瞻博网络 RDMA 感知负载平衡 (LB) 和 BGP-DPF – GPU 后端交换矩阵作
本节介绍RDMA感知负载均衡(RLB)与BGP-DPF解决方案的作详情。
RDMA 感知负载平衡 (RLB) 通过将瞻博网络的 BGP-DPF(确定性路径转发)与主机上的高级软件集成相结合,为 AI 工作负载引入了确定性路径转发。这种方法可确保流量在稳态运行期间遵循预定义的一致路径通过网络交换矩阵,同时在发生故障时保持稳健的回退机制。
在基于 RoCEv2 的 RDMA 通信中,单个大型流通常会分解成多个子流,每个子流都与一个不同的队列对 (QP) 相关联。这些子流通常使用相同的源和目标 IP 地址以及目标 UDP 端口 (4791),仅不同之处在于它们随机选择的源端口。因此,基于 ECMP 的标准负载平衡可能会将多个子流散列到同一链路,从而导致分布不均匀和性能不可预测。
利比引入了确定性,为每个子流分配一个唯一的 IP 地址,并使用这些 IP 地址来引导子流跨特定路径,而不是依赖基于哈希的负载平衡,后者将负载平衡挑战转化为路由问题,其中每个 RDMA 子流都映射到通过交换矩阵的特定路径,从而消除随机性并确保一致的行为和有序交付。
该解决方案可确保每个流量都遵循通过网络交换矩阵的预先确定路径:
- RDMA 流量根据控制平面上的 BGP 导出策略和颜色社区标记映射到确定性路径,为 AI/机器学习工作负载提供高度可预测的负载分配和转发。通过消除流量哈希,该方法可确保按顺序传递,并有效防止稳态条件下的链路拥塞。
- 这种映射消除了传统哈希方法引入的可变性,从而实现了跨所有工作负载的可预测流量分布。
- 如果链路发生故障,系统会自动回退到动态负载平衡 (DLB),从而允许流量重新路由并以最小的中断完成任务。
- 使用标准以太网、RoCEv2 和 BGP 协议,无需昂贵的 NIC 进行喷洒或重新订购。
瞻博网络 RDMA 感知负载平衡 (LB) 和 BGP-DPF – 控制平面
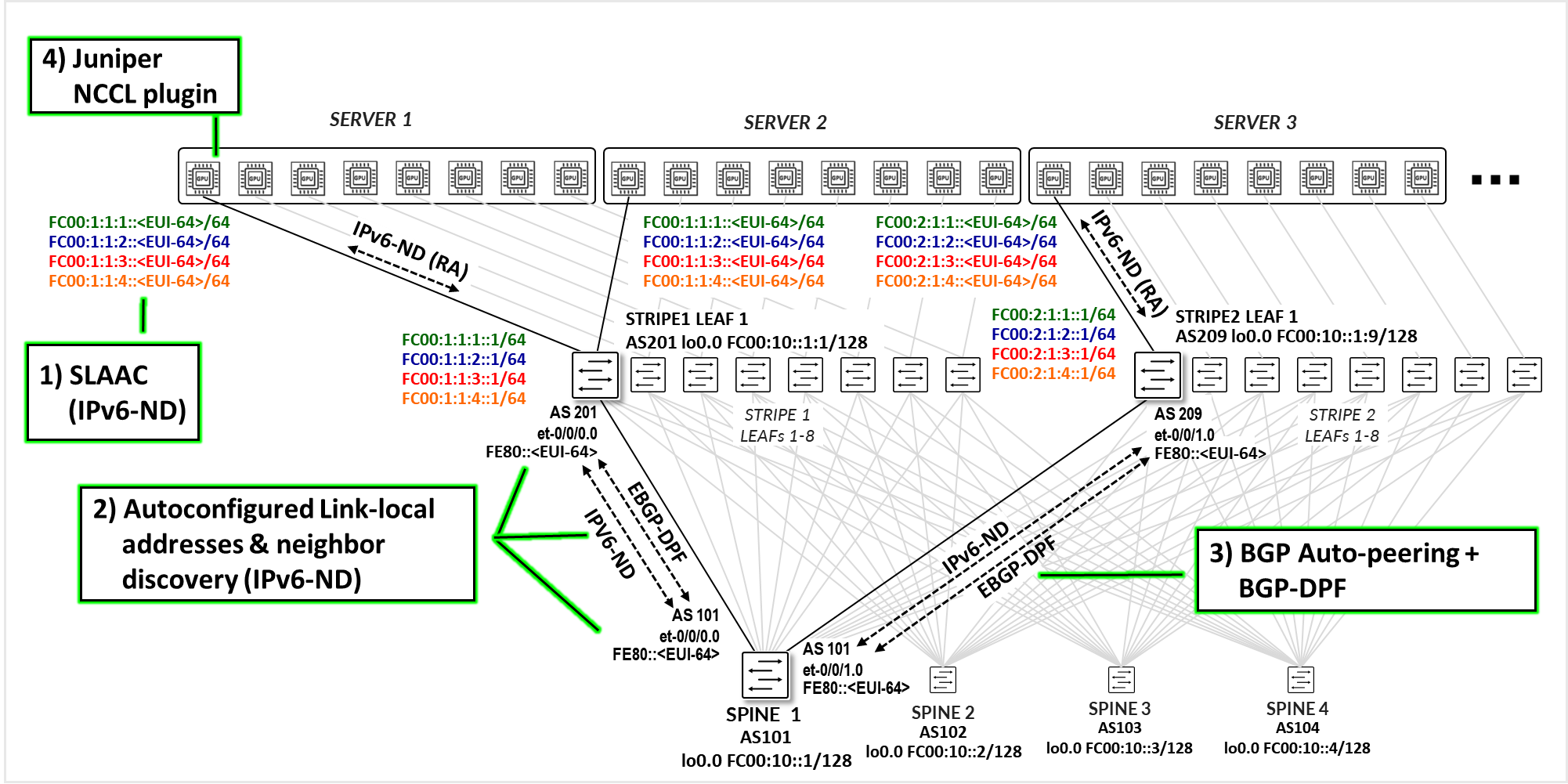
此解决方案的控制平面由四个主要组件组成,如 图 1 所示。
- 基于 IPv6 路由器通告 (IPv6-ND.
- 在 叶节点和主干节点上自动分配链路本地 IPv6 地址,结合 使用 IPv6 路由器通告 (IPv6-ND) 的邻接方发现。
- 使用 BGP 邻接方自动发现(IPv6 链路本地和邻接方发现)的瞻博网络 EBGP-DPF。
- 服务器上的 瞻博网络 NCCL 插件 。
每个组件将在接下来的几节中详细介绍。
使用 SLAAC(无状态地址自动配置)自动分配 GPU 服务器 IPv6 地址
为了支持可扩展和自动化的 IPv6 地址分配,GPU 服务器使用 SLAAC 获取其 IPv6 地址。这不仅无需手动编辑每台服务器上的网络计划配置文件,还可以根据需要灵活添加或删除 IPv6 地址,以支持将流量固定到网络拓扑,特别是在每个接口需要多个 IPv6 地址的情况下。
SLAAC(无状态地址自动配置)是 IPv6 中定义的一种机制,使主机能够自动生成自己的 IP 地址,而无需手册配置或 DHCP 服务器。服务器侦听连接的叶节点定期发送的路由器通告 (注册机关) 消息。叶节点必须显式配置为在连接到服务器的下游接口上发送注册机关消息。这些消息包括一个 IPv6 前缀和指示是否应使用 SLAAC 的标志。然后,服务器通过将播发的前缀与使用 EUI-64 格式从其 MAC 地址派生的 64 位接口标识符组合来组合其 IPv6 地址。这种方法可实现高效且可扩展的地址配置,特别是在动态或大规模环境中。
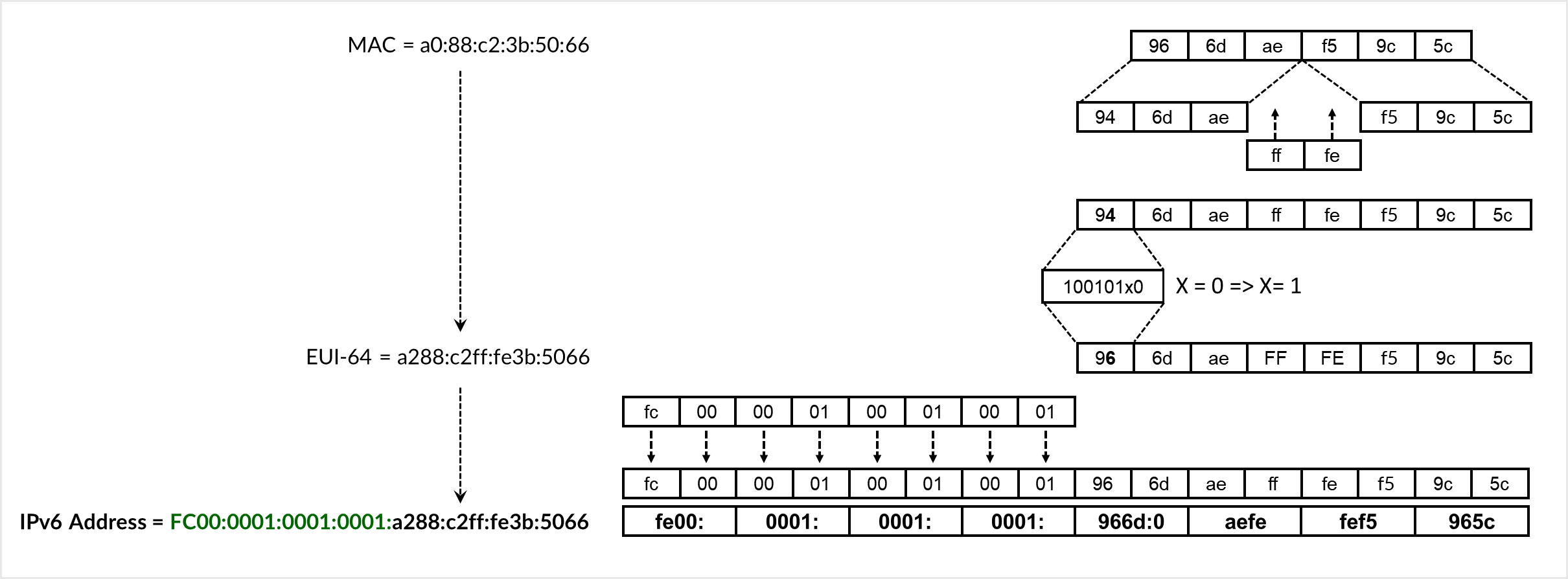
EUI-64 转换过程包括拆分 48 位 MAC 地址、在中间插入 ff:fe 以及翻转通用/本地 (U/L) 位。如 图 2 所示,MAC 地址 96:6d:ae:f5:05:c0 转换为 EUI-64 标识符 966d:aeff:fef5:05c0。然后,播发的前缀 FC00:0000:0001:0001::/64 会被前置,以形成完整的 IPv6 地址 FC00:0000:0001:0001:966d:aeff:fef5:05c0。
在 图 3 描述的示例中, Stripe 1 Leaf 1 接口 irb.2 配置了 IPv6 地址 FC00:1:1:1::1/64、FC00:1:1:2::1/64、FC00:1:1:3::1/64 和 FC00:1:1:4::1/64。接口还具有从接口的 MAC 地址自动生成的链路本地地址。交换机配置为发送播发 FC00:1:1:1:/64、FC00:1:1:2:::/64、FC00:1:1:3::/64 和 FC00:1:1:4:/64 前缀的路由器通告 (RA)。然后,服务器 H100-01 通过 SLAAC 使用其MAC 地址在其gpu0_eth接口上自动配置相应的 IPv6 地址。
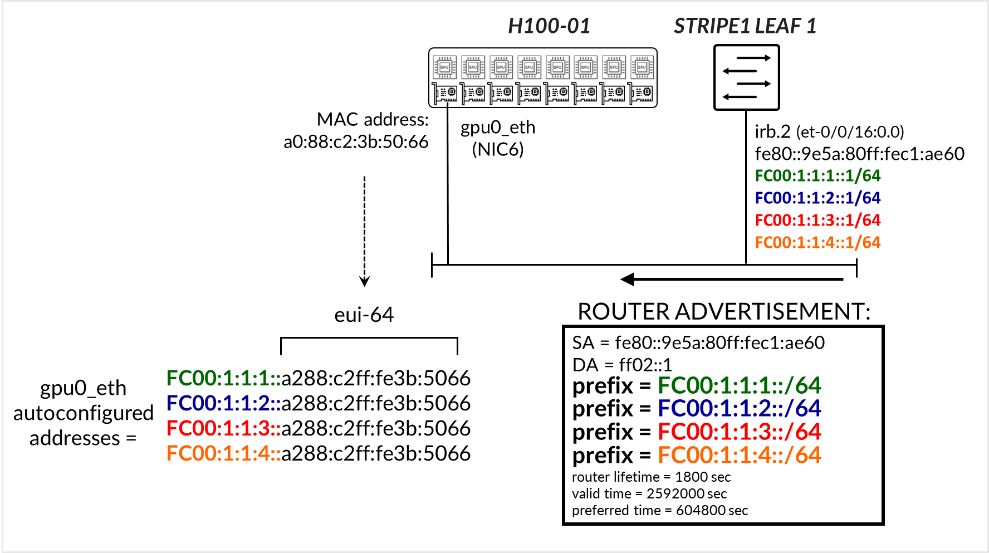 SLAAC 示例
SLAAC 示例
请注意,每个接口上都会播发多个 IPv6 前缀。前缀的数量,因此分配给每个 GPU 服务器接口的 IPv6 地址数量取决于上行链路(叶节点和主干节点之间的连接)的数量。
我们建议您遵循以下准则:队列对数 = IPv6 地址数 = 上行链路数(叶至主干链路)。有关更多详细信息,请参阅建议的队列对数部分。
下图演示了具有四个主干节点的方案,显示每个叶-主干连接一个链路或每个连接两个链路。目标是为不同的流量设置不同的 IPv6 地址,然后根据这些流量的地址跨不同的路径转发这些流量。
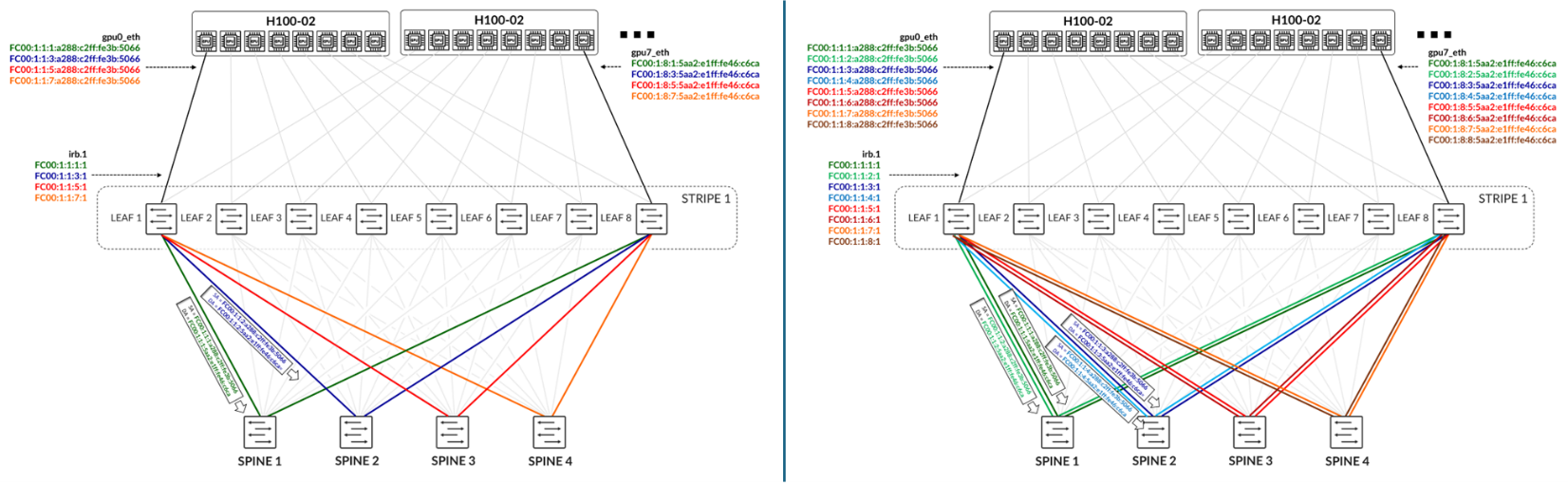
如果每个叶主干连接只有一个链路:
- 每个 GPU 接口只需要四个 IPv6 地址。
- 服务器 1 上分配给 gpu0_eth 的第一个 IPv6 地址 (H100-01) 与服务器 2 上分配给 gpu7_eth 的第一个 IPv6 地址 (H100-02) 之间的流量应被视为绿色流量,并通过主干 1 进行转发。
- 服务器 1 上分配给 gpu0_eth 的第二个 IPv6 地址与服务器 2 上分配给 gpu7_eth 的第二个 IPv6 地址之间的流量应被视为蓝色流量,并通过主干 2 进行转发。
如果每个叶主干连接有两个链路:
- 每个 GPU 连接需要八个 IPv6 地址。
- 服务器 1 上分配给 gpu0_eth 的第一个和第二个 IPv6 地址与服务器 2 上分配给 gpu7_eth 的第一个和第二个 IPv6 地址之间的流量应分别被视为深绿色和浅绿色流量,并通过主干 1 进行转发。
- 在服务器 1 上分配给 gpu0_eth 的第三个和第四个 IPv6 地址与在服务器 2 上分配给gpu7_eth的第三个和第四个 IPv6 地址之间的流量应分别被视为深蓝色和浅蓝色流量,并通过主干 2 进行转发。
RDMA 流将映射到服务器端的不同 IPv6 地址。这将在 瞻博网络 RDMA 感知负载平衡 (LB) 和 BGP-DPF – 转发平面 部分中介绍。
叶节点和主干节点上的自动链路本地 IPv6 地址分配和邻接方发现
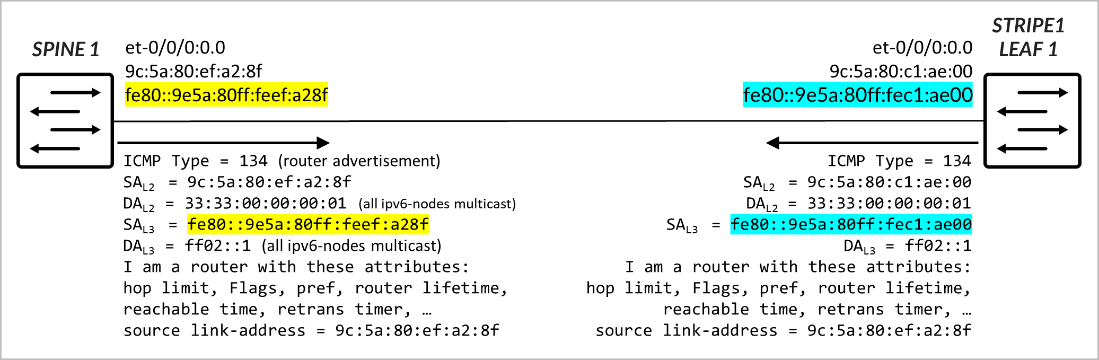
叶节点和主干节点之间的接口不需要显式配置的地址。只需在每个接口上启用 IPv6(例如,通过配置家族 inet6)即可。启用 IPv6 时,接口会自动在 fe80::/10 范围内生成一个链路本地 IPv6 地址,可用于与直接连接的邻接方进行通信。链路本地地址的构造采用 EUI-64 格式,与服务器将其 IPv6 地址构造为 SLAAC 的一部分的方式相同。这简化了配置,无需在叶主干链路上手册 IP 寻址,同时仍允许控制平面协议(如 BGP)建立通信。
叶节点和主干节点必须配置为在相互连接的接口上发送路由器通告 (注册机关) 消息,从而启用自动邻接方发现。每个路由器都会通告自己唯一的链路本地地址,以及 MAC 地址、路由器寿命、MTU 和其他相关选项等附加信息。
BGP 会话自动发现和 BGP-DPF(确定性路径转发)
一旦设备通过 IPv6 邻接方发现学习了彼此的本地链路地址,叶节点和主干节点之间的 EBGP 会话就会自动建立。这项瞻博网络功能称为 BGP 自动发现或 BGP 自动对等互连,利用 Junos OS 对以下方面的支持:
- RFC 4861:邻接方发现 IP 版本 6 (IPv6)
- RFC 2462:IPv6 无状态地址自动配置
传统上,BGP 需要显式配置邻居 IP、自治系统 (AS) 编号和路由策略来控制路由交换。使用 BGP 未编号对等互连时,每个节点都配置为在指定接口上接受动态对等方。会话在本地链路地址之间形成,这些地址通过点对点链路上的 IPv6 路由器通告自动生成和交换。因此,无需手动定义邻居 IP,即可在交换矩阵中建立 BGP 会话,从而简化部署并提高可扩展性。因此,会话配置最少的设置,包括本地 AS 编号、可接受的远程 AS 编号列表(用于发现的对等方)和 IPv6 邻接方发现。
这些会话还配置为充当 BGP-DPF(确定性路径转发)会话,其中每个对等方都与交换 矩阵颜色相关联,该颜色定义分配给该对等方交换矩阵路径的颜色。
这些颜色在配置的policy-options下定义为BGP扩展社区,格式为color:0:<tag>。 表 1 显示了一些示例。
| 颜色(社区) | 聚合前缀 |
|---|---|
| 绿 | 颜色:0:1 |
| 蓝 | 颜色:0:2 |
| 红 | 颜色:0:3 |
| 橙 | 颜色:0:4 |
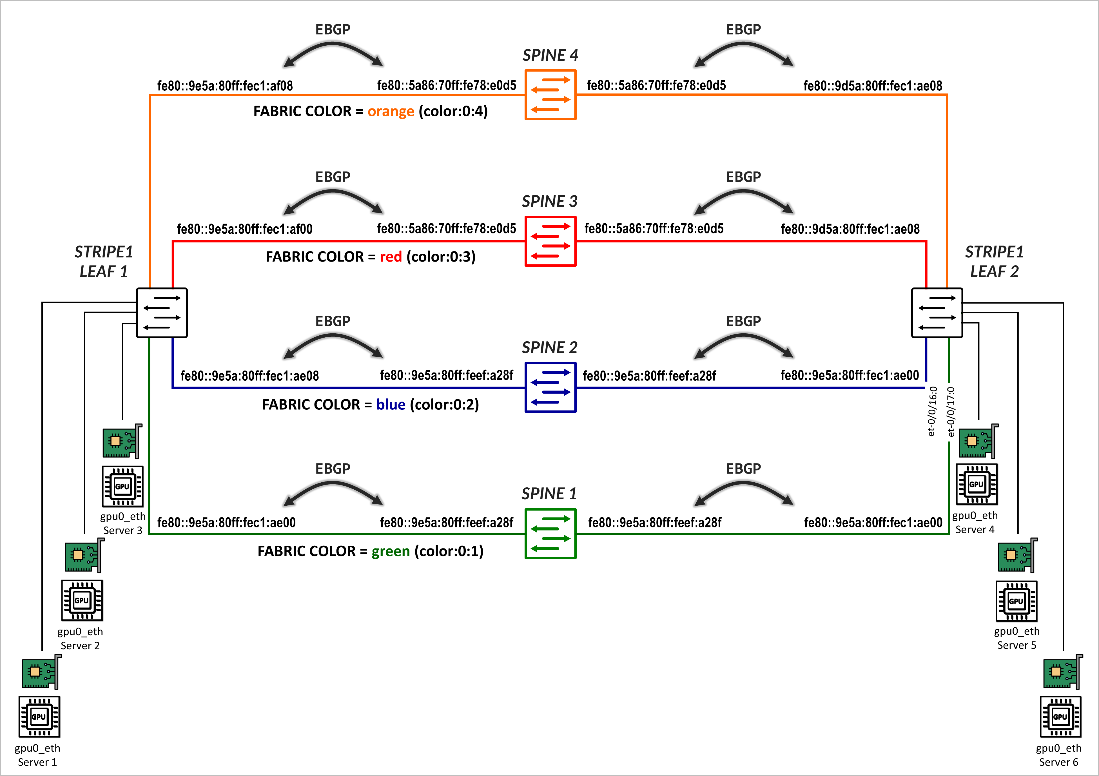
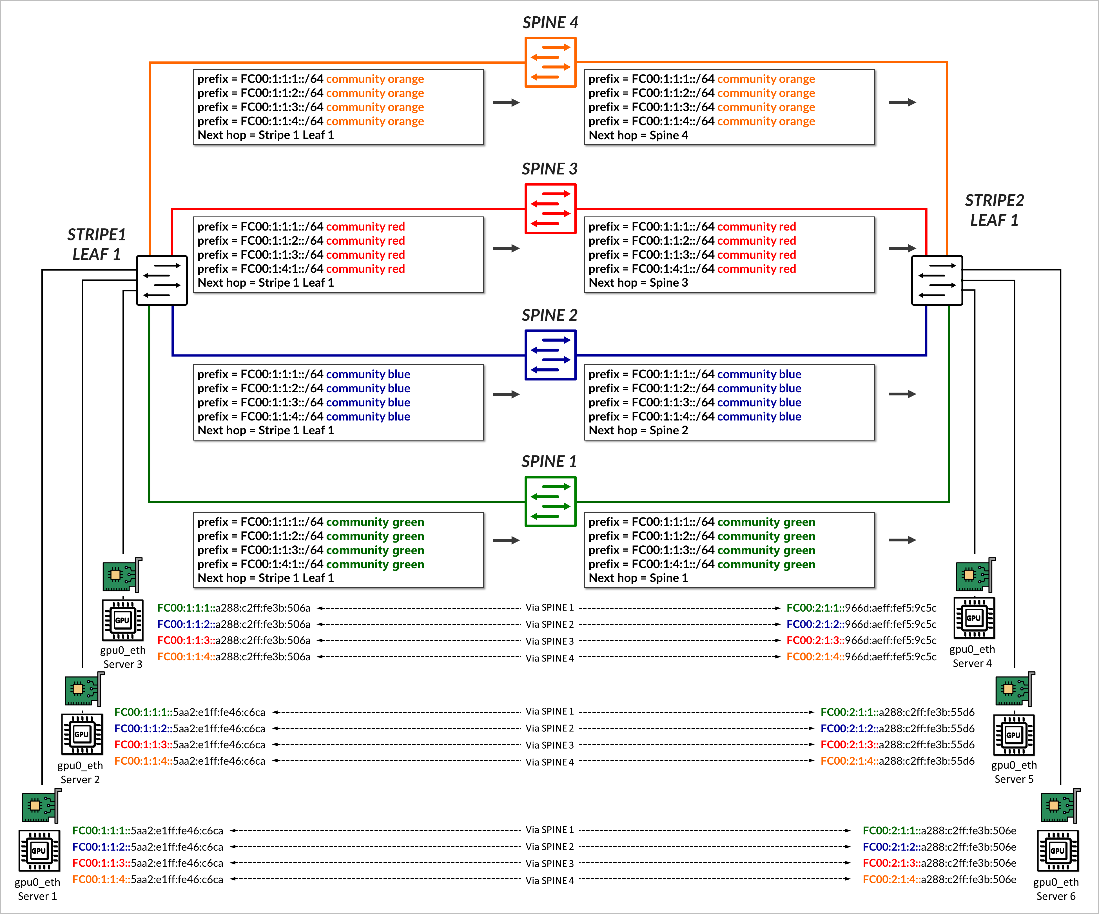
建立 BGP 会话后,每个叶节点通过路由器通告 (RA) 向 GPU 服务器播发的同一单独 /64 IPv6 前缀,如 使用 IPv6 SLAAC 的 GPU 服务器到叶节点连接部分中所述 。 所有前缀都会播发到所有主干,并使用与相应交换矩阵链路颜色匹配的 BGP 颜色社区进行标记,如 图 7 所示。
AIGP BGP 路径属性用于确定每个前缀的前缀对等方(路径)。
AIGP(累积 IGP)是 RFC 7311 中定义的 BGP 路径属性,允许 BGP 跨 BGP 跃点携带类似于 IGP 成本的累积指标。启用后,AIGP 值将成为 BGP 最佳路径选择算法的一部分,具体影响标准 BGP 决胜局(如路由器 ID 或最短 AS 路径)之前的决策。
在 Junos 中,如果存在 AIGP 属性,则 BGP 将首选 AIGP 值最低的路径。如果路由上不存在 AIGP,则该路由将被视为具有实际上无限的成本,因此它不如包含有效 AIGP 值的任何路径的首选。例如,AIGP = 1 的路由优先于没有 AIGP 属性的路由。
在通往主干的首选路径上,前缀以 AIGP = 0 进行播发,在到所有其他主干的路径上 不使用 AIGP 属性 ,如 中的示例所示。
图 12:使用 AIGP 的前缀广告示例
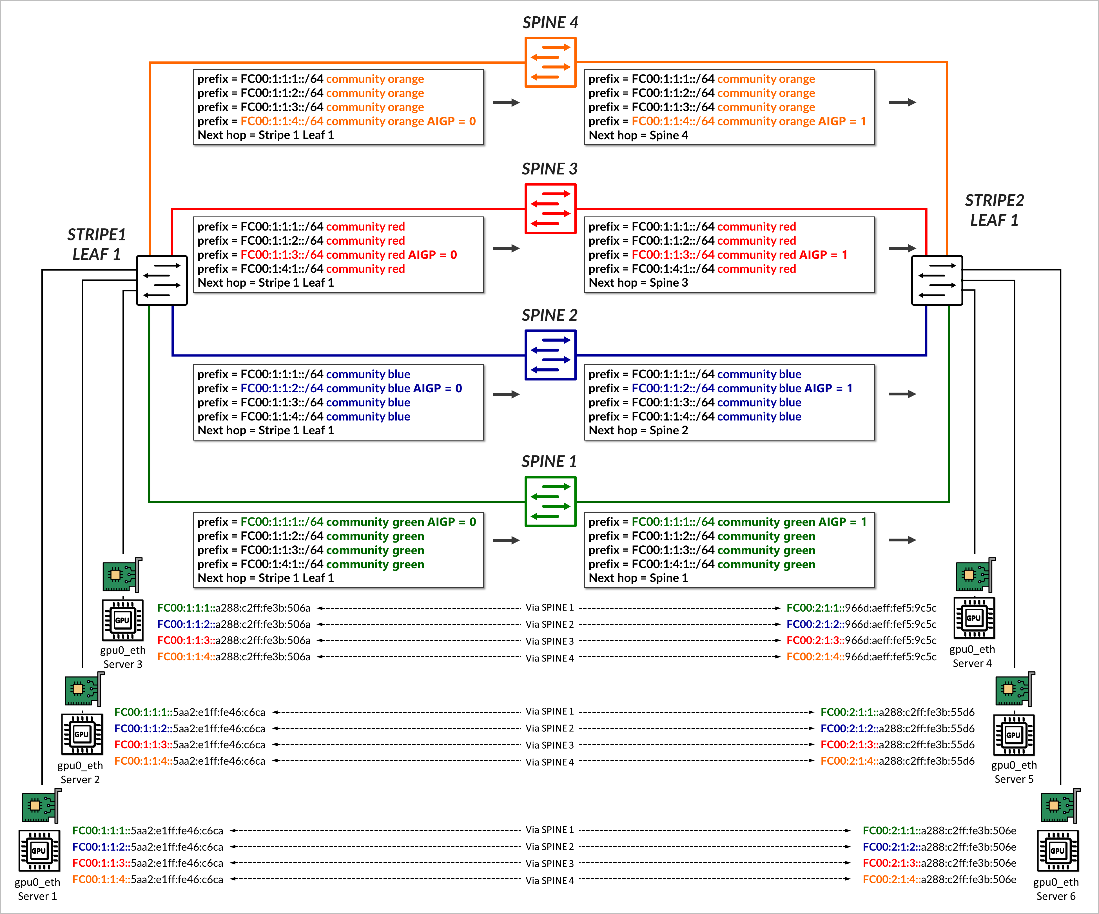
在此示例中,stripe1-leaf1 将前缀 FC00:1:1:1::/64、FC00:1:1:2::/64、FC00:1:1:3::/64 和 FC00:1:1:4::/64 播发给主干 1 到 4,颜色社区分别为绿色、蓝色、红色和橙色。每个前缀都以 AIGP = 0 发送到特定主干,如 表 2 所示。
| 同辈 | ||||
|---|---|---|---|---|
| 主干 1 | 、主干 2 | 、主干 3 | 、主干 4 | |
| 广告前缀 | 颜色(公共区)、AIGP 值 | |||
| FC00:1:1:1::/64 | 绿色, AIGP 0 | 绿 | 绿 | 绿 |
| FC00:1:1:2::/64 | 蓝 | 蓝色, AIGP 0 | 蓝 | 蓝 |
| FC00:1:1:3::/64 | 红 | 红 | 红色,AIGP 0 | 红 |
| FC00:1:1:4::/64 | 橙 | 橙 | 橙 | 橙色,AIGP 0 |
然后,每个主干将所有收到的前缀播发到远程叶节点, 而不更改社区值,而是 更新的 AIGP 值 1,反映从主干到原始播发叶的 IGP 成本。如前所述,由于不存在 AIGP,所有其他路由都被视为具有无限成本。
在选择 BGP 路由期间,接收叶节点使用此信息。例如,stripe2-leaf1 接收前缀 FC00:1:1:1::/64 的四个副本,每个主干接收一个,但选择从 主干 1 接收的路径,因为它具有 最低的 AIGP 指标 (1),如 图 8 所示。
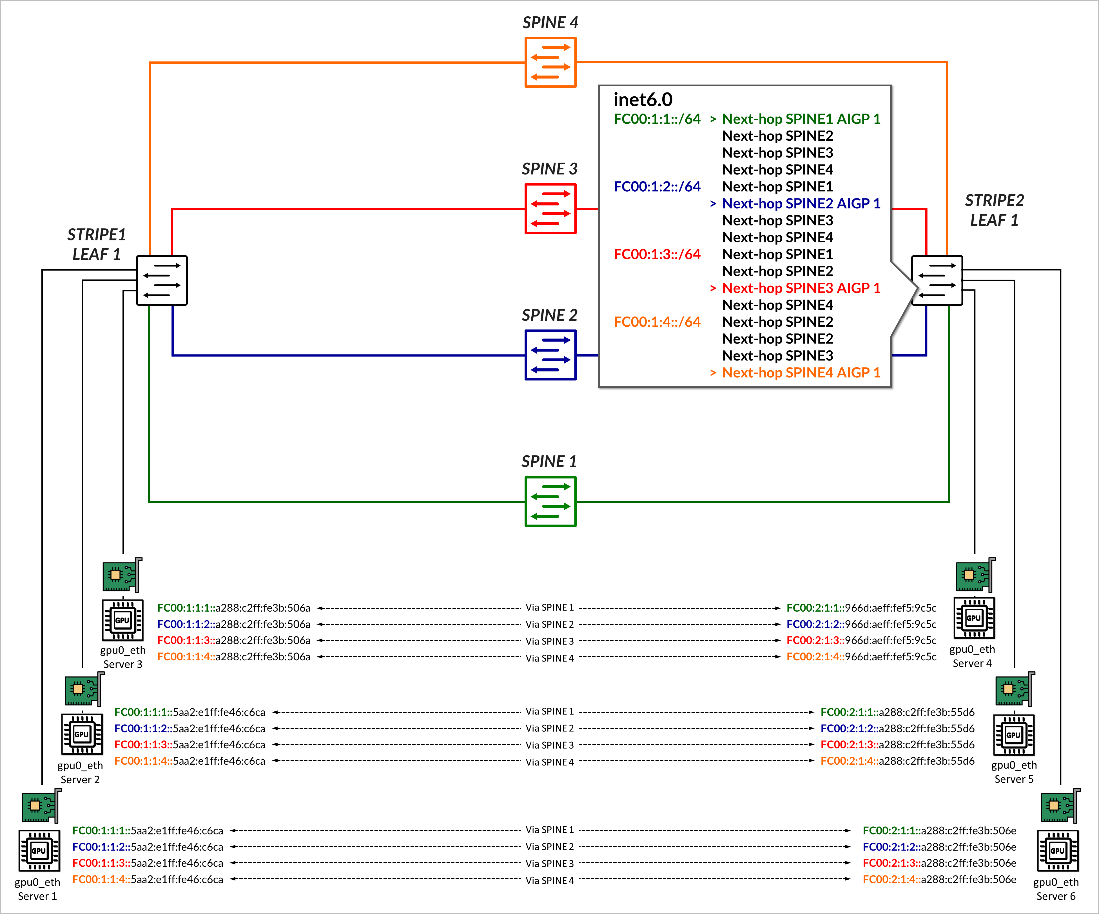
这样就可以根据广告叶的转发意图进行 确定的、按前缀的路径选择 。这将显示在 瞻博网络 RDMA 感知负载平衡 (LB) 和 BGP-DPF - 转发平面 部分。
服务器上的瞻博网络 NCCL 插件。
在典型的 RDMA 实施中,当在两个端点之间建立多个队列对 (QP) 时,生成的流量共享相同的协议、源和目标 IP 地址以及目的端口(通常为 RoCEv2 的 UDP 端口 4791)。源端口通常从相似的瞬时范围内选择,从而产生非常相似的 5 元组。借助等价多路径 (ECMP) 等负载平衡机制,流量会根据 5 元组进行散列,这决定了流到出口接口的分配。这通常会导致多个 QP 被哈希到同一条链路。增强功能(例如在哈希中包含 QP 标识符或使用基于拥塞指标的动态负载平衡 (DLB))可以改善流量分布。但是,这些机制并不能保证一致性,流量仍可能被分配给同一链路。此外,动态条件引起的重新分配可能会导致数据包交付无序和延迟可变,从而对作业性能产生负面影响。
为了应对这些挑战,瞻博网络开发了 NCCL 网络插件——一个共享库,通过拦截和自定义 RDMA 连接的建立和使用方式来扩展 NCCL 的本机功能。该插件不再仅仅依赖 NCCL 的内置逻辑来进行设备发现、拓扑选择和数据移动,而是支持高级功能,例如确定性路径选择和拓扑感知流量分段,专为 RoCEv2 交换矩阵上的 AI 工作负载量身定制。
瞻博网络 NCCL 网络插件通过将单个 RDMA 流拆分为多个子流,实现 RDMA 流量的确定性转发。系统会为每个子流分配一个通过 SLAAC 生成的唯一 IPv6 地址,并映射到入口叶交换机上的特定上行链路。这使得流量能够在多个接口上确定性且均匀地分配。每个队列对 (QP) 使用不同的 IPv6 地址可确保路径选择的一致性,并得到现代 NIC 和网络设备的全面支持。
为了实现这一点,该插件将要传输的内存区域划分为更小的段,每个段分配给不同的子流,如 图 9 所示。每个分段使用单独的 RDMA 队列对 (QP)。
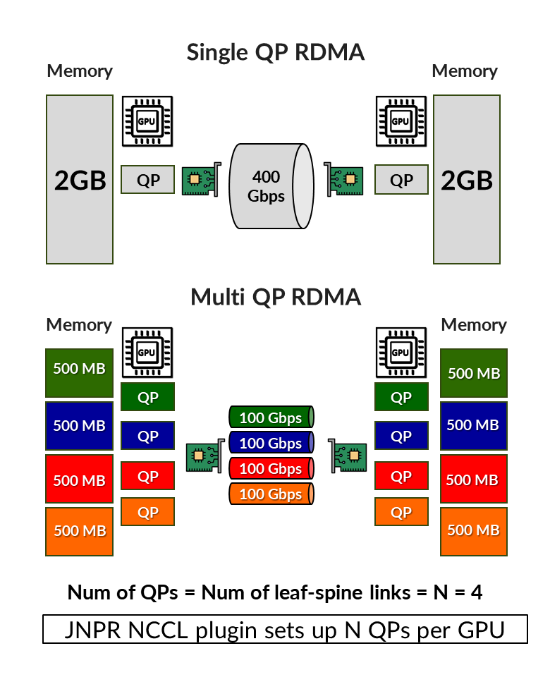
子流并发传输。虽然必须在每个子流中保留数据包的排序,但不需要跨不同子流进行有序传递。下一节将介绍转发平面如何处理这些子流,包括如何在每个跃点处理这些子流,以及如何在整个交换矩阵中保留确定付。
推荐:队列对数 = IPv6 地址数 = 上行链路数(叶至主干链路)。 有关更多详细信息,请参阅建议的队列对数部分。
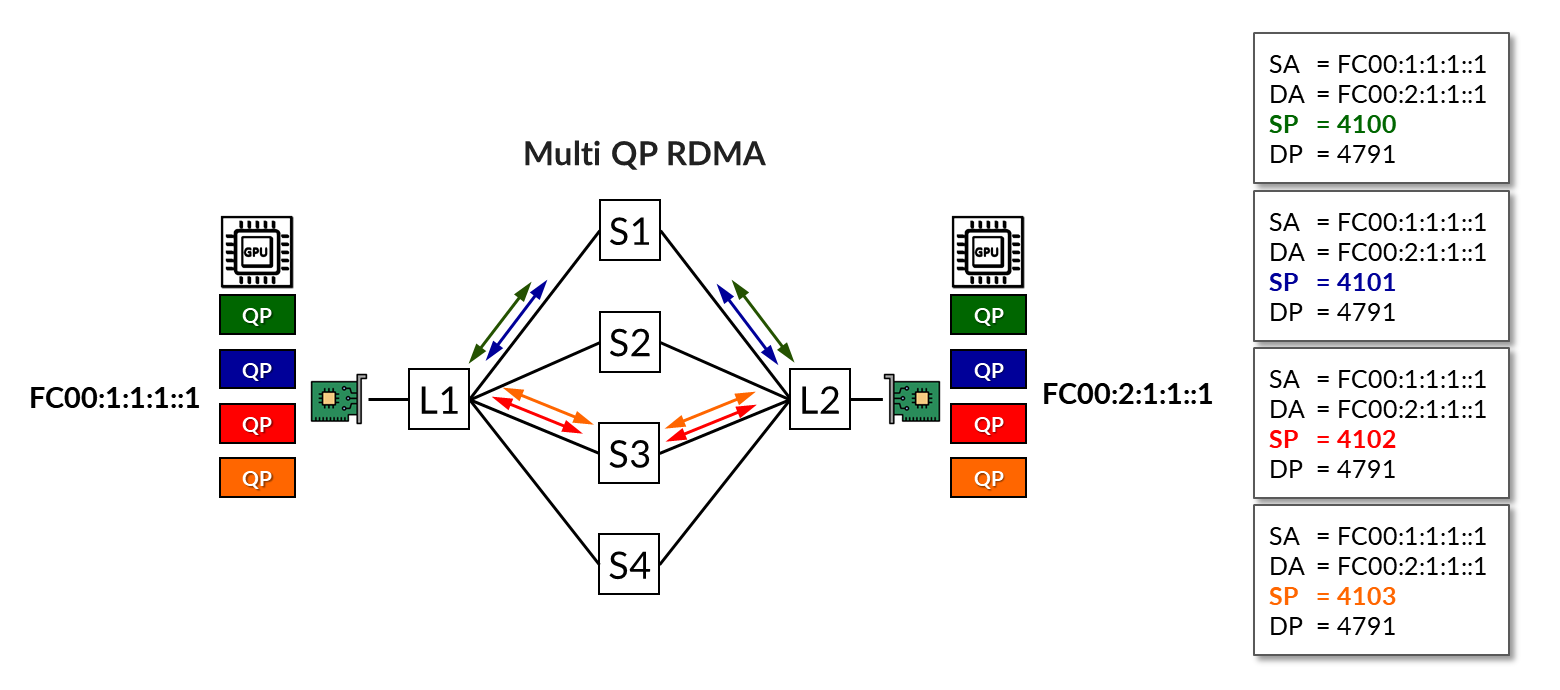
在 图 10 所示的示例中,使用了四个 QP。这四个共享相同的协议 (UDP)、源地址 (fc00:1:1:1::1)、目标地址 (fc00:2:1:1::1) 和目标端口 (4791),仅源端口号不同。
负载平衡(不带 RLB)机制分配了两个流穿过 主干 1 ,另外两个流穿过 主干 3,使通过 主干 2 和 4 的路径闲置。
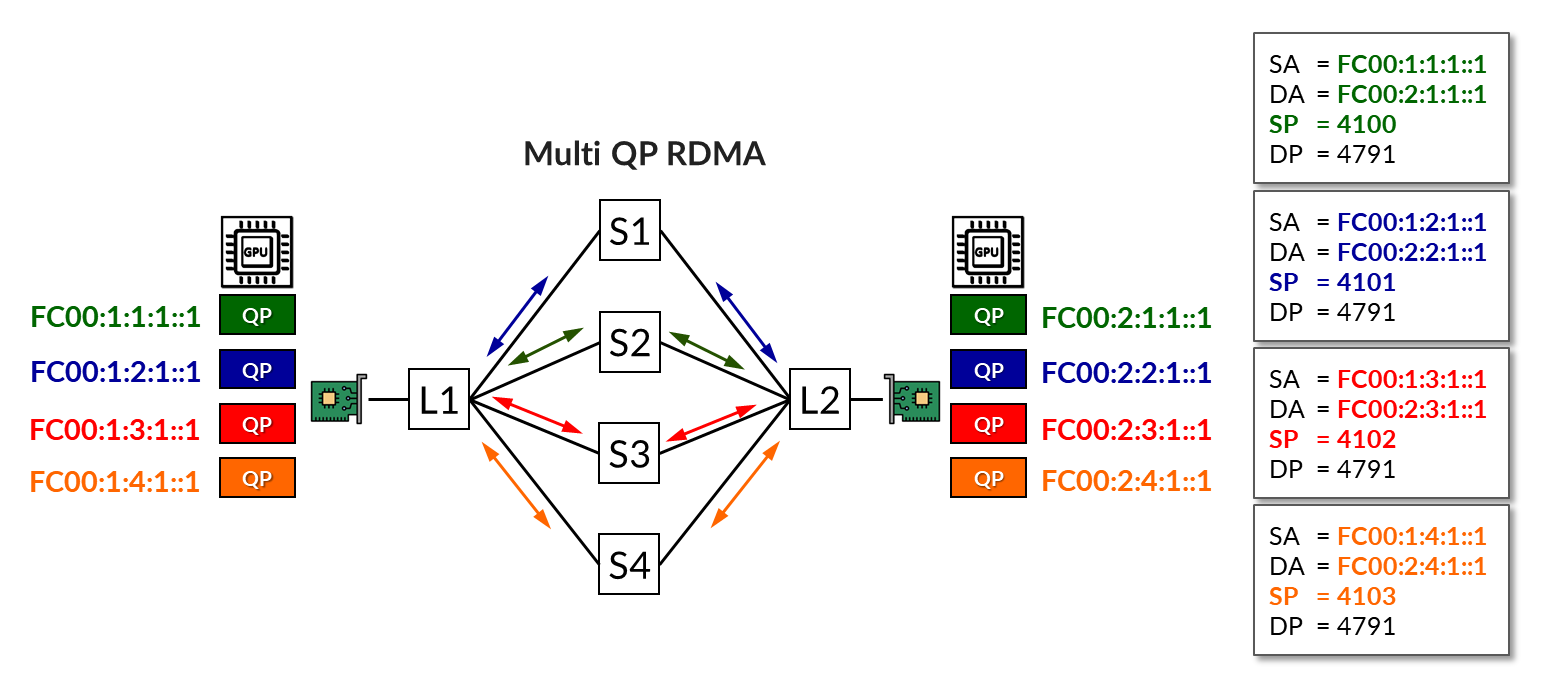
相同的示例,但现在使用 RLB,如 图 11 所示。在此场景中,将为每个 NIC 分配多个 IPv6 地址,如 使用 IPv6 SLAAC 的 GPU 服务器到叶节点连接 部分中所述。然后,将每个 QP 映射到不同的地址。因此,系统会根据BGP色社区和策略控制确定性地将流量分配给特定的上行链路,如 BGP会话自动发现和 BGP-DPF(确定性路径转发) 部分所述。
瞻博网络 RDMA 感知负载平衡 (LB) 和 BGP-DPF – 转发平面
建立 RDMA 子流并将每个子流映射到唯一的 IPv6 源地址后,通过交换矩阵的转发将遵循控制平面定义的确定性路径。每个子流都由其源和目标 IPv6 地址标识,被发送至本地叶交换机,后者会执行转转发表查找。BGP 决策过程之前选择的可用下一跃点会导致叶确定性地将数据包转发到相应的主干节点。
当主干收到数据包时,它会执行路由查找,并将数据包转发到相应的远程叶节点。由于主干在每个前缀只维护一个路由,因此转发是一致且确定的。
在远程分叶,数据包从主干到达,并被转发到与目标 IPv6 地址关联的目标 GPU (NIC)。
在 图 12 所示的示例中,GPU0 QP1 的流量映射到服务器 1 上的 IPv6 地址 FC00:1:1:4::a288:c2ff:fe3b:506a,以及服务器 4 上的 IPv6 地址 FC00:2:1:4::966d:aeff:fef5:9c5c。这两个地址分别对应于前缀 FC00:1:1:4::/64 和 FC00:2:1:4::/64,如之前在 BGP会话自动发现和 BGP-DPF(确定性路径转发) 部分所述,它们通过主干 4 在路径上使用 AIGP 属性进行播发。
这些地址之间的流量将通过链路转发至主干 4(如果可用)。
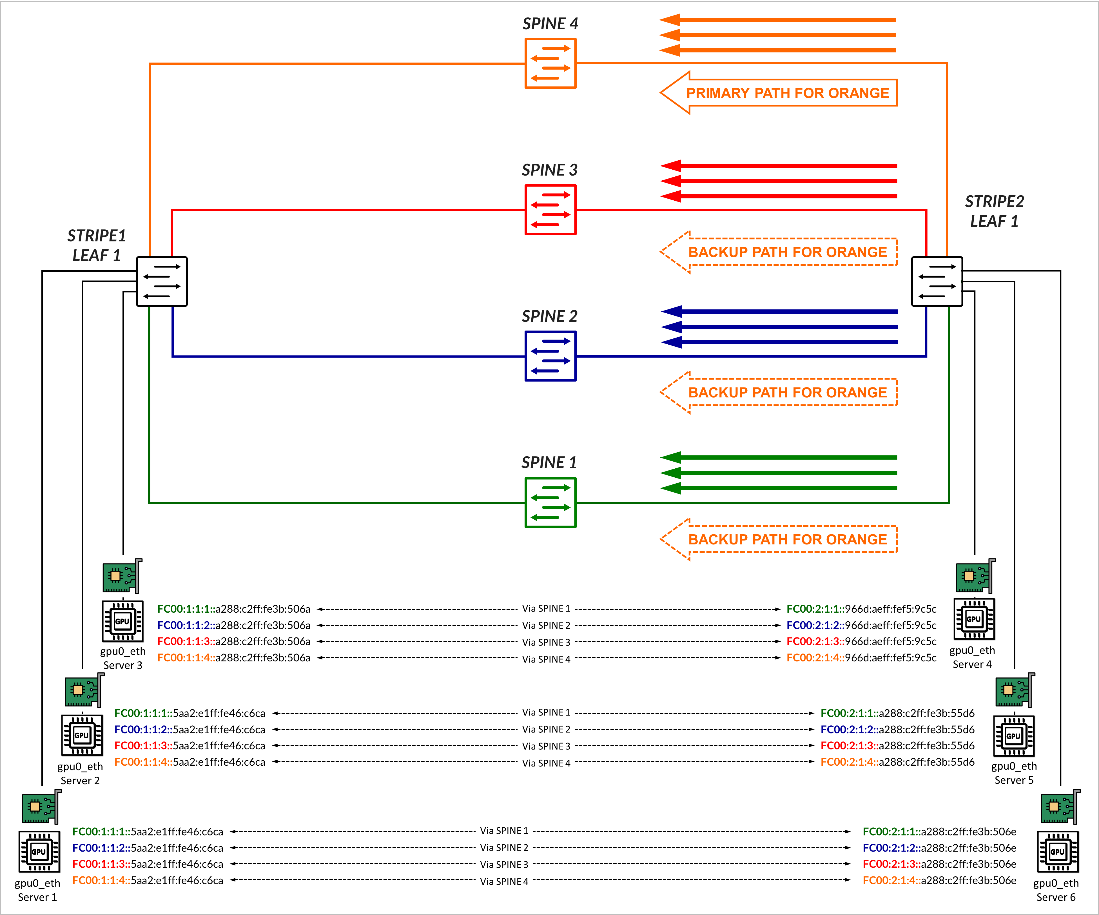 期间的流量转发示例
期间的流量转发示例
如果出现故障,转发将回退到动态负载平衡 (DLB)。在此示例中,如果指向主干 4 的链路出现故障,路由将从路由表中消失,并且发往前缀 FC00:1:1:4::/64 的流量将使用 DLB 在其他 3 条路径(备份路径)中转发,以平衡流量。如 图 13 所示。
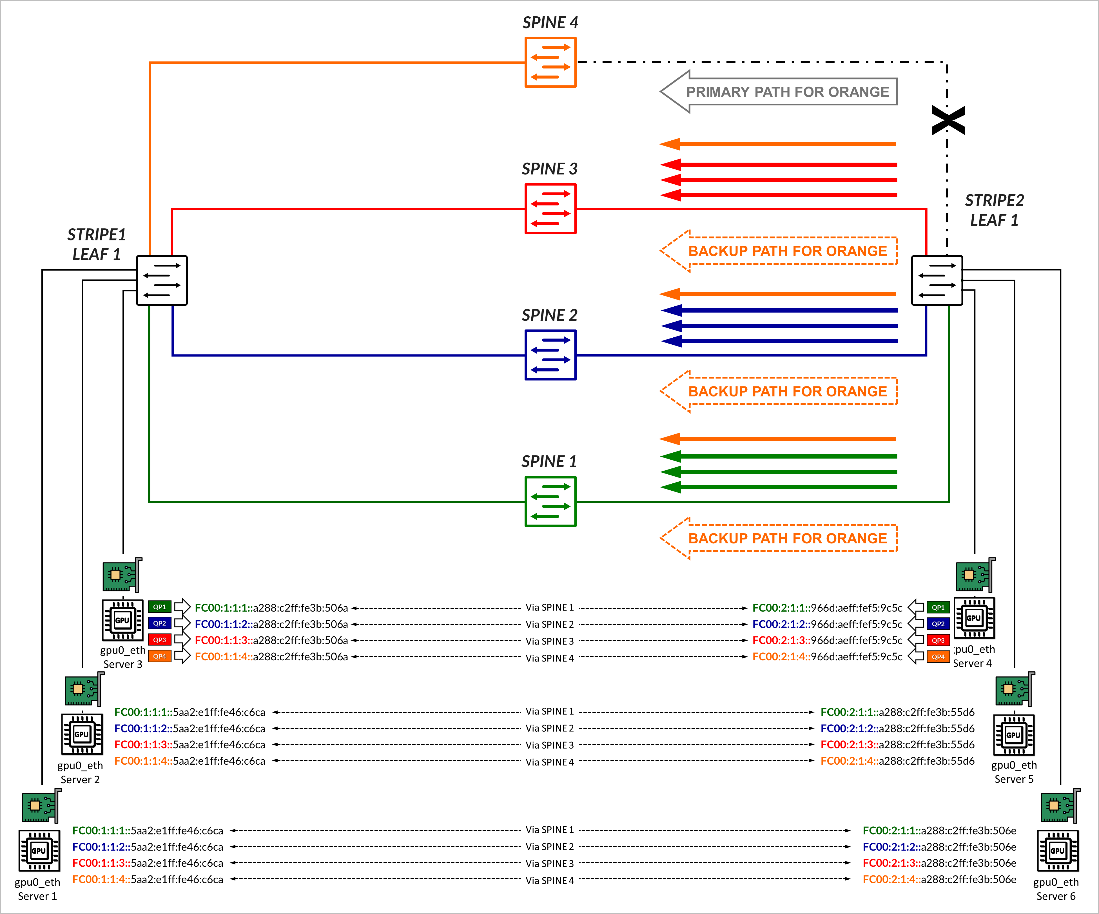 后的流量转发示例
后的流量转发示例