Contrail Networking Analytics
Overview: Analytics
Analytics is an optional feature set in Juniper Cloud-Native Contrail® Networking™ Release 22.1. It is packaged separately from the Contrail Networking core CNI components and has its own installation procedure. The package consists of a combination of open-source software and Juniper developed software.
The analytics features are categorized into the following high-level functional areas:
- Metrics—Statistical time series data collected from the Contrail Networking components and the base Kubernetes system.
- Flow and Session Records—Network traffic information collected from the Contrail Networking vRouter.
- Sandesh User Visible Entities (UVE)—Records representing the system-wide state of externally visible objects that are collected from the Contrail Networking vRouter and control node components.
- Logs—Log messages collected from Kubernetes pods.
- Introspect—A diagnostic utility that provides an ability to browse the internal state of the Contrail Networking components.
Metrics
Data Model
Metric information is based on a numerical time series data model. Each data point in a
series is a sample of some system state that gets collected at a regular interval. A sampled
value is recorded along with a timestamp at which the collection occurred. A sample record
can also contain an optional set of key-value pairs called labels. Labels provide a
dimension capability for metrics where a given combination of labels for the same metric
name identifies a particular dimensional instantiation of that metric. For example, a metric
named api_http_requests_total can utilize labels in order to provide
visibility into the request counts at a URL and method type level. In the following example,
the metric record for a sample value of 10 will include a set of labels that indicate the
type of request.
api_http_requests_total{method="POST", handler="/messages"} 10
Metric Data Types
Although all metric sample values are just numbers, there is a concept of type within this numerical data model. A metric is considered to be one of the following types:
- Counter—A cumulative metric that represents a single monotonically increasing counter whose value can only increase or be reset to zero on restart.
- Gauge—A metric that represents a single numerical value that can arbitrarily go up and down.
- Histogram—A histogram samples observations (usually things like request durations or response sizes) and counts them in configurable buckets. The histogram also provides a sum of all observed values.
- Summary—Similar to a histogram, a summary samples observations (usually things like request durations and response sizes). While it also provides a total count of observations and a sum of all observed values, the summary calculates configurable quantiles over a sliding time window.
The metric functionality in Contrail Networking is implemented by Prometheus. For additional details about the metric data model, refer to the documentation at Prometheus.
Supported Metrics
The set of metrics supported by the analytics solution are categorized as shown below:
- Contrail Networking Metric List—Metrics collected from the vRouter and control node components.
- Kubernetes Metric List—Metrics collected from
various Kubernetes components, such as
apiserver,etcd,kubelet, and so on. - Cluster Node Metrics—Host-level metrics collected from the Kubernetes cluster nodes.
Alerts
Alerts are generated based on an analysis of collected metric data. Every supported alert type is based on a rule definition that contains the following information:
- Alert Name—A unique string identifier for the alert type.
- Condition Expression—A Prometheus query language expression that gets evaluated against collected metric values in order to determine if the alert condition exists.
- Condition Duration—The amount of time the problematic condition has to exist in order for the alert to be generated.
- Severity—The alert level (critical, major, warning, info).
- Summary—A short description of the problematic condition.
- Description—A detailed description of the problematic condition.
The Contrail Networking analytics solution installs a set of predefined alert rules. You can also define your own custom alert rules. This is supported by the creation of PrometheusRule Kubernetes resources in the namespace where the analytics helm chart is deployed. An example of a custom alert rule is shown below.
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: acme-corp-rules
spec:
groups:
- name: acme-corp.rules
rules:
- alert: HostUnusualNetworkThroughputOut
expr: "sum by (instance) (rate(node_network_transmit_bytes_total[2m])) / 1024 / 1024 > 100"
labels:
severity: warning
annotations:
summary: "Host unusual network throughput out (instance {{ $labels.instance }})"
description: "Host network interfaces are sending too much data (> 100 MB/s)\n VALUE = {{ $value }}"
Generated alerts are stored as records in Prometheus and can be viewed in the Grafana UI. Integration with external systems, such as PagerDuty, OpsGenie, email, and so on for alert notification is also supported with the AlertManager component.
Architecture
As shown in Figure 1, Prometheus is the core component of the metrics architecture. Prometheus implements the following functionality:
- Collection—A periodic polling mechanism that invokes API calls against other components (exporters) to pull values for a set of metrics.
- Storage—A time series database that provides persistence for the metrics collected from the exporters.
- Query—An API supporting an expression language called PromQL (Prometheus query language) that allows the historical metric information to be retrieved from the database.
- Alerting—A framework providing an ability to define rules that produce alerts when certain conditions are observed in the collected metric data.
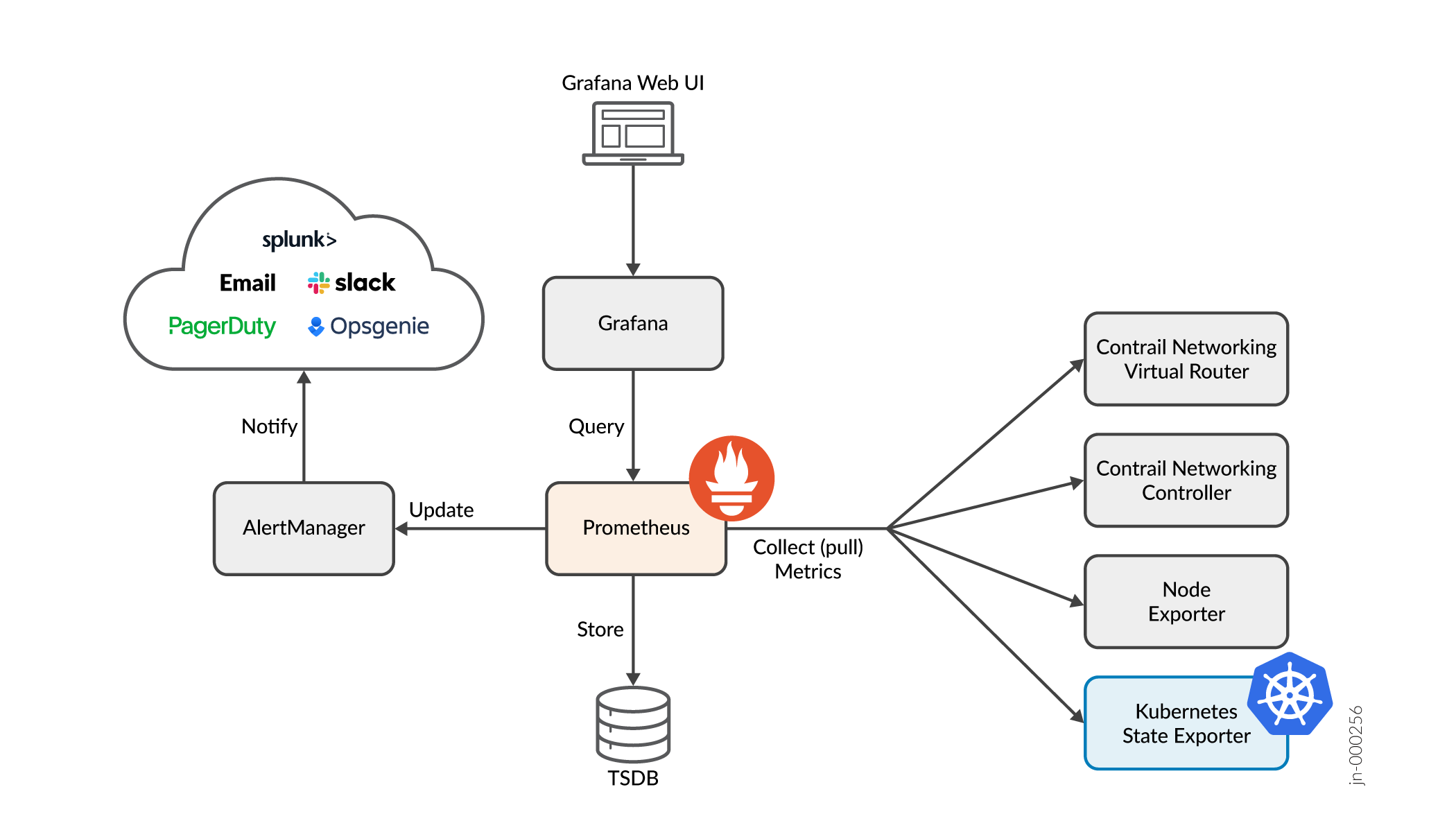
The other components of the metrics architecture are:
- Grafana—A service that provides a Web UI interface allowing the user to visualize the metric data in graphs.
- AlertManager—An integration service that notifies external systems of alerts generated by Prometheus.
Configuration
The metrics functionality does not require any configuration by the end-user. The installation of analytics takes care of configuring Prometheus to collect from the set of exporters that provide all of the metrics described in the Supported Metrics section above. A group of default alerting rules is also automatically setup as part of the installation. This base functionality, however, can be extended by the end-user through additional configuration after the installation. For example, customer-specific alerting rules can be defined and the AlertManager can be configured to integrate with any of the supported external systems present in your environment.
The configuration of Prometheus and AlertManager involves an additional architectural component called the Prometheus Operator. As shown in Figure 2, configuration is specified as Kubernetes custom resources. The operator is responsible for translating the contents of these resources into the native configuration understood by the Prometheus components, updating the components accordingly, and then taking care of restarting the components whenever a particular configuration change requires a restart.
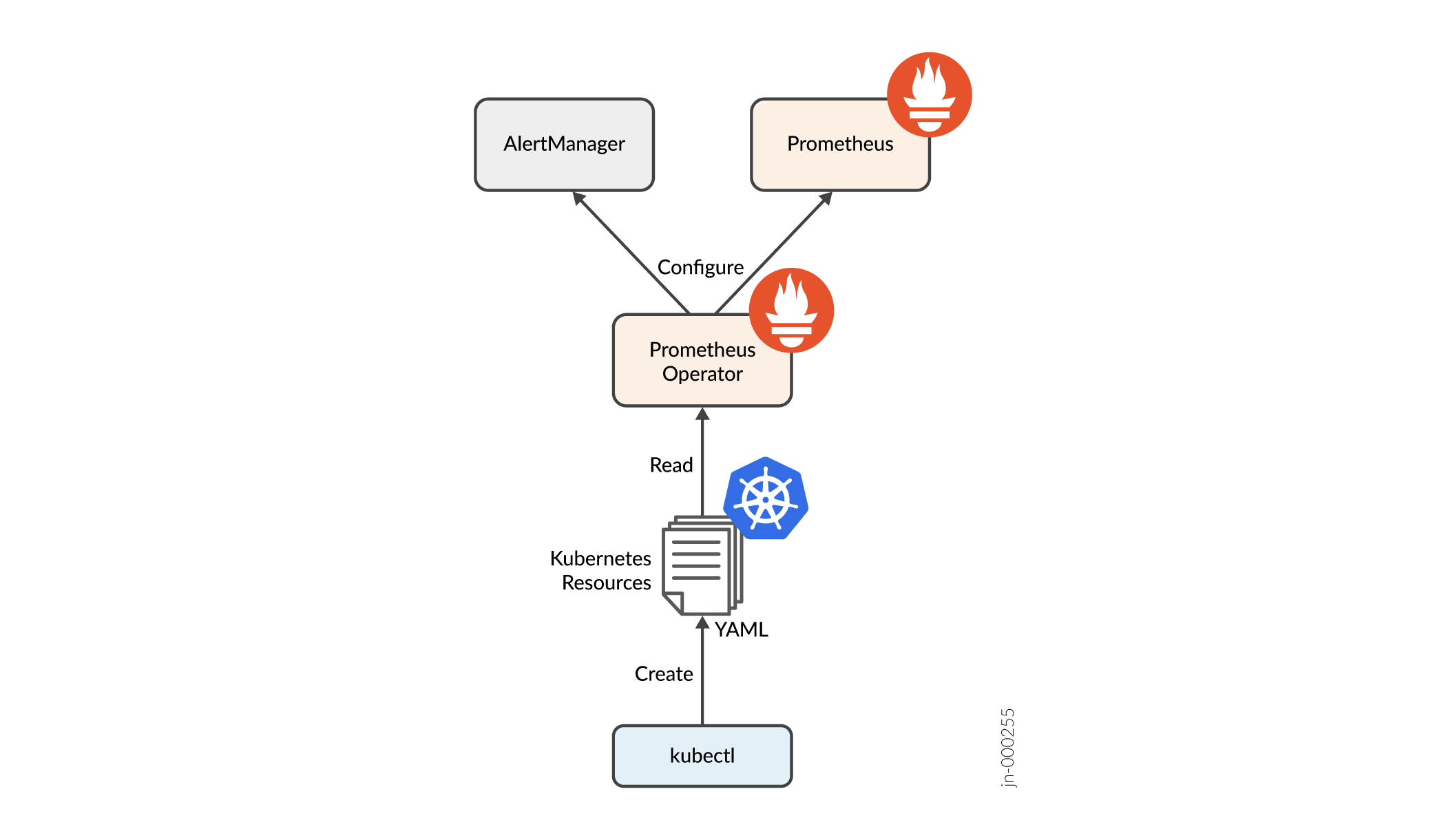
Documentation for the full set of resources supported by the operator is available at Prometheus Operator API. It is recommended, however, that customers limit their configurations to the subset of resource types related to alert rule definition and external system integration.
Grafana
The main UI for viewing metric data and alerts is Grafana. The Grafana service is setup and automatically configured with Prometheus as a data source as part of the analytics installation. A set of default dashboards are also created.
Access the Grafana Web UI at: https://<k8sClusterIP>/grafana/login.
The default login credentials are user admin and password
prom-operator.