Monitoring and Troubleshooting
This section describes the network monitoring and troubleshooting features of Junos OS.
Ping Hosts
Purpose
Use the CLI ping command to verify that a host can be reached over the network.
This command is useful for diagnosing host and network connectivity problems. The
device sends a series of Internet Control Message Protocol (ICMP) echo (ping)
requests to a specified host and receives ICMP echo responses.
Action
To use the ping command to send four requests
(ping count) to host3:
ping host count number
Sample Output
command-name
ping host3 count 4 user@switch> ping host3 count 4 PING host3.site.net (192.0.2.111): 56 data bytes 64 bytes from 192.0.2.111: icmp_seq=0 ttl=122 time=0.661 ms 64 bytes from 192.0.2.111: icmp_seq=1 ttl=122 time=0.619 ms 64 bytes from 192.0.2.111: icmp_seq=2 ttl=122 time=0.621 ms 64 bytes from 192.0.2.111: icmp_seq=3 ttl=122 time=0.634 ms --- host3.site.net ping statistics --- 4 packets transmitted, 4 packets received, 0% packet loss round-trip min/avg/max/stddev = 0.619/0.634/0.661/0.017 ms
Meaning
The
pingresults show the following information:Size of the ping response packet (in bytes).
IP address of the host from which the response was sent.
Sequence number of the ping response packet. You can use this value to match the ping response to the corresponding ping request.
Time-to-live (ttl) hop-count value of the ping response packet.
Total time between the sending of the ping request packet and the receiving of the ping response packet, in milliseconds. This value is also called round-trip time.
Number of ping requests (probes) sent to the host.
Number of ping responses received from the host.
Packet loss percentage.
Round-trip time statistics: minimum, average, maximum, and standard deviation of the round-trip time.
Monitor Traffic Through the Router or Switch
For diagnosing a problem, display real-time statistics about the traffic passing through physical interfaces on the router or switch.
To display real-time statistics about physical interfaces, perform these tasks:
- Display Real-Time Statistics About All Interfaces on the Router or Switch
- Display Real-Time Statistics About an Interface on the Router or Switch
Display Real-Time Statistics About All Interfaces on the Router or Switch
Purpose
Display real-time statistics about traffic passing through all interfaces on the router or switch.
Action
To display real-time statistics about traffic passing through all interfaces on the router or switch:
user@host> monitor interface traffic
Sample Output
command-name
user@host> monitor interface traffic host name Seconds: 15 Time: 12:31:09 Interface Link Input packets (pps) Output packets (pps) so-1/0/0 Down 0 (0) 0 (0) so-1/1/0 Down 0 (0) 0 (0) so-1/1/1 Down 0 (0) 0 (0) so-1/1/2 Down 0 (0) 0 (0) so-1/1/3 Down 0 (0) 0 (0) t3-1/2/0 Down 0 (0) 0 (0) t3-1/2/1 Down 0 (0) 0 (0) t3-1/2/2 Down 0 (0) 0 (0) t3-1/2/3 Down 0 (0) 0 (0) so-2/0/0 Up 211035 (1) 36778 (0) so-2/0/1 Up 192753 (1) 36782 (0) so-2/0/2 Up 211020 (1) 36779 (0) so-2/0/3 Up 211029 (1) 36776 (0) so-2/1/0 Up 189378 (1) 36349 (0) so-2/1/1 Down 0 (0) 18747 (0) so-2/1/2 Down 0 (0) 16078 (0) so-2/1/3 Up 0 (0) 80338 (0) at-2/3/0 Up 0 (0) 0 (0) at-2/3/1 Down 0 (0) 0 (0) Bytes=b, Clear=c, Delta=d, Packets=p, Quit=q or ESC, Rate=r, Up=^U, Down=^D
Meaning
The sample output displays traffic data for active
interfaces and the amount that each field has changed since the command
started or since the counters were cleared by using the C key. In this example, the monitor interface command has
been running for 15 seconds since the command was issued or since
the counters last returned to zero.
Display Real-Time Statistics About an Interface on the Router or Switch
Purpose
Display real-time statistics about traffic passing through an interface on the router or switch.
Action
To display traffic passing through an interface on the router or switch, use the following Junos OS CLI operational mode command:
user@host> monitor interface interface-name
Sample Output
command-name
user@host> monitor interface so-0/0/1 Next='n', Quit='q' or ESC, Freeze='f', Thaw='t', Clear='c', Interface='i' R1 Interface: so-0/0/1, Enabled, Link is Up Encapsulation: PPP, Keepalives, Speed: OC3 Traffic statistics: Input bytes: 5856541 (88 bps) Output bytes: 6271468 (96 bps) Input packets: 157629 (0 pps) Output packets: 157024 (0 pps) Encapsulation statistics: Input keepalives: 42353 Output keepalives: 42320 LCP state: Opened Error statistics: Input errors: 0 Input drops: 0 Input framing errors: 0 Input runts: 0 Input giants: 0 Policed discards: 0 L3 incompletes: 0 L2 channel errors: 0 L2 mismatch timeouts: 0 Carrier transitions: 1 Output errors: 0 Output drops: 0 Aged packets: 0 Active alarms : None Active defects: None SONET error counts/seconds: LOS count 1 LOF count 1 SEF count 1 ES-S 77 SES-S 77 SONET statistics: BIP-B1 0 BIP-B2 0 REI-L 0 BIP-B3 0 REI-P 0 Received SONET overhead: F1 : 0x00 J0 : 0xZ
Meaning
The sample output shows the input and output packets for a particular SONET interface
(so-0/0/1). The information can include common interface failures, such
as SONET/SDH and T3 alarms, loopbacks detected, and increases in framing errors.
To control the output of the command while it is running, use the keys shown in Table 1.
Action |
Key |
|---|---|
Display information about the next interface. The |
|
Display information about a different interface. The command prompts you for the name of a specific interface. |
|
Freeze the display, halting the display of updated statistics. |
|
Thaw the display, resuming the display of updated statistics. |
|
Clear (zero) the current delta counters since |
|
Stop the |
|
See the CLI Explorer for details on
using match conditions with the monitor traffic command.
Dynamic Ternary Content Addressable Memory Overview
Ternary Content Addressable Memory (TCAM) is used by various applications like firewall, connectivity fault management, PTPoE, RFC 2544, etc. The Packet Forwarding Engine (PFE) in ACX Series routers uses TCAM with defined TCAM space limits. The allocation of TCAM resources for various filter applications are statically distributed. This static allocation leads to inefficient utilization of TCAM resources when all the filter applications might not use this TCAM resource simultaneously.
The dynamic allocation of TCAM space in routers efficiently allocates the available TCAM resources for various filter applications. In the dynamic TCAM model, various filter applications (such as inet-firewall, bridge-firewall, cfm-filters, etc.) can optimally utilize the available TCAM resources as and when required. Dynamic TCAM resource allocation is usage driven and is dynamically allocated for filter applications on a need basis. When a filter application no longer uses the TCAM space, the resource is freed and available for use by other applications. This dynamic TCAM model caters to higher scale of TCAM resource utilization based on application’s demand.
- Applications using Dynamic TCAM Infrastructure
- Features Using TCAM Resource
- Monitoring TCAM Resource Usage
- Example: Monitoring and Troubleshooting the TCAM Resource
- Monitoring and Troubleshooting TCAM Resource in ACX Series Routers
- Service Scaling on ACX5048 and ACX5096 Routers
Applications using Dynamic TCAM Infrastructure
The following filter application categories use the dynamic TCAM infrastructure:
Firewall filter—All the firewall configurations
Implicit filter—Routing Engine (RE) demons using filters to achieve its functionality. For example, connectivity fault management, IP MAC validation, etc.
Dynamic filters—Applications using filters to achieve the functionality at the PFE level. For example, logical interface level fixed classifier, RFC 2544, etc. RE demons will not know about these filters.
System-init filters—Filters that require entries at the system level or fixed set of entries at router's boot sequence. For example, Layer 2 and Layer 3 control protocol trap, default ARP policer, etc.
Note:The System-init filter which has the applications for Layer 2 and Layer 3 control protocols trap is essential for the overall system functionality. The applications in this control group consume a fixed and minimal TCAM space from the overall TCAM space. The system-init filter will not use the dynamic TCAM infrastructure and will be created when the router is initialized during the boot sequence.
Features Using TCAM Resource
Applications using the TCAM resource is termed tcam-app in this document. For example, inet-firewall, bridge-firewall, connectivity fault management, link fault management, and so on are all different tcam-apps.
Table 2 describes the list of tcam-apps that use TCAM resources.
TCAM Apps/TCAM Users |
Feature/Functionality |
TCAM Stage |
|---|---|---|
bd-dtag-validate |
Bridge domain dual-tagged validate Note:
This feature is not supported on ACX5048 and ACX5096 routers. |
Egress |
bd-tpid-swap |
Bridge domain vlan-map with swap tpid operation |
Egress |
cfm-bd-filter |
Connectivity fault management implicit bridge-domain filters |
Ingress |
cfm-filter |
Connectivity fault management implicit filters |
Ingress |
cfm-vpls-filter |
Connectivity fault management implicit vpls filters Note:
This feature is supported only on ACX5048 and ACX5096 routers. |
Ingress |
cfm-vpls-ifl-filter |
Connectivity fault management implicit vpls logical interface filters Note:
This feature is supported only on ACX5048 and ACX5096 routers. |
Ingress |
cos-fc |
Logical interface level fixed classifier |
Pre-ingress |
fw-ccc-in |
Circuit cross-connect family ingress firewall |
Ingress |
fw-family-out |
Family level egress firewall |
Egress |
fw-fbf |
Firewall filter-based forwarding |
Pre-ingress |
fw-fbf-inet6 |
Firewall filter-based forwarding for inet6 family |
Pre-ingress |
fw-ifl-in |
Logical interface level ingress firewall |
Ingress |
fw-ifl-out |
Logical interface level egress firewall |
Egress |
fw-inet-ftf |
Inet family ingress firewall on a forwarding-table |
Ingress |
fw-inet6-ftf |
Inet6 family ingress firewall on a forwarding-table |
Ingress |
fw-inet-in |
Inet family ingress firewall |
Ingress |
fw-inet-rpf |
Inet family ingress firewall on RPF fail check |
Ingress |
fw-inet6-in |
Inet6 family ingress firewall |
Ingress |
fw-inet6-family-out |
Inet6 Family level egress firewall |
Egress |
fw-inet6-rpf |
Inet6 family ingress firewall on a RPF fail check |
Ingress |
fw-inet-pm |
Inet family firewall with port-mirror action Note:
This feature is not supported on ACX5048 and ACX5096 routers. |
Ingress |
fw-l2-in |
Bridge family ingress firewall on Layer 2 interface |
Ingress |
fw-mpls-in |
MPLS family ingress firewall |
Ingress |
fw-semantics |
Firewall sharing semantics for CLI configured firewall |
Pre-ingress |
fw-vpls-in |
VPLS family ingress firewall on VPLS interface |
Ingress |
ifd-src-mac-fil |
Physical interface level source MAC filter |
Pre-ingress |
ifl-statistics-in |
Logical level interface statistics at ingress |
Ingress |
ifl-statistics-out |
Logical level interface statistics at egress |
Egress |
ing-out-iff |
Ingress application on behalf of egress family filter for log and syslog |
Ingress |
ip-mac-val |
IP MAC validation |
Pre-ingress |
ip-mac-val-bcast |
IP MAC validation for broadcast |
Pre-ingress |
ipsec-reverse-fil |
Reverse filters for IPsec service Note:
This feature is not supported on ACX5048 and ACX5096 routers. |
Ingress |
irb-cos-rw |
IRB CoS rewrite |
Egress |
lfm-802.3ah-in |
Link fault management (IEEE 802.3ah) at ingress Note:
This feature is not supported on ACX5048 and ACX5096 routers. |
Ingress |
lfm-802.3ah-out |
Link fault management (IEEE 802.3ah) at egress |
Egress |
lo0-inet-fil |
Looback interface inet filter |
Ingress |
lo0-inet6-fil |
Looback interface inet6 filter |
Ingress |
mac-drop-cnt |
Statistics for drops by MAC validate and source MAC filters |
Ingress |
mrouter-port-in |
Multicast router port for snooping |
Ingress |
napt-reverse-fil |
Reverse filters for network address port translation (NAPT) service Note:
This feature is not supported on ACX5048 and ACX5096 routers. |
Ingress |
no-local-switching |
Bridge no-local-switching |
Ingress |
ptpoe |
Point-to-Point-Over-the-Ethernet traps Note:
This feature is not supported on ACX5048 and ACX5096 routers. |
Ingress |
ptpoe-cos-rw |
CoS rewrite for PTPoE Note:
This feature is not supported on ACX5048 and ACX5096 routers. |
Egress |
rfc2544-layer2-in |
RFC2544 for Layer 2 service at ingress |
Pre-ingress |
rfc2544-layer2-out |
RFC2544 for Layer 2 service at egress Note:
This feature is not supported on ACX5048 and ACX5096 routers. |
Egress |
service-filter-in |
Service filter at ingress Note:
This feature is not supported on ACX5048 and ACX5096 routers. |
Ingress |
Monitoring TCAM Resource Usage
You can use the show and clear commands to monitor and troubleshoot dynamic TCAM resource usage.
Table 3 summarizes the command-line interface (CLI) commands you can use to monitor and troubleshoot dynamic TCAM resource usage.
Task |
Command |
|---|---|
Display the shared and the related applications for a particular application |
|
Display the TCAM resource usage for an application and stages (egress, ingress, and pre-ingress) |
(ACX5448) show pfe filter hw summary |
Display the TCAM resource usage errors for applications and stages (egress, ingress, and pre-ingress) |
|
Clears the TCAM resource usage error statistics for applications and stages (egress, ingress, and pre-ingress) |
Example: Monitoring and Troubleshooting the TCAM Resource
This section describes a use case where you can monitor and troubleshoot TCAM resources using show commands. In this use case scenario, you have configured Layer 2 services and the Layer 2 service-related applications are using TCAM resources. The dynamic approach, as shown in this example, gives you the complete flexibility to manage TCAM resources on a need basis.
The service requirement is as follows:
Each bridge domain has one UNI and one NNI interface
Each UNI interface has:
One logical interface level policer to police the traffic at 10 Mbps.
Multifield classifier with four terms to assign forwarding class and loss-priority.
Each UNI interface configures CFM UP MEP at the level 4.
Each NNI interface configures CFM DOWN MEP at the level 2
Let us consider a scenario where there are 100 services configured on the router. With this scale, all the applications are configured successfully and the status shows OK state.
-
Viewing TCAM resource usage for all stages.
To view the TCAM resource usage for all stages (egress, ingress, and pre-ingress), use the
show pfe tcam usage all-tcam-stages detailcommand. On ACX5448 routers, use theshow pfe filter hw summarycommand to view the TCAM resource usgae.user@host> show pfe tcam usage all-tcam-stages detail Slot 0 Tcam Resource Stage: Pre-Ingress -------------------------------- Free [hw-grps: 3 out of 3] No dynamic tcam usage Tcam Resource Stage: Ingress ---------------------------- Free [hw-grps: 2 out of 8] Group: 11, Mode: SINGLE, Hw grps used: 3, Tcam apps: 2 Used Allocated Available Errors Tcam-Entries 800 1024 224 0 Counters 800 1024 224 0 Policers 0 1024 1024 0 App tcam usage: ---------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- cfm-filter 500 500 0 3 OK cfm-bd-filter 300 300 0 2 OK Group: 8, Mode: DOUBLE, Hw grps used: 2, Tcam apps: 1 Used Allocated Available Errors Tcam-Entries 500 512 12 0 Counters 500 1024 524 0 Policers 0 1024 1024 0 App tcam usage: ---------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- fw-l2-in 500 500 0 2 OK fw-semantics 0 X X 1 OK Group: 14, Mode: SINGLE, Hw grps used: 1, Tcam apps: 1 Used Allocated Available Errors Tcam-Entries 200 512 312 0 Counters 200 512 312 0 Policers 100 512 412 0 App tcam usage: ---------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- fw-ifl-in 200 200 100 1 OK Tcam Resource Stage: Egress --------------------------- Free [hw-grps: 3 out of 3] No dynamic tcam usage Configure additional Layer 2 services on the router.
For example, add 20 more services on the router, thereby increasing the total number of services to 120. After adding more services, you can check the status of the configuration by verifying either the syslog message using the command
show log messages, or by running theshow pfe tcam errorscommand.The following is a sample syslog message output showing the TCAM resource shortage for Ethernet-switching family filters for newer configurations by running the
show log messagesCLI command.[Sat Jul 11 16:10:33.794 LOG: Err] ACX Error (dfw):acx_dfw_check_phy_slice_availability :Insufficient phy slices to accomodate grp:13/IN_IFF_BRIDGE mode:1/DOUBLE [Sat Jul 11 16:10:33.794 LOG: Err] ACX Error (dfw):acx_dfw_check_resource_availability :Could not write filter: f-bridge-ge-0/0/0.103-i, insufficient TCAM resources [Sat Jul 11 16:10:33.794 LOG: Err] ACX Error (dfw):acx_dfw_update_filter_in_hw :acx_dfw_check_resource_availability failed for filter:f-bridge-ge-0/0/0.103-i [Sat Jul 11 16:10:33.794 LOG: Err] ACX Error (dfw):acx_dfw_create_hw_instance :Status:1005 Could not program dfw(f-bridge-ge-0/0/0.103-i) type(IN_IFF_BRIDGE)! [1005] [Sat Jul 11 16:10:33.794 LOG: Err] ACX Error (dfw):acx_dfw_bind_shim :[1005] Could not create dfw(f-bridge-ge-0/0/0.103-i) type(IN_IFF_BRIDGE) [Sat Jul 11 16:10:33.794 LOG: Err] ACX Error (dfw):acx_dfw_bind :[1000] bind failed for filter f-bridge-ge-0/0/0.103-i
If you use the
show pfe tcam errors all-tcam-stages detailCLI command to verify the status of the configuration, the output will be as shown below:user@host> show pfe tcam errors all-tcam-stages detail Slot 0 Tcam Resource Stage: Pre-Ingress -------------------------------- Free [hw-grps: 3 out of 3] No dynamic tcam usage Tcam Resource Stage: Ingress ---------------------------- Free [hw-grps: 2 out of 8] Group: 11, Mode: SINGLE, Hw grps used: 3, Tcam apps: 2 Used Allocated Available Errors Tcam-Entries 960 1024 64 0 Counters 960 1024 64 0 Policers 0 1024 1024 0 App tcam usage: ---------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- cfm-filter 600 600 0 3 OK cfm-bd-filter 360 360 0 2 OK Group: 8, Mode: DOUBLE, Hw grps used: 2, Tcam apps: 1 Used Allocated Available Errors Tcam-Entries 510 512 2 18 Counters 510 1024 514 0 Policers 0 1024 1024 0 App tcam usage: ---------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- fw-l2-in 510 510 0 2 FAILED fw-semantics 0 X X 1 OK App error statistics: ---------------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- fw-l2-in 18 0 0 2 FAILED fw-semantics 0 X X 1 OK Group: 14, Mode: SINGLE, Hw grps used: 1, Tcam apps: 1 Used Allocated Available Errors Tcam-Entries 240 512 272 0 Counters 240 512 272 0 Policers 120 512 392 0 App tcam usage: ---------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- fw-ifl-in 240 240 120 1 OK Tcam Resource Stage: Egress --------------------------- Free [hw-grps: 3 out of 3] No dynamic tcam usageThe output indicates that the fw-l2-in application is running out of TCAM resources and moves into a FAILED state. Although there are two TCAM slices available at the ingress stage, the fw-l2-in application is not able to use the available TCAM space due to its mode (DOUBLE), resulting in resource shortage failure.
-
Fixing the applications that have failed due to the shortage of TCAM resouces.
The fw-l2-in application failed because of adding more number of services on the routers, which resulted in shortage of TCAM resources. Although other applications seems to work fine, it is recommended to deactivate or remove the newly added services so that the fw-l2-in application moves to an OK state. After removing or deactivating the newly added services, you need to run the
show pfe tcam usageandshow pfe tcam errorcommands to verify that there are no more applications in failed state.To view the TCAM resource usage for all stages (egress, ingress, and pre-ingress), use the
show pfe tcam usage all-tcam-stages detailcommand. For ACX5448 routers, use theshow pfe filter hw summarycommand to to view the TCAM resource usage.user@host> show pfe tcam usage all-tcam-stages detail Slot 0 Tcam Resource Stage: Pre-Ingress -------------------------------- Free [hw-grps: 3 out of 3] No dynamic tcam usage Tcam Resource Stage: Ingress ---------------------------- Free [hw-grps: 2 out of 8] Group: 11, Mode: SINGLE, Hw grps used: 3, Tcam apps: 2 Used Allocated Available Errors Tcam-Entries 800 1024 224 0 Counters 800 1024 224 0 Policers 0 1024 1024 0 App tcam usage: ---------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- cfm-filter 500 500 0 3 OK cfm-bd-filter 300 300 0 2 OK Group: 8, Mode: DOUBLE, Hw grps used: 2, Tcam apps: 1 Used Allocated Available Errors Tcam-Entries 500 512 12 18 Counters 500 1024 524 0 Policers 0 1024 1024 0 App tcam usage: ---------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- fw-l2-in 500 500 0 2 OK fw-semantics 0 X X 1 OK Group: 14, Mode: SINGLE, Hw grps used: 1, Tcam apps: 1 Used Allocated Available Errors Tcam-Entries 200 512 312 0 Counters 200 512 312 0 Policers 100 512 412 0 App tcam usage: ---------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- fw-ifl-in 200 200 100 1 OK Tcam Resource Stage: Egress --------------------------- Free [hw-grps: 3 out of 3] No dynamic tcam usageTo view TCAM resource usage errors for all stages (egress, ingress, and pre-ingress), use the
show pfe tcam errors all-tcam-stagescommand.user@host> show pfe tcam errors all-tcam-stages detail Slot 0 Tcam Resource Stage: Pre-Ingress -------------------------------- No tcam usage Tcam Resource Stage: Ingress ---------------------------- Group: 11, Mode: SINGLE, Hw grps used: 3, Tcam apps: 2 Errors Resource-Shortage Tcam-Entries 0 0 Counters 0 0 Policers 0 0 Group: 8, Mode: DOUBLE, Hw grps used: 2, Tcam apps: 1 Errors Resource-Shortage Tcam-Entries 18 0 Counters 0 0 Policers 0 0 Group: 14, Mode: SINGLE, Hw grps used: 1, Tcam apps: 1 Errors Resource-Shortage Tcam-Entries 0 0 Counters 0 0 Policers 0 0 Tcam Resource Stage: Egress --------------------------- No tcam usageYou can see that all the applications using the TCAM resources are in OK state and indicates that the hardware has been successfully configured.
As shown in the example, you will need to run the show pfe tcam errors and
show pfe tcam usage commands at each step to ensure that your
configurations are valid and that the applications using TCAM resource are in OK state.
For ACX5448 routers, use the show pfe filter hw summary command to view
the TCAM resource usage.
Monitoring and Troubleshooting TCAM Resource in ACX Series Routers
The dynamic allocation of Ternary Content Addressable Memory (TCAM) space in ACX Series efficiently allocates the available TCAM resources for various filter applications. In the dynamic TCAM model, various filter applications (such as inet-firewall, bridge-firewall, cfm-filters, etc.) can optimally utilize the available TCAM resources as and when required. Dynamic TCAM resource allocation is usage driven and is dynamically allocated for filter applications on a need basis. When a filter application no longer uses the TCAM space, the resource is freed and available for use by other applications. This dynamic TCAM model caters to higher scale of TCAM resource utilization based on application’s demand. You can use the show and clear commands to monitor and troubleshoot dynamic TCAM resource usage in ACX Series routers.
Applications using the TCAM resource is termed tcam-app in this document.
Dynamic Ternary Content Addressable Memory Overview shows the task and the commands to monitor and troubleshoot TCAM resources in ACX Series routers
|
How to |
Command |
|---|---|
|
View the shared and the related applications for a particular application. |
|
|
View the number of applications across all tcam stages. |
|
|
View the number of applications using the TCAM resource at a specified stage. |
|
|
View the TCAM resource used by an application in detail. |
|
|
View the TCAM resource used by an application at a specified stage. |
|
|
Know the number of TCAM resource consumed by a tcam-app |
|
|
View the TCAM resource usage errors for all stages. |
|
|
View the TCAM resource usage errors for a stage |
|
|
View the TCAM resource usage errors for an application. |
|
|
View the TCAM resource usage errors for an application along with its other shared application. |
|
|
Clear the TCAM resource usage error statistics for all stages. |
|
|
Clear the TCAM resource usage error statistics for a specified stage |
|
|
Clear the TCAM resource usage error statistics for an application. |
|
To know more about dynamic TCAM in ACX Series, see Dynamic Ternary Content Addressable Memory Overview.
Service Scaling on ACX5048 and ACX5096 Routers
On ACX5048 and ACX5096 routers, a typical service (such as ELINE, ELAN and IP VPN) that is deployed might require applications (such as policers, firewall filters, connectivity fault management IEEE 802.1ag, RFC2544) that uses the dynamic TCAM infrastructure.
Service applications that uses TCAM resources is limited by the TCAM resource availability. Therefore, the scale of the service depends upon the consumption of the TCAM resource by such applications.
A sample use case for monitoring and troubleshooting service scale in ACX5048 and ACX5096 routers can be found at the Dynamic Ternary Content Addressable Memory Overview section.
Troubleshoot DNS Name Resolution in Logical System Security Policies (Primary Administrators Only)
Problem
Description
The address of a hostname in an address book entry that is used in a security policy might fail to resolve correctly.
Cause
Normally, address book entries that contain dynamic hostnames refresh automatically for security devices. The TTL field associated with a DNS entry indicates the time after which the entry should be refreshed in the policy cache. Once the TTL value expires, the security device automatically refreshes the DNS entry for an address book entry.
However, if the security device is unable to obtain a response from the DNS server (for example, the DNS request or response packet is lost in the network or the DNS server cannot send a response), the address of a hostname in an address book entry might fail to resolve correctly. This can cause traffic to drop as no security policy or session match is found.
Solution
The primary administrator can use the show security dns-cache command to display
DNS cache information on the security device. If the DNS
cache information needs to be refreshed, the primary administrator can use the
clear security dns-cache command.
These commands are only available to the primary administrator on devices that are configured for logical systems. This command is not available in user logical systems or on devices that are not configured for logical systems.
See Also
Troubleshoot the Link Services Interface
To solve configuration problems on a link services interface:
- Determine Which CoS Components Are Applied to the Constituent Links
- Determine What Causes Jitter and Latency on the Multilink Bundle
- Determine If LFI and Load Balancing Are Working Correctly
- Determine Why Packets Are Dropped on a PVC Between a Juniper Networks Device and a Third-Party Device
Determine Which CoS Components Are Applied to the Constituent Links
Problem
Description
You are configuring a multilink bundle, but you also have traffic without MLPPP encapsulation passing through constituent links of the multilink bundle. Do you apply all CoS components to the constituent links, or is applying them to the multilink bundle enough?
Solution
You can apply a scheduler map to the multilink bundle and its constituent links. Although you can apply several CoS components with the scheduler map, configure only the ones that are required. We recommend that you keep the configuration on the constituent links simple to avoid unnecessary delay in transmission.
Cos Component |
Multilink Bundle |
Constituent Links |
Explanation |
|---|---|---|---|
Classifier |
Yes |
No |
CoS classification takes place on the incoming side of the interface, not on the transmitting side, so no classifiers are needed on constituent links. |
Forwarding class |
Yes |
No |
Forwarding class is associated with a queue, and the queue is applied to the interface by a scheduler map. The queue assignment is predetermined on the constituent links. All packets from Q2 of the multilink bundle are assigned to Q2 of the constituent link, and packets from all the other queues are queued to Q0 of the constituent link. |
Scheduler map |
Yes |
Yes |
Apply scheduler maps on the multilink bundle and the constituent link as follows:
|
Shaping rate for a per-unit scheduler or an interface-level scheduler |
No |
Yes |
Because per-unit scheduling is applied only at the end point, apply this shaping rate to the constituent links only. Any configuration applied earlier is overwritten by the constituent link configuration. |
Transmit-rate exact or queue-level shaping |
Yes |
No |
The interface-level shaping applied on the constituent links overrides any shaping on the queue. Thus apply transmit-rate exact shaping on the multilink bundle only. |
Rewrite rules |
Yes |
No |
Rewrite bits are copied from the packet into the fragments automatically during fragmentation. Thus what you configure on the multilink bundle is carried on the fragments to the constituent links. |
Virtual channel group |
Yes |
No |
Virtual channel groups are identified through firewall filter rules that are applied on packets only before the multilink bundle. Thus you do not need to apply the virtual channel group configuration to the constituent links. |
See Also
Determine What Causes Jitter and Latency on the Multilink Bundle
Problem
Description
To test jitter and latency, you send three streams of IP packets. All packets have the same IP precedence settings. After configuring LFI and CRTP, the latency increased even over a noncongested link. How can you reduce jitter and latency?
Solution
To reduce jitter and latency, do the following:
Make sure that you have configured a shaping rate on each constituent link.
Make sure that you have not configured a shaping rate on the link services interface.
Make sure that the configured shaping rate value is equal to the physical interface bandwidth.
If shaping rates are configured correctly, and jitter still persists, contact the Juniper Networks Technical Assistance Center (JTAC).
Determine If LFI and Load Balancing Are Working Correctly
Problem
Description
In this case, you have a single network that supports multiple services. The network transmits data and delay-sensitive voice traffic. After configuring MLPPP and LFI, make sure that voice packets are transmitted across the network with very little delay and jitter. How can you find out if voice packets are being treated as LFI packets and load balancing is performed correctly?
Solution
When LFI is enabled, data (non-LFI) packets are encapsulated with an MLPPP header and fragmented to packets of a specified size. The delay-sensitive, voice (LFI) packets are PPP-encapsulated and interleaved between data packet fragments. Queuing and load balancing are performed differently for LFI and non-LFI packets.
To verify that LFI is performed correctly, determine that packets are fragmented and encapsulated as configured. After you know whether a packet is treated as an LFI packet or a non-LFI packet, you can confirm whether the load balancing is performed correctly.
Solution Scenario—Suppose two Juniper Networks devices, R0 and R1, are connected by a multilink bundle lsq-0/0/0.0 that aggregates two serial links, se-1/0/0 and se-1/0/1. On R0 and R1, MLPPP and LFI are enabled on the link services interface and the fragmentation threshold is set to 128 bytes.
In this example, we used a packet generator to generate voice and data streams. You can use the packet capture feature to capture and analyze the packets on the incoming interface.
The following two data streams were sent on the multilink bundle:
100 data packets of 200 bytes (larger than the fragmentation threshold)
500 data packets of 60 bytes (smaller than the fragmentation threshold)
The following two voice streams were sent on the multilink bundle:
100 voice packets of 200 bytes from source port 100
300 voice packets of 200 bytes from source port 200
To confirm that LFI and load balancing are performed correctly:
Only the significant portions of command output are displayed and described in this example.
Verify packet fragmentation. From operational mode, enter the
show interfaces lsq-0/0/0command to check that large packets are fragmented correctly.user@R0#> show interfaces lsq-0/0/0 Physical interface: lsq-0/0/0, Enabled, Physical link is Up Interface index: 136, SNMP ifIndex: 29 Link-level type: LinkService, MTU: 1504 Device flags : Present Running Interface flags: Point-To-Point SNMP-Traps Last flapped : 2006-08-01 10:45:13 PDT (2w0d 06:06 ago) Input rate : 0 bps (0 pps) Output rate : 0 bps (0 pps) Logical interface lsq-0/0/0.0 (Index 69) (SNMP ifIndex 42) Flags: Point-To-Point SNMP-Traps 0x4000 Encapsulation: Multilink-PPP Bandwidth: 16mbps Statistics Frames fps Bytes bps Bundle: Fragments: Input : 0 0 0 0 Output: 1100 0 118800 0 Packets: Input : 0 0 0 0 Output: 1000 0 112000 0 ... Protocol inet, MTU: 1500 Flags: None Addresses, Flags: Is-Preferred Is-Primary Destination: 9.9.9/24, Local: 9.9.9.10Meaning—The output shows a summary of packets transiting the device on the multilink bundle. Verify the following information on the multilink bundle:The total number of transiting packets = 1000
The total number of transiting fragments=1100
The number of data packets that were fragmented =100
The total number of packets sent (600 + 400) on the multilink bundle match the number of transiting packets (1000), indicating that no packets were dropped.
The number of transiting fragments exceeds the number of transiting packets by 100, indicating that 100 large data packets were correctly fragmented.
Corrective Action—If the packets are not fragmented correctly, check your fragmentation threshold configuration. Packets smaller than the specified fragmentation threshold are not fragmented.Verify packet encapsulation. To find out whether a packet is treated as an LFI or non-LFI packet, determine its encapsulation type. LFI packets are PPP encapsulated, and non-LFI packets are encapsulated with both PPP and MLPPP. PPP and MLPPP encapsulations have different overheads resulting in different-sized packets. You can compare packet sizes to determine the encapsulation type.
A small unfragmented data packet contains a PPP header and a single MLPPP header. In a large fragmented data packet, the first fragment contains a PPP header and an MLPPP header, but the consecutive fragments contain only an MLPPP header.
PPP and MLPPP encapsulations add the following number of bytes to a packet:
PPP encapsulation adds 7 bytes:
4 bytes of header+2 bytes of frame check sequence (FCS)+1 byte that is idle or contains a flag
MLPPP encapsulation adds between 6 and 8 bytes:
4 bytes of PPP header+2 to 4 bytes of multilink header
Figure 1 shows the overhead added to PPP and MLPPP headers.
Figure 1: PPP and MLPPP Headers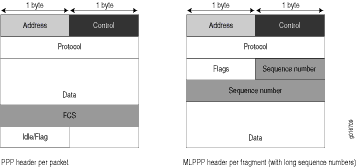
For CRTP packets, the encapsulation overhead and packet size are even smaller than for an LFI packet. For more information, see Example: Configuring the Compressed Real-Time Transport Protocol.
Table 6 shows the encapsulation overhead for a data packet and a voice packet of 70 bytes each. After encapsulation, the size of the data packet is larger than the size of the voice packet.
Table 6: PPP and MLPPP Encapsulation Overhead Packet Type
Encapsulation
Initial Packet Size
Encapsulation Overhead
Packet Size after Encapsulation
Voice packet (LFI)
PPP
70 bytes
4 + 2 + 1 = 7 bytes
77 bytes
Data fragment (non-LFI) with short sequence
MLPPP
70 bytes
4 + 2 + 1 + 4 + 2 = 13 bytes
83 bytes
Data fragment (non-LFI) with long sequence
MLPPP
70 bytes
4 + 2 + 1 + 4 + 4 = 15 bytes
85 bytes
From operational mode, enter the
show interfaces queuecommand to display the size of transmitted packet on each queue. Divide the number of bytes transmitted by the number of packets to obtain the size of the packets and determine the encapsulation type.Verify load balancing. From operational mode, enter the
show interfaces queuecommand on the multilink bundle and its constituent links to confirm whether load balancing is performed accordingly on the packets.user@R0> show interfaces queue lsq-0/0/0 Physical interface: lsq-0/0/0, Enabled, Physical link is Up Interface index: 136, SNMP ifIndex: 29 Forwarding classes: 8 supported, 8 in use Egress queues: 8 supported, 8 in use Queue: 0, Forwarding classes: DATA Queued: Packets : 600 0 pps Bytes : 44800 0 bps Transmitted: Packets : 600 0 pps Bytes : 44800 0 bps Tail-dropped packets : 0 0 pps RED-dropped packets : 0 0 pps … Queue: 1, Forwarding classes: expedited-forwarding Queued: Packets : 0 0 pps Bytes : 0 0 bps … Queue: 2, Forwarding classes: VOICE Queued: Packets : 400 0 pps Bytes : 61344 0 bps Transmitted: Packets : 400 0 pps Bytes : 61344 0 bps … Queue: 3, Forwarding classes: NC Queued: Packets : 0 0 pps Bytes : 0 0 bps …user@R0> show interfaces queue se-1/0/0 Physical interface: se-1/0/0, Enabled, Physical link is Up Interface index: 141, SNMP ifIndex: 35 Forwarding classes: 8 supported, 8 in use Egress queues: 8 supported, 8 in use Queue: 0, Forwarding classes: DATA Queued: Packets : 350 0 pps Bytes : 24350 0 bps Transmitted: Packets : 350 0 pps Bytes : 24350 0 bps ... Queue: 1, Forwarding classes: expedited-forwarding Queued: Packets : 0 0 pps Bytes : 0 0 bps … Queue: 2, Forwarding classes: VOICE Queued: Packets : 100 0 pps Bytes : 15272 0 bps Transmitted: Packets : 100 0 pps Bytes : 15272 0 bps … Queue: 3, Forwarding classes: NC Queued: Packets : 19 0 pps Bytes : 247 0 bps Transmitted: Packets : 19 0 pps Bytes : 247 0 bps …user@R0> show interfaces queue se-1/0/1 Physical interface: se-1/0/1, Enabled, Physical link is Up Interface index: 142, SNMP ifIndex: 38 Forwarding classes: 8 supported, 8 in use Egress queues: 8 supported, 8 in use Queue: 0, Forwarding classes: DATA Queued: Packets : 350 0 pps Bytes : 24350 0 bps Transmitted: Packets : 350 0 pps Bytes : 24350 0 bps … Queue: 1, Forwarding classes: expedited-forwarding Queued: Packets : 0 0 pps Bytes : 0 0 bps … Queue: 2, Forwarding classes: VOICE Queued: Packets : 300 0 pps Bytes : 45672 0 bps Transmitted: Packets : 300 0 pps Bytes : 45672 0 bps … Queue: 3, Forwarding classes: NC Queued: Packets : 18 0 pps Bytes : 234 0 bps Transmitted: Packets : 18 0 pps Bytes : 234 0 bpsMeaning—The output from these commands shows the packets transmitted and queued on each queue of the link services interface and its constituent links. Table 7 shows a summary of these values. (Because the number of transmitted packets equaled the number of queued packets on all the links, this table shows only the queued packets.)Table 7: Number of Packets Transmitted on a Queue Packets Queued
Bundle lsq-0/0/0.0
Constituent Link se-1/0/0
Constituent Link se-1/0/1
Explanation
Packets on Q0
600
350
350
The total number of packets transiting the constituent links (350+350 = 700) exceeded the number of packets queued (600) on the multilink bundle.
Packets on Q2
400
100
300
The total number of packets transiting the constituent links equaled the number of packets on the bundle.
Packets on Q3
0
19
18
The packets transiting Q3 of the constituent links are for keepalive messages exchanged between constituent links. Thus no packets were counted on Q3 of the bundle.
On the multilink bundle, verify the following:
The number of packets queued matches the number transmitted. If the numbers match, no packets were dropped. If more packets were queued than were transmitted, packets were dropped because the buffer was too small. The buffer size on the constituent links controls congestion at the output stage. To correct this problem, increase the buffer size on the constituent links.
The number of packets transiting Q0 (600) matches the number of large and small data packets received (100+500) on the multilink bundle. If the numbers match, all data packets correctly transited Q0.
The number of packets transiting Q2 on the multilink bundle (400) matches the number of voice packets received on the multilink bundle. If the numbers match, all voice LFI packets correctly transited Q2.
On the constituent links, verify the following:
The total number of packets transiting Q0 (350+350) matches the number of data packets and data fragments (500+200). If the numbers match, all the data packets after fragmentation correctly transited Q0 of the constituent links.
Packets transited both constituent links, indicating that load balancing was correctly performed on non-LFI packets.
The total number of packets transiting Q2 (300+100) on constituent links matches the number of voice packets received (400) on the multilink bundle. If the numbers match, all voice LFI packets correctly transited Q2.
LFI packets from source port
100transitedse-1/0/0, and LFI packets from source port200transitedse-1/0/1. Thus all LFI (Q2) packets were hashed based on the source port and correctly transited both constituent links.
Corrective Action—If the packets transited only one link, take the following steps to resolve the problem:Determine whether the physical link is
up(operational) ordown(unavailable). An unavailable link indicates a problem with the PIM, interface port, or physical connection (link-layer errors). If the link is operational, move to the next step.Verify that the classifiers are correctly defined for non-LFI packets. Make sure that non-LFI packets are not configured to be queued to Q2. All packets queued to Q2 are treated as LFI packets.
Verify that at least one of the following values is different in the LFI packets: source address, destination address, IP protocol, source port, or destination port. If the same values are configured for all LFI packets, the packets are all hashed to the same flow and transit the same link.
Use the results to verify load balancing.
Determine Why Packets Are Dropped on a PVC Between a Juniper Networks Device and a Third-Party Device
Problem
Description
You are configuring a permanent virtual circuit (PVC) between T1, E1, T3, or E3 interfaces on a Juniper Networks device and a third-party device, and packets are being dropped and ping fails.
Solution
If the third-party device does not have the same FRF.12 support as the Juniper Networks device or supports FRF.12 in a different way, the Juniper Networks device interface on the PVC might discard a fragmented packet containing FRF.12 headers and count it as a "Policed Discard."
As a workaround, configure multilink bundles on both peers, and configure fragmentation thresholds on the multilink bundles.
Troubleshoot Security Policies
- Synchronize Policies Between Routing Engine and Packet Forwarding Engine
- Check a Security Policy Commit Failure
- Verify a Security Policy Commit
- Debug Policy Lookup
Synchronize Policies Between Routing Engine and Packet Forwarding Engine
Problem
Description
Security policies are stored in the routing engine and the packet forwarding engine. Security policies are pushed from the Routing Engine to the Packet Forwarding Engine when you commit configurations. If the security policies on the Routing Engine are out of sync with the Packet Forwarding Engine, the commit of a configuration fails. Core dump files may be generated if the commit is tried repeatedly. The out of sync can be due to:
A policy message from Routing Engine to the Packet Forwarding Engine is lost in transit.
An error with the routing engine, such as a reused policy UID.
Environment
The policies in the Routing Engine and Packet Forwarding Engine must be in sync for the configuration to be committed. However, under certain circumstances, policies in the Routing Engine and the Packet Forwarding Engine might be out of sync, which causes the commit to fail.
Symptoms
When the policy configurations are modified
and the policies are out of sync, the following error message displays
- error: Warning: policy might be out of sync between
RE and PFE <SPU-name(s)> Please request security
policies check/resync.
Solution
Use the show security policies checksum command to display the security policy checksum value and use the request security policies resync command to synchronize the
configuration of security policies in the Routing Engine and Packet
Forwarding Engine, if the security policies are out of sync.
Check a Security Policy Commit Failure
Problem
Description
Most policy configuration failures occur during a commit or runtime.
Commit failures are reported directly on the CLI when you execute the CLI command commit-check in configuration mode. These errors are configuration errors, and you cannot commit the configuration without fixing these errors.
Solution
To fix these errors, do the following:
Review your configuration data.
Open the file /var/log/nsd_chk_only. This file is overwritten each time you perform a commit check and contains detailed failure information.
Verify a Security Policy Commit
Problem
Description
Upon performing a policy configuration commit, if you notice that the system behavior is incorrect, use the following steps to troubleshoot this problem:
Solution
Operational show Commands—Execute the operational commands for security policies and verify that the information shown in the output is consistent with what you expected. If not, the configuration needs to be changed appropriately.
Traceoptions—Set the
traceoptionscommand in your policy configuration. The flags under this hierarchy can be selected as per user analysis of theshowcommand output. If you cannot determine what flag to use, the flag optionallcan be used to capture all trace logs.user@host#
set security policies traceoptions <flag all>
You can also configure an optional filename to capture the logs.
user@host# set security policies traceoptions <filename>
If you specified a filename in the trace options, you can look in the /var/log/<filename> for the log file to ascertain if any errors were reported in the file. (If you did not specify a filename, the default filename is eventd.) The error messages indicate the place of failure and the appropriate reason.
After configuring the trace options, you must recommit the configuration change that caused the incorrect system behavior.
Debug Policy Lookup
Problem
Description
When you have the correct
configuration, but some traffic was incorrectly dropped or permitted,
you can enable the lookup flag in the security policies
traceoptions. The lookup flag logs the lookup related traces
in the trace file.
Solution
user@host# set security policies traceoptions <flag lookup>