Descripción general del BGP
Descripción de BGP
El BGP es un protocolo de puerta de enlace exterior (EGP) que se usa para intercambiar información de enrutamiento entre enrutadores de diferentes sistemas autónomos (AS). La información de enrutamiento del BGP incluye la ruta completa a cada destino. BGP utiliza la información de enrutamiento para mantener una base de datos de información de accesibilidad de la red, que intercambia con otros sistemas BGP. El BGP usa la información de accesibilidad de la red para crear un gráfico de conectividad del AS, lo que permite al BGP eliminar los bucles de enrutamiento y aplicar las políticas del nivel del AS.
Las extensiones de BGP multiprotocolo (MBGP) permiten que BGP admita la versión 6 de IP (IPv6). MBGP define los atributos MP_REACH_NLRI y MP_UNREACH_NLRI, que se utilizan para transportar la información de accesibilidad de IPv6. Los mensajes de actualización de información de accesibilidad de la capa de red (NLRI) contienen prefijos de direcciones IPv6 de rutas factibles.
BGP permite el enrutamiento basado en políticas. Puede utilizar políticas de enrutamiento para elegir entre varias rutas a un destino y para controlar la redistribución de la información de enrutamiento.
El BGP utiliza TCP como protocolo de transporte, utilizando el puerto 179 para establecer conexiones. La ejecución sobre un protocolo de transporte confiable elimina la necesidad de que el BGP implemente la fragmentación de actualizaciones, la retransmisión, el reconocimiento y la secuenciación.
El software de protocolo de enrutamiento de Junos OS es compatible con la versión 4 del BGP. Esta versión de BGP agrega compatibilidad con el enrutamiento interdominio sin clase (CIDR), lo que elimina el concepto de clases de red. En lugar de asumir qué bits de una dirección representan la red observando el primer octeto, CIDR le permite especificar explícitamente el número de bits en la dirección de red, lo que proporciona un medio para disminuir el tamaño de las tablas de enrutamiento. La versión 4 del BGP también es compatible con la agregación de rutas, incluida la agregación de rutas de AS.
En esta sección se tratan los siguientes temas:
- Sistemas autónomos
- Rutas de AS y atributos
- BGP externo e interno
- Varias instancias de BGP
- Permitir tráfico de protocolo para interfaces en una zona de seguridad
Sistemas autónomos
Un sistema autónomo (AS) es un conjunto de enrutadores que están bajo una sola administración técnica y normalmente usan un único protocolo de puerta de enlace interior y un conjunto común de métricas para propagar la información de enrutamiento dentro del conjunto de enrutadores. Para otros AS, un AS parece tener un único plan de enrutamiento interior coherente y presenta una imagen coherente de los destinos a los que se puede llegar a través de él.
Rutas de AS y atributos
La información de enrutamiento que intercambian los sistemas BGP incluye la ruta completa a cada destino, así como información adicional sobre la ruta. La ruta del AS es la secuencia de sistemas autónomos que atravesó la ruta, y se incluye información adicional de la ruta en los atributos de la ruta. El BGP usa la ruta del AS y los atributos de ruta para determinar por completo la topología de la red. Una vez que el BGP entiende la topología, puede detectar y eliminar bucles de enrutamiento, así como seleccionar entre grupos de rutas para aplicar las preferencias administrativas y las decisiones de la política de enrutamiento.
BGP externo e interno
El BGP admite dos tipos de intercambios de información de enrutamiento: intercambios entre diferentes AS e intercambios dentro de un solo AS. Cuando se usa en AS, el BGP se denomina BPG externo (EBGP) y las sesiones de BGP llevan a cabo enrutamiento entre AS. Cuando se usa en un AS, el BGP se denomina BGP interno (IBGP) y las sesiones de BGP llevan a cabo enrutamiento intra-AS. La figura 1 ilustra AS, IBGP y EBGP.
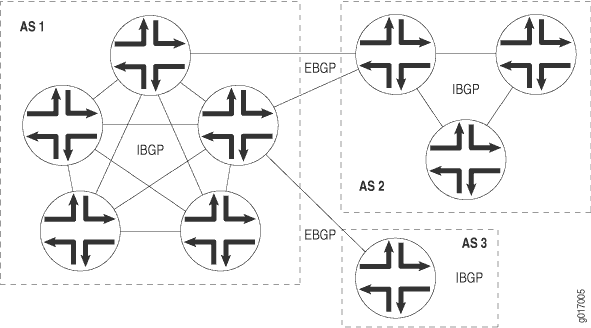
Un sistema BGP comparte información de accesibilidad de la red con los sistemas BGP adyacentes, a los que se hace referencia como vecinos o pares.
Los sistemas BGP están organizados en grupos. En un grupo de IBGP, todos los pares del grupo (denominados pares internos) están en el mismo AS. Los pares internos pueden estar en cualquier parte del AS local y no tienen que estar directamente conectados entre sí. Los grupos internos utilizan rutas de un IGP para resolver direcciones de reenvío. También propagan rutas externas entre todos los demás enrutadores internos que ejecutan IBGP, calculando el siguiente salto tomando el próximo salto del BGP recibido con la ruta y resolviéndolo utilizando información de uno de los protocolos de puerta de enlace interiores.
En un grupo EBGP, los pares del grupo (denominados pares externos) están en AS distintos y por lo general comparten una subred. En un grupo externo, el siguiente salto se calcula con respecto a la interfaz que se comparte entre el par externo y el enrutador local.
Varias instancias de BGP
Puede configurar varias instancias de BGP en los siguientes niveles jerárquicos:
-
[edit routing-instances routing-instance-name protocols] -
[edit logical-systems logical-system-name routing-instances routing-instance-name protocols]
Varias instancias de BGP se utilizan principalmente para la compatibilidad con VPN de capa 3.
Los pares IGP y los pares BGP externos (EBGP) (tanto multisalto como multisalto) son compatibles con las instancias de enrutamiento. El emparejamiento de BGP se establece en una de las interfaces configuradas en la jerarquía de instancias de enrutamiento .
Cuando un vecino de BGP envía mensajes de BGP al dispositivo de enrutamiento local, la interfaz entrante en la que se reciben estos mensajes debe configurarse en la misma instancia de enrutamiento en la que existe la configuración del vecino de BGP. Esto es cierto para los vecinos que están a un solo salto o a varios saltos de distancia.
Las rutas aprendidas del par BGP se agregan a la tabla instance-name.inet.0 de forma predeterminada. Puede configurar políticas de importación y exportación para controlar el flujo de información que entra y sale de la tabla de enrutamiento de instancias.
Para la compatibilidad con VPN de capa 3, configure el BGP en el enrutador perimetral del proveedor (PE) para recibir rutas del enrutador perimetral del cliente (CE) y enviar las rutas de las instancias al enrutador CE si es necesario. Puede utilizar varias instancias de BGP para mantener tablas de reenvío por sitio independientes para mantener el tráfico VPN separado en el enrutador de PE.
Puede configurar políticas de importación y exportación que permitan al proveedor de servicios controlar y limitar la velocidad del tráfico hacia y desde el cliente.
Puede configurar una sesión de múltiples saltos de EBGP para una instancia de enrutamiento VRF. Además, puede configurar el par EBGP entre los enrutadores PE y CE utilizando la dirección de circuito cerrado del enrutador CE en lugar de las direcciones de interfaz.
Permitir tráfico de protocolo para interfaces en una zona de seguridad
En los firewalls de la serie SRX, debe habilitar el tráfico de entrada de host esperado en las interfaces especificadas o en todas las interfaces de la zona. De lo contrario, el tráfico entrante destinado a este dispositivo se elimina de forma predeterminada.
Por ejemplo, para permitir el tráfico del BGP en una zona específica del firewall de la serie SRX, siga estos pasos:
[edit]
user@host# set security zones security-zone trust host-inbound-traffic protocols bgp
[edit]
user@host# set security zones security-zone trust interfaces ge-0/0/1.0 host-inbound-traffic protocols bgp
Ver también
Descripción general de rutas de BGP
Una ruta de BGP es un destino, descrito como un prefijo de dirección IP, e información que describe la ruta al destino.
En la siguiente información se describe la ruta de acceso:
Ruta de AS, que es una lista de números del AS que una ruta pasa para llegar al enrutador local. El primer número de la ruta es el del último AS de la ruta, el AS más cercano al enrutador local. El último número de la ruta de acceso es el AS más alejado del enrutador local, que generalmente es el origen de la ruta de acceso.
Los atributos de ruta que contienen información adicional acerca de la ruta del AS que se usa en la política de enrutamiento.
Los pares del BGP anuncian rutas entre sí en los mensajes de actualización.
El BGP almacena sus rutas en la tabla de enrutamiento de Junos OS (inet.0). La tabla de enrutamiento almacena la siguiente información acerca de las rutas del BGP:
Información de enrutamiento aprendida de los mensajes de actualización recibidos de los pares
Información de enrutamiento local que el BGP aplica a las rutas debido a políticas locales
Información que el BGP anuncia a los pares del BGP en los mensajes de actualización
Para cada prefijo de la tabla de enrutamiento, el proceso de protocolo de enrutamiento selecciona una única mejor ruta, denominada ruta activa. A menos que configure el BGP para anunciar varias rutas al mismo destino, el BGP anuncia solo la ruta activa.
El enrutador BGP que anuncia primero una ruta le asigna uno de los siguientes valores para identificar su origen. Durante la selección de ruta, se prefiere el valor de origen más bajo.
0: el enrutador aprendió originalmente la ruta mediante un IGP (OSPF, SI-SI o una ruta estática).
1: el enrutador aprendió originalmente la ruta mediante un EGP (muy probablemente BGP).
2: se desconoce el origen de la ruta.
Ver también
Descripción general de la resolución de rutas de BGP
Una ruta interna de BGP (IBGP) con una dirección de próximo salto a un vecino de BGP remoto (protocolo de próximo salto) debe tener su próximo salto resuelto mediante otra ruta. El BGP agrega esta ruta al módulo de resolución rpd para la resolución del siguiente salto. Si se usa RSVP en la red, el siguiente salto del BGP se resuelve mediante la ruta de entrada RSVP. Esto da como resultado que la ruta del BGP apunte a un próximo salto indirecto y el próximo salto indirecto apunte a un próximo salto de reenvío. El próximo salto de reenvío se deriva del próximo salto de ruta RSVP. A menudo hay un gran conjunto de rutas internas de BGP que tienen el mismo protocolo del próximo salto y, en tales casos, el conjunto de rutas del BGP haría referencia al mismo próximo salto indirecto.
Antes de la versión 17.2R1 de Junos OS, el módulo de resolución del proceso de protocolo de enrutamiento (RPD) resolvía las rutas dentro del IBGP de las siguientes maneras:
Resolución parcial de ruta: el siguiente salto de protocolo se resuelve en función de rutas auxiliares, como rutas RSVP o IGP. Los valores de métrica se derivan de las rutas auxiliares y el siguiente salto se denomina el siguiente salto de reenvío de resolución heredado de las rutas auxiliares. Estos valores de métrica se utilizan para seleccionar rutas en la base de información de enrutamiento (RIB), también conocida como tabla de enrutamiento.
Resolución de ruta completa: se deriva el siguiente salto final y se denomina próximo salto de reenvío de la tabla de enrutamiento de kernel (KRT) según la política de exportación de reenvío.
A partir de Junos OS versión 17.2R1, el módulo de resolución de rpd está optimizado para aumentar la transferencia de datos del flujo de procesamiento entrante, acelerando la tasa de aprendizaje de RIB y FIB. Con esta mejora, la resolución de la ruta se ve afectada de la siguiente manera:
Los métodos de resolución de rutas parcial y completa se activan para cada ruta de IBGP, aunque cada ruta puede heredar el mismo próximo salto de reenvío resuelto o los siguientes saltos de reenvío KRT.
La selección de la ruta del BGP se aplaza hasta que se realice una resolución completa de la ruta para la información de accesibilidad de la capa de red (NLRI) recibida de un vecino del BGP, que podría no ser la mejor ruta en la RIB después de la selección de ruta.
Los beneficios de la optimización del solucionador rpd incluyen:
Menor costo de búsqueda de resolución RIB: la salida de la ruta resuelta se guarda en una caché de resolución, de modo que los mismos valores de métrica y próximo salto derivados se pueden heredar a otro conjunto de rutas que comparten el mismo comportamiento de ruta en lugar de realizar un flujo de resolución de ruta parcial y completo. Esto reduce el costo de búsqueda de resolución de ruta al mantener solo el estado de resolución más frecuente en una caché con profundidad limitada.
Optimización de la selección de rutas del BGP: el algoritmo de selección de rutas del BGP se activa dos veces por cada ruta de IBGP recibida: primero, mientras se agrega la ruta en el RIB con el siguiente salto como inutilizable y, segundo, mientras se agrega la ruta con un siguiente salto resuelto en el RIB (después de la resolución de ruta). Esto da como resultado la selección de la mejor ruta dos veces. Con la optimización del solucionador, el proceso de selección de ruta se activa en el flujo de recepción solo después de obtener la información del siguiente salto del módulo del solucionador.
Almacenamiento en caché interno para evitar búsquedas frecuentes: la caché de resolución mantiene el estado de resolución más frecuente y, como resultado, la funcionalidad de búsqueda, como la búsqueda de salto siguiente y la búsqueda de ruta, se realiza desde la caché local.
Grupo de equivalencia de ruta: cuando diferentes rutas comparten el mismo estado de reenvío o se reciben del mismo protocolo en el siguiente salto, las rutas pueden pertenecer a un grupo de equivalencia de ruta. Este enfoque evita la necesidad de realizar una resolución de ruta completa para dichas rutas. Cuando una ruta nueva requiere una resolución de ruta completa, primero se busca en la base de datos del grupo de equivalencia de ruta, la cual contiene la salida de ruta resuelta, como el próximo salto indirecto y el próximo salto de reenvío.
Ver también
Descripción general de los mensajes BGP
Todos los mensajes BGP tienen el mismo encabezado de tamaño fijo, que contiene un campo de marcador que se usa tanto para la sincronización como para la autenticación, un campo de longitud que indica la longitud del paquete y un campo de tipo que indica el tipo de mensaje (por ejemplo, abrir, actualizar, notificación, mantener alive, etc.).
En esta sección se tratan los siguientes temas:
- Mensajes abiertos
- Mensajes de actualización
- Mensajes de Keepalive
- Mensajes de notificación
- Mensajes de actualización de ruta
Mensajes abiertos
Después de establecer una conexión TCP entre dos sistemas BGP, intercambian mensajes abiertos de BGP para crear una conexión BGP entre ellos. Una vez que se establece la conexión, los dos sistemas pueden intercambiar mensajes BGP y tráfico de datos.
Los mensajes abiertos constan del encabezado BGP más los siguientes campos:
Versión: el número de versión actual del BGP es 4.
Número de AS local: esto se configura incluyendo la
autonomous-systeminstrucción en el nivel de[edit routing-options]jerarquía o[edit logical-systems logical-system-name routing-options].Tiempo de espera: valor de tiempo de espera propuesto. El tiempo de espera local se configura con la instrucción BGP
hold-time.Identificador BGP: dirección IP del sistema BGP. Esta dirección se determina cuando se inicia el sistema y es la misma para cada interfaz local y cada par BGP. Puede configurar el identificador de BGP incluyendo la
router-idinstrucción en el nivel de[edit routing-options]jerarquía o[edit logical-systems logical-system-name routing-options]. De forma predeterminada, el BGP utiliza la dirección IP de la primera interfaz que encuentra en el enrutador.Longitud del campo de parámetro y el propio parámetro: estos son campos opcionales.
Mensajes de actualización
Los sistemas BGP envían mensajes de actualización para intercambiar información de accesibilidad de la red. Los BGP usan esta información para crear un gráfico que describa las relaciones que existen entre todos los AS conocidos.
Los mensajes de actualización constan del encabezado BGP más los siguientes campos opcionales:
Longitud de rutas inviables: longitud del campo de rutas retiradas
Rutas retiradas: prefijos de dirección IP para las rutas que se retiran del servicio porque ya no se consideran accesibles
Longitud total del atributo de ruta: longitud del campo de atributos de ruta; Enumera los atributos de ruta para una ruta factible a un destino
Atributos de ruta: propiedades de las rutas, incluido el origen de la ruta, el discriminador de salida múltiple (MED), la preferencia del sistema de origen por la ruta e información sobre agregación, comunidades, confederaciones y reflexión de rutas
Información de accesibilidad de la capa de red (NLRI): prefijos de direcciones IP de rutas factibles que se anuncian en el mensaje de actualización
Mensajes de Keepalive
Los sistemas BGP intercambian mensajes de keepalive para determinar si un vínculo o host falló o ya no está disponible. Los mensajes de Keepalive se intercambian con la frecuencia suficiente para que el temporizador de espera no caduque. Estos mensajes solo contienen el encabezado BGP.
Mensajes de notificación
Los sistemas BGP envían mensajes de notificación cuando se detecta una condición de error. Una vez enviado el mensaje, se cierran la sesión del BGP y la conexión TCP entre los sistemas del BGP. Los mensajes de notificación constan del encabezado del BGP más el código y subcódigo de error, y los datos que describen el error.
Mensajes de actualización de ruta
Los sistemas BGP envían mensajes de actualización de rutas a un par solo si han recibido el anuncio de la capacidad de actualización de rutas del par. Un sistema BGP debe anunciar la capacidad de actualización de ruta a sus pares mediante el anuncio de capacidades de BGP si desea recibir mensajes de actualización de ruta. Este mensaje opcional se envía para solicitar actualizaciones de ruta dinámicas y entrantes de BGP a pares BGP o para enviar actualizaciones de ruta saliente a un par BGP.
Los mensajes de actualización de ruta constan de los siguientes campos:
AFI: identificador de familia de direcciones (16 bits).
Res: campo reservado (8 bits), que el remitente debe establecer en 0 y el receptor debe ignorar.
SAFI: identificador de familia de direcciones posterior (8 bits).
Si un par sin la capacidad de actualización de ruta recibe un mensaje de solicitud de actualización de ruta de un par remoto, el receptor ignora el mensaje.
Ver también
Descripción del particionamiento de RIB de BGP y el subproceso de E/S de actualización de BGP
El procesamiento de rutas de BGP suele tener varias etapas de canalización, como recibir la actualización, analizar la actualización, crear ruta, resolver el próximo salto, aplicar la política de exportación de un grupo de par BGP, formar actualizaciones por par y enviar actualizaciones a los pares.
El particionamiento de BGP RIB divide un BGP RIB unificado en varios sub-RIB y cada sub-RIB maneja un subconjunto de rutas de BGP. Un subproceso RPD independiente denominado subproceso de partición BGP sirve a cada sub-RIB para lograr la simultaneidad. Los subprocesos de partición del BGP son responsables de todas las etapas de la canalización de procesamiento de rutas del BGP, con la excepción de formar actualizaciones por par y enviar actualizaciones a los pares. Los subprocesos de partición del BGP reciben las actualizaciones enviadas por los pares de los subprocesos de E/S de actualización del BGP con los subprocesos de E/S de actualización del BGP aplicando un hash a los prefijos de las actualizaciones y envía las actualizaciones a los subprocesos de partición del BGP aplicables en función del cálculo del hash. El subproceso de partición del BGP procesa la configuración de la misma manera que el subproceso principal de RPD, crea pares, grupos, tablas de rutas y usa la información de configuración para el procesamiento de rutas del BGP.
Actualización de BGP Los subprocesos de E/S son responsables del final de esta canalización de BGP, lo que implica generar actualizaciones por par para grupos de BGP individuales y enviarlas al par o pares. Un subproceso de actualización puede servir a uno o varios grupos BGP. Los subprocesos de E/S de actualización de BGP crean actualizaciones para grupos en paralelo e independientemente de otros grupos a los que otros subprocesos de actualización atienden. Esto podría ofrecer una mejora significativa de la convergencia en una carga de trabajo de escritura pesada, que implica publicidad a muchos pares repartidos en muchos grupos. Los subprocesos de E/S de actualización de BGP también son responsables de escribir y leer desde los sockets TCP de los pares de BGP, que anteriormente proporcionaban los subprocesos de BGPIO (de ahí el sufijo E/S en E/S de actualización de BGP).
Los subprocesos de E/S de actualización de BGP se pueden configurar independientemente de la función de particionamiento de RIB, pero su uso es obligatorio con el particionamiento de RIB, a fin de lograr una mejor eficiencia de empaquetado de prefijos en mensajes de actualización de BGP salientes. El particionamiento de BGP divide el RIB en varios sub RIB que son servidos por subprocesos RPD separados. Por lo tanto, los prefijos que podrían haber entrado en una sola actualización saliente terminan en diferentes fragmentos. Para poder crear actualizaciones de BGP con prefijos con el mismo atributo saliente que podrían pertenecer a diferentes subprocesos de partición RPD, todos los subprocesos de partición envían información de anuncio compacta para que los prefijos se anuncien a un subproceso de actualización que sirva a ese grupo de par BGP. Esto permite que el subproceso de actualización que sirve a este grupo par BGP empaquete prefijos con los mismos atributos, que potencialmente pertenezcan a diferentes particiones en el mismo mensaje de actualización saliente. Esto minimiza el número de actualizaciones que se anuncian y, por lo tanto, ayuda a mejorar la convergencia. El subproceso de E/S de actualización gestiona las cachés locales de los contenedores de pares, grupos, prefijos, TSI y RIB.
El subproceso de actualización de BGP y el particionamiento de BGP RIB están deshabilitados de forma predeterminada. Si configura el enhebrado de actualización y el particionamiento de costillas en un motor de enrutamiento, RPD crea subprocesos de actualización. De forma predeterminada, la cantidad de subprocesos de actualización y subprocesos de partición creados es la misma que la cantidad de núcleos de CPU en el motor de enrutamiento. El subproceso de actualización solo se admite en un proceso de protocolo de enrutamiento (RPD) de 64 bits. Opcionalmente, puede especificar el número de subprocesos que desea crear mediante set update-threading <number-of-threads> instrucciones and set rib-sharding <number-of-threads> en el [edit system processes routing bgp] nivel de jerarquía. Para el subproceso de actualización de BGP, el intervalo es actualmente de 1 a 128 y para el particionamiento de RIB de BGP, el intervalo es actualmente de 1 a 31.
Cuando se configura NSR para las funciones de particionamiento de RIB de BGP y E/S de actualización de BGP, el RPD de respaldo crea el mismo número de subprocesos de partición de BGP y E/S de actualización de BGP en el motor de enrutamiento de respaldo. Los subprocesos de E/S de actualización de BGP RPD de respaldo leen la actualización de BGP replicada, otros mensajes recibidos de los pares, así como la actualización de BGP replicada y otros mensajes enviados a los pares. Según el hash de prefijos, los subprocesos de E/S de actualización de BGP RPD de respaldo envían estos mensajes BGP al fragmento de BGP aplicable y a los subprocesos principales de RPD. La partición del BGP y los subprocesos principales de RPD en el RPD de respaldo crean el estado de ruta recibida y anunciada mediante estos mensajes de BGP replicados. Cuando se produce un error en el motor de enrutamiento principal, el motor de enrutamiento de respaldo se convierte en el motor de enrutamiento principal y el RPD de respaldo se convierte en el RPD principal sin problemas sin afectar las sesiones del BGP con los pares.
Descripción de la selección de ruta de BGP
Para cada prefijo de la tabla de enrutamiento, el proceso de protocolo de enrutamiento selecciona una única mejor ruta. Después de seleccionar la mejor ruta, la ruta se instala en la tabla de enrutamiento. La mejor ruta se convierte en la ruta activa si un protocolo no aprende el mismo prefijo con un valor de preferencia global más bajo (más preferido), también conocido como distancia administrativa. El algoritmo para determinar la ruta activa es el siguiente:
-
Compruebe que se puede resolver el siguiente salto.
-
Elija la ruta con el valor de preferencia más bajo (preferencia de proceso de protocolo de enrutamiento).
Las rutas que no son aptas para usarse para el reenvío (por ejemplo, porque fueron rechazadas por la política de enrutamiento o porque no se puede acceder a un salto siguiente) tienen una preferencia de –1 y nunca se eligen.
-
Prefiera la ruta con mayor preferencia local.
Para rutas que no sean de BGP, elija la ruta con el valor de preferencia 2 más bajo.
-
Si el atributo protocolo de puerta de enlace interior acumulado (AIGP) está habilitado, agregue la métrica IGP y prefiera la ruta con el atributo AIGP inferior.
-
Prefiera la ruta con el valor de ruta del sistema autónomo (AS) más corto (omitido si la
as-path-ignoreinstrucción está configurada).Un segmento de confederación (secuencia o conjunto) tiene una longitud de ruta de 0. Un conjunto de AS tiene una longitud de ruta de 1.
-
Prefiera la ruta con el código de origen más bajo.
Las rutas aprendidas de un IGP tienen un código de origen más bajo que las aprendidas de un protocolo de puerta de enlace exterior (EGP), y ambas tienen códigos de origen más bajos que las rutas incompletas (rutas cuyo origen se desconoce).
-
Prefiera la ruta con la métrica más baja de discriminador de salida múltiple (MED).
Dependiendo de si se configura el comportamiento de selección de ruta de la tabla de enrutamiento no determinista, hay dos casos posibles:
-
Si no se configura el comportamiento de selección de ruta de la tabla de enrutamiento no determinista (es decir, si la
path-selection cisco-nondeterministicinstrucción no se incluye en la configuración del BGP), para las rutas con los mismos números de AS vecinos en la parte frontal de la ruta del AS, prefiera la ruta con la métrica MED más baja. Para comparar siempre los MED, independientemente de si el par de AS de los enrutadores comparados son las mismas, incluya lapath-selection always-compare-medinstrucción. -
Si se configura un comportamiento de selección de ruta de tabla de enrutamiento no determinista (es decir, la
path-selection cisco-nondeterministicinstrucción se incluye en la configuración del BGP), prefiera la ruta con la métrica MED más baja.
Las confederaciones no se tienen en cuenta al determinar los AS vecinos. Una métrica MED faltante se trata como si hubiera un MED presente, pero cero.
Nota:La comparación de MED funciona para la selección de una sola ruta dentro de un AS (cuando la ruta no incluye una ruta de AS), aunque este uso es poco común.
De forma predeterminada, solo se comparan las MED de los enrutadores que tengan los mismos sistemas autónomos par (AS). Puede configurar opciones de selección de ruta de la tabla de enrutamiento para obtener diferentes comportamientos.
-
-
Prefiera rutas estrictamente internas, que incluyen rutas IGP y rutas generadas localmente (estáticas, directas, locales, etc.).
-
Prefiera rutas de BGP estrictamente externas (EBGP) a rutas externas aprendidas a través de sesiones internas de BGP (IBGP).
-
Prefiera la ruta cuyo próximo salto se resuelva a través de la ruta IGP con la métrica más baja. Las rutas BGP que se resuelven a través de IGP son preferibles a las rutas inalcanzables o rechazadas.
Nota:Una ruta se considera una ruta de BGP de igual costo (y se usará para el reenvío) si se realiza un desempate después del paso anterior. Se tienen en cuenta todas las rutas en con los mismos AS vecinos aprendidas por un vecino de BGP habilitado para multirruta.
La multirruta BGP no se aplica a rutas que comparten el mismo costo de MED-plus-IGP, pero difieren en el costo de IGP. La selección de rutas múltiples se basa en la métrica de costo IGP, incluso si dos rutas tienen el mismo costo MED más IGP.
-
Si ambas rutas son externas, prefiera la ruta más antigua, en otras palabras, la ruta que se aprendió primero. Esto se hace para minimizar la oscilación de rutas. Esta regla no se utiliza si se cumple alguna de las siguientes condiciones:
-
path-selection external-enrutador-id está configurado.
-
Ambos pares tienen el mismo ID de enrutador.
-
Cualquiera de los pares es un par de confederación.
-
Ninguna de las rutas es la ruta activa actual.
-
-
Prefiera la ruta del par con el ID de enrutador más bajo. Para cualquier ruta con un atributo de ID de originador, sustituya el ID del enrutador por el ID de originador durante la comparación del ID del enrutador.
-
Prefiera la ruta con la longitud de lista de clústeres más corta. La longitud es 0 para ninguna lista.
-
Prefiera la ruta del par con la dirección IP del par más baja.
-
Prefiera una ruta principal a una ruta secundaria. Una ruta principal es aquella que pertenece a la tabla de enrutamiento. Una ruta secundaria es aquella que se agrega a la tabla de enrutamiento mediante una política de exportación.
- Selección de ruta de tabla de enrutamiento
- Selección de ruta de la tabla BGP
- Efectos de anunciar múltiples rutas a un destino
Selección de ruta de tabla de enrutamiento
El paso de ruta de AS más corto del algoritmo, de forma predeterminada, evalúa la longitud de la ruta de AS y determina la ruta activa. Puede configurar una opción que permita a Junos OS omitir este paso del algoritmo si incluye la opción as-path-ignor.
A partir de Junos OS versión 14.1R8, 14.2R7, 15.1R4, 15.1F6 y 16.1R1, la opción as-path-ignore se admite para instancias de enrutamiento.
La selección de la ruta del proceso de enrutamiento tiene lugar antes de que el BGP entregue la ruta a la tabla de enrutamiento para que tome su decisión. Para configurar el comportamiento de selección de ruta de la tabla de enrutamiento, incluya la path-selection instrucción:
path-selection { (always-compare-med | cisco-non-deterministic | external-router-id); as-path-ignore; l2vpn-use-bgp-rules; med-plus-igp { igp-multiplier number; med-multiplier number; } }
Para obtener una lista de los niveles de jerarquía en los que puede incluir esta instrucción, consulte la sección Resumen de instrucciones para esta instrucción.
La selección de ruta de la tabla de enrutamiento se puede configurar de una de las siguientes maneras:
-
Emular el comportamiento predeterminado del IOS de Cisco (cisco-no determinista). Este modo evalúa rutas en el orden en que se reciben y no las agrupa de acuerdo con sus AS vecinos. Con
cisco-non-deterministicel modo, la ruta activa siempre es la primera. Todas las rutas inactivas, pero elegibles, siguen la ruta activa y se mantienen en el orden en que se recibieron, con la ruta más reciente primero. Las rutas no elegibles permanecen al final de la lista.Por ejemplo, supongamos que tiene tres anuncios de ruta para la ruta 192.168.1.0 /24:
-
Ruta 1: aprendida a través de EBGP; Ruta de AS de 65010; MED de 200
-
Ruta 2: aprendida a través del IBGP; Ruta de AS de 65020; MED de 150; Costo de IGP de 5
-
Ruta 3: aprendida a través de IBGP; Ruta de AS de 65010; MED de 100; Costo IGP de 10
Estos anuncios se reciben en rápida sucesión, en un segundo, en el orden indicado. La ruta 3 se recibe más recientemente, por lo que el dispositivo enrutador la compara con la ruta 2, el siguiente anuncio más reciente. El costo para el par del IBGP es mejor para la ruta 2, por lo que el dispositivo de enrutamiento elimina la ruta 3 de la contención. Cuando se comparan las rutas 1 y 2, el dispositivo de enrutamiento prefiere la ruta 1 porque se recibe de un par EBGP. Esto permite que el dispositivo de enrutamiento instale la ruta 1 como la ruta activa de la ruta.
Nota:No recomendamos usar esta opción de configuración en su red. Se proporciona únicamente con fines de interoperabilidad para permitir que todos los dispositivos de enrutamiento de la red realicen selecciones de ruta coherentes.
-
Siempre comparando MED sin importar si el par de AS de los enrutadores comparados son las mismas (always-compare-med).
Anule la regla de que Si ambas rutas son externas, se prefiere la ruta actualmente activa (external-enrutador-id). Continúe con el siguiente paso (paso 15) en el proceso de selección de ruta.
Agregar el costo de IGP al destino del siguiente salto al valor MED antes de comparar los valores de MED para la selección de ruta (
med-plus-igp).La multirruta BGP no se aplica a rutas que comparten el mismo costo de MED más IGP, pero difieren en el costo de IGP. La selección de rutas múltiples se basa en la métrica de costo IGP, incluso si dos rutas tienen el mismo costo MED más IGP.
Selección de ruta de la tabla BGP
Se siguen los siguientes parámetros para la selección de ruta del BGP:
-
Prefiera el valor de preferencia local más alto.
-
Prefiera la longitud de ruta de AS más corta.
-
Prefiera el valor de origen más bajo.
-
Prefiera el valor MED más bajo.
-
Prefiera las rutas aprendidas de un par de EBGP sobre un par de IBGP.
-
Prefiera la mejor salida de AS.
-
Para las rutas recibidas por EBGP, prefiera la ruta activa actual.
-
Prefiera rutas del par con el ID de enrutador más bajo.
-
Prefiera rutas con la longitud de clúster más corta.
-
Prefiera rutas del par con la dirección IP del par más baja. Los pasos 2, 6 y 12 son los criterios RPD.
Efectos de anunciar múltiples rutas a un destino
El BGP anuncia solo la ruta activa, a menos que configure el BGP para anunciar varias rutas a un destino.
Supongamos que un dispositivo de enrutamiento tiene en su tabla de enrutamiento cuatro rutas a un destino y está configurado para anunciar hasta tres rutas (add-path send path-count 3). Las tres rutas se eligen en función de los criterios de selección de rutas. Es decir, las tres mejores rutas se eligen en orden de selección de ruta. El mejor camino es el camino activo. Esta ruta se elimina de la consideración y se elige una nueva mejor ruta. Este proceso se repite hasta que se alcanza el número especificado de rutas.
Ver también
Resolución de ruta de servicio mejorada para múltiples rutas de BGP con siguiente salto de lista
Junos OS mejora la resolución de rutas de servicio para rutas auxiliares de multirruta BGP que utilizan estructuras de lista siguiente. Ahora, el solucionador de rutas crea y mantiene dependencias internas para todas las rutas contribuyentes en una ruta multirruta, lo que permite una nueva resolución precisa y dinámica cuando cambian los próximos saltos indirectos, independientemente de si la ruta contribuyente está activa o inactiva.
Esta función mejora la estabilidad de la ruta de servicio y evita rutas de reenvío obsoletas en redes que usan BGP ECMP con resolución indirecta de próximo salto.
- Beneficios
- Antes de empezar
- Cómo funciona la función
- Ejemplo operativo
- Referencia a los comandos de la CLI
- Limitaciones
Beneficios
- Mantiene un reenvío preciso para las rutas de servicio resueltas a través de la multirruta BGP.
- Activa la reresolución cuando cambia cualquier ruta contribuyente, no solo la ruta principal.
- Admite topologías híbridas de multirruta iBGP y eBGP con próximos saltos indirectos.
- Evita la pérdida de tráfico causada por estados de resolución obsoletos u obsoletos.
Antes de empezar
Asegúrese de que la instrucción del comando BGP multirruta list-nexthop esté habilitada para las familias de direcciones pertinentes. No se requiere ninguna configuración nueva para habilitar esta función.
Cómo funciona la función
Cuando una ruta de servicio se resuelve en una ruta de multirruta de BGP con un salto siguiente de lista, RPD realiza las acciones siguientes:
Camina por todos los componentes del próximo salto en la lista siguiente.
Establece relaciones de dependencia entre la ruta auxiliar de multirruta y cada ruta que contribuye.
Almacena estas dependencias en una base de datos interna utilizando una estructura de árbol de patricia. Crea estas relaciones bajo demanda:
Solo se crea una instancia de un nodo del árbol Patricia cuando la primera ruta de servicio se resuelve a través de la ruta auxiliar de multirruta.
Cuando la última ruta de servicio dependiente ya no se resuelve a través de esa ruta de multirruta, el nodo correspondiente se elimina automáticamente del árbol.
Monitorea los cambios indirectos del próximo salto mediante devoluciones de llamada de gancho KRT.
Vuelve a resolver las rutas de servicio dependientes cada vez que cambia una ruta contribuyente (activa o inactiva).
Este comportamiento se aplica independientemente de si la ruta contribuyente está activa o inactiva en el conjunto de multirrutas.
Ejemplo operativo
Escenario:
Una ruta de servicio (9.9.9.9/32) se resuelve a través de una ruta de multirruta BGP (1.1.1.9/32) con las siguientes rutas contribuyentes:
iBGP path-1(principal/activo): a través7.7.7.7de →1.2.3.4→10.50.10.1iBGP path-2: a través de8.8.8.8
Si iBGP path-2 los cambios (por ejemplo, debido a una actualización de próximo salto), Junos OS detectará el cambio y volverá a resolver la ruta de servicio dependiente.
Referencia a los comandos de la CLI
Puede utilizar los siguientes comandos para ver las relaciones de resolución list-nexthop y supervisar las dependencias de ruta de multirruta en próximos saltos indirectos.
-
show route resolution list-nhMuestra los identificadores indirectos del próximo salto (INH) en la base de datos interna de dependencias list-nexthop, junto con las rutas multirruta del BGP que dependen de ellos. Este comando sólo muestra las rutas auxiliares de multirruta utilizando un INH específico.
Ejemplo de salida:
user@router> show route resolution list-nh Indirect next-hop statistics in List-nexthop database: Inh adds: 9, Inh deletes: 4 Inh change callback: registered Indirect next-hop: Inh handle: 0x8969d30; Inh protocol nexthop: 8.8.8.8 Multipath route: 1.1.1.0/24, resolver node: 0xf9e9ed8 Indirect next-hop: Inh handle: 0x8969b98; Inh protocol nexthop: 7.7.7.7 Multipath route: 1.1.1.0/24, resolver node: 0xf9e9ed8 Multipath route: 3.3.3.0/24, resolver node: 0x8d88cb8
-
show route resolution list-nh protocol-next-hop <nexthop>Muestra todas las rutas de multirruta que utilizan un próximo salto indirecto específico.
Ejemplo:
user@router> show route resolution list-nh protocol-next-hop 9.9.9.9 Protocol Nexthop: 9.9.9.9 Used by: - Multipath Route: 1.1.1.0/24 - Multipath Route: 2.2.2.0/24 - Multipath Route: 3.3.3.0/24 -
show krt indirect-next-hopMuestra información de la tabla de rutas del kernel para un índice de próximo salto indirecto dado, incluido el número de rutas multirruta que dependen de ese próximo salto. Este comando muestra los recuentos de referencias y las dependencias de reenvío relacionadas con rutas de multirruta.
Ejemplo de salida:
user@router> show krt indirect-next-hop index 1048574 Indirect Nexthop: Index: 1048574 Protocol next-hop address: 7.7.7.7 ... INH list-nh dependent count: 2
Confirma
dependent count: 2que dos rutas multirruta están utilizando actualmente este próximo salto indirecto.
Limitaciones
- Solo se aplica a las rutas de multirruta del BGP con list-nexthops compuestos por rutas iBGP o iBGP/eBGP híbridas.
- Las rutas de multirruta de BGP con solo colaboradores de eBGP no se ven afectadas.
- No se admiten familias de direcciones mixtas en una sola lista-próximo salto.
Ver también
Estándares compatibles con BGP
Junos OS admite sustancialmente los siguientes RFC y borradores de Internet, los cuales definen estándares para el BGP de la versión 4 de IP (IPv4).
Para obtener una lista de los estándares BGP IP versión 6 (IPv6) compatibles, consulte Estándares IPv6 compatibles.
El BGP de Junos OS admite la autenticación para intercambios de protocolos (autenticación MD5).
-
RFC 1745, BGP4/IDRP para interacción IP—OSPF
-
RFC 1772, Aplicación del protocolo de puerta de enlace de frontera en Internet
-
RFC 1997, Atributo de comunidades de BGP
-
RFC 2283, Extensiones multiprotocolo para BGP-4
-
RFC 2385, Protección de sesiones de BGP a través de la opción de firma TCP MD5
-
RFC 2439, Amortiguación de flaps de ruta BGP
-
RFC 2545, Uso de extensiones multiprotocolo BGP-4 para enrutamiento entre dominios IPv6
-
RFC 2796, Reflexión de ruta BGP: una alternativa al IBGP de malla completa
-
RFC 2858, Extensiones multiprotocolo para BGP-4
-
RFC 2918, Capacidad de Actualizar de ruta para BGP-4
-
RFC 3065, Confederaciones de sistemas autónomos para BGP
-
RFC 3107, Llevar información de etiquetas en BGP-4
-
RFC 3345, Condición de oscilación de ruta persistente del Protocolo de puerta de enlace de frontera (BGP)
-
RFC 3392, Anuncio de capacidades con BGP-4
-
RFC 4271, Un protocolo de puerta de enlace de frontera 4 (BGP-4)
-
RFC 4273, Definiciones de objetos administrados para BGP-4
-
RFC 4360, Atributo de comunidades extendidas del BGP
-
RFC 4364, Redes privadas virtuales (VPN) de IP de BGP/MPLS
-
RFC 4456, Reflexión de ruta del BGP: una alternativa al BGP interno de malla completa (IBGP)
-
RFC 4486, Subcódigos para el mensaje de notificación de cese del BGP
-
RFC 4576, Uso de un bit de opciones de anuncio de estado de vínculo (LSA) para evitar bucles en redes privadas virtuales (VPN) de IP de BGP/MPLS
-
RFC 4659, Extensión de red privada virtual (VPN) IP BGP-MPLS para VPN IPv6
-
RFC 4632, Enrutamiento entre dominios sin clase (CIDR): El plan de agregación y asignación de direcciones de Internet
-
RFC 4684, Distribución de rutas restringidas para Protocolo de puerta de enlace de frontera/Conmutación de etiquetas multiprotocolo (BGP/MPLS), protocolo de Internet (IP), redes privadas virtuales (VPN)
-
RFC 4724, Mecanismo de reinicio agraciado para BGP
-
RFC 4760, Extensiones multiprotocolo para BGP-4
-
RFC 4781, Mecanismo de reinicio agraciado para BGP con MPLS
-
RFC 4798, Conexión de islas IPv6 a través de IPv4 MPLS mediante enrutadores de borde de proveedor IPv6 (6PE)
No se admite la opción 4b (redistribución de eBGP de rutas IPv6 etiquetadas de AS a AS vecinos).
-
RFC 4893, El BGP es compatible con el espacio de número de AS de cuatro octetos
-
RFC 5004, Evite las mejores transiciones de ruta de BGP de una externa a otra
-
RFC 5065, Confederaciones de sistemas autónomos para BGP
-
RFC 5082, El mecanismo de seguridad TTL generalizado (GTSM)
-
RFC 5291, Capacidad de filtrado de rutas de salida para BGP-4 (compatibilidad parcial)
-
RFC 5292, Filtro de ruta saliente basado en prefijos de dirección para BGP-4 (compatibilidad parcial)
Los dispositivos que ejecutan Junos OS pueden recibir mensajes ORF basados en prefijos.
-
RFC 5396, Representación textual de números de sistemas autónomos (AS)
-
RFC 5492, Anuncio de capacidades con BGP-4
-
RFC 5512, El identificador de familia de direcciones posteriores (SAFI) de encapsulación del BGP y el atributo de encapsulación de túnel del BGP
-
RFC 5549, Publicidad de información de accesibilidad de la capa de red IPv4 con un próximo salto IPv6
-
RFC 8955, Difusión de reglas de especificación de flujo
-
RFC 8956, Difusión de reglas de especificación de flujo para IPv6
-
RFC 5668, Comunidad extendida de BGP específico de AS de 4 octetos
-
RFC 5701, Atributo de comunidad extendido del BGP específico de la dirección IPv6
-
RFC 5925, La opción de autenticación TCP
-
RFC 6286, Identificador BGP único autónomo en todo el sistema para BGP-4: totalmente compatible
-
RFC 6368, BGP interno como protocolo de borde de proveedor/cliente para redes privadas virtuales (VPN) de IP de BGP/MPLS
-
RFC 6774, Distribución de diversas rutas de BGP
-
RFC 6793, Compatibilidad del BGP con espacio de número de sistema autónomo (AS) de cuatro octetos
-
RFC 6810, La infraestructura de clave pública de recursos (RPKI) al protocolo de enrutador
-
RFC 6811, Validación de origen del prefijo BGP
-
RFC 6996, Reserva del sistema autónomo (AS) para uso privado
-
RFC 7300, Reservación de los números del último sistema autónomo (AS)
-
RFC 7311, El atributo de métrica de IGP acumulado para BGP
-
RFC 7404, Usar solo direccionamiento local de vínculo dentro de una red IPv6
-
RFC 7432, VPN Ethernet basada en MPLS del BGP (eVPN)
-
RFC 7606, Gestión de errores revisada para mensajes de actualización de BGP
-
RFC 7611, BGP ACCEPT_OWN atributo de la comunidad
Apoyamos el RFC al permitir que los enrutadores de Juniper acepten rutas recibidas de un reflector de ruta con el valor community
accept-own. -
RFC 7752, Distribución en dirección norte de información de estado de vínculos e ingeniería de tráfico (TE) mediante BGP
-
RFC 7854, Protocolo de monitoreo de BGP (BMP)
-
RFC 7911, Anuncio de varias rutas en BGP
-
RFC 8097, Estado de validación de origen del prefijo BGP Comunidad extendida
-
RFC 8210, La infraestructura de clave pública de recursos (RPKI) a protocolo de enrutador, versión 1
-
RFC 8212, Comportamiento de propagación de rutas de BGP externo predeterminado (EBGP) sin políticas: totalmente compatible
Excepciones:
Los comportamientos del RFC 8212 no se implementan de forma predeterminada para evitar la interrupción de la configuración existente del cliente. El comportamiento predeterminado se sigue manteniendo para aceptar y anunciar todas las rutas con respecto a los pares EBGP.
-
RFC 8277, Uso de BGP para enlazar etiquetas MPLS a prefijos de dirección
-
RFC 8326, Apagado agraciado de la sesión del BGP
-
RFC 8481, Aclaraciones para la validación de origen del BGP basada en la infraestructura de clave pública de recursos (RPKI)
-
RFC 8538, Compatibilidad de mensajes de notificación para reinicio satisfactorio del BGP
-
RFC 8571, BGP: anuncio de estado del vínculo (BGP-LS) de extensiones métricas de rendimiento de ingeniería de tráfico de IGP
-
RFC 8584, Marco para la extensibilidad de la elección de reenviador designado de VPN Ethernet
-
RFC 8642, Comportamiento de políticas para comunidades BGP conocidas
-
RFC 8669, Extensiones de identificador de segmento de prefijo de enrutamiento por segmentos para BGP
-
RFC 8810, Revisión de los procedimientos de registro de códigos de capacidad
-
RFC 8814, Señalización, profundidad máxima de SID (MSD) mediante el Protocolo de puerta de enlace de frontera: estado del vínculo (compatibilidad parcial)
-
RFC 8950, Publicidad de información de accesibilidad de la capa de red IPv4 (NLRI) con un próximo salto IPv6
-
RFC 8955
-
RFC 8956 (en inglés)
-
RFC 9003, Comunicación de apagado administrativo extendido del BGP
-
RFC 9012, El atributo de encapsulación de túnel del BGP
-
RFC 9029, Actualizaciones de la política de asignación para el Protocolo de puerta de enlace de frontera: registros de parámetros de estado de vínculo (BGP-LS)
-
RFC 9069, Compatibilidad con RIB local en el protocolo de monitoreo BGP (BMP)
-
RFC 9085, Protocolo de puerta de enlace de frontera: extensiones de estado de vínculo (BGP-LS) para enrutamiento por segmentos
-
RFC 9117, Procedimiento de validación revisado para la difusión de especificaciones de flujo de BGP. Esto permite que las especificaciones de flujo se originen en el mismo sistema autónomo que el par BGP que realiza la validación.
-
RFC 9234, Prevención y detección de fugas de ruta mediante roles en mensajes UPDATE y OPEN
-
RFC 9384, Subcódigo de notificación de cese de BGP para detección de reenvío bidireccional (BFD)
-
Borrador de Internet draft-idr-rfc8203bis-00, Comunicación de cierre administrativo del BGP (caduca en octubre de 2018)
-
Borrador de Internet draft-ietf-grow-bmp-adj-rib-out-01, Soporte para Adj-RIB-Out en BGP Protocolo de monitoreo (BMP) (caduca el 3 de septiembre de 2018)
-
Borrador de Internet draft-ietf-idr-aigp-06, El atributo de métrica de IGP acumulado para BGP (caduca en diciembre de 2011)
-
Borrador de Internet draft-ietf-idr-as0-06, Codificación del procesamiento de AS 0 (caduca en febrero de 2013)
-
Borrador de Internet draft-ietf-idr-link-bandwidth-06.txt, Comunidad extendida de ancho de banda de vínculo BGP (caduca en julio de 2013)
-
Borrador de Internet draft-ietf-sidr-origin-validation-signaling-00, Comunidad extendida de validación de origen de prefijo BGP (soporte parcial) (caduca en mayo de 2011)
La comunidad extendida (estado de validación de origen) se admite en la política de enrutamiento de Junos OS. No se admite el cambio especificado en el procedimiento de selección de ruta.
-
Borrador de Internet draft-kato-bgp-ipv6-link-local-00.txt, Emparejamiento BGP4+ mediante dirección local de vínculo IPv6
Los siguientes RFC y borradores de Internet no definen estándares, sino que proporcionan información sobre BGP y tecnologías relacionadas. El GTI-I los clasifica de diversas maneras como "experimentales" o "informativos".
-
RFC 1965, Confederaciones de sistemas autónomos para BGP
-
RFC 1966, Reflexión de ruta BGP: una alternativa al IBGP de malla completa
-
RFC 2270, Uso de un AS dedicado para sitios alojados en un solo proveedor
-
RFC 3345, Condición de oscilación de ruta persistente del Protocolo de puerta de enlace de frontera (BGP)
-
RFC 3562, Consideraciones de administración de claves para la opción de firma TCP MD5
-
Borrador de Internet draft-ietf-ngtrans-bgp-túnel-04.txt, Conexión de islas IPv6 a través de nubes IPv4 con BGP (caduca en julio del 2002)
Ver también
Tabla de historial de cambios
La compatibilidad de la función depende de la plataforma y la versión que utilice. Utilice el Explorador de características para determinar si una característica es compatible con su plataforma.