IP Fabric GPU Backend Fabric Architecture
The GPU backend fabric in this cluster is built using Juniper QFX5240-64OD switches, which serve as both leaf and spine nodes, as shown in Figure 1. The architecture includes two stripes, each composed of eight QFX5240 leaf nodes. All leaf nodes are interconnected across four QFX5240 spine nodes, forming a Layer 3 IPv6 fabric that uses EBGP for route advertisement and native IPv6 for forwarding.
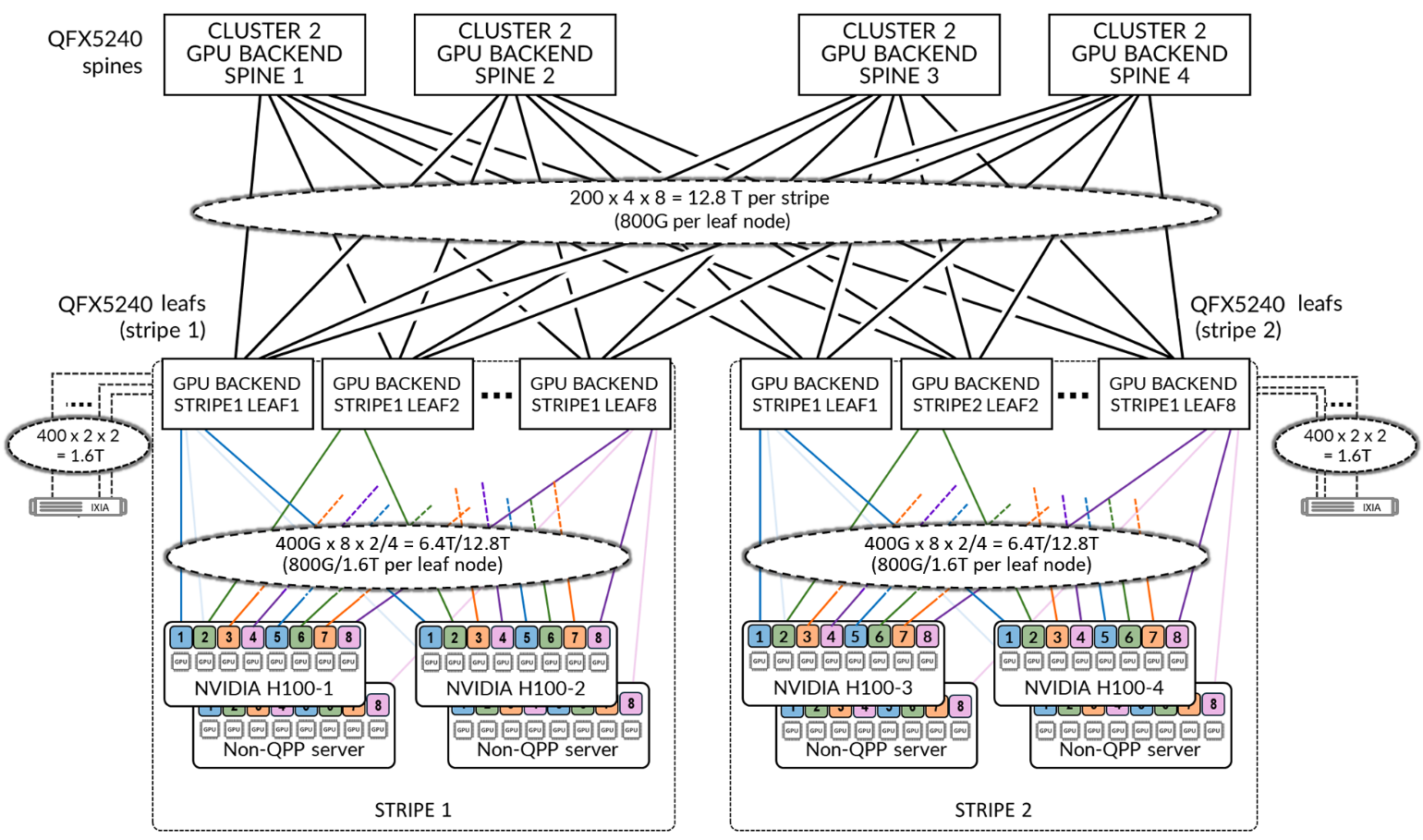
The NVIDIA H100 as well as the non-queue pair pinning (non-QPP) servers connect to the leaf nodes using 400GE interfaces. The leaf-to-spine links are also configured with 400GE uplinks. While the Juniper QFX5240 switches support 800GE uplinks to the spine nodes (refer to Table 1), the current configuration uses 400GE. This choice is intentional. By selecting 400GE uplinks, congestion scenarios can be tested with the existing resources.
| Leaf-to-Spine Link Speed |
Leaf Uplink Capacity (per leaf) |
Total Leaf-to-Spine BW |
Server-to-Leaf BW (4 servers) |
Server-to-Leaf BW (8 servers) |
Oversubscription Ratio (4 servers) |
Oversubscription Ratio (8 servers) |
|---|---|---|---|---|---|---|
| 200 Gbps | 4 × 200G = 800 Gbps | 12.8 Tbps | 12.8 Tbps | 25.6 Tbps |
1:1 (balanced) |
2:1 (oversubscribed) |
| 400 Gbps | 4 × 400G = 1.6 Tbps | 25.6 Tbps | 12.8 Tbps | 25.6 Tbps |
1:2 (overprovisioned) |
1:1 (balanced) |
| 800 Gbps | 4 × 800G = 3.2 Tbps | 51.2 Tbps | 12.8 Tbps | 25.6 Tbps |
1:4 (heavily overprovisioned) |
1:2 (overprovisioned) |
Currently, the lab includes four servers where Queue Pair Pinning (QPP) can be implemented. Two additional non-QPP-enabled servers per stripe were added, increasing the total server bandwidth to match the available spine uplink capacity. Additional RoCEv2 traffic is injected using an IXIA traffic generator to create realistic congestion scenarios and validate congestion control mechanisms.
A summary of the GPU backend fabric components and their connectivity is provided in Tables 2 and 3 below.
| Stripe | GPU Servers |
GPU Backend Leaf nodes switch model |
GPU Backend Spine nodes switch model |
|---|---|---|---|
| 1 |
H100 x 2 (H100-01 & H100-02) |
QFX5240-64OD x 8 (gpu-backend-001_leaf#; #=1-8) |
QFX5240-64OD x 4 (gpu-backend-spine#; #=1-4) |
| 2 |
H100 x 2 (H100-01 & H100-02) |
QFX5240-64OD x 8 (gpu-backend-002_leaf#; #=1-8) |
| Stripe |
GPU Servers <=> GPU Backend Leaf Nodes |
GPU Backend Leaf Nodes <=> GPU Backend Spine Nodes |
|---|---|---|
| 1 |
Total number of 400GE links between servers and leaf nodes = 8 (number of GPUs per server) x 1 (number of 400GE server to leaf links) x4 (number of servers) = 32 |
Total number of 400GE links between GPU backend leaf nodes and spine nodes = 8 (number of leaf nodes) x 2 (number of 400GE links per leaf to spine connection) x 4 (number of spine nodes) = 64 |
| 2 |
Total number of 400GE links between servers and leaf nodes = 8 (number of GPUs per server) x 1 (number of 400GE server to leaf links) x 4 (number of servers) = 32 |
Total number of 400GE links between GPU backend leaf nodes and spine nodes = 8 (number of leaf nodes) x 2 (number of 400GE links per leaf to spine connection) x 4 (number of spine nodes) = 64 |
Oversubscription Factor
The speed and number of links between the GPU servers and leaf nodes, as well as the links between the leaf and spine nodes, determine the overall oversubscription factor of the fabric.
With only the four NVIDIA H100 QPP-enabled servers connecting to the fabric using 8 × 400GE interfaces (3.2 Tbps per server), the total server-to-leaf bandwidth is 12.8 Tbps. Each of the 16 leaf nodes connects to four spine nodes using 400GE links, providing a total leaf-to-spine bandwidth of 25.6 Tbps (see Table 4). This results in a 1:2 ratio, meaning the fabric is overprovisioned 1:2, providing more than enough bandwidth for full GPU-to-GPU communication—even under 100% inter-stripe traffic.
To implement a balanced, non-oversubscribed (1:1) configuration that can still be congested for testing we introduced additional RoCEv2 traffic, two additional servers per stripe, without Queue Pair Pinning (QPP) support, were added. This brings the total to eight servers, increasing the server-to-leaf bandwidth to 25.6 Tbps (see Table 5), which matches the available spine uplink capacity. In this extended setup, additional RoCEv2 traffic is injected using IXIA to create realistic congestion scenarios and validate congestion control mechanisms across the backend fabric.
The recommendation is to deploy the fabric following a 1:1 subscription factor.
| Server to Leaf Bandwidth per Stripe | ||||
|---|---|---|---|---|
| Stripe |
Number of servers per Stripe |
Number of 400 GE server <=> leaf links per server (Same as number of leaf nodes & number of GPUs per server) |
Server <=> Leaf Link Bandwidth [Gbps] |
Total Servers <=> Leaf Links Bandwidth per stripe [Tbps] |
| 1 | 2 | 8 | 400 Gbps | 2 x 8 x 400 Gbps = 6.4 Tbps |
| 2 | 2 | 8 | 400 Gbps | 2 x 8 x 400 Gbps = 6.4 Tbps |
|
Total Server <=> Leaf Bandwidth |
12.8 Tbps | |||
| Leaf nodes to spine nodes bandwidth per Stripe | |||||
|---|---|---|---|---|---|
| Stripe | Number of leaf nodes | Number of spine nodes |
Number of 400 GE leaf <=> spine links per leaf node |
Server <=> Leaf Link Bandwidth [Gbps] |
Bandwidth Leaf <=> Spine Per Stripe [Tbps] |
| 1 | 8 | 4 | 1 | 400 Gbps | 8 x 4 x 1 x 400 Gbps = 12.8 Tbps |
| 2 | 8 | 4 | 1 | 400 Gbps | 8 x 4 x 1 x 400 Gbps = 12.8 Tbps |
|
Total Leaf <=> Spine Bandwidth |
25.6 Tbps | ||||
| Server to Leaf Bandwidth per Stripe | ||||
|---|---|---|---|---|
| Stripe |
Number of servers per Stripe |
Number of 400 GE server ó lea links per server (Same as number of leaf nodes & number of GPUs per server) |
Server <=> Leaf Link Bandwidth [Gbps] |
Total Servers <=> Leaf Links Bandwidth per stripe [Tbps] |
| 1 | 4 | 8 | 400 Gbps | 4 x 8 x 400 Gbps = 12.8 Tbps |
| 2 | 4 | 8 | 400 Gbps | 4 x 8 x 400 Gbps = 12.8 Tbps |
|
Total Server <=> Leaf Bandwidth |
25.6 Tbps | |||
GPU Servers to leaf nodes connectivity follows the Rail-optimized architecture as described in the Backend GPU Rail Optimized Stripe Architecture section of the AI Data Center Network with Juniper Apstra, NVIDIA GPUs, and WEKA Storage JVD.