솔루션 아키텍처
이전 섹션에서 설명한 세 가지 패브릭(프론트엔드, GPU 백엔드, 스토리지 백엔드)은 그림 2와 같이 전체 AI JVD 솔루션 아키텍처에서 서로 연결되어 있습니다.
그림 2: AI JVD 솔루션 아키텍처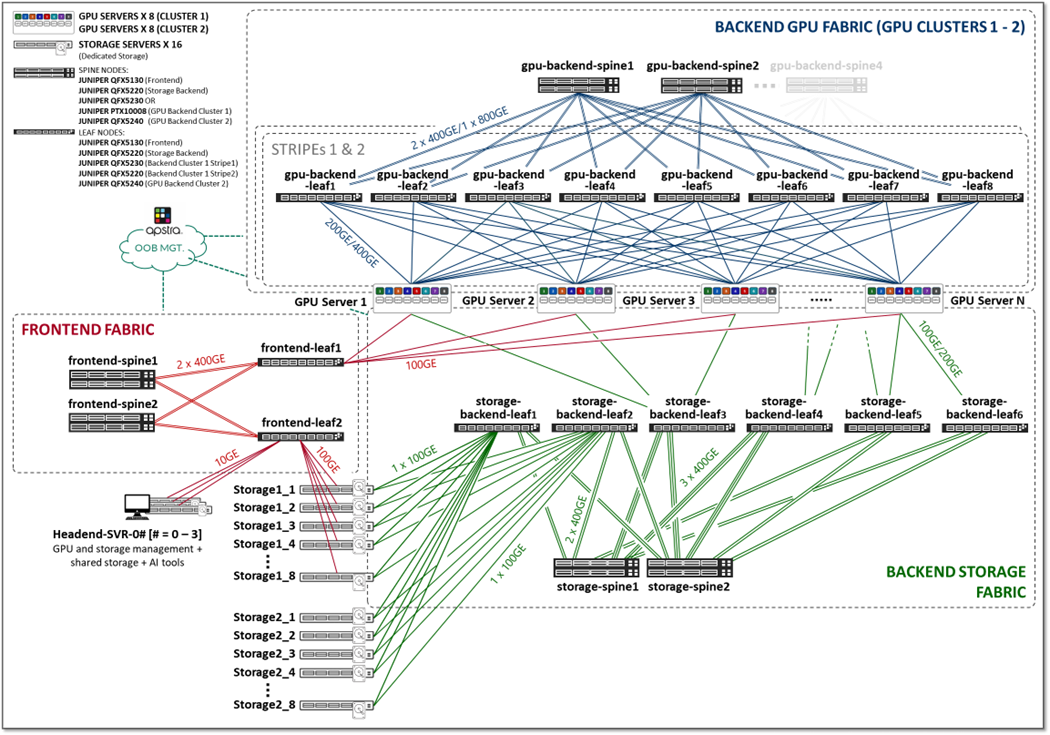
프론트엔드 패브릭
프론트엔드 패브릭는 사용자가 AI 시스템과 상호 작용하여 작업 일정, 리소스 할당 및 수명 주기 관리를 처리하는 SLURM, Kubernetes 및 기타 AI 워크플로 관리자와 같은 도구를 사용하여 교육 및 추론 작업 워크플로를 조정할 수 있는 인프라를 제공합니다.
이러한 상호 작용은 과도한 데이터 흐름을 생성하지 않으며 지연 또는 패킷 손실에 대한 엄격한 요구 사항을 부과하지 않습니다. 그 결과, 컨트롤 플레인 트래픽은 패브릭에 엄격한 성능 요구를 하지 않습니다.
프 론트엔드 패브릭 설계는 그림 3과 같이 고가용성(HA)이 없는 3단계 L3 IP 패브릭으로 구성됩니다. 이 아키텍처는 프론트엔드에 필요한 연결에 대한 간단하고 효과적인 솔루션을 제공합니다. 그러나 EVPN/VXLAN을 포함한 모든 패브릭 아키텍처를 사용할 수 있었습니다. HA 지원 프론트엔드 패브릭이 필요한 경우 주니퍼 Apstra JVD를 사용하는 3단계를 따르는 것이 좋습니다.
그림 3: 프론트엔드 패브릭 아키텍처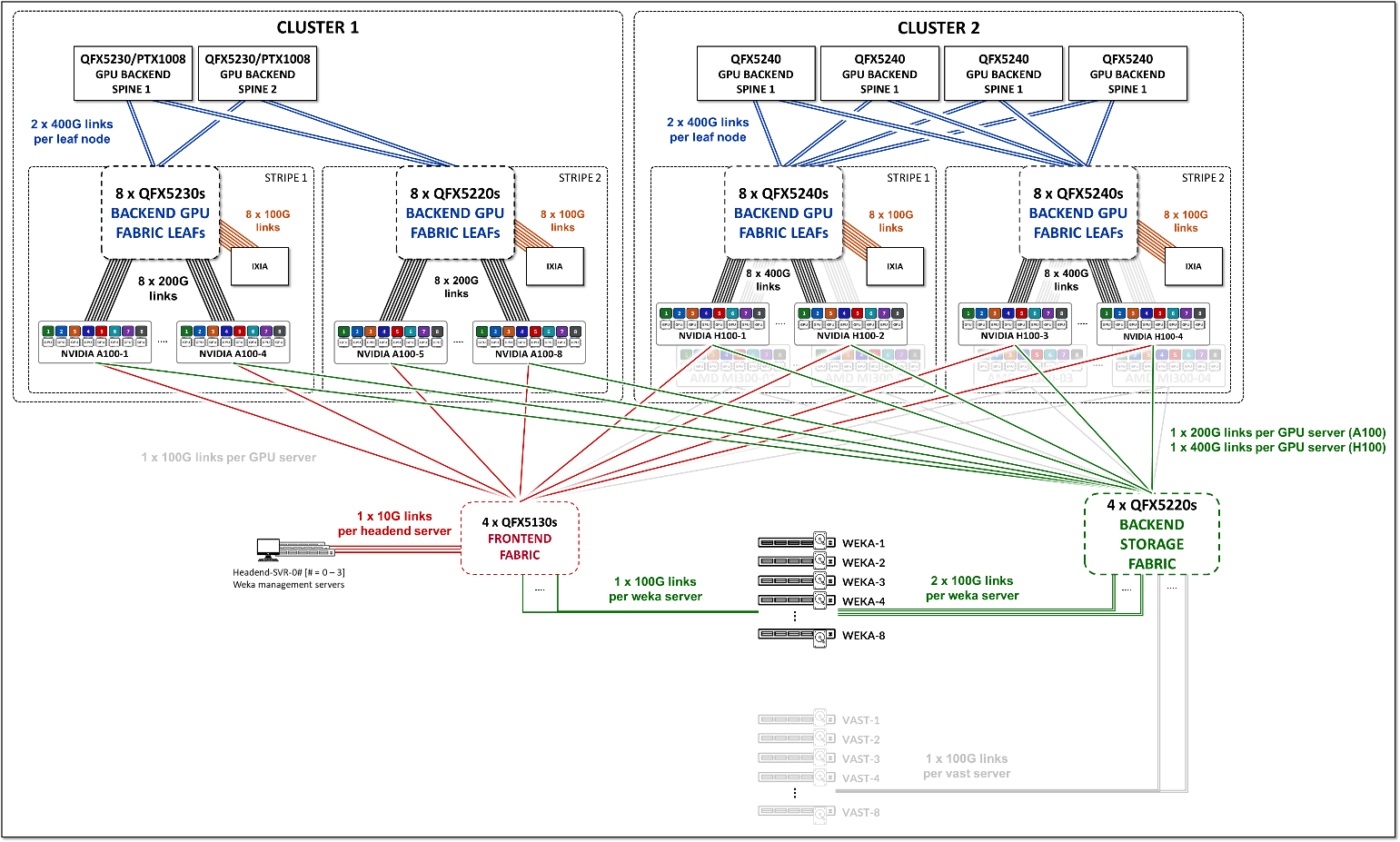
리프 노드 수는 AI 클러스터의 서버 및 스토리지 디바이스 수뿐만 아니라 AI 작업 스케줄링, 리소스 할당 및 수명 주기 관리에 사용되는 기타 디바이스의 수에 따라 달라집니다.
스파인 노드 수는 설계에 원하는 구독 요소에 따라 달라집니다. 1:1 구독 요소는 필요하지 않습니다. 컨트롤 플레인 트래픽에 대해 보통 초과 구독은 설계가 복원력을 유지하고 컨트롤 플레인 안정성에 영향을 미칠 수 있는 혼잡을 피하는 경우 허용됩니다.
패브릭은 이 문서의 네트워킹 섹션에 설명된 IP 주소 지정 및 EBGP 구성 세부 정보가 있는 경로 보급을 위해 EBGP를 사용하는 L3 IP 패브릭입니다. 특별한 로드 밸런싱 메커니즘은 필요하지 않습니다. 중복 L3 경로의 ECMP는 일반적으로 충분합니다.
컨트롤 플레인 트래픽이 일반적으로 스토리지 또는 GPU 패브릭에 비해 대역폭을 많이 차지하지 않는다는 점을 감안할 때, 엄격한 QoS 메커니즘은 선택 사항이며 버스트 비제어 트래픽과 링크를 공유하는 경우에만 권장됩니다.
이 JVD에서 검증된 프런트 엔드 패브릭의 디바이스 및 연결은 다음 표에 요약되어 있습니다.
표 1: 프런트 엔드 패브릭에 연결된 검증된 관리 디바이스 및 GPU 서버
| GPU 서버 | 저장 장치 | 헤드엔드 서버 |
|---|---|---|
|
웨카 CSE-LB16TS-R860AWP-A |
수퍼마이크로 SYS-6019U-TR4 |
표 2: 검증된 프론트엔드 패브릭 리프 및 스파인 노드
| 프론트엔드 패브릭 리프 노드 스위치 모델 | 프론트엔드 패브릭 스파인 노드 스위치 모델 |
|---|---|
| QFX5130-32CD | QFX5130-32CD |
| QFX5220-32CD | QFX5220-32CD |
표 3: 프론트엔드 패브릭의 헤드엔드 서버와 리프 노드 간의 검증된 연결
| 리프 연결에 대한 GPU 서버당 링크 | 서버 유형 |
|---|---|
| 1 x 10GE | 수퍼마이크로 SYS-6019U-TR4 |
표 4: 프런트 엔드의 GPU 서버와 리프 노드 간의 유효성 검사된 연결
| 리프 연결에 대한 GPU 서버당 링크 | 서버 유형 |
|---|---|
| 1 x 100GE | 엔비디아 A100 |
| 1 x 100GE | 엔비디아 H100 |
표 5: 프런트 엔드의 리프와 스파인 노드 간의 유효성 검사된 연결
| 리프 및 스파인 연결당 링크 | 리프 노드 모델 | 스파인 노드 모델 |
|---|---|---|
| 2 x 400GE | QFX5130-32CD | QFX5130-32CD |
이 JVD에 대한 테스트는 그림과 같이 두 개의 리프 노드에 연결된 8개의 NVIDIA A100 GPU 서버와 4개의 NVIDIA H100 GPU 서버를 사용하여 수행되었으며, 이 리프 노드는 다시 두 개의 스파인 노드에 연결되었습니다.
그림 4: 프론트엔드 패브릭 JVD 테스트 토폴로지
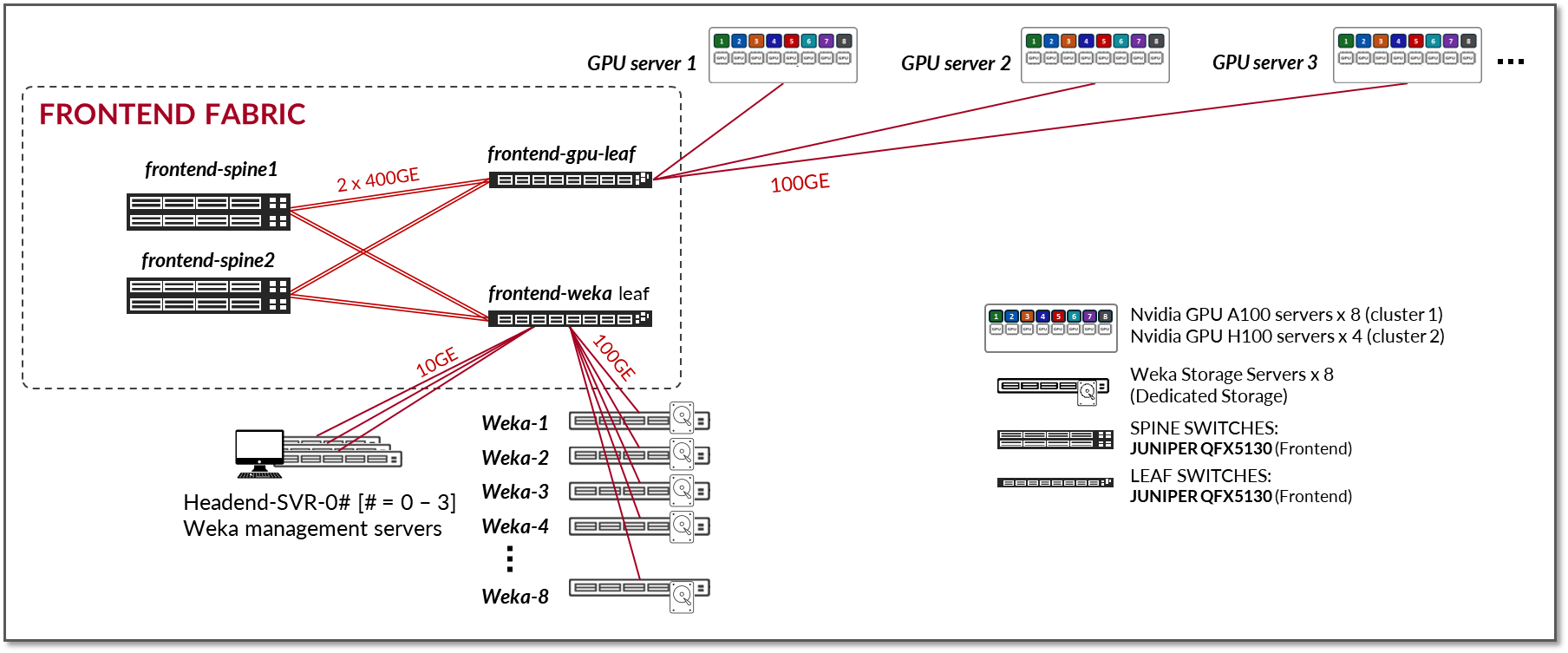
- GPU 서버는 100G 인터페이스(ConnectX-6/ConnectX-7 NIC)를 사용하여 리프 노드에 연결됩니다.
- Weka 디바이스는 100G 인터페이스를 사용하여 리프 노드에 연결됩니다
표 6: 총 프런트 엔드 GPU 서버<=> 프런트 엔드 리프 노드 링크 수 및 테스트된 대역폭
| GPU 서버 <=> 프론트엔드 리프 노드 | 대역폭 |
|---|---|
| 100GE 링크 GPU 서버 수 ó 프론트엔드 리프 노드 = 12 (서버당 1개) |
12 x 100GE = 1.2Tbps |
| 스토리지 디바이스 간 100GE 링크 수 ó 프론트엔드 리프 노드 = 8 (저장 장치당 1개) |
8 x 100GE = 0.8Tbps |
| 총 대역폭 = | 2.0Tbps |
표 7: 총 프론트엔드 리프 노드<=> 프론트엔드 스파인 노드 링크 수 및 테스트된 대역폭
| 프론트엔드 리프 노드 <=> 프론트엔드 스파인 노드 | 대역폭 | |
|---|---|---|
| 프론트엔드 리프 노드와 스파인 노드 간의 400GE 링크 수 = 8 (리프 노드 2개 x 스파인 노드 2개, 리프-스파인 연결당 링크 2개 스파인) |
8 x 400GE = 3.2Tbps | |
| 총 대역폭 = | 3.2Tbps | |
| 초과 구독 금지. | ||
GPU 백엔드 패브릭
GPU 백엔드 패브릭은 RoCEv2(RDMA over Converged Ethernet)를 사용하여 GPU가 클러스터 내에서 서로 통신할 수 있는 인프라를 제공합니다. ROCEv2는 GPU가 InfiniBand 프로토콜과 같이 통신할 수 있도록 하여 데이터센터 효율성을 높이고, 전반적인 복잡성을 줄이며, 데이터 전송 성능을 향상시킵니다.
프론트엔드 패브릭과 달리 GPU 백엔드 패브릭은 대역폭 집약적이고 지연에 민감한 데이터 플레인 트래픽을 전송합니다. 패킷 손실, 과도한 지연 또는 지터는 작업 완료 시간에 큰 영향을 미칠 수 있으므로 피해야 합니다. 결과적으로 GPU 백엔드 패브릭의 주요 설계 목표 중 하나는 거의 무손실에 가까운 이더넷 패브릭을 제공하는 동시에 GPU 간 트래픽에 대해 최대 처리량, 최소 지연 시간 및 최소 네트워크 간섭 을 제공하는 것입니다. RoCEv2는 패킷 손실이 최소화되는 환경에서 가장 효율적으로 작동하여 최적의 작업 완료 시간에 직접적으로 기여합니다.
이 JVD의 GPU 백엔드 패브릭은 이러한 요구 사항을 충족하도록 설계되었습니다. 이 설계는 그림 5와 같이 3단계 IP Clos, 레일 최적화 스트라이프 아키텍처를 따릅니다. 레일 최적화 스트라이프 아키텍처 에 대한 자세한 내용은 이후 섹션에서 설명합니다.
그림 5: GPU 백엔드 패브릭 아키텍처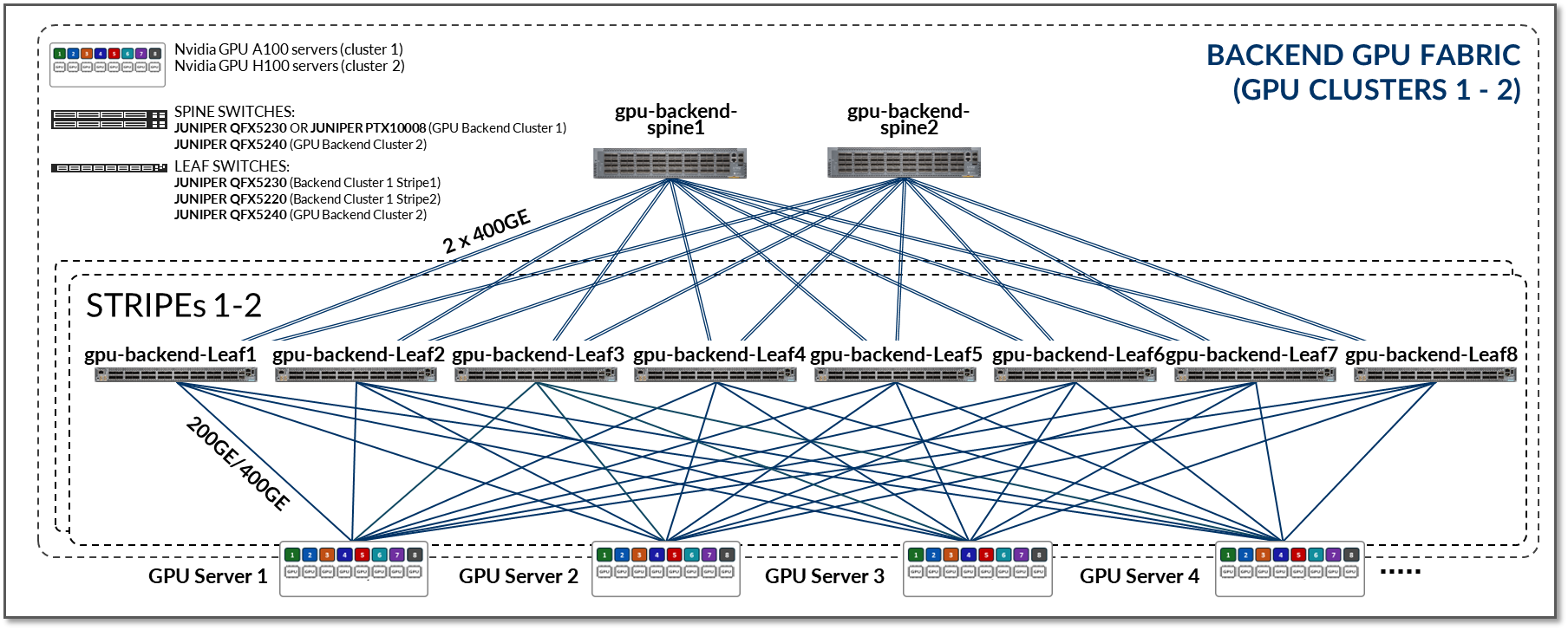
패브릭은 이 문서의 네트워킹 섹션에 설명된 IP 주소 지정 및 EBGP 구성 세부 정보를 갖춘 경로 보급을 위해 EBGP를 사용하는 L3 IP 패브릭으로 작동합니다.
레일 최적화 아키텍처에서 리프 노드 수는 서버당 GPU 수에 따라 결정되며, 이 JVD에 포함된 Nvidia 서버의 경우 8개입니다. 스파인 노드 수와 GPU 서버와 리프 노드 간, 리프와 스파인 노드 간의 링크 속도 및 스파인 노드 수는 GPU 백엔드 패브릭의 유효 대역폭 및 초과 구독 특성을 결정합니다.
프론트엔드 패브릭과 달리 GPU 백엔드 패브릭은 대용량 RoCEv2 트래픽에 충분한 대역폭을 보장하고 혼잡, 패킷 손실 및 과도한 지연을 방지하기 위해 초과 구독되지 않은 설계(1:1 구독 계수)가 필요합니다.
GPU 백엔드 패브릭 내의 트래픽 분포는 동적 로드 밸런싱(DLB), 글로벌 로드 밸런싱 및 적응형 로드 밸런싱(ALB)과 같은 고급 로드 밸런싱 기술과 결합된 여러 동일 비용 L3 경로에서 ECMP에 의존합니다. 이러한 내용은 이 문서의 로드 밸런싱 섹션에 설명되어 있습니다.
GPU 백엔드 패브릭은 손실과 지연에 민감한 RoCEv2 트래픽을 전송하기 때문에 이 설계는 ECN(명시적 혼잡 알림)을 활용하고 선택적으로 PFC(우선순위 플로우 제어)를 사용하여 RDMA 트래픽에 대한 무손실 또는 거의 무손실 동작을 달성할 수 있는 DCQCN(Data Center Quantized Congestion Notification)을 통합합니다. 이러한 메커니즘은 이 문서의 서비스 등급 섹션 에 자세히 설명되어 있습니다.
이 JVD에서 검증된 GPU 백엔드 패브릭의 디바이스 및 연결은 다음 표에 요약되어 있습니다.
표 8: GPU 백엔드 패브릭에 연결된 검증된 관리 디바이스 및 GPU 서버.
| GPU 서버 | 저장 장치 | 헤드엔드 서버 |
|---|---|---|
|
웨카 CSE-LB16TS-R860AWP-A |
수퍼마이크로 SYS-6019U-TR4 |
표 9: 검증된 GPU 백엔드 패브릭 리프 노드
| GPU 백엔드 패브릭 리프 노드 스위치 모델 |
|---|
| QFX5220-32CD |
| QFX5230-64CD |
| QFX5240-64OD |
| QFX5241-64OD |
표 10: 검증된 GPU 백엔드 패브릭 스파인 노드
| GPU 백엔드 패브릭 스파인 노드 스위치 모델 |
|---|
| QFX5230-64CD |
| QFX5240-64OD |
| QFX5241-64OD |
| PTX10008 LC1201 |
| PTX10008 LC1301 |
표 11: GPU 백엔드 패브릭에서 GPU 서버와 리프 노드 간의 검증된 연결
| 리프 연결에 대한 GPU 서버당 링크 | 서버 유형 |
|---|---|
| 1 x 200GE | 엔비디아 A100 |
| GPU 서버당 1 x 400GE 링크-리프 연결 | 엔비디아 H100 |
표 12: GPU 백엔드 패브릭의 리프와 스파인 노드 간의 유효성 검사된 연결
| 리프 및 스파인 연결당 링크 | 리프 노드 모델 | 스파인 노드 모델 |
|---|---|---|
| 1 x 400GE | QFX5220-32CD | QFX5230-32CD |
| 1 x 400GE | QFX5230-32CD | QFX5230-32CD |
| 2 x 400GE | QFX5240-64OD | QFX5240-64OD |
| 1 x 800GE | QFX5240-64OD | QFX5240-64OD |
| 1 x 400GE | QFX5220-32CD | PTX10008 LC1201 |
| 1 x 400GE | QFX5230-32CD | PTX10008 LC1201 |
| 1 x 800GE | QFX5240-64OD | PTX10008 LC1301 |
| 2 x 800GE | QFX5240-64OD | PTX10008 LC1301 |
이 JVD에 대한 테스트는 다음과 같이 두 개의 스트라이프에 연결된 8개의 NVIDIA A100 GPU 서버와 4개의 NVIDIA H100 GPU 서버를 사용하여 수행되었습니다.
그림 6: GPU 백엔드 패브릭 JVD 테스트 토폴로지
- 각 Nvidia A100 서버는 200G 인터페이스(ConnectX-7 NIC)를 사용하여 리프 노드에 연결됩니다.
- 각 Nvidia H100 서버는 400G 인터페이스(ConnectX-7 NIC)를 사용하여 리프 노드에 연결됩니다.
표 13: 스트라이프당 서버에서 리프 대역폭까지
| 스트라이프 | 서버 수 스트라이프당 |
서버 수<=서버당 리프 링크 >개 (서버당 리프 노드 수 및 GPU 수와 동일) |
서버 <=> 리프 링크 대역폭 [Gbps] |
총 서버 <=리프 링크 >개 스트라이프당 대역폭 [Tbps] |
|---|---|---|---|---|
| 1 | 2 H100 | 8 | 400Gbps | 2 x 8 x 400Gbps = 6.4Tbps |
| 4 A100 | 8 | 200Gbps | 4 x 8 x 200Gbps = 6.4Tbps | |
| 2 | 2 H100 | 8 | 400Gbps | 2 x 8 x 400Gbps = 6.4Tbps |
| 4 A100 | 8 | 200Gbps | 4 x 8 x 200Gbps = 6.4Tbps | |
| 총 서버 <=> 리프 대역폭 | 25.6Tbps | |||
표 14: 리프 및 스파인으로 QFX5240 스트라이프당 리프-스파인 대역폭
| 스트라이프 | 수 리프 노드 |
스파인 노드 수 | 수 400Gbps 리프 <=> 스파인 링크 리프 노드당 |
서버 <=> 리프 링크 대역폭 [Gbps] |
대역폭 리프 <=스트라이프당 스파인 >개 [Tbps] |
|---|---|---|---|---|---|
| 1 | 8 | 4 | 2 | 400 | 8 x 2 x 2 x 400Gbps = 12.8Tbps |
| 2 | 8 | 4 | 2 | 400 | 8 x 2 x 2 x 400Gbps = 12.8Tbps |
| 총 서버 <=> 리프 대역폭 | 25.6Tbps | ||||
GPU 백엔드 패브릭 구독 계수
구독 요소는 위의 두 표의 숫자를 비교하여 간단히 계산됩니다.
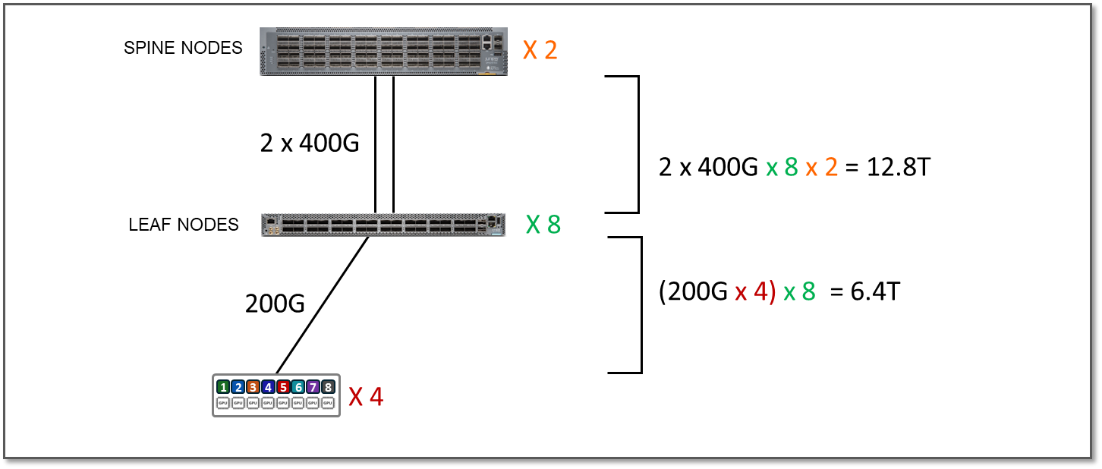
JVD 테스트 환경에서 서버와 리프 노드 간의 대역폭은 스트라이프당 25.6Tbps인 반면, 리프와 스파스파인 노드 간에 사용 가능한 대역폭은 스트라이프당 25.6Tbps입니다. 즉, 이 트래픽이 100% 스트라이프 간인 경우에도 패브릭에 GPU 간의 모든 트래픽을 처리할 수 있는 충분한 용량이 있지만 이제는 추가 서버를 수용할 수 있는 추가 용량이 없습니다. 이 경우 구독 요소는 1:1(구독 없음)입니다.
그림 7: 1:1 구독 계수
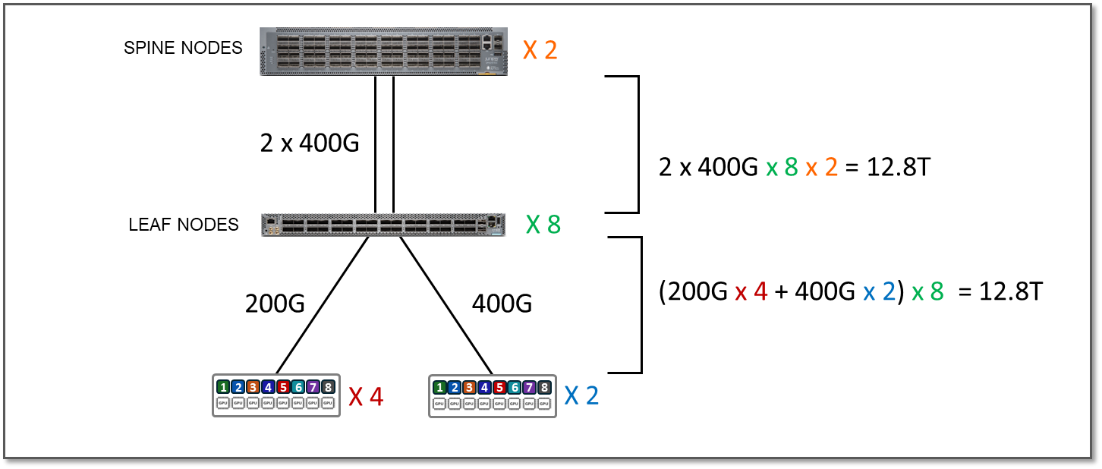
오버서브스크립션 테스트를 실행하기 위해 그림 8의 예와 같이 리프와 스파인 간의 인터페이스 중 일부를 비활성화하여 사용 가능한 대역폭을 줄였습니다.
그림 8: 2:1 구독 비율(초과 구독)
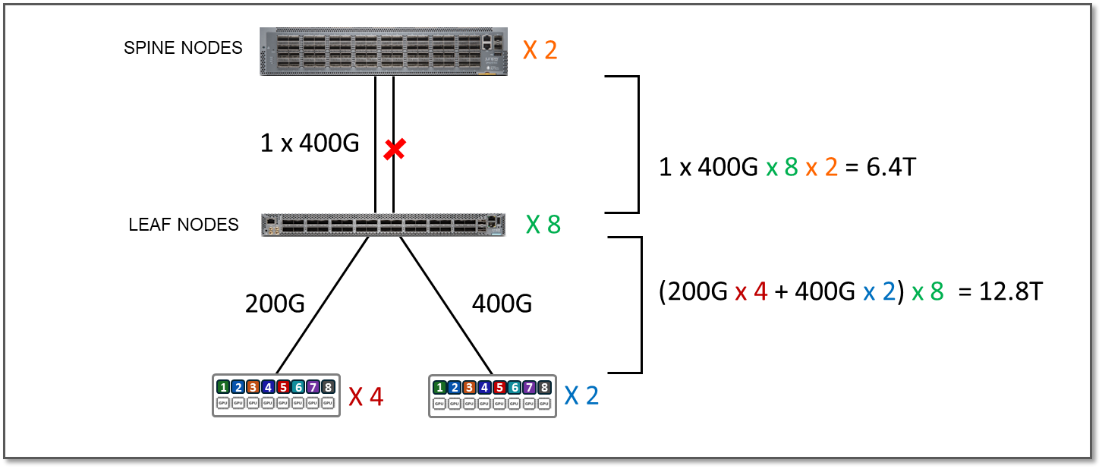
스트라이프당 총 서버-리프 링크 대역폭은 변경되지 않았습니다. 이전 시나리오의 표 15와 같이 여전히 12.8Tbps입니다.
그러나 리프와 스파스파인 노드 간에 사용할 수 있는 대역폭은 이제 스트라이프당 6.4Tbps에 불과합니다.
표 15: 스트라이프 리프당 스파인 대역폭
| 스트라이프당 리프-스파인 대역폭 | |||
| 리프 <=스파인 노드당 및 스트라이프당 스파인 링크 >개 | 속도 리프 <=> 스파인 링크 [Gbps] |
스파인 노드 수 | 총 대역폭 리프 <=스트라이프당 스파인 >개 [Tbps] |
| 8 | 1 x 400 | 2 | 6.4 |
즉, 이 트래픽이 100% 스트라이프 간인 경우에도 패브릭에 GPU 간의 모든 트래픽을 처리할 수 있는 용량이 더 이상 충분하지 않아 잠재적으로 혼잡 및 트래픽 손실이 발생할 수 있습니다. 이 경우 초과 구독 계수는 2:1입니다.
혼잡 및 고장 테스트 결과는 JVD 테스트 보고서에 포함되어 있습니다.
GPU 간 통신 최적화
레일 최적화 토폴로지의 최적화는 GPU 통신을 관리하여 혼잡과 지연을 최소화하고 처리량을 최대화하는 방법을 나타냅니다. 이 최적화 전략의 핵심은 가능하면 트래픽을 로컬로 유지하는 것입니다. GPU 통신이 동일한 레일이나 스트라이프 내, 심지어 서버 내에서도 유지되도록 함으로써 스파인이나 외부 링크를 통과할 필요성이 줄어들어 지연이 줄어들고 혼잡이 최소화되며 전반적인 효율성이 향상됩니다.
트래픽 현지화가 우선시되지만 대규모 GPU 클러스터에서는 스트라이프 간 통신이 필요합니다. 스트라이프 간 통신은 병목 현상과 패킷 손실을 방지하기 위해 사용 가능한 링크에 대한 적절한 라우팅 및 밸런싱 기술을 통해 최적화됩니다.
최적화의 핵심은 토폴로지를 활용하여 트래픽을 가장 짧고 혼잡도가 가장 적은 경로를 따라 전달함으로써 네트워크가 확장되더라도 일관된 성능을 보장하는 데 있습니다. 동일한 서버에 있는 GPU 간의 트래픽은 내부 서버 패브릭(벤더에 따라 다름)을 통해 로컬로 전달될 수 있는 반면, 서로 다른 서버의 GPU 간 트래픽은 외부 GPU 백엔드 인프라에서 발생합니다. 서로 다른 서버에 있는 GPU 간의 통신은 레일 내부 또는 레일 간/스트라이프 간일 수 있습니다.
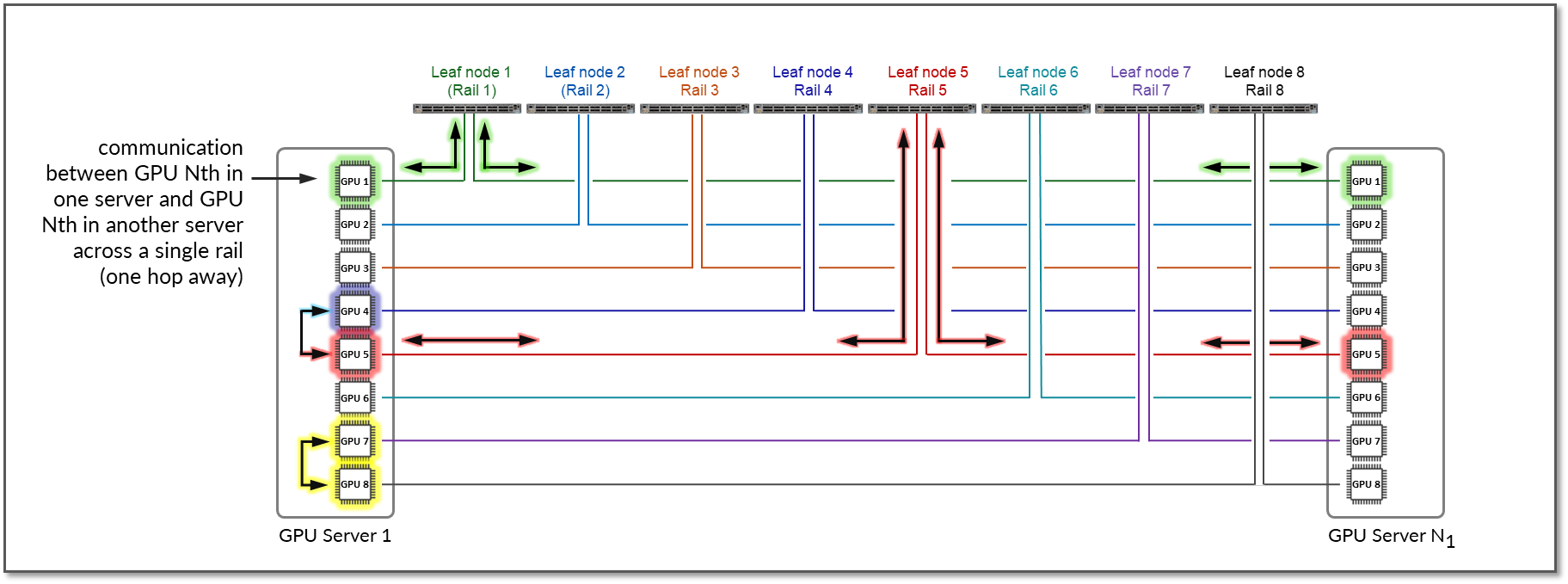
레일 내 트래픽은 로컬 리프 노드에서 스위칭(레이어 2에서 처리)됩니다. 이러한 설계에 따라 서로 다른 서버(그러나 동일한 스트라이프에 있음)에 있는 GPU 간의 데이터는 항상 동일한 레일과 단일 스위치에서 이동됩니다. 이렇게 하면 GPU가 서로 1홉 떨어져 있고 별도의 독립적인 고대역폭 채널을 생성하여 경합을 최소화하고 성능을 극대화할 수 있습니다. 반면, 레일 간/스트라이프 간 트래픽은 리프 노드의 IRB 인터페이스와 리프 노드를 연결하는 스파인 노드를 통해 라우팅됩니다(레이어 3에서 처리됨).
그림 8에 나타난 예를 고려하십시오
- 서버 1의 GPU 1과 GPU 2 간의 통신은 서버의 내부 패브릭(1)에서 발생합니다
- 서버 1-4의 GPU 1 사이와 서버 1-4의 GPU 8 간의 통신은 각각 리프 1과 리프 8에서 발생합니다(2).
- GPU 1과 GPU 8(서버 1-4) 간의 통신은 리프1, 스파인 노드 및 리프8(3)에서 발생합니다
그림 8: 레일 간 vs. 레일 내 GPU-GPU 통신
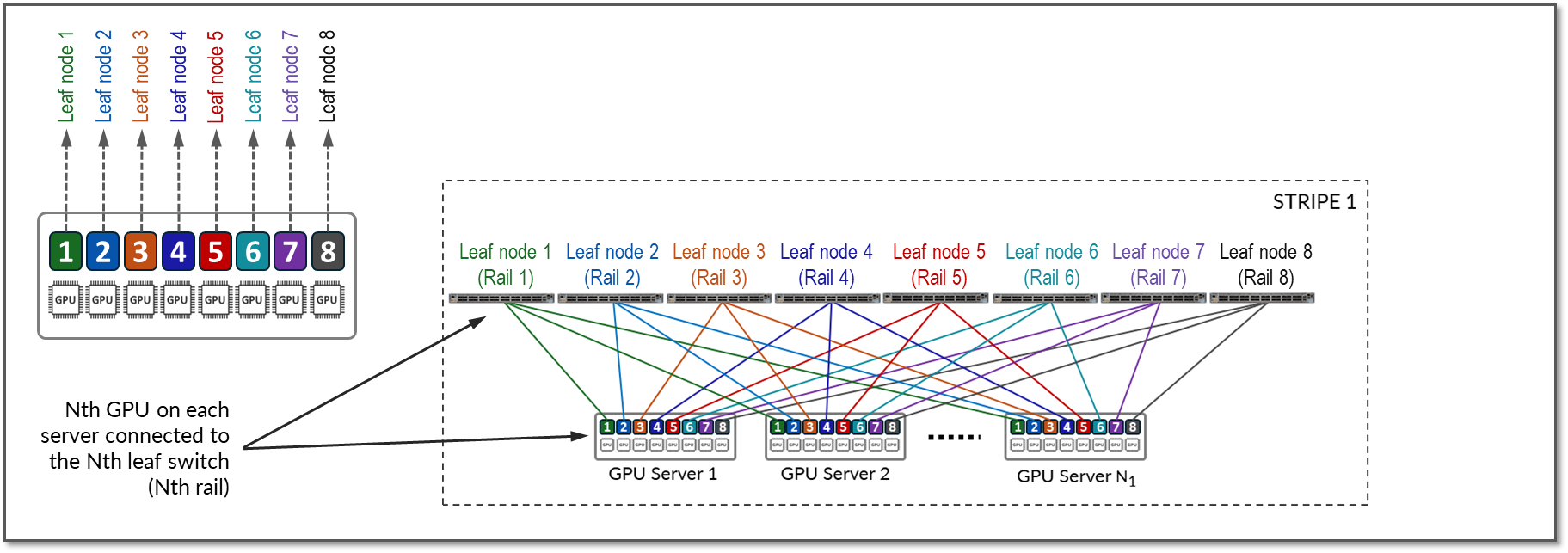
그림 10은 리프 스위치 1-8에서 GPU 1-8을 각각 연결하는 1 개의 스트라이프 와 8개의 레일이 있는 토폴로지를 나타냅니다.
서버 1의 GPU 7과 GPU 8 간의 통신은 내부 패브릭에서 발생하고, 서버 1의 GPU 1과 서버 N1의 GPU 1 간의 통신은 리프 스위치 1(동일한 레일 내)에서 발생합니다.
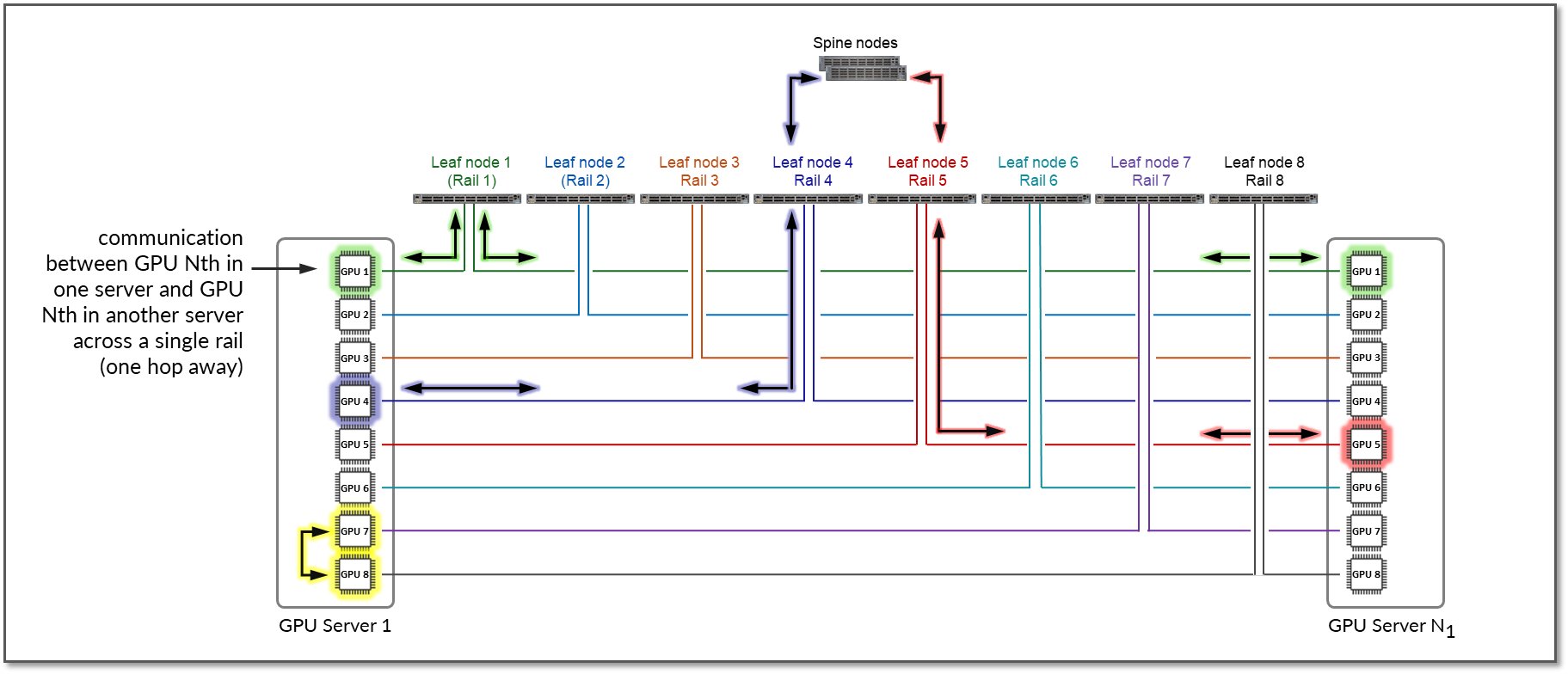
서로 다른 스트라이프의 GPU와 서로 다른 서버 간의 통신이 필요한 경우(예: 서버 1의 GPU 4가 서버 N1의 GPU 5와 통신), 데이터는 먼저 대상 GPU와 동일한 레일의 GPU 인터페이스로 이동되므로 레일을 교차하지 않고 대상 GPU로 데이터를 보냅니다.
이러한 설계에 따라 서로 다른 서버(그러나 동일한 스트라이프)에 있는 GPU 간의 데이터는 항상 동일한 레일과 하나의 단일 스위치에서 이동됩니다. 이는 GPU가 서로 1홉 떨어져 있고 별도의 독립적인 고대역폭 채널을 생성하여 경합을 최소화하고 성능을 극대화합니다.
그림 9와 같이 NVIDIA H100 GPU 서버에서 GPU는 NVLink 및 NV스위치를 통해 상호 연결되어 단일 서버 내에서 400Gbps GPU 간 고대역폭, 저지연, 양방향 GPU 간 통신을 제공합니다.
그림 9: NVIDIA HGX/DGX GPU 상호 연결 아키텍처
자세한 내용은 NVIDIA DGX H100/H200 시스템 소개 - NVIDIA DGX H100/H200 사용자 가이드를 참조하세요.
NVIDIA GPU는 NVLink 및 NVSwitch 를 활용하여 GPU, CPU 및 기타 시스템 구성 요소 간에 고대역폭, 저지연 통신을 제공합니다. 이 상호 연결 패브릭은 여러 링크의 트래픽을 동적으로 관리하여 노드 내 GPU 통신을 위한 최적화된 경로를 제공하고 효율적인 집합 운영을 지원합니다.
기본적으로 NVIDIA GPU 플랫폼은 GPU-GPU 트래픽의 대기 시간을 최소화하기 위해 PXN(Parallel Execution Networks)을 사용하여 구현된 토폴로지 인식 라우팅 및 로컬 최적화를 구현합니다. 동일한 서버의 GPU 간의 통신은 인피니티 패브릭을 통해 전달되며 노드 내에 유지되며 외부 이더넷 패브릭을 통과하지 않습니다. 여러 서버에서 동일한 등급의 GPU 간의 트래픽은 스트라이프 내부로 유지됩니다.
그림 12는 서버 1의 GPU1이 서버 2의 GPU1과 통신하는 예를 보여줍니다. 트래픽은 리프 노드 1에 의해 전달되며 레일 1 내에 유지됩니다.
또한 서버 1의 GPU4가 서버 2의 GPU5와 통신하고자 하고 서버 1의 GPU5가 AMD의 인피니티 패브릭에서 로컬 홉으로 사용할 수 있는 경우, 트래픽은 자연스럽게 이 경로를 선호하여 성능을 최적화하고 GPU 간 통신을 레일 내부로 유지합니다.
그림 10: 로컬 최적화를 통한 두 서버 간의 GPU 간 레일 간 통신.
예를 들어 워크로드 제약 때문에 로컬 최적화가 불가능한 경우 트래픽은 로컬 홉(내부 패브릭)을 우회하고 RDMA(오프 노드 NIC 기반 통신)를 사용해야 합니다. 이러한 경우 서버 1의 GPU4는 RDMA를 사용하여 NIC를 통해 직접 데이터를 전송하여 서버 2의 GPU5와 통신하고, 그림 11과 같이 패브릭을 통해 전달됩니다.
그림 11: 로컬 최적화가 없는 두 서버 간의 GPU 간 레일 간 통신.
이 예는 서버 1의 GPU 4와 서버 N1의 GPU 5 간의 통신이 리프 스위치 1, 스파인 노드 및 리프 스위치 5(서로 다른 두 레일 사이)를 통해 진행된다는 것을 보여줍니다.
백엔드 GPU 레일 최적화 스트라이프 아키텍처
앞서 설명했듯이 레일 최적화 스트라이프 아키텍처 는 GPU 간의 효율적인 데이터 전송을 제공하며, 특히 합리적인 시간 내에 작업을 완료하기 위해 원활한 데이터 전송이 필요한 AI 대규모 언어 모델(LLM) 학습 워크로드와 같이 계산 집약적인 작업 중에 더욱 그렇습니다. 레일 최적화 토폴로지는 대역폭 경합, 지연 시간, 네트워크 간섭을 최소화하여 성능을 극대화하고 데이터가 네트워크 전반에 효율적이고 안정적으로 전송될 수 있도록 보장하는 것을 목표로 합니다.
레일 최적화 스트라이프 아키텍처에는 레일 과 스트라이프라는 두 가지 중요한 개념이 있습니다.
서버의 GPU는 1-8로 번호가 매겨지며, 숫자는 그림 6과 같이 서버에서 GPU의 위치를 나타냅니다. 이 숫자는 GPU가 위치하는 서버의 GPU와 관련하여 순위 또는 더 구체적으로 "로컬 순위"라고 하거나 단일 작업에 할당된 모든 GPU(여러 서버에서)와 관련하여 "글로벌 순위"라고 합니다.
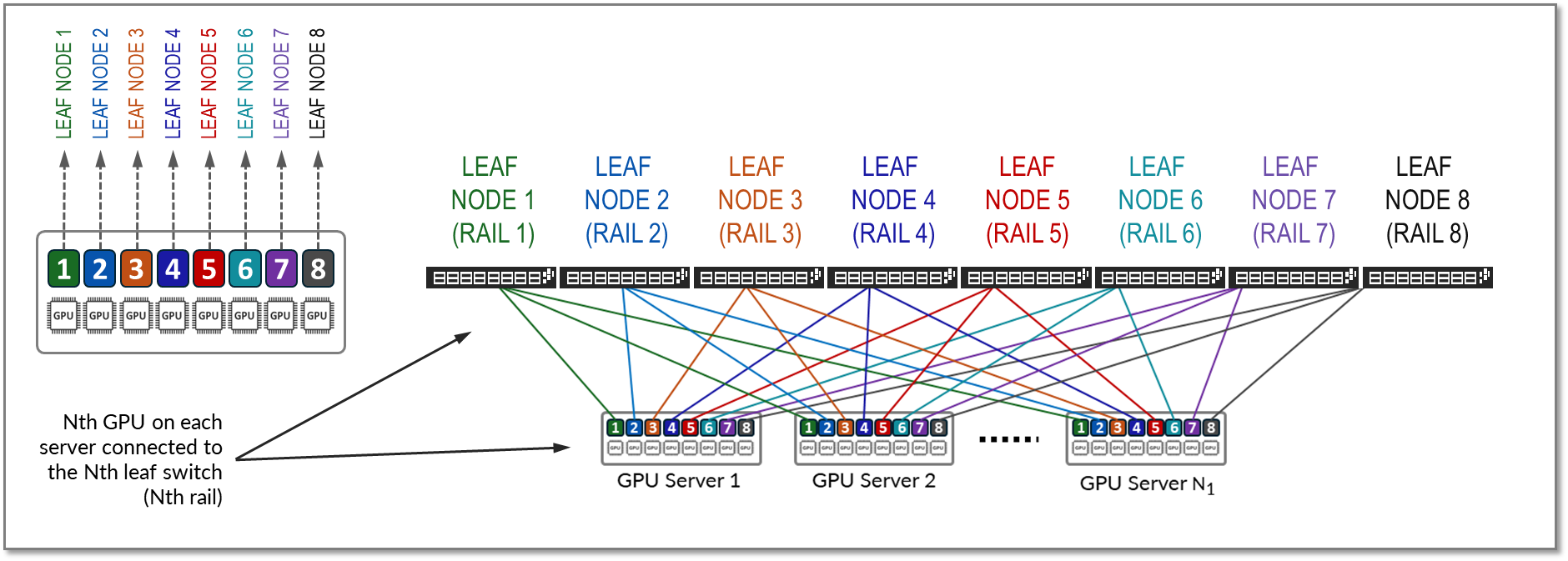
레일은 패브릭의 리프 노드 중 하나에서 동일한 순서의 GPU를 연결합니다. 즉, 그림 10과 같이 레일 Nth는 모든 서버의 N번째 위치에 있는 모든 GPU를 리프 노드 Nth에 연결합니다.
그림 10: 레일 최적화 아키텍처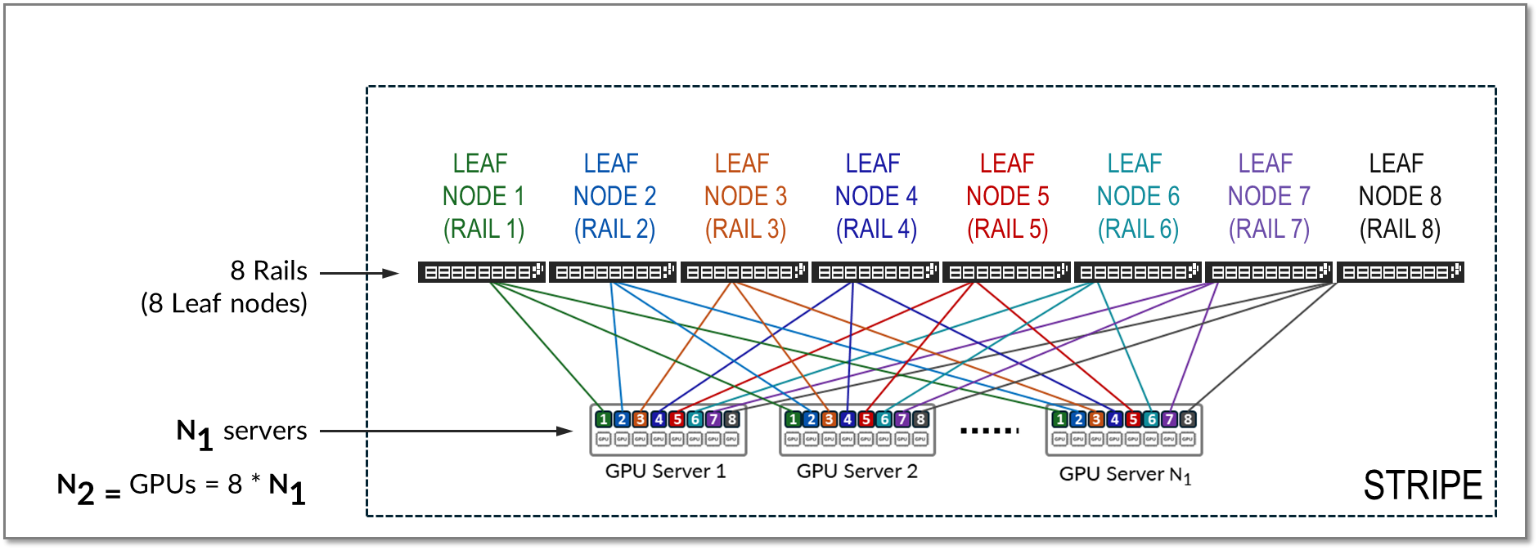 의 레일
의 레일
스트라이프는 그림 11과 같이 여러 레일로 구성되며 여러 리프 노드와 GPU 서버를 포함하는 설계 모듈 또는 빌딩 블록을 나타냅니다. 이 빌딩 블록을 복제하여 AI 클러스터를 확장할 수 있습니다.
그림 11: 레일 최적화 아키텍처의 스트라이프
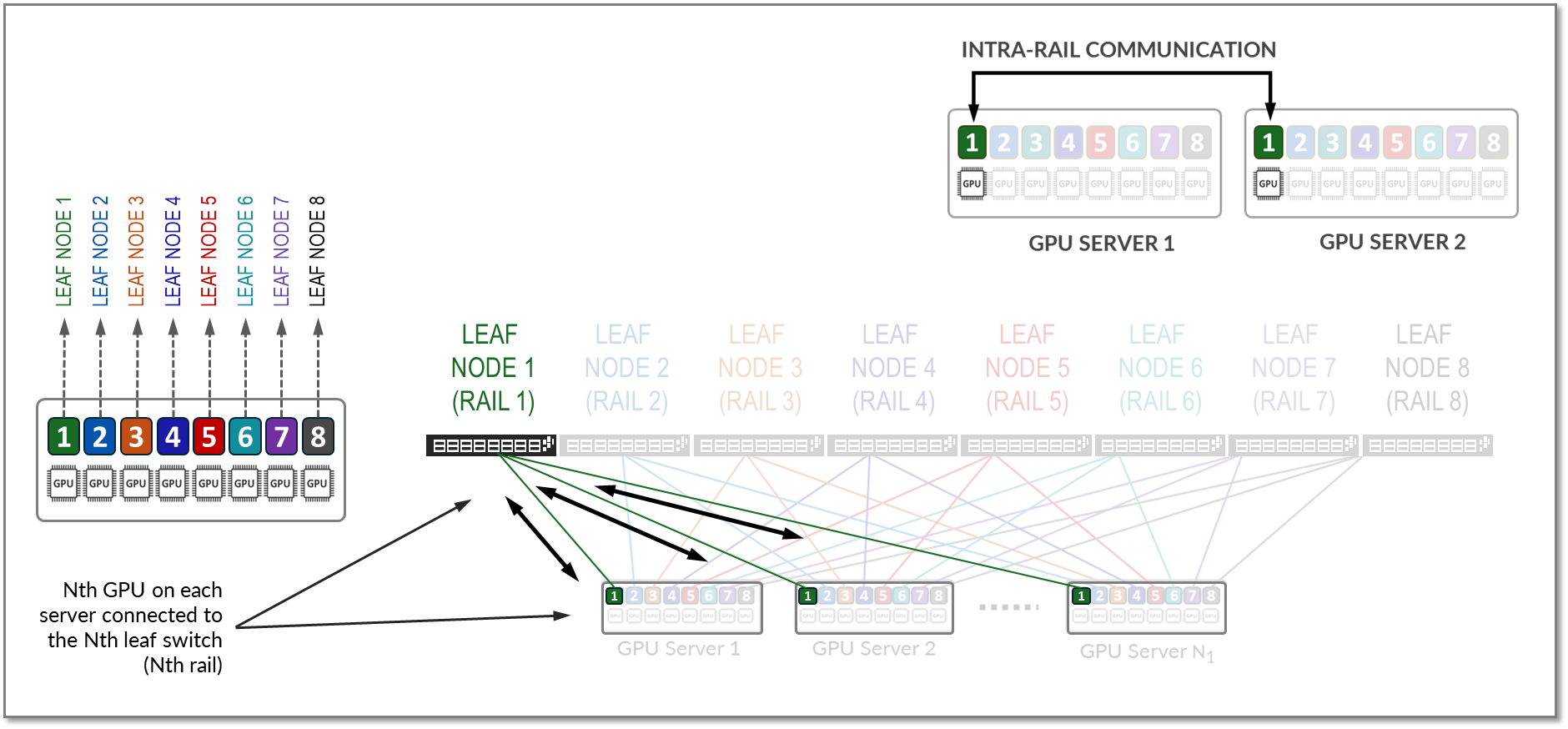
그림 12와 같이 동일한 순위의 GPU 간의 모든 트래픽(레일 내부 트래픽)은 리프 노드 수준에서 전달됩니다.
그림 12: 레일 내 GPU 투 GPU 트래픽 예.
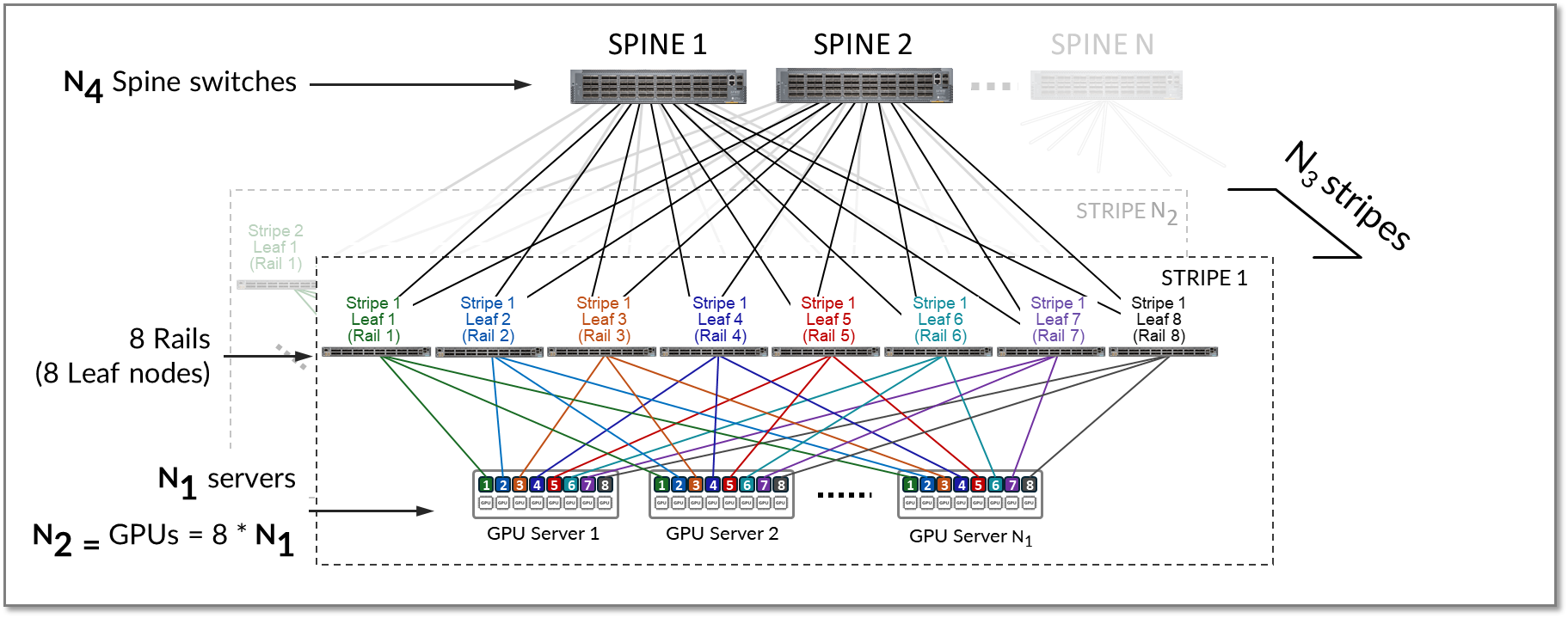
스트라이프를 복제하여 AI 클러스터의 서버(N1) 및 GPU(N2) 수를 확장할 수 있습니다. 그런 다음 그림 13과 같이 여러 스트라이프(N3)가 스파인 스위치 전반에 걸쳐 연결됩니다.
그림 13: 스파인 노드를 통해 연결된 여러 스트라이프
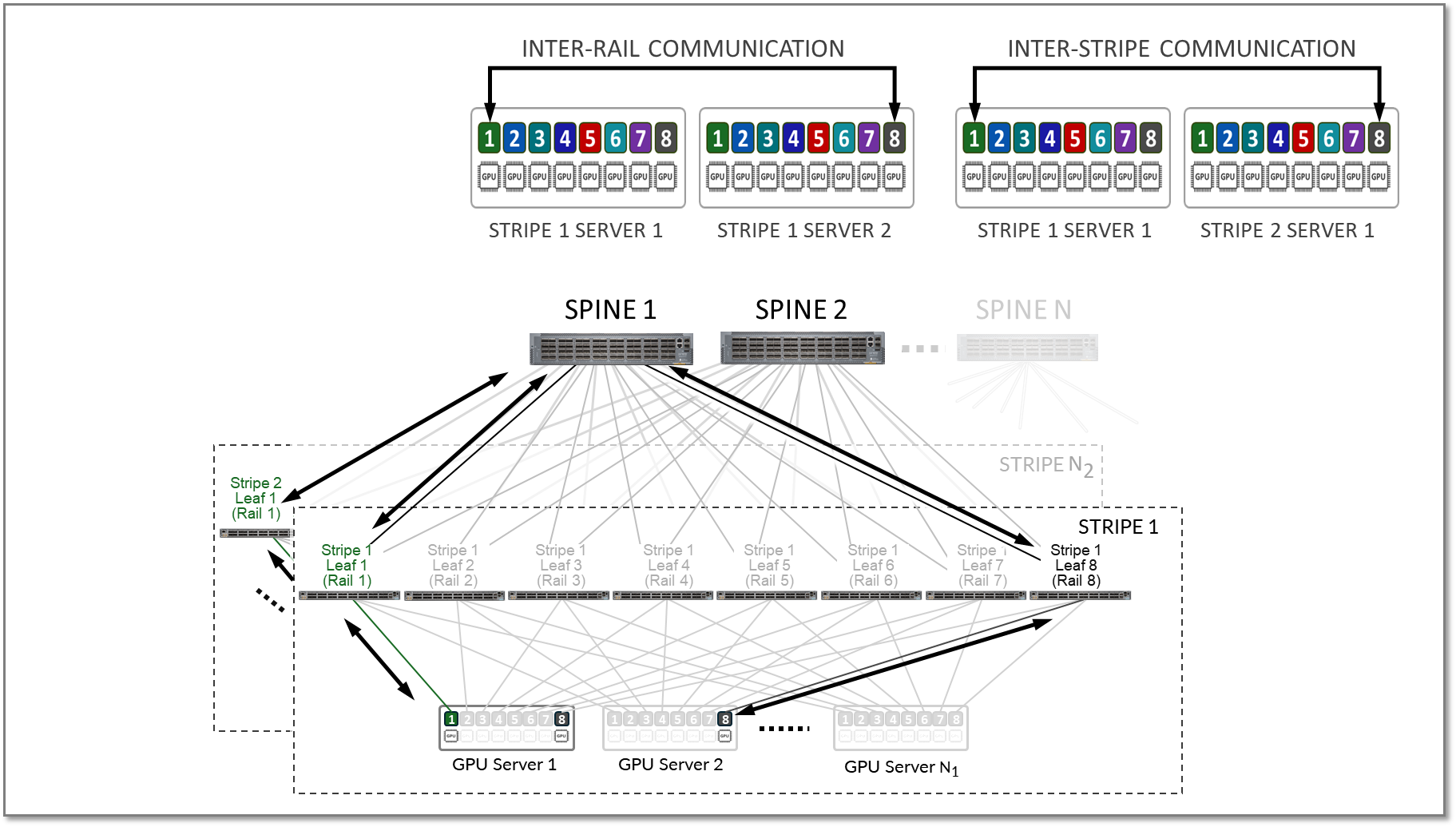
레 일 간 트래픽과 스트라이프 간 트래픽은 그림 14와 같이 스파인 노드를 통해 전달됩니다.
그림 14. 레일 간 및 스트라이프 간 GPU 투 GPU 트래픽 예시입니다.
레일 최적화 아키텍처에서 리프 및 스파스파인 노드, 서버 및 GPU 수 계산
레일 최적화 아키텍처에서 단일 스트라이프의 리프 노드 수는 서버당 GPU 수(레일 수)로 정의됩니다. 각 NVIDIA DGX H100 GPU 서버에는 8개의 NVIDIA H100 Tensor 코어 GPU가 포함되어 있습니다. 따라서 단일 스트라이프에는 8개의 리프 노드(8개의 레일)가 포함됩니다.
리프 노드 수 = 서버당 GPU 수 = 8
단일 스트라이프(N1)에서 지원되는 최대 서버 수는 스위치 모델에 따라 리프 노드에서 사용 가능한 포트 수 로 정의됩니다.
GPU 서버와 리프 노드 간의 총 대역폭은 1:1 구독 비율을 유지하려면 리프와 스파인 노드 간의 총 대역폭과 일치해야 합니다.
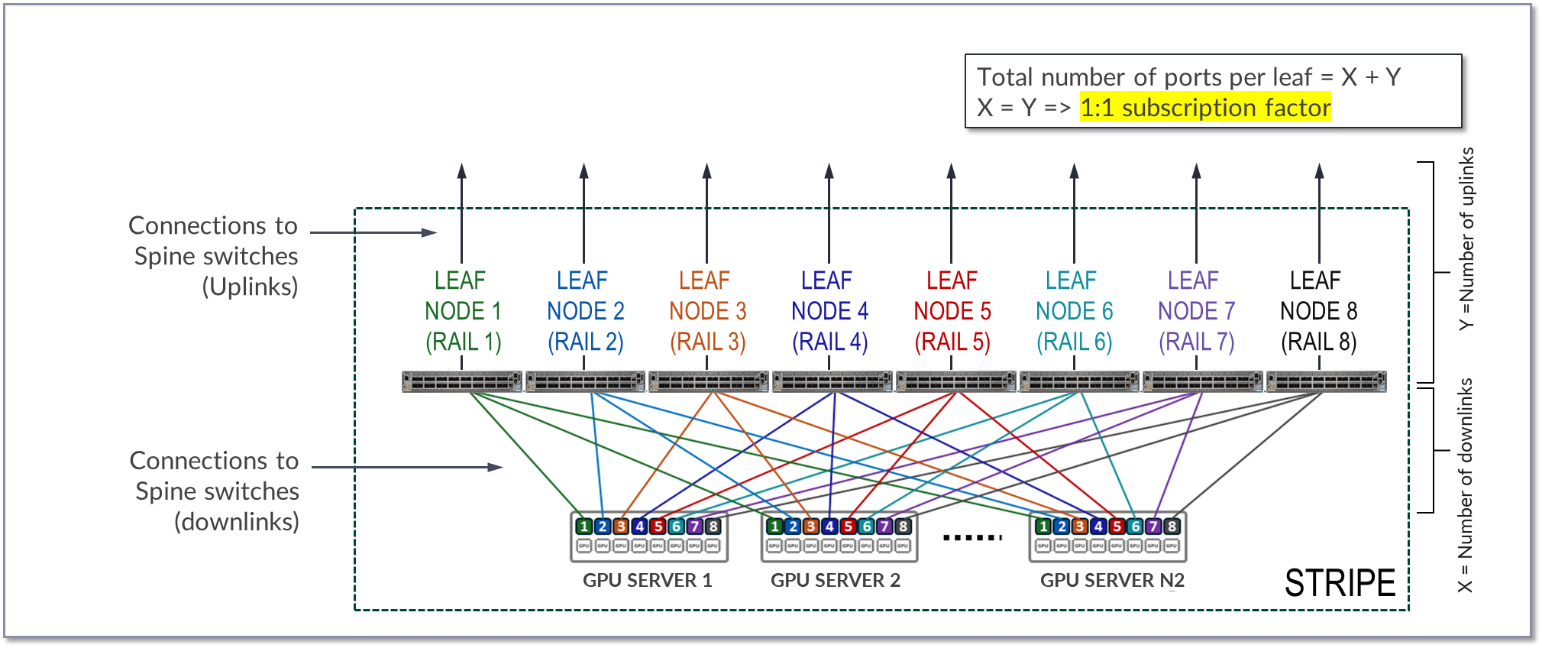
리프 노드의 모든 인터페이스가 동일한 속도로 작동한다고 가정하면 인터페이스의 절반은 GPU 서버에 연결하는 데 사용되고 나머지 절반은 스파인 연결에 사용됩니다. 따라서 스트라이프의 최대 서버 수는 각 리프 노드에서 사용 가능한 포트 수의 절반으로 계산됩니다.
그림 15. 1:1 구독 비율에 대한 업링크 및 다운링크 수
다이어그램에서 X는 다운링크(리프 노드와 GPU 서버 간의 링크) 수를 나타내고, Y는 업링크(리프 노드와 스파인 노드 간의 링크) 수를 나타내스파인 노드입니다. 1:1 구독 요소를 허용하려면 X가 Y와 같아야 합니다.
각 리프 노드에서 사용 가능한 포트 수는 X + Y 또는 2 * X와 같습니다.
스트라이프의 모든 서버에는 스트라이프의 모든 리프에 연결된 하나의 포트가 있으므로 스트라이프의 최대 서버 수(N1)는 X와 같습니다.
N1(스트라이프당 최대 서버 수) = 사용 가능한 포트 수 ÷ 2
스트라이프의 최대 GPU 수는 서버당 GPU 수를 곱하여 계산됩니다.
N2(최대 GPU 수) = N1(스트라이프당 최대 서버 수) * 8
사용 가능한 포트의 총 수는 리프 노드에 사용되는 스위치 모델에 따라 다릅니다. 표 16은 몇 가지 예를 보여줍니다.
표 16: 스트라이프당 지원되는 최대 GPU 수
| 리프 노드 QFX 스위치 모델 |
스위치당 사용 가능한 총 400GE 포트 수 | 1:1 구독을 위해 스트라이프당 지원되는 최대 서버 수 (N1) |
서버당 GPU | 스트라이프당 지원되는 최대 GPU 수 (N2) |
|---|---|---|---|---|
| QFX5220-32CD | 32 | 32 ÷ 2 = 16 | 8 | 서버 16개 x 서버당 GPU 8개 = GPU 128개 |
| QFX5230-64CD | 64 | 64 ÷ 2 = 32 | 8 | 서버 32개 x GPU 8개/서버 = GPU 256개 |
| QFX5240-64OD QFX5241-64OD |
128 | 128 ÷ 2 = 64 | 8 | 서버 64개 x GPU 8개/서버 = GPU 512개 |
- QFX5220-32CD 스위치는 32개의 400GE 포트를 제공합니다(16개는 서버 연결에 사용되고 16개는 스파인 스파인 노드 연결에 사용됨)
- QFX5230-64CD 스위치는 최대 64개의 400GE 포트를 제공합니다(32개는 서버 연결에 사용되고 32개는 스파인 노드 연결에 사용됨).
- QFX5240-64OD 스위치는 최대 128개의 400GE 포트를 제공합니다(64개는 서버 연결에 사용되고 64개는 스파인 노드 연결에 사용됨).
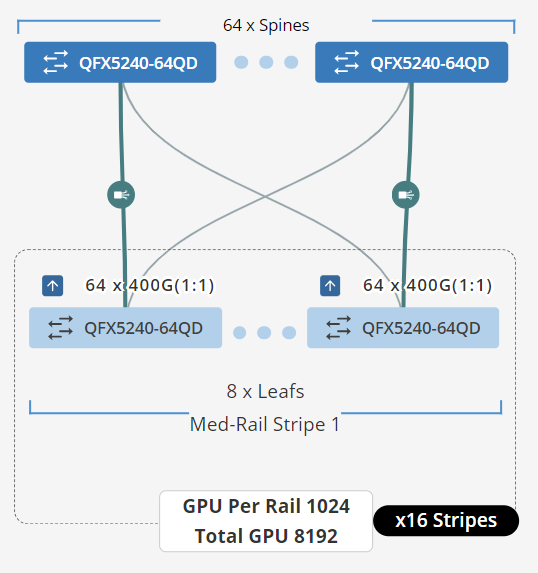
더 큰 규모를 달성하기 위해 그림 10과 같이 일련의 스파인 노드(N4)를 사용하여 여러 스트라이프(N3)를 연결할 수 있습니다.
그림 16: 스파인 노드에서 연결된 여러 스트라이프.
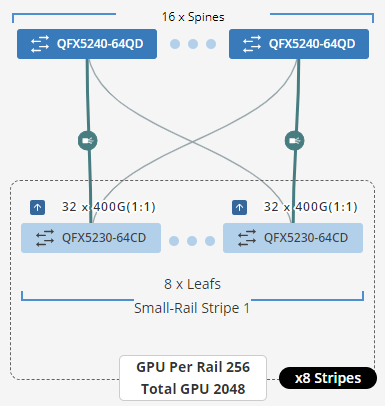
필요한 스트라이프 수(N3)는 필요한 GPU 수와 스트라이프당 최대 GPU 수(N2)를 기준으로 계산됩니다.
예를 들어, 필요한 GPU(GPU) 수가 16,000이고 패브릭이 리프 노드로 QFX5240-64OD를 사용한다고 가정합니다.
사용 가능한 400G 포트 수는 128개이며, 이는 다음을 의미합니다.
- 스트라이프당 최대 서버 수(N1) = 64
- 스트라이프당 최대 GPU 수(N2) = 512
필요한 스트라이프 수 (N3)는 다음과 같이 필요한 GPU 수와 스트라이프당 GPU 수를 나누어 계산됩니다.
N 3(스트라이프 수) = GPU ÷ N 2(스트라이프당 최대 GPU 수) = 16000 ÷ 512 = 32개 스트라이프(반올림)
스트라이프당 32개의 스트라이프와 64개의 서버가 있는 이 클러스터는 16,384개의 GPU를 제공할 수 있습니다.
필요한 스트라이프 수(N 3)와 리프 노드당 업링크 포트 수(Y)를 알면 얼마나 많은 스파인 노드가 필요한지 계산할 수 있습니다.
X = Y = N1 기억하기
먼저 필요한 스트라이프 수에 8(스트라이프당 리프 노드 수)을 곱하여 총 리프 노드 수를 계산할 수 있습니다.
총 리프 노드 수 = N3 x 8 = 32 x 8 = 256
그런 다음 총 업링크 수를 리프 노드당 업링크 수(N1) 와 총 리프 노드 수를 곱하여 얻을 수 있습니다.
총 업링크 수 = N1 x 256 = 64 x 256 = 16384
필요한 스파인 수(N4)는 총 업링크 수를 각 스파인 노드에서 사용 가능한 포트 수로 나누어 결정할 수 있으며, 리프 노드의 경우 스파인 역할에 사용되는 스위치 모델에 따라 다릅니다.
필요한 스파인 수(N4) = 16384 / 각 스파인 노드에서 사용 가능한 포트 수
예를 들어, 스파인 노드가 QFX5240/41인 경우 각 스파인 노드에서 사용 가능한 포트 수는 128입니다.
표 17: 두 줄무늬에 대한 스파인 노드 수.
| 스파인 노드 QFX 스위치 모델 |
스위치당 최대 400GE 인터페이스 수 | 64개의 스트라이프가 있는 필요한 스파인 수(N4) |
|---|---|---|
| QFX5240-64OD | 128 | 32768 ÷ 128 = 128 |
| PTX10008 LC1201 | 288 | 32768 ÷ 288 ~ 57 |
| PTX10008 LC1301 |
576 | 32768 ÷ 576 ~ 29 |
스토리지 백엔드 패브릭
스토리지 백엔드 패브릭은 GPU 서버에서 액세스할 수 있는 스토리지 디바이스에 대한 연결 인프라를 제공합니다.
스토리지 인프라의 성능은 AI 워크플로우의 효율성에 큰 영향을 미칩니다. 데이터에 대한 빠른 액세스를 제공하는 스토리지 시스템은 AI 모델을 훈련하는 시간을 크게 줄일 수 있습니다. 마찬가지로, 효율적인 데이터 쿼리 및 인덱싱을 지원하는 스토리지 시스템은 AI 워크플로에서 전처리 및 기능 추출 완료 시간을 최소화할 수 있습니다.
소규모 클러스터에서는 각 GPU 서버의 로컬 스토리지를 사용하거나 오픈 소스 또는 상용 소프트웨어를 사용하여 이 스토리지를 함께 통합하는 것으로 충분할 수 있습니다. 워크로드가 더 많은 대규모 클러스터에서는 수집을 위한 데이터 세트 스테이징과 훈련 중 클러스터 체크포인트를 제공하기 위해 외부 전용 스토리지 시스템이 필요합니다.
두 개의 주요 플랫폼인 WEKA와 Vast Storage는 GPU 환경의 공유 스토리지를 위한 최첨단 솔루션을 제공합니다. 우리는 실험실에서 두 가지 솔루션을 모두 테스트했지만 이 JVD는 Weka 스토리지 솔루션에 중점을 둡니다. 따라서 이 문서의 나머지 섹션과 이 문서의 다른 섹션에서는 Weka 스토리지 장치 및 스토리지 백엔드 패브릭에 대한 연결에 대한 세부 정보를 다룹니다.
방대한 스토리지에 대한 자세한 내용은 주 니퍼 Apstra, AMD GPU, Broadcom NIC, AMD Pollara NIC 및 주니퍼 검증 설계(JVD)인 방대한 스토리지를 통한 AI 데이터센터 네트워크에 포함되어 있습니다.
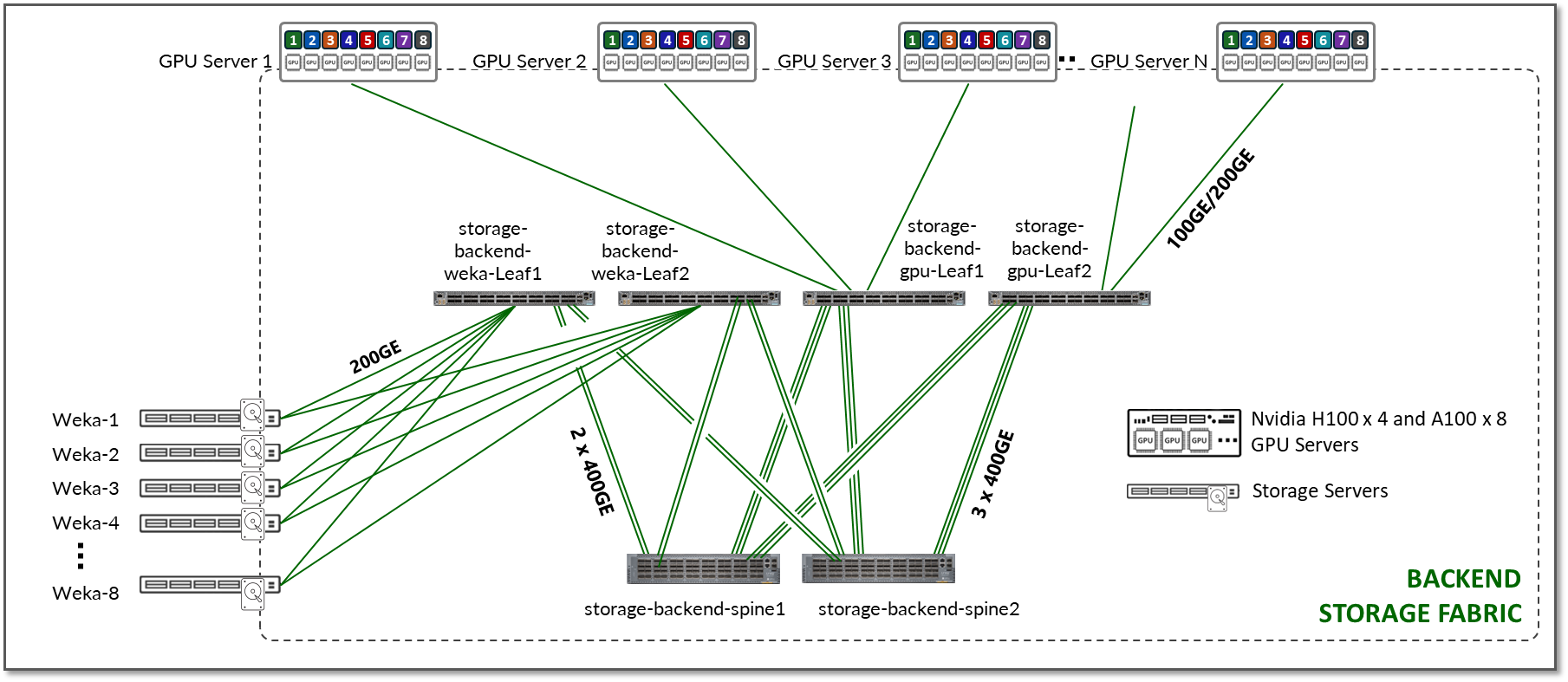
JVD의 스토리지 백엔드 패브릭 설계도 그림 17과 같이 3단계 IP clos 아키텍처를 따릅니다. 스토리지 클러스터에는 레일 최적화의 개념이 없습니다. 각 GPU 서버는 GPU당 하나가 아닌 리프 노드에 대한 단일 연결을 갖습니다.
그림 17: 스토리지 백엔드 패브릭 아키텍처
리프 노드 수는 GPU 수, AI 클러스터에 있는 서버 및 스토리지 디바이스 수에 따라 달라집니다.
스파인 노드 수는 설계에 원하는 구독 요소에 따라 달라집니다. GPU 백엔드 패브릭 과 마찬가지로 스토리지 패브릭 도 대용량 트래픽에 충분한 대역폭을 보장하고 혼잡, 패킷 손실, 과도한 지연을 방지하기 위해 초과 구독되지 않은 설계 (1:1 구독 비율)가 필요합니다.
스토리지 트래픽은 NFS, POSIX 및 RoCEv2를 비롯한 다양한 전송 메커니즘을 사용할 수 있습니다. RoCEv2의 경우 GPU 백엔드 패브릭에 대해 설명한 것과 동일한 로드 밸런싱 및 서비스 등급 메커니즘을 구현해야 합니다. 이러한 내용은 이 문서의 로드 밸런싱 및 서비스 등급 섹션에 설명되어 있습니다.
이 JVD에서 검증된 스토리지 패브릭의 디바이스 및 연결은 다음 표에 요약되어 있습니다.
표 18: 검증된 스토리지 패브릭 리프 및 스파인 노드
| 스토리지 패브릭 리프 노드 스위치 모델 | 스토리지패브릭 스파인 노드 스위치 모델 |
|---|---|
| QFX5130-32CD | QFX5130-32CD |
| QFX5220-32CD | QFX5220-32CD |
| QFX5230-32CD | QFX5230-32CD |
| QFX5230-64CD | QFX5230-64CD |
| QFX5240-64OD | QFX5240-64OD |
표 19: 스토리지 패브릭의 GPU 서버, 스토리지 디바이스 및 리프 노드 간의 검증된 연결
| 리프 연결에 대한 GPU 서버당 링크 | 서버 유형 |
|---|---|
| 1 x 100GE | 엔비디아 A100 |
| 1 x 100GE | 엔비디아 H100 |
| 1 x 200GE | 웨카 |
표 20: 스토리지 패브릭의 리프와 스파인 노드 간의 검증된 연결
| 리프 및 스파인 연결당 링크 | 리프 노드 모델 | 스파인 노드 모델 |
|---|---|---|
| 2 x 400GE, 3 x 400GE | QFX5130-32CD | QFX5130-32CD |
| 2 x 400GE, 3 x 400GE | QFX5130-32CD | QFX5130-32CD |
| 2 x 400GE, 3 x 400GE | QFX5240-32CD QFX5241-32CD |
QFX5240-32CD QFX5241-32CD |
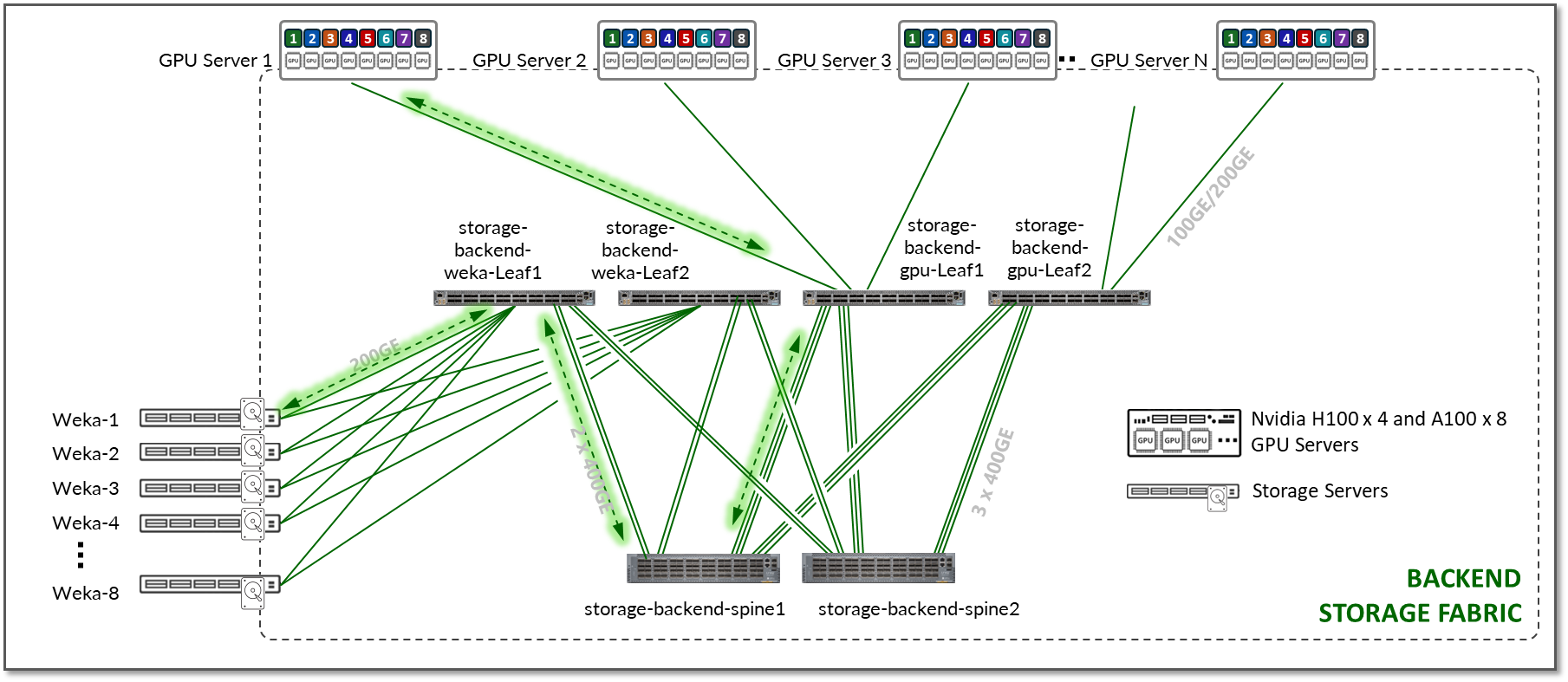
이 JVD에 대한 테스트는 그림 18과 같이 4개의 리프 노드에 연결된 8개의 NVIDIA A100 GPU 서버, 4개의 NVIDIA H100 GPU 서버 및 8개의 WEKA 스토리지 장치를 사용하여 수행되었으며, 이들은 차례로 2개의 스파인 노드에 연결되었습니다.
그림 18: 스토리지 패브릭 JVD 테스트 토폴로지
- 각 Nvidia A100 서버는 200G 인터페이스(ConnectX-7 NIC)를 사용하여 리프 노드에 연결됩니다.
- 각 Nvidia H100 서버는 400G 인터페이스(ConnectX-7 NIC)를 사용하여 리프 노드에 연결됩니다.
- 각 Weka 디바이스
표 21: 총 스토리지 링크 수 및 테스트된 대역폭
| GPU 서버 <=> 스토리지 리프 노드 | 스토리지 리프 노드 <=> 프론트엔드 스파인 노드 |
|---|---|
|
사이의 총 400GE 링크 수 프론트엔드 리프 노드 및 스파스파인 노드 = 20 (리프-스파인 연결당 2-3개 링크) |
| 총 대역폭 = 5.6Tbps | 총 대역폭 = 6.4Tbps |
| 초과 구독 없음. |
GPU 백엔드 패브릭 확장
AI 클러스터의 크기는 워크로드의 특정 요구 사항에 따라 크게 달라집니다. AI 클러스터의 노드 수는 기계 학습 모델의 복잡성, 데이터 세트의 크기, 원하는 학습 속도 및 사용 가능한 예산과 같은 요소의 영향을 받습니다. 그 수는 노드가 100개 미만인 소규모 클러스터부터 10,000개의 컴퓨팅, 스토리지 및 네트워킹 노드로 구성된 데이터센터 전체 클러스터에 이르기까지 다양합니다. 경로 다양성 및 PFC 장애 경로 감소를 위해 항상 최소 4개의 스파인을 구축해야 합니다.
표 22: 패브릭 스케일링 - 디바이스 및 포지셔닝
| 소형 | 중형 | 대형 |
|---|---|---|
| 64 – 2048 GPU | 2048 – 8192 GPU | 8192 – 32768 GPU |
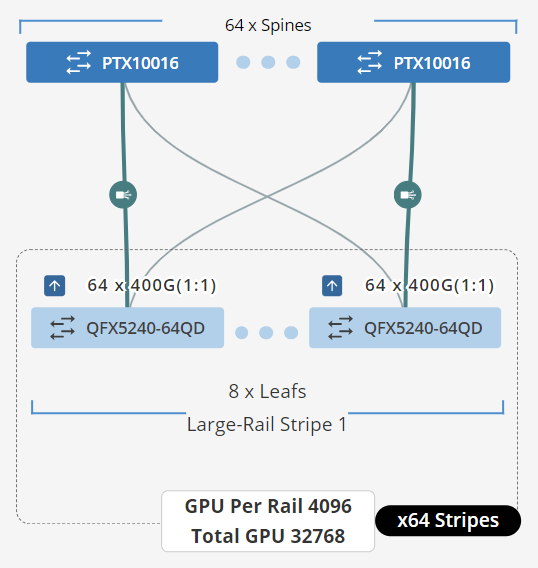
| 최대 2048개의 GPU를 지원하는 주니퍼 QFX5240-64CD/QFX5240-64OD/QD 또는 QFX5230-64CD는 스파인 및 리프 디바이스로 사용하여 단일 또는 이중 스트라이프 애플리케이션을 지원할 수 있습니다. 모범 사례 권장 사항을 따르려면 단일 스트라이프 패브릭에도 최소 4개의 스파인을 배포해야 합니다. | 2048 – 8192 GPU를 지원하는 주니퍼 QFX5240-64CD/QFX5240-64OD/QD는 스파인 및 리프 디바이스로 사용하여 적절한 확장성을 달성할 수 있습니다. 이 3단계 레일 기반 패브릭 설계는 64개의 스파인과 1024개의 리프 노드에서 16개의 스트라이프에 대한 물리적 연결을 제공하여 1:1 구독 처리량 모델을 유지합니다. | 8192개 이상의 GPU를 지원하는 인프라의 경우, 주니퍼 PTX1000x 섀시 스파인 및 QFX5240-64CD/QFX5240-64OD/QD 리프 노드는 최대 32768개의 GPU를 지원할 수 있습니다. 이 3단계 레일 기반 패브릭 설계는 64개의 스파인과 4096개의 리프 노드에서 64개의 스트라이프에 대한 물리적 연결을 제공하여 1:1 구독 처리량 모델을 유지합니다. |
 |
 |
 |
주니퍼 하드웨어 및 소프트웨어 구성 요소
이 솔루션 설계를 위해 아래의 주니퍼 제품 및 소프트웨어 버전은 다음과 같습니다. 이 JVD에 문서화된 설계는 검증된 솔루션의 기본 표현으로 간주됩니다. 주니퍼는 완전한 솔루션 제품군의 일부로서 반복적인 사용 사례 테스트 중에 하드웨어 디바이스를 다른 모델과 정기적으로 교체합니다. 이 문서에서 검증된 각 스위치 플랫폼은 지정된 버전의 Junos OS 및 Apstra 관리 소프트웨어를 사용하여 동일한 엄격한 역할 기반 테스트를 거칩니다.
검증된 주니퍼 하드웨어 및 소프트웨어 솔루션 구성 요소
다음 표에는 이 JVD에 대해 검증된 주니퍼 디바이스가 요약되어 있으며, 여기에는 주니퍼 Apstra, AMD GPU 및 VAST Storage—JVD(주니퍼 검증 설계)를 사용하여 AI 데이터센터 네트워크에 대해 테스트된 디바이스가 포함되어 있습니다
표 23: 검증된 디바이스 및 위치 지정
| 디바이스 | 프론트엔드 패브릭 | ,GPU, 백엔드 패브릭 | ,스토리지 패브릭 | |||
|---|---|---|---|---|---|---|
| 리프 | 스파인 | 리프 | 스파인 | 리프 | 스파인 | |
| QFX5130-32CD | X | X | X | X | ||
| QFX5220-32CD | X | X | X | X | X | |
| QFX5230-32CD | X | X | X | |||
| QFX5230-64CD | X | X | X | X | ||
| QFX5240-64OD | X | X | X | X | ||
| QFX5241-64OD | X | X | X | X | ||
| PTX10008 JNP10K-LC1201 | X | |||||
| PTX10008 JNP10K-LC1301 | X | |||||
주니퍼 소프트웨어 구성 요소
다음 표에는 역할별로 테스트하고 검증된 소프트웨어 버전이 요약되어 있습니다.
표 24: 플랫폼 권장 릴리스
| 플랫폼 | 역할 | Junos OS 릴리스 |
|---|---|---|
| QFX5240-64CD | GPU 백엔드 리프 | 23.4X100-D20 |
| QFX5240-64OD/QD | GPU 백엔드 스파인 | 23.4X100-D42 |
| QFX5220-32CD | GPU 백엔드 리프 | 23.4X100-D20 |
| QFX5230-64CD | GPU 백엔드 리프 | 23.4X100-D20 |
| QFX5240-64CD | GPU 백엔드 스파인 | 23.4X100-D20 |
| QFX5240-64OD/QD | GPU 백엔드 스파인 | 23.4X100-D42 |
| QFX5230-64CD | GPU 백엔드 스파인 | 23.4X100-D20 |
| PTX10008(LC1201 포함) | GPU 백엔드 스파인 | 23.4R2-S3 |
| QFX5130-32CD | 프론트엔드 리프 | 23.43R2-S3 |
| QFX5130-32CD | 프론트엔드 스파인 | 23.43R2-S3 |
| QFX5220-32CD | 스토리지 백엔드 리프 | 23.4X100-D20 |
| QFX5230-64CD | 스토리지 백엔드 리프 | 23.4X100-D20 |
| QFX5240-64CD | 스토리지 백엔드 리프 | 23.4X100-D20 |
| QFX5240-64OD/QD | 스토리지 백엔드 리프 | 23.4X100-D42 |
| QFX5220-32CD | 스토리지 백엔드 스파인 | 23.4X100-D20 |
| QFX5230-64CD | 스토리지 백엔드 스파인 | 23.4X100-D20 |
| QFX5240-64CD | 스토리지 백엔드 스파인 | 23.4X100-D20 |
| QFX5240-64OD/QD | 스토리지 백엔드 스파인 | 23.4X100-D42 |