Requisitos previos de instalación en Ubuntu
Para instalar e implementar correctamente un clúster de Paragon Automation, debe tener un host de control que instale el software de distribución en varios nodos del clúster. Puede descargar el software de distribución en el host de control y, a continuación, crear y configurar los archivos de instalación para ejecutar la instalación desde el host de control. Debe tener acceso a Internet para descargar los paquetes en el host de control. También debe tener acceso a Internet en los nodos del clúster para descargar cualquier software adicional, como parches de Docker y OS. El orden de las tareas de instalación se muestra en un nivel alto en la Figura 1.
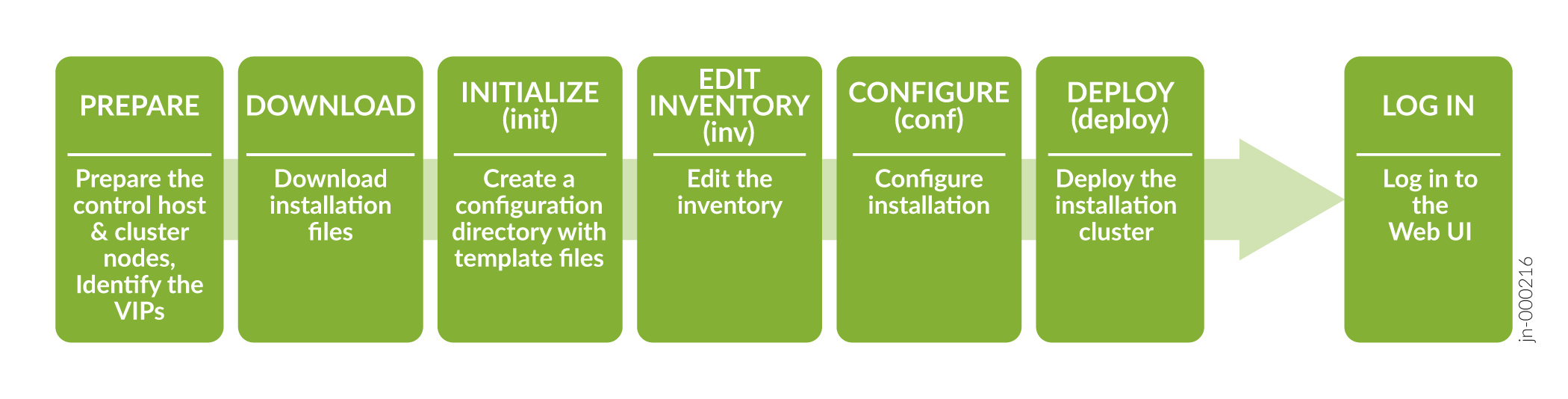
Antes de descargar e instalar el software de distribución, debe configurar el host de control y los nodos del clúster como se describe en este tema.
Preparar el host de control
El host de control es una máquina dedicada que organiza la instalación y actualización de un clúster de Paragon Automation. Lleva a cabo las operaciones de Ansible que ejecutan el instalador de software e instalan el software en los nodos del clúster, como se ilustra en Funciones del host de control.
Debe descargar los paquetes del instalador en el host de control de Ansible. Como parte del proceso de instalación de Paragon Automation, el host de control instala los paquetes adicionales necesarios en los nodos del clúster. Los paquetes incluyen paquetes opcionales de SO, Docker y Elasticsearch. Todos los microservicios, incluidos los microservicios de terceros, se descargan en los nodos del clúster. Los microservicios no acceden a ningún registro público durante la instalación.
El host de control puede estar en un dominio de difusión distinto del de los nodos del clúster, pero debe asegurarse de que el host de control pueda usar SSH para conectarse a todos los nodos.
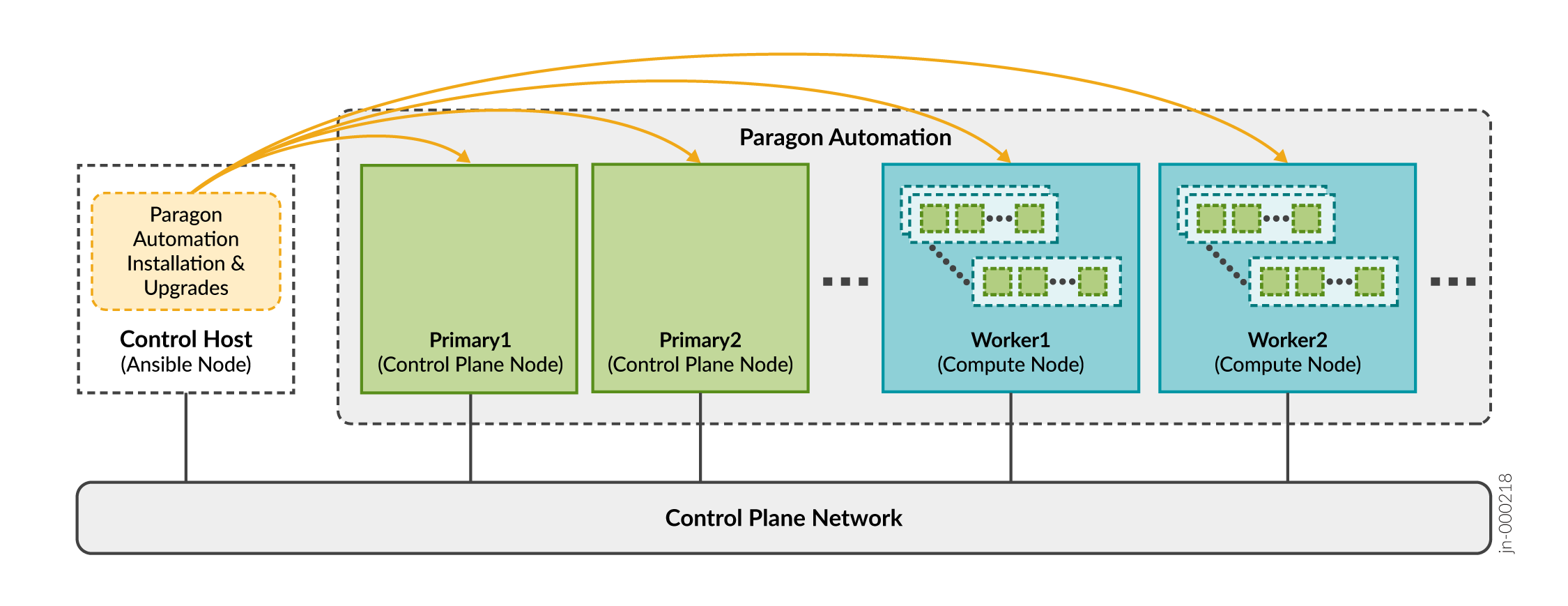 del host de control
del host de control
Una vez completada la instalación, el host de control no desempeña ninguna función en el funcionamiento del clúster. Sin embargo, necesitará que el host de control actualice el software o cualquier componente, realice cambios en el clúster o reinstale el clúster si falla un nodo. También puede utilizar el host de control para archivar archivos de configuración. Le recomendamos que mantenga el host de control disponible, y no lo utilice para otra cosa, después de la instalación.
Prepare el host de control para el proceso de instalación de la siguiente manera:
Preparar nodos de clúster
- Paragon Automation y los dispositivos administrados
- Paragon Automation y el administrador de red
Se recomienda colocar todos los nodos en el mismo dominio de difusión. Para nodos de clúster en diferentes dominios de difusión, consulte Configurar equilibrio de carga para obtener más configuración de equilibrio de carga.
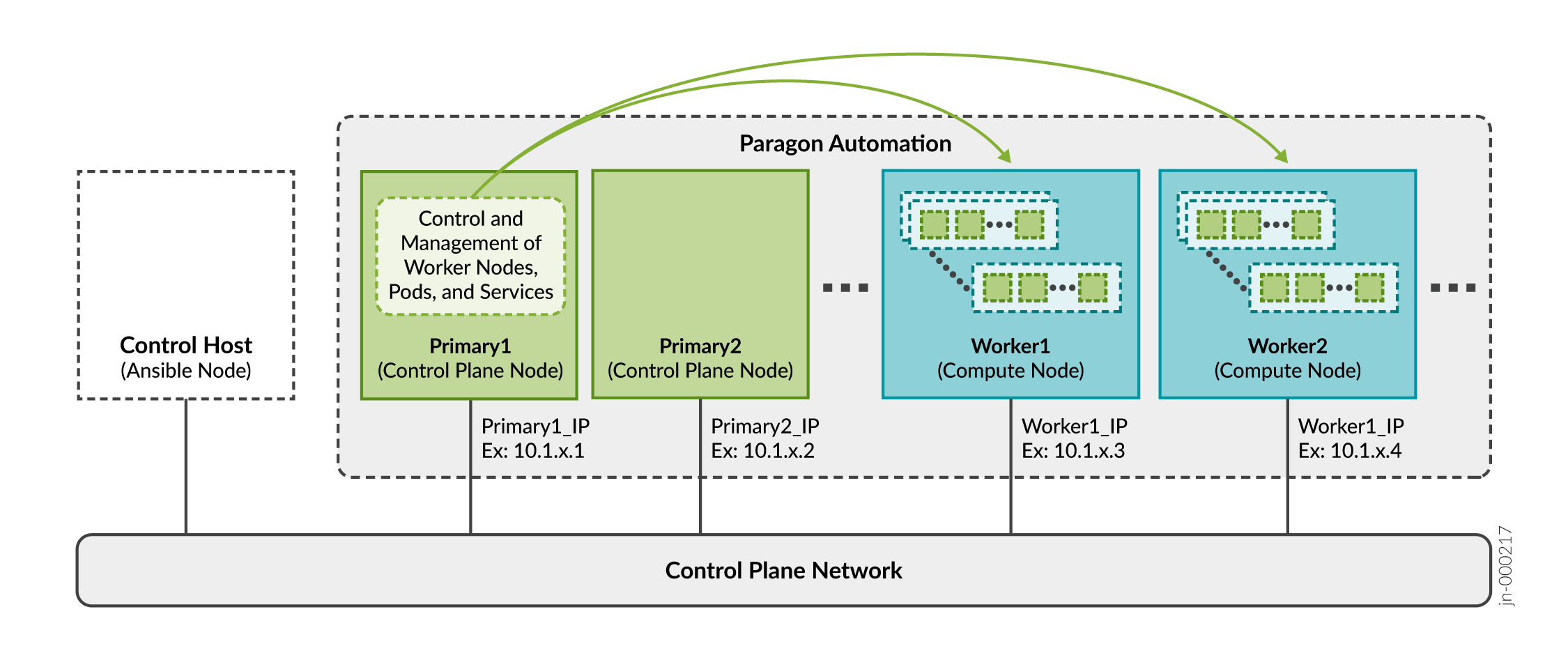 del nodo del clúster
del nodo del clúster
Como se describe en Requisitos del sistema de Paragon Automation, puede instalar Paragon Automation mediante una implementación de varios nodos.
Debe preparar los nodos del clúster para el proceso de instalación de Paragon Automation de la siguiente manera:
Consideraciones sobre la dirección IP virtual
Un pod es la unidad de computación desplegable más pequeña creada y administrada en Kubernetes. Un pod contiene uno o más contenedores, con almacenamiento compartido y recursos de red, y con instrucciones específicas sobre cómo ejecutar las aplicaciones. Los contenedores son el nivel más bajo de procesamiento y se ejecutan aplicaciones o microservicios en contenedores.
El nodo principal del clúster determina qué nodo de trabajo albergará un pod y contenedores determinados.
Todas las funciones de Paragon Automation se implementan mediante una combinación de microservicios. Debe hacer que algunos de estos microservicios sean accesibles desde fuera del clúster, ya que proporcionan servicios a usuarios finales (dispositivos administrados) y administradores. Por ejemplo, debe hacer que el servicio pceserver sea accesible para establecer sesiones de protocolo de elemento de cálculo de ruta (PCEP) entre los enrutadores perimetrales del proveedor (PE) y Paragon Automation.
Debe exponer estos servicios fuera del clúster de Kubernetes con direcciones específicas a las que se pueda acceder desde dispositivos externos. Dado que un servicio puede ejecutarse en cualquiera de los nodos de trabajo en un momento dado, debe utilizar direcciones IP virtuales (VIP) como direcciones externas. No debe utilizar la dirección de un nodo de trabajo determinado como dirección externa.
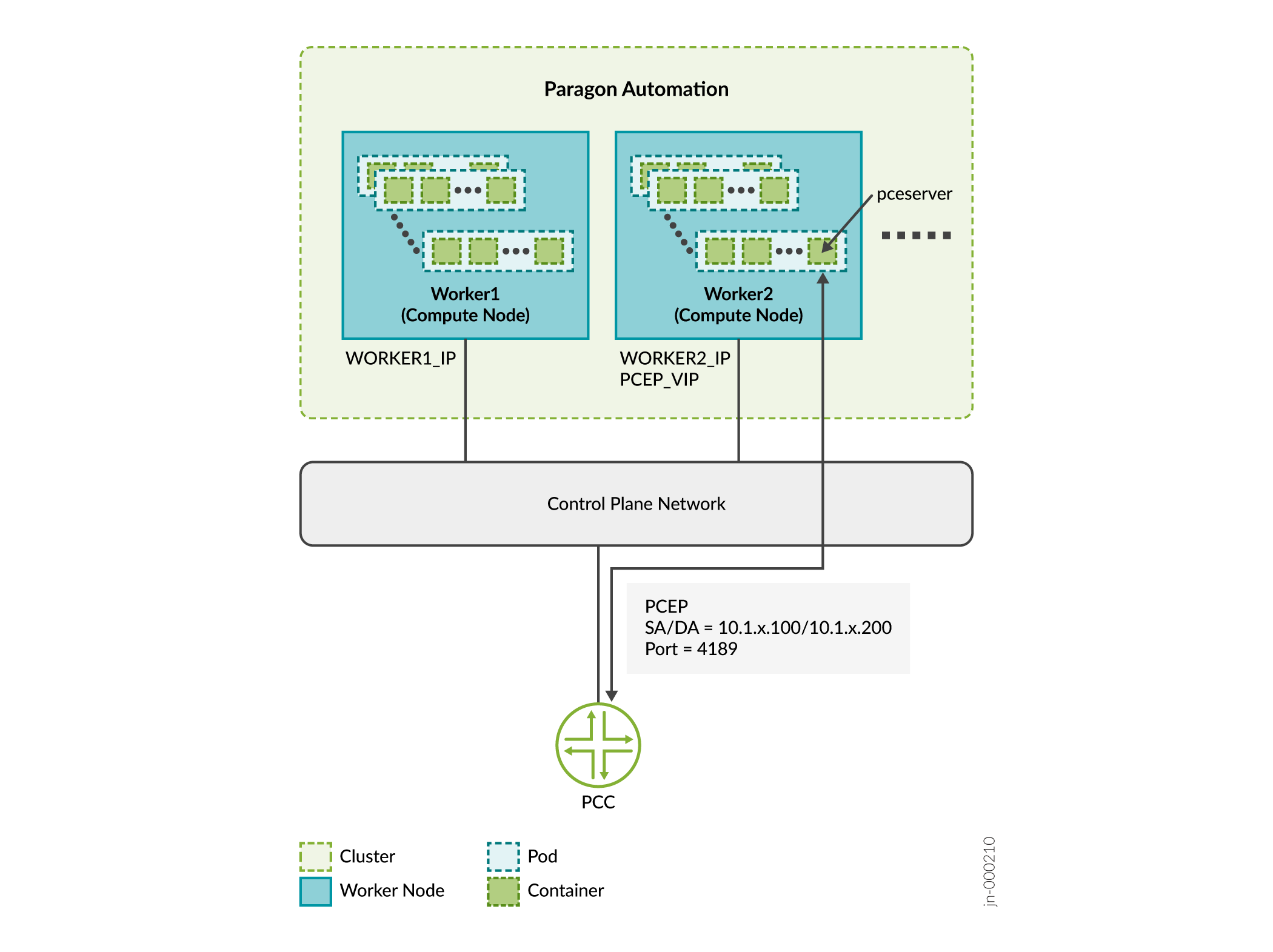
En este ejemplo:
-
Considere que el trabajador 1 es 10.1.x.3 y el trabajador 2 es 10.1.x.4.
-
IP DE SERVICIO = PCEP VIP es 10.1.x.200
-
PCC_IP es 10.1.x.100
Los servicios de Paragon Automation utilizan uno de dos métodos para exponer servicios fuera del clúster:
-
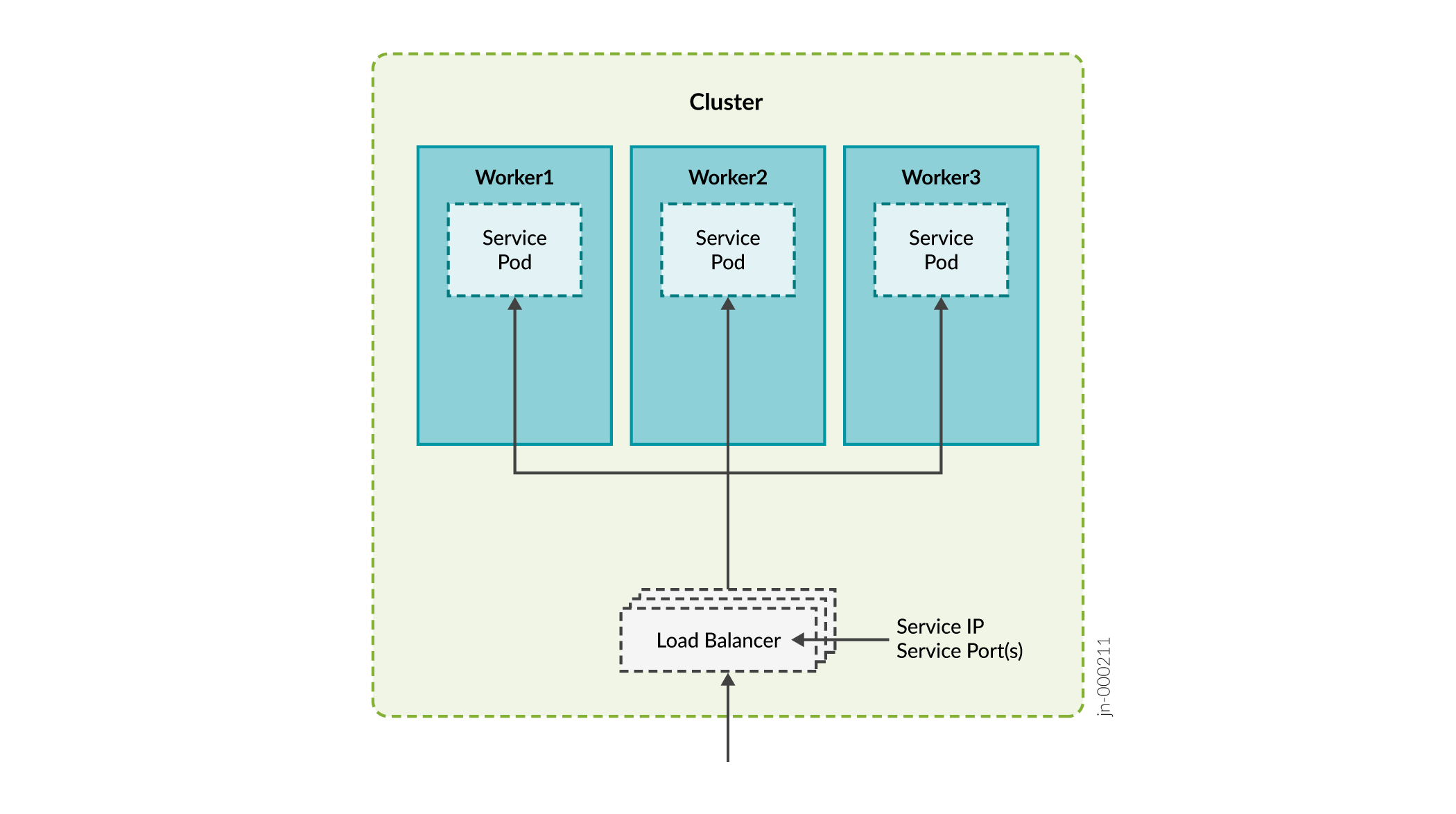
Equilibrador de carga: cada equilibrador de carga está asociado a una dirección IP específica y enruta el tráfico externo a un servicio específico del clúster. Este es el método predeterminado para muchas instalaciones de Kubernetes en la nube. El método del equilibrador de carga admite varios protocolos y varios puertos por servicio. Cada servicio tiene su propio equilibrador de carga y dirección IP.
-
Paragon Automation utiliza el equilibrador de carga MetalLB. MetalLB simula un balanceador de carga externo administrando direcciones IP virtuales en el modo de capa 2 o interactúa con enrutadores externos en el modo de capa 3. MetalLB proporciona infraestructura de equilibrio de carga al clúster de kubernetes.
Los servicios del tipo "LoadBalancer" interactuarán con la infraestructura de equilibrio de carga de Kubernetes para asignar una dirección IP accesible externamente. Algunos servicios pueden compartir una dirección IP externa.
-
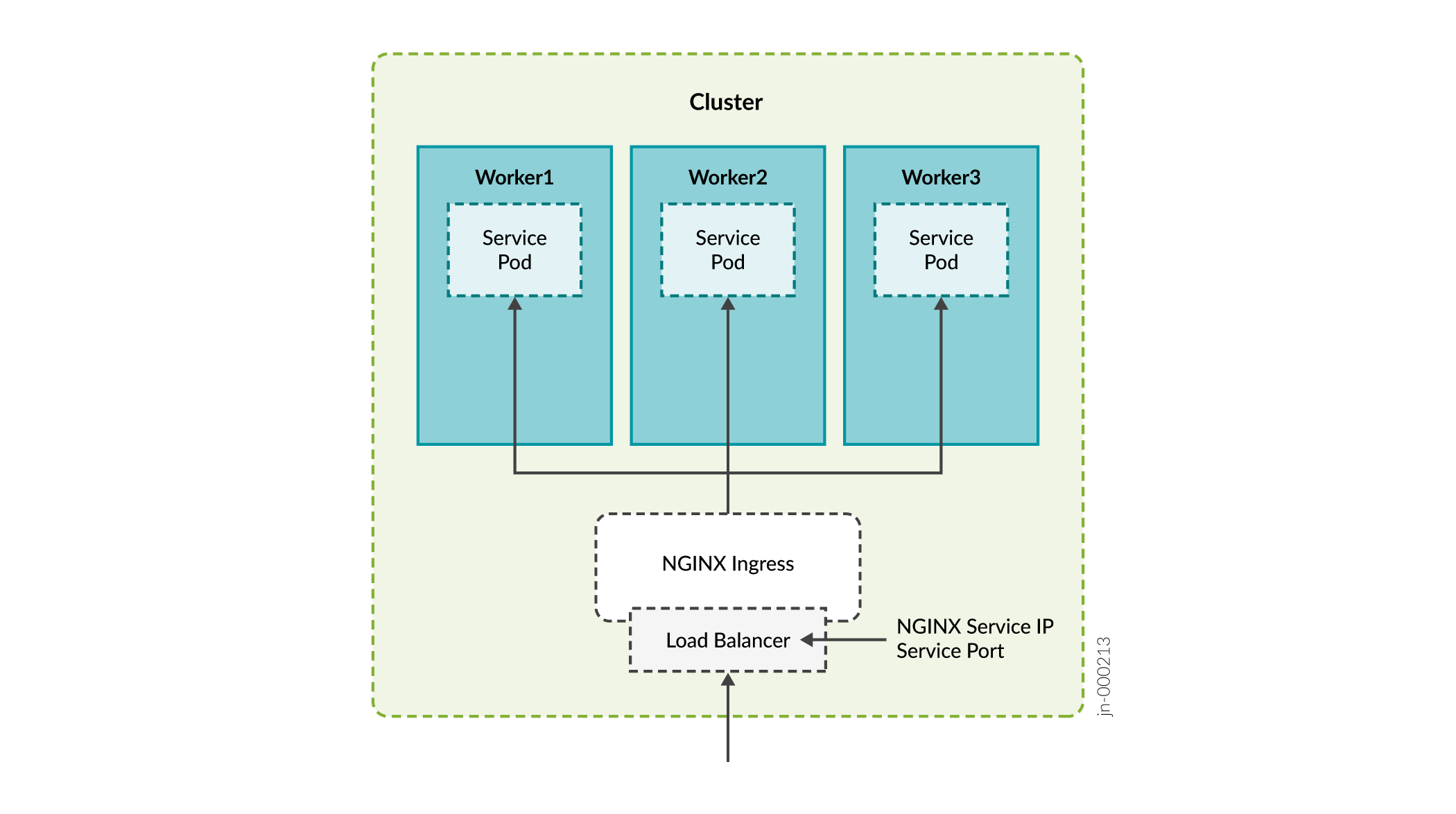
Ingress: el método de entrada actúa como un proxy para traer tráfico al clúster y, a continuación, utiliza el enrutamiento de servicios internos para enrutar el tráfico a su destino. Bajo el capó, este método también usa un servicio de equilibrador de carga para exponerse al mundo para que pueda actuar como ese proxy.
Paragon Automation utiliza los siguientes servidores proxy de entrada:
- Embajador
- Nginx
Los dispositivos externos al clúster necesitan acceder a los siguientes servicios y, por lo tanto, estos servicios requieren una dirección VIP.
| Descripción de la dirección VIP requerida | Equilibrador/proxy de carga | |
|---|---|---|
| Controlador de entrada |
Se utiliza para acceder a la GUI de Paragon Automation a través de la Web. Paragon Automation proporciona un servidor web común que proporciona acceso a los componentes y las aplicaciones. El acceso al servidor se administra a través del controlador de entrada de Kubernetes. |
Embajador MetalLB |
| Servicios de Paragon Insights |
Se usa para servicios de Insights como syslog, relé DHCP y JTI. | MetalLB |
| Servidor PCE de Paragon Pathfinder |
Se utiliza para establecer sesiones de PCEP con dispositivos en la red. |
MetalLB |
| Proxy receptor de captura SNMP (opcional) |
Usuario del proxy del receptor de captura SNMP sólo si se requiere esta funcionalidad. |
MetalLB |
| Controlador de entrada Nginx de infraestructura |
Se utiliza como proxy para el servidor de flujo de red de Paragon Pathfinder y, opcionalmente, el servidor PCE de Paragon Pathfinder. El controlador de entrada Nginx necesita un VIP dentro del grupo de balanceadores de carga MetalLB. Esto significa que durante el proceso de instalación debe incluir esta dirección como parte de los intervalos de direcciones IP del equilibrador de carga que deberá incluir al crear el archivo de configuración. |
Nginx MetalLB |
| Pathfinder Netflowd |
Se utiliza para el servidor de flujo de red de Paragon Pathfinder. Netflowd puede usar Nginx como proxy, en cuyo caso no requerirá su propia dirección VIP. |
MetalLB |
| Servidor PCEP (opcional) |
Se utiliza para el servidor PCE para la autenticación MD5. |
- |
| cRPD (Opcional) |
Se utiliza para conectarse al pod BGP Monitoring Protocol (BMP) para la autenticación MD5. |
- |
Puertos utilizados por el Embajador:
-
Redireccionamiento HTTP 80 (TCP) a HTTPS
-
HTTPS 443 (TCP)
-
Paragon Planner 7000 (TCP)
-
DCS/NETCONF iniciado 7804 (TCP)
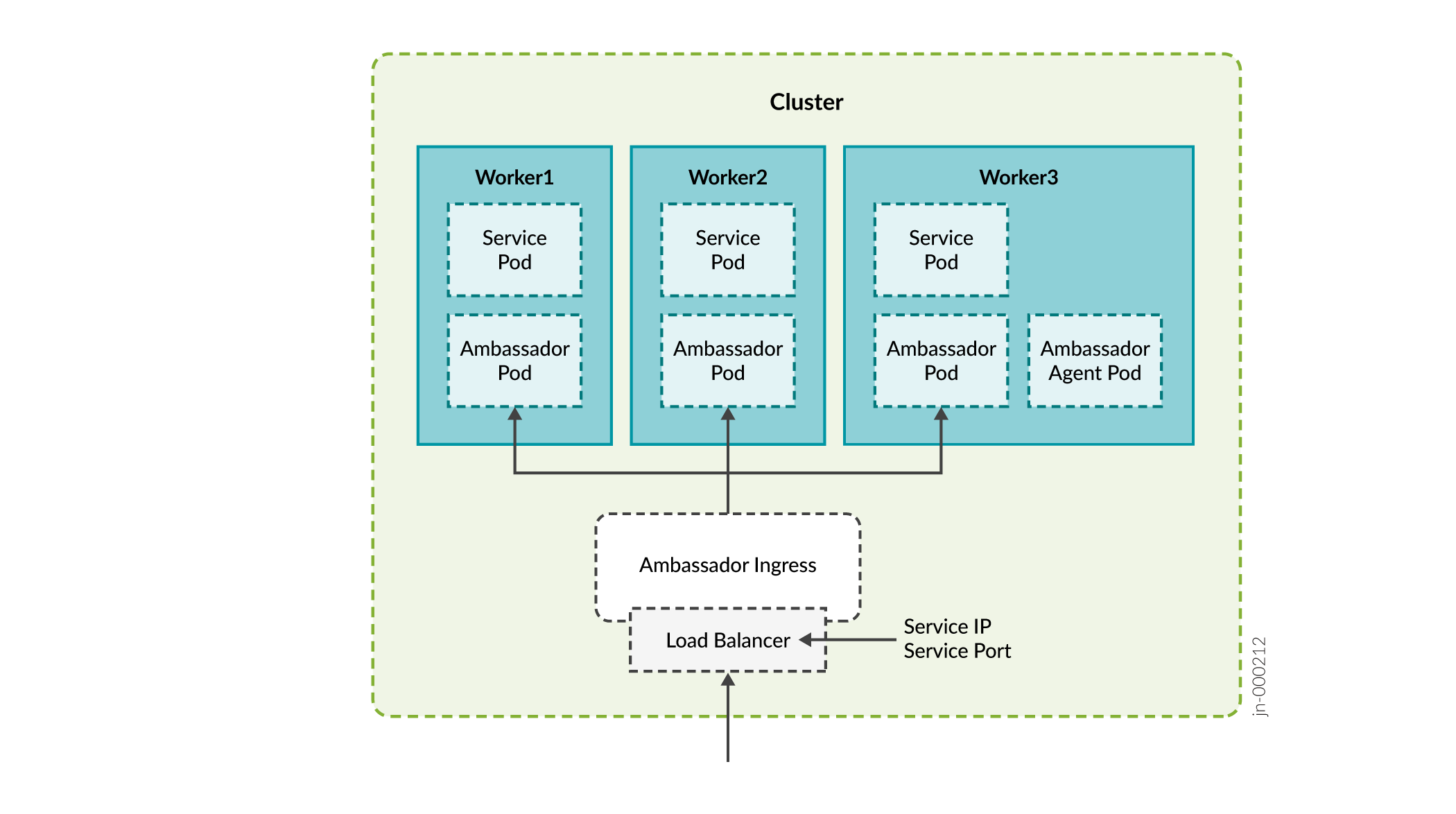
Puertos usados por Insights Services, el servidor de elementos de cálculo de ruta (PCE) y SNMP:
-
Servicios de información
JTI 4000 (UDP)
DHCP (ZTP) 67 (UDP)
SYSLOG 514 (UDP)
Proxy SNMP 162 (UDP)
-
Servidor PCE
PCEP 4189 (TCP)
-
SNMP
Receptor de captura SNMP 162 (UDP)
Puertos utilizados por el controlador Nginx:
-
NetFlow 9000 (UDP)
-
PCEP 4189 (TCP)
Uso de Nginx para PCEP
Durante el proceso de instalación, se le preguntará si desea habilitar el proxy de entrada para PCEP. Puede seleccionar desde o Nginx-Ingress como proxy del servidor del elemento de cálculo de ruta (NonePCE).
Si selecciona Nginx-Ingress como proxy, no es necesario configurar la VIP para el servidor PCE descrito en la tabla 1. En este caso, la dirección VIP para el controlador de entrada Nginx de infraestructura también se utiliza para el servidor PCE. Si elige no usar un proxy de flujo de red, la VIP para el controlador de entrada Nginx de infraestructura también se usa para flujo de red.
El beneficio de usar Nginx es que puede usar una sola dirección IP para múltiples servicios.
 Nginx
Nginx
Direcciones VIP para autenticación MD5
Puede configurar la autenticación MD5 para proteger las sesiones PCEP entre el enrutador y Paragon Pathfinder, así como para asegurarse de que el servicio BMP se empareja con el enrutador BGP-LS correcto. Paragon Automation utiliza Multus para proporcionar la interfaz secundaria en el servidor PCE y el pod BMP para el acceso directo al enrutador. Necesita las siguientes direcciones VIP en la misma subred que los nodos del clúster:
-
Dirección VIP para el servidor PCE en formato CIDR
-
Dirección VIP para cRPD en formato CIDR
El grupo de direcciones VIP del equilibrador de carga MetalLB no debe contener estas direcciones VIP.
Si elige configurar la autenticación MD5, también debe configurar la clave de autenticación y las direcciones IP virtuales en los enrutadores. También debe configurar la clave de autenticación en la interfaz de usuario de Paragon Automation.
-
MD5 en sesiones de PCEP.: configure la clave de autenticación MD5 en el enrutador y la interfaz de usuario y la dirección VIP de Paragon Automation en el enrutador.
-
Configure lo siguiente en la CLI de Junos:
user@pcc# set protocols pcep pce pce-id authentication-key pce-md5-keyuser@pcc# set protocols pcep pce pce-id destination-ipv4-address vip-for-pce -
Introduzca la clave de pce-md5-key autenticación en el campo MD5 String (Cadena MD5) de la sección Protocols:PCEP de la página Configuration > Devices > Edit.Device Name
La clave de autenticación MD5 debe ser menor o igual que 79 caracteres.
-
-
MD5 en cRPD: determine la clave de autenticación MD5 de cRPD y configure la clave y la dirección VIP de cRPD en el router.
Determine o establezca la clave de autenticación MD5 de las siguientes maneras.
Ejecute el script de comandos y habilite la
confautenticación MD5 en cRPD. Busque elcrpd_auth_keyparámetro en el archivo config.yml . Si hay una clave presente, indica que cRPD está configurado para MD5. Por ejemplo:crpd_auth_key : northstar. Puede utilizar la clave presente en el archivo config.yml (o también puede editar la clave) e introducirla en el router.Si no hay ninguna clave de autenticación MD5 presente en el archivo config.yml , debe iniciar sesión en cRPD y establecer la clave de autenticación mediante uno de los siguientes comandos:
set groups extra protocols bgp group name authentication-key crpd-md5-keyo
set protocols bgp group name authentication-key crpd-md5-keyLa clave de autenticación MD5 debe ser menor o igual que 79 caracteres.
Configure el enrutador para habilitar MD5 para cRPD.
user@pcc# set protocols bgp group name neighbor vip-for-crpd authentication-key md5-key
Debe identificar todas las direcciones VIP necesarias antes de iniciar el proceso de instalación de Paragon Automation. Se le pedirá que introduzca estas direcciones como parte del proceso de instalación.
Configurar equilibrio de carga
Las VIP se gestionan en la capa 2 de forma predeterminada. Cuando todos los nodos del clúster se encuentran en el mismo dominio de difusión, cada dirección VIP se asigna a un nodo del clúster a la vez. El modo de capa 2 proporciona conmutación por error de la VIP y no proporciona equilibrio de carga real. Para un verdadero equilibrio de carga entre los nodos del clúster o si los nodos se encuentran en dominios de difusión diferentes, debe configurar el equilibrio de carga en la capa 3.
Debe configurar un enrutador BGP para anunciar la dirección VIP en la red. Asegúrese de que el enrutador BGP utiliza ECMP para equilibrar las sesiones TCP/IP entre diferentes hosts. Conecte el enrutador BGP directamente a los nodos del clúster.
Para configurar el equilibrio de carga en los nodos del clúster, edite el archivo config.yml . Por ejemplo:
metallb_config:
peers:
- peer-address: 192.x.x.1 ## address of BGP router
peer-asn: 64501 ## autonomous system number of BGP router
my-asn: 64500 ## ASN of cluster
address-pools:
- name: default
protocol: bgp
addresses:
- 10.x.x.0/24
En este ejemplo, el enrutador BGP en 192.x.x.1 es responsable de anunciar la accesibilidad de las direcciones VIP con el prefijo 10.x.x.0/24 al resto de la red. El clúster asigna la dirección VIP de este intervalo y anuncia la dirección de los nodos del clúster que pueden controlar la dirección.
Configurar el servidor DNS (opcional)
Puede tener acceso a la puerta de enlace web principal a través de la dirección VIP del controlador de entrada o mediante un nombre de host configurado en el servidor del Sistema de nombres de dominio (DNS) que se resuelve en la dirección VIP del controlador de entrada. Debe configurar el servidor DNS solo si desea utilizar un nombre de host para tener acceso a la puerta de enlace web.
Agregue el nombre de host al DNS como un registro A, AAAA o CNAME. Para configuraciones de laboratorio y prueba de concepto (POC), puede agregar el nombre de host al archivo /etc/hosts en los nodos del clúster.