Sur cette page
Exemples de chargement d’une configuration à partir d’un fichier ou du terminal
Fonctionnement de l’encodage de caractères sur les équipements Juniper Networks
A propos de la spécification d’instructions et d’identificateurs
A propos du chargement d’une configuration à partir d’un fichier
Charger des données de configuration JSON avec des entrées de liste non ordonnées
Chargement des fichiers de configuration
Le chargement de fichiers de configuration sur l’appareil est utile pour charger des parties des fichiers de configuration qui peuvent être communs à de nombreux appareils au sein d’un réseau.
Exemples de chargement d’une configuration à partir d’un fichier ou du terminal
Vous pouvez créer un fichier contenant les données de configuration d’un équipement Juniper Networks, copier le fichier sur le périphérique local, puis charger le fichier dans l’interface de ligne de commande. Une fois que vous avez chargé le fichier, vous pouvez le valider pour activer la configuration sur l’appareil, ou vous pouvez modifier la configuration de manière interactive à l’aide de l’interface de ligne de commande et valider la configuration ultérieurement.
Vous pouvez également créer une configuration tout en tapant sur le terminal, puis charger la configuration. Le chargement d’une configuration à partir du terminal est utile lorsque vous coupez des parties existantes de la configuration et que vous les collez ailleurs dans la configuration.
Pour charger un fichier de configuration existant qui se trouve sur l’appareil, vous utilisez la commande du load mode de configuration :
[edit] user@host# load (factory-default | merge | override | patch | replace | set | update) filename <relative> <json>
Pour charger une configuration à partir du terminal, vous utilisez la version suivante de la load commande de mode de configuration. Appuyez sur Ctrl-d pour terminer la saisie.
[edit] user@host# load (factory-default | merge | override | patch | replace | set | update) terminal <relative> <json>
Pour remplacer l’intégralité d’une configuration, vous devez spécifier l’option à n’importe override quel niveau de la hiérarchie. Une load override opération remplace complètement la configuration candidate actuelle par le fichier que vous chargez. Ainsi, si vous avez enregistré une configuration complète, vous utilisez cette option.
Une override opération ignore la configuration candidate actuelle et charge la configuration dans filename laquelle vous tapez au niveau du terminal. Lorsque vous utilisez l’option override et validez la configuration, tous les processus système analysent la configuration.
Pour remplacer des parties d’une configuration, vous devez spécifier l’option replace . L’opération load replace recherche les replace: balises que vous avez ajoutées au fichier chargé. L’opération remplace ensuite ces parties de la configuration candidate par ce qui est spécifié après la balise. Ceci est utile lorsque vous souhaitez avoir plus de contrôle sur ce qui est modifié. Pour que cette opération fonctionne, vous devez inclure replace: des balises dans le fichier ou la configuration que vous tapez sur le terminal. Le logiciel recherche les balises, supprime les instructions existantes du même nom, le cas échéant, et les replace: remplace par la configuration entrante. S’il n’existe pas d’instruction du même nom, l’opération replace ajoute à la configuration les instructions marquées de la replace: balise.
Si, dans une override opération ou merge, vous spécifiez un fichier ou tapez du texte contenant replace: des balises, celles-ci replace: sont ignorées. Dans ce scénario, l’opération override ou merge est prioritaire et est exécutée.
Si vous effectuez une replace opération et que le fichier que vous spécifiez n’a pas de replace: balises, replace l’opération s’exécute en tant qu’opération merge. L’opération replace s’exécute également en tant qu’opération si le texte que vous tapez n’a merge pas de replace: balises. Ces informations peuvent être utiles si vous exécutez des scripts automatisés et que vous ne pouvez pas savoir à l’avance s’ils doivent effectuer une replace opération ou une merge opération. Les scripts peuvent utiliser l’opération pour couvrir l’un ou l’autre replace cas.
L’opération load merge fusionne la configuration du fichier ou du terminal enregistré avec la configuration candidate existante. Ces informations sont utiles si vous ajoutez de nouvelles sections de configuration. Par exemple, supposons que vous ajoutiez une configuration BGP au niveau de la [edit protocols] hiérarchie, alors qu’il n’y en avait pas auparavant. Vous pouvez utiliser l’opération load merge pour combiner la configuration entrante avec la configuration candidate existante. Si la configuration existante et la configuration entrante contiennent des instructions contradictoires, les instructions de la configuration entrante remplacent celles de la configuration existante.
Pour remplacer uniquement les parties de la configuration qui ont été modifiées, vous spécifiez l’option à n’importe update quel niveau de la hiérarchie. L’opération load update compare la configuration candidate et les nouvelles données de configuration. Cette opération modifie uniquement les parties de la configuration candidate qui sont différentes de la nouvelle configuration. Vous pouvez utiliser cette opération, par exemple, s’il existe une configuration BGP existante et que le fichier que vous chargez la modifie d’une manière ou d’une autre.
Les options merge, override, et update prennent en charge le chargement des données de configuration au format JSON (JavaScript Object Notation). Lorsque vous chargez des données de configuration qui utilisent le format JSON, vous devez spécifier l’option json dans la commande. Pour charger des données de configuration JSON contenant des entrées de liste non ordonnées, c’est-à-dire des entrées de liste dont la clé de liste n’est pas nécessairement le premier élément de l’entrée de liste, reportez-vous à la section Charger des données de configuration JSON avec des entrées de liste non ordonnées.
Pour modifier une partie de la configuration à l’aide d’un fichier de correctif, vous devez spécifier l’option patch . L’opération load patch charge une entrée de fichier ou de terminal qui contient des modifications de configuration. Tout d’abord, sur un appareil qui a déjà les modifications de configuration, vous tapez la show | compare commande pour afficher les différences entre deux configurations. Ensuite, vous pouvez charger les différences sur un autre appareil. L’avantage de la load patch commande est qu’elle vous évite d’avoir à copier des extraits de différents niveaux hiérarchiques dans un fichier texte avant de les charger dans l’équipement cible. Cela peut être un gain de temps utile si vous configurez plusieurs appareils avec les mêmes options. Par exemple, supposons que vous configuriez une stratégie de routage sur le routeur1 et que vous souhaitiez répliquer la configuration de la stratégie sur le routeur2, le routeur3 et le routeur4. Vous pouvez utiliser l’opération load patch .
Dans cet exemple, vous allez d’abord exécuter la show | compare commande.
Exemple :
user@router1# show | compare rollback 3
[edit protocols ospf]
+ export default-static;
- export static-default
[edit policy-options]
+ policy-statement default-static {
+ from protocol static;
+ then accept;
+ }En continuant cet exemple, vous copiez la sortie de la show | compare commande dans le presse-papiers, en veillant à inclure les niveaux hiérarchiques. Sur les routeurs 2, 3 et 4, vous tapez load patch terminal et collez la sortie. Vous appuyez ensuite sur Entrée et appuyez sur Ctrl-d pour terminer l’opération. Si l’entrée patch spécifie des valeurs différentes pour une instruction existante, l’entrée patch remplace l’instruction existante.
Pour utiliser l’option merge, replace, set ou update sans spécifier le niveau hiérarchique complet, vous devez spécifier l’optionrelative. Cette option charge la configuration entrante par rapport à votre point de montage actuel dans la hiérarchie de configuration.
Exemple :
[edit system]
user@host# show static-host-mapping
bob sysid 987.654.321ab
[edit system]
user@host# load replace terminal relative
[Type ^D at a new line to end input]
replace: static-host-mapping {
bob sysid 0123.456.789bc;
}
load complete
[edit system]
user@host# show static-host-mapping
bob sysid 0123.456.789bc;
Pour charger une configuration contenant set des commandes de mode de configuration, spécifiez l’option set . Cette option exécute les instructions de configuration ligne par ligne au fur et à mesure qu’elles sont stockées dans un fichier ou à partir d’un terminal. Les instructions peuvent contenir n’importe quelle commande de mode de configuration, telle que set, edit, exitet top.
Pour copier un fichier de configuration d’un autre système réseau vers le routeur local, vous pouvez utiliser les utilitaires SSH et Telnet, comme décrit dans l’Explorateur CLI.
Si vous travaillez dans un environnement Critères communs, des messages de journal système sont créés chaque fois qu’un secret attribut est modifié (par exemple, un changement de mot de passe ou une modification du secret partagé RADIUS). Ces modifications sont consignées lors des opérations de chargement de configuration suivantes :
load merge load replace load override load update
Fonctionnement de l’encodage de caractères sur les équipements Juniper Networks
Les données de configuration et la sortie des commandes opérationnelles de Junos OS peuvent contenir des caractères non-ASCII, qui ne font pas partie du jeu de caractères ASCII 7 bits. Lors de l’affichage de données opérationnelles ou de configuration dans certains formats ou au sein d’un certain type de session, le logiciel échappe et encode ces caractères. Le logiciel échappe ou encode les caractères à l’aide de la référence de caractères décimaux UTF-8 équivalente.
L’interface de ligne de commande tente d’afficher tous les caractères non-ASCII dans les données de configuration produites au format texte, ensemble ou JSON. L’interface de ligne de commande tente également d’afficher ces caractères dans la sortie de commande produite au format texte. Dans les cas exceptionnels, l’interface de ligne de commande affiche la référence de caractères décimaux UTF-8 à la place. (Les cas exceptionnels incluent les données de configuration au format XML et la sortie de commande au format XML ou JSON,) Dans les sessions de protocoles NETCONF et Junos XML, un résultat similaire s’affiche si vous demandez des données de configuration ou une sortie de commande contenant des caractères non ASCII. Dans ce cas, le serveur renvoie la référence de caractères décimaux UTF-8 équivalente pour ces caractères pour tous les formats.
Par exemple, supposons que le compte utilisateur suivant, qui contient la lettre minuscule latine n avec un tilde (ñ), soit configuré sur l’appareil.
[edit] user@host# set system login user mariap class super-user uid 2007 full-name "Maria Peña"
Lorsque vous affichez la configuration résultante au format texte, l’interface de ligne de commande imprime le caractère correspondant.
[edit] user@host# show system login user mariap full-name "Maria Peña"; uid 2007; class super-user;
Lorsque vous affichez la configuration résultante au format XML dans l’interface de ligne de commande, le caractère ñ correspond à sa référence ñde caractère décimal UTF-8 équivalente. Le même résultat se produit si vous affichez la configuration dans n’importe quel format dans une session de protocole NETCONF ou Junos XML.
[edit]
user@host# show system login user mariap | display xml
<rpc-reply xmlns:junos="http://xml.juniper.net/junos/17.2R1/junos">
<configuration junos:changed-seconds="1494033077" junos:changed-localtime="2017-05-05 18:11:17 PDT">
<system>
<login>
<user>
<name>mariap</name>
<full-name>Maria Peña</full-name>
<uid>2007</uid>
<class>super-user</class>
</user>
</login>
</system>
</configuration>
<cli>
<banner>[edit]</banner>
</cli>
</rpc-reply>
Lorsque vous chargez des données de configuration sur un périphérique, vous pouvez charger des caractères non-ASCII à l’aide de leurs références de caractères décimaux UTF-8 équivalentes.
A propos de la spécification d’instructions et d’identificateurs
Cette rubrique fournit des détails sur les instructions de conteneur CLI et les instructions leaf afin que vous sachiez comment les spécifier lors de la création de fichiers de configuration ASCII. Cette rubrique décrit également comment l’interface de ligne de commande effectue une vérification de type pour vérifier que les données que vous avez saisies sont au format correct.
Spécification d’instructions
Les instructions sont affichées de deux manières, soit avec des accolades ({ }), soit sans :
-
Nom et identificateur de l’instruction, avec une ou plusieurs instructions de niveau inférieur entre accolades :
statement-name1 identifier-name { statement-name2; additional-statements; } -
Nom de l’instruction, identificateur et un identificateur unique :
statement-name identifier-name1 identifier-name2;
Le statement-name est le nom de l’instruction. Il identifier-name s’agit d’un nom ou d’une autre chaîne qui identifie de manière unique une instance d’une instruction. Vous utilisez un identificateur lorsqu’une instruction peut être spécifiée plus d’une fois dans une configuration.
Lorsque vous spécifiez une instruction, vous devez spécifier un nom d’instruction, un nom d’identificateur ou les deux, en fonction de la hiérarchie des instructions.
Vous spécifiez les identificateurs de l’une des manières suivantes :
-
identifier-name—Il identifier-name s’agit d’un mot-clé utilisé pour identifier de manière unique une instruction lorsqu’une instruction peut être spécifiée plusieurs fois dans une instruction.
-
identifier-name value—The identifier-name est un mot-clé, et le est value une variable d’option obligatoire.
-
identifier-name [value1 value2 value3
...]—Le identifier-name est un mot-clé qui accepte plusieurs valeurs. Les crochets sont obligatoires lorsque vous spécifiez un ensemble de valeurs ; Toutefois, elles sont facultatives lorsque vous ne spécifiez qu’une seule valeur.
Les exemples suivants illustrent la façon dont les instructions et les identificateurs sont spécifiés dans la configuration :
protocol { # Top-level statement (statement-name).
ospf { # Statement under "protocol" (statement-name).
area 0.0.0.0 { # OSPF area "0.0.0.0" (statement-name identifier-name),
interface so-0/0/0 { # which contains an interface named "so-0/0/0."
hello-interval 25; # Identifier and value (identifier-name value).
priority 2; # Identifier and value (identifier-name value).
disable; # Flag identifier (identifier-name).
}
interface so-0/0/1; # Another instance of "interface," named so-0/0/1,
} # this instance contains no data, so no braces
} # are displayed.
}
policy-options { # Top-level statement (statement-name).
term term1 { # Statement under "policy-options"
# (statement-name value).
from { # Statement under "term" (statement-name).
route-filter 10.0.0.0/8 orlonger reject; # One identifier ("route-filter") with
route-filter 127.0.0.0/8 orlonger reject; # multiple values.
route-filter 128.0.0.0/16 orlonger reject;
route-filter 149.20.64.0/24 orlonger reject;
route-filter 172.16.0.0/12 orlonger reject;
route-filter 191.255.0.0/16 orlonger reject;
}
then { # Statement under "term" (statement-name).
next term; # Identifier (identifier-name).
}
}
}
Lorsque vous créez un fichier de configuration ASCII, vous spécifiez des instructions et des identificateurs. Chaque instruction a un style préféré, et l’interface de ligne de commande utilise ce style lors de l’affichage de la configuration en réponse à une commande de mode show de configuration. Vous pouvez spécifier des instructions et des identificateurs de l’une des manières suivantes :
-
Énoncé suivi d’identifiants :
statement-name identifier-name [...] identifier-name value [...];
-
Instruction suivie d’identificateurs entre accolades :
statement-name { identifier-name; [...] identifier-name value; [...] } -
Pour certains identificateurs répétitifs, vous pouvez utiliser un ensemble d’accolades pour toutes les instructions :
statement-name { identifier-name value1; identifier-name value2; }
Vérification du type CLI
Lorsque vous spécifiez des identificateurs et des valeurs, l’interface de ligne de commande effectue une vérification de type pour vérifier que les données que vous avez saisies sont au format correct. Par exemple, pour une instruction dans laquelle vous devez spécifier une adresse IP, l’interface de ligne de commande exige que vous saisissiez une adresse dans un format valide. Sinon, un message d’erreur indique ce que vous devez taper. répertorie les types de données vérifiés par la CLI. Les types d’entrée de configuration CLI sont les suivants :
|
Type de données |
Format |
Exemples |
|---|---|---|
|
Nom de l’interface physique (utilisé dans la hiérarchie [ |
|
Correct: Incorrect: |
|
Nom complet de l’interface |
|
Correct: Incorrect: |
|
Nom d’interface complet ou abrégé (utilisé dans des endroits autres que la hiérarchie [ |
|
Correct: |
|
Adresse IP |
|
Correct: Sample translations:
|
|
Adresse IP (préfixe de destination) et longueur du préfixe |
|
Correct: Sample translations:
|
|
Adresse de l’Organisation internationale de normalisation (ISO) |
|
Correct: Sample translations:
|
|
Identificateur de zone OSPF (ID) |
|
Correct: Sample translations:
|
A propos du chargement d’une configuration à partir d’un fichier
Les exemples suivants illustrent le processus de chargement d’une configuration à partir d’un fichier.
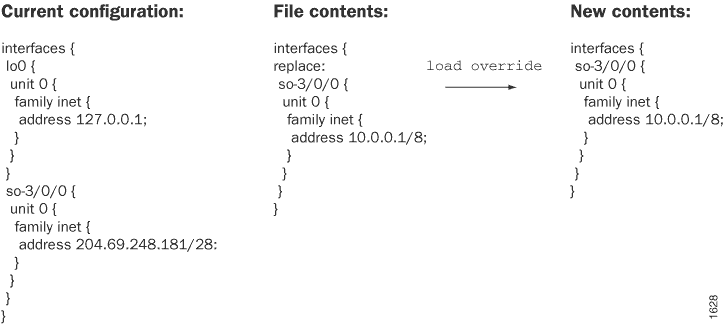
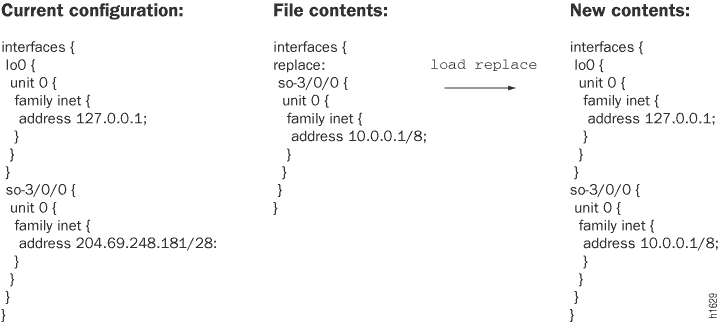
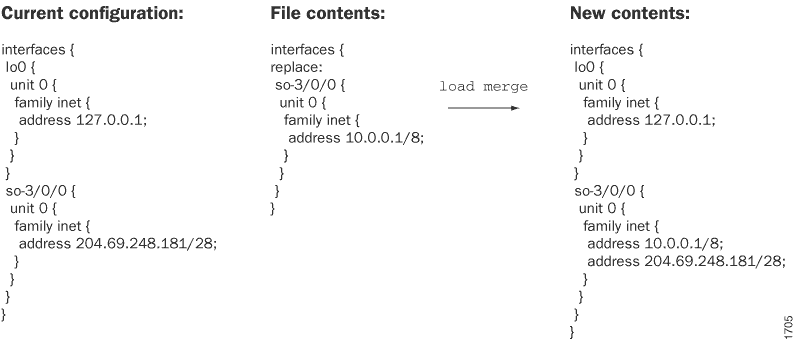


Chargement d’un fichier de configuration
Vous pouvez créer un fichier de configuration sur votre système local, copier le fichier sur l’appareil, puis charger le fichier dans l’interface de ligne de commande. Une fois que vous avez chargé le fichier de configuration, vous pouvez le valider pour activer la configuration sur l’appareil. Vous pouvez également modifier la configuration de manière interactive à l’aide de la CLI et la valider ultérieurement.
Pour télécharger un fichier de configuration à partir de votre système local :
Pour afficher les résultats des étapes de configuration avant de valider la configuration, tapez la show commande à l’invite de l’utilisateur.
Pour valider ces modifications dans la configuration active, tapez la commit commande à l’invite de l’utilisateur. Vous pouvez également modifier la configuration de manière interactive à l’aide de la CLI et la valider ultérieurement.
Charger des données de configuration JSON avec des entrées de liste non ordonnées
Le schéma Junos définit certains objets de configuration sous forme de listes. Dans les données de configuration JSON, une instance de liste est codée sous la forme d’une paire nom/tableau, et les éléments du tableau sont des objets JSON. En règle générale, l’ordre des membres dans une entrée de liste codée en JSON est arbitraire, car les objets JSON sont des collections de membres fondamentalement non ordonnées. Toutefois, le schéma Junos exige que les clés de liste précèdent toutes les autres branches d’une entrée de liste et apparaissent dans l’ordre spécifié par le schéma.
Par exemple, l’objet user au niveau de la [edit system login] hiérarchie est une liste où name est la clé de liste qui identifie de manière unique chaque utilisateur.
list user {
key name;
description "Username";
uses login-user-object;
}Dans l’exemple de données de configuration suivant, la clé de liste (name) est le premier élément pour chaque utilisateur. Par défaut, lorsque vous chargez des données de configuration JSON, les équipements Junos exigent que les clés de liste précèdent toutes les autres branches d’une entrée de liste et apparaissent dans l’ordre spécifié par le schéma.
{
"configuration" : {
"system" : {
"login" : {
"user" : [
{
"name" : "operator",
"class" : "operator",
"uid" : 3001
},
{
"name" : "security-admin",
"class" : "super-user",
"uid" : 3002
}
]
}
}
}
}Les équipements Junos proposent deux options pour charger des données de configuration JSON contenant des entrées de liste non ordonnées, c’est-à-dire des entrées de liste dont la clé de liste n’est pas nécessairement le premier élément.
-
Utilisez la
request system convert-json-configurationcommande mode opérationnel pour produire des données de configuration JSON avec des entrées de liste ordonnées avant de charger les données sur l’appareil. -
Configurez l’instruction
reorder-list-keysau niveau de la[edit system configuration input format json]hiérarchie. Une fois que vous avez configuré l’instruction, vous pouvez charger les données de configuration JSON avec des entrées de liste non ordonnées, et l’appareil réorganise les clés de liste comme requis par le schéma Junos pendant l’opération de chargement.
Lorsque vous configurez l’instruction, l’analyse reorder-list-keys de la configuration peut prendre beaucoup plus de temps, en fonction de la taille de la configuration et du nombre de listes. Ainsi, pour les configurations volumineuses ou les configurations comportant de nombreuses listes, nous vous recommandons d’utiliser la request system convert-json-configuration commande au lieu de l’instruction reorder-list-keys .
Par exemple, supposons que le user-data.json fichier contienne la configuration JSON suivante. Si vous essayiez de charger la configuration, l’appareil émettrait une erreur de chargement car la clé name de liste n’est pas le premier élément de cette entrée de admin2 liste.
user@host> file show /var/tmp/user-data.json
{
"configuration" : {
"system" : {
"login" : {
"user" : [
{
"name" : "admin1",
"class" : "super-user",
"uid" : 3003
},
{
"class" : "super-user",
"name" : "admin2",
"uid" : 3004
}
]
}
}
}
}Si vous utilisez la commande avec le fichier précédent en entrée, la request system convert-json-configuration commande génère le fichier de sortie spécifié avec les données de configuration JSON que le périphérique Junos peut analyser pendant l’opération de chargement.
user@host> request system convert-json-configuration /var/tmp/user-data.json output-filename user-data-ordered.json
user@host> file show user-data-ordered.json
{
"configuration":{
"system":{
"login":{
"user":[
{
"name":"admin1",
"class":"super-user",
"uid":3003
},
{
"name":"admin2",
"class":"super-user",
"uid":3004
}
]
}
}
}
}Vous pouvez également configurer l’instruction de reorder-list-keys configuration.
user@host# set system configuration input format json reorder-list-keys user@host# commit
Une fois que vous avez configuré l’instruction, vous pouvez charger le fichier de configuration JSON d’origine avec des entrées de liste non ordonnées, et l’appareil gère les entrées de liste lorsqu’il analyse la configuration.
user@host# load merge json /var/tmp/user-data.json load complete