Visão geral do BGP
Entendendo o BGP
O BGP é um protocolo de gateway exterior (EGP) usado para trocar informações de roteamento entre roteadores em diferentes sistemas autônomos (ASs). As informações de roteamento BGP incluem a rota completa para cada destino. O BGP usa as informações de roteamento para manter um banco de dados de informações de acessibilidade de rede, que ele troca com outros sistemas BGP. O BGP usa as informações de alcance da rede para construir um gráfico de conectividade AS, o que permite que o BGP remova loops de roteamento e aplique decisões de política no nível AS.
As extensões MBGP (Multiprotocol BGP (Multiprotocol ) permitem que BGP ofereçam suporte ao IP versão 6 (IPv6). O MBGP define os atributos MP_REACH_NLRI e MP_UNREACH_NLRI, que são usados para transportar informações de acessibilidade IPv6. As mensagens de atualização das informações de alcance da camada de rede (Network Layer Reachability Information, NLRI) transportam prefixos de endereço IPv6 de rotas viáveis.
O BGP permite o roteamento baseado em políticas. Você pode usar políticas de roteamento para escolher entre vários caminhos para um destino e controlar a redistribuição das informações de roteamento.
O BGP usa TCP como protocolo de transporte, usando a porta 179 para estabelecer conexões. A execução de um protocolo de transporte confiável elimina a necessidade de o BGP implementar a fragmentação, a retransmissão, o reconhecimento e o sequenciamento de atualizações.
O software do protocolo de roteamento do Junos OS oferece suporte ao BGP versão 4. Esta versão do BGP adiciona suporte para roteamento entre domínios sem classificação (CIDR), o que elimina o conceito de classes de rede. Em vez de assumir quais bits de um endereço representam a rede olhando para o primeiro octeto, o CIDR permite que você especifique explicitamente o número de bits no endereço de rede, fornecendo assim um meio de diminuir o tamanho das tabelas de roteamento. O BGP versão 4 também oferece suporte à agregação de rotas, incluindo a agregação de caminhos AS.
Esta seção discute os seguintes tópicos:
- Sistemas autônomos
- Caminhos e atributos do AS
- BGP externo e interno
- Múltiplas instâncias do BGP
- Permitir Tráfego de Protocolo para Interfaces em uma Zona de Segurança
Sistemas autônomos
Um sistema autônomo (AS) é um conjunto de roteadores que estão sob uma única administração técnica e normalmente usam um único protocolo de gateway interior e um conjunto comum de métricas para propagar informações de roteamento dentro do conjunto de roteadores. Para outros ASs, um AS parece ter um plano de roteamento interno único e coerente e apresenta uma imagem consistente de quais destinos podem ser alcançados por ele.
Caminhos e atributos do AS
As informações de roteamento que os sistemas BGP trocam incluem a rota completa para cada destino, bem como informações adicionais sobre a rota. O caminho AS é a sequência de sistemas autônomos percorridos pela rota, e informações adicionais da rota são incluídas nos atributos do caminho. O BGP usa o caminho AS e os atributos de caminho para determinar completamente a topologia da rede. Depois que o BGP entende a topologia, ele pode detectar e eliminar loops de roteamento e selecionar entre grupos de rotas para impor preferências administrativas e decisões de política de roteamento.
BGP externo e interno
O BGP oferece suporte a dois tipos de trocas de informações de roteamento: trocas entre diferentes ASs e trocas dentro de um único AS. Quando usado entre ASs, o BGP é chamado de BGP externo (EBGP) e as sessões de BGP executam o roteamento entre AS. Quando usado em um AS, o BGP é chamado de BGP interno (IBGP) e as sessões de BGP executam o roteamento intra-AS. A Figura 1 ilustra ASs, IBGP e EBGP.
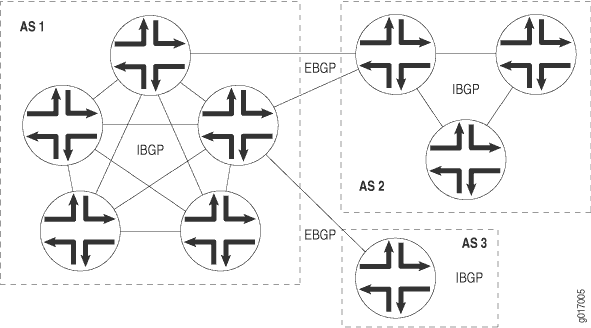
Um sistema BGP compartilha informações de alcance de rede com sistemas BGP adjacentes, que são chamados de vizinhos ou pares.
Os sistemas BGP são organizados em grupos. Em um grupo do IBGP, todos os pares do grupo — chamados de pares internos — estão no mesmo AS. Os pares internos podem estar em qualquer lugar do AS local e não precisam estar diretamente conectados uns aos outros. Grupos internos usam rotas de um IGP para resolver endereços de encaminhamento. Eles também propagam rotas externas entre todos os outros roteadores internos que executam o IBGP, calculando o próximo salto pegando o próximo salto do BGP recebido com a rota e resolvendo-o usando informações de um dos protocolos de gateway interno.
Em um grupo EBGP, os pares do grupo — chamados de pares externos — estão em ASs diferentes e normalmente compartilham uma sub-rede. Em um grupo externo, o próximo salto é calculado em relação à interface que é compartilhada entre o peer externo e o roteador local.
Múltiplas instâncias do BGP
Você pode configurar várias instâncias do BGP nos seguintes níveis de hierarquia:
-
[edit routing-instances routing-instance-name protocols] -
[edit logical-systems logical-system-name routing-instances routing-instance-name protocols]
Várias instâncias de BGP são usadas principalmente para suporte VPN de Camada 3.
Os peers IGP e os peers BGP (EBGP) externos (não multihop e multihop) são todos suportados para instâncias de roteamento. O peering BGP é estabelecido em uma das interfaces configuradas na hierarquia routing-instances .
Quando um vizinho BGP envia mensagens BGP para o dispositivo de roteamento local, a interface de entrada na qual essas mensagens são recebidas deve ser configurada na mesma instância de roteamento em que a configuração do vizinho BGP existe. Isso é verdade para vizinhos que estão a um único salto ou vários saltos de distância.
As rotas aprendidas com o peer BGP são adicionadas à tabela instance-name.inet.0 por padrão. Você pode configurar políticas de importação e exportação para controlar o fluxo de informações para dentro e para fora da tabela de roteamento de instâncias.
Para suporte à VPN de Camada 3, configure o BGP no roteador de borda do provedor (PE) para receber rotas do roteador de borda do cliente (CE) e enviar as rotas das instâncias para o roteador CE, se necessário. Você pode usar várias instâncias do BGP para manter tabelas de encaminhamento separadas por site para manter o tráfego VPN separado no roteador PE.
Você pode configurar políticas de importação e exportação que permitem que o provedor de serviços controle e limite a taxa de tráfego de e para o cliente.
Você pode configurar uma sessão multihop EBGP para uma instância de roteamento VRF. Além disso, você pode configurar o peer EBGP entre os roteadores PE e CE usando o endereço de loopback do roteador CE em vez dos endereços de interface.
Permitir Tráfego de Protocolo para Interfaces em uma Zona de Segurança
Nos firewalls da Série SRX, você deve habilitar o tráfego de entrada de host esperado nas interfaces especificadas ou em todas as interfaces da zona. Caso contrário, o tráfego de entrada destinado a este dispositivo será descartado por padrão.
Por exemplo, para permitir o tráfego BGP em uma zona específica do firewall da Série SRX, use a seguinte etapa:
[edit]
user@host# set security zones security-zone trust host-inbound-traffic protocols bgp
[edit]
user@host# set security zones security-zone trust interfaces ge-0/0/1.0 host-inbound-traffic protocols bgp
Veja também
Visão geral das rotas BGP
Uma rota BGP é um destino, descrito como um prefixo de endereço IP, e informações que descrevem o caminho para o destino.
As informações a seguir descrevem o caminho:
Caminho AS, que é uma lista de números dos ASs pelos quais uma rota passa para chegar ao roteador local. O primeiro número no caminho é o do último AS no caminho — o AS mais próximo do roteador local. O último número no caminho é o AS mais distante do roteador local, que geralmente é a origem do caminho.
Atributos de caminho, que contêm informações adicionais sobre o caminho AS usado na política de roteamento.
Os peers BGP anunciam rotas entre si em mensagens de atualização.
O BGP armazena suas rotas na tabela de roteamento do Junos OS (inet.0). A tabela de roteamento armazena as seguintes informações sobre as rotas BGP:
Informações de roteamento aprendidas com mensagens de atualização recebidas de pares
Informações de roteamento local que o BGP aplica a rotas devido a políticas locais
Informações que o BGP anuncia para pares BGP em mensagens de atualização
Para cada prefixo na tabela de roteamento, o processo de protocolo de roteamento seleciona um único melhor caminho, chamado de caminho ativo. A menos que você configure o BGP para anunciar vários caminhos para o mesmo destino, o BGP anuncia apenas o caminho ativo.
O roteador BGP que primeiro anuncia uma rota atribui a ela um dos seguintes valores para identificar sua origem. Durante a seleção de rota, o valor de origem mais baixo é preferido.
0— O roteador originalmente aprendeu a rota através de um IGP (OSPF, IS-IS ou uma rota estática).
1— O roteador originalmente aprendeu a rota através de um EGP (provavelmente BGP).
2 — A origem da rota é desconhecida.
Veja também
Visão geral da resolução de rotas BGP
Uma rota BGP (IBGP) interna com um endereço de próximo salto para um vizinho BGP remoto (próximo salto do protocolo) deve ter seu próximo salto resolvido usando alguma outra rota. O BGP adiciona essa rota ao módulo de resolvedor rpd para resolução de próximo salto. Se o RSVP for usado na rede, o próximo salto do BGP será resolvido usando a rota de entrada do RSVP. Isso resulta na rota BGP apontando para um próximo salto indireto e o próximo salto indireto apontando para um próximo salto de encaminhamento. O próximo salto de encaminhamento é derivado do próximo salto da rota RSVP. Geralmente, há um grande conjunto de rotas BGP internas que têm o mesmo protocolo no próximo salto e, nesses casos, o conjunto de rotas BGP faria referência ao mesmo próximo salto indireto.
Antes do Junos OS Release 17.2R1, o módulo resolvedor do processo de protocolo de roteamento (rpd) resolveu rotas dentro do IBGP e recebeu rotas das seguintes maneiras:
Resolução parcial de rotas — o próximo salto do protocolo é resolvido com base em rotas auxiliares, como rotas RSVP ou IGP. Os valores de métrica são derivados das rotas auxiliares e o próximo salto é chamado de encaminhamento do resolvedor do próximo salto herdado das rotas auxiliares. Esses valores de métrica são usados para selecionar rotas na base de informações de roteamento (RIB), também conhecida como tabela de roteamento.
Resolução completa da rota — o próximo salto final é derivado e é referido como o próximo salto de encaminhamento da tabela de roteamento do kernel (KRT) com base na política de exportação de encaminhamento.
A partir do Junos OS Release 17.2R1, o módulo resolver do rpd é otimizado para aumentar a taxa de transferência do fluxo de processamento de entrada, acelerando a taxa de aprendizado de RIB e FIB. Com esse aprimoramento, a resolução da rota é afetada da seguinte maneira:
Os métodos de resolução de rota parcial e completa são acionados para cada rota do IBGP, embora cada rota possa herdar o mesmo próximo salto de encaminhamento resolvido ou o próximo salto de encaminhamento KRT.
A seleção de caminho BGP é adiada até que a resolução completa da rota seja executada para informações de alcance de camada de rede (NLRI) recebidas de um vizinho BGP, que pode não ser a melhor rota no RIB após a seleção de rota.
Os benefícios da otimização do resolvedor rpd incluem:
Menor custo de pesquisa de resolução de RIB — A saída do caminho resolvido é salva em um cache de resolvedor, para que os mesmos valores derivados de próximo salto e métrica possam ser herdados para outro conjunto de rotas que compartilham o mesmo comportamento de caminho em vez de executar o fluxo de resolução de rota parcial e completo. Isso reduz o custo de pesquisa de resolução de rota, mantendo apenas o estado do resolvedor mais frequente em um cache com profundidade limitada.
Otimização de seleção de rota BGP — O algoritmo de seleção de rota BGP é acionado duas vezes para cada rota IBGP recebida — primeiro, ao adicionar a rota no RIB com o próximo salto como inutilizável e, segundo, ao adicionar a rota com um próximo salto resolvido no RIB (após a resolução da rota). Isso resulta na seleção da melhor rota duas vezes. Com a otimização do resolvedor, o processo de seleção de rota é acionado no fluxo de recebimento somente após obter as informações do próximo salto do módulo do resolvedor.
Cache interno para evitar pesquisas frequentes — o cache do resolvedor mantém o estado do resolvedor mais frequente e, como resultado, a funcionalidade de pesquisa, como pesquisa de próximo salto e pesquisa de rota, é feita a partir do cache local.
Grupo de equivalência de caminho — Quando caminhos diferentes compartilham o mesmo estado de encaminhamento ou são recebidos do mesmo protocolo no próximo salto, os caminhos podem pertencer a um grupo de equivalência de caminho. Essa abordagem evita a necessidade de executar a resolução completa de rotas para esses caminhos. Quando um novo caminho requer resolução de rota completa, ele é pesquisado primeiro no banco de dados do grupo de equivalência de caminho, que contém a saída do caminho resolvido, como próximo salto indireto e encaminhamento do próximo salto.
Veja também
Visão geral das mensagens BGP
Todas as mensagens BGP têm o mesmo cabeçalho de tamanho fixo, que contém um campo de marcador usado para sincronização e autenticação, um campo de comprimento que indica o comprimento do pacote e um campo de tipo que indica o tipo de mensagem (por exemplo, open, update, notification, keepalive e assim por diante).
Esta seção discute os seguintes tópicos:
- Mensagens abertas
- Atualizar mensagens
- Mensagens de manutenção de atividade
- Mensagens de notificação
- Mensagens de Atualizar de Rota
Mensagens abertas
Depois que uma conexão TCP é estabelecida entre dois sistemas BGP, eles trocam mensagens abertas BGP para criar uma conexão BGP entre eles. Depois que a conexão é estabelecida, os dois sistemas podem trocar mensagens BGP e tráfego de dados.
As mensagens abertas consistem no cabeçalho BGP mais os seguintes campos:
Versão — O número da versão atual do BGP é 4.
Número do AS local — você configura isso incluindo a
autonomous-systemdeclaração no[edit routing-options]nível da hierarquia or[edit logical-systems logical-system-name routing-options].Tempo de espera — Valor de tempo de espera proposto. Você configura o tempo de espera local com a BGP
hold-timedeclaração.Identificador BGP — endereço IP do sistema BGP. Esse endereço é determinado quando o sistema é iniciado e é o mesmo para cada interface local e cada peer BGP. Você pode configurar o identificador BGP incluindo a
router-iddeclaração no[edit routing-options]nível de hierarquia or[edit logical-systems logical-system-name routing-options]. Por padrão, o BGP usa o endereço IP da primeira interface que encontra no roteador.Comprimento do campo de parâmetro e o próprio parâmetro — Esses são campos opcionais.
Atualizar mensagens
Os sistemas BGP enviam mensagens de atualização para trocar informações de alcance da rede. Os sistemas BGP usam essas informações para construir um gráfico que descreve as relações entre todos os ASs conhecidos.
As mensagens de atualização consistem no cabeçalho BGP mais os seguintes campos opcionais:
Comprimento de rotas inviáveis — Comprimento do campo de rotas retiradas
Rotas retiradas — prefixos de endereço IP para as rotas que estão sendo retiradas de serviço porque não são mais consideradas alcançáveis
Comprimento total do atributo do caminho — Comprimento do campo de atributos do caminho; Ele lista os atributos de caminho para uma rota viável para um destino
Atributos de caminho — Propriedades das rotas, incluindo a origem do caminho, o discriminador de saída múltipla (MED), a preferência do sistema de origem pela rota e informações sobre agregação, comunidades, confederações e reflexão de rota
Informações de alcance da camada de rede (Network Layer Reachability Information, NLRI) — prefixos de endereço IP de rotas viáveis sendo anunciadas na mensagem de atualização
Mensagens de manutenção de atividade
Os sistemas BGP trocam mensagens keepalive para determinar se um link ou host falhou ou não está mais disponível. As mensagens keepalive são trocadas com frequência suficiente para que o temporizador de espera não expire. Essas mensagens consistem apenas no cabeçalho BGP.
Mensagens de notificação
Os sistemas BGP enviam mensagens de notificação quando uma condição de erro é detectada. Depois que a mensagem é enviada, a sessão BGP e a conexão TCP entre os sistemas BGP são fechadas. As mensagens de notificação consistem no cabeçalho BGP mais o código e o subcódigo de erro e os dados que descrevem o erro.
Mensagens de Atualizar de Rota
Os sistemas BGP enviam mensagens de atualização de rota para um peer somente se tiverem recebido o anúncio de recurso de atualização de rota do peer. Um sistema BGP deve anunciar o recurso de atualização de rota para seus pares usando o anúncio de recursos BGP se quiser receber mensagens de atualização de rota. Essa mensagem opcional é enviada para solicitar atualizações dinâmicas de rota BGP de peers BGP ou para enviar atualizações de rota de saída para um peer BGP.
As mensagens de atualização de rota consistem nos seguintes campos:
AFI — Identificador de família de endereços (16 bits).
Res — Campo reservado (8 bits), que deve ser definido como 0 pelo remetente e ignorado pelo destinatário.
SAFI — Identificador de família de endereços subsequente (8 bits).
Se um peer sem o recurso de atualização de rota receber uma mensagem de solicitação de atualização de rota de um peer remoto, o receptor ignorará a mensagem.
Veja também
Entender a fragmentação de RIB do BGP e o thread de E/S de atualização do BGP
O processamento de rotas BGP geralmente tem vários estágios de pipeline, como receber atualização, analisar atualização, criar rota, resolver next-hop, aplicar a política de exportação de um grupo de peer BGP, formar atualizações por peer e enviar atualizações aos peers.
A fragmentação de BGP RIB divide um BGP RIB unificado em vários sub-RIBs e cada sub-RIB lida com um subconjunto de rotas BGP. O thread RPD separado denominado thread de fragmento BGP atende a cada sub-RIB para obter simultaneidade. Os threads de fragmento BGP são responsáveis por todos os estágios do pipeline de processamento de rotas BGP, com exceção da formação de atualizações por peer e do envio de atualizações aos peers. Os threads de fragmento BGP recebem as atualizações enviadas por pares dos threads de E/S de atualização de BGP com os threads de E/S de atualização de BGP fazendo hash dos prefixos nas atualizações e enviam as atualizações para os threads de fragmento BGP aplicáveis com base no cálculo de hash. O thread de fragmento BGP processa a configuração da mesma maneira que o thread principal do RPD, cria pares, grupos, tabelas de rotas e usa as informações de configuração para processamento de rotas BGP.
Os threads de E/S de atualização de BGP são responsáveis pelo final desse pipeline BGP, envolvendo a geração de atualizações por peer para grupos BGP individuais e o envio para os peers. Um thread de atualização pode atender a um ou mais grupos BGP. Os threads de E/S de atualização de BGP constroem atualizações para grupos em paralelo e independentemente de outros grupos que estão sendo atendidos por outros threads de atualização. Isso pode oferecer uma melhoria significativa de convergência em uma carga de trabalho de gravação pesada, que envolve publicidade para muitos pares espalhados por muitos grupos. Os threads de E/S de atualização de BGP também são responsáveis por gravar e ler os soquetes TCP dos peers BGP que eram fornecidos anteriormente por threads BGPIO (daí o sufixo IO em BGP Update IO).
Os threads de E/S de atualização do BGP podem ser configurados independentemente do recurso de fragmentação RIB, mas são obrigatórios para uso com a fragmentação RIB, a fim de obter uma melhor eficiência de empacotamento de prefixo na mensagem de atualização BGP de saída. A fragmentação de BGP divide o RIB em vários sub-RIBs que são atendidos por threads RPD separados. Portanto, os prefixos que poderiam ter entrado em uma única atualização de saída acabam em fragmentos diferentes. Para poder construir atualizações de BGP com prefixos com o mesmo atributo de saída que pode pertencer a diferentes threads de fragmento RPD, todos os threads de fragmento enviam informações de anúncio compactas para prefixos a serem anunciados para um thread de atualização que atende a esse grupo de peer BGP. Isso permite que o thread de atualização, atendendo a esse grupo de peer BGP, empacote prefixos com os mesmos atributos, potencialmente pertencentes a fragmentos diferentes na mesma mensagem de atualização de saída. Isso minimiza o número de atualizações a serem anunciadas e, portanto, ajuda a melhorar a convergência. O thread de E/S de atualização gerencia caches locais de contêineres de peer, grupo, prefixo, TSI e RIB.
O thread de atualização de BGP e a fragmentação de RIB de BGP estão desabilitados por padrão. Se você configurar o threading de atualização e o sharding de nervuras em um mecanismo de roteamento, o RPD criará threads de atualização. Por padrão, o número de threads de atualização e threads de fragmento criados é o mesmo que o número de núcleos de CPU no mecanismo de roteamento. O threading de atualização só é suportado em um processo de protocolo de roteamento de 64 bits (rpd). Opcionalmente, você pode especificar o número de threads que deseja criar usando set update-threading <number-of-threads> instruções and set rib-sharding <number-of-threads> no nível da [edit system processes routing bgp] hierarquia. Para o thread de atualização do BGP, o intervalo é atualmente de 1 a 128 e para a fragmentação BGP RIB, o intervalo é atualmente de 1 a 31.
Quando você configura o NSR para os recursos de fragmentação BGP RIB e BGP Update IO, o RPD de backup cria o mesmo número de threads de fragmento BGP e BGP Update IO no mecanismo de roteamento de backup. Os threads de E/S de atualização de BGP RPD de backup leem a atualização de BGP replicada, outras mensagens recebidas dos pares, bem como a atualização de BGP replicada e outras mensagens enviadas aos pares. Com base no hash de prefixos, os threads de E/S de atualização de BGP RPD de backup enviam essas mensagens BGP para o fragmento BGP aplicável e os threads principais do RPD. O fragmento BGP e os threads principais do RPD no RPD de backup criam o estado da rota recebida e anunciada usando essas mensagens BGP replicadas. Quando o mecanismo de roteamento primário falha, o mecanismo de roteamento de backup se torna o mecanismo de roteamento primário e o RPD de backup se torna o RPD principal sem afetar as sessões de BGP com os pares.
Entender a seleção de caminho BGP
Para cada prefixo na tabela de roteamento, o processo de protocolo de roteamento seleciona um único melhor caminho. Depois que o melhor caminho é selecionado, a rota é instalada na tabela de roteamento. O melhor caminho se torna a rota ativa se o mesmo prefixo não for aprendido por um protocolo com um valor de preferência global menor (mais preferencial), também conhecido como distância administrativa. O algoritmo para determinar a rota ativa é o seguinte:
-
Verifique se o próximo salto pode ser resolvido.
-
Escolha o caminho com o menor valor de preferência (protocolo de roteamento, preferência, processo).
As rotas que não são elegíveis para serem usadas para encaminhamento (por exemplo, porque foram rejeitadas pela política de roteamento ou porque um próximo salto está inacessível) têm uma preferência de –1 e nunca são escolhidas.
-
Prefira o caminho com maior preferência local.
Para caminhos não BGP, escolha o caminho com o valor de preference2 mais baixo.
-
Se o atributo AIGP (interior gateway protocol) acumulado estiver habilitado, adicione a métrica IGP e prefira o caminho com o atributo AIGP inferior.
-
Prefira o caminho com o valor de caminho do sistema autônomo (AS) mais curto (ignorado se a
as-path-ignoreinstrução estiver configurada).Um segmento de confederação (sequência ou conjunto) tem um comprimento de caminho de 0. Um conjunto AS tem um comprimento de caminho de 1.
-
Prefira a rota com o código de origem inferior.
As rotas aprendidas de um IGP têm um código de origem inferior àquelas aprendidas de um protocolo de gateway exterior (EGP), e ambas têm códigos de origem inferiores às rotas incompletas (rotas cuja origem é desconhecida).
-
Prefira o caminho com a menor métrica de discriminador múltiplo de saída (MED).
Dependendo se o comportamento de seleção de caminho da tabela de roteamento não determinístico está configurado, há dois casos possíveis:
-
Se o comportamento de seleção de caminho da tabela de roteamento não determinístico não estiver configurado (ou seja, se a
path-selection cisco-nondeterministicdeclaração não estiver incluída na configuração do BGP), para caminhos com os mesmos números de AS vizinhos na frente do caminho de AS, prefira o caminho com a métrica de MED mais baixa. Para sempre comparar MEDs, independentemente de os ASs peer das rotas comparadas serem iguais ou não, inclua apath-selection always-compare-meddeclaração. -
Se o comportamento de seleção de caminho da tabela de roteamento não determinístico estiver configurado (ou seja, a
path-selection cisco-nondeterministicinstrução está incluída na configuração do BGP), prefira o caminho com a métrica MED mais baixa.
As confederações não são consideradas ao determinar os ASs vizinhos. Uma métrica MED ausente é tratada como se um MED estivesse presente, mas zero.
Observação:A comparação MED funciona para seleção de caminho único em um AS (quando a rota não inclui um caminho AS), embora esse uso seja incomum.
Por padrão, somente os MEDs de rotas que têm os mesmos sistemas autônomos (ASs) de peer são comparados. Você pode configurar opções de seleção de caminho da tabela de roteamento para obter diferentes comportamentos.
-
-
Prefira caminhos estritamente internos, que incluem rotas IGP e rotas geradas localmente (estáticas, diretas, locais e assim por diante).
-
Prefira caminhos BGP (EBGP) estritamente externos a caminhos externos aprendidos por meio de sessões BGP (IBGP) internas.
-
Prefira o caminho cujo próximo salto é resolvido por meio da rota IGP com a métrica mais baixa. As rotas BGP resolvidas por meio do IGP são preferidas em relação às rotas inalcançáveis ou rejeitadas.
Observação:Um caminho é considerado um caminho de igual custo BGP (e será usado para encaminhamento) se um tie-break for executado após a etapa anterior. Todos os caminhos com o mesmo AS vizinho, aprendidos por um vizinho BGP habilitado para multipath, são considerados.
O multipath BGP não se aplica a caminhos que compartilham o mesmo custo MED-plus-IGP, mas diferem no custo do IGP. A seleção de caminhos múltiplos é baseada na métrica de custo do IGP, mesmo que dois caminhos tenham o mesmo custo de MED mais IGP.
-
Se ambos os caminhos forem externos, prefira o caminho mais antigo, ou seja, o caminho que foi aprendido primeiro. Isso é feito para minimizar a oscilação de rota. Essa regra não será usada se qualquer uma das seguintes condições for verdadeira:
-
path-selection external-roteador-id está configurado.
-
Ambos os pares têm o mesmo ID de roteador.
-
Qualquer um dos pares é um par de confederação.
-
Nenhum dos caminhos é o caminho ativo atual.
-
-
Prefira o caminho do peer com o ID de roteador mais baixo. Para qualquer caminho com um atributo de ID do originador, substitua o ID do originador pelo ID do roteador durante a comparação do ID do roteador.
-
Prefira o caminho com o menor comprimento de lista de cluster. O comprimento é 0 para nenhuma lista.
-
Prefira o caminho do peer com o endereço IP do peer mais baixo.
-
Prefira uma rota primária a uma rota secundária. Uma rota primária é aquela que pertence à tabela de roteamento. Uma rota secundária é aquela que é adicionada à tabela de roteamento por meio de uma política de exportação.
- Seleção de caminho da tabela de roteamento
- Seleção de caminho da tabela BGP
- Efeitos da publicidade de vários caminhos para um destino
Seleção de caminho da tabela de roteamento
A etapa mais curta do caminho AS do algoritmo, por padrão, avalia o comprimento do caminho AS e determina o caminho ativo. Você pode configurar uma opção que permite que o Junos OS ignore essa etapa do algoritmo, incluindo a opção as-path-ignore .
A partir do Junos OS Release 14.1R8, 14.2R7, 15.1R4, 15.1F6 e 16.1R1, a opção as-path-ignore é suportada para instâncias de roteamento.
A seleção do caminho do processo de roteamento ocorre antes que o BGP entregue o caminho para a tabela de roteamento para tomar sua decisão. Para configurar o comportamento de seleção do caminho da tabela de roteamento, inclua a path-selection declaração:
path-selection { (always-compare-med | cisco-non-deterministic | external-router-id); as-path-ignore; l2vpn-use-bgp-rules; med-plus-igp { igp-multiplier number; med-multiplier number; } }
Para obter uma lista de níveis de hierarquia nos quais você pode incluir essa instrução, consulte a seção de resumo da instrução para esta declaração.
A seleção do caminho da tabela de roteamento pode ser configurada de uma das seguintes maneiras:
-
Emule o comportamento padrão do Cisco IOS (cisco-não-determinístico). Esse modo avalia as rotas na ordem em que são recebidas e não as agrupa de acordo com o AS vizinho. Com
cisco-non-deterministico modo, o caminho ativo é sempre o primeiro. Todos os caminhos inativos, mas qualificados, seguem o caminho ativo e são mantidos na ordem em que foram recebidos, com o caminho mais recente primeiro. Os caminhos não qualificados permanecem no final da lista.Por exemplo, suponha que você tenha três anúncios de caminho para a rota 192.168.1.0 /24:
-
Caminho 1 – aprendido por meio do EBGP; Caminho AS de 65010; MED de 200
-
Caminho 2 – aprendido por meio do IBGP; Caminho AS de 65020; MED de 150; Custo de IGP de 5
-
Caminho 3 – aprendido por meio do IBGP; Caminho AS de 65010; MED de 100; Custo de IGP de 10
Esses anúncios são recebidos em rápida sucessão, dentro de um segundo, na ordem listada. O caminho 3 é recebido mais recentemente, portanto, o dispositivo de roteamento o compara com o caminho 2, o próximo anúncio mais recente. O custo para o peer do IBGP é melhor para o caminho 2, de modo que o dispositivo de roteamento elimina o caminho 3 da contenção. Ao comparar os caminhos 1 e 2, o dispositivo de roteamento prefere o caminho 1 porque é recebido de um peer EBGP. Isso permite que o dispositivo de roteamento instale o caminho 1 como o caminho ativo para a rota.
Observação:Não recomendamos o uso dessa opção de configuração em sua rede. Ele é fornecido exclusivamente para interoperabilidade para permitir que todos os dispositivos de roteamento na rede façam seleções de rota consistentes.
-
Sempre comparando MEDs, independentemente de os ASs peer das rotas comparadas serem ou não os mesmos (always-compare-med).
Substitua a regra de que Se ambos os caminhos forem externos, o caminho ativo no momento é o preferido (external-roteador-id). Continue com a próxima etapa (Etapa 15) no processo de seleção de caminho.
Adicionando o custo do IGP ao destino do próximo salto ao valor MED antes de comparar os valores MED para seleção de caminho (
med-plus-igp).O BGP multipath não se aplica a caminhos que compartilham o mesmo custo MED-plus-IGP, mas diferem no custo do IGP. A seleção de caminhos múltiplos é baseada na métrica de custo do IGP, mesmo que dois caminhos tenham o mesmo custo de MED mais IGP.
Seleção de caminho da tabela BGP
Os seguintes parâmetros são seguidos para a seleção de caminho do BGP:
-
Prefira o valor de preferência local mais alto.
-
Prefira o menor comprimento de caminho AS.
-
Prefira o valor de origem mais baixo.
-
Prefira o valor MED mais baixo.
-
Prefira rotas aprendidas de um peer EBGP em vez de um peer IBGP.
-
Prefira a melhor saída de AS.
-
Para rotas recebidas pelo EBGP, prefira a rota ativa atual.
-
Prefira rotas do peer com o ID de roteador mais baixo.
-
Prefira caminhos com o menor comprimento de cluster.
-
Prefira rotas do peer com o endereço IP de peer mais baixo. As etapas 2, 6 e 12 são os critérios do RPD.
Efeitos da publicidade de vários caminhos para um destino
O BGP anuncia apenas o caminho ativo, a menos que você configure o BGP para anunciar vários caminhos para um destino.
Suponha que um dispositivo de roteamento tenha em sua tabela de roteamento quatro caminhos para um destino e esteja configurado para anunciar até três caminhos (add-path send path-count 3). Os três caminhos são escolhidos com base nos critérios de seleção de caminho. Ou seja, os três melhores caminhos são escolhidos na ordem de seleção de caminho. O melhor caminho é o caminho ativo. Este caminho é removido da consideração e um novo melhor caminho é escolhido. Esse processo é repetido até que o número especificado de caminhos seja atingido.
Veja também
Resolução aprimorada de rota de serviço para BGP multipath com lista de nexthop
O Junos OS melhora a resolução de rotas de serviço para rotas auxiliares multipath BGP que usam estruturas list-nexthop. O resolvedor de rotas agora cria e mantém dependências internas para todos os caminhos contribuintes em uma rota multipath, permitindo uma redefinição precisa e dinâmica quando os nexthops indiretos mudam, independentemente de a rota contribuinte estar ativa ou inativa.
Esse recurso melhora a estabilidade da rota de serviço e evita caminhos de encaminhamento obsoletos em redes que usam BGP ECMP com resolução indireta de nexthop.
- Benefícios
- Antes de começar
- Como o recurso funciona
- Exemplo operacional
- Referência de comandos da CLI
- Limitações
Benefícios
- Mantém o encaminhamento preciso para rotas de serviço resolvidas por BGP multipath.
- Aciona a reresolução quando qualquer caminho de contribuição é alterado, não apenas o caminho do lead.
- Oferece suporte a topologias híbridas de iBGP e eBGP multipath com nexthops indiretos.
- Evita a perda de tráfego causada por estados de resolução obsoletos ou desatualizados.
Antes de começar
Certifique-se de que a instrução de comando BGP multipath list-nexthop esteja habilitada para as famílias de endereços relevantes. Nenhuma nova configuração é necessária para habilitar esse recurso.
Como o recurso funciona
Quando uma rota de serviço é resolvida em uma rota multipath BGP com um list-nexthop, o RPD executa as seguintes ações:
Percorre todos os componentes nexthop na lista nexthop.
Estabelece relações de dependência entre a rota auxiliar de multipath e cada caminho de contribuição.
Armazena essas dependências em um banco de dados interno usando uma estrutura de árvore patricia. Cria esses relacionamentos sob demanda:
Um nó de árvore Patricia é instanciado somente quando a primeira rota de serviço é resolvida por meio da rota auxiliar multipath.
Quando a última rota de serviço dependente não é mais resolvida por meio dessa rota multipath, o nó correspondente é removido automaticamente da árvore.
Monitora alterações indiretas de nexthop usando retornos de chamada de gancho KRT.
Resolve novamente as rotas de serviço dependentes sempre que uma rota contribuinte (ativa ou inativa) é alterada.
Esse comportamento se aplica independentemente de a rota contribuinte estar ativa ou inativa no conjunto de multipath.
Exemplo operacional
Cenário:
Uma rota de serviço (9.9.9.9/32) é resolvida em uma rota multipath BGP (1.1.1.9/32) com os seguintes caminhos contribuintes:
iBGP path-1(lead/ativo): via7.7.7.7→1.2.3.4→10.50.10.1iBGP path-2: via8.8.8.8
Se iBGP path-2 houver alterações (por exemplo, devido a uma atualização do próximo salto), o Junos OS detectará a mudança e resolverá novamente a rota de serviço dependente.
Referência de comandos da CLI
Você pode usar os comandos a seguir para visualizar os relacionamentos do resolvedor list-nexthop e monitorar dependências de rota multipath em nexthops indiretos.
-
show route resolution list-nhExibe identificadores indireto de next-hop (INH) no banco de dados interno de dependência list-nexthop, juntamente com as rotas BGP multipath que dependem deles. Esse comando mostra apenas as rotas auxiliares de multipath usando um INH específico.
Exemplo de saída:
user@router> show route resolution list-nh Indirect next-hop statistics in List-nexthop database: Inh adds: 9, Inh deletes: 4 Inh change callback: registered Indirect next-hop: Inh handle: 0x8969d30; Inh protocol nexthop: 8.8.8.8 Multipath route: 1.1.1.0/24, resolver node: 0xf9e9ed8 Indirect next-hop: Inh handle: 0x8969b98; Inh protocol nexthop: 7.7.7.7 Multipath route: 1.1.1.0/24, resolver node: 0xf9e9ed8 Multipath route: 3.3.3.0/24, resolver node: 0x8d88cb8
-
show route resolution list-nh protocol-next-hop <nexthop>Exibe todas as rotas multipath que usam um nexthop indireto específico.
Exemplo:
user@router> show route resolution list-nh protocol-next-hop 9.9.9.9 Protocol Nexthop: 9.9.9.9 Used by: - Multipath Route: 1.1.1.0/24 - Multipath Route: 2.2.2.0/24 - Multipath Route: 3.3.3.0/24 -
show krt indirect-next-hopExibe informações da tabela de rotas do kernel para um determinado índice nexthop indireto, incluindo quantas rotas multipath dependem desse nexthop. Esse comando mostra contagens de referência e dependências de encaminhamento relacionadas a rotas multipath.
Exemplo de saída:
user@router> show krt indirect-next-hop index 1048574 Indirect Nexthop: Index: 1048574 Protocol next-hop address: 7.7.7.7 ... INH list-nh dependent count: 2
O
dependent count: 2confirma que duas rotas multipath estão usando atualmente esse nexthop indireto.
Limitações
- Aplica-se apenas a rotas multipath BGP com list-nexthops compostas por caminhos iBGP ou híbridos iBGP/eBGP.
- As rotas multipath BGP com apenas colaboradores eBGP não são afetadas.
- Não há suporte para famílias de endereços mistos em uma única lista-nexthop.
Veja também
Padrões suportados para BGP
O Junos OS oferece suporte substancial aos seguintes RFCs e rascunhos da Internet, que definem padrões para o BGP IP versão 4 (IPv4).
Para obter uma lista de padrões BGP IP versão 6 (IPv6) suportados, consulte Padrões IPv6 suportados.
O Junos OS BGP oferece suporte à autenticação para trocas de protocolo (autenticação MD5).
-
RFC 1745, BGP4/IDRP para IP — interação OSPF
-
RFC 1772, Aplicação do Border Gateway Protocol na Internet
-
RFC 1997, atributo de comunidades BGP
-
RFC 2283, extensões multiprotocolo para BGP-4
-
RFC 2385, proteção de sessões BGP por meio da opção de assinatura TCP MD5
-
RFC 2439, amortecimento de flap de rota BGP
-
RFC 2545, uso de extensões multiprotocolo BGP-4 para roteamento entre domínios IPv6
-
RFC 2796, reflexão de rota BGP — uma alternativa ao IBGP de malha completa
-
RFC 2858, extensões multiprotocolo para BGP-4
-
RFC 2918, recurso de Atualizar de Rota para BGP-4
-
RFC 3065, Confederações de sistemas autônomos para BGP
-
RFC 3107, transportando informações de rótulo no BGP-4
-
RFC 3345, condição de oscilação de rota persistente do Border Gateway Protocol (BGP)
-
RFC 3392, Anúncio de recursos com BGP-4
-
RFC 4271, um protocolo de gateway de borda 4 (BGP-4)
-
RFC 4273, Definições de Objetos Gerenciados para BGP-4
-
RFC 4360, atributo de comunidades estendidas do BGP
-
RFC 4364, redes privadas virtuais (VPNs) IP BGP/MPLS
-
RFC 4456, Reflexão de rota BGP: uma alternativa ao BGP interno de malha completa (IBGP)
-
RFC 4486, subcódigos para mensagem de notificação de cessação de BGP
-
RFC 4576, usando um bit de opções de anúncio de estado de enlace (LSA) para evitar loops em redes privadas virtuais (VPNs) IP BGP/MPLS
-
RFC 4659, extensão de rede privada virtual (VPN) IP BGP-MPLS para VPN IPv6
-
RFC 4632, roteamento entre domínios sem classe (CIDR): o plano de atribuição e agregação de endereços da Internet
-
RFC 4684, distribuição de rota restrita para protocolo de gateway de borda/comutação de rótulo multiprotocolo (BGP/MPLS), protocolo de Internet (IP), redes privadas virtuais (VPNs)
-
RFC 4724, mecanismo de reinicialização gracioso para BGP
-
RFC 4760, extensões multiprotocolo para BGP-4
-
RFC 4781, mecanismo de reinicialização gracioso para BGP com MPLS
-
RFC 4798, Conectando ilhas IPv6 por IPv4 MPLS usando roteadores de borda de provedor IPv6 (6PE)
A opção 4b (redistribuição eBGP de rotas IPv6 rotuladas do AS para o AS vizinho) não é suportada.
-
RFC 4893, suporte BGP para espaço numérico AS de quatro octetos
-
RFC 5004, evite as transições de melhor caminho do BGP de um externo para outro
-
RFC 5065, Confederações de sistemas autônomos para BGP
-
RFC 5082, o mecanismo de segurança TTL generalizado (GTSM)
-
RFC 5291, recurso de filtragem de rota de saída para BGP-4 (suporte parcial)
-
RFC 5292, filtro de rota de saída baseado em prefixo de endereço para BGP-4 (suporte parcial)
Os dispositivos que executam o Junos OS podem receber mensagens ORF baseadas em prefixo.
-
RFC 5396, Representação Textual de Números de Sistema Autônomo (AS)
-
RFC 5492, Anúncio de recursos com BGP-4
-
RFC 5512, o identificador de família de endereços subsequentes (SAFI) de encapsulamento BGP e o atributo de encapsulamento de túnel BGP
-
RFC 5549, anunciando informações de alcance da Camada de Rede IPv4 com um próximo salto IPv6
-
RFC 8955, Disseminação de Regras de Especificação de Fluxo
-
RFC 8956, disseminação de regras de especificação de fluxo para IPv6
-
RFC 5668, comunidade estendida de BGP específica de 4 octetos AS
-
RFC 5701, atributo de comunidade estendida BGP específico de endereço IPv6
-
RFC 5925, a opção de autenticação TCP
-
RFC 6286, identificador BGP exclusivo em todo o sistema autônomo para BGP-4 totalmente compatível
-
RFC 6368, BGP interno como protocolo de borda de provedor/cliente para redes privadas virtuais (VPNs) IP BGP/MPLS
-
RFC 6774, distribuição de diversos caminhos BGP
-
RFC 6793, suporte BGP para espaço numérico de sistema autônomo (AS) de quatro octetos
-
RFC 6810, o recurso infraestrutura de chave pública (RPKI) para protocolo de roteador
-
RFC 6811, validação de origem do prefixo BGP
-
RFC 6996, Reserva de Sistema Autônomo (AS) para Uso Privado
-
RFC 7300, Reserva dos Últimos Números do Sistema Autônomo (AS)
-
RFC 7311, o atributo de métrica de IGP acumulado para BGP
-
RFC 7404, usando apenas endereçamento local de enlace dentro de uma rede IPv6
-
RFC 7432, VPN Ethernet baseada em BGP MPLS (eVPN)
-
RFC 7606, tratamento de erros revisado para mensagens BGP UPDATE
-
RFC 7611, BGP atributo da comunidade ACCEPT_OWN
Oferecemos suporte ao RFC permitindo que os roteadores da Juniper aceitem rotas recebidas de um refletor de rota com o valor da
accept-owncomunidade. -
RFC 7752, distribuição ao norte de informações de estado de enlace e engenharia de tráfego (TE) usando BGP
-
RFC 7854, protocolo de monitoramento BGP (BMP)
-
RFC 7911, anúncio de vários caminhos no BGP
-
RFC 8097, prefixo BGP, estado de validação de origem, comunidade estendida
-
RFC 8210, o recurso infraestrutura de chave pública (RPKI) para protocolo de roteador, versão 1
-
RFC 8212, comportamento de propagação de rota BGP externa (EBGP) padrão sem políticas - totalmente compatível
Exceções:
Os comportamentos no RFC 8212 não são implementados por padrão para evitar a interrupção da configuração existente do cliente. O comportamento padrão ainda é mantido para aceitar e anunciar todas as rotas em relação aos pares EBGP.
-
RFC 8277, usando o BGP para vincular rótulos MPLS a prefixos de endereço
-
RFC 8326, desligamento gracioso da sessão BGP
-
RFC 8481, esclarecimentos sobre a validação de origem do BGP com base na infraestrutura de chave pública (RPKI) do recurso
-
RFC 8538, suporte de mensagem de notificação para reinicialização graciosa do BGP
-
RFC 8571, BGP - Anúncio de estado do enlace (BGP-LS) de extensões de métrica de desempenho de engenharia de tráfego IGP
-
RFC 8584, estrutura para VPN Ethernet Encaminhamento designado Extensibilidade de eleição
-
RFC 8642, comportamento de política para comunidades BGP conhecidas
-
RFC 8669, prefixo de roteamento por segmentos, extensões de identificador de segmento para BGP
-
RFC 8810, revisão dos procedimentos de registro de códigos de capacidade
-
Profundidade máxima de SID (MSD) de sinalização RFC 8814 usando o protocolo de gateway de borda - Estado do enlace (suporte parcial)
-
RFC 8950, anunciando informações de alcance de camada de rede (NLRI) IPv4 com um próximo salto IPv6
-
RFC 8955
-
RFC 8956
-
RFC 9003, comunicação de desligamento administrativo BGP estendido
-
RFC 9012, o atributo de encapsulamento de túnel BGP
-
RFC 9029, Atualizações da Política de Alocação para o Protocolo de Gateway de Borda - Registros de Parâmetros de Estado do Enlace (BGP-LS)
-
RFC 9069, suporte para RIB local no protocolo de monitoramento BGP (BMP)
-
RFC 9085, Border Gateway Protocol - Extensões BGP-LS (Link State) para Roteamento por segmentos
-
RFC 9117, Procedimento de validação revisado para disseminação de especificações de fluxo BGP. Isso permite que as especificações de fluxo sejam originadas dentro do mesmo sistema autônomo que o peer BGP que executa a validação.
-
RFC 9234, prevenção e detecção de vazamento de rota usando funções em mensagens UPDATE e OPEN
-
RFC 9384, um subcódigo de cessação de notificação de BGP para detecção de encaminhamento bidirecional (BFD)
-
Rascunho da Internet draft-idr-rfc8203bis-00, Comunicação de desligamento administrativo do BGP (expira em outubro de 2018)
-
Rascunho da Internet draft-ietf-grow-bmp-adj-rib-out-01, suporte para Adj-RIB-Out no protocolo de monitoramento BGP (BMP) (expira em 3 de setembro de 2018)
-
Rascunho da Internet-ietf-idr-aigp-06, O atributo de métrica IGP acumulado para BGP (expira em dezembro de 2011)
-
Rascunho da Internet-ietf-idr-as0-06, Codificação do processamento AS 0 (expira em fevereiro de 2013)
-
Rascunho da Internet draft-ietf-idr-link-bandwidth-06.txt, Comunidade Estendida de Largura de Banda de Link BGP (expira em julho de 2013)
-
Rascunho da Internet draft-ietf-sidr-origin-validation-signaling-00, prefixo BGP, estado de validação de origem, comunidade estendida (suporte parcial) (expira em maio de 2011)
A comunidade estendida (estado de validação de origem) é suportada na política de roteamento do Junos OS. A alteração especificada no procedimento de seleção de rota não é suportada.
-
draft-kato-bgp-ipv6-link-local-00.txt de rascunho da Internet, peering BGP4+ usando endereço local de link IPv6
Os RFCs e o rascunho da Internet a seguir não definem padrões, mas fornecem informações sobre o BGP e tecnologias relacionadas. O IETF os classifica como "Experimentais" ou "Informativos".
-
RFC 1965, Confederações de Sistemas Autônomos para BGP
-
RFC 1966, BGP Route Reflection — uma alternativa ao IBGP de malha completa
-
RFC 2270, usando um AS dedicado para sites hospedados em um único provedor
-
RFC 3345, condição de oscilação de rota persistente do Border Gateway Protocol (BGP)
-
RFC 3562, considerações de gerenciamento de chaves para a opção de assinatura TCP MD5
-
Rascunho da Internet draft-ietf-ngtrans-bgp-túnel-04.txt, Conectando ilhas IPv6 em nuvens IPv4 com BGP (expira em julho de 2002)
Veja também
Tabela de histórico de alterações
A compatibilidade com recursos é determinada pela plataforma e versão utilizada. Use o Explorador de recursos para determinar se um recurso é compatível com sua plataforma.