이 페이지의 내용
인라인 Multlink 서비스
WAN 인터페이스용 인라인 MLPPP 개요
시분할 멀티플렉싱(TDM)을 위한 인라인 멀티링크 PPP(MLPPP), 멀티링크 프레임 릴레이(FRF.16) 및 멀티링크 프레임 릴레이 엔드투엔드(FRF.15) WAN 인터페이스는 PIC 또는 DPC(Dense Port Concentrator) 없이 패킷 포워딩 엔진을 통해 번들링 서비스를 제공합니다.
전통적으로 번들링 서비스는 여러 개의 저속 링크를 번들로 묶어 더 높은 대역폭 파이프를 만드는 데 사용됩니다. 이 결합된 대역폭은 모든 링크의 트래픽에 사용할 수 있으며 번들에서 링크 단편화 및 인터리빙(LFI)을 지원하여 우선순위가 높은 패킷 전송 지연을 줄입니다.
이 지원에는 동일한 번들에 대한 여러 링크와 MLPPP에 대한 멀티클래스 확장이 포함됩니다. 이 서비스를 통해 추가 DPC 슬롯 없이 서비스 번들링 서비스를 활성화하여 서비스 DPC를 지원하고 다른 MIC를 위한 슬롯을 확보할 수 있습니다.
MLPPP는 MX 시리즈 Virtual Chassis에서 지원되지 않습니다.
Junos OS 릴리스 15.1부터 채널화된 E1/T1 서킷 에뮬레이션 MIC를 사용하여 MX80, MX104, MX240, MX480 및 MX960 라우터에서 인라인 MLPPP 인터페이스를 구성할 수 있습니다. 채널화된 E1/T1 서킷 에뮬레이션 MIC에서는 최대 8개의 인라인 MLPPP 인터페이스 번들이 지원되며, 이는 호환 가능한 다른 MIC에서 인라인 MLPPP 번들을 지원하는 것과 유사합니다.
WAN 인터페이스에 대한 인라인 MLPPP를 구성하면 다음과 같은 서비스의 이점이 있습니다.
-
PSTN(Public Switched Telephone Network) 기반 액세스 네트워크를 사용하는 레이어 3 VPN 및 DIA 서비스를 위한 CE-PE 링크입니다.
-
PSTN이 MPLS 네트워크에 사용되는 경우 PE-P 링크입니다.
이 기능은 다음 서비스 프로바이더에서 사용됩니다.
-
PSTN을 사용하여 중대형 기업 고객에게 PSTN 기반 액세스 네트워크를 통해 레이어 3 VPN 및 DIA 서비스를 제공하는 서비스 프로바이더.
-
SONET 기반 코어 네트워크를 갖춘 서비스 프로바이더.
다음 그림에서는 이 기능의 범위를 보여 줍니다.
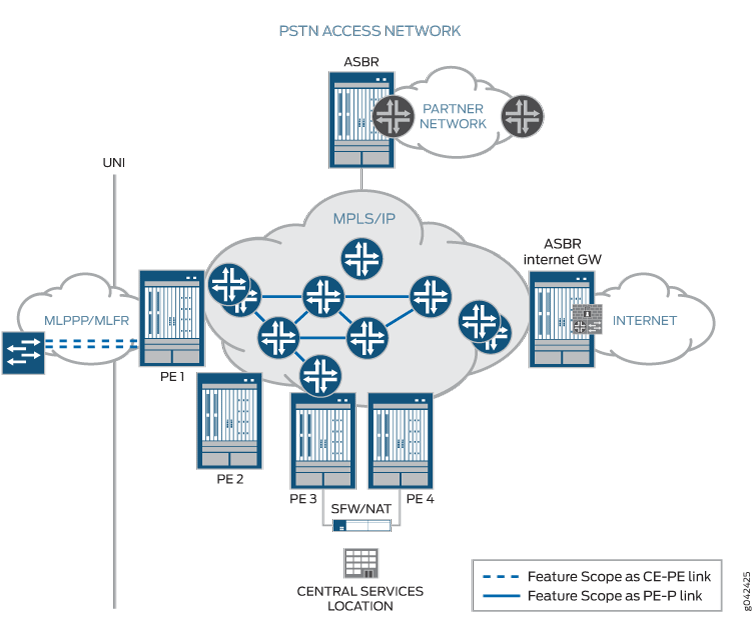 용 인라인 MLPPP
용 인라인 MLPPP
VPN에서 많은 소규모 사이트를 연결하려면 MLPPP/MLFR 기술과 함께 TDM 회로를 번들로 묶는 것이 더 높은 대역폭과 링크 중복을 제공하는 유일한 방법입니다.
MLPPP를 사용하면 여러 PPP 링크를 단일 멀티링크 번들로 묶을 수 있으며, MLFR을 사용하면 여러 프레임 릴레이 DLCI(데이터 링크 연결 식별자)를 단일 멀티링크 번들로 묶을 수 있습니다. 멀티링크 번들은 T1, E1 및 직렬 링크와 같은 저속 링크를 어그리게이션하여 추가적인 대역폭, 로드 밸런싱 및 중복을 제공합니다.
MLPPP는 여러 구성 링크를 하나의 더 큰 PPP 번들로 집계하기 위한 프로토콜입니다. MLFR을 사용하면 역 멀티플렉싱을 통해 여러 프레임 릴레이 링크를 어그리게이션할 수 있습니다. MLPPP 및 MLFR은 저속 T1 및 E1 서비스 간의 서비스 옵션을 제공합니다. 추가 대역폭을 제공할 뿐만 아니라 여러 링크를 번들링하면 전용 액세스 서비스에 한 수준의 장애 허용 능력이 추가될 수 있습니다. 여러 인터페이스에 걸쳐 묶음을 구현할 수 있기 때문에 단일 인터페이스에 장애가 발생할 때 액세스 손실로부터 사용자를 보호할 수 있습니다.
WAN 인터페이스에 대한 인라인 MLPPP를 구성하려면 다음을 참조하십시오.
또한보십시오
LSQ 인터페이스의 링크 레이어 오버헤드를 위한 번들 대역폭 예약
링크 레이어 오버헤드는 직렬 링크의 비트 스터핑으로 인해 구성 링크에서 패킷 드롭을 유발할 수 있습니다. 비트 스터핑은 데이터가 제어 정보로 해석되는 것을 방지하는 데 사용됩니다.
기본적으로 총 번들 대역폭의 4%가 링크 레이어 오버헤드를 위해 따로 설정됩니다. 대부분의 네트워크 환경에서 평균 링크 레이어 오버헤드는 1.6%입니다. 따라서 안전 장치로 4%를 권장합니다. 자세한 내용은 RFC 4814, 해시 및 스터핑: 네트워크 디바이스 벤치마킹에서 간과된 요소를 참조하십시오.
링크 서비스 IQ(lsq-) 인터페이스의 경우, 링크 레이어 오버헤드를 위해 따로 마련될 번들 대역폭의 비율을 구성할 수 있습니다. 이를 위해 다음 문을 포함합니다.link-layer-overhead
link-layer-overhead percent;
다음 계층 수준에서 이 문을 포함할 수 있습니다.
[edit interfaces interface-name mlfr-uni-nni-bundle-options][edit interfaces interface-name unit logical-unit-number][edit logical-systems logical-system-name interfaces interface-name unit logical-unit-number]
값을 0%에서 50%까지 구성할 수 있습니다.
또한보십시오
인라인 LSQ 서비스 활성화
시분할 멀티플렉싱(TDM)을 위한 인라인 멀티링크 PPP(MLPPP), 멀티링크 프레임 릴레이(FRF.16) 및 멀티링크 프레임 릴레이 엔드투엔드(FRF.15) WAN 인터페이스는 PIC 또는 DPC(Dense Port Concentrator) 없이 패킷 포워딩 엔진을 통해 번들링 서비스를 제공합니다.
전통적으로 번들링 서비스는 여러 개의 저속 링크를 번들로 묶어 더 높은 대역폭 파이프를 만드는 데 사용됩니다. 이 결합된 대역폭은 모든 링크의 트래픽에 사용할 수 있으며 번들에서 링크 단편화 및 인터리빙(LFI)을 지원하여 우선순위가 높은 패킷 전송 지연을 줄입니다.
이 지원에는 동일한 번들에 대한 여러 링크와 MLPPP에 대한 멀티클래스 확장이 포함됩니다. 이 서비스를 통해 추가 DPC 슬롯 없이 서비스 번들링 서비스를 활성화하여 서비스 DPC를 지원하고 다른 MIC를 위한 슬롯을 확보할 수 있습니다.
인라인 LSQ 논리적 인터페이스(lsq-라고 함)는 서비스 PIC가 필요하지 않은 레이어 2 번들링 서비스를 제공하기 위해 패킷 포워딩 엔진에 상주하는 가상 서비스 논리적 인터페이스입니다. 명명 규칙은 lsq-slot/pic/0입니다.
MX240, MX480, MX960, MX2008, MX2010, MX2020, MX10003 라우터의 MPC1, MPC2, MPC3, MPC6, MPC8, MPC9가 현재 지원하는 MIC의 호환성 매트릭스를 보려면 여기 를 클릭하십시오.
Type1 MPC에는 하나의 논리 장치(LU)만 있습니다. 따라서 하나의 LSQ 논리적 인터페이스만 생성할 수 있습니다. Type1 MPC를 구성할 때는 PIC 슬롯 0을 사용합니다. Type2 MPC에는 두 개의 LU가 있습니다. 따라서 두 개의 LSQ 논리적 인터페이스를 생성할 수 있습니다. Type2 MPC를 구성할 때는 PIC 슬롯 0과 슬롯 2를 사용합니다.
하나의 루프백 스트림으로 각 LSQ 논리적 인터페이스를 구성합니다. 이 스트림은 일반 스트림처럼 형성될 수 있으며 인라인 서비스(SI) 인터페이스와 같은 다른 인라인 인터페이스와 공유됩니다.
FRF.16 번들을 지원하려면 명명 규칙 lsq-slot/pic/0:bundle_idbundle_id 으로 논리적 인터페이스를 생성합니다. 여기서 범위는 0에서 254까지입니다. 기본 LSQ 논리 인터페이스에서 생성된 논리 인터페이스를 MLPPP 또는 FRF.16로 구성할 수 있습니다.
SI 및 LSQ 논리적 인터페이스는 동일한 스트림을 공유할 수 있고 해당 스트림에는 여러 LSQ 논리적 인터페이스가 있을 수 있기 때문에 모든 논리적 인터페이스 관련 셰이핑은 레이어 1 노드가 아닌 레이어 2 노드에서 구성됩니다. 그 결과, SI가 활성화되면 구성에 따라 스트림 대역폭을 1Gb 또는 10Gb로 제한하는 대신 SI 인터페이스에 할당된 레이어 2 대기열만 1Gb 또는 10Gb로 형성됩니다.
MLPPP 및 FRF.15의 경우, 각 LSQ 논리적 인터페이스는 번들당 하나의 고유한 레이어 3 노드를 구성하여 총 번들 대역폭(제어 패킷 플로우 오버헤드를 가진 멤버 링크 대역폭의 합계)을 기반으로 형성됩니다. 마찬가지로, 각 FRF.16 논리적 인터페이스는 번들당 하나의 고유한 레이어 2 노드를 구성하여 총 번들 대역폭을 기반으로 형성됩니다. FRF16 논리적 인터페이스 데이터 링크 연결 식별자(DLCI)는 레이어 3 노드에 매핑됩니다.
인라인 LSQ 서비스를 활성화하고 지정된 PIC에 대한 논리적 인터페이스를 생성 lsq- 하려면 multi-link-layer-2-inline 및 mlfr-uni-nni-bundles-inline 구성 문을 지정합니다.
[edit chassis fpc number pic number] user@host# set multi-link-layer-2-inline user@host# set mlfr-uni-nni-bundles-inline number
단일 패킷 포워딩 엔진을 가진 MX80 및 MX104 라우터에서는 FPC 0 및 PIC 0에서만 LSQ 논리적 인터페이스를 구성할 수 있습니다. 해당 번들이 작동하려면 채널화된 카드가 슬롯 FPC 0/0에 있어야 합니다.
예를 들어, 슬롯 1의 Type1 MPC에서 PIC 0에 대한 인라인 서비스를 활성화하려면:
[edit chassis fpc 1 pic 0] user@host# set multi-link-layer-2-inline user@host# set mlfr-uni-nni-bundles-inline 1
그 결과, 논리적 인터페이스 lsq-1/0/0 및 lsq-1/0/0:0이 생성됩니다. 인라인 멀티링크 프레임 릴레이 UNI(사용자-네트워크 인터페이스) 및 NNI(네트워크-네트워크 인터페이스) 번들의 수는 1로 설정됩니다.
예를 들어, 슬롯 5에 설치된 Type2 MPC에서 PIC 0과 PIC 2 모두에 대한 인라인 서비스를 활성화하려면:
[edit chassis fpc 5 pic 0] user@host# set multi-link-layer-2-inline user@host# set mlfr-uni-nni-bundles-inline 1 [edit chassis fpc 5 pic 2] user@host# set multi-link-layer-2-inline user@host# set mlfr-uni-nni-bundles-inline 1
그 결과 논리적 인터페이스 lsq-5/0/0, lsq-5/0/0:0, lsq-5/0/0:1, lsq-5/2/0, lsq-5/2/0:0, lsq-5/2/0:1이 생성됩니다. 인라인 멀티링크 프레임 릴레이 UNI(사용자-네트워크 인터페이스) 및 NNI(네트워크-네트워크 인터페이스) 번들의 수는 1로 설정됩니다.
여기서 PIC 번호는 인라인 LSQ 인터페이스를 바인딩하기 위해 올바른 LU를 선택하기 위한 앵커로만 사용됩니다. 묶음 서비스는 논리적 PIC가 오프라인 상태인 경우에도 바인딩된 패킷 포워딩 엔진이 작동하는 한 운영됩니다.
또한보십시오
MLPPP를 사용하여 LSQ 인터페이스를 NxT1 또는 NxE1 번들로 구성
MLPPP를 사용하여 xT1 번들을 구성N하려면 서로 다른 T1 링크를 번들로 어그리게이션 N 합니다. NxT1 번들은 예를 들어 라우팅 인접성을 나타낼 수 있기 때문에 논리적 인터페이스라고 합니다. T1 링크를 MLPPP 번들로 어그리게이션하려면 계층 수준에서 문을 포함 bundle 합니다.[edit interfaces t1-fpc/pic/port unit logical-unit-number family mlppp]
[edit interfaces t1-fpc/pic/port unit logical-unit-number family mlppp] bundle lsq-fpc/pic/port.logical-unit-number;
링크 서비스 IQ 인터페이스는 T1 및 E1 물리적 인터페이스를 모두 지원합니다. 이러한 지침은 T1 인터페이스에 적용되지만 E1 인터페이스의 구성은 유사합니다.
링크 서비스 IQ 인터페이스 속성을 구성하려면 계층 수준에서 [edit interfaces lsq-fpc/pic/port unit logical-unit-number] 다음 문을 포함합니다.
[edit interfaces lsq-fpc/pic/port unit logical-unit-number]
drop-timeout milliseconds;
encapsulation multilink-ppp;
fragment-threshold bytes;
link-layer-overhead percent;
minimum-links number;
mrru bytes;
short-sequence;
family inet {
address address;
}
ACX 시리즈 라우터는 드롭 타임아웃 및 링크 레이어 오버헤드 속성을 지원하지 않습니다.
논리적 링크 서비스 IQ 인터페이스는 MLPPP 번들을 나타냅니다. MLPPP 번들의 경우, M Series 라우터에는 4개의 관련 대기열이 있고 M320 및 T 시리즈 라우터에는 8개의 관련 대기열이 있습니다. 스케줄러는 스케줄링 정책에 따라 대기열에서 패킷을 제거합니다. 일반적으로 하나의 대기열에 엄격한 우선 순위를 지정하고 나머지 대기열은 구성한 가중치에 비례하여 서비스됩니다.
MLPPP의 경우, 링크 서비스 IQ 인터페이스(lsq)와 각 구성 링크에 단일 스케줄러 맵을 할당합니다. 대기열 0, 1, 2 및 3의 전송 속도와 버퍼 크기에 대해 95, 0, 0 및 5%의 대역폭을 할당하는 M Series 및 T 시리즈 라우터의 기본 스케줄러는 LFI 또는 멀티클래스 트래픽을 구성할 때 적합하지 않습니다. 따라서 MLPPP의 경우, 대기열 0에서 3까지 0%가 아닌 전송 속도와 버퍼 크기를 가진 단일 스케줄러를 구성하고, 이 스케줄러를 링크 서비스 IQ 인터페이스(lsq)와 각 구성 링크에 할당해야 합니다. 예: MLPPP를 사용하여 LSQ 인터페이스를 NxT1 번들로 구성합니다.
M320 및 T 시리즈 라우터의 경우, 대기열 0에서 7까지의 기본 스케줄러 전송 속도 및 버퍼 크기 비율은 95, 0, 0, 5, 0, 0, 0, 0, 0%입니다.
하나의 MLPP, MLFR 또는 MFR 번들 인터페이스에 속하는 멤버 링크가 다른 번들 인터페이스로 이동되거나 두 번들 인터페이스 간에 링크가 스왑되는 경우, 구성이 올바르게 적용되도록 삭제 및 추가 작업 사이에 커밋이 필요합니다.
번들에 링크가 두 개 이상 있는 경우, 계층 수준에서 문을 포함 per-unit-scheduler 해야 합니다.[edit interfaces lsq-fpc/pic/port]
[edit interfaces lsq-fpc/pic/port] per-unit-scheduler;
스케줄링 정책을 구성하고 적용하려면 계층 수준에서 [edit class-of-service] 다음 문을 포함합니다.
[edit class-of-service]
interfaces {
t1-fpc/pic/port unit logical-unit-number {
scheduler-map map-name;
}
}
forwarding-classes {
queue queue-number class-name;
}
scheduler-maps {
map-name {
forwarding-class class-name scheduler scheduler-name;
}
}
schedulers {
scheduler-name {
buffer-size (percent percentage | remainder | temporal microseconds);
priority priority-level;
transmit-rate (rate | percent percentage | remainder) <exact>;
}
}
링크 서비스 IQ 인터페이스의 경우, 엄격한 우선 순위 대기열의 트래픽이 다른 대기열이 서비스되기 전에 전송되기 때문에 엄격한 우선 순위가 높은 대기열이 다른 세 개의 대기열을 고갈시킬 수 있습니다. 이 구현은 서비스 등급 사용자 가이드(라우터 및 EX9200 스위치)에 설명된 대로 엄격한 우선 순위가 높은 대기열이 높은 우선 순위 대기열과 라운드 로빈을 수행하는 표준 Junos CoS 구현과는 다릅니다.
스케줄러가 대기열에서 패킷을 제거한 후 특정 작업이 수행됩니다. 이 작업은 패킷이 다중 링크 캡슐화 대기열(단편화 및 시퀀싱) 또는 비캡슐화 대기열(단편화 없이 해시)에서 왔는지에 따라 달라집니다. 각 대기열은 서로 독립적으로 다중 링크 캡슐화 또는 비캡슐화로 지정할 수 있습니다. 기본적으로 모든 포워딩 클래스의 트래픽은 다중 링크 캡슐화됩니다. 대기열에서 패킷 단편화 처리를 구성하려면 계층 수준에서 문을 포함 fragmentation-maps 합니다.[edit class-of-service]
fragmentation-maps {
map-name {
forwarding-class class-name {
fragment-threshold bytes;
multilink-class number;
no-fragmentation;
}
}
}
MLPPP를 사용하는 xT1 번들의 경우N, 다중 링크 캡슐화 대기열에 사용되는 바이트별 로드 밸런싱은 캡슐화되지 않은 대기열에 사용되는 플로우 단계별 로드 밸런싱보다 우수합니다. 다른 모든 고려 사항은 동일합니다. 따라서 모든 대기열을 다중 링크 캡슐화하도록 구성하는 것이 좋습니다. 구성에 문을 포함 fragment-threshold 함으로써 이 작업을 수행합니다. 대기열의 트래픽을 다중 링크 캡슐화가 아닌 비 캡슐화되도록 설정하기로 선택한 경우 단편화 맵에 문을 포함 no-fragmentation 합니다. 이 multilink-class 문을 사용하여 포워딩 클래스를 멀티클래스 MLPPP(MCML)에 매핑할 수 있습니다. . 단편화 맵에 대한 자세한 내용은 LSQ 인터페이스에서 클래스를 포워딩하여 CoS 단편화 구성을 참조하십시오.
패킷이 다중 링크 캡슐화 대기열에서 제거되면 소프트웨어는 패킷에 MLPPP 헤더를 제공합니다. MLPPP 헤더에는 카운터에서 사용 가능한 다음 시퀀스 번호로 채워지는 시퀀스 번호 필드가 포함되어 있습니다. 그런 다음 소프트웨어는 패킷을 다른 T1 링크 중 N 하나에 배치합니다. 링크는 다양한 T1 링크에서 부하를 분산하기 위해 패킷별로 선택됩니다.
패킷이 최소 링크 최대 전송 단위(MTU)를 초과하거나 대기열에 계층 수준에서 [edit class-of-service fragmentation-maps map-name forwarding-class class-name] 구성된 부분 임계값이 있는 경우, 소프트웨어는 패킷을 두 개 이상의 부분으로 분할하며, 이러한 부분에는 연속된 다중 링크 시퀀스 번호가 할당됩니다. 각 조각에 대한 발신 링크는 다른 모든 조각과 독립적으로 선택됩니다.
단편화 맵에 명령문을 포함 fragment-threshold 하지 않으면 계층 수준에서 [edit interfaces interface-name unit logical-unit-number] 설정한 단편화 임계값이 모든 포워딩 클래스의 기본값이 됩니다. 구성의 어느 곳에서도 최대 조각 크기를 설정하지 않은 경우, 패킷이 번들의 모든 링크 중 가장 작은 최대 전송 단위(MTU)를 초과하면 패킷이 조각화됩니다.
구성의 어느 곳에서도 최대 조각 크기를 설정하지 않더라도 계층 수준에서 [edit interfaces lsq-fpc/pic/port unit logical-unit-number] 문을 포함하여 mrru 최대 수신 재구성 단위(MRRU)를 구성할 수 있습니다. MRRU는 MTU와 유사하지만 링크 서비스 인터페이스에만 적용됩니다. 기본적으로 MRRU 크기는 1500바이트이며, 1500바이트에서 4500바이트까지 구성할 수 있습니다. 자세한 내용은 다중 링크 및 링크 서비스 논리적 인터페이스에서 MRRU 구성을 참조하십시오.
캡슐화되지 않은 대기열에서 패킷이 제거되면 일반 PPP 헤더와 함께 전송됩니다. MLPPP 헤더가 없기 때문에 시퀀스 번호 정보가 없습니다. 따라서 소프트웨어는 패킷 재정렬을 방지하기 위해 특별한 조치를 취해야 합니다. 패킷 재정렬을 방지하기 위해 소프트웨어는 패킷을 다른 T1 링크 중 N 하나에 배치합니다. 링크는 헤더의 값을 해시하여 결정됩니다. IP의 경우, 소프트웨어는 소스 주소, 대상 주소 및 IP 프로토콜을 기반으로 해시를 계산합니다. MPLS의 경우, 소프트웨어는 최대 5개의 MPLS 레이블 또는 4개의 MPLS 레이블과 IP 헤더를 기반으로 해시를 계산합니다.
UDP 및 TCP의 경우 소프트웨어는 소스 및 대상 포트, 소스 및 대상 IP 주소를 기반으로 해시를 계산합니다. 이는 동일한 TCP/UDP 플로우에 속하는 모든 패킷이 항상 동일한 T1 링크를 통과하므로 재정렬할 수 없음을 보장합니다. 그러나 다양한 T1 링크의 부하가 균형을 이루는 것은 아닙니다. 플로우가 많으면 일반적으로 부하가 균형을 이룹니다.
서로 다른 T1 인터페이스는 N 주니퍼 네트웍스 또는 다른 벤더의 다른 라우터에 연결됩니다. 맨 엔드의 라우터는 모든 T1 링크에서 패킷을 수집합니다. 패킷에 MLPPP 헤더가 있는 경우, 시퀀스 번호 필드를 사용하여 패킷을 시퀀스 번호 순서로 되돌립니다. 패킷에 일반 PPP 헤더가 있는 경우, 소프트웨어는 패킷이 도착한 순서대로 패킷을 수락하고 패킷을 리어셈블하거나 재정렬하려는 시도를 하지 않습니다.
예: MLPPP를 사용하여 LSQ 인터페이스를 NxT1 번들로 구성
[edit chassis]
fpc 1 {
pic 3 {
adaptive-services {
service-package layer-2;
}
}
}
[edit interfaces]
t1-0/0/0 {
encapsulation ppp;
unit 0 {
family mlppp {
bundle lsq-1/3/0.1; # This adds t1-0/0/0 to the specified bundle.
}
}
}
t1-0/0/1 {
encapsulation ppp;
unit 0 {
family mlppp {
bundle lsq-1/3/0.1;
}
}
}
lsq-1/3/0 {
unit 1 { # This is the virtual link that concatenates multiple T1s.
encapsulation multilink-ppp;
drop-timeout 1000;
fragment-threshold 128;
link-layer-overhead 0.5;
minimum-links 2;
mrru 4500;
short-sequence;
family inet {
address 10.2.3.4/24;
}
}
[edit interfaces]
lsq-1/3/0 {
per-unit-scheduler;
}
[edit class-of-service]
interfaces {
lsq-1/3/0 { # multilink PPP constituent link
unit 0 {
scheduler-map sched-map1;
}
}
t1-0/0/0 { # multilink PPP constituent link
unit 0 {
scheduler-map sched-map1;
}
t1-0/0/1 { # multilink PPP constituent link
unit 0 {
scheduler-map sched-map1;
}
forwarding-classes {
queue 0 be;
queue 1 ef;
queue 2 af;
queue 3 nc;
}
scheduler-maps {
sched-map1 {
forwarding-class af scheduler af-scheduler;
forwarding-class be scheduler be-scheduler;
forwarding-class ef scheduler ef-scheduler;
forwarding-class nc scheduler nc-scheduler;
}
}
schedulers {
af-scheduler {
transmit-rate percent 30;
buffer-size percent 30;
priority low;
}
be-scheduler {
transmit-rate percent 25;
buffer-size percent 25;
priority low;
}
ef-scheduler {
transmit-rate percent 40;
buffer-size percent 40;
priority strict-high; # voice queue
}
nc-scheduler {
transmit-rate percent 5;
buffer-size percent 5;
priority high;
}
}
fragmentation-maps {
fragmap-1 {
forwarding-class be {
fragment-threshold 180;
}
forwarding-class ef {
fragment-threshold 100;
}
}
}
[edit interfaces]
lsq-1/3/0 {
unit 0 {
fragmentation-map fragmap-1;
}
}
또한보십시오
FRF.16을 사용하여 LSQ 인터페이스를 NxT1 또는 NxE1 번들로 구성
FRF.16을 사용하여 xT1 번들을 구성 N하려면 서로 다른 T1 링크를 번들로 어그리게이션 N 합니다. NxT1 번들은 DLCI로 식별되는 잠재적으로 많은 수의 프레임 릴레이 PVC를 전달합니다. 각 DLCI는 예를 들어 라우팅 인접성을 나타낼 수 있기 때문에 논리적 인터페이스라고 합니다.
T1 링크를 FRF.16 번들로 어그리게이션하려면 계층 수준에서 문을 포함 mlfr-uni-nni-bundles 하고 계층 수준에서 [edit interfaces t1-fpc/pic/port unit logical-unit-number family mlfr-uni-nni] 문을 포함 bundle [edit chassis fpc slot-number pic slot-number] 합니다.
[edit chassis fpc slot-number pic slot-number] mlfr-uni-nni-bundles number; [edit interfaces t1-fpc/pic/port unit logical-unit-number family mlfr-uni-nni] bundle lsq-fpc/pic/port:channel;
링크 서비스 IQ 인터페이스는 T1 및 E1 물리적 인터페이스를 모두 지원합니다. 이러한 지침은 T1 인터페이스에 적용되지만 E1 인터페이스의 구성은 유사합니다.
링크 서비스 IQ 인터페이스 속성을 구성하려면 계층 수준에서 [edit interfaces lsq- fpc/pic/port:channel] 다음 문을 포함합니다.
[edit interfaces lsq- fpc/pic/port:channel]
encapsulation multilink-frame-relay-uni-nni;
dce;
mlfr-uni-nni-options {
acknowledge-retries number;
acknowledge-timer milliseconds;
action-red-differential-delay (disable-tx | remove-link);
drop-timeout milliseconds;
fragment-threshold bytes;
hello-timer milliseconds;
link-layer-overhead percent;
lmi-type (ansi | itu);
minimum-links number;
mrru bytes;
n391 number;
n392 number;
n393 number;
red-differential-delay milliseconds;
t391 number;
t392 number;
yellow-differential-delay milliseconds;
}
unit logical-unit-number {
dlci dlci-identifier;
family inet {
address address;
}
}
링크 서비스 IQ 채널은 FRF.16 번들을 나타냅니다. 각 DLCI에는 4개의 대기열이 연결됩니다. 스케줄러는 스케줄링 정책에 따라 대기열에서 패킷을 제거합니다. 링크 서비스 IQ 인터페이스에서는 일반적으로 하나의 대기열을 엄격하게 우선순위로 지정합니다. 나머지 대기열은 구성한 가중치에 비례하여 처리됩니다.
링크 서비스 IQ 인터페이스의 경우, 엄격한 우선 순위 대기열의 트래픽이 다른 대기열이 서비스되기 전에 전송되기 때문에 엄격한 우선 순위 대기열이 다른 세 개의 대기열을 고갈시킬 수 있습니다. 이 구현은 서비스 등급 사용자 가이드(라우터 및 EX9200 스위치)에 설명된 대로 엄격한 우선 순위가 높은 대기열이 높은 우선 순위 대기열과 라운드 로빈을 수행하는 표준 Junos CoS 구현과는 다릅니다.
번들에 링크가 두 개 이상 있는 경우, 계층 수준에서 문을 포함 per-unit-scheduler 해야 합니다.[edit interfaces lsq-fpc/pic/port:channel]
[edit interfaces lsq-fpc/pic/port:channel] per-unit-scheduler;
FRF.16의 경우, 링크 서비스 IQ 인터페이스lsq()와 각 링크 서비스 IQ DLCI에 단일 스케줄러 맵을 할당하거나, 예제 : FRF.16을 사용하여 LSQ 인터페이스를 NxT1 번들로 구성하는 것과 같이 번들의 다양한 DLCI에 서로 다른 스케줄러 맵을 할당할 수 있습니다.
FRF.16 번들의 구성 링크의 경우, 사용자 지정 스케줄러를 구성할 필요가 없습니다. LFI와 멀티클래스는 FRF.16에서 지원되지 않기 때문에 각 구성 링크의 트래픽은 대기열 0에서 전송됩니다. 즉, 대기열 0에서 대부분의 대역폭을 사용할 수 있도록 허용해야 합니다. M Series 및 T 시리즈 라우터의 경우, 대기열 0에서 3까지의 기본 스케줄러의 전송 속도 및 버퍼 크기 비율은 95, 0, 0, 5%입니다. 이러한 기본 스케줄러는 모든 사용자 트래픽을 대기열 0으로 보내고 모든 네트워크 제어 트래픽을 대기열 3으로 전송하므로 FRF.16의 동작에 매우 적합합니다. 원하는 경우 95, 0, 0 및 5% 대기열 동작을 명시적으로 복제하는 사용자 지정 스케줄러를 구성하고 구성 링크에 적용할 수 있습니다.
M320 및 T 시리즈 라우터의 경우, 대기열 0에서 7까지의 기본 스케줄러 전송 속도 및 버퍼 크기 비율은 95, 0, 0, 5, 0, 0, 0, 0, 0%입니다.
하나의 MLPP, MLFR 또는 MFR 번들 인터페이스에 속하는 멤버 링크가 다른 번들 인터페이스로 이동되거나 두 번들 인터페이스 간에 링크가 스왑되는 경우, 구성이 올바르게 적용되도록 삭제 및 추가 작업 사이에 커밋이 필요합니다.
스케줄링 정책을 구성하고 적용하려면 계층 수준에서 [edit class-of-service] 다음 문을 포함합니다.
[edit class-of-service]
interfaces {
lsq-fpc/pic/port:channel {
unit logical-unit-number {
scheduler-map map-name;
}
}
}
forwarding-classes {
queue queue-number class-name;
}
scheduler-maps {
map-name {
forwarding-class class-name scheduler scheduler-name;
}
}
schedulers {
scheduler-name {
buffer-size (percent percentage | remainder | temporal microseconds);
priority priority-level;
transmit-rate (rate | percent percentage | remainder) <exact>;
}
}
대기열에서 패킷 단편화 처리를 구성하려면 계층 수준에서 문을 포함 fragmentation-maps 합니다.[edit class-of-service]
[edit class-of-service]
fragmentation-maps {
map-name {
forwarding-class class-name {
fragment-threshold bytes;
}
}
}
FRF.16 트래픽의 경우, 다중 링크 캡슐화된(단편화 및 시퀀싱된) 대기열만 지원됩니다. 이는 모든 포워딩 클래스에 대한 기본 대기 동작입니다. FRF.16은 프로토콜이 모든 패킷이 단편화 헤더를 전달해야 하기 때문에 캡슐화되지 않은 트래픽을 허용하지 않습니다. 큰 패킷이 여러 조각으로 분할되면 조각에는 연속된 일련 번호가 있어야 합니다. 따라서 FRF.16 트래픽의 계층 수준에서 [edit class-of-service fragmentation-maps map-name forwarding-class class-name] 문을 포함 no-fragmentation 할 수 없습니다. FRF.16의 경우, 음성 또는 기타 지연에 민감한 트래픽을 전송하려는 경우 느린 링크를 사용하면 안 됩니다. T1 속도 이상에서는 직렬화 지연이 충분히 작아서 명시적 LFI를 사용할 필요가 없습니다.
패킷이 다중 링크 캡슐화 대기열에서 제거되면 소프트웨어는 패킷에 FRF.16 헤더를 제공합니다. FRF.16 헤더에는 카운터에서 사용 가능한 다음 시퀀스 번호로 채워지는 시퀀스 번호 필드가 포함되어 있습니다. 그런 다음 소프트웨어는 패킷을 다른 T1 링크 중 N 하나에 배치합니다. 링크는 다양한 T1 링크에서 부하를 분산하기 위해 패킷별로 선택됩니다.
패킷이 최소 링크 최대 전송 단위(MTU)를 초과하거나 대기열에 계층 수준에서 [edit class-of-service fragmentation-maps map-name forwarding-class class-name] 구성된 부분 임계값이 있는 경우, 소프트웨어는 패킷을 두 개 이상의 부분으로 분할하며, 이러한 부분에는 연속된 다중 링크 시퀀스 번호가 할당됩니다. 각 조각에 대한 발신 링크는 다른 모든 조각과 독립적으로 선택됩니다.
단편화 맵에 명령문을 포함 fragment-threshold 하지 않으면 또는 [edit interfaces interface-name mlfr-uni-nni-bundle-options] 계층 수준에서 [edit interfaces interface-name unit logical-unit-number] 설정한 단편화 임계값이 모든 포워딩 클래스의 기본값이 됩니다. 구성의 어느 곳에서도 최대 조각 크기를 설정하지 않은 경우, 패킷이 번들의 모든 링크 중 가장 작은 최대 전송 단위(MTU)를 초과하면 패킷이 조각화됩니다.
구성의 어느 곳에서도 최대 조각 크기를 설정하지 않더라도 또는 [edit interfaces interface-name mlfr-uni-nni-bundle-options] 계층 수준에서 [edit interfaces lsq-fpc/pic/port unit logical-unit-number] 문을 포함하여 mrru 최대 수신 재구성 단위(MRRU)를 구성할 수 있습니다. MRRU는 최대 전송 단위(MTU)와 유사하지만 링크 서비스 인터페이스에만 적용됩니다. 기본적으로 MRRU 크기는 1500바이트이며 1500바이트에서 4500바이트까지 구성할 수 있습니다. 자세한 내용은 다중 링크 및 링크 서비스 논리적 인터페이스에서 MRRU 구성을 참조하십시오.
서로 다른 T1 인터페이스는 N 주니퍼 네트웍스 또는 다른 벤더의 다른 라우터에 연결됩니다. 맨 엔드의 라우터는 모든 T1 링크에서 패킷을 수집합니다. 각 패킷에는 FRF.16 헤더가 있기 때문에 시퀀스 번호 필드는 패킷을 시퀀스 번호 순서로 되돌리는 데 사용됩니다.
예: FRF.16을 사용하여 LSQ 인터페이스를 NxT1 번들로 구성
여러 CoS 스케줄러 맵과 함께 FRF.16을 사용하여 xT1 번들을 구성 N합니다.
[edit chassis fpc 1 pic 3]
adaptive-services {
service-package layer-2;
}
mlfr-uni-nni-bundles 2; # Creates channelized LSQ interfaces/FRF.16 bundles.
[edit interfaces]
t1-0/0/0 {
encapsulation multilink-frame-relay-uni-nni;
unit 0 {
family mlfr-uni-nni {
bundle lsq-1/3/0:1;
}
}
}
t1-0/0/1 {
encapsulation multilink-frame-relay-uni-nni;
unit 0 {
family mlfr-uni-nni {
bundle lsq-1/3/0:1;
}
}
}
lsq-1/3/0:1 { # Bundle link consisting of t1-0/0/0 and t1-0/0/1
per-unit-scheduler;
encapsulation multilink-frame-relay-uni-nni;
dce; # One end needs to be configured as DCE.
mlfr-uni-nni-bundle-options {
drop-timeout 180;
fragment-threshold 64;
hello-timer 180;
minimum-links 2;
mrru 3000;
link-layer-overhead 0.5;
}
unit 0 {
dlci 26; # Each logical unit maps a single DLCI.
family inet {
address 10.2.3.4/24;
}
}
unit 1 {
dlci 42;
family inet {
address 10.20.30.40/24;
}
}
unit 2 {
dlci 69;
family inet {
address 10.20.30.40/24;
}
}
[edit class-of-service]
scheduler-maps {
sched-map-lsq0 {
forwarding-class af scheduler af-scheduler-lsq0;
forwarding-class be scheduler be-scheduler-lsq0;
forwarding-class ef scheduler ef-scheduler-lsq0;
forwarding-class nc scheduler nc-scheduler-lsq0;
}
sched-map-lsq1 {
forwarding-class af scheduler af-scheduler-lsq1;
forwarding-class be scheduler be-scheduler-lsq1;
forwarding-class ef scheduler ef-scheduler-lsq1;
forwarding-class nc scheduler nc-scheduler-lsq1;
}
}
schedulers {
af-scheduler-lsq0 {
transmit-rate percent 60;
buffer-size percent 60;
priority low;
}
be-scheduler-lsq0 {
transmit-rate percent 30;
buffer-size percent 30;
priority low;
}
ef-scheduler-lsq0 {
transmit-rate percent 5;
buffer-size percent 5;
priority strict-high;
}
nc-scheduler-lsq0 {
transmit-rate percent 5;
buffer-size percent 5;
priority high;
}
af-scheduler-lsq1 {
transmit-rate percent 50;
buffer-size percent 50;
priority low;
}
be-scheduler-lsq1 {
transmit-rate percent 30;
buffer-size percent 30;
priority low;
}
ef-scheduler-lsq1 {
transmit-rate percent 15;
buffer-size percent 15;
priority strict-high;
}
nc-scheduler-lsq1 {
transmit-rate percent 5;
buffer-size percent 5;
priority high;
}
}
interfaces {
lsq-1/3/0:1 { # MLFR FRF.16
unit 0 {
scheduler-map sched-map-lsq0;
}
unit 1 {
scheduler-map sched-map-lsq1;
}
}
또한보십시오
FRF.15를 사용하여 LSQ 인터페이스를 NxT1 또는 NxE1 번들로 구성
이 예는 N링크 서비스 IQ 인터페이스에서 FRF.15를 사용하여 xT1 번들을 구성합니다. FRF.15는 FRF.12를 사용하여 단일 소수 T1 또는 E1 인터페이스에 대한 LSQ 인터페이스 구성에 설명된 것처럼 FRF.12와 유사합니다. 차이점은 FRF.15는 번들에서 여러 물리적 링크를 지원하는 반면, FRF.12는 번들당 하나의 물리적 링크만 지원한다는 것입니다. FRF.15의 Junos OS 구현을 위해 물리적 링크당 하나의 DLCI를 구성할 수 있습니다.
링크 서비스 IQ 인터페이스는 T1 및 E1 물리적 인터페이스를 모두 지원합니다. 이 예는 T1 인터페이스를 언급하지만 E1 인터페이스의 구성은 유사합니다.
[edit interfaces]
lsq-1/3/0 {
per-unit-scheduler;
unit 0 {
dlci 69;
encapsulation multilink-frame-relay-end-to-end;
}
}
unit 1 {
dlci 13;
encapsulation multilink-frame-relay-end-to-end;
}
# First physical link
t1-1/1/0:1 {
encapsulation frame-relay;
unit 0 {
family mlfr-end-to-end {
bundle lsq-1/3/0.0;
}
}
}
# Second physical link
t1-1/1/0:2 {
encapsulation frame-relay;
unit 0 {
family mlfr-end-to-end {
bundle lsq-1/3/0.0;
}
}
}
또한보십시오
MLPPP 및 LFI를 사용한 단일 소수 T1 또는 E1 인터페이스에 대한 LSQ 인터페이스 구성
단일 분수 T1 인터페이스를 구성할 때, 예를 들어 라우팅 인접성을 나타낼 수 있기 때문에 논리적 인터페이스라고 합니다.
논리적 링크 서비스 IQ 인터페이스는 MLPPP 번들을 나타냅니다. 4개의 대기열이 논리적 인터페이스와 연결됩니다. 스케줄러는 스케줄링 정책에 따라 대기열에서 패킷을 제거합니다. 일반적으로 하나의 대기열에 엄격한 우선 순위를 지정하고 나머지 대기열은 구성한 가중치에 비례하여 서비스됩니다.
MLPPP 및 LFI를 사용하여 단일 분수 T1 인터페이스를 구성하려면 하나의 DS0(분수 T1) 인터페이스를 링크 서비스 IQ 인터페이스와 연결합니다. 분수 T1 인터페이스를 링크 서비스 IQ 인터페이스와 연결하려면 계층 수준에서 문을 포함 bundle 합니다.[edit interfaces ds-fpc/pic/port:channel unit logical-unit-number family mlppp]
[edit interfaces ds-fpc/pic/port:channel unit logical-unit-number family mlppp] bundle lsq-fpc/pic/port.logical-unit-number;
링크 서비스 IQ 인터페이스는 T1 및 E1 물리적 인터페이스를 모두 지원합니다. 이러한 지침은 T1 인터페이스에 적용되지만 E1 인터페이스의 구성은 유사합니다.
링크 서비스 IQ 인터페이스 속성을 구성하려면 계층 수준에서 [edit interfaces lsq-fpc/pic/port unit logical-unit-number] 다음 문을 포함합니다.
[edit interfaces lsq-fpc/pic/port unit logical-unit-number]
drop-timeout milliseconds;
encapsulation multilink-ppp;
fragment-threshold bytes;
link-layer-overhead percent;
minimum-links number;
mrru bytes;
short-sequence;
family inet {
address address;
}
MLPPP의 경우, 링크 서비스 IQ(lsq) 인터페이스와 각 구성 링크에 단일 스케줄러 맵을 할당합니다. 대기열 0, 1, 2 및 3의 전송 속도와 버퍼 크기에 대해 95, 0, 0 및 5%의 대역폭을 할당하는 M Series 및 T 시리즈 라우터의 기본 스케줄러는 LFI 또는 멀티클래스 트래픽을 구성할 때 적합하지 않습니다. 따라서 MLPPP의 경우, 대기열 0에서 3까지 0%가 아닌 전송 속도와 버퍼 크기를 가진 단일 스케줄러를 구성하고, 이 스케줄러를 링크 서비스 IQ(lsq) 인터페이스와 각 구성 링크 및 각 구성 링크에 할당해야 합니다. 예: MLPPP 및 LFI를 사용한 분수 T1 인터페이스에 대한 LSQ 인터페이스 구성.
M320 및 T 시리즈 라우터의 경우, 대기열 0에서 7까지의 기본 스케줄러 전송 속도 및 버퍼 크기 비율은 95, 0, 0, 5, 0, 0, 0, 0, 0%입니다.
스케줄링 정책을 구성하고 적용하려면 계층 수준에서 [edit class-of-service] 다음 문을 포함합니다.
[edit class-of-service]
interfaces {
ds-fpc/pic/port.channel {
scheduler-map map-name;
}
}
forwarding-classes {
queue queue-number class-name;
}
scheduler-maps {
map-name {
forwarding-class class-name scheduler scheduler-name;
}
}
schedulers {
scheduler-name {
buffer-size (percent percentage | remainder | temporal microseconds);
priority priority-level;
transmit-rate (rate | percent percentage | remainder) <exact>;
}
}
링크 서비스 IQ 인터페이스의 경우, 엄격한 우선 순위 대기열의 트래픽이 다른 대기열이 서비스되기 전에 전송되기 때문에 엄격한 우선 순위가 높은 대기열은 다른 모든 대기열을 고갈시킬 수 있습니다. 이 구현은 서비스 등급 사용자 가이드(라우터 및 EX9200 스위치)에 설명된 바와 같이 엄격한 우선 순위가 높은 대기열이 무한 크레딧을 받고 높은 우선 순위 대기열과 라운드 로빈을 수행하는 표준 Junos CoS 구현과는 다릅니다.
스케줄러가 대기열에서 패킷을 제거한 후 특정 작업이 수행됩니다. 이 작업은 패킷이 다중 링크 캡슐화 대기열(단편화 및 시퀀싱) 또는 비캡슐화 대기열(단편화 없이 해시)에서 왔는지에 따라 달라집니다. 각 대기열은 서로 독립적으로 다중 링크 캡슐화 또는 비캡슐화로 지정할 수 있습니다. 기본적으로 모든 포워딩 클래스의 트래픽은 다중 링크 캡슐화됩니다. 대기열에서 패킷 단편화 처리를 구성하려면 계층 수준에서 문을 포함 fragmentation-maps 합니다.[edit class-of-service]
[edit class-of-service]
fragmentation-maps {
map-name {
forwarding-class class-name {
fragment-threshold bytes;
no-fragmentation;
}
}
}
대기열이 짧은 지연으로 작은 패킷을 전송해야 하는 경우, 문을 no-fragmentation 포함하여 대기열을 캡슐화되지 않도록 구성합니다. 대기열이 정상적인 지연으로 큰 패킷을 전송해야 하는 경우, 문을 fragment-threshold 포함하여 대기열을 멀티링크 캡슐화하도록 구성합니다. 대기열이 짧은 지연으로 큰 패킷을 전송해야 하는 경우, 더 빠른 링크를 사용하고 대기열을 캡슐화되지 않도록 구성하는 것이 좋습니다. 단편화 맵에 대한 자세한 내용은 LSQ 인터페이스에서 클래스를 포워딩하여 CoS 단편화 구성을 참조하십시오.
패킷이 다중 링크 캡슐화 대기열에서 제거되면 단편화됩니다. 패킷이 최소 링크 최대 전송 단위(MTU)를 초과하거나 대기열에 계층 수준에서 [edit class-of-service fragmentation-maps map-name forwarding-class class-name] 구성된 부분 임계값이 있는 경우, 소프트웨어는 패킷을 두 개 이상의 부분으로 분할하며, 이러한 부분에는 연속된 다중 링크 시퀀스 번호가 할당됩니다.
단편화 맵에 명령문을 포함 fragment-threshold 하지 않으면 계층 수준에서 [edit interfaces interface-name unit logical-unit-number] 설정한 단편화 임계값이 모든 포워딩 클래스의 기본값이 됩니다. 구성의 어느 곳에서도 최대 조각 크기를 설정하지 않은 경우, 패킷이 번들의 모든 링크 중 가장 작은 최대 전송 단위(MTU)를 초과하면 패킷이 조각화됩니다.
구성의 어느 곳에서도 최대 조각 크기를 설정하지 않더라도 계층 수준에서 [edit interfaces lsq-fpc/pic/port unit logical-unit-number] 문을 포함하여 mrru 최대 수신 재구성 단위(MRRU)를 구성할 수 있습니다. MRRU는 MTU와 유사하지만 링크 서비스 인터페이스에만 적용됩니다. 기본적으로 MRRU 크기는 1500바이트이며, 1500바이트에서 4500바이트까지 구성할 수 있습니다. 자세한 내용은 다중 링크 및 링크 서비스 논리적 인터페이스에서 MRRU 구성을 참조하십시오.
패킷이 다중 링크 캡슐화 대기열에서 제거되면 소프트웨어는 패킷에 MLPPP 헤더를 제공합니다. MLPPP 헤더에는 카운터에서 사용 가능한 다음 시퀀스 번호로 채워지는 시퀀스 번호 필드가 포함되어 있습니다. 그런 다음 소프트웨어는 패킷을 분수 T1 링크에 배치합니다. 다른 대기열의 트래픽은 패킷의 두 부분 사이에 인터리브될 수 있습니다.
캡슐화되지 않은 대기열에서 패킷이 제거되면 일반 PPP 헤더와 함께 전송됩니다. 그런 다음 패킷은 가능한 한 빨리 분수 T1 링크에 배치됩니다. 필요한 경우, 패킷은 다른 대기열의 패킷 조각 사이에 배치됩니다.
분수 T1 인터페이스는 주니퍼 네트웍스 또는 다른 공급업체의 다른 라우터에 연결됩니다. 맨 끝의 라우터는 분수 T1 링크에서 패킷을 수집합니다. 패킷에 MLPPP 헤더가 있는 경우, 소프트웨어는 패킷이 더 큰 패킷의 일부라고 가정하고 단편 번호 필드는 더 큰 패킷을 리어셈블하는 데 사용됩니다. 패킷에 일반 PPP 헤더가 있는 경우, 소프트웨어는 패킷이 도착한 순서대로 패킷을 수락하고 소프트웨어는 패킷을 재조합하거나 재정렬하려는 시도를 하지 않습니다.
예: MLPPP 및 LFI를 사용한 분수 T1 인터페이스에 대한 LSQ 인터페이스 구성
단일 소수 T1 논리적 인터페이스를 구성합니다.
[edit interfaces]
lsq-0/2/0 {
per-unit-scheduler;
unit 0 {
encapsulation multilink-ppp;
link-layer-overhead 0.5;
family inet {
address 10.40.1.1/30;
}
}
}
ct3-1/0/0 {
partition 1 interface-type ct1;
}
ct1-1/0/0:1 {
partition 1 timeslots 1-2 interface-type ds;
}
ds-1/0/0:1:1 {
encapsulation ppp;
unit 0 {
family mlppp {
bundle lsq-0/2/0.0;
}
}
}
[edit class-of-service]
interfaces {
ds-1/0/0:1:1 { # multilink PPP constituent link
unit 0 {
scheduler-map sched-map1;
}
}
forwarding-classes {
queue 0 be;
queue 1 ef;
queue 2 af;
queue 3 nc;
}
scheduler-maps {
sched-map1 {
forwarding-class af scheduler af-scheduler;
forwarding-class be scheduler be-scheduler;
forwarding-class ef scheduler ef-scheduler;
forwarding-class nc scheduler nc-scheduler;
}
}
schedulers {
af-scheduler {
transmit-rate percent 20;
buffer-size percent 20;
priority low;
}
be-scheduler {
transmit-rate percent 20;
buffer-size percent 20;
priority low;
}
ef-scheduler {
transmit-rate percent 50;
buffer-size percent 50;
priority strict-high; # voice queue
}
nc-scheduler {
transmit-rate percent 10;
buffer-size percent 10;
priority high;
}
}
fragmentation-maps {
fragmap-1 {
forwarding-class be {
fragment-threshold 180;
}
forwarding-class ef {
fragment-threshold 100;
}
}
}
[edit interfaces]
lsq-0/2/0 {
unit 0 {
fragmentation-map fragmap-1;
}
}
또한보십시오
FRF.12를 사용하여 단일 소수 T1 또는 E1 인터페이스에 대한 LSQ 인터페이스 구성
FRF.16을 사용하여 단일 분수 T1 인터페이스를 구성하려면 DS0 인터페이스를 링크 서비스 IQ(lsq) 인터페이스와 연결합니다. 단일 분수 T1을 구성할 때, 분수 T1은 DLCI에 의해 식별된 잠재적으로 많은 수의 프레임 릴레이 PVC를 전달합니다. 각 DLCI는 예를 들어 라우팅 인접성을 나타낼 수 있기 때문에 논리적 인터페이스라고 합니다. DS0 인터페이스를 링크 서비스 IQ 인터페이스와 연결하려면 계층 수준에서 문을 포함 bundle 합니다.[edit interfaces ds-fpc/pic/port:channel unit logical-unit-number family mlfr-end-to-end]
[edit interfaces ds-fpc/pic/port:channel unit logical-unit-number family mlfr-end-to-end] bundle lsq-fpc/pic/port.logical-unit-number;
링크 서비스 IQ 인터페이스는 T1 및 E1 물리적 인터페이스를 모두 지원합니다. 이러한 지침은 T1 인터페이스에 적용되지만 E1 인터페이스의 구성은 유사합니다.
링크 서비스 IQ 인터페이스 속성을 구성하려면 계층 수준에서 [edit interfaces lsq-fpc/pic/port unit logical-unit-number] 다음 문을 포함합니다.
[edit interfaces lsq-fpc/pic/port unit logical-unit-number]
drop-timeout milliseconds;
encapsulation multilink-frame-relay-end-to-end;
fragment-threshold bytes;
link-layer-overhead percent;
minimum-links number;
mrru bytes;
short-sequence;
family inet {
address address;
}
논리적 링크 서비스 IQ 인터페이스는 FRF.12 번들을 나타냅니다. 각 논리적 인터페이스에는 4개의 대기열이 연결됩니다. 스케줄러는 스케줄링 정책에 따라 대기열에서 패킷을 제거합니다. 일반적으로 하나의 대기열에 엄격한 우선 순위를 지정하고 나머지 대기열은 구성한 가중치에 비례하여 서비스됩니다.
FRF.12의 경우, 링크 서비스 IQ 인터페이스(lsq)와 각 구성 링크에 단일 스케줄러 맵을 할당합니다. M Series 및 T 시리즈 라우터의 경우, LFI 또는 멀티클래스 트래픽을 구성할 때 대기열 0, 1, 2 및 3의 전송 속도와 버퍼 크기에 대해 95, 0, 0 및 5%의 대역폭을 할당하는 기본 스케줄러가 적합하지 않습니다. 따라서 FRF.12의 경우, 대기열 0에서 3까지 0%가 아닌 전송 속도와 버퍼 크기로 스케줄러를 구성하고, 예시와 같이 링크 서비스 IQ 인터페이스(lsq) 및 각 구성 링크에 할당해야 합니다 . FRF.12를 사용한 분수 T1 인터페이스에 대한 LSQ 인터페이스 구성.
M320 및 T 시리즈 라우터의 경우, 대기열 0에서 7까지의 기본 스케줄러 전송 속도 및 버퍼 크기 비율은 95, 0, 0, 5, 0, 0, 0, 0, 0%입니다.
스케줄링 정책을 구성하고 적용하려면 계층 수준에서 [edit class-of-service] 다음 문을 포함합니다.
[edit class-of-service]
interfaces {
ds-fpc/pic/port.channel {
scheduler-map map-name;
}
}
forwarding-classes {
queue queue-number class-name;
}
scheduler-maps {
map-name {
forwarding-class class-name scheduler scheduler-name;
}
}
schedulers {
scheduler-name {
buffer-size (percent percentage | remainder | temporal microseconds);
priority priority-level;
transmit-rate (rate | percent percentage | remainder) <exact>;
}
}
링크 서비스 IQ 인터페이스의 경우, 엄격한 우선 순위 대기열의 트래픽이 다른 대기열이 서비스되기 전에 전송되기 때문에 엄격한 우선 순위 대기열이 다른 세 개의 대기열을 고갈시킬 수 있습니다. 이 구현은 서비스 등급 사용자 가이드(라우터 및 EX9200 스위치)에 설명된 대로 엄격한 우선 순위가 높은 대기열이 높은 우선 순위 대기열과 라운드 로빈을 수행하는 표준 Junos CoS 구현과는 다릅니다.
스케줄러가 대기열에서 패킷을 제거한 후 특정 작업이 수행됩니다. 이 작업은 패킷이 다중 링크 캡슐화 대기열(단편화 및 시퀀싱) 또는 비캡슐화 대기열(단편화 없이 해시)에서 왔는지에 따라 달라집니다. 각 대기열은 서로 독립적으로 다중 링크 캡슐화 또는 비캡슐화로 지정할 수 있습니다. 기본적으로 모든 포워딩 클래스의 트래픽은 다중 링크 캡슐화됩니다. 대기열에서 패킷 단편화 처리를 구성하려면 계층 수준에서 문을 포함 fragmentation-maps 합니다.[edit class-of-service]
[edit class-of-service]
fragmentation-maps {
map-name {
forwarding-class class-name {
fragment-threshold bytes;
no-fragmentation;
}
}
}
대기열이 짧은 지연으로 작은 패킷을 전송해야 하는 경우, 문을 no-fragmentation 포함하여 대기열을 캡슐화되지 않도록 구성합니다. 대기열이 정상적인 지연으로 큰 패킷을 전송해야 하는 경우, 문을 fragment-threshold 포함하여 대기열을 멀티링크 캡슐화하도록 구성합니다. 대기열이 짧은 지연으로 큰 패킷을 전송해야 하는 경우, 더 빠른 링크를 사용하고 대기열을 캡슐화되지 않도록 구성하는 것이 좋습니다. 단편화 맵에 대한 자세한 내용은 LSQ 인터페이스에서 클래스를 포워딩하여 CoS 단편화 구성을 참조하십시오.
패킷이 다중 링크 캡슐화 대기열에서 제거되면 단편화됩니다. 패킷이 최소 링크 최대 전송 단위(MTU)를 초과하거나 대기열에 계층 수준에서 [edit class-of-service fragmentation-maps map-name forwarding-class class-name] 구성된 부분 임계값이 있는 경우, 소프트웨어는 패킷을 두 개 이상의 부분으로 분할하며, 이러한 부분에는 연속된 다중 링크 시퀀스 번호가 할당됩니다.
단편화 맵에 명령문을 포함 fragment-threshold 하지 않으면 계층 수준에서 [edit interfaces interface-name unit logical-unit-number] 설정한 단편화 임계값이 모든 포워딩 클래스의 기본값이 됩니다. 구성의 어느 곳에서도 최대 조각 크기를 설정하지 않은 경우, 패킷이 번들의 모든 링크 중 가장 작은 최대 전송 단위(MTU)를 초과하면 패킷이 조각화됩니다.
구성의 어느 곳에서도 최대 조각 크기를 설정하지 않더라도 계층 수준에서 [edit interfaces lsq-fpc/pic/port unit logical-unit-number] 문을 포함하여 mrru 최대 수신 재구성 단위(MRRU)를 구성할 수 있습니다. MRRU는 최대 전송 단위(MTU)와 유사하지만 링크 서비스 인터페이스에만 적용됩니다. 기본적으로 MRRU 크기는 1500바이트이며 1500바이트에서 4500바이트까지 구성할 수 있습니다. 자세한 내용은 다중 링크 및 링크 서비스 논리적 인터페이스에서 MRRU 구성을 참조하십시오.
패킷이 다중 링크 캡슐화 대기열에서 제거되면 소프트웨어는 패킷에 FRF.12 헤더를 제공합니다. FRF.12 헤더에는 카운터에서 사용 가능한 다음의 시퀀스 번호로 채워지는 시퀀스 번호 필드가 포함되어 있습니다. 그런 다음 소프트웨어는 패킷을 분수 T1 링크에 배치합니다. 다른 대기열의 트래픽은 패킷의 두 부분 사이에 인터리브될 수 있습니다.
캡슐화되지 않은 대기열에서 패킷이 제거되면 일반 프레임 릴레이 헤더로 전송됩니다. 그런 다음 패킷은 가능한 한 빨리 분수 T1 링크에 배치됩니다. 필요한 경우, 패킷은 다른 대기열의 패킷 조각 사이에 배치됩니다.
분수 T1 인터페이스는 주니퍼 네트웍스 또는 다른 공급업체의 다른 라우터에 연결됩니다. 맨 끝의 라우터는 분수 T1 링크에서 패킷을 수집합니다. 패킷에 FRF.12 헤더가 있는 경우, 소프트웨어는 패킷이 더 큰 패킷의 단편이라고 가정하고 단편 번호 필드는 더 큰 패킷을 리어셈블하는 데 사용됩니다. 패킷에 일반 프레임 릴레이 헤더가 있는 경우, 소프트웨어는 패킷이 도착한 순서대로 패킷을 수락하고 소프트웨어는 패킷을 리어셈블하거나 재정렬하려고 시도하지 않습니다.
캡슐화되지 않은 대기열의 전체 패킷은 다중 링크 캡슐화 대기열의 조각 사이에 배치될 수 있습니다. 그러나 한 멀티링크 캡슐화 대기열의 조각은 다른 다중 링크 캡슐화 대기열의 조각과 인터리브될 수 없습니다. 이것이 FRF.12( Frame Relay Fragmentation Implementation Agreement) 사양의 의도입니다. 서로 다른 두 개의 대기열의 조각이 인터리브된 경우, 헤더 필드에는 조각을 분리하기에 충분한 정보가 없을 수 있습니다.
예: FRF.12를 사용하여 분수 T1 인터페이스에 대한 LSQ 인터페이스 구성
FRF.12(단편화 포함 및 LFI 미포함)
이 예는 128KB DS0 인터페이스를 보여줍니다. 에는 대기열 0(be)으로 분류되는 하나의 트래픽 스트림ge-0/0/0이 있습니다. 패킷은 링크 서비스 IQ(lsq-) 인터페이스에서 단편화 맵에 구성된 임계값에 따라 단편화됩니다.
[edit chassis]
fpc 0 {
pic 3 {
adaptive-services {
service-package layer-2;
}
}
}
[edit interfaces]
ge-0/0/0 {
unit 0 {
family inet {
address 20.1.1.1/24 {
arp 20.1.1.2 mac 00.00.5e.00.53.56;
}
}
}
}
ce1-0/2/0 {
partition 1 timeslots 1-2 interface-type ds;
}
ds-0/2/0:1 {
no-keepalives;
dce;
encapsulation frame-relay;
unit 0 {
dlci 100;
family mlfr-end-to-end {
bundle lsq-0/3/0.0;
}
}
}
lsq-0/3/0 {
per-unit-scheduler;
unit 0 {
encapsulation multilink-frame-relay-end-to-end;
family inet {
address 10.200.0.78/30;
}
}
}
fxp0 {
unit 0 {
family inet {
address 172.16.1.162/24;
}
}
}
lo0 {
unit 0 {
family inet {
address 10.0.0.1/32;
}
}
}
[edit class-of-service]
forwarding-classes {
queue 0 be;
queue 1 ef;
queue 2 af;
queue 3 nc;
}
interfaces {
lsq-0/3/0 {
unit 0 {
fragmentation-map map1;
}
}
}
fragmentation-maps {
map1 {
forwarding-class {
be {
fragment-threshold 160;
}
}
}
}
단편화 및 LFI가 있는 FRF.12
이 예는 512KB DS0 번들과 4개의 대기열로 분류된 4개의 트래픽 스트림 ge-0/0/0 을 보여줍니다. 조각 크기는 대기열 0, 대기열 1 및 대기열 2의 경우 160입니다. 대기열 3의 음성 스트림에는 LFI가 구성되어 있습니다.
[edit chassis]
fpc 0 {
pic 3 {
adaptive-services {
service-package layer-2;
}
}
}
[edit interfaces]
ge-0/0/0 {
unit 0 {
family inet {
address 20.1.1.1/24 {
arp 20.1.1.2 mac 00.00.5e.00.53.56;
}
}
}
ce1-0/2/0 {
partition 1 timeslots 1-8 interface-type ds;
}
ds-0/2/0:1 {
no-keepalives;
dce;
encapsulation frame-relay;
unit 0 {
dlci 100;
family mlfr-end-to-end {
bundle lsq-0/3/0.0;
}
}
}
lsq-0/3/0 {
per-unit-scheduler;
unit 0 {
encapsulation multilink-frame-relay-end-to-end;
family inet {
address 10.200.0.78/30;
}
}
}
[edit class-of-service]
classifiers {
inet-precedence ge-interface-classifier {
forwarding-class be {
loss-priority low code-points 000;
}
forwarding-class ef {
loss-priority low code-points 010;
}
forwarding-class af {
loss-priority low code-points 100;
}
forwarding-class nc {
loss-priority low code-points 110;
}
}
}
forwarding-classes {
queue 0 be;
queue 1 ef;
queue 2 af;
queue 3 nc;
}
interfaces {
lsq-0/3/0 {
unit 0 {
scheduler-map sched2;
fragmentation-map map2;
}
}
ds-0/2/0:1 {
scheduler-map link-map2;
}
ge-0/0/0 {
unit 0 {
classifiers {
inet-precedence ge-interface-classifier;
}
}
}
}
scheduler-maps {
sched2 {
forwarding-class be scheduler economy;
forwarding-class ef scheduler business;
forwarding-class af scheduler stream;
forwarding-class nc scheduler voice;
}
link-map2 {
forwarding-class be scheduler link-economy;
forwarding-class ef scheduler link-business;
forwarding-class af scheduler link-stream;
forwarding-class nc scheduler link-voice;
}
}
fragmentation-maps {
map2 {
forwarding-class {
be {
fragment-threshold 160;
}
ef {
fragment-threshold 160;
}
af {
fragment-threshold 160;
}
nc {
no-fragmentation;
}
}
}
schedulers {
economy {
transmit-rate percent 26;
buffer-size percent 26;
}
business {
transmit-rate percent 26;
buffer-size percent 26;
}
stream {
transmit-rate percent 35;
buffer-size percent 35;
}
voice {
transmit-rate percent 13;
buffer-size percent 13;
}
link-economy {
transmit-rate percent 26;
buffer-size percent 26;
}
link-business {
transmit-rate percent 26;
buffer-size percent 26;
}
link-stream {
transmit-rate percent 35;
buffer-size percent 35;
}
link-voice {
transmit-rate percent 13;
buffer-size percent 13;
}
}
}
}
또한보십시오
MLPPP를 통한 압축 RTP를 위해 구성된 T3 링크에 대한 LSQ 인터페이스 구성
이 예는 MLPPP 캡슐화를 사용하여 링크 서비스 IQ 인터페이스에서 단일 T3 인터페이스를 번들로 제공합니다. 단일 T3 인터페이스를 다중 링크 번들에 바인딩하면 T3 인터페이스에서 압축 RTP(CRTP)를 구성할 수 있습니다.
이 시나리오는 MLPPP 번들에만 적용됩니다. Junos OS는 현재 프레임 릴레이를 통한 CRTP를 지원하지 않습니다. 자세한 내용은 음성 서비스에 대한 서비스 인터페이스 구성을 참조하십시오.
패킷 직렬화 지연은 무시할 수 있기 때문에 DS3 속도에서 LFI를 구성할 필요가 없습니다.
[edit interfaces]
t3-0/0/0 {
unit 0 {
family mlppp {
bundle lsq-1/3/0.1;
}
}
}
lsq-1/3/0.1 {
encapsulation multilink-ppp;
}
compression {
rtp {
# cRTP parameters go here
#
port minimum 2000 maximum 64009;
}
}
이 구성은 기본 단편화 맵을 사용하므로 모든 포워딩 클래스(대기열)가 다중 링크 헤더와 함께 전송됩니다.
다중 링크 헤더를 제거하기 위해 모든 대기열이 계층 수준에서 [edit class-of-service fragmentation-maps map-name forwarding-class class-name] 문을 갖는 no-fragmentation 단편화 맵을 구성하고 다음과 같이 인터페이스에 단편화 맵을 lsq-1/3/0.1 연결할 수 있습니다.
[edit class-of-service]
fragmentation-maps {
fragmap {
forwarding-class {
be {
no-fragmentation;
}
af {
no-fragmentation;
}
ef {
no-fragmentation;
}
nc {
no-fragmentation;
}
}
}
}
interfaces {
lsq-1/3/0.1 {
fragmentation-map fragmap;
}
}
또한보십시오
FRF를 사용하여 LSQ 인터페이스를 T3 또는 OC3 번들로 구성합니다.12
이 예는 링크에 다중 논리적 인터페이스(DLCI)를 사용하여 클리어 채널 T3 또는 OC3 인터페이스를 구성합니다. 이 시나리오에서 각 DLCI는 고객을 나타냅니다. DLCI는 송신 PIC에서 특정 속도(xDS0)N로 형성됩니다. 이를 통해 프레임 릴레이 DLCI에서 FRF.12 종단 간 프로토콜을 사용하여 LFI를 구성할 수 있습니다.
이를 위해서는 먼저 물리적 인터페이스에 논리적 인터페이스(DLCI)를 구성합니다. 그런 다음 DLCI를 번들로 묶어 번들당 하나의 DLCI만 있도록 합니다.
물리적 인터페이스는 각 DLCI에 셰이핑 속도를 연결할 수 있는 DLCI별 스케줄링이 가능해야 합니다. 자세한 정보는 라우팅 디바이스용 Junos OS 네트워크 인터페이스 라이브러리를 참조하십시오.
송신 PIC에서 조각 손실을 방지하려면 링크 서비스 IQ 논리적 인터페이스와 송신 DLCI에 셰이핑 속도를 할당해야 합니다. DLCI의 셰이핑 속도는 각 DLCI에 사용할 수 있는 대역폭의 양을 지정합니다. 링크 서비스 IQ 인터페이스의 셰이핑 속도는 번들과 연결된 DLCI에 할당된 셰이핑 속도와 일치해야 합니다.
송신 인터페이스에도 스케줄러 맵이 연결되어 있어야 합니다. 음성을 전달하는 대기열은 엄격한 우선 순위가 높아야 하고 다른 모든 대기열은 우선 순위가 낮아야 합니다. 이것이 LFI를 가능하게 합니다.
이 예는 대기열의 음성 트래픽을 ef 보여줍니다. 음성 트래픽은 대량 데이터와 인터리브됩니다. 또는 멀티클래스 MLPPP를 사용하여 서로 다른 멀티링크 클래스에서 여러 클래스의 트래픽을 전송할 수 있습니다.
[edit interfaces]
t3-0/0/0 {
per-unit-scheduler;
encapsulation frame-relay;
unit 0 {
dlci 69;
family mlfr-end-to-end {
bundle lsq-1/3/0.0;
}
}
unit 1 {
dlci 42;
family mlfr-end-to-end {
bundle lsq-1/3/0.1;
}
}
}
lsq-1/3/0 {
unit 0 {
encapsulation multilink-frame-relay-end-to-end;
}
fragment-threshold 320; # Multilink packets must be fragmented
}
unit 1 {
encapsulation multilink-frame-relay-end-to-end;
}
fragment-threshold 160;
[edit class-of-service]
scheduler-maps {
sched { # Scheduling parameters that apply to bundles on AS or Multiservices PICs.
...
}
pic-sched {
# Scheduling parameters for egress DLCIs.
# The voice queue should be strict-high priority.
# All other queues should be low priority.
...
}
fragmentation-maps {
fragmap {
forwarding-class {
ef {
no-fragmentation;
}
# Voice is carried in the ef queue.
# It is interleaved with bulk data.
}
}
}
interfaces {
t3-0/0/0 {
unit 0 {
shaping-rate 512k;
scheduler-map pic-sched;
}
unit 1 {
shaping-rate 128k;
scheduler-map pic-sched;
}
}
lsq-1/3/0 { # Assign fragmentation and scheduling to LSQ interfaces.
unit 0 {
shaping-rate 512k;
scheduler-map sched;
fragmentation-map fragmap;
}
unit 1 {
shaping-rate 128k;
scheduler-map sched;
fragmentation-map fragmap;
}
}
FRF.12가 링크 서비스 IQ 인터페이스와 작동하는 방식에 대한 자세한 내용은 FRF.12를 사용하여 단일 분수 T1 또는 E1 인터페이스에 대한 LSQ 인터페이스 구성을 참조하십시오.
또한보십시오
MLPPP를 사용하여 ATM2 IQ 인터페이스에 대한 LSQ 인터페이스 구성
이 예는 링크 서비스 IQ 인터페이스와 함께 번들로 제공되는 MLPPP를 사용하여 ATM2 IQ 인터페이스를 구성합니다. 이를 통해 ATM 가상 회로에서 LFI를 구성할 수 있습니다.
이러한 유형의 구성의 경우 ATM2 IQ 인터페이스에 LLC 캡슐화가 있어야 합니다.
이 시나리오에서 지원되는 ATM PIC는 다음과 같습니다.
2포트 OC-3/STM1 ATM2 IQ
4포트 DS3 ATM2 IQ
AAL5를 통한 가상 서킷 멀티플렉싱 PPP는 지원되지 않습니다. 프레임 릴레이는 지원되지 않습니다. 여러 ATM VC를 단일 논리적 인터페이스로 묶는 것은 지원되지 않습니다.
DS3 및 OC3 인터페이스와는 달리, ATM PIC에 대해 별도의 스케줄러 맵을 생성할 필요가 없습니다. ATM의 경우, 라우팅 디바이스용 Junos OS 네트워크 인터페이스 라이브러리에 설명된 대로 계층 수준에서 [edit interfaces at-fpc/pic/port atm-options] CoS 구성 요소를 정의합니다.
번들로 제공되는 ATM 논리적 인터페이스에서 RED 프로필을 구성하지 마십시오. ATM 인터페이스에서는 드롭이 발생하지 않습니다.
이 예에서는 두 개의 ATM VC가 구성되어 두 개의 링크 서비스 IQ 번들로 묶여 있습니다. 단편화 맵은 음성 트래픽을 다른 다중 링크 트래픽과 인터리브하는 데 사용됩니다. MLPPP가 사용되기 때문에 각 링크 서비스 IQ 번들을 CRTP에 대해 구성할 수 있습니다.
[edit interfaces]
at-1/2/0 {
atm-options {
vpi 0;
pic-type atm2;
}
unit 0 {
vci 0.69;
encapsulation atm-mlppp-llc;
family mlppp {
bundle lsq-1/3/0.10;
}
}
unit 1 {
vci 0.42;
encapsulation atm-mlppp-llc;
family mlppp {
bundle lsq-1/3/0.11;
}
}
}
lsq-1/3/0 {
unit 10 {
encapsulation multilink-ppp;
}
# Large packets must be fragmented.
# You can specify fragmentation for each forwarding class.
fragment-threshold 320;
compression {
rtp {
port minimum 2000 maximum 64009;
}
}
}
unit 11 {
encapsulation multilink-ppp;
}
fragment-threshold 160;
[edit class-of-service]
scheduler-maps {
sched { # Scheduling parameters that apply to LSQ bundles on AS or Multiservices PICs.
...
}
fragmentation-maps {
fragmap {
forwarding-class {
ef {
no-fragmentation;
}
}
}
}
interfaces { # Assign fragmentation and scheduling parameters to LSQ interfaces.
lsq-1/3/0 {
unit 0 {
shaping-rate 512k;
scheduler-map sched;
fragmentation-map fragmap;
}
unit 1 {
shaping-rate 128k;
scheduler-map sched;
fragmentation-map fragmap;
}
}
또한보십시오
변경 내역 표
기능 지원은 사용 중인 플랫폼과 릴리스에 따라 결정됩니다. 기능 탐색기를 사용하여 플랫폼에서 기능이 지원되는지 확인합니다.