このページの目次
プローブの紹介
プローブは、インテントベース分析における抽象化の基本単位です。一般に、所与のプローブは、ネットワークから何らかのデータセットのデータを消費し、それに対して様々な連続した集約および計算を行い、そしてオプションで、異常が発生する当該集約および計算の条件を指定する。
プローブは有向非巡回グラフ(DAG)であり、グラフのノードはプロセッサとステージです。ステージは、オペレーターが検査できるコンテキストに関連付けられたデータです。プロセッサは、入力データから出力データを生成および削減する一連の操作です。プロセッサーへの入力は 1 または多ステージであり、プロセッサーからの出力も 1 または多ステージです。プローブDAGのエッジの方向性は、この入出力フローを表します。
重要なのは、プローブの初期プロセッサが特殊であり、入力段がないことです。それらは概念的にはデータのジェネレータです。これらをソースプロセッサと呼びます。
IBAは、コレクターからプローブに未加工のテレメトリを取り込んで知識(異常、アグリゲーションなど)を抽出することで機能します。特定のコレクターは、テレメトリをメトリックのコレクションとして公開し、各メトリックには ID (つまり、キーと値のペアのセット) と値があります。IBAプローブでは、多くの場合、グラフクエリが使用され、メトリックのIDを完全に指定して、その値をプローブに取り込む必要があります。この機能を使用すると、プローブはインジェスト フィルターを使用して ID を部分的に指定したメトリックを取り込むことができるため、不明な ID を持つメトリックのインジェストが可能になります。
一部のプローブは自動的に作成されます。これらのプローブは自動的には削除されません。これにより、運用面および実装面で物事がシンプルに保たれます。
プロセッサ
プローブの入力プロセッサは、データ処理パイプラインを開始するために、未加工のテレメトリをプローブに取り込むために必要な構成を処理します。これらのプロセッサーの場合、ステージ出力項目の数 (1 つまたは複数) は、指定されたグラフ照会の結果の数と等しくなります。たとえば、複数のグラフ クエリが指定されている場合。 graph_query: [A, B]の場合、クエリ A は 5 ノードに一致し、クエリ B は 10 ノードに一致し、クエリ A の結果には 0 から 4 のインデックスを使用して query_result アクセスでき、クエリ B の結果には 5 から 14 のインデックスを使用してアクセスできます。
プロセッサの入力タイプや出力タイプが指定されていない場合、プロセッサは in という 1 つの入力を受け取り、 out という 1 つの出力を生成します。
一部のプロセッサ フィールドは 式と呼ばれます。場合によっては、それらは グラフクエリ であり、そのように記載されています。それ以外の場合は、値を生成する Python 式 です。たとえば、累積プロセッサでは、duration は秒 900を含む整数 (例:) で指定することも、 60 * 15式として指定することもできます。ただし、式の方が便利な場合があり、式をパラメーター化する方法は複数あります。
式は文字列値をサポートします。文字列およびサポート式であるプロセッサ構成パラメーターでは、静的値を指定するときに特別な引用符を使用する必要があります。たとえば、 state: "up" は静的文字列ではなく変数 "up" を参照しているため無効であるため、次のようにする必要があります。 state: '"up"'
式は常にグラフクエリに関連付けられ、そのクエリの結果に一致するたびに実行されます。式の実行コンテキストは、クエリで指定されたすべての変数が、関連付けられた一致結果内の名前付きノードに解決されるようなものです。詳細については、「 サービス データ コレクター の例」を参照してください。
グラフベースのプロセッサは query_tag_filter で拡張され、タグでグラフクエリ結果をフィルタリングできるようになりました。IBA プローブでは、タグはサーバーと外部ルーター、特に ECMP 不均衡(外部インターフェイス)プローブとトータル東西トラフィック プローブのフィルター条件としてのみ使用されます。特定のプロセッサ情報については、「関連情報」セクションの 「プローブ プロセッサ 」を参照してください。
インジェスト フィルター
"インジェスト フィルター" を使用すると、1 つのクエリ結果で複数のメトリックをプローブに取り込むことができます。表データ・タイプは、単一ステージ出力項目の一部として複数のメトリックを保管するために使用されます。テーブルのデータ型には、既存の型 ts dssnsに対応するために 、 、 table_ts table_dss- がそれぞれ含まれます。table_ns
IBA収集フィルター
収集フィルターは、ターゲット・デバイスから収集されるメトリックを決定します。
所与のデバイス上の所与のコレクターに対する収集フィルターは、異なるプローブ内に存在するインジェスト・フィルターの集合に過ぎない。IBAまたはプローブのコンテキスト外でサービスを有効にする一環として指定することもできますが、ここではサービス有効化の既存の優先順位ルールが適用され、特定の優先順位レベルのフィルターのみが集約されます。複数のプローブが特定のデバイス上の特定のサービスを対象とするインジェスト フィルターを指定する場合、収集されるメトリックは和集合、つまり、いずれかのフィルターに一致するとメトリックが発行されます。このため、データは、IBAプローブに取り込まれる前に、コントローラーコンポーネントによってフィルタリングされます。
このフィルターはテレメトリ コレクターによって評価され、多くの場合、基盤となるデバイスのオペレーティング システムから取得される使用可能なメトリックのサブセットをより適切に制御します (たとえば、膨大な数のルートを取得するのではなく、ルートのサブセットのみを取得する場合など)。いずれの場合も、コレクション フィルターに一致するメトリックのみが生のテレメトリとして公開されます。
デバイスでサービスを有効にする一環として、サービスのコレクション フィルターを指定できるようになりました。このフィルターは、"self.service_config.collection_filters" の一部としてコレクターに提供される追加入力になります。
IBA フィルター フォーマット
フィルター (取り込みと収集) の設計/使いやすさの目標を次に示します
- オーサリングの容易さ - 特定のプローブ作成者がそれを指定する
- ほとんどの場合、ケースはanyに一致し、可能な値の特定のリストと一致し、等価一致、キーに数値があるかどうかの範囲チェックです。
- 効率的な評価 - フィルターが収集または取り込みのホット パスで評価される場合。
- 集計可能 - 複数のフィルターが集計されるため、この集計ロジックが個々のコレクターの責任になる必要はありません。
- プログラミング言語に依存しない - フィルターを操作するコンポーネントは、将来的にはPythonやC ++、またはその他の言語にすることができます。
- プログラム可能 - コントローラ自体やコレクタによるフィルタ周辺の将来のプログラマビリティに対応して、使いやすさ、パフォーマンスなどを強化します。
上記の目標を考慮して、filter1 の推奨および例示的なスキーマを次に示します。これをよりよく理解するために、具体的な例については、インジェスト フィルターのセクションを参照してください。
FILTER_SCHEMA = s.Dict(s.Object(
'type': s.Enum(['any', 'equals', 'list', 'pattern', 'range', 'prefix']),
'value': s.OneOf({
'equals': s.OneOf([s.String(), s.Integer()]),
'list': s.List(s.String(), validate=s.Length(min=1)),
'pattern': s.List(s.String(), validate=s.Length(min=1)),
'range': s.AnomalyRange(), validate=s.Length(min=1),
'prefix': s.Object({
'prefixsubnet': s.Ipv6orIpv4NetworkAddress(),
'ge_mask': s.Optional(s.Integer()),
'le_mask': s.Optional(s.Integer()),
'eq_mask': s.Optional(s.Integer())
})
), key_type=s.String(description=
'Name of the key in metric identity. Missing metric identity keys are '
'assumed to match any value'))
フィルター仕様の1つのインスタンスは、指定されたすべてのキーの AND として解釈されます(別名、キーごとの制約)。複数のプローブからの複数のフィルター仕様は、フィルターレベルで はOR と見なされます。
ここに示すスキーマは、要件を伝えるためのものです。記載されたユースケースを達成する任意の方法を選択できます。
コレクター プロセッサの構成で指定されているコレクター プロセッサadditional_properties、特別な context. 名前空間を使用してアクセスできます。たとえば、コレクターがプロパティ system_roleを定義している場合、次のように使用できます。
duration: 60 * (15 if context.system_role == "leaf" else 10)
項目コンテキストは、項目セットがコレクター・プロセッサー構成から派生した元のセットから変更されていない限り使用できます。このセットを変更するプロセッサをデータが通過すると、そのデータは使用できなくなります (たとえば、グループ化プロセッサ)。
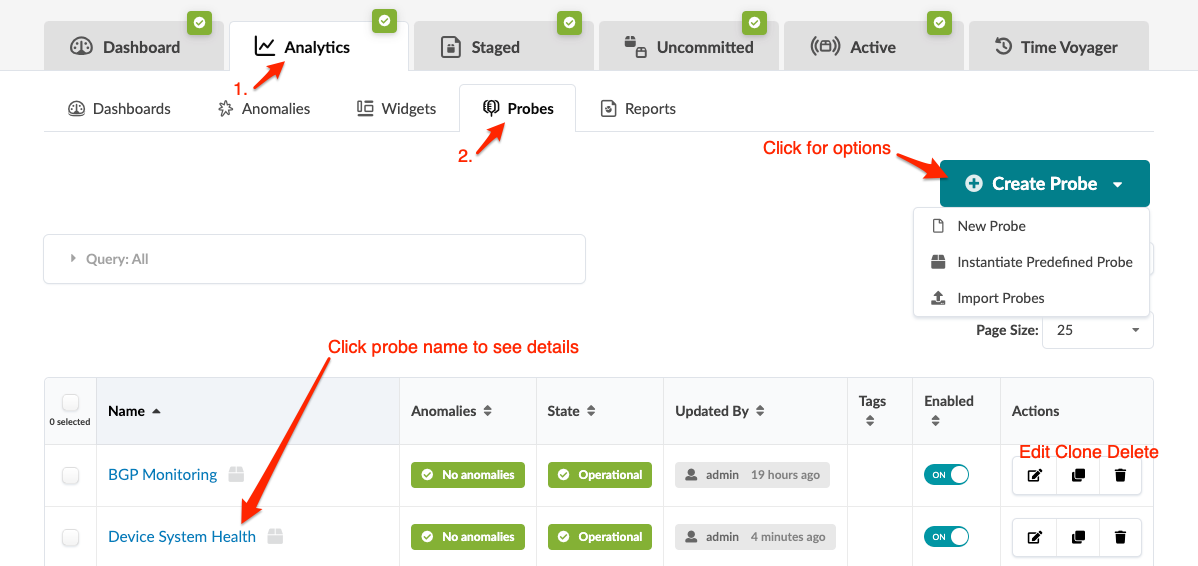
ブループリントから [分析] > [プローブ ] に移動して、プローブのテーブル ビューに移動します。プローブの詳細に移動するには、その名前をクリックします。プローブのインスタンス化、作成、クローン作成、編集、削除、インポート、エクスポートができます。以下のスクリーンショットは、Apstraバージョン4.2.0用です。Apstraバージョン4.2.1では、一部のメニュータブの名前変更、移動、追加が行われました。
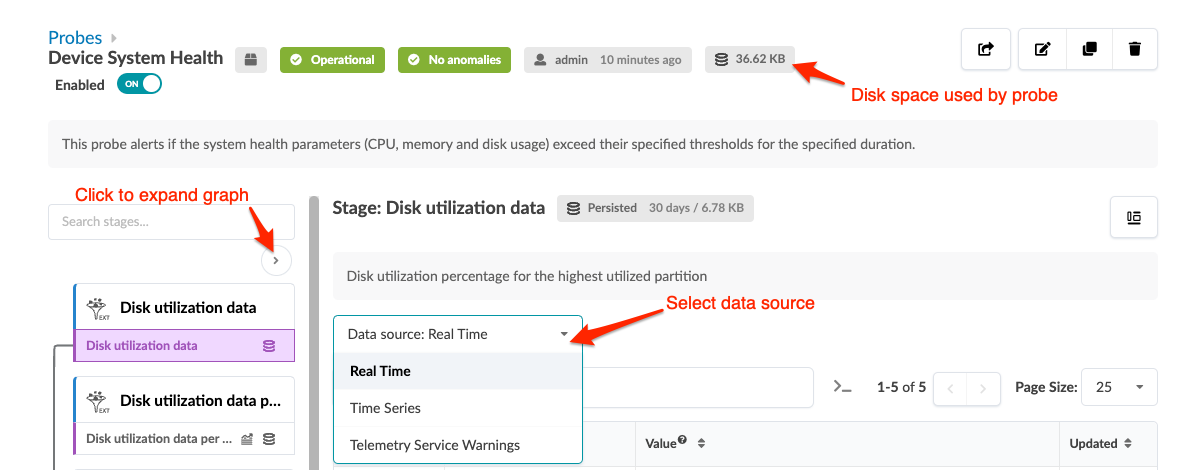
一部のプローブでは、さまざまな方法でステージを表示できます。たとえば、[ デバイス システムの正常性] という名前のプローブをクリックすると、次の画像が表示されます。データ ソースを リアルタイム から 時系列に変更し、さまざまな方法でデータを集計できます。また、必要に応じて、各プローブで使用されているディスク容量も確認できます。
Apstraコントローラのディスク容量が不足している場合、古いテレメトリデータファイルは削除されます。古いテレメトリデータを保持するには、 Apstra VMクラスターを使用して容量を増やします。
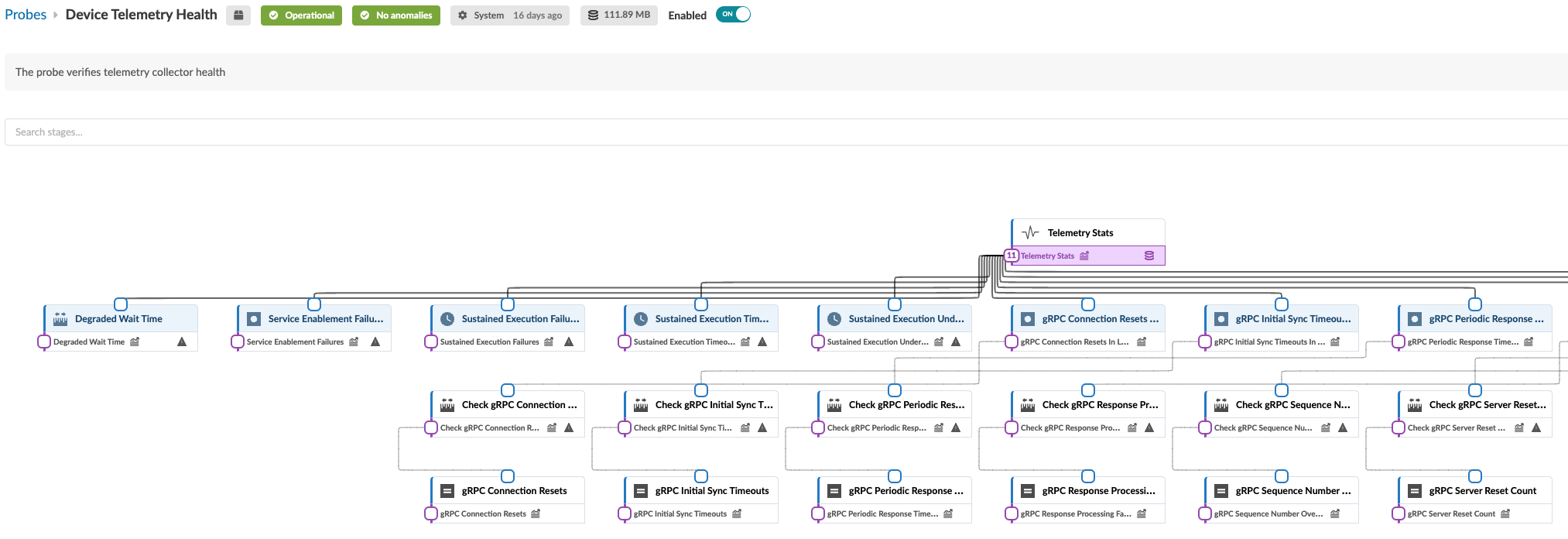
数十のプロセッサを備えた非線形プローブの構造とロジックは、標準ビューでは簡単に区別できません。展開ボタン(左側のパネルの上部)をクリックすると、プロセッサの相互関係が拡大表示されます。たとえば、次の図は、 デバイス テレメトリ正常性 プローブの展開ビューの一部を示しています。
データソース
適用可能なステージでは、データの収集に使用するソース (リアルタイムまたは時系列) を指定できます。時系列では、データの収集方法を次のようにカスタマイズできます。
-
アグリゲーションタイプ(Apstraバージョン4.2.0の新機能)
-
なし
-
allOf - ブール値 - 期間内のすべてのサンプルに当てはまる場合は真
-
anyOf - ブール値 - 期間内の少なくとも 1 つのサンプルに当てはまる場合は真
-
平均 - 集計期間の平均値
-
最後 - 集計期間の最後の値
-
最大 - 集計期間の最大値
-
最小値 - 集計期間の最小値
-
-
集計期間(オフ、または指定された秒数、分数、時間数、日数)
-
収集する時点 (最後の分数、時間数、または日数)