Chassis Cluster Redundancy Group Failover
A redundancy group (RG) includes and manages a collection of objects on both nodes of a cluster to provide high-availability. Each redundancy group acts as an independent unit of failover and is primary on only one node at a time. For more information, see the following topics:
Understanding Chassis Cluster Redundancy Group Failover
Chassis cluster employs a number of highly efficient failover mechanisms that promote high availability to increase your system's overall reliability and productivity.
A redundancy group is a collection of objects that fail over as a group. Each redundancy group
monitors a set of objects (physical interfaces), and each monitored object is assigned a weight.
Each redundancy group has an initial threshold of 255. When a monitored object
fails, the weight of the object is subtracted from the threshold value of the redundancy group.
When the threshold value reaches zero, the redundancy group fails over to the other node. As a
result, all the objects associated with the redundancy group fail over as well. Graceful restart
of the routing protocols enables the SRX Series Firewall to minimize traffic disruption during a
failover.
Back-to-back failovers of a redundancy group in a short interval can cause the cluster to exhibit unpredictable behavior. To prevent such unpredictable behavior, configure a dampening time between failovers. On failover, the previous primary node of a redundancy group moves to the secondary-hold state and stays in the secondary-hold state until the hold-down interval expires. After the hold-down interval expires, the previous primary node moves to the secondary state.
Configuring the hold-down interval prevents back-to-back failovers from occurring within the duration of hold-down interval.
The hold-down interval affects manual failovers, as well as automatic failovers associated with monitoring failures.
The default dampening time for a redundancy group 0 is 300 seconds
(5 minutes) and is configurable to up to 1800 seconds with the hold-down-interval statement. For some configurations, such
as those with a large number of routes or logical interfaces, the
default interval or the user-configured interval might not be sufficient.
In such cases, the system automatically extends the dampening time
in increments of 60 seconds until the system is ready for failover.
Redundancy groups x (redundancy groups numbered 1 through 128) have a default dampening time of 1 second, with a range from 0 through 1800 seconds.
On SRX Series Firewalls, chassis cluster failover performance is optimized to scale with more logical interfaces. Previously, during redundancy group failover, gratuitous arp (GARP) is sent by the Juniper Services Redundancy Protocol (jsrpd) process running in the Routing Engine on each logical interface to steer the traffic to the appropriate node. With logical interface scaling, the Routing Engine becomes the checkpoint and GARP is directly sent from the Services Processing Unit (SPU).
Preemptive Failover Delay Timer
A redundancy group is in the primary state (active) on one node and in the secondary state (backup) on the other node at any given time.
You can enable the preemptive behavior on both nodes in a redundancy group and assign a priority value for each node in the redundancy group. The node in the redundancy group with the higher configured priority is initially designated as the primary in the group, and the other node is initially designated as the secondary in the redundancy group.
When a redundancy group swaps the state of its nodes between primary and secondary, there is a possibility that a subsequent state swap of its nodes can happen again soon after the first state swap. This rapid change in states results in flapping of the primary and secondary systems.
Starting with Junos OS Release 17.4R1, a failover delay timer is introduced on SRX Series Firewalls in a chassis cluster to limit the flapping of redundancy group state between the secondary and the primary nodes in a preemptive failover.
To prevent the flapping, you can configure the following parameters:
-
Preemptive delay –The preemptive delay time is the amount of time a redundancy group in a secondary state waits when the primary state is down in a preemptive failover before switching to the primary state. This delay timer delays the immediate failover for a configured period of time––between 1 and 21,600 seconds.
-
Preemptive limit–The preemptive limit restricts the number of preemptive failovers (between 1 to 50) during a configured preemptive period, when
preemptionis enabled for a redundancy group. -
Preemptive period–Time period (1 to 1440 seconds) during which the preemptive limit is applied, that is, number of configured preemptive failovers are applied when preempt is enabled for a redundancy group.
Consider the following scenario where you have configured a preemptive period as 300 seconds and preemptive limit as 50.
When the preemptive limit is configured as 50, the count starts at 0 and increments with a first preemptive failover; this process continues until the count reaches the configured preemptive limit, that is 50, before the preemptive period expires. When the preemptive limit (50) is exceeded, you must manually reset the preempt count to allow preemptive failovers to occur again.
When you have configured the preemptive period as 300 seconds, and if the time difference between the first preemptive failover and the current failover has already exceeded 300 seconds, and the preemptive limit (50) is not yet reached, then the preemptive period will be reset. After resetting, the last failover is considered as the first preemptive failover of the new preemptive period and the process starts all over again.
The preemptive delay can be configured independent of the failover limit. Configuring the preemptive delay timer does not change the existing preemptive behavior.
This enhancement enables the administrator to introduce a failover delay, which can reduce the number of failovers and result in a more stable network state due to the reduction in active /standby flapping within the redundancy group.
- Understanding Transition from Primary State to Secondary State with Preemptive Delay
- Configuring Preemptive Delay Timer
Understanding Transition from Primary State to Secondary State with Preemptive Delay
Consider the following example, where a redundancy group, that
is primary on the node 0 is ready for preemptive transition to the
secondary state during a failover. Priority is assigned to each node
and the preemptive option is also enabled for the nodes.
Figure 1 illustrates the sequence of steps in transition from the primary state to the secondary state when a preemptive delay timer is configured.
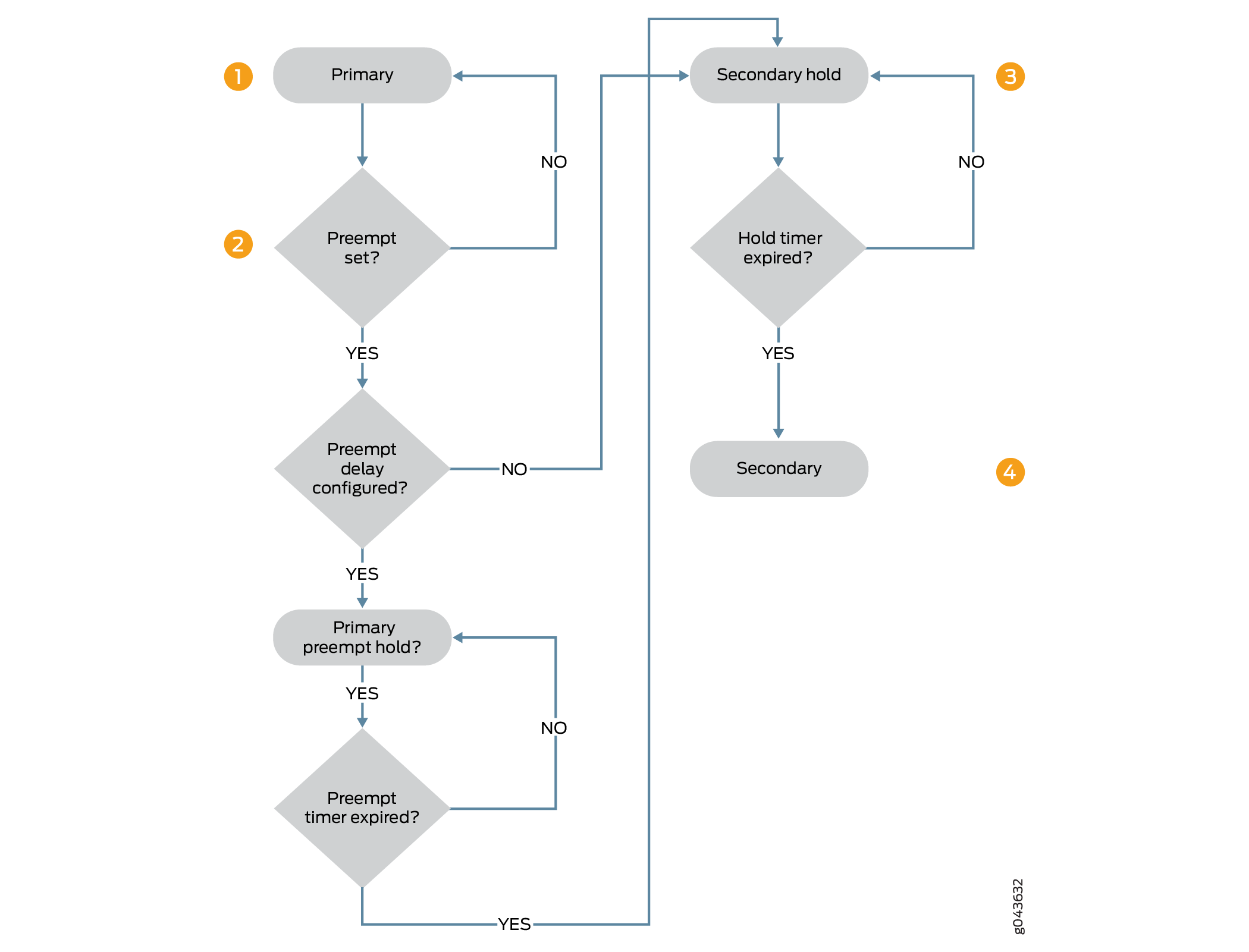
-
The node in the primary state is ready for preemptive transition to secondary state if the
preemptiveoption is configured, and the node in secondary state has the priority over the node in primary state. If the preemptive delay is configured, the node in the primary state transitions to primary-preempt-hold state . If preemptive delay is not configured, then instant transition to the secondary state happens. -
The node is in primary-preempt-hold state waiting for the preemptive delay timer to expire. The preemptive delay timer is checked and transition is held until the timer expires. The primary node stays in the primary-preempt-hold state until the timer expires, before transitioning to the secondary state.
-
The node transitions from primary-preempt-hold state into secondary-hold state and then to the secondary state.
-
The node stays in the secondary-hold state for the default time (1 second) or the configured time (a minimum of 300 seconds), and then the node transitions to the secondary state.
If your chassis cluster setup experiences an abnormal number of flaps, you must check your link and monitoring timers to make sure they are set correctly. Be careful when while setting timers in high latency networks to avoid getting false positives.
Configuring Preemptive Delay Timer
This topic explains how to configure the delay timer on SRX Series Firewalls in a chassis cluster. Back-to-back redundancy group failovers that occur too quickly can cause a chassis cluster to exhibit unpredictable behavior. Configuring the delay timer and failover rate limit delays immediate failover for a configured period of time.
To configure the preemptive delay timer and failover rate limit between redundancy group failovers:
-
Enable preemptive failover for a redundancy group.
You can set the delay timer between 1 and 21,600 seconds. Default value is 1 second.
{primary:node1} [edit chassis cluster redundancy-group number preempt] user@host# set delay interval -
Set up a limit for preemptive failover.
You can set maximum number of preemptive failovers between 1 to 50 and time period during which the limit is applied between 1 to 1440 seconds.
{primary:node1}[edit chassis cluster redundancy-group number preempt] user@host# set limit limit period period
In the following example, you are setting the preemptive delay timer to 300 seconds, and the preemptive limit to 10 for a premptive period of 600 seconds. That is, this configuration delays immediate failover for 300 seconds, and it limits a maximum of 10 preemptive failovers in a duration of 600 seconds.
{primary:node1}[edit chassis cluster redundancy-group 1 preempt]
user@host# set delay 300 limit 10 period 600You can use the clear chassis clusters preempt-count command to clear the preempt failover counter for all redundancy
groups. When a preempt limit is configured, the counter starts with
a first preemptive failover and the count is reduced; this process
continues until the count reaches zero before the timer expires. You
can use this command to clear the preempt failover counter and reset
it to start again.
See Also
Understanding Chassis Cluster Redundancy Group Manual Failover
You can initiate a redundancy group x (redundancy groups numbered 1 through 128) failover manually. A manual failover applies until a failback event occurs.
For example, suppose that you manually do a redundancy group 1 failover from node 0 to node 1. Then an interface that redundancy group 1 is monitoring fails, dropping the threshold value of the new primary redundancy group to zero. This event is considered a failback event, and the system returns control to the original redundancy group.
You can also initiate a redundancy group 0 failover manually if you want to change the primary node for redundancy group 0. You cannot enable preemption for redundancy group 0.
If preempt is added to a redundancy group configuration, the device with the higher priority in the group can initiate a failover to become primary. By default, preemption is disabled. For more information on preemeption, see preempt (Chassis Cluster).
When you do a manual failover for redundancy group 0, the node in the primary state transitions to the secondary-hold state. The node stays in the secondary-hold state for the default or configured time (a minimum of 300 seconds) and then transitions to the secondary state.
State transitions in cases where one node is in the secondary-hold state and the other node reboots, or the control link connection or fabric link connection is lost to that node, are described as follows:
Reboot case—The node in the secondary-hold state transitions to the primary state; the other node goes dead (inactive).
Control link failure case—The node in the secondary-hold state transitions to the ineligible state and then to a disabled state; the other node transitions to the primary state.
Fabric link failure case—The node in the secondary-hold state transitions directly to the ineligible state.
Starting with Junos OS Release 12.1X46-D20 and Junos OS Release 17.3R1, fabric monitoring is enabled by default. With this enabling, the node transitions directly to the ineligible state in case of fabric link failures.
Starting with Junos OS Release 12.1X47-D10 and Junos OS Release 17.3R1, fabric monitoring is enabled by default. With this enabling, the node transitions directly to the ineligible state in case of fabric link failures.
Keep in mind that during an in-service software upgrade (ISSU), the transitions described here cannot happen. Instead, the other (primary) node transitions directly to the secondary state because Juniper Networks releases earlier than 10.0 do not interpret the secondary-hold state. While you start an ISSU, if one of the nodes has one or more redundancy groups in the secondary-hold state, you must wait for them to move to the secondary state before you can do manual failovers to make all the redundancy groups be primary on one node.
Be cautious and judicious in your use of redundancy group 0 manual failovers. A redundancy group 0 failover implies a Routing Engine failover, in which case all processes running on the primary node are killed and then spawned on the new primary Routing Engine. This failover could result in loss of state, such as routing state, and degrade performance by introducing system churn.
In some Junos OS releases, for redundancy groups x, it is possible to do a manual failover on a node that has 0 priority.
We recommend that you use the show chassis cluster status command to check the redundancy group node priorities before doing
the manual failover. However,
from Junos OS Releases 12.1X44-D25, 12.1X45-D20, 12.1X46-D10, and
12.1X47-D10 and later, the readiness check mechanism for manual failover
is enhanced to be more restrictive, so that you cannot set manual
failover to a node in a redundancy group that has 0 priority. This
enhancement prevents traffic from being dropped unexpectedly due to
a failover attempt to a 0 priority node, which is not ready to accept
traffic.
Initiating a Chassis Cluster Manual Redundancy Group Failover
Before you begin, complete the following tasks:
You can initiate a failover manually with the request command. A manual failover bumps up the priority of
the redundancy group for that member to 255.
Be cautious and judicious in your use of redundancy group 0 manual failovers. A redundancy group 0 failover implies a Routing Engine (RE) failover, in which case all processes running on the primary node are killed and then spawned on the new primary Routing Engine (RE). This failover could result in loss of state, such as routing state, and degrade performance by introducing system churn.
Unplugging the power cord and holding the power button to initiate a chassis cluster redundancy group failover might result in unpredictable behavior.
For redundancy groups x (redundancy groups numbered 1 through 128), it is possible to do a manual failover on a node that has 0 priority. We recommend that you check the redundancy group node priorities before doing the manual failover.
Use the show command to display the
status of nodes in the cluster:
{primary:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 1
node0 254 primary no no
node1 1 secondary no no
Output to this command indicates that node 0 is primary.
Use the request command to trigger a
failover and make node 1 primary:
{primary:node0}
user@host> request chassis cluster failover redundancy-group 0 node 1
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Initiated manual failover for redundancy group 0Use the show command to display the
new status of nodes in the cluster:
{secondary-hold:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 2
node0 254 secondary-hold no yes
node1 255 primary no yes
Output to this command shows that node 1 is now primary and node 0 is in the secondary-hold state. After 5 minutes, node 0 will transition to the secondary state.
You can reset the failover for redundancy groups
by using the request command. This change is propagated
across the cluster.
{secondary-hold:node0}
user@host> request chassis cluster failover reset redundancy-group 0
node0:
--------------------------------------------------------------------------
No reset required for redundancy group 0.
node1:
--------------------------------------------------------------------------
Successfully reset manual failover for redundancy group 0
You cannot trigger a back-to-back failover until the 5-minute interval expires.
{secondary-hold:node0}
user@host> request chassis cluster failover redundancy-group 0 node 0
node0:
--------------------------------------------------------------------------
Manual failover is not permitted as redundancy-group 0 on node0 is in secondary-hold state.
Use the show command to display the
new status of nodes in the cluster:
{secondary-hold:node0}
user@host> show chassis cluster status redundancy-group 0
Cluster ID: 9
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 2
node0 254 secondary-hold no no
node1 1 primary no no
Output to this command shows that a back-to-back failover has not occurred for either node.
After doing a manual failover, you must issue the reset failover command before requesting another failover.
When the primary node fails and comes back up, election of the primary node is done based on regular criteria (priority and preempt).
Example: Configuring a Chassis Cluster with a Dampening Time Between Back-to-Back Redundancy Group Failovers
This example shows how to configure the dampening time between back-to-back redundancy group failovers for a chassis cluster. Back-to-back redundancy group failovers that occur too quickly can cause a chassis cluster to exhibit unpredictable behavior.
Requirements
Before you begin:
Understand redundancy group failover. See Understanding Chassis Cluster Redundancy Group Failover .
Understand redundancy group manual failover. See Understanding Chassis Cluster Redundancy Group Manual Failover.
Overview
The dampening time is the minimum interval allowed between back-to-back failovers for a redundancy group. This interval affects manual failovers and automatic failovers caused by interface monitoring failures.
In this example, you set the minimum interval allowed between back-to-back failovers to 420 seconds for redundancy group 0.
Configuration
Procedure
Step-by-Step Procedure
To configure the dampening time between back-to-back redundancy group failovers:
Set the dampening time for the redundancy group.
{primary:node0}[edit] user@host# set chassis cluster redundancy-group 0 hold-down-interval 420If you are done configuring the device, commit the configuration.
{primary:node0}[edit] user@host# commit
Understanding SNMP Failover Traps for Chassis Cluster Redundancy Group Failover
Chassis clustering supports SNMP traps, which are triggered whenever there is a redundancy group failover.
The trap message can help you troubleshoot failovers. It contains the following information:
The cluster ID and node ID
The reason for the failover
The redundancy group that is involved in the failover
The redundancy group’s previous state and current state
These are the different states that a cluster can be in at any given instant: hold, primary, secondary-hold, secondary, ineligible, and disabled. Traps are generated for the following state transitions (only a transition from a hold state does not trigger a trap):
primary <–> secondary
primary –> secondary-hold
secondary-hold –> secondary
secondary –> ineligible
ineligible –> disabled
ineligible –> primary
secondary –> disabled
A transition can be triggered because of any event, such as interface monitoring, SPU monitoring, failures, and manual failovers.
The trap is forwarded over the control link if the outgoing interface is on a node different from the node on the Routing Engine that generates the trap.
You can specify that a trace log be generated by setting the traceoptions flag snmp statement.
Verifying Chassis Cluster Failover Status
Purpose
Display the failover status of a chassis cluster.
Action
From the CLI, enter the show chassis cluster status command:
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 3
Node name Priority Status Preempt Manual failover
Redundancy-group: 0, Failover count: 1
node0 254 primary no no
node1 2 secondary no no
Redundancy-group: 1, Failover count: 1
node0 254 primary no no
node1 1 secondary no no
{primary:node1}
user@host> show chassis cluster status
Cluster ID: 15
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 5
node0 200 primary no no
node1 0 lost n/a n/a
Redundancy group: 1 , Failover count: 41
node0 101 primary no no
node1 0 lost n/a n/a{primary:node1}
user@host> show chassis cluster status
Cluster ID: 15
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 5
node0 200 primary no no
node1 0 unavailable n/a n/a
Redundancy group: 1 , Failover count: 41
node0 101 primary no no
node1 0 unavailable n/a n/a
Clearing Chassis Cluster Failover Status
To clear the failover status of a chassis cluster, enter the clear chassis cluster failover-count command from the CLI:
{primary:node1}
user@host> clear chassis cluster failover-count
Cleared failover-count for all redundancy-groupsChange History Table
Feature support is determined by the platform and release you are using. Use Feature Explorer to determine if a feature is supported on your platform.