デバイスとインターフェイスの正常性を自動的に監視し、異常を検知
このトピックでは、Routing Director がデバイスの健全性を自動的に監視して異常を検出する方法と、GUI を使用してデバイスの健全性に関連する異常を表示する方法について説明します。
デバイスとインターフェイスの正常性監視と異常検知の概要
-
デバイスの正常性と異常検知は、このリリースのベータ機能です。
-
デバイスの健全性を監視するには、ルーティング ディレクター クラスタのインストール時に AI/ML(
install-aiml)とデバイス 健全性モニタリング(enable-device-health)を有効にする必要があります。詳細については、「 クラスターのデプロイ」を参照してください。AI/MLを有効にするには、追加のシステムリソース(CPUとメモリ)が必要になります。AI/MLに必要なその他のリソースについては、 ハードウェア要件を参照してください。
ネットワークの状態を確認するには、ネットワーク内のデバイスとそのインターフェイスの状態を監視する必要があります。Routing Directorは、AI/ML(AI:人工知能\ [AI]および機械学習 [ML])技術を使用して、デバイスの健全性に関連するKPI(主要パフォーマンス指標)を自動的に監視し、発生した異常を自動的に検出します。また、ルーティング・ディレクターは、デバイスが動作しているときに、デバイスの温度異常の根本原因分析(RCA)も実行します。
デバイスのヘルスステータスを定期的に監視し、デバイスとインターフェイスのヘルス異常をタイムリーに検出することで、事業者は対策を講じ、発生した問題の影響を最小限に抑えることができます
ルーティングディレクターは、以下のシナリオでデバイスの健全性を監視します。
-
デバイスのオンボーディング中—デバイスがオンボーディング中、ルーティングディレクターはデバイスの健全性を監視し、異常が発生した場合にはアラートを生成します。
デバイスがオンボーディングされる際、以前にオンボーディングされた同じモデルの他のデバイスが存在する場合、ルーティングディレクターはデータを比較して異常を検出します。ただし、特定のモデルのデバイスが初めてオンボードされる場合、履歴データが不足しているため、異常検知の有効性は制限されます。
-
デバイスの運用中—デバイスが正常にオンボーディングされ、管理された後、ルーティングディレクターは、デバイスの健全性に関連するKPIを継続的に監視します。ルーティングディレクターは、各デバイスの各KPIについて、KPIを監視し、範囲を予測し、異常が発生した場合には検出します。デバイスの動作中、Routing Director は、そのデバイスの履歴データと予測範囲に基づいて、デバイスの正常性の異常を(30 分以内に)検出します。
-
検証フェーズでは、デバイスの正常性監視に使用される ML モデルの MAPE スコアは 2.5 から 6.5 の間で変化することが観察されました。
-
KPI 値が変更された後、予測範囲が安定するまでに約 2 時間かかります。
温度異常のRCA
デバイスが動作している場合、ルーティング・ディレクターは、ルーティングエンジンの温度とルーティングエンジンのCPU温度に関連する問題のRCAを提供します。ルーティング・ディレクターは、温度問題を引き起こす可能性のあるさまざまな属性(CPU使用率、ファン回転率、吸気温度)を分析します。また、ルーティング・ディレクターは、デバイスの温度を予想範囲と比較します。分析と比較に基づいて、ルーティング・ディレクターはアラート、問題の予想される理由、および問題を引き起こした可能性のあるイベントの詳細を提供します。 図1 は、ルーティングエンジン温度の異常に関するRCAログを示すサンプルページを示しています。
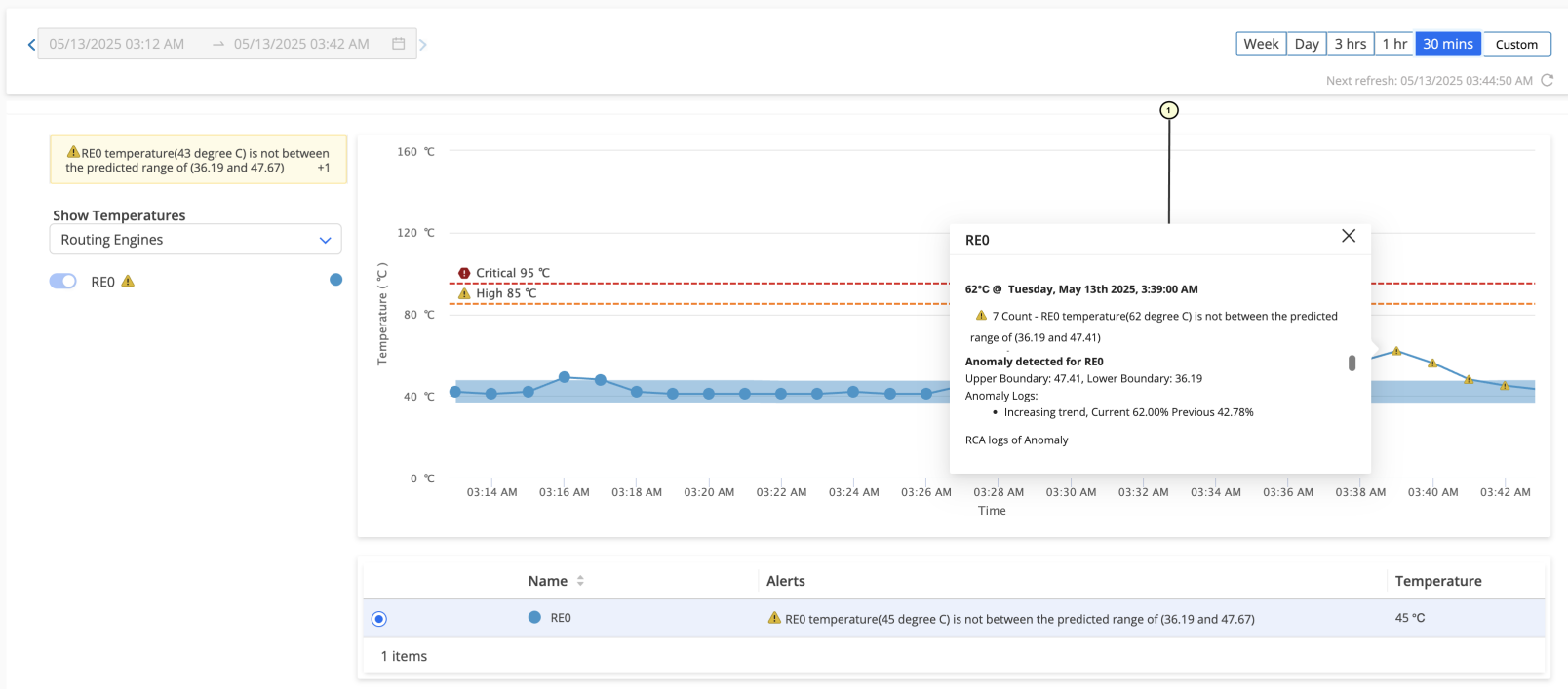 のRCAを示すサンプルページ
のRCAを示すサンプルページ
|
1
—
デバイス温度RCAの詳細 |
デバイスの健全性 KPI
表 1 は、ルーティング ディレクターが各デバイスについて監視するデバイスの健全性 KPI を示しています。
| KPI | コンポーネントパラメータ | |
|---|---|---|
| CPU | ルーティングエンジン ラインカード |
CPU 使用率 (%) |
| 記憶 | ルーティングエンジン ラインカード |
メモリ使用率(%) |
| 扇 | 該当なし | RPM の割合(%) |
| 温度 |
|
現在の温度 |
表 2 は、ルーティング ディレクターが各インターフェイスについて監視するインターフェイスの健全性に関連する KPI を示しています。
| KPI | の説明 |
|---|---|
| 光インターフェイス Rx 電力 光インターフェイスのTxパワー |
現在の光インターフェイス パワー レベル(dBm)。 |
| 入力トラフィック 出力トラフィック |
現在のトラフィック(Mbps)。 |
| 光/モジュール温度 |
現在の光学系温度(°C)。 |
GUIでデバイスとインターフェイスの正常性異常を表示する
[ Device-Name ] ページの [ハードウェア(Hardware)] アコーディオンで、デバイスのデバイスの正常性異常を表示および監視できます。
デバイスの正常性異常を表示および監視するには、次の手順を実行します。
For more information on the hardware accordion, see Hardware Data and Test Results and on interface accordion, see Interfaces Data and Test Results.
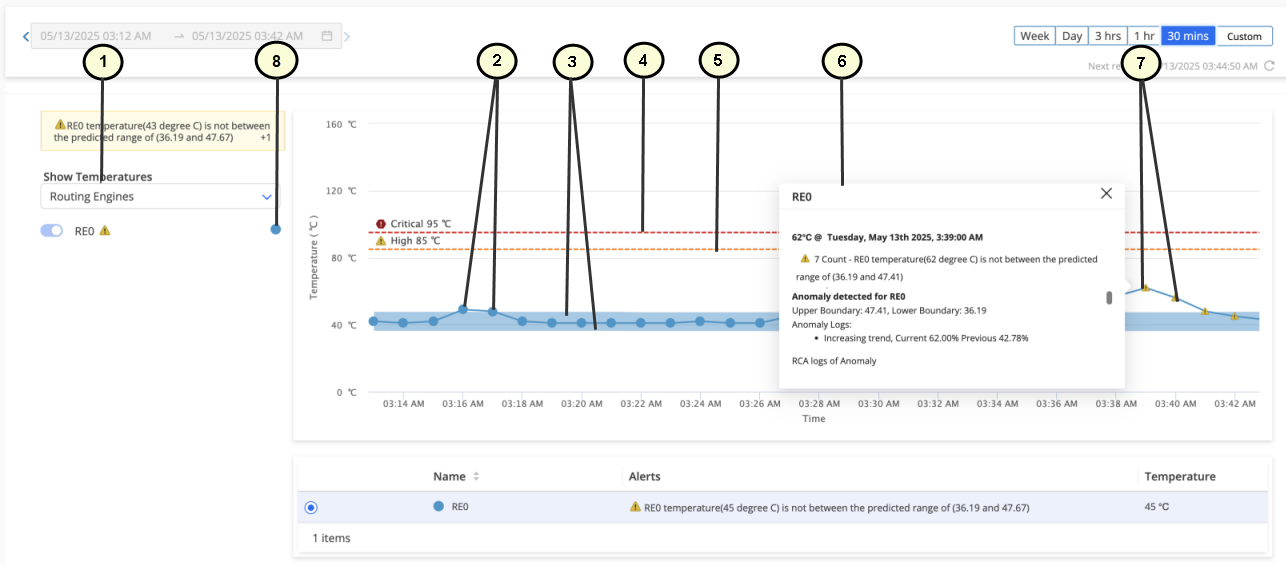
|
1
—
KPI |
5
—
High threshold marker |
|
2
—
Circle icons indicating that the KPI is normal |
6
—
Pop-up showing details of device health anomaly. |
|
3
—
Upper and lower boundaries (dynamic thresholds) for the data displayed in the graph |
7
—
Triangle icons indicating an anomaly when the higher threshold is breached. |
|
4
—
Critical threshold marker |
8
—
Legend showing the colors for different sub-components used in the graphs |
Figure shows the input traffic through et-0/0/1 interface on a device during a 30 minute interval. A warning (indicated by the yellow triangle icon) is raised to indicate an anomaly in the projected input traffic rate,
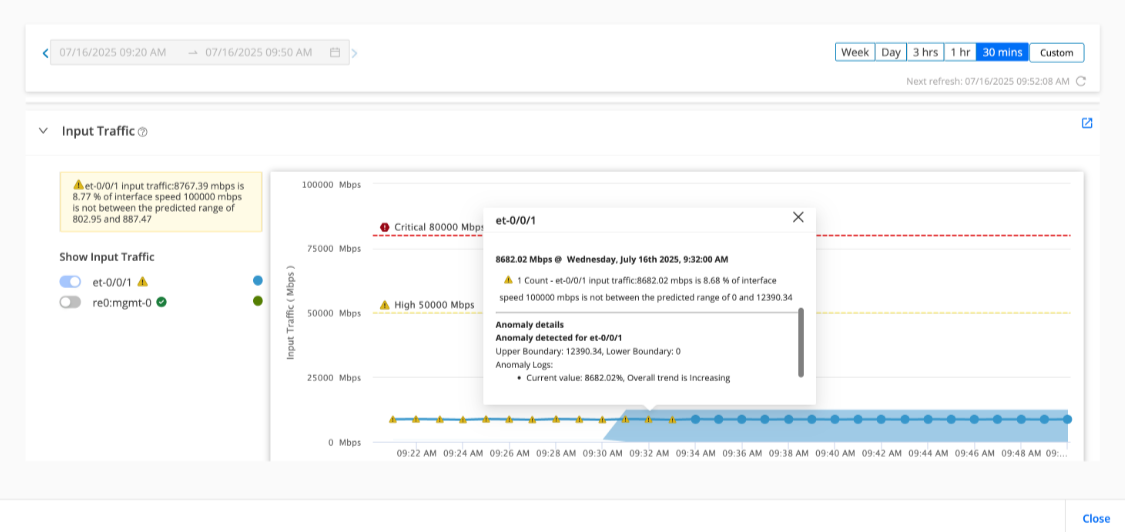
A KPI value is considered:
-
Anomalous if the KPI value is outside the dynamic threshold (shaded area of the map) for nine consecutive intervals or nine minutes of data collection.
-
Normal if the KPI value falls within the dynamic threshold for three consecutive intervals of data collection.
If the KPI value continues to be outside the dynamic threshold for more than nine consecutive intervals, the dynamic threshold adapts to the new values and a new dynamic threshold is created. An alert is raised if the KPI value crosses the High or Critical values irrespective of whether the value falls within the dynamic threshold or not.