IP 交换矩阵 GPU 后端交换矩阵架构
此群集中的 GPU 后端交换矩阵是使用瞻博网络 QFX5240-64OD 交换机构建的,这些交换机既充当叶交换机,又充当主干节点,如 图 1 所示。该体系结构包括两条条带,每条由八个QFX5240叶节点组成。所有叶节点通过四个QFX5240主干节点互连,形成第 3 层 IPv6 交换矩阵,使用 EBGP 进行路由通告,使用原生 IPv6 进行转发。
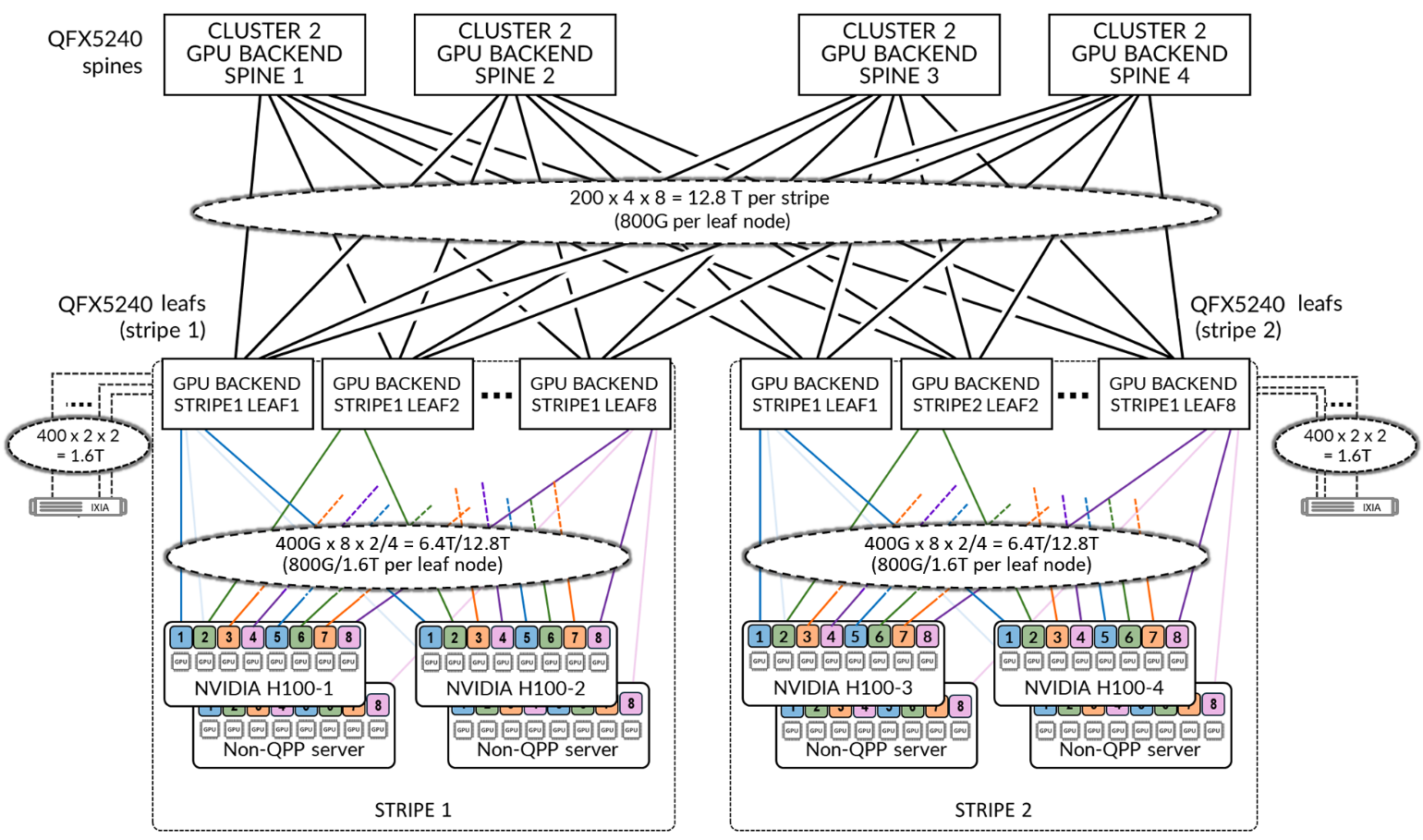
NVIDIA H100 以及非队列对固定(非 QPP)服务器使用 400GE 接口连接到叶节点。叶脊链路也配置了 400GE 上行链路。瞻博网络 QFX5240 交换机支持到 主干节点 的 800GE 上行链路(参见 表 1),但当前配置使用 400GE。这种选择是有意为之的。通过选择 400GE 上行链路,可以使用现有资源测试拥塞场景。
| 叶脊链路速度 | 叶式上行链路 能力 (每叶) |
总 从叶脊式设计 BW |
服务器到叶边界线 (4 台服务器) |
服务器到叶边界线 (8 台服务器) |
认购超额 率 (4 台服务器) |
超额订阅率 (8 台服务器) |
|---|---|---|---|---|---|---|
| 200 Gbps | 4 × 200G = 800 Gbps | 12.8 Tbps | 12.8 Tbps | 25.6 Tbps | 1:1 (平衡) |
2:1 (超额认购) |
| 400 Gbps | 4 × 400G = 1.6 Tbps | 25.6 Tbps | 12.8 Tbps | 25.6 Tbps | 1:2 (预留空间) |
1:1 (平衡) |
| 800 Gbps | 4 × 800G = 3.2 Tbps | 51.2 Tbps | 12.8 Tbps | 25.6 Tbps | 1:4 (严重过度配置) |
1:2 (预留空间) |
目前,该实验室包括四台服务器,可以在其中实施队列对固定 (QPP)。每个条带额外添加了两个不支持 QPP 的服务器,从而增加了服务器总带宽以匹配可用的主干上行链路容量。使用 IXIA 流量生成器注入额外的 RoCEv2 流量,以创建真实的拥塞场景并验证拥塞控制机制。
下面的表 2 和表 3 总结了 GPU 后端交换矩阵组件及其连接性。
| Stripe | GPU 服务器 | GPU 后端叶设备 节点交换机型号 |
GPU 后端主干节点 交换机型号 |
|---|---|---|---|
| 1 | 高 100 x 2 (H100-01 & H100-02) |
QFX5240-64 外径 x 8 (gpu-backend-001_leaf#; #=1-8) |
QFX5240-64 外径 x 4 (gpu-backend-spine#; #=1-4) |
| 2 | 高 100 x 2 (H100-01 & H100-02) |
QFX5240-64 外径 x 8 (gpu-backend-002_leaf#; #=1-8) |
| 条纹 | GPU 服务器 <=> GPU 后端叶节点 |
GPU 后端叶节点 <=> GPU 后端主干节点 |
|---|---|---|
| 1 | 400GE 链路总数 服务器和叶节点之间 = 8(每台服务器的 GPU 数)x 1(400GE 服务器到叶链路的数量)x4(服务器数量)= 32 |
400GE 链路总数 GPU 后端叶节点和主干节点之间 = 8(叶节点数)x 2(每个枝叶到主干连接的 400GE 链路数)x 4(主干节点数)= 64 |
| 2 | 400GE 链路总数 服务器和叶节点之间 = 8(每台服务器的 GPU 数)x 1(400GE 服务器到叶链路的数量)x 4(服务器数量)= 32 |
400GE 链路总数 GPU 后端叶节点和主干节点之间 = 8(叶节点数)x 2(每个枝叶到主干连接的 400GE 链路数)x 4(主干节点数)= 64 |
超额订阅因素
GPU 服务器和叶节点之间的链路速度和数量,以及叶节点和主干节点之间的链路,决定了交换矩阵的整体超额订阅因素。
如果只有四台支持 NVIDIA H100 QPP 的服务器使用 8 × 400GE 接口(每台服务器 3.2 Tbps)连接到交换矩阵,则服务器到叶的总带宽为 12.8 Tbps。16 个叶节点中的每一个都使用 400GE 链路连接到 4 个主干节点,提供 25.6 Tbps 的叶脊带宽总带宽(参见 表 4)。这会产生 1:2 的比率,这意味着交换矩阵以 1:2 的比例过度配置,即使在 100% 的条纹间流量下,也能为完整的 GPU 到 GPU 通信提供足够的带宽。
为了实现平衡的、非超额订阅 (1:1) 的配置(测试时仍然会拥塞),我们引入了额外的 RoCEv2 流量,每个条带添加了两个额外的服务器,不支持队列对固定 (QPP)。这样一来,服务器总数达到 8 台,服务器到叶的带宽增加到 25.6 Tbps(参见 表 5),这与可用的主干上行链路容量相匹配。在此扩展设置中,使用 IXIA 注入额外的 RoCEv2 流量,以创建真实的拥塞场景并验证整个后端交换矩阵的拥塞控制机制。
建议按照 1:1 的订阅因素部署交换矩阵。
| 每个条带的服务器到叶带宽 | ||||
|---|---|---|---|---|
| 条纹 | 服务器数量 每个 Stripe |
每台服务器的 400 GE 服务器数 <=> 个叶链路 (与叶节点数和每台服务器的 GPU 数相同) |
服务器 <=>叶 链路带宽 [Gbps] |
服务器总数 <=> 叶链路 每条带带宽 [Tbps] |
| 1 | 2 | 8 | 400 Gbps | 2 个 8 个 400 Gbps = 6.4 Tbps |
| 2 | 2 | 8 | 400 Gbps | 2 个 8 个 400 Gbps = 6.4 Tbps |
| 总 服务器 <=>叶带宽 |
12.8 Tbps | |||
| 叶节点到主干节点每个条带的带宽 | |||||
|---|---|---|---|---|---|
| 条带 | 叶节点数 | 主干节点数 | 400 GE 叶<数=> 个主干链路 每叶节点 |
服务器 <=>叶 链路带宽 [Gbps] |
带宽叶<=>主干 每条带 [Tbps] |
| 1 | 8 | 4 | 1 | 400 Gbps | 8 x 4 x 1 x 400 Gbps = 12.8 Tbps |
| 2 | 8 | 4 | 1 | 400 Gbps | 8 x 4 x 1 x 400 Gbps = 12.8 Tbps |
| 总 叶<=>主干带宽 |
25.6 Tbps | ||||
| 每个条带的服务器到叶带宽 | ||||
|---|---|---|---|---|
| 条纹 | 服务器数量 每个 Stripe |
每个服务器的 400 GE 服务器 ó lea 链路数 (与叶节点数量 & 相同 每台服务器的 GPU 数量) |
服务器 <=>叶 链路带宽 [Gbps] |
服务器总数 <=> 叶链路 每条带带宽 [Tbps] |
| 1 | 4 | 8 | 400 Gbps | 4 x 8 x 400 Gbps = 12.8 Tbps |
| 2 | 4 | 8 | 400 Gbps | 4 x 8 x 400 Gbps = 12.8 Tbps |
| 总 服务器 <=>叶带宽 |
25.6 Tbps | |||
GPU 服务器到叶节点的连接遵循 Rail 优化架构,如 Juniper Apstra、NVIDIA GPU 和 WEKA Storage JVD 的 AI 数据中心网络的 后端 GPU Rail 优化条形架构 部分所述。