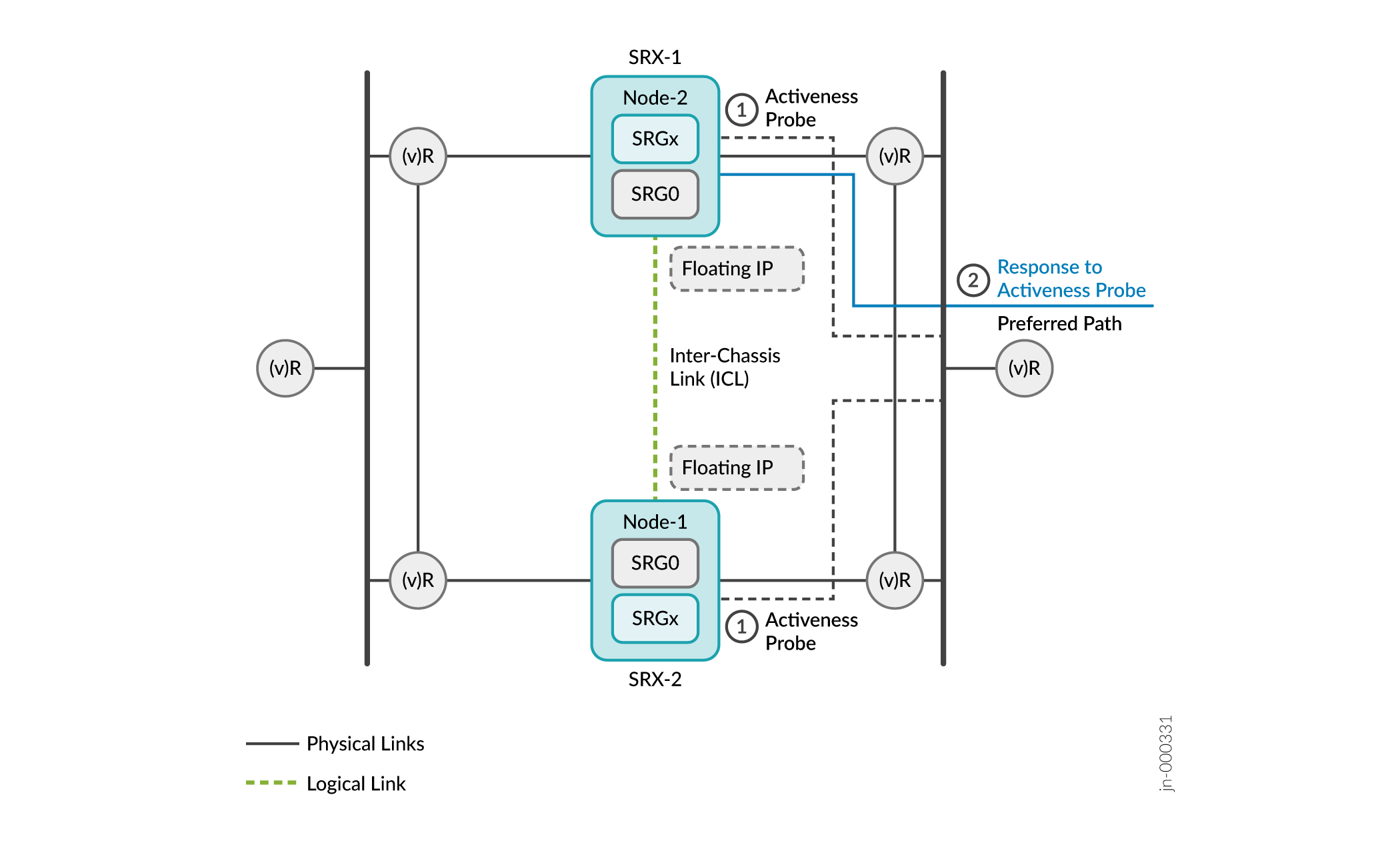 de atividade
de atividade
- Na inicialização, os dispositivos entram no estado de espera e começam a sondar continuamente. Os dispositivos usam o endereço IP flutuante (endereço IP de origem de sondagem de ativação) como o endereço IP de origem e os endereços IP dos roteadores upstream como o endereço IP de destino para a sonda de determinação de atividade.
-
O roteador que hospeda o endereço IP de destino da sonda responde ao firewall da Série SRX que está disponível em seu caminho de roteamento preferido. No exemplo a seguir, o SRX-1 recebe a resposta do roteador upstream.
Figura 11: Determinação e aplicação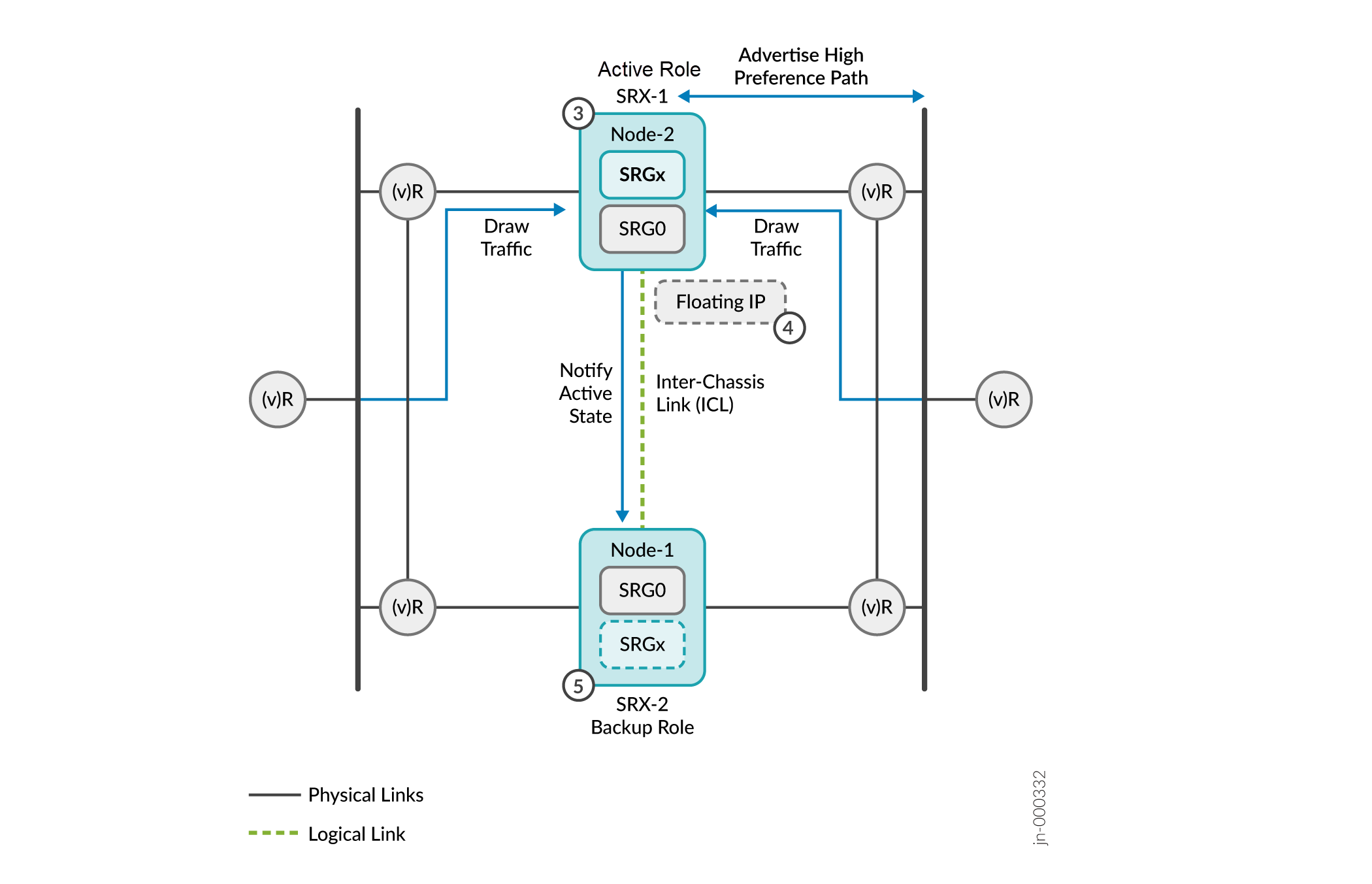 da atividade
da atividade
-
O SRX-1 se promove à função ativa desde que recebeu a resposta da sondagem. O SRX-1 comunica sua mudança de função ao outro dispositivo e assume o papel ativo.
-
Após a determinação da atividade, o nó ativo (SRX-1):
- Hospeda o endereço IP flutuante atribuído a ele.
- Anuncia o caminho de alta preferência para vizinhos BGP adjacentes.
- Continua a anunciar o caminho de preferência ativo (superior) para todas as rotas remotas e locais para atrair o tráfego.
- Notifica o status do nó ativo para o outro nó por meio da ICL.
-
O outro dispositivo (SRX-2) interrompe a sondagem e assume a função de backup. O nó de backup anuncia a prioridade padrão (inferior), garantindo que os roteadores upstream não encaminhem nenhum pacote para o nó de backup.
O módulo de alta disponibilidade de múltiplos nós adiciona rotas de sinal ativas e de backup para o SRG à tabela de roteamento quando o nó se move para a função ativa. Em caso de falhas de nó, a ICL fica inativa e o nó ativo atual libera sua função ativa e remove a rota de sinal ativa. Agora, o nó de backup detecta a condição por meio de suas sondas e faz a transição para a função ativa. A preferência de rota é trocada para direcionar todo o tráfego para o novo nó ativo.
O switch no anúncio de preferência de rota faz parte das políticas de roteamento configuradas nos firewalls da Série SRX. Você deve configurar a política de roteamento para incluir a rota de sinal ativa com a if-route-exists condição.
- Para implantações de gateway padrão
- para implantações híbridas
- Prioridade e preempção de ativação
- Definindo as configurações da sonda de ativação
Para implantações de gateway padrão
Se ambos os nós estiverem inicializando ao mesmo tempo, o sistema de alta disponibilidade de vários nós usará o valor de prioridade configurado de um SRG para determinar a atividade. A aplicação de ativação ocorre quando o nó com um SRG1+ ativo possui o endereço IP virtual (VIP) e o endereço MAC virtual (VMAC). Essa ação aciona o ARP gratuito (GARP) em direção aos switches em ambos os lados e resulta na atualização das tabelas MAC nos switches.
para implantações híbridas
A aplicação da atividade ocorre no lado da Camada 3, quando a rota de sinal configurada impõe a ativação com os anúncios de rota correspondentes. No lado da Camada 2, o firewall da Série SRX aciona um ARP gratuito (GARP) para a camada de switch e possui os endereços VIP e VMAC
Quando o failover acontece e o nó de backup antigo faz a transição para a função ativa, a preferência de rota é trocada para direcionar todo o tráfego para o novo nó ativo.
Prioridade e preempção de ativação
Configure a prioridade de preempção (1-254) para SRG1+. Você deve configurar o valor de preempção em ambos os nós. A opção preempt garante que o tráfego sempre volte para o nó especificado, quando o nó se recupera de um failover.
Você pode configurar a prioridade de ativação e a preempção para um SRG1+ como no exemplo a seguir:
[edit]
user@host# show chassis high-availability
services-redundancy-group 1 {
preemption;
activeness-priority 200;
}
Consulte Configuração de Alta Disponibilidade de Vários Nós em uma Rede de Camada 3 para obter o exemplo de configuração completo.
Desde que os nós possam se comunicar entre si por meio da ICL, a prioridade de ativação é honrada.
Definindo as configurações da sonda de ativação
A partir do Junos OS 22.4R1, gateway padrão (comutação) e em implantações híbridas de alta disponibilidade de múltiplos nós, você pode, opcionalmente, configurar parâmetros de sondagem de ativação usando as seguintes declarações:
[edit] user@host# set chassis high-availability services-redundancy-group 1 activeness-probe multiplier <> user@host# set chassis high-availability services-redundancy-group 1 activeness-probe minimal-interval <>
O intervalo de sondagem define o período de tempo entre as sondas enviadas aos endereços IP de destino. Você pode definir o intervalo de sondagem como 1000 milissegundos.
O valor do multiplicador determina o período de tempo, após o qual o nó de backup faz a transição para o estado ativo, se o nó de backup não receber resposta às sondas de ativação do nó de peer.
O padrão é 2, o valor mínimo é 2 e o máximo é 15.
Exemplo: Se você configurar o valor do multiplicador como dois, o nó de backup fará a transição para o estado ativo se não receber uma resposta à solicitação de sondagem de ativação do nó peer após dois segundos.
Você pode configurar multiplier e minimal-interval em implantações híbridas e de comutação.
Em implantações de modo híbrido, se você tiver configurado os detalhes do IP de destino da investigação para determinação da atividade (usando a activeness-probe dest-ip instrução), não configure os multiplier valores e minimal-interval . Configure esses parâmetros quando estiver usando a sondagem de ativação baseada em VIP.
Resiliência e failover
A solução Multinode High Availability oferece suporte à redundância no nível de serviço. A redundância no nível de serviço minimiza o esforço necessário para sincronizar o plano de controle entre os nós.
Depois que a configuração de alta disponibilidade de vários nós determina a atividade, ela negocia o estado de alta disponibilidade (HA) subsequente por meio da ICL. O nó de backup envia sondas ICMP usando o endereço IP flutuante. Se a ICL estiver ativa, o nó obterá a resposta à sondagem e permanecerá como o nó de backup. Se a ICL estiver inativa e não houver resposta de sondagem, o nó de backup fará a transição para o nó ativo.
O SRG1 do nó de backup anterior agora faz a transição para o estado ativo e continua a operar perfeitamente. Quando a transição acontece, o endereço IP flutuante é atribuído ao SRG1 ativo. Dessa forma, o endereço IP flutua entre os nós ativos e de backup e permanece acessível a todos os hosts conectados. Assim, o tráfego continua a fluir sem qualquer interrupção.
Serviços, como VPN IPsec, que exigem estados de plano de controle e plano de dados são sincronizados entre os nós. Sempre que um nó ativo falha para essa função de serviço, o plano de controle e o plano de dados fazem failover para o nó de backup ao mesmo tempo.
Os nós usam as seguintes mensagens para sincronizar dados:
- Mensagens do aplicativo de controle do Mecanismo de Roteamento para o Mecanismo de Roteamento
- Mecanismo de Roteamento Mensagens relacionadas à configuração
- Mensagens RTO do plano de dados
Criptografia de link interchassis (ICL)
Na alta disponibilidade de múltiplos nós, os nós ativos e de backup se comunicam entre si usando um enlace de interchassis (ICL) conectado em uma rede roteada ou conectado diretamente. A ICL é um link IP lógico e é estabelecido usando endereços IP que são roteáveis na rede.
Os nós usam a ICL para sincronizar os estados do plano de controle e do plano de dados entre eles. A comunicação da ICL pode passar por uma rede compartilhada ou não confiável, e os pacotes enviados pela ICL podem atravessar um caminho que nem sempre é confiável. Portanto, você deve proteger os pacotes que atravessam a ICL criptografando o tráfego usando padrões IPsec.
O IPsec protege o tráfego estabelecendo um túnel de criptografia para a ICL. Quando você aplica a criptografia de link de HA, o tráfego de HA flui entre os nós somente por meio do túnel seguro e criptografado. Sem a criptografia de link de HA, a comunicação entre os nós pode não ser segura.
Para criptografar o link de HA para a ICL:
- Instale o pacote Junos IKE em seu firewall da Série SRX usando o seguinte comando:
request system software add optional://junos-ike.tgz. - Configure um perfil VPN para o tráfego de HA e aplique o perfil para ambos os nós. O túnel IPsec negociado entre os firewalls da Série SRX usa o protocolo IKEv2.
-
Certifique-se de ter incluído a declaração ha-link-encryption em sua configuração de VPN IPsec. Exemplo: user@host# definir segurança ipsec vpn vpn-name ha-link-encryption.
Recomendamos o seguinte para configurar uma ICL:
-
Use portas e redes com menor probabilidade de estarem saturadas.
-
Não usar as portas de HA dedicadas (portas de controle e de malha, se disponíveis no firewall da Série SRX)
-
Vincule a ICL à interface de loopback (lo0) ou a uma interface Ethernet agregada (ae0) e tenha mais de um link físico (LAG/LACP) que garante a diversidade de caminhos para maior resiliência.
-
Você pode usar uma porta Ethernet de receita nos firewalls da Série SRX para configurar uma conexão ICL. Certifique-se de separar o tráfego de trânsito nas interfaces de receita do tráfego de alta disponibilidade (HA).
-
Uma verificação de validação foi introduzida para restringir a configuração do MTU do túnel para túneis de criptografia de link de HA em uma configuração de alta disponibilidade de vários nós. A verificação de validação garante que a MTU de ponta a ponta para links de HA usando criptografia IPv6 atenda ao requisito mínimo de 2000 bytes, ajudando a manter o desempenho e a confiabilidade ideais durante operações de alta disponibilidade.
Por exemplo, se sua configuração incluir a seguinte sub-rotina em que túnel-mtu é menor que 2000, você receberá um erro de verificação de confirmação: user@host# set security ipsec vpn L3HA_IPSEC_VPN túnel-mtu <bytes>
Consulte Configurando a Alta Disponibilidade de Vários Nós , para obter mais detalhes.
Criptografia de link baseada em PKI para ICL
A partir do Junos OS Release 22.3R1, oferecemos suporte à criptografia de enlace baseada em PKI para enlace de interchassis (ICL) em alta disponibilidade de múltiplos nós. Como parte desse suporte, agora você pode gerar e armazenar objetos PKI específicos do nó, como pares de chaves locais, certificados locais e solicitações de assinatura de certificado em ambos os nós. Os objetos são específicos para nós locais e são armazenados em locais específicos em ambos os nós.
Os objetos locais do nó permitem distinguir entre objetos PKI usados para criptografia ICL e objetos PKI usados para túnel VPN IPsec criado entre dois pontos de extremidade.
Você pode usar os comandos a seguir executados no nó local para trabalhar com objetos PKI específicos do nó.
| Gerando um par de chaves privada/pública para um nó local | |
| Gerando e registrando um certificado digital local em um nó local |
|
| Limpar certificados específicos do nó | |
| Exiba certificados locais específicos do nó e solicitações de certificado. |
Em seu dispositivo de segurança em Alta Disponibilidade de Vários Nós, se você tiver configurado a opção de reinscrição automática e se a ICL ficar inativa no momento do gatilho de reinscrição, ambos os dispositivos começarão a registrar o mesmo certificado separadamente com o servidor de CA e baixarão o mesmo arquivo CRL. Depois que a alta disponibilidade de vários nós restabelece a ICL, a configuração usa apenas um certificado local. Você deve sincronizar os certificados do nó ativo para o nó de backup usando o user@host> request security pki sync-from-peer comando no nó de backup.
Se você não sincronizar os certificados, o problema de incompatibilidade de certificado entre nós pares persistirá até a próxima nova inscrição.
Opcionalmente, você pode habilitar o TPM (módulo de plataforma confiável) em ambos os nós antes de gerar qualquer par de chaves nos nós. Consulte Usando o módulo de plataforma confiável para vincular segredos em dispositivos da Série SRX.
Detecção e Prevenção de Split-Brain
A detecção de cérebro dividido ou o conflito de atividade acontece quando a ICL entre dois nós de alta disponibilidade de vários nós está inativa e ambos os nós não podem mais se comunicar para obter o status de nó de mesmo nível.
- Sondagem de cérebro dividido baseada em ICMP
- Sondagem de cérebro dividido baseada em BFD
- Configurar a sondagem Split-Brain
- Suporte a sistemas lógicos e sistemas de locatário
Sondagem de cérebro dividido baseada em ICMP
Considere um cenário em que dois dispositivos da Série SRX fazem parte da configuração de alta disponibilidade de múltiplos nós. Vamos considerar o SRX-1 como nó local e o nó remoto SRX-2. O nó local está atualmente em função ativa e hospedando endereço IP flutuante para direcionar o tráfego para ele. O roteador upstream tem um caminho de prioridade mais alta para o nó local.
Quando a ICL entre os nós fica inativa, ambos os nós iniciam uma sonda de determinação de atividade (sonda ICMP). Os nós usam o endereço IP flutuante (endereço IP de determinação de atividade) como endereço IP de origem e endereços IP dos roteadores upstream como endereço IP de destino para as sondas.
Caso 1: Se o nó ativo estiver ativo
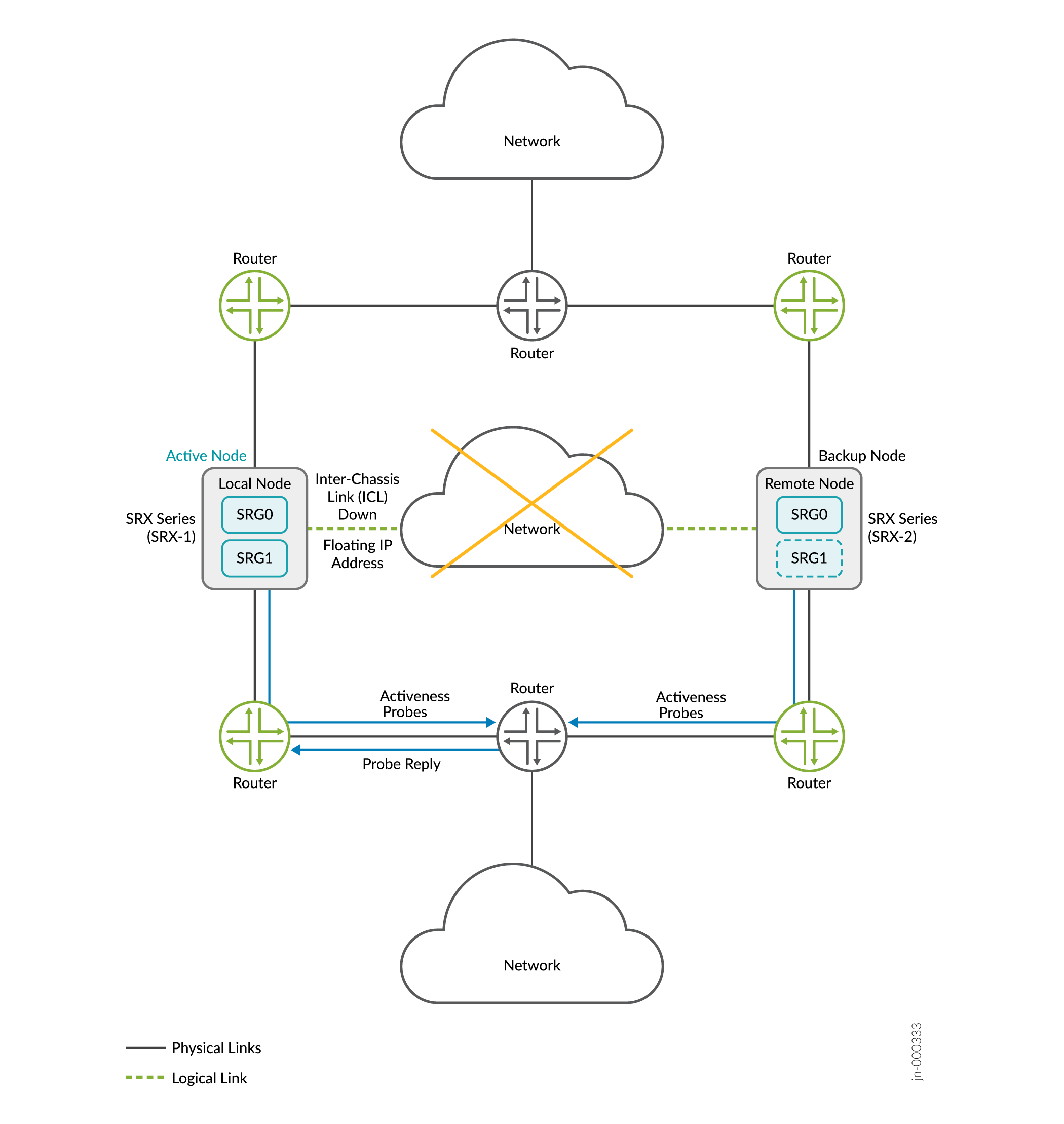
- O roteador upstream, que hospeda o endereço IP de destino da sonda, recebe as sondas ICMP de ambos os nós.
- O roteador upstream responde apenas ao nó ativo; porque sua configuração tem um caminho de preferência mais alto para o nó ativo
- O nó ativo retém a função ativa.
Se o nó ativo estiver inativo:
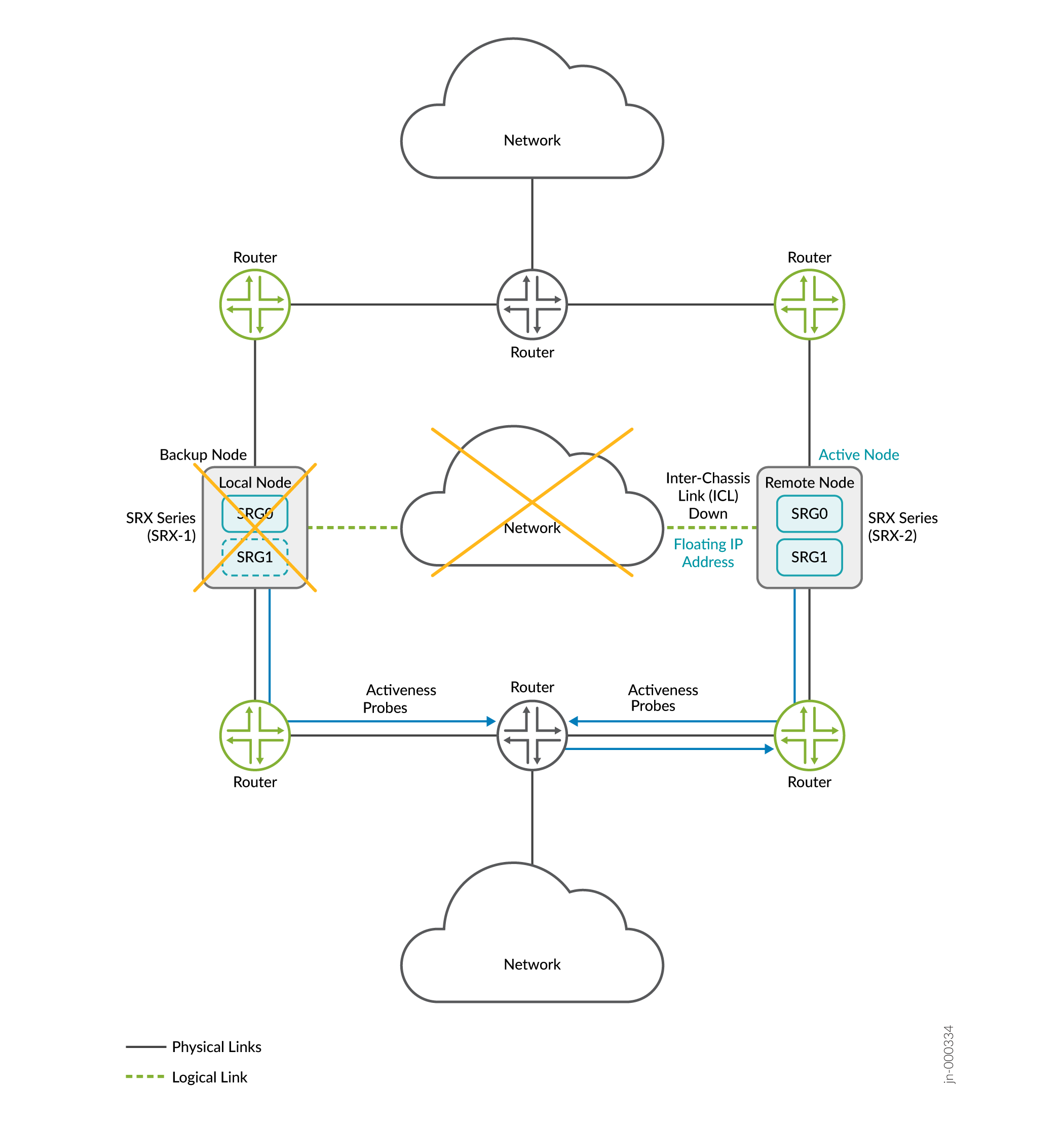
- O nó remoto reinicia as sondas de determinação de atividade.
- O roteador que hospeda o endereço IP de destino da sondagem perdeu seu caminho de preferência mais alto (do antigo nó ativo) e responde ao nó remoto.
- O resultado da sondagem é um sucesso para o nó remoto e o nó remoto faz a transição para o estado ativo.
- Como demonstrado nos casos acima, as sondas de determinação de atividade e a configuração de preferência de caminho mais alta no roteador upstream garantem que um nó sempre permaneça na função ativa e evita a ocorrência de split-brain.
Sondagem de cérebro dividido baseada em BFD
No Junos OS Release 23.4R1, oferecemos suporte à sondagem de cérebro dividido baseada em BFD para gateway padrão e modo híbrido de implantações para alta disponibilidade de vários nós.
A falha do Interchassis Link (ICL) geralmente pode ser atribuída a dois fatores principais: interrupções na rede ou configurações inconsistentes. Você pode usar o teste de ativação para determinar o nó que pode assumir a função ativa para cada SRG1+. Com base no resultado da sondagem, um dos nós faz a transição para o estado ativo e essa ação evita o cenário de cérebro derramado.
Com a sondagem de cérebro dividido baseada em BFD, agora você pode ter um controle mais granular sobre as sondas, pois pode definir a interface, o intervalo mínimo e os multiplicadores. Na sondagem de cérebro dividido baseada em BFD, a sondagem começa imediatamente após um SRG ser configurado e começar a funcionar. Na sondagem de cérebro dividido baseada em ICMP padrão, a sondagem começa somente depois que o enlace ICL cai.
Em comparação, a sondagem baseada em BFD é muito mais proativa das seguintes maneiras para garantir uma resposta mais rápida para evitar cenários de cérebro dividido:
-
A sondagem é iniciada diretamente após uma configuração SRG.
-
Se o BFD ICL e a sonda de cérebro dividido quebrarem ao mesmo tempo, o nó de backup assumirá imediatamente a função ativa e assumirá o VIP.
Isso garante uma resposta mais rápida para evitar cenários de cérebro dividido.
Como funciona?
Quando a ICL está inativa e ambos os dispositivos estão inicializando, os nós inicialmente entram em um estado HOLD e aguardam que o nó peer seja ativado e se conecte. Por qualquer motivo, se o outro nó não aparecer, o sistema inicia sondas cerebrais divididas para os endereços IP hospedados em diferentes dispositivos na rede. Se o processo for concluído com êxito, um nó fará a transição para ativo e o outro para backup. Antes do sucesso da sondagem, se ocorrer alguma falha de monitoramento de caminho/falha interna do monitor de hardware, ambos os nós se tornarão inelegíveis para evitar um cenário de cérebro dividido.
Se a sonda de cérebro dividido falhar por qualquer motivo, os nós permanecerão no estado HOLD e continuarão a sondagem. O IP da sonda de cérebro dividido deve estar sempre disponível na rede. Com exceção do IPsec, todo o tráfego de aplicativos não sofrerá perda no SRX, desde que o roteamento esteja disponível, mesmo no estado HOLD.
Quando ambos os nós estiverem no estado Hold ou Inelegível, nenhum tráfego será encaminhado até que o nó se torne ativo/backup novamente.
Observação:
- O cérebro dividido é baseado nas sondas de atividade diferentes das sondas do monitor de caminho. Ele só é acionado quando a ICL/comunicação é interrompida entre os nós MNHA
- Quando o Interchassis Link (ICL) entre os nós é quebrado, ambos os nós iniciam sondas cerebrais divididas. O nó ativo mantém o domínio enquanto sua sonda não falhar. Recomenda-se hospedar o IP de sondagem em um caminho que garanta a acessibilidade contínua, desde que o nó da Série SRX esteja íntegro. Uma mudança de estado será acionada somente se a investigação do nó ativo atual falhar e a investigação do nó de backup atual for bem-sucedida.
- Nos modos de comutação e híbridos, o direcionamento de tráfego usa o IP virtual (VIP), que só funciona no estado ACTIVE. O sistema não deve permanecer no estado HOLD após o temporizador de espera expirar, pois ele sondará o peer MNHA para resolver a situação de cérebro dividido.
Diferença na sondagem baseada em ICMP e baseada em BFD
A tabela a seguir mostra as diferenças na sondagem baseada em ICMP e na sondagem baseada em BFD para detecção de cérebro dividido.
| Parâmetros |
Sondagem baseada em ICMP |
Sondagem baseada em BFD |
|---|---|---|
| Tipo de sonda | Pacote ICMP | Pacote BFD, BFD de salto único |
| Intervalo mínimo | 1000 ms | O intervalo mínimo de BFD do firewall da Série SRX depende da plataforma. Por exemplo: Firewalls SRX5000-line com SPC3, o intervalo é de 100 ms. SRX4200, o intervalo é de 300ms. |
| Sondagens de nó de backup SRG | Sim | Sim |
| Sondagens de nó ativo SRG | Não | Sim |
| Resolução de cérebro dividido SRG quando a ICL está inativa | Somente quando a ICL cair. | Depois que o SRG estiver configurado. |
| Não é possível | Possível | |
| Opções de configuração |
show chassis
high-availability services-redundancy-group 1
activeness-probe
dest-ip {
192.168.21.1;
src-ip 192.168.21.2;
} |
show chassis
high-availability services-redundancy-group 1
activeness-probe
bfd-liveliness {
source-ip 192.168.21.1; (inet address of the local SRX sub interface)
destination-ip 192.168.21.2; (inet address of the peers SRX sub interface)
interface xe-0/0/1.0;
} |
A figura a seguir mostra as opções de configuração para sondagem baseada em ICMP e sondagem baseada em BFD para detecção de cérebro dividido.
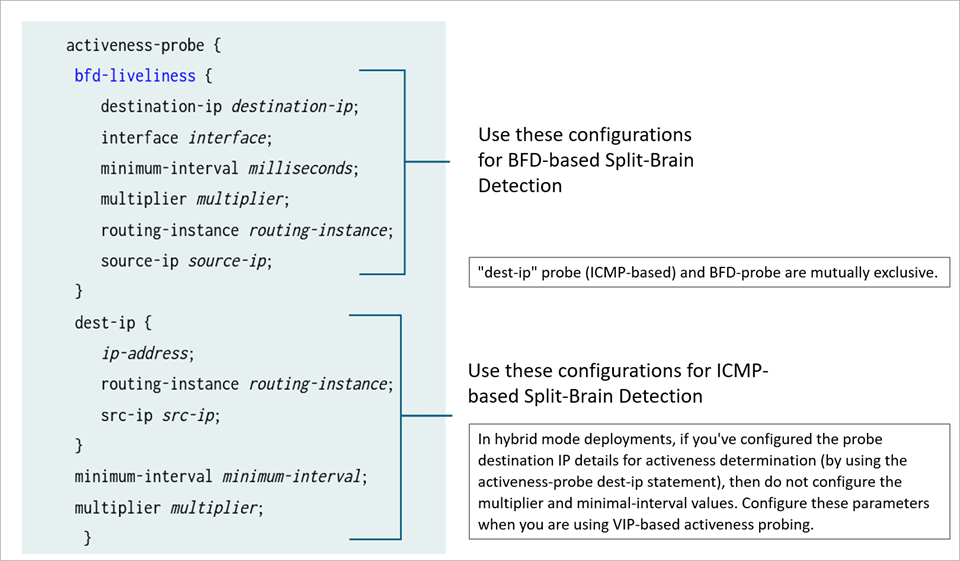 baseada em ICMP e BFD
baseada em ICMP e BFD
A sondagem baseada em ICMP e as sondas baseadas em BFD são mutuamente exclusivas.
No modo híbrido e nas implantações de gateway padrão, você pode configurar o intervalo e o limite de sondagem de atividade nos dois níveis a seguir:
-
Nível global aplicável à sondagem de cérebro dividido baseada em ICMP
-
Nível BFD-Liveliness que é específico para a sonda de cérebro dividido BFD. Ao configurar a sondagem baseada em BFD, não configure global
minimum-intervalemultiplieroptions underactiveness-probedeclaração.
Para configurar a sonda de ativação para implantações de gateway padrão, use a interface de endereço IP virtual primário (VIP1) em ambos os nós (local e peer) para configurar sua sonda de ativação. O IP de destino é do nó peer e o IP de origem é do nó local. Ambos os VIPs devem ter o mesmo valor de índice. Os endereços IP devem ser os endereços inet atribuídos à interface LAN do firewall da Série SRX.
Configurar a sondagem Split-Brain
Você pode configurar a sondagem de cérebro dividido em uma configuração de alta disponibilidade de nó multinó das seguintes maneiras:-
Roteamento e modo híbrido — Se você configurou os detalhes do IP de destino da sonda para determinação da atividade (usando a
activeness-probe dest-ipdeclaração), não configure os valores de multiplicador e intervalo mínimo. Configure esses parâmetros quando estiver usando a sondagem de ativação baseada em VIP.[edit] [set chassis high-availability services-redundancy-group 1 activeness-probe dest-ip <neighbor_ip_address> src-ip <srx_anycast_IP>]
-
Modo híbrido e de comutação — sondagem de cérebro dividido de Camada 2 usando ICMP. Use o tipo de sondagem ICMP e defina o intervalo e o limite de tempo limite usando a seguinte declaração:
[edit] [set chassis high-availability services-redundancy-group 1 activeness-probe minimum-interval <interval> multiplier <integer>
-
Modo híbrido e de comutação — sondagem de cérebro dividido de Camada 2 usando BFD. Use o tipo de sonda BFD e defina o limite de tempo limite que pode ser inferior a um segundo com base no intervalo mínimo de BFD configurado.
[edit] [set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness source-ip <ip-address> destination-ip <ip-address> interface <vip1_ifl_interface> minimum-interval <interval> multiplier <integer>
A Figura 15 mostra a topologia de exemplo. Dois firewalls da Série SRX são conectados a roteadores adjacentes no lado da confiança e da desconfiança, formando uma vizinhança BGP. Um enlace de interchassis lógico (ICL) criptografado conecta os nós em uma rede roteada. Os nós se comunicam entre si usando um endereço IP roteável (endereço IP flutuante) pela rede.
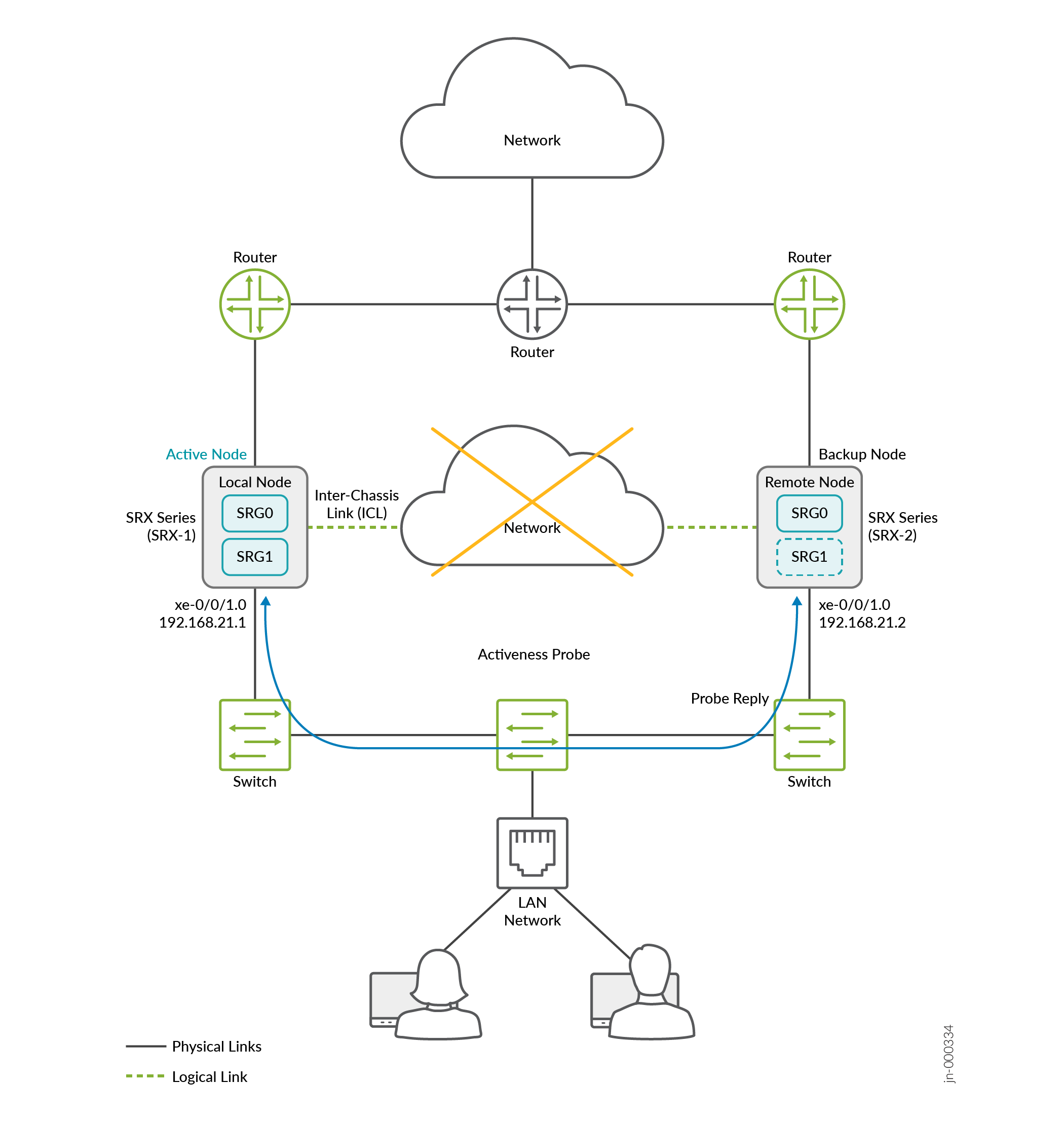 de cérebro dividido
de cérebro dividido
Vamos considerar o SRX-1 como um nó local e o SRX-2 como um nó remoto. O nó local está atualmente em função ativa e o roteador upstream tem um caminho de prioridade mais alta para o nó local.
Para activeness-probe, você deve configurar as seguintes opções:
-
Endereço IP de origem: use o endereço IP virtual 1 (VIP1) do SRG1 do nó local.
-
Endereço IP de destino: use o VIP1 do SRG1 do nó de peer.
-
Interface: Interface associada ao VIP1
Neste exemplo, atribua um endereço IP virtual (VIP) (192.168.21.1) e uma interface xe-0/0/1.0 para animação BFD. Aqui, você configura a sondagem de cérebro dividido baseada em BFD especificando os endereços IP de origem e destino e a interface.
Os nós usam o endereço inet da família da interface associada ao endereço IP virtual (VIP1) do SRG1.
Ambos os nós iniciam uma sonda de determinação de ativação (sonda baseada em BFD) assim que os SRGs começam a operar.
Para sondagem de cérebro dividido baseada em BFD, você deve:
- Configure endereços IP de origem e destino correspondentes para o mesmo SRG em ambos os nós.
- Configure a opção para determinar o
activeness-prioritynó ativo como resultado da sondagem de cérebro dividido.
A tabela a seguir mostra como a configuração de alta disponibilidade de vários nós resolve a situação de cérebro dividido com sondagem baseada em BFD quando a ICL está inativa. Dependendo dos estados do nó e dos resultados da sondagem, o sistema de alta disponibilidade de múltiplos nós seleciona o nó para assumir a função ativa.
A Tabela 4 mostra como a configuração de alta disponibilidade de vários nós resolve a situação de cérebro dividido com sondagem baseada em BFD quando a ICL está inativa. Dependendo dos estados do nó e dos resultados da sondagem, o sistema de alta disponibilidade de múltiplos nós seleciona o nó para assumir a função ativa.
Neste exemplo, supomos que SRG1 do nó 1 tenha a prioridade de atividade mais alta.
| Estado do Nó 1 | Estado de sondagem do nó 1 | Estado do nó 2 | Estado de sondagem do nó 2 | Transição de nó para o estado ativo SRG1 |
| Ativo | Para baixo | Inelegível | Sem sondagem | Nó 1 |
| Ativo | Para cima | backup | Para cima | Nó 1 |
| Ativo | Para cima | Ativo | Para cima | Nó 1 (desempate) |
| backup | Para baixo | Inelegível | Sem sondagem | Nó 1 |
| backup | Para cima | backup | Para cima | Nó 1 (desempate) |
| backup | Para cima | Ativo | Para cima | Nó 2 |
| Inelegível | Sem sondagem | Inelegível | Sem sondagem | Nenhum nó |
| Inelegível | Sem sondagem | backup | Para baixo | Nó 2 |
| Inelegível | Sem sondagem | Ativo | Para baixo | Nó 2 |
Configuração de exemplo
Nó 1:
set chassis high-availability services-redundancy-group 1 activeness-priority 1 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness destination-ip 192.168.21.2 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness source-ip 192.168.21.1 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness interface xe-0/0/1.0 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness minimum-interval 300 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness multiplier 3
Nó 2:
set chassis high-availability services-redundancy-group 1 activeness-priority 200 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness destination-ip 192.168.21.1 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness source-ip 192.168.21.2 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness interface xe-0/0/1.0 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness minimum-interval 300 set chassis high-availability services-redundancy-group 1 activeness-probe bfd-liveliness multiplier 3
Verificação
-
Use o
(Sondagem baseada em BFD)show chassis high-availability services-redundancy-group 1comando para ver o tipo de sonda de cérebro dividido configurada no dispositivo.user@host> show chassis high-availability services-redundancy-group 1 .. Split-brain Prevention Probe Info: DST-IP: 192.168.21.2 SRC-IP: N/A Routing Instance: default Type: BFD Probe Interval: 300ms Multiplier: 3 Status: RUNNING Result: REACHABLE Reason: N/A ..user@host> show chassis high-availability services-redundancy-group 1 .. Split-brain Prevention Probe Info: DST-IP: 192.168.21.2 SRC-IP: 192.168.21.1 Routing Instance: default Type: ICMP Probe Status: NOT RUNNING Result: N/A Reason: N/A .. -
Use o comando para ver se o
show bfd sessionstatus da sondagem baseada em BFD.user@host> show bfd session Detect Transmit Address State Interface Time Interval Multiplier 192.168.0.2 Up 0.300 0.100 3 192.168.21.2 Up xe-0/0/1.0 0.300 0.100 3 1 sessions, 1 clients Cumulative transmit rate 0.5 pps, cumulative receive rate 0.0 ppsNo exemplo, você pode notar que a sondagem de cérebro dividido baseada em BFD está em execução para a interface xe-0/0/1.0.
-
Use o
show chassis high-availability services-redundancy-group 1comando para obter os detalhes das sondas baseadas em BFD.user@host> show chassis high-availability services-redundancy-group 1 SRG failure event codes: BF BFD monitoring IP IP monitoring IF Interface monitoring CP Control Plane monitoring Services Redundancy Group: 1 Deployment Type: ROUTING Status: ACTIVE Activeness Priority: 200 Preemption: ENABLED Process Packet In Backup State: NO Control Plane State: READY System Integrity Check: N/A Failure Events: NONE Peer Information: Peer Id: 1 Status : N/A Health Status: SRG NOT CONFIGURED Failover Readiness: UNKNOWN Activeness Remote Priority: 100
Suporte a sistemas lógicos e sistemas de locatário
Os sistemas lógicos para firewalls da Série SRX permitem particionar um único dispositivo em contextos seguros e um sistema de locatário particiona logicamente o firewall físico em um firewall lógico separado e isolado.
Um sistema de locatário particiona logicamente o firewall físico em um firewall lógico separado e isolado. Embora semelhantes aos sistemas lógicos, os sistemas de locatário têm escalabilidade muito maior e menos recursos de roteamento.
Os firewalls da Série SRX na configuração de alta disponibilidade multinós oferecem suporte a sistemas lógicos e sistemas de locatários no grupo de redundância de serviços 0 (SRG0).
O comportamento de uma configuração de alta disponibilidade de vários nós com firewalls da Série SRX executando sistemas lógicos é o mesmo de uma configuração em que os nós da Série SRX não executam sistemas lógicos. Não há diferença nos eventos que disparam um failover de nó. Especificamente, se o monitoramento da interface estiver habilitado no SRG0 e um link associado a um único sistema lógico falhar (que está sendo monitorado), o dispositivo fará failover para outro nó. Esse failover ocorre por meio de anúncios de preferência de rota na configuração de alta disponibilidade de vários nós.
Antes de configurar os sistemas lógicos ou de locatário, você deve configurar a Alta Disponibilidade de Múltiplos Nós. Cada nó na configuração de alta disponibilidade deve ter uma configuração idêntica. Certifique-se de que o nome, o perfil e os recursos de segurança ou interfaces correspondentes dos sistemas lógicos ou de locatários dentro dos sistemas lógicos ou de locatários sejam os mesmos. Todas as configurações lógicas ou do sistema de locatários são sincronizadas e replicadas entre os dois nós.
Use grupos de configuração do Junos para configurar recursos e funções e sincronize a configuração usando a [edit system commit peers-synchronize] opção em sua configuração de alta disponibilidade de vários nós. Consulte Sincronização de configuração entre nós de alta disponibilidade de vários nós.
Ao usar firewalls da Série SRX com sistemas lógicos em uma alta disponibilidade de vários nós, você deve comprar e instalar o mesmo número de licenças para cada nó na configuração.
Para obter mais informações, consulte o Guia do Usuário de Sistemas Lógicos e Sistemas de Locatário para Dispositivos de Segurança.
Tabela de histórico de alterações
A compatibilidade com recursos é determinada pela plataforma e versão utilizada. Use o Explorador de recursos para determinar se um recurso é compatível com sua plataforma.