EN ESTA PÁGINA
Descripción del procesamiento del tráfico en dispositivos de seguridad
Descripción del comportamiento de procesamiento predeterminado para el tráfico IPv4
Descripción del procesamiento de tráfico en dispositivos SRX210 y SRX320
Descripción del procesamiento del tráfico en dispositivos de línea SRX3000 y SRX1400
Descripción del procesamiento del tráfico en dispositivos SRX4600
Descripción del procesamiento del tráfico en dispositivos de línea SRX5000
Descripción del procesamiento de flujo en dispositivos SRX5K-SPC3
Descripción general del procesamiento de tráfico en los firewalls de la serie SRX
Junos OS para dispositivos de seguridad integra las capacidades de seguridad de red y enrutamiento de Juniper Networks. Los paquetes que entran y salen de un dispositivo se someten a un procesamiento basado en paquetes y en flujos.
Descripción del procesamiento del tráfico en dispositivos de seguridad
Junos OS para dispositivos de seguridad integra las capacidades de enrutamiento y seguridad de red de primera clase de Juniper Networks. Junos OS incluye una amplia gama de filtros basados en paquetes, clasificadores de clase de servicio (CoS) y funciones de modelado de tráfico, así como un amplio y completo conjunto de funciones de seguridad basadas en flujos que incluyen políticas, pantallas, traducción de direcciones de red (NAT) y otros servicios basados en flujos.
El tráfico que entra y sale de un dispositivo de seguridad se procesa de acuerdo con las características que configure, como filtros de paquetes, políticas de seguridad y pantallas. Por ejemplo, el software puede determinar:
Si el paquete está permitido en el dispositivo
Qué pantallas de firewall aplicar al paquete
La ruta que toma el paquete para llegar a su destino
Qué CoS aplicar al paquete, si lo hubiera.
Si se debe aplicar NAT para traducir la dirección IP del paquete
Si el paquete requiere una puerta de enlace de capa de aplicación (ALG)
Los paquetes que entran y salen de un dispositivo se someten a un procesamiento basado en paquetes y en flujos:
El procesamiento de paquetes basado en flujos trata los paquetes relacionados, o una secuencia de paquetes, de la misma manera. El tratamiento de paquetes depende de las características que se establecieron para el primer paquete de la secuencia de paquetes, que se conoce como flujo.
Para la arquitectura de procesamiento distribuido de la puerta de enlace de servicios, todo el procesamiento basado en flujos se produce en la SPU y el muestreo es compatible con varios subprocesos. La secuenciación de paquetes se mantiene para los paquetes muestreados.
El procesamiento de paquetes basado en paquetes, o sin estado, trata los paquetes discretamente. Cada paquete se evalúa individualmente para el tratamiento.
Para la arquitectura de procesamiento distribuido de la puerta de enlace de servicios, parte del procesamiento basado en paquetes, como la formación del tráfico, se produce en la NPU. Parte del procesamiento basado en paquetes, como la aplicación de clasificadores a un paquete, se produce en la SPU.
En este tema se incluyen las siguientes secciones:
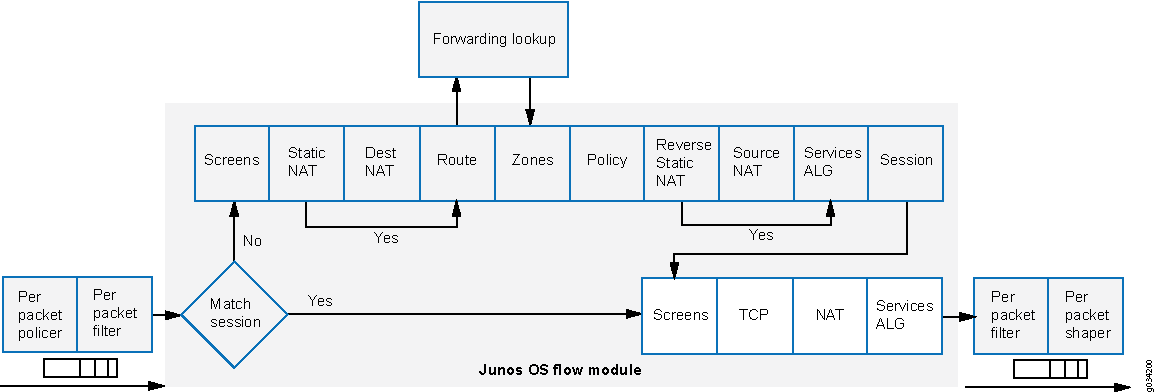
Descripción del procesamiento basado en flujos
Un paquete se somete a un procesamiento basado en flujo después de que se le han aplicado filtros basados en paquetes y se le han aplicado algunas pantallas. Todo el procesamiento basado en flujo para un solo flujo se produce en una sola unidad de procesamiento de servicios (SPU). Una SPU procesa los paquetes de un flujo de acuerdo con las características de seguridad y otros servicios configurados para la sesión.
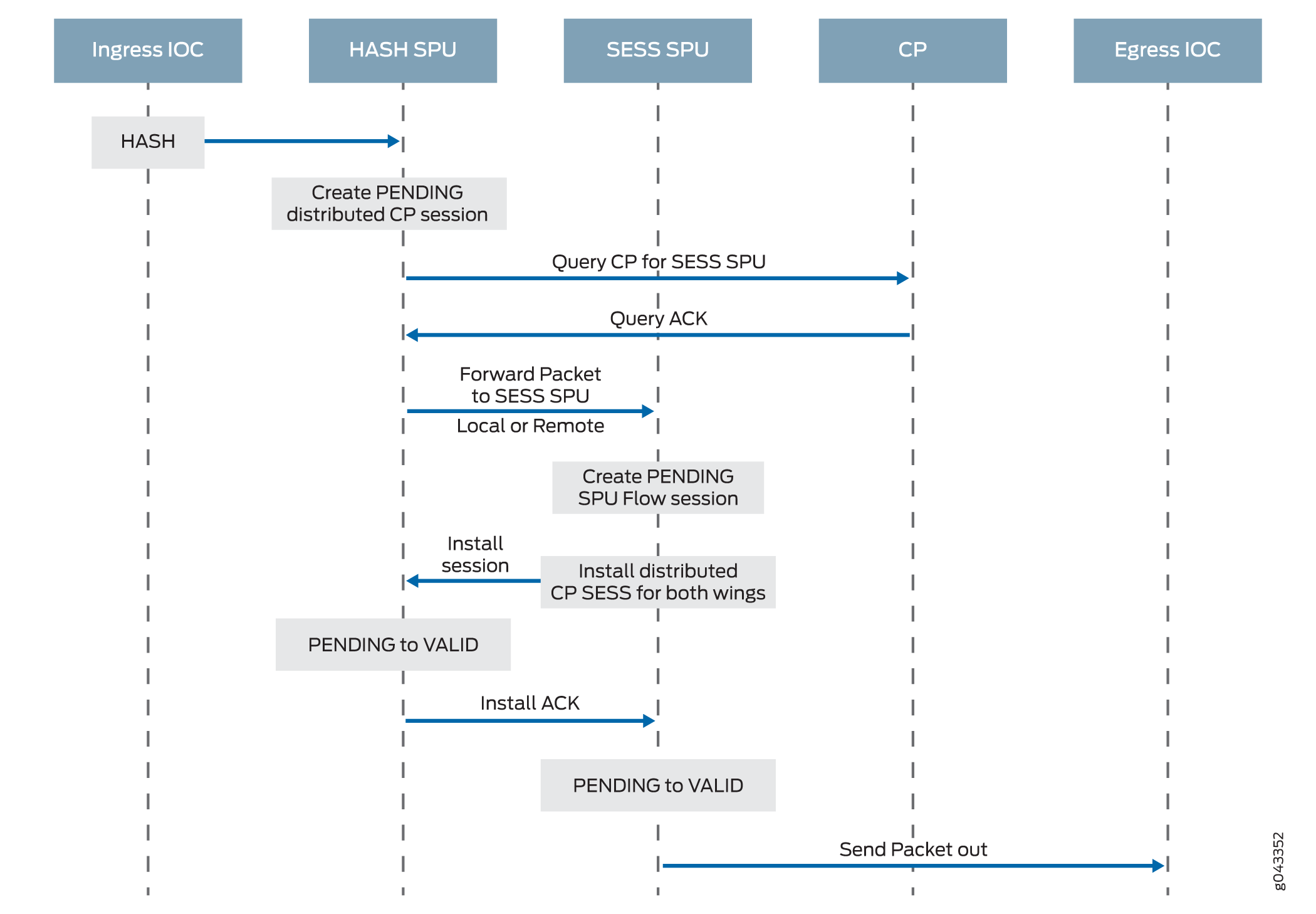
En la figura 1 se muestra una vista conceptual de cómo se produce el procesamiento del tráfico basado en flujos en la puerta de enlace de servicios.
 basado en flujos
basado en flujos
Un flujo es una secuencia de paquetes relacionados que cumplen los mismos criterios de coincidencia y comparten las mismas características. Junos OS trata los paquetes que pertenecen al mismo flujo de la misma manera.
Los valores de configuración que determinan el destino de un paquete, como la política de seguridad que se le aplica, si requiere una puerta de enlace de capa de aplicación (ALG), si se aplica NAT para traducir la dirección IP de origen o destino del paquete, se evalúan para el primer paquete de un flujo.
Para determinar si existe un flujo para un paquete, la NPU intenta hacer coincidir la información del paquete con la de una sesión existente según los siguientes criterios de coincidencia:
Dirección de origen
Dirección de destino
Puerto de origen
Puerto de destino
Protocolo
Número de token de sesión único para una zona y un enrutador virtual determinados
Zonas y políticas
La política de seguridad que se va a usar para el primer paquete de un flujo se almacena en caché en una tabla de flujo para su uso con el mismo flujo y flujos estrechamente relacionados. Las políticas de seguridad están asociadas a zonas. Una zona es una colección de interfaces que definen un límite de seguridad. La zona entrante de un paquete, determinada por la interfaz a través de la cual llegó, y su zona de salida, según lo determinado por la búsqueda de reenvío, determinan conjuntamente qué política se usa para los paquetes del flujo.
Flujos y sesiones
El procesamiento de paquetes basado en flujos, que tiene estado, requiere la creación de sesiones. Se crea una sesión para el primer paquete de un flujo con los siguientes propósitos:
Almacenar la mayoría de las medidas de seguridad a aplicar a los paquetes del flujo.
Para almacenar en caché información sobre el estado del flujo.
Por ejemplo, la información de registro y recuento de un flujo se almacena en caché en su sesión. (Algunas pantallas de firewall con estado se basan en valores de umbral que pertenecen a sesiones individuales o a todas las sesiones).
Para asignar los recursos necesarios para el flujo de características como NAT.
Proporcionar un marco para características como ALG y características de firewall.
La mayor parte del procesamiento de paquetes se produce en el contexto de un flujo, lo que incluye:
Gestión de políticas, NAT, zonas y la mayoría de las pantallas.
Gestión de ALG y autenticación.
Descripción del procesamiento basado en paquetes
Un paquete se somete a un procesamiento basado en paquetes cuando se quita de la cola en su interfaz de entrada y antes de agregarse a la cola en su interfaz de salida.
El procesamiento basado en paquetes aplica filtros de firewall sin estado, funciones de CoS y algunas pantallas a paquetes discretos.
Cuando un paquete llega a una interfaz, se le aplican comprobaciones de cordura, filtros basados en paquetes, algunas funciones de CoS y algunas pantallas.
Antes de que un paquete salga del dispositivo, se aplican al paquete todos los filtros basados en paquetes, algunas funciones de CoS y algunas pantallas asociadas con la interfaz.
Los filtros y las características de CoS suelen asociarse con una o más interfaces para influir en qué paquetes pueden transitar por el sistema y para aplicar acciones especiales a los paquetes según sea necesario.
En los temas siguientes se describen los tipos de características basadas en paquetes que puede configurar y aplicar al tráfico de tránsito.
Filtros de firewall sin estado
También conocidos como listas de control de acceso (ACL), los filtros de firewall sin estado controlan el acceso y limitan las tasas de tráfico. Evalúan estáticamente el contenido de los paquetes que transitan por el dispositivo desde un origen a un destino, o de los paquetes que se originan en el motor de enrutamiento o están destinados a él. Un filtro de firewall sin estado evalúa cada paquete, incluidos los paquetes fragmentados.
Puede aplicar un filtro de firewall sin estado a una interfaz de entrada o salida, o a ambas. Un filtro contiene uno o más términos, y cada término consta de dos componentes: condiciones de coincidencia y acciones. De forma predeterminada, se descarta un paquete que no coincida con un filtro de firewall.
Puede planear y diseñar filtros de firewall sin estado para utilizarlos con diversos fines, por ejemplo, para limitar el tráfico a determinados protocolos, direcciones IP de origen o destino o velocidades de datos. Los filtros de firewall sin estado se ejecutan en la NPU.
Características de clase de servicio
Las características de CoS le permiten clasificar y dar forma al tráfico. Las características de CoS se ejecutan en la NPU.
Clasificadores de agregado de comportamiento (BA): estos clasificadores funcionan en paquetes a medida que ingresan al dispositivo. Mediante el uso de clasificadores de agregados de comportamiento, el dispositivo agrega diferentes tipos de tráfico en una sola clase de reenvío para recibir el mismo tratamiento de reenvío. Los clasificadores de BA permiten establecer la clase de reenvío y la prioridad de pérdida de un paquete en función del valor Servicio diferenciado (DiffServ).
Modelado del tráfico: puede dar forma al tráfico asignando niveles de servicio con diferentes características de retraso, fluctuación y pérdida de paquetes a aplicaciones particulares atendidas por flujos de tráfico específicos. El modelado de tráfico es especialmente útil para aplicaciones en tiempo real, como la transmisión de voz y video.
Pantallas
Algunas pantallas, como las pantallas de denegación de servicio (DoS), se aplican a un paquete fuera del proceso de flujo. Se ejecutan en la Unidad de Procesamiento de Red (NPU).
Descripción del comportamiento de procesamiento predeterminado para el tráfico IPv4
El modo de procesamiento basado en flujos es necesario para que funcionen características de seguridad como zonas, pantallas y políticas de firewall. De forma predeterminada, el firewall de la serie SRX está habilitado para el reenvío basado en flujos para el tráfico IPv4 en todos los dispositivos, excepto en la serie SRX300 y SRX550M dispositivos que están configurados en modo de caída. A partir de Junos OS versión 15.1X49-D70 y Junos OS versión 17.3R1, para los dispositivos serie SRX1500, SRX4100, SRX4200, SRX5400, SRX5600, SRX5800 y vSRX Virtual Firewall, no es necesario reiniciar el dispositivo cuando cambie los modos entre el modo de flujo, el modo de paquete y el modo de entrega. En el caso de los dispositivos serie SRX300 y SRX550M, debe reiniciar el dispositivo al cambiar entre el modo de flujo, el modo de paquetes y el modo de entrega.
SRX300 Series and SRX550M
Para la serie SRX300 y los dispositivos SRX550M, el modo de procesamiento predeterminado se establece en modo de caída debido a limitaciones de memoria. En este caso, debe reiniciar el dispositivo después de cambiar el modo de procesamiento del modo de colocación predeterminado al modo de procesamiento basado en flujo o al modo de procesamiento basado en paquetes, es decir, entre modos en estos dispositivos.
Para el procesamiento del modo de caída, el tráfico se deja caer directamente, no se reenvía. Difiere del procesamiento en modo de paquete para el que se maneja el tráfico pero no se aplican procesos de seguridad.
Configuring an SRX Series Device as a Border Router
Cuando un firewall de la serie SRX de cualquier tipo está habilitado para el procesamiento basado en flujo o el modo de entrega, para configurar el dispositivo como un enrutador de borde debe cambiar el modo a procesamiento basado en paquetes para MPLS. En este caso, para configurar el firewall de la serie SRX en modo de paquete para MPLS, utilice la set security forwarding-options family mpls mode packet-based instrucción.
Como se mencionó anteriormente, para la serie SRX300 y los dispositivos SRX550M, cada vez que cambie los modos de procesamiento, debe reiniciar el dispositivo.
Descripción del procesamiento de tráfico en dispositivos SRX210 y SRX320
En este tema se describe el proceso que llevan a cabo las puertas de enlace de servicios SRX210 y SRX320 para establecer una sesión para paquetes que pertenecen a un flujo que transita por el dispositivo. Los servicios de flujo de los dispositivos SRX210 y SRX320 son de un solo subproceso y no distribuidos. Aunque difieren de los otros firewalls de la serie SRX en este sentido, se sigue el mismo modelo de flujo y se implementa la misma interfaz de línea de comandos (CLI).
Para ilustrar el establecimiento de la sesión y el "paseo" de paquetes, incluidos los puntos en los que se aplican los servicios a los paquetes de un flujo, el ejemplo descrito en las secciones siguientes utiliza el caso simple de una sesión de unidifusión:
- Descripción del procesamiento de flujos y la gestión de sesiones
- Descripción del procesamiento del primer paquete
- Descripción de la creación de sesiones
- Descripción del procesamiento de ruta rápida
Descripción del procesamiento de flujos y la gestión de sesiones
En este tema se explica cómo se configura una sesión para procesar los paquetes que componen un flujo. En el tema siguiente, la SPU hace referencia al subproceso del plano de datos del firewall SRX210 o SRX320.
Al principio, el subproceso del plano de datos recupera el paquete y realiza comprobaciones básicas de cordura en él. Luego procesa el paquete para filtros sin estado y clasificadores CoS y aplica algunas pantallas.
Descripción del procesamiento del primer paquete
Para determinar si un paquete pertenece a un flujo existente, el dispositivo intenta hacer coincidir la información del paquete con la de una sesión existente según los siguientes seis criterios de coincidencia:
Dirección de origen
Dirección de destino
Puerto de origen
Puerto de destino
Protocolo
Token único de una zona determinada y enrutador virtual
La SPU comprueba en su tabla de sesión si hay una sesión existente para el paquete. Si no se encuentra ninguna sesión existente, la SPU configura una sesión para el flujo. Si se encuentra una coincidencia de sesión, la sesión ya se ha creado, por lo que la SPU realiza un procesamiento de ruta rápida en el paquete.
Descripción de la creación de sesiones
Al configurar la sesión, la SPU ejecuta los siguientes servicios para el paquete:
Pantallas
Búsqueda de rutas
Búsqueda de políticas
Búsqueda de servicio
NAT, si es necesario
Después de configurar una sesión, se utiliza para todos los paquetes que pertenecen al flujo. Los paquetes de un flujo se procesan de acuerdo con los parámetros de su sesión. Para el resto de los pasos relacionados con el procesamiento de paquetes, continúe con el paso 1 en "Procesamiento de ruta rápida". Todos los paquetes se someten a un procesamiento de ruta rápida.
Descripción del procesamiento de ruta rápida
Si un paquete coincide con una sesión, Junos OS realiza un procesamiento de ruta rápida como se describe en los pasos siguientes. Después de que se ha configurado una sesión para el primer paquete de un flujo, también se somete a un procesamiento de ruta rápida. Todos los paquetes se someten a un procesamiento de ruta rápida.
La SPU aplica características de seguridad basadas en flujos al paquete.
Se aplican las pantallas configuradas.
Se realizan comprobaciones TCP.
Se aplican servicios de flujo, como NAT, ALG e IPsec, si es necesario.
La SPU prepara el paquete para su reenvío y lo transmite.
Se aplican filtros de paquetes de enrutamiento.
Se aplica la formación de tráfico.
Se aplica la priorización de tráfico.
Se aplica la programación de tráfico.
El paquete se transmite.
Descripción del procesamiento del tráfico en dispositivos de línea SRX3000 y SRX1400
Junos OS para las puertas de enlace de servicios SRX1400, SRX3400 y SRX3600 integra las capacidades de enrutamiento y seguridad de red de clase mundial de las redes de Juniper. Junos OS para estas puertas de enlace de servicio incluye una amplia gama de servicios de seguridad, como políticas, pantallas, traducción de direcciones de red, clasificadores de clase de servicio y el amplio y completo conjunto de servicios basados en flujos que también son compatibles con los demás dispositivos de las puertas de enlace de servicios.
La arquitectura de procesamiento paralelo distribuido de los dispositivos SRX1400, SRX3400 y SRX3600 incluye varios procesadores para administrar sesiones y ejecutar procesamiento de seguridad y otros servicios. Esta arquitectura proporciona una mayor flexibilidad y permite un alto rendimiento y un rendimiento rápido.
En las secciones siguientes se describe la arquitectura de procesamiento utilizando dispositivos SRX3400 y SRX3600 como ejemplo:
En este tema se incluye la siguiente información:
- Componentes involucrados en la configuración de una sesión
- Descripción de la ruta de datos para sesiones de unidifusión
- Búsqueda de sesión y criterios de coincidencia de paquetes
- Descripción de la creación de sesiones: primer procesamiento de paquetes
- Descripción del procesamiento de ruta rápida
Componentes involucrados en la configuración de una sesión
Aquí hay una descripción general de los principales componentes involucrados en la configuración de una sesión para un paquete y el procesamiento de los paquetes a medida que transitan por los dispositivos SRX3400 y SRX3600:
Unidades de procesamiento de servicios (SPU): los procesadores principales de los dispositivos SRX3400 y SRX3600 residen en tarjetas de procesamiento de servicios (SPC). Establecen y administran flujos de tráfico y realizan la mayor parte del procesamiento de paquetes en un paquete a medida que transita por el dispositivo. Cada SPU mantiene una tabla hash para una búsqueda rápida de sesiones. La SPU realiza todo el procesamiento basado en flujos para un paquete, incluida la aplicación de servicios de seguridad, clasificadores y moldeadores de tráfico. Todos los paquetes que pertenecen al mismo flujo son procesados por la misma SPU.
La SPU mantiene una tabla de sesión con entradas para todas las sesiones que estableció y cuyos paquetes procesa. Cuando una SPU recibe un paquete de una NPU, comprueba su tabla de sesión para asegurarse de que el paquete le pertenece.
Para dispositivos SRX3400 y SRX3600, una SPU actúa en concierto realizando sus funciones regulares de gestión de sesiones y procesamiento de flujo y actuando como un punto central en el que arbitra sesiones y asigna recursos. Cuando una SPU funciona de esta manera, se dice que está en modo combinado.
Punto central: el punto central se utiliza para asignar la administración de sesiones a las SPU según criterios de equilibrio de carga. Distribuye las sesiones de forma inteligente para evitar que ocurran varias SPU que puedan manejar erróneamente el mismo flujo. El punto central sigue los criterios de equilibrio de carga en la asignación de sesiones a SPU. Si la sesión existe, el punto central reenvía los paquetes de ese flujo a la SPU que lo aloja. También redirige los paquetes a la SPU correcta en caso de que la NPU no lo haga.
Para los dispositivos SRX3400 y SRX3600, una SPU siempre se ejecuta en lo que se conoce como modo combinado en el que implementa tanto la funcionalidad del punto central como la funcionalidad de administración de flujo y sesión. En el modo combinado, la SPU y el punto central comparten la misma infraestructura de subproceso de equilibrio de carga (LBT) y subproceso de pedido de paquetes (POT). .
Motor de enrutamiento (RE): el motor de enrutamiento ejecuta el plano de control y administra el procesador del plano de control (CPP).
Descripción de la ruta de datos para sesiones de unidifusión
Junos OS para las puertas de enlace de servicios SRX3400 y SRX3600 es un sistema distribuido de procesamiento paralelo, alto rendimiento y alto rendimiento. En este tema se describe el proceso de establecer una sesión para paquetes que pertenecen a un flujo que transita por el dispositivo.
Para ilustrar el establecimiento de una sesión y el "paseo" de paquetes, incluidos los puntos en los que se aplican los servicios a los paquetes de un flujo, en el ejemplo siguiente se utiliza el caso simple de una sesión de unidifusión. Este "paseo" de paquetes reúne el procesamiento basado en paquetes y el procesamiento basado en flujos que Junos OS realiza en el paquete.
Búsqueda de sesión y criterios de coincidencia de paquetes
Para determinar si un paquete pertenece a un flujo existente, el dispositivo intenta hacer coincidir la información del paquete con la de una sesión existente según los siguientes seis criterios de coincidencia:
Dirección de origen
Dirección de destino
Puerto de origen
Puerto de destino
Protocolo
Token único de una zona determinada y enrutador virtual
Descripción de la creación de sesiones: primer procesamiento de paquetes
En este tema se explica cómo se configura una sesión para procesar los paquetes que componen un flujo. Para ilustrar el proceso, este tema utiliza un ejemplo con una fuente "a" y un destino "b". La dirección desde el origen hasta el destino de los paquetes del flujo se denomina (a -> b). La dirección desde el destino hasta el origen se denomina (b -> a).
Un paquete llega a una interfaz en el dispositivo y el COI lo procesa.
El COI elimina la cola del paquete y lo envía a la NPU con la que se comunica.
La NPU recibe el paquete del COI y lo procesa.
La NPU realiza comprobaciones básicas de cordura en el paquete y aplica algunas pantallas configuradas para la interfaz al paquete.
Si se encuentra una coincidencia de sesión, la sesión ya se ha creado en una SPU que se le asignó, por lo que la NPU reenvía el paquete a la SPU para su procesamiento junto con el ID de sesión.
Ejemplo: El paquete (a ->b) llega a NPU1 desde IOC1. NPU1 realiza comprobaciones de cordura y aplica pantallas DoS al paquete. NPU1 comprueba su tabla de sesión en busca de una coincidencia de tupla y no se encuentra ninguna sesión existente. NPU1 reenvía el paquete al punto central de SPU1 para su asignación a una SPU.
El punto central crea una sesión con un estado "Pendiente".
El punto central mantiene una tabla de sesión global que incluye entradas para todas las sesiones que existen en todas las SPU del dispositivo. Participa en la creación de sesiones y delega y arbitra la asignación de recursos de sesión.
Este proceso consta de las siguientes partes:
El punto central comprueba la tabla de sesión y la tabla de puerta para determinar si existe una sesión o una puerta para el paquete que recibe de la NPU. (Una NPU ha reenviado un paquete al punto central porque su tabla indica que no hay sesión para él. El punto central verifica esta información antes de asignar una SPU para la sesión.)
Si no hay ninguna entrada que coincida con el paquete en ninguna de las tablas, el punto central crea un ala pendiente para la sesión y selecciona una SPU que se utilizará para la sesión, en función de su algoritmo de equilibrio de carga.
El punto central reenvía el primer paquete del flujo a la SPU seleccionada en un mensaje que le indica que configure una sesión local para utilizarla en el flujo de paquetes.
Ejemplo: El punto central crea un ala pendiente (a ->b) para la sesión. Selecciona SPU1 que se utilizará para la sesión. Envía a SPU1 el paquete (a->b) junto con un mensaje para crear una sesión para él. (Resulta que SPU1 es la SPU que se ejecuta en modo combinado. Por lo tanto, sus servicios de administración de sesión y procesamiento de flujo se utilizan para la sesión.
La SPU configura la sesión.
Cada SPU también tiene una tabla de sesión, que contiene información sobre sus sesiones. Cuando la SPU recibe un mensaje desde el punto central para configurar una sesión, comprueba su tabla de sesión para asegurarse de que no existe ya una sesión para el paquete.
Si no hay ninguna sesión existente para el paquete, la SPU configura la sesión localmente.
La SPU envía un mensaje al punto central, diciéndole que instale la sesión.
Durante el procesamiento del primer paquete, si NAT está habilitada, la SPU asigna recursos de dirección IP para NAT. En este caso, el procesamiento del primer paquete para la sesión se suspende hasta que se complete el proceso de asignación de NAT.
La SPU agrega a la cola cualquier paquete adicional para el flujo que pueda recibir hasta que se haya instalado la sesión.
Ejemplo: SPU1 crea la sesión para (a ->b) y envía un mensaje al punto central (implementado en la misma SPU) diciéndole que instale la sesión pendiente.
El punto central instala la sesión.
Establece el estado del ala pendiente de la sesión en activa.
Instala el ala inversa para la sesión como un ala activa.
Envía un mensaje ACK (confirmación) a la SPU, indicando que la sesión está instalada.
Ejemplo: El punto central recibe un mensaje de SPU1 para instalar la sesión para (a->b). Establece el estado de sesión para el ala (a->b) en activa. Instala el ala inversa (b->a) para la sesión y la activa; Esto permite la entrega de paquetes desde la dirección inversa del flujo: destino (b) para ser entregado a la fuente (a).
La SPU configura la sesión sobre las NPU de entrada y salida.
Las NPU mantienen información sobre una sesión para el reenvío y la entrega de paquetes. La información de sesión se configura en las NPU de salida y entrada (que a veces son las mismas) para que los paquetes puedan enviarse directamente a la SPU que administra sus flujos y no al punto central para la redirección.
Se lleva a cabo un procesamiento de ruta rápida.
Para el resto de los pasos relacionados con el procesamiento de paquetes, continúe con el paso 1 en "Descripción del procesamiento de ruta rápida".
Descripción del procesamiento de ruta rápida
Todos los paquetes se someten a un procesamiento de ruta rápida. Sin embargo, si existe una sesión para un paquete, el paquete se somete a un procesamiento de ruta rápida y omite el proceso del primer paquete. Cuando ya hay una sesión para el flujo del paquete, el paquete no transita por el punto central.
Así es como funciona el procesamiento de ruta rápida: Las NPU en las interfaces de salida y entrada contienen tablas de sesión que incluyen la identificación de la SPU que administra el flujo de un paquete. Dado que las NPU tienen esta información de sesión, todo el tráfico del flujo, incluido el tráfico inverso, se envía directamente a esa SPU para su procesamiento.
En dispositivos SRX1400, SRX3400 y SRX3600, la funcionalidad iflset no es compatible con interfaces agregadas como reth.
Descripción del procesamiento del tráfico en dispositivos SRX4600
El firewall SRX4600 de Juniper Networks integra servicios de enrutamiento y seguridad basados en flujos, que incluyen seguridad avanzada y mitigación de amenazas, así como seguridad tradicional de firewall con estado. La infraestructura basada en flujos de Junos OS proporciona la base y el marco para los servicios basados en aplicaciones de la Capa 4 a la Capa 7. El firewall SRX4600 está diseñado para implementarse como un firewall integrado en el borde y el núcleo del centro de datos de grandes empresas, así como en el borde del campus. También se puede desplegar como puerta de enlace de seguridad LTE y firewall Gi/SGi.
En este tema se incluye el siguiente contenido:
- Descripción de los escenarios de despliegue de SRX4600 Firewall y sus características
- Fundamentos de la sesión y el procesamiento basado en flujos
- Componentes subyacentes de flujo y sesión implementados en los firewalls de la serie SRX
Descripción de los escenarios de despliegue de SRX4600 Firewall y sus características
El firewall SRX4600 se puede implementar en muchas áreas para proteger su entorno y sus recursos. Suele utilizarse para proteger el borde y el núcleo del centro de datos de las siguientes maneras:
Implementación del firewall de SRX4600 como firewall perimetral del centro de datos
Puede implementar el firewall SRX4600 en el borde de su centro de datos para proporcionar a las aplicaciones y servicios que aloja una protección óptima. Cada centro de datos tiene un punto de entrada para permitir que los clientes accedan a los servicios del centro de datos, pero los agresores maliciosos pueden aprovecharlo para lanzar ataques contra estos servicios. Una gran cantidad de tráfico que entra en el centro de datos es tráfico de entrada a Internet. Solo por esa razón, es esencial implementar una seguridad sólida y de múltiples capas en el borde del centro de datos. El firewall SRX4600 bloquea los ataques de manera efectiva y confiable, y le permite configurar el sistema para frustrar tipos específicos de ataques. El firewall SRX4600 es compatible con el marco de la red segura definida por software (SDSN) de Juniper, incluida la nube de prevención avanzada de amenazas (ATP Cloud) de Juniper, que se basa en inteligencia automatizada y procesable que se puede compartir rápidamente para reconocer y mitigar amenazas. La figura 2 muestra el firewall SRX4600 desplegado en el borde del centro de datos junto con un enrutador MX480 y conmutadores de la serie EX.
Figura 2: Implementación del firewall de SRX4600 en el borde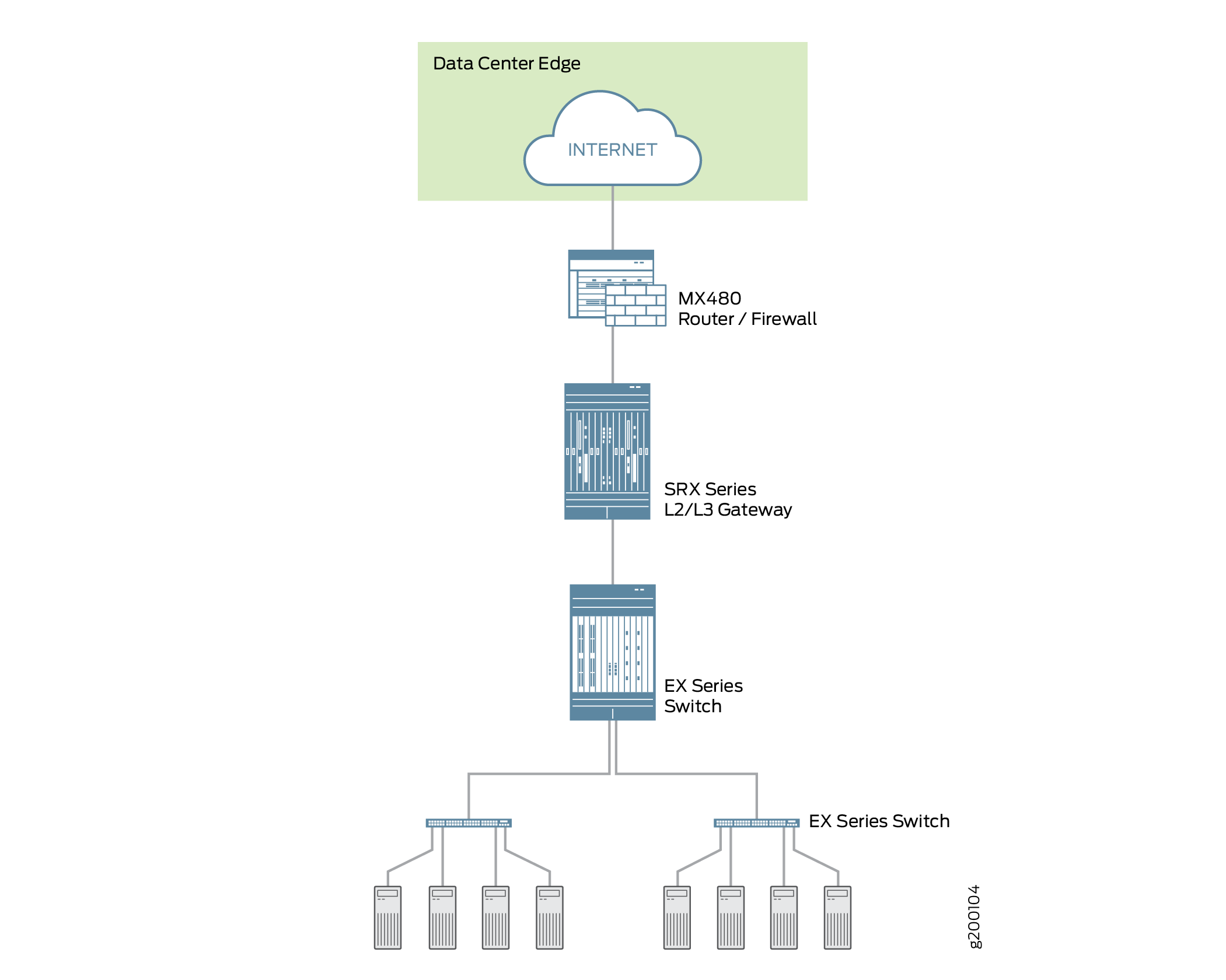 del centro de datos
del centro de datos
Implementación del firewall de SRX4600 en el núcleo del centro de datos
Puede implementar el firewall SRX4600 en el núcleo del centro de datos para proporcionar seguridad mejorada y garantizar que se cumplan los requisitos de cumplimiento. El procesamiento del centro de datos se ha vuelto cada vez más dinámico, lo que requiere una definición clara de la red y el cumplimiento de los requisitos. Para garantizar el cumplimiento, puede utilizar el firewall SRX4600 para segmentar la red general en redes de servidores individuales y proteger el tráfico dentro de ellas. El firewall SRX4600 proporciona alta disponibilidad y automatización, y sus servicios de alto rendimiento de capa 3 y capa 4 cumplen con los requisitos de seguridad del núcleo del centro de datos. La figura 3 muestra el firewall SRX4600 desplegado como un firewall de varias capas en el núcleo del centro de datos.
Figura 3: Implementación del firewall SRX4600 en el núcleo del centro de datos
del centro de datos
Además de sus funciones avanzadas antimalware, el firewall SRX4600 admite las siguientes funciones:
Firewall de estado
Conjunto de seguridad de aplicaciones
Seguridad de contenido (Sophos AV, filtrado web, antispam)
IDP
Alta disponibilidad (clúster de chasis)
Puertos de control de alta disponibilidad (10 G)
Compatibilidad con MACsec para puertos HA
Interfaces Ethernet a través de QSFP28 (modos 100G/40G/4x10G), QSFP+ (modos 40G/4x10G) y SFP+ (modo 10G)
VPN IPsec, incluidas AutoVPN y VPN de grupov2
QoS y servicios de red
J-Web
Políticas de enrutamiento con multidifusión
Fundamentos de la sesión y el procesamiento basado en flujos
Para comprender el procesamiento de flujo en el firewall SRX4600, es importante comprender los fundamentos del flujo.
Un flujo es una secuencia de paquetes relacionados que cumplen los mismos criterios de coincidencia y comparten las mismas características. Junos OS trata los paquetes que pertenecen al mismo flujo de la misma manera. La arquitectura de una puerta de enlace de servicios de la serie SRX y la forma en que gestiona los flujos de paquetes están estrechamente acopladas. En consecuencia, en parte, el flujo se implementa de manera diferente en toda la familia de firewalls de la serie SRX debido a sus diferencias arquitectónicas.
El procesamiento de paquetes basado en flujos, que tiene estado, requiere la creación de sesiones. Las sesiones se crean en función del enrutamiento y otra información de clasificación de tráfico para almacenar información y asignar recursos para un flujo. Las sesiones almacenan en caché información sobre el estado del flujo y almacenan la mayoría de las medidas de seguridad que se aplicarán a los paquetes del flujo. Debido a las diferencias arquitectónicas entre dispositivos, las sesiones también se administran de manera diferente en diferentes dispositivos.
Independientemente de estas diferencias, conceptualmente el proceso de flujo es el mismo en todas las puertas de enlace de servicios, y las sesiones tienen los mismos propósitos y las mismas características.
Componentes subyacentes de flujo y sesión implementados en los firewalls de la serie SRX
Los firewalls de la serie SRX usan los mismos componentes de infraestructura para admitir el flujo y administrar las sesiones, pero no todos los dispositivos los implementan todos.
Para entender el flujo, es esencial entender los siguientes componentes y cómo se utilizan:
La Unidad de Procesamiento de Servicios (SPU)
Una SPU administra la sesión para un flujo de paquetes. Aplica características de seguridad y otros servicios al paquete. También aplica filtros, clasificadores y moldeadores de tráfico de firewall sin estado basados en paquetes al paquete.
El punto central (CP)
El punto central es una SPU que el sistema utiliza para asignar recursos y distribuir la administración de sesiones entre las SPU. Cuando se procesa el primer paquete de un flujo, el punto central determina qué SPU usar para la sesión de ese paquete. El firewall SRX4600 no implementa un punto central.
La unidad de procesamiento de red (NPU) y la sesión de procesamiento de red
Una NPU es un procesador que se ejecuta en una tarjeta de E/S (IOC) y procesa paquetes discretamente. Cuando se crea un flujo, los paquetes siguientes del flujo coinciden con la sesión en la NPU. La NPU controla procesos adicionales, como la comprobación de la secuencia TCP, el procesamiento del tiempo de vida (TTL) y la traducción de encabezados de capa 2. Una NPU mejora el rendimiento en el sentido de que se evita el reenvío de paquetes adicional entre una SPU de sesión y una SPU hash. El firewall SRX4600 implementa una NPU.
La arquitectura de flujo del firewall SRX4600 se ha mejorado para optimizar el uso de los procesadores Xeon™ multinúcleo avanzados del dispositivo SRX4600. El firewall de SRX4600 implementa el uso de un subproceso de sesión dedicado para evitar problemas como la administración de paquetes fuera de orden en un flujo. Utiliza la sesión de procesamiento de red para garantizar que los paquetes se reenvíen al subproceso dedicado correcto. Los paquetes se distribuyen a diferentes subprocesos de acuerdo con el modelo de distribución de sesiones basado en hash.
Descripción del procesamiento del tráfico en dispositivos de línea SRX5000
Junos OS en dispositivos SRX5000 es un sistema distribuido, de procesamiento paralelo, de alto rendimiento y alto rendimiento. La arquitectura de procesamiento paralelo distribuido de la línea SRX5000 de puertas de enlace de servicios incluye varios procesadores para administrar sesiones y ejecutar procesamiento de seguridad y otros servicios. Esta arquitectura proporciona una mayor flexibilidad y permite un alto rendimiento y un rendimiento rápido.
En los dispositivos SRX1400, SRX3400, SRX3600, SRX5400, SRX5600 y SRX5800, las negociaciones de IKE que implican un recorrido NAT no funcionan si el par IKE está detrás de un dispositivo NAT que cambiará la dirección IP de origen de los paquetes IKE durante la negociación. Por ejemplo, si el dispositivo NAT está configurado con DIP, cambia la IP de origen porque el protocolo IKE cambia el puerto UDP de 500 a 4500.
Las tarjetas de E/S (IOC) y las tarjetas de procesamiento de servicios (SPC) en dispositivos de línea de SRX5000 contienen unidades de procesamiento que procesan un paquete a medida que atraviesa el dispositivo. Una IOC tiene una o más unidades de procesamiento de red (NPU) y una SPC tiene una o más unidades de procesamiento de servicios (SPU).
Estas unidades de procesamiento tienen diferentes responsabilidades. Todos los servicios basados en flujo para un paquete se ejecutan en una sola SPU. Las responsabilidades de estas NPU no están claramente delineadas con respecto al otro tipo de servicios que se ejecutan en ellas. .)
Por ejemplo:
Una NPU procesa paquetes discretamente. Realiza comprobaciones de cordura y aplica algunas pantallas configuradas para la interfaz, como las pantallas de denegación de servicio (DoS), al paquete.
Una SPU administra la sesión para el flujo de paquetes y aplica características de seguridad y otros servicios al paquete. También aplica filtros, clasificadores y moldeadores de tráfico de firewall sin estado basados en paquetes al paquete.
Una NPU reenvía un paquete a la SPU mediante el algoritmo hash. Sin embargo, para algunas aplicaciones, como ALG, el sistema necesitará consultar el punto central de la aplicación para determinar en qué SPU se debe procesar el paquete.
Estas partes discretas y cooperantes del sistema, incluido el punto central, almacenan la información que identifica si existe una sesión para un flujo de paquetes y la información con la que se compara un paquete para determinar si pertenece a una sesión existente.
Esta arquitectura permite que el dispositivo distribuya el procesamiento de todas las sesiones en varias SPU. También permite que una NPU determine si existe una sesión para un paquete, verifique el paquete y aplique pantallas al paquete. La forma en que se maneja un paquete depende de si es el primer paquete de un flujo.
En las secciones siguientes se describe la arquitectura de procesamiento utilizando dispositivos SRX5400, SRX5600 y SRX5800 como ejemplo:
- Descripción del procesamiento del primer paquete
- Descripción del procesamiento de ruta rápida
- Descripción de la ruta de datos para sesiones de unidifusión
- Descripción de las unidades de procesamiento de servicios
- Descripción de las características del programador
- Descripción de la agrupación de procesadores de red
Descripción del procesamiento del primer paquete
La figura 4 ilustra la ruta que toma el primer paquete de un flujo cuando ingresa al dispositivo: la NPU determina que no existe ninguna sesión para el paquete y la NPU envía el paquete al punto central distribuido para configurar una sesión de punto central distribuida. Luego, el punto central distribuido envía un mensaje al punto central de la aplicación para seleccionar la SPU para configurar una sesión para el paquete y procesar el paquete. Luego, el punto central distribuido envía el paquete a esa SPU. La SPU procesa el paquete y lo envía a la NPU para su transmisión desde el dispositivo. (Esta descripción de alto nivel no aborda la aplicación de características a un paquete).
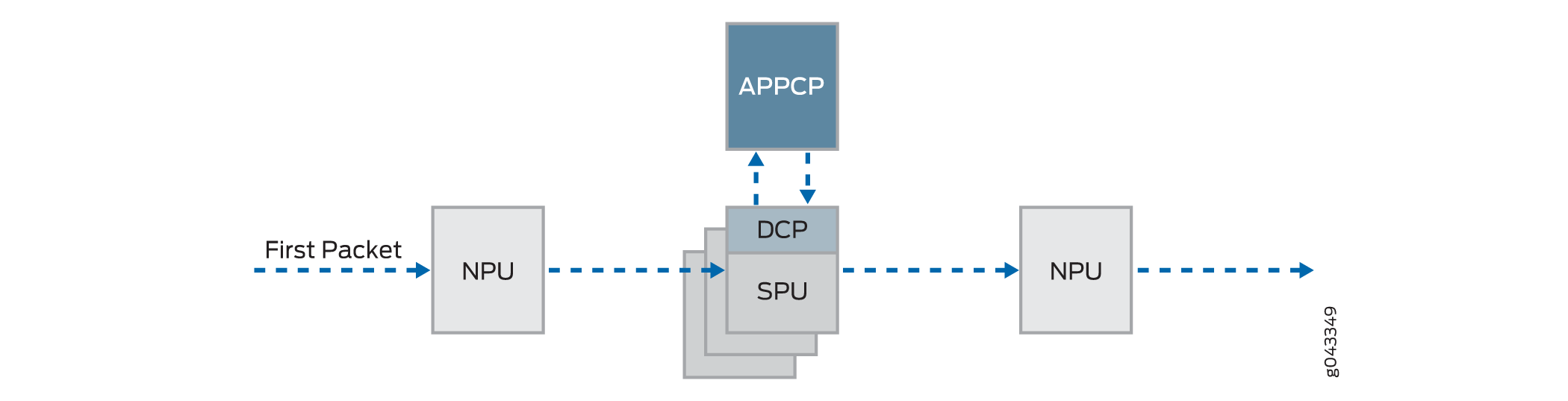 del primer paquete
del primer paquete
Después de que el primer paquete de un flujo ha atravesado el sistema y se ha establecido una sesión para él, se somete a un procesamiento de ruta rápida.
Los paquetes subsiguientes en el flujo también se someten a un procesamiento de ruta rápida; en este caso, después de que cada paquete entra en la sesión y la NPU encuentra una coincidencia para él en su tabla de sesión, la NPU reenvía el paquete a la SPU que administra su sesión.
La figura 5 ilustra el procesamiento de ruta rápida. Esta es la ruta que toma un paquete cuando ya se ha establecido un flujo para sus paquetes relacionados. (También es la ruta que toma el primer paquete de un flujo después de la sesión para que se haya configurado el flujo que inició el paquete). Después de que el paquete entra en el dispositivo, la NPU encuentra una coincidencia para el paquete en su tabla de sesión y reenvía el paquete a la SPU que administra la sesión del paquete. Tenga en cuenta que el paquete omite la interacción con el punto central.
Descripción del procesamiento de ruta rápida
En la siguiente sección se explica cómo se crea una sesión y el proceso al que se somete un paquete a medida que transita por el dispositivo.
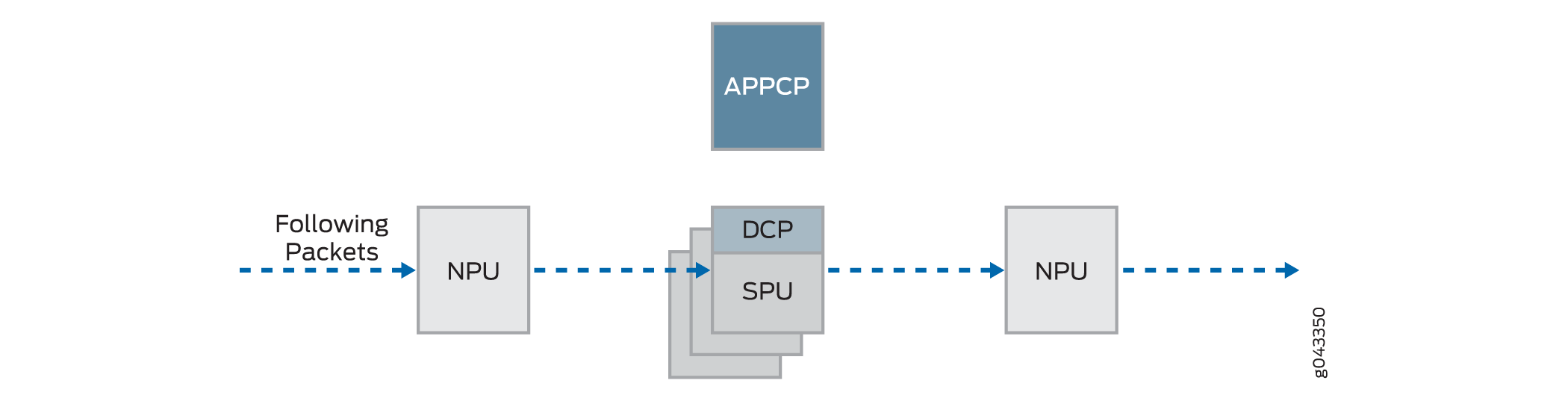 de ruta rápida
de ruta rápida
Aquí hay una descripción general de los principales componentes involucrados en la configuración de una sesión para un paquete y el procesamiento de paquetes, tanto discretamente como como parte de un flujo a medida que transitan por los dispositivos SRX5400, SRX5600 y SRX5800.
Unidades de procesamiento de red (NPU): las NPU residen en IOC. Se encargan de la comprobación de la cordura de los paquetes y la aplicación de algunas pantallas. Las NPU mantienen tablas de sesión que utilizan para determinar si existe una sesión para un paquete entrante o para el tráfico inverso.
La tabla de sesión de NPU contiene una entrada para una sesión si la sesión se establece en una SPU para un paquete que había entrado previamente en el dispositivo a través de la interfaz y fue procesado por esta NPU. La SPU instala la sesión en la tabla NPU cuando crea la sesión.
Una NPU determina si existe una sesión para un paquete comprobando la información del paquete con su tabla de sesión. Si el paquete coincide con una sesión existente, la NPU envía el paquete y los metadatos correspondientes a la SPU. Si no hay sesión, las NPU envían el paquete a una SPU que se calcula utilizando el algoritmo hash.
Unidades de procesamiento de servicios (SPU): los procesadores principales de los dispositivos SRX5400, SRX5600 y SRX5800 residen en SPC. Las SPU establecen y administran flujos de tráfico y realizan la mayor parte del procesamiento de paquetes en un paquete a medida que transita por el dispositivo. Cada SPU mantiene una tabla hash para una búsqueda rápida de sesiones. La SPU aplica filtros, clasificadores y moldeadores de tráfico de firewall sin estado al tráfico. Una SPU realiza todo el procesamiento basado en flujo para un paquete y la mayoría del procesamiento basado en paquetes. Cada SPU multinúcleo procesa paquetes de forma independiente, con una interacción mínima entre las SPU en la misma SPC o en una diferente. Todos los paquetes que pertenecen al mismo flujo son procesados por la misma SPU.
La SPU mantiene una tabla de sesión con entradas para todas las sesiones que estableció y cuyos paquetes procesa. Cuando una SPU recibe un paquete de una NPU, comprueba su tabla de sesión para asegurarse de que el paquete le pertenece. También comprueba su tabla de sesión cuando recibe un paquete del punto central distribuido y envía un mensaje para establecer una sesión para ese paquete a fin de comprobar que no hay una sesión existente para el paquete.
Punto central: la arquitectura del punto central se divide en dos módulos, el punto central de la aplicación y el punto central distribuido. El punto central de la aplicación es responsable de la administración de recursos globales y del equilibrio de carga, mientras que el punto central distribuido es responsable de la identificación del tráfico (coincidencia global de sesiones). La funcionalidad de punto central de la aplicación se ejecuta en la SPU de punto central dedicada, mientras que la funcionalidad de punto central distribuido se distribuye al resto de las SPU. Ahora las sesiones de punto central ya no están en la SPU de punto central dedicada, sino con el punto central distribuido en otras SPU de flujo.
Motor de enrutamiento: el motor de enrutamiento ejecuta el plano de control.
Descripción de la ruta de datos para sesiones de unidifusión
En esta sección se describe el proceso de establecer una sesión para paquetes que pertenecen a un flujo que transita por el dispositivo.
Para ilustrar el establecimiento de una sesión y el "paseo" de paquetes, incluidos los puntos en los que se aplican los servicios a los paquetes de un flujo, en este ejemplo se utiliza el caso simple de una sesión de unidifusión.
Este "paseo" de paquetes reúne el procesamiento basado en paquetes y el procesamiento basado en flujos que Junos OS realiza en el paquete.
- Búsqueda de sesiones y criterios de coincidencia de paquetes
- Descripción de la creación de sesiones: procesamiento de primer paquete
- Descripción del procesamiento de ruta rápida
Búsqueda de sesiones y criterios de coincidencia de paquetes
Para determinar si un paquete pertenece a un flujo existente, el dispositivo intenta hacer coincidir la información del paquete con la de una sesión existente según los siguientes seis criterios de coincidencia:
Dirección de origen
Dirección de destino
Puerto de origen
Puerto de destino
Protocolo
Token único de una zona determinada y enrutador virtual
Descripción de la creación de sesiones: procesamiento de primer paquete
En esta sección se explica cómo se configura una sesión para procesar los paquetes que componen un flujo. Para ilustrar el proceso, esta sección utiliza un ejemplo con una fuente "a" y un destino "b". La dirección desde el origen hasta el destino de los paquetes del flujo se denomina (a ->b). La dirección desde el destino hasta la fuente se conoce como (b->a).
Paso 1. Un paquete llega a una interfaz en el dispositivo y la NPU lo procesa.
En esta sección se describe cómo se maneja un paquete cuando llega a una IOC de entrada de firewall de la serie SRX.
El paquete llega al IOC del dispositivo y es procesado por la NPU en el IOC.
La NPU realiza comprobaciones básicas de cordura en el paquete y aplica algunas pantallas configuradas para la interfaz al paquete.
La NPU comprueba su tabla de sesión en busca de una sesión existente para el paquete. (Comprueba la tupla del paquete con las de los paquetes de las sesiones existentes en su tabla de sesiones).
Si no se encuentra ninguna sesión existente, la NPU reenvía el paquete a la SPU hash.
Si se encuentra una coincidencia de sesión, la sesión ya se ha creado en una SPU que se le asignó, por lo que la NPU reenvía el paquete a la SPU para su procesamiento junto con el ID de sesión.
Example: El paquete (a ->b) llega a NPU1. NPU1 realiza comprobaciones de cordura y aplica pantallas DoS al paquete. NPU1 comprueba su tabla de sesión en busca de una coincidencia de tupla y no se encuentra ninguna sesión existente. NPU1 reenvía el paquete a una SPU.
Paso 2. El punto central distribuido crea una sesión con un estado "pendiente".
Cuando una NPU recibe un paquete, la NPU lo envía al punto central distribuido, según el algoritmo hash. A continuación, el punto central distribuido busca la tabla de sesión del punto central distribuido y crea una entrada si es necesario.
Este proceso consta de las siguientes partes:
El punto central distribuido comprueba su tabla de sesión para determinar si existe una sesión para el paquete recibido de la NPU. (Una NPU reenvía un paquete al punto central distribuido porque no puede encontrar una sesión existente para el paquete)
Si no hay ninguna entrada que coincida con el paquete en la tabla de sesión de punto central distribuido, el punto central distribuido crea un ala pendiente para la sesión. A continuación, el punto central distribuido envía un mensaje de consulta al punto central de la aplicación para seleccionar una SPU que se utilizará para la sesión.
Al recibir el mensaje de consulta, el punto central de la aplicación comprueba su tabla de puertas para determinar si existe una puerta para el paquete. Si se coincide una puerta o se activa algún otro algoritmo de distribución de sesión, el punto central de la aplicación selecciona otra SPU para procesar el paquete; de lo contrario, se selecciona la SPU (es decir, la SPU del punto central distribuido). Por último, el punto central de la aplicación envía una respuesta de consulta al punto central distribuido.
Al recibir la respuesta a la consulta, el punto central distribuido reenvía el primer paquete en flujo a la SPU seleccionada en un mensaje que indica a la SPU que configure una sesión local que se utilizará para el flujo de paquetes. Por ejemplo, el punto central distribuido crea un ala pendiente (a ->b) para la sesión. El punto central de la aplicación selecciona SPU1 que se utilizará para ello. El punto central distribuido envía a SPU1 el paquete (a->b) junto con un mensaje para crear una sesión para el punto central distribuido.
Example: El punto central distribuido crea un ala pendiente (a ->b) para la sesión. Selecciona SPU1 para utilizarlo. Envía a SPU1 el paquete (a->b) junto con un mensaje para crear una sesión para él.
Paso 3. La SPU configura la sesión.
Cada SPU también tiene una tabla de sesión, que contiene información sobre sus sesiones. Cuando la SPU recibe un mensaje del punto central distribuido para configurar una sesión, comprueba su tabla de sesión para asegurarse de que no existe ya una sesión para el paquete.
Si no hay ninguna sesión existente para el paquete, la SPU configura la sesión localmente.
La SPU envía un mensaje al punto central distribuido indicándole que instale la sesión.
Nota:Durante el procesamiento del primer paquete, si NAT está habilitada, la SPU asigna recursos de dirección IP para NAT. En este caso, el procesamiento del primer paquete para la sesión se suspende hasta que se complete el proceso de asignación de NAT.
La SPU agrega a la cola cualquier paquete adicional para el flujo que pueda recibir hasta que se haya instalado la sesión.
Example: SPU1 crea la sesión para (a ->b) y envía un mensaje al punto central distribuido dirigiéndole a instalar la sesión pendiente.
Paso 4. El punto central distribuido instala la sesión.
El punto central distribuido recibe el mensaje de instalación de la SPU.
El punto central distribuido establece el estado del ala pendiente de la sesión en activo.
El punto central distribuido instala el ala inversa para la sesión como un ala activa.
Nota:Para algunos casos, como NAT, el ala inversa puede instalarse en un punto central distribuido diferente del punto central distribuido del ala inicial.
Envía un mensaje de confirmación (ACK) a la SPU, indicando que la sesión está instalada.
Example: El punto central distribuido recibe un mensaje de SPU1 para instalar la sesión para el ala (a->b). Establece el estado de sesión para el ala (a->b) en activa. Instala el ala inversa (b->a) para la sesión y la activa; Esto permite la entrega de paquetes desde la dirección inversa del flujo: destino (b) para ser entregado a la fuente (a).
Paso 5. La SPU establece la sesión sobre las NPU de entrada y salida.
Las NPU mantienen información sobre una sesión para el reenvío y la entrega de paquetes. La información de sesión se configura en las NPU de salida y entrada (que a veces son las mismas) para que los paquetes se puedan enviar directamente a la SPU que administra sus flujos y no al punto central distribuido para su redirección.
Paso 6. Se lleva a cabo un procesamiento de ruta rápida.
Para el resto de los pasos relacionados con el procesamiento de paquetes, continúe con el paso 1 en Descripción del procesamiento de ruta rápida.
La figura 6 ilustra la primera parte del proceso que sufre el primer paquete de un flujo después de llegar al dispositivo. En este punto, se configura una sesión para procesar el paquete y el resto de los paquetes que pertenecen a su flujo. Posteriormente, este y el resto de los paquetes en el flujo se someten a un procesamiento de ruta rápida.
 del primer paquete
del primer paquete
Descripción del procesamiento de ruta rápida
Todos los paquetes se someten a un procesamiento de ruta rápida. Sin embargo, si existe una sesión para un paquete, el paquete se somete a un procesamiento de ruta rápida y omite el proceso del primer paquete. Cuando ya hay una sesión para el flujo del paquete, el paquete no transita por el punto central.
Así es como funciona el procesamiento de ruta rápida: Las NPU en las interfaces de salida y entrada contienen tablas de sesión que incluyen la identificación de la SPU que administra el flujo de un paquete. Dado que las NPU tienen esta información de sesión, todo el tráfico del flujo, incluido el tráfico inverso, se envía directamente a esa SPU para su procesamiento.
Para ilustrar el proceso de ruta rápida, esta sección utiliza un ejemplo con una fuente "a" y un destino "b". La dirección desde el origen hasta el destino para los paquetes del flujo se conoce como (a->b). La dirección desde el destino hasta la fuente se conoce como (b->a).
Paso 1. Un paquete llega al dispositivo y la NPU lo procesa.
En esta sección se describe cómo se administra un paquete cuando llega a la IOC de una puerta de enlace de servicios.
El paquete llega al IOC del dispositivo y es procesado por la NPU en la tarjeta.
La NPU realiza comprobaciones de cordura y aplica algunas pantallas, como las pantallas de denegación de servicio (DoS), al paquete.
La NPU identifica una entrada para una sesión existente en su tabla de sesión con la que coincide el paquete.
La NPU reenvía el paquete junto con los metadatos de su tabla de sesión, incluida la información del ID de sesión y de la tupla del paquete, a la SPU que administra la sesión para el flujo, aplica filtros de firewall sin estado y características de CoS a sus paquetes, y maneja el procesamiento del flujo del paquete y la aplicación de seguridad y otras características.
Example: El paquete (a ->b) llega a NPU1. NPU1 realiza comprobaciones de cordura en el paquete, le aplica pantallas DoS y comprueba su tabla de sesión en busca de una coincidencia de tupla. Encuentra una coincidencia y que existe una sesión para el paquete en SPU1. NPU1 reenvía el paquete a SPU1 para su procesamiento.
Paso 2. La SPU de la sesión procesa el paquete.
La mayor parte del procesamiento de un paquete se produce en la SPU a la que está asignada su sesión. El paquete se procesa para características basadas en paquetes, como filtros de firewall sin estado, moldeadores de tráfico y clasificadores, si corresponde. La seguridad configurada basada en flujos y los servicios relacionados, como características de firewall, NAT, ALG, etc., se aplican al paquete. (Para obtener información sobre cómo se determinan los servicios de seguridad para una sesión.
Antes de procesar el paquete, la SPU comprueba su tabla de sesiones para comprobar que el paquete pertenece a una de sus sesiones.
La SPU procesa el paquete para las características y servicios aplicables.
Example: SPU1 recibe el paquete (a->b) de NPU1. SPU1 comprueba su tabla de sesión para comprobar que el paquete pertenece a una de sus sesiones. Luego procesa el paquete (a ->b) de acuerdo con los filtros de entrada y las características de CoS que se aplican a su interfaz de entrada. La SPU aplica las características y servicios de seguridad que están configurados para el flujo del paquete hacia ella, en función de su zona y políticas. Si alguno está configurado, aplica filtros de salida, moldeadores de tráfico y pantallas adicionales al paquete.
Paso 3. La SPU reenvía el paquete a la NPU.
La SPU reenvía el paquete a la NPU.
La NPU aplica al paquete las pantallas aplicables asociadas con la interfaz.
Example: SPU1 reenvía el paquete (a ->b) a NPU2, y NPU2 aplica pantallas DoS.
Paso 4. La interfaz transmite el paquete desde el dispositivo.
Example: La interfaz transmite el paquete (a->b) desde el dispositivo.
Paso 5. Un paquete de tráfico inverso llega a la interfaz de salida y la NPU lo procesa.
Este paso refleja el paso 1 exactamente al revés. Consulte el paso 1 de esta sección para obtener más información.
Example: El paquete (b->a) llega a NPU2. NPU2 comprueba su tabla de sesión en busca de una coincidencia de tupla. Encuentra una coincidencia y que existe una sesión para el paquete en SPU1. NPU2 reenvía el paquete a SPU1 para su procesamiento.
Paso 6. La SPU de la sesión procesa el paquete de tráfico inverso.
Este paso es el mismo que el paso 2, excepto que se aplica al tráfico inverso. Consulte el paso 2 de esta sección para obtener más información.
Example: SPU1 recibe el paquete (b->a) de NPU2. Comprueba su tabla de sesión para verificar que el paquete pertenece a la sesión identificada por NPU2. A continuación, aplica al paquete las características basadas en paquetes configuradas para la interfaz de la NPU1. Procesa el paquete (b->a) de acuerdo con las características de seguridad y otros servicios configurados para su flujo, según su zona y políticas.
Paso 7. La SPU reenvía el paquete de tráfico inverso a la NPU.
Este paso es el mismo que el paso 3, excepto que se aplica al tráfico inverso. Consulte el paso 3 de esta sección para obtener más información.
Example: SPU1 reenvía el paquete (b->a) a NPU1. NPU1 procesa cualquier pantalla configurada para la interfaz.
8. La interfaz transmite el paquete desde el dispositivo.
Este paso es el mismo que el paso 4, excepto que se aplica al tráfico inverso. Consulte el paso 4 de esta sección para obtener más información.
Ejemplo: La interfaz transmite el paquete (b->a) desde el dispositivo.
La figura 7 ilustra el proceso por el que se somete un paquete cuando llega al dispositivo y existe una sesión para el flujo al que pertenece el paquete.
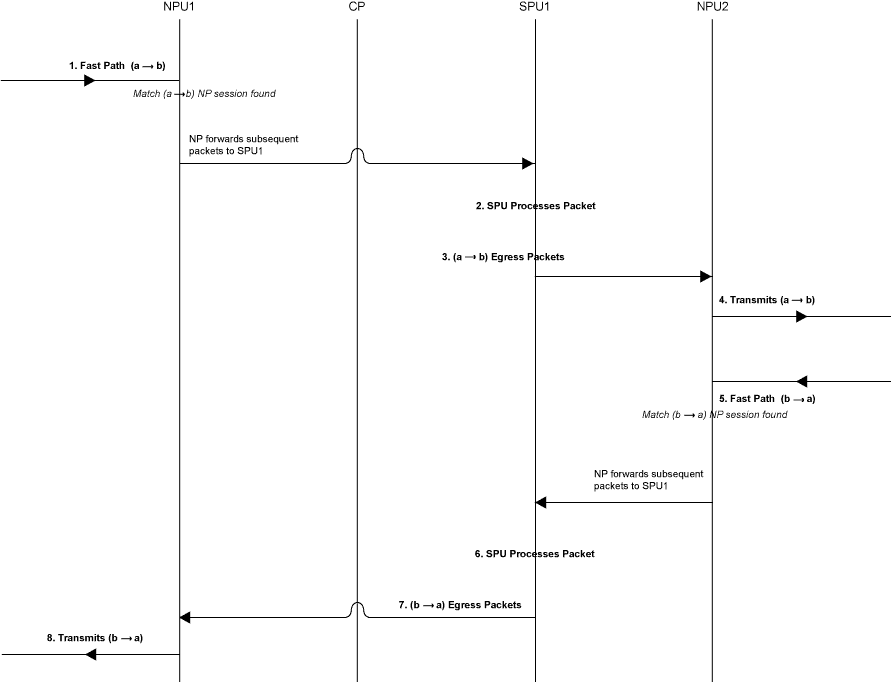 de ruta rápida
de ruta rápida
Descripción de las unidades de procesamiento de servicios
Para una interfaz física determinada, la SPU recibe paquetes de entrada de todos los procesadores de red en el paquete de procesadores de red asociado con la interfaz física. La SPU extrae información del paquete del procesador de red de la interfaz física y utiliza el mismo algoritmo hash de 5 tuplas para asignar un flujo a un índice de procesador de red. Para determinar el procesador de red, la SPU realiza una búsqueda en el índice del procesador de red en el paquete de procesadores de red. La SPU envía paquetes de salida al módulo de interfaz física (PIM) local de la interfaz física para el tráfico saliente.
El procesador de red y la SPU utilizan el mismo algoritmo hash de 5 tuplas para obtener los valores hash de los paquetes.
Descripción de las características del programador
Para dispositivos SRX5400, SRX5600 y SRX5800, la IOC admite las siguientes características jerárquicas del programador:
IFL – La configuración del paquete de procesadores de red se almacena en la estructura de datos de la interfaz física. Por ejemplo, los dispositivos SRX5400, SRX5600 y SRX5800 tienen un máximo de 48 PIM. La interfaz física puede usar una máscara de bits de 48 bits para indicar el PIM, o el tráfico del procesador de red desde esta interfaz física se distribuye además del procesador de red principal de la interfaz física.
En dispositivos de línea SRX5000, la funcionalidad iflset no es compatible con interfaces agregadas como reth.
IFD: la interfaz lógica asociada con la interfaz física de un paquete de procesadores de red se pasa a todas las IOC que tienen un PIM en el paquete de procesadores de red.
Descripción de la agrupación de procesadores de red
La función de agrupación de procesadores de red está disponible en los dispositivos de línea SRX5000. Esta característica permite la distribución del tráfico de datos desde una interfaz a varios procesadores de red para el procesamiento de paquetes. Se asigna un procesador de red primario para una interfaz que recibe el tráfico de entrada y distribuye los paquetes a otros procesadores de red secundarios. Un solo procesador de red puede actuar como procesador de red primario o como procesador de red secundario para varias interfaces. Un solo procesador de red sólo puede unirse a un paquete de procesadores de red.
Limitaciones de la agrupación de procesadores de red
La funcionalidad de agrupación de procesadores de red tiene las siguientes limitaciones:
La agrupación de procesadores de red permite un total de 16 PIM por paquete y 8 sistemas de paquetes de procesadores de red diferentes.
Debe reiniciar el dispositivo para aplicar los cambios de configuración en el paquete.
La agrupación de procesadores de red se encuentra por debajo de la interfaz reth en la arquitectura general. Puede elegir una o ambas interfaces del paquete de procesadores de red para formar la interfaz reth.
Si la IOC se elimina de un paquete de procesador de red, se perderán los paquetes reenviados al PIM en esa IOC.
Cuando el paquete de procesadores de red está habilitado, los umbrales de inundación de sincronización ICMP, UDP y TCP ya no se aplican a una interfaz. Los paquetes se distribuyen a múltiples procesadores de red para su procesamiento. Estos umbrales se aplican a cada procesador de red del paquete de procesadores de red.
La agrupación de procesadores de red no se admite en el modo de capa 2.
Debido a las restricciones de memoria en el procesador de red, el número de puertos agrupados del procesador de red que se admiten por PIM es limitado. Dentro del paquete de procesadores de red, cada puerto debe tener un índice de puerto global. El índice global de puertos se calcula mediante la fórmula siguiente:
Global_port_index = (global_pic * 16) + port_offset
Los grupos de agregación de vínculos (LAG) y los LAG de interfaz Ethernet redundantes en implementaciones de clúster de chasis pueden coexistir con la agrupación de procesadores de red. Sin embargo, ni los LAG ni los LAG de interfaz Ethernet redundantes pueden superponerse o compartir vínculos físicos con un paquete de procesadores de red.
Descripción de la caché de sesión
- Visión general
- Instalación selectiva de caché de sesión
- Mejora de la afinidad de sesión VPN IPsec mediante la caché de sesión
- Orden de paquetes de fragmentación mediante caché de sesión NP
Visión general
Los dispositivos SRX5K-MPC (IOC2), SRX5K-MPC3-100G10G (IOC3) y SRX5K-MPC3-40G10G (IOC3) en dispositivos SRX5400, SRX5600 y SRX5800 admiten la caché de sesión y la instalación selectiva de la memoria caché de sesión.
La caché de sesión se utiliza para almacenar en caché una conversación entre el procesador de red (NP) y la SPU en una IOC. Una conversación puede ser una sesión, tráfico de túnel GTP-U, tráfico de túnel VPN IPsec, etc. Una conversación tiene dos entradas de caché de sesión, una para el tráfico entrante y la otra para el tráfico inverso. Dependiendo de dónde estén los puertos de entrada y salida de tráfico, dos entradas pueden residir en el mismo procesador de red o en procesadores de red diferentes. Las IOC admiten caché de sesión para sesiones IPv6.
Una entrada de caché de sesión también se denomina ala de sesión.
La caché de sesión en el IOC aprovecha la funcionalidad de Express Path (anteriormente conocida como descarga de servicios) y ayuda a evitar problemas como la alta latencia y la caída del rendimiento de IPsec.
Una entrada de caché de sesión registra:
A qué SPU se debe reenviar el tráfico de la conversión
A qué puerto de salida se debe reenviar el tráfico de la conversión en el modo Express Path
Qué procesamiento hacer para el tráfico de salida, por ejemplo, traducción de NAT en modo Express Path
A partir de Junos OS versión 15.1X49-D10 y Junos OS versión 17.3R1, la caché de sesión de las sesiones en el COI ayuda a resolver ciertos problemas de rendimiento. La SPU ahora puede indicar a la caché de sesión del COI que reenvíe el tráfico posterior a una SPU de ancla específica.
A partir de Junos OS versión 15.1X49-D10, el SRX5K-MPC (IOC2) y el IOC3 admiten la afinidad de sesión VPN mediante un módulo de flujo y caché de sesión mejorados. A partir de Junos OS versión 12.3X48-D30, en IOC2, se admite la afinidad de sesión VPN a través de la caché de sesión.
Otro tráfico se procesaba a las SPU en función de su información clave de 5 tuplas. El tráfico VPN empleaba el concepto de SPU anclada, que no necesariamente coincidía con las funciones de la SPU de flujo. El procesador de red sólo podía reenviar los paquetes a la SPU de flujo basada en el hash de 5 tuplas. Luego, la SPU de flujo reenvió el paquete a la SPU anclada. Esto creó un salto adicional para el tráfico VPN, lo que desperdició el ancho de banda de la estructura del conmutador y redujo el rendimiento de VPN aproximadamente a la mitad. Esta reducción del rendimiento se produjo porque el tráfico aún tenía que volver a la SPU de flujo después de procesarla en la SPU anclada.
La tabla de caché de sesión ahora se extiende en IOC para admitir las sesiones NP. El tráfico de Express Path y el tráfico NP comparten la misma tabla de caché de sesión en IOC. El tráfico de Express Path es reenviado por la propia IOC, ya sea localmente o a otra IOC, ya que el tráfico no requiere ningún servicio de la SPU. El tráfico NP se reenvía a la SPU especificada en la caché de sesión para su posterior procesamiento. Todas las entradas de caché de sesión son compartidas tanto por el tráfico de sesión de Express Path como por el tráfico NP.
Para habilitar la caché de sesión en las IOC, debe ejecutar el set chassis fpc <fpc-slot> np-cache comando.
La IOC2 y la IOC3 utilizan el mecanismo de eliminación de sesiones de retraso. Las mismas sesiones (sesiones con las mismas cinco tuplas) que se eliminan y luego se vuelven a instalar inmediatamente no se almacenan en caché en las IOC.
Instalación selectiva de caché de sesión
Para evitar una latencia alta, mejorar el rendimiento de IPSec y utilizar mejor los valiosos recursos, se aplican ciertos mecanismos de prioridad tanto al módulo de flujo como a la IOC.
Las IOC mantienen y supervisan los niveles de umbral de uso de la caché de sesión. Las IOC también comunican el uso de caché de sesión a la SPU, de modo que cuando se alcanza un determinado umbral de uso de caché de sesión, la SPU solo envía solicitudes de instalación de caché de sesión para sesiones de tráfico selectivo de alta prioridad.
Las aplicaciones como IDP, ALG necesitan procesar paquetes en orden. Una SPU tiene varios subprocesos de flujo para manejar paquetes que pertenecen a una sesión, el subproceso de equilibrio de carga (LBT) y el orden de paquetes del subproceso de pedido de paquetes (POT) pueden asegurarse de que el tráfico pase a través del firewall en orden, no puede garantizar que la aplicación procese paquetes que pertenecen a la misma sesión en orden. La serialización por flujo proporciona el método de que solo un paquete de procesamiento de subprocesos de flujo SPU pertenezca a la misma sesión a la vez, para que las aplicaciones puedan recibir, procesar y enviar paquetes en orden. Otros subprocesos de flujo pueden realizar el procesamiento de serialización de flujo para otras sesiones al mismo tiempo.
Los siguientes cuatro niveles de prioridad se utilizan para determinar qué tipo de tráfico puede instalar la caché de sesión en las IOC:
Priority 1 (P1)— Tráfico calificado IPSec y Express Path
Priority 2 (P2)— Orden de fragmentación
Priority 3 (P3)— Tráfico de tráfico NAT/SZ (serialización de sesión)
Priority 4(P3)— Todos los demás tipos de tráfico
Las IOC mantienen y supervisan los niveles de umbral para el uso de la caché de sesión y actualizan el uso actual de caché de sesión en tiempo real a la SPU. La SPU solicita al COI que instale la caché de sesión para determinadas sesiones de tráfico de alta prioridad. El uso de caché de sesión para sesiones de tráfico de alta prioridad se define en la tabla:
Tipo de tráfico |
0% < utilización < 25% |
25% < utilización < 50% |
50% < utilización < 75% |
75% < utilización < 100% |
|---|---|---|---|---|
Tráfico de IPsec y Express Path |
Sí |
Sí |
Sí |
Sí |
Fragmentación Ordenar el tráfico |
Sí |
Sí |
Sí |
No |
Tráfico NAT/SZ |
Sí |
Sí |
No |
No |
Otro tráfico |
Sí |
No |
No |
No |
Para conservar las entradas de sesión en el IOC, el módulo de flujo instala selectivamente las sesiones en el IOC. Para facilitar la selección de la instalación de la sesión, el IOC mantiene los umbrales correspondientes para proporcionar una indicación al módulo de flujo (sobre qué tan llena está la tabla de caché de sesión en las IOC). Se agregan dos bits en el meta encabezado para indicar el estado actual de utilización de la tabla de caché. Todos los paquetes que van a la SPU llevarán estos dos bits de estado para informar al módulo de flujo de la utilización de la tabla de caché en la IOC.
Mejora de la afinidad de sesión VPN IPsec mediante la caché de sesión
Los firewalls de la serie SRX son sistemas completamente distribuidos y se asigna un túnel IPsec y se ancla a una SPU específica. Todo el tráfico que pertenece a un túnel IPsec se cifra y descifra en su SPU anclada en túnel. Para lograr un mejor rendimiento de IPsec, IOC mejora el módulo de flujo para crear sesiones para el tráfico basado en túnel IPsec (antes del cifrado y después del descifrado) en su SPU anclada en túnel, e instala caché de sesión para las sesiones, de modo que la IOC pueda redirigir los paquetes directamente a la misma SPU para minimizar la sobrecarga de reenvío de paquetes. El tráfico de Express Path y el tráfico NP comparten la misma tabla de caché de sesión en IOC.
Debe habilitar la caché de sesión en las IOC y establecer la política de seguridad para determinar si una sesión es para el modo Express Path (anteriormente conocido como descarga de servicios) en el concentrador PIC flexible (FPC) seleccionado.
Para habilitar el uso de afinidad VPN IPsec, el set security flow load-distribution session-affinity ipsec comando.
Para habilitar la afinidad VPN IPsec, también debe habilitar la caché de sesión en IOC mediante el set chassis fpc <fpc-slot> np-cache comando.
Orden de paquetes de fragmentación mediante caché de sesión NP
Una sesión puede constar de paquetes normales y fragmentados. Con la distribución basada en hash, se pueden usar claves de 5 y 3 tuplas para distribuir paquetes normales y fragmentados a diferentes SPU, respectivamente. En los firewalls de la serie SRX, todos los paquetes de la sesión se reenvían a una SPU de procesamiento. Debido a la latencia de reenvío y procesamiento, es posible que la SPU de procesamiento no garantice el orden de los paquetes de la sesión.
La caché de sesión en las IOC garantiza el orden de los paquetes de una sesión con paquetes fragmentados. Se asigna una entrada de caché de sesión para los paquetes normales de la sesión y se utiliza una clave de 3 tuplas para encontrar los paquetes fragmentados. Al recibir el primer paquete fragmentado de la sesión, el módulo de flujo permite a la IOC actualizar la entrada de caché de sesión para recordar los paquetes fragmentados para la SPU. Más tarde, el COI reenvía todos los paquetes posteriores de la sesión a la SPU para garantizar el orden de los paquetes de una sesión con paquetes fragmentados.
Configuración de la asignación de IOC a NPC
Una asignación de tarjeta de entrada/salida (IOC) a tarjeta de procesamiento de red (NPC) requiere que asigne una IOC a una NPC. Sin embargo, puede asignar varias IOC a un solo NPC. Para equilibrar la potencia de procesamiento en el NPC en la SRX3400 y SRX3600 puertas de enlace de servicios, el proceso de chasis (daemon) ejecuta un algoritmo que realiza la asignación. Asigna un IOC a un NPC que tiene la menor cantidad de IOC asignados. También puedes usar la interfaz de línea de comandos (CLI) para asignar una IOC específica a un NPC específico. Cuando configure la asignación, el proceso del chasis usará primero su configuración y, a continuación, aplicará el algoritmo NPC de menor número para el resto de las IOC.
La compatibilidad de plataforma depende de la versión de Junos OS en su instalación.
Para configurar la asignación de IOC a NPC:
[edit]
set chassis ioc-npc-connectivity {
ioc slot-number npc (none | slot-number);
}
Consulte la Tabla 2 para obtener una descripción de las set chassis ioc-npc-connectivity opciones.
Opción |
Descripción |
|---|---|
coi slot-number |
Especifique el número de ranura IOC. El rango es de 0 a 7 para dispositivos SRX3400 y de 0 a 12 para SRX3600 dispositivos. |
Npc slot-number |
Especifique el número de ranura NPC. El rango es de 0 a 7 para dispositivos SRX3400 y de 0 a 12 para dispositivos SRX3600 y SRX 4600. |
ninguno |
El proceso de chasis asigna la conexión para la IOC en particular. |
Debe reiniciar el control de chasis después de confirmar el set chassis ioc-npc-connectivity comando.
Descripción del procesamiento de flujo en dispositivos SRX5K-SPC3
Se introduce la tarjeta de procesamiento de servicios SRX5K-SPC3 para mejorar el rendimiento de los servicios de seguridad en la puerta de enlace de servicios de seguridad SRX5000. La tarjeta SPC3 admite un mayor rendimiento, mantiene su confiabilidad ya que conserva la funcionalidad y escalabilidad del clúster del chasis para el procesamiento de servicios.
La tarjeta SPC3 proporciona compatibilidad con las siguientes características de seguridad:
Puerta de enlace de la capa de aplicación (ALG). [Ver Descripción general de ALG]
Antimalware avanzado (Juniper ATP Cloud). [Consulte Administración de prevención avanzada de amenazas de Juniper Sky]
Conjunto de seguridad de aplicaciones. [Consulte la Guía del usuario de seguridad de aplicaciones para dispositivos de seguridad]
Implementación del procesamiento de paquetes basado en flujos
Protocolo de tunelización GPRS (GTP) y protocolo de transmisión de control de flujo (SCTP). [Consulte la Guía del usuario del servicio general de paquetes radio para dispositivos de seguridad]
Alta disponibilidad (clúster de chasis). [Consulte la Guía del usuario del clúster de chasis para dispositivos de la serie SRX]
Detección y prevención de intrusiones (IDP). [Consulte Descripción general de la detección y prevención de intrusiones]
Traducción de direcciones de red (NAT). [Consulte la Guía del usuario de traducción de direcciones de red para dispositivos de seguridad]
Firewall de estado
Proxy SSL. [ Consulte Proxy SSL]
Autenticación de usuario de firewall. [Consulte la Guía del usuario de autenticación y firewalls de usuario integrados para dispositivos de seguridad]
Seguridad de contenido (antivirus, filtrado web, filtrado de contenido y antispam). [Consulte la Guía del usuario de UTM para dispositivos de seguridad]
El flujo de seguridad se ha mejorado para admitir la tarjeta SPC3 con todas las características de seguridad existentes que son compatibles con la tarjeta SPC2.
Se aplican las siguientes limitaciones a la tarjeta SPC3 en Junos OS versión 18.2R1-S1:
No se admite la interoperabilidad de la tarjeta SPC3 y la tarjeta SPC2.
La funcionalidad VPN IPsec no es compatible con la tarjeta SPC3.
A partir de Junos OS versión 18.2R1-S1, se introduce una nueva tarjeta de procesamiento de servicio (SPC3) para los dispositivos de línea SRX5000. La introducción de la nueva tarjeta mejora la escalabilidad y el rendimiento del dispositivo y mantiene su fiabilidad, ya que conserva la funcionalidad del clúster del chasis. La tarjeta SPC3 admite un mayor rendimiento y escalabilidad para el procesamiento de servicios.
En los dispositivos de línea SRX5000, la tarjeta SPC3 interopera con tarjetas de E/S (IOC2, IOC3), tarjeta de control de conmutador (SCB2, SCB3), motores de enrutamiento y tarjetas SPC2.
A partir de Junos OS versión 18.4R1, se admite una combinación de tarjetas SPC3 y SPC2 en dispositivos de línea SRX5000.
Si va a agregar las tarjetas SPC3 en SRX5000 línea de dispositivos, la nueva tarjeta SPC3 debe instalarse en la ranura con el número más bajo de cualquier SPC. La tarjeta SPC3 instalada en la ranura original con el número más bajo proporciona la funcionalidad de punto central (CP) en modo mixto. Por ejemplo, si la puerta de enlace de servicios contiene una combinación de tarjetas SPC2 y SPC3, una SPC3 debe ocupar la ranura con el número más bajo de cualquier SPC del chasis. Esta configuración garantiza que la funcionalidad de punto central (CP) en modo mixto la realice la tarjeta SPC3.
En los dispositivos de línea SRX5000 que funcionan en modo mixto, el procesamiento de flujo se comparte entre las tarjetas SPC3 y SPC2. El procesamiento de puntos centrales tiene lugar en la ranura SPC de número más bajo para la que está instalada una tarjeta SPC3.
Cuando los firewalls de la serie SRX funcionan en modo de clúster de chasis, las tarjetas SPC3 y SPC2 deben instalarse en las mismas ubicaciones de ranura en cada chasis.
- Descripción de la arquitectura de software SPC3
- Descripción de la distribución de carga
- Descripción de la descarga de sesión y servicio (SOF) de NP
- Descripción de la compatibilidad con J-Flow en SPC3
- Descripción de la compatibilidad con SPU de depuración de rutas de datos (E2E)
- Descripción del manejo de la fragmentación, la compatibilidad con ISSU e ISHU
Descripción de la arquitectura de software SPC3
La arquitectura de flujo SPC3 es la misma que la arquitectura CP-Lite. La SPC3 tiene físicamente dos unidades de procesamiento de servicios (SPU) y cada SPU tiene dos CPU.
Cuando instala una o dos SPC3, el procesamiento del tráfico utiliza el 75% de la primera SPC. Cuando instala tres o más SPC3, el procesamiento de tráfico utiliza el 50% de la primera SPC.
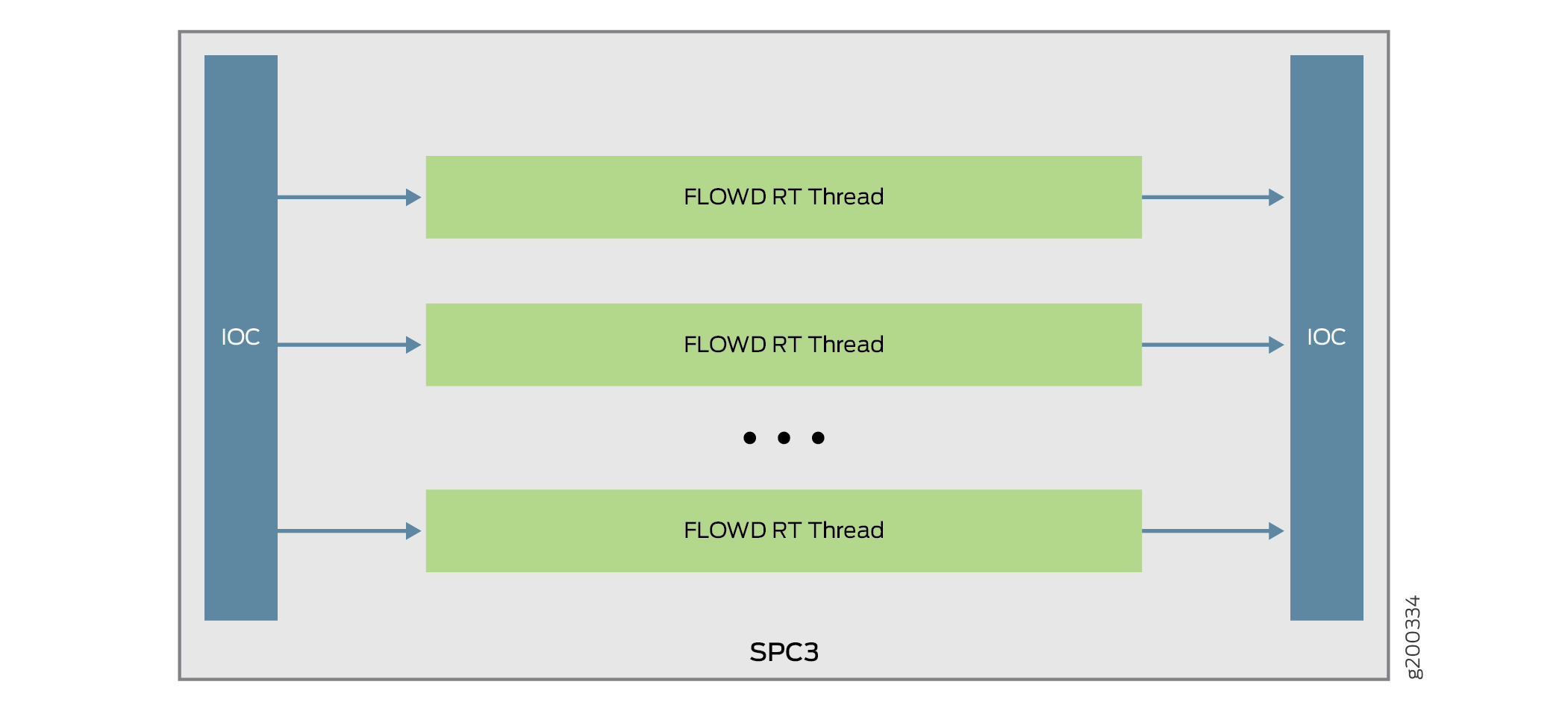
Se cambia la forma en que el COI aplica un algoritmo hash a los paquetes para procesar el flujo. La figura muestra el flujo de paquetes del firewall de la serie SRX con SPC3.
En SPC3, los paquetes se distribuyen directamente desde IOC a cada núcleo. Dado que la COI aplica directamente un algoritmo hash de paquetes al subproceso RT fluido, se elimina el subproceso LBT original. Los paquetes ahora se entregan al subproceso fluido en lugar de SPU. Si el flujo de seguridad instala sesiones NP, en lugar del ID de SPU, la COI utiliza el ID de subproceso de sesión para reenviar paquetes para corregir el subproceso asociado con la sesión.
 fluido
fluido
Descripción de la distribución de carga
Todos los paquetes que lleguen a través de un puerto de ingresos se distribuirán a diferentes SPU según el algoritmo hash, que es el mismo que el hash existente de los dispositivos de línea SRX5000 basado en la arquitectura CP-Lite. El método hash varía según los distintos tipos de tráfico. En la tabla siguiente se enumeran los métodos hash.
Protocolo |
Puertos |
Hash (método) |
|
|---|---|---|---|
TCP
|
Puerto SRC L4 y puerto DST |
Hash por 5-tupla |
|
UDP |
Normal |
Puerto SRC L4 y puerto DST |
Hash por 5-tupla |
GTP |
Puerto SRC L4 y puerto DST |
Hash por 5-tupla |
|
IKE |
Puerto SRC L4 y puerto DST
|
Hashed por par IP |
|
ICMP |
|
La información de ICMP se codifica con 5 tuplas; El error ICMP es hash por 3-tupla (sin información de puertos) |
|
SCTP |
Puerto SRC L4 y puerto DST |
Hash por 5-tupla |
|
ESP |
SPI |
Hashed por par IP |
|
AH |
SPI |
Hashed por par IP |
|
GRE |
Si PPTP alg está habilitado, sport = id de llamada; dport = 0 De forma predeterminada, el puerto es 0x00010001 |
Hash por 3-tupla |
|
PIM |
De forma predeterminada, los puertos PIM 0x00010001 |
Hash por 3-tupla |
|
FRAGMENTO |
Primer fragmento, tiene los puertos normales Ninguno primer fragmento, sin puertos |
Hash por 3-tupla |
|
Otro paquete IP |
Puertos 0x00010001 |
Hash por 3-tupla |
|
NINGUNA IP |
No aplica |
Hash por dirección Mac y tipo de Ethernet (ID de Vlan) |
|
Descripción de la descarga de sesión y servicio (SOF) de NP
La sesión de procesador de red (NP) es una sesión basada en IOC que permite y establece las sesiones SPU. Los paquetes que pasan la sesión NP tienen las siguientes ventajas:
Evita la búsqueda de sesión en SPU para obtener un mejor rendimiento.
Evita el reenvío de paquetes adicionales entre la SPU de sesión y la SPU hash.
La descarga de servicio es un tipo especial de sesión NP para proporcionar una función de baja latencia para la sesión que necesita un servicio básico de firewall. Los paquetes que llegan a la sesión SOF en una IOC omiten el procesamiento de paquetes en SPU y son reenviados directamente por IOC. Los siguientes tipos de tráfico admiten la descarga de servicios:
Firewall básico (sin plugin ni fragmentos), TCP IPv4 e IPv6, tráfico UDP
TDR IPv4
1 multidifusión de entrada y 1 entrada y salida de ventilador
ALG como sesión de datos FTP
Descripción de la compatibilidad con J-Flow en SPC3
J-Flow es la versión de Juniper del mecanismo de monitoreo de tráfico estándar de la industria. Proporciona una función para exportar instantáneas de las estadísticas de tráfico de red al servidor remoto para el monitoreo de la red y el procesamiento de datos adicionales. J-Flow es compatible con los formatos v5, v8 y v9. Todas estas tres versiones son compatibles con SPC3.
Descripción de la compatibilidad con SPU de depuración de rutas de datos (E2E)
La depuración de ruta de datos proporciona una característica de depuración de paquetes de extremo a extremo (E2E) basada en filtros en dispositivos SRX5000 Line. Rastrea la ruta del paquete y volca el contenido del paquete.
En SPC3, JEXEC es el único tipo de evento E2E que se admite y se admiten los siguientes tipos de acción E2E:
Contar
Vertedero
Rastro
Resumen de trazas
Descripción del manejo de la fragmentación, la compatibilidad con ISSU e ISHU
En SPC3, los paquetes fragmentados se reenvían al "núcleo de fragmento" en un PFE específico basado en sus valores de tupla de encabezado. Después de recibir un paquete fragmentado, flow realiza la desfragmentación y reenvía el paquete a su núcleo de sesión. La lógica de flujo no cambia y sigue siendo la misma.
Mientras se realiza la ISSU, las SPU virtuales se sincronizan con identificadores de SPU virtuales relacionados. El soporte de ISHU se basa en la arquitectura CP-Lite. Básicamente, se admiten dos operaciones ISHU:
Inserte una nueva SPC en el nodo secundario.
Reemplace una SPC en el nodo secundario y el número de SPC debe ser el mismo que el del nodo principal.
Tabla de historial de cambios
La compatibilidad con las funciones viene determinada por la plataforma y la versión que esté utilizando. Utilice el Explorador de características para determinar si una característica es compatible con su plataforma.