Fundamentos de Kubernetes
Este capítulo presenta Kubernetes, así como los términos básicos, los conceptos clave y la mayoría de los componentes a los que se hace referencia con frecuencia en Kubernetes Architecture. En este capítulo también se proporcionan algunos ejemplos en un entorno de clúster Kubernetes para mostrar las ideas clave acerca de los objetos de Kubernetes básicos.
¿Qué es Kubernetes?
Puede encontrar la definición oficial de Kubernetes aquí (https://kubernetes.io/):
“Kubernetes (K8s) es un sistema de código abierto para automatizar la implementación, el escalado y la administración de aplicaciones contenedoras. Agrupa los contenedores que componen una aplicación en unidades lógicas para facilitar su administración y descubrimiento. Kubernetes se basa en 15 años de experiencia en la ejecución de cargas de trabajo de producción en Google, en combinación con las mejores ideas y prácticas de la comunidad.”
Estos son algunos hechos importantes sobre Kubernetes:
Es’un proyecto de código abierto Iniciado por Google
TI’es un producto maduro y estable
’S una herramienta de orquestación
Es’una plataforma que trata con los contenedores en un nivel superior
Kubernetes fue creado por un grupo de ingenieros en Google en el 2014, con un modelo de diseño y desarrollo influido por el sistema interno de Google’s, Borg. Kubernetes define un conjunto de objetos de creación que proporcionan de forma colectiva mecanismos que organizan aplicaciones contenedoras a través de un clúster distribuido de nodos, basándose en los recursos del sistema (CPU, memoria u otras métricas personalizadas). Kubernetes simplifica la complejidad de la administración de un grupo de contenedores al proporcionar API de REST para las funciones requeridas.
En términos sencillos, las tecnologías de contenedor como Docker le proporcionan la capacidad de empaquetar y distribuir aplicaciones contenedoras, mientras que un sistema de orquestación como Kubernetes permite implementar y administrar los contenedores a un nivel relativamente más alto. y de una manera mucho más fácil.
Muchos documentos de Kubernetes suelen abreviar la tecnología como K8S (o K-ocho caracteres-S) y la versión principal actual (en la redacción de este libro) es v 1.14.
El capítulo 1 declaró que el acoplador es una tecnología de contenedor predominante y madura, ¿por qué necesita Kubernetes? Técnicamente hablando, Kubernetes funciona a un nivel relativamente superior que los acopladores, así que ¿qué significa exactamente?
Bueno, al comparar Kubernetes con Docker, una analogía útil es comparar Python con el lenguaje C. C es lo suficientemente potente para compilar casi todo, incluido un conjunto de API y componentes fundamentales del sistema operativo, pero en la práctica probablemente preferirá escribir secuencias de comandos para automatizar tareas en su carga de trabajo, lo que significa que el uso de Python es mucho más que si se utiliza C. Con Python solo debe considerar qué módulo existente proporciona las funciones necesarias, importarlo en su aplicación y, a continuación, centrarse rápidamente en cómo usar la característica para llevar a cabo lo que necesita. Rara vez es necesario preocuparse de las llamadas API del sistema de bajo nivel y los detalles del hardware.
Una analogía de la red son los protocolos de Internet de TCP/IP. Cuando desarrolle una herramienta de transferencia de archivos como FTP, naturalmente, prefiere iniciar el trabajo de acuerdo con un socket TCP en lugar de con un socket sin procesar. Con el socket TCP se encuentra en la parte superior del protocolo TCP, lo que proporciona una base mucho más sólida que incluye todas las características de confiabilidad integradas, como detección de errores, control de flujo y congestión, retransmisión, etc. Lo que debe tener en cuenta es cómo entregar los datos desde un extremo y recibirlos en el otro extremo. Con un socket sin formato, se trabaja en el protocolo IP y en una capa más baja, por lo que es necesario tener en cuenta e implementar todas las características de confiabilidad antes de poder empezar a trabajar en las características de transferencia de archivos de la herramienta.
Por lo tanto, de nuevo a Kubernetes. Suponiendo que desea ejecutar varios contenedores en varios equipos, tendrá que hacer mucho trabajo si interactúa con el acoplador directamente. Las tareas siguientes deben estar, al menos mínima, en la lista de aspectos de los que hay que preocuparse:
Loging en equipos diferentes, y la creación de contenedores, a través de la red
Escalar hacia arriba o hacia abajo cuando se realicen cambios de demanda agregando o quitando contenedores
Mantener el almacenamiento de información coherente con varias instancias de una aplicación
Distribución de la carga entre los contenedores que se ejecutan en distintos nodos
Inicio de contenedores nuevos en equipos diferentes si algo no funciona
Comprobará rápidamente que realizar todas estas operaciones de forma manual con Docker será abrumador. Con las abstracciones de alto nivel y los objetos que las representan en la API Kubernetes, todas estas tareas serán mucho más sencillas.
Kubernetes no es la única herramienta de este tipo, Docker tiene su propia herramienta de orquestación denominada Swarm. Pero eso’es una explicación para otro libro. Este libro se centra en Kubernetes.
Arquitectura y componentes de Kubernetes
Hay dos tipos de nodos en un clúster de Kubernetes y cada uno de ellos ejecuta un conjunto bien definido de procesos:
Nodo principal: también llamados nodo maestro o maestro, son el cabezal y el cerebro que realiza todo el pensamiento y toma todas estas decisiones; Aquí se encuentra toda la inteligencia.
Nodo de trabajo: llamado también nodo o Minion,’las manos y los pies que llevan a cabo la mano de obra.
Los nodos son controlados por el maestro y, en la mayoría de los casos, solo necesita hablar con el maestro.
Una de las interfaces más comunes entre usted y el clúster es la herramienta de línea de comandos kubectl. Se instala como una aplicación cliente, ya sea en el mismo nodo maestro o en un equipo independiente, como en su PC. Independientemente de dónde se esté, puede comunicarse con el maestro a través de la API de REST que expone el maestro.
Más adelante en este libro puede ver un ejemplo de uso de kubectl para crear objetos Kubernetes. Por ahora, solo tiene que recordar, siempre que trabaje con el comando kubectl,’se esté comunicando con’el maestro de clústeres.
El término "nodo" puede ser ambiguo – semánticamente puede significar dos cosas en el contexto de este libro. Normalmente, un nodo se refiere a una unidad lógica de un clúster, como un servidor, que puede ser física o virtual. En el contexto de los clústeres de Kubernetes, un nodo suele hacer referencia específicamente a un nodo de trabajo.
Rara vez es necesario eludir el maestro y trabajar con los nodos, pero puede iniciar sesión en un nodo y ejecutar todos los comandos del acoplador para comprobar el estado de la ejecución de los contenedores. Un ejemplo de esto aparece más adelante en este capítulo.
Máster Kubernetes
Un nodo maestro de Kubernetes, o patrón, es el cerebro. El maestro de clúster proporciona el plano de control que toma todas las decisiones globales sobre el clúster. Por ejemplo, cuando necesite que el clúster genere un contenedor, el maestro decidirá qué nodo distribuirá la tarea e iniciará un nuevo contenedor. Este procedimiento se denomina programación.
El maestro es responsable de mantener el estado deseado para el clúster. Cuando asigne un pedido para este servidor Web, asegúrese de que siempre hay dos contenedores entre sí. El maestro supervisa el estado de ejecución y genera un nuevo contenedor cada vez que se ejecutan menos de dos contenedores de servidor web debido a errores.
Normalmente sólo necesita un único nodo maestro en el clúster, aunque también es posible replicarlo para obtener una mayor disponibilidad y redundancia. Una colección’de procesos que se ejecutan en el nodo maestro implementa las funciones de maestro s:
kube-apiserver: Es el front-end del plano de control y proporciona API de REST.kube-scheduler: Realiza la programación y decide dónde colocar los contenedores según el quirements del sistema (CPU, memoria, almacenamiento, etc.) y otros parámetros o restricciones personalizados (p. ej., especificaciones de afinidad).kube-controller-manager: El único proceso que controla la mayoría de los distintos tipos de controladora, lo que garantiza que el estado del sistema será el que debería ser. Los ejemplos de controladores pueden ser:Controladora de duplicación
ReplicaSet
Implementación
Controlador de servicio
etcd: Base de datos en la que se almacena el estado del sistema.
En aras de la simplicidad, algunos componentes no se enumeran (p. ej., el administrador de la nube, el servidor DNS, kubelet). No son componentes triviales ni escasos, pero omitirlos ahora nos ayuda a superar los conceptos básicos de Kubernetes.
Nodo Kubernetes
Los nodos Kubernetes de un clúster son los equipos que ejecutan las aplicaciones de usuario final. En los entornos de producción, puede haber decenas o centenares de nodos en un clúster, dependiendo de las escalas diseñadas mientras funcionan con el capó que proporciona un clúster. Por lo general, todos los contenedores y cargas de trabajo se ejecutan en nodos. Un nodo ejecuta los siguientes procesos:
Kubelet: El proceso del agente de Kubernetes que se ejecuta en el maestro y en todos los nodos. Interactúa con el maestro (a través del proceso Kube-apiserver) y administra los contenedores en el host local.
Kube-proxy: Este proceso implementa el servicio Kubernetes (que se presentó en el capítulo 3) mediante Linux iptable en el nodo.
Contenedor-tiempo de ejecución: O el contenedor – local principalmente acoplador en el’mercado de hoy, que mantiene todas las aplicaciones de Dockerized en ejecución.
El término proxy puede parecer confuso para los principiantes de Kubernetes’, ya que no es realmente un proxy en la arquitectura de Kubernetes actual. Kube-proxy es un sistema que manipula tablas IP de Linux en el nodo para que el tráfico entre los pods y los nodos fluya correctamente.
Flujo de trabajo Kubernetes
Hasta ahora,’ha leído información acerca del maestro y el nodo, y los principales procesos que se ejecutan en cada uno de ellos. Ahora es’hora de ver cómo funcionan los elementos juntos, como se muestra en la Figure 1.
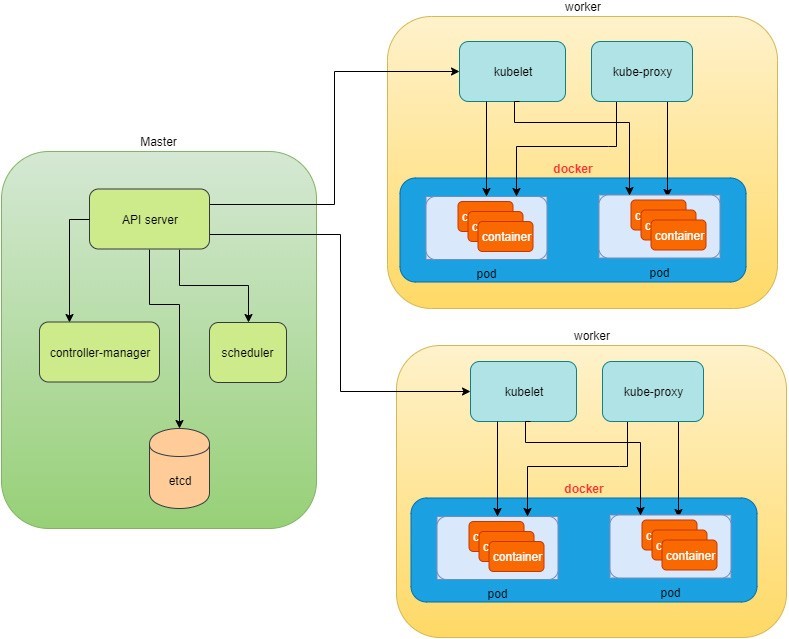
En la parte superior de la Figure 1, a través de kubectl comandos, se comunica con el maestro Kubernetes, que administra los dos cuadros de nodo a la derecha. Kubectl interactúa con el proceso principal Kube-apiserver a través de la API de REST que está expuesta al usuario y otros procesos del sistema.
Deje’que s envíe algunos comandos – kubectl algo parecido kubectl create x, para generar un nuevo contenedor. Puede proporcionar detalles sobre el contenedor que se va a generar junto con sus comportamientos de ejecución, y estas especificaciones pueden proporcionarse como kubectl parámetros de línea de comandos, u opciones y valores definidos en un archivo de configuración (en breve, aparece un ejemplo). El flujo de trabajo sería:
El cliente kubectlprimero traducirá su comando de CLI a una o más llamadas Rest API y lo enviará a Kube-apiserver.
Después de validar estas llamadas a API REST, Kube-apiserver entiende la tarea y llama al proceso Kube-programador para seleccionar un nodo de entre los disponibles para ejecutar el trabajo. Este es el procedimiento de programación.
Una vez que Kube-Scheduler devuelva el nodo de destino, Kube-apiserver lo enviará con todos los detalles que describen la tarea.
El proceso kubelet del nodo de destino recibe la tarea y se comunica con el motor de contenedor, por ejemplo, el motor de acoplamiento de la Figure 1, para generar un contenedor con todos los parámetros proporcionados.
Este trabajo y sus especificaciones se grabarán en una base de datos centralizada etcd. Su trabajo consiste en conservar y proporcionar acceso a todos los datos del clúster.
En realidad, un Master también puede ser un nodo de alta funcionalidad y transportar a los trabajadores de los pods igual que un nodo. Por lo tanto, los componentes proxy de kubelet y Kube existentes en node también pueden existir en el Master. En la Figure 1,’no incluimos estos componentes en el patrón para proporcionar una separación conceptual simplificada del maestro y del nodo. En su instalación puede utilizar el comando kubectl get pods --all-namespaces
-o wide para enumerar todos los pods con su ubicación. Los pods generados en el Master se ejecutan normalmente como parte del propio – sistema Kubernetes, normalmente dentro de un espacio de nombres del sistema Kube. El espacio de nombres Kubernetes se explica en el capítulo 3.
Evidentemente, esto es un flujo de trabajo simplificado, pero debe obtener la idea básica. De hecho, con la potencia de Kubernetes, rara vez es necesario trabajar directamente con contenedores. Trabaja con objetos de mayor nivel que tienden a ocultar la mayoría de los detalles de las operaciones de bajo nivel.
Por ejemplo, en la Figure 1 , cuando se da la tarea de generar contenedores, en vez de decir lo siguiente: cree dos contenedores y asegúrese de generar otros nuevos si falla alguno, en la práctica, debe decir: Cree un objeto RC (controlador de replicación) con la réplica dos.
Una vez que los dos contenedores de acoplamiento estén funcionando, kubeapiserver interactuará con Kube-Controller-Manager para seguir supervisando el estado del trabajo y tomar todas las medidas necesarias para asegurarse de que el estado de ejecución sea como se definió. Por ejemplo, si alguno de los contenedores del acoplador funciona, se generará automáticamente un nuevo contenedor y se quitará el dañado.
El RC de este ejemplo es uno de los objetos que proporciona el proceso de Kubernetes Kube-Controller-Manager. Los objetos Kubernetes proporcionan una capa de abstracción adicional que recibe el mismo trabajo (y normalmente más) bajo el capó, de una manera más sencilla y limpia. Y dado que trabaja en un nivel superior y se mantiene lejos de los detalles de bajo nivel, los objetos de Kubernetes reducen claramente su tiempo de implementación general, el esfuerzo de los cerebros y la solución de problemas. Let’-s examine.
Objetos Kubernetes
Ahora que ya conoce la función de Master y del nodo en un clúster Kubernetes, y que comprende el modelo de flujo de trabajo’en Kubernetes Architecture, deje que vea más objetos en la arquitectura Kubernetes.
Los’objetos Kubernetes s representan:
Cargas de trabajo y aplicaciones de contenedor implementadas
Sus recursos de red y disco asociados
Otra información acerca de lo que está haciendo el clúster.
Los objetos utilizados con más frecuencia son:
Caja
Vida
Montaje
Cryptography
Los objetos de nivel superior (controladores) son:
ReplicationController
ReplicaSet
Implementación
StatefulSet
DaemonSet
Función
Los objetos de alto nivel se construyen sobre los objetos básicos, lo que proporciona funciones adicionales de funcionalidad y conveniencia.
En el front end, Kubernetes hace cosas a través de un grupo de objetos, por lo que con Kubernetes solo debe pensar en cómo describir su tarea en el archivo de configuración de los objetos,’no tendrá que preocuparse de cómo se implementará en el nivel de contenedor. De acuerdo con el capó, Kubernetes interactúa con el motor de contenedor para coordinar la programación y ejecución de los contenedores en Kubelets. El propio motor de contenedor es responsable de ejecutar la imagen de contenedor real (por ejemplo, una compilación de Docker).
Existen más ejemplos acerca de cada objeto y su potencia mágica en el capítulo 3. Primero, echemos’un vistazo al objeto más fundamental: caja.
Creación de un conjunto pod de Kubernetes
Pod es el primer objeto Kubernetes que aprenderá. El sitio web Kubernetes describe un conjunto Pod como el siguiente:
Una caja Pod (como Pod of ballenas o PEA POD) es un grupo de uno o varios contenedores (como contenedores de acoplamiento), con almacenamiento/red compartida, y una especificación de cómo ejecutar los contenedores.
Efectos
Pod es esencialmente un grupo de contenedores.
Todos los contenedores de una Pod comparten recursos de red y almacenamiento.
Por lo’tanto, ¿cuál es la ventaja de utilizar Pod en comparación con la antigua forma de tratar con cada contenedor individual? ’Consideremos un caso de uso simple: está implementando un servicio Web con un acoplador y no solo necesita el servicio front-end, por ejemplo un servidor Apache, sino también algunos servicios de soporte, como un servidor de base de datos, un servidor de registro, un servidor de supervisión, etc. Cada uno de estos servicios de soporte debe estar en ejecución en su propio contenedor. Por lo tanto, siempre se encuentra trabajando con un grupo de acoplamiento siempre que se necesita un contenedor de servicios Web. En producción, el mismo escenario se aplica también a la mayoría de los otros servicios. Finalmente, usted pregunta: ¿Hay alguna manera de agrupar un montón de contenedores de acoplamiento en una unidad de nivel superior, por lo que solo debe preocuparse una vez los detalles de interacción inter-container de bajo nivel?
Pod proporciona la abstracción de nivel superior exacta necesaria en el envoltorio de uno o más contenedores en un objeto. Si el servicio web es demasiado popular y una sola instancia Pod no’puede llevar la carga, puede replicar y escalar el mismo grupo de contenedores (ahora en forma de un objeto POD), ascendente y descendente, con la ayuda de otros objetos (RC, Deployment) (normalmente en unos segundos). Esto aumenta en gran medida la eficacia de la implementación y mantenimiento.
Además, los contenedores de la misma caja Pod comparten el mismo espacio de red, por lo que los contenedores se pueden comunicar fácilmente con otros contenedores del mismo conjunto de equipos como si estuvieran en el mismo equipo, manteniendo al mismo tiempo un grado de aislamiento de los demás. Más adelante en este libro encontrará más información acerca de estas ventajas.
Ahora, veamos’lo que he húmedo y aprenda cómo usar un archivo de configuración para iniciar un conjunto Pod en un clúster Kubernetes.
Archivo YAML para Kubernetes
Junto con muchas otras muchas formas de configurar Kubernetes, YAML es el formato estándar utilizado en un archivo de configuración Kubernetes. La YAML se utiliza ampliamente, por lo que lo más probable es que ya esté familiarizado con ella. Si no es así’, no es un gran negocio, ya que YAML es un lenguaje bastante fácil de aprender. Cada línea de la configuración YAML de un conjunto Pod se detalla y debe comprender el formato YAML como un derivado del proceso de aprendizaje Pod.
El archivo de configuración Pod en formato YAML es:
YAML utiliza tres tipos de datos básicos:
Scalar (cadenas o números): elemento de datos Atom, cadenas como Pod-1, número de puerto 80.
Asignaciones (algoritmos hash/diccionarios): los pares clave-valor se pueden anidar. apiVersion: V1 es una asignación. la clave apiVersion tiene un valor de v1.
Secuencias (matrices o listas): colección de valores ordenados, sin clave. Los elementos de la lista se indican con un signo. El valor de los contenedores de claves es una lista que incluye dos contenedores.
En este ejemplo, también está viendo YAML estructura de datos anidada:
Asignación de un mapa: Spec es la clave de un mapa, en la que se define’una especificación Pod s. En este ejemplo, sólo se define el comportamiento de los contenedores que se iniciarán en la caja Pod. El valor es otro mapa con la clave que se encuentra en los contenedores.
Asignación de una lista. Los valores de los contenedores de claves son una lista de dos elementos: contenedor de servidor y cliente, cada uno de los cuales de nuevo, son una asignación que describe el contenedor individual con unos cuantos atributos como el nombre, la imagen y los puertos que se van a exponer.
Otras características que debería conocer acerca de YAML:
Distingue mayúsculas de minúsculas
Los elementos del mismo nivel comparten la misma sangría izquierda, la cantidad de sangría no importa
Los caracteres de tabulación no se pueden usar como sangría
Las líneas en blanco no importan
Utilice # para comentar una línea
Utilice una sola comilla ' para omitir el significado especial de cualquier carácter
Antes de profundizar en más detalles sobre el archivo YAML’, deje que s finalice la creación de Pod:
$ kubectl create -f pod-2containers-do-one.yaml pod/pod-1 created $ kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE pod-1 0/2 ContainerCreating 0 18s 10.47.255.237 cent333<none> $ kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE pod-1 2/2 Running 0 18s 10.47.255.237 cent333 <none>
Hay. Hemos creado nuestro primer objeto – Kubernetes un pod denominado Pod-1. Pero, ¿dónde están los contenedores? La salida ofrece las siguientes pistas: se ha iniciado una caja Pod-1 (nombre), que contiene dos contenedores (preparados/2), en el nodo Kubernetes Worker cent333 con una dirección IP asignada de 10.47.255.237. Los dos contenedores de la caja Pod están en funcionamiento (READY 2/) y su estado de ejecución no es 27S sin reiniciar. A’continuación se muestra un breve comentario línea por línea acerca de lo que está haciendo la configuración de YAML:
Línea 1: Esta es una línea de comentario que utiliza # antes del texto, puede colocar cualquier comentario en el archivo YAML (A lo largo de este libro, usamos esta primera línea para asignar un nombre al archivo YAML. El nombre de archivo se utilizará posteriormente en el comando al crear el objeto a partir del archivo YAML.)
Líneas 2, 3, 4, 8: Las cuatro asignaciones YAML son los componentes principales de la definición Pod:
ApiVersion: Hay distintas versiones, por ejemplo, V2. Aquí, específicamente, es la versión 1.
Redondeo Recuerde que hay distintos tipos de objetos Kubernetes, y aquí queremos que Kubernetes crear un objeto Pod. Más adelante, verá el tipo ReplicationController, o servicio, en los ejemplos de otros objetos.
Datos Para identificar los objetos creados. Aparte del nombre del objeto que se va a crear, otros metadatos importantes son las etiquetas. Y leerá más acerca de esto en el capítulo 3.
Spec Esto proporciona la especificación sobre el comportamiento del conjunto Pod.
Líneas 9-15: La especificación Pod se muestra aquí acerca de los dos contenedores. El sistema descarga las imágenes, inicia cada contenedor con un nombre y expone los puertos especificados, respectivamente.
Estos’son’los s que se ejecutan dentro de la caja Pod:
$ kubectl describe pod pod-1 | grep -iC1 container IP: 10.47.255.237 Containers: server: Container ID: docker://9f8032f4fbe2f0d5f161f76b6da6d7560bd3c65e0af5f6e8d3186c6520cb3b7d Image: contrailk8sdayone/contrail-webserver -- client: Container ID: docker://d9d7ffa2083f7baf0becc888797c71ddba78cd951f6724a10c7fec84aefce988 Image: contrailk8sdayone/ubuntu -- Ready True ContainersReady True PodScheduled True -- Normal Pulled 3m2s kubelet, cent333 Successfully pulled image "contrailk8sdayone/contrail-webserver" Normal Created 3m2s kubelet, cent333 Created container Normal Started 3m2s kubelet, cent333 Started container Normal Pulling 3m2s kubelet, cent333 pulling image "contrailk8sdayone/ubuntu" Normal Pulled 3m1s kubelet, cent333 Successfully pulled image "contrailk8sdayone/ubuntu" Normal Created 3m1s kubelet, cent333 Created container Normal Started 3m1s kubelet, cent333 Started container
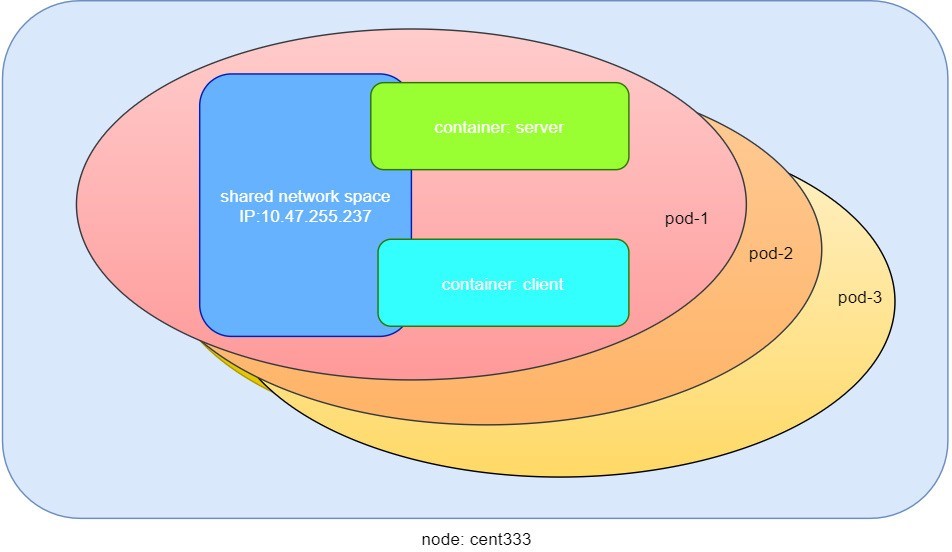
No es sorprendente que la Pod-1 se componga de dos contenedores declarados en el archivo YAML, el servidor y el cliente respectivamente, con una dirección IP asignada por Kubernetes clúster y compartida entre todos los contenedores, tal y como se muestra en la Figure 2:
Pausar contenedor
Si inicia sesión en el nodo cent333, verá’los contenedores de acoplamiento que se ejecutan dentro de la caja Pod:
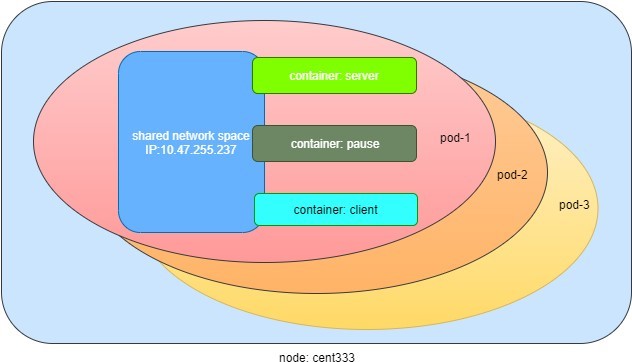
$ docker ps | grep -E "ID|pod-1" CONTAINER ID IMAGE COMMAND ... PORTS NAMES d9d7ffa2083f contrailk8sdayone/ubuntu "/sbin/init" ... k8s_client_pod-1_default_f8b42343-d87a-11e9-9a1e-0050569e6cfc_0 9f8032f4fbe2 contrailk8sdayone/contrail-webserver "python app-dayone.py" ... k8s_server_pod-1_default_f8b42343-d87a-11e9-9a1e-0050569e6cfc_0 969ec6d93683 k8s.gcr.io/pause:3.1 "/pause" ... k8s_POD_pod-1_default_f8b42343-d87a-11e9-9a1e-0050569e6cfc_0
El tercer contenedor con nombre de imagen k8s.gcr.io/pause es un contenedor especial creado para cada conjunto Pod por el sistema Kubernetes. El contenedor pausar se crea para administrar los recursos de red de la caja Pod, que comparten todos los contenedores de dicho conjunto Pod.
La Figure 3 muestra un conjunto Pod que incluye unos cuantos contenedores de usuario y un contenedor pausar.
Comunicación intra-Pod
En el patrón Kubernetes, deje’que inicie sesión en un contenedor del maestro:
#login to pod-1's container client $ kubectl exec -it pod-1 -c client bash root@pod-1:/# #login to pod-1's container server $ kubectl exec -it pod-1 -c server bash root@pod-1:/app-dayone#
Si ha jugado alguna vez con Docker, se dará cuenta inmediatamente de que esto es bastante agradable. Recuerde que los contenedores se iniciaron en uno de los nodos, por lo que si utiliza Docker primero deberá iniciar sesión en el nodo remoto correcto y, a continuación, utilizar un comando similar de dockr Exec para iniciar sesión en cada contenedor. Kubernetes oculta estos detalles. Le permite hacer todo desde un nodo – al maestro.
Y ahora comprueba los procesos que se ejecutan en el contenedor:
Contenedor de servidor
root@pod-1:/app-dayone# ps aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.0 55912 17356 ? Ss 12:18 0:00 python app-dayo root 7 0.5 0.0 138504 17752 ? Sl 12:18 0:05 /usr/bin/python root 10 0.0 0.0 18232 1888 pts/0 Ss 12:34 0:00 bash root 19 0.0 0.0 34412 1444 pts/0 R+ 12:35 0:00 ps aux root@pod-1:/app-dayone# ss -ant State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 128 *:80 *:* LISTEN 0 128 *:22 *:* LISTEN 0 128 :::22 :::* root@pod-1:/app-dayone# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 116: eth0@if117: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:f8:e6:63:7e:d8 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 10.47.255.237/12 scope global eth0 valid_lft forever preferred_lft forever
El contenedor cliente
$ kubectl exec -it pod-1 -c client bash root@pod-1:/# ps aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.0 32716 2088 ? Ss 12:18 0:00 /sbin/init root 41 0.0 0.0 23648 888 ? Ss 12:18 0:00 cron root 47 0.0 0.0 61364 3064 ? Ss 12:18 0:00 /usr/sbin/sshd syslog 111 0.0 0.0 116568 1172 ? Ssl 12:18 0:00 rsyslogd root 217 0.2 0.0 18168 1916 pts/0 Ss 12:45 0:00 bash root 231 0.0 0.0 15560 1144 pts/0 R+ 12:45 0:00 ps aux root@pod-1:/# ss -ant State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 128 *:80 *:* LISTEN 0 128 *:22 *:* LISTEN 0 128 :::22 :::* root@pod-1:/# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 116: eth0@if117: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:f8:e6:63:7e:d8 brd ff:ff:ff:ff:ff:ff inet 10.47.255.237/12 scope global eth0 valid_lft forever preferred_lft forever
Este comando de salida de PS muestra que cada contenedor está ejecutando su propio proceso. Sin embargo, los resultados del comando SS e IP indican que ambos contenedores comparten el mismo entorno de red exacto, por lo que ambos ven el puerto expuesto entre sí. Por lo tanto, la comunicación entre los contenedores de una caja Pod puede producirse simplemente utilizando localhost. ’Para comprobarlo, inicie una conexión TCP con el comando rizo.
Supongamos que desde el contenedor cliente desea obtener una página web desde el contenedor servidor. Puede simplemente iniciar rizo con la dirección IP de localhost:
root@pod-1:/# curl localhost
<html>
<style>
h1 {color:green}
h2 {color:red}
</style>
<div align="center">
<head>
<title>Contrail Pod</title>
</head>
<body>
<h1>Hello</h1><br><h2>This page is served by a <b>Contrail</b> pod</h2><br><h3>IP address = 10.47.255.237<br>Hostname = pod-1</h3>
<img src="/static/giphy.gif">
</body>
</div>
</html>
Puede ver que la conexión está establecida y que la página web se ha descargado correctamente.
A continuación’, permita que s supervise el estado de conexión TCP: la conexión se estableció correctamente:
root@pod-1:/# ss -ant State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 128 *:80 *:* LISTEN 0 128 *:22 *:* TIME-WAIT 0 0 127.0.0.1:80 127.0.0.1:34176 #<--- LISTEN 0 128 :::22 :::*
Y se puede ver la misma conexión exacta desde el contenedor servidor:
$ kubectl exec -it pod-1 -c server bash root@pod-1:/app-dayone# ss -ant State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 128 *:80 *:* LISTEN 0 128 *:22 *:* TIME-WAIT 0 0 127.0.0.1:80 127.0.0.1:34176 #<--- LISTEN 0 128 :::22 :::*
Herramienta Kubectl
Hasta ahora’Ve el objeto creado por el comando kubectl. Este comando, al igual que el comando Docker World, es la interfaz en el mundo Kubernetes para comunicarse con el clúster o, más concretamente, Kubernetes Master, a través de Kubernetes API. Es’una herramienta versátil que ofrece opciones para completar todo tipo de tareas que necesitaría tratar con Kubernetes.
Como ejemplo rápido, suponiendo que haya habilitado la característica de finalización automática para kubectl, puede enumerar todas las opciones compatibles con su entorno actual iniciando sesión en el patrón y escribiendo kubectl, seguido de dos pulsaciones de tecla de tabulación:
root@test1:~# kubectl<TAB><TAB> alpha attach completion create exec logs proxy set wait annotate auth config delete explain options replace taint api-resources autoscale convert describe patch rollout top api-versions certificate drain get plugin run uncordon apply cluster-info cp edit label port-forward scale version expose cordon
Para configurar la finalización automática para el comando kubectl, siga las instrucciones de la opción ayuda-finalización:
finalización de kubectl-h
Si está’seguro, disodos verá y aprende algunas de estas opciones en el resto de este manual.