SUR CETTE PAGE
Exemple : Limitation du nombre de préfixes exportés vers OSPF
Présentation de la distribution pondérée du trafic ECMP sur les voisins OSPFv2 à un saut
Exemple : distribution pondérée du trafic ECMP sur des voisins OSPFv2 à un saut
Exemple : Ajustement dynamique des métriques de l’interface OSPF en fonction de la bande passante
Exemple : Configuration d’OSPF pour que les périphériques de routage semblent surchargés
Exemple : Configuration des options d’algorithme SPF pour OSPF
configuration de l’actualisation OSPF et réduction du flooding dans les topologies stables
Exemple : configuration de la synchronisation entre LDP et OSPF
Exemple : Désactivation de la compatibilité OSPFv2 avec RFC 1583
configuration du contrôle de routage OSPF
Comprendre la synthèse de route OSPF
Les routeurs de bordure de zone (ABR) envoient des annonces de liens récapitulatifs pour décrire les itinéraires vers d’autres zones. En fonction du nombre de destinations, une zone peut être inondée d’un grand nombre d’enregistrements d’état de lien, qui peuvent utiliser les ressources du périphérique de routage. Pour réduire le nombre d’annonces inondées dans une zone, vous pouvez configurer l’ABR pour fusionner ou résumer une plage d’adresses IP et envoyer des informations d’accessibilité sur ces adresses dans une seule annonce LSA (Link-State Advertisement). Vous pouvez synthétiser une ou plusieurs plages d’adresses IP, où toutes les routes qui correspondent à la plage de zones spécifiée sont filtrées à la limite de la zone et le résumé est annoncé à leur place.
Pour une zone OSPF, vous pouvez synthétiser et filtrer les préfixes intra-zone. Tous les itinéraires qui correspondent à la plage de zones spécifiée sont filtrés à la limite de la zone et le résumé est annoncé à leur place. Dans le cas d’une zone pas si trapue (NSSA) OSPF, vous ne pouvez fusionner ou filtrer que les LSA externes NSSA (Type 7) avant qu’ils ne soient convertis en LSA externes AS (Type 5) et qu’ils pénètrent dans la zone dorsale. Toutes les routes externes apprises dans la zone qui n’entrent pas dans la plage de l’un des préfixes sont annoncées individuellement dans d’autres zones.
En outre, vous pouvez également limiter le nombre de préfixes (routes) exportés vers OSPF. En définissant un nombre maximal de préfixes défini par l’utilisateur, vous empêchez le périphérique de routage d’inonder un nombre excessif de routes dans une zone.
Exemple : Synthétisation des plages de routes dans les annonces d’état de lien OSPF envoyées dans la zone dorsale
Cet exemple montre comment synthétiser les routes envoyées dans la zone de la dorsale.
Exigences
Avant de commencer :
Configurez les identificateurs de routeur pour les périphériques de votre réseau OSPF. Reportez-vous à la section Exemple : Configuration d’un identificateur de routeur OSPF.
Contrôlez le choix du routeur désigné par l’OSPF. Voir Exemple : Contrôle de l’élection du routeur désigné OSPF
Configurez un itinéraire statique. Voir Exemples : configuration de routes statiques dans la bibliothèque de protocoles de routage Junos OS pour les périphériques de routage.
Aperçu
Vous pouvez synthétiser une plage d’adresses IP pour réduire la taille de la base de données d’état de liens du routeur dorsal. Tous les itinéraires qui correspondent à la plage de zones spécifiée sont filtrés à la limite de la zone et le résumé est annoncé à leur place.
La figure 1 illustre la topologie utilisée dans cet exemple. R5 est l’ABR entre la zone 0.0.0.4 et la dorsale. Les réseaux de la zone 0.0.0.4 sont 10.0.8.4/30, 10.0.8.0/30 et 10.0.8.8/30, qui peuvent être résumés comme 10.0.8.0/28. R3 est l’ABR entre la zone NSSA 0.0.0.3 et la dorsale. Les réseaux de la zone 0.0.0.3 sont 10.0.4.4/30, 10.0.4.0/30 et 10.0.4.12/30, ce qui peut être résumé comme suit : 10.0.4.0/28. La zone 0.0.0.3 contient également la route statique externe 3.0.0.8, qui sera inondée dans tout le réseau.
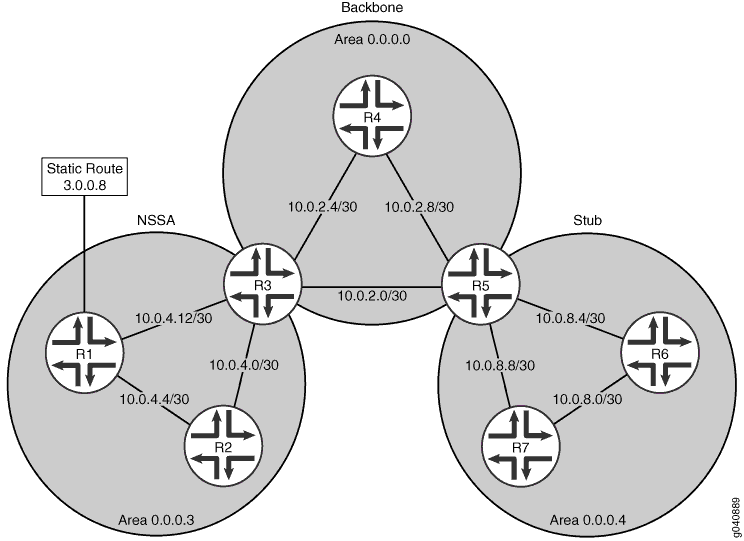
Dans cet exemple, vous configurez les ABR pour la synthèse d’itinéraire en incluant les paramètres suivants :
area-range : pour une zone, récapitule une plage d’adresses IP lors de l’envoi d’annonces récapitulatives de liens intra-zone. Dans le cas d’une NSSA, récapitule une plage d’adresses IP lors de l’envoi d’annonces d’état de lien NSSA (LSA de type 7). Les préfixes spécifiés sont utilisés pour agréger les routes externes apprises dans la zone lorsque les routes sont annoncées dans d’autres zones.
network/mask-length : indique la plage d’adresses IP récapitulative et le nombre de bits significatifs dans le masque réseau.
Topologie
Configuration
Configuration rapide de la CLI
Pour configurer rapidement la synthèse de route d’une zone OSPF, copiez les commandes suivantes et collez-les dans l’interface de ligne de commande. Voici la configuration sur ABR R5 :
[edit] set interfaces fe-0/0/1 unit 0 family inet address 10.0.8.3/30 set interfaces fe-0/0/2 unit 0 family inet address 10.0.8.4/30 set interfaces fe-0/0/0 unit 0 family inet address 10.0.2.3/30 set interfaces fe-0/0/4 unit 0 family inet address 10.0.2.5/30 set protocols ospf area 0.0.0.4 stub set protocols ospf area 0.0.0.4 interface fe-0/0/1 set protocols ospf area 0.0.0.4 interface fe-0/0/2 set protocols ospf area 0.0.0.0 interface fe-0/0/0 set protocols ospf area 0.0.0.0 interface fe-0/0/4 set protocols ospf area 0.0.0.4 area-range 10.0.8.0/28
Pour configurer rapidement la synthèse de route d’un NSSA OSPF, copiez les commandes suivantes et collez-les dans l’interface de ligne de commande. Voici la configuration sur ABR R3 :
[edit] set interfaces fe-0/0/1 unit 0 family inet address 10.0.4.10/30 set interfaces fe-0/0/2 unit 0 family inet address 10.0.4.1/30 set interfaces fe-0/0/0 unit 0 family inet address 10.0.2.1/30 set interfaces fe-0/0/4 unit 0 family inet address 10.0.2.7/30 set protocols ospf area 0.0.0.3 interface fe-0/0/1 set protocols ospf area 0.0.0.3 interface fe-0/0/2 set protocols ospf area 0.0.0.0 interface fe-0/0/0 set protocols ospf area 0.0.0.0 interface fe-0/0/4 set protocols ospf area 0.0.0.3 area-range 10.0.4.0/28 set protocols ospf area 0.0.0.3 nssa set protocols ospf area 0.0.0.3 nssa area-range 3.0.0.0/8
Procédure
Procédure étape par étape
Pour récapituler les routes envoyées à la zone dorsale :
Configurez les interfaces.
Note:Pour OSPFv3, incluez les adresses IPv6.
[edit] user@R5#
set interfaces fe-0/0/1 unit 0 family inet address 10.0.8.3/30user@R5#set interfaces fe-0/0/2 unit 0 family inet address 10.0.8.4/30user@R5#set interfaces fe-0/0/0 unit 0 family inet address 10.0.2.3/30user@R5#set interfaces fe-0/0/4 unit 0 family inet address 10.0.2.5/30[edit] user@R3#
set interfaces fe-0/0/1 unit 0 family inet address 10.0.4.10/30user@R3#set interfaces fe-0/0/2 unit 0 family inet address 10.0.4.1/30user@R3#set interfaces fe-0/0/0 unit 0 family inet address 10.0.2.1/30user@R3#set interfaces fe-0/0/4 unit 0 family inet address 10.0.2.7/30Configurez le type de zone OSPF.
Note:Pour OSPFv3, incluez l’instruction
ospf3au niveau de la[edit protocols]hiérarchie.[edit] user@R5# set protocols ospf area 0.0.0.4 stub
[edit] user@R3# set protocols ospf area 0.0.0.3 nssa
Affectez les interfaces aux zones OSPF.
user@R5#
set protocols ospf area 0.0.0.4 interface fe-0/0/1user@R5#set protocols ospf area 0.0.0.4 interface fe-0/0/2user@R5#set protocols ospf area 0.0.0.0 interface fe-0/0/0user@R5#set protocols ospf area 0.0.0.0 interface fe-0/0/4user@R3#
set protocols ospf area 0.0.0.3 interface fe-0/0/1user@R3#set protocols ospf area 0.0.0.3 interface fe-0/0/2user@R3#set protocols ospf area 0.0.0.0 interface fe-0/0/0user@R3#set protocols ospf area 0.0.0.0 interface fe-0/0/4Récapitulez les itinéraires qui sont inondés dans la dorsale.
[edit] user@R5# set protocols ospf area 0.0.0.4 area-range 10.0.8.0/28
[edit] user@R3# set protocols ospf area 0.0.0.3 area-range 10.0.4.0/28
Sur ABR R3, empêchez la route statique externe de quitter la zone 0.0.0.3.
[edit] user@R3# set protocols ospf area 0.0.0.3 nssa area-range 3.0.0.0/8
Si vous avez terminé de configurer les périphériques, validez la configuration.
[edit] user@host# commit
Résultats
Confirmez votre configuration en entrant les commandes et show interfaces . show protocols ospf Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
Configuration sur ABR R5 :
user@R5# show interfaces
fe-0/0/0 {
unit 0 {
family inet {
address 10.0.2.3/32;
}
}
}
fe-0/0/1 {
unit 0 {
family inet {
address 10.0.8.3/32;
}
}
}
fe-0/0/2 {
unit 0 {
family inet {
address 10.0.8.4/32;
}
}
}
fe-0/0/4 {
unit 0 {
family inet {
address 10.0.2.5/32;
}
}
}
user@R5# show protocols ospf
area 0.0.0.0 {
interface fe-0/0/0.0;
interface fe-0/0/4.0;
}
area 0.0.0.4 {
stub;
area-range 10.0.8.0/28;
interface fe-0/0/1.0;
interface fe-0/0/2.0;
}
Configuration sur ABR R3 :
user@R3# show interfaces
fe-0/0/0 {
unit 0 {
family inet {
address 10.0.2.1/32;
}
}
}
fe-0/0/1 {
unit 0 {
family inet {
address 10.0.4.10/32;
}
}
}
fe-0/0/2 {
unit 0 {
family inet {
address 10.0.4.1/32;
}
}
}
fe-0/0/4 {
unit 0 {
family inet {
address 10.0.2.7/32;
}
}
}
user@R3t# show protocols ospf
area 0.0.0.0 {
interface fe-0/0/0.0;
interface fe-0/0/4.0;
}
area 0.0.0.3 {
nssa {
area-range 3.0.0.0/8 ;
}
area-range 10.0.4.0/28;
interface fe-0/0/1.0;
interface fe-0/0/2.0;
}
Pour confirmer votre configuration OSPFv3, entrez les show interfaces commandes and show protocols ospf3 .
Vérification
Vérifiez que la configuration fonctionne correctement.
Vérification de l’itinéraire résumé
But
Vérifiez que les itinéraires que vous avez configurés pour la synthèse d’itinéraires sont agrégés par les ABR avant qu’ils n’entrent dans la zone dorsale. Confirmez la synthèse de route en vérifiant les entrées de la base de données d’état de liaison OSPF pour les périphériques de routage dans la dorsale.
Action
À partir du mode opérationnel, entrez la show ospf database commande pour OSPFv2, puis entrez la show ospf3 database commande pour OSPFv3.
Exemple : Limitation du nombre de préfixes exportés vers OSPF
Cet exemple montre comment limiter le nombre de préfixes exportés vers OSPF.
Exigences
Avant de commencer :
Configurez les interfaces des appareils. Reportez-vous à la bibliothèque d’interfaces réseau Junos OS pour les périphériques de routage.
Configurez les identificateurs de routeur pour les périphériques de votre réseau OSPF. Reportez-vous à la section Exemple : Configuration d’un identificateur de routeur OSPF.
Contrôlez le choix du routeur désigné par l’OSPF. Voir Exemple : Contrôle de l’élection du routeur désigné OSPF
Configurez un réseau OSPF à zone unique. Reportez-vous à la section Exemple : Configuration d’un réseau OSPF monozone.
Configurez un réseau OSPF multizone. Reportez-vous à la section Exemple : Configuration d’un réseau OSPF multizone.
Aperçu
Par défaut, il n’y a pas de limite au nombre de préfixes (routes) pouvant être exportés dans OSPF. En autorisant l’exportation d’un nombre illimité de routes vers OSPF, le périphérique de routage peut être submergé et potentiellement inonder un nombre excessif de routes dans une zone.
Vous pouvez limiter le nombre de routes exportées au format OSPF afin de réduire la charge sur le périphérique de routage et d’éviter ce problème potentiel. Si le périphérique de routage dépasse la valeur d’exportation de préfixe configurée, il purge les préfixes externes et passe dans un état de surcharge. Cet état garantit que le périphérique de routage n’est pas submergé lorsqu’il tente de traiter les informations de routage. Le numéro limite d’exportation du préfixe peut être compris entre 0 et 4 294 967 295.
Dans cet exemple, vous configurez une limite d’exportation de préfixe de 100 000 en incluant l’instruction prefix-export-limit .
Topologie
Configuration
Configuration rapide de la CLI
Pour limiter rapidement le nombre de préfixes exportés vers OSPF, copiez les commandes suivantes, collez-les dans un fichier texte, supprimez les sauts de ligne, modifiez tous les détails nécessaires pour qu’ils correspondent à votre configuration réseau, copiez et collez les commandes dans l’interface de ligne de commande au niveau de la hiérarchie [edit], puis passez commit en mode de configuration.
[edit] set protocols ospf prefix-export-limit 100000
Procédure
Procédure étape par étape
Pour limiter le nombre de préfixes exportés vers OSPF :
Configurez la valeur limite d’exportation du préfixe.
Note:Pour OSPFv3, incluez l’instruction
ospf3au niveau de la[edit protocols]hiérarchie.[edit] user@host# set protocols ospf prefix-export-limit 100000
Si vous avez terminé de configurer l’appareil, validez la configuration.
[edit] user@host# commit
Résultats
Confirmez votre configuration en entrant la show protocols ospf commande. Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
user@host# show protocols ospf prefix-export-limit 100000;
Pour confirmer votre configuration OSPFv3, entrez la show protocols ospf3 commande.
Vérification
Vérifiez que la configuration fonctionne correctement.
Vérification de la limite d’exportation de préfixe
But
Vérifiez le compteur d’exportation de préfixe qui affiche le nombre de routes exportées dans OSPF.
Action
À partir du mode opérationnel, entrez la show ospf overview commande pour OSPFv2, puis entrez la show ospf3 overview commande pour OSPFv3.
Présentation du contrôle du trafic OSPF
Une fois qu’une topologie est partagée sur le réseau, OSPF l’utilise pour acheminer les paquets entre les nœuds du réseau. Un coût est attribué à chaque chemin entre voisins en fonction du débit de l’interface. L’algorithme par défaut calcule la métrique de l’interface en fonction d’une bande passante de référence de 100 Mbit/s à l’aide de la formule cost = reference-bandwidth / interface bandwidth. Par conséquent, toute interface fonctionnant à 100 Mbits/s ou plus se voit attribuer la même valeur de métrique, soit 1. Vous pouvez affecter manuellement la métrique de l’interface OSPF pour remplacer la valeur par défaut. Par ailleurs, étant donné que les plates-formes Juniper actuelles prennent en charge des interfaces qui fonctionnent à 400 Gbit/s, il est souvent judicieux de configurer une valeur plus élevée reference-bandwidth . La configuration d’une valeur de bande passante de référence basée sur un multiple de l’interface la plus rapide de votre réseau optimise automatiquement les chemins réseau en fonction de la vitesse de l’interface et offre une marge de croissance pour la vitesse du réseau.
La somme des coûts sur un chemin particulier entre les hôtes détermine le coût global du chemin. Les paquets sont ensuite acheminés le long du chemin le plus court à l’aide de l’algorithme shortest-path-first (SPF). S’il existe plusieurs chemins de coût égal entre une adresse source et une adresse de destination, OSPF achemine les paquets le long de chaque chemin alternativement, selon la méthode Round Robin. Les itinéraires avec des métriques de chemin total plus faibles sont préférés à ceux avec des métriques de chemin plus élevées.
Vous pouvez utiliser les méthodes suivantes pour contrôler le trafic OSPF :
-
Contrôlez le coût de chaque segment de réseau OSPF
-
Ajustez dynamiquement les métriques de l’interface OSPF en fonction de la bande passante
-
Contrôle de la sélection de route OSPF
- Contrôle du coût de chaque segment de réseau OSPF
- Ajustement dynamique des mesures de l’interface OSPF en fonction de la bande passante
- Contrôle des préférences de routage OSPF
Contrôle du coût de chaque segment de réseau OSPF
OSPF utilise la formule suivante pour déterminer le coût d’un itinéraire :
cost = reference-bandwidth / interface bandwidth
Vous pouvez modifier la valeur de la bande passante de référence, qui est utilisée pour calculer le coût de l’interface par défaut. La valeur de bande passante de l’interface n’est pas configurable par l’utilisateur et se réfère à la bande passante réelle de l’interface physique.
Par défaut, OSPF attribue une métrique de coût par défaut de 1 à toute liaison supérieure à 100 Mbit/s, et une métrique de coût par défaut de 0 à l’interface de bouclage (lo0). Aucune bande passante n’est associée à l’interface de bouclage.
Pour contrôler le flux de paquets sur le réseau, OSPF vous permet d’attribuer manuellement un coût (ou une métrique) à un segment de chemin particulier. Lorsque vous spécifiez une mesure pour une interface OSPF spécifique, cette valeur est utilisée pour déterminer le coût des routes annoncées à partir de cette interface. Par exemple, si tous les routeurs du réseau OSPF utilisent des valeurs de métrique par défaut et que vous augmentez la métrique sur une interface à 5, tous les chemins via cette interface ont une métrique calculée supérieure à la métrique par défaut et ne sont pas préférés.
Toute valeur que vous configurez pour la métrique remplace le comportement par défaut de l’utilisation de la valeur de bande passante de référence pour calculer le coût de route de cette interface.
Lorsqu’il existe plusieurs routes à coût égal vers la même destination dans une table de routage, un jeu ECMP (equal-cost multipath) est formé. Si un ECMP est défini pour la route active, le logiciel Junos OS utilise un algorithme de hachage pour choisir l’une des adresses de saut suivant dans l’ECMP défini à installer dans la table de transfert.
Vous pouvez configurer Junos OS de manière à ce que plusieurs entrées de saut suivant d’un jeu ECMP soient installées dans la table de transfert. Définissez une stratégie de routage d’équilibrage de charge en incluant une ou plusieurs instructions de configuration d’instructions de stratégie au niveau hiérarchique [edit policy-options], avec l’action load-balance per-packet. Appliquez ensuite la stratégie de routage aux routes exportées de la table de routage vers la table de transfert.
Ajustement dynamique des mesures de l’interface OSPF en fonction de la bande passante
Vous pouvez spécifier un ensemble de valeurs de seuil de bande passante et des valeurs de mesure associées pour une interface OSPF ou pour une topologie sur une interface OSPF. Lorsque la bande passante d’une interface change (par exemple, si le décalage perd un membre de l’interface ou si la vitesse de l’interface est modifiée de manière administrative), Junos OS définit automatiquement la métrique de l’interface sur la valeur associée à la valeur de seuil de bande passante appropriée. Junos OS utilise la plus petite valeur de seuil de bande passante configurée, égale ou supérieure à la bande passante réelle de l’interface, pour déterminer la valeur de la métrique. Si la bande passante de l’interface est supérieure à l’une des valeurs de seuil de bande passante configurées, la valeur de mesure configurée pour l’interface est utilisée à la place des valeurs de mesure basées sur la bande passante configurées. La possibilité de recalculer la métrique d’une interface lorsque sa bande passante change est particulièrement utile pour les interfaces agrégées.
Vous devez également configurer une mesure pour l’interface lorsque vous activez des mesures basées sur la bande passante.
Contrôle des préférences de routage OSPF
Vous pouvez contrôler le flux de paquets sur le réseau à l’aide des préférences de routage. Les préférences de route permettent de sélectionner l’itinéraire à installer dans la table de transfert lorsque plusieurs protocoles calculent des itinéraires vers la même destination. L’itinéraire avec la valeur de préférence la plus faible est sélectionné.
Par défaut, les routes OSPF internes ont une valeur de préférence de 10 et les routes OSPF externes ont une valeur de préférence de 150. Bien que les paramètres par défaut conviennent à la plupart des environnements, vous souhaiterez peut-être modifier les paramètres par défaut si tous les périphériques de routage de votre réseau OSPF utilisent les valeurs de préférence par défaut ou si vous envisagez de migrer d’OSPF vers un autre protocole IGP (Interior Gateway Protocol). Si tous les périphériques utilisent les valeurs de préférence d’itinéraire par défaut, vous pouvez modifier les préférences d’itinéraire pour vous assurer que le chemin à travers un périphérique particulier est sélectionné pour la table de transfert chaque fois qu’il existe plusieurs chemins de coût égal vers une destination. Lors de la migration d’OSPF vers un autre IGP, la modification des préférences de routage vous permet d’effectuer la migration de manière contrôlée.
Voir aussi
Exemple : Contrôle du coût de chaque segment de réseau OSPF
Cet exemple montre comment contrôler le coût de chaque segment de réseau OSPF.
Exigences
Avant de commencer :
Configurez les interfaces des appareils. Reportez-vous au Guide de l’utilisateur des interfaces pour les dispositifs de sécurité.
Configurez les identificateurs de routeur pour les périphériques de votre réseau OSPF. Reportez-vous à la section Exemple : Configuration d’un identificateur de routeur OSPF.
Contrôlez le choix du routeur désigné par l’OSPF. Voir Exemple : Contrôle de l’élection du routeur désigné OSPF
Configurez un réseau OSPF à zone unique. Reportez-vous à la section Exemple : Configuration d’un réseau OSPF monozone.
Aperçu
Toutes les interfaces OSPF ont un coût, qui est une mesure de routage utilisée dans le calcul de l’état de la liaison. Les itinéraires avec des métriques de chemin total inférieures sont préférés à ceux avec des métriques de chemin plus élevées. Dans cet exemple, nous explorons comment contrôler le coût des segments de réseau OSPF.
Par défaut, OSPF attribue une métrique de coût par défaut de 1 à toute liaison supérieure à 100 Mbit/s, et une métrique de coût par défaut de 0 à l’interface de bouclage (lo0). Aucune bande passante n’est associée à l’interface de bouclage. Cela signifie que toutes les interfaces supérieures à 100 Mbit/s ont la même mesure de coût par défaut de 1. S’il existe plusieurs chemins de coût égal entre une adresse source et une adresse de destination, OSPF achemine les paquets le long de chaque chemin alternativement, selon la méthode Round Robin.
Le fait d’avoir la même métrique par défaut peut ne pas poser de problème si toutes les interfaces fonctionnent à la même vitesse. Si les interfaces fonctionnent à des vitesses différentes, vous remarquerez peut-être que le trafic n’est pas acheminé sur l’interface la plus rapide, car OSPF achemine les paquets de manière égale sur les différentes interfaces. Par exemple, si votre périphérique de routage possède des interfaces Fast Ethernet et Gigabit Ethernet exécutant OSPF, chacune de ces interfaces a une métrique de coût par défaut de 1.
Dans le premier exemple, vous définissez la bande passante de référence sur 10 g (10 Gbit/s, indiquée par 10 000 000 000 bits) en incluant l’instruction reference-bandwidth (bande passante de référence ). Avec cette configuration, OSPF attribue à l’interface Fast Ethernet une métrique par défaut de 100 et à l’interface Gigabit Ethernet une métrique de 10. Étant donné que l’interface Gigabit Ethernet a la métrique la plus basse, l’OSPF la sélectionne lors du routage des paquets. La plage est comprise entre 9600 et 1 000 000 000 000 bits.
La Figure 2 montre trois périphériques de routage dans la zone 0.0.0.0 et suppose que la liaison entre le périphérique R2 et le périphérique R3 est encombrée par d’autres types de trafic. Vous pouvez également contrôler le flux de paquets sur le réseau en affectant manuellement une métrique à un segment de chemin particulier. Toute valeur que vous configurez pour la métrique remplace le comportement par défaut de l’utilisation de la valeur de bande passante de référence pour calculer le coût de route de cette interface. Pour éviter que le trafic de l’appareil R3 n’aille directement à l’équipement R2, vous ajustez la métrique sur l’interface de l’appareil R3 qui se connecte à l’appareil R1 afin que tout le trafic passe par l’équipement R1.
Dans le deuxième exemple, vous définissez la métrique sur 5 sur l’interface fe-1/0/1 sur l’appareil R3 qui se connecte à l’appareil R1 en incluant l’instruction métrique . La plage est comprise entre 1 et 65 535.
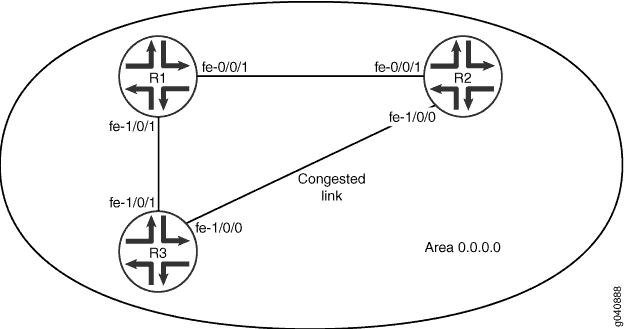 métrique OSPF
métrique OSPF
Topologie
Configuration
- Configuration de la bande passante de référence
- Configuration d’une métrique pour une interface OSPF spécifique
Configuration de la bande passante de référence
Configuration rapide de la CLI
Pour configurer rapidement la bande passante de référence, copiez les commandes suivantes, collez-les dans un fichier texte, supprimez les sauts de ligne, modifiez tous les détails nécessaires pour qu’ils correspondent à la configuration de votre réseau, copiez et collez les commandes dans l’interface de ligne de commande au niveau de la hiérarchie [edit], puis passez commit en mode configuration.
[edit] set protocols ospf reference-bandwidth 10g
Procédure étape par étape
Pour configurer la bande passante de référence :
Configurez la bande passante de référence pour calculer le coût de l’interface par défaut.
Note:Pour spécifier OSPFv3, incluez l’instruction ospf3 au niveau de la hiérarchie [edit protocols].
[edit] user@host# set protocols ospf reference-bandwidth 10g
Pourboire:Dans cet exemple, vous entrez 10g pour spécifier une bande passante de référence de 10 Gbit/s. Que vous saisissiez 10g ou 100000000000, la sortie de la commande show protocols ospf affiche 10 Gbit/s sous forme de 10g, et non 10000000000.
Si vous avez terminé de configurer l’appareil, validez la configuration.
[edit] user@host# commit
Note:Répétez cette configuration complète sur tous les périphériques de routage d’un réseau partagé.
Résultats
Confirmez votre configuration en entrant la commande show protocols ospf . Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
user@host# show protocols ospf reference-bandwidth 10g;
Pour confirmer votre configuration OSPFv3, entrez la commande show protocols ospf3 .
Configuration d’une métrique pour une interface OSPF spécifique
Configuration rapide de la CLI
Pour configurer rapidement une mesure pour une interface OSPF spécifique, copiez les commandes suivantes, collez-les dans un fichier texte, supprimez les sauts de ligne, modifiez tous les détails nécessaires pour qu’ils correspondent à la configuration de votre réseau, copiez et collez les commandes dans l’interface de ligne de commande au niveau de la hiérarchie [modifier], puis passez commit en mode de configuration.
[edit] set protocols ospf area 0.0.0.0 interface fe-1/0/1 metric 5
Procédure étape par étape
Pour configurer la métrique d’une interface OSPF spécifique :
Créez une zone OSPF.
Note:Pour spécifier OSPFv3, incluez l’instruction ospf3 au niveau de la hiérarchie [edit protocols].
[edit] user@host# edit protocols ospf area 0.0.0.0
Configurez la métrique du segment de réseau OSPF.
[edit protocols ospf area 0.0.0.0 ] user@host# set interface fe-1/0/1 metric 5
Si vous avez terminé de configurer l’appareil, validez la configuration.
[edit protocols ospf area 0.0.0.0 ] user@host# commit
Résultats
Confirmez votre configuration en entrant la commande show protocols ospf . Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
user@host# show protocols ospf
area 0.0.0.0 {
interface fe-1/0/1.0 {
metric 5;
}
}
Pour confirmer votre configuration OSPFv3, entrez la commande show protocols ospf3 .
Vérification
Vérifiez que la configuration fonctionne correctement.
Vérification de la métrique configurée
But
Vérifiez le paramètre de mesure sur l’interface. Vérifiez que le champ Coût affiche la mesure configurée de l’interface (coût). Lors du choix des chemins vers une destination, OSPF utilise le chemin le moins coûteux.
Action
À partir du mode opérationnel, entrez la commande show ospf interface detail pour OSPFv2, puis entrez la commande show ospf3 interface detail pour OSPFv3.
Présentation de la distribution pondérée du trafic ECMP sur les voisins OSPFv2 à un saut
Le routage multichemin à coût égal (ECMP) est une technique populaire pour équilibrer la charge du trafic sur plusieurs chemins. Lorsque ECMP est activé, si les chemins d’accès à une destination distante ont le même coût, le trafic est réparti entre ces chemins dans des proportions égales. Une répartition égale du trafic sur plusieurs chemins n’est pas souhaitable si les liaisons locales vers les routeurs adjacents vers la destination finale ont une capacité inégale. En règle générale, la répartition du trafic entre deux liaisons est égale et l’utilisation des liaisons est la même. Toutefois, si la capacité d’un bundle Ethernet agrégé change, une répartition égale du trafic entraîne un déséquilibre dans l’utilisation des liaisons. Dans ce cas, l’ECMP pondéré permet de équilibrage de charge de trafic entre des chemins de coût égal proportionnellement à la capacité des liaisons locales.
À titre d’exemple, il y a deux appareils interconnectés avec un paquet Ethernet agrégé avec quatre liaisons et une seule liaison du même coût. Dans des conditions normales, les bundles AE et le lien unique sont utilisés de manière uniforme pour répartir le trafic. Toutefois, si un lien du bundle AE tombe en panne, une modification de la capacité de la liaison entraîne une utilisation inégale des liens. La charge ECMP pondérée équilibre le trafic entre les chemins de coût égal proportionnellement à la capacité des liaisons locales. Dans ce cas, le trafic est réparti dans une proportion de 30/40 entre le bundle AE et la liaison unique.
Cette fonctionnalité fournit un routage ECMP pondéré vers les voisins OSPFv2 distants d’un saut de distance. Le système d’exploitation prend en charge cette fonctionnalité uniquement sur les routeurs immédiatement connectés et ne prend pas en charge l’ECMP pondéré sur les routeurs à sauts multiples, c’est-à-dire sur les routeurs distants de plus d’un saut.
Pour activer la distribution pondérée du trafic ECMP sur les voisins OSPFv2 directement connectés, configurez weighted one-hop l’instruction au niveau de la [edit protocols ospf spf-options multipath] hiérarchie.
Vous devez configurer une stratégie d’équilibrage de charge par paquet avant de configurer cette fonctionnalité. Le WECMP sera opérationnel si une politique d’équilibrage de charge par paquet est en place.
Pour les interfaces logiques, vous devez configurer la bande passante de l’interface afin de répartir le trafic sur des chemins multiples de coût égal en fonction de la bande passante de l’interface physique sous-jacente. Si vous ne configurez pas la bande passante logique pour chaque interface logique, le système d’exploitation suppose que toute la bande passante de l’interface physique est disponible pour chaque interface logique.
Exemple : distribution pondérée du trafic ECMP sur des voisins OSPFv2 à un saut
Cet exemple permet de configurer le routage ECMP (Weighted Equal Cost Multi-Path) pour distribuer le trafic vers des voisins OSPFv2 distants d’un saut afin d’assurer un équilibrage de charge optimal.
Notre équipe de test de contenu a validé et mis à jour cet exemple.
| Temps de lecture |
Durée : 30 minutes |
| Temps de configuration |
20 minutes |
- Exemples de conditions préalables
- Avant de commencer
- Présentation fonctionnelle
- Vue d’ensemble de la topologie
- Illustration topologique
- Étapes de configuration R0
- Vérification
- Annexe 1 : Définir les commandes sur tous les équipements
Exemples de conditions préalables
| Configuration matérielle requise |
Deux routeurs MX Series. |
| Configuration logicielle requise |
Junos OS version 24.2R1 ou ultérieure s’exécute sur tous les équipements. |
Avant de commencer
| Avantages |
Le routage ECMP pondéré répartit le trafic de manière inégale sur plusieurs chemins pour un meilleur équilibrage de charge. Elle est plus efficace qu’une répartition égale du trafic lors de l’équilibrage de charge par paquet. |
| En savoir plus |
Présentation de la distribution pondérée du trafic ECMP sur des voisins OSPF à un saut |
Présentation fonctionnelle
| Technologies utilisées |
|
| Tâches de vérification primaires |
|
Vue d’ensemble de la topologie
Cet exemple de configuration illustre trois paquets Ethernet agrégés ae0, ae1 et ae2 avec deux liaisons configurées entre le routeur R0 et le routeur R1. Le moteur de transfert de paquets répartit le trafic de manière inégale entre les trois paquets Ethernet lorsqu’une liaison tombe en panne, en fonction de la bande passante disponible.
| Nom d’hôte |
Rôle |
Fonction |
|---|---|---|
| R0 |
Appareil sur lequel le WECMP est configuré. |
R0 envoie le trafic à R1. |
| R1 |
L’appareil qui est directement connecté à R0. |
R1 reçoit le trafic de R0. |
Illustration topologique
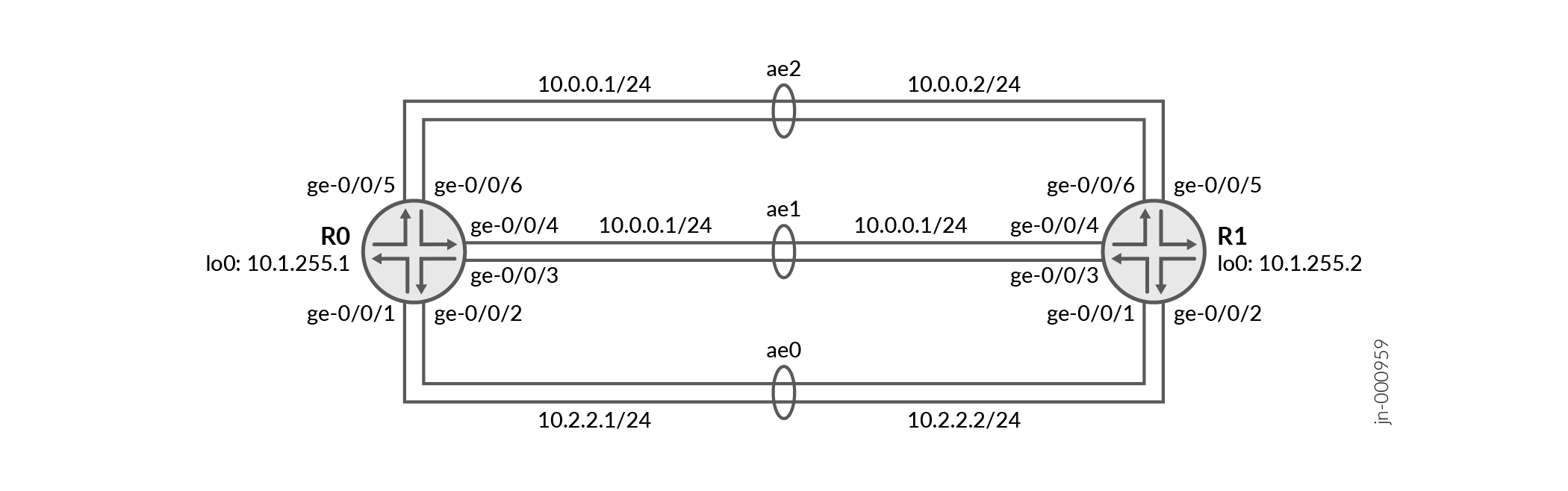 OSPFv2 à un saut
OSPFv2 à un saut
Étapes de configuration R0
Pour obtenir des exemples de configurations complets sur R0, voir : Annexe 1 : Définir des commandes sur tous les périphériques
Cette section met en évidence les principales tâches de configuration nécessaires pour configurer le périphérique R0 pour cet exemple. La première étape est commune à la configuration des interfaces Ethernet agrégées. Les étapes suivantes sont spécifiques à la configuration d’OSPF sur les bundles AE et à la configuration d’ECMP pondéré.
-
Configurez les deux liaisons membres des bundles Ethernet agrégés ae0, ae1 et ae2.
Configurez l’adresse IP et le protocole LACP (Link Aggregation Control Protocol) pour les interfaces Ethernet agrégées ae0, ae1 et ae2.
Configurez les interfaces Ethernet agrégées (ae0, ae1 et ae2) pour le balisage VLAN.
Configurez l’adresse de l’interface de bouclage.
Configurez l’identificateur de routeur OSPF en saisissant la valeur de configuration [router-id].
Configurez les interfaces logiques avec une bande passante appropriée en fonction de la bande passante physique sous-jacente.
Note:Pour les interfaces logiques, configurez la bande passante de l’interface afin de répartir le trafic sur des chemins multiples à coût égal en fonction de la bande passante de l’interface opérationnelle sous-jacente. Lorsque vous configurez plusieurs interfaces logiques sur une seule interface, configurez la bande passante logique appropriée pour chaque interface logique afin d’afficher la distribution de trafic souhaitée sur les interfaces logiques.
Configurez une interface de tunnel et spécifiez la quantité de bande passante à réserver au trafic de tunnel sur chaque moteur de transfert de paquets de R0.
[edit] set interfaces ge-0/0/1 gigether-options 802.3ad ae0 set interfaces ge-0/0/2 gigether-options 802.3ad ae0 set interfaces ge-0/0/3 gigether-options 802.3ad ae1 set interfaces ge-0/0/4 gigether-options 802.3ad ae1 set interfaces ge-0/0/5 gigether-options 802.3ad ae2 set interfaces ge-0/0/6 gigether-options 802.3ad ae2
[edit] set interfaces ae0 aggregated-ether-options minimum-links 1 set interfaces ae0 aggregated-ether-options lacp active set interfaces ae1 aggregated-ether-options minimum-links 1 set interfaces ae1 aggregated-ether-options lacp active set interfaces ae2 aggregated-ether-options minimum-links 1 set interfaces ae2 aggregated-ether-options lacp active
[edit] set interfaces ae0 vlan-tagging set interfaces ae1 vlan-tagging set interfaces ae2 vlan-tagging
[edit] set interfaces lo0 unit 0 family inet address 10.1.255.1/32
[edit] set routing-options router-id 10.1.255.1
[edit] set interfaces ae0 unit 0 vlan-id 6 set interfaces ae0 unit 0 family inet address 10.0.0.1/24 set interfaces ae1 unit 0 vlan-id 16 set interfaces ae1 unit 0 family inet address 10.0.1.1/24 set interfaces ae2 unit 0 vlan-id 26 set interfaces ae2 unit 0 family inet address 10.2.2.1/24
Spécifiez le nombre maximal d’interfaces ECMP pondérées que vous souhaitez configurer. Activez le basculement normal et spécifiez le nombre d’interfaces Ethernet agrégées à créer.
[edit] set chassis maximum-ecmp 64 set chassis aggregated-devices ethernet device-count 3
Configurez OSPF sur toutes les interfaces et sur les bundles AE.
[edit]set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae1.0 set protocols ospf area 0.0.0.0 interface ae2.0 set protocols ospf area 0.0.0.0 interface lo0.0Configurez l’équilibrage de charge par paquet.
[edit] set policy-options policy-statement pplb then load-balance per-packet
Appliquez une stratégie d’équilibrage de charge par paquet.
[edit] set routing-options forwarding-table export ppl
Activez la distribution pondérée du trafic ECMP sur les voisins OSPFv2 directement connectés.
[edit] set protocols ospf spf-options multipath weighted one-hop
Vérification
| Tâche de vérification | des commandes |
|---|---|
| afficher l’itinéraire étendu | Vérifiez la répartition égale du trafic sur des chemins multiples de coût égal. |
| afficher l’itinéraire étendu | Vérifiez la répartition inégale du trafic sur la bande passante disponible. |
| afficher les interfaces étendues | Vérifiez la répartition inégale du trafic sur la bande passante disponible. |
- Vérification de la répartition égale du trafic sur plusieurs chemins de coût égal
- Vérification de la répartition inégale du trafic sur la bande passante disponible
Vérification de la répartition égale du trafic sur plusieurs chemins de coût égal
But
Pour vérifier que le trafic est équitablement réparti sur les paquets Ethernet agrégés.
Action
À partir du mode opérationnel, entrez la show route 10.1.255.2 extensive commande.
user@R0> show route 10.1.255.2 extensive
inet.0: 17 destinations, 17 routes (17 active, 0 holddown, 0 hidden)
10.1.255.2/32 (1 entry, 1 announced)
TSI:
KRT in-kernel 10.1.255.2/32 -> {list:10.0.0.2, 10.0.1.2, 10.2.2.2}
*OSPF Preference: 10
Next hop type: Router, Next hop index: 0
Address: 0x819a814
Next-hop reference count: 2, Next-hop session id: 0
Kernel Table Id: 0
Next hop: 10.0.0.2 via ae0.0 weight 0x1 balance 33%
Session Id: 0
Next hop: 10.0.1.2 via ae1.0 weight 0x1 balance 33%, selected
Session Id: 0
Next hop: 10.2.2.2 via ae2.0 weight 0x1 balance 33%
Session Id: 0
State: <Active Int>
Age: 4d 17:55:37 Metric: 1
Validation State: unverified
Area: 0.0.0.0
Task: OSPF
Announcement bits (1): 0-KRT
AS path: I
Thread: junos-main
user@R0> show interfaces ae0.0 extensive
Logical interface ae0.0 (Index 337) (SNMP ifIndex 578) (Generation 173)
Flags: Up SNMP-Traps 0x4000 VLAN-Tag [ 0x8100.6 ] Encapsulation: ENET2
Statistics Packets pps Bytes bps
Bundle:
Input : 89241 0 7140674 0
Output: 89244 0 8731668 0
Adaptive Statistics:
Adaptive Adjusts: 0
Adaptive Scans : 0
Adaptive Updates: 0
Link:
ge-0/0/1.0
Input : 47583 0 3807058 0
Output: 0 0 0 0
ge-0/0/2.0
Input : 41632 0 3331512 0
Output: 89243 0 8731574 0
Aggregate member links: 2
Marker Statistics: Marker Rx Resp Tx Unknown Rx Illegal Rx
ge-0/0/1.0 0 0 0 0
ge-0/0/2.0 0 0 0 0
Protocol inet, MTU: 1500
Max nh cache: 75000, New hold nh limit: 75000, Curr nh cnt: 1, Curr new hold cnt: 0, NH drop cnt: 0
Generation: 177, Route table: 0
Flags: Sendbcast-pkt-to-re, 0x0
Addresses, Flags: Is-Preferred Is-Primary
Destination: 10.0.0/24, Local: 10.0.0.1, Broadcast: 10.0.0.255, Generation: 157
Protocol multiservice, MTU: Unlimited, Generation: 178, Route table: 0
Flags: Is-Primary, 0x0
Policer: Input: __default_arp_policer__
user@R0> show interfaces ae1.0 extensive
Logical interface ae1.0 (Index 362) (SNMP ifIndex 593) (Generation 175)
Flags: Up SNMP-Traps 0x4000 VLAN-Tag [ 0x8100.16 ] Encapsulation: ENET2
Statistics Packets pps Bytes bps
Bundle:
Input : 89631 0 7194074 312
Output: 89626 1 8793864 784
Adaptive Statistics:
Adaptive Adjusts: 0
Adaptive Scans : 0
Adaptive Updates: 0
Link:
ge-0/0/3.0
Input : 89631 0 7194074 312
Output: 89626 0 8793864 0
ge-0/0/4.0
Input : 0 0 0 0
Output: 0 0 0 0
Aggregate member links: 2
Marker Statistics: Marker Rx Resp Tx Unknown Rx Illegal Rx
ge-0/0/3.0 0 0 0 0
ge-0/0/4.0 0 0 0 0
Protocol inet, MTU: 1500
Max nh cache: 75000, New hold nh limit: 75000, Curr nh cnt: 1, Curr new hold cnt: 0, NH drop cnt: 0
Generation: 180, Route table: 0
Flags: Sendbcast-pkt-to-re, 0x0
Addresses, Flags: Is-Preferred Is-Primary
Destination: 10.0.1/24, Local: 10.0.1.1, Broadcast: 10.0.1.255, Generation: 159
Protocol multiservice, MTU: Unlimited, Generation: 181, Route table: 0
Flags: 0x0
Policer: Input: __default_arp_policer__
user@R0> show interfaces ae2.0 extensive
Logical interface ae2.0 (Index 364) (SNMP ifIndex 592) (Generation 177)
Flags: Up SNMP-Traps 0x4000 VLAN-Tag [ 0x8100.26 ] Encapsulation: ENET2
Statistics Packets pps Bytes bps
Bundle:
Input : 89612 0 7193002 0
Output: 89664 0 8797828 0
Adaptive Statistics:
Adaptive Adjusts: 0
Adaptive Scans : 0
Adaptive Updates: 0
Link:
ge-0/0/5.0
Input : 89612 0 7193002 0
Output: 89664 0 8797828 0
ge-0/0/6.0
Input : 0 0 0 0
Output: 0 0 0 0
Aggregate member links: 2
Marker Statistics: Marker Rx Resp Tx Unknown Rx Illegal Rx
ge-0/0/5.0 0 0 0 0
ge-0/0/6.0 0 0 0 0
Protocol inet, MTU: 1500
Max nh cache: 75000, New hold nh limit: 75000, Curr nh cnt: 1, Curr new hold cnt: 0, NH drop cnt: 0
Generation: 183, Route table: 0
Flags: Sendbcast-pkt-to-re, 0x0
Addresses, Flags: Is-Preferred Is-Primary
Destination: 10.2.2/24, Local: 10.2.2.1, Broadcast: 10.2.2.255, Generation: 161
Protocol multiservice, MTU: Unlimited, Generation: 184, Route table: 0
Flags: 0x0
Policer: Input: __default_arp_policer__
Signification
OSPF répartit le trafic de manière égale lorsque les trois paquets Ethernet agrégés disposent de la même bande passante.
Vérification de la répartition inégale du trafic sur la bande passante disponible
But
Pour vérifier qu’OSPF répartit le trafic de manière inégale lorsqu’une des liaisons agrégées est indisponible pendant l’équilibrage de charge par paquet en fonction de la bande passante disponible.
Action
Désactivez l’un des liens du bundle ae0. À partir du mode opérationnel, entrez la show route 10.1.255.2 extensive commande.
user@R0> show route 10.1.255.2 extensive
inet.0: 17 destinations, 17 routes (17 active, 0 holddown, 0 hidden)
10.1.255.2/32 (1 entry, 1 announced)
TSI:
KRT in-kernel 10.1.255.2/32 -> {list:10.0.0.2, 10.0.1.2, 10.2.2.2}
*OSPF Preference: 10
Next hop type: Router, Next hop index: 0
Address: 0x819ba14
Next-hop reference count: 2, Next-hop session id: 0
Kernel Table Id: 0
Next hop: 10.0.0.2 via ae0.0 weight 0x1 balance 20%
Session Id: 0
Next hop: 10.0.1.2 via ae1.0 weight 0x1 balance 40%, selected
Session Id: 0
Next hop: 10.2.2.2 via ae2.0 weight 0x1 balance 40%
Session Id: 0
State: <Active Int>
Age: 23 Metric: 1
Validation State: unverified
Area: 0.0.0.0
Task: OSPF
Announcement bits (1): 0-KRT
AS path: I
Thread: junos-main
Signification
OSPF en déduit que le bundle ae0 dispose d’une bande passante moindre. Par conséquent, modifie l’équilibrage de charge par paquet en fonction de la bande passante disponible. Selon la sortie, seulement 20 % de la bande passante est disponible sur ae0 car l’une des liaisons Ethernet agrégées est en panne. Ainsi, OSPF répartit le trafic de manière inégale en fonction de la bande passante disponible.
Annexe 1 : Définir les commandes sur tous les équipements
Pour configurer rapidement cet exemple, copiez les commandes suivantes, collez-les dans un fichier texte, supprimez les sauts de ligne, modifiez tous les détails nécessaires pour qu’ils correspondent à votre configuration réseau, puis copiez et collez les commandes dans l’interface de ligne de commande au niveau de la hiérarchie [modifier].
R0
set system host-name R0 set chassis maximum-ecmp 64 set chassis aggregated-devices ethernet device-count 3 set interfaces ge-0/0/1 description "LinkID: R0R1-1" set interfaces ge-0/0/1 gigether-options 802.3ad ae0 set interfaces ge-0/0/2 description "LinkID: R0R1-2" set interfaces ge-0/0/2 gigether-options 802.3ad ae0 set interfaces ge-0/0/3 description "LinkID: R0R1-3" set interfaces ge-0/0/3 gigether-options 802.3ad ae1 set interfaces ge-0/0/4 description "LinkID: R0R1-4" set interfaces ge-0/0/4 gigether-options 802.3ad ae1 set interfaces ge-0/0/5 description "LinkID: R0R1-5" set interfaces ge-0/0/5 gigether-options 802.3ad ae2 set interfaces ge-0/0/6 description "LinkID: R0R1-6" set interfaces ge-0/0/6 gigether-options 802.3ad ae2 set interfaces ae0 vlan-tagging set interfaces ae0 aggregated-ether-options minimum-links 1 set interfaces ae0 aggregated-ether-options lacp active set interfaces ae0 unit 0 vlan-id 6 set interfaces ae0 unit 0 family inet address 10.0.0.1/24 set interfaces ae1 vlan-tagging set interfaces ae1 aggregated-ether-options minimum-links 1 set interfaces ae1 aggregated-ether-options lacp active set interfaces ae1 unit 0 vlan-id 16 set interfaces ae1 unit 0 family inet address 10.0.1.1/24 set interfaces ae2 vlan-tagging set interfaces ae2 aggregated-ether-options minimum-links 2 set interfaces ae2 aggregated-ether-options lacp active set interfaces ae2 unit 0 vlan-id 26 set interfaces ae2 unit 0 family inet address 10.2.2.1/24 set interfaces lo0 unit 0 family inet address 10.1.255.1/32 set policy-options policy-statement pplb then load-balance per-packet set routing-options router-id 10.1.255.1 set routing-options forwarding-table export pplb set protocols ospf spf-options multipath weighted one-hop set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae1.0 set protocols ospf area 0.0.0.0 interface ae2.0 set protocols ospf area 0.0.0.0 interface lo0.0
R1
set system host-name R1 set chassis maximum-ecmp 64 set chassis aggregated-devices ethernet device-count 3 set interfaces ge-0/0/1 description "LinkID: R0R1-1" set interfaces ge-0/0/1 gigether-options 802.3ad ae0 set interfaces ge-0/0/2 description "LinkID: R0R1-2" set interfaces ge-0/0/2 gigether-options 802.3ad ae0 set interfaces ge-0/0/3 description "LinkID: R0R1-3" set interfaces ge-0/0/3 gigether-options 802.3ad ae1 set interfaces ge-0/0/4 description "LinkID: R0R1-4" set interfaces ge-0/0/4 gigether-options 802.3ad ae1 set interfaces ge-0/0/5 description "LinkID: R0R1-5" set interfaces ge-0/0/5 gigether-options 802.3ad ae2 set interfaces ge-0/0/6 description "LinkID: R0R1-6" set interfaces ge-0/0/6 gigether-options 802.3ad ae2 set interfaces ae0 vlan-tagging set interfaces ae0 aggregated-ether-options minimum-links 1 set interfaces ae0 aggregated-ether-options lacp active set interfaces ae0 unit 0 vlan-id 6 set interfaces ae0 unit 0 family inet address 10.0.0.2/24 set interfaces ae1 vlan-tagging set interfaces ae1 aggregated-ether-options minimum-links 1 set interfaces ae1 aggregated-ether-options lacp active set interfaces ae1 unit 0 vlan-id 16 set interfaces ae1 unit 0 family inet address 10.0.1.2/24 set interfaces ae2 vlan-tagging set interfaces ae2 aggregated-ether-options minimum-links 2 set interfaces ae2 aggregated-ether-options lacp active set interfaces ae2 unit 0 vlan-id 26 set interfaces ae2 unit 0 family inet address 10.2.2.2/24 set interfaces lo0 unit 0 family inet address 10.1.255.2/32 set routing-options router-id 10.1.255.2 set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae1.0 set protocols ospf area 0.0.0.0 interface ae2.0 set protocols ospf area 0.0.0.0 interface lo0.0
Exemple : Ajustement dynamique des métriques de l’interface OSPF en fonction de la bande passante
Cet exemple montre comment ajuster dynamiquement les métriques de l’interface OSPF en fonction de la bande passante.
Configuration
Configuration rapide de la CLI
Pour configurer rapidement les valeurs de seuil de bande passante et les valeurs de mesure associées pour une interface OSPF, copiez les commandes suivantes, collez-les dans un fichier texte, supprimez les sauts de ligne, modifiez tous les détails nécessaires pour qu’ils correspondent à votre configuration réseau, copiez et collez les commandes dans l’interface de ligne de commande au niveau de la hiérarchie [modifier], puis passez commit en mode de configuration.
[edit] set protocols ospf area 0.0.0.0 interface ae0.0 metric 5 set protocols ospf area 0.0.0.0 interface ae0.0 bandwidth-based-metrics bandwidth 1g metric 60 set protocols ospf area 0.0.0.0 interface ae0.0 bandwidth-based-metrics bandwidth 10g metric 50
Procédure étape par étape
Pour configurer la métrique d’une interface OSPF spécifique :
-
Créez une zone OSPF.
Note:Pour spécifier OSPFv3, incluez l’instruction ospf3 au niveau de la hiérarchie [edit protocols].
[edit] user@host# edit protocols ospf area 0.0.0.0
-
Configurez la métrique du segment de réseau OSPF.
[edit protocols ospf area 0.0.0.0 ] user@host# set interface ae0 metric 5
-
Configurez les valeurs de seuil de bande passante et les valeurs de mesure associées. Avec cette configuration, lorsque la bande passante de l’interface Ethernet agrégée est de 1 G, l’OSPF prend en compte la métrique 60 pour cette interface. Lorsque la bande passante de l’interface Ethernet agrégée est de 10 Gbit/s, l’OSPF prend en compte la métrique 50 pour cette interface.
[edit protocols ospf area 0.0.0.0 ] user@host# set interface ae0.0 bandwidth-based-metrics bandwidth 1g metric 60 user@host# set interface ae0.0 bandwidth-based-metrics bandwidth 10g metric 50
-
Si vous avez terminé de configurer l’appareil, validez la configuration.
[edit protocols ospf area 0.0.0.0 ] user@host# commit
Résultats
Confirmez votre configuration en entrant la commande show protocols ospf . Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
user@host# show protocols ospf
area 0.0.0.0 {
interface ae0.0 {
bandwidth-based-metrics {
bandwidth 1g metric 60;
bandwidth 10g metric 50;
}
metric 5;
}
}
Pour confirmer votre configuration OSPFv3, entrez la commande show protocols ospf3 .
Exigences
Avant de commencer :
Configurez les interfaces des appareils. Reportez-vous au Guide de l’utilisateur des interfaces pour les dispositifs de sécurité.
Configurez les identificateurs de routeur pour les périphériques de votre réseau OSPF. Reportez-vous à la section Exemple : Configuration d’un identificateur de routeur OSPF.
Contrôlez le choix du routeur désigné par l’OSPF. Voir Exemple : Contrôle de l’élection du routeur désigné OSPF
Configurez un réseau OSPF à zone unique. Reportez-vous à la section Exemple : Configuration d’un réseau OSPF monozone.
Aperçu
Vous pouvez spécifier un ensemble de valeurs de seuil de bande passante et de valeurs de mesure associées pour une interface OSPF. Lorsque la bande passante d’une interface change, Junos OS définit automatiquement la métrique de l’interface sur la valeur associée à la valeur de seuil de bande passante appropriée. Lorsque vous configurez des valeurs de mesure basées sur la bande passante, vous configurez généralement plusieurs valeurs de bande passante et de métrique.
Dans cet exemple, vous configurez l’interface OSPF ae0 pour les mesures basées sur la bande passante en incluant l’instruction bandwidth-based-metrics et les paramètres suivants :
bandwidth : spécifie le seuil de bande passante en bits par seconde. La plage est comprise entre 9600 et 1 000 000 000 000 000.
metric : spécifie la valeur de métrique à associer à une valeur de bande passante spécifique. La plage est comprise entre 1 et 65 535.
Topologie
Vérification
Vérifiez que la configuration fonctionne correctement.
Vérification de la métrique configurée
But
Vérifiez le paramètre de mesure sur l’interface. Vérifiez que le champ Coût affiche la mesure configurée de l’interface (coût). Lors du choix des chemins vers une destination, OSPF utilise le chemin le moins coûteux.
Action
À partir du mode opérationnel, entrez la commande show ospf interface detail pour OSPFv2, puis entrez la commande show ospf3 interface detail pour OSPFv3.
Exemple : Contrôle des préférences de routage OSPF
Cet exemple montre comment contrôler la sélection de route OSPF dans la table de transfert. Cet exemple montre également comment vous pouvez contrôler la sélection de route si vous migrez d’OSPF vers un autre IGP.
Configuration
Configuration rapide de la CLI
Pour configurer rapidement les valeurs de préférence de route OSPF, copiez les commandes suivantes, collez-les dans un fichier texte, supprimez les sauts de ligne, modifiez tous les détails nécessaires pour qu’ils correspondent à votre configuration réseau, copiez et collez les commandes dans l’interface de ligne de commande au niveau de la hiérarchie [modifier], puis passez commit en mode de configuration.
[edit] set protocols ospf preference 168 external-preference 169
Procédure étape par étape
Pour configurer la sélection d’itinéraire, procédez comme suit :
Entrez dans le mode de configuration OSPF et définissez les préférences de routage externe et interne.
Note:Pour spécifier OSPFv3, incluez l’instruction
ospf3au niveau de la[edit protocols]hiérarchie.[edit] user@host# set protocols ospf preference 168 external-preference 169
Si vous avez terminé de configurer l’appareil, validez la configuration.
[edit] user@host# commit
Résultats
Confirmez votre configuration en entrant la show protocols ospf commande. Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
user@host# show protocols ospf preference 168; external-preference 169;
Pour confirmer votre configuration OSPFv3, entrez la show protocols ospf3 commande.
Exigences
Cet exemple suppose qu’OSPF est correctement configuré et en cours d’exécution sur votre réseau et que vous souhaitez contrôler la sélection de route, car vous envisagez de migrer d’OSPF vers un autre IGP.
Configurez les interfaces des appareils. Reportez-vous au Guide de l’utilisateur des interfaces pour les dispositifs de sécurité.
Configurez l’IGP vers lequel vous souhaitez migrer.
Aperçu
Les préférences de route permettent de sélectionner l’itinéraire à installer dans la table de transfert lorsque plusieurs protocoles calculent des itinéraires vers la même destination. L’itinéraire avec la valeur de préférence la plus faible est sélectionné.
Par défaut, les routes OSPF internes ont une valeur de préférence de 10 et les routes OSPF externes ont une valeur de préférence de 150. Vous souhaiterez peut-être modifier ce paramètre si vous envisagez de migrer d’OSPF vers une autre IGP. La modification des préférences de routage vous permet d’effectuer la migration de manière contrôlée.
Cet exemple fait les hypothèses suivantes :
OSPF est déjà en cours d’exécution sur votre réseau.
Vous souhaitez migrer d’OSPF vers IS-IS.
Vous avez configuré IS-IS en fonction des exigences de votre réseau et vous avez confirmé son bon fonctionnement.
Dans cet exemple, vous augmentez les valeurs de préférence de route OSPF pour les rendre moins préférées que les routes IS-IS en spécifiant 168 pour les routes OSPF internes et 169 pour les routes OSPF externes. Les routes internes IS-IS ont une préférence de 15 (pour le niveau 1) ou 18 (pour le niveau 2), et les routes externes ont une préférence de 160 (pour le niveau 1) ou 165 (pour le niveau 2). En général, il est préférable de conserver les paramètres par défaut du nouveau protocole afin de minimiser les complexités et de simplifier tout ajout futur de périphériques de routage au réseau. Pour modifier les valeurs de préférence de route OSPF, configurez les paramètres suivants :
preference: spécifie la préférence de route pour les routes OSPF internes. Par défaut, les routes OSPF internes ont une valeur de 10. La plage est comprise entre 0 et 4 294967 295 (232 – 1).external-preference: spécifie la préférence de route pour les routes OSPF externes. Par défaut, les routes OSPF externes ont une valeur de 150. La plage est comprise entre 0 et 4 294967 295 (232 – 1).
Topologie
Vérification
Vérifiez que la configuration fonctionne correctement.
Vérification de l’itinéraire
But
Vérifiez que l’IGP utilise l’itinéraire approprié. Une fois que le nouvel IGP est devenu le protocole préféré (dans cet exemple, IS-IS), vous devez surveiller le réseau pour détecter tout problème. Une fois que vous avez confirmé que le nouvel IGP fonctionne correctement, vous pouvez supprimer la configuration OSPF du périphérique de routage en entrant la delete ospf commande au niveau de la [edit protocols] hiérarchie.
Action
À partir du mode opérationnel, entrez la show route commande.
Comprendre la fonction de surcharge OSPF
Si le temps écoulé après l’activation de l’instance OSPF est inférieur au délai d’expiration spécifié, le mode de surcharge est défini.
Vous pouvez configurer le périphérique de routage local de manière à ce qu’il semble être surchargé. Un périphérique de routage surchargé détermine qu’il ne peut plus gérer le trafic de transit OSPF, ce qui entraîne l’envoi du trafic de transit OSPF vers d’autres périphériques de routage. Le trafic OSPF vers les interfaces directement connectées continue d’atteindre le périphérique de routage. Vous pouvez configurer le mode de surcharge pour de nombreuses raisons, notamment :
Si vous souhaitez que le périphérique de routage participe au routage OSPF, mais que vous ne souhaitez pas qu’il soit utilisé pour le trafic de transit. Il peut s’agir d’un équipement de routage connecté au réseau à des fins d’analyse, mais qui n’est pas considéré comme faisant partie du réseau de production, comme les équipements de routage de gestion du réseau.
Si vous effectuez la maintenance d’un périphérique de routage dans un réseau de production. Vous pouvez déplacer le trafic hors de ce périphérique de routage afin que les services réseau ne soient pas interrompus pendant votre fenêtre de maintenance.
Vous pouvez configurer ou désactiver le mode de surcharge dans OSPF avec ou sans délai d’expiration. Sans délai d’expiration, le mode de surcharge est défini jusqu’à ce qu’il soit explicitement supprimé de la configuration. Avec un délai d’expiration, le mode de surcharge est défini si le temps écoulé depuis le démarrage de l’instance OSPF est inférieur au délai d’expiration spécifié.
Un minuteur est démarré pour la différence entre le délai d’expiration et le temps écoulé depuis le démarrage de l’instance. Lorsque la minuterie expire, le mode de surcharge est effacé. En mode de surcharge, l’annonce LSA (router link-state advertisement) provient de toutes les liaisons de routeur de transit (sauf stub) définies sur une métrique de 0xFFFF. Les liens du routeur stub sont annoncés avec le coût réel des interfaces correspondant au stub. Cela permet au trafic de transit d’éviter le périphérique de routage surchargé et d’emprunter des chemins autour du périphérique de routage. Cependant, les liens du périphérique de routage surchargé sont toujours accessibles.
Le périphérique de routage peut également entrer dynamiquement dans l’état de surcharge, indépendamment de la configuration de l’équipement pour qu’il apparaisse surchargé. Par exemple, si le périphérique de routage dépasse la limite de préfixes OSPF configurée, il purge les préfixes externes et entre dans un état de surcharge.
En cas de configurations incorrectes, le grand nombre de routes peut entrer dans OSPF, ce qui peut nuire aux performances du réseau. Pour éviter cela, prefix-export-limit il faut configurer ce qui purgera les externes et empêchera le réseau de l’impact négatif.
En autorisant l’exportation d’un nombre illimité de routes vers OSPF, le périphérique de routage peut être submergé et potentiellement inonder un nombre excessif de routes dans une zone. Vous pouvez limiter le nombre de routes exportées au format OSPF afin de réduire la charge sur le périphérique de routage et d’éviter ce problème potentiel.
Par défaut, il n’y a pas de limite au nombre de préfixes (routes) pouvant être exportés dans OSPF. Pour éviter cela, prefix-export-limit il faut configurer ce qui purgera les externes et empêchera le réseau.
À partir de la version 18.2 de Junos OS, les fonctionnalités suivantes sont prises en charge par Stub Router dans votre réseau OSPF lorsque l’OSPF est surchargé :
Autoriser la fuite de routes : les préfixes externes sont redistribués lors d’une surcharge OSPF et les préfixes proviennent d’un coût normal.
Annoncer le réseau stub avec la métrique max : les réseaux stub sont annoncés avec la métrique maximale lors de la surcharge OSPF.
Annoncer le préfixe intra-zone avec la métrique max : les préfixes intra-zone sont annoncés avec la métrique maximale lors de la surcharge OSPF.
Annoncer le préfixe externe avec la mesure maximale possible : les préfixes externes OSPF AS sont redistribués lors de la surcharge OSPF et les préfixes sont annoncés avec le coût maximal.
Vous pouvez désormais configurer les éléments suivants lorsque OSPF est surchargé :
allow-route-leakingau niveau de la[edit protocols <ospf | ospf3> overload]hiérarchie pour annoncer les préfixes externes avec un coût normal.stub-networkau niveau de la[edit protocols ospf overload]hiérarchie pour annoncer le réseau stub avec la métrique maximale.intra-area-prefixau niveau de la hiérarchie pour annoncer le[edit protocols ospf3 overload]préfixe intra-zone avec la métrique maximale.as-externalau niveau de la hiérarchie pour annoncer le[edit protocols <ospf | ospf3> overload]préfixe externe avec la métrique maximale.
Pour limiter le nombre de préfixes exportés vers OSPF :
[edit] set protocols ospf prefix-export-limit number
Le numéro limite d’exportation du préfixe peut être compris entre 0 et 4 294 967 295.
Voir aussi
Exemple : Configuration d’OSPF pour que les périphériques de routage semblent surchargés
Cet exemple montre comment configurer un périphérique de routage exécutant OSPF pour qu’il semble surchargé.
Exigences
Avant de commencer :
Configurez les interfaces des appareils. Reportez-vous au Guide de l’utilisateur des interfaces pour les dispositifs de sécurité.
Configurez les identificateurs de routeur pour les périphériques de votre réseau OSPF. Reportez-vous à la section Exemple : Configuration d’un identificateur de routeur OSPF.
Contrôlez le choix du routeur désigné par l’OSPF. Voir Exemple : Contrôle de l’élection du routeur désigné OSPF
Configurez un réseau OSPF à zone unique. Reportez-vous à la section Exemple : Configuration d’un réseau OSPF monozone.
Configurez un réseau OSPF multizone. Reportez-vous à la section Exemple : Configuration d’un réseau OSPF multizone.
Aperçu
Vous pouvez configurer un périphérique de routage local exécutant OSPF pour qu’il semble surchargé, ce qui permet au périphérique de routage local de participer au routage OSPF, mais pas pour le trafic de transit. Lorsqu’elles sont configurées, les métriques de l’interface de transit sont définies sur la valeur maximale de 65535.
Cet exemple inclut les paramètres suivants :
surcharge : configure le périphérique de routage local de sorte qu’il semble surchargé. Vous pouvez configurer cette option si vous souhaitez que le périphérique de routage participe au routage OSPF, mais que vous ne souhaitez pas qu’il soit utilisé pour le trafic de transit, ou si vous effectuez une maintenance sur un périphérique de routage dans un réseau de production.
Timeout seconds—(Facultatif) Spécifie le nombre de secondes pendant lesquelles la surcharge est réinitialisée. Si aucun intervalle de délai d’attente n’est spécifié, le périphérique de routage reste dans l’état de surcharge jusqu’à ce que l’instruction de surcharge soit supprimée ou qu’un délai d’attente soit défini. Dans cet exemple, vous configurez 60 secondes comme durée pendant laquelle le périphérique de routage reste à l’état de surcharge. Par défaut, l’intervalle de délai d’attente est de 0 seconde (cette valeur n’est pas configurée). La plage est de 60 à 1800 secondes.
Topologie
Configuration
Procédure
Configuration rapide de la CLI
Pour configurer rapidement un périphérique de routage local afin qu’il apparaisse comme surchargé, copiez les commandes suivantes, collez-les dans un fichier texte, supprimez les sauts de ligne, modifiez tous les détails nécessaires pour qu’ils correspondent à votre configuration réseau, copiez et collez les commandes dans l’interface de ligne de commande au niveau de la hiérarchie [modifier], puis passez commit en mode de configuration.
[edit] set protocols ospf overload timeout 60
Procédure étape par étape
Pour configurer un périphérique de routage local afin qu’il apparaisse surchargé :
Entrez en mode de configuration OSPF.
Note:Pour spécifier OSPFv3, incluez l’instruction
ospf3au niveau de la[edit protocols]hiérarchie.[edit] user@host# edit protocols ospfConfigurez le périphérique de routage local à surcharger.
[edit protocols ospf] user@host# set overload(Facultatif) Configurez le nombre de secondes pendant lesquelles la surcharge est réinitialisée.
[edit protocols ospf] user@host#
set overload timeout 60(Facultatif) Configurez la limite du nombre de préfixes exportés vers OSPF, afin de minimiser la charge sur le périphérique de routage et d’éviter que le périphérique ne passe en mode de surcharge.
[edit protocols ospf] user@host# set prefix-export-limit 50
Si vous avez terminé de configurer l’appareil, validez la configuration.
[edit protocols ospf] user@host# commit
Résultats
Confirmez votre configuration en entrant la show protocols ospf commande. Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration. La sortie inclut l’option timeout et prefix-export-limit les instructions.
user@host# show protocols ospf prefix-export-limit 50; overload timeout 60;
Pour confirmer votre configuration OSPFv3, entrez la show protocols ospf3 commande.
Vérification
Vérifiez que la configuration fonctionne correctement.
- Vérification que le trafic s’est déplacé hors des appareils
- Vérification des métriques de l’interface de transit
- Vérification de la configuration de la surcharge
- Vérification de la viabilité du saut suivant
Vérification que le trafic s’est déplacé hors des appareils
But
Vérifiez que le trafic s’est déplacé hors des appareils en amont.
Action
À partir du mode opérationnel, entrez la show interfaces detail commande.
Vérification des métriques de l’interface de transit
But
Vérifiez que les métriques de l’interface de transit sont définies sur la valeur maximale de 65535 sur l’équipement voisin en aval.
Action
À partir du mode opérationnel, entrez la show ospf database router detail advertising-router address commande pour OSPFv2, puis entrez la show ospf3 database router detail advertising-router address commande pour OSPFv3.
Vérification de la configuration de la surcharge
But
Vérifiez que la surcharge est configurée en examinant le champ Surcharge configurée. Si le minuteur de surcharge est également configuré, ce champ affiche également le temps restant avant son expiration.
Action
À partir du mode opérationnel, entrez la commande OSPFv2 et la show ospf overview show ospf3 overview commande OSPFv3.
Vérification de la viabilité du saut suivant
But
Vérifiez la configuration du tronçon suivant viable sur l’équipement voisin en amont. Si l’appareil voisin est surchargé, il n’est pas utilisé pour le trafic de transit et n’est pas affiché dans la sortie.
Action
À partir du mode opérationnel, entrez la show route address commande.
Comprendre les options de l’algorithme SPF pour OSPF
L’OSPF utilise l’algorithme SPF (Shortest-path-first), également appelé algorithme de Dijkstra, pour déterminer l’itinéraire permettant d’atteindre chaque destination. L’algorithme SPF décrit comment OSPF détermine l’itinéraire pour atteindre chaque destination, et les options SPF contrôlent les temporisateurs qui dictent le moment où l’algorithme SPF s’exécute. En fonction de votre environnement réseau et de vos exigences, vous souhaiterez peut-être modifier les options SPF. Prenons l’exemple d’un environnement à grande échelle où un grand nombre d’appareils inondent les annonces d’état de lien (LSA) dans toute la zone. Dans cet environnement, il est possible de recevoir un grand nombre de LSA à traiter, ce qui peut consommer des ressources mémoire. En configurant les options SPF, vous continuez à vous adapter à l’évolution de la topologie du réseau, mais vous pouvez minimiser la quantité de ressources mémoire utilisées par les périphériques pour exécuter l’algorithme SPF.
Vous pouvez configurer les options SPF suivantes :
Délai entre la détection d’un changement de topologie et l’exécution effective de l’algorithme SPF.
Nombre maximal de fois que l’algorithme SPF peut s’exécuter successivement avant le début du minuteur de retenue.
Temps nécessaire pour maintenir ou attendre avant d’exécuter un autre calcul SPF après que l’algorithme SPF ait exécuté successivement le nombre de fois configuré. Si le réseau se stabilise pendant la période d’attente et que l’algorithme SPF n’a pas besoin de s’exécuter à nouveau, le système revient aux valeurs configurées pour le délai et
rapid-runsles instructions.
Exemple : Configuration des options d’algorithme SPF pour OSPF
Cet exemple montre comment configurer les options de l’algorithme SPF. Les options SPF contrôlent les minuteries qui déterminent le moment où l’algorithme SPF s’exécute.
Exigences
Avant de commencer :
Configurez les interfaces des appareils. Reportez-vous à la bibliothèque d’interfaces réseau Junos OS pour les périphériques de routage.
Configurez les identificateurs de routeur pour les périphériques de votre réseau OSPF. Reportez-vous à la section Exemple : Configuration d’un identificateur de routeur OSPF.
Contrôlez le choix du routeur désigné par l’OSPF. Voir Exemple : Contrôle de l’élection du routeur désigné OSPF
Configurez un réseau OSPF à zone unique. Reportez-vous à la section Exemple : Configuration d’un réseau OSPF monozone.
Configurez un réseau OSPF multizone. Reportez-vous à la section Exemple : Configuration d’un réseau OSPF multizone.
Aperçu
OSPF utilise l’algorithme SPF pour déterminer l’itinéraire permettant d’atteindre chaque destination. Tous les dispositifs de routage d’une zone exécutent cet algorithme en parallèle, stockant les résultats dans leurs bases de données topologiques individuelles. Les périphériques de routage ayant des interfaces vers plusieurs zones exécutent plusieurs copies de l’algorithme. Les options SPF contrôlent les temporisateurs utilisés par l’algorithme SPF.
Avant de modifier les paramètres par défaut, vous devez avoir une bonne compréhension de votre environnement réseau et de ses exigences.
Cet exemple montre comment configurer les options d’exécution de l’algorithme SPF. Vous incluez l’instruction spf-options et les options suivantes :
delay : configure le temps (en millisecondes) entre la détection d’une topologie et l’exécution effective du SPF. Lorsque vous modifiez le temporisateur, tenez compte de vos besoins en matière de reconvergence du réseau. Par exemple, vous souhaitez spécifier une valeur de minuterie qui peut vous aider à identifier les anomalies dans le réseau, tout en permettant à un réseau stable de converger rapidement. Par défaut, l’algorithme SPF s’exécute 200 millisecondes après la détection d’une topologie. La plage est de 50 à 8000 millisecondes.
rapid-runs : configure le nombre maximal de fois que l’algorithme SPF peut s’exécuter successivement avant le début du minuteur de retenue. Par défaut, le nombre de calculs SPF qui peuvent se produire successivement est de 3. La plage est comprise entre 1 et 10. Chaque algorithme SPF est exécuté après le délai SPF configuré. Lorsque le nombre maximal de calculs SPF est atteint, le minuteur de retenue commence. Tout calcul SPF ultérieur n’est pas exécuté avant l’expiration du délai de retenue.
holddown : configure le temps nécessaire pour maintenir ou attendre avant d’exécuter un autre calcul SPF après que l’algorithme SPF a exécuté successivement le nombre maximal configuré de fois. Par défaut, le temps de maintien est de 5000 millisecondes. La plage est de 2000 à 20 000 millisecondes. Si le réseau se stabilise pendant la période d’attente et que l’algorithme SPF n’a pas besoin de s’exécuter à nouveau, le système revient aux valeurs configurées pour le délai et
rapid-runsles instructions.
Topologie
Configuration
Configuration rapide de la CLI
Pour configurer rapidement les options SPF, copiez les commandes suivantes et collez-les dans l’interface de ligne de commande.
[edit] set protocols ospf spf-options delay 210 set protocols ospf spf-options rapid-runs 4 set protocols ospf spf-options holddown 5050
Procédure
Procédure étape par étape
Pour configurer les options SPF :
Entrez en mode de configuration OSPF.
Note:Pour spécifier OSPFv3, incluez l’instruction
ospf3au niveau de la[edit protocols]hiérarchie.[edit] user@host# edit protocols ospf
Configurez le délai SPF.
[edit protocols ospf] user@host# set spf-options delay 210
Configurez le nombre maximal d’exécutions successives de l’algorithme SPF.
[edit protocols ospf] user@host# set spf-options rapid-runs 4
Configurez la minuterie de maintien SPF.
[edit protocols ospf] user@host# set spf-options holddown 5050
Si vous avez terminé de configurer l’appareil, validez la configuration.
[edit protocols ospf] user@host# commit
Résultats
Confirmez votre configuration en entrant la show protocols ospf commande. Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
user@host# show protocols ospf
spf-options {
delay 210;
holddown 5050;
rapid-runs 4;
}
Pour confirmer votre configuration OSPFv3, entrez la show protocols ospf3 commande.
Vérification
Vérifiez que la configuration fonctionne correctement.
Vérification des options SPF
But
Vérifiez que SPF fonctionne conformément aux exigences de votre réseau. Passez en revue le champ de délai SPF, le champ de retenue SPF et les champs Exécutions rapides SPF.
Action
À partir du mode opérationnel, entrez la show ospf overview commande pour OSPFv2, puis entrez la show ospf3 overview commande pour OSPFv3.
configuration de l’actualisation OSPF et réduction du flooding dans les topologies stables
La norme OSPF exige que chaque annonce LSA (link-state advertisement) soit actualisée toutes les 30 minutes. L’implémentation Juniper Networks actualise les LSA toutes les 50 minutes. Par défaut, tout LSA qui n’est pas actualisé expire au bout de 60 minutes. Cette exigence peut entraîner une surcharge de trafic qui rend difficile la mise à l’échelle des réseaux OSPF. Vous pouvez remplacer le comportement par défaut en spécifiant que le bit DoNotAge doit être défini dans les LSA auto-générés lorsqu’ils sont initialement envoyés par le routeur ou le commutateur. Tout LSA dont le bit DoNotAge est défini est réinondé uniquement lorsqu’une modification se produit dans le LSA. Cette fonctionnalité réduit ainsi la surcharge du trafic protocolaire tout en permettant à tout LSA modifié d’être inondé immédiatement. Les routeurs ou commutateurs activés pour la réduction des inondations continuent d’envoyer des paquets hello à leurs voisins et d’ancienneté les LSA auto-créés dans leurs bases de données.
L’implémentation Juniper de l’actualisation OSPF et de la réduction des inondations est basée sur la norme RFC 4136, OSPF Refresh and Flooding Reduction in Stable Topologies. Cependant, l’implémentation de Juniper n’inclut pas l’intervalle d’inondation forcée défini dans la RFC. Si vous n’implémentez pas l’intervalle d’inondation forcée, vous vous assurez que les LSA avec le bit DoNotAge défini sont réinondés uniquement lorsqu’une modification se produit.
Cette fonctionnalité est prise en charge dans les cas suivants :
Interfaces OSPFv2 et OSPFv3
Domaines OSPFv3
Liens virtuels OSPFv2 et OSPFv3
Liens fictifs OSPFv2
Interfaces homologues OSPFv2
Toutes les instances de routage prises en charge par OSPF
Systèmes logiques
Pour configurer la réduction du flooding pour une interface OSPF, incluez l’instruction flood-reduction au niveau de la [edit protocols (ospf | ospf3) area area-id interface interface-id] hiérarchie.
Si vous configurez la réduction du flooding pour une interface configurée en tant que circuit de demande, les LSA ne sont pas initialement inondés, mais envoyés uniquement lorsque leur contenu a changé. Les paquets Hello et les LSA sont envoyés et reçus sur une interface de circuit à la demande uniquement lorsqu’un changement se produit dans la topologie du réseau.
Dans l’exemple suivant, l’interface OSPF so-0/0/1.0 est configurée pour la réduction des inondations. Par conséquent, le bit DoNotAge est défini sur tous les LSA générés par les routes qui traversent l’interface spécifiée lorsqu’ils sont initialement inondés, et les LSA ne sont actualisés que lorsqu’une modification se produit.
[edit]
protocols ospf {
area 0.0.0.0 {
interface so-0/0/1.0 {
flood-reduction;
}
interface lo0.0;
interface so-0/0/0.0;
}
}
À partir de la version 12.2 de Junos OS, vous pouvez configurer un intervalle d’inondation LSA (link-state advertisement) global par défaut dans OSPF pour les LSA auto-générés en incluant l’instruction lsa-refresh-interval minutes au niveau de la [edit protocols (ospf | ospf3)] hiérarchie. L’implémentation Juniper Networks actualise les LSA toutes les 50 minutes. La plage est de 25 à 50 minutes. Par défaut, tout LSA qui n’est pas actualisé expire au bout de 60 minutes.
Si l’intervalle d’actualisation LSA global est configuré pour OSPF et que la réduction d’inondation OSPF est configurée pour une interface spécifique dans une zone OSPF, la configuration de réduction d’inondation OSPF est prioritaire pour cette interface spécifique.
Comprendre la synchronisation entre LDP et IGP
LDP est un protocole de distribution d’étiquettes dans les applications qui ne sont pas liées à l’ingénierie du trafic. Les étiquettes sont distribuées selon le meilleur chemin déterminé par le protocole IGP (Interior Gateway Protocol). Si la synchronisation entre LDP et l’IGP n’est pas maintenue, le chemin d’accès au commutateur d’étiquettes (LSP) s’arrête. Lorsque le LDP n’est pas entièrement opérationnel sur une liaison donnée (une session n’est pas établie et les étiquettes ne sont pas échangées), l’IGP annonce le lien avec la métrique de coût maximum. Le lien n’est pas privilégié mais reste dans la topologie du réseau.
La synchronisation LDP n’est prise en charge que sur les interfaces point à point actives et les interfaces LAN configurées en tant que point à point sous IGP. La synchronisation LDP n’est pas prise en charge lors du redémarrage normal.
Voir aussi
Exemple : configuration de la synchronisation entre LDP et OSPF
Cet exemple montre comment configurer la synchronisation entre LDP et OSPFv2.
Exigences
Avant de commencer :
Configurez les interfaces des appareils. Reportez-vous à la bibliothèque d’interfaces réseau Junos OS pour les périphériques de routage.
Configurez les identificateurs de routeur pour les périphériques de votre réseau OSPF. Reportez-vous à la section Exemple : Configuration d’un identificateur de routeur OSPF.
Contrôlez le choix du routeur désigné par l’OSPF. Voir Exemple : Contrôle de l’élection du routeur désigné OSPF
Configurez un réseau OSPF à zone unique. Reportez-vous à la section Exemple : Configuration d’un réseau OSPF monozone.
Configurez un réseau OSPF multizone. Reportez-vous à la section Exemple : Configuration d’un réseau OSPF multizone.
Aperçu
Dans cet exemple, configurez la synchronisation entre LDP et OSPFv2 en effectuant les tâches suivantes :
Activez LDP sur l’interface so-1/0/3, qui est membre de la zone OSPF 0.0.0.0, en incluant l’instruction
ldpau niveau de la[edit protocols]hiérarchie. Vous pouvez configurer une ou plusieurs interfaces. Par défaut, LDP est désactivé sur le périphérique de routage.Activez la synchronisation LDP en incluant l’instruction
ldp-synchronizationau niveau de la[edit protocols ospf area area-id interface interface-name]hiérarchie. Cette instruction active la synchronisation LDP en annonçant la mesure de coût maximal jusqu’à ce que LDP soit opérationnel sur la liaison.Configurez la durée (en secondes) pendant laquelle le périphérique de routage annonce la mesure de coût maximal pour une liaison qui n’est pas entièrement opérationnelle en incluant l’instruction
hold-timeau niveau de la[edit protocols ospf area area-id interface interface-name ldp-synchronization]hiérarchie. Si vous ne configurez pas l’instructionhold-time, la valeur par défaut de hold-time est infinie. La plage est de 1 à 65 535 secondes. Dans cet exemple, configurez 10 secondes pour l’intervalle de temps de maintien.
Cet exemple montre également comment désactiver la synchronisation entre LDP et OSPFv2 en incluant l’instruction disable au niveau de la [edit protocols ospf area area-id interface interface-name ldp-synchronization] hiérarchie.
Topologie
Configuration
- Activation de la synchronisation entre LDP et OSPFv2
- Désactivation de la synchronisation entre LDP et OSPFv2
Activation de la synchronisation entre LDP et OSPFv2
Configuration rapide de la CLI
L’exemple suivant vous oblige à naviguer à différents niveaux dans la hiérarchie de configuration. Pour plus d’informations sur la navigation dans la CLI, reportez-vous au Guide de l’utilisateur Modification de la configuration de Junos OS dans CLI.
Pour activer rapidement la synchronisation entre LDP et OSPFv2, copiez les commandes suivantes, supprimez les sauts de ligne, puis collez-les dans l’interface de ligne de commande.
[edit] set protocols ldp interface so-1/0/3 set protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-syncrhonization hold-time 10
Procédure étape par étape
Pour activer la synchronisation entre LDP et OSPFv2 :
Activez LDP sur l’interface.
[edit] user@host# set protocols ldp interface so-1/0/3
Configurez la synchronisation LDP et, si vous le souhaitez, configurez une période de 10 secondes pour annoncer la mesure de coût maximal pour une liaison qui n’est pas entièrement opérationnelle.
[edit ] user@host# edit protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization
Configurez une période de 10 secondes pour annoncer la mesure de coût maximale pour une liaison qui n’est pas entièrement opérationnelle.
[edit protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization ] user@host# set hold-time 10
Si vous avez terminé de configurer l’appareil, validez la configuration.
[edit protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization] user@host# commit
Résultats
Confirmez votre configuration en saisissant les show protocols ldp commandes and show protocols ospf . Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
user@host# show protocols ldp interface so-1/0/3.0;
user@host# show protocols ospf
area 0.0.0.0 {
interface so-1/0/3.0 {
ldp-synchronization {
hold-time 10;
}
}
}
Désactivation de la synchronisation entre LDP et OSPFv2
Configuration rapide de la CLI
Pour désactiver rapidement la synchronisation entre LDP et OSPFv2, copiez la commande suivante et collez-la dans l’interface de ligne de commande.
[edit] set protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization disable
Procédure étape par étape
Pour désactiver la synchronisation entre LDP et OSPF :
Désactivez la synchronisation en incluant l’instruction
disable.[edit ] user@host# set protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization disable
Si vous avez terminé de configurer l’appareil, validez la configuration.
[edit] user@host# commit
Résultats
Confirmez votre configuration en entrant la show protocols ospf commande. Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
user@host# show protocols ospf
area 0.0.0.0 {
interface so-1/0/3.0 {
ldp-synchronization {
disable;
}
}
}
Vérification
Vérifiez que la configuration fonctionne correctement.
Vérification de l’état de synchronisation LDP de l’interface
But
Vérifiez l’état actuel de la synchronisation LDP sur l’interface. L’état de synchronisation LDP affiche les informations relatives à l’état actuel et le champ Config holdtime affiche l’intervalle de temps d’attente configuré.
Action
À partir du mode opérationnel, entrez la show ospf interface extensive commande.
Compatibilité OSPFv2 avec la norme RFC 1583 Présentation
Par défaut, l’implémentation Junos OS d’OSPFv2 est compatible avec RFC 1583, OSPF version 2. Cela signifie que Junos OS conserve un seul meilleur chemin vers un routeur de limite de système autonome (AS) dans la table de routage OSPF, plutôt que plusieurs chemins intra-AS, s’ils sont disponibles. Vous pouvez désormais désactiver la compatibilité avec la RFC 1583. Il est préférable de le faire lorsque la même destination externe est annoncée par les routeurs de limite AS qui appartiennent à différentes zones OSPF. Lorsque vous désactivez la compatibilité avec la norme RFC 1583, la table de routage OSPF conserve les multiples chemins intra-AS disponibles, que le routeur utilise pour calculer les routes externes AS, comme défini dans la RFC 2328, OSPF version 2. Le fait de pouvoir utiliser plusieurs chemins disponibles pour calculer une route externe AS permet d’éviter les boucles de routage.
Voir aussi
Exemple : Désactivation de la compatibilité OSPFv2 avec RFC 1583
Cet exemple montre comment désactiver la compatibilité OSPFv2 avec RFC 1583 sur le périphérique de routage.
Exigences
Aucune configuration spéciale au-delà de l’initialisation de l’appareil n’est requise avant de désactiver la compatibilité OSPFv2 avec RFC 1583.
Aperçu
Par défaut, l’implémentation Junos OS d’OSPF est compatible avec la norme RFC 1583. Cela signifie que Junos OS conserve un seul meilleur chemin vers un routeur de limite de système autonome (AS) dans la table de routage OSPF, plutôt que plusieurs chemins intra-AS, s’ils sont disponibles. Vous pouvez désactiver la compatibilité avec RFC 1583. Il est préférable de le faire lorsque la même destination externe est annoncée par les routeurs de limite AS qui appartiennent à différentes zones OSPF. Lorsque vous désactivez la compatibilité avec la norme RFC 1583, la table de routage OSPF conserve les multiples chemins intra-AS disponibles, que le routeur utilise pour calculer les routes externes AS, comme défini dans la RFC 2328. Le fait de pouvoir utiliser plusieurs chemins disponibles pour calculer une route externe AS permet d’éviter les boucles de routage. Pour réduire le risque de boucles de routage, configurez la même compatibilité RFC sur tous les périphériques OSPF d’un domaine OSPF.
Topologie
Configuration
Procédure
Configuration rapide de la CLI
Pour désactiver rapidement la compatibilité OSPFv2 avec la RFC 1583, copiez les commandes suivantes, collez-les dans un fichier texte, supprimez les sauts de ligne, modifiez tous les détails nécessaires pour qu’ils correspondent à votre configuration réseau, copiez et collez les commandes dans l’interface de ligne de commande au niveau de la hiérarchie [modifier], puis passez commit en mode de configuration. Vous configurez ce paramètre sur tous les appareils qui font partie du domaine OSPF.
[edit] set protocols ospf no-rfc-1583
Procédure étape par étape
Pour désactiver la compatibilité OSPFv2 avec la RFC 1583 :
Désactivez la RFC 1583.
[edit] user@host# set protocols ospf no-rfc-1583
Si vous avez terminé de configurer l’appareil, validez la configuration.
[edit] user@host# commit
Note:Répétez cette configuration sur chaque périphérique de routage qui fait partie d’un domaine de routage OSPF.
Résultats
Confirmez votre configuration en entrant la show protocols ospf commande. Si la sortie n’affiche pas la configuration prévue, répétez les instructions de cet exemple pour corriger la configuration.
user@host# show protocols ospf no-rfc-1583;
Vérification
Vérifiez que la configuration fonctionne correctement.