EN ESTA PÁGINA
Reservar ancho de banda de paquete para sobrecarga de capa de vínculo en interfaces LSQ
Configuración de interfaces LSQ como paquetes NxT1 o NxE1 usando MLPPP
Configuración de interfaces LSQ como paquetes NxT1 o NxE1 mediante FRF.16
Configuración de interfaces LSQ como paquetes NxT1 o NxE1 mediante FRF.15
Configuración de interfaces LSQ para interfaces T1 o E1 fraccionarias simples mediante MLPPP y LFI
Configuración de interfaces LSQ para interfaces T1 o E1 fraccionarias únicas mediante FRF.12
Configuración de interfaces LSQ para vínculos T3 configurados para RTP comprimido a través de MLPPP
Configuración de interfaces LSQ como paquetes T3 u OC3 mediante FRF.12
Configuración de interfaces LSQ para interfaces IQ ATM2 mediante MLPPP
Servicios de Multlink en línea
Descripción general de MLPPP en línea para interfaces WAN
PPP multivínculo en línea (MLPPP), Multilink Frame Relay (FRF.16) y Multilink Frame Relay de extremo a extremo (FRF.15) para multiplexación por división de tiempo (TDM) Las interfaces WAN proporcionan servicios de agrupación a través del motor de reenvío de paquetes sin necesidad de una PIC o un concentrador de puerto denso (CPC).
Tradicionalmente, los servicios de agrupación se usan para agrupar varios vínculos de baja velocidad para crear una canalización de ancho de banda más alta. Este ancho de banda combinado está disponible para el tráfico de todos los vínculos y admite la fragmentación e intercalación de vínculos (LFI) en el paquete, lo que reduce el retraso en la transmisión de paquetes de alta prioridad.
Este soporte incluye varios enlaces en el mismo paquete, así como una extensión multiclase para MLPPP. A través de este servicio, puede habilitar la agrupación de servicios sin ranuras CPC adicionales para admitir Service CPC y liberar las ranuras para otras MIC.
MLPPP no es compatible con el chasis virtual de la serie MX.
A partir de Junos OS versión 15.1, puede configurar interfaces MLPPP en línea en enrutadores MX80, MX104, MX240, MX480 y MX960 con MIC de emulación de circuito E1/T1 canalizadas. Se admite un máximo de hasta ocho paquetes de interfaces MLPPP en línea en las MIC de emulación de circuito E1/T1 canalizadas, de forma similar a la compatibilidad con paquetes de MLPPP en línea en otras MIC con las que son compatibles.
La configuración de MLPPP en línea para interfaces WAN beneficia a los siguientes servicios:
-
Vínculo CE-PE para el servicio VPN y DIA de capa 3 con redes de acceso basadas en redes telefónicas conmutadas (RTC).
-
Vínculo PE-P cuando se usa RTC para redes MPLS.
Esta función la utilizan los siguientes proveedores de servicios:
-
Proveedores de servicios que usan RTC para ofrecer servicio VPN de capa 3 y DIA con redes de acceso basadas en RTC a clientes empresariales medianos o grandes.
-
Proveedores de servicios con redes centrales basadas en SONET.
La siguiente figura ilustra el alcance de esta característica:
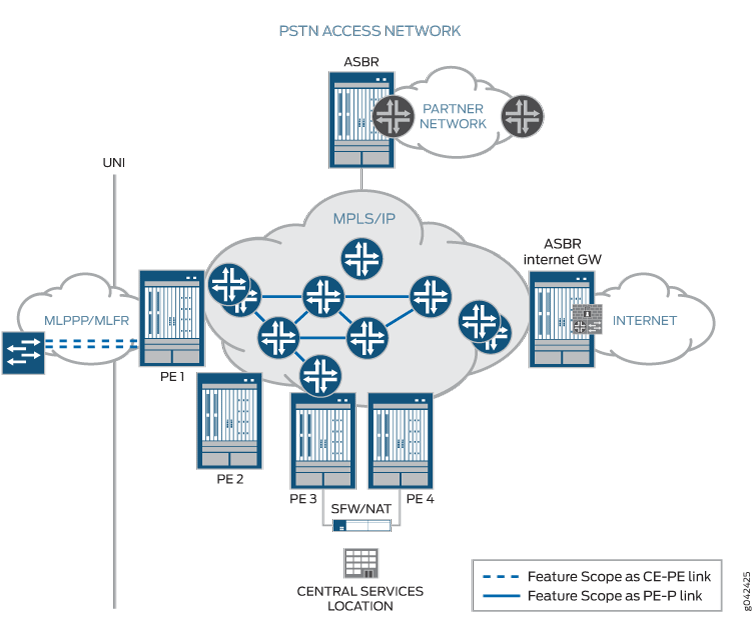 WAN
WAN
Para conectar muchos sitios más pequeños en VPN, agrupar los circuitos TDM junto con la tecnología MLPPP/MLFR es la única manera de ofrecer un mayor ancho de banda y redundancia de enlace.
MLPPP le permite agrupar varios vínculos PPP en un único paquete de multivínculos, y MLFR le permite agrupar varios identificadores de conexión de vínculos de datos (DLCI) de Frame Relay en un único paquete de multivínculos. Los paquetes de enlaces múltiples proporcionan ancho de banda, equilibrio de carga y redundancia adicionales mediante la adición de enlaces de baja velocidad, como T1, E1 y enlaces en serie.
MLPPP es un protocolo para agregar varios enlaces constituyentes en un paquete PPP más grande. MLFR le permite agregar varios vínculos de Frame Relay mediante multiplexación inversa. MLPPP y MLFR ofrecen opciones de servicio entre los servicios T1 y E1 de baja velocidad. Además de proporcionar ancho de banda adicional, agrupar varios enlaces puede agregar un nivel de tolerancia a errores a su servicio de acceso dedicado. Dado que puede implementar la agrupación en varias interfaces, puede proteger a los usuarios contra la pérdida de acceso cuando falla una sola interfaz.
Para configurar MLPPP en línea para interfaces WAN, consulte:
Ver también
Reservar ancho de banda de paquete para sobrecarga de capa de vínculo en interfaces LSQ
La sobrecarga de la capa de vínculo puede causar caídas de paquetes en los vínculos constituyentes debido al relleno de bits en los vínculos en serie. El relleno de bits se utiliza para evitar que los datos se interpreten como información de control.
De forma predeterminada, el 4 por ciento del ancho de banda total del paquete se reserva para la sobrecarga de la capa de vínculo. En la mayoría de los entornos de red, la sobrecarga promedio de la capa de vínculo es del 1,6 %. Por lo tanto, recomendamos el 4 por ciento como salvaguarda. Para obtener más información, consulte RFC 4814, Hash and Stuffing: Factores pasados por alto en la evaluación comparativa de dispositivos de red.
Para las interfaces IQ (lsq-) de servicios de vínculo, puede configurar el porcentaje de ancho de banda del paquete que se reservará para la sobrecarga de la capa de vínculo. Para ello, incluya la link-layer-overhead declaración:
link-layer-overhead percent;
Puede incluir esta instrucción en los siguientes niveles de jerarquía:
[edit interfaces interface-name mlfr-uni-nni-bundle-options][edit interfaces interface-name unit logical-unit-number][edit logical-systems logical-system-name interfaces interface-name unit logical-unit-number]
Puede configurar el valor para que esté del 0 al 50 por ciento.
Ver también
Habilitación de servicios LSQ en línea
PPP multivínculo en línea (MLPPP), Multilink Frame Relay (FRF.16) y Multilink Frame Relay de extremo a extremo (FRF.15) para multiplexación por división de tiempo (TDM) Las interfaces WAN proporcionan servicios de agrupación a través del motor de reenvío de paquetes sin necesidad de una PIC o un concentrador de puerto denso (CPC).
Tradicionalmente, los servicios de agrupación se usan para agrupar varios vínculos de baja velocidad para crear una canalización de ancho de banda más alta. Este ancho de banda combinado está disponible para el tráfico de todos los vínculos y admite la fragmentación e intercalación de vínculos (LFI) en el paquete, lo que reduce el retraso en la transmisión de paquetes de alta prioridad.
Este soporte incluye varios enlaces en el mismo paquete, así como una extensión multiclase para MLPPP. A través de este servicio, puede habilitar la agrupación de servicios sin ranuras CPC adicionales para admitir Service CPC y liberar las ranuras para otras MIC.
La interfaz lógica LSQ en línea (denominada lsq-) es una interfaz lógica de servicio virtual que reside en el motor de reenvío de paquetes para proporcionar servicios de agrupación de capa 2 que no necesitan una PIC de servicio. La convención de nomenclatura es lsq-slot/pic/0.
Haga clic aquí para obtener una matriz de compatibilidad de las MIC actualmente compatibles con MPC1, MPC2, MPC3, MPC6, MPC8 y MPC9 en los enrutadores MX240, MX480, MX960, MX2008, MX2010, MX2020 y MX10003.
Una MPC tipo 1 solo tiene una unidad lógica (LU); por lo tanto, solo se puede crear una interfaz lógica LSQ. Cuando configure una MPC tipo 1, utilice la ranura PIC 0. La MPC tipo 2 tiene dos LU; por lo tanto, se pueden crear dos interfaces lógicas LSQ. Cuando configure una MPC tipo 2, utilice las ranuras PIC 0 y 2.
Configure cada interfaz lógica LSQ con una secuencia de circuito cerrado. Esta secuencia puede tener la forma de una secuencia normal y se comparte con otras interfaces en línea, como la interfaz de servicios en línea (SI).
Para admitir paquetes FRF.16, cree interfaces lógicas con la convención lsq-slot/pic/0:bundle_idde nomenclatura , donde bundle_id puede oscilar entre 0 y 254. Puede configurar interfaces lógicas creadas en la interfaz lógica LSQ principal como MLPPP o FRF.16.
Dado que las interfaces lógicas SI y LSQ pueden compartir la misma secuencia y puede haber varias interfaces lógicas LSQ en esa secuencia, cualquier modelado relacionado con la interfaz lógica se configura en el nodo de capa 2 en lugar del nodo de capa 1. Como resultado, cuando se habilita el SI, en lugar de limitar el ancho de banda de transmisión a 1 Gb o 10 Gb según la configuración, solo la cola de capa 2 asignada para la interfaz SI tiene forma de 1 Gb o 10 Gb.
Para MLPPP y FRF.15, cada interfaz lógica LSQ se forma en función del ancho de banda total del paquete (suma de los anchos de banda de vínculo miembro con sobrecarga de flujo de paquetes de control) mediante la configuración de un nodo único de capa 3 por paquete. De manera similar, cada interfaz lógica FRF.16 se forma en función del ancho de banda total del paquete mediante la configuración de un nodo único de capa 2 por paquete. Los identificadores de conexión de vínculo de datos (DLCI) de interfaz lógica FRF16 se asignan a los nodos de capa 3.
Para habilitar los servicios LSQ en línea y crear la lsq- interfaz lógica para la PIC especificada, especifique las instrucciones de configuración multi-link-layer-2-inline y mlfr-uni-nni-bundles-inline .
[edit chassis fpc number pic number] user@host# set multi-link-layer-2-inline user@host# set mlfr-uni-nni-bundles-inline number
En enrutadores MX80 y MX104 que tengan un único motor de reenvío de paquetes, puede configurar la interfaz lógica LSQ solo en FPC 0 y PIC 0. La tarjeta canalizada debe estar en la ranura FPC 0/0 para que funcione el paquete correspondiente.
Por ejemplo, para habilitar el servicio en línea para PIC 0 en una MPC tipo 1 en la ranura 1:
[edit chassis fpc 1 pic 0] user@host# set multi-link-layer-2-inline user@host# set mlfr-uni-nni-bundles-inline 1
Como resultado, se crean las interfaces lógicas lsq-1/0/0 y lsq-1/0/0:0. El número de paquetes de interfaz multivínculo en línea de usuario a red (UNI) y de interfaz de red a red (NNI) se establece en 1.
Por ejemplo, para habilitar el servicio en línea para PIC 0 y PIC 2 en una MPC tipo 2 instalada en la ranura 5:
[edit chassis fpc 5 pic 0] user@host# set multi-link-layer-2-inline user@host# set mlfr-uni-nni-bundles-inline 1 [edit chassis fpc 5 pic 2] user@host# set multi-link-layer-2-inline user@host# set mlfr-uni-nni-bundles-inline 1
Como resultado, se crean las interfaces lógicas lsq-5/0/0, lsq-5/0/0:0, lsq-5/0/0:1, lsq-5/2/0, lsq-5/2/0:0 y lsq-5/2/0:1. El número de paquetes de interfaz multivínculo en línea de usuario a red (UNI) y de interfaz de red a red (NNI) se establece en 1.
El número PIC aquí solo se usa como anclaje para elegir la LU correcta para enlazar la interfaz LSQ en línea. Los servicios de agrupación están operativos mientras el motor de reenvío de paquetes al que está enlazado esté operativo, aun si la PIC lógica está sin conexión.
Ver también
Configuración de interfaces LSQ como paquetes NxT1 o NxE1 usando MLPPP
Para configurar un Npaquete xT1 con MLPPP, agregue N diferentes vínculos T1 en un paquete. El Npaquete xT1 se denomina interfaz lógica, ya que puede representar, por ejemplo, una adyacencia de enrutamiento. Para agregar vínculos T1 en un paquete MLPPP, incluya la bundle instrucción en el nivel de [edit interfaces t1-fpc/pic/port unit logical-unit-number family mlppp] jerarquía:
[edit interfaces t1-fpc/pic/port unit logical-unit-number family mlppp] bundle lsq-fpc/pic/port.logical-unit-number;
Las interfaces IQ de servicios de vínculo son compatibles con interfaces físicas T1 y E1. Estas instrucciones se aplican a las interfaces T1, pero la configuración para las interfaces E1 es similar.
Para configurar las propiedades de la interfaz IQ de servicios de vínculo, incluya las siguientes instrucciones en el nivel de [edit interfaces lsq-fpc/pic/port unit logical-unit-number] jerarquía:
[edit interfaces lsq-fpc/pic/port unit logical-unit-number]
drop-timeout milliseconds;
encapsulation multilink-ppp;
fragment-threshold bytes;
link-layer-overhead percent;
minimum-links number;
mrru bytes;
short-sequence;
family inet {
address address;
}
Los enrutadores de la serie ACX no admiten las propiedades de tiempo de espera de caída ni de sobrecarga de capa de vínculo.
La interfaz IQ de servicios de vínculo lógico representa el paquete MLPPP. Para el paquete MLPPP, hay cuatro colas asociadas en enrutadores serie M y ocho colas asociadas en enrutadores M320 y serie T. Un programador elimina paquetes de las colas según una política de programación. Normalmente, designa una cola para que tenga prioridad estricta y las colas restantes se atienden en proporción a los pesos que configure.
Para MLPPP, asigne una única asignación de programador a la interfaz IQ de servicios de vínculo (lsq) y a cada vínculo constituyente. Los programadores predeterminados para los enrutadores serie M y serie T, que asignan un ancho de banda del 95, 0, 0 y 5 por ciento para la velocidad de transmisión y el tamaño de búfer de las colas 0, 1, 2 y 3, no son adecuados cuando se configura LFI o tráfico multiclase. Por lo tanto, para MLPPP, debe configurar un único programador con velocidades de transmisión y tamaños de búfer distintos del cero por ciento para las colas del 0 al 3, y asignar este programador a la interfaz IQ de servicios de vínculo (lsq) y a cada vínculo constituyente, como se muestra en Ejemplo: Configuración de una interfaz LSQ como un paquete NxT1 mediante MLPPP.
Para los enrutadores M320 y serie T, la velocidad de transmisión predeterminada del programador y los porcentajes de tamaño de búfer para las colas del 0 al 7 son 95, 0, 0, 5, 0, 0, 0, 0 y 0 por ciento.
Si el vínculo de miembro que pertenece a una interfaz de agrupación MLPP, MLFR o MFR se mueve a otra interfaz de agrupación, o si los vínculos se intercambian entre dos interfaces de agrupación, se requiere una confirmación entre las operaciones de eliminación y adición para asegurarse de que la configuración se aplica correctamente.
Si el paquete tiene más de un vínculo, debe incluir la per-unit-scheduler instrucción en el nivel de [edit interfaces lsq-fpc/pic/port] jerarquía:
[edit interfaces lsq-fpc/pic/port] per-unit-scheduler;
Para configurar y aplicar la política de programación, incluya las siguientes instrucciones en el nivel de [edit class-of-service] jerarquía:
[edit class-of-service]
interfaces {
t1-fpc/pic/port unit logical-unit-number {
scheduler-map map-name;
}
}
forwarding-classes {
queue queue-number class-name;
}
scheduler-maps {
map-name {
forwarding-class class-name scheduler scheduler-name;
}
}
schedulers {
scheduler-name {
buffer-size (percent percentage | remainder | temporal microseconds);
priority priority-level;
transmit-rate (rate | percent percentage | remainder) <exact>;
}
}
Para las interfaces IQ de servicios de vínculo, una cola de prioridad alta estricta puede privar a las otras tres colas porque el tráfico en una cola de prioridad alta estricta se transmite antes de que se atienda a cualquier otra cola. Esta implementación es diferente a la implementación estándar de CoS de Junos en la que una cola de prioridad alta estricta realiza operaciones rotativas con colas de prioridad alta, como se describe en la Guía del usuario de clase de servicio (enrutadores y conmutadores EX9200).
Después de que el programador elimina un paquete de una cola, se realiza una acción determinada. La acción depende de si el paquete proviene de una cola encapsulada de múltiples vínculos (fragmentada y secuenciada) o de una cola no encapsulada (con hash sin fragmentación). Cada cola puede designarse como multivínculo encapsulada o no encapsulada, independientemente de la otra. De forma predeterminada, el tráfico en todas las clases de reenvío está encapsulado multivínculo. Para configurar el manejo de fragmentación de paquetes en una cola, incluya la fragmentation-maps instrucción en el nivel de [edit class-of-service] jerarquía:
fragmentation-maps {
map-name {
forwarding-class class-name {
fragment-threshold bytes;
multilink-class number;
no-fragmentation;
}
}
}
Para Nlos paquetes xT1 que utilizan MLPPP, el equilibrio de carga en bytes utilizado en colas encapsuladas multivínculo es superior al equilibrio de carga en flujo utilizado en colas no encapsuladas. Todas las demás consideraciones son iguales. Por lo tanto, le recomendamos que configure todas las colas para que estén encapsuladas con varios vínculos. Esto se hace incluyendo la fragment-threshold instrucción en la configuración. Si decide establecer que el tráfico de una cola sea no encapsulado en lugar de multivínculo, incluya la no-fragmentation instrucción en el mapa de fragmentación. Utilice la multilink-class instrucción para asignar una clase de reenvío a una MLPPP multiclase (MCML). . Para obtener más información acerca de las asignaciones de fragmentación, consulte Configurar la fragmentación de CoS mediante clase de reenvío en interfaces LSQ.
Cuando se elimina un paquete de una cola encapsulada con varios vínculos, el software le da al paquete un encabezado MLPPP. El encabezado MLPPP contiene un campo de número de secuencia, que se rellena con el siguiente número de secuencia disponible de un contador. Luego, el software coloca el paquete en uno de los N diferentes vínculos T1. El vínculo se elige paquete por paquete para equilibrar la carga en los distintos vínculos T1.
Si el paquete supera la UMT mínima de vínculo, o si una cola tiene un umbral de fragmento configurado en el [edit class-of-service fragmentation-maps map-name forwarding-class class-name] nivel jerárquico, el software divide el paquete en dos o más fragmentos, a los que se les asignan números de secuencia de multivínculo consecutivos. El vínculo saliente para cada fragmento se selecciona independientemente de todos los demás fragmentos.
Si no incluye la fragment-threshold instrucción en la asignación de fragmentación, el umbral de fragmentación que establezca en el [edit interfaces interface-name unit logical-unit-number] nivel de jerarquía es el predeterminado para todas las clases de reenvío. Si no establece un tamaño máximo de fragmento en ninguna parte de la configuración, los paquetes se fragmentan si superan la UMT más pequeña de todos los vínculos del paquete.
Incluso si no establece un tamaño máximo de fragmento en ninguna parte de la configuración, puede configurar la unidad reconstruida máxima recibida (MRRU) incluyendo la mrru instrucción en el nivel de [edit interfaces lsq-fpc/pic/port unit logical-unit-number] jerarquía. La MRRU es similar a la UMT, pero es específica para las interfaces de servicios de vínculo. De forma predeterminada, el tamaño de MRRU es de 1500 bytes y puede configurarlo para que sea de 1500 a 4500 bytes. Para obtener más información, consulte Configurar MRRU en interfaces lógicas de multivínculo y servicios de vínculo.
Cuando se elimina un paquete de una cola no encapsulada, se transmite con un encabezado PPP sin formato. Dado que no hay encabezado MLPPP, no hay información de número de secuencia. Por lo tanto, el software debe tomar medidas especiales para evitar el reordenamiento de paquetes. Para evitar el reordenamiento de paquetes, el software coloca el paquete en uno de los N diferentes vínculos T1. El vínculo se determina mediante el hash de los valores del encabezado. Para IP, el software calcula el hash en función de la dirección de origen, la dirección de destino y el protocolo IP. Para MPLS, el software calcula el hash en función de hasta cinco etiquetas MPLS o cuatro etiquetas MPLS y el encabezado IP.
Para UDP y TCP, el software calcula el hash en función de los puertos de origen y destino, así como de las direcciones IP de origen y destino. Esto garantiza que todos los paquetes que pertenecen al mismo flujo TCP/UDP siempre pasan por el mismo vínculo T1 y, por lo tanto, no se pueden reordenar. Sin embargo, no garantiza que la carga en los distintos vínculos T1 esté equilibrada. Si hay muchos flujos, la carga suele estar equilibrada.
Las N diferentes interfaces T1 se vinculan a otro enrutador, que puede ser de Juniper Networks o de otro proveedor. El enrutador en el otro extremo recopila paquetes de todos los vínculos T1. Si un paquete tiene un encabezado MLPPP, el campo de número de secuencia se utiliza para volver a colocar el paquete en el orden del número de secuencia. Si el paquete tiene un encabezado PPP sin formato, el software acepta el paquete en el orden en que llega y no hace ningún intento de volver a ensamblar o reordenar el paquete.
Ejemplo: Configuración de una interfaz LSQ como agrupación NxT1 mediante MLPPP
[edit chassis]
fpc 1 {
pic 3 {
adaptive-services {
service-package layer-2;
}
}
}
[edit interfaces]
t1-0/0/0 {
encapsulation ppp;
unit 0 {
family mlppp {
bundle lsq-1/3/0.1; # This adds t1-0/0/0 to the specified bundle.
}
}
}
t1-0/0/1 {
encapsulation ppp;
unit 0 {
family mlppp {
bundle lsq-1/3/0.1;
}
}
}
lsq-1/3/0 {
unit 1 { # This is the virtual link that concatenates multiple T1s.
encapsulation multilink-ppp;
drop-timeout 1000;
fragment-threshold 128;
link-layer-overhead 0.5;
minimum-links 2;
mrru 4500;
short-sequence;
family inet {
address 10.2.3.4/24;
}
}
[edit interfaces]
lsq-1/3/0 {
per-unit-scheduler;
}
[edit class-of-service]
interfaces {
lsq-1/3/0 { # multilink PPP constituent link
unit 0 {
scheduler-map sched-map1;
}
}
t1-0/0/0 { # multilink PPP constituent link
unit 0 {
scheduler-map sched-map1;
}
t1-0/0/1 { # multilink PPP constituent link
unit 0 {
scheduler-map sched-map1;
}
forwarding-classes {
queue 0 be;
queue 1 ef;
queue 2 af;
queue 3 nc;
}
scheduler-maps {
sched-map1 {
forwarding-class af scheduler af-scheduler;
forwarding-class be scheduler be-scheduler;
forwarding-class ef scheduler ef-scheduler;
forwarding-class nc scheduler nc-scheduler;
}
}
schedulers {
af-scheduler {
transmit-rate percent 30;
buffer-size percent 30;
priority low;
}
be-scheduler {
transmit-rate percent 25;
buffer-size percent 25;
priority low;
}
ef-scheduler {
transmit-rate percent 40;
buffer-size percent 40;
priority strict-high; # voice queue
}
nc-scheduler {
transmit-rate percent 5;
buffer-size percent 5;
priority high;
}
}
fragmentation-maps {
fragmap-1 {
forwarding-class be {
fragment-threshold 180;
}
forwarding-class ef {
fragment-threshold 100;
}
}
}
[edit interfaces]
lsq-1/3/0 {
unit 0 {
fragmentation-map fragmap-1;
}
}
Ver también
Configuración de interfaces LSQ como paquetes NxT1 o NxE1 mediante FRF.16
Para configurar un Npaquete xT1 con FRF.16, agregue N diferentes vínculos T1 en un paquete. El Npaquete xT1 incluye una cantidad potencialmente grande de PVC Frame Relay, identificados por sus DLCI. Cada DLCI se denomina interfaz lógica, ya que puede representar, por ejemplo, una adyacencia de enrutamiento.
Para agregar vínculos T1 en un paquete FRF.16, incluya la mlfr-uni-nni-bundles instrucción en el nivel de [edit chassis fpc slot-number pic slot-number] jerarquía e incluya la bundle instrucción en el nivel de [edit interfaces t1-fpc/pic/port unit logical-unit-number family mlfr-uni-nni] jerarquía:
[edit chassis fpc slot-number pic slot-number] mlfr-uni-nni-bundles number; [edit interfaces t1-fpc/pic/port unit logical-unit-number family mlfr-uni-nni] bundle lsq-fpc/pic/port:channel;
Las interfaces IQ de servicios de vínculo son compatibles con interfaces físicas T1 y E1. Estas instrucciones se aplican a las interfaces T1, pero la configuración para las interfaces E1 es similar.
Para configurar las propiedades de la interfaz IQ de servicios de vínculo, incluya las siguientes instrucciones en el nivel de [edit interfaces lsq- fpc/pic/port:channel] jerarquía:
[edit interfaces lsq- fpc/pic/port:channel]
encapsulation multilink-frame-relay-uni-nni;
dce;
mlfr-uni-nni-options {
acknowledge-retries number;
acknowledge-timer milliseconds;
action-red-differential-delay (disable-tx | remove-link);
drop-timeout milliseconds;
fragment-threshold bytes;
hello-timer milliseconds;
link-layer-overhead percent;
lmi-type (ansi | itu);
minimum-links number;
mrru bytes;
n391 number;
n392 number;
n393 number;
red-differential-delay milliseconds;
t391 number;
t392 number;
yellow-differential-delay milliseconds;
}
unit logical-unit-number {
dlci dlci-identifier;
family inet {
address address;
}
}
El canal IQ de servicios de vínculo representa el paquete FRF.16. Cuatro colas están asociadas con cada DLCI. Un programador elimina paquetes de las colas según una política de programación. En la interfaz IQ de servicios de vínculo, normalmente se designa una cola para que tenga prioridad estricta. Las colas restantes se atienden en proporción a los pesos que configure.
En el caso de las interfaces IQ de servicios de vínculo, una cola de prioridad alta estricta puede privar de servicio a las otras tres colas, ya que el tráfico de una cola de prioridad alta estricta se transmite antes de que se atienda a cualquier otra cola. Esta implementación es diferente a la implementación estándar de CoS de Junos en la que una cola de prioridad alta estricta realiza operaciones rotativas con colas de prioridad alta, como se describe en la Guía del usuario de clase de servicio (enrutadores y conmutadores EX9200).
Si el paquete tiene más de un vínculo, debe incluir la per-unit-scheduler instrucción en el nivel de [edit interfaces lsq-fpc/pic/port:channel] jerarquía:
[edit interfaces lsq-fpc/pic/port:channel] per-unit-scheduler;
Para FRF.16, puede asignar una única asignación de programador a la interfaz IQ de servicios de vínculo (lsq) y a cada DLCI IQ de servicios de vínculo, o puede asignar diferentes asignaciones de programador a los distintos DLCI del paquete, como se muestra en Ejemplo: Configuración de una interfaz LSQ como agrupación NxT1 mediante FRF.16.
Para los vínculos constituyentes de un paquete FRF.16, no es necesario configurar un programador personalizado. Dado que LFI y multiclase no son compatibles con FRF.16, el tráfico de cada vínculo constituyente se transmite desde la cola 0. Esto significa que debe permitir que la cola 0 utilice la mayor parte del ancho de banda. Para enrutadores serie M y serie T, la velocidad de transmisión predeterminada de los programadores y los porcentajes de tamaño de búfer para las colas del 0 al 3 son 95, 0, 0 y 5 por ciento. Estos programadores predeterminados envían todo el tráfico de usuarios a la cola 0 y todo el tráfico de control de red a la cola 3 y, por lo tanto, son adecuados para el comportamiento de FRF.16. Si lo desea, puede configurar un programador personalizado que replique explícitamente el comportamiento de cola del 95, 0, 0 y 5 por ciento, y aplicarlo a los vínculos que lo componen.
Para los enrutadores M320 y serie T, la velocidad de transmisión predeterminada del programador y los porcentajes de tamaño de búfer para las colas del 0 al 7 son 95, 0, 0, 5, 0, 0, 0, 0 y 0 por ciento.
Si el vínculo de miembro que pertenece a una interfaz de agrupación MLPP, MLFR o MFR se mueve a otra interfaz de agrupación, o si los vínculos se intercambian entre dos interfaces de agrupación, se requiere una confirmación entre las operaciones de eliminación y adición para asegurarse de que la configuración se aplica correctamente.
Para configurar y aplicar la política de programación, incluya las siguientes instrucciones en el nivel de [edit class-of-service] jerarquía:
[edit class-of-service]
interfaces {
lsq-fpc/pic/port:channel {
unit logical-unit-number {
scheduler-map map-name;
}
}
}
forwarding-classes {
queue queue-number class-name;
}
scheduler-maps {
map-name {
forwarding-class class-name scheduler scheduler-name;
}
}
schedulers {
scheduler-name {
buffer-size (percent percentage | remainder | temporal microseconds);
priority priority-level;
transmit-rate (rate | percent percentage | remainder) <exact>;
}
}
Para configurar el manejo de fragmentación de paquetes en una cola, incluya la fragmentation-maps instrucción en el nivel de [edit class-of-service] jerarquía:
[edit class-of-service]
fragmentation-maps {
map-name {
forwarding-class class-name {
fragment-threshold bytes;
}
}
}
Para el tráfico FRF.16, solo se admiten colas encapsuladas multivínculo (fragmentadas y secuenciadas). Este es el comportamiento de cola predeterminado para todas las clases de reenvío. FRF.16 no permite el tráfico no encapsulado porque el protocolo requiere que todos los paquetes lleven el encabezado de fragmentación. Si un paquete grande se divide en varios fragmentos, los fragmentos deben tener números secuenciales consecutivos. Por lo tanto, no puede incluir la no-fragmentation instrucción en el nivel de jerarquía para el [edit class-of-service fragmentation-maps map-name forwarding-class class-name] tráfico FRF.16. Para FRF.16, si desea transportar voz o cualquier otro tráfico sensible a la latencia, no debe usar enlaces lentos. A velocidades T1 y superiores, el retraso de serialización es lo suficientemente pequeño como para que no sea necesario usar LFI explícita.
Cuando se elimina un paquete de una cola encapsulada multivínculo, el software le da al paquete un encabezado FRF.16. El encabezado FRF.16 contiene un campo de número de secuencia, que se rellena con el siguiente número de secuencia disponible de un contador. Luego, el software coloca el paquete en uno de los N diferentes vínculos T1. El vínculo se elige paquete por paquete para equilibrar la carga en los distintos vínculos T1.
Si el paquete supera la UMT mínima de vínculo, o si una cola tiene un umbral de fragmento configurado en el [edit class-of-service fragmentation-maps map-name forwarding-class class-name] nivel jerárquico, el software divide el paquete en dos o más fragmentos, a los que se les asignan números de secuencia de multivínculo consecutivos. El vínculo saliente para cada fragmento se selecciona independientemente de todos los demás fragmentos.
Si no incluye la fragment-threshold instrucción en la asignación de fragmentación, el umbral de fragmentación que establezca en el [edit interfaces interface-name unit logical-unit-number] nivel de jerarquía o [edit interfaces interface-name mlfr-uni-nni-bundle-options] es el predeterminado para todas las clases de reenvío. Si no establece un tamaño máximo de fragmento en ninguna parte de la configuración, los paquetes se fragmentan si superan la UMT más pequeña de todos los vínculos del paquete.
Incluso si no establece un tamaño máximo de fragmento en ninguna parte de la configuración, puede configurar la unidad reconstruida máxima recibida (MRRU) incluyendo la mrru instrucción en el [edit interfaces lsq-fpc/pic/port unit logical-unit-number] nivel de jerarquía o [edit interfaces interface-name mlfr-uni-nni-bundle-options] . La MRRU es similar a la UMT, pero es específica para las interfaces de servicios de vínculo. De forma predeterminada, el tamaño de MRRU es de 1500 bytes y puede configurarlo para que sea de 1500 a 4500 bytes. Para obtener más información, consulte Configurar MRRU en interfaces lógicas de multivínculo y servicios de vínculo.
Las N diferentes interfaces T1 se vinculan a otro enrutador, que puede ser de Juniper Networks o de otro proveedor. El enrutador en el otro extremo recopila paquetes de todos los vínculos T1. Dado que cada paquete tiene un encabezado FRF.16, el campo de número de secuencia se utiliza para volver a colocar el paquete en el orden del número de secuencia.
Ejemplo: Configuración de una interfaz LSQ como un paquete NxT1 utilizando FRF.16
Configure un Npaquete xT1 con FRF.16 con varias asignaciones de programador de CoS:
[edit chassis fpc 1 pic 3]
adaptive-services {
service-package layer-2;
}
mlfr-uni-nni-bundles 2; # Creates channelized LSQ interfaces/FRF.16 bundles.
[edit interfaces]
t1-0/0/0 {
encapsulation multilink-frame-relay-uni-nni;
unit 0 {
family mlfr-uni-nni {
bundle lsq-1/3/0:1;
}
}
}
t1-0/0/1 {
encapsulation multilink-frame-relay-uni-nni;
unit 0 {
family mlfr-uni-nni {
bundle lsq-1/3/0:1;
}
}
}
lsq-1/3/0:1 { # Bundle link consisting of t1-0/0/0 and t1-0/0/1
per-unit-scheduler;
encapsulation multilink-frame-relay-uni-nni;
dce; # One end needs to be configured as DCE.
mlfr-uni-nni-bundle-options {
drop-timeout 180;
fragment-threshold 64;
hello-timer 180;
minimum-links 2;
mrru 3000;
link-layer-overhead 0.5;
}
unit 0 {
dlci 26; # Each logical unit maps a single DLCI.
family inet {
address 10.2.3.4/24;
}
}
unit 1 {
dlci 42;
family inet {
address 10.20.30.40/24;
}
}
unit 2 {
dlci 69;
family inet {
address 10.20.30.40/24;
}
}
[edit class-of-service]
scheduler-maps {
sched-map-lsq0 {
forwarding-class af scheduler af-scheduler-lsq0;
forwarding-class be scheduler be-scheduler-lsq0;
forwarding-class ef scheduler ef-scheduler-lsq0;
forwarding-class nc scheduler nc-scheduler-lsq0;
}
sched-map-lsq1 {
forwarding-class af scheduler af-scheduler-lsq1;
forwarding-class be scheduler be-scheduler-lsq1;
forwarding-class ef scheduler ef-scheduler-lsq1;
forwarding-class nc scheduler nc-scheduler-lsq1;
}
}
schedulers {
af-scheduler-lsq0 {
transmit-rate percent 60;
buffer-size percent 60;
priority low;
}
be-scheduler-lsq0 {
transmit-rate percent 30;
buffer-size percent 30;
priority low;
}
ef-scheduler-lsq0 {
transmit-rate percent 5;
buffer-size percent 5;
priority strict-high;
}
nc-scheduler-lsq0 {
transmit-rate percent 5;
buffer-size percent 5;
priority high;
}
af-scheduler-lsq1 {
transmit-rate percent 50;
buffer-size percent 50;
priority low;
}
be-scheduler-lsq1 {
transmit-rate percent 30;
buffer-size percent 30;
priority low;
}
ef-scheduler-lsq1 {
transmit-rate percent 15;
buffer-size percent 15;
priority strict-high;
}
nc-scheduler-lsq1 {
transmit-rate percent 5;
buffer-size percent 5;
priority high;
}
}
interfaces {
lsq-1/3/0:1 { # MLFR FRF.16
unit 0 {
scheduler-map sched-map-lsq0;
}
unit 1 {
scheduler-map sched-map-lsq1;
}
}
Ver también
Configuración de interfaces LSQ como paquetes NxT1 o NxE1 mediante FRF.15
En este ejemplo, se configura un Npaquete xT1 utilizando FRF.15 en una interfaz IQ de servicios de vínculo. FRF.15 es similar a FRF.12, como se describe en Configuración de interfaces LSQ para interfaces T1 o E1 fraccionarias simples mediante FRF.12. La diferencia es que FRF.15 admite varios vínculos físicos en un paquete, mientras que FRF.12 solo admite un vínculo físico por paquete. Para la implementación de Junos OS de FRF.15, puede configurar un DLCI por vínculo físico.
Las interfaces IQ de servicios de vínculo son compatibles con interfaces físicas T1 y E1. En este ejemplo, se hace referencia a interfaces T1, pero la configuración de las interfaces E1 es similar.
[edit interfaces]
lsq-1/3/0 {
per-unit-scheduler;
unit 0 {
dlci 69;
encapsulation multilink-frame-relay-end-to-end;
}
}
unit 1 {
dlci 13;
encapsulation multilink-frame-relay-end-to-end;
}
# First physical link
t1-1/1/0:1 {
encapsulation frame-relay;
unit 0 {
family mlfr-end-to-end {
bundle lsq-1/3/0.0;
}
}
}
# Second physical link
t1-1/1/0:2 {
encapsulation frame-relay;
unit 0 {
family mlfr-end-to-end {
bundle lsq-1/3/0.0;
}
}
}
Ver también
Configuración de interfaces LSQ para interfaces T1 o E1 fraccionarias simples mediante MLPPP y LFI
Cuando se configura una interfaz T1 fraccionaria única, se denomina interfaz lógica, ya que puede representar, por ejemplo, una adyacencia de enrutamiento.
La interfaz IQ de servicios de vínculo lógico representa el paquete MLPPP. Cuatro colas están asociadas con la interfaz lógica. Un programador elimina paquetes de las colas según una política de programación. Normalmente, designa una cola para que tenga prioridad estricta y las colas restantes se atienden en proporción a los pesos que configure.
Para configurar una sola interfaz T1 fraccionaria mediante MLPPP y LFI, asocie una interfaz DS0 (T1 fraccionaria) con una interfaz IQ de servicios de vínculo. Para asociar una interfaz T1 fraccionaria con una interfaz IQ de servicios de vínculo, incluya la bundle instrucción en el nivel de [edit interfaces ds-fpc/pic/port:channel unit logical-unit-number family mlppp] jerarquía:
[edit interfaces ds-fpc/pic/port:channel unit logical-unit-number family mlppp] bundle lsq-fpc/pic/port.logical-unit-number;
Las interfaces IQ de servicios de vínculo son compatibles con interfaces físicas T1 y E1. Estas instrucciones se aplican a las interfaces T1, pero la configuración para las interfaces E1 es similar.
Para configurar las propiedades de la interfaz IQ de servicios de vínculo, incluya las siguientes instrucciones en el nivel de [edit interfaces lsq-fpc/pic/port unit logical-unit-number] jerarquía:
[edit interfaces lsq-fpc/pic/port unit logical-unit-number]
drop-timeout milliseconds;
encapsulation multilink-ppp;
fragment-threshold bytes;
link-layer-overhead percent;
minimum-links number;
mrru bytes;
short-sequence;
family inet {
address address;
}
Para MLPPP, asigne una única asignación de programador a la interfaz IQ () de servicios de vínculo ylsq a cada vínculo constituyente. Los programadores predeterminados para los enrutadores serie M y serie T, que asignan un ancho de banda del 95, 0, 0 y 5 por ciento para la velocidad de transmisión y el tamaño de búfer de las colas 0, 1, 2 y 3, no son adecuados cuando se configura LFI o tráfico multiclase. Por lo tanto, para MLPPP, debe configurar un único programador con velocidades de transmisión de porcentaje distintas de cero y tamaños de búfer para las colas del 0 al 3, y asignar este programador a la interfaz IQ () de servicios de vínculo ylsq a cada vínculo constituyente y a cada vínculo constituyente, como se muestra en Ejemplo: Configuración de una interfaz LSQ para una interfaz T1 fraccionaria utilizando MLPPP y LFI.
Para los enrutadores M320 y serie T, la velocidad de transmisión predeterminada del programador y los porcentajes de tamaño de búfer para las colas del 0 al 7 son 95, 0, 0, 5, 0, 0, 0, 0 y 0 por ciento.
Para configurar y aplicar la política de programación, incluya las siguientes instrucciones en el nivel de [edit class-of-service] jerarquía:
[edit class-of-service]
interfaces {
ds-fpc/pic/port.channel {
scheduler-map map-name;
}
}
forwarding-classes {
queue queue-number class-name;
}
scheduler-maps {
map-name {
forwarding-class class-name scheduler scheduler-name;
}
}
schedulers {
scheduler-name {
buffer-size (percent percentage | remainder | temporal microseconds);
priority priority-level;
transmit-rate (rate | percent percentage | remainder) <exact>;
}
}
Para las interfaces IQ de servicios de vínculo, una cola de prioridad alta estricta puede privar a todas las demás colas porque el tráfico en una cola de prioridad alta estricta se transmite antes de que se atienda a cualquier otra cola. Esta implementación es diferente a la implementación estándar de CoS de Junos, en la que una cola de prioridad alta estricta recibe créditos infinitos y realiza operaciones rotativas con colas de prioridad alta, como se describe en la Guía del usuario de clase de servicio (enrutadores y conmutadores EX9200).
Después de que el programador elimina un paquete de una cola, se realiza una acción determinada. La acción depende de si el paquete proviene de una cola encapsulada de múltiples vínculos (fragmentada y secuenciada) o de una cola no encapsulada (con hash sin fragmentación). Cada cola puede designarse como multivínculo encapsulada o no encapsulada, independientemente de la otra. De forma predeterminada, el tráfico en todas las clases de reenvío está encapsulado multivínculo. Para configurar el manejo de fragmentación de paquetes en una cola, incluya la fragmentation-maps instrucción en el nivel de [edit class-of-service] jerarquía:
[edit class-of-service]
fragmentation-maps {
map-name {
forwarding-class class-name {
fragment-threshold bytes;
no-fragmentation;
}
}
}
Si necesita que la cola transmita paquetes pequeños con baja latencia, configure la cola para que no esté encapsulada incluyendo la no-fragmentation instrucción. Si necesita que la cola transmita paquetes grandes con latencia normal, configure la cola para que esté encapsulada con varios vínculos incluyendo la fragment-threshold instrucción. Si necesita que la cola transmita paquetes grandes con baja latencia, le recomendamos que utilice un vínculo más rápido y configure la cola para que no esté encapsulada. Para obtener más información acerca de las asignaciones de fragmentación, consulte Configurar la fragmentación de CoS mediante clase de reenvío en interfaces LSQ.
Cuando se elimina un paquete de una cola encapsulada de varios vínculos, se fragmenta. Si el paquete supera la UMT mínima de vínculo, o si una cola tiene un umbral de fragmento configurado en el [edit class-of-service fragmentation-maps map-name forwarding-class class-name] nivel jerárquico, el software divide el paquete en dos o más fragmentos, a los que se les asignan números de secuencia de multivínculo consecutivos.
Si no incluye la fragment-threshold instrucción en la asignación de fragmentación, el umbral de fragmentación que establezca en el [edit interfaces interface-name unit logical-unit-number] nivel de jerarquía es el predeterminado para todas las clases de reenvío. Si no establece un tamaño máximo de fragmento en ninguna parte de la configuración, los paquetes se fragmentan si superan la UMT más pequeña de todos los vínculos del paquete.
Incluso si no establece un tamaño máximo de fragmento en ninguna parte de la configuración, puede configurar la unidad reconstruida máxima recibida (MRRU) incluyendo la mrru instrucción en el nivel de [edit interfaces lsq-fpc/pic/port unit logical-unit-number] jerarquía. La MRRU es similar a la UMT, pero es específica para las interfaces de servicios de vínculo. De forma predeterminada, el tamaño de MRRU es de 1500 bytes y puede configurarlo para que sea de 1500 a 4500 bytes. Para obtener más información, consulte Configurar MRRU en interfaces lógicas de multivínculo y servicios de vínculo.
Cuando se elimina un paquete de una cola encapsulada con varios vínculos, el software le da al paquete un encabezado MLPPP. El encabezado MLPPP contiene un campo de número de secuencia, que se rellena con el siguiente número de secuencia disponible de un contador. Luego, el software coloca el paquete en el vínculo T1 fraccionario. El tráfico de otra cola puede intercalarse entre dos fragmentos del paquete.
Cuando se elimina un paquete de una cola no encapsulada, se transmite con un encabezado PPP sin formato. Luego, el paquete se coloca en el vínculo T1 fraccionado lo antes posible. Si es necesario, el paquete se coloca entre los fragmentos de un paquete de otra cola.
La interfaz T1 fraccionada se vincula a otro enrutador, que puede ser de Juniper Networks u otro proveedor. El enrutador en el otro extremo recopila paquetes del vínculo T1 fraccionado. Si un paquete tiene un encabezado MLPPP, el software asume que el paquete es un fragmento de un paquete más grande y el campo de número de fragmento se usa para volver a ensamblar el paquete más grande. Si el paquete tiene un encabezado PPP sin formato, el software acepta el paquete en el orden en que llega, y el software no hace ningún intento de volver a ensamblar o reordenar el paquete.
Ejemplo: Configuración de una interfaz LSQ para una interfaz T1 fraccionaria utilizando MLPPP y LFI
Configure una interfaz lógica T1 fraccionaria única:
[edit interfaces]
lsq-0/2/0 {
per-unit-scheduler;
unit 0 {
encapsulation multilink-ppp;
link-layer-overhead 0.5;
family inet {
address 10.40.1.1/30;
}
}
}
ct3-1/0/0 {
partition 1 interface-type ct1;
}
ct1-1/0/0:1 {
partition 1 timeslots 1-2 interface-type ds;
}
ds-1/0/0:1:1 {
encapsulation ppp;
unit 0 {
family mlppp {
bundle lsq-0/2/0.0;
}
}
}
[edit class-of-service]
interfaces {
ds-1/0/0:1:1 { # multilink PPP constituent link
unit 0 {
scheduler-map sched-map1;
}
}
forwarding-classes {
queue 0 be;
queue 1 ef;
queue 2 af;
queue 3 nc;
}
scheduler-maps {
sched-map1 {
forwarding-class af scheduler af-scheduler;
forwarding-class be scheduler be-scheduler;
forwarding-class ef scheduler ef-scheduler;
forwarding-class nc scheduler nc-scheduler;
}
}
schedulers {
af-scheduler {
transmit-rate percent 20;
buffer-size percent 20;
priority low;
}
be-scheduler {
transmit-rate percent 20;
buffer-size percent 20;
priority low;
}
ef-scheduler {
transmit-rate percent 50;
buffer-size percent 50;
priority strict-high; # voice queue
}
nc-scheduler {
transmit-rate percent 10;
buffer-size percent 10;
priority high;
}
}
fragmentation-maps {
fragmap-1 {
forwarding-class be {
fragment-threshold 180;
}
forwarding-class ef {
fragment-threshold 100;
}
}
}
[edit interfaces]
lsq-0/2/0 {
unit 0 {
fragmentation-map fragmap-1;
}
}
Ver también
Configuración de interfaces LSQ para interfaces T1 o E1 fraccionarias únicas mediante FRF.12
Para configurar una interfaz T1 fraccionaria única con FRF.16, asocie una interfaz DS0 con una interfaz IQ (lsq) de servicios de vínculo. Cuando se configura un T1 fraccionario único, el T1 fraccionario incluye un número potencialmente grande de PVC de Frame Relay identificados por sus DLCI. Cada DLCI se denomina interfaz lógica, ya que puede representar, por ejemplo, una adyacencia de enrutamiento. Para asociar la interfaz DS0 con una interfaz IQ de servicios de vínculo, incluya la bundle instrucción en el nivel de [edit interfaces ds-fpc/pic/port:channel unit logical-unit-number family mlfr-end-to-end] jerarquía:
[edit interfaces ds-fpc/pic/port:channel unit logical-unit-number family mlfr-end-to-end] bundle lsq-fpc/pic/port.logical-unit-number;
Las interfaces IQ de servicios de vínculo son compatibles con interfaces físicas T1 y E1. Estas instrucciones se aplican a las interfaces T1, pero la configuración para las interfaces E1 es similar.
Para configurar las propiedades de la interfaz IQ de servicios de vínculo, incluya las siguientes instrucciones en el nivel de [edit interfaces lsq-fpc/pic/port unit logical-unit-number] jerarquía:
[edit interfaces lsq-fpc/pic/port unit logical-unit-number]
drop-timeout milliseconds;
encapsulation multilink-frame-relay-end-to-end;
fragment-threshold bytes;
link-layer-overhead percent;
minimum-links number;
mrru bytes;
short-sequence;
family inet {
address address;
}
La interfaz IQ de servicios de vínculo lógico representa el paquete FRF.12. Se asocian cuatro colas con cada interfaz lógica. Un programador elimina paquetes de las colas según una política de programación. Normalmente, designa una cola para que tenga prioridad estricta y las colas restantes se atienden en proporción a los pesos que configure.
Para FRF.12, asigne una única asignación de programador a la interfaz IQ de servicios de vínculo (lsq) y a cada vínculo constituyente. Para enrutadores serie M y serie T, los programadores predeterminados, que asignan un ancho de banda del 95, 0, 0 y 5 por ciento para la velocidad de transmisión y el tamaño de búfer de las colas 0, 1, 2 y 3, no son adecuados cuando se configura LFI o tráfico multiclase. Por lo tanto, para FRF.12, debe configurar programadores con velocidades de transmisión de porcentaje distintas de cero y tamaños de búfer para las colas del 0 al 3, y asignarlos a la interfaz IQ de servicios de vínculo (lsq) y a cada vínculo constituyente, como se muestra en Ejemplos: Configuración de una interfaz LSQ para una interfaz T1 fraccionaria mediante FRF.12.
Para los enrutadores M320 y serie T, la velocidad de transmisión predeterminada del programador y los porcentajes de tamaño de búfer para las colas del 0 al 7 son 95, 0, 0, 5, 0, 0, 0, 0 y 0 por ciento.
Para configurar y aplicar la política de programación, incluya las siguientes instrucciones en el nivel de [edit class-of-service] jerarquía:
[edit class-of-service]
interfaces {
ds-fpc/pic/port.channel {
scheduler-map map-name;
}
}
forwarding-classes {
queue queue-number class-name;
}
scheduler-maps {
map-name {
forwarding-class class-name scheduler scheduler-name;
}
}
schedulers {
scheduler-name {
buffer-size (percent percentage | remainder | temporal microseconds);
priority priority-level;
transmit-rate (rate | percent percentage | remainder) <exact>;
}
}
En el caso de las interfaces IQ de servicios de vínculo, una cola de prioridad alta estricta puede privar de servicio a las otras tres colas, ya que el tráfico de una cola de prioridad alta estricta se transmite antes de que se atienda a cualquier otra cola. Esta implementación es diferente a la implementación estándar de CoS de Junos en la que una cola de prioridad alta estricta realiza operaciones rotativas con colas de prioridad alta, como se describe en la Guía del usuario de clase de servicio (enrutadores y conmutadores EX9200).
Después de que el programador elimina un paquete de una cola, se realiza una acción determinada. La acción depende de si el paquete proviene de una cola encapsulada de múltiples vínculos (fragmentada y secuenciada) o de una cola no encapsulada (con hash sin fragmentación). Cada cola puede designarse como multivínculo encapsulada o no encapsulada, independientemente de la otra. De forma predeterminada, el tráfico en todas las clases de reenvío está encapsulado multivínculo. Para configurar el manejo de fragmentación de paquetes en una cola, incluya la fragmentation-maps instrucción en el nivel de [edit class-of-service] jerarquía:
[edit class-of-service]
fragmentation-maps {
map-name {
forwarding-class class-name {
fragment-threshold bytes;
no-fragmentation;
}
}
}
Si necesita que la cola transmita paquetes pequeños con baja latencia, configure la cola para que no esté encapsulada incluyendo la no-fragmentation instrucción. Si necesita que la cola transmita paquetes grandes con latencia normal, configure la cola para que esté encapsulada con varios vínculos incluyendo la fragment-threshold instrucción. Si necesita que la cola transmita paquetes grandes con baja latencia, le recomendamos que utilice un vínculo más rápido y configure la cola para que no esté encapsulada. Para obtener más información acerca de las asignaciones de fragmentación, consulte Configurar la fragmentación de CoS mediante clase de reenvío en interfaces LSQ.
Cuando se elimina un paquete de una cola encapsulada de varios vínculos, se fragmenta. Si el paquete supera la UMT mínima de vínculo, o si una cola tiene un umbral de fragmento configurado en el [edit class-of-service fragmentation-maps map-name forwarding-class class-name] nivel jerárquico, el software divide el paquete en dos o más fragmentos, a los que se les asignan números de secuencia de multivínculo consecutivos.
Si no incluye la fragment-threshold instrucción en la asignación de fragmentación, el umbral de fragmentación que establezca en el [edit interfaces interface-name unit logical-unit-number] nivel de jerarquía es el predeterminado para todas las clases de reenvío. Si no establece un tamaño máximo de fragmento en ninguna parte de la configuración, los paquetes se fragmentan si superan la UMT más pequeña de todos los vínculos del paquete.
Incluso si no establece un tamaño máximo de fragmento en ninguna parte de la configuración, puede configurar la unidad reconstruida máxima recibida (MRRU) incluyendo la mrru instrucción en el nivel de [edit interfaces lsq-fpc/pic/port unit logical-unit-number] jerarquía. La MRRU es similar a la UMT, pero es específica para las interfaces de servicios de vínculo. De forma predeterminada, el tamaño de MRRU es de 1500 bytes y puede configurarlo para que sea de 1500 a 4500 bytes. Para obtener más información, consulte Configurar MRRU en interfaces lógicas de multivínculo y servicios de vínculo.
Cuando se elimina un paquete de una cola encapsulada multivínculo, el software le da al paquete un encabezado FRF.12. El encabezado FRF.12 contiene un campo de número de secuencia, que se rellena con el siguiente número de secuencia disponible de un contador. Luego, el software coloca el paquete en el vínculo T1 fraccionario. El tráfico de otra cola puede intercalarse entre dos fragmentos del paquete.
Cuando se elimina un paquete de una cola no encapsulada, se transmite con un encabezado Frame Relay sin formato. Luego, el paquete se coloca en el vínculo T1 fraccionado lo antes posible. Si es necesario, el paquete se coloca entre los fragmentos de un paquete de otra cola.
La interfaz T1 fraccionada se vincula a otro enrutador, que puede ser de Juniper Networks u otro proveedor. El enrutador en el otro extremo recopila paquetes del vínculo T1 fraccionado. Si un paquete tiene un encabezado FRF.12, el software asume que el paquete es un fragmento de un paquete más grande y el campo de número de fragmento se utiliza para volver a ensamblar el paquete más grande. Si el paquete tiene un encabezado Frame Relay sin formato, el software acepta el paquete en el orden en que llega y el software no intenta volver a ensamblar o reordenar el paquete.
Un paquete completo de una cola no encapsulada se puede colocar entre fragmentos de una cola encapsulada multivínculo. Sin embargo, los fragmentos de una cola encapsulada multivínculo no se pueden intercalar con fragmentos de otra cola encapsulada multivínculo. Esta es la intención de la especificación FRF.12, Acuerdo de implementación de fragmentación de Frame Relay. Si se intercalaron fragmentos de dos colas diferentes, es posible que los campos de encabezado no tengan suficiente información para separarlos.
Ejemplos: Configuración de una interfaz LSQ para una interfaz T1 fraccionaria mediante FRF.12
FRF.12 con fragmentación y sin LFI
En este ejemplo, se muestra una interfaz DS0 de 128 KB. Hay un flujo de tráfico en ge-0/0/0, que se clasifica en la cola 0 (be). Los paquetes se fragmentan en la interfaz IQ () de servicios de vínculo segúnlsq- el umbral configurado en el mapa de fragmentación.
[edit chassis]
fpc 0 {
pic 3 {
adaptive-services {
service-package layer-2;
}
}
}
[edit interfaces]
ge-0/0/0 {
unit 0 {
family inet {
address 20.1.1.1/24 {
arp 20.1.1.2 mac 00.00.5e.00.53.56;
}
}
}
}
ce1-0/2/0 {
partition 1 timeslots 1-2 interface-type ds;
}
ds-0/2/0:1 {
no-keepalives;
dce;
encapsulation frame-relay;
unit 0 {
dlci 100;
family mlfr-end-to-end {
bundle lsq-0/3/0.0;
}
}
}
lsq-0/3/0 {
per-unit-scheduler;
unit 0 {
encapsulation multilink-frame-relay-end-to-end;
family inet {
address 10.200.0.78/30;
}
}
}
fxp0 {
unit 0 {
family inet {
address 172.16.1.162/24;
}
}
}
lo0 {
unit 0 {
family inet {
address 10.0.0.1/32;
}
}
}
[edit class-of-service]
forwarding-classes {
queue 0 be;
queue 1 ef;
queue 2 af;
queue 3 nc;
}
interfaces {
lsq-0/3/0 {
unit 0 {
fragmentation-map map1;
}
}
}
fragmentation-maps {
map1 {
forwarding-class {
be {
fragment-threshold 160;
}
}
}
}
FRF.12 con fragmentación y LFI
En este ejemplo, se muestra un paquete DS0 de 512 KB y cuatro flujos de tráfico que ge-0/0/0 se clasifican en cuatro colas. El tamaño del fragmento es 160 para las colas 0, 1 y 2. La secuencia de voz en la cola 3 tiene LFI configurada.
[edit chassis]
fpc 0 {
pic 3 {
adaptive-services {
service-package layer-2;
}
}
}
[edit interfaces]
ge-0/0/0 {
unit 0 {
family inet {
address 20.1.1.1/24 {
arp 20.1.1.2 mac 00.00.5e.00.53.56;
}
}
}
ce1-0/2/0 {
partition 1 timeslots 1-8 interface-type ds;
}
ds-0/2/0:1 {
no-keepalives;
dce;
encapsulation frame-relay;
unit 0 {
dlci 100;
family mlfr-end-to-end {
bundle lsq-0/3/0.0;
}
}
}
lsq-0/3/0 {
per-unit-scheduler;
unit 0 {
encapsulation multilink-frame-relay-end-to-end;
family inet {
address 10.200.0.78/30;
}
}
}
[edit class-of-service]
classifiers {
inet-precedence ge-interface-classifier {
forwarding-class be {
loss-priority low code-points 000;
}
forwarding-class ef {
loss-priority low code-points 010;
}
forwarding-class af {
loss-priority low code-points 100;
}
forwarding-class nc {
loss-priority low code-points 110;
}
}
}
forwarding-classes {
queue 0 be;
queue 1 ef;
queue 2 af;
queue 3 nc;
}
interfaces {
lsq-0/3/0 {
unit 0 {
scheduler-map sched2;
fragmentation-map map2;
}
}
ds-0/2/0:1 {
scheduler-map link-map2;
}
ge-0/0/0 {
unit 0 {
classifiers {
inet-precedence ge-interface-classifier;
}
}
}
}
scheduler-maps {
sched2 {
forwarding-class be scheduler economy;
forwarding-class ef scheduler business;
forwarding-class af scheduler stream;
forwarding-class nc scheduler voice;
}
link-map2 {
forwarding-class be scheduler link-economy;
forwarding-class ef scheduler link-business;
forwarding-class af scheduler link-stream;
forwarding-class nc scheduler link-voice;
}
}
fragmentation-maps {
map2 {
forwarding-class {
be {
fragment-threshold 160;
}
ef {
fragment-threshold 160;
}
af {
fragment-threshold 160;
}
nc {
no-fragmentation;
}
}
}
schedulers {
economy {
transmit-rate percent 26;
buffer-size percent 26;
}
business {
transmit-rate percent 26;
buffer-size percent 26;
}
stream {
transmit-rate percent 35;
buffer-size percent 35;
}
voice {
transmit-rate percent 13;
buffer-size percent 13;
}
link-economy {
transmit-rate percent 26;
buffer-size percent 26;
}
link-business {
transmit-rate percent 26;
buffer-size percent 26;
}
link-stream {
transmit-rate percent 35;
buffer-size percent 35;
}
link-voice {
transmit-rate percent 13;
buffer-size percent 13;
}
}
}
}
Ver también
Configuración de interfaces LSQ para vínculos T3 configurados para RTP comprimido a través de MLPPP
En este ejemplo, se agrupa una sola interfaz T3 en una interfaz IQ de servicios de vínculo con encapsulación MLPPP. Enlazar una sola interfaz T3 a un paquete de multivínculo le permite configurar el RTP comprimido (CRTP) en la interfaz T3.
Este escenario solo se aplica a los paquetes MLPPP. Actualmente, Junos OS no admite CRTP a través de Frame Relay. Para obtener más información, consulte Configurar interfaces de servicios para servicios de voz.
No es necesario configurar LFI a velocidades DS3, ya que el retraso de serialización de paquetes es insignificante.
[edit interfaces]
t3-0/0/0 {
unit 0 {
family mlppp {
bundle lsq-1/3/0.1;
}
}
}
lsq-1/3/0.1 {
encapsulation multilink-ppp;
}
compression {
rtp {
# cRTP parameters go here
#
port minimum 2000 maximum 64009;
}
}
Esta configuración utiliza una asignación de fragmentación predeterminada, lo que da como resultado que todas las clases de reenvío (colas) se envíen con un encabezado multivínculo.
Para eliminar los encabezados multivínculo, puede configurar una asignación de fragmentación en la que todas las colas tengan la no-fragmentation instrucción en el nivel de [edit class-of-service fragmentation-maps map-name forwarding-class class-name] jerarquía y adjuntar la asignación de fragmentación a la lsq-1/3/0.1 interfaz, como se muestra a continuación:
[edit class-of-service]
fragmentation-maps {
fragmap {
forwarding-class {
be {
no-fragmentation;
}
af {
no-fragmentation;
}
ef {
no-fragmentation;
}
nc {
no-fragmentation;
}
}
}
}
interfaces {
lsq-1/3/0.1 {
fragmentation-map fragmap;
}
}
Ver también
Configuración de interfaces LSQ como paquetes T3 u OC3 mediante FRF.12
En este ejemplo, se configura una interfaz T3 u OC3 de canal sin cifrar con varias interfaces lógicas (DLCI) en el vínculo. En este escenario, cada DLCI representa a un cliente. Los DLCI se forman en la PIC de salida a una velocidad determinada (NxDS0). Esto le permite configurar LFI mediante el protocolo de extremo a extremo FRF.12 en DLCI de Frame Relay.
Para ello, configure primero las interfaces lógicas (DLCI) en la interfaz física. A continuación, agrupe los DLCI para que solo haya un DLCI por paquete.
La interfaz física debe ser capaz de programar por DLCI, lo que le permite asociar velocidades de modelación a cada DLCI. Para obtener más información, consulte la biblioteca de interfaces de red de Junos OS para dispositivos de enrutamiento.
Para evitar caídas de fragmentos en la PIC de salida, debe asignar una velocidad de modelación a las interfaces lógicas IQ de servicios de vínculo y a los DLCI de salida. Las velocidades de modelación en DLCI especifican cuánto ancho de banda está disponible para cada DLCI. La velocidad de modelación en interfaces IQ de servicios de vínculo debe coincidir con la velocidad de modelación asignada al DLCI asociado con el paquete.
Las interfaces de salida también deben tener una asignación de programador asociada. La cola que transporta la voz debe ser de prioridad alta estricta, mientras que todas las demás colas deben ser de prioridad baja. Esto hace posible LFI.
En este ejemplo, se muestra el tráfico de voz en la ef cola. El tráfico de voz se intercala con datos masivos. Alternativamente, puede usar MLPPP multiclase para transportar varias clases de tráfico en diferentes clases de multivínculo.
[edit interfaces]
t3-0/0/0 {
per-unit-scheduler;
encapsulation frame-relay;
unit 0 {
dlci 69;
family mlfr-end-to-end {
bundle lsq-1/3/0.0;
}
}
unit 1 {
dlci 42;
family mlfr-end-to-end {
bundle lsq-1/3/0.1;
}
}
}
lsq-1/3/0 {
unit 0 {
encapsulation multilink-frame-relay-end-to-end;
}
fragment-threshold 320; # Multilink packets must be fragmented
}
unit 1 {
encapsulation multilink-frame-relay-end-to-end;
}
fragment-threshold 160;
[edit class-of-service]
scheduler-maps {
sched { # Scheduling parameters that apply to bundles on AS or Multiservices PICs.
...
}
pic-sched {
# Scheduling parameters for egress DLCIs.
# The voice queue should be strict-high priority.
# All other queues should be low priority.
...
}
fragmentation-maps {
fragmap {
forwarding-class {
ef {
no-fragmentation;
}
# Voice is carried in the ef queue.
# It is interleaved with bulk data.
}
}
}
interfaces {
t3-0/0/0 {
unit 0 {
shaping-rate 512k;
scheduler-map pic-sched;
}
unit 1 {
shaping-rate 128k;
scheduler-map pic-sched;
}
}
lsq-1/3/0 { # Assign fragmentation and scheduling to LSQ interfaces.
unit 0 {
shaping-rate 512k;
scheduler-map sched;
fragmentation-map fragmap;
}
unit 1 {
shaping-rate 128k;
scheduler-map sched;
fragmentation-map fragmap;
}
}
Para obtener más información sobre cómo FRF.12 funciona con interfaces IQ de servicios de vínculos, consulte Configuración de interfaces LSQ para interfaces T1 o E1 fraccionarias simples mediante FRF.12.
Ver también
Configuración de interfaces LSQ para interfaces IQ ATM2 mediante MLPPP
En este ejemplo, se configura una interfaz IQ ATM2 con MLPPP incluido con interfaces IQ de servicios de vínculo. Esto le permite configurar LFI en circuitos virtuales ATM.
Para este tipo de configuración, la interfaz IQ ATM2 debe tener encapsulación LLC.
En este caso, se admiten las siguientes PIC ATM:
IQ ATM2 OC-3/STM1 de 2 puertos
DS3 ATM2 IQ de 4 puertos
No se admite PPP multiplexado por circuito virtual mediante AAL5. No se admite Frame Relay. No se admite la agrupación de varios VC ATM en una sola interfaz lógica.
A diferencia de las interfaces DS3 y OC3, no es necesario crear una asignación de programador independiente para la PIC ATM. Para ATM, los componentes de CoS se definen en el nivel jerárquico [edit interfaces at-fpc/pic/port atm-options] , tal y como se describe en la biblioteca de interfaces de red de Junos OS para dispositivos de enrutamiento.
No configure perfiles RED en interfaces lógicas ATM que estén agrupadas. No se producen caídas en la interfaz ATM.
En este ejemplo, se configuran dos VC ATM y se agrupan en dos paquetes IQ de servicios de vínculo. Un mapa de fragmentación se utiliza para intercalar el tráfico de voz con otro tráfico de multivínculo. Dado que se usa MLPPP, cada paquete de IQ de servicios de vínculo se puede configurar para CRTP.
[edit interfaces]
at-1/2/0 {
atm-options {
vpi 0;
pic-type atm2;
}
unit 0 {
vci 0.69;
encapsulation atm-mlppp-llc;
family mlppp {
bundle lsq-1/3/0.10;
}
}
unit 1 {
vci 0.42;
encapsulation atm-mlppp-llc;
family mlppp {
bundle lsq-1/3/0.11;
}
}
}
lsq-1/3/0 {
unit 10 {
encapsulation multilink-ppp;
}
# Large packets must be fragmented.
# You can specify fragmentation for each forwarding class.
fragment-threshold 320;
compression {
rtp {
port minimum 2000 maximum 64009;
}
}
}
unit 11 {
encapsulation multilink-ppp;
}
fragment-threshold 160;
[edit class-of-service]
scheduler-maps {
sched { # Scheduling parameters that apply to LSQ bundles on AS or Multiservices PICs.
...
}
fragmentation-maps {
fragmap {
forwarding-class {
ef {
no-fragmentation;
}
}
}
}
interfaces { # Assign fragmentation and scheduling parameters to LSQ interfaces.
lsq-1/3/0 {
unit 0 {
shaping-rate 512k;
scheduler-map sched;
fragmentation-map fragmap;
}
unit 1 {
shaping-rate 128k;
scheduler-map sched;
fragmentation-map fragmap;
}
}
Ver también
Tabla de historial de cambios
La compatibilidad de la función depende de la plataforma y la versión que utilice. Utilice el Explorador de características para determinar si una característica es compatible con su plataforma.