Auf dieser Seite
BGP – Übersicht
Grundlegendes zu BGP
BGP ist ein externes Gateway-Protokoll (EGP), das zum Austausch von Routing-Informationen zwischen Routern in verschiedenen autonomen Systemen (ASs) verwendet wird. Die BGP-Routing-Informationen umfassen die vollständige Route zu jedem Ziel. BGP verwendet die Routing-Informationen, um eine Datenbank mit Informationen zur Netzwerkerreichbarkeit zu verwalten, die es mit anderen BGP-Systemen austauscht. BGP verwendet die Informationen zur Netzwerkerreichbarkeit, um ein Diagramm der AS-Konnektivität zu erstellen, das es BGP ermöglicht, Routing-Schleifen zu entfernen und Richtlinienentscheidungen auf AS-Ebene durchzusetzen.
Multiprotocol BGP (MBGP)-Erweiterungen ermöglichen BGP die Unterstützung von IP Version 6 (IPv6).MBGP definiert die Attribute MP_REACH_NLRI und MP_UNREACH_NLRI, die zum Übertragen von IPv6-Erreichbarkeitsinformationen verwendet werden. NLRI-Aktualisierungsnachrichten (Network Layer Reachability Information) enthalten IPv6-Adresspräfixe möglicher Routen.
BGP ermöglicht richtlinienbasiertes Routing. Sie können Routing-Richtlinien verwenden, um zwischen mehreren Pfaden zu einem Ziel auszuwählen und die Neuverteilung von Routing-Informationen zu steuern.
BGP verwendet TCP als Transportprotokoll und verwendet Port 179 zum Herstellen von Verbindungen. Durch die Ausführung über ein zuverlässiges Transportprotokoll ist BGP nicht mehr erforderlich, um Updatefragmentierung, erneute Übertragung, Bestätigung und Sequenzierung zu implementieren.
Die Routing-Protokoll-Software von Junos OS unterstützt BGP Version 4. Diese Version von BGP bietet Unterstützung für Classless Interdomain Routing (CIDR), wodurch das Konzept der Netzwerkklassen entfällt. Anstatt anzunehmen, welche Bits einer Adresse das Netzwerk darstellen, indem Sie sich das erste Oktett ansehen, können Sie mit CIDR die Anzahl der Bits in der Netzwerkadresse explizit angeben und so die Größe der Routing-Tabellen verringern. BGP Version 4 unterstützt auch die Aggregation von Routen, einschließlich der Aggregation von AS-Pfaden.
In diesem Abschnitt werden die folgenden Themen behandelt:
- Autonome Systeme
- AS-Pfade und -Attribute
- Externes und internes BGP
- Mehrere BGP-Instanzen
- Protokolldatenverkehr für Schnittstellen in einer Sicherheitszone zulassen
Autonome Systeme
Ein autonomes System (AS) ist eine Gruppe von Routern, die einer einzigen technischen Administration unterstehen und normalerweise ein einziges Interior-Gateway-Protokoll und einen gemeinsamen Satz von Metriken verwenden, um Routing-Informationen innerhalb der Gruppe von Routern weiterzugeben. Für andere AS scheint ein AS einen einzigen, kohärenten internen Routingplan zu haben und vermittelt ein konsistentes Bild davon, welche Ziele über ihn erreichbar sind.
AS-Pfade und -Attribute
Die Routing-Informationen, die BGP-Systeme austauschen, umfassen die vollständige Route zu jedem Ziel sowie zusätzliche Informationen über die Route. Der AS-Pfad ist die Abfolge der autonomen Systeme, die die Route durchquert hat, und zusätzliche Routeninformationen sind in den Pfadattributenenthalten. BGP verwendet den AS-Pfad und die Pfadattribute, um die Netzwerktopologie vollständig zu bestimmen. Sobald BGP die Topologie verstanden hat, kann es Routing-Schleifen erkennen und beseitigen und zwischen Gruppen von Routen auswählen, um administrative Einstellungen und Routing-Richtlinienentscheidungen durchzusetzen.
Externes und internes BGP
BGP unterstützt zwei Arten des Austauschs von Routing-Informationen: Austausch zwischen verschiedenen AS und Austausch innerhalb eines einzelnen AS. Bei Verwendung unter AS wird BGP als externes BGP (EBGP) bezeichnet, und BGP-Sitzungen führen ein Inter-AS-Routingdurch. Bei Verwendung in einem AS wird BGP als internes BGP (IBGP) bezeichnet, und BGP-Sitzungen führen ein AS-internes Routingdurch. Abbildung 1 veranschaulicht ASs, IBGP und EBGP.
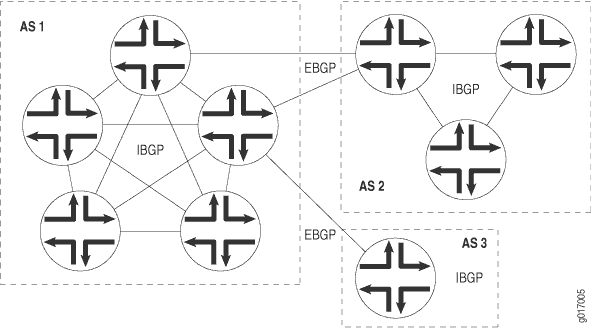
Ein BGP-System teilt Informationen zur Netzwerkerreichbarkeit mit benachbarten BGP-Systemen, die als Nachbarn oder Peersbezeichnet werden.
BGP-Systeme sind in Gruppenangeordnet. In einer IBGP-Gruppe befinden sich alle Peers in der Gruppe – so genannte interne Peers– in derselben AS. Interne Peers können sich überall im lokalen AS befinden und müssen nicht direkt miteinander verbunden sein. Interne Gruppen verwenden Routen von einer IGP, um Weiterleitungsadressen aufzulösen. Sie verteilen auch externe Routen an alle anderen internen Router, auf denen IBGP ausgeführt wird, und berechnen den nächsten Hop, indem sie den nächsten BGP-Hop, der mit der Route empfangen wird, mithilfe von Informationen aus einem der internen Gateway-Protokolle auflösen.
In einer EBGP-Gruppe befinden sich die Peers in der Gruppe – sogenannte externe Peers– in verschiedenen ASs und teilen sich normalerweise ein Subnetz. In einer externen Gruppe wird der nächste Hop in Bezug auf die Schnittstelle berechnet, die vom externen Peer und dem lokalen Router gemeinsam genutzt wird.
Mehrere BGP-Instanzen
Sie können mehrere BGP-Instanzen auf den folgenden Hierarchieebenen konfigurieren:
-
[edit routing-instances routing-instance-name protocols] -
[edit logical-systems logical-system-name routing-instances routing-instance-name protocols]
Mehrere BGP-Instanzen werden in erster Linie für die Unterstützung von Layer 3 VPN verwendet.
IGP-Peers und externe BGP (EBGP)-Peers (sowohl Nicht-Multihop als auch Multihop) werden alle für Routing-Instanzen unterstützt. BGP-Peering wird über eine der in der routing-instances Hierarchie konfigurierten Schnittstellen eingerichtet.
Wenn ein BGP-Nachbar BGP-Nachrichten an das lokale Routinggerät sendet, muss die eingehende Schnittstelle, auf der diese Nachrichten empfangen werden, in derselben Routinginstanz konfiguriert werden, in der die BGP-Nachbarkonfiguration vorhanden ist. Dies gilt für Nachbarn, die nur einen oder mehrere Hops entfernt sind.
Routen, die vom BGP-Peer gelernt wurden, werden der instance-name.inet.0 Tabelle standardmäßig hinzugefügt. Sie können Import- und Exportrichtlinien konfigurieren, um den Informationsfluss in und aus der Instance-Routing-Tabelle zu steuern.
Konfigurieren Sie für die Layer-3-VPN-Unterstützung BGP auf dem Provider-Edge-Router (PE), um Routen vom Kunden-Edge-Router (CE) zu empfangen und die Routen der Instanzen bei Bedarf an den CE-Router zu senden. Sie können mehrere BGP-Instanzen verwenden, um separate Weiterleitungstabellen pro Standort zu verwalten, um den VPN-Datenverkehr auf dem PE-Router getrennt zu halten.
Sie können Import- und Exportrichtlinien konfigurieren, die es dem Service Provider ermöglichen, den Datenverkehr zum und vom Kunden zu steuern und die Rate zu begrenzen.
Sie können eine EBGP-Multihop-Sitzung für eine VRF-Routing-Instanz konfigurieren. Außerdem können Sie den EBGP-Peer zwischen dem PE- und dem CE-Router einrichten, indem Sie die Loopback-Adresse des CE-Routers anstelle der Schnittstellenadressen verwenden.
Protokolldatenverkehr für Schnittstellen in einer Sicherheitszone zulassen
Bei Firewallsder SRX-Serie müssen Sie den erwarteten eingehenden Host-Datenverkehr auf den angegebenen Schnittstellen oder allen Schnittstellen der Zone aktivieren. Andernfalls wird eingehender Datenverkehr, der für dieses Gerät bestimmt ist, standardmäßig verworfen.
Führen Sie beispielsweise den folgenden Schritt aus, um BGP-Datenverkehr in einer bestimmten Zone Ihrer Firewallder SRX-Serie zuzulassen:
[edit] user@host# set security zones security-zone trust host-inbound-traffic protocols bgp
[edit] user@host# set security zones security-zone trust interfaces ge-0/0/1.0 host-inbound-traffic protocols bgp
Siehe auch
BGP-Routen im Überblick
Eine BGP-Route ist ein Ziel, das als IP-Adresspräfix beschrieben wird, und Informationen, die den Pfad zum Ziel beschreiben.
Die folgenden Informationen beschreiben den Pfad:
AS-Pfad, bei dem es sich um eine Liste der Nummern der ASs handelt, die eine Route durchläuft, um den lokalen Router zu erreichen. Die erste Zahl im Pfad ist die des letzten AS im Pfad – der AS, der dem lokalen Router am nächsten ist. Die letzte Zahl im Pfad ist der AS, der am weitesten vom lokalen Router entfernt ist, der in der Regel der Ursprung des Pfads ist.
Pfadattribute, die zusätzliche Informationen über den AS-Pfad enthalten, der in der Routingrichtlinie verwendet wird.
BGP-Peers kündigen sich gegenseitig Routen in Aktualisierungsnachrichten an.
BGP speichert seine Routen in der Routing-Tabelle von Junos OS (inet.0). In der Routing-Tabelle werden die folgenden Informationen zu BGP-Routen gespeichert:
Routinginformationen aus Updatenachrichten, die von Peers empfangen wurden
Lokale Routing-Informationen, die BGP aufgrund lokaler Richtlinien auf Routen anwendet
Informationen, die BGP BGP-Peers in Aktualisierungsmeldungen ankündigt
Für jedes Präfix in der Routing-Tabelle wählt der Routing-Protokollprozess einen einzigen besten Pfad aus, den so genannten aktiven Pfad. Sofern Sie BGP nicht so konfigurieren, dass mehrere Pfade zum gleichen Ziel angekündigt werden, kündigt BGP nur den aktiven Pfad an.
Der BGP-Router, der eine Route zuerst ankündigt, weist ihr einen der folgenden Werte zu, um ihren Ursprung zu identifizieren. Bei der Routenauswahl wird der niedrigste Ursprungswert bevorzugt.
0– Der Router hat die Route ursprünglich über ein IGP (OSPF, IS-IS oder eine statische Route) gelernt.
1– Der Router hat die Route ursprünglich über ein EGP (höchstwahrscheinlich BGP) gelernt.
2—Der Ursprung der Route ist unbekannt.
Siehe auch
BGP-Routenauflösung – Übersicht
Bei einer internen BGP-Route (IBGP) mit einer Next-Hop-Adresse zu einem Remote-BGP-Nachbarn (Protokoll nächster Hop) muss der nächste Hop über eine andere Route aufgelöst werden. BGP fügt diese Route dem rpd-Resolver-Modul hinzu, um die Auflösung des nächsten Hops zu ermöglichen. Wenn RSVP im Netzwerk verwendet wird, wird der nächste BGP-Hop mithilfe der RSVP-Eingangsroute aufgelöst. Dies führt dazu, dass die BGP-Route auf einen indirekten nächsten Hop und der indirekte nächste Hop auf einen weiterleitenden nächsten Hop verweist. Der Weiterleitungs-Next-Hop wird vom nächsten Hop der RSVP-Route abgeleitet. Es gibt häufig eine große Anzahl interner BGP-Routen, die dasselbe Protokoll für den nächsten Hop haben, und in solchen Fällen würde der Satz von BGP-Routen auf denselben indirekten nächsten Hop verweisen.
Vor Junos OS Version 17.2R1 löste das Resolver-Modul des Routing-Protokoll-Prozesses (RPD) Routen innerhalb des IBGP auf folgende Weise auf:
Partial Route Resolution: Der nächste Hop des Protokolls wird basierend auf Hilfsrouten wie RSVP- oder IGP-Routen aufgelöst. Die Metrikwerte werden von den Hilfsrouten abgeleitet, und der nächste Hop wird als Resolver bezeichnet, der den nächsten Hop weiterleitet und von Hilfsrouten geerbt wurde. Diese Metrikwerte werden für die Auswahl von Routen in der Routing-Informationsbasis (RIB) verwendet, die auch als Routing-Tabelle bezeichnet wird.
Vollständige Routenauflösung: Der letzte nächste Hop wird abgeleitet und basierend auf der Weiterleitungsexportrichtlinie als Kernel-Routing-Tabelle (KRT) bezeichnet, die den nächsten Hop weiterleitet.
Ab Junos OS Version 17.2R1 ist das Resolver-Modul von rpd optimiert, um den Durchsatz des eingehenden Verarbeitungsflusses zu erhöhen und die Lernrate von RIB und FIB zu beschleunigen. Mit dieser Erweiterung wird die Routenauflösung wie folgt beeinflusst:
Die Methoden zur Auflösung der partiellen und vollständigen Route werden für jede IBGP-Route ausgelöst, obwohl jede Route die gleichen aufgelösten nächsten Hops für die Weiterleitung oder die nächste KRT-Weiterleitung erben kann.
Die BGP-Pfadauswahl wird zurückgestellt, bis die vollständige Routenauflösung für NLRI (Network Layer Reachability Information) durchgeführt wurde, die von einem BGP-Nachbarn empfangen wurde, der nach der Routenauswahl möglicherweise nicht die beste Route im RIB ist.
Zu den Vorteilen der rpd-Resolver-Optimierung gehören:
Niedrigere Suchkosten für die RIB-Auflösung: Die Ausgabe des aufgelösten Pfads wird in einem Resolver-Cache gespeichert, sodass dieselben abgeleiteten Werte für den nächsten Hop und die gleichen Metrikwerte an einen anderen Satz von Routen mit demselben Pfadverhalten vererbt werden können, anstatt sowohl einen teilweisen als auch einen vollständigen Routenauflösungsfluss durchzuführen. Dadurch werden die Kosten für die Suche nach der Routenauflösung reduziert, da nur der häufigste Resolverstatus in einem Cache mit begrenzter Tiefe beibehalten wird.
BGP-Routenauswahloptimierung – Der BGP-Routenauswahlalgorithmus wird für jede empfangene IBGP-Route zweimal ausgelöst – erstens, während die Route im RIB mit dem nächsten Hop als unbrauchbar hinzugefügt wird, und zweitens, während die Route mit einem aufgelösten nächsten Hop im RIB hinzugefügt wird (nach der Routenauflösung). Dies führt dazu, dass die beste Route zweimal ausgewählt wird. Bei der Resolver-Optimierung wird der Routenauswahlprozess im Empfangsfluss erst ausgelöst, nachdem die Next-Hop-Informationen vom Resolver-Modul abgerufen wurden.
Internes Caching zur Vermeidung häufiger Lookups: Der Resolver-Cache behält den Status des häufigsten Resolvers bei, sodass die Lookup-Funktionen, wie z. B. die Suche nach dem nächsten Hop und die Routensuche, über den lokalen Cache ausgeführt werden.
Pfadäquivalenzgruppe: Wenn verschiedene Pfade denselben Weiterleitungsstatus aufweisen oder vom nächsten Hop desselben Protokolls empfangen werden, können die Pfade zu einer Pfadäquivalenzgruppe gehören. Dieser Ansatz vermeidet die Notwendigkeit, für solche Pfade eine vollständige Routenauflösung durchzuführen. Wenn für einen neuen Pfad eine vollständige Routenauflösung erforderlich ist, wird er zunächst in der Datenbank der Pfadäquivalenzgruppe gesucht, die die aufgelöste Pfadausgabe enthält, z. B. indirekter nächster Hop und Weiterleitung des nächsten Hops.
Siehe auch
Übersicht über BGP-Nachrichten
Alle BGP-Nachrichten haben denselben Header mit fester Größe, der ein Markierungsfeld enthält, das sowohl für die Synchronisierung als auch für die Authentifizierung verwendet wird, ein Längenfeld, das die Länge des Pakets angibt, und ein Typfeld, das den Nachrichtentyp angibt (z. B. open, update, notification, keepalive usw.).
In diesem Abschnitt werden die folgenden Themen behandelt:
- Offene Nachrichten
- Nachrichten aktualisieren
- Keepalive-Nachrichten
- Benachrichtigungen
- Route-Refresh-Meldungen
Offene Nachrichten
Nachdem eine TCP-Verbindung zwischen zwei BGP-Systemen hergestellt wurde, tauschen sie offene BGP-Nachrichten aus, um eine BGP-Verbindung zwischen ihnen herzustellen. Sobald die Verbindung hergestellt ist, können die beiden Systeme BGP-Nachrichten und Datenverkehr austauschen.
Offene Nachrichten bestehen aus dem BGP-Header und den folgenden Feldern:
Version: Die aktuelle BGP-Versionsnummer ist 4.
Lokale AS-Nummer: Sie konfigurieren dies, indem Sie die
autonomous-systemAnweisung auf der[edit routing-options]Hierarchieebene "oder[edit logical-systems logical-system-name routing-options]" einschließen.Haltezeit: Vorgeschlagener Wert für die Haltezeit. Sie konfigurieren die lokale Haltezeit mit der BGP-Anweisung
hold-time.BGP-Kennung: IP-Adresse des BGP-Systems. Diese Adresse wird beim Systemstart ermittelt und ist für jede lokale Schnittstelle und jeden BGP-Peer gleich. Sie können den BGP-Bezeichner konfigurieren, indem Sie die
router-idAnweisung auf der[edit routing-options]Hierarchieebene "oder[edit logical-systems logical-system-name routing-options]" einfügen. Standardmäßig verwendet BGP die IP-Adresse der ersten Schnittstelle, die es im Router findet.Parameterfeldlänge und der Parameter selbst: Hierbei handelt es sich um optionale Felder.
Nachrichten aktualisieren
BGP-Systeme senden Update-Nachrichten, um Informationen zur Netzwerkerreichbarkeit auszutauschen. BGP-Systeme verwenden diese Informationen, um einen Graphen zu erstellen, der die Beziehungen zwischen allen bekannten AS beschreibt.
Aktualisierungsnachrichten bestehen aus dem BGP-Header und den folgenden optionalen Feldern:
Länge nicht realisierbarer Routen: Länge des Feldes "Zurückgezogene Routen"
Zurückgezogene Routen – IP-Adresspräfixe für die Routen, die aus dem Betrieb genommen werden, da sie nicht mehr als erreichbar gelten
Gesamtlänge des Pfadattributs: Länge des Feldes "Pfadattribute"; Es listet die Pfadattribute für eine praktikable Route zu einem Ziel auf
Pfadattribute: Eigenschaften der Routen, einschließlich des Pfadursprungs, des Multiple Exit Discriminator (MED), der Präferenz des Ursprungssystems für die Route und Informationen zu Aggregation, Communities, Konföderationen und Routenreflektion
NLRI (Network Layer Reachability Information): IP-Adresspräfixe möglicher Routen, die in der Aktualisierungsmeldung angekündigt werden
Keepalive-Nachrichten
BGP-Systeme tauschen Keepalive-Nachrichten aus, um festzustellen, ob eine Verbindung oder ein Host ausgefallen oder nicht mehr verfügbar ist. Keepalive-Nachrichten werden oft genug ausgetauscht, damit der Hold-Timer nicht abläuft. Diese Nachrichten bestehen nur aus dem BGP-Header.
Benachrichtigungen
BGP-Systeme senden Benachrichtigungen, wenn eine Fehlerbedingung erkannt wird. Nachdem die Nachricht gesendet wurde, werden die BGP-Sitzung und die TCP-Verbindung zwischen den BGP-Systemen geschlossen. Benachrichtigungen bestehen aus dem BGP-Header sowie dem Fehlercode und -subcode sowie Daten, die den Fehler beschreiben.
Route-Refresh-Meldungen
BGP-Systeme senden Routenaktualisierungsnachrichten nur dann an einen Peer, wenn sie die Ankündigung der Routenaktualisierungsfunktion vom Peer erhalten haben. Ein BGP-System muss seinen Peers die Routenaktualisierungsfunktion mithilfe der BGP-Funktionsankündigung ankündigen, wenn es Routenaktualisierungsnachrichten empfangen möchte. Diese optionale Nachricht wird gesendet, um dynamische, eingehende BGP-Routenaktualisierungen von BGP-Peers oder ausgehende Routenaktualisierungen von einem BGP-Peer anzufordern.
Routenaktualisierungsmeldungen bestehen aus den folgenden Feldern:
AFI – Address Family Identifier (16 Bit).
Res: Reserviertes Feld (8 Bit), das vom Absender auf 0 gesetzt und vom Empfänger ignoriert werden muss.
SAFI – Subsequent Address Family Identifier (8 Bit).
Wenn ein Peer ohne die Funktion "Route-Refresh" eine Anforderungsnachricht für die Routenaktualisierung von einem Remote-Peer empfängt, ignoriert der Empfänger die Nachricht.
Siehe auch
Grundlegendes zu BGP RIB-Sharding und BGP-Update-E/A-Thread
Die BGP-Routenverarbeitung umfasst in der Regel mehrere Pipeline-Phasen, z. B. das Empfangen von Updates, das Parsen von Updates, das Erstellen von Routen, das Auflösen des nächsten Hops, das Anwenden der Exportrichtlinie einer BGP-Peer-Gruppe, das Erstellen von Updates pro Peer und das Senden von Updates an Peers.
BGP-RIB-Sharding teilt ein einheitliches BGP-RIB in mehrere Sub-RIBs auf, und jedes Sub-RIB verarbeitet eine Teilmenge von BGP-Routen. Ein separater RPD-Thread, der als BGP-Shard-Thread bezeichnet wird, bedient jedes untergeordnete RIB von, um Parallelität zu erreichen. BGP-Shard-Threads sind für alle Phasen der BGP-Routenverarbeitungspipeline verantwortlich, mit Ausnahme der Bildung von Updates pro Peer und des Sendens von Updates an Peers. BGP-Shard-Threads empfangen die Updates, die von Peers von den BGP-Update-E/A-Threads gesendet werden, wobei die BGP-Update-E/A-Threads die Präfixe in den Updates hashen, und senden die Updates basierend auf der Hashberechnung an die entsprechenden BGP-Shard-Threads. Der BGP-Shard-Thread verarbeitet die Konfiguration auf die gleiche Weise wie der RPD-Hauptthread, erstellt Peers, Gruppen und Routing-Tabellen und verwendet die Konfigurationsinformationen für die BGP-Routenverarbeitung.
BGP-Update-E/A-Threads sind für das Ende dieser BGP-Pipeline verantwortlich, d. h. das Generieren von Updates pro Peer für einzelne BGP-Gruppen und das Senden dieser Updates an die Peers. Ein Update-Thread kann eine oder mehrere BGP-Gruppen bedienen. BGP-Update-E/A-Threads erstellen Updates für Gruppen parallel und unabhängig von anderen Gruppen, die von anderen Update-Threads bedient werden. Dies kann eine erhebliche Konvergenzverbesserung bei einer schreibintensiven Workload bieten, die Werbung an viele Peers erfordert, die über viele Gruppen verteilt sind. BGP-Update-IO-Threads sind auch für das Schreiben und Lesen in die TCP-Sockets der BGP-Peers verantwortlich, was zuvor von BGPIO-Threads bereitgestellt wurde (daher das Suffix IO in BGP Update IO).
BGP-Update-E/A-Threads können unabhängig von der RIB-Sharding-Funktion konfiguriert werden, müssen jedoch zwingend mit RIB-Sharding verwendet werden, um eine bessere Effizienz beim Präfixpacken in ausgehenden BGP-Aktualisierungsnachrichten zu erreichen. BGP-Sharding teilt das RIB in mehrere Sub-RIBs auf, die von separaten RPD-Threads bedient werden. Daher landen Präfixe, die in ein einzelnes ausgehendes Update hätten aufgenommen werden können, in verschiedenen Shards. Um BGP-Updates mit Präfixen mit demselben ausgehenden Attribut erstellen zu können, die zu verschiedenen RPD-Shard-Threads gehören können, senden alle Shard-Threads kompakte Ankündigungsinformationen für Präfixe, die an einen Update-Thread angekündigt werden sollen, der diese BGP-Peergruppe bedient. Auf diese Weise kann der Update-Thread, der diese BGP-Peer-Gruppe bedient, Präfixe mit denselben Attributen packen, die möglicherweise zu verschiedenen Shards in derselben ausgehenden Update-Nachricht gehören. Dies minimiert die Anzahl der anzukündigenden Updates und trägt so zur Verbesserung der Konvergenz bei. Der Update IO-Thread verwaltet lokale Caches von Peer-, Gruppen-, Präfix-, TSI- und RIB-Containern.
BGP-Update-Thread und BGP-RIB-Sharding sind standardmäßig deaktiviert. Wenn Sie Update-Threading und Rib-Sharding in einer Routing-Engine konfigurieren, erstellt RPD Update-Threads. Standardmäßig entspricht die Anzahl der erstellten Update-Threads und Shard-Threads der Anzahl der CPU-Kerne der Routing-Engine. Updatethreading wird nur für einen 64-Bit-Routing-Protokollprozess (RPD) unterstützt. Optional können Sie die Anzahl der Threads angeben, die Sie erstellen möchten, indem Sie and-Anweisungen set rib-sharding <number-of-threads> auf Hierarchieebene [edit system processes routing bgp] verwendenset update-threading <number-of-threads> . Für BGP-Update-Threads liegt der Bereich derzeit zwischen 1 und 128 und für BGP-RIB-Sharding zwischen 1 und 31.
Wenn Sie NSR für die Funktionen BGP RIB Sharding und BGP Update IO konfigurieren, erstellt der Backup-RPD die gleiche Anzahl von BGP-Shard- und BGP-Update-E/A-Threads in der Backup-Routing-Engine. Die Backup-RPD-BGP-Update-E/A-Threads lesen das replizierte BGP-Update, andere von den Peers empfangene Nachrichten sowie das replizierte BGP-Update und andere an die Peers gesendete Nachrichten. Basierend auf dem Hashing von Präfixen senden die Backup-RPD-BGP-Update-IO-Threads diese BGP-Nachrichten an den entsprechenden BGP-Shard und die RPD-Hauptthreads. Der BGP-Shard und die RPD-Hauptthreads in der Backup-RPD erstellen den Status der empfangenen und angekündigten Route mithilfe dieser replizierten BGP-Nachrichten. Wenn die primäre Routing-Engine ausfällt, wird die Backup-Routing-Engine zur primären Routing-Engine, und die Backup-RPD wird nahtlos zur primären RPD, ohne die BGP-Sitzungen mit den Peers zu beeinträchtigen.
Grundlegendes zur BGP-Pfadauswahl
Für jedes Präfix in der Routing-Tabelle wählt der Routing-Protokollprozess einen einzigen besten Pfad aus. Nachdem der beste Pfad ausgewählt wurde, wird die Route in der Routing-Tabelle installiert. Der beste Pfad wird zur aktiven Route, wenn derselbe Präfix nicht von einem Protokoll mit einem niedrigeren (bevorzugteren) globalen Präferenzwert gelernt wird, der auch als administrative Distanz bezeichnet wird. Der Algorithmus zur Bestimmung der aktiven Route lautet wie folgt:
-
Vergewissern Sie sich, dass der nächste Hop aufgelöst werden kann.
-
Wählen Sie den Pfad mit dem niedrigsten Präferenzwert (Routing-Protokoll-Prozesspräferenz).
Routen, die nicht für die Weiterleitung verwendet werden können (z. B. weil sie von der Routingrichtlinie abgelehnt wurden oder weil auf einen nächsten Hop nicht zugegriffen werden kann), haben eine Präferenz von –1 und werden nie ausgewählt.
-
Bevorzugen Sie den Pfad mit höherer lokaler Präferenz.
Wählen Sie für Nicht-BGP-Pfade den Pfad mit dem niedrigsten preference2 Wert aus.
-
Wenn das AIGP-Attribut (Accumulated Interior Gateway Protocol) aktiviert ist, fügen Sie die IGP-Metrik hinzu, und bevorzugen Sie den Pfad mit dem niedrigeren AIGP-Attribut.
-
Bevorzugen Sie den Pfad mit dem kürzesten AS-Pfadwert (Autonomous System) (wird übersprungen, wenn die
as-path-ignoreAnweisung konfiguriert ist).Ein Konföderationssegment (Sequenz oder Satz) hat eine Pfadlänge von 0. Eine AS-Menge hat eine Pfadlänge von 1.
-
Bevorzugen Sie die Route mit dem niedrigeren Ursprungscode.
Routen, die von einem IGP gelernt wurden, haben einen niedrigeren Ursprungscode als solche, die von einem Exterior Gateway Protocol (EGP) gelernt wurden, und beide haben niedrigere Ursprungscodes als unvollständige Routen (Routen, deren Ursprung unbekannt ist).
-
Bevorzugen Sie den Pfad mit der niedrigsten MED-Metrik (Multiple Exit Discriminator).
Je nachdem, ob das Auswahlverhalten für den Pfad der nicht deterministischen Routingtabelle konfiguriert ist, gibt es zwei mögliche Fälle:
-
Wenn das nicht deterministische Verhalten bei der Auswahl des Routing-Tabellenpfads nicht konfiguriert ist (d. h., wenn die
path-selection cisco-nondeterministicAnweisung nicht in der BGP-Konfiguration enthalten ist), bevorzugen Sie für Pfade mit denselben benachbarten AS-Nummern am Anfang des AS-Pfads den Pfad mit der niedrigsten MED-Metrik. Um MEDs immer unabhängig davon zu vergleichen, ob die Peer-ASs der verglichenen Routen identisch sind, fügen Sie diepath-selection always-compare-medAnweisung ein. -
Wenn ein nicht deterministisches Verhalten bei der Auswahl des Routing-Tabellenpfads konfiguriert ist (d. h., die
path-selection cisco-nondeterministicAnweisung ist in der BGP-Konfiguration enthalten), bevorzugen Sie den Pfad mit der niedrigsten MED-Metrik.
Konföderationen werden bei der Bestimmung benachbarter AS nicht berücksichtigt. Eine fehlende MED-Metrik wird so behandelt, als ob eine MED vorhanden, aber null wäre.
HINWEIS:Der MED-Vergleich funktioniert für die Auswahl eines einzelnen Pfads innerhalb eines AS (wenn die Route keinen AS-Pfad enthält), obwohl diese Verwendung ungewöhnlich ist.
Standardmäßig werden nur die MEDs von Routen verglichen, die über dieselben Peer Autonomous Systems (ASs) verfügen. Sie können Optionen für die Auswahl des Routing-Tabellenpfads konfigurieren, um unterschiedliche Verhaltensweisen zu erzielen.
-
-
Bevorzugen Sie rein interne Pfade, die IGP-Routen und lokal generierte Routen (statisch, direkt, lokal usw.) enthalten.
-
Bevorzugen Sie ausschließlich externe BGP-Pfade (EBGP) gegenüber externen Pfaden, die durch interne BGP-Sitzungen (IBGP) erlernt wurden.
-
Bevorzugen Sie den Pfad, dessen nächster Hop über die IGP-Route mit der niedrigsten Metrik aufgelöst wird. BGP-Routen, die über IGP aufgelöst werden, werden gegenüber nicht erreichbaren oder abgelehnten Routen bevorzugt.
HINWEIS:Ein Pfad wird als BGP-Pfad mit gleichen Kosten betrachtet (und für die Weiterleitung verwendet), wenn nach dem vorherigen Schritt ein Tie-Break ausgeführt wird. Dabei werden alle Pfade mit demselben benachbarten AS berücksichtigt, die von einem Multipath-fähigen BGP-Nachbarn gelernt wurden.
BGP-Multipath gilt nicht für Pfade, die die gleichen MED-plus-IGP-Kosten haben, sich aber in den IGP-Kosten unterscheiden. Die Auswahl von Multipath-Pfaden basiert auf der IGP-Kostenmetrik, auch wenn zwei Pfade die gleichen MED-plus-IGP-Kosten haben.
-
Wenn beide Pfade extern sind, bevorzugen Sie den ältesten Pfad, also den Pfad, der zuerst gelernt wurde. Dies geschieht, um das Flapping von Routen zu minimieren. Diese Regel wird nicht verwendet, wenn eine der folgenden Bedingungen erfüllt ist:
-
path-selection external-router-id konfiguriert ist.
-
Beide Peers haben dieselbe Router-ID.
-
Bei beiden Peers handelt es sich um Konföderationspeers.
-
Keiner der beiden Pfade ist der aktuell aktive Pfad.
-
-
Bevorzugen Sie eine primäre Route gegenüber einer sekundären Route. Eine primäre Route ist eine Route, die zur Routing-Tabelle gehört. Eine sekundäre Route ist eine Route, die der Routingtabelle über eine Exportrichtlinie hinzugefügt wird.
-
Bevorzugen Sie den Pfad vom Peer mit der niedrigsten Router-ID. Ersetzen Sie für jeden Pfad mit einem Absender-ID-Attribut die Router-ID während des Router-ID-Vergleichs durch die Absender-ID.
-
Bevorzugen Sie den Pfad mit der kürzesten Länge der Clusterliste. Die Länge ist 0 für keine Liste.
-
Bevorzugen Sie den Pfad vom Peer mit der niedrigsten Peer-IP-Adresse.
- Auswahl des Routing-Tabellenpfads
- Auswahl des BGP-Tabellenpfads
- Auswirkungen der Werbung für mehrere Pfade zu einem Ziel
Auswahl des Routing-Tabellenpfads
Der kürzeste AS-Pfadschritt des Algorithmus wertet standardmäßig die Länge des AS-Pfads aus und bestimmt den aktiven Pfad. Sie können eine Option konfigurieren, die es Junos OS ermöglicht, diesen Schritt des Algorithmus zu überspringen, indem Sie die as-path-ignore Option einschließen.
Ab Junos OS Version 14.1R8, 14.2R7, 15.1R4, 15.1F6 und 16.1R1 wird die as-path-ignore Option für Routing-Instanzen unterstützt.
Die Auswahl des Routing-Prozesspfads erfolgt, bevor BGP den Pfad an die Routing-Tabelle übergibt, um seine Entscheidung zu treffen. Um das Verhalten bei der Auswahl des Routing-Tabellenpfads zu konfigurieren, fügen Sie die path-selection folgende Anweisung ein:
path-selection { (always-compare-med | cisco-non-deterministic | external-router-id); as-path-ignore; l2vpn-use-bgp-rules; med-plus-igp { igp-multiplier number; med-multiplier number; } }
Eine Liste der Hierarchieebenen, auf denen Sie diese Anweisung einschließen können, finden Sie im Abschnitt Anweisungszusammenfassung für diese Anweisung.
Die Auswahl des Routingtabellenpfads kann auf eine der folgenden Arten konfiguriert werden:
-
Emulieren Sie das Cisco IOS-Standardverhalten (cisco-non-deterministic). In diesem Modus werden Routen in der Reihenfolge ihres Eingangs ausgewertet und nicht nach ihren benachbarten AS gruppiert. Im Modus
cisco-non-deterministicsteht der aktive Pfad immer an erster Stelle. Alle inaktiven, aber zulässigen Pfade folgen dem aktiven Pfad und werden in der Reihenfolge beibehalten, in der sie empfangen wurden, wobei der neueste Pfad zuerst angezeigt wird. Nicht förderfähige Pfade verbleiben am Ende der Liste.Angenommen, Sie haben drei Pfadankündigungen für die Route 192.168.1.0 /24:
-
Pfad 1 – erlernt durch EBGP; AS-Pfad von 65010; MED von 200
-
Pfad 2 – erlernt durch IBGP; AS-Pfad von 65020; MED von 150; IGP-Kosten von 5
-
Pfad 3 – erlernt durch IBGP; AS-Pfad von 65010; MED von 100; IGP-Kosten von 10
Diese Anzeigen werden in schneller Folge, innerhalb einer Sekunde, in der angegebenen Reihenfolge empfangen. Pfad 3 wurde zuletzt empfangen, sodass das Routinggerät ihn mit Pfad 2, der nächstneuesten Ankündigung, vergleicht. Die Kosten für den IBGP-Peer sind für Pfad 2 besser, sodass das Routing-Gerät Pfad 3 von Konflikten ausschließt. Beim Vergleich der Pfade 1 und 2 bevorzugt das Routinggerät Pfad 1, da er von einem EBGP-Peer empfangen wird. Dadurch kann das Routing-Gerät Pfad 1 als aktiven Pfad für die Route installieren.
HINWEIS:Es wird nicht empfohlen, diese Konfigurationsoption in Ihrem Netzwerk zu verwenden. Sie dient ausschließlich der Interoperabilität, damit alle Routing-Geräte im Netzwerk eine konsistente Routenauswahl treffen können.
-
Vergleichen von MEDs immer, unabhängig davon, ob die Peer-ASs der verglichenen Routen identisch sind oder nicht (always-compare-med).
Überschreiben Sie die Regel, dass der aktuell aktive Pfad bevorzugt wird, wenn beide Pfade extern sind (external-router-id). Fahren Sie mit dem nächsten Schritt (Schritt 12) im Pfadauswahlprozess fort.
Hinzufügen der IGP-Kosten zum Next-Hop-Ziel zum MED-Wert vor dem Vergleich der MED-Werte für die Pfadauswahl (
med-plus-igp).BGP-Multipath gilt nicht für Pfade, die die gleichen MED-plus-IGP-Kosten haben, sich aber in den IGP-Kosten unterscheiden. Die Auswahl von Multipath-Pfaden basiert auf der IGP-Kostenmetrik, auch wenn zwei Pfade die gleichen MED-plus-IGP-Kosten haben.
Auswahl des BGP-Tabellenpfads
Die folgenden Parameter werden für die Pfadauswahl von BGP befolgt:
-
Bevorzugen Sie den höchsten lokalen Präferenzwert.
-
Bevorzugen Sie die kürzeste AS-Pfadlänge.
-
Bevorzugen Sie den niedrigsten Ursprungswert.
-
Bevorzugen Sie den niedrigsten MED-Wert.
-
Bevorzugen Sie Routen, die von einem EBGP-Peer gelernt wurden, gegenüber einem IBGP-Peer.
-
Bevorzugen Sie den besten Ausstieg aus AS.
-
Bevorzugen Sie für EBGP-empfangene Routen die aktuell aktive Route.
-
Bevorzugen Sie Routen vom Peer mit der niedrigsten Router-ID.
-
Bevorzugen Sie Pfade mit der kürzesten Clusterlänge.
-
Bevorzugen Sie Routen vom Peer mit der niedrigsten Peer-IP-Adresse. Die Schritte 2, 6 und 12 sind die RPD-Kriterien.
Auswirkungen der Werbung für mehrere Pfade zu einem Ziel
BGP kündigt nur den aktiven Pfad an, es sei denn, Sie konfigurieren BGP so, dass mehrere Pfade zu einem Ziel angekündigt werden.
Angenommen, ein Routinggerät hat in seiner Routing-Tabelle vier Pfade zu einem Ziel und ist so konfiguriert, dass es bis zu drei Pfade ankündigt (add-path send path-count 3). Die drei Pfade werden auf der Grundlage von Pfadauswahlkriterien ausgewählt. Das heißt, die drei besten Pfade werden in der Reihenfolge der Pfadauswahl ausgewählt. Der beste Pfad ist der aktive Pfad. Dieser Pfad wird aus der Betrachtung genommen und ein neuer bester Pfad gewählt. Dieser Vorgang wird so lange wiederholt, bis die angegebene Anzahl von Pfaden erreicht ist.
Siehe auch
Verbesserte Serviceroutenauflösung für BGP Multipath mit List Nexthop
Junos OS verbessert die Serviceroutenauflösung in BGP-Multipath-Hilfsrouten, die list-nexthop-Strukturen verwenden. Der Routenresolver erstellt und verwaltet jetzt interne Abhängigkeiten für alle beitragenden Pfade in einer Multipath-Route und ermöglicht so eine genaue und dynamische Neuauflösung, wenn sich indirekte Nexthops ändern, unabhängig davon, ob die beitragende Route aktiv oder inaktiv ist.
Diese Funktion verbessert die Stabilität der Serviceroute und verhindert veraltete Weiterleitungspfade in Netzwerken, die BGP ECMP mit indirekter NextHop-Auflösung verwenden.
- Vorteile
- Vorbereitungen
- Funktionsweise der Funktion
- Betriebsbeispiel
- CLI-Befehlsreferenz
- Begrenzungen
Vorteile
- Sorgt für eine genaue Weiterleitung von Servicerouten, die über BGP-Multipath aufgelöst werden.
- Löst eine erneute Auflösung aus, wenn sich ein beitragender Pfad ändert, nicht nur der Lead-Pfad.
- Unterstützt hybride iBGP- und eBGP-Multipath-Topologien mit indirekten NextHops.
- Verhindert Datenverkehrsverluste durch veraltete oder veraltete Auflösungszustände.
Vorbereitungen
Stellen Sie sicher, dass die Befehlsanweisung BGP multipath list-nexthop für die relevanten Adressfamilien aktiviert ist. Es ist keine neue Konfiguration erforderlich, um diese Funktion zu aktivieren.
Funktionsweise der Funktion
Wenn eine Dienstroute über eine BGP-Multipath-Route mit einem list-nexthop aufgelöst wird, führt RPD die folgenden Aktionen aus:
Führt alle nexthop-Komponenten in list-nexthop durch.
Richtet Abhängigkeitsbeziehungen zwischen der Multipath-Hilfsroute und den einzelnen beitragenden Pfaden ein.
Speichert diese Abhängigkeiten in einer internen Datenbank mithilfe einer Patricia-Baumstruktur. Erstellt diese Beziehungen auf Bedarf:
Ein Patricia-Strukturknoten wird nur instanziiert, wenn die erste Dienstroute durch die Multipath-Hilfsroute aufgelöst wird.
Wenn die letzte abhängige Dienstroute nicht mehr über diese Multipath-Route aufgelöst wird, wird der entsprechende Knoten automatisch aus der Struktur entfernt.
Überwacht indirekte Nexthop-Änderungen mithilfe von KRT-Hook-Callbacks.
Löst die abhängigen Dienstrouten immer dann wieder auf, wenn sich eine beitragende Route (aktiv oder inaktiv) ändert.
Dieses Verhalten gilt unabhängig davon, ob die beitragende Route im Multipath-Satz aktiv oder inaktiv ist.
Betriebsbeispiel
Szenario:
Eine Dienstroute (9.9.9.9/32) wird über eine BGP-Multipath-Route (1.1.1.9/32) mit den folgenden beitragenden Pfaden aufgelöst:
iBGP path-1(federführend/aktiv): über7.7.7.7→1.2.3.4→10.50.10.1iBGP path-2: via8.8.8.8
Bei iBGP path-2 Änderungen (z. B. aufgrund eines NextHop-Updates) erkennt Junos OS die Änderung und löst die abhängige Serviceroute erneut auf.
CLI-Befehlsreferenz
Sie können die folgenden Befehle verwenden, um die Beziehungen zwischen Liste und NextHop-Resolver anzuzeigen und Multipath-Routenabhängigkeiten von indirekten NextHops zu überwachen.
-
show route resolution list-nhZeigt indirekte Next-Hop-Handles (INH) in der internen list-nexthop-Abhängigkeitsdatenbank zusammen mit den von ihnen abhängigen BGP-Multipath-Routen an. Dieser Befehl zeigt nur die Multipath-Hilfsrouten an, die einen bestimmten INH verwenden.
Beispielausgabe:
user@router> show route resolution list-nh Indirect next-hop statistics in List-nexthop database: Inh adds: 9, Inh deletes: 4 Inh change callback: registered Indirect next-hop: Inh handle: 0x8969d30; Inh protocol nexthop: 8.8.8.8 Multipath route: 1.1.1.0/24, resolver node: 0xf9e9ed8 Indirect next-hop: Inh handle: 0x8969b98; Inh protocol nexthop: 7.7.7.7 Multipath route: 1.1.1.0/24, resolver node: 0xf9e9ed8 Multipath route: 3.3.3.0/24, resolver node: 0x8d88cb8
-
show route resolution list-nh protocol-next-hop <nexthop>Zeigt alle Multipath-Routen an, die einen bestimmten indirekten Nexthop verwenden.
Beispiel:
user@router> show route resolution list-nh protocol-next-hop 9.9.9.9 Protocol Nexthop: 9.9.9.9 Used by: - Multipath Route: 1.1.1.0/24 - Multipath Route: 2.2.2.0/24 - Multipath Route: 3.3.3.0/24 -
show krt indirect-next-hopZeigt Informationen zur Kernel-Routing-Tabelle für einen bestimmten indirekten NextHop-Index an, einschließlich der Anzahl der Multipath-Routen, die von diesem Nexthop abhängig sind. Mit diesem Befehl werden Verweiszähler und Weiterleitungsabhängigkeiten im Zusammenhang mit Multipath-Routen angezeigt.
Beispielausgabe:
user@router> show krt indirect-next-hop index 1048574 Indirect Nexthop: Index: 1048574 Protocol next-hop address: 7.7.7.7 ... INH list-nh dependent count: 2
Das
dependent count: 2bestätigt, dass derzeit zwei Multipath-Routen diesen indirekten Nexthop verwenden.
Begrenzungen
- Gilt nur für BGP-Multipath-Routen mit Listen-NextHops, die aus iBGP- oder hybriden iBGP/eBGP-Pfaden bestehen.
- BGP-Multipath-Routen, bei denen nur eBGP-Mitwirkende vorhanden sind, sind nicht betroffen.
- Gemischte Adressfamilien in einem einzelnen Listen-Nexthop werden nicht unterstützt.
Siehe auch
Unterstützte Standards für BGP
Junos OS unterstützt im Wesentlichen die folgenden RFCs und Internet-Entwürfe, die Standards für IP Version 4 (IPv4) BGP definieren.
Eine Liste der unterstützten BGP-Standards der IP-Version 6 (IPv6) finden Sie unter Unterstützte IPv6-Standards.
Junos OS BGP unterstützt die Authentifizierung für den Protokollaustausch (MD5-Authentifizierung).
-
RFC 1745, BGP4/IDRP für IP-OSPF-Interaktion
-
RFC 1772, Anwendung des Border Gateway Protocol im Internet
-
RFC 1997, BGP-Community-Attribut
-
RFC 2283, Multiprotokoll-Erweiterungen für BGP-4
-
RFC 2385, Schutz von BGP-Sitzungen über die TCP MD5-Signaturoption
-
RFC 2439, BGP-Klappendämpfung
-
RFC 2545, Verwendung von BGP-4-Multiprotokollerweiterungen für IPv6-Inter-Domain-Routing
-
RFC 2796, BGP Route Reflection – Eine Alternative zu Full Mesh IBGP
-
RFC 2858, Multiprotokoll-Erweiterungen für BGP-4
-
RFC 2918, Routenaktualisierungsfunktion für BGP-4
-
RFC 3065, Autonomous System Confederations for BGP (Autonome Systemkonföderationen für BGP)
-
RFC 3107, Carrying Label Information in BGP-4
-
RFC 3345, Border Gateway Protocol (BGP) Persistente Route-Oszillationsbedingung
-
RFC 3392, Ankündigung zu Funktionen mit BGP-4
-
RFC 4271, A Border Gateway Protocol 4 (BGP-4)
-
RFC 4273, Definitionen verwalteter Objekte für BGP-4
-
RFC 4360, BGP Extended Communities-Attribut
-
RFC 4364, BGP/MPLS IP Virtual Private Networks (VPNs)
-
RFC 4456, BGP-Routenreflexion: Eine Alternative zu Full Mesh Internal BGP (IBGP)
-
RFC 4486, Subcodes für BGP Cease Notification Message
-
RFC 4576, Verwendung eines LSA-Optionsbits (Link State Advertisement) zur Verhinderung von Schleifen in BGP/MPLS-IP-VPNs (Virtual Private Networks)
-
RFC 4659, BGP-MPLS-IP-VPN-Erweiterung (Virtual Private Network) für IPv6-VPN
-
RFC 4632, Classless Inter-Domain Routing (CIDR): Der Zuweisungs- und Aggregationsplan für Internetadressen
-
RFC 4684, Constrained Route Distribution für Border Gateway Protocol/MultiProtocol Label Switching (BGP/MPLS) Internet Protocol (IP) Virtual Private Networks (VPNs)
-
RFC 4724, Graceful-Restart-Mechanismus für BGP
-
RFC 4760, Multiprotokoll-Erweiterungen für BGP-4
-
RFC 4781, Graceful Restart Mechanism für BGP mit MPLS
-
RFC 4798, Verbinden von IPv6-Inseln über IPv4-MPLS mithilfe von IPv6-Provider-Edge-Routern (6PE)
Option 4b (eBGP-Neuverteilung von gekennzeichneten IPv6-Routen von AS zu benachbarten AS) wird nicht unterstützt.
-
RFC 4893, BGP-Unterstützung für den Vier-Oktett-AS-Nummernraum
-
RFC 5004, Vermeiden Sie BGP-Übergänge mit dem besten Pfad von einem externen zu einem anderen
-
RFC 5065, Autonomous System Confederations für BGP
-
RFC 5082, Der verallgemeinerte TTL-Sicherheitsmechanismus (GTSM)
-
RFC 5291, Filterfunktion für ausgehende Routen für BGP-4 (teilweise Unterstützung)
-
RFC 5292, Address-Prefix-Based Outbound Route Filter für BGP-4 (teilweise Unterstützung)
Geräte mit Junos OS können präfixbasierte ORF-Nachrichten empfangen.
-
RFC 5396, Textuelle Darstellung von AS-Nummern (Autonomous System)
-
RFC 5492, Ankündigung zu Funktionen mit BGP-4
-
RFC 5512, Der BGP Encapsulation Subsequent Address Family Identifier (SAFI) und das BGP Tunnel Encapsulation Attribute
-
RFC 5549, Ankündigung von IPv4-Informationen zur Erreichbarkeit der Netzwerkschicht mit einem IPv6 Next Hop
-
RFC 8955, Verbreitung von Ablaufspezifikationsregeln
-
RFC 8956, Verbreitung von Datenstromspezifikationsregeln für IPv6
-
RFC 5668, 4-Oktett-AS-spezifische BGP-Extended Community
-
RFC 5701, IPv6-Adressenspezifisches erweitertes Community-Attribut für BGP
-
RFC 5925, Die TCP-Authentifizierungsoption
-
RFC 6286, Autonomous-systemwide Unique BGP Identifier for BGP-4 – vollständig konform
-
RFC 6368, Internes BGP als Anbieter-/Kunden-Edge-Protokoll für BGP/MPLS-IP Virtual Private Networks (VPNs)
-
RFC 6774, Verteilung verschiedener BGP-Pfade
-
RFC 6793, BGP-Unterstützung für den AS-Nummernraum (Autonomous System) mit vier Oktetten
-
RFC 6810, Das Resource Public Key Infrastructure (RPKI)-to-Router-Protokoll
-
RFC 6811, Ursprungsvalidierung von BGP-Präfixen
-
RFC 6996, Reservierung für autonome Systeme (AS) für den privaten Gebrauch
-
RFC 7300, Reservierung der letzten AS-Nummern (Autonomous System)
-
RFC 7311, Das kumulierte IGP-Metrikattribut für BGP
-
RFC 7404, Nur Link-Local-Adressierung innerhalb eines IPv6-Netzwerks
-
RFC 7432, BGP MPLS-basiertes Ethernet-VPN (eVPN)
-
RFC 7606, Überarbeitete Fehlerbehandlung für BGP-UPDATE-Meldungen
-
RFC 7611, BGP ACCEPT_OWN Community-Attribut
Wir unterstützen den RFC, indem wir es Juniper Routern ermöglichen, Routen zu akzeptieren, die von einem Routenreflektor mit dem
accept-ownCommunity-Wert empfangen werden. -
RFC 7752, North-bound-Verteilung von Link-State- und Traffic Engineering (TE)-Informationen mithilfe von BGP
-
RFC 7854, BGP-Überwachungsprotokoll (BMP)
-
RFC 7911, Ankündigung mehrerer Pfade in BGP
-
RFC 8097, BGP-Präfix, Ursprungsvalidierungsstatus, erweiterte Community
-
RFC 8210, Das Resource Public Key Infrastructure (RPKI)-zu-Router-Protokoll, Version 1
-
RFC 8212, Default External BGP (EBGP) Route Propagation Behavior without Policies – vollständig konform
Ausnahmen:
Die Verhaltensweisen in RFC 8212 sind standardmäßig nicht implementiert, um eine Unterbrechung der bestehenden Kundenkonfiguration zu vermeiden. Das Standardverhalten wird weiterhin beibehalten, um alle Routen in Bezug auf EBGP-Peers zu akzeptieren und anzukündigen.
-
RFC 8277, Verwenden von BGP zum Binden von MPLS-Bezeichnungen an Adresspräfixe
-
RFC 8326, Ordnungsgemäßes Herunterfahren der BGP-Sitzung
-
RFC 8481, Erläuterungen zur BGP-Ursprungsvalidierung basierend auf der Resource Public Key Infrastructure (RPKI)
-
RFC 8538, Unterstützung von Benachrichtigungsmeldungen für einen ordnungsgemäßen BGP-Neustart
-
RFC 8571, BGP - Link State (BGP-LS) Advertisement of IGP Traffic Engineering Performance Metric Extensions
-
RFC 8584, Framework for Ethernet VPN Designated Forwarder Election Extensibility
-
RFC 8642, Richtlinienverhalten für bekannte BGP-Communities
-
RFC 8669, Segment-Routing-Präfix-Segment-ID-Erweiterungen für BGP
-
RFC 8810, Überarbeitung der Registrierungsverfahren für Capability Codes
-
RFC 8814 Signalisierung der maximalen SID-Tiefe (MSD) unter Verwendung des Border Gateway Protocol – Verbindungsstatus (teilweise Unterstützung)
-
RFC 8950, Ankündigung von IPv4 Network Layer Reachability Information (NLRI) mit einem IPv6 Next Hop
-
RFC 8955
-
RFC 8956
-
RFC 9003, Erweiterte BGP-Kommunikation zum administrativen Herunterfahren
-
RFC 9012, Das BGP-Tunnelkapselungsattribut
-
RFC 9029, Aktualisierungen der Zuordnungsrichtlinie für die Border Gateway Protocol – Link State (BGP-LS) Parameters Registrys
-
RFC 9069, Unterstützung für lokale RIB im BGP Monitoring Protocol (BMP)
-
RFC 9085, Border Gateway Protocol – Link State (BGP-LS)-Erweiterungen für Segment-Routing
-
RFC 9117, Überarbeitetes Validierungsverfahren für die Verbreitung von BGP-Datenstromspezifikationen. Dadurch können die Datenstromspezifikationen im selben autonomen System wie der BGP-Peer erstellt werden, der die Validierung durchführt.
-
RFC 9234, Verhinderung und Erkennung von Routenlecks mithilfe von Rollen in UPDATE- und OPEN-Nachrichten
-
RFC 9384, Ein BGP Cease NOTIFICATION-Subcode für Bidirectional Forwarding Detection (BFD)
-
Internet-Entwurf draft-idr-rfc8203bis-00, BGP Administrative Shutdown Communication (läuft im Oktober 2018 ab)
-
Internet-Entwurf draft-ietf-grow-bmp-adj-rib-out-01, Unterstützung für Adj-RIB-Out im BGP Monitoring Protocol (BMP) (läuft am 3. September 2018 ab)
-
Internet-Entwurf draft-ietf-idr-aigp-06, The Accumulated IGP Metric Attribute for BGP (läuft im Dezember 2011 ab)
-
Internet-Entwurf draft-ietf-idr-as0-06, Kodifizierung der AS-0-Verarbeitung (gültig bis Februar 2013)
-
Internet-Entwurf draft-ietf-idr-link-bandwidth-06.txt, BGP Link Bandwidth Extended Community (gültig bis Juli 2013)
-
Internet-Entwurf draft-ietf-sidr-origin-validation-signaling-00, BGP Prefix Origin Validation State, Extended Community (teilweise Unterstützung) (läuft im Mai 2011 aus)
Die erweiterte Community (Ursprungsvalidierungsstatus) wird in der Routing-Richtlinie von Junos OS unterstützt. Die angegebene Änderung im Routenauswahlverfahren wird nicht unterstützt.
-
Internet-Entwurfs-draft-kato-bgp-ipv6-link-local-00.txt, BGP4+-Peering mit IPv6 Link-Local-Adresse
Die folgenden RFCs und Internet-Entwürfe definieren keine Standards, sondern geben Auskunft über BGP und verwandte Technologien. Die IETF klassifiziert sie unterschiedlich als "experimentell" oder "informativ".
-
RFC 1965, Autonomous System Confederations for BGP (Autonome Systemkonföderationen für BGP)
-
RFC 1966, BGP Route Reflection – Eine Alternative zu vollmaschigem IBGP
-
RFC 2270, Verwendung eines dedizierten AS für Standorte, die von einem einzigen Anbieter verwaltet werden
-
RFC 3345, Border Gateway Protocol (BGP) Persistente Route-Oszillationsbedingung
-
RFC 3562, Überlegungen zur Schlüsselverwaltung für die TCP MD5-Signaturoption
-
Internet-Entwurf draft-ietf-ngtrans-bgp-tunnel-04.txt, Connecting IPv6 Islands across IPv4 Clouds with BGP (Läuft im Juli 2002 ab)
Siehe auch
Tabellarischer Änderungsverlauf
Die Unterstützung der Funktion hängt von der Plattform und der Version ab, die Sie benutzen. Verwenden Sie Feature Explorer, um festzustellen, ob eine Funktion auf Ihrer Plattform unterstützt wird.